Detection of Non-Technical Losses Using SOSTLink and Bidirectional Gated Recurrent Unit to Secure Smart Meters


 , , ,
, , , 
Abstract
1. Introduction
- The problem of imbalanced data is solved by employing the Smote Over Sampling Tomik Link (SOSTLink) sampling method.
- Feature extraction is done by applying Kernel Principal Component Analysis (KPCA) that reduces dimensionality.
- The Bidirectional Gated Recurrent Unit (BGRU) model is used as classifier, which is used to detect NTL in smart grid.
- Finally, we have used suitable metrics to evaluate the performance of proposed model including Receiver Operating Characteristic (ROC) curve, F1-score, precision, and recall.
2. Literature Review
3. Problem Statement
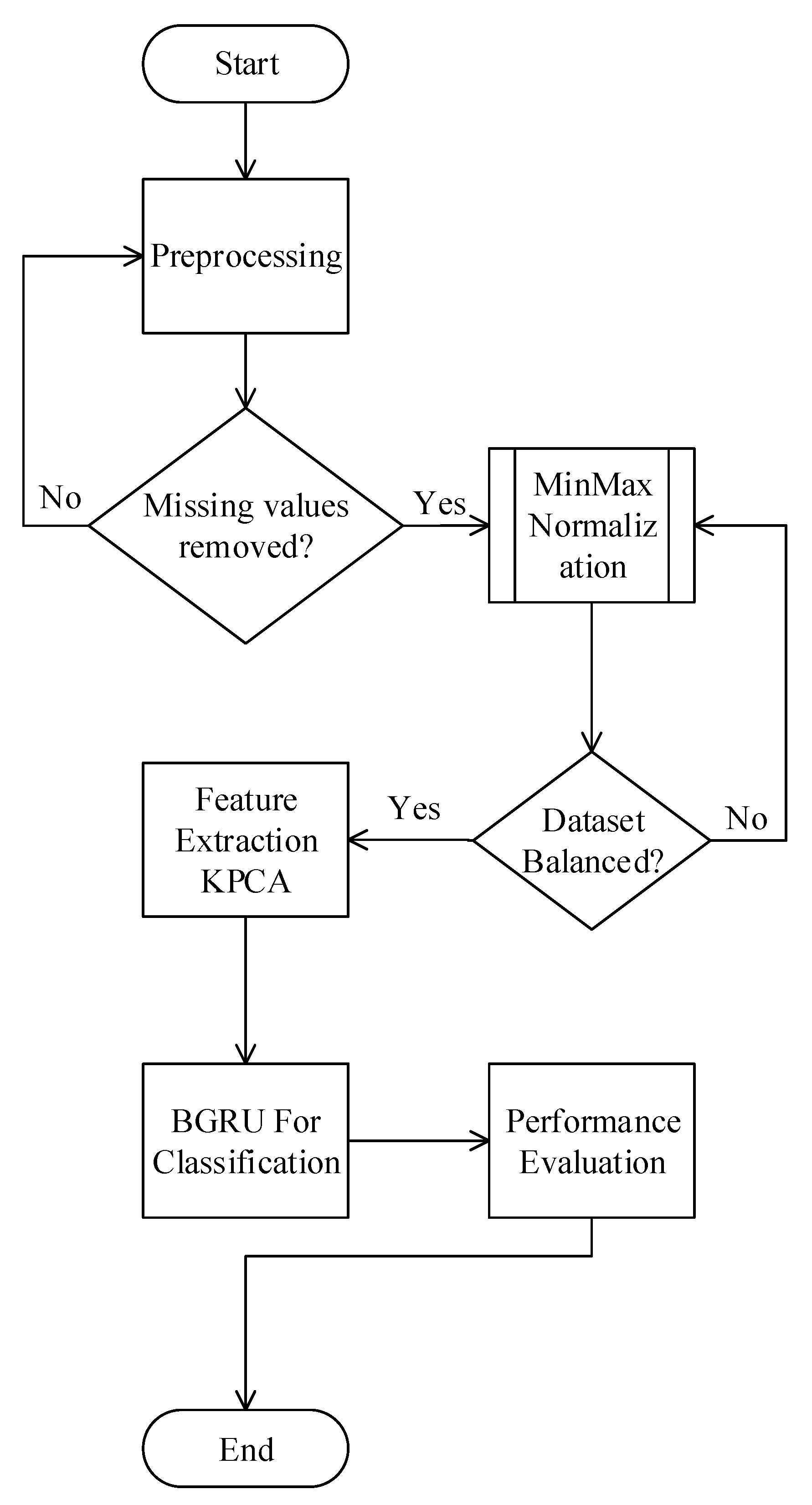
4. Proposed Model
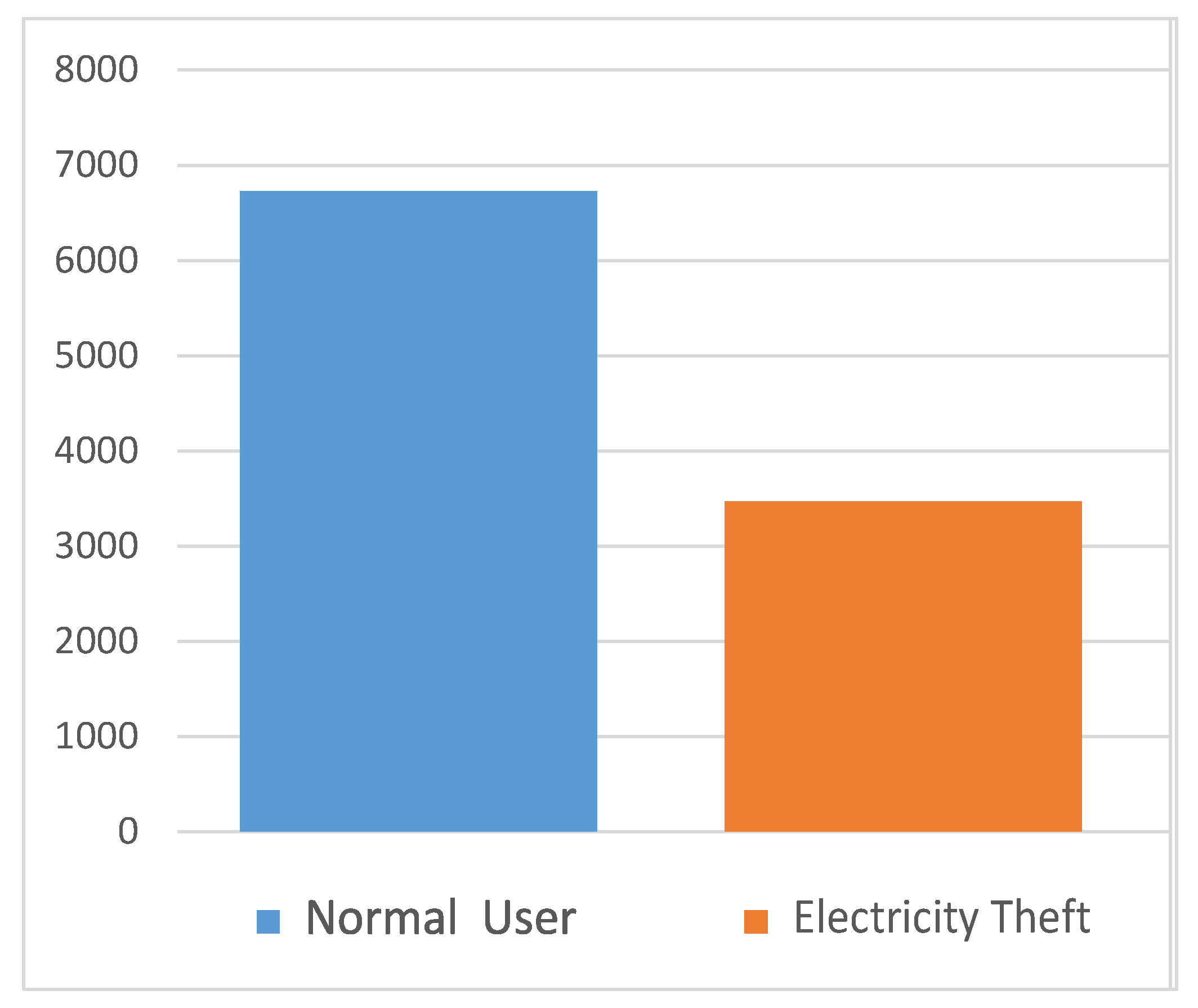
4.1. Electricity Consumption Data
4.2. Data Preprocessing
4.3. Handling Imbalance Data
- Read input from the dataset.
- Minority samples are generated from input dataset.
- Majority samples, which are nearest neighbors of minority observation, are also generated.
- Combine both observation samples from majority and minority.
- Delete all majority samples that are the nearest neighbor of minority samples.
- Now dataset is undersampled as observations from majority class are removed.
4.4. Feature Extraction using KPCA
- The first step is the choice of kernel mapping .
- Based on training data , we get K.
- To get and , solve eigenvalue problem of K.
- For each given data point x, obtain its principal components in the feature space:
4.5. Bidirectional Gated Recurrent Unit for Classification
4.6. Study of Hyperparameters Used for Experiments
5. Experimental Results
5.1. Performance Comparison
5.1.1. Decision Tree
5.1.2. Support Vector Machine
5.1.3. Logistic Regression
5.1.4. Random Forest
5.1.5. Convolutional Neural Network
5.1.6. Long Short Term Memory
5.1.7. Multilayer Perceptron-Convolutional Neural Network
5.2. Performance Metrics
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Rao, K.R.M. The services sector in the Indian economy. In Services Marketing; Maran, A., Soma, B., Eds.; Pearson Education: Noida, India, 2011; pp. 76–77. [Google Scholar]
- Masip-Bruin, X.; Marin-Tordera, E.; Jukan, A.; Ren, G.J. Managing resources continuity from the edge to the cloud: Architecture and performance. Future Gener. Comput. Syst. 2018, 79, 777–785. [Google Scholar] [CrossRef]
- Guo, Z.; Zhou, K.; Zhang, X.; Yang, S. A deep learning model for short-term power load and probability density forecasting. Energy 2018, 160, 1186–1200. [Google Scholar] [CrossRef]
- Wang, K.; Xu, C.; Zhang, Y.; Guo, S.; Zomaya, A.Y. Robust big data analytics for electricity price forecasting in the smart grid. IEEE Trans. Big Data 2017, 5, 34–45. [Google Scholar] [CrossRef]
- Khalid, R.; Javaid, N.; Al-zahrani, F.A.; Aurangzeb, K.; Qazi, E.U.H.; Ashfaq, T. Electricity Load and Price Forecasting Using Jaya-Long Short Term Memory (JLSTM) in Smart Grids. Entropy 2020, 22, 10. [Google Scholar] [CrossRef]
- Tong, C.; Li, J.; Lang, C.; Kong, F.; Niu, J.; Rodrigues, J.J. An efficient deep model for day-ahead electricity load forecasting with stacked denoising auto-encoders. J. Parallel Distrib. Comput. 2018, 117, 267–273. [Google Scholar] [CrossRef]
- Punmiya, R.; Choe, S. Energy theft detection using gradient boosting theft detector with feature engineering-based preprocessing. IEEE Trans. Smart Grid 2019, 10, 2326–2329. [Google Scholar] [CrossRef]
- Aslam, S.; Khalid, A.; Javaid, N. Towards efficient energy management in smart grids considering microgrids with day-ahead energy forecasting. Electr. Power Syst. Res. 2020, 182, 106232. [Google Scholar] [CrossRef]
- Simões, P.F.M.; Souza, R.C.; Calili, R.F.; Pessanha, J.F.M. Analysis and short-term predictions of non-technical loss of electric power based on mixed effects models. Soc. Econ. Plan. Sci. 2020, 100804. [Google Scholar] [CrossRef]
- Komolafe, O.M.; Udofia, K.M. Review of electrical energy losses in Nigeria. Niger. J. Technol. 2020, 39, 246–254. [Google Scholar]
- Li, J.; Wang, F. Non-Technical Loss Detection in Power Grids with Statistical Profile Images Based on Semi-Supervised Learning. Sensors 2020, 20, 236. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, T.; Sun, H.; Zhang, K.; Liu, P. Hidden Electricity Theft by Exploiting Multiple-Pricing Scheme in Smart Grids. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2453–2468. [Google Scholar] [CrossRef]
- Jawad, Y.A.; Ayyash, I. Analyze the Loss of Electricity in Palestine Case Study: Ramallah and Al-Bireh Governorate. Int. J. Energy Econ. Policy 2020, 10, 7–15. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, Y.; Niu, X.; Dai, H.N.; Zhou, Y. Wide and deep convolutional neural networks for electricity-theft detection to secure smart grids. IEEE Trans. Ind. Inform. 2017, 14, 1606–1615. [Google Scholar] [CrossRef]
- Naz, A.; Javaid, N.; Rasheed, M.B.; Haseeb, A.; Alhussein, M.; Aurangzeb, K. Game Theoretical Energy Management with Storage Capacity Optimization and Photo-Voltaic Cell Generated Power Forecasting in Micro Grid. Sustainability 2019, 11, 2763. [Google Scholar] [CrossRef]
- Mujeeb, S.; Alghamdi, T.A.; Ullah, S.; Fatima, A.; Javaid, N.; Saba, T. Exploiting Deep Learning for Wind Power Forecasting Based on Big Data Analytics. Appl. Sci. 2019, 9, 4417. [Google Scholar] [CrossRef]
- Assia, M.; Khelifa, B. A Hybrid Model for Anomalies Detection in AMI System Combining K-means Clustering and Deep Neural Network. CMC Tech Sci. Press 2019, 60, 15–39. [Google Scholar] [CrossRef]
- Razavi, R.; Gharipour, A.; Fleury, M.; Akpan, I.J. A practical feature-engineering framework for electricity theft detection in smart grids. Appl. Energy 2019, 238, 481–494. [Google Scholar] [CrossRef]
- Avila, N.F.; Figueroa, G.; Chu, C.C. NTL Detection in Electric Distribution Systems Using the Maximal Overlap Discrete Wavelet-Packet Transform and Random Undersampling Boosting. IEEE Trans. Power Syst. 2018, 33, 7171–7180. [Google Scholar] [CrossRef]
- Manzoor, A.; Javaid, N.; Ullah, I.; Abdul, W.; Almogren, A.; Alamri, A. An intelligent hybrid heuristic scheme for smart metering based demand side management in smart homes. Energies 2017, 10, 1258. [Google Scholar] [CrossRef]
- Ramos, C.C.; Rodrigues, D.; de Souza, A.N.; Papa, J.P. On the study of commercial losses in Brazil: A binary black hole algorithm for theft characterization. IEEE Trans. Smart Grid 2018, 9, 676–683. [Google Scholar] [CrossRef]
- Zheng, K.; Chen, Q.; Wang, Y.; Kang, C.; Xia, Q. A novel combined data-driven approach for electricity theft detection. IEEE Trans. Ind. Inform. 2019, 15, 1809–1819. [Google Scholar] [CrossRef]
- Commission for Energy Regulation. CER Smart Metering Project Electricity Customer Behaviour Trial, 2009–2010; SN: 0012-00; Irish Social Science Data Archive: Dublin, Ireland, 2012.
- Fenza, G.; Gallo, M.; Loia, V. Drift-aware methodology for anomaly detection in smart grid. IEEE Access 2019, 7, 9645–9657. [Google Scholar] [CrossRef]
- Spirić, J.V.; Stanković, S.S.; Dočić, M.B. Identification of suspicious electricity customers. Int. J. Electr. Power Energy Syst. 2018, 95, 635–643. [Google Scholar] [CrossRef]
- Li, W.; Logenthiran, T.; Phan, V.T.; Woo, W.L. A novel smart energy theft system (SETS) for IoT-based smart home. IEEE Int. Things J. 2019, 6, 5531–5539. [Google Scholar] [CrossRef]
- Micheli, G.; Soda, E.; Vespucci, M.T.; Gobbi, M.; Bertani, A. Big data analytics: An aid to detection of non-technical losses in power utilities. Comput. Manag. Sci. 2019, 16, 329–343. [Google Scholar] [CrossRef]
- Coma-Puig, B.; Carmona, J. Bridging the Gap between Energy Consumption and Distribution through Non-Technical Loss Detection. Energies 2019, 12, 1748. [Google Scholar] [CrossRef]
- Viegas, J.L.; Esteves, P.R.; Vieira, S.M. Clustering-based novelty detection for identification of non-technical losses. Int. J. Electr. Power Energy Syst. 2018, 101, 301–310. [Google Scholar] [CrossRef]
- Saeed, M.S.; Mustafa, M.W.; Sheikh, U.U.; Jumani, T.A.; Mirjat, N.H. Ensemble Bagged Tree Based Classification for Reducing Non-Technical Losses in Multan Electric Power Company of Pakistan. Electronics 2019, 8, 860. [Google Scholar] [CrossRef]
- Ghasemi, A.A.; Gitizadeh, M. Detection of illegal consumers using pattern classification approach combined with Levenberg-Marquardt method in smart grid. Int. J. Electr. Power Energy Syst. 2018, 99, 363–375. [Google Scholar] [CrossRef]
- Buzau, M.M.; Tejedor-Aguilera, J.; Cruz-Romero, P.; Gómez-Expósito, A. Detection of non-technical losses using smart meter data and supervised learning. IEEE Trans. Smart Grid 2018, 10, 2661–2670. [Google Scholar] [CrossRef]
- Li, S.; Han, Y.; Yao, X.; Yingchen, S.; Wang, J.; Zhao, Q. Electricity Theft Detection in Power Grids with Deep Learning and Random Forests. J. Electr. Comput. Eng. 2019, 1–12. [Google Scholar] [CrossRef]
- Hasan, M.; Toma, R.N.; Nahid, A.A.; Islam, M.M.; Kim, J.M. Electricity Theft Detection in Smart Grid Systems: A CNN-LSTM Based Approach. Energies 2019, 12, 3310. [Google Scholar] [CrossRef]
- Singh, S.K.; Bose, R.; Joshi, A. Energy theft detection for AMI using principal component analysis based reconstructed data. IET Cyber Phys. Syst. Theory Appl. 2019, 4, 179–185. [Google Scholar] [CrossRef]
- Buzau, M.; Tejedor-Aguilera, J.; Cruz-Romero, P.; Gómez-Expósito, A. Hybrid Deep Neural Networks for Detection of Non-Technical Losses in Electricity Smart Meters. IEEE Trans. Power Syst. 2020, 35, 1254–1263. [Google Scholar] [CrossRef]
- Wang, W.; Song, J.; Xu, G.; Li, Y.; Wang, H.; Su, C. ContractWard: Automated Vulnerability Detection Models for Ethereum Smart Contracts. IEEE Trans. Netw. Sci. Eng. 2020, 1–12. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Kim, P.S.; Lee, D.G.; Lee, S.W. Discriminative context learning with gated recurrent unit for group activity recognition. Pattern Recognit. 2018, 76, 149–161. [Google Scholar] [CrossRef]
- Lee, H.G.; Park, G.; Kim, H. Effective integration of morphological analysis and named entity recognition based on a recurrent neural network. Pattern Recognit. Lett. 2018, 112, 361–365. [Google Scholar] [CrossRef]
- Ding, N.; Ma, H.; Gao, H.; Ma, Y.; Tan, G. Real-time anomaly detection based on long short-Term memory and Gaussian Mixture Model. Comput. Electr. Eng. 2020, 79, 106458. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Problems | Proposed Solution |
|---|---|---|
| 1 | Trapped in local minima | Adam optimization |
| 2 | Time complexity of hybrid model | BGRU single model |
| 3 | Imbalanced class | SOSTLink method |
| 4 | Underfitting | SOSTLink method |
| 5 | Missing values are not handled | Imputation is performed |
| 6 | FPR is not calculated | FPR is calculated |
| Problem Addressed | Solution Proposed | Dataset | Limitations |
|---|---|---|---|
| One-dimensional data fails to capture periodicity [14] | Wide and deep CNN | SGCC (2014–2016) | Computational complexity, FPR is not calculated, Imbalance class problem |
| Required label dataset with additional information, poor accuracy [22] | Combine two techniques. MIC-CFSFDP | Irish CER smart metering project | Additional hardware cost FPR is not calculated, Low detection accuracy |
| NTL detection [19] | RusBoost and MODWPT | Industrial and commercial sectors in Honduras of China | Underfitting, time complexity Selection of a biased sample, loss of information |
| Feature engineering required [21] | BBHA | Brazilian electricity regulatory agency | Trapped in local minima, No preprocessing, Imbalance class problem |
| Hacking of smart meters [17] | Combine two techniques. K-means and DNN | Irish (2012) | Imbalance dataset |
| Smart meter hacking, counterfeit the data [18] | Finite mixture model clustering and a genetic programming algorithm | Real time data from Ireland in (2009–2010) | High FPR |
| NTL detection and accuracy is low [11] | Proposed a methodology in which collected data is represented as image with the help of deep learning. | power company in China. | Imbalance class problem, Selection of a biased sample |
| Electricity theft detection and high FPR [24] | LSTM | Electricity load diagrams (2011–2014) | High prediction error, High delay time in anomaly occur and detection |
| Loss between electricity usage and electricity supply [25] | Fuzzy logic | Customers monthly invoiced bills | Require experts for analyses, Complex, Takes a lot of time to develop Fuzzy rules |
| Less number of verified customers in dataset, due to which accuracy is compromised [7] | GBTD | Smart energy dataset by Irish | Computationally expensive |
| ETD in IoT-based network [26] | SETs | Data is collected from Aeon lab named as Z-Wave based in UK | Additional hardware cost and maintenance cost |
| NTL detection [27] | Multiple Linear Regression model | Ministry of Power distribution based in India (2013) | Not explain the impact of accurately detected users |
| Detection of energy theft in utilities is a challenge [28] | Implement machine learning technique in utility company to detect gap between generation and consumption | Data is collected from leading electricity provider in Spain | FPR is not calculated, Imbalance dataset |
| NTL detection is performed on synthetic data set to achieve low FPR [29] | GK clustering | Data is collected from commission for energy regulation based in Irish | Class imbalance problem, Need large data and experts, Time complexity is high |
| NTL detection in Pakistan [30] | ensemble bagged tree-based algorithm | MEPCO in Pakistan | Computationally expensive |
| NTL detection [31] | PNN and Levenberg–Marquardt | Pennsylvania–New Jersey–Maryland (PJM) Largest power system operator based in US | Accuracy is low, FPR is not calculated, imbalance dataset |
| Not rank the customers according to their anomalous behavior [32] | XG Boost | Data is collected from commercial and industrial users of Endesa | Cannot handle large data, High execution time, memory hungry |
| NTL detection [33] | CNN and RF | Data is collected from sustainable energy authority of Ireland and electricity utility of London | Time complexity is high because of hybrid model |
| Energy theft [34] | Combines CNN and LSTM for theft detection | SGCC | High execution time |
| Parameters | Values of BGRU | Values of LSTM |
|---|---|---|
| Input Neuron | 30,600 | 643,200 |
| Activation Function | Sigmoid | Sigmoid |
| Number of Outputs | 100 | 400 |
| Epoch | 25 | 25 |
| Number of dense layer | 101 | 401 |
| Execution time | 36s per iteration | 73s per iteration |
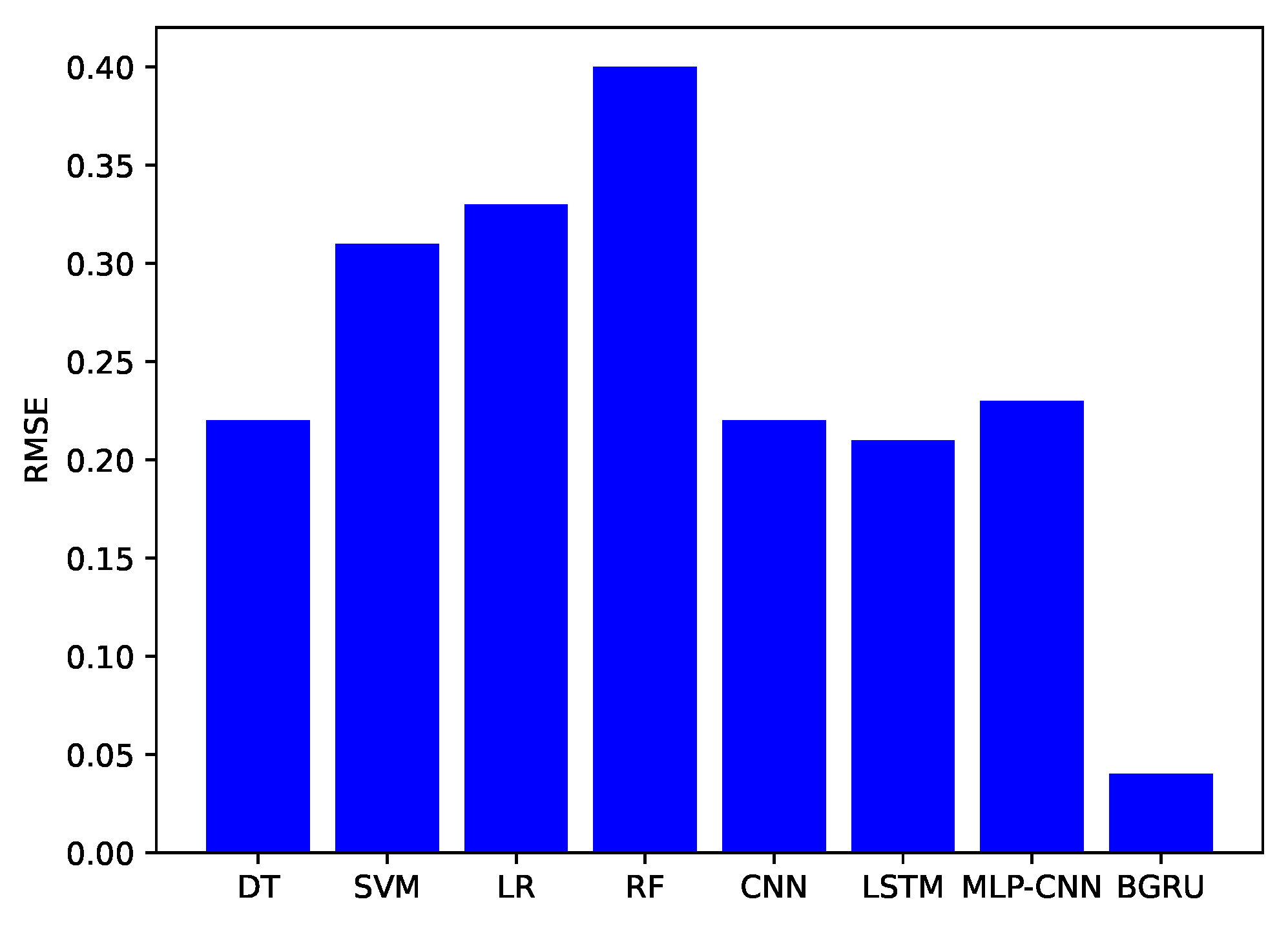
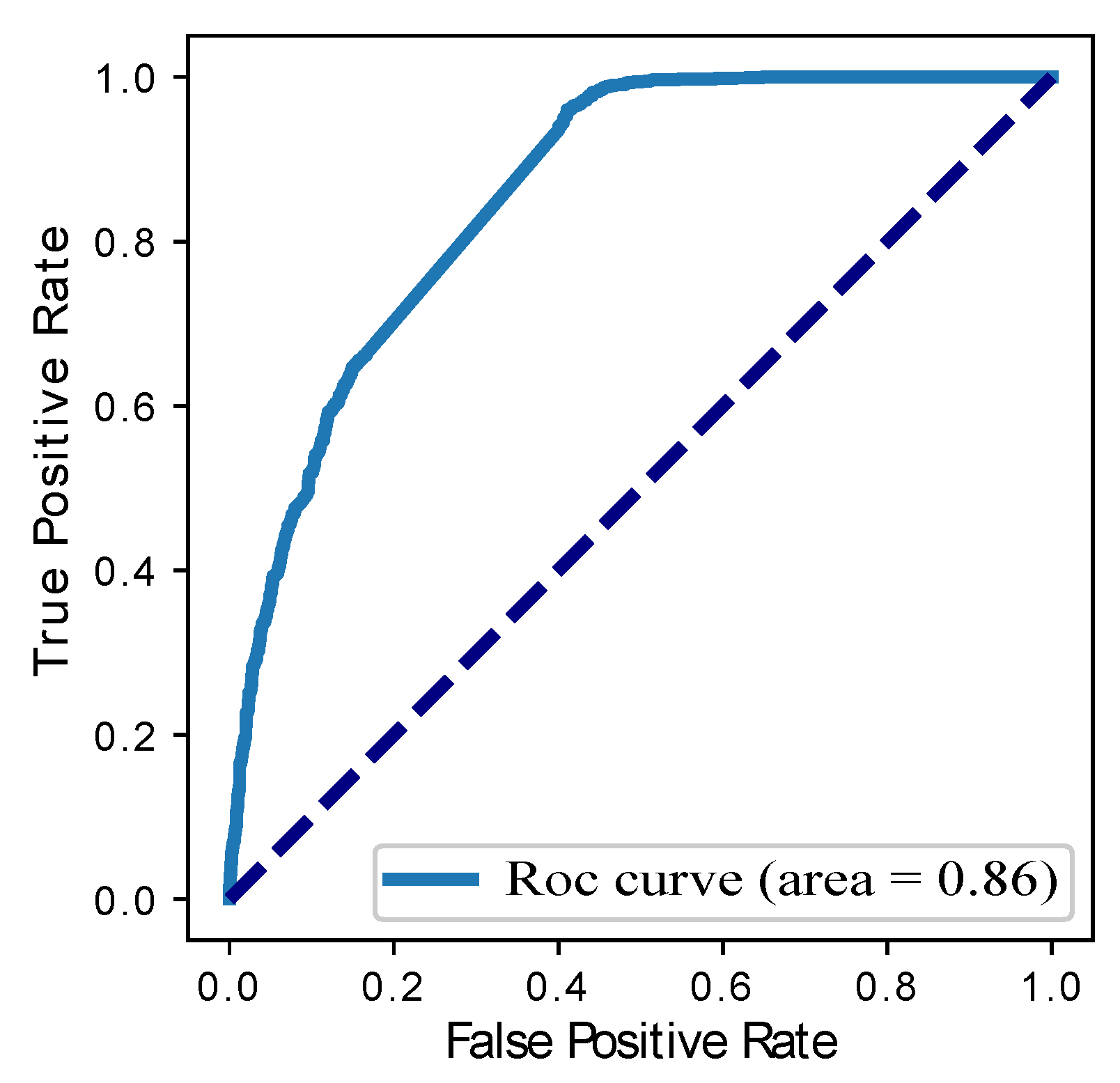
| Models | Precision | Recall | F1-Score | ROC Curve | RMSE |
|---|---|---|---|---|---|
| LR | 0.72 | 0.73 | 0.65 | 0.73 | 0.33 |
| RF | 0.72 | 0.70 | 0.60 | 0.70 | 0.40 |
| SVM | 0.69 | 0.58 | 0.56 | 0.57 | 0.31 |
| DT | 0.75 | 0.71 | 0.72 | 0.70 | 0.22 |
| CNN | 0.65 | 0.73 | 0.85 | 0.65 | 0.22 |
| LSTM | 0.72 | 0.71 | 0.72 | 0.82 | 0.21 |
| MLP-CNN | 0.71 | 0.67 | 0.68 | 0.81 | 0.23 |
| Our Proposed BGRU | 0.80 | 0.89 | 0.85 | 0.86 | 0.04 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gul, H.; Javaid, N.; Ullah, I.; Qamar, A.M.; Afzal, M.K.; Joshi, G.P. Detection of Non-Technical Losses Using SOSTLink and Bidirectional Gated Recurrent Unit to Secure Smart Meters. Appl. Sci. 2020, 10, 3151. https://doi.org/10.3390/app10093151
Gul H, Javaid N, Ullah I, Qamar AM, Afzal MK, Joshi GP. Detection of Non-Technical Losses Using SOSTLink and Bidirectional Gated Recurrent Unit to Secure Smart Meters. Applied Sciences. 2020; 10(9):3151. https://doi.org/10.3390/app10093151
Chicago/Turabian StyleGul, Hira, Nadeem Javaid, Ibrar Ullah, Ali Mustafa Qamar, Muhammad Khalil Afzal, and Gyanendra Prasad Joshi. 2020. "Detection of Non-Technical Losses Using SOSTLink and Bidirectional Gated Recurrent Unit to Secure Smart Meters" Applied Sciences 10, no. 9: 3151. https://doi.org/10.3390/app10093151
APA StyleGul, H., Javaid, N., Ullah, I., Qamar, A. M., Afzal, M. K., & Joshi, G. P. (2020). Detection of Non-Technical Losses Using SOSTLink and Bidirectional Gated Recurrent Unit to Secure Smart Meters. Applied Sciences, 10(9), 3151. https://doi.org/10.3390/app10093151