An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease

 , ,
, ,  ,
,  ,
, 

Abstract
1. Introduction
2. Background
3. Methodology
3.1. Parkinson’s Disease
3.2. Signal’s Transformation
3.3. Experimental Design
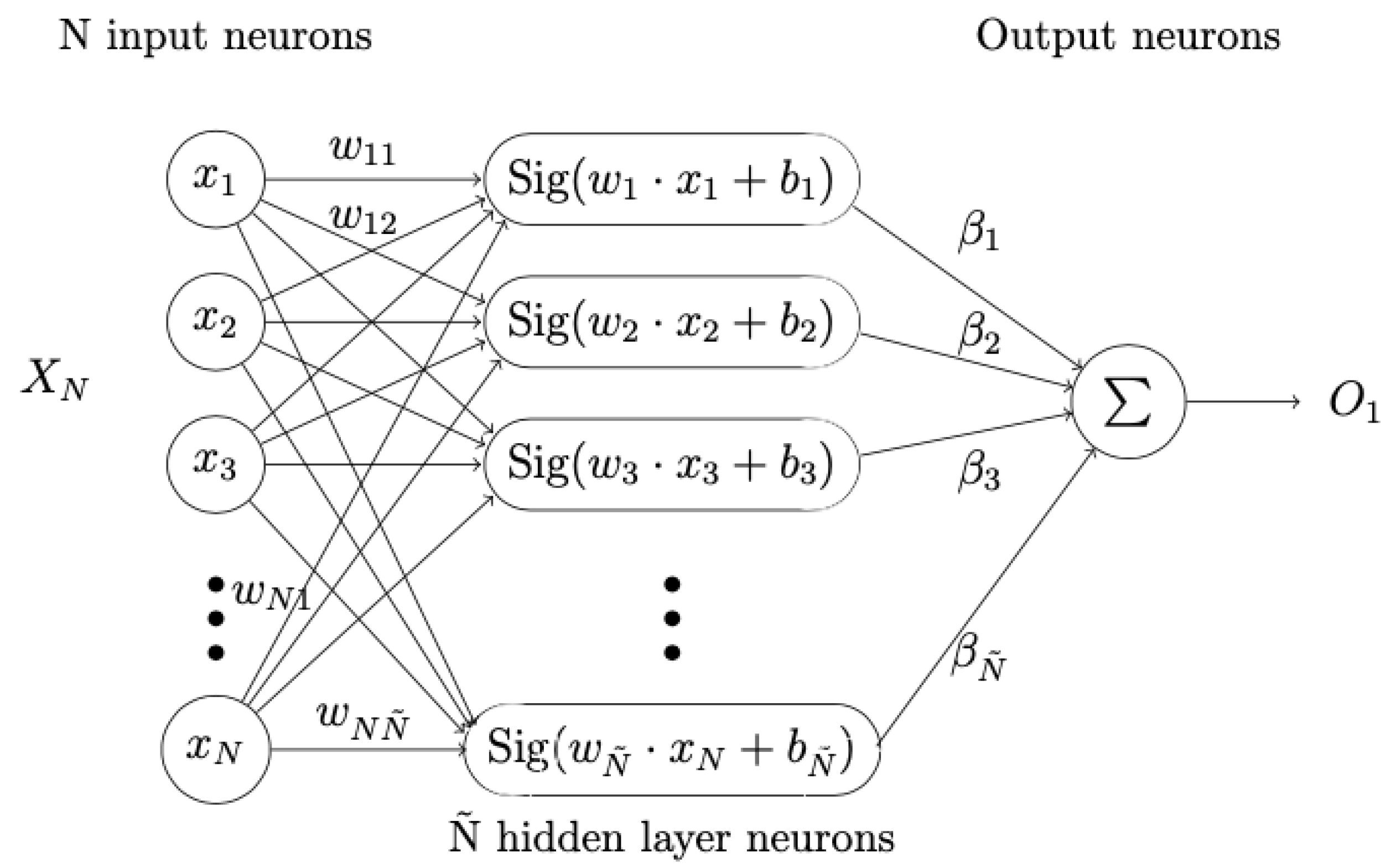
4. Extreme Learning Machine
- Randomly generate input weight and bias , .
- Calculate the hidden layer output matrix H.
- Calculate the weight .
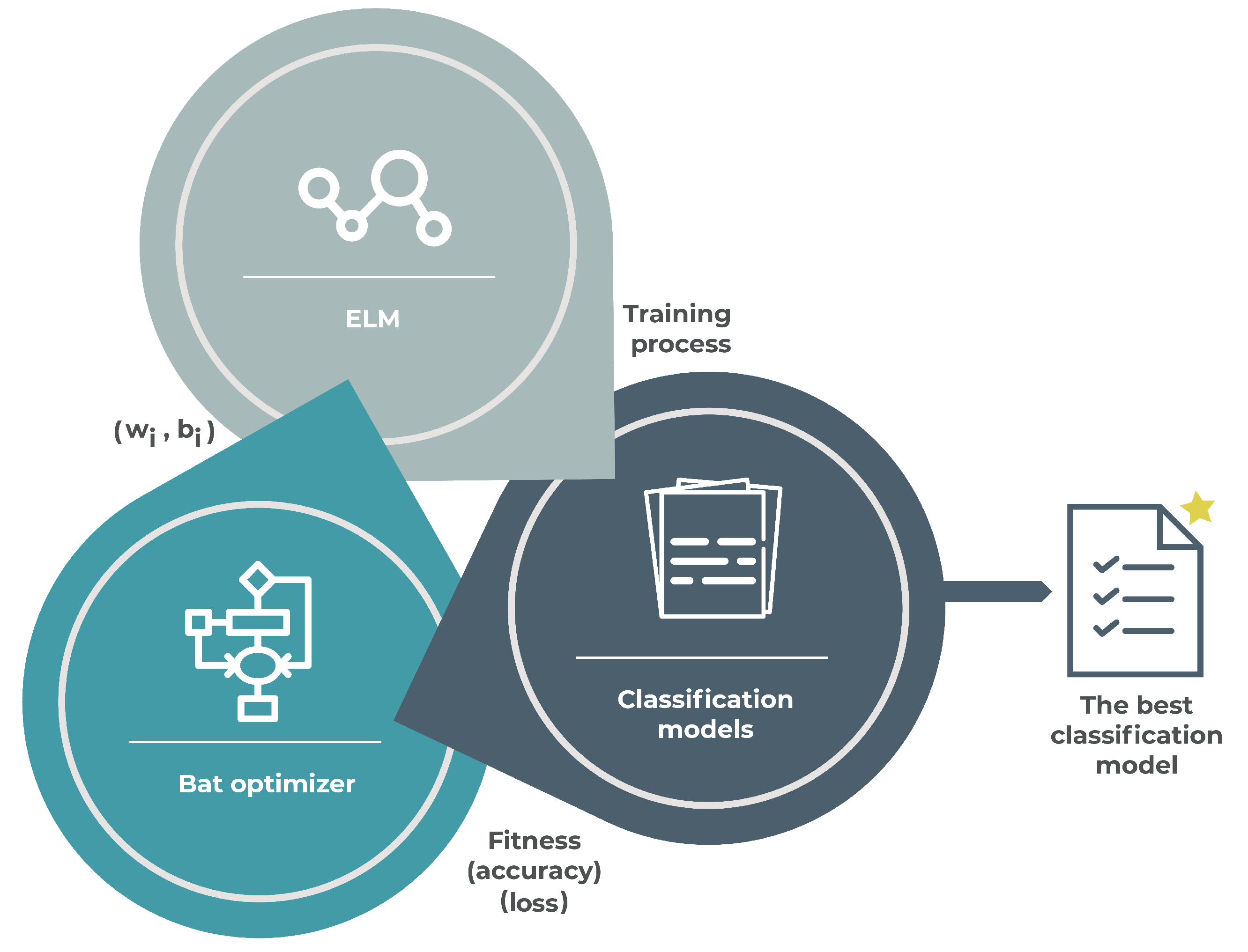
5. Proposed Approach
- It is assumed that all bats use echolocation to determine distances, and all of them are able to distinguish food, prey, and background barriers.
- A bat searches for prey with position that initially is random. Bats changes its frequency depending on the proximity of their target, then affecting velocity. Thus, to change their position, all bats used frequency calculated by Equation (4) and velocity computed by Equation (5). The new position is defined by Equation (6). The bat algorithm is considered a frequency-tuning algorithm that provides a balanced combination of exploration and exploitation. While more (positive) velocity, more exploration, less (positive) velocity, more exploitation.
| Algorithm 1: Bat algorithm. |
 |
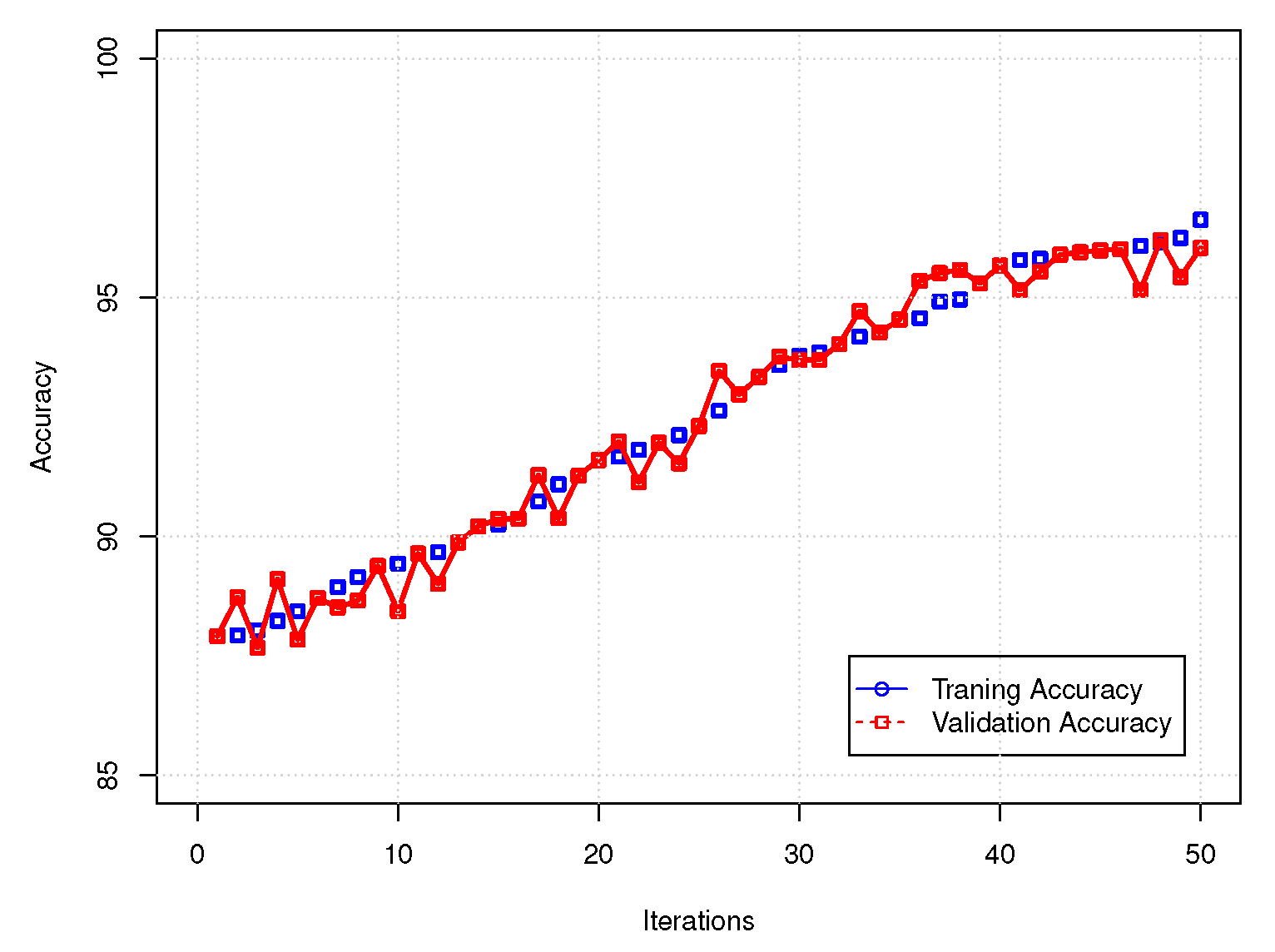
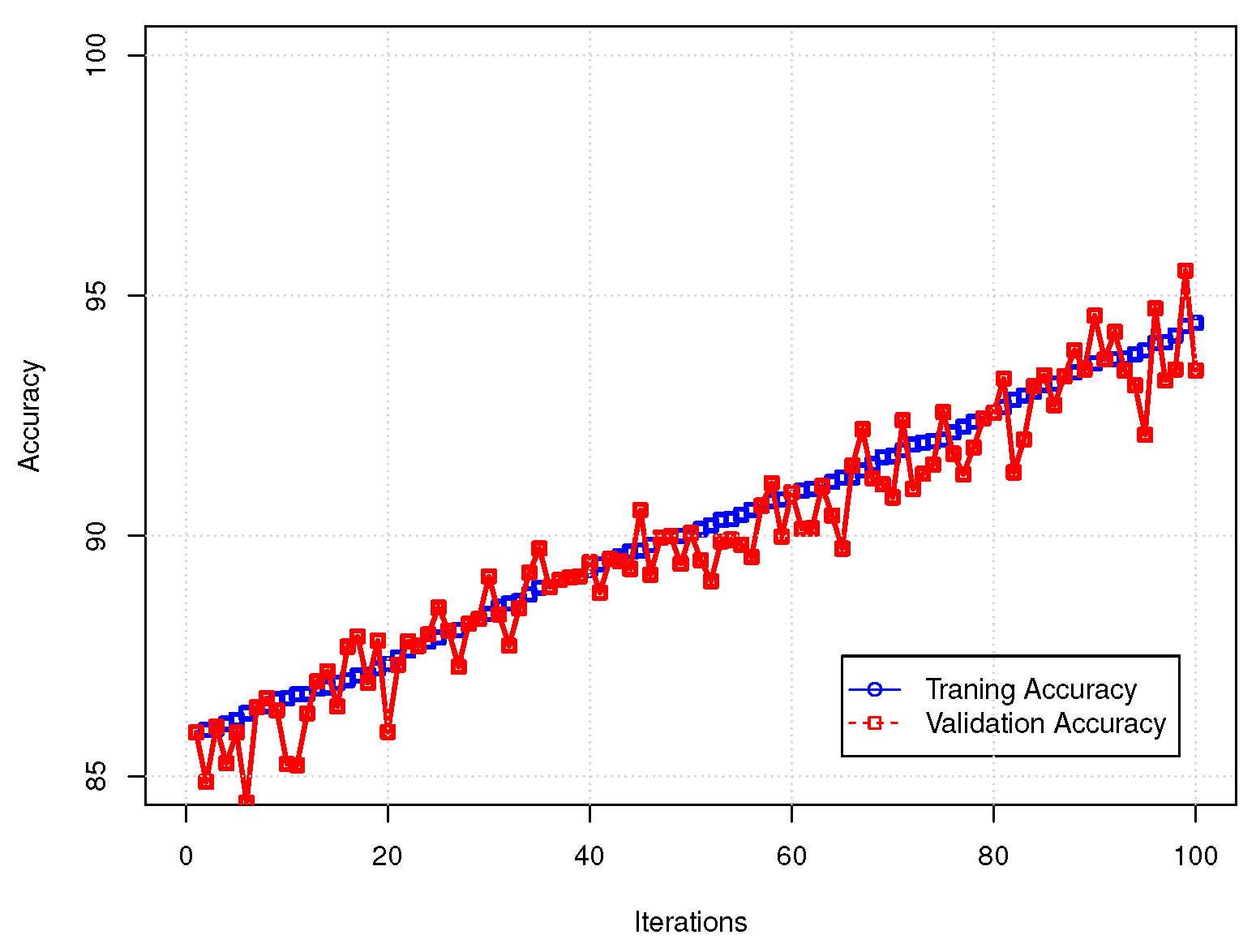
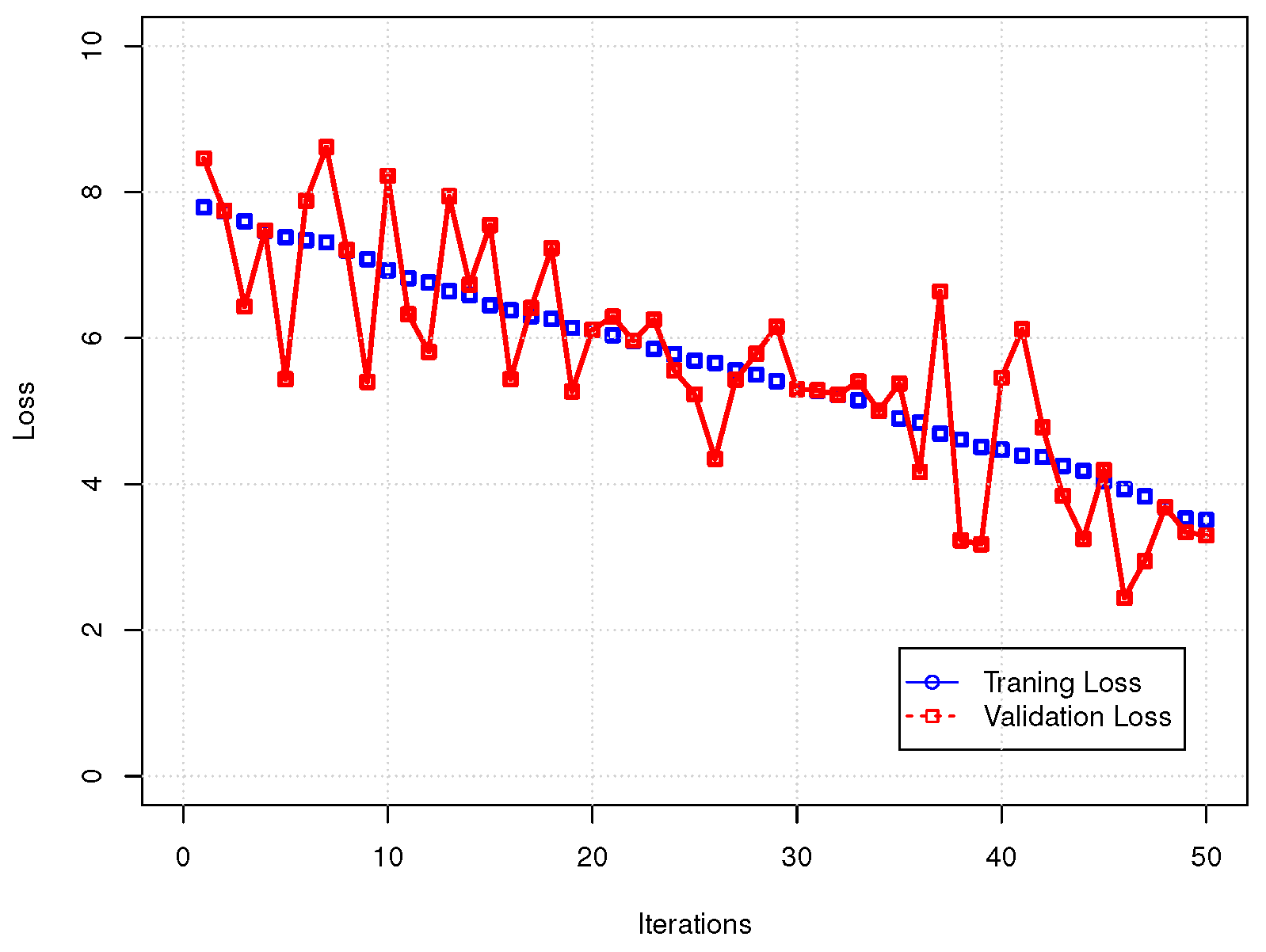
6. Computational Experiments
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Poewe, W.; Seppi, K.; Tanner, C.M.; Halliday, G.M.; Brundin, P.; Volkmann, J.; Schrag, A.E.; Lang, A.E. Parkinson disease. Nat. Rev. Dis. Primers 2017, 3. [Google Scholar] [CrossRef] [PubMed]
- Oung, Q.W.; Muthusamy, H.; Lee, H.L.; Basah, S.N.; Yaacob, S.; Sarillee, M.; Lee, C.H. Technologies for Assessment of Motor Disorders in Parkinson’s Disease: A Review. Sensors 2015, 15, 21710–21745. [Google Scholar] [CrossRef] [PubMed]
- Kieburtz, K.; Tilley, B.C.; Elm, J.J.; Babcock, D.; Hauser, R.; Ross, G.W.; Augustine, A.H.; Augustine, E.U.; Aminoff, M.J.; Bodis-Wollner, I.G.; et al. Effect of Creatine Monohydrate on Clinical Progression in Patients With Parkinson Disease: A Randomized Clinical Trial. JAMA 2015, 313, 584–593. [Google Scholar] [CrossRef] [PubMed]
- Bernardo, L.S.; Quezada, A.; Munoz, R.; Maia, F.M.; Pereira, C.R.; Wu, W.; de Albuquerque, V.H.C. Handwritten pattern recognition for early Parkinson’s disease diagnosis. Pattern Recognit. Lett. 2019, 78–84. [Google Scholar] [CrossRef]
- Gelb, D.J.; Oliver, E.; Gilman, S. Diagnostic criteria for Parkinson disease. Arch. Neurol. 1999, 56, 33–39. [Google Scholar] [CrossRef]
- Erdogdu Sakar, B.; Serbes, G.; Sakar, C.O. Analyzing the effectiveness of vocal features in early telediagnosis of Parkinson’s disease. PLoS ONE 2017, 12, e0182428. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Wu, T.; Yao, M.; Yang, J. Dolphin swarm algorithm. Front. Inf. Technol. Electron. Eng. 2016, 17, 717–729. [Google Scholar] [CrossRef]
- Eltaeib, T.; Mahmood, A. Differential Evolution: A Survey and Analysis. Appl. Sci. 2018, 8, 1945. [Google Scholar] [CrossRef]
- Chakraborty, A.; Kar, A.K. Swarm Intelligence: A Review of Algorithms. In Nature-Inspired Computing and Optimization; Springer International Publishing: Cham, Switzerland, 2017; pp. 475–494. [Google Scholar] [CrossRef]
- Câmara, D. Evolution and Evolutionary Algorithms. In Bio-inspired Networking; Elsevier: Amsterdam, The Netherlands, 2015; pp. 1–30. [Google Scholar] [CrossRef]
- Darwish, A. Bio-inspired computing: Algorithms review, deep analysis, and the scope of applications. Future Comput. Inform. J. 2018, 3, 231–246. [Google Scholar] [CrossRef]
- Bermejo, J.F.; Fernández, J.F.G.; Polo, F.O.; Márquez, A.C. A Review of the Use of Artificial Neural Network Models for Energy and Reliability Prediction. A Study of the Solar PV, Hydraulic and Wind Energy Sources. Appl. Sci. 2019, 9, 1844. [Google Scholar] [CrossRef]
- Firdaus, M.; Pratiwi, S.E.; Kowanda, D.; Kowanda, A. Literature review on Artificial Neural Networks Techniques Application for Stock Market Prediction and as Decision Support Tools. In Proceedings of the 2018 Third International Conference on Informatics and Computing (ICIC), Palembang, Indonesia, 17–18 October 2018. [Google Scholar] [CrossRef]
- Zhang, G. Neural networks for classification: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2000, 30, 451–462. [Google Scholar] [CrossRef]
- Bashiri, M.; Geranmayeh, A.F. Tuning the parameters of an artificial neural network using central composite design and genetic algorithm. Scientia Iranica 2011, 18, 1600–1608. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Wang, D.H.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Yang, X. A New Metaheuristic Bat-Inspired Algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar]
- Munoz, R.; Olivares, R.; Taramasco, C.; Villarroel, R.; Soto, R.; Alonso-Sánchez, M.F.; Merino, E.; de Albuquerque, V.H.C. A new EEG software that supports emotion recognition by using an autonomous approach. Neural Comput. Appl. 2018. [Google Scholar] [CrossRef]
- Taramasco, C.; Olivares, R.; Munoz, R.; Soto, R.; Villar, M.; de Albuquerque, V.H.C. The patient bed assignment problem solved by autonomous bat algorithm. Appl. Soft Comput. 2019, 81, 105484. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Roberts, S.J.; Costello, D.A.; Moroz, I.M. Exploiting Nonlinear Recurrence and Fractal Scaling Properties for Voice Disorder Detection. BioMed Eng. OnLine 2007, 6, 23. [Google Scholar] [CrossRef]
- Paredes, C.; Schuck, A. The Use of Wavelet Packet Transform and Artificial Neural Networks in Analysis and Classification of Dysphonic Voices. IEEE Trans. Biomed. Eng. 2007, 54, 1898–1900. [Google Scholar] [CrossRef][Green Version]
- Khamparia, A.; Gupta, D.; Nguyen, N.G.; Khanna, A.; Pandey, B.; Tiwari, P. Sound Classification Using Convolutional Neural Network and Tensor Deep Stacking Network. IEEE Access 2019, 7, 7717–7727. [Google Scholar] [CrossRef]
- Purwins, H.; Li, B.; Virtanen, T.; Schluter, J.; Chang, S.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Select. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef]
- Rabiner, L. On the use of autocorrelation analysis for pitch detection. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 24–33. [Google Scholar] [CrossRef]
- Markel, J. The SIFT algorithm for fundamental frequency estimation. IEEE Trans. Audio Electroacoust. 1972, 20, 367–377. [Google Scholar] [CrossRef]
- Smitha; Shetty, S.; Hegde, S.; Dodderi, T. Classification of Healthy and Pathological voices using MFCC and ANN. In Proceedings of the 2018 Second International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bangalore, India, 9–10 February 2018. [Google Scholar] [CrossRef]
- Firdos, S.; Umarani, K. Disordered voice classification using SVM and feature selection using GA. In Proceedings of the 2016 Second International Conference on Cognitive Computing and Information Processing (CCIP), Mysore, India, 12–13 August 2016. [Google Scholar] [CrossRef]
- Lu, N.; Zhou, J.; He, Y.; Liu, Y. Particle Swarm Optimization for Parameter Optimization of Support Vector Machine Model. In Proceedings of the 2009 Second International Conference on Intelligent Computation Technology and Automation, Changsha, China, 10–11 October 2009. [Google Scholar] [CrossRef]
- Subbulakshmi, C.V.; Deepa, S.N. Medical Dataset Classification: A Machine Learning Paradigm Integrating Particle Swarm Optimization with Extreme Learning Machine Classifier. Sci. World J. 2015, 2015, 1–12. [Google Scholar] [CrossRef]
- Xu, Y.; Yao, F.; Chai, S.; Sun, L. Multi-objective optimization of extreme learning machine using physical programming. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016. [Google Scholar] [CrossRef]
- Cai, Y.; Liu, X.; Wu, Y.; Hu, P.; Wang, R.; Wu, B.; Cai, Z. Extreme Learning Machine Based on Evolutionary Multi-objective Optimization. In Communications in Computer and Information Science; Springer: Singapore, 2017; pp. 420–435. [Google Scholar] [CrossRef]
- Mao, W.; Tian, M.; Cao, X.; Xu, J. Model selection of extreme learning machine based on multi-objective optimization. Neural Comput. Appl. 2012, 22, 521–529. [Google Scholar] [CrossRef]
- Yunusova, Y.; Weismer, G.; Westbury, J.R.; Lindstrom, M.J. Articulatory Movements During Vowels in Speakers With Dysarthria and Healthy Controls. J. Speech Lang. Hear. Res. 2008, 51, 596–611. [Google Scholar] [CrossRef]
- Falk, T.H.; Chan, W.Y.; Shein, F. Characterization of atypical vocal source excitation, temporal dynamics and prosody for objective measurement of dysarthric word intelligibility. Speech Commun. 2012, 54, 622–631. [Google Scholar] [CrossRef]
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 25 November 2019).
- Noda, J.J.; Travieso-González, C.M.; Sánchez-Rodríguez, D.; Alonso-Hernández, J.B. Acoustic Classification of Singing Insects Based on MFCC/LFCC Fusion. Appl. Sci. 2019, 9, 4097. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel Speech Signal Processing Algorithms for High-Accuracy Classification of Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef]
- Noda, J.; Travieso, C.; Sánchez-Rodríguez, D. Fusion of Linear and Mel Frequency Cepstral Coefficients for Automatic Classification of Reptiles. Appl. Sci. 2017, 7, 178. [Google Scholar] [CrossRef]
- Humayoo, M.; Cheng, X. Parameter Estimation with the Ordered l2 Regularization via an Alternating Direction Method of Multipliers. Appl. Sci. 2019, 9, 4291. [Google Scholar] [CrossRef]
- Lilliefors, H. On the Kolmogorov-Smirnov Test for Normality with Mean and Variance Unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Mann, H.; Donald, W. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Statist. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Gavrilescu, M.; Vizireanu, N. Feedforward Neural Network-Based Architecture for Predicting Emotions from Speech. Data 2019, 4, 101. [Google Scholar] [CrossRef]
- Cao, W.; Gao, J.; Ming, Z.; Cai, S. Some Tricks in Parameter Selection for Extreme Learning Machine. IOP Conf. Ser. Mater. Sci. Eng. 2017, 261, 012002. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Yao, X. A Survey of Automatic Parameter Tuning Methods for Metaheuristics. IEEE Trans. Evol. Comput. 2019, 1–16. [Google Scholar] [CrossRef]
- Stützle, T.; López-Ibáñez, M.; Pellegrini, P.; Maur, M.; de Oca, M.M.; Birattari, M.; Dorigo, M. Parameter Adaptation in Ant Colony Optimization. In Autonomous Search; Springer: Berlin/Heidelberg, Germany, 2011; pp. 191–215. [Google Scholar] [CrossRef]
- Talbi, E. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Yang, X. Nature-Inspired Metaheuristic Algorithms, 2nd ed.; Luniver Press: Beckington, UK, 2010. [Google Scholar]
- Yang, X.; Gandomi, A.H. Bat algorithm: A novel approach for global engineering optimization. Eng. Comput. 2012, 29, 464–483. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, C.; Zhao, Y.; Shi, Z. Adaptive Bat Algorithm Optimization Strategy for Observation Matrix. Appl. Sci. 2019, 9, 3008. [Google Scholar] [CrossRef]
- Nguyen, T.; Pan, J.; Dao, T. A Compact Bat Algorithm for Unequal Clustering in Wireless Sensor Networks. Appl. Sci. 2019, 9, 1973. [Google Scholar] [CrossRef]
- Bangyal, W.H.; Ahmad, J.; Rauf, H.T. Optimization of Neural Network Using Improved Bat Algorithm for Data Classification. J. Med. Imaging Health Inform. 2019, 9, 670–681. [Google Scholar] [CrossRef]
- Jaddi, N.S.; Abdullah, S.; Hamdan, A.R. Optimization of neural network model using modified bat-inspired algorithm. Appl. Soft Comput. 2015, 37, 71–86. [Google Scholar] [CrossRef]
- Yang, X.S.; He, X. Bat algorithm: Literature review and applications. Int. J. Bio-Inspired Comput. 2013, 5, 141. [Google Scholar] [CrossRef]
- Marwala, T. Handbook of Machine Learning; World Scientific: Singapore, 2018. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
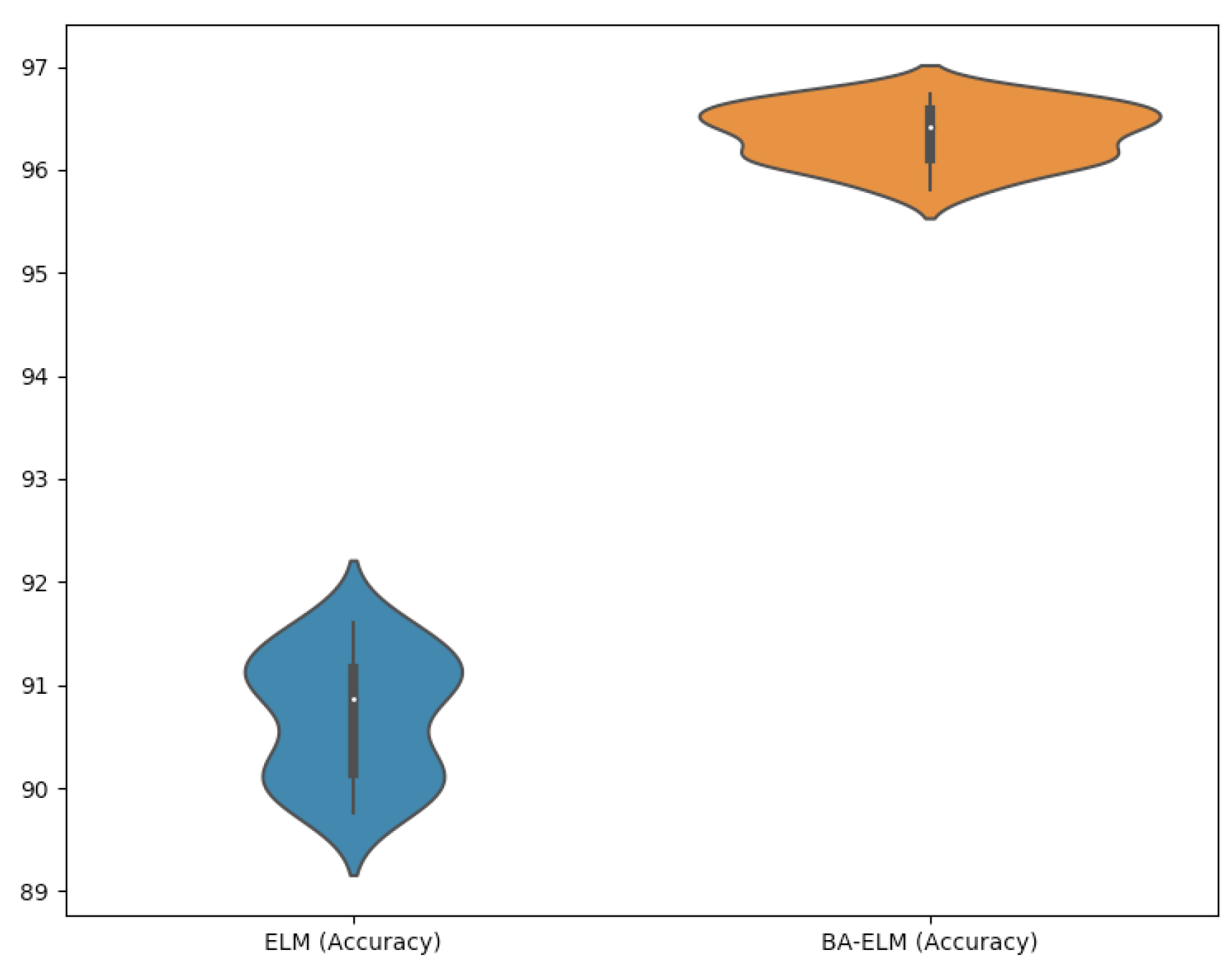
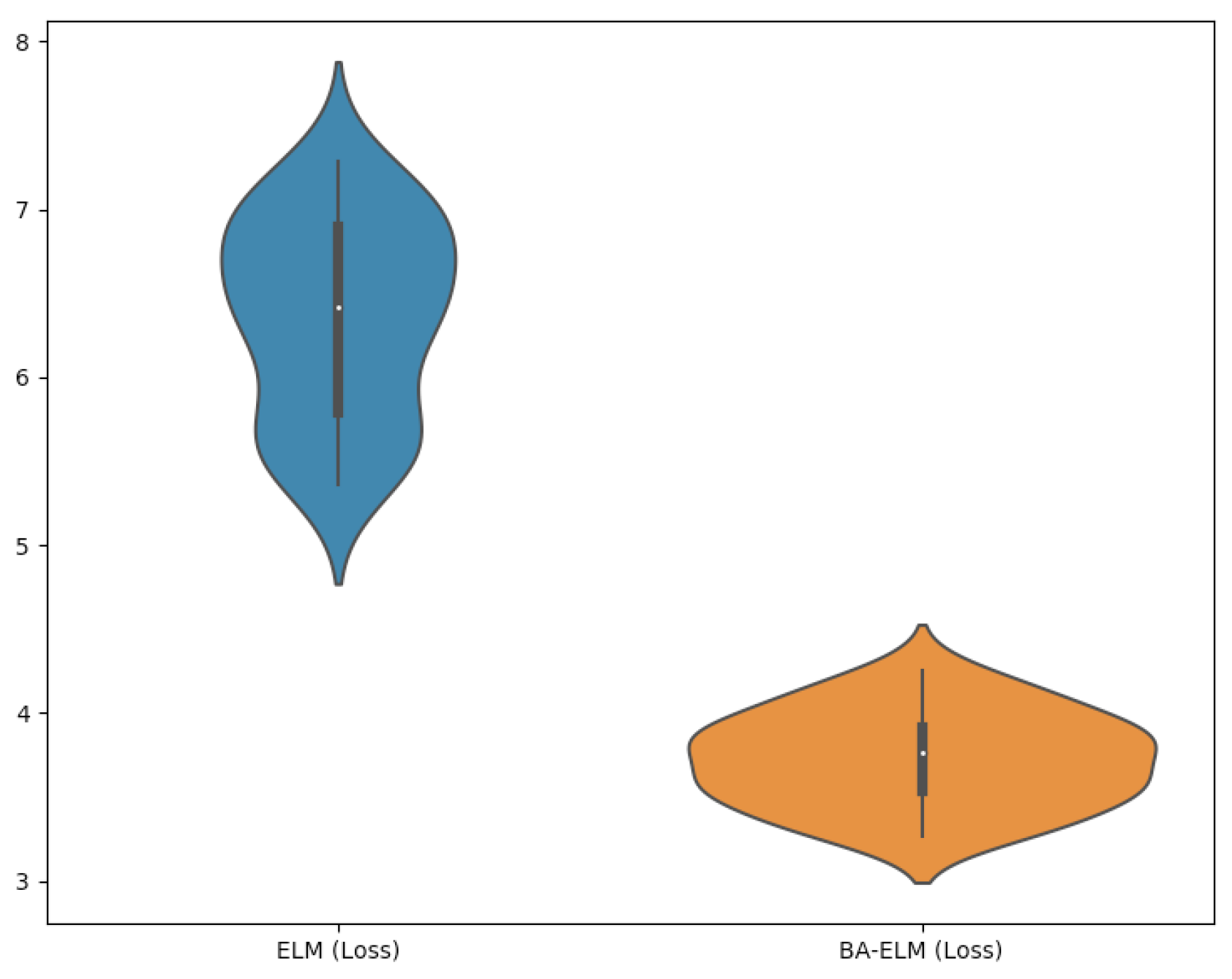
| Statistical Comparison | ||||
|---|---|---|---|---|
| Item | Accuracy | Loss | ||
| ELM | BA-ELM | ELM | BA-ELM | |
| Average | 90.70 | 96.34 | 6.35 | 3.72 |
| Standard deviation | 0.59 | 0.27 | 0.58 | 0.27 |
| Minimum | 89.76 | 95.81 | 5.36 | 3.27 |
| 1-IQR (25%) | 90.14 | 96.11 | 5.78 | 3.53 |
| 2-IQR (50%) | 90.87 | 96.41 | 6.42 | 3.77 |
| 3-IQR (75%) | 91.15 | 96.58 | 6.89 | 3.91 |
| Maximum | 91.61 | 96.74 | 7.29 | 4.25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivares, R.; Munoz, R.; Soto, R.; Crawford, B.; Cárdenas, D.; Ponce, A.; Taramasco, C. An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease. Appl. Sci. 2020, 10, 1827. https://doi.org/10.3390/app10051827
Olivares R, Munoz R, Soto R, Crawford B, Cárdenas D, Ponce A, Taramasco C. An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease. Applied Sciences. 2020; 10(5):1827. https://doi.org/10.3390/app10051827
Chicago/Turabian StyleOlivares, Rodrigo, Roberto Munoz, Ricardo Soto, Broderick Crawford, Diego Cárdenas, Aarón Ponce, and Carla Taramasco. 2020. "An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease" Applied Sciences 10, no. 5: 1827. https://doi.org/10.3390/app10051827
APA StyleOlivares, R., Munoz, R., Soto, R., Crawford, B., Cárdenas, D., Ponce, A., & Taramasco, C. (2020). An Optimized Brain-Based Algorithm for Classifying Parkinson’s Disease. Applied Sciences, 10(5), 1827. https://doi.org/10.3390/app10051827