5.1. Preliminary Experiments
In order to test the QoS metrics provider agent and the model describing non-functional properties, we have created a test-bench consisting of six and nine executions of Barthel and Get Up & Go tests, respectively. As aforementioned, these tests were artificially created, being the responses of the human to the questions, or to commands emanated from the robot, entered by hand. These closed tests have been designed taking into account the most common scenarios that we found during the execution of real Barthel or Get Up & Go tests, and they cover situations that affect the non-functional properties defined in this paper. As aforementioned, this test-bench allows us to intensively validate the correct response of the whole framework.
The relevant features of the Barthel tests included in the test-bench are depicted in
Table 2. The test-bench allows us to monitor the evolution of the properties defined in Listing 1 simulating that the patient answers each one of the questions using voice (VR), the Remote Control device (RC), or the touch screen (TS). We include situations where the patient answers in the first attempt (1st), in the second attempt (2nd), or just does not answer a question (QNA). We have also included situations where the patient presses the pause button or calls the doctor. In both cases we consider that the session is posteriorly restarted (PR and CDR, respectively). Finally, we also consider spurious failures on the detection of the person (NPD).
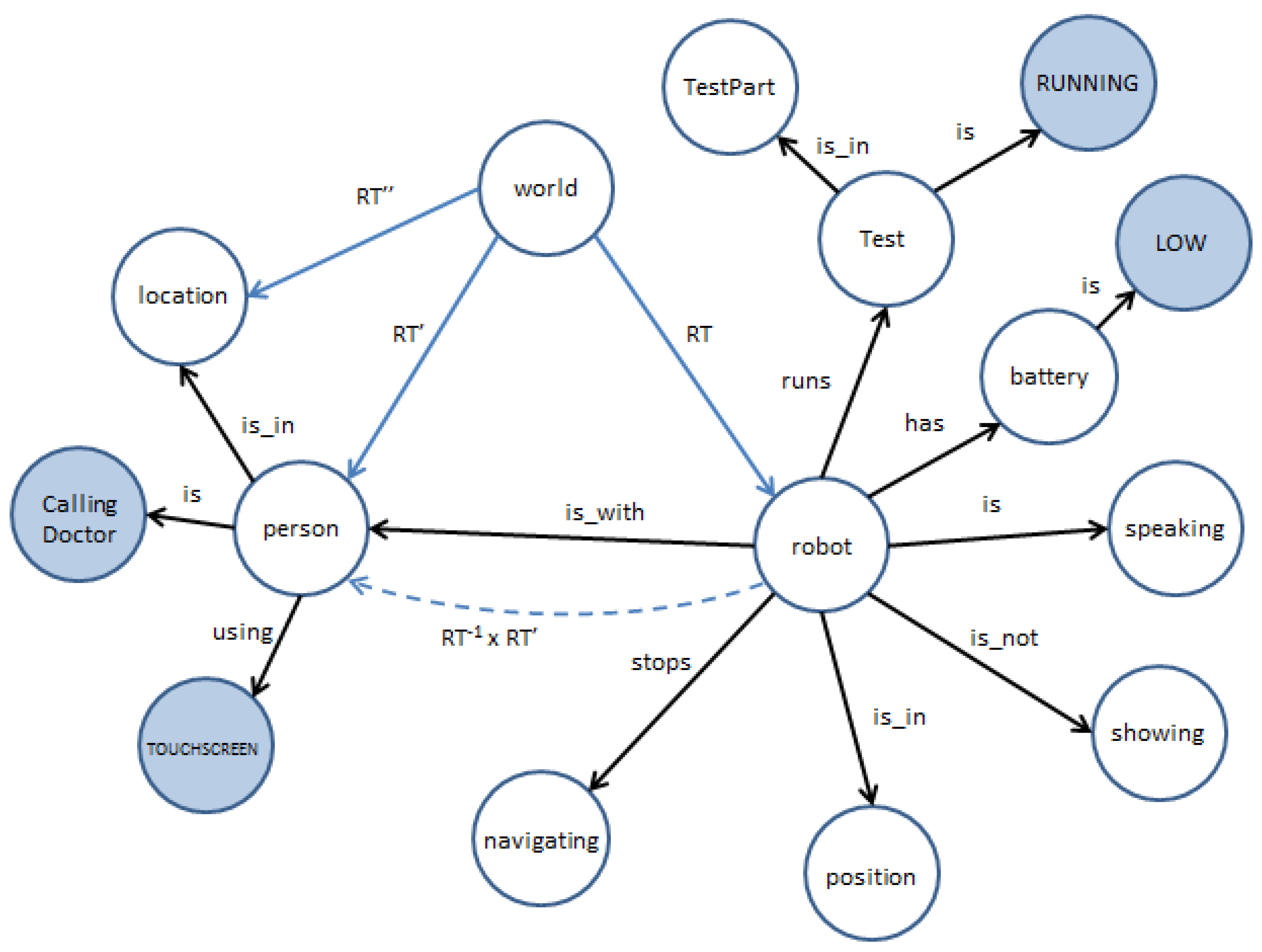
The properties to monitor when running a Barthel test are
Performance,
Interaction and
VoiceInteractionQuality. After choosing a final list of observations,
Table 3 details the statistical features of these properties when running the six Barthel tests in
Table 2. As statistical features we choose the minimum (min), maximum (max), average (avg), standard deviation (sd) and the final value of the property when the test is finished (last). It is worth noting that all the properties have a default value of 0.5 if they were not initialized explicitly (see Listing 1). In Barthel #1 test, where the simulated user always answered in the first attempt using the verbal channel, results show how the reference value for each property increase up to a maximum (and last) value of 0,98 (
Performance) and 1 (
Interaction and
VoiceInteractionQuality), the average value is also very high, around 0.8. This clearly demonstrates to the decision making agent in the software architecture that the test is going well and that the patient is proactively interacting with the robot. Moreover, this agent could also appreciate that this user prefers the verbal channel for interaction. On the other hand, in Barthel #2 (third column,
Table 2), simulated answers were always captured using the touch screen on the torso of the robot or the remote control. In this case, we can note the significant difference on the
VoiceInteractionQuality property. It starts with a reference value of 0.5 which, during the test, decreases until 0.0 (last value). The robot correctly captured the responses to the questionnaire and the patient-robot interaction was fluent. But the
VoiceInteractionQuality metric shows that this user prefers to not use the verbal channel.
Barthel #3 (fourth column,
Table 2) shows a scenario where the user answers all the questions, but in the second attempt and using the touch screen interface. The behaviour of the
VoiceInteractionQuality property is similar to the one obtained in Barthel #2 (meaning that a non-verbal channel for interaction is preferred). However, the last values of the
Performance and
Interaction metrics are less than 0.18. This can be interpreted as correct: the robot must repeat all questions to the patient for capturing a response, and the patient-robot interaction was not fluent. Barthel #4, #5 and #6 (fifth-seventh columns,
Table 2) incorporate new situations, such as questions not answered (QNA), patients suddenly undetected (NPD), calls to the doctor (CDR) and patients that pause the test (PR). We also emulate the scenario where patients sometimes answer in the first attempt but, in other cases, they answer in the second attempt. For example, in Barthel #4, the average and last values of the
Performance metric are similar to the ones obtained in the execution of the Barthel #3. However, the standard deviation of this metric in the execution of the Barthel #4 is greater. The reason is that the patient in Barthel #4 sometimes answers in the first attempt and sometimes in the second attempt (or does not answer). All these situations have an impact on the evolution of the
Performance property. Significantly, the fact that the simulated patient in Barthel #4 answered four of the questions in the first attempt provokes that the
Interaction metric provides an average value of 0.61. This value is greater than the one obtained for the patient that run the Barthel #3. But it is a low value. Sometimes the patient answered fluently, and sometimes she needed a second attempt or did not provide an answer. The metrics associated to the execution of the Barthel #5 and #6 are affected by the multitude of uncommon situations included in both executions. In the execution of the Barthel #5, the simulation includes one call to the doctor and two pauses on the session. The result is a very poor
Performance (these situations implied that the robot was not able to perform the complete test by itself). However, having a look to the evolution of Barthel #5 (sixth column,
Table 2) we can infer that, after receiving help by the doctor (question 6), the human-robot interaction was fluent. The final
Interaction value is therefore high (0.94), correctly capturing this fact. Finally, Barthel #6 shows the typical response when the robot deals with a patient that is really uncomfortable in the interaction with the robot.
As the QoS metrics are being continuously monitored, it is important to analyse their evolution over time.
Table 4 (Right) depicts how the
Performance,
Interaction and
VoiceInteractionQuality metrics evolve during the execution of the test Barthel #4.
Table 4 (Left) summarizes the observations detected by the Complex Event Processor, linked to the instant of time on which they were generated, and to the context stored in the DSR. With respect to
Table 2, we can note the presence of two new context values in the
Table 4 (Left): PD indicates that the person is detected and the session can start; and FINISHED states that the 10 questions were captured and the session can end. For instance, ten seconds after starting the test the PersonDetected (PD) context is annotated by the
Person agent in the DSR, firing the observations two and eight (O2:O8). Both observations reinforce
Performance and
Interaction (as defined in Listing 3). Then, about two minutes later (t = 135 s), the user answered the first question of the Barthel test in the first attempt using the voice recognition system (fifth column,
Table 2). These contexts fire the O13, O2, and O7 observations, increasing the three QoS properties. Observations that decrease these properties are, for instance, O6, O11 that are fired when the patient does not answer the question in the first attempt (t = 205 s), or O5 and O10 in the case the patient does not answer the question after the two attempts (t = 340 s).
Regarding the Get Up & Go test, we have added to the test-bench nine simulated tests.
Table 5 provides a brief description of each test. It can be seen that they consider different execution alternatives, such as the
Person agent losing the patient for a few seconds, or the patient calling the doctor during the visual presentation of how she must perform the test.
For the Get Up & Go test, the framework only computes two metrics:
Performance and
Interaction. It is worth noting that the
VoiceInteractionQuality is not used in this test because the user does not have to answer any question. Statistical features of the obtained metrics when we execute the nine tests are illustrated in
Table 6. Specifically, the table shows the minimum (min), maximum (max), and the final value (last) of the two properties. In contrast to Barthel tests, we have not considered the average and deviation values. The reason for discarding them is that, contrary to the Barthel test where the robot maintains the control over the time slots for answering a question, in the Get Up & Go test, the time is controlled by the patient. That is, a patient has a maximum time of 300 s to perform all the movements on the Get Up & Go test, i.e., sitting on the chair, getting up, walking and sitting on the chair again. But, within this interval of time, she will decide for instance when she sits on or gets up off the chair. As the observations are typically generated in the transition between two actions, the metrics can maintain their values during a few seconds. The result is that the metrics associated with two correctly executed tests can present very different average and deviation features. As the minimum, maximum and last values are not affected by the test duration or the temporal distance between consecutive performed actions, they can be used for characterizing the
Performance and
Interaction metrics.
As
Table 5 shows, the first Get Up & Go test was successfully performed. Hence, both metrics only growed with time. We can note that the minimum value for
Performance and
Interaction is 0.5 (the initial reference value), whereas the maximum value is the same as the final value. In this test,
Performance and
Interaction increased their values during the test execution until reaching 0.9987 and 0.9857 respectively. This means that the session was successfully addressed and that the patient correctly responded to the commands from the robot. The second Get Up & Go test is similar to the first one. However, the robot lost the patient for a few seconds at the beginning of the test. As a result,
Performance and
Interaction decreased their values falling below 0.5. The maximum and final values are also close to 1.0, meaning that the patient successfully finished the test and correctly interpreted the commands from the robot.
In the Get Up & Go #3 the robot also lost the patient at the beginning of the session (
!PersonDetected). Moreover, when detected, she did not stay next to the chair in a first attempt (
!PersonIsNextToChair). The robot was forced to repeat the instructions. This decreased the
Performance and
Interaction metrics, but, as the test was correctly executed, the final values are close to 1.0. As expected (the commands from the robot were not correctly understood for the first attempt), the last value of the
Interaction metric is lower than the last value of the
Performance one. The same initial situations were simulated for the Get Up & Go #4. However, in this case, the patient does not stay next to the chair in the last attempt. This implies a severe penalty in the
Performance and
Interaction metrics since the robot was forced to repeat the instructions and wait for the patient. As it is described in
Table 5, the test ends before the robot can assess the test. This provokes very final values for the
Performance and
Interaction metrics. In the test Get Up & Go #5 the patient performed the test after not following correctly the robot instructions (she sat down on the chair in the second attempt). That implies that the robot had to repeat instructions and, therefore, there was a penalty for the
Performance and
Interaction metrics. As was the case for the execution of the Get Up & Go #3, this situation affected a little more to the
Interaction metric.
Get Up & Go #6 and #7 describe two examples where the system does not return a score. This may be caused by a problem related to the tracking system (Person agent) or, as it occurred in these two cases, when the patient has not completed one of the actions asked by the CLARC robot. Finally, tests #8 and #9 are similar. The difference lies in the button pressed by the patient. While in the execution of the Get Up & Go #8 the patient pressed the pause button, in the test #9 the patient pressed the CallingDoctor button. In the first case, the patient restarted the test using the resume button. However, in the test #9, it was the doctor who pressed the continue button.
Table 7 shows the response of the framework (context, observations and metrics) during the execution of the Get Up & Go #9. In this example, after visualizing the introductory video (t = 120 s), the patient called the doctor for help. This decreased the
Performance and
Interaction metrics because of the observations five (O5) and nine (O9) generated by the Complex Event Processor. We can assume that, after describing the test to the patient, the doctor pressed the
continue button (
RESTARTED). This action (t = 140 s) triggered observations that increase both metrics. For the rest of the test, the patient followed the robot instructions (as detailed in
Table 5). Thus, the generated observations increased the
Performance and
Interaction metrics until reaching values close to 1.0 for the end of the test.
5.2. Experiments in Real Scenarios
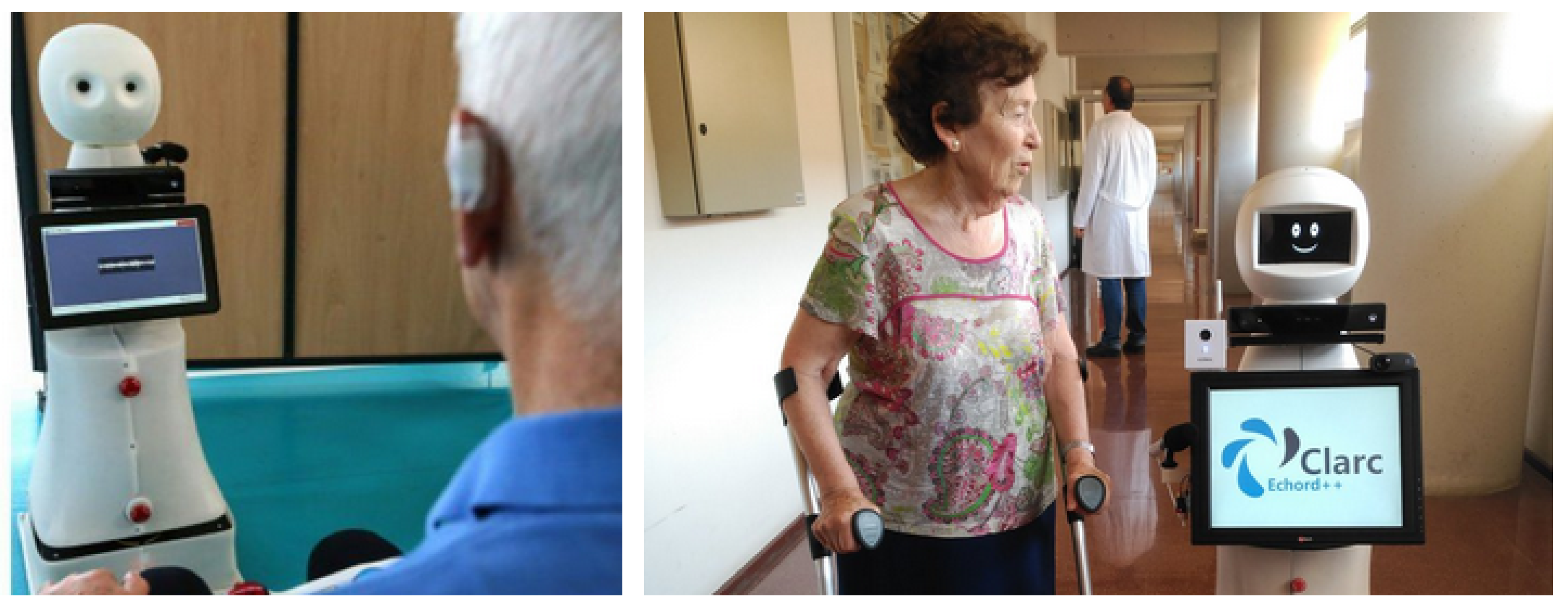
In the consortium of the CLARC project, there are two research groups that are very close to end-users. One of them is a research group of the Hospital Virgen del Rocio of Seville (Spain), and the other one is from the University of Troyes (France), which has strong links with the Hospital of Reims (France). Thus, from January 2019 to March 2019, a CLARC robot (in its final version) was deployed at the Hospital of Reims (see
Figure 8 (left)) and two others (first versions of CLARC) at the Hospital Virgen del Rocio (see
Figure 8 (right)). The one at Reims worked in the geriatric unit, but those in Seville were tested in several care centres. Several complete test executions were recorded in both scenarios and deeply analyzed. The experimental evaluation on this Section is built using 22 Barthel tests and 13 Get Up & Go tests.
Table 8 details the Barthel tests performed with real patients. Each column provides the patient’s response to each question on the test. As in the previous Section, we detail how patients answered each question: if they used the remote control (RC), the touch screen (TS) or the voice interface (VR), and if they answered in the first (1st) or second (2nd) attempt (or did not answer (QNA)). We can also know if they pressed the pause/restart buttons (PR) or the calling doctor/restart buttons (CDR), or if they were undetected for a while (NPD). We are grouped in the same row of the table the patients that completed the test exhibiting the same behaviour. For instance, patients #3, #5, #7, #17, and #22 completed the tests in the same way: answering all the questions in the first attempt (1st) using the touch screen (TS). From the point-of-view of our system, the evolution of the QoS metrics for the group of users in each one of the rows of the table is practically identical, regardless of the small differences in the response time of the patients.
Table 9 depicts the results obtained on these tests. Considering each row of
Table 8 as a group, the groups of patients G#1, G#4, and G#10 (3 patients in total) answered using the voice recognition system, groups G#2, G#3, G#5, and G#6 (9 patients) used the touchscreen, whereas the rest of patients (10 patients) answered using the Remote Control device. Regarding Group G #1 (
Table 9), the patient answered all questions in the first attempt except question 4. The
Performance and
Interaction metrics provide last values close to 1.0. Moreover, the
VoiceInteractionQuality property never decreases below the initial value (0.5) and it reaches a maximum value of 1. This shows that the patient always answered using voice. As for the
Performance, there was a penalty due to an unanswered question (Q4). This is illustrated in a minimum value of 0.45, as well as the fact that the maximum value reached is 0.91, with an average value of 0.68 (the optimal average value is 0.82, as we can see in the data associated with G #3, the perfect case where the patient answered all questions in the first attempt). Finally, the
Interaction property for G #1 was also influenced by the question not answered by the patient. However, it recovered quickly to almost reach the optimal value obtained during these tests. The evolution of the three properties (
Performance,
Interaction and
VoiceInteractionQuality) are depicted in
Table 10 (Right). The observations provided by the Complex Event Processor are shown in
Table 10 (Left). This table also describes the context information captured from the DSR.
The rest of patients that used voice recognition to answer questions obtained uneven results. For instance, Patient #4 did not answer seven questions. Although the remaining questions were answered on the first attempt, the Performance and Interaction values are very low. However, this did not affect the VoiceInteractionQuality property, which decreases its value only when the patient answered using the Remote Control device or the touch screen. Patient #19 (G #10) performed the test perfectly, answering questions on the first attempt. The metrics obtained by this patient can be considered a reference value for validating other patients.
Patients in the group G #3 also performed the test answering questions on the first attempt but using the touch screen on the torso of the robot. Due to this, the VoiceInteractionQuality decreased during the test until it reached a value of 0, indicating that these patients used a non-verbal channel for interacting with the robot. Patients #6 and #8 did not answer question four and two, respectively. Comparing these two patients, we can see how the maximum and the final value are nearly identical, as expected. The minimum and the average differ slightly as the observations associated with the Question non Answered occurred in different instants of time. Both patients always used the touchscreen (the VoiceInteractionQuality metric ends close to 0.0).
The remaining 10 patients have completed the test using the Remote Control device. Patients in group G #7 obtain identical results that the ones in G #3. Although the only difference was the interaction mechanism used, the values obtained for the VoiceInteractionQuality property are identical, since neither used voice interaction. Patients #11 (G #8) and #15 (G #9) also performed the test in a similar way, as they both answered the first question at the second chance. However, Patient #11, before answering, paused the test and then resumed it. If we observe the model (Listing 3), we can see how pausing and resuming the test significantly affects Performance but very little Interaction. This is the reason why worse results are obtained for Performance and practically identical for the Interaction property.
Table 11 and
Table 12 show how patients performed the Get Up & Go tests and the results obtained, respectively. Twelve patients performed the tests properly: they followed the robot instructions and the robot was able to detect all the movements and return a score. In that case, results show how the
Performance and the
Interaction properties reach almost 1.0, as expected. More details are available in
Table 13. Only Patient #4 did not complete the test. The robot only detected the patient standing next to the chair and sat down. Thus, the minimum values for
Performance and
Interaction remain at 0.5 and the maximum values reach 0.93, although the latest values are lower than those obtained by the other patients.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



