
Complete Genome Sequence Analysis of Kribbella sp. CA-293567 and Identification of the Kribbellichelins A & B and Sandramycin Biosynthetic Gene Clusters
 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Strains
2.2. DNA Extraction
2.3. Whole Genome Sequencing
2.4. Bioinformatic Analysis
3. Results and Discussion
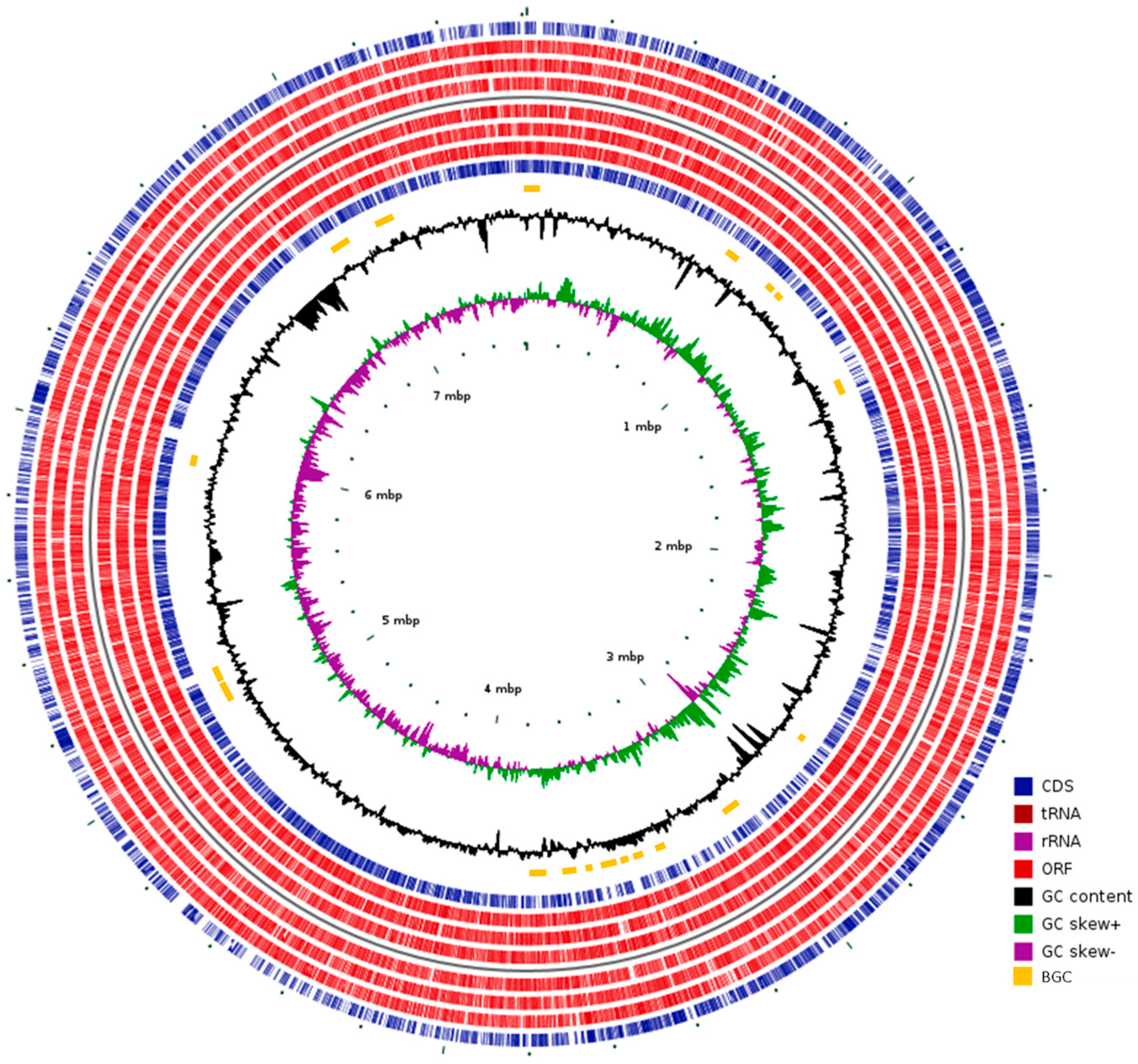
3.1. Whole Genome Sequencing
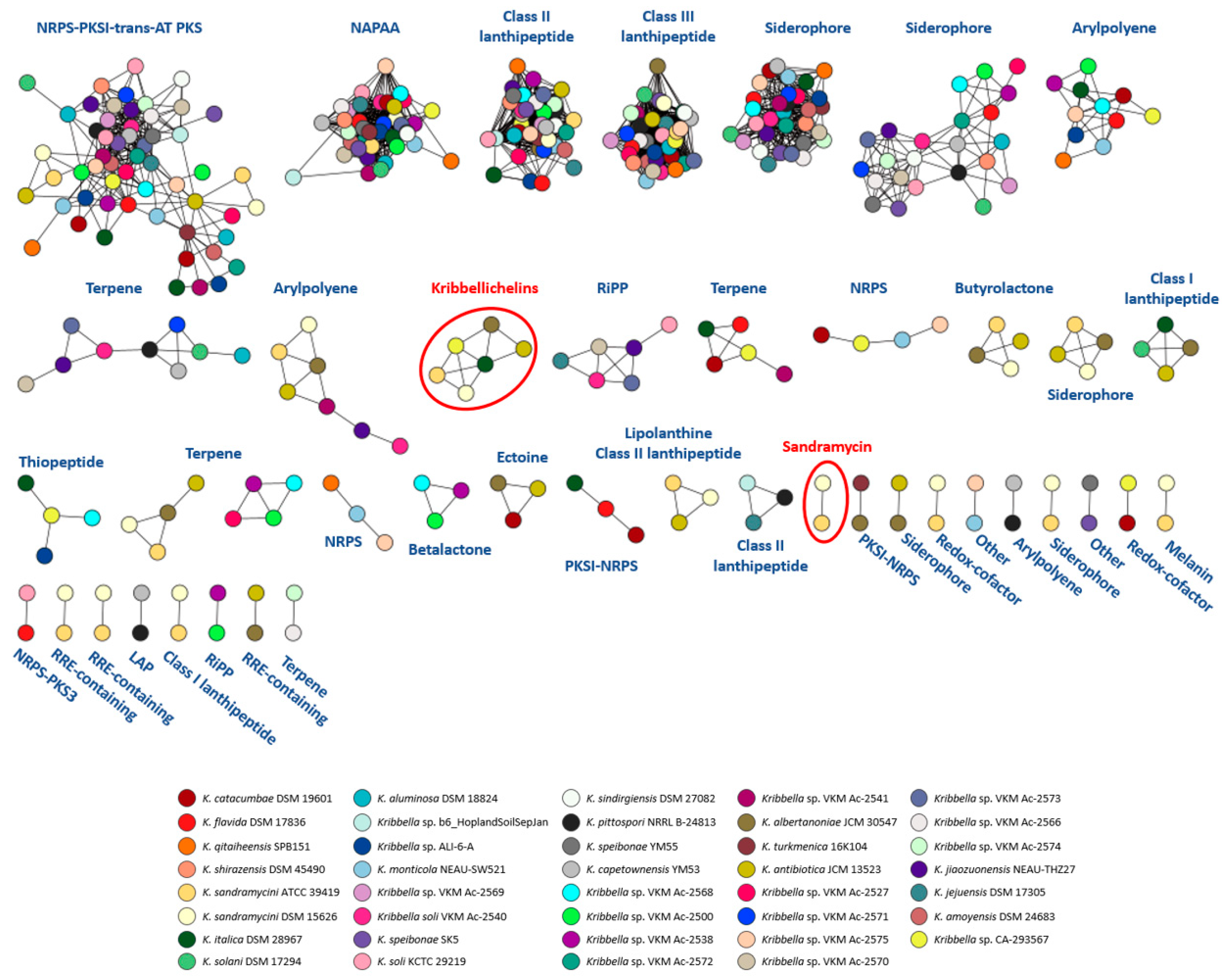
3.2. Secondary Metabolites BGC Analysis
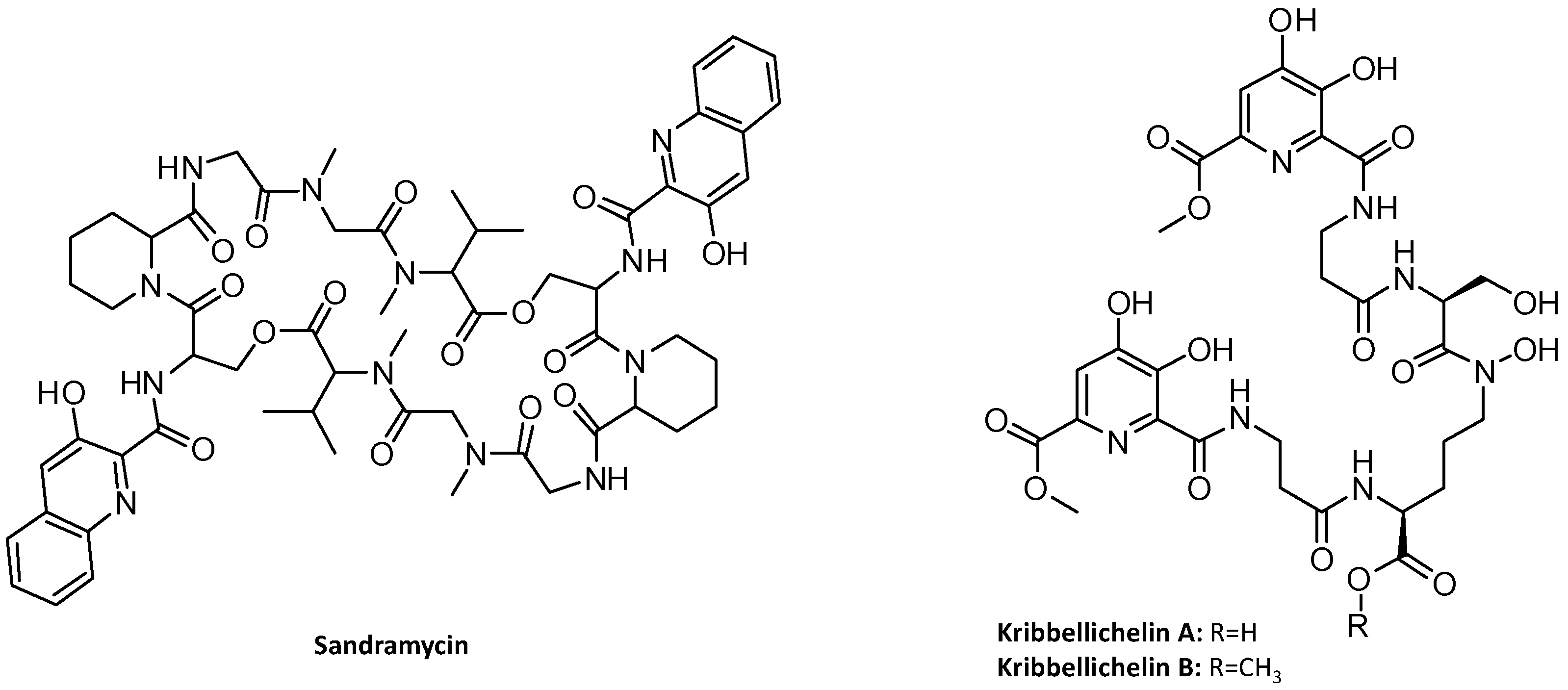
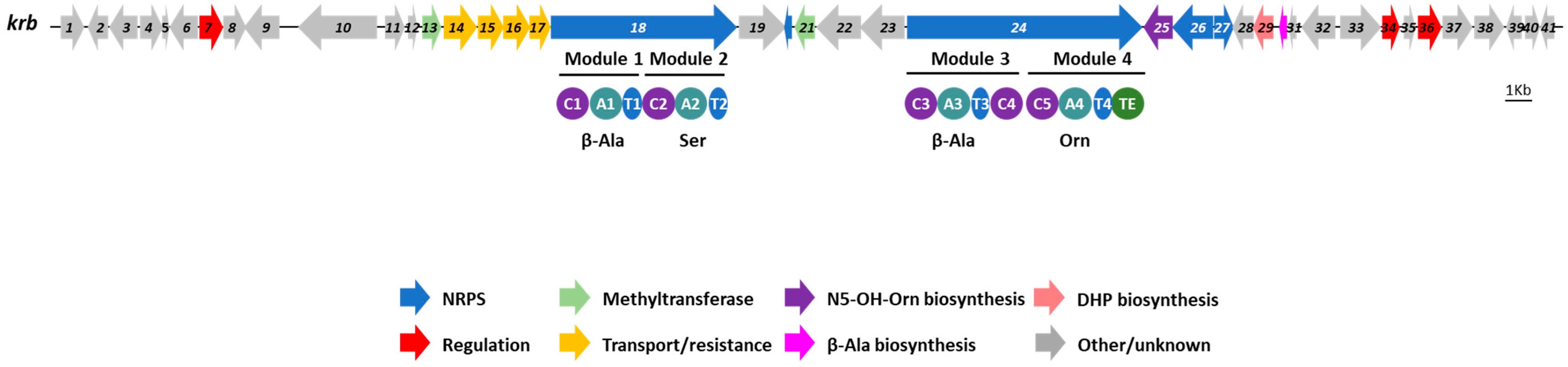
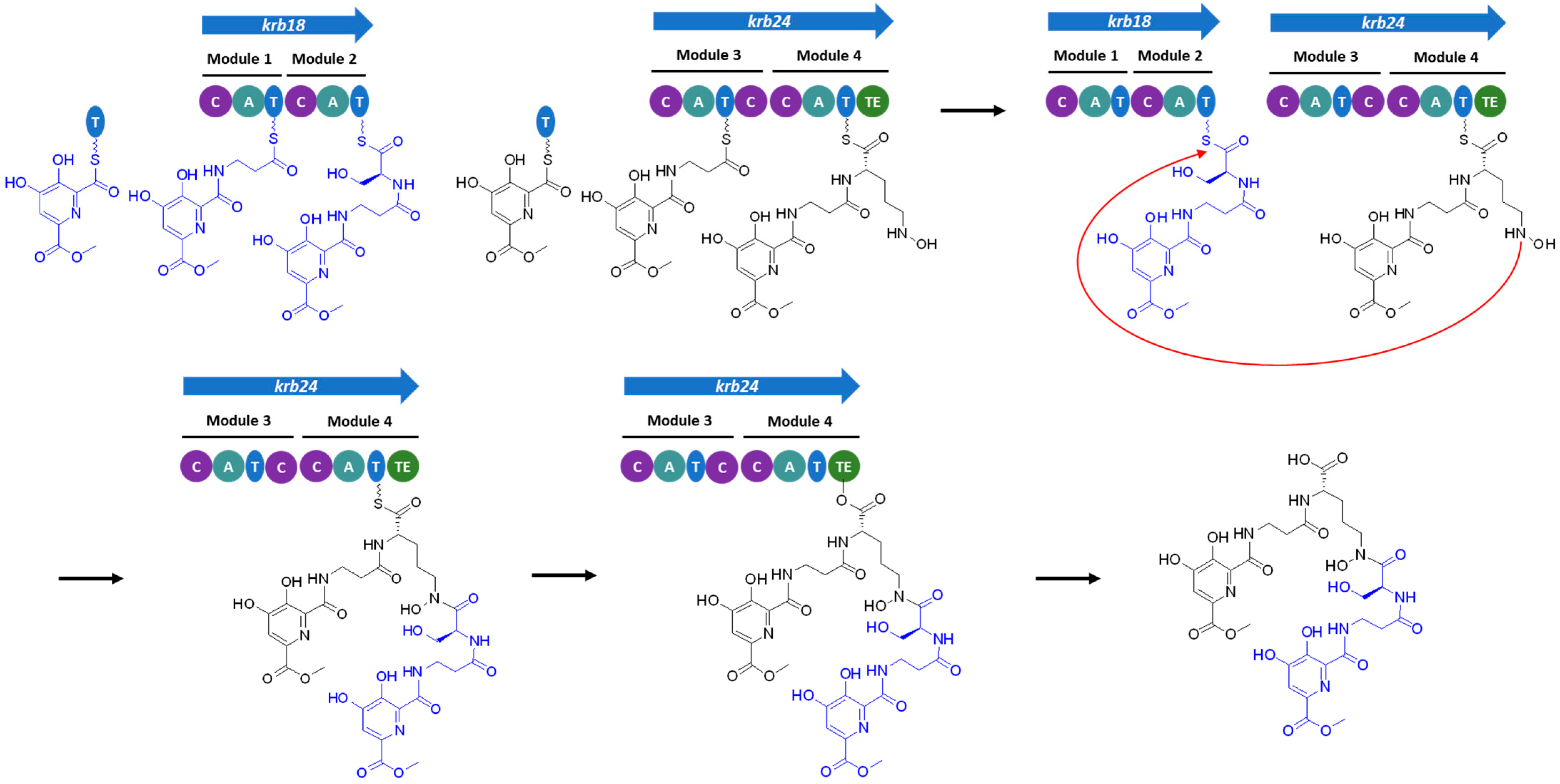
3.3. Identification of the Kribbellichelins A and B BGC
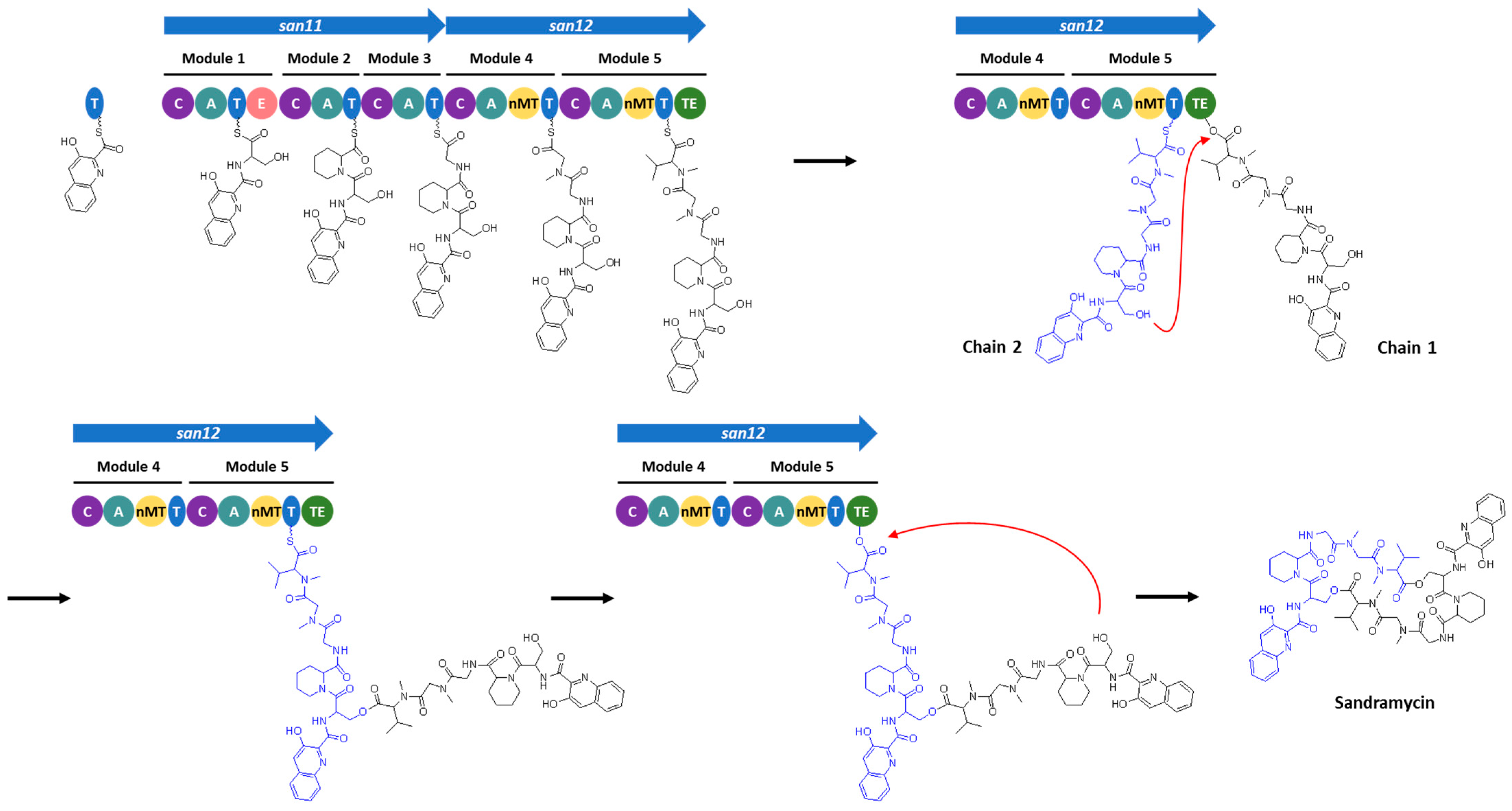
3.4. Identification of the Sandramycin BGC
3.5. Comparative Genomic Analysis of Kribbella Strains
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abouelhassan, Y.; Garrison, A.T.; Yang, H.; Chávez-Riveros, A.; Burch, G.M.; Huigens, R.W. Recent Progress in Natural-Product-Inspired Programs Aimed to Address Antibiotic Resistance and Tolerance. J. Med. Chem. 2019, 62, 7618–7642. [Google Scholar] [CrossRef]
- Miethke, M.; Pieroni, M.; Weber, T.; Brönstrup, M.; Hammann, P.; Halby, L.; Arimondo, P.B.; Glaser, P.; Aigle, B.; Bode, H.B.; et al. Towards the Sustainable Discovery and Development of New Antibiotics. Nat. Rev. Chem. 2021, 5, 726–749. [Google Scholar] [CrossRef] [PubMed]
- Murray, C.J.; Ikuta, K.S.; Sharara, F.; Swetschinski, L.; Robles Aguilar, G.; Gray, A.; Han, C.; Bisignano, C.; Rao, P.; Wool, E.; et al. Global Burden of Bacterial Antimicrobial Resistance in 2019: A Systematic Analysis. Lancet 2022, 399, 629–655. [Google Scholar] [CrossRef]
- Iskandar, K.; Murugaiyan, J.; Halat, D.H.; El Hage, S.; Chibabhai, V.; Adukkadukkam, S.; Roques, C.; Molinier, L.; Salameh, P.; Van Dongen, M. Antibiotic Discovery and Resistance: The Chase and the Race. Antibiotics 2022, 11, 182. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Han, R.; Xu, Y.; Li, N.; Wang, J.; Dan, W. Recent Progress of Antibacterial Natural Products: Future Antibiotics Candidates. Bioorg. Chem. 2020, 101, 103922. [Google Scholar] [CrossRef] [PubMed]
- Newman, D.J.; Cragg, G.M. Natural Products as Sources of New Drugs over the Nearly Four Decades from 01/1981 to 09/2019. J. Nat. Prod. 2020, 83, 770–803. [Google Scholar] [CrossRef]
- Hobson, C.; Chan, A.N.; Wright, G.D. The Antibiotic Resistome: A Guide for the Discovery of Natural Products as Antimicrobial Agents. Chem. Rev. 2021, 121, 3464–3494. [Google Scholar] [CrossRef]
- Genilloud, O. Actinomycetes: Still a Source of Novel Antibiotics. Nat. Prod. Rep. 2017, 34, 1203–1232. [Google Scholar] [CrossRef]
- Barka, E.A.; Vatsa, P.; Sanchez, L.; Gaveau-Vaillant, N.; Jacquard, C.; Meier-Kolthoff, J.P.; Klenk, H.-P.; Clément, C.; Ouhdouch, Y.; van Wezel, G.P. Correction for Barka et Al., Taxonomy, Physiology, and Natural Products of Actinobacteria. Microbiol. Mol. Biol. Rev. 2016, 80, 1–43. [Google Scholar] [CrossRef]
- Jose, P.A.; Maharshi, A.; Jha, B. Actinobacteria in Natural Products Research: Progress and Prospects. Microbiol. Res. 2021, 246, 126708. [Google Scholar] [CrossRef]
- Donald, L.; Pipite, A.; Subramani, R.; Owen, J.; Keyzers, R.A.; Taufa, T. Streptomyces: Still the Biggest Producer of New Natural Secondary Metabolites, a Current Perspective. Microbiol. Res. 2022, 13, 418–465. [Google Scholar] [CrossRef]
- Bérdy, J. Bioactive Microbial Metabolites. J. Antibiot. 2005, 58, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Subramani, R.; Aalbersberg, W. Culturable Rare Actinomycetes: Diversity, Isolation and Marine Natural Product Discovery. Appl. Microbiol. Biotechnol. 2013, 97, 9291–9321. [Google Scholar] [CrossRef] [PubMed]
- Ezeobiora, C.E.; Igbokwe, N.H.; Amin, D.H.; Enwuru, N.V.; Okpalanwa, C.F.; Mendie, U.E. Uncovering the Biodiversity and Biosynthetic Potentials of Rare Actinomycetes. Future J. Pharm. Sci. 2022, 8, 23. [Google Scholar] [CrossRef]
- Tiwari, K.; Gupta, R.K. Diversity and Isolation of Rare Actinomycetes: An Overview. Crit. Rev. Microbiol. 2013, 39, 256–294. [Google Scholar] [CrossRef] [PubMed]
- Katti, A.K.S.; Ak, S.; Mudgulkar, S.B. Diversity and Classification of Rare Actinomycetes. In Actinobacteria. Rhizosphere Biology; Yaradoddi, J.S., Kontro, M.H., Ganachari, S.V., Eds.; Springer: Singapore, 2021; pp. 117–142. [Google Scholar] [CrossRef]
- Tiwari, K.; Gupta, R.K. Rare Actinomycetes: A Potential Storehouse for Novel Antibiotics. Crit. Rev. Biotechnol. 2012, 32, 108–132. [Google Scholar] [CrossRef]
- Tiwari, K.; Gupta, R.K. Bioactive Metabolites from Rare Actinomycetes. In Studies in Natural Products Chemistry; Atta-ur, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2014; pp. 419–512. [Google Scholar] [CrossRef]
- Jose, P.A.; Sivakala, K.K.; Jha, B. Non-Streptomyces Actinomycetes and Natural Products: Recent Updates. In Studies in Natural Products Chemistry; Atta-ur, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2014; pp. 395–409. [Google Scholar] [CrossRef]
- Bundale, S.; Singh, J.; Begde, D.; Nashikkar, N.; Upadhyay, A. Rare Actinobacteria: A Potential Source of Bioactive Polyketides and Peptides. World J. Microbiol. Biotechnol. 2019, 35, 92. [Google Scholar] [CrossRef]
- Ding, T.; Yang, L.J.; Zhang, W.D.; Shen, Y.H. The Secondary Metabolites of Rare Actinomycetes: Chemistry and Bioactivity. RSC Adv. 2019, 9, 21964–21988. [Google Scholar] [CrossRef]
- Al-Fadhli, A.A.; Threadgill, M.D.; Mohammed, F.; Sibley, P.; Al-Ariqi, W.; Parveen, I. Macrolides from Rare Actinomycetes: Structures and Bioactivities. Int. J. Antimicrob. Agents 2022, 59, 106523. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, Q.; Zhang, L.; She, J.; Li, J.; Zhang, W.; Zhang, H.; Zhu, Y.; Zhang, C. Antifungal Macrolides Kongjuemycins from Coral-Associated Rare Actinomycete Pseudonocardia kongjuensis SCSIO 11457. Org. Lett. 2022, 24, 3482–3487. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, Z.; Fukaya, K.; Urabe, D.; Harunari, E.; Oku, N.; Igarashi, Y. Catellatolactams A-C, Plant Growth-Promoting Ansamacrolactams from a Rare Actinomycete of the Genus Catellatospora. J. Nat. Prod. 2022, 85, 1993–1999. [Google Scholar] [CrossRef] [PubMed]
- Keller, L.; Oueis, E.; Kaur, A.; Safaei, N.; Kirsch, S.H.; Gunesch, A.P.; Haid, S.; Rand, U.; Čičin-Šain, L.; Fu, C.; et al. Persicamidines—Unprecedented Sesquarterpenoids with Potent Antiviral Bioactivity against Coronaviruses. Angew. Chem. Int. Ed. Engl. 2022, e202214595. [Google Scholar] [CrossRef]
- Lazzarini, A.; Cavaletti, L.; Toppo, G.; Marinelli, F. Rare Genera of Actinomycetes as Potential Producers of New Antibiotics. Antonie Van Leeuwenhoek Int. J. Gen. Mol. Microbiol. 2000, 78, 399–405. [Google Scholar] [CrossRef]
- Genilloud, O. Mining Actinomycetes for Novel Antibiotics in the Omics Era: Are We Ready to Exploit This New Paradigm? Antibiotics 2018, 7, 85. [Google Scholar] [CrossRef] [PubMed]
- Baltz, R.H. Genome Mining for Drug Discovery: Progress at the Front End. J. Ind. Microbiol. Biotechnol. 2021, 48, kuab044. [Google Scholar] [CrossRef] [PubMed]
- Singh, T.A.; Passari, A.K.; Jajoo, A.; Bhasin, S.; Gupta, V.K.; Hashem, A.; Alqarawi, A.A.; Abd_Allah, E.F. Tapping into Actinobacterial Genomes for Natural Product Discovery. Front. Microbiol. 2021, 12, 1662. [Google Scholar] [CrossRef]
- Kenshole, E.; Herisse, M.; Michael, M.; Pidot, S.J. Natural Product Discovery through Microbial Genome Mining. Curr. Opin. Chem. Biol. 2021, 60, 47–54. [Google Scholar] [CrossRef]
- Bauman, K.D.; Butler, K.S.; Moore, B.S.; Chekan, J.R. Genome Mining Methods to Discover Bioactive Natural Products. Nat. Prod. Rep. 2021, 38, 2100–2129. [Google Scholar] [CrossRef]
- Malit, J.J.L.; Leung, H.Y.C.; Qian, P.Y. Targeted Large-Scale Genome Mining and Candidate Prioritization for Natural Product Discovery. Mar. Drugs 2022, 20, 398. [Google Scholar] [CrossRef]
- Medema, M.H.; de Rond, T.; Moore, B.S. Mining Genomes to Illuminate the Specialized Chemistry of Life. Nat. Rev. Genet. 2021, 22, 553–571. [Google Scholar] [CrossRef]
- Choi, S.S.; Kim, H.J.; Lee, H.S.; Kim, P.; Kim, E.S. Genome Mining of Rare Actinomycetes and Cryptic Pathway Awakening. Process Biochem. 2015, 50, 1184–1193. [Google Scholar] [CrossRef]
- Parte, A.C. LPSN—List of Prokaryotic Names with Standing in Nomenclature. Nucleic Acids Res. 2014, 42, D613–D616. [Google Scholar] [CrossRef] [PubMed]
- Park, Y. Classification of Nocardioides fulvus IF0 14399 and Nocardioides sp. ATCC 39419 In Kribbella gen. nov., as Kribbella flavida sp. nov. and Kribbella sandramycini sp. nov. Int. J. Syst. Bacteriol. 1999, 49, 743–752. [Google Scholar] [CrossRef] [PubMed]
- Igarashi, M.; Sawa, R.; Yamasaki, M.; Hayashi, C.; Umekita, M.; Hatano, M.; Fujiwara, T.; Mizumoto, K.; Nomoto, A. Kribellosides, Novel RNA 5′-Triphosphatase Inhibitors from the Rare Actinomycete Kribbella sp. MI481-42F6. J. Antibiot. 2017, 70, 582–589. [Google Scholar] [CrossRef] [PubMed]
- Matson, J.A.; Bush, J.A. Sandramycin, a novel antitumor antibiotic produced by a Nocardioides sp. Production, isolation, characterization and biological properties. J. Antibiot. 1989, 42, 1763–1767. [Google Scholar] [CrossRef] [PubMed]
- Matson, J.A.; Colson, K.L.; Belofsky, G.N.; Bleiberg, B.B. Sandramycin, a Novel Antitumor Antibiotic Produced by a Nocardioides sp. II. Structure Determination. J. Antibiot. 1993, 46, 162–166. [Google Scholar] [CrossRef]
- Virués-Segovia, J.R.; Reyes, F.; Ruíz, S.; Martín, J.; Fernández-Pastor, I.; Justicia, C.; de la Cruz, M.; Díaz, C.; Mackenzie, T.A.; Genilloud, O.; et al. Kribbellichelins A and B, Two New Antibiotics from Kribbella sp. CA-293567 with Activity against Several Human Pathogens. Molecules 2022, 27, 6355. [Google Scholar] [CrossRef]
- Shi, X.; Huang, L.; Song, K.; Zhao, G.; Liu, Y.; Lv, L.; Du, Y.L. Enzymatic Tailoring in Luzopeptin Biosynthesis Involves Cytochrome P450-Mediated Carbon–Nitrogen Bond Desaturation for Hydrazone Formation. Angew. Chem. Int. Ed. 2021, 60, 19821–19828. [Google Scholar] [CrossRef]
- Kieser, T.; Bibb, M.J.; Buttner, M.J.; Chater, K.F.; Hopwood, D.A. (Eds.) Practical Streptomyces Genetics. A Laboratory Manual; John Innes Foundation: Norwich, UK, 2000; ISBN 9780708406236. [Google Scholar]
- Rhoads, A.; Au, K.F. PacBio Sequencing and Its Applications. Genom. Proteom. Bioinform. 2015, 13, 278–289. [Google Scholar] [CrossRef]
- Quail, M.A.; Kozarewa, I.; Smith, F.; Scally, A.; Stephens, P.J.; Durbin, R.; Swerdlow, H.; Turner, D.J. A Large Genome Center’s Improvements to the Illumina Sequencing System. Nat. Methods 2008, 5, 1005–1010. [Google Scholar] [CrossRef]
- Walker, B.J.; Abeel, T.; Shea, T.; Priest, M.; Abouelliel, A.; Sakthikumar, S.; Cuomo, C.A.; Zeng, Q.; Wortman, J.; Young, S.K.; et al. Pilon: An Integrated Tool for Comprehensive Microbial Variant Detection and Genome Assembly Improvement. PLoS ONE 2014, 9, e112963. [Google Scholar] [CrossRef] [PubMed]
- Manni, M.; Berkeley, M.R.; Seppey, M.; Simão, F.A.; Zdobnov, E.M. BUSCO Update: Novel and Streamlined Workflows along with Broader and Deeper Phylogenetic Coverage for Scoring of Eukaryotic, Prokaryotic, and Viral Genomes. Mol. Biol. Evol. 2021, 38, 4647–4654. [Google Scholar] [CrossRef] [PubMed]
- Blin, K.; Shaw, S.; Kloosterman, A.M.; Charlop-Powers, Z.; van Wezel, G.P.; Medema, M.H.; Weber, T. AntiSMASH 6.0: Improving Cluster Detection and Comparison Capabilities. Nucleic Acids Res. 2021, 49, W29–W35. [Google Scholar] [CrossRef] [PubMed]
- Skinnider, M.A.; Johnston, C.W.; Gunabalasingam, M.; Merwin, N.J.; Kieliszek, A.M.; MacLellan, R.J.; Li, H.; Ranieri, M.R.M.; Webster, A.L.H.; Cao, M.P.T.; et al. Comprehensive Prediction of Secondary Metabolite Structure and Biological Activity from Microbial Genome Sequences. Nat. Commun. 2020, 11, 6058. [Google Scholar] [CrossRef] [PubMed]
- Johnson, M.; Zaretskaya, I.; Raytselis, Y.; Merezhuk, Y.; McGinnis, S.; Madden, T.L. NCBI BLAST: A Better Web Interface. Nucleic Acids Res. 2008, 36, W5–W9. [Google Scholar] [CrossRef] [PubMed]
- Navarro-Muñoz, J.C.; Selem-Mojica, N.; Mullowney, M.W.; Kautsar, S.A.; Tryon, J.H.; Parkinson, E.I.; De Los Santos, E.L.C.; Yeong, M.; Cruz-Morales, P.; Abubucker, S.; et al. A Computational Framework to Explore Large-Scale Biosynthetic Diversity. Nat. Chem. Biol. 2020, 16, 60–68. [Google Scholar] [CrossRef]
- Smoot, M.E.; Ono, K.; Ruscheinski, J.; Wang, P.-L.; Ideker, T. Cytoscape 2.8: New Features for Data Integration and Network Visualization. Bioinformatics 2011, 27, 431–432. [Google Scholar] [CrossRef]
- Arkin, A.P.; Cottingham, R.W.; Henry, C.S.; Harris, N.L.; Stevens, R.L.; Maslov, S.; Dehal, P.; Ware, D.; Perez, F.; Canon, S.; et al. KBase: The United States Department of Energy Systems Biology Knowledgebase. Nat. Biotechnol. 2018, 36, 566–569. [Google Scholar] [CrossRef]
- Seemann, T. Prokka: Rapid Prokaryotic Genome Annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Stothard, P.; Grant, J.R.; Van Domselaar, G. Visualizing and comparing circular genomes using the CGView family of tools. Brief Bioinform. 2019, 20, 1576–1582. [Google Scholar] [CrossRef]
- Jiang, J.; He, X.; Cane, D.E. Biosynthesis of the Earthy Odorant Geosmin by a Bifunctional Streptomyces coelicolor Enzyme. Nat. Chem. Biol. 2007, 3, 711–715. [Google Scholar] [CrossRef] [PubMed]
- Ohnishi, Y.; Ishikawa, J.; Hara, H.; Suzuki, H.; Ikenoya, M.; Ikeda, H.; Yamashita, A.; Hattori, M.; Horinouchi, S. Genome Sequence of the Streptomycin-Producing Microorganism Streptomyces griseus IFO 13350. J. Bacteriol. 2008, 190, 4050–4060. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Van Der Donk, W.A. Biosynthesis of the Class III Lantipeptide Catenulipeptin. ACS Chem. Biol. 2012, 7, 1529–1535. [Google Scholar] [CrossRef]
- Cimermancic, P.; Medema, M.H.; Claesen, J.; Kurita, K.; Wieland Brown, L.C.; Mavrommatis, K.; Pati, A.; Godfrey, P.A.; Koehrsen, M.; Clardy, J.; et al. Insights into secondary metabolism from a global analysis of prokaryotic biosynthetic gene clusters. Cell 2014, 158, 412–421. [Google Scholar] [CrossRef] [PubMed]
- Cronan, J.E. β-Alanine Synthesis in Escherichia coli. J. Bacteriol. 1980, 141, 1291–1297. [Google Scholar] [CrossRef]
- Pote, S.; Pye, S.E.; Sheahan, T.E.; Gawlicka-Chruszcz, A.; Majorek, K.A.; Chruszcz, M. 4-Hydroxy-Tetrahydrodipicolinate Reductase from Neisseria gonorrhoeae—Structure and Interactions with Coenzymes and Substrate Analog. Biochem. Biophys. Res. Commun. 2018, 503, 1993–1999. [Google Scholar] [CrossRef]
- Niu, G.; Liu, G.; Tian, Y.; Tan, H. SanJ, an ATP-Dependent Picolinate-CoA Ligase, Catalyzes the Conversion of Picolinate to Picolinate-CoA during Nikkomycin Biosynthesis in Streptomyces ansochromogenes. Metab. Eng. 2006, 8, 183–195. [Google Scholar] [CrossRef]
- Scapin, G.; Reddy, S.G.; Zheng, R.; Blanchard, J.S. Three-Dimensional Structure of Escherichia Coli Dihydrodipicolinate Reductase in Complex with NADH and the Inhibitor 2,6-Pyridinedicarboxylate. Biochemistry 1997, 36, 15081–15088. [Google Scholar] [CrossRef]
- Minowa, Y.; Araki, M.; Kanehisa, M. Comprehensive Analysis of Distinctive Polyketide and Nonribosomal Peptide Structural Motifs Encoded in Microbial Genomes. J. Mol. Biol. 2007, 368, 1500–1517. [Google Scholar] [CrossRef]
- Sigrist, R.; Luhavaya, H.; McKinnie, S.M.K.; Ferreira Da Silva, A.; Jurberg, I.D.; Moore, B.S.; Gonzaga De Oliveira, L. Nonlinear Biosynthetic Assembly of Alpiniamide by a Hybrid Cis/ Trans-AT PKS-NRPS. ACS Chem. Biol. 2020, 15, 1067–1077. [Google Scholar] [CrossRef]
- Lombó, F.; Velasco, A.; Castro, A.; De La Calle, F.; Braña, A.F.; Sánchez-Puelles, J.M.; Méndez, C.; Salas, J.A. Deciphering the Biosynthesis Pathway of the Antitumor Thiocoraline from a Marine Actinomycete and Its Expression in Two Streptomyces Species. ChemBioChem 2006, 7, 366–376. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Haltli, B.; Feng, X.; Cai, P.; Summers, M.; Lotvin, J.; He, M. Investigation of the Biosynthesis of the Pipecolate Moiety of Neuroprotective Polyketide Meridamycin. J. Antibiot. 2011, 64, 533–538. [Google Scholar] [CrossRef] [PubMed]
- Gatto, G.J.; Boyne, M.T.; Kelleher, N.L.; Walsh, C.T. Biosynthesis of Pipecolic Acid by RapL, a Lysine Cyclodeaminase Encoded in the Rapamycin Gene Cluster. J. Am. Chem. Soc. 2006, 128, 3838–3847. [Google Scholar] [CrossRef]
- Gatto, G.J.; McLoughlin, S.M.; Kelleher, N.L.; Walsh, C.T. Elucidating the Substrate Specificity and Condensation Domain Activity of FkbP, the FK520 Pipecolate-Incorporating Enzyme. Biochemistry 2005, 44, 5993–6002. [Google Scholar] [CrossRef] [PubMed]
- Namwat, W.; Kamioka, Y.; Kinoshita, H.; Yamada, Y.; Nihira, T. Characterization of Virginiamycin S Biosynthetic Genes from Streptomyces virginiae. Gene 2002, 286, 283–290. [Google Scholar] [CrossRef]
- Sandmann, A.; Sasse, F.; Müller, R. Identification and Analysis of the Core Biosynthetic Machinery of Tubulysin, a Potent Cytotoxin with Potential Anticancer Activity. Chem. Biol. 2004, 11, 1071–1079. [Google Scholar] [CrossRef]
- Müller, C.; Nolden, S.; Gebhardt, P.; Heinzelmann, E.; Lange, C.; Puk, O.; Welzel, K.; Wohlleben, W.; Schwartz, D. Sequencing and Analysis of the Biosynthetic Gene Cluster of the Lipopeptide Antibiotic Friulimicin in Actinoplanes friuliensis. Antimicrob. Agents Chemother. 2007, 51, 1028–1037. [Google Scholar] [CrossRef]
- Takahashi, K.; Koshino, H.; Esumi, Y. SW-163C and E, Novel Antitumor Depsipeptides Produced by Streptomyces Sp. II. Structure Elucidation. J. Antibiot. 2001, 54, 622–627. [Google Scholar] [CrossRef]
- Baz, J.P.; Canedo, L.M.; Puentes, J.L.F.; Elipe, M.V.S. Thiocoraline, a Novel Depsipeptide with Antitumor Activity Produced by a Marine Micromonospora. II. Physico-chemical Properties and Structure Determination. J. Antibiot. 1997, 50, 738–741. [Google Scholar] [CrossRef] [PubMed]
- Okada, H.; Suzuki, H.; Yoshinari, T.; Arakawa, H.; Okura, A.; Suda, H.; Yamada, A.; Uemura, D. A New Topoisomerase II Inhibitor, BE-22179, Produced by a Streptomycete. I. Producing Strain, Fermentation, Isolation and Biological Activity. J. Antibiot. 1994, 47, 129–135. [Google Scholar] [CrossRef] [PubMed]
- Toda, S.; Sugawara, K.; Nlshiyama, Y.; Ohbayashi, M.; Ohkusa, N.; Yamamoto, H.; Konishi, M.; Oki, T. Quinaldopeptin, a Novel Antibiotic of the Quinomycin Family. J. Antibiot. 1990, 43, 796–808. [Google Scholar] [CrossRef]
- Fernández, J.; Marín, L.; Álvarez-Alonso, R.; Redondo, S.; Carvajal, J.; Villamizar, G.; Villar, C.J.; Lombó, F. Biosynthetic Modularity Rules in the Bisintercalator Family of Antitumor Compounds. Mar. Drugs 2014, 12, 2668–2699. [Google Scholar] [CrossRef]
- Mori, S.; Shrestha, S.K.; Fernández, J.; Álvarez San Millán, M.; Garzan, A.; Al-Mestarihi, A.H.; Lombó, F.; Garneau-Tsodikova, S. Activation and Loading of the Starter Unit during Thiocoraline Biosynthesis. Biochemistry 2017, 56, 4457–4467. [Google Scholar] [CrossRef]
- Fischbach, M.A.; Walsh, C.T. Assembly-Line Enzymology for Polyketide and Nonribosomal Peptide Antibiotics: Logic, Machinery, and Mechanisms. Chem. Rev. 2006, 106, 3468–3496. [Google Scholar] [CrossRef] [PubMed]
- Clugston, S.L.; Sieber, S.A.; Marahiel, M.A.; Walsh, C.T. Chirality of Peptide Bond-Forming Condensation Domains in Nonribosomal Peptide Synthetases: The C5 Domain of Tyrocidine Synthetase Is a DCL Catalyst. Biochemistry 2003, 42, 12095–12104. [Google Scholar] [CrossRef] [PubMed]
- Hoyer, K.M.; Mahlert, C.; Marahiel, M.A. The Iterative Gramicidin S Thioesterase Catalyzes Peptide Ligation and Cyclization. Chem. Biol. 2007, 14, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Murphy, A.C.; Samborskyy, M.; Prediger, P.; Dias, L.C.; Leadlay, P.F. Iterative Mechanism of Macrodiolide Formation in the Anticancer Compound Conglobatin. Chem. Biol. 2015, 22, 745–754. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Fang, Y.; Yang, Y.; Qin, Y.; Wu, P.; Wang, T.; Lai, H.; Meng, L.; Wang, D.; Zheng, Z.; et al. Elaiophylin, a Novel Autophagy Inhibitor, Exerts Antitumor Activity as a Single Agent in Ovarian Cancer Cells. Autophagy 2015, 11, 1849–1863. [Google Scholar] [CrossRef]
- Little, R.F.; Hertweck, C. Chain Release Mechanisms in Polyketide and Non-Ribosomal Peptide Biosynthesis. Nat. Prod. Rep. 2022, 39, 163–205. [Google Scholar] [CrossRef]
- Biswas, T.; Zolova, O.E.; Lombó, F.; de la Calle, F.; Salas, J.A.; Tsodikov, O.V.; Garneau-Tsodikova, S. A New Scaffold of an Old Protein Fold Ensures Binding to the Bisintercalator Thiocoraline. J. Mol. Biol. 2010, 397, 495–507. [Google Scholar] [CrossRef]
- Männle, D.; McKinnie, S.M.K.; Mantri, S.S.; Steinke, K.; Lu, Z.; Moore, B.S.; Ziemert, N.; Kaysser, L. Comparative Genomics and Metabolomics in the Genus Nocardia. mSystems 2020, 5, e00125-20. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Type | From | To | Most Similar Known Cluster (MIBiG Ref) | Similarity |
|---|---|---|---|---|---|
| Region 1 | RRE-containing, thiopeptide, Linear azol(in)e-containing peptide | 712,243 | 741,688 | Conglobatin (BGC0001215) | 15% |
| Region 2 | Class II lanthipeptide | 896,153 | 919,056 | ||
| Region 3 | Class III lanthipeptide | 925,937 | 944,819 | Catenulipeptin (BGC0000501) | 60% |
| Region 4 | Arylpolyene | 1,300,657 | 1,341,691 | Triacsins (BGC0001983) | 6% |
| Region 5 | Aminoglycoside/aminocyclitol cluster | 2,603,585 | 2,624,304 | Vazabitide A (BGC0001818) | 6% |
| Region 6 | NRPS-like, NRPS | 2,931,152 | 2,996,460 | Thiocoraline (BGC0000445) | 34% |
| Region 7 | Terpene | 3,232,919 | 3,254,062 | Geosmin (BGC0000661) | 100% |
| Region 8 | Siderophore | 3,326,381 | 3,339,918 | ||
| Region 9 | Class III lanthipeptide | 3,364,301 | 3,386,850 | Catenulipeptin (BGC0000501) | 60% |
| Region 10 | NRPS | 3,404,482 | 3,470,234 | A54145 (BGC0000291) | 6% |
| Region 11 | Terpene | 3,492,238 | 3,513,224 | Isorenieratene (BGC0000664) | 28% |
| Region 12 | Type I PKS, NRPS | 3,555,559 | 3,604,623 | ||
| Region 13 | NRPS | 3,659,495 | 3,718,843 | Amychelin (BGC0000300) | 25% |
| Region 14 | TransAT-PKS, NRPS, Type I PKS | 5,038,833 | 5,103,685 | Kanamycin (BGC0000703) | 1% |
| Region 15 | Type III PKS | 5,114,083 | 5,155,129 | Alkylresorcinol (BGC0000282) | 100% |
| Region 16 | RRE-containing | 5,910,597 | 5,930,747 | SCO-2138 (BGC0000595) | 14% |
| Region 17 | NAPAA | 6,874,817 | 6,908,755 | ||
| Region 18 | Redox-cofactor | 7,052,415 | 7,074,428 | Lankacidin C (BGC0001100) | 20% |
| Region 19 | Phenazine | 7,585,752 | 7,606,243 | Endophenazines A/B (BGC0001080) | 33% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Hidalgo, M.; García, M.J.; González, I.; Oves-Costales, D.; Genilloud, O. Complete Genome Sequence Analysis of Kribbella sp. CA-293567 and Identification of the Kribbellichelins A & B and Sandramycin Biosynthetic Gene Clusters. Microorganisms 2023, 11, 265. https://doi.org/10.3390/microorganisms11020265
Sánchez-Hidalgo M, García MJ, González I, Oves-Costales D, Genilloud O. Complete Genome Sequence Analysis of Kribbella sp. CA-293567 and Identification of the Kribbellichelins A & B and Sandramycin Biosynthetic Gene Clusters. Microorganisms. 2023; 11(2):265. https://doi.org/10.3390/microorganisms11020265
Chicago/Turabian StyleSánchez-Hidalgo, Marina, María Jesús García, Ignacio González, Daniel Oves-Costales, and Olga Genilloud. 2023. "Complete Genome Sequence Analysis of Kribbella sp. CA-293567 and Identification of the Kribbellichelins A & B and Sandramycin Biosynthetic Gene Clusters" Microorganisms 11, no. 2: 265. https://doi.org/10.3390/microorganisms11020265
APA StyleSánchez-Hidalgo, M., García, M. J., González, I., Oves-Costales, D., & Genilloud, O. (2023). Complete Genome Sequence Analysis of Kribbella sp. CA-293567 and Identification of the Kribbellichelins A & B and Sandramycin Biosynthetic Gene Clusters. Microorganisms, 11(2), 265. https://doi.org/10.3390/microorganisms11020265