
Recognition of Concrete Surface Cracks Based on Improved TransUNet


Abstract
1. Introduction
2. Related Principles
2.1. Overview of the TransUNet Algorithm
2.2. Limitations of the TransUNet Algorithm
3. Improvements to the TransUNet Algorithm
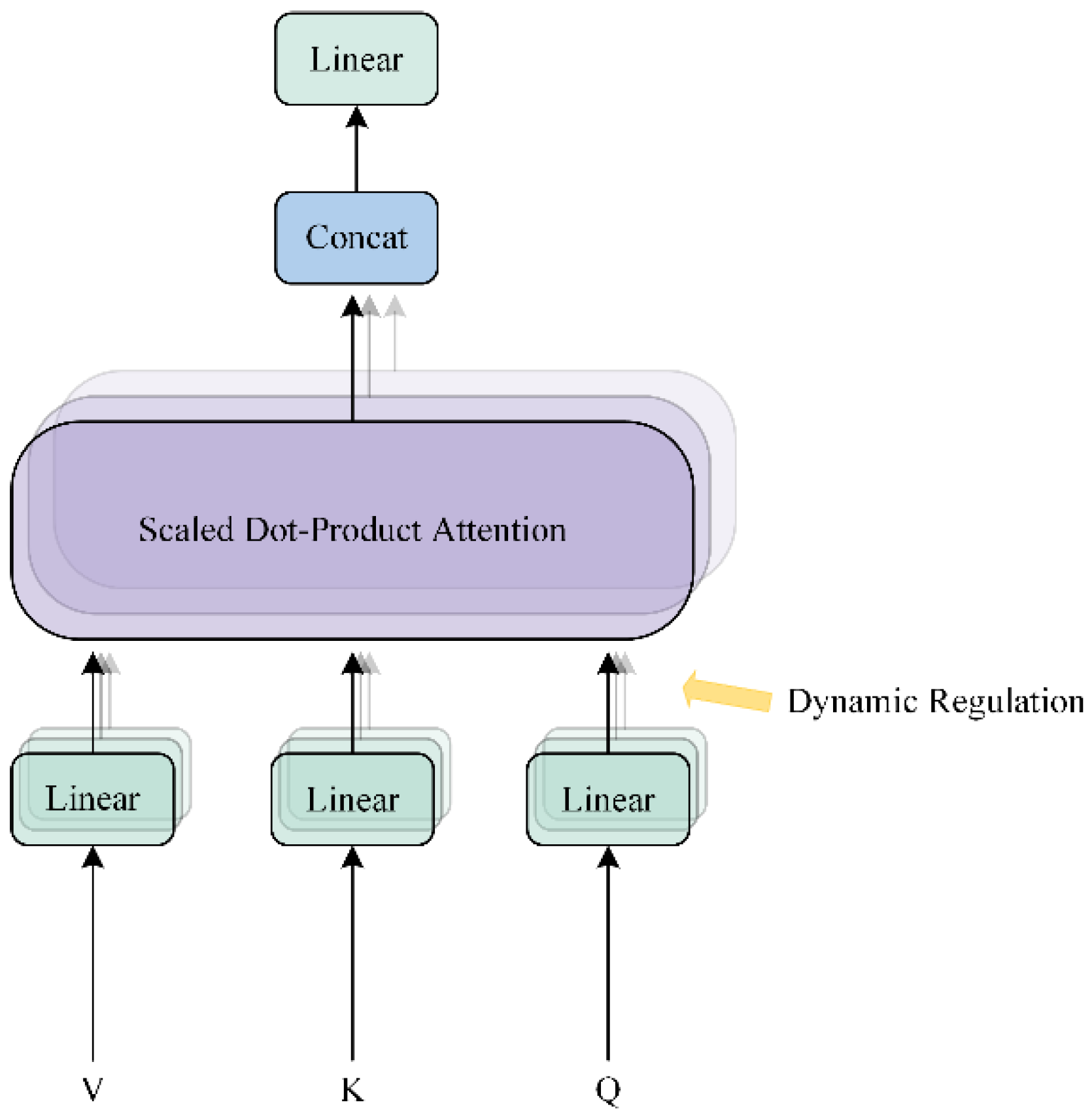
3.1. Adaptive Multi-Head Self-Attention Mechanism
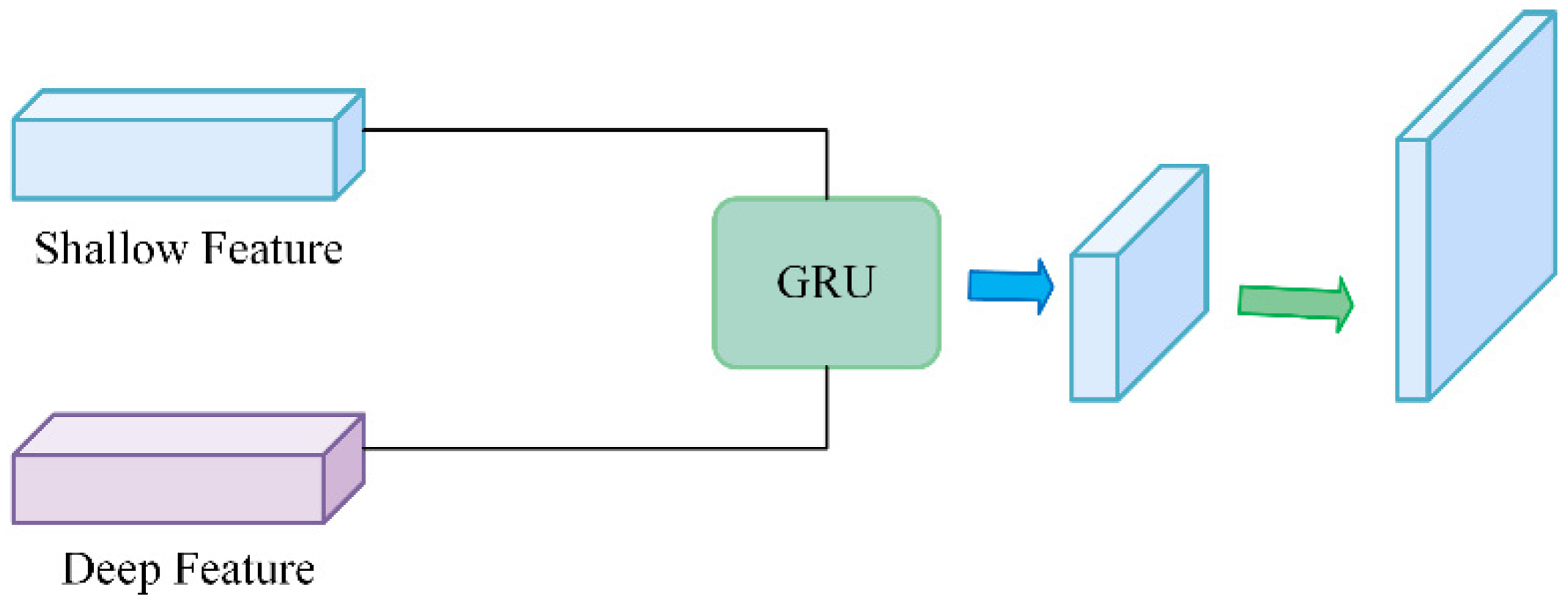
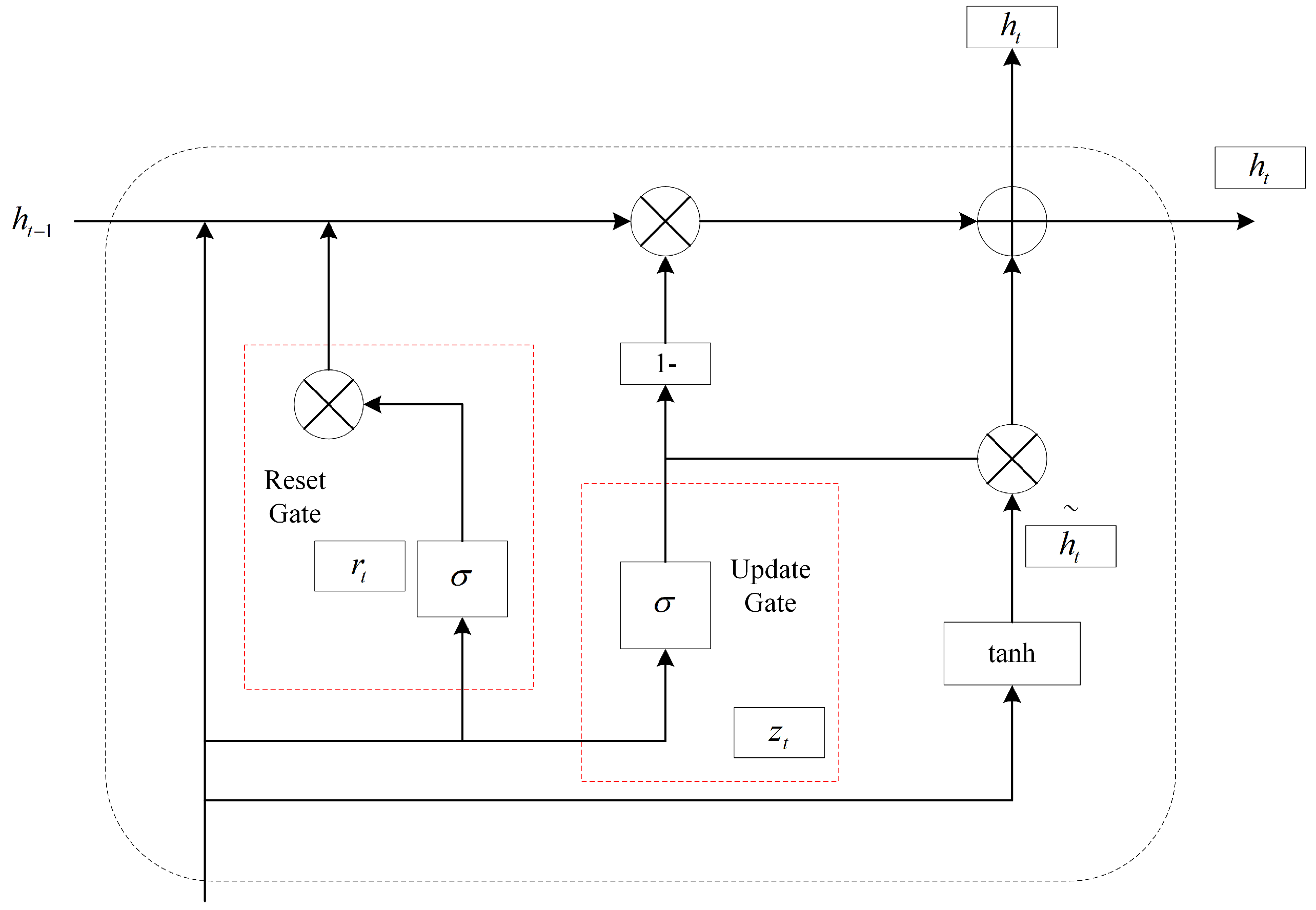
3.2. GRU-T
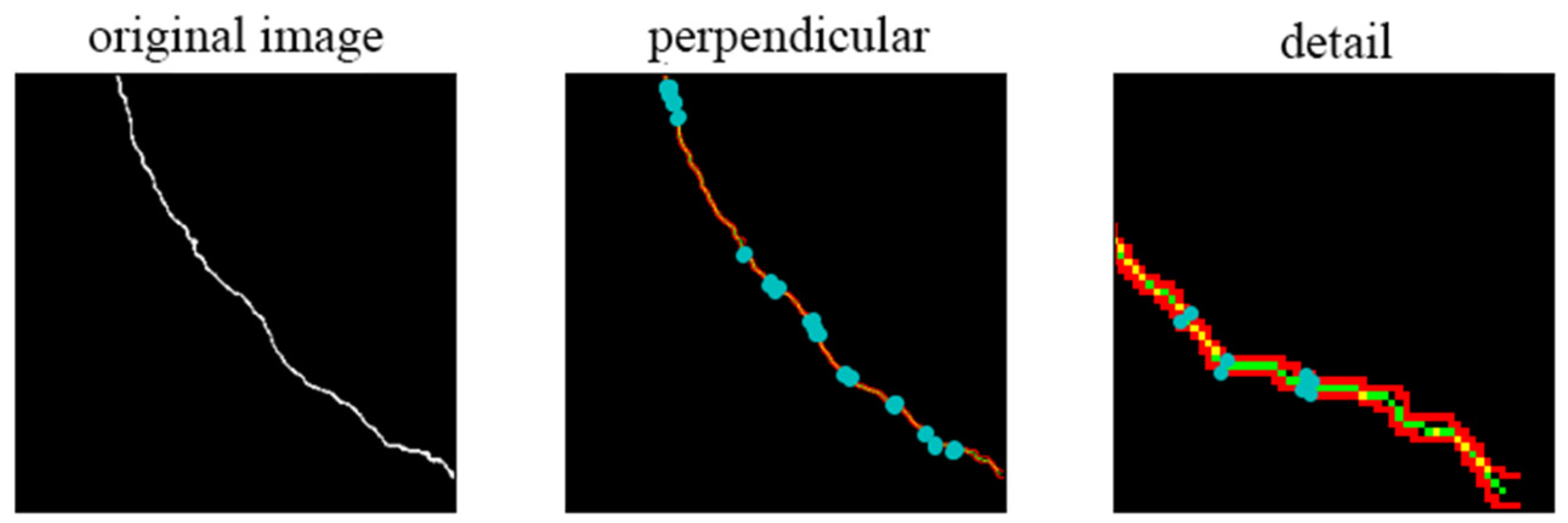
3.3. Orthogonal Skeleton Method
4. Experiments and Results
4.1. Dataset
4.2. Experimental Setup and Evaluation Metrics
4.3. Experimental Results and Analysis
4.3.1. Comparison of Ablation Experiments
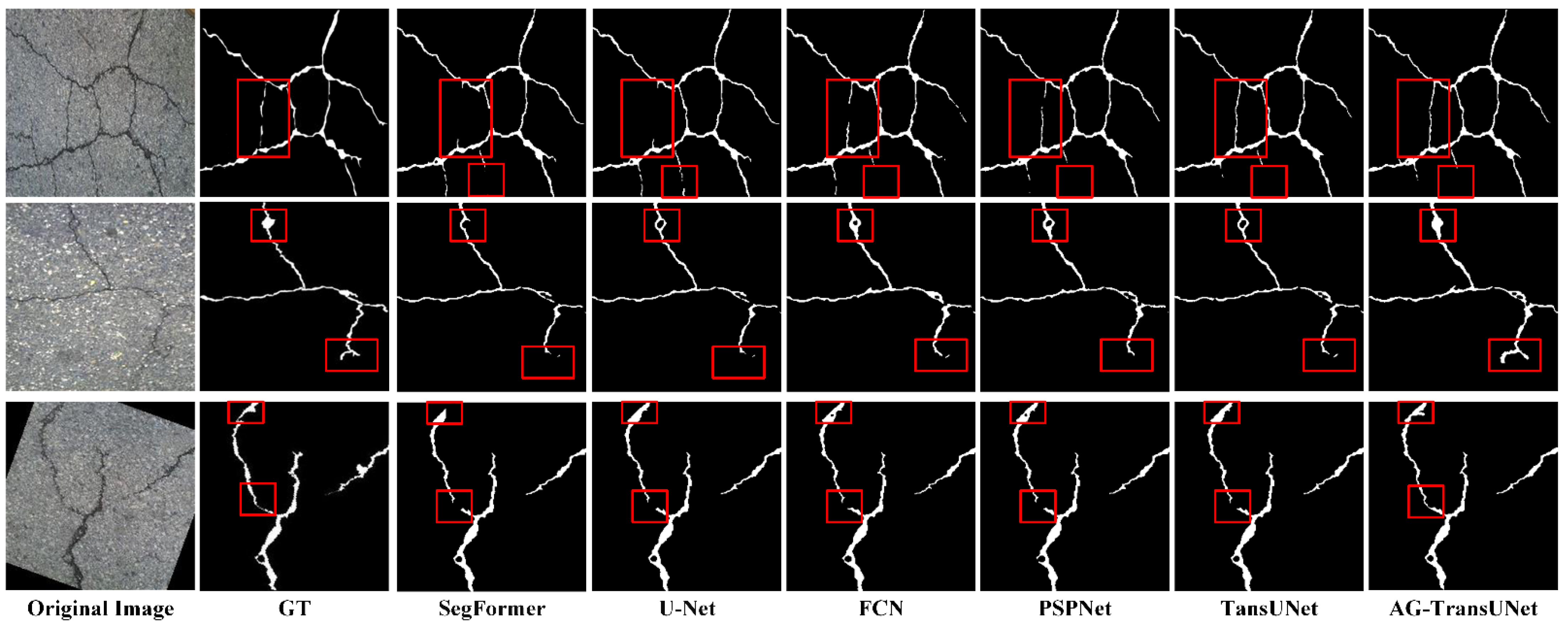
4.3.2. Evaluation of Practical Application
- 1.
- CFD Dataset Experiment
- 2.
- Concrete Crack Dataset Experiment
4.3.3. Orthogonal Skeleton Method and Crack Width
5. Conclusions
- (1)
- By introducing the adaptive multi-head self-attention mechanism, this study significantly enhances the model’s flexibility and accuracy in crack detection. This mechanism dynamically adjusts the number and distribution of attention heads based on the features of the input image, allowing the model to autonomously optimize the allocation of attention resources when processing images of varying complexity. This enables the precise capture of key crack information. The mechanism is particularly effective in high-noise environments and complex backgrounds, substantially reducing the probability of false positives and missed detections, thereby providing support for the accuracy and robustness of crack detection.
- (2)
- To further improve crack segmentation performance, this study designs and implements a novel decoding module, GRU-T. This module combines the temporal sequence processing capability of the GRU with the image processing functions of a traditional decoder, enabling a more effective fusion of deep feature information with shallow detail information. The GRU-T module is particularly suited for handling crack images in complex backgrounds because it can capture fine crack features and preserve edge details, thereby enhancing segmentation accuracy. Additionally, the module shows good performance in processing elongated and narrow cracks, reducing edge discontinuities, and mitigating the impact of noise on the segmentation results.
- (3)
- This paper proposes a crack width calculation method based on the orthogonal skeleton line method to address the limitations of traditional methods in measurement accuracy. By extracting the skeleton line of the crack and calculating the width along the orthogonal direction, this method can accurately measure the actual crack width, making it particularly suitable for cracks with complex shapes and blurred edges. Experimental results demonstrate that the application of the orthogonal skeleton line method on the dataset used in this study achieves good measurement accuracy. The method provides a reliable and efficient solution for crack width measurement in structural health monitoring.
- (4)
- The improved model proposed in this paper demonstrates superior performance in crack detection and crack width calculation. Experiments on different datasets fully validate that the model has efficient detection ability. On the CFD dataset, AG-TransUNet outperforms the original TransUNet with a 4.05% increase in precision, a 2.59% improvement in F1-score, and a 0.36% enhancement in IoU. On the concrete crack dataset, AG-TransUNet achieves a 2.21% increase in precision, a 5.63% improvement in F1-score, and a 9.07% enhancement in IoU. Additionally, the crack width calculation method based on the orthogonal skeleton approach achieves an average error of 3.88%.
- (5)
- Although AG-TransUNet shows better segmentation accuracy and robustness, it still has some limitations. The model’s performance is affected by image quality, variations in crack morphology, and environmental conditions, which may affect its generalization in different scenarios. Future research will focus on further optimizing the design of the adaptive multi-head self-attention mechanism and the GRU-T module, particularly to enhance the model’s segmentation accuracy in complex environments and reduce the error of crack width calculation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Zu’bi, M.; Fan, M.; Al Rjoub, Y.; Ashteyat, A.; Al-Kheetan, M.J.; Anguilano, L. The effect of length and inclination of carbon fiber reinforced polymer laminates on shear capacity of near-surface mounted retrofitted reinforced concrete beams. Struct. Concr. 2021, 22, 3677–3691. [Google Scholar] [CrossRef]
- Qu, Z.; Chen, W.; Wang, S.Y.; Yi, T.M.; Liu, L. A Crack Detection Algorithm for Concrete Pavement Based on Attention Mechanism and Multi-Features Fusion. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11710–11719. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Zhang, Z.J.; Qi, D.P.; Liu, Y. Automatic Crack Detection and Classification Method for Subway Tunnel Safety Monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Vivekananthan, V.; Vignesh, R.; Vasanthaseelan, S.; Joel, E.; Kumar, K.S. Concrete bridge crack detection by image processing technique by using the improved OTSU method. Mater. Today 2023, 74, 1002–1007. [Google Scholar] [CrossRef]
- Oron, S.; Dekel, T.; Xue, T.; William, T.F.; Avidan, S. Best-Buddies Similarity-Robust Template Matching Using Mutual Nearest Neighbors. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1799–1813. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zhang, J. Efficient and lightweight monitoring network for cracks in complex background regions based on adaptive perception. Automat. Constr. 2024, 166, 105614. [Google Scholar] [CrossRef]
- Gharehbaghi, V.; Farsangi, N.E.; Yang, T.Y.; Noori, M.; Kontoni, D.-P.N. A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection. Sensors 2022, 22, 8986. [Google Scholar] [CrossRef]
- Arya, D.; Ghosh, S.K.; Toshniwal, D. Automatic Recognition of Road Cracks Using Gray-Level Co-occurrence Matrix and Machine Learning. In Proceedings of the 2022 International Conference on Machine Intelligence and Signal Processing, Allahabad, India, 12–14 March 2022. [Google Scholar]
- Liu, J.; Zhao, Z.; Lv, C.S.; Ding, Y.F.; Chang, H.L.; Xie, Q.Y. An image enhancement algorithm to improve road tunnel crack transfer detection. Constr. Build. Mater. 2022, 348, 128583. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Qiao, W.T.; Zhang, H.W.; Zhu, F.; Wu, Q.D. A crack identification method for concrete structures using improved U-Net convolutional neural networks. Math. Probl. Eng. 2021, 2021, 6654996. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, R.X.; Yu, J.Y.; Li, F.; Yang, R.T.; Wang, Y.D. Automatic bridge crack detection using Unmanned aerial vehicle and Faster R-CNN. Constr. Build. Mater. 2023, 362, 129659. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, Z.; Yeoh, J.K.W.; Gu, X.Y.; Dong, Q.; Chen, Y.H.; Wu, W.X.; Wang, L.T.; Wang, D.Y. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Automat. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, L.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.Z.; Xie, Y.C.; Jiang, L.M.; Cao, Y.; Liu, B.Y. DMA-Net: DeepLab with Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Fan, Z.; Lin, H.B.; Li, C.; Sun, J.; Bruno, S.; Loprencipe, G. Use of Parallel ResNet for High-Performance Pavement Crack Detection and Measurement. Sustainability 2022, 14, 1825. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- López Droguett, E.; Tapia, J.; Yáñez, C.; Boroschek, R. Semantic segmentation model for crack images from concrete bridges for mobile devices. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2020, 236, 570–583. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Ji, X.; Leung, A.K.; Chen, Z.; Jiang, Z.L.; Tang, Y.C. Automatic classification of asphalt pavement cracks using a novel integrated generative adversarial network and improved VGG model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Tan, M.X.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar] [CrossRef]
- Satheesh, K.G.; Narender, C.; Selvan, S.T.; Rajakum, V. Automatic Detection of Road Cracks using EfficientNet with Residual U-Net-based Segmentation and YOLOv5-based Detection. Int. J. Recent Innov. Trends Comput. Commun. 2023, 11, 17762. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Paramar, N.; Uszkoreit, J.; Jones, L.; N.Gomea, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Shamsabadi, E.A.; Xu, C.; Rao, A.S.; Nguyen, T.; Ngo, T.; Dias-da-Costa, D. Vision transformer-based autonomous crack detection on asphalt and concrete surfaces. Automat. Constr. 2022, 140, 104316. [Google Scholar] [CrossRef]
- Moez, K. Generative Adversarial Networks. In Proceedings of the 2023 International Conference on Computing Communication and Networking Technologies, Delhi, India, 6–8 July 2023. [Google Scholar]
- Seker, A.; Perumal, V. CFC-GAN: Forecasting Road Surface Crack Using Forecasted Crack Generative Adversarial Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21378–21391. [Google Scholar] [CrossRef]
- Chen, J.N.; Lu, Y.Y.; Yu, Q.H.; Luo, X.D.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y.Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Attention Mechanism | GRU-T | F1-Score/% | IoU/% | Time/s |
|---|---|---|---|---|---|
| 0 | 80.36 | 73.52 | 5899 | ||
| 1 | √ | 82.87 | 76.36 | 6513 | |
| 2 | √ | 85.18 | 76.29 | 6309 | |
| 3 | √ | √ | 88.64 | 77.06 | 5667 |
| Model | Precision/% | Recall/% | F1-Score/% | IoU/% |
|---|---|---|---|---|
| SegFormer | 70.32 | 74.05 | 72.19 | 77.63 |
| U-Net | 76.28 | 72.78 | 73.64 | 72.59 |
| FCN | 77.23 | 71.03 | 72.56 | 71.36 |
| PSPNet | 77.29 | 72.51 | 74.69 | 72.04 |
| TransUNet | 87.21 | 85.69 | 86.05 | 76.70 |
| AG-TransUNet | 91.26 | 87.87 | 88.64 | 77.06 |
| Model | Precision/% | Recall/% | F1-Score/% | IoU/% |
|---|---|---|---|---|
| SegFormer | 67.71 | 76.59 | 71.85 | 77.70 |
| U-Net | 65.89 | 65.44 | 64.29 | 60.41 |
| FCN | 58.80 | 68.32 | 63.57 | 58.34 |
| PSPNet | 53.47 | 63.28 | 55.19 | 40.39 |
| TransUNet | 84.27 | 78.30 | 81.48 | 68.98 |
| AG-TransUNet | 86.48 | 87.63 | 87.11 | 78.05 |
| Crack No. | Calculated Width/mm | Actual Width/mm | Error/mm | Relative Error/% |
|---|---|---|---|---|
| 1 | 3.44 | 3.26 | 0.18 | 5.52 |
| 2 | 6.26 | 5.97 | 0.29 | 4.86 |
| 3 | 4.98 | 4.72 | 0.26 | 5.51 |
| 4 | 4.95 | 5.00 | 0.05 | 1.00 |
| 5 | 4.65 | 4.87 | 0.21 | 4.31 |
| 6 | 13.08 | 12.95 | 0.13 | 1.00 |
| 7 | 12.71 | 13.06 | 0.35 | 2.67 |
| 8 | 16.35 | 17.21 | 0.86 | 4.99 |
| 9 | 22.89 | 21.75 | 1.14 | 5.24 |
| 10 | 23.52 | 22.69 | 0.83 | 3.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, X.; Liu, Y.; Dai, J. Recognition of Concrete Surface Cracks Based on Improved TransUNet. Buildings 2025, 15, 541. https://doi.org/10.3390/buildings15040541
Dong X, Liu Y, Dai J. Recognition of Concrete Surface Cracks Based on Improved TransUNet. Buildings. 2025; 15(4):541. https://doi.org/10.3390/buildings15040541
Chicago/Turabian StyleDong, Xuwei, Yang Liu, and Jinpeng Dai. 2025. "Recognition of Concrete Surface Cracks Based on Improved TransUNet" Buildings 15, no. 4: 541. https://doi.org/10.3390/buildings15040541
APA StyleDong, X., Liu, Y., & Dai, J. (2025). Recognition of Concrete Surface Cracks Based on Improved TransUNet. Buildings, 15(4), 541. https://doi.org/10.3390/buildings15040541