Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Preliminary Concepts
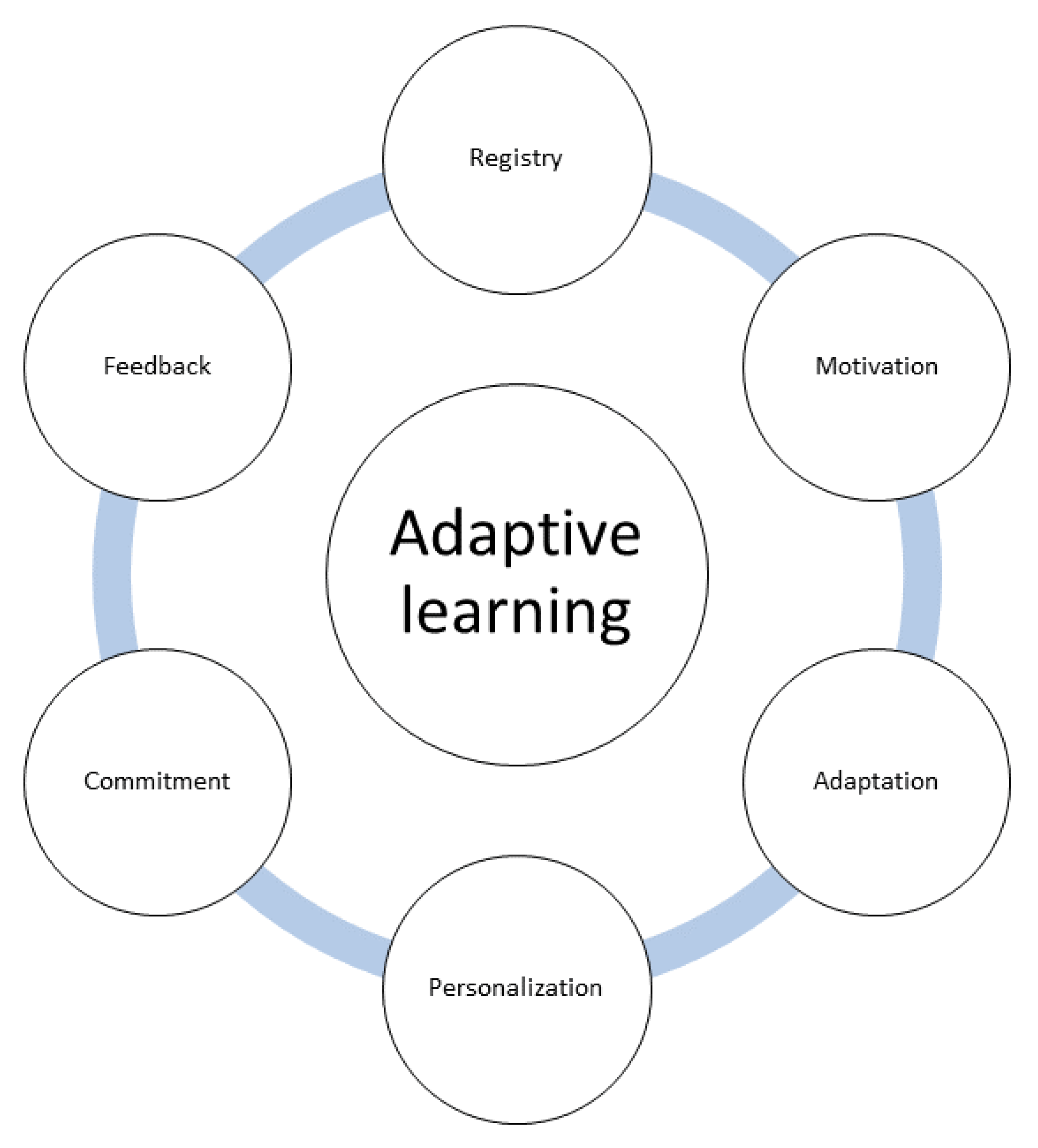
2.1. Adaptive Learning
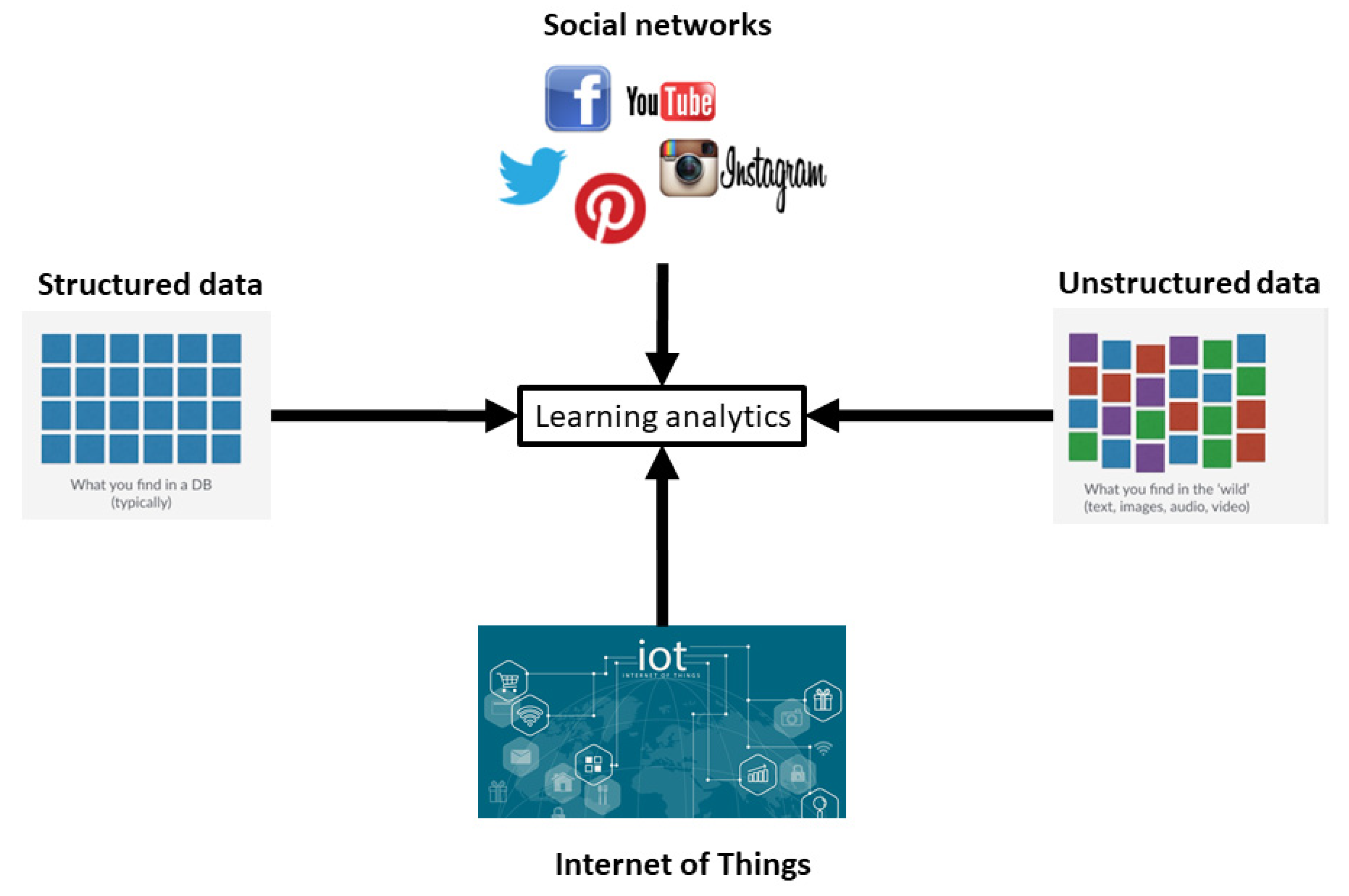
2.2. Big Data
3. Methods
3.1. Data
3.2. Description of the Application Environment of an Adaptive Learning Model
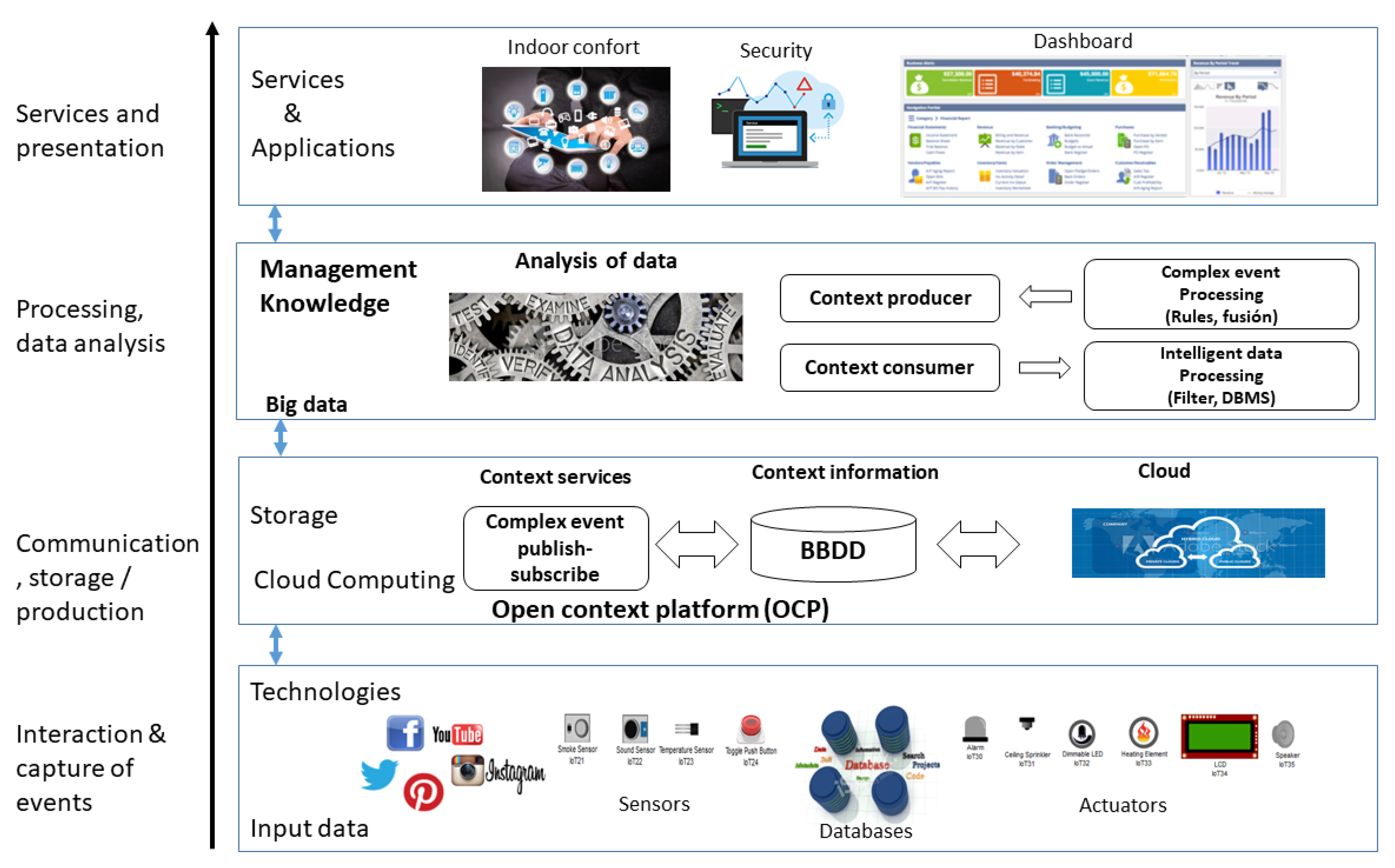
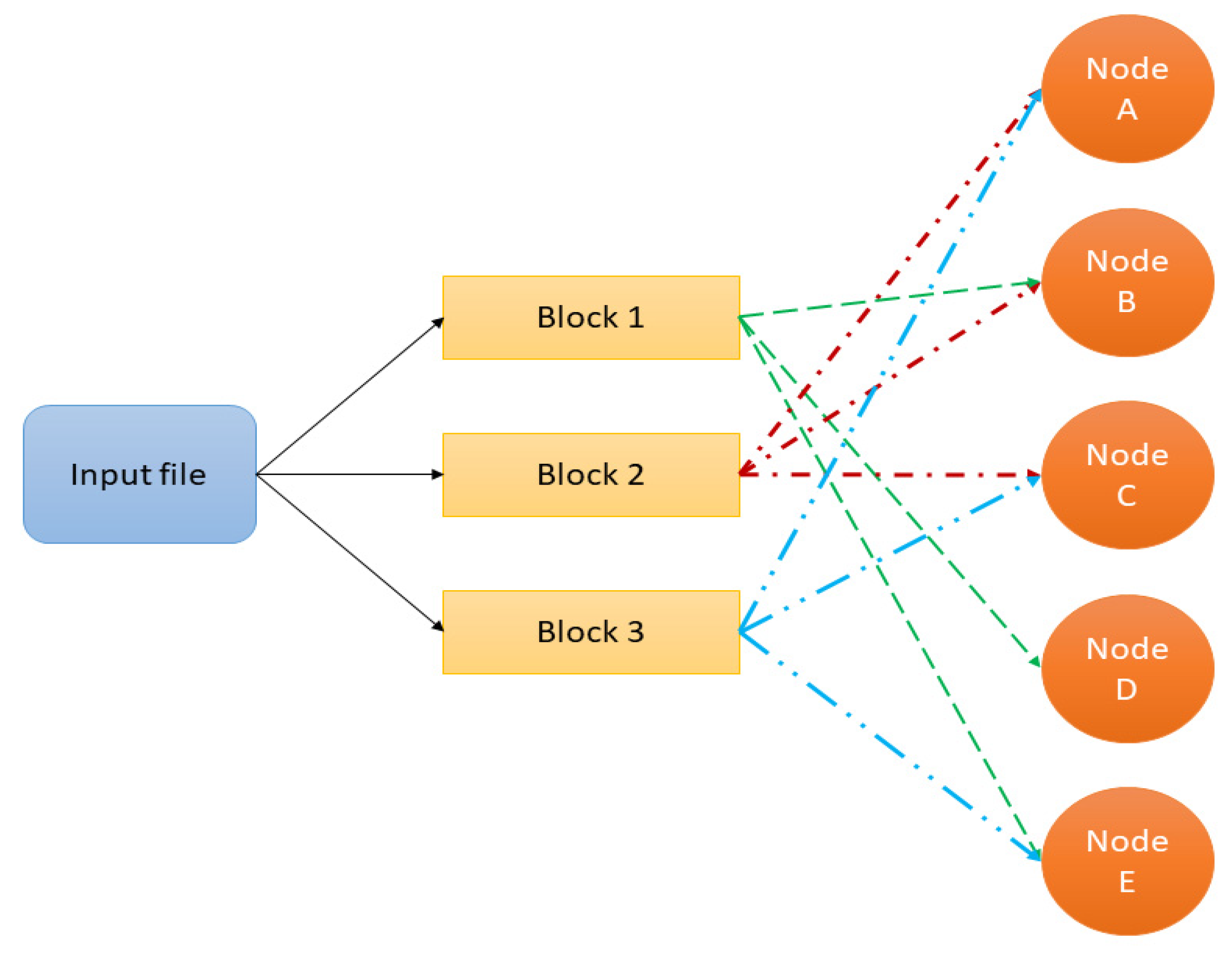
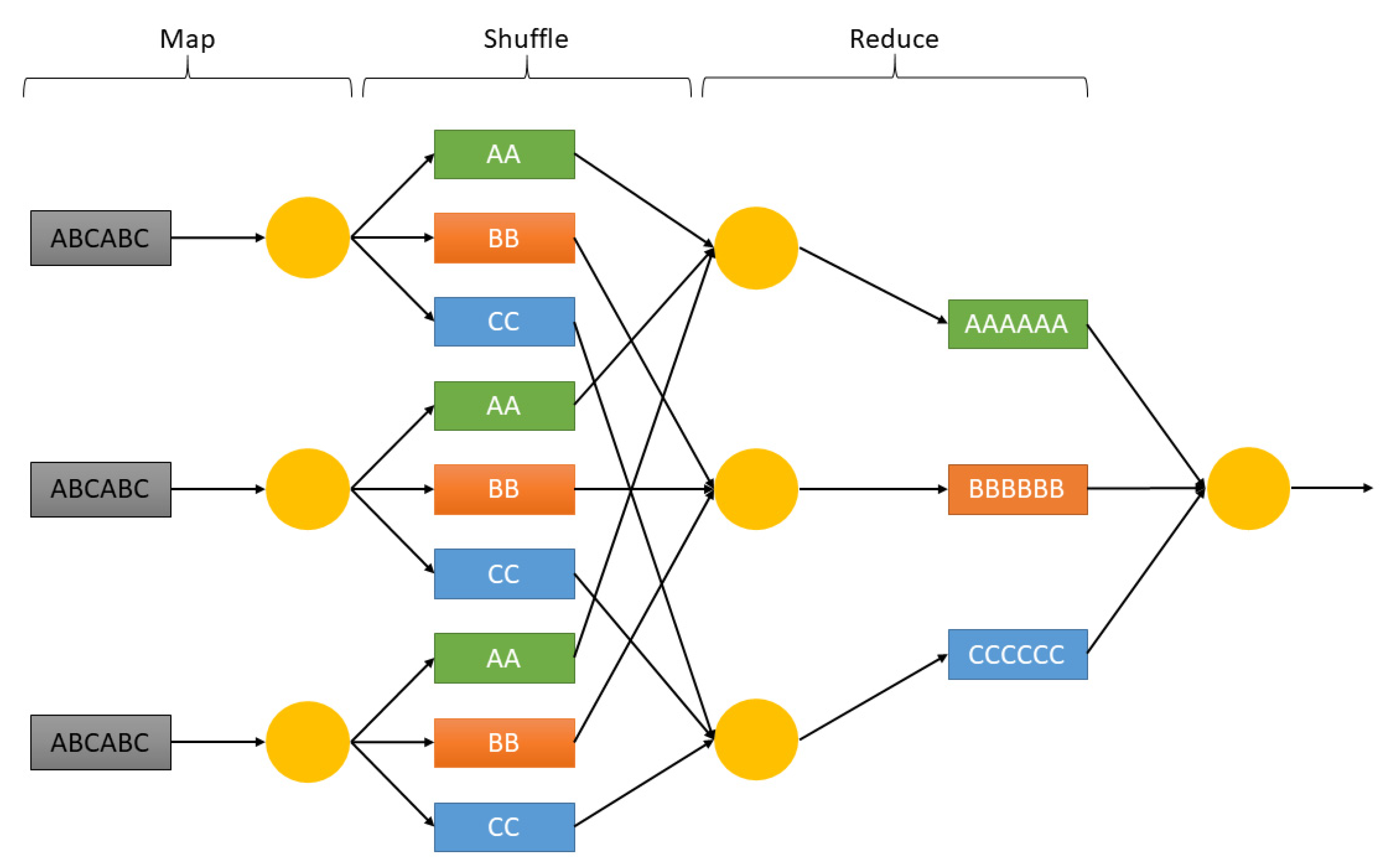
3.3. Technology for Data Analysis
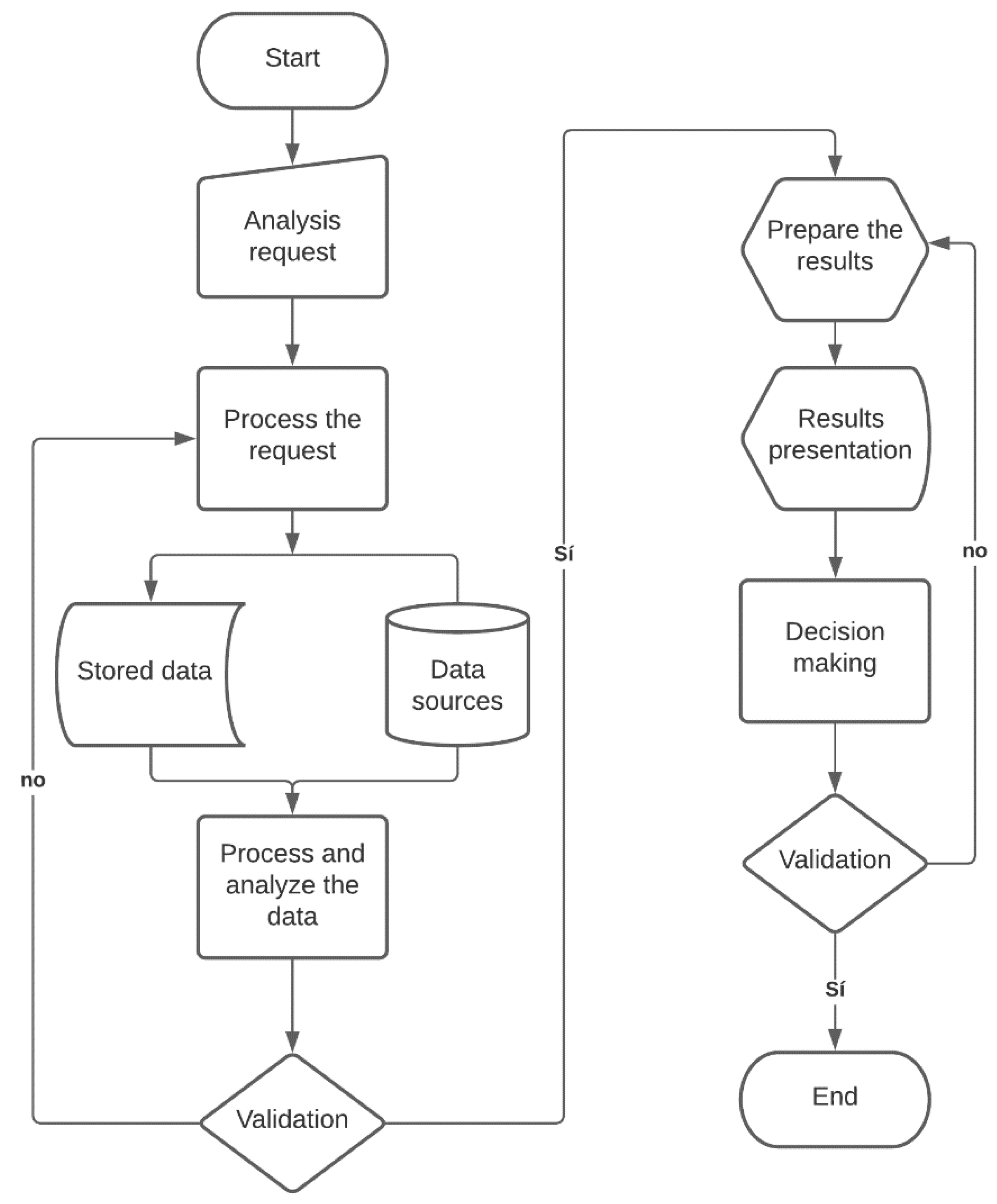
3.4. Model for Data Analysis in a University Environment
3.5. Deployment of a Big Data Framework
3.6. Integration of a Big Data Model in Adaptive Learning
4. Results
4.1. Description of the Application Environment and Population Considered
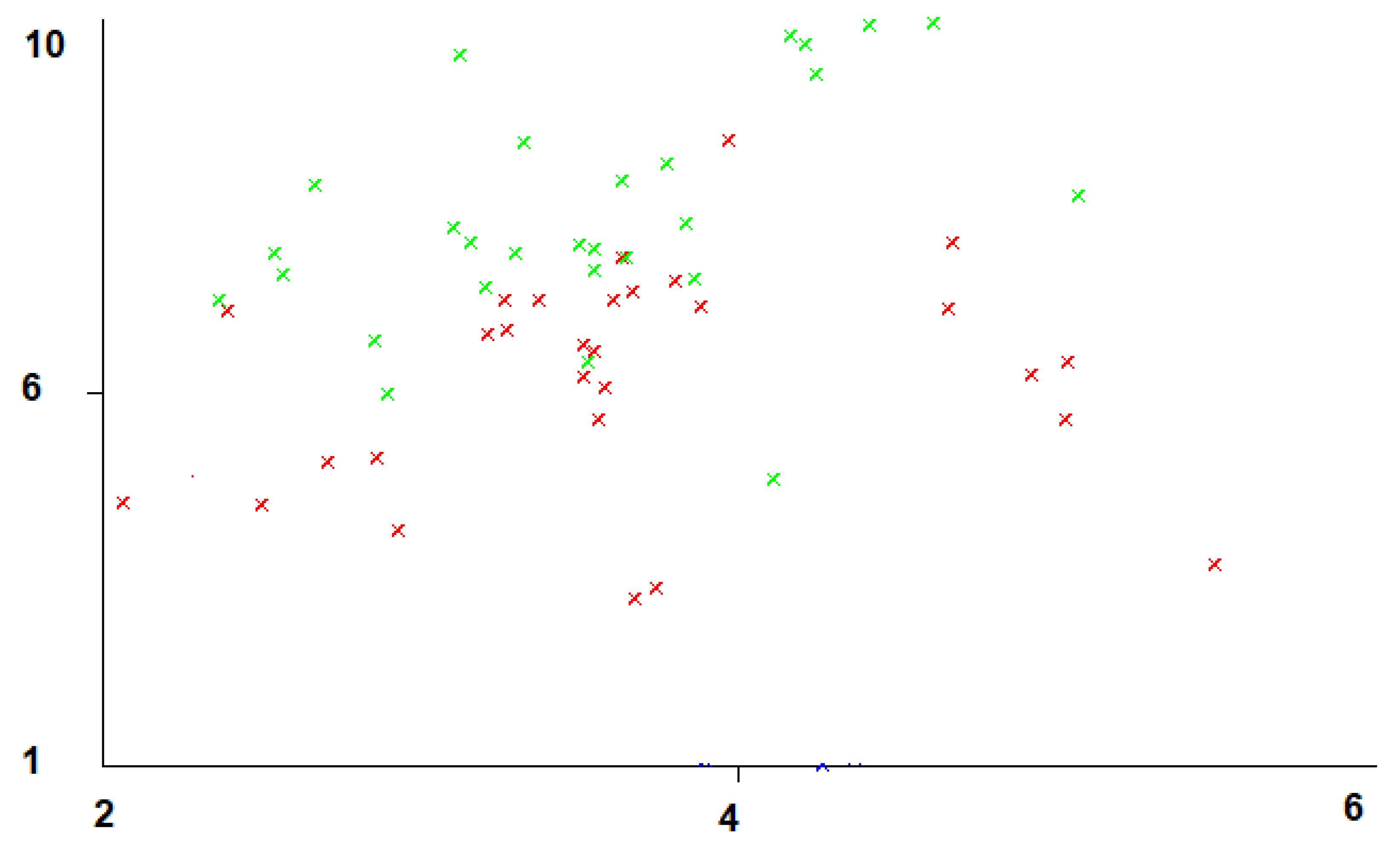
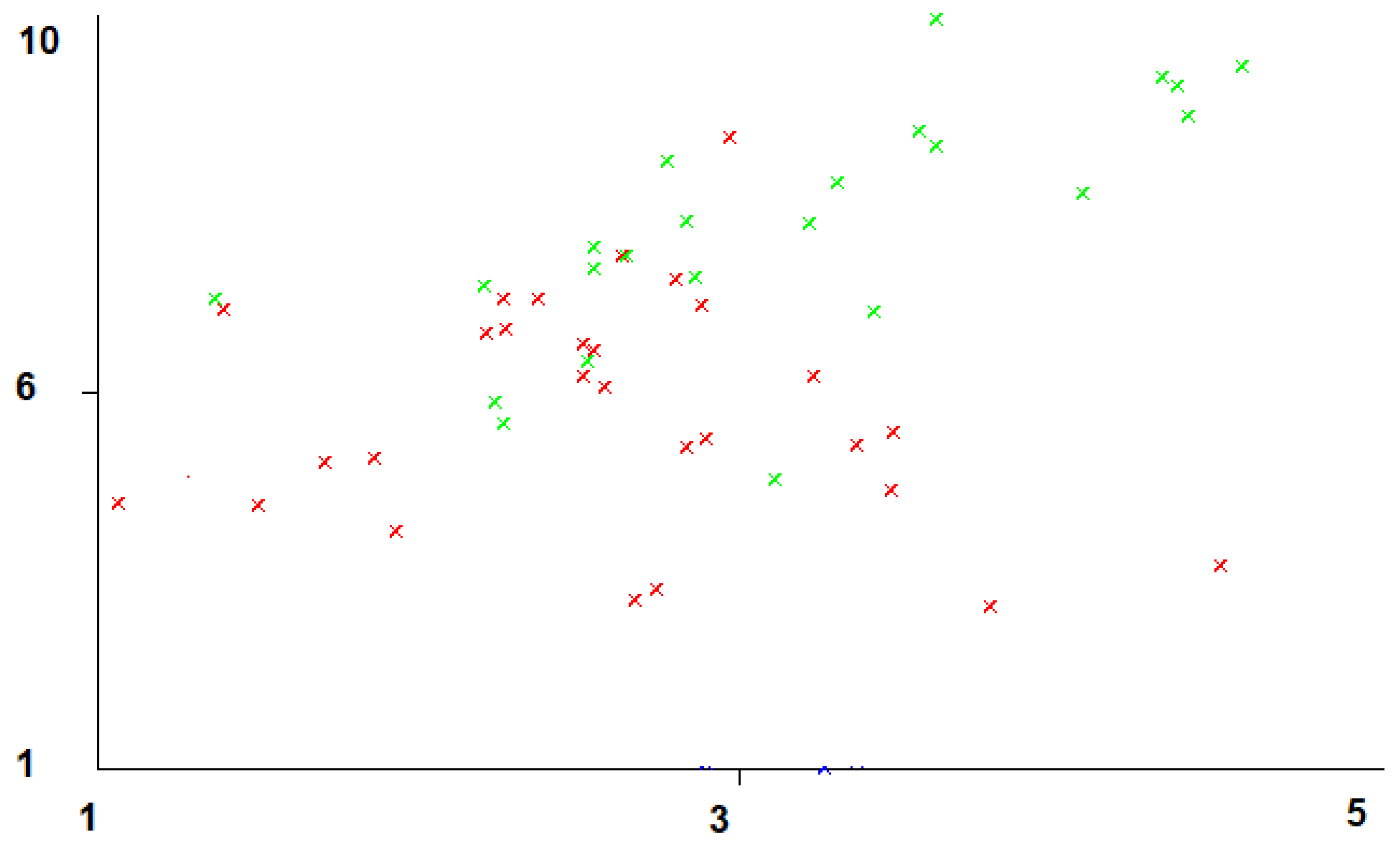
4.2. Data Considered in the Analysis
- Identify computer systems, their elements and the interaction between them.
- Apply the best industry practices in solving basic IT problems.
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vasconcelos, F.H.L.; Da Silva, T.E.V.; Mota, J.C.M.; Silva, T.E.V. Multilinear Educational Data Analysis for Evaluation of Engineering Education. IEEE Lat. Am. Trans. 2015, 13, 2785–2791. [Google Scholar] [CrossRef]
- Katz, I.R. Testing Information Literacy in Digital Environments: ETS’s iSkills Assessment. Inf. Technol. Libr. 2007, 26, 3–12. [Google Scholar] [CrossRef]
- Fathema, N.; Shannon, D.; Ross, M. Expanding The Technology Acceptance Model (TAM) to Examine Faculty Use of Learning Management Systems (LMSs) In Higher Education Institutions. J. Online Learn. Teach. 2015, 11, 210–232. [Google Scholar]
- Hill, J.R.; Hannafin, M.J. Teaching and learning in digital environments: The resurgence of resource-based learning. Educ. Technol. Res. Dev. 2001, 49, 37–52. [Google Scholar] [CrossRef]
- Cook, D.J.; Augusto, J.C.; Jakkula, V.R. Ambient intelligence: Technologies, applications, and opportunities. Pervasive Mob. Comput. 2009, 5, 277–298. [Google Scholar] [CrossRef]
- Hassan, R. Network Time and the New Knowledge Epoch. Time Soc. 2003, 12, 225–241. [Google Scholar] [CrossRef]
- Leidner, D. Globalization, culture, and information: Towards global knowledge transparency. J. Strat. Inf. Syst. 2010, 19, 69–77. [Google Scholar] [CrossRef]
- Amory, A.; Seagram, R. Educational game models: Conceptualization and evaluation. S. Afr. J. High. Educ. 2004, 17, 206–217. [Google Scholar] [CrossRef]
- Literat, I. Implications of massive open online courses for higher education: Mitigating or reifying educational inequities? High. Educ. Res. Dev. 2015, 34, 1164–1177. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Luján-Mora, S. Analysis of data mining techniques applied to LMS for personalized education. In Proceedings of the IEEE World Engineering Education Conference (EDUNINE), Santos, Brazil, 19–22 March 2017; pp. 85–89. [Google Scholar]
- Cohen, J. Parents as Educational Models and Definers. J. Marriage Fam. 1987, 49, 339–351. [Google Scholar] [CrossRef]
- Kanwar, A.; Kodhandaraman, B.; Umar, A. Toward Sustainable Open Education Resources: A Perspective From the Global South. Am. J. Distance Educ. 2010, 24, 65–80. [Google Scholar] [CrossRef]
- Huang, Y.-M.; Liang, T.-H.; Su, Y.-N.; Chen, N.-S. Empowering personalized learning with an interactive e-book learning system for elementary school students. Educ. Technol. Res. Dev. 2012, 60, 703–722. [Google Scholar] [CrossRef]
- Li, H.; Liu, S.-M.; Yu, X.-H.; Tang, S.-L.; Tang, C.-K. Coronavirus disease 2019 (COVID-19): Current status and future perspectives. Int. J. Antimicrob. Agents 2020, 55, 105951. [Google Scholar] [CrossRef] [PubMed]
- Villegas-Ch, W.; Román-Cañizares, M.; Palacios-Pacheco, X. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Appl. Sci. 2020, 10, 5371. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Luján-Mora, S.; Buenaño-Fernandez, D.; Palacios-Pacheco, X. Big data, the next step in the evolution of educational data analysis. In Proceedings of the Advances in Intelligent Systems and Computing, Libertad, Ecuador, 21–25 July 2018; Volume 721, pp. 138–147. [Google Scholar]
- Palacios-Pacheco, X.; Villegas-Ch, W.; Luján-Mora, S. Application of Data Mining for the Detection of Variables that Cause University Desertion. In Proceedings of the Communications in Computer and Information Science, Athens, Greece, 12–13 December 2019; Volume 895, pp. 510–520. [Google Scholar]
- Chen, C.-M.; Lee, H.-M.; Chen, Y.-H. Personalized e-learning system using Item Response Theory. Comput. Educ. 2005, 44, 237–255. [Google Scholar] [CrossRef]
- Chen, C.-M. Personalized E-learning system with self-regulated learning assisted mechanisms for promoting learning performance. Expert Syst. Appl. 2009, 36, 8816–8829. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Buenaño-Fernandez, D.; Luján-Mora, S. Comprehensive learning system based on the analysis of data and the recommendation of activities in a distance education environment. Int. J. Eng. Educ. 2019, 35, 1316–1325. [Google Scholar]
- Li, X.; Zhang, F.; Wang, Y. Research on Big Data Architecture, Key Technologies and Its Measures. In Proceedings of the 2013 IEEE 11th International Conference on Dependable, Autonomic and Secure Computing, Chengdu, China, 21–22 December 2013; pp. 1–4. [Google Scholar]
- Verma, C.; Pandey, R. Big Data representation for grade analysis through Hadoop framework. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 312–315. [Google Scholar]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Ortiz-Garcés, I.; Luján-Mora, S. Management of educative data in university students with the use of big data techniques. Rev. Ibérica Sist. Tecnol. Informação 2019, E19, 227–238. [Google Scholar]
- Wijaya, R.; Pudjoatmodjo, B. An overview and implementation of extraction-transformation-loading (ETL) process in data warehouse (Case study: Department of agriculture). In Proceedings of the 2015 3rd International Conference on Information and Communication Technology (ICoICT), Nusa Dua, Indonesia, 27–29 May 2015; pp. 70–74. [Google Scholar]
- Kim, T.; Lim, J. Designing an Efficient Cloud Management Architecture for Sustainable Online Lifelong Education. Sustainability 2019, 11, 1523. [Google Scholar] [CrossRef]
- Tianbo, Z. The Internet of Things Promoting Higher Education Revolution. In Proceedings of the 2012 Fourth International Conference on Multimedia Information Networking and Security, Nanjing, China, 2–4 November 2012; pp. 790–793. [Google Scholar]
- Strohbach, M.; Ziekow, H.; Gazis, V.; Akiva, N. Towards a Big Data Analytics Framework for IoT and Smart City Applications. In Modeling and Optimization in Science and Technologies; Springer: Berlin/Heidelberg, Germany, 2015; Volume 4, pp. 257–282. ISBN 978-3-319-09176-1. [Google Scholar]
- Mahmud, M.S.; Huang, J.Z.; Salloum, S.; Emara, T.Z.; Sadatdiynov, K. A survey of data partitioning and sampling methods to support big data analysis. Big Data Min. Anal. 2020, 3, 85–101. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Arias-Navarrete, A.; Palacios-Pacheco, X. Proposal of an Architecture for the Integration of a Chatbot with Artificial Intelligence in a Smart Campus for the Improvement of Learning. Sustainability 2020, 12, 1500. [Google Scholar] [CrossRef]
- Márquez-Vera, C.; Morales, C.R.; Soto, S.V. Predicting School Failure and Dropout by Using Data Mining Techniques. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2013, 8, 7–14. [Google Scholar] [CrossRef]
- Sun, Y.; Song, H.; Jara, A.J.; Bie, R. Internet of Things and Big Data Analytics for Smart and Connected Communities. IEEE Access 2016, 4, 766–773. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Lujan-Mora, S.; Buenano-Fernandez, D. Application of a Data Mining Method in to LMS for the Improvement of Engineering Courses in Networks. In Proceedings of the 10th International Conference of Education, Research and Innovation (Iceri2017), Seville, Spain, 16–18 November 2017; pp. 6374–6381. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S.; Buenaño-Fernandez, D. Data mining toolkit for extraction of knowledge from LMS. In Proceedings of the ACM International Conference Proceeding Series, Moscow, Russia, 18–21 April 2017; Volume 1346, pp. 31–35. [Google Scholar]
- Huda, M.; Maseleno, A.; Shahrill, M.; Jasmi, K.A.; Mustari, I.; Basiron, B. Exploring Adaptive Teaching Competencies in Big Data Era. Int. J. Emerg. Technol. Learn. (iJET) 2017, 12, 68. [Google Scholar] [CrossRef]
- Kerr, P. Adaptive learning. ELT J. 2016, 70, 88–93. [Google Scholar] [CrossRef]
- Janssen, M.; Van Der Voort, H.; Wahyudi, A. Factors influencing big data decision-making quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Winter, R.; Winter, R.; Strauch, B. A Method for Demand-driven Information Requirements Analysis in Data Warehousing Projects. In Proceedings of the 36th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 6–9 January 2003. [Google Scholar]
- Merla, P.; Liang, Y. Data analysis using hadoop MapReduce environment. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Chennai, India, 23–24 February 2017; pp. 4783–4785. [Google Scholar]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Luján-Mora, S. Application of a Smart City Model to a Traditional University Campus with a Big Data Architecture: A Sustainable Smart Campus. Sustainability 2019, 11, 2857. [Google Scholar] [CrossRef]
- Álvarez-Campana, M.; López, G.L.; Vazquez, E.; Villagra, V.A.; Berrocal, J. Smart CEI Moncloa: An IoT-based Platform for People Flow and Environmental Monitoring on a Smart University Campus. Sensors 2017, 17, 2856. [Google Scholar] [CrossRef]
- Saraladevi, B.; Pazhaniraja, N.; Paul, P.V.; Basha, M.S.; Dhavachelvan, P. Big Data and Hadoop-a Study in Security Perspective. Procedia Comput. Sci. 2015, 50, 596–601. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; Volume 26, pp. 1–10. [Google Scholar] [CrossRef]
- Cohen, J.; Acharya, S. Towards a more secure Apache Hadoop HDFS infrastructure: Anatomy of a targeted advanced persistent threat against HDFS and analysis of trusted computing based countermeasures. In Proceedings of the Network and System Security NSS 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7873, pp. 735–741. [Google Scholar] [CrossRef]
- Ghazi, M.R.; Gangodkar, D. Hadoop, MapReduce and HDFS: A Developers Perspective. Procedia Comput. Sci. 2015, 48, 45–50. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. Mapreduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Dai, W.; Ji, W. A MapReduce Implementation of C4.5 Decision Tree Algorithm. Int. J. Database Theory Appl. 2014, 7, 49–60. [Google Scholar] [CrossRef]
- Atif, Y.; Mathew, S.S.; Lakas, A. Building a smart campus to support ubiquitous learning. J. Ambient. Intell. Humaniz. Comput. 2014, 6, 223–238. [Google Scholar] [CrossRef]
- Picciano, A.G. The Evolution of Big Data and Learning Analytics in American Higher Education. Online Learn. 2012, 16, 9–20. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Luján-Mora, S. Systematic Review of Evidence on Data Mining Applied to LMS Platforms for Improving E-Learning. In Proceedings of the International Technology, Education and Development Conference, Valencia, Spain, 6–8 March 2017; pp. 6537–6545. [Google Scholar]
- Ferguson, R. Learning analytics: Drivers, developments and challenges. Int. J. Technol. Enhanc. Learn. 2012, 4, 304. [Google Scholar] [CrossRef]
- Boumiza, S.; Souilem, D.; Bekiarski, A. Workflow approach to design automatic tutor in e-learning environment. In Proceedings of the 2016 International Conference on Control, Decision and Information Technologies (CoDIT), St. Julian’s, Malta, 6–8 April 2016; pp. 263–268. [Google Scholar]
- Baicun, W.; Jiyuan, Z.; Xianming, Q.; Jingchen, D.; Yanhong, Z. Research on New-Generation Intelligent Manufacturing based on Human-Cyber-Physical Systems. Chin. J. Eng. Sci. 2018, 20, 29–34. [Google Scholar] [CrossRef]
- McHugh, J.; Cuddihy, P.E.; Williams, J.W.; Aggour, K.S.; Vijay, S.K.; Mulwad, V. Integrated access to big data polystores through a knowledge-driven framework. Proc. IEEE Int. Conf. Big Data 2018, 2018, 1494–1503. [Google Scholar]
- He, C.; Lu, Y.; Swanson, D. Matchmaking: A New MapReduce Scheduling Technique. In Proceedings of the 2011 IEEE Third International Conference on Cloud Computing Technology and Science, Athens, Greece, 29 November–1 December 2011; pp. 40–47. [Google Scholar]
- Mazumdar, S.; Dhar, S. Hadoop as Big Data Operating System—The Emerging Approach for Managing Challenges of Enterprise Big Data Platform. In Proceedings of the 2015 IEEE First International Conference on Big Data Computing Service and Applications, Redwood City, CA, USA, 30 March–2 April 2015 ; pp. 499–505. [Google Scholar]
- Hillier, D.; Mitchell, A.; Millwood, R. ‘Change of heart!’: A new e-learning model geared to addressing complex and sensitive public health issues. Innov. Educ. Teach. Int. 2005, 42, 277–287. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Instances | Percentage of Hits |
|---|---|---|
| Correctly Classified Instances | 141 | 94% |
| Incorrectly Classified Instances | 9 | 72.115% |
| Kappa statistic | 0.91 | |
| Mean absolute error | 0.0598 | |
| Root mean squared error | 0.193 | |
| Relative absolute error | 13.4523% | |
| Root relative squared error | 40.9465% | |
| Total Number of Instances | 150 |
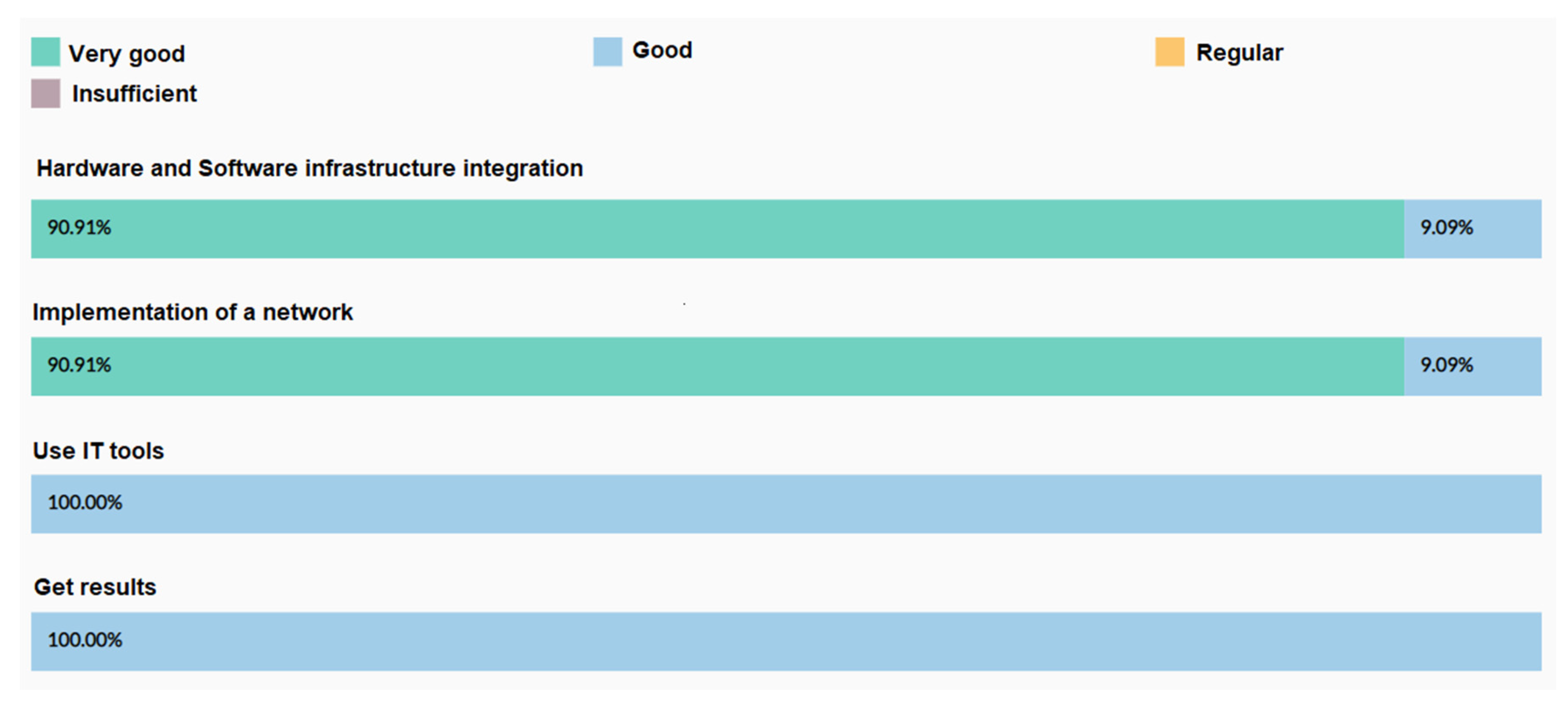
| Elements | Very Good | Good | Regular | Insufficient |
|---|---|---|---|---|
| Hardware and Software Infrastructure Integration | Integrates the appropriate concepts in the installation of the Operating System and assembly of computer components in a justified, structured and efficient way. | Integrate the concepts in the installation of the Operating System and assembly of computer components in a justified, structured and efficient way. | Integrates the concepts in the installation of the Operating System and assembly of computer components in a justified and structured way. | Integrates the basic concepts in the installation of the Operating System and assembly of computer components. |
| Learning outcomes | ||||
| 1 | X | X | ||
| 2 | X | X | ||
| Implementation of a data network | Properly configure the active equipment and manage network standards aligned to the solution of the problem | Configure the active equipment and manage network standards aligned to the solution of the problem. | Configure active equipment and manage network standards aligned to the partial solution of the problem. | It partially configures the active equipment and handles network standards, but they are not aligned to the solution of the problem. |
| Learning outcomes | ||||
| 2 | X | X | ||
| 7 | X | X | X | |
| Use IT tools | Optimally uses TI tools in the implementation of networks and infrastructure. | Use TI tools in network and infrastructure deployment. | Partially use TI tools in network deployment. | Use only TI tools. |
| Learning outcomes | ||||
| 2 | X | X | ||
| Get results | Obtains efficient and viable results that provide the solution in a structured way and with technical support. | It obtains efficient results that provide the solution in a structured way and with technical support. | Obtains partial results with technical support that contribute to the solution. | Get results without technical support that do not contribute to the solution. |
| Learning outcomes | ||||
| 3 | X | X | X | |
| 7 | X | X |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch, W.; Roman-Cañizares, M.; Jaramillo-Alcázar, A.; Palacios-Pacheco, X. Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment. Appl. Sci. 2020, 10, 7016. https://doi.org/10.3390/app10207016
Villegas-Ch W, Roman-Cañizares M, Jaramillo-Alcázar A, Palacios-Pacheco X. Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment. Applied Sciences. 2020; 10(20):7016. https://doi.org/10.3390/app10207016
Chicago/Turabian StyleVillegas-Ch, William, Milton Roman-Cañizares, Angel Jaramillo-Alcázar, and Xavier Palacios-Pacheco. 2020. "Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment" Applied Sciences 10, no. 20: 7016. https://doi.org/10.3390/app10207016
APA StyleVillegas-Ch, W., Roman-Cañizares, M., Jaramillo-Alcázar, A., & Palacios-Pacheco, X. (2020). Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment. Applied Sciences, 10(20), 7016. https://doi.org/10.3390/app10207016