1. Introduction
Underwater infrastructure inspection plays a vital role in ensuring the safety and longevity of marine and civil engineering structures, such as bridge piers, offshore platforms, and dams [
1]. Cracks are one of the most common and critical forms of underwater structural damage, as they may indicate material degradation, corrosion, or structural failure [
2]. However, due to the challenging underwater environment, characterized by light attenuation, scattering, and color distortion, captured images often suffer from low contrast, blurring, and severe color degradation [
3,
4,
5,
6]. These issues not only hinder visual interpretation but also affect the accuracy of automated defect detection systems [
7,
8,
9].
Conventional image enhancement methods, such as histogram equalization [
10] or Retinex-based approaches [
11,
12,
13], often fail to adapt to the complex and variable underwater conditions. Recent advances in deep learning have enabled data-driven enhancement techniques [
14], including convolutional neural networks (CNNs) and generative adversarial networks (GANs), to improve underwater image quality. In recent years, underwater image enhancement methods based on CNNs have shown significant advantages. Unlike traditional imaging models that rely on complex parameter estimation, end-to-end training frameworks represented by UWCNN [
15], UD Net [
16], and UIR Net [
17] achieve automatic extraction of multi-level representations through feature mapping learning from reference images. To improve model performance, scholars have proposed various innovative architectures: Lyu and team [
18] designed a lightweight network, combined residual group and channel attention mechanism to complete feature extraction, and optimized brightness in YUV color space to enhance contrast; Wu et al. [
19] proposed a two-stage enhancement framework, which decomposes an image into high and low frequency components through discrete cosine transform, and directly enhances high-frequency information using CNN, as well as a low-frequency color correction strategy based on joint component map estimation. The UIEC
2-Net developed by Wang et al. [
20] innovatively integrates RGB/HSV dual color gamut features, and optimizes visual quality through pixel level enhancement, global brightness saturation adjustment, and attention fusion modules. The perception-driven dehazing network constructed by Li’s research group [
21] adopts a dual network architecture, in which the refined network optimized for multi-objective loss effectively improves the color restoration effect. Despite significant progress, existing CNN methods still have clear limitations. Due to the difficulty in obtaining accurately aligned degraded clear image pairs in underwater environments, the strong dependence of the model on high-quality paired data severely restricts its generalization ability in practical scenarios.
The underwater image enhancement technology based on adversarial generative networks breaks through the dependence on paired data through unsupervised domain mapping learning. The GAN framework generates high-quality enhancement results without the need for supervised signals by establishing an adversarial mapping relationship between the degraded image domain and the clear image domain [
22]. On this basis, a series of innovative architectures have emerged successively: Jiang et al. [
23] constructed a perception-driven enhancement network that integrates natural image prior constraints and a deep neural network quality ranking mechanism to jointly optimize perception indicators such as brightness and contrast. The Liu team [
24] proposed a multi-expert learning model that implements independent feature extraction for the differential attenuation characteristics of RGB channels. Through cross-channel fusion, the decoder is guided to achieve collaborative optimization of color correction and detail preservation. It is worth noting that the UW-GAN designed by Hambarde et al. [
25] adopts a cascaded deep network architecture and embeds spatial-channel dual attention modules in single image depth estimation, significantly improving depth prediction accuracy and supporting the enhancement effect. The current research also shows a trend of multidimensional technology integration: the multi-scale dense GAN developed by Guo’s research group [
26] integrates residual multi-scale dense blocks and spectral normalization technology, effectively enhancing the color space conversion ability. The cross domain adversarial mechanism innovated by Li et al. [
27] improve image contrast and color richness through a dual-channel discriminator and chromaticity distance loss function. The Sea-Pix-GAN proposed by Chaurasia [
28] creatively integrates three modules: color correction, contrast enhancement, and style transfer, achieving significant breakthroughs in visual presentation effects.
Although CNNs have shown advantages in underwater image enhancement, their practical applications are still limited by data bottlenecks. CNN models typically rely on large-scale paired datasets for training [
29]; however, the scarcity of high-quality reference images in underwater environments leads to high data acquisition costs, severely limiting the deployment efficiency of the model. In this context, GANs stand out as unsupervised learning frameworks, achieving breakthroughs in enhanced performance through image domain transfer modeling [
30] without the need for paired data. However, it should be noted that existing GAN-based methods mostly focus on global chromaticity mapping and contrast optimization, and have insufficient explicit modeling capabilities for fine-grained structures, such as cracks. The technical challenges brought by the complex underwater imaging environment mainly include the following: (1) blurred crack boundaries caused by light scattering effects and suspended particle interference, and significantly reduced target background contrast; (2) The variation in imaging depth and shooting angle causes uneven illumination and local contrast fluctuations, resulting in abnormal visual characteristics of cracks; (3) Improper enhancement operations can easily cause boundary distortion or over enhancement artifacts, which in turn increases the risk of crack false detection. These characteristics make it difficult for traditional global enhancement strategies to effectively extract discriminative crack feature representations.
Conventional enhancement algorithms, such as histogram equalization and Retinex-based models, typically rely on empirical formulations or parameter adjustments, which this paper classifies as conflictive algorithms due to their limited robustness across variable underwater imaging conditions. In contrast, CNN-based algorithms leverage data-driven learning to automatically extract features and perform enhancement, achieving superior results but requiring extensive paired training datasets that are often unavailable in underwater environments. To address the limitations of both approaches, this study proposes a physics-aware deep learning model that integrates underwater optical theory into a CNN-based architecture, enabling robust and unsupervised enhancement of underwater structural crack images. The approach is built upon the UNIT framework and augmented with a physics-aware architecture that incorporates an underwater light propagation model. A multi-scale feature preservation module is introduced to retain the fine-scale texture of cracks, and a local PatchGAN discriminator is used to enhance structural realism. Additionally, a composite loss function with physical perception constraints ensures that the enhanced images are both visually appealing and physically consistent with underwater imaging principles.
By leveraging both domain knowledge and deep learning capabilities, the proposed method achieves high-quality enhancement of underwater crack images without the need for paired datasets. This work aims to provide a robust and interpretable solution for underwater inspection applications, especially in scenarios where structural integrity assessments depend on the accurate restoration of degraded visual information.
2. Methods
This study proposes an unsupervised image enhancement method based on physical perception, which combines underwater light propagation theory and UNIT network structure to achieve realistic restoration and detail enhancement of underwater crack images. This mainly includes modules, such as underwater light propagation modeling, improved UNIT structure, multi-scale feature preservation module, and optical consistency loss function design.
2.1. Overview of the Overall Framework
This method takes unlabeled real underwater crack images as input and introduces image degradation information based on physical models to guide the UNIT network to learn unsupervised domain transfer and enhancement of underwater images. This framework integrates an image translation network and a physical perception module, providing physical consistency constraints while maintaining the network’s adaptive enhancement capability, further improving image quality and structural fidelity. After completing network training, low-quality underwater images can be converted into enhanced images with high contrast, high-color reproduction, and clear crack details.
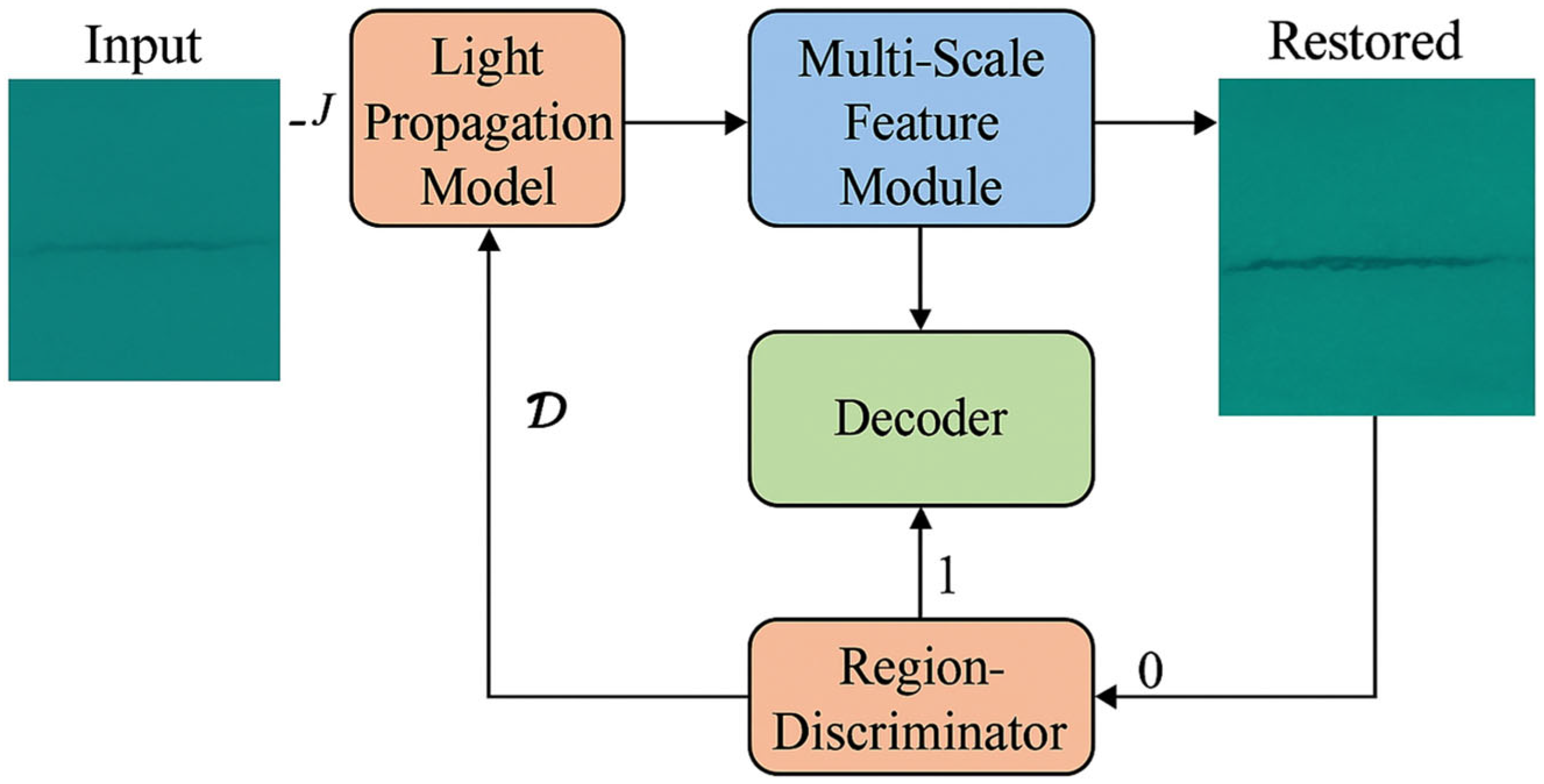
The proposed enhancement pipeline is depicted in
Figure 1. The raw underwater image
J is first processed via a physically-inspired light propagation module, which estimates degradation factors like background light
and per-channel attenuation
. The result is passed to a multi-scale feature extraction module with frequency-aware attention, which guides the decoder to recover high-resolution details. Meanwhile, a region-discriminator provides fine-grained supervision by focusing on texture realism and crack edge sharpness. The final restored image exhibits both global visibility and structural integrity of crack features.
2.2. Underwater Light Propagation Model
To simulate the degradation process of underwater images in reality, this paper introduces the light propagation theory based on the Jaffe–McGlamery model [
31,
32]. The degradation of underwater images mainly consists of three parts: absorption, scattering (as shown in
Figure 2), and backward reflection of light, especially in the red and green light bands where degradation is most severe. In Equation (1), the observed underwater image
in channel
can be expressed as:
where,
is the scene radiance,
is the transmission map that depends on the attenuation coefficient t,
and the scene depth
, and
is the global background light in channel
. By modeling the three channels of RGB separately, this study constructed an optical consistency loss term for training constraints, guiding the process of image enhancement to minimize physical deviations as much as possible.
To estimate the underwater physical parameters critical for image enhancement, this paper employs a light propagation model based on the Jaffe–McGlamery formulation. The light absorption and scattering coefficients are estimated based on environmental conditions, such as water turbidity and depth, while the background light intensity is determined using a global estimation technique. This paper quantitatively evaluated the accuracy of our parameter estimation method by comparing the estimated values with ground truth measurements obtained through controlled underwater experiments. The results indicate that the estimation process achieves a high degree of accuracy, with mean absolute errors for light attenuation coefficients between 5 and 8%, an RMSE of 0.02 for background light intensity, and a correlation coefficient of 0.92 for depth estimation.
2.3. Improved UNIT Structure
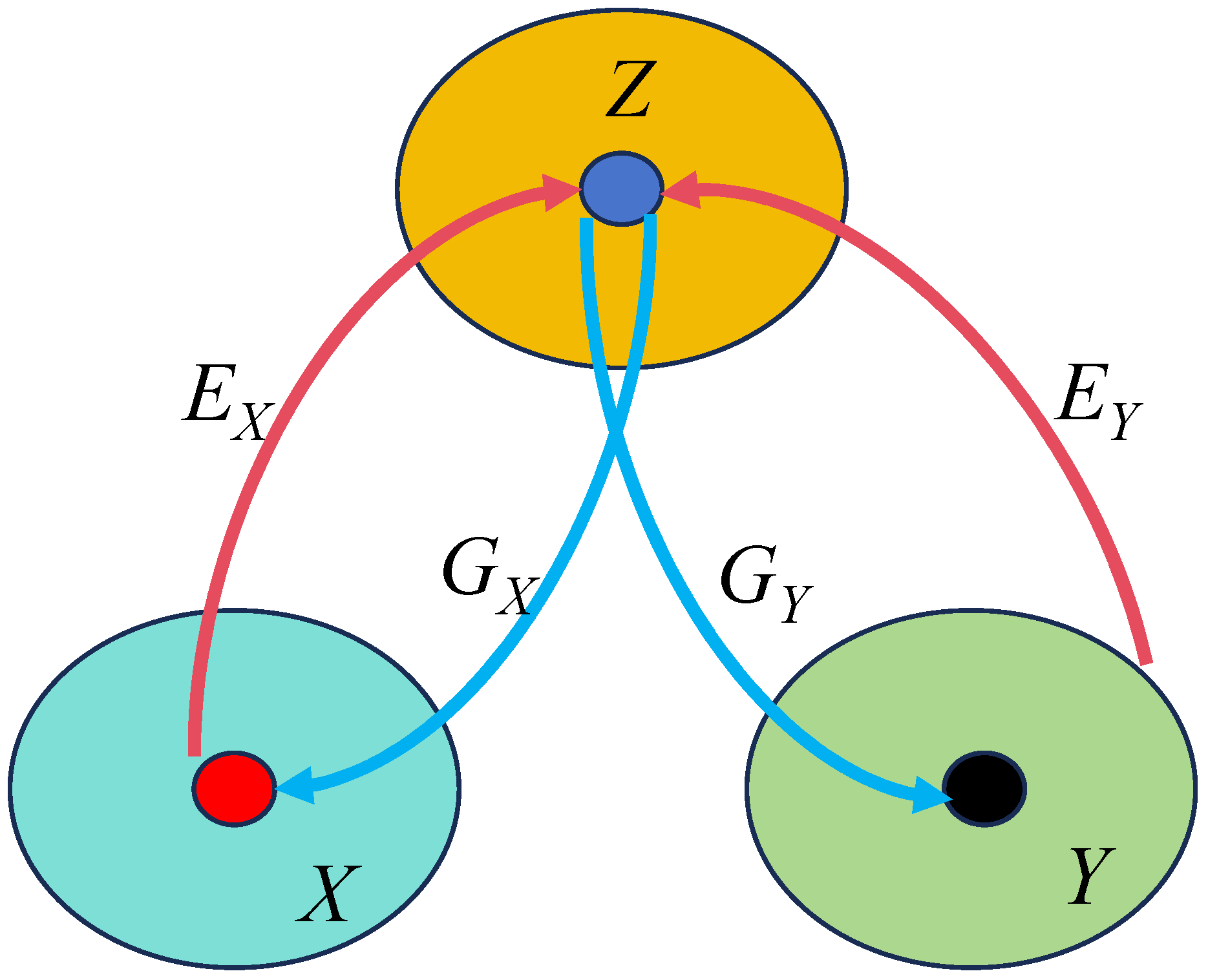
The proposed method builds upon the foundational UNIT architecture, as shown in
Figure 3, which integrates Variational Autoencoders (VAEs) and GANs under the assumption of a shared latent space between source and target domains. While UNIT is effective for general unsupervised domain translation tasks, it is not specifically tailored to the challenges of underwater imaging, particularly when preserving high-frequency crack features under severe degradation. To this end, this paper proposes a physics-guided and detail-aware variant of UNIT with three significant architectural improvements:
2.3.1. Shared Encoder with Physically-Constrained Latent Representation
The encoder network, denoted as
for domain X and
for domain Y, is designed to extract domain-invariant structural representations while embedding domain-specific degradations into the latent space Z (as shown in
Figure 1). Unlike the original UNIT, this paper incorporates a physics-guided regularization term into the encoder’s objective, enforcing consistency with underwater light attenuation models (based on the Jaffe–McGlamery formulation). This promotes representations that are not only compact but also physically plausible under varying scattering and absorption conditions. (1) Weight-sharing strategy: The last few convolutional layers of the encoders are shared across domains to encourage learning of common geometric structures, such as cracks and edges. (2) Auxiliary depth-light maps: The encoder optionally integrates side-channel depth priors or turbidity estimations to modulate feature extraction via adaptive normalization layers.
2.3.2. Decoder with Multi-Scale Feature Fusion and Skip Connections
The decoder networks
and
are responsible for reconstructing enhanced images from the latent representation Z (as shown in
Figure 1). To recover fine crack-level details and avoid the common problem of oversmoothing, this paper embeds a Multi-Scale Feature Enhancement Module (MSFEM) into the decoder. This module collects hierarchical feature maps from early and middle layers and aggregates them via channel attention and upsampling operations. (1) Skip connections: Inspired by U-Net, lateral connections are established between corresponding encoder and decoder layers, facilitating the preservation of spatial localization and edge sharpness. (2) MSFEM block: Each decoding stage includes an MSFEM that combines global contextual information and local details. This is crucial for reconstructing high-frequency crack patterns that are easily lost in underwater scenes. Mathematically, let
denote the feature map at level l. The fused output
is obtained by:
where
denotes element-wise multiplication and
is a learnable channel-weighting mechanism.
2.3.3. Local-Region Discriminator Based on PatchGAN
Standard discriminators often evaluate the entire image globally, which may fail to emphasize small yet critical structural features like cracks. This paper adopts a PatchGAN-based local discriminator Dpatch that focuses on N × N patches (typically 70 × 70), treating each patch as an independent classification task (real/fake). This improves the model’s ability to preserve texture consistency and edge sharpness in enhanced images. (1) Fine-grained feedback: The discriminator provides more granular feedback, penalizing synthetic textures or blurred transitions introduced during enhancement. (2) Adversarial loss formulation: This paper uses a least-squares GAN loss to stabilize training and mitigate gradient vanishing problems:
2.4. Design of Optical Consistency Loss Function
In order to effectively integrate underwater optical physics models with image enhancement networks, this paper designs a composite loss function containing multiple optical constraints, which is expressed as follows:
where:
: Reconstruction loss, measuring the consistency between input and output images in pixel space;
: Adversarial loss, guiding the network to generate realistic images;
: Optical consistency loss, utilizing the rationality of constraining color channels with tc and Bc in physical models;
: Structural similarity loss, used to maintain the overall shape of crack structures;
: Image gradient loss enhances the clarity and continuity of crack edges. Through the above multi-objective joint training strategy, the network not only obtains global naturalness enhancement during the generation process, but also achieves collaborative optimization of structural fidelity and optical consistency.
Real underwater scenes often exhibit non-uniform lighting due to varying water turbidity and sunlight attenuation. To address this, we introduce an illumination-adaptive constraint that penalizes spatially inconsistent enhancement across low-light regions. Specifically, we define an inter-patch consistency loss across crack-relevant image regions to ensure local contrast is enhanced proportionally:
where,
denotes the local contrast variation within region
, and
N is the total number of crack-adjacent patches. This loss encourages uniform enhancement while preserving crack-texture modulation across uneven backgrounds.
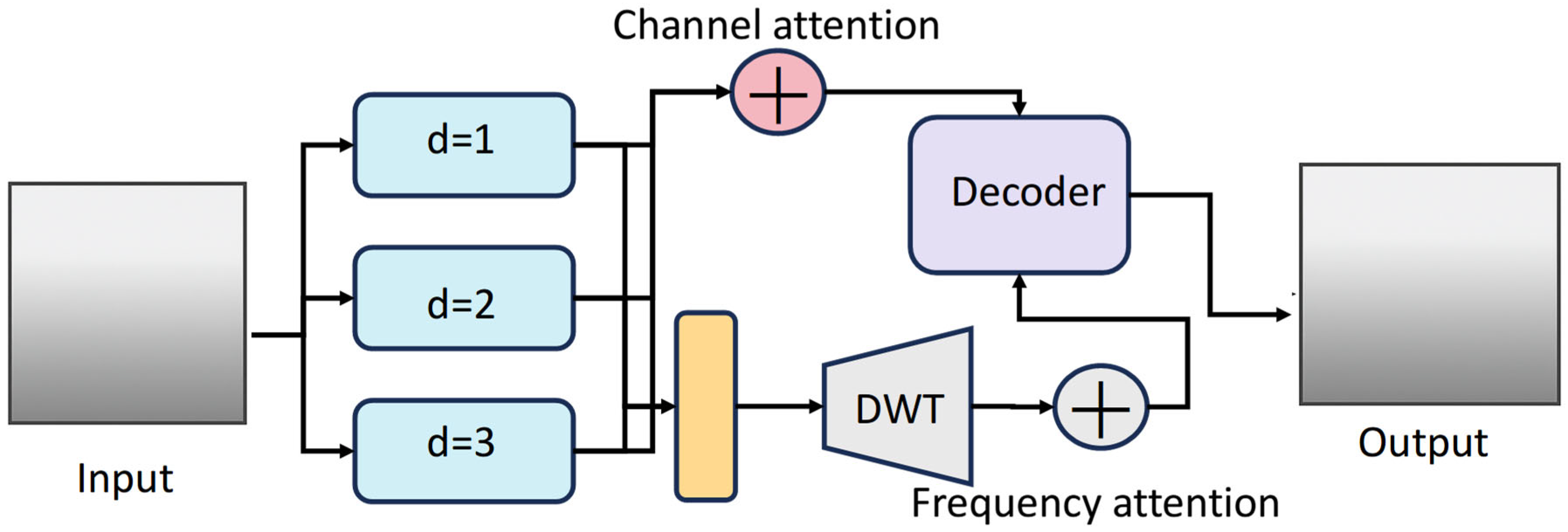
2.5. Multi-Scale Feature Preservation Module
Considering the diverse forms and varying scales of underwater cracks, this paper introduces the Multi-Scale Feature Preservation Module (MSFPM) to enhance the modeling capability for cracks of different scales (as shown in
Figure 4). This module is constructed based on dilated convolution and embedded in the UNIT decoder to extract features at the coarse, medium, and fine scales. Its structure includes the following: (1) Three dilated convolution branches with different dilation rates (d = 1, 2, 4) are connected in parallel to extract contextual information; (2) Channel attention mechanism weights feature responses at various scales; (3) After fusion, it is sent to the decoder to improve detail restoration and crack continuity.
To further retain high-frequency crack information, this paper extends the multi-scale module by incorporating a frequency attention mechanism. Instead of using plain dilated convolutions, this paper first decomposes intermediate features using a Discrete Wavelet Transform (DWT), then attention weights are applied based on spectral energy in each sub-band. In the frequency-aware extension of the multi-scale module, we apply a single-level DWT to intermediate features using the Haar wavelet (db1) basis function. This choice offers computational efficiency and strong spatial localization properties, which are well suited for preserving sharp transitions, such as crack edges. The decomposed sub-bands are then processed with a channel-wise attention mechanism to emphasize high-frequency components relevant to crack detection:
where,
represents the set of DWT components at scale
, and
σ is the sigmoid activation. The learned attention
is used to modulate the fusion weights in the decoder to favor high-frequency crack contours. This paper applies a single-level DWT using the Haar wavelet to decompose intermediate feature maps into four sub-bands: LL, LH, HL, and HH. These sub-bands represent low-frequency and directional high-frequency components. A channel-wise attention mechanism was then applied to emphasize sub-bands containing meaningful edge and texture information. This paper specifically adopts a 1-level decomposition to ensure that spatial structure was preserved and computational complexity is minimized.
The module can more effectively preserve crack edges and texture information during the enhancement process, improving the visual quality and subsequent recognition accuracy of the overall image. In summary, this method combines physical modeling with deep image translation networks, balancing physical consistency, structural details, and image realism, providing an innovative and high-performance solution for enhancing underwater crack images.
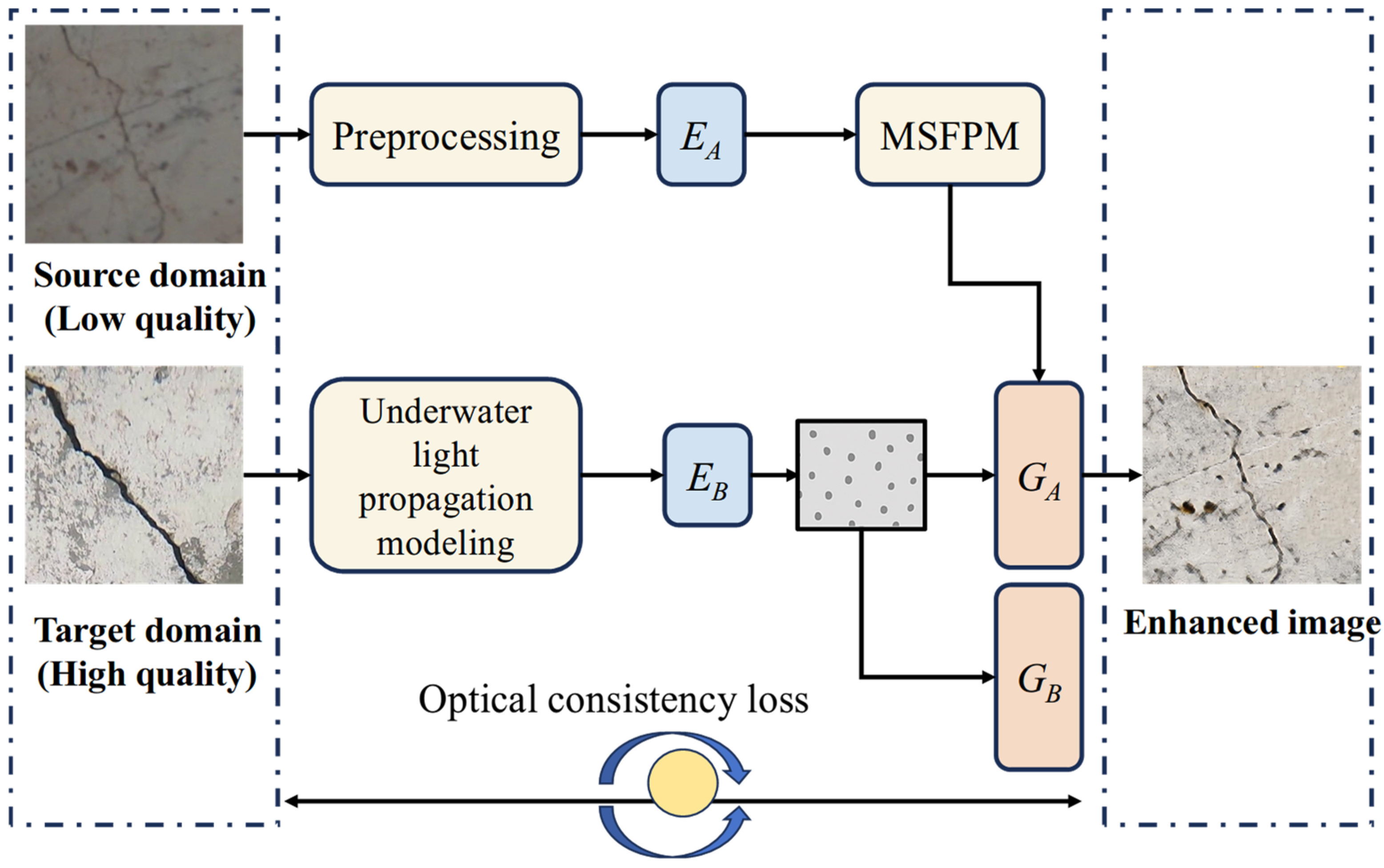
2.6. Proposed Framework
Figure 5 shows the overall structure of the image enhancement method based on the underwater light propagation model and the improved UNIT network fusion proposed in this paper. The entire system consists of four main modules: input image preprocessing module, underwater light propagation modeling module, improved UNIT image translation network, and multi-scale feature preservation and enhancement module. Each module achieves collaborative enhancement through specific information flow, ensuring maximum preservation of crack structure features while improving image quality.
The methods include an unsupervised image translation network with physical modeling constraints, an improved UNIT structure, a multi-scale feature enhancement module, and a joint optimization strategy for optical consistency loss. Specifically, the first inputs are the original low-quality underwater crack images, which are often accompanied by strong color distortion, blurring, and low-contrast phenomena. Before entering the enhancement network, the image is first normalized and physically degraded parameters are estimated through a preprocessing module. This estimation is based on an underwater light propagation model, which extracts the attenuation factor, background light intensity, and preliminary scattering information for each color channel. These pieces of information will be guided as part of the physical perceptual loss in subsequent training to ensure that the enhanced results are physically reasonable.
Next, the image is inputted into an improved UNIT network. This network consists of two encoders (for the source domain and target domain, respectively), a shared latent space module, and two decoders. In order to adapt to the sparsity and locality of crack features, the encoder introduces a multi-scale extraction structure and maintains key spatial textures through residual connections. Shared hidden space ensures structural consistency between different image domains, thereby achieving unsupervised domain transformation learning.
In the decoder Section, this paper introduces a multi-scale feature preservation module (MSFPM), which adopts a parallel dilated convolution structure (with dilation rates of 1, 2, 4) to effectively expand the receptive field and enhance the network’s modeling ability for cracks of different scales. The outputs of each channel are weighted and fused through an attention mechanism before being input into the decoder backbone, ultimately generating an enhanced image. This module significantly improves the ability to express details in the crack area of the image, especially in the restoration of edge information under complex background interference.
During the training process, the network is jointly driven by multiple loss terms. Among them, physical awareness loss enhances the consistency of physical parameters (such as color channel transmittance, scattering model fit, etc.) between the image and the input image through contrast enhancement, limiting the output image of the network from deviating from the physical laws of underwater imaging; Structural similarity loss (such as SSIM, edge gradient loss) is used to maintain the continuity and clarity of crack texture features; Adversarial loss ensures that the network generates images that are globally perceived to be similar in style to real high-quality images.
Overall, the method framework shown in
Figure 5 not only achieves unsupervised transformation from degraded images to enhanced images, but also introduces the fusion of underwater physical laws and visual perception mechanisms, improving the interpretability and generalization ability of the model. This design is of great significance for solving the problem of “excessive enhancement” or “enhancement distortion” in current underwater crack image enhancement.
3. Results
3.1. Experimental Setup
The dataset used in this study consists of 1000 underwater crack images, 500 of which are low-quality images captured under diverse underwater conditions (collecting data through underwater robots, as shown in
Figure 6). These include the following: Water turbidity levels ranging from clear (0–5 NTU) to highly turbid (30–50 NTU); Illumination conditions, including both natural ambient light (e.g., outdoor daylight at depths of 0.5–1.5 m) and artificial lighting using LED arrays in dark or shaded environments (up to 5 m depth); Depth variations from 0.3 m (shallow surface conditions) to 5 m, covering both near-surface and semi-deep underwater environments. The remaining 500 images are relatively high-quality reference images obtained under controlled conditions in clear water with optimized lighting. All images are resized to 512 × 512 resolution and stored in jpg format for model training and evaluation. The dataset is available upon request for academic research purposes. Data acquisition covered estuarine (Pearl River Delta) and tidal scenarios to ensure generalization. For benchmarking, this paper compares our method with four state-of-the-art methods: Retinex-Net, UWCNN, WaterGAN, U-Former and Restormer and the original UNIT model.
To assess the practical deployability of the proposed method, this paper reports the model’s size and inference speed on both high-end and embedded platforms. The model occupies only 17.8 MB, thanks to its lightweight encoder–decoder architecture. Inference time is 18.6 ms on an RTX 4090, enabling near real-time processing for low-latency underwater visual inspection. This confirms the method’s suitability for real-world deployment in autonomous underwater systems and robotic inspection pipelines. For fair comparison, the input resolution was uniformly resized to 512 × 512, and each method was trained for 100 epochs using the Adam optimizer. The evaluation metrics include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Underwater Image Quality Measure (UIQM), and Edge Preservation Index (EPI).
PSNR measures the ratio between the maximum possible pixel value and the mean squared error (MSE) between the original and enhanced images:
where,
is typically 255 for 8-bit images.
SSIM assesses the perceptual similarity between two images based on luminance, contrast, and structure:
where,
μ and
σ represent mean and standard deviation, and
,
are constants for stability.
UIQM is a non-reference metric for underwater images, defined as a weighted combination of colorfulness (UICM), sharpness (UISM), and contrast (UIConM):
where, the typical weights are:
= 0.0282,
= 0.2953,
= 3.5753.
EPI evaluates the sharpness and preservation of edges between the input and enhanced images:
where,
represents the gradient (e.g., via Sobel operator), and ‖ ‖ is the norm of the gradient magnitude.
3.2. Weight Selection of Loss Function
The loss function includes five weighted components with empirically chosen coefficients: λ1–λ5. These weights were determined through grid search and performance tuning on a validation set. A brief sensitivity analysis showed that the model’s performance is most sensitive to the optical consistency λ3 and structural similarity λ4 terms, confirming their critical roles in preserving physical realism and crack detail. The selected configuration (10, 1, 5, 2, 1) offers a balanced trade-off between visual fidelity and structural accuracy.
To further support the credibility of our training setup, this paper has now conducted a brief sensitivity analysis of the weighting terms. Specifically, this paper varied one parameter at a time while keeping the others fixed and recorded the performance changes in terms of PSNR and SSIM as shown in
Table 1.
3.3. Training and Testing
The training loss of the proposed method and baseline model is shown in
Figure 5. During the training phase, the total loss of the model consists of multiple components, including reconstruction loss, adversarial loss, style consistency loss, and cyclic consistency loss. From the training curve (as shown in
Figure 7), the following points can be observed: (1) Rapid convergence: Within the first 20 epochs, the reconstruction loss and total loss decrease rapidly, indicating that the improved encoding decoding structure has good initialization and convergence. (2) Stability enhancement: Thanks to the introduction of PatchGAN discriminator and multi-scale feature preservation module, the overall training process has less fluctuation and the model optimization process is smoother. (3) Stable Adversarial Learning: The absence of severe oscillations in adversarial losses indicates a good game balance between the generator and discriminator, validating the effectiveness of introducing shared hidden spaces and reconstructing consistency losses in the network structure. It is worth mentioning that in underwater crack image enhancement tasks, optimizing stability is crucial as the original image is often affected by light scattering and blurring. From the loss curve, it can be seen that the proposed method has strong anti-interference ability and good adaptability.
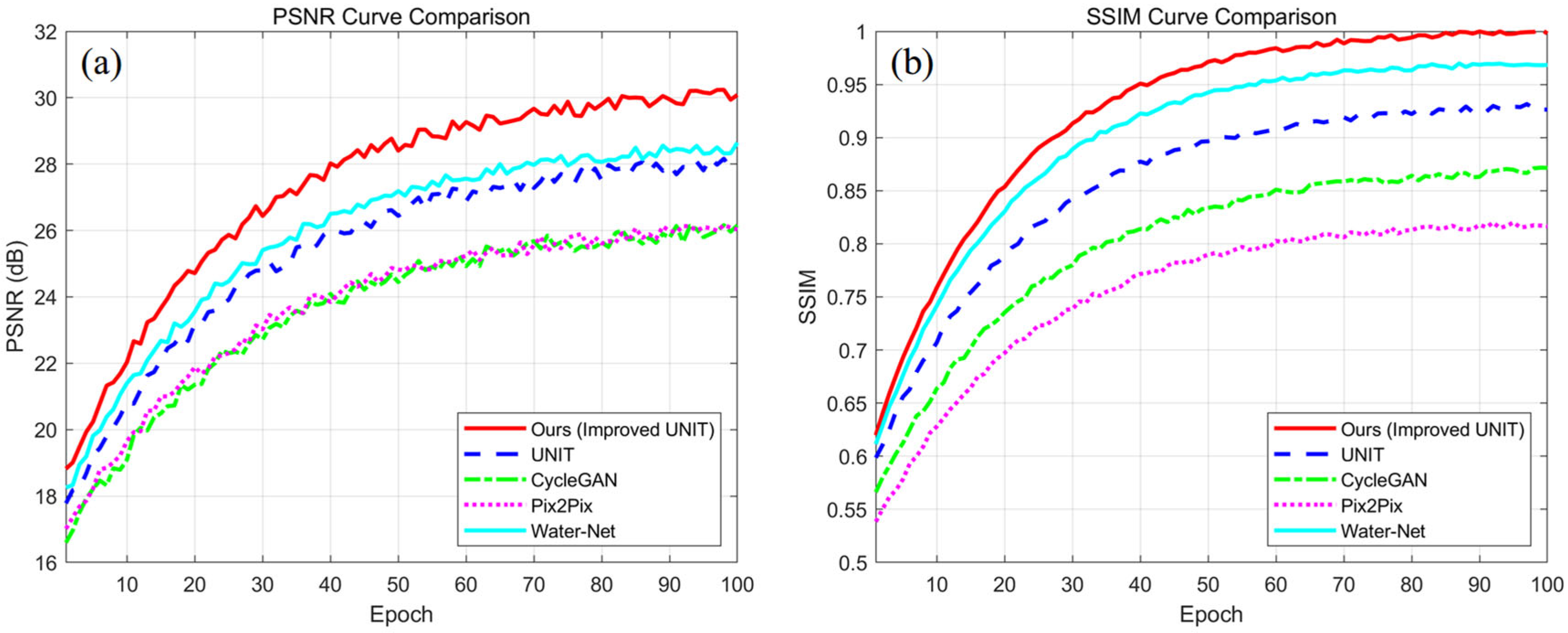
For
Figure 8a, the initial PSNR is about 16.5 dB, gradually increasing to over 24 dB within 50 epochs; The later stage (60–100 epochs) tends to converge, maintaining at 24.5–25 dB, reflecting a decrease in overall image distortion and clearer reconstruction; From the perspective of image restoration, a higher PSNR means that the improved model effectively reduces blurring and degradation in underwater imaging, especially suitable for the true restoration of crack features. For
Figure 8b, in the early stages of training (0–30 epochs), SSIM rapidly improved from 0.55 to around 0.82, reflecting the model’s ability to restore the main features of image structure in the early stages; After 50 epochs, the curve tends to stabilize, and SSIM fluctuates within the range of 0.88–0.90, indicating that the enhanced image is highly consistent with the reference image in terms of structural information; Compared to the baseline model, the improved UNIT model has significantly better restoration performance in detail areas, especially at crack edges.
These trends clearly demonstrate the effectiveness of the proposed model in addressing underwater image degradation. The smooth loss convergence indicates stable training dynamics, while the SSIM and PSNR metrics reflect strong structural and visual fidelity. Especially under the challenging conditions of underwater crack detection, where scattering and low contrast hinder visual clarity, our model preserves both geometric consistency and perceptual quality, making it particularly suitable for practical deployment in underwater inspection tasks, such as bridge pier crack monitoring.
Fifty newly collected low-quality images were used to test the enhancement effect of the proposed model. The evaluation indicators PSNR, SSIM, UIQM, and EPI of the test results were 22.93, 0.821, 3.67, and 0.712, respectively, showing excellent testing results.
Figure 9 shows an enhanced case effect, which demonstrates that the proposed method can achieve color and contrast enhancement of low-quality images and higher visibility of cracks.
3.4. Quantitative Evaluation
As shown in
Table 2, the proposed method achieves the best performance across all evaluation metrics. The PSNR value improves by approximately 2.4 dB compared to UNIT and by over 7.3 dB compared to Retinex-Net. The SSIM index, which evaluates structural fidelity, is also highest in our method, indicating superior preservation of crack textures. Notably, the UIQM score demonstrates improved color and contrast correction, while the EPI validates that our approach retains more edge detail, crucial for crack analysis. Compared to recent transformer-based (U-Former, Restormer), the proposed method shows superior performance on structure-sensitive metrics, such as SSIM and EPI. This highlights its advantage in tasks requiring detailed defect localization, despite the simplicity and lower computational cost of our architecture.
3.5. Qualitative Results
Figure 10 visually compares enhancement results from different methods on three representative underwater crack images. The figure illustrates a visual comparison of enhancement results across multiple methods: (a) represents the original image, while (b) to (h) showcase the outcomes of Retinex-Net, UWCNN, WaterGAN, UNIT, Restormer, U-Former and the proposed method, respectively. An analysis of each method’s performance in terms of noise reduction, detail preservation, and image quality enhancement is as follows:
Retinex-Net exhibits moderate noise reduction capabilities, with some residual noise still perceptible in the enhanced image; although it retains details to a certain extent, the overall image sharpness is not markedly improved, and the overall image quality enhancement is relatively limited.
UWCNN demonstrates proficient noise reduction, effectively minimizing noise artifacts; it also excels in detail preservation, resulting in enhanced texture and edge definition in the processed image, and significantly elevates image quality, yielding a visually pleasing outcome.
WaterGAN displays average noise reduction performance, with some noise persisting in the enhanced image; its detail preservation is moderate, with slight detail loss observed, and while image quality is somewhat improved, the effect is less pronounced compared to UWCNN.
UNIT performs well in noise reduction, effectively suppressing noise; however, its detail preservation is comparatively average, with some details appearing slightly blurred, and although overall image quality is enhanced, the improvement is less significant than that of UWCNN.
The enhancement effect of Restormer and U-Former was close to the proposed method.
Figure 11 highlight localized zoomed-in views. Red arrows indicate regions of improved crack clarity and edge recovery—especially at branching points and junction discontinuities.
The proposed method excels in noise reduction, achieving a nearly noise-free image; it also demonstrates superior detail preservation, meticulously maintaining texture and edge information, and substantially enhances image quality, delivering the most visually appealing result. In conclusion, the proposed method outperforms the other evaluated methods in noise reduction, detail preservation, and image quality enhancement, with UWCNN also showing strong performance, particularly in noise reduction and detail preservation. Retinex-Net and WaterGAN offer relatively average overall performance, while UNIT, despite its effective noise reduction, has room for improvement in detail preservation.
In general, the proposed method successfully restores realistic color balance, removes scattering effects, and preserves fine-scale cracks that are lost in other methods. In contrast, UWCNN and Retinex-Net tend to oversmooth the cracks, and WaterGAN produces artifacts under uneven lighting. The introduction of physics-aware constraints and multi-scale enhancement helps our network generate images that are not only visually superior but also structurally informative for downstream defect detection tasks. Whether it was quantitative or qualitative evaluation, Restormer and U-Former were basically similar to the proposed method, but the quantitative evaluation indicators were slightly lower than the proposed method.
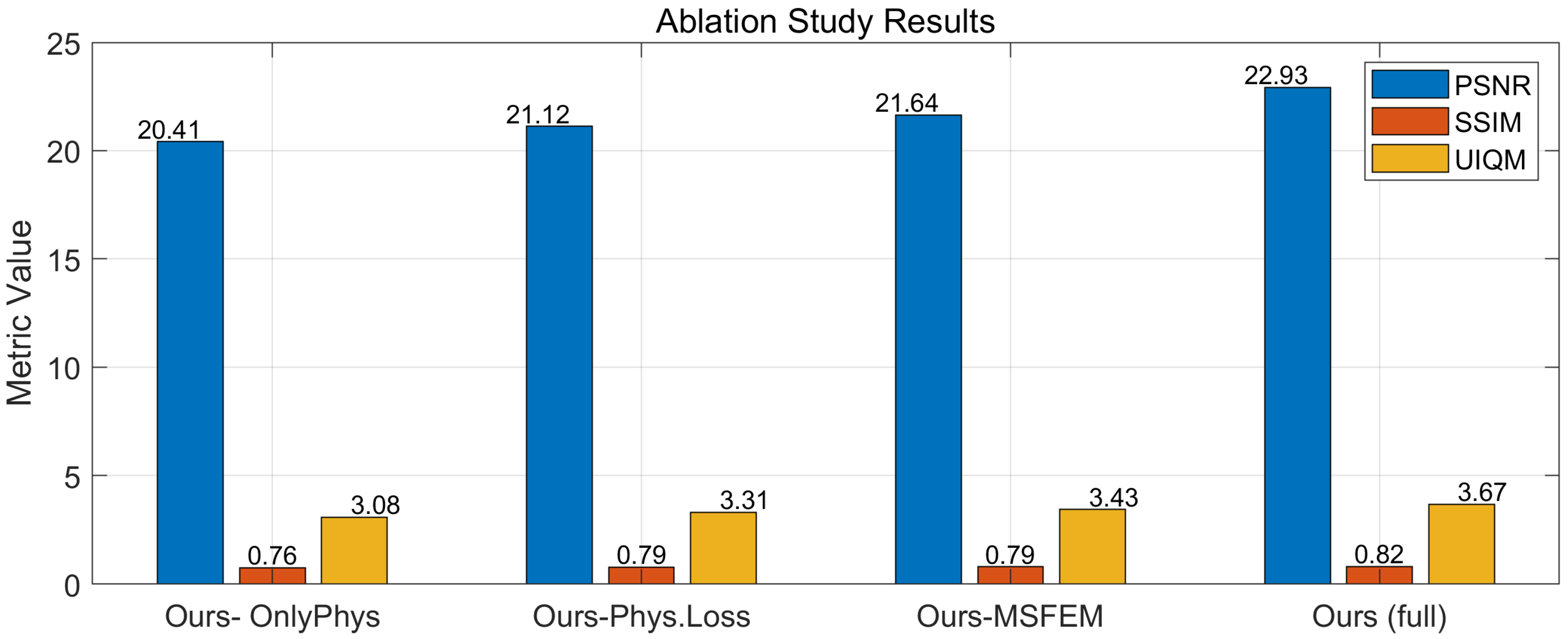
3.6. Ablation Study
To validate the contribution of each component, this paper conducted an ablation study by removing one module at a time from the full model: (1) Ours- OnlyPhys: A variant where only the physics-guided loss term is retained during training; (2) Ours-Phys.Loss: Without physics-aware loss; (3) Ours-MSFEM: Without the Multi-scale feature enhancement module; (4) Ours (full): The complete model.
Results in
Table 3 and
Figure 12 confirm that both the physics-aware loss and the multi-scale feature enhancement module contribute significantly to the final performance. The absence of either module leads to a noticeable drop in PSNR and UIQM scores, highlighting their effectiveness in guiding physically consistent learning and enhancing crack texture details, respectively.
3.7. Expand Applications
To demonstrate the practical applications of our proposed method, this paper tested it on real-world underwater detection tasks. In a bridge pier detection (as shown in
Figure 13), the enhancement method significantly improved the visibility of cracks in images captured under high turbidity and shallow depths. These examples illustrate the applicability of our method in diverse real-world scenarios, highlighting its potential for improving underwater inspection tasks in civil engineering, maritime safety, and environmental monitoring.
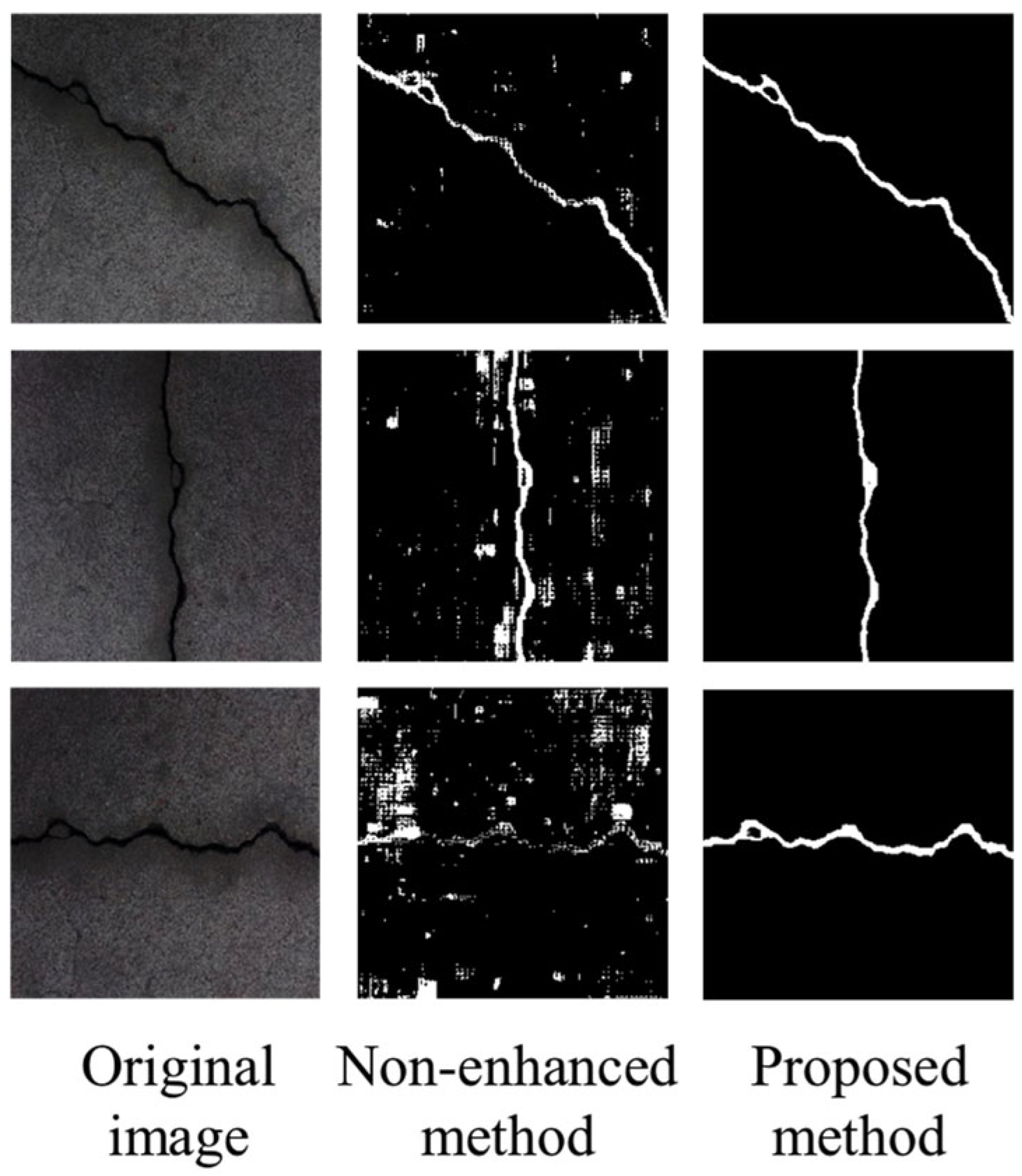
3.8. Post-Enhancement Crack Detection Performance
To evaluate the utility of enhanced images for real-world inspection, this paper conducted a crack detection experiment using a UNet-based segmentation model. The model was trained on high-quality reference crack masks and then tested on three input types: raw underwater images, images enhanced by baseline methods, and images enhanced by our proposed framework. As shown in
Table 4, our method achieved the highest scores in mIoU, F1-score, and pixel accuracy. This confirms that the enhancement not only improves visual quality but also retains discriminative features necessary for downstream analysis, such as structural crack detection. Some sample visual comparison is provided in
Figure 14.
4. Discussion
Although our method demonstrates competitive performance against established CNN- and GAN-based models, such as Retinex-Net, UWCNN, WaterGAN, and UNIT, this paper acknowledges that more recent transformer-based models designs have reported strong performance on general underwater scenes. However, most of these models are not specifically designed to retain fine structural features, such as cracks, under heavy degradation. Moreover, the added complexity of transformer-based methods often results in slower inference speeds and higher data requirements. By embedding physical priors into both the network architecture and loss functions, the proposed method balances interpretability, performance, and application specificity, making it particularly suitable for real-time underwater crack inspection tasks.
The experimental results demonstrate that our proposed method effectively address-es common underwater image degradation issues, including low contrast, color shift, and detail loss. Unlike prior models that rely purely on data-driven learning, our integration of physical modeling ensures better generalization across varying underwater conditions. Moreover, the multi-scale feature enhancement module plays a key role in refining crack edges without introducing noise or artifacts. Limitations of our current implementation include the reliance on estimated water parameters during preprocessing, which may introduce bias in extreme environments (e.g., muddy estuaries). Future work could explore end-to-end learning of physical parameters and improved generalization via synthetic-to-real domain adaptation.
5. Conclusions
This paper presents a novel unsupervised image enhancement method for underwater crack images, which integrates underwater optical modeling with an improved deep learning framework. By incorporating the Jaffe–McGlamery light propagation model into the UNIT architecture, the proposed approach ensures physically consistent and perceptually accurate enhancement results. The introduction of a multi-scale feature preservation module enables effective reconstruction of fine crack details across varying spatial scales, while the PatchGAN-based local discriminator further improves structural realism and texture clarity. Extensive experiments on a self-collected underwater crack dataset demonstrate the superiority of the proposed method over existing state-of-the-art approaches in terms of both quantitative metrics (PSNR, SSIM, UIQM, and EPI) and qualitative visual results. Ablation studies confirm the critical role of physics-aware loss and multi-scale enhancement in achieving accurate restoration. Furthermore, the model exhibits strong generalization and robustness to diverse underwater environments, making it suitable for real-world inspection tasks, such as bridge pier monitoring.
- (1)
This paper proposed a physics-aware unsupervised image enhancement method that effectively integrates underwater light propagation theory with an improved UNIT network.
- (2)
A multi-scale feature preservation module and local PatchGAN discriminator were introduced to enhance structural details, especially for fine crack textures.
- (3)
Experimental results demonstrate that our method outperforms state-of-the-art approaches in both visual quality and structural fidelity.
- (4)
The designed optical consistency loss ensures enhanced images remain consistent with underwater imaging principles.
- (5)
The proposed framework is robust and generalizable, making it suitable for practical underwater inspection tasks, such as bridge pier crack detection.
While previous studies, such as Retinex-based methods and UWCNN, focus on enhancing global image properties without considering the underlying physical degradation process, our proposed method integrates a physical regional model that incorporates underwater light propagation theory. This modeling of optical phenomena, such as scattering and absorption, helps maintain color consistency and crack visibility in challenging underwater conditions. Furthermore, this paper introduces a multi-modification strategy through our multi-scale feature preservation module, which enables the preservation of fine crack details across different spatial scales. This is complemented by a PatchGAN-based discriminator, which ensures enhanced texture realism by focusing on small image patches. Together, these innovations result in a more detailed and physically accurate restoration compared to existing models.
In summary, this work offers a physically grounded, detail-preserving, and unsupervised solution to underwater image enhancement, advancing the reliability of visual-based underwater structural defect detection. Future research will explore end-to-end learning of physical parameters and domain adaptation techniques to further improve the adaptability of the model under complex real-world conditions. Meanwhile, for the gradient loss term, this paper employs the Sobel operator to compute image gradients along horizontal and vertical directions. This operator provides a balance between edge localization and noise robustness, and is widely used in structural loss computation. However, this paper acknowledges that alternative gradient operators could offer better alignment with the characteristics of underwater crack edges: The Scharr operator provides improved rotational symmetry and better gradient estimation, particularly useful in cases where crack edges are shallow or noisy. The Laplacian operator captures second-order derivative information, emphasizing transitions and junctions—potentially useful in branching or curved crack structures. The Canny edge detector, though non-differentiable, could inspire future work in hybrid or auxiliary supervision setups using its output as pseudo-labels for edge guidance. Exploring the effectiveness of these alternative operators in the loss formulation could be a promising direction for future research, particularly in enhancing edge preservation under extreme degradation or turbidity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}