
Predictive Models for Environmental Perception in Multi-Type Parks and Their Generalization Ability: Integrating Pre-Training and Reinforcement Learning

Abstract
1. Introduction
- A multimodal deep learning framework for environmental perception is developed, integrating image and text data. By employing a cross-attention mechanism, information from various models is effectively integrated, overcoming the limitations of existing studies that rely on single-modal data.
- Pre-training is combined with GRPO-based reinforcement learning to capture common perceptual features of parks through self-supervised learning, while enhancing the model’s ability to represent differentiated perceptions across park types via a dynamic sample-selection strategy.
- A zero-shot learning-based environmental perception evaluation method is designed to verify the model’s generalization performance in perceptual prediction on unseen park types. This approach provides an effective solution to the cross-type generalization challenge in urban park environmental perception evaluation.
2. Materials and Methods
2.1. Prediction Method for Comprehensive Evaluation of Multi-Types Based on Pre-Training and Reinforcement Learning
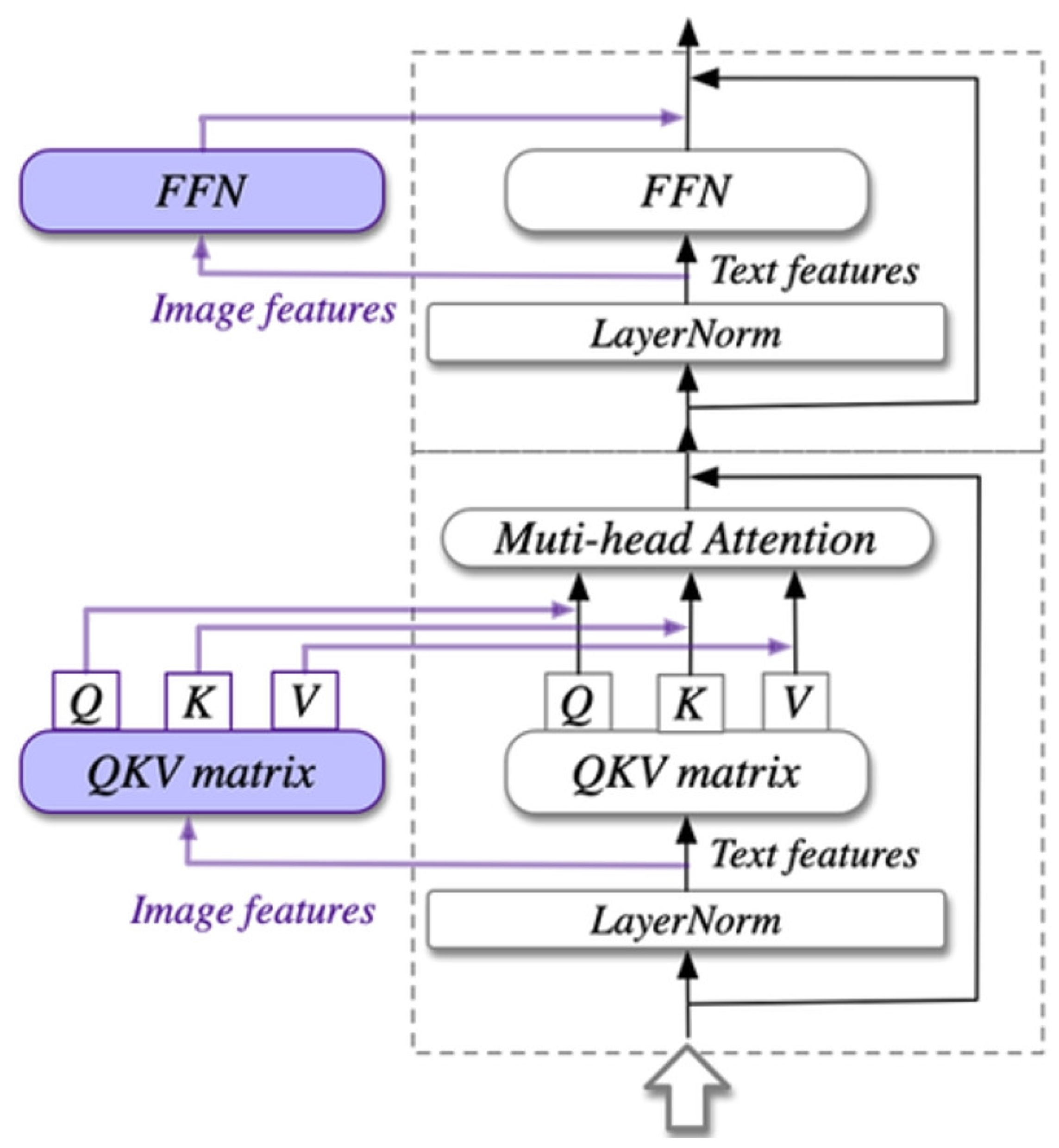
2.2. Multimodal Pre-Training Modeling
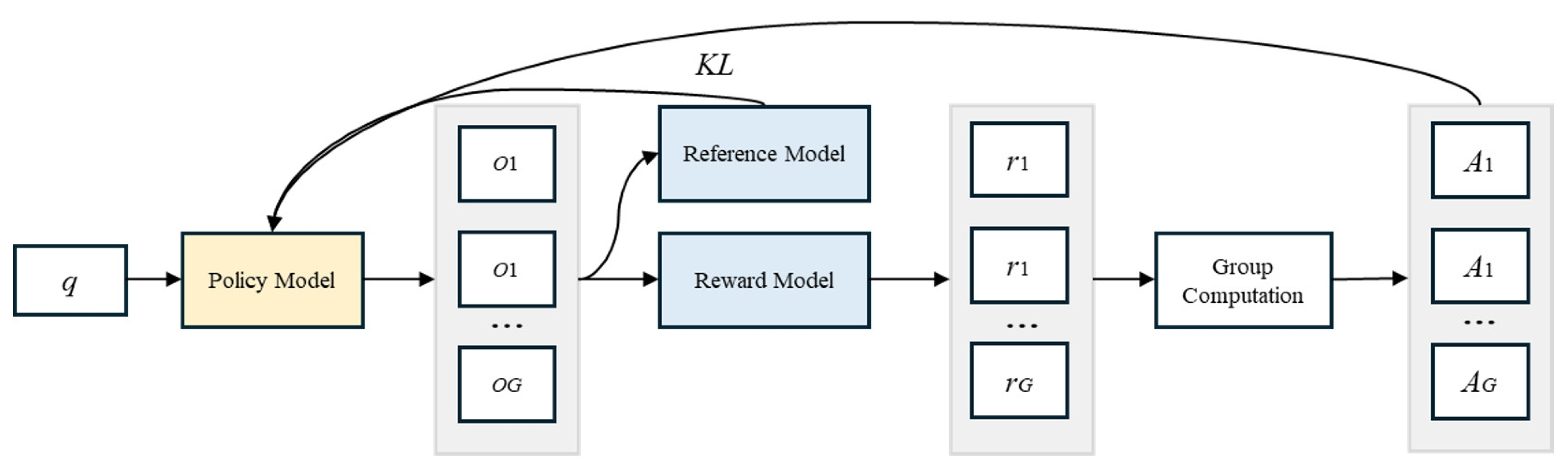
2.3. GRPO-Based Reinforcement Learning Approach
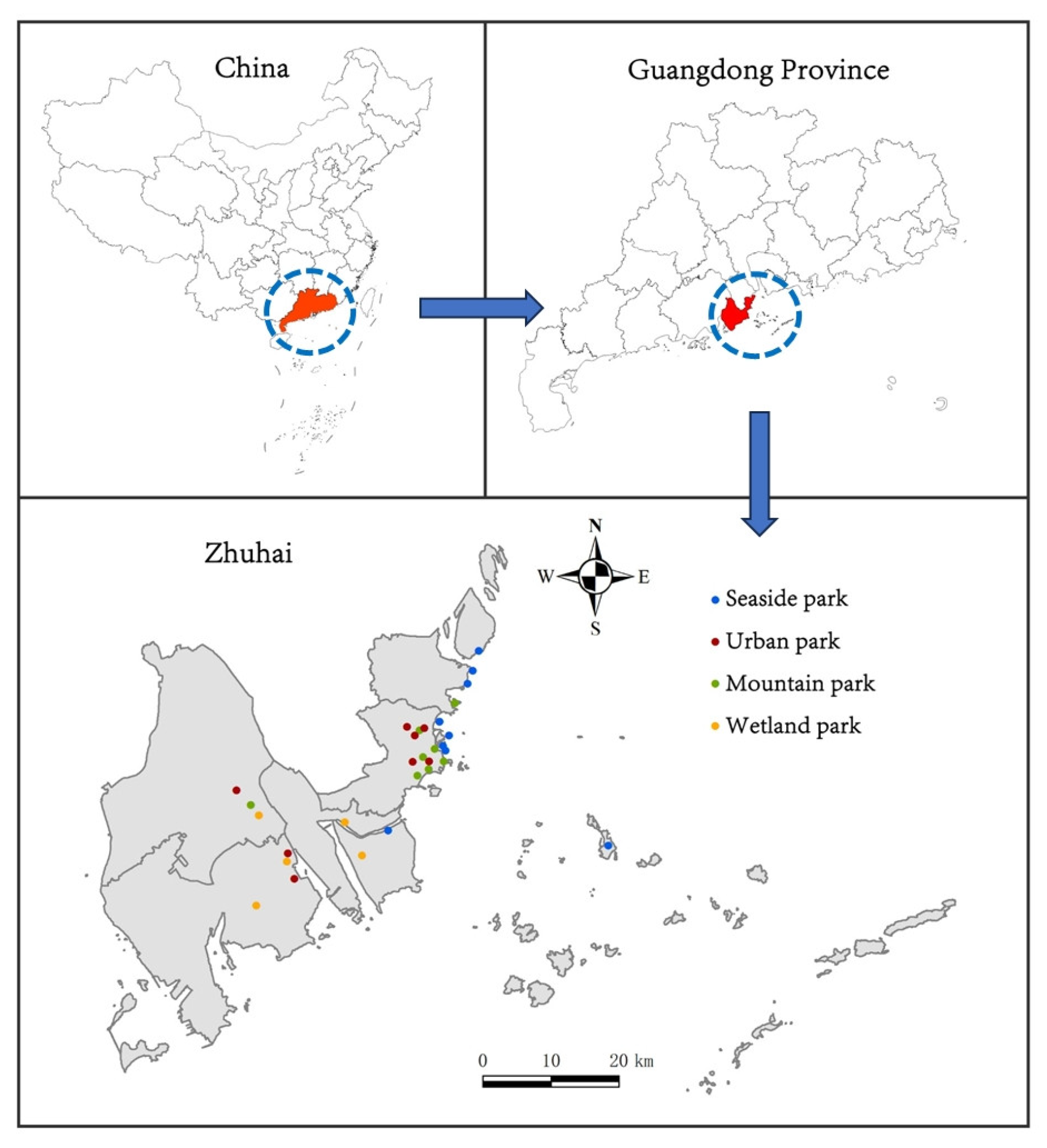
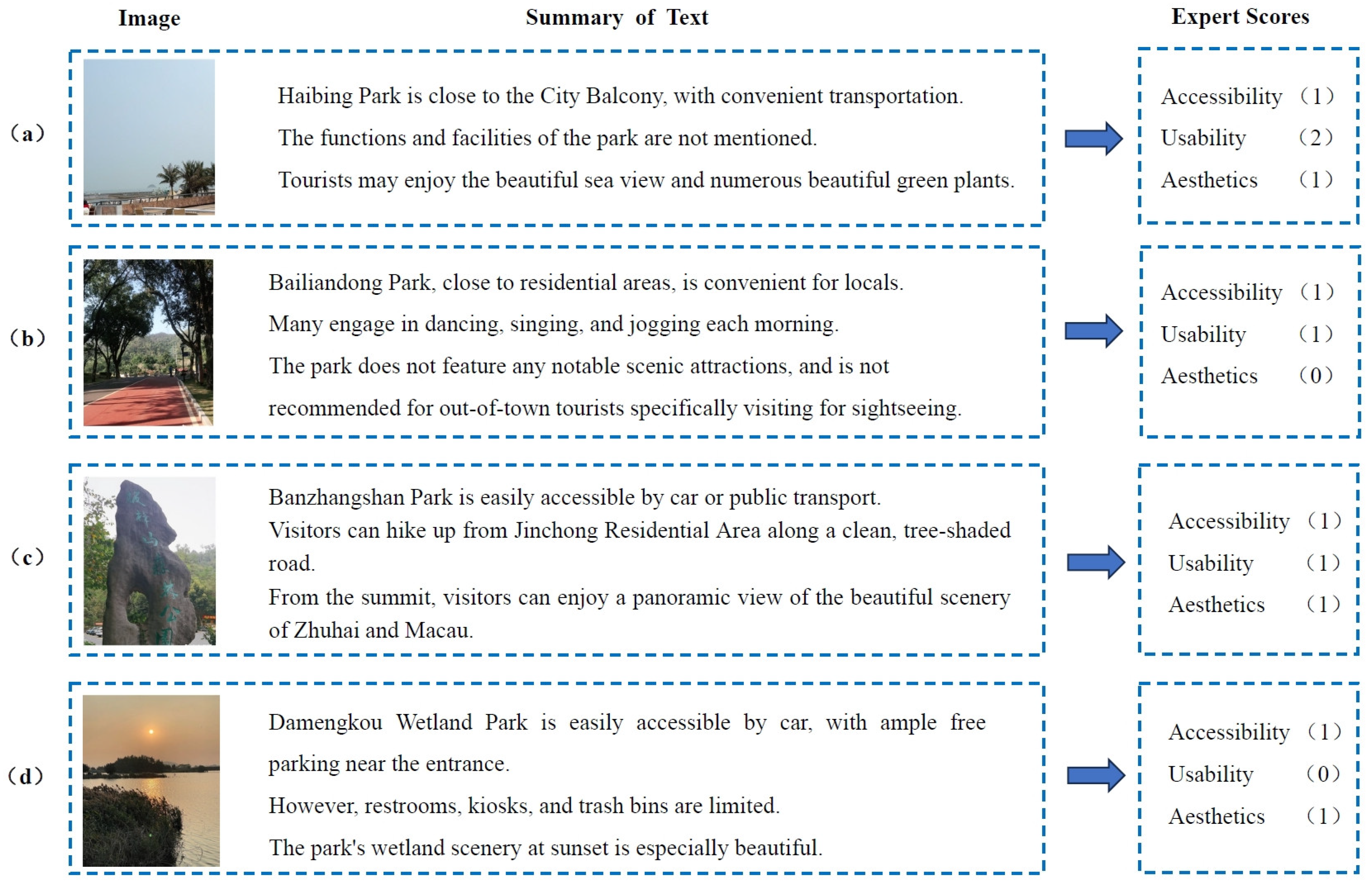
2.4. Park Data Collection and Evaluation Metrics
3. Results
3.1. Comparison of Model Prediction Results
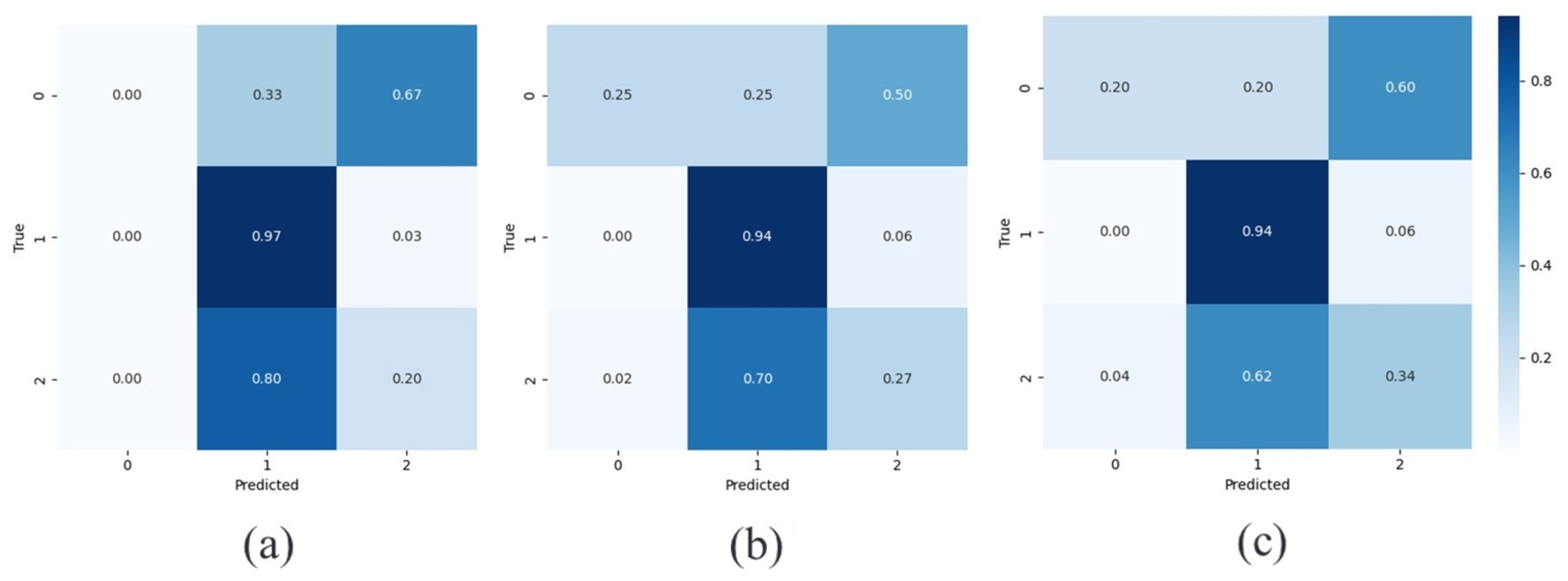
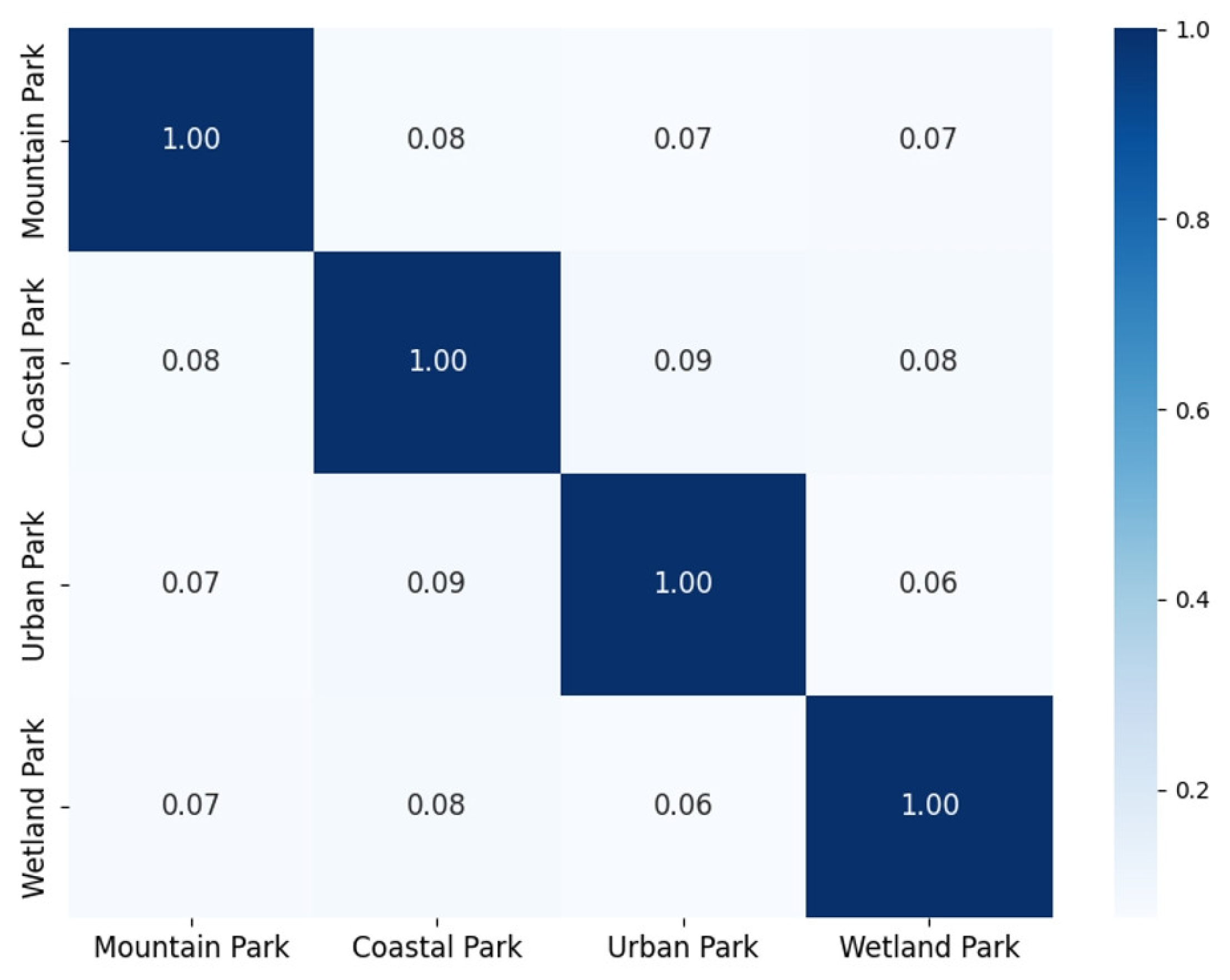
3.2. Experimental Analysis of Generalizability in Different Park Types
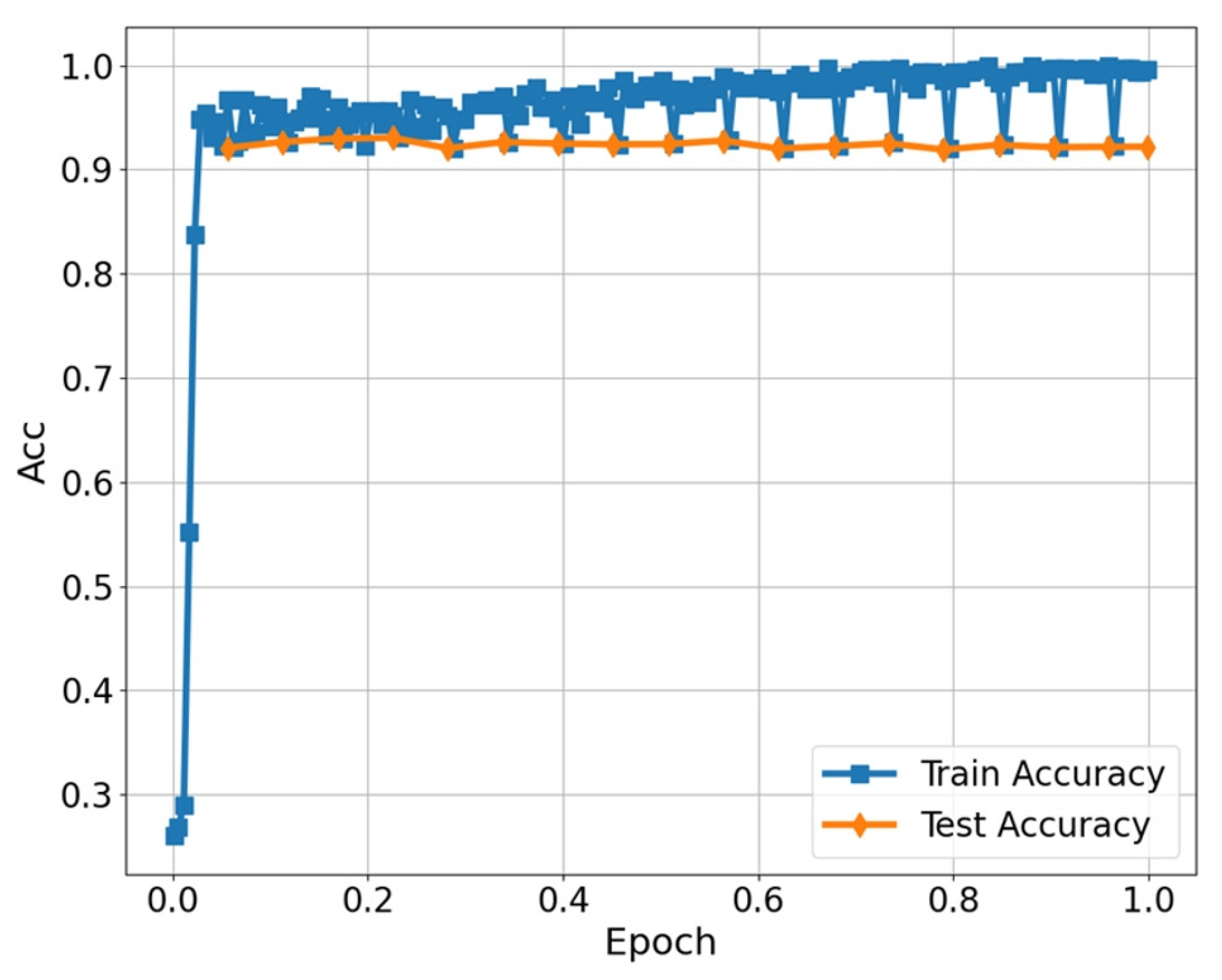
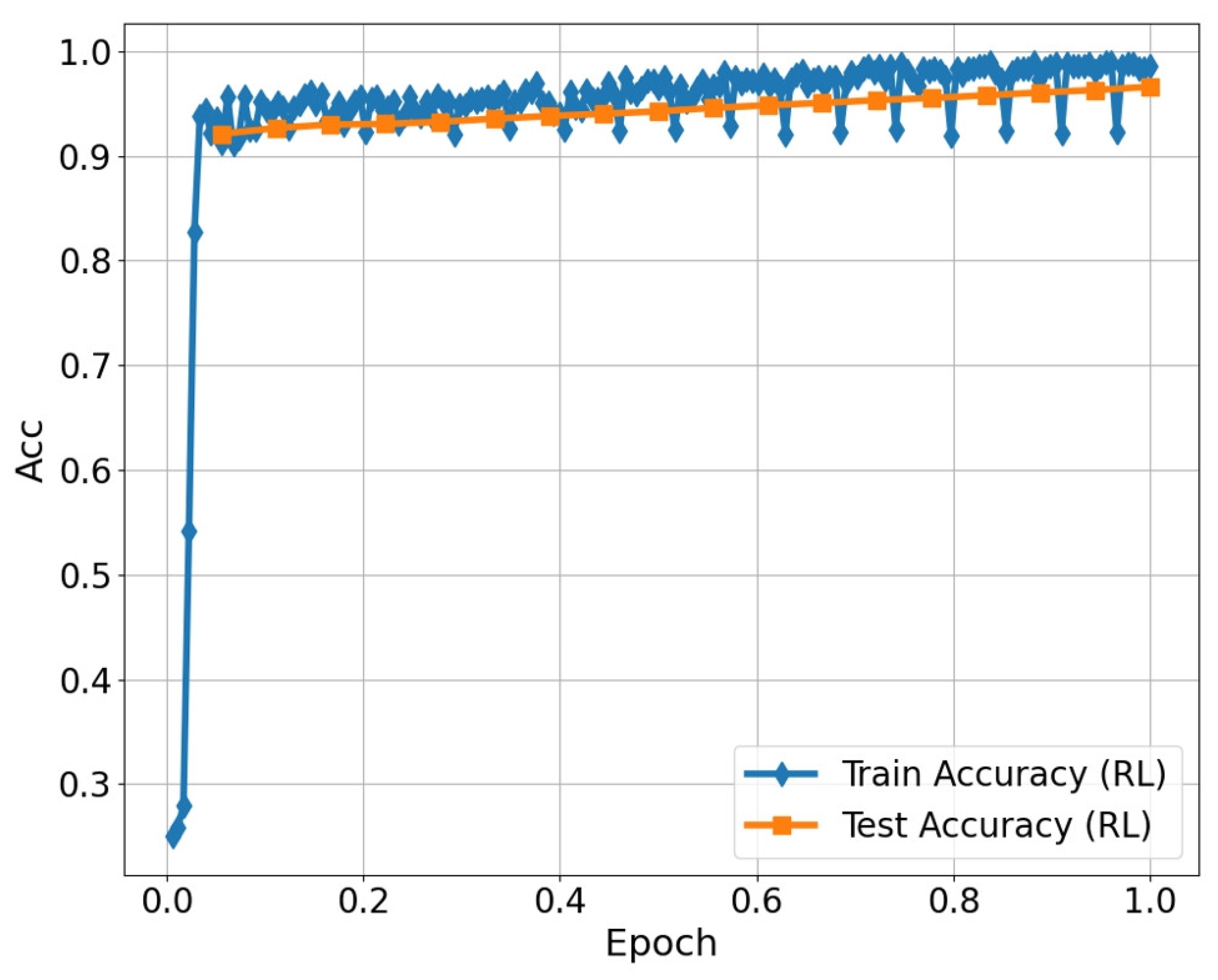
3.3. Analysis of Ablation Experiment on RL
4. Discussion
4.1. Methodological Implications of Multimodal Modeling
4.2. Application Scenarios of Multimodal Modeling
4.3. Research Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GRPO | Group Relative Policy Optimization |
| RNNs | Recurrent Neural Networks |
| CNNs | Convolutional Neural Networks |
| LLMs | Large-scale language models |
References
- Wang, Y.; Chen, F. Research on Environmental Behavior of Urban Parks in the North of China during Cold Weather—Nankai Park as a Case Study. Buildings 2024, 14, 2742. [Google Scholar] [CrossRef]
- Wu, Y.; Zhou, W.; Zhang, H.; Liu, Q.; Yan, Z.; Lan, S. Relationships between Green Space Perceptions, Green Space Use, and the Multidimensional Health of Older People: A Case Study of Fuzhou, China. Buildings 2024, 14, 1544. [Google Scholar] [CrossRef]
- Fagerholm, N.; Eilola, S.; Arki, V. Outdoor Recreation and Nature’s Contribution to Well-Being in a Pandemic Situation-Case Turku, Finland. Urban For. Urban Green. 2021, 64, 127257. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wang, X. Reexamine the Value of Urban Pocket Parks under the Impact of the COVID-19. Urban For. Urban Green. 2021, 64, 127294. [Google Scholar] [CrossRef] [PubMed]
- Puhakka, R. University Students’ Participation in Outdoor Recreation and the Perceived Well-Being Effects of Nature. J. Outdoor Recreat. Tour. 2021, 36, 100425. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, J.; Wei, W.; Zhao, B. Effects of Urban Parks on Residents’ Expressed Happiness before and during the COVID-19 Pandemic. Landsc. Urban Plan. 2021, 212, 104118. [Google Scholar] [CrossRef]
- Kong, L.; Liu, Z.; Pan, X.; Wang, Y.; Guo, X.; Wu, J. How Do Different Types and Landscape Attributes of Urban Parks Affect Visitors’ Positive Emotions? Landsc. Urban Plan. 2022, 226, 104482. [Google Scholar] [CrossRef]
- Creed, C.; Carvalho, J.S. Exploring the User Experience, Quality, and Provision of Urban Greenspace: A Mixed-Method Approach. Urban For. Urban Green. 2024, 100, 128470. [Google Scholar] [CrossRef]
- Wang, R.; Cao, M.; Yao, Y.; Wu, W. The Inequalities of Different Dimensions of Visible Street Urban Green Space Provision: A Machine Learning Approach. Land Use Policy 2022, 123, 106410. [Google Scholar] [CrossRef]
- Lau, K.K.-L.; Yung, C.C.-Y.; Tan, Z. Usage and Perception of Urban Green Space of Older Adults in the High-Density City of Hong Kong. Urban For. Urban Green. 2021, 64, 127251. [Google Scholar] [CrossRef]
- Huang, W.; Zhao, X.; Lin, G.; Wang, Z.; Chen, M. How to Quantify Multidimensional Perception of Urban Parks? Integrating Deep Learning-Based Social Media Data Analysis with Questionnaire Survey Methods. Urban For. Urban Green. 2025, 107, 128754. [Google Scholar] [CrossRef]
- Biernacka, M.; Łaszkiewicz, E.; Kronenberg, J. Park Availability, Accessibility, and Attractiveness in Relation to the Least and Most Vulnerable Inhabitants. Urban For. Urban Green. 2022, 73, 127585. [Google Scholar] [CrossRef]
- Byrne, J.; Wolch, J. Nature, Race, and Parks: Past Research and Future Directions for Geographic Research. Prog. Hum. Geogr. 2009, 33, 743–765. [Google Scholar] [CrossRef]
- Yao, W.; Yun, J.; Zhang, Y.; Meng, T.; Mu, Z. Usage Behavior and Health Benefit Perception of Youth in Urban Parks: A Case Study from Qingdao, China. Front. Public Health 2022, 10, 923671. [Google Scholar] [CrossRef]
- Chitra, B.; Jain, M.; Chundelli, F.A. Understanding the Soundscape Environment of an Urban Park through Landscape Elements. Environ. Technol. Innov. 2020, 19, 100998. [Google Scholar] [CrossRef]
- Yoon, J.I.; Lim, S.; Kim, M.-L.; Joo, J. The Relationship between Perceived Restorativeness and Place Attachment for Hikers at Jeju Gotjawal Provincial Park in South Korea: The Moderating Effect of Environmental Sensitivity. Front. Psychol. 2023, 14, 1201112. [Google Scholar] [CrossRef]
- Subiza-Pérez, M.; Hauru, K.; Korpela, K.; Haapala, A.; Lehvävirta, S. Perceived Environmental Aesthetic Qualities Scale (PEAQS)–A Self-Report Tool for the Evaluation of Green-Blue Spaces. Urban For. Urban Green. 2019, 43, 126383. [Google Scholar] [CrossRef]
- Rivera, E.; Timperio, A.; Loh, V.H.Y.; Deforche, B.; Veitch, J. Critical Factors Influencing Adolescents’ Active and Social Park Use: A Qualitative Study Using Walk-along Interviews. Urban For. Urban Green. 2021, 58, 126948. [Google Scholar] [CrossRef]
- Mak, B.K.L.; Jim, C.Y. Contributions of Human and Environmental Factors to Concerns of Personal Safety and Crime in Urban Parks. Secur. J. 2022, 35, 263–293. [Google Scholar] [CrossRef]
- Gosal, A.S.; Geijzendorffer, I.R.; Václavík, T.; Poulin, B.; Ziv, G. Using Social Media, Machine Learning and Natural Language Processing to Map Multiple Recreational Beneficiaries. Ecosyst. Serv. 2019, 38, 100958. [Google Scholar] [CrossRef]
- Liu, W.; Hu, X.; Song, Z.; Yuan, X. Identifying the Integrated Visual Characteristics of Greenway Landscape: A Focus on Human Perception. Sustain. Cities Soc. 2023, 99, 104937. [Google Scholar] [CrossRef]
- He, H.; Sun, R.; Li, J.; Li, W. Urban Landscape and Climate Affect Residents’ Sentiments Based on Big Data. Appl. Geogr. 2023, 152, 102902. [Google Scholar] [CrossRef]
- Wang, Z.; Miao, Y.; Xu, M.; Zhu, Z.; Qureshi, S.; Chang, Q. Revealing the Differences of Urban Parks’ Services to Human Wellbeing Based upon Social Media Data. Urban For. Urban Green. 2021, 63, 127233. [Google Scholar] [CrossRef]
- Li, J.; Fu, J.; Gao, J.; Zhou, R.; Wang, K.; Zhou, K. Effects of the Spatial Patterns of Urban Parks on Public Satisfaction: Evidence from Shanghai, China. Landsc. Ecol. 2023, 38, 1265–1277. [Google Scholar] [CrossRef]
- Shang, Z.; Cheng, K.; Jian, Y.; Wang, Z. Comparison and Applicability Study of Analysis Methods for Social Media Text Data: Taking Perception of Urban Parks in Beijing as an Example. Landsc. Archit. Front. 2023, 11, 8. [Google Scholar] [CrossRef]
- Huai, S.; Liu, S.; Zheng, T.; Van De Voorde, T. Are Social Media Data and Survey Data Consistent in Measuring Park Visitation, Park Satisfaction, and Their Influencing Factors? A Case Study in Shanghai. Urban For. Urban Green. 2023, 81, 127869. [Google Scholar] [CrossRef]
- Luo, J.; Zhao, T.; Cao, L.; Biljecki, F. Water View Imagery: Perception and Evaluation of Urban Waterscapes Worldwide. Ecol. Indic. 2022, 145, 109615. [Google Scholar] [CrossRef]
- Yang, C.; Liu, T.; Zhang, S. Using Flickr Data to Understand Image of Urban Public Spaces with a Deep Learning Model: A Case Study of the Haihe River in Tianjin. IJGI 2022, 11, 497. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, Y.; Li, C. Discovering the Tourists’ Behaviors and Perceptions in a Tourism Destination by Analyzing Photos’ Visual Content with a Computer Deep Learning Model: The Case of Beijing. Tour. Manag. 2019, 75, 595–608. [Google Scholar] [CrossRef]
- Chen, Z.; Sheng, Y.; Luo, D.; Huang, Y.; Huang, J.; Zhu, Z.; Yao, X.; Fu, W.; Dong, J.; Lan, Y. Landscape Characteristics in Mountain Parks across Different Urban Gradients and Their Relationship with Public Response. Forests 2023, 14, 2406. [Google Scholar] [CrossRef]
- Chen, J.; van den Bosch, C.C.K.; Lin, C.; Liu, F.; Huang, Y.; Huang, Q.; Wang, M.; Zhou, Q.; Dong, J. Effects of Personality, Health and Mood on Satisfaction and Quality Perception of Urban Mountain Parks. Urban For. Urban Green. 2021, 63, 127210. [Google Scholar] [CrossRef]
- Song, S.; Goo, J.Y.J.E.; Ying, L.S.M.; Todd, P.A. Urban Coastal Parks: What Does the Public Want and What Are the Effects of Priming and Socio-Demographic Background? Urban For. Urban Green. 2025, 105, 128666. [Google Scholar] [CrossRef]
- Chakraborty, S.; Saha, S.K.; Ahmed Selim, S. Recreational Services in Tourism Dominated Coastal Ecosystems: Bringing the Non-Economic Values into Focus. J. Outdoor Recreat. Tour. 2020, 30, 100279. [Google Scholar] [CrossRef]
- Roberts, M.; Glenk, K.; McVittie, A. Urban Residents Value Multi-Functional Urban Greenspaces. Urban For. Urban Green. 2022, 74, 127681. [Google Scholar] [CrossRef]
- Mäntymaa, E.; Jokinen, M.; Juutinen, A.; Lankia, T.; Louhi, P. Providing Ecological, Cultural and Commercial Services in an Urban Park: A Travel Cost–Contingent Behavior Application in Finland. Landsc. Urban Plan. 2021, 209, 104042. [Google Scholar] [CrossRef]
- Lee, L.-H. Perspectives on Landscape Aesthetics for the Ecological Conservation of Wetlands. Wetlands 2017, 37, 381–389. [Google Scholar] [CrossRef]
- Li, J.; Pan, Q.; Peng, Y.; Feng, T.; Liu, S.; Cai, X.; Zhong, C.; Yin, Y.; Lai, W. Perceived Quality of Urban Wetland Parks: A Second-Order Factor Structure Equation Modeling. Sustainability 2020, 12, 7204. [Google Scholar] [CrossRef]
- Filali, H.; Riffi, J.; Boulealam, C.; Mahraz, M.A.; Tairi, H. Multimodal Emotional Classification Based on Meaningful Learning. BDCC 2022, 6, 95. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, X.; Wang, W.; Liang, C. Emotion Recognition Using Multimodal Deep Learning in Multiple Psychophysiological Signals and Video. Int. J. Mach. Learn. Cybern. 2020, 11, 923–934. [Google Scholar] [CrossRef]
- Gandhi, A.; Adhvaryu, K.; Poria, S.; Cambria, E.; Hussain, A. Multimodal Sentiment Analysis: A Systematic Review of History, Datasets, Multimodal Fusion Methods, Applications, Challenges and Future Directions. Inf. Fusion 2023, 91, 424–444. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep Learning-Based Multimodal Emotion Recognition from Audio, Visual, and Text Modalities: A Systematic Review of Recent Advancements and Future Prospects. Expert Syst. Appl. 2024, 237, 121692. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems 32 (NIPS 2019), Vancouver, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Chen, Y.-C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: UNiversal Image-TExt Representation Learning. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12375, pp. 104–120. [Google Scholar] [CrossRef]
- Alrbai, M.; Al-Dahidi, S.; Alahmer, H.; Al-Ghussain, L.; Al-Rbaihat, R.; Hayajneh, H.; Alahmer, A. Integration and Optimization of a Waste Heat Driven Organic Rankine Cycle for Power Generation in Wastewater Treatment Plants. Energy 2024, 308, 132829. [Google Scholar] [CrossRef]
- Ji, L.; Xiao, S.; Feng, J.; Gao, W.; Zhang, H. Multimodal Large Model Pretraining, Adaptation and Efficiency Optimization. Neurocomputing 2025, 619, 129138. [Google Scholar] [CrossRef]
- He, J.; Hu, H. MF-BERT: Multimodal Fusion in Pre-Trained BERT for Sentiment Analysis. IEEE Signal Process. Lett. 2022, 29, 454–458. [Google Scholar] [CrossRef]
- Ma, H.; Fan, B.; Ng, B.K.; Lam, C.-T. VL-Meta: Vision-Language Models for Multimodal Meta-Learning. Mathematics 2024, 12, 286. [Google Scholar] [CrossRef]
- Cao, Y.; Zhao, H.; Cheng, Y.; Shu, T.; Chen, Y.; Liu, G.; Liang, G.; Zhao, J.; Yan, J.; Li, Y. Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 9737–9757. [Google Scholar] [CrossRef]
- Xiong, L.; Wang, H.; Chen, X.; Sheng, L.; Xiong, Y.; Liu, J.; Xiao, Y.; Chen, H.; Han, Q.-L.; Tang, Y. DeepSeek: Paradigm Shifts and Technical Evolution in Large AI Models. IEEE/CAA J. Autom. Sinica 2025, 12, 841–858. [Google Scholar] [CrossRef]
- Wang, W.; Zheng, V.W.; Yu, H.; Miao, C. A Survey of Zero-Shot Learning: Settings, Methods, and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–37. [Google Scholar] [CrossRef]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2251–2265. [Google Scholar] [CrossRef]
- Houichime, T.; El Amrani, Y. Context Is All You Need: A Hybrid Attention-Based Method for Detecting Code Design Patterns. IEEE Access 2025, 13, 9689–9707. [Google Scholar] [CrossRef]
- Al-hammuri, K.; Gebali, F.; Kanan, A.; Chelvan, I.T. Vision Transformer Architecture and Applications in Digital Health: A Tutorial and Survey. Vis. Comput. Ind. Biomed. Art 2023, 6, 14. [Google Scholar] [CrossRef] [PubMed]
- Blanchard, A.E.; Shekar, M.C.; Gao, S.; Gounley, J.; Lyngaas, I.; Glaser, J.; Bhowmik, D. Automating Genetic Algorithm Mutations for Molecules Using a Masked Language Model. IEEE Trans. Evol. Computat. 2022, 26, 793–799. [Google Scholar] [CrossRef]
- Xie, Y.; Gu, L.; Harada, T.; Zhang, J.; Xia, Y.; Wu, Q. Rethinking Masked Image Modelling for Medical Image Representation. Med. Image Anal. 2024, 98, 103304. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Wang, M.; Zhang, J.; Li, D.; Duan, J. A Review of Large Language Models: Fundamental Architectures, Key Technological Evolutions, Interdisciplinary Technologies Integration, Optimization and Compression Techniques, Applications, and Challenges. Electronics 2024, 13, 5040. [Google Scholar] [CrossRef]
- Huai, S.; Chen, F.; Liu, S.; Canters, F.; Van De Voorde, T. Using Social Media Photos and Computer Vision to Assess Cultural Ecosystem Services and Landscape Features in Urban Parks. Ecosyst. Serv. 2022, 57, 101475. [Google Scholar] [CrossRef]
- Ren, W.; Zhan, K.; Chen, Z.; Hong, X.-C. Research on Landscape Perception of Urban Parks Based on User-Generated Data. Buildings 2024, 14, 2776. [Google Scholar] [CrossRef]
- Zheng, Y.; Lin, Y.; Zhao, L.; Wu, T.; Jin, D.; Li, Y. Spatial Planning of Urban Communities via Deep Reinforcement Learning. Nat. Comput. Sci. 2023, 3, 748–762. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, T.; Zhang, Y.; Zhao, B.; Wang, T.; Cui, C.; Yin, Y. Deep Semantic-Aware Network for Zero-Shot Visual Urban Perception. Int. J. Mach. Learn. Cybern. 2022, 13, 1197–1211. [Google Scholar] [CrossRef]
- Ghermandi, A.; Langemeyer, J.; Van Berkel, D.; Calcagni, F.; Depietri, Y.; Egarter Vigl, L.; Fox, N.; Havinga, I.; Jäger, H.; Kaiser, N.; et al. Social Media Data for Environmental Sustainability: A Critical Review of Opportunities, Threats, and Ethical Use. One Earth 2023, 6, 236–250. [Google Scholar] [CrossRef]
- Park, S.; Kim, S.; Lee, J.; Heo, B. Evolving Norms: Social Media Data Analysis on Parks and Greenspaces Perception Changes before and after the COVID 19 Pandemic Using a Machine Learning Approach. Sci. Rep. 2022, 12, 13246. [Google Scholar] [CrossRef]
- Huai, S.; Van De Voorde, T. Which Environmental Features Contribute to Positive and Negative Perceptions of Urban Parks? A Cross-Cultural Comparison Using Online Reviews and Natural Language Processing Methods. Landsc. Urban Plan. 2022, 218, 104307. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Park Type | Mountain Park | Seaside Park | Urban Park | Wetland Park |
|---|---|---|---|---|
| Sample size | 6504 | 9334 | 4844 | 3785 |
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| LSTM | 0.79 | 0.74 | 0.77 | 0.75 |
| CNN | 0.81 | 0.75 | 0.78 | 0.76 |
| Our | 0.85 | 0.82 | 0.84 | 0.83 |
| Training Set | Test Set | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| A, B, C | D | 0.86 | 0.82 | 0.86 | 0.83 |
| A, B, D | C | 0.83 | 0.80 | 0.82 | 0.81 |
| A, C, D | B | 0.81 | 0.77 | 0.79 | 0.78 |
| B, C, D | A | 0.80 | 0.75 | 0.78 | 0.76 |
| Training Set | Test Set | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| A, B, C | D | 0.80 | 0.77 | 0.80 | 0.78 |
| A, B, D | C | 0.80 | 0.77 | 0.79 | 0.79 |
| A, C, D | B | 0.79 | 0.76 | 0.78 | 0.77 |
| B, C, D | A | 0.78 | 0.74 | 0.76 | 0.75 |
| Training Set | Test Set | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| A, B, C | D | 0.88 | 0.87 | 0.88 | 0.87 |
| A, B, D | C | 0.85 | 0.82 | 0.84 | 0.83 |
| A, C, D | B | 0.84 | 0.80 | 0.83 | 0.81 |
| B, C, D | A | 0.82 | 0.79 | 0.79 | 0.80 |
| Category | Item | Description |
|---|---|---|
| Input Data | Image data | User-uploaded park images, associated with corresponding texts, sourced from https://www.dianping.com/ (accessed on 18 February 2025). |
| Text data | Textual reviews of parks provided by users, associated with corresponding images, collected from https://www.dianping.com/ (accessed on 18 February 2025). | |
| Park type | Four categories: seaside, urban, mountainous, and wetland parks | |
| Dimension labels (manual) | Accessibility, usability, and aesthetics (annotated by three planning experts using majority vote) | |
| Model Architecture | Text encoder | For extracting semantic features from text |
| Image encoder | For extracting visual features | |
| Multimodal fusion module | Attention-based text–image feature fusion strategy | |
| Training Strategy | Pre-training | Self-supervised learning approach for mining latent representations of text and images |
| Reinforcement learning | Policy gradient method employed for optimizing sample selection and modal fusion pathways | |
| Evaluation Metrics | Accuracy | The proportion of correctly predicted cases among all prediction instances |
| Precision | The proportion of truly positive samples among all instances predicted as positive by the model | |
| Recall | The ratio of positive samples in the original dataset that are correctly identified by the model | |
| F1 Score | The harmonic mean of precision and recall | |
| Experimental Design | Train/test strategy | Three types of parks were used for training, while the remaining type was reserved for testing to evaluate the model’s cross-type generalization capability |
| Sample size | Over 24,000 samples were collected from user-generated image–text reviews of 31 urban parks in Zhuhai sourced from https://www.dianping.com/ (accessed on 18 February 2025). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Xia, T.; Cao, Z.; Li, Y.; Lin, X.; Bai, R. Predictive Models for Environmental Perception in Multi-Type Parks and Their Generalization Ability: Integrating Pre-Training and Reinforcement Learning. Buildings 2025, 15, 2364. https://doi.org/10.3390/buildings15132364
Chen K, Xia T, Cao Z, Li Y, Lin X, Bai R. Predictive Models for Environmental Perception in Multi-Type Parks and Their Generalization Ability: Integrating Pre-Training and Reinforcement Learning. Buildings. 2025; 15(13):2364. https://doi.org/10.3390/buildings15132364
Chicago/Turabian StyleChen, Kangen, Tao Xia, Zhoutong Cao, Yiwen Li, Xiuhong Lin, and Rushan Bai. 2025. "Predictive Models for Environmental Perception in Multi-Type Parks and Their Generalization Ability: Integrating Pre-Training and Reinforcement Learning" Buildings 15, no. 13: 2364. https://doi.org/10.3390/buildings15132364
APA StyleChen, K., Xia, T., Cao, Z., Li, Y., Lin, X., & Bai, R. (2025). Predictive Models for Environmental Perception in Multi-Type Parks and Their Generalization Ability: Integrating Pre-Training and Reinforcement Learning. Buildings, 15(13), 2364. https://doi.org/10.3390/buildings15132364