
Multi-Scale Crack Detection and Quantification of Concrete Bridges Based on Aerial Photography and Improved Object Detection Network
 , ,
, , 
Abstract
1. Introduction
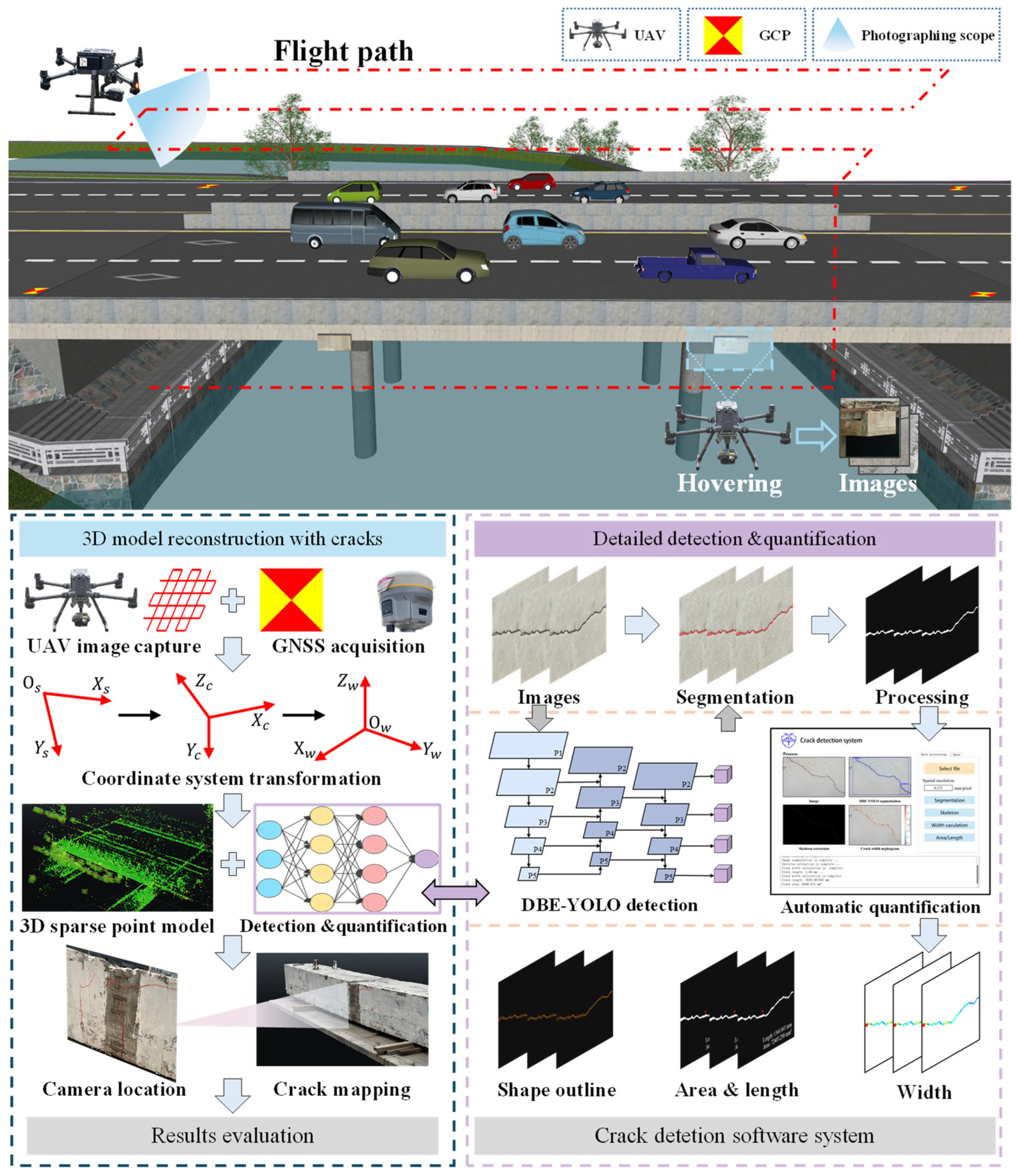
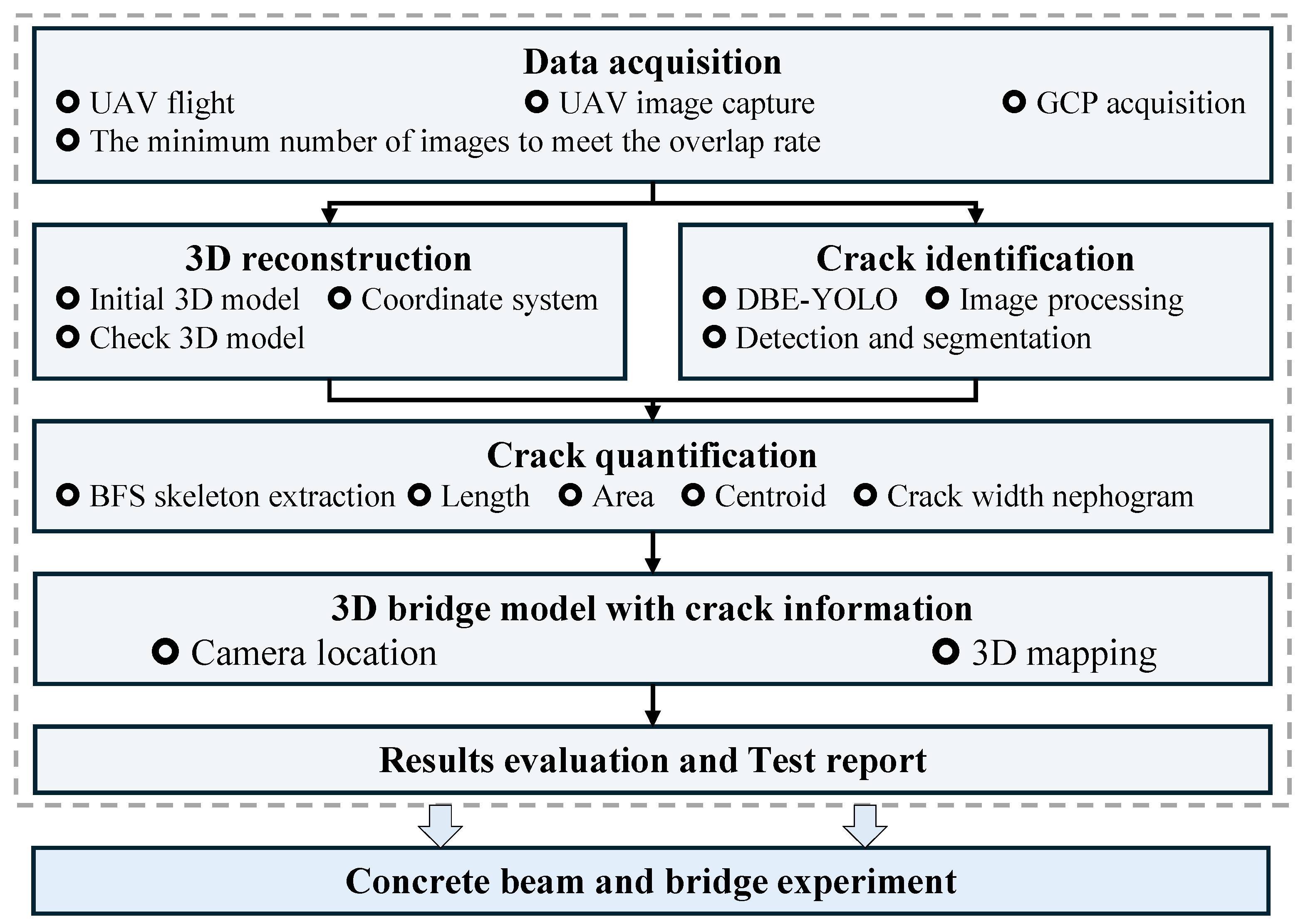
2. Framework of the Proposed Method
3. Methodology
3.1. Three-Dimensional Model Based on SfM
3.1.1. Image Data Acquisition Using UAVs
3.1.2. Image-Based 3D Reconstruction
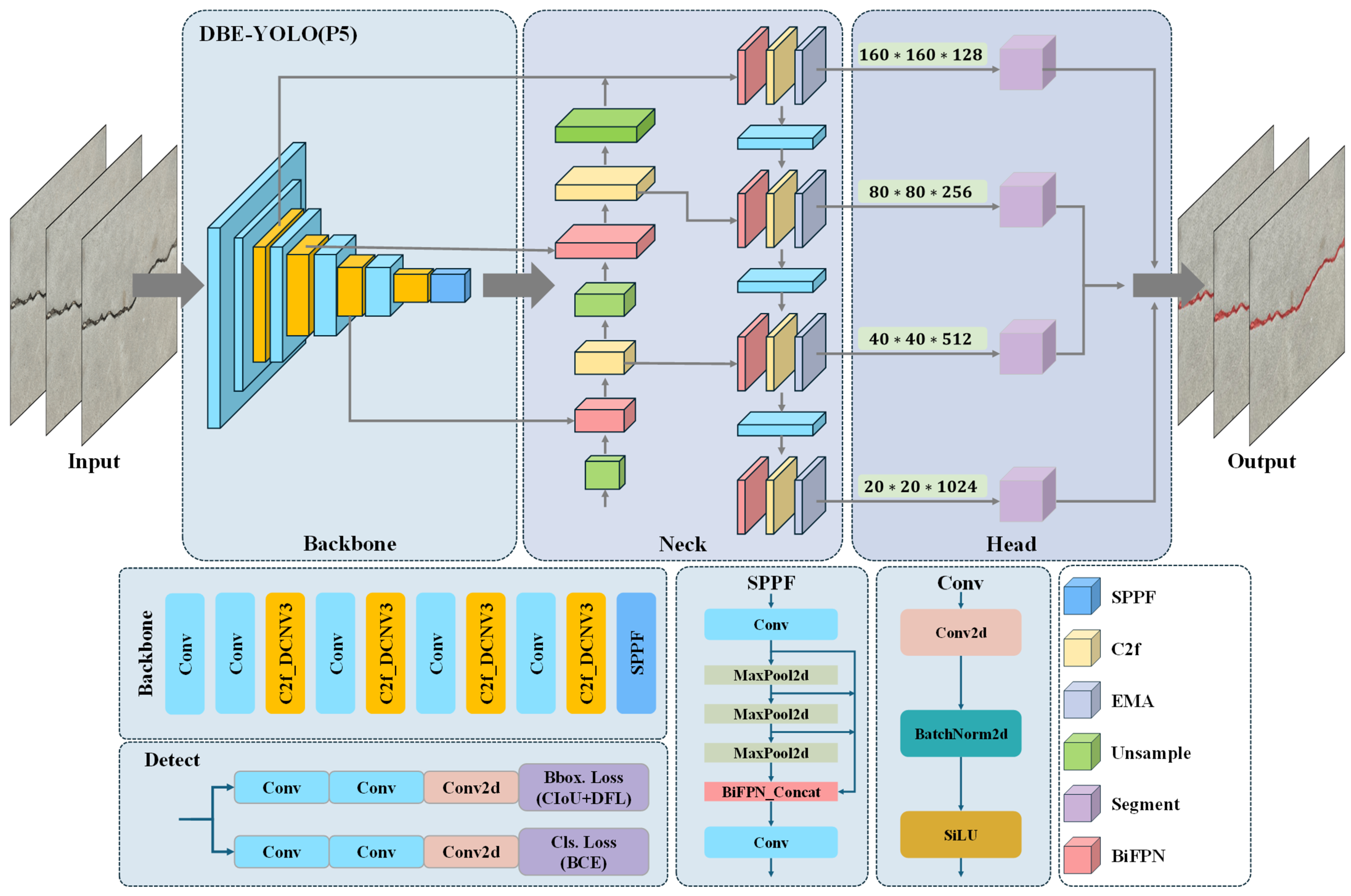
3.2. Improvement of Crack Detection and Segmentation Network
3.2.1. YOLOv8-Based Network
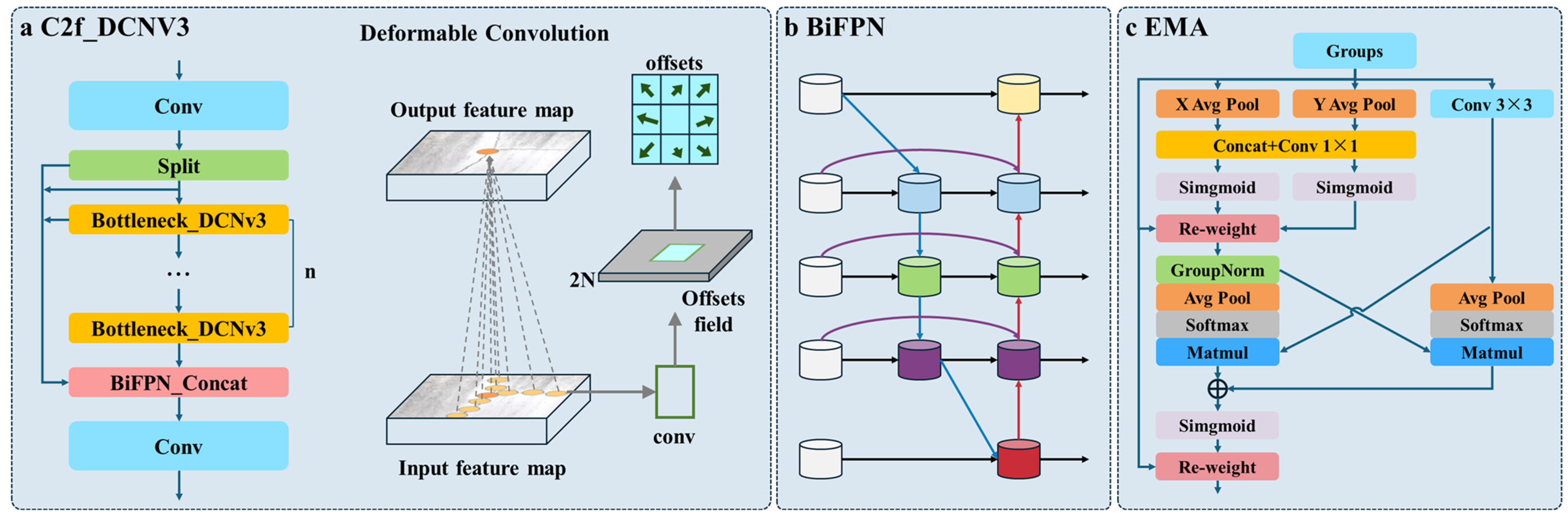
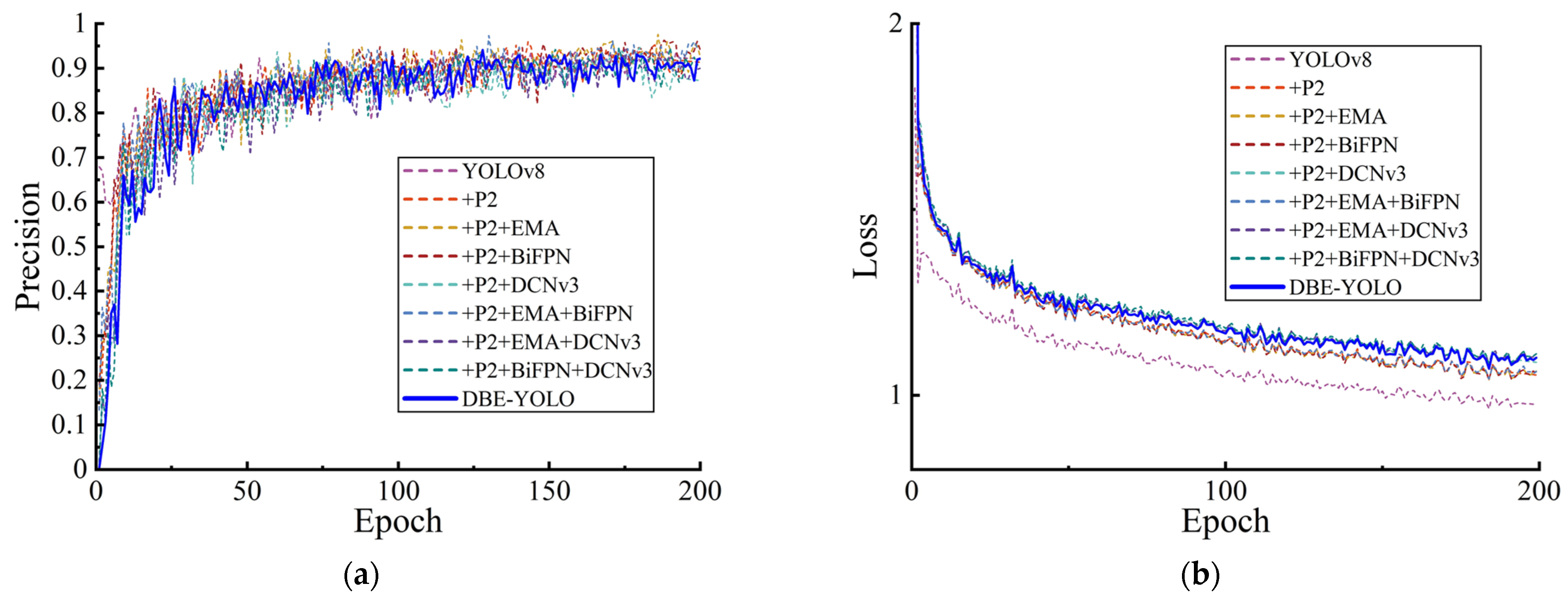
3.2.2. Improvements in DBE-YOLO
- 1.
- C2f_DCNv3 into the backbone
- 2.
- BiFPN into the neck
- 3.
- EMA into the neck.
3.2.3. Evaluation Indicators
3.3. Quantification Methods for Crack Parameters
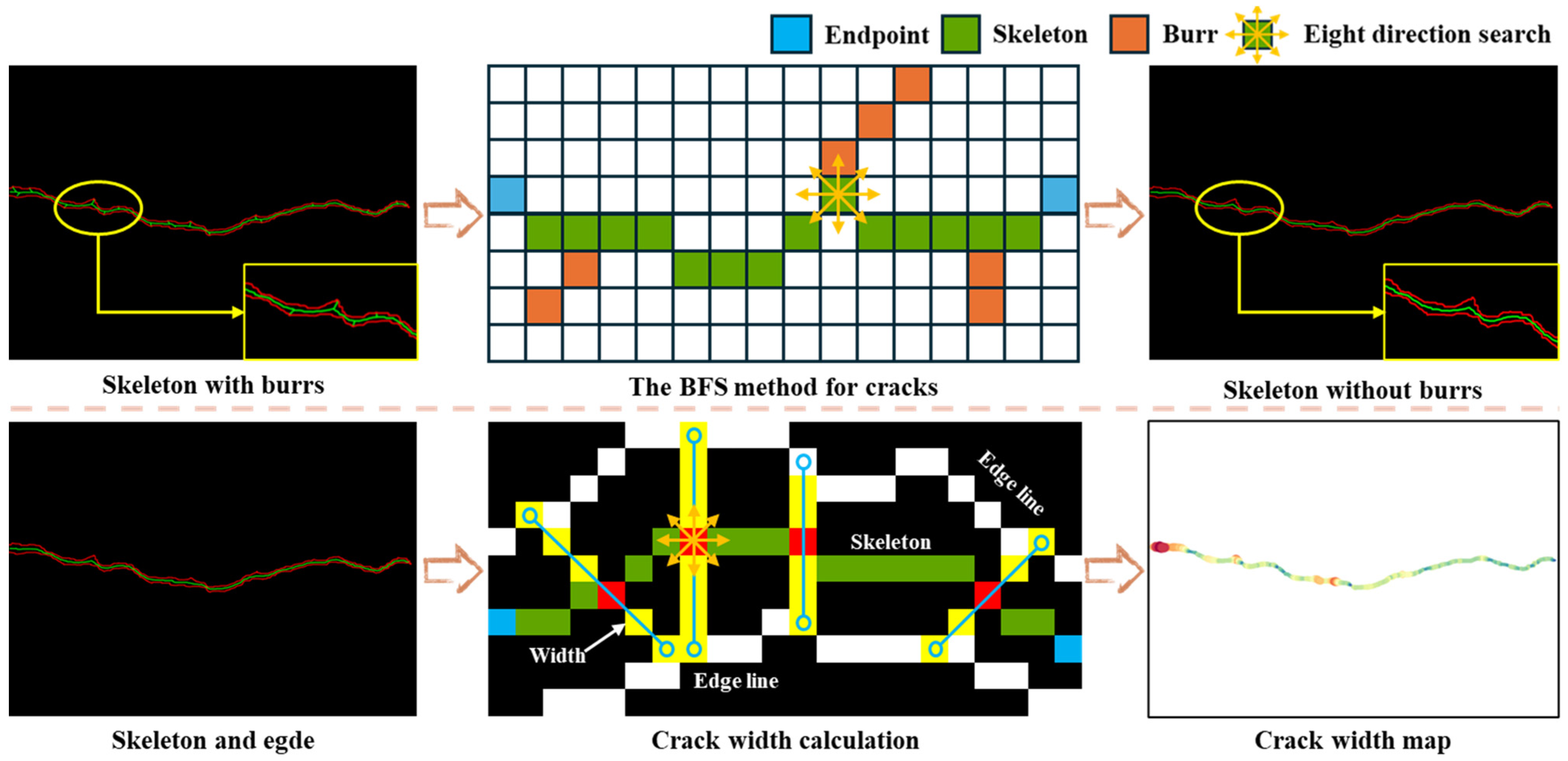
3.3.1. Crack Width Calculation Method
- 1.
- Crack skeleton extraction
- 2.
- Crack skeleton extraction
3.3.2. Crack Length, Area, and Centroid Method
3.3.3. Crack Detection System
3.4. Procedure of the Proposed Method
- Step 1: Data acquisition: Based on the bridge type and inspection task requirements, GCPs, overlap rates, and flight paths are determined. The UAV captures images, while the GNSS receiver collects GCP information.
- Step 2: 3D reconstruction: The collected data are used for 3D reconstruction, ensuring complete area coverage.
- Step 3: Crack detection, segmentation, and quantification: The images are processed by an automatic system, which enables the cracks to be identified, segmented, and quantified, providing accurate physical information and width maps of the cracks.
- Step 4: Crack mapping: By integrating the recovered camera poses, the crack quantification data are mapped onto the 3D model, enabling the 3D visualization of the cracks.
- Step 5: Bridge inspection report: Inspection results are generated by current standards. Based on crack distribution, areas of concern are highlighted to support the assessment of bridge structural safety.
4. Experimental Test
4.1. Crack Detection Results Based on DBE-YOLO
4.2. Verification on an Experimental Beam
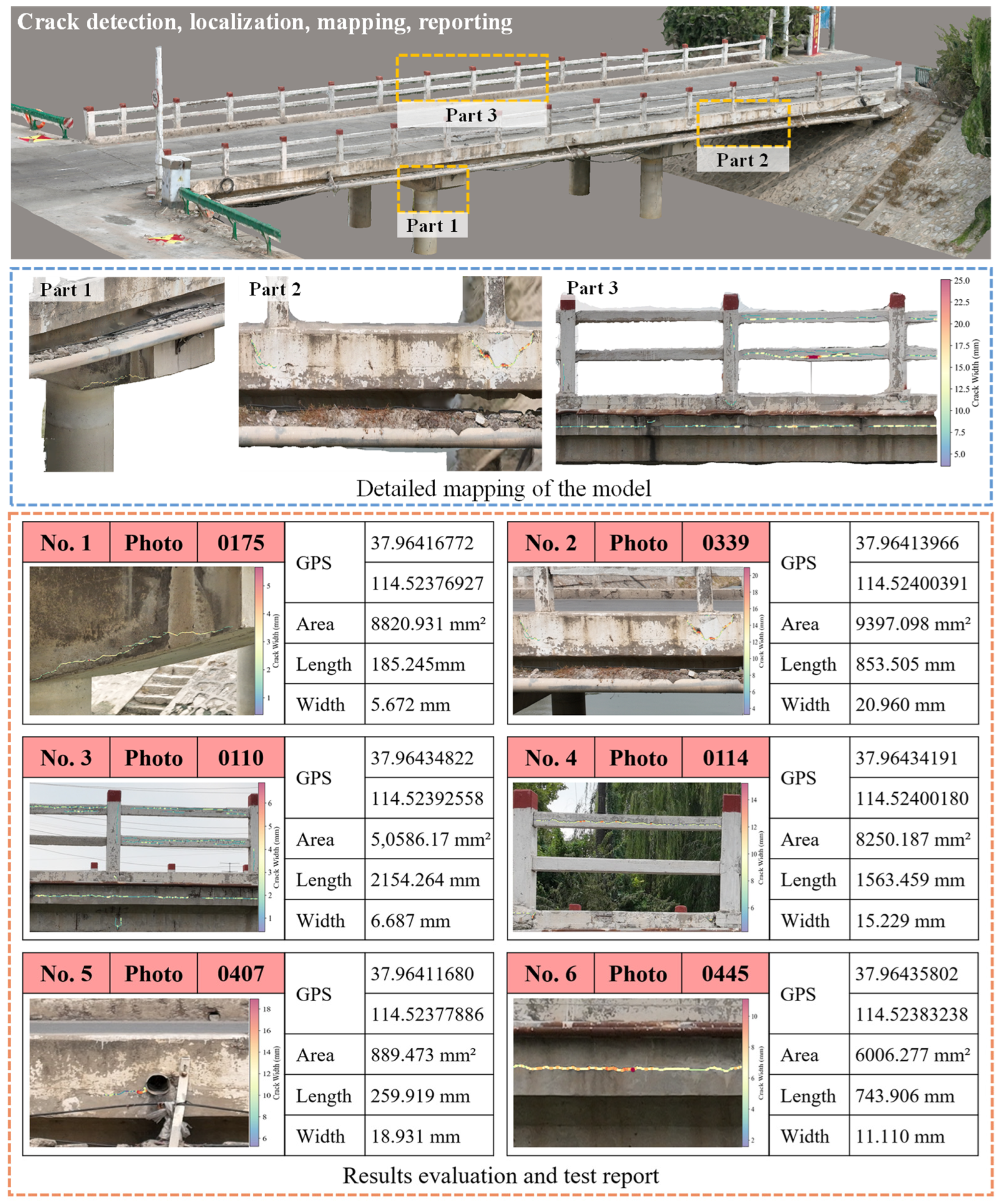
5. Field Test and Implementation
5.1. Field Design and Testing Strategy
5.2. Three-Dimensional Visualization and Mapping of Cracks in the Bridge
6. Conclusions
- An improved DBE-YOLO crack detection network is proposed. To address the challenges posed by complex backgrounds in UAV-captured images and limitations in multi-scale crack detection, the proposed DBE-YOLO integrates DCNv3, BiFPN, EMA, and multi-scale detection heads. This approach reduces information loss during transmission and enhances both crack feature extraction and detection capabilities at macro- and micro-scales. Experimental results show that DBE-YOLO improves segmentation accuracy by 3.19% and F1 score by 3.8% compared to the original model.
- An automated crack detection system has been developed. The DBE-YOLO model and the proposed crack quantification methods are integrated into the system to improve detection efficiency and enable rapid crack quantification. This system automatically generates detection data and crack width maps. Experimental results demonstrate that this method can automatically and rapidly process large volumes of crack images and compute crack parameters, effectively overcoming the issue of information loss caused by fragmented processes in traditional methods while also alleviating the workload associated with large-scale image processing.
- High-precision 3D modeling and crack visualization can be achieved. The 3D model of the bridge is constructed using RTK and GCP data. Crack information is then mapped onto the 3D model based on the recovered camera poses, generating a 3D visualization of the cracks. Experimental results show that the generated 3D bridge model with cracks provides a comprehensive spatial distribution of the cracks and produces an intuitive, verifiable inspection report, providing a novel approach for rapid bridge crack inspection.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Matos, J.C.; Nicoletti, V.; Kralovanec, J.; Sousa, H.S.; Gara, F.; Moravcik, M.; Morais, M.J. Comparison of Condition Rating Systems for Bridges in Three European Countries. Appl. Sci. 2023, 13, 12343. [Google Scholar] [CrossRef]
- Aljagoub, D.; Na, R.; Cheng, C. Toward Practical Guidelines for Infrared Thermography of Concrete Bridge Decks: A Preliminary Investigation across U.S. Climate Zones. Case Stud. Constr. Mater. 2025, 22, e04502. [Google Scholar]
- Teng, S.; Liu, Z.; Li, X. Improved YOLOv3-Based Bridge Surface Defect Detection by Combining High- and Low-Resolution Feature Images. Buildings 2022, 12, 1225. [Google Scholar] [CrossRef]
- Sohaib, M.; Arif, M.; Kim, J.-M. Evaluating YOLO Models for Efficient Crack Detection in Concrete Structures Using Transfer Learning. Buildings 2024, 14, 3928. [Google Scholar] [CrossRef]
- Faris, N.; Zayed, T.; Fares, A. Review of Condition Rating and Deterioration Modeling Approaches for Concrete Bridges. Buildings 2025, 15, 219. [Google Scholar] [CrossRef]
- Shahin, M.; Chen, F.F.; Maghanaki, M.; Hosseinzadeh, A.; Zand, N.; Khodadadi Koodiani, H. Improving the Concrete Crack Detection Process via a Hybrid Visual Transformer Algorithm. Sensors 2024, 24, 3247. [Google Scholar] [CrossRef]
- Chen, W.; He, Z.; Zhang, J. Online Monitoring of Crack Dynamic Development Using Attention-Based Deep Networks. Autom. Constr. 2023, 154, 105022. [Google Scholar]
- Jiang, S.; Zhang, J.; Wang, W.; Wang, Y. Automatic Inspection of Bridge Bolts Using Unmanned Aerial Vision and Adaptive Scale Unification-Based Deep Learning. Remote Sens. 2023, 15, 328. [Google Scholar] [CrossRef]
- Mirzazade, A.; Popescu, C.; Blanksvärd, T.; Täljsten, B. Workflow for Off-Site Bridge Inspection Using Automatic Damage Detection-Case Study of the Pahtajokk Bridge. Remote Sens. 2021, 13, 2665. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.; Li, J.Q.; Yang, E.; Qiu, S. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces with a Recurrent Neural Network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic Pixel-Level Detection of Vertical Cracks in Asphalt Pavement Based on GPR Investigation and Improved Mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar]
- Tran, T.S.; Nguyen, S.D.; Lee, H.J.; Tran, V.P. Advanced Crack Detection and Segmentation on Bridge Decks Using Deep Learning. Constr. Build. Mater. 2023, 400, 132839. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated Bridge Surface Crack Detection and Segmentation Using Computer Vision-Based Deep Learning Model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar]
- Qiu, Q.; Lau, D. Real-Time Detection of Cracks in Tiled Sidewalks Using YOLO-Based Method Applied to Unmanned Aerial Vehicle (UAV) Images. Autom. Constr. 2023, 147, 104745. [Google Scholar]
- Li, J.; Yuan, C.; Wang, X. Real-Time Instance-Level Detection of Asphalt Pavement Distress Combining Space-to-Depth (SPD) YOLO and Omni-Scale Network (OSNet). Autom. Constr. 2023, 155, 105062. [Google Scholar]
- Meng, S.; Gao, Z.; Zhou, Y.; He, B.; Djerrad, A. Real-time Automatic Crack Detection Method Based on Drone. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 849–872. [Google Scholar]
- Jiang, S.; Zhang, Y.; Wang, F.; Xu, Y. Three-Dimensional Reconstruction and Damage Localization of Bridge Undersides Based on Close-Range Photography Using UAV. Meas. Sci. Technol. 2025, 36, 015423. [Google Scholar] [CrossRef]
- Chen, J.; Lu, W.; Lou, J. Automatic Concrete Defect Detection and Reconstruction by Aligning Aerial Images onto Semantic-rich Building Information Model. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 1079–1098. [Google Scholar]
- Perry, B.J.; Guo, Y.; Atadero, R.; Van De Lindt, J.W. Streamlined Bridge Inspection System Utilizing Unmanned Aerial Vehicles (UAVs) and Machine Learning. Measurement 2020, 164, 108048. [Google Scholar] [CrossRef]
- Han, Q.; Liu, X.; Xu, J. Detection and Location of Steel Structure Surface Cracks Based on Unmanned Aerial Vehicle Images. J. Build. Eng. 2022, 50, 104098. [Google Scholar]
- Jiang, S.; Zhang, J. Real-time Crack Assessment Using Deep Neural Networks with Wall-climbing Unmanned Aerial System. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 549–564. [Google Scholar]
- Lei, B.; Ren, Y.; Wang, N.; Huo, L.; Song, G. Design of a New Low-Cost Unmanned Aerial Vehicle and Vision-Based Concrete Crack Inspection Method. Struct. Health Monit. 2020, 19, 1871–1883. [Google Scholar]
- Salaan, C.J.O.; Okada, Y.; Mizutani, S.; Ishii, T.; Koura, K.; Ohno, K.; Tadokoro, S. Close Visual Bridge Inspection Using a UAV with a Passive Rotating Spherical Shell. J. Field Robot. 2018, 35, 850–867. [Google Scholar] [CrossRef]
- Ding, W.; Yang, H.; Yu, K.; Shu, J. Crack Detection and Quantification for Concrete Structures Using UAV and Transformer. Autom. Constr. 2023, 152, 104929. [Google Scholar] [CrossRef]
- Ong, J.C.H.; Ismadi, M.-Z.P.; Wang, X. A Hybrid Method for Pavement Crack Width Measurement. Measurement 2022, 197, 111260. [Google Scholar] [CrossRef]
- He, X.; Tang, Z.; Deng, Y.; Zhou, G.; Wang, Y.; Li, L. UAV-Based Road Crack Object-Detection Algorithm. Autom. Constr. 2023, 154, 105014. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Buatik, A.; Mohamad, H.; Zhou, M.; Kongsilp, S.; Poovarodom, N. Integrated Pixel-Level CNN-FCN Crack Detection via Photogrammetric 3D Texture Mapping of Concrete Structures. Autom. Constr. 2022, 140, 104388. [Google Scholar] [CrossRef]
- Kalfarisi, R.; Wu, Z.Y.; Soh, K. Crack Detection and Segmentation Using Deep Learning with 3D Reality Mesh Model for Quantitative Assessment and Integrated Visualization. J. Comput. Civ. Eng. 2020, 34, 04020010. [Google Scholar] [CrossRef]
- Wang, F.; Zou, Y.; Del Rey Castillo, E.; Lim, J.B.P. Optimal UAV Image Overlap for Photogrammetric 3D Reconstruction of Bridges. IOP Conf. Ser. Earth Environ. Sci. 2022, 1101, 022052. [Google Scholar]
- Feng, C.-Q.; Li, B.-L.; Liu, Y.-F.; Zhang, F.; Yue, Y.; Fan, J.-S. Crack Assessment Using Multi-Sensor Fusion Simultaneous Localization and Mapping (SLAM) and Image Super-Resolution for Bridge Inspection. Autom. Constr. 2023, 155, 105047. [Google Scholar]
- Martínez-Espejo Zaragoza, I.; Caroti, G.; Piemonte, A.; Riedel, B.; Tengen, D.; Niemeier, W. Structure from Motion (SfM) Processing of UAV Images and Combination with Terrestrial Laser Scanning, Applied for a 3D-Documentation in a Hazardous Situation. Geomat. Nat. Hazards Risk 2017, 8, 1492–1504. [Google Scholar]
- Saleem, M.R.; Park, J.-W.; Lee, J.-H.; Jung, H.-J.; Sarwar, M.Z. Instant Bridge Visual Inspection Using an Unmanned Aerial Vehicle by Image Capturing and Geo-Tagging System and Deep Convolutional Neural Network. Struct. Health Monit. 2021, 20, 1760–1777. [Google Scholar] [CrossRef]
- Lin, J.J.; Ibrahim, A.; Sarwade, S.; Golparvar-Fard, M. Bridge Inspection with Aerial Robots: Automating the Entire Pipeline of Visual Data Capture, 3D Mapping, Defect Detection, Analysis, and Reporting. J. Comput. Civ. Eng. 2021, 35, 04020064. [Google Scholar]
- Liu, Y.; Nie, X.; Fan, J.; Liu, X. Image-based Crack Assessment of Bridge Piers Using Unmanned Aerial Vehicles and Three-dimensional Scene Reconstruction. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 511–529. [Google Scholar]
- Zhou, L.; Jiang, Y.; Jia, H.; Zhang, L.; Xu, F.; Tian, Y.; Ma, Z.; Liu, X.; Guo, S.; Wu, Y.; et al. UAV Vision-Based Crack Quantification and Visualization of Bridges: System Design and Engineering Application. Struct. Health Monit. 2024, 24, 1083–1100. [Google Scholar] [CrossRef]
- Tavasci, L.; Nex, F.; Gandolfi, S. Reliability of Real-Time Kinematic (RTK) Positioning for Low-Cost Drones’ Navigation across Global Navigation Satellite System (GNSS) Critical Environments. Sensors 2024, 24, 6096. [Google Scholar] [CrossRef]
- Cheng, Z.; Gong, W.; Tang, H.; Juang, C.H.; Deng, Q.; Chen, J.; Ye, X. UAV Photogrammetry-Based Remote Sensing and Preliminary Assessment of the Behavior of a Landslide in Guizhou, China. Eng. Geol. 2021, 289, 106172. [Google Scholar]
- Tan, Y.; Li, G.; Cai, R.; Ma, J.; Wang, M. Mapping and Modelling Defect Data from UAV Captured Images to BIM for Building External Wall Inspection. Autom. Constr. 2022, 139, 104284. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: New York, NY, USA, 2023; pp. 14408–14419. [Google Scholar]
- Wang, S.; Dong, Q.; Chen, X.; Chu, Z.; Li, R.; Hu, J.; Gu, X. Measurement of Asphalt Pavement Crack Length Using YOLO V5-BiFPN. J. Infrastruct. Syst. 2024, 30, 04024005. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Zhao, S.; Kang, F.; Li, J.; Ma, C. Structural Health Monitoring and Inspection of Dams Based on UAV Photogrammetry with Image 3D Reconstruction. Autom. Constr. 2021, 130, 103832. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Intelligent Segmentation Method for Blurred Cracks and 3D Mapping of Width Nephograms in Concrete Dams Using UAV Photogrammetry. Autom. Constr. 2024, 157, 105145. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2025. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yurtkulu, S.C.; Şahin, Y.H.; Unal, G. Semantic Segmentation with Extended DeepLabv3 Architecture. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; IEEE: New York, NY, USA; pp. 1–4. [Google Scholar]
- Hussain, M. YOLOv1 to v8: Unveiling Each Variant–A Comprehensive Review of YOLO. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- CJJT233-2015; Technical Code for Test and Evaluation of City Bridges. Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2015.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Item | Version | Parameter | Value |
|---|---|---|---|
| OS | Windows 11 | Input shape | 640 × 640 |
| Python | 3.8 | Epoch | 200 |
| PyTorch | 1.12.0 | Batch Size | 16 |
| CUDA | 12.2 | Optimizer | Adam |
| CPU | Intel i9-13900 KF | Momentum | 0.9 |
| RAM | 96 GB | Learning rate | 0.0001 |
| GPU | RTX 3090(24 GB) | Patience | 30 |
| Network Structure | |||
|---|---|---|---|
| U-Net | 92.73 | 82.77 | 87.46 |
| FCN | 90.13 | 81.70 | 85.70 |
| DeepLabv3+ | 90.89 | 85.74 | 88.23 |
| YOLOv5 | 81.49 | 69.25 | 74.87 |
| YOLOv8 | 93.60 | 77.35 | 84.71 |
| DBE-YOLO | 96.79 | 81.54 | 88.51 |
| Group | Method | |||||
|---|---|---|---|---|---|---|
| 1 | YOLOv8m-seg | 93.60 | 77.35 | 81.63 | 69.36 | 84.71 |
| 2 | + P2 | 89.14 | 77.46 | 81.52 | 70.52 | 82.89 |
| 3 | + P2 + EMA | 95.30 | 76.66 | 83.78 | 74.42 | 84.97 |
| 4 | + P2 + BiFPN | 94.44 | 74.87 | 82.66 | 72.25 | 83.53 |
| 5 | + P2 + DCNv3 | 88.73 | 75.47 | 80.66 | 70.75 | 81.56 |
| 6 | + P2 + EMA + BiFPN | 95.59 | 77.27 | 84.85 | 76.46 | 85.46 |
| 7 | + P2 + EMA + DCNv3 | 91.64 | 82.46 | 85.35 | 76.10 | 86.81 |
| 8 | + P2 + BiFPN + DCNv3 | 95.91 | 76.21 | 84.41 | 73.93 | 84.93 |
| 9 | DBE-YOLO | 96.79 | 81.54 | 87.74 | 78.56 | 88.51 |
| Number | Proposed Method (mm) | Width (mm) | AE (mm) | RE (%) |
|---|---|---|---|---|
| 1 | 1.062 | 1.02 | 0.042 | 4.11 |
| 2 | 2.484 | 2.54 | −0.056 | 2.21 |
| 3 | 1.027 | 0.93 | 0.097 | 10.43 |
| 4 | 2.932 | 2.86 | 0.072 | 2.51 |
| 5 | 4.701 | 4.76 | −0.059 | 1.23 |
| 6 | 5.520 | 5.28 | 0.24 | 4.55 |
| 7 | 1.686 | 1.55 | 0.136 | 8.77 |
| 8 | 2.525 | 2.47 | 0.055 | 2.23 |
| ME | / | / | / | 4.51 |
| SD | / | / | / | 3.35 |
| Number | Proposed Method (mm) | Width (mm) | AE (mm) | RE (%) |
|---|---|---|---|---|
| 1 | 5.672 | 5.83 | −0.158 | 2.71 |
| 2 | 20.960 | 22.32 | −1.360 | 6.09 |
| 3 | 6.687 | 7.53 | −0.843 | 11.20 |
| 4 | 15.229 | 14.57 | 0.659 | 4.52 |
| 5 | 18.931 | 20.34 | −1.409 | 6.93 |
| 6 | 11.110 | 10.46 | 0.650 | 6.21 |
| ME | / | / | / | 6.28 |
| SD | / | / | / | 2.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Jia, H.; Jiang, S.; Xu, F.; Tang, H.; Xiang, C.; Wang, G.; Zheng, H.; Chen, L. Multi-Scale Crack Detection and Quantification of Concrete Bridges Based on Aerial Photography and Improved Object Detection Network. Buildings 2025, 15, 1117. https://doi.org/10.3390/buildings15071117
Zhou L, Jia H, Jiang S, Xu F, Tang H, Xiang C, Wang G, Zheng H, Chen L. Multi-Scale Crack Detection and Quantification of Concrete Bridges Based on Aerial Photography and Improved Object Detection Network. Buildings. 2025; 15(7):1117. https://doi.org/10.3390/buildings15071117
Chicago/Turabian StyleZhou, Liming, Haowen Jia, Shang Jiang, Fei Xu, Hao Tang, Chao Xiang, Guoqing Wang, Hemin Zheng, and Lingkun Chen. 2025. "Multi-Scale Crack Detection and Quantification of Concrete Bridges Based on Aerial Photography and Improved Object Detection Network" Buildings 15, no. 7: 1117. https://doi.org/10.3390/buildings15071117
APA StyleZhou, L., Jia, H., Jiang, S., Xu, F., Tang, H., Xiang, C., Wang, G., Zheng, H., & Chen, L. (2025). Multi-Scale Crack Detection and Quantification of Concrete Bridges Based on Aerial Photography and Improved Object Detection Network. Buildings, 15(7), 1117. https://doi.org/10.3390/buildings15071117