1. Introduction
With the demographic dividend gradually waning, labor costs and management expenses soaring, profit margins narrowing, and competition in the construction sector intensifying, traditional building industries’ high energy consumption and strong environmental impacts have become increasingly prominent under the “double carbon” policy [
1]. Prefabricated construction has gained increasing significance in this context. Contrary to traditional construction, prefabricated buildings consist of components manufactured in factories that are assembled on-site through reliable connections. Compared to conventional cast-in-place concrete structures, prefabricated architecture boasts advantages such as faster construction speed, shorter duration, fewer wet work processes on the construction site, and lesser pollution [
2].
However, precast concrete components, owing to the influence of multiple factors such as technology and management, exhibit prominent quality issues [
3]. Common occurrences of component fractures resulting from product structural deficiencies and improper handling during transportation and installation have been observed [
4,
5]. These phenomena lead to a reduction in the local stiffness of components, causing discontinuities in materials, posing a significant threat to building safety [
6]. However, traditional crack detection methodologies exhibit inefficiencies and subjectivity and fail to meet the requirements of actual engineering projects [
7,
8].
In recent years, with the rapid development of artificial intelligence technology, object detection techniques based on deep learning have demonstrated broad application prospects in various fields. Zhang et al. propose a Transformer object detection model based on multi-channel attention (MCCA) and dimensionality feature aggregation (DFAM), aiming to enhance the accuracy of detecting offending animals in images with occlusion or blur [
9]. An et al. propose a model based on deep neural networks that utilize photo recognition to identify common edible nuts and estimate their nutritional components, enabling precise tracking of nut calorific content and nutrients [
10]. Gan et al. proposed ARSFusion, a fusion network that realizes efficient integration of infrared and visible light images in road scenes under all-weather conditions through an adaptive feature aggregation mechanism that adjusts to varying lighting conditions [
11]. Ha et al. tackled the challenge of detecting blocks in soil-retaining walls under diverse lighting conditions by integrating RGB enhancement with Mask R-CNN [
12].
In this context, the YOLO series algorithms have garnered significant attention in the field of civil engineering, with Raushan et al. assessing the performance of YOLOv3-v10 in three distinct scenarios of architectural damage. The experimental results demonstrate the efficacy of the YOLO model in detecting and localizing multiple features within damaged backgrounds [
13]. Jiang et al. proposed the Fast-YOLO object detection algorithm based on the YOLOv3 network architecture, enabling high-precision detection of concrete damage [
14]. Gan et al. combined the YOLOv5-DeepSORT object tracking algorithm with deep parameter optimization for trajectory prediction, realizing dynamic assessment of worker safety risk levels [
15].
Cracks are common structural defects in buildings and roads and have been extensively studied by numerous researchers. Pham et al. proposed a deep learning and image processing-based framework for the automatic detection and quantification of ground cracks [
16]. Li et al. introduced a fusion model based on grid classification and box detection (GCBD) for asphalt pavement crack detection, addressing limitations of traditional methods in perceptual field coverage, topological optimization, and computational efficiency [
17]. Zhu et al. designed a lightweight encoder–decoder network that enhances detection accuracy in complex backgrounds while supporting efficient model deployment [
18]. Zheng et al. proposed the CAL-ISM framework, which tackles challenges such as high annotation costs, limited model generalization, and low accuracy in width measurement [
19]. Dong et al. developed YOLOv5-AH, an improved version of YOLOv5 that achieves a balance between detection accuracy and inference speed in pavement crack detection [
20]. Mayya et al. proposed a three-phase framework to address background interference in stone crack detection, achieving high-precision detection and classification [
21]. Li et al. further introduced the OUR-Net algorithm, which decouples and fuses high- and low-frequency features of pavement cracks, significantly improving segmentation accuracy in complex scenes [
22]. Huang et al. proposed a lightweight feature attention fusion network to reduce computational costs and enhance real-time performance in pavement crack segmentation [
23]. Fan et al. developed a probabilistic fusion-based deep convolutional neural network model to address accuracy limitations and quantization requirements in crack detection and measurement tasks [
24].
Previous studies have enhanced crack detection accuracy by incorporating attention mechanisms, multi-scale feature fusion, and network architecture optimization. However, most of these studies have concentrated on concrete crack detection under relatively simple conditions. For scenarios involving complex backgrounds, many approaches rely on image preprocessing techniques, such as adding artificial noise or adjusting image brightness. Nevertheless, these methods fall short of accurately replicating the real-world complexity encountered during actual production and manufacturing processes. In contrast, crack detection in precast concrete components involves several additional challenges, including the following:
(1) Precast concrete components typically contain numerous embedded holes and reserved steel bars to facilitate interconnection during construction [
25,
26]. These embedded holes often appear as prominent dark regions in images, while the reserved steel bars exhibit linear features that resemble cracks. Such characteristics substantially increase the complexity of accurate crack detection.
(2) In the production and transportation of precast concrete components, QR codes are often affixed to facilitate component management by recording relevant information [
27]. However, due to their distinct linear structures and high contrast, QR codes can interfere with crack detection tasks. In particular, during the identification of shallow or hairline cracks, the model may mistakenly interpret the edges of QR code regions as cracks, leading to false positives.
(3) There is a lack of research in the application of existing crack detection algorithms to precast concrete components, as conventional feature extraction paradigms fail to effectively transfer to this specific scenario, resulting in limited detection effectiveness.
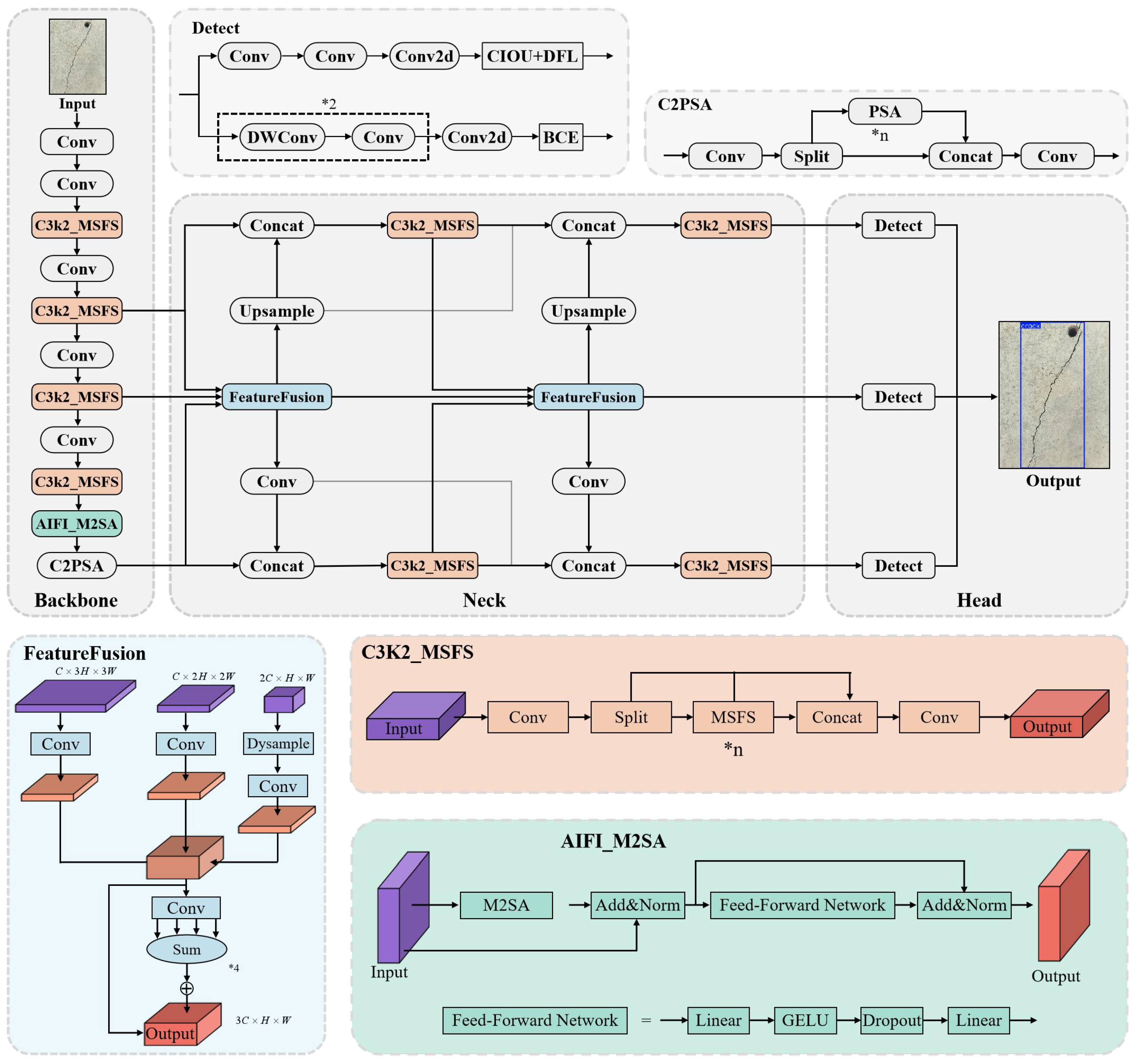
In light of these concerns, this paper presents a Precast Concrete Components Crack Detection Model (PC3D-YOLO), which is trained and validated on three datasets. The experimental results demonstrate that the PC3D-YOLO model possesses a larger reception field and enhanced cross-modal communication capability, mitigates the impact of max-pooling on feature extraction in the original model, and enables the model to capture more detailed contextual information for features of different sizes. The article’s principal contributions are as follows:
(1) This study integrates the precast concrete components’ crack images provided by Wuhan Construction New Building Materials Green Industry Science & Technology Co., Ltd., Wuhan, Hubei, China, with those from the SDNET2018 dataset, using the Labelimg software for image annotation. Ultimately, a dataset was constructed for this study.
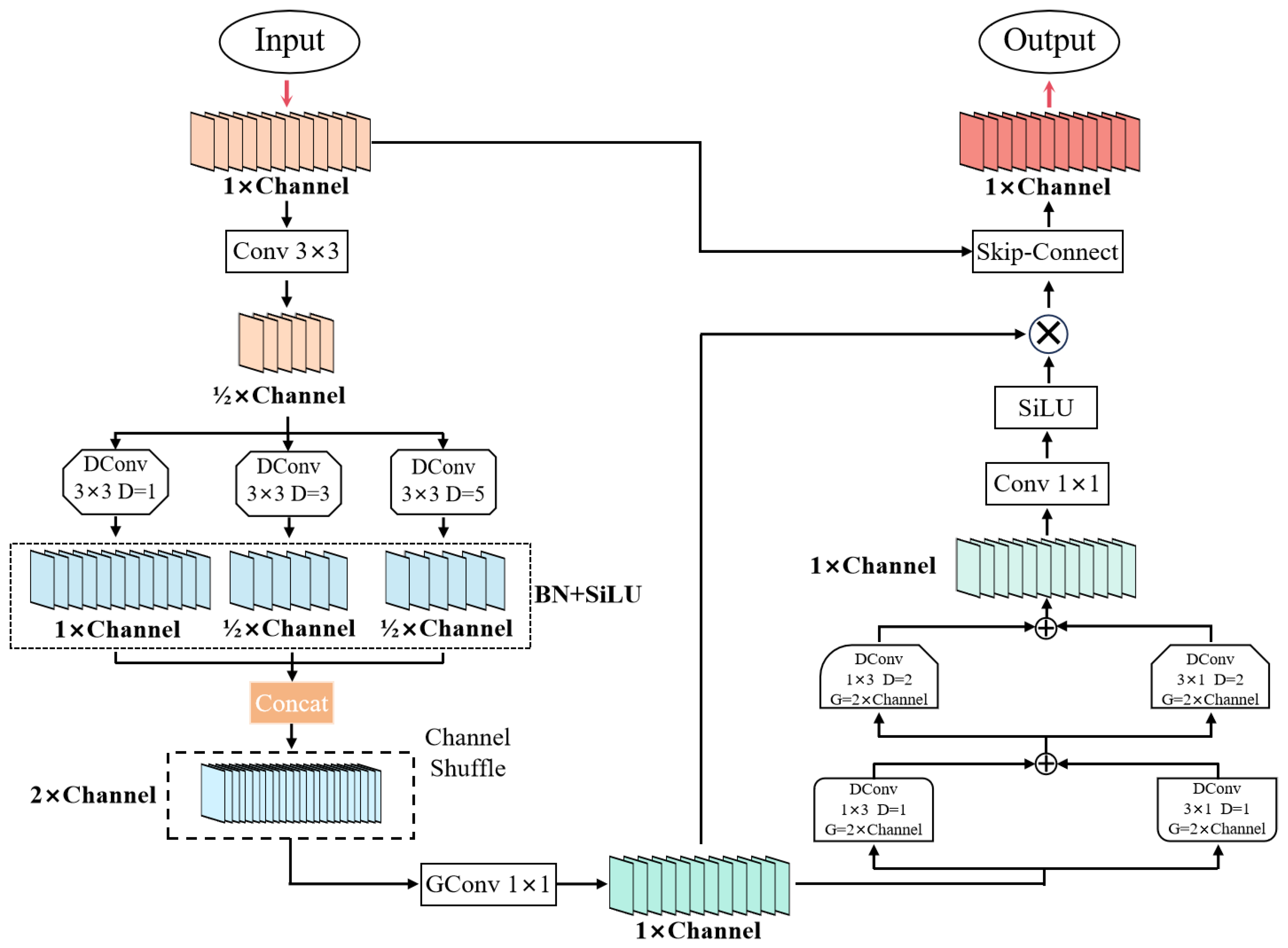
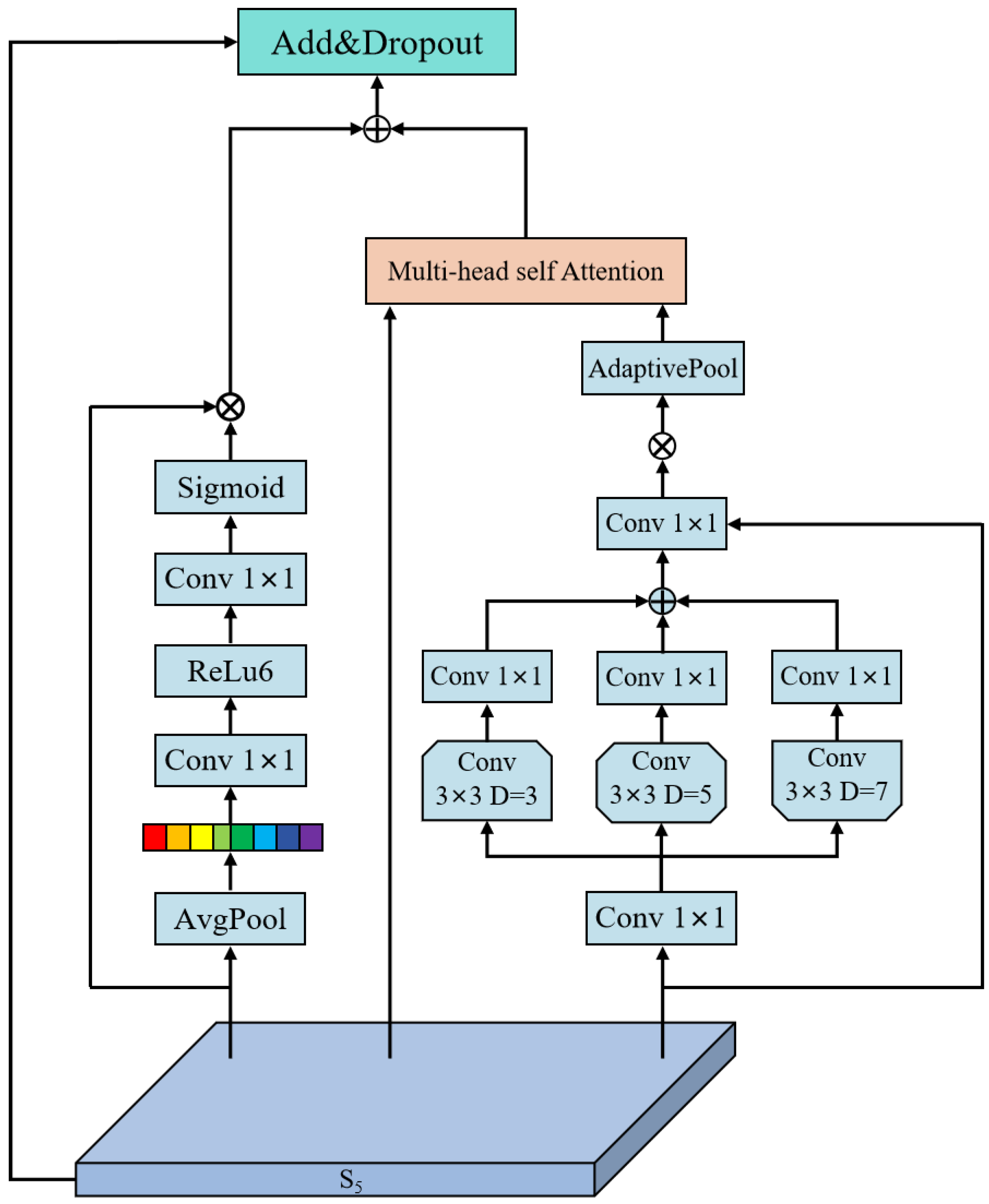
(2) This study proposes the Multi-Dilation Spatial-Channel Fusion with Shuffling (MSFS) module for feature extraction from complex backgrounds to target cracks.
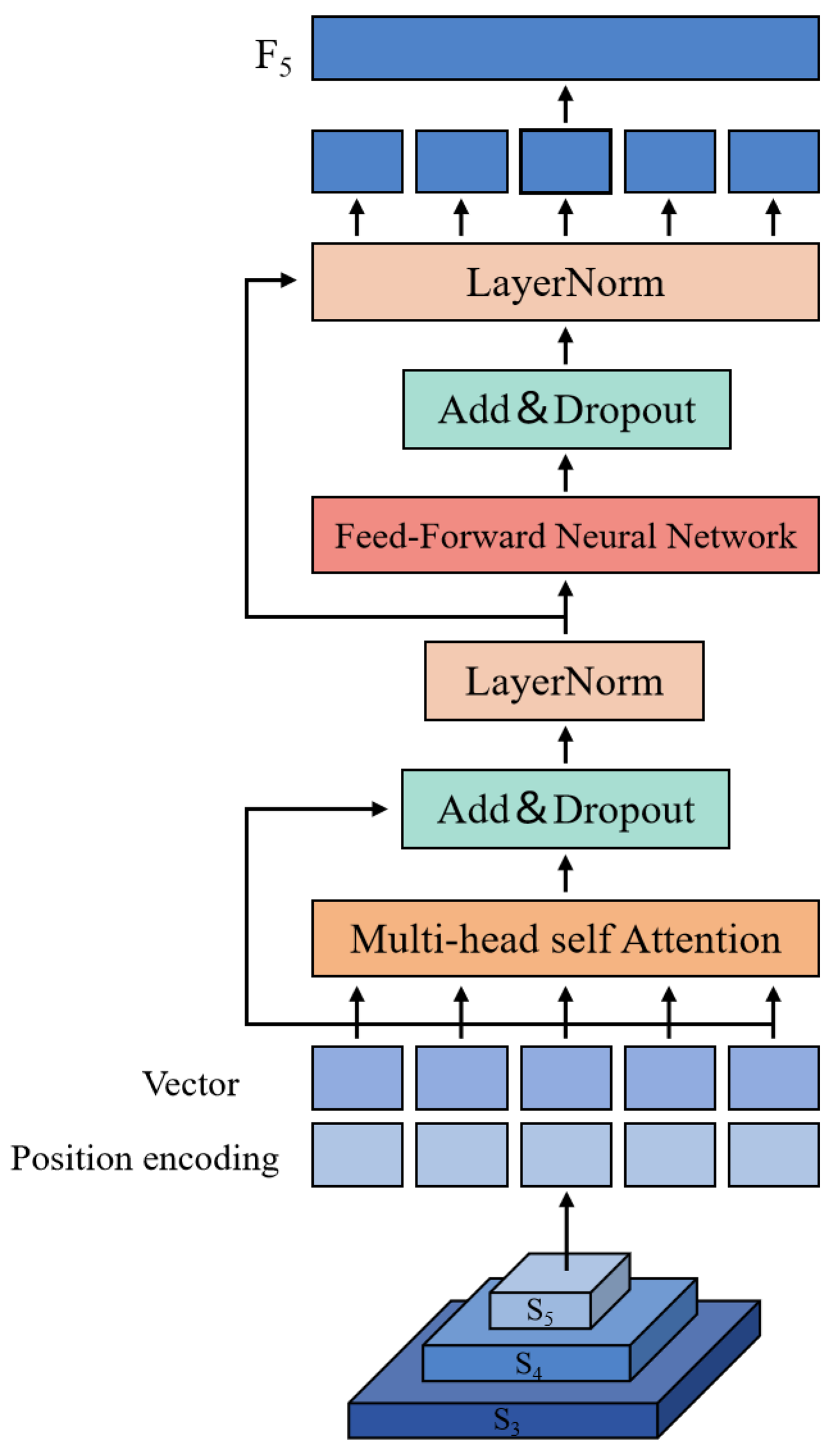
(3) This study adopts an Attention-based Intrascale Feature Interaction (AIFI_M2SA) module, which enhances the integration of information regarding crack features.
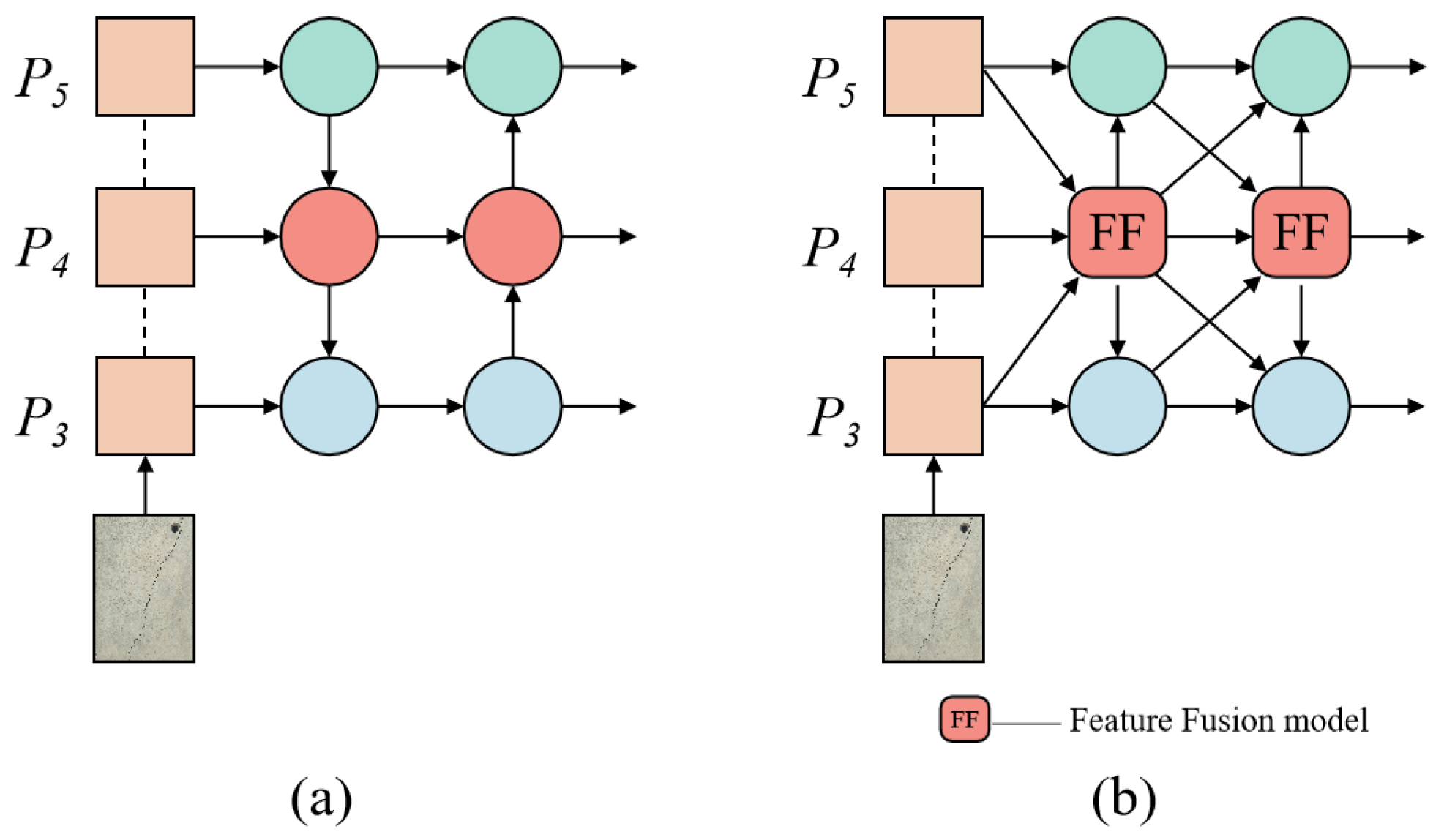
(4) This research is designed with the Multi-Scale Context Diffusion Network (MSCD-Net), which employs parallel deep convolutions to capture cross-scale information, enabling the fusion and diffusion of contextual information.
4. Result and Discussion
4.1. Comparative Experiments
To comprehensively evaluate the performance of the PC3D-YOLO model in the task of detecting cracks in precast concrete components, this section selects some mainstream models and conducts comparative experiments with them on the three datasets shown in
Table 1, as shown in
Table 2,
Table 3 and
Table 4. Among these, YOLOv8-CD and YOLOv10-DECA are advanced methods specifically designed for concrete crack detection tasks.
From
Table 2,
Table 3 and
Table 4, it can be seen that the two-stage algorithm Faster R-CNN exhibits inferior overall performance in terms of average precision (AP), with an AP@50 (model average precision when IOU = 0.5) of 78.3%, 64.0%, and 71.7%, respectively, and an AP@50-95 (model average precision when IOU = 0.5–0.95) of 48.7%, 39.9%, and 42.6%. At the same time, there is a problem with low recall. The reason may lie in the RPN candidate box filtering mechanism within the algorithm, as well as the two-stage accumulation of errors. Moreover, as two-stage algorithms require the generation of candidate boxes followed by classification and regression, the overall process is relatively complex and computationally intensive, which leads to slower detection speeds.
Among single-stage algorithms, the FCOS and SSD models demonstrate relatively poor performance in both detection accuracy and speed, whereas the YOLO series generally achieves better results. Notably, PC3D-YOLO delivers the highest detection accuracy, with AP@50 scores of 86.3%, 83.1%, and 89.7%, and AP@50-95 scores of 65.6%, 67.6%, and 69.9% across the three datasets. These results confirm the effectiveness of the proposed algorithmic improvements, which substantially reduce the interference caused by complex backgrounds, enable the extraction of richer feature representations, and enhance both the accuracy and robustness of crack detection in precast concrete components.
Although this improvement in accuracy comes at the cost of a certain reduction in detection speed, it is acceptable within the context of this study. Crack detection for precast concrete components is primarily conducted during the production and quality inspection phases, where real-time performance is not critically required. Furthermore, the achieved inference speed of approximately 62.4 FPS is sufficient to meet the demands of most real-time detection applications.
Regarding the relatively poor performance of YOLOv7 among the YOLO series models, this study attributes the issue to the absence of large-kernel convolutions, which are essential for capturing long-range dependencies. Additionally, its feature optimization relies primarily on the inherent design of the Efficient Layer Aggregation Network (ELAN), which may limit its ability to handle complex backgrounds. In contrast, YOLOv8 incorporates the Concatenate-to-Fuse (C2f) module, which not only preserves intermediate layer features but also enables parallel fusion of multi-scale features. This significantly enhances the model’s feature extraction capability in complex scenes. YOLOv11 incorporates a C2PSA layer following the SPPF layer to enhance feature representation through an attention mechanism, which is a key factor contributing to its improved detection accuracy.
To intuitively demonstrate the effectiveness of the proposed model improvements, this paper visualizes the detection results of the PC3D-YOLO model and the YOLO series models on the PC3 dataset, as illustrated in
Figure 10.
In Scene I, all models in the YOLO series were able to detect cracks. However, YOLOv7 exhibited noticeable localization inaccuracies. This may be attributed to its anchor-based mechanism, which can lead to significant positioning errors when there is a large discrepancy between the predefined anchor sizes and the actual target dimensions. Compared with other models, PC3D-YOLO showed better detection results, including more intensive attention to cracks.
In Scene II, the crack is located at the corner of the window frame, and non-structural regions are inevitably captured during the image acquisition process. These irrelevant areas introduce considerable interference into the detection task. Additionally, most YOLO models possess a relatively limited receptive field, which hinders their ability to analyze crack features from a global perspective. As a result, issues such as false detections and repeated detections may occur. In contrast, the improved model incorporates a larger receptive field and a more effective feature interaction mechanism, enabling it to accurately localize the crack target even in complex environments.
In contrast to Scenes I and II, Scene III presents a more complex image background with fewer distinguishable features for effective crack detection. Experimental results clearly indicate that most YOLO models fail to identify cracks under these conditions. Furthermore, both YOLOv8 and YOLOv11 produce false detections, primarily due to the presence of dark regions caused by reserved holes, which resemble cracks in color, as well as the geometric similarity between reserved steel bars and actual cracks. In comparison, PC3D-YOLO demonstrated superior capability in extracting and distinguishing crack features, achieving more accurate detection in this challenging scenario.
In Scene IV, the use of QR codes to encode precast concrete components during the manufacturing process was simulated. Yet, due to the multitude of pixel blocks constituting QR codes, they readily form color high-contrast zones that exhibit certain similarities in geometric characteristics with cracks, thus being susceptible to false detection. Conversely, PC3D-YOLO exhibits better performance in this scenario.
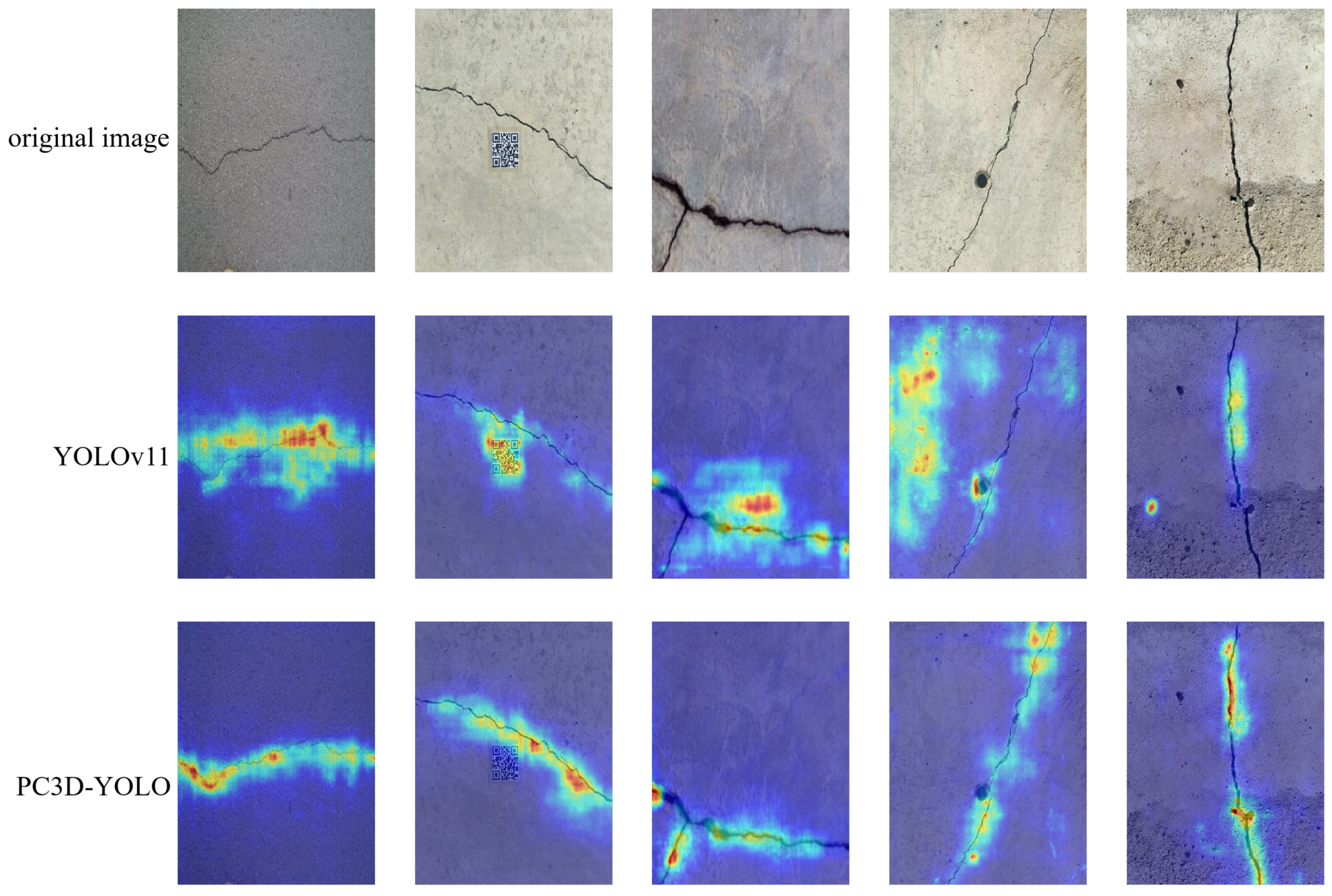
Furthermore, to intuitively illustrate the enhancement of feature extraction in PC3D-YOLO, this study visualizes the feature maps of PC3D-YOLO and YOLOv11 in the form of heatmaps, as shown in
Figure 11. Visualization results indicate that the YOLOv11 model exhibits limitations in both feature extraction and target localization. In contrast, PC3D-YOLO is able to capture crack features more accurately and comprehensively, owing to the incorporation of a larger receptive field and a multi-scale feature interaction mechanism. These enhancements enable PC3D-YOLO to maintain robust detection performance even in complex environments, highlighting its advantages over traditional YOLO models.
In summary, the enhanced model demonstrated exceptional performance in handling complex scenes, confirming the effectiveness of the model improvement design. It substantiated that the PC3D-YOLO model offered a more robust and reliable solution for the task of target detection of cracks in prefabricated concrete components.
4.2. Ablation Experiment
Testing the YOLOv11 algorithm as a baseline model on three datasets.
Table 5,
Table 6 and
Table 7 show the results of the ablation experiment. Experiment A represents the results obtained with YOLOv11. From experiments B, C, and E, it can be seen that after introducing the MSFS module and AIFI_M2SA module into the backbone network, a larger reception field is achieved, enabling the detection of critical characteristic information in complex backgrounds. Both recall and mAP have shown significant improvements, indicating that these modules enhance the ability of the backbone network to extract crack features. From experiment D, it can be seen that MSCD-Net’s improvement in the neck network is effective, and in experiments F and G, it demonstrates its ability to further refine feature extraction and fusion processes with the improved backbone network. In conclusion, the PC3D-YOLO algorithm exhibited significant contributions in enhancing the performance and model optimization of crack detection for precast concrete components via the adoption of multiple improvement strategies. When trained on three distinct datasets, the models achieved substantial performance gains compared to the baseline. Specifically, recall rose by 3.4%, 3.0%, and 4.9%; AP@50 rose by 2.8%, 3.3%, and 2.1%; and AP@50-95 showed improvements of 4.6%, 5.5%, and 3.2%, respectively.
4.3. Analysis of MSFS Module
4.3.1. Module Effect Validation Experiments
To validate the effectiveness of the MSFS module in target detection algorithms, this experiment introduced the DBB module [
51], RFAConv module [
52], and DWR module [
28] into the backbone network C3k2 module as alternatives for the Bottleneck module, and performed comparative experiments on the PC3 dataset. The experiment is shown in
Table 8.
From experimental results, it can be inferred that the DBB module exhibits high precision and recall rates in this group of comparative experiments due to its adoption of a structural reparameterization conversion method (introducing different reception fields and multi-branch structures during training, while equating the DBB module to a convolution during inference), but its average precision is relatively poor under high thresholds. This may be attributed to algorithmic localization errors. In the group comparative experiment involving the MSFS module, all four evaluation indicators attained their optimal values, demonstrating the superiority of the module in extracting crack characteristics from precast concrete components.
To showcase the global feature extraction capabilities of MSFS, this paper will display the reception field of experiment group modules through visualization techniques, allowing for the observation of the model’s attention range in terms of image size. The results are shown in
Figure 12.
Evidently, the YOLOv11 model possesses a narrower reception field upon sampling, whereas the DWR module, despite offering a larger reception field, exhibits lower attention to the periphery and still lags in its ability to capture global information. In contrast, the MSFS module expands on the original field of view while also enhancing the attention to image regions, thereby significantly boosting the ability to extract crack features.
4.3.2. Channel Mixing and Contrast Experiment
To verify the significance of channel mixing for cross-channel information exchange within the module, this study set up different channel mixing numbers (g = 1, 2, 4, 8, 16) and investigated the impact of channel mixing on module accuracy, to determine the optimal number of mixing groups. As shown in
Table 9, the experimental results are as follows:
From the experimental results, it can be observed that models utilizing channel mixing (Groups > 1) consistently outperform those without channel mixing (Groups = 1). When , the model’s overall indicator increased as the group size grew, yet when the groups reached 16, their performance declined. This could be due to the excessive group size causing too few input channels per group, thus compromising the feature expression capacity. Consequently, the final study set the number of channels per module in MSFS to 8.
5. Discussion
While the PC3D-YOLO model exhibits high detection performance in the field of detecting cracks in precast concrete components, there still exist some limitations in its application in industrial scenarios. Firstly, the model’s higher computational complexity and parameter count may pose challenges for deployment on mobile hardware platforms. Given that the model, during its construction, incorporates multiple branches and multi-scale convolutions, it enhances its contextual perception and multi-scale feature extraction capabilities in complex scenes. However, this inevitably leads to increased computational complexity and parameter count. Future improvements can be achieved through knowledge distillation and model pruning to enable model lightweighting without loss, for adaptation in different deployment scenarios.
Furthermore, the self-made dataset employed in this study is partially sourced from an open-source dataset, which, although it captures concrete crack data, lacks the manufacturing features of precast components, thus failing to fully reflect the distribution characteristics of precast structures. In future research, by collecting more comprehensive data from pre-fabrication production lines, a specialized dataset with coupled characteristics of process damage can be constructed, further enhancing the model’s ability to generalize under diverse environmental conditions.
It is also worth noting that PC3D-YOLO has been validated on three distinct datasets, which differ in background textures, crack morphologies, and image acquisition conditions, thereby offering a certain degree of diversity. The model’s consistent performance across these datasets suggests a promising level of generalization to varying environments. However, it has not yet been evaluated on other material types such as steel or marble, nor under challenging conditions such as low-light environments or occlusions. These areas still warrant further investigation to comprehensively evaluate and improve the model’s performance.
Future research could explore the application of this method to other defect detection tasks, such as structural steel frameworks, by fine-tuning the model on domain-specific datasets to verify its generalization capability. In addition, further efforts are needed to enhance the quantitative extraction of crack geometric features—including length, width, and location—to support more accurate structural evaluation and engineering decision-making.
6. Conclusions
To tackle the challenge in detecting cracks of precast concrete components, where image scenes are complex and feature extraction of target objects is difficult, this paper proposes PC3D-YOLO. Using multiple experimental analyses, potential technical solutions for the detection of defects in precast concrete components of prefabricated building structures have been provided. The primary findings of this study can thus be summarized as follows:
(1) By introducing the MSFS module into the original network structure of YOLOv11, multi-scale feature information is extracted, enhancing the communication between different channels and enabling modeling with continuity in both horizontal and vertical directions. Compared to the baseline model, it achieved a significant improvement in recall by 3.8%, along with a 2.0% increase in AP@50.
(2) Introducing the AIFI_M2SA module addresses the issue of feature information loss in the original SPPF module during the feature extraction process. This is accomplished by integrating multi-scale and multi-head attention with channel attention, thereby constructing a stronger global context dependence relationship.
(3) Employing MSCD-Net as the neck network for the improved model, it realizes a rich contextual feature in each scale by focusing and diffusing feature information.
(4) It was evaluated on three datasets using comparative experiments, ablation experiments, and module experiments. The results showed a maximum improvement of 4.9% in recall and 5.5% in AP, further demonstrating the high accuracy of PC3D-YOLO and its adaptability across diverse scenarios.
(5) Compared with two advanced algorithms specifically designed for concrete crack detection, the proposed PC3D-YOLO model achieves superior performance across all three datasets. Notably, on the DECA dataset, it achieves an AP@50 that is 2.5% higher than YOLOv8-CD and 4.1% higher than YOLOv10-DECA. These results further demonstrate the effectiveness and advancement of the proposed approach in the field of concrete crack detection.
In the future, the dataset will be expanded to cover a wider range of defect types, thereby further enhancing the model’s capabilities in classifying different defect types. Additionally, the proposed PC3D-YOLO model shall undergo lightweighting processing to facilitate integration with embedded devices, enabling the deployment of a precast concrete components crack inspection application at the edge.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}