Bridge Crack Detection Based on SSENets

 , ,
, ,
Abstract
1. Introduction
- We designed an embedded module with skip-connection strategy, which was called Skip-Squeeze-and-Excitation (SSE) module. By inserting the SSE module into the existing network, the detection accuracy can be improved without increasing the computational complexity.
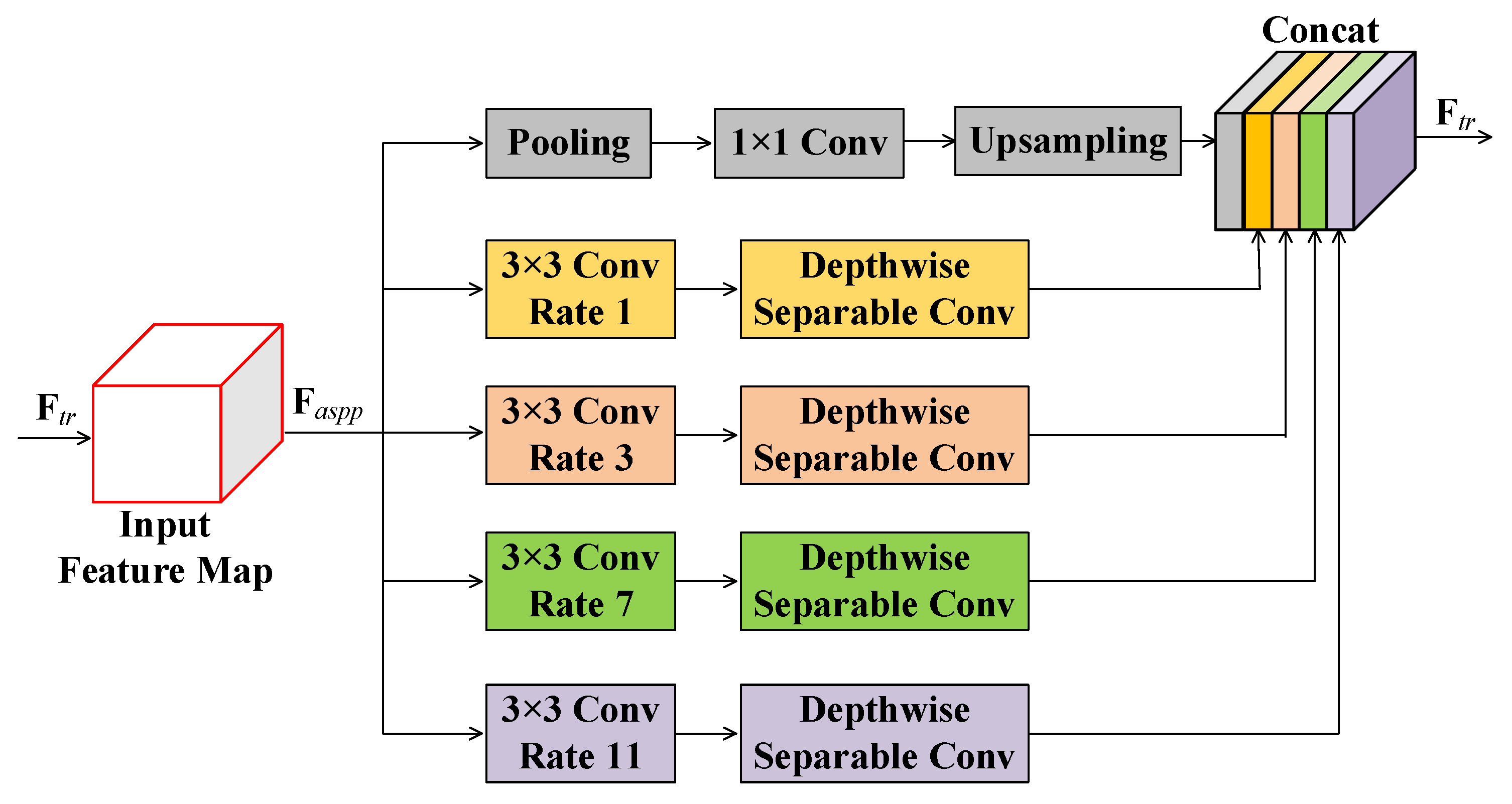
- Considering the large span of crack size in the crack detection task, we introduced the Atrous Spatial Pyramid Pooling (ASPP) module into our model. It can effectively improve the detection accuracy by capturing the context of images in multiple scales.
- Based on the above-mentioned modules, we proposed SSENets, which was applied to the bridge crack detection task. The detection accuracy of SSENets can reach 97.77%, which is higher than the traditional classification models and the model proposed by Xu et al. [25] under the same model complexity.
2. Materials and Methods
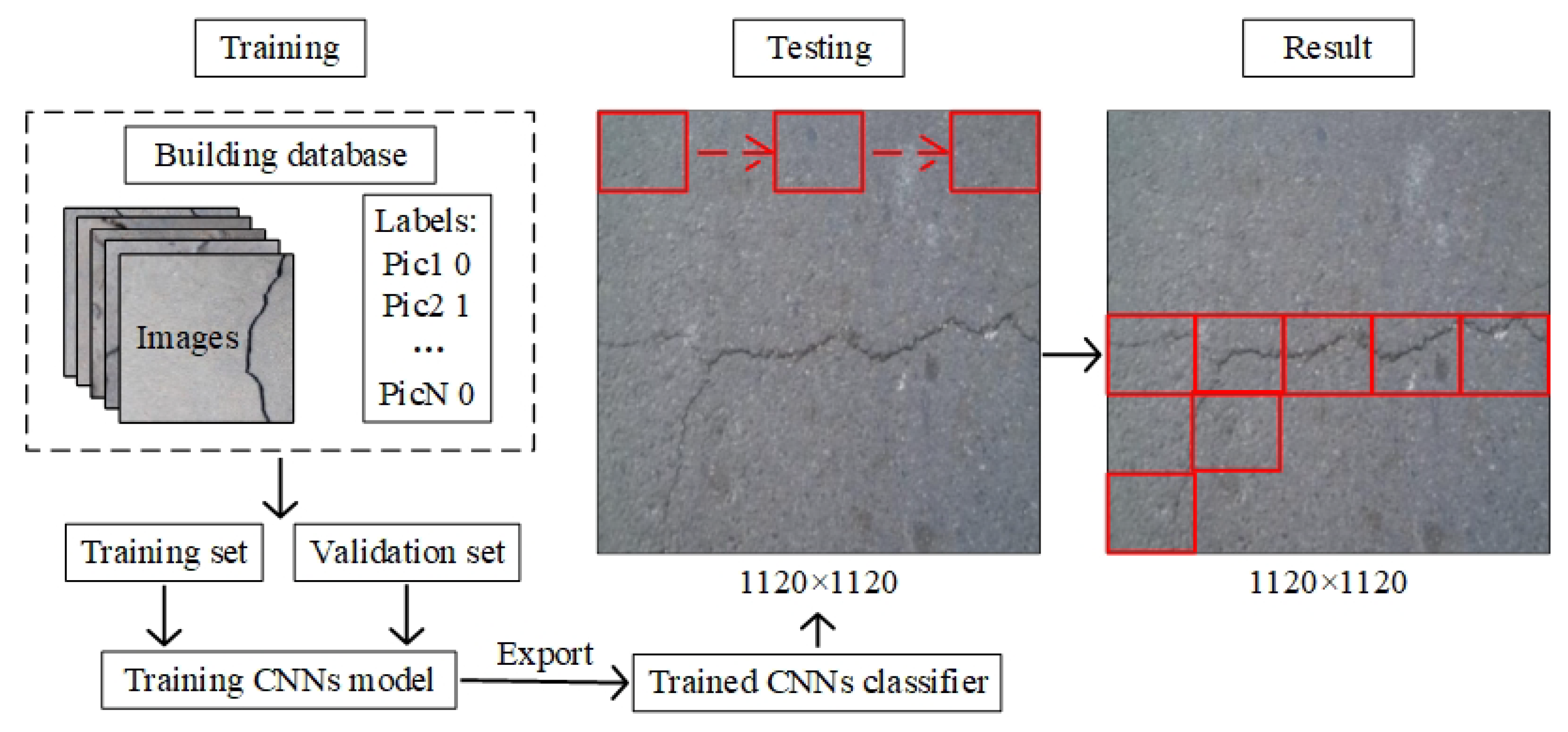
2.1. Datasets
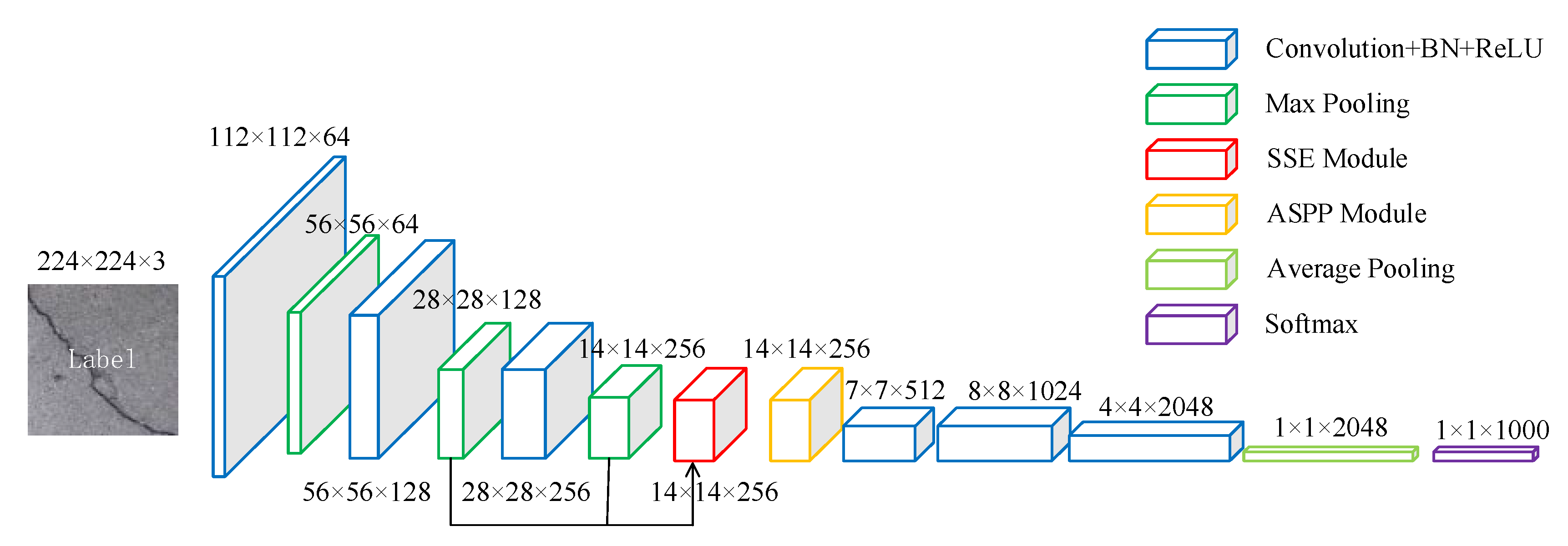
2.2. Proposed Network
2.3. Skip-Squeeze-and-Excitation Module
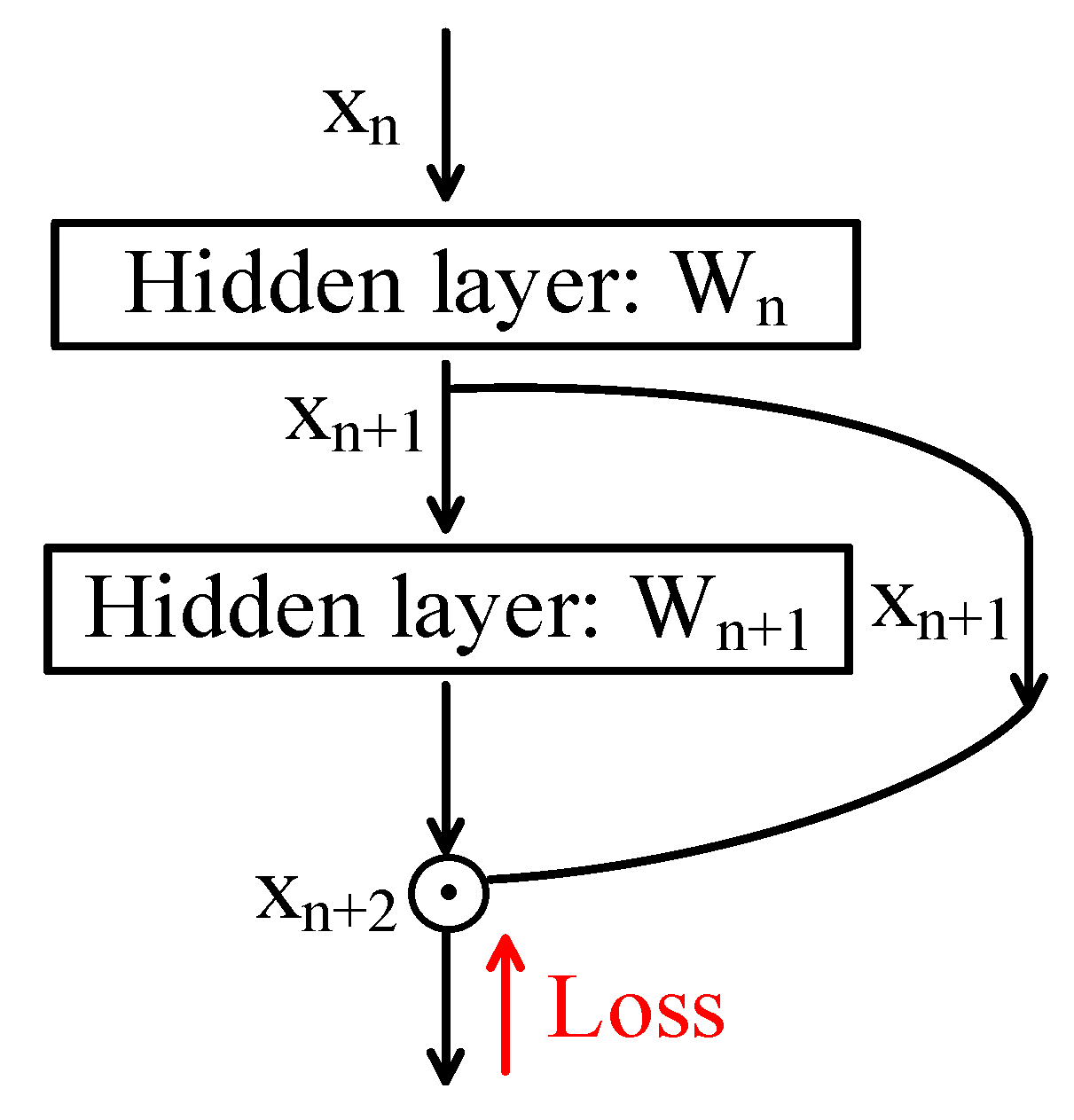
2.3.1. Skip-Connection
2.3.2. Squeeze
2.3.3. Excitation
2.4. Atrous Spatial Pyramid Pooling Module
3. Experimental Results and Ablation Study
3.1. Hyperparameters
3.2. Experimental Results
3.3. Ablation Study
3.3.1. SSE Module
3.3.2. Reduction Ratio
3.3.3. Location of SSE Module
3.3.4. Skipping Span of SSE Module
3.3.5. ASPP Module
3.4. Evaluation and Discussion
3.4.1. Performance of Models
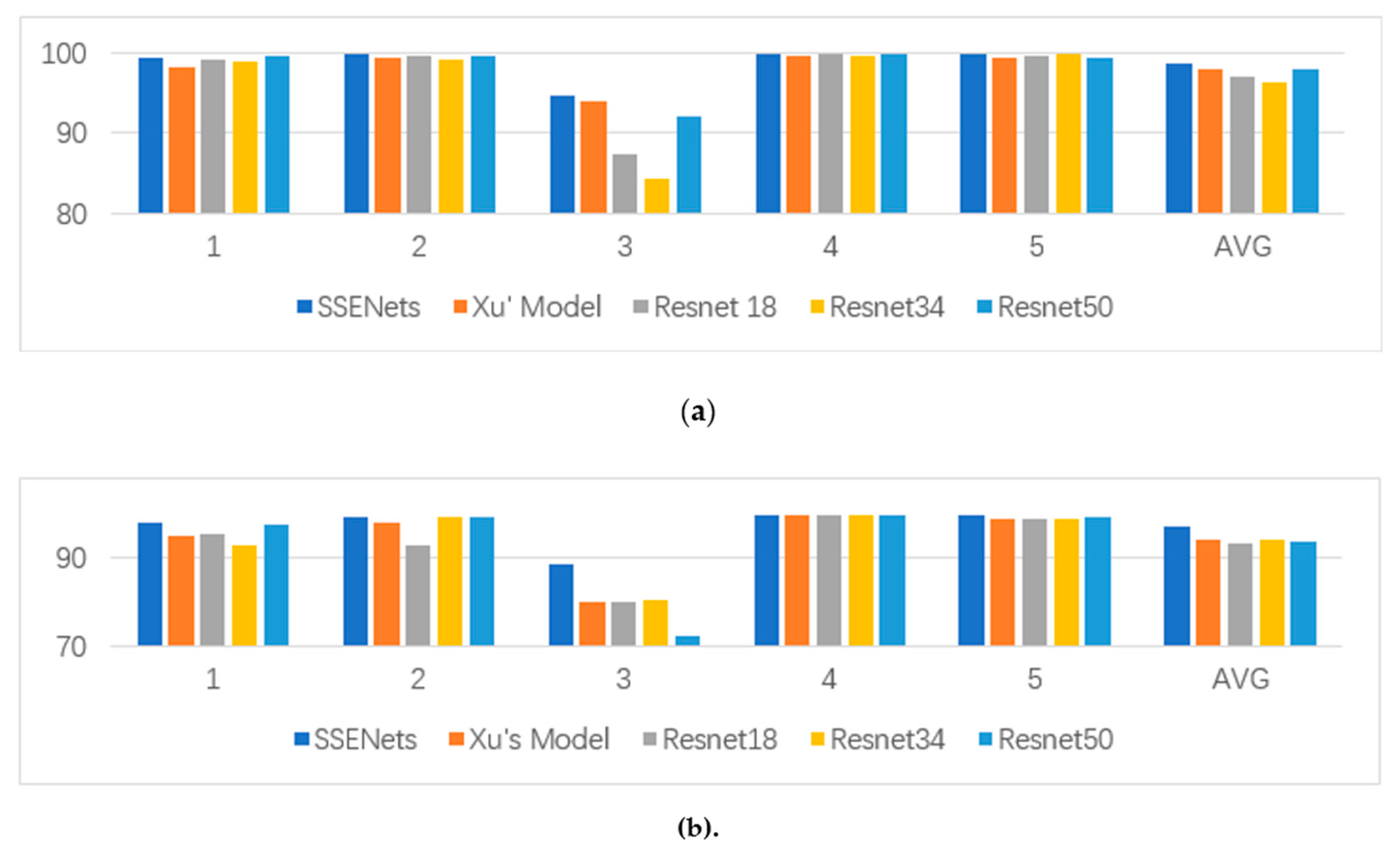
3.4.2. The 5-Fold Cross-Validation
3.4.3. Computational Efficiency and Complexity of Models
3.4.4. Discussion
- In Section 3.4.1, Table 7 shows SSENets achieves a better performance in terms of accuracy, precision, specificity and score, compared with other models. It proves that the designed embedded SSE module, which selects feature maps of different depths as inputs, and can improve the effectiveness of the model by recalibrating the feature maps by squeeze operator and excitation operator.
- As shown in Table 8 and Table 9, the testing accuracy has been improved more in comparison to the training accuracy, which shows that SSENets has a better generalization ability. Besides, all the models get low detection accuracy at the third fold cross-validation. The reason is that its testing set contains about two-thirds of the background images, which makes the number of cracks images in training set is far more less than background images. Though this situation will affect the training results of models, SSENets still achieve a higher detection accuracy than other models. Considering the great improvement in the specificity factor, which is shown in Table 7, we conclude that SSENets can reduce the proportion of background images that are classified as crack images.
- Taking advantage of depthwise separable convolution, SSENets has smaller FLOPs and a shorter running time, compared to Resnets. Therefore, SSENets can greatly reduce the complexity of the model and improve the calculation efficiency, thus improving the detection performance of the model.
- Though SSENets could achieve a high detection accuracy in most situations, it still has limitations. As the number of negative samples in the training set decreases, the detection accuracy of SSENets will decrease, so we will devote future work to improving this problem.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alipour, M.; Harris, D.K. Increasing the robustness of material-specific deep learning models for crack detection across different materials. Eng. Struct. 2020, 206, 110157. [Google Scholar] [CrossRef]
- Jahangiri, A.; Rakha, H.A.; Dingus, T.A. Adopting Machine Learning Methods to Predict Red-light Running Violations. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015; pp. 650–655. [Google Scholar]
- Jahangiri, A.; Rakha, H.A. Applying Machine Learning Techniques to Transportation Mode Recognition Using Mobile Phone Sensor Data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2406–2417. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic Road Crack Segmentation Using Entropy and Image Dynamic Thresholding. In Proceedings of the 2009 17th European Signal Processing Conference, Piscataway, NJ, USA, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Elbehiery, H.; Hefnawy, A.; Elewa, M. Surface Defects Detection for Ceramic Tiles Using Image Processing and Morphological Techniques. In Proceedings of the WEC’05: 3rd World Enformatika Conference, Istanbul, Turkey, 27–29 April 2005; pp. 158–162. [Google Scholar]
- Georgieva, K.; Koch, C.; König, M. Wavelet Transform on Multi-GPU for Real-Time Pavement Distress Detection. In Proceedings of the Computing in Civil Engineering 2015. International Workshop on Computing in Civil Engineering, Reston, VA, USA, 21–23 June 2015; American Society of Civil Engineers. pp. 99–106. [Google Scholar]
- Zhang, A.; Li, Q.J.; Wang, K.C.R. Matched Filtering Algorithm for Pavement Cracking Detection. J. Transp. Res. Rec. 2013, 2367, 30–42. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional Neural Networks Applied to House Numbers Digit Classification. In Proceedings of the 2012 21st International Conference on Pattern Recognition, Univ Tsukuba, Tsukuba, Japan, 11–15 November 2012; pp. 3288–3291. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 10 December 2015; pp. 770–778. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V.; IEEE. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 Ieee/Cvf Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2017; pp. 6517–6525. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; VanGool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9912, pp. 20–36. [Google Scholar]
- Zhang, A.; Wang, K.C.P.; Li, B. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. J. Comput.-Aided Civil Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Fei, Y.; Wang, K.C.P.; Zhang, A. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images Through Deep-Learning-Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2020, 21, 273–284. [Google Scholar] [CrossRef]
- Song, W.D.; Jia, G.H.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors 2020, 20, 717. [Google Scholar] [CrossRef] [PubMed]
- Kaseko, M.S.; Ritchie, S.G. A neural network-based methodology for pavement crack detection and classification. Transp. Res. C Emerg. Technol. 1993, 1, 275–291. [Google Scholar] [CrossRef]
- Chou, J.; Cheng, H.D. Pavement distress classification using neural networks. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, New York, NY, USA, 2–5 October 1994; pp. 397–401. [Google Scholar]
- Nguyen, T.S.; Avila, M.; Begot, S. Automatic detection and classification of defect on road pavement using anisotropy measure. In Proceedings of the 2009 17th European Signal Processing Conference, New York, NY, USA, 24–28 August 2009; pp. 617–621. [Google Scholar]
- Moussa, G.; Hussain, K. A new technique for automatic detection and parameters estimation of pavement crack. In Proceedings of the 4th Int. MultiConf. Eng. Technol. Innov., Orlando, FL, USA, 19–22 July 2011; pp. 11–16. [Google Scholar]
- Daniel, A.; Preeja, V. Automatic road distress detection and analysis. Int. J. Comput. Appl. 2014, 101, 18–23. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Buyukozturk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Aided Civil Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 1–9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on International Conference on Machine Learning JMLR.org, Lile, France, 6–11 July 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inceptionv4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First Aaai Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 18–23 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–25 June 2010. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Bridge Crack Detection Based on SSENets. Available online: https://github.com/543630836/Crack_detection_SSENets (accessed on 25 May 2020).
- Wilson, D.R.; Martinez, T.R. The need for small learning rates on large problems. In Proceedings of the International Joint Conference on Neural Networks, Proceedings (Cat. No. 01CH37222), IJCNN’01, Washington, DC, USA, 15–19 July 2001; pp. 115–119. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batchnormalization: Accelerating deepnetwork training byreducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]







{kind=link}
{kind=link}
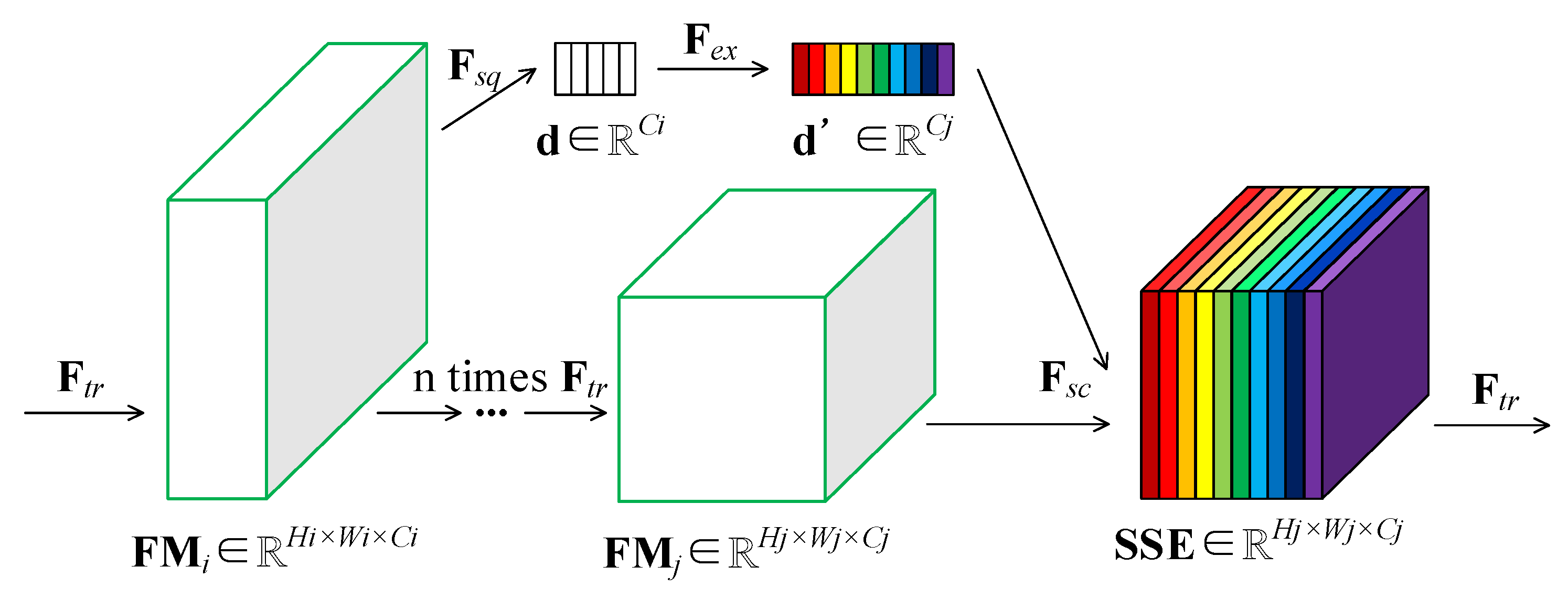{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Epochs | Accuracy |
|---|---|---|
| SSENets | 100 | 97.77% |
| Xu’s Model | 100 | 96.37% |
| Resnet18 | 100 | 93.56% |
| Resnet34 | 100 | 94.89% |
| Resnet50 | 100 | 95.71% |
| SE Module | SSE Module | Epochs | Accuracy |
|---|---|---|---|
| - | - | 100 | 95.53% |
| √ | - | 100 | 96.23% |
| - | √ | 100 | 97.77% |
| Reduction Ratio | Epochs | Input | Accuracy |
|---|---|---|---|
| 0.5 | 100 | Con_2, Con_3 | 97.77% |
| 1 | 100 | Con_2, Con_3 | 96.29% |
| 2 | 100 | Con_2, Con_3 | 96.29% |
| 4 | 100 | Con_2, Con_3 | 95.30% |
| 8 | 100 | Con_2, Con_3 | 94.40% |
| Input | Epochs | Accuracy |
|---|---|---|
| Con_1, Con_2 | 100 | 95.47% |
| Con_2, Con_3 | 100 | 96.87% |
| Con_3, Con_4 | 100 | 95.88% |
| Con_4, Con_5 | 100 | 94.81% |
| Con_5, Con_6 | 100 | 95.05% |
| Skipping Span | Epochs | Accuracy |
|---|---|---|
| Con_5, Con_6 | 100 | 95.05% |
| Con_4, Con_6 | 100 | 95.30% |
| Con_3, Con_6 | 100 | 95.64% |
| Con_2, Con_6 | 100 | 95.88% |
| Con_1, Con_6 | 100 | 96.62% |
| ASPP Rate | Epochs | Accuracy |
|---|---|---|
| - | 100 | 93.49% |
| [1,3,6,9] | 100 | 95.36% |
| [1,3,7,11] | 100 | 95.53% |
| [1,4,8,12] | 100 | 94.32% |
| Model | Accuracy | Precision | Sensitive | Specificity | F1 Score |
|---|---|---|---|---|---|
| SSENets | 97.77% | 95.45% | 100% | 95.83% | 97.67% |
| Xu’s Model | 96.37% | 93.94% | 100% | 91.66% | 96.88% |
| Resnet18 | 93.56% | 88.46% | 100% | 89.96% | 93.88% |
| Resnet34 | 94.89% | 89.47% | 100% | 90.91% | 94.44% |
| Resnet50 | 95.71% | 93.33% | 100% | 88.89% | 95.55% |
| Model | 1 | 2 | 3 | 4 | 5 | AVG |
|---|---|---|---|---|---|---|
| SSENets | 99.28% | 99.90% | 94.59% | 99.79% | 99.69% | 98.65% |
| Xu’s Model | 98.04% | 99.28% | 93.92% | 99.59% | 99.28% | 98.02% |
| Resnet18 | 99.07% | 99.49% | 87.44% | 99.79% | 99.59% | 97.07% |
| Resnet34 | 98.76% | 99.17% | 84.34% | 99.59% | 99.79% | 96.33% |
| Resnet50 | 99.48% | 99.49% | 91.97% | 99.69% | 99.28% | 97.98% |
| Model | 1 | 2 | 3 | 4 | 5 | AVG |
|---|---|---|---|---|---|---|
| SSENets | 98.10% | 99.18% | 88.57% | 99.79% | 99.79% | 97.09% |
| Xu’s Model | 94.74% | 97.94% | 79.81% | 99.79% | 98.66% | 94.19% |
| Resnet18 | 95.47% | 92.89% | 79.81% | 99.48% | 98.89% | 93.31% |
| Resnet34 | 92.89% | 99.07% | 80.33% | 99.48% | 98.76% | 94.11% |
| Resnet50 | 97.52% | 99.28% | 72.40% | 99.79% | 99.07% | 93.61% |
| Model | Epochs | FLOPs | Running Time |
|---|---|---|---|
| SSENets | 100 | 2.54 G | 95 min 49 s |
| Xu’s Model | 100 | 2.53 G | 94 min 52 s |
| Resnet18 | 100 | 1.82 G | 53 min 8 s |
| Resnet34 | 100 | 3.67 G | 74 min 38 s |
| Resnet50 | 100 | 4.12 G | 138 min 51 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Xu, H.; Tian, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Bridge Crack Detection Based on SSENets. Appl. Sci. 2020, 10, 4230. https://doi.org/10.3390/app10124230
Li H, Xu H, Tian X, Wang Y, Cai H, Cui K, Chen X. Bridge Crack Detection Based on SSENets. Applied Sciences. 2020; 10(12):4230. https://doi.org/10.3390/app10124230
Chicago/Turabian StyleLi, Haotian, Hongyan Xu, Xiaodong Tian, Yi Wang, Huaiyu Cai, Kerang Cui, and Xiaodong Chen. 2020. "Bridge Crack Detection Based on SSENets" Applied Sciences 10, no. 12: 4230. https://doi.org/10.3390/app10124230
APA StyleLi, H., Xu, H., Tian, X., Wang, Y., Cai, H., Cui, K., & Chen, X. (2020). Bridge Crack Detection Based on SSENets. Applied Sciences, 10(12), 4230. https://doi.org/10.3390/app10124230