Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network

Abstract
1. Introduction
2. Related Works
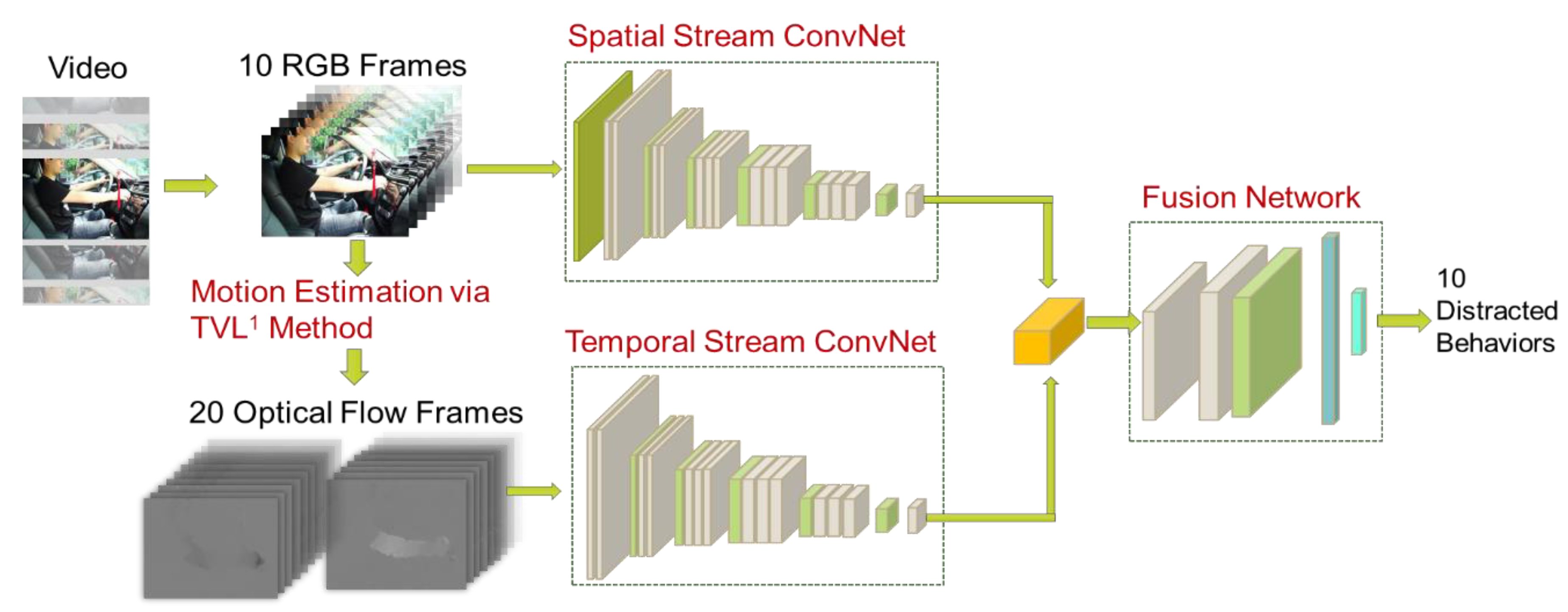
3. Method
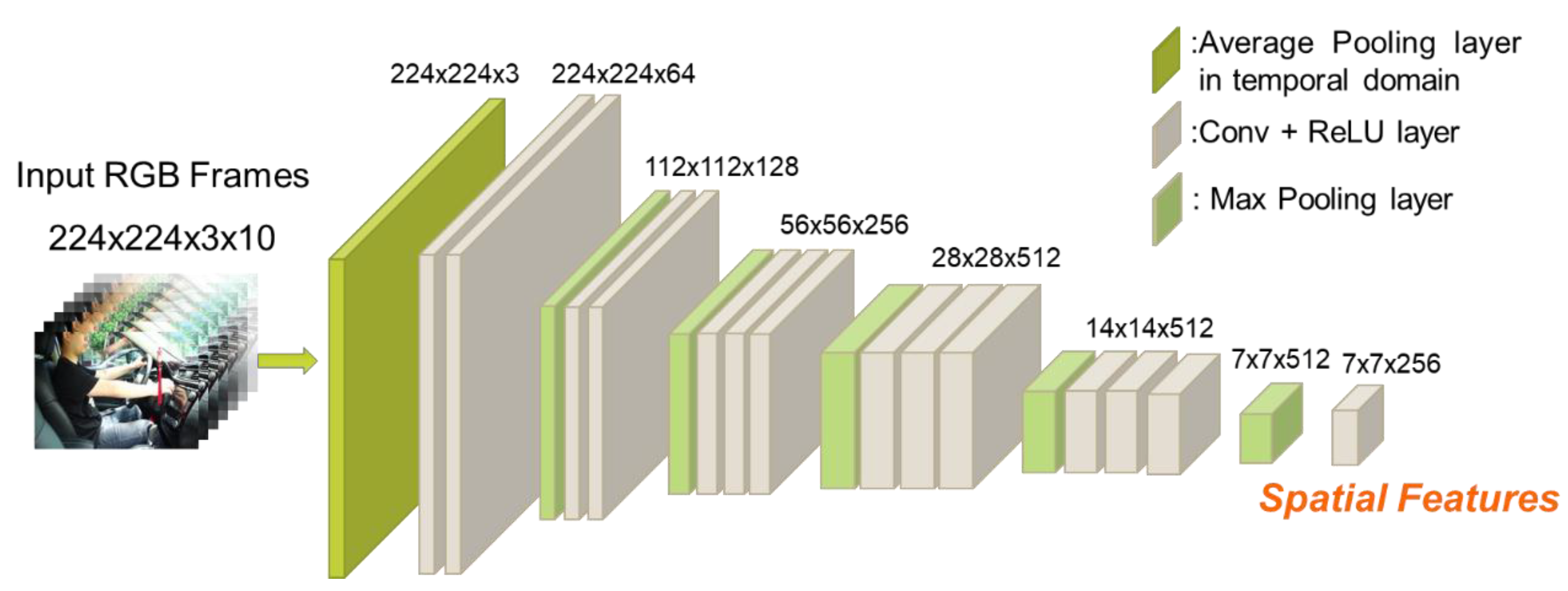
3.1. Spatial Stream ConvNet
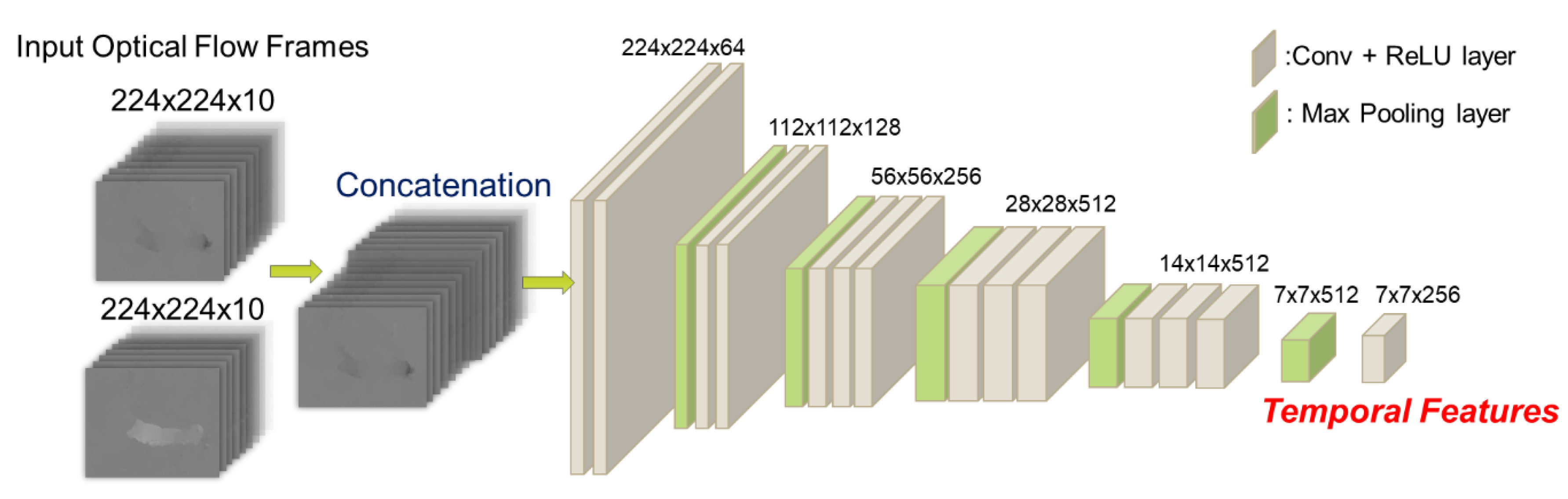
3.2. Temporal Stream ConvNet
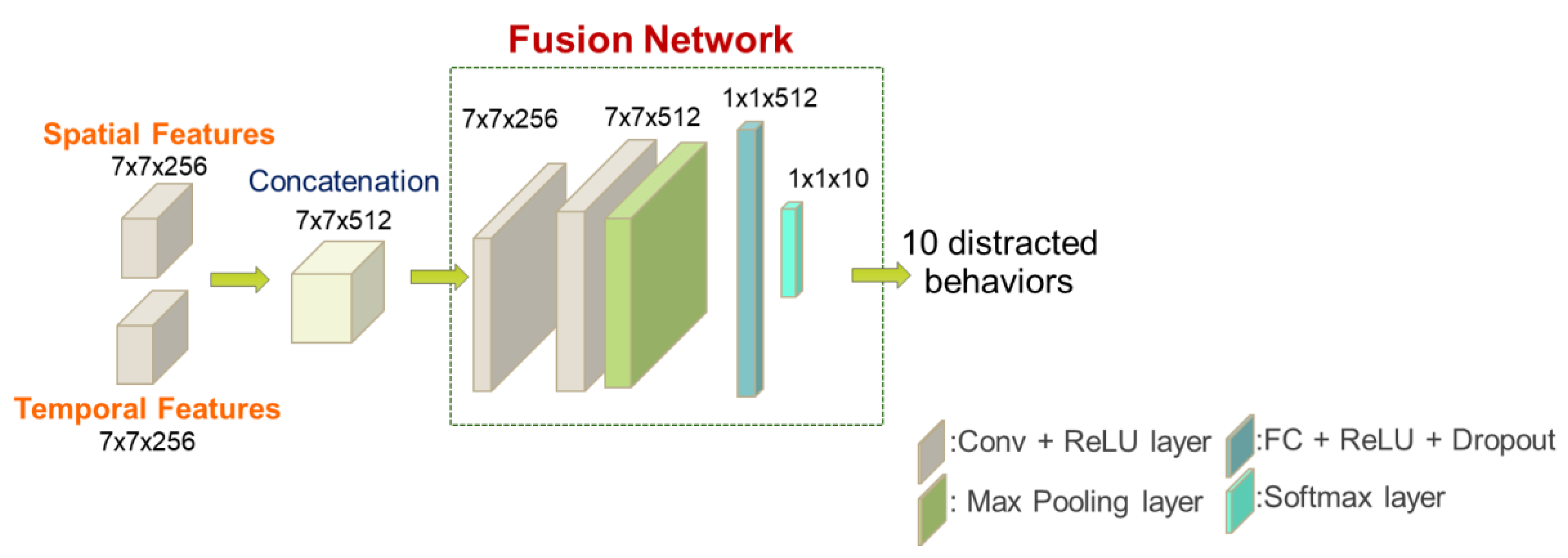
3.3. Classification of Distractions by a Fusion Network
4. Experiment Results
4.1. Dataset and Experimental Setting
4.2. Comparison with Existing Systems
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization (WHO). Global Status Report. Available online: https://www.who.int/violence_injury_prevention/road_safety_status/2018/en/ (accessed on 13 February 2019).
- Eraqi, H.; Abouelnaga, Y.; Saad, M.H.; Moustafa, M. Driver Distraction Identification with an Ensemble of Convolutional Neural Networks. J. Adv. Transp. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Lee, J.D. Driving safety. Rev. Hum. Factor Ergonom. 2005, 1, 172–218. [Google Scholar] [CrossRef]
- Traffic Safety Facts. Available online: https://www.nhtsa.gov/risky-driving/distracted-driving (accessed on 13 February 2019).
- Distracted Driving. 2016. Available online: https://www.cdc.gov/motorvehiclesafety/distracted_driving/ (accessed on 13 February 2019).
- National Highway Traffic Safety Administration. Traffic Safety Facts. Available online: https://www.nhtsa.gov/risky-driving/distracted-driving (accessed on 13 February 2019).
- Zhang, X.; Zheng, N.; Wang, F.; He, Y. Visual recognition of driver hand-held cell phone use based on hidden CRF. In Proceedings of the 2011 IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 10–12 July 2011; pp. 248–251. [Google Scholar]
- Berri, R.; Silva, A.G.; Parpinelli, R.S.; Girardi, E.; Arthur, R. A Pattern Recognition System for Detecting Use of Mobile Phones While Driving. In Proceedings of the International Conference on Computer Vision Theory and Applications, Lisbon, Portugal, 5–8 January 2014. [Google Scholar]
- Craye, C.; Karray, F. Driver distraction detection and recognition using RGB-D sensor. arXiv 2015, arXiv:1502.00250. [Google Scholar]
- Seshadri, K.; Juefei-Xu, F.; Pal, D.K.; Savvides, M.; Thor, C.P. Driver cell phone usage detection on Strategic Highway Research Program (SHRP2) face view videos. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 35–43. [Google Scholar]
- Das, N.; Ohn-Bar, E.; Trivedi, M.M. On Performance Evaluation of Driver Hand Detection Algorithms: Challenges, Dataset, and Metrics. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 2953–2958. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Pdf ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hoang, T.; Do, T.-T.; Le Tan, D.-K.; Cheung, N.-M. Selective Deep Convolutional Features for Image Retrieval. In Proceedings of the 2017 ACM on Web Science Conference—WebSci ’17, Troy, NY, USA, 25–28 June 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Le, T.H.N.; Zheng, Y.; Zhu, C.; Luu, K.; Savvides, M. Multiple Scale Faster-RCNN Approach to Driver’s Cell-Phone Usage and Hands on Steering Wheel Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 46–53. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Yuen, K.; Martin, S.; Trivedi, M.M. Looking at faces in a vehicle: A deep CNN based approach and evaluation. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar]
- Streiffer, C.; Raghavendra, R.; Benson, T.; Srivatsa, M. Darnet: A deep learning solution for distracted driving detection. In Proceedings of the ACM/IFIP/USENIX Middleware Conference, Las Vegas, NV, USA, 11–15 December 2017; pp. 22–28. [Google Scholar]
- Majdi, M.S.; Ram, S.; Gill, J.T.; Rodriguez, J.J. Drive-Net: Convolutional Network for Driver Distraction Detection. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018; pp. 1–4. [Google Scholar]
- Tran, D.; Do, H.M.; Sheng, W.; Bai, H.; Chowdhary, G. Real-time detection of distracted driving based on deep learning. IET Intell. Transp. Syst. 2018, 12, 1210–1219. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. In Proceedings of the Workshop on Machine Learning for Intelligent Transportation Systems, Montréal, QC, Canada, 8 December 2018. [Google Scholar]
- Baheti, B.; Gajre, S.; Talbar, S. Detection of Distracted Driver Using Convolutional Neural Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1032–1038. [Google Scholar]
- Masood, S.; Rai, A.; Aggarwal, A.; Doja, M.; Ahmad, M. Detecting distraction of drivers using Convolutional Neural Network. Pattern Recognit. Lett. 2018. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A Duality Based Approach for Realtime TV-L 1 Optical Flow. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4713. [Google Scholar]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Laptev, I.; Lindeberg, T. Velocity adaptation of space-time interest points. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; pp. 432–439. [Google Scholar]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior Recognition via Sparse Spatio-Temporal Features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2006. [Google Scholar]
- Sadanand, S.; Corso, J.J. Action bank: A high-level representation of activity in video. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Wang, H.; Schmid, C. Action Recognition with Improved Trajectories. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. arXiv 2018, arXiv:1806.11230. [Google Scholar]
- Martin, S.; Ohn-Bar, E.; Tawari, A.; Trivedi, M.M.; Martin, S. Understanding head and hand activities and coordination in naturalistic driving videos. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2014; pp. 884–889. [Google Scholar]
- Ohn-Bar, E.; Martin, S.; Trivedi, M.M. Driver hand activity analysis in naturalistic driving studies: Challenges, algorithms, and experimental studies. J. Electron. Imaging 2013, 22, 41119. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, B.; He, J.; Lian, J. Recognition of driving postures by contourlet transform and random forests. IET Intell. Transp. Syst. 2012, 6, 161–168. [Google Scholar] [CrossRef]
- StateFarm’s Distracted Driver Detection Dataset. Available online: https://www.kaggle.com/c/state-farm-distracted-driver-detection (accessed on 13 February 2019).
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L.; Shetty, S.; Leung, T. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Darrell, T.; Saenko, K. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Ng, J.Y.-H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Lin, J.C.W.; Shao, Y.; Zhou, Y.; Pirouz, M.; Chen, H.C. A Bi-LSTM mention hypergraph model with encoding schema for mention extraction. Eng. Appl. Artif. Intell. 2019, 85, 175–181. [Google Scholar] [CrossRef]
- Lin, J.C.W.; Shao, Y.; Fournier-Viger, Y.; Hamido, P.F. BILU-NEMH: A BILU neural-encoded mention hypergraph for mention extraction. Inf. Sci. 2019, 496, 53–64. [Google Scholar] [CrossRef]
- Yan, C.; Coenen, F.; Zhang, B. Driving posture recognition by convolutional neural networks. IET Comput. Vis. 2016, 10, 103–114. [Google Scholar] [CrossRef]
- Chuang, Y.-W.; Kuo, C.-H.; Sun, S.-W.; Chang, P.-C. Driver behavior recognition using recurrent neural network in multiple depth cameras environment. Electron. Imaging 2019, 2019, 56-1–56-7. [Google Scholar] [CrossRef]
- Gebert, P.; Roitberg, A.; Haurilet, M.; Stiefelhagen, R. End-to-end Prediction of Driver Intention using 3D Convolutional Neural Networks. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 969–974. [Google Scholar]
- Xu, L.; Fujimura, K. Real-Time Driver Activity Recognition with Random Forests. In Proceedings of the 6th international conference on Multimodal interfaces—ICMI ’04, Seattle, WA, USA, 17–19 September 2014; Association for Computing Machinery (ACM): New York, NY, USA, 2014; pp. 1–8. [Google Scholar]
- Martin, M.; Popp, J.; Anneken, M.; Voit, M.; Stiefelhagen, R. Body Pose and Context Information for Driver Secondary Task Detection. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 2015–2021. [Google Scholar]
- Martin, M.; Roiterg, A.; Haurilet, M.; Horne, M.; Reib, S.; Voit, M.; Stiefelhagen, R. Drive & Act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles. In Proceedings of the International Conference on Computer Vision, Thessaloniki, Greece, 23–25 September 2019. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Soleymani, S.; Dabouei, A.; Kazemi, H.; Dawson, J.; Nasrabadi, N.M. Multi-Level Feature Abstraction from Convolutional Neural Networks for Multimodal Biometric Identification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3469–3476. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Accuracy (%) |
|---|---|---|
| Spatial Stream ConvNet | Original Split | 94.44 |
| VGG-16 with Regularization [25] | Original Split | 96.31 |
| Spatial Stream ConvNet | Re-Split | 76.25 |
| VGG-16 with Regularization [25] | Re-Split | 77.15 |
| Model | Spatial Stream ConvNet | Temporal Stream ConvNet | Fusion Result |
|---|---|---|---|
| Two-Stream Method 27 | 9.52 | 39.68 | 38.10 |
| Two-Stream Method 27 with Pre-trained model | 12.98 | 41.27 | 39.68 |
| Proposed Method | 33.34 | 9.52 | 34.92 |
| Proposed Method with Pre-trained models | 49.21 | 65.08 | 68.25 |
| Safe Driving | Text Right | Phone Right | Text Left | Phone Left | Adjusting Radio | Drinking | Reaching Behind | Hair or Makeup | Talking to Passenger | |
| Safe Driving | 0.80 | 0.0 | 0.0 | 0.0 | 0.20 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Text Right | 0.0 | 0.75 | 0.0 | 0.0 | 0.0 | 0.0 | 0.25 | 0.0 | 0.0 | 0.0 |
| Phone Right | 0.0 | 0.0 | 0.33 | 0.0 | 0.0 | 0.0 | 0.17 | 0.0 | 0.50 | 0.0 |
| Text Left | 0.0 | 0.0 | 0.0 | 1.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Phone Left | 0.0 | 0.0 | 0.0 | 0.0 | 1.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Adjusting Radio | 0.11 | 0.22 | 0.0 | 0.0 | 0.0 | 0.56 | 0.0 | 0.11 | 0.0 | 0.0 |
| Drinking | 0.0 | 0.13 | 0.25 | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 | 0.12 | 0.0 |
| Reaching Behind | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.25 | 0.0 | 0.75 | 0.0 | 0.0 |
| Hair or Makeup | 0.0 | 0.0 | 0.14 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.86 | 0.0 |
| Talking to Passenger | 0.0 | 0.0 | 0.11 | 0.0 | 0.0 | 0.0 | 0.0 | 0.23 | 0.0 | 0.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-C.; Lee, C.-Y.; Huang, P.-Y.; Lin, C.-R. Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network. Appl. Sci. 2020, 10, 1908. https://doi.org/10.3390/app10061908
Chen J-C, Lee C-Y, Huang P-Y, Lin C-R. Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network. Applied Sciences. 2020; 10(6):1908. https://doi.org/10.3390/app10061908
Chicago/Turabian StyleChen, Ju-Chin, Chien-Yi Lee, Peng-Yu Huang, and Cheng-Rong Lin. 2020. "Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network" Applied Sciences 10, no. 6: 1908. https://doi.org/10.3390/app10061908
APA StyleChen, J.-C., Lee, C.-Y., Huang, P.-Y., & Lin, C.-R. (2020). Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network. Applied Sciences, 10(6), 1908. https://doi.org/10.3390/app10061908