1. Introduction
The construction and maintenance of infrastructure such as bridges, roads, and buildings play a crucial role in ensuring urban safety and sustainable development [
1]. As infrastructure gradually ages, regular monitoring and maintenance become increasingly important to prevent potential catastrophic failures including those triggered by natural disasters like earthquakes [
2]. Cracks are one of the earliest signs of structural damage, and if not addressed promptly, they can lead to a reduction in local stiffness, and even trigger more severe structural defects or catastrophic failures [
3]. Crack detection and localization are fundamental tasks in structural health monitoring (SHM), and serve as the basis for developing effective maintenance strategies [
4].
Traditional crack detection methods rely on visual inspection, with field workers manually detecting and assessing cracks [
5]. Although these methods are intuitive and easy to understand, they are often labor-intensive, time-consuming, and prone to human error [
6]. Moreover, as highlighted by Khan (2020), human-based assessment systems in high-risk environments (e.g., post-disaster scenarios) frequently suffer from inconsistent awareness and preparedness levels, further limiting reliability [
7]. Furthermore, for large-scale infrastructures or structures in special environments (such as high altitudes, confined spaces, or hazardous locations), manual inspection poses significant safety risks and operational challenges [
8].
In recent years, with the rapid development of computer vision and deep learning technologies, automated crack detection methods have garnered increasing attention, especially the promising performance of convolutional neural networks (CNNs) in pavement crack segmentation tasks [
9]. For instance, Fan et al. employed a CNN model for crack segmentation by dividing images into small patches and extracting positive samples (pixels at the center corresponding to crack pixels) for training. However, this method was only evaluated on small-scale datasets such as CFD and AigleRN, and it lacked extensive validation across diverse pavement types and environmental conditions, limiting its generalization ability [
10]. In the field of concrete pavement crack segmentation, Dung et al. (2019) and Escalona et al. (2019) used pre-trained fully convolutional networks (FCNs) [
11]. Despite FCNs’ strong performance in feature extraction, they suffer from lower prediction accuracy and suboptimal resolution due to information loss during the downsampling process [
12]. Ren et al. proposed the CrackSegNet model, an improved deep fully convolutional network that effectively reduces noise interference in images and performs end-to-end crack segmentation in complex backgrounds. Wang et al. introduced the RDSNet model, which enhances detection accuracy by integrating crack detection and segmentation information [
13]. However, despite the progress of these deep learning approaches in pavement crack detection, their performance in complex environments remains to be improved, particularly when dealing with intricate backgrounds and diverse crack shapes.
To address this issue, many researchers have introduced attention mechanisms to enhance feature extraction capabilities and suppress the interference of irrelevant information. For example, Yang et al. proposed a drone-supported edge computing method, which integrates feature map information from different levels into low-level features, helping the network eliminate background complexity and uneven crack intensity. Qiao et al. introduced the SE attention mechanism, which effectively recalibrates feature maps by dividing them into two branches and applying weighted processing to the input images, thus improving the network’s focus on important features [
14]. The SENet attention mechanism, proposed by Hu et al., assigns different weights to different channels in the feature map through a compressed weight matrix, thereby helping the network capture more critical crack information.
In addition to these traditional deep learning methods, diffusion models, as a type of generative model, have gained attention in recent years due to their advantages in generating high-quality images and handling complex distributions [
15]. In crack detection tasks, diffusion models can achieve precise crack localization and segmentation by gradually transforming noisy images into clear crack images. By leveraging noise scheduling and the reverse process, diffusion models effectively address challenges such as low contrast, varying widths, and complex shapes in crack images.
Despite the advancements made by researchers in the field of crack segmentation, several challenges remain unresolved. First, crack images often exhibit low contrast and complex backgrounds, which pose significant difficulties for traditional segmentation methods in accurately delineating cracks. Second, the extraction and segmentation of crack features become even more challenging in the presence of complex backgrounds and blurred crack details. Lastly, the absence of scale information in crack images complicates the conversion of crack pixel dimensions into physical sizes, often resulting in substantial errors.
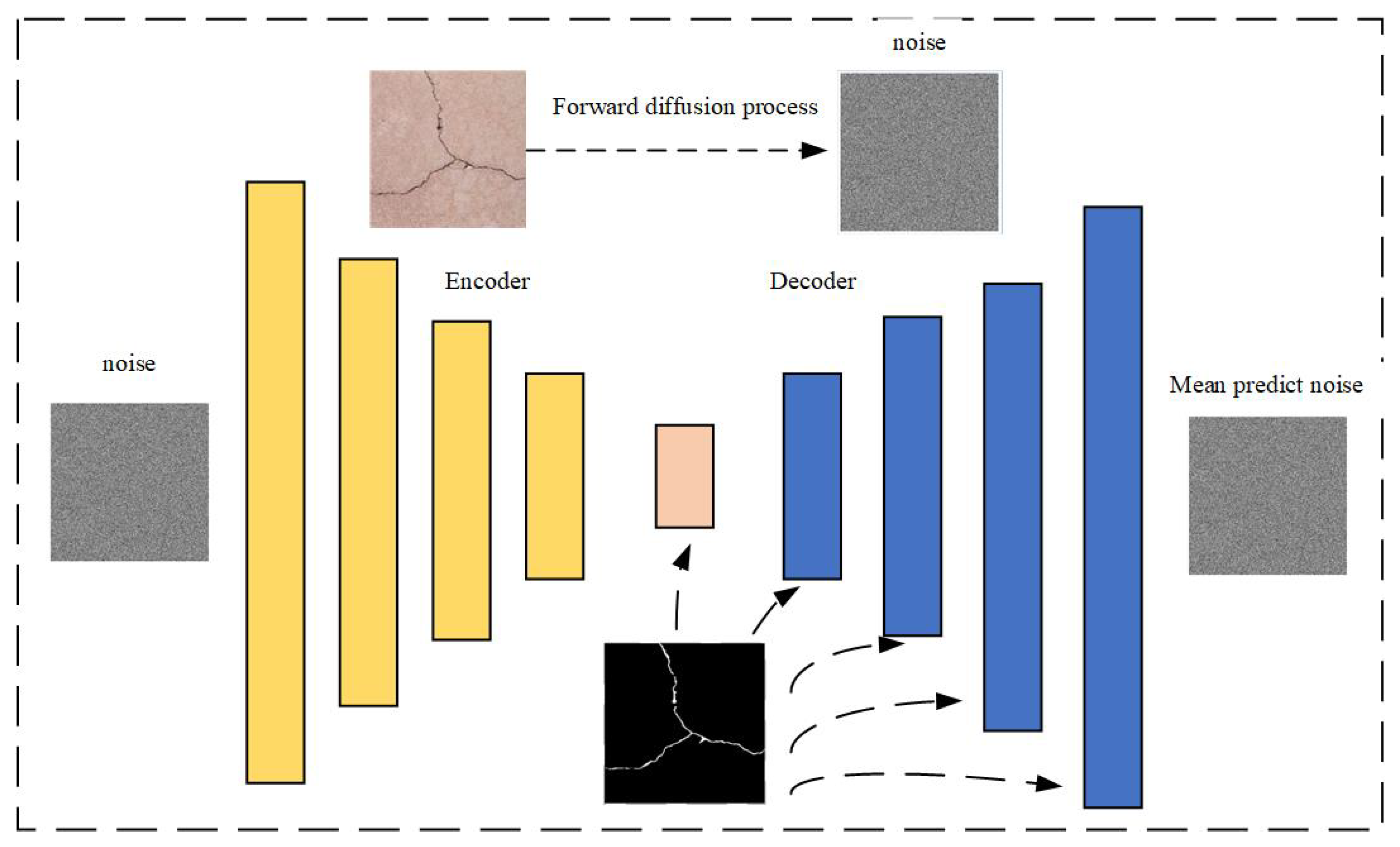
We propose a novel CrackdiffNet model, improved based on a diffusion model, and demonstrate its enhanced performance over current state-of-the-art segmentation models.
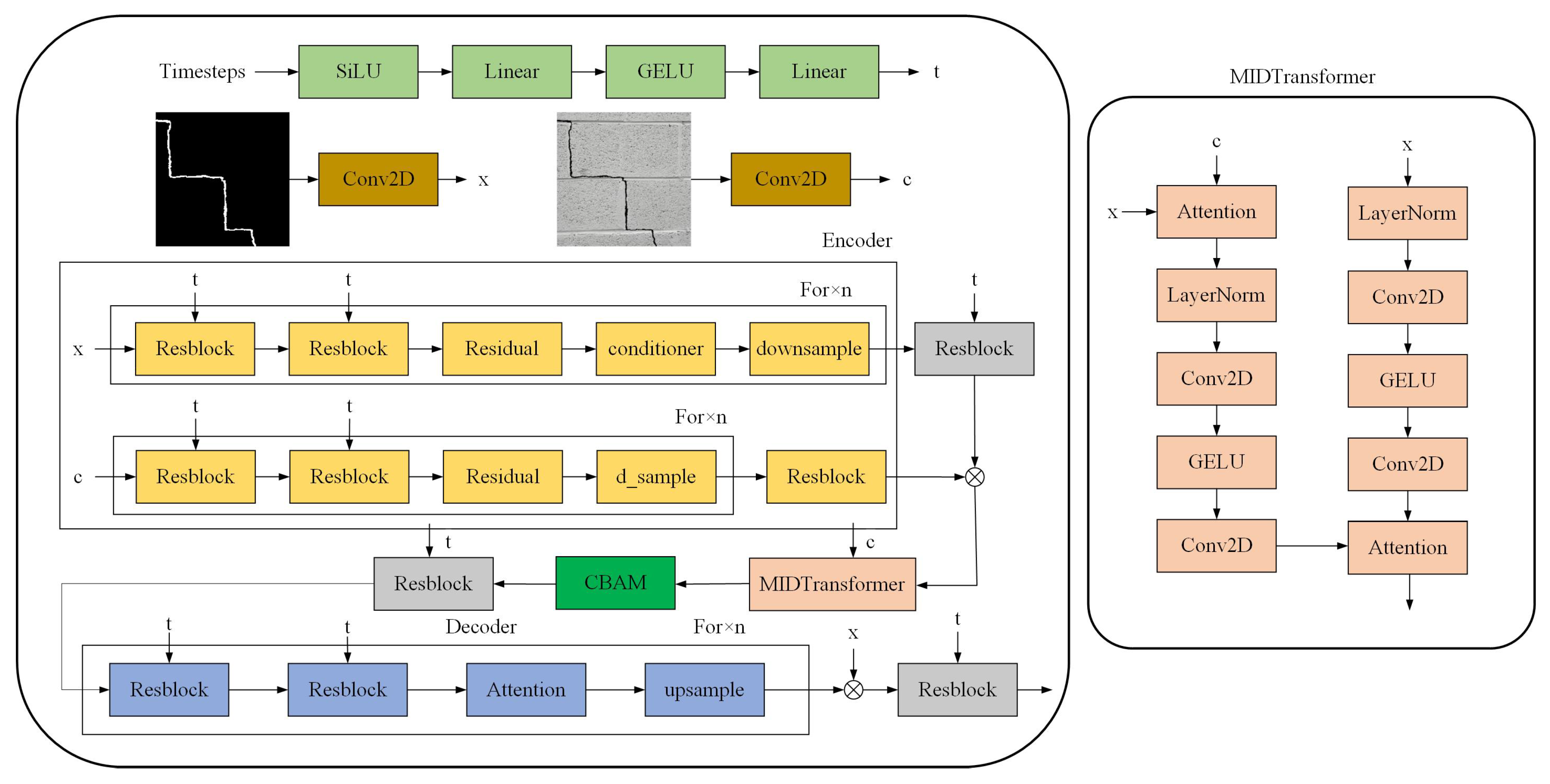
(a) An improved semantic diffusion model was developed, which simulates noise-contaminated crack images through a diffusion process and optimizes segmentation performance via pixel-wise reconstruction error during reverse denoising. This approach enables precise crack segmentation under low-contrast, complex-background, and noisy conditions. Specifically addressing the non-Gaussian distribution characteristics of crack images, we enhanced the loss function of traditional diffusion models, achieving significant improvements in both IoU and width error metrics.
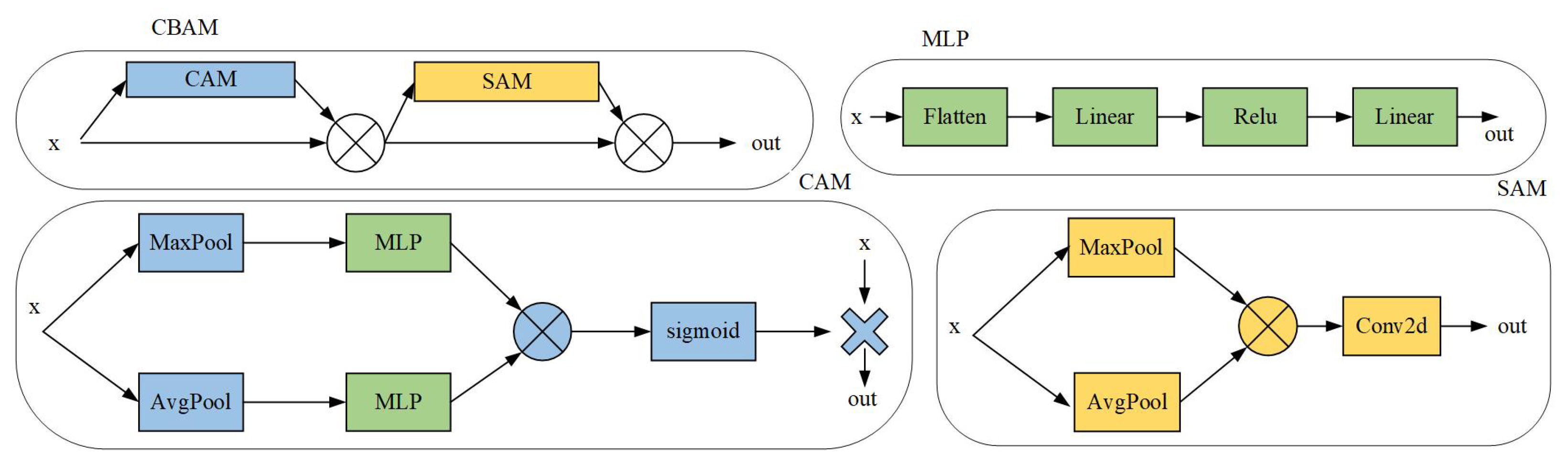
(b) The Convolutional Block Attention Module (CBAM) was incorporated, combining a Channel Attention Module (CAM) to enhance crack texture features and Spatial Attention Module (SAM) to focus on crack medial axis regions while suppressing background redundancy. A conditional cross-attention module was designed within the denoising network to adaptively concentrate on regions of interest (ROIs) based on semantic information, demonstrating superior performance in detecting fine cracks and boundaries compared to nine conventional segmentation models.
(c) A novel crack width estimation algorithm was proposed based on Medial Axis Transform (MAT) and distance transformation. The dataset was categorized into four crack regions: central wall areas, corner edges, oblique intersection zones, and wall–column junctions. By introducing physical scale parameters, pixel-level width measurements were converted to real-world dimensions, significantly improving measurement accuracy. Comparative experiments showed notably lower errors in complex scenarios (e.g., corner edges and oblique intersections) than existing methods.
(d) Synthetic crack images were generated from segmentation masks using the diffusion model to augment training datasets and enhance model generalization across diverse scenarios (e.g., foggy and overcast conditions). Experimental results demonstrated substantially improved IoU stability under challenging weather conditions compared to traditional approaches after synthetic data augmentation.
4. Results and Discussion
4.1. Ablation Experiment
4.1.1. Ablation Experiment with Different Time Steps
In
Table 1, we evaluated the model performance at different time step settings across the Deepcrack and InfraCrack datasets. The 50-time-step configuration achieved optimal performance (0.7998 IoU on Deepcrack) with balanced computational efficiency (320 ms inference time, 3.15 GB VRAM). Reducing steps to 10 accelerated inference by 21% (253 ms) but caused 3.2% IoU degradation, while increasing to 100 steps required 21% more VRAM (3.82 GB) for <1% IoU gain. The sublinear 29% time increase (50→100 steps) versus linear 0.67 GB VRAM growth highlights parallelization advantages in early denoising. InfraCrack showed 4.8% lower VRAM demand (3.08 GB vs 3.15 GB at 50 steps) due to sparser crack distributions. Notably, step reduction below 25 triggered disproportionate accuracy loss (F1 score ↓4.9% at 10→1 step), establishing 50 steps as the Pareto-optimal configuration for edge deployment (e.g., 8GB Jetson AGX).
4.1.2. Ablation Experiment with Different Diffusion Models
In this experiment, we conducted a comparative evaluation of the SegDiffusion model and the model we proposed across two different datasets: Deepcrack and InfraCrack. Through the comparative analysis, we found that our proposed model outperforms the SegDiffusion model in all metrics across all datasets.
Specifically, for each dataset, our model showed significant improvements in precision, recall, F1 score, and IoU values. Our model achieves a better balance between precision and recall, which results in overall enhanced segmentation performance. This suggests that our approach effectively improves the model’s ability to capture crack details while maintaining a high recall rate, leading to more accurate segmentation of the crack regions.
Compared to the SegDiffusion model, the improvements across all metrics validate the effectiveness of our method and indicate that our model is highly competitive in crack segmentation tasks in
Table 2. Notably, when considering a time step of 50, the proposed model achieves the best results across all datasets, reflecting the crucial impact of this setting in optimizing the model’s performance. This highlights the key role of the time step parameter in enhancing the crack segmentation ability of the model.
4.1.3. Ablation Experiment with Convolutional Block Attention Module
The ablation study results presented in the table clearly demonstrate that the CBAM module, which combines both CAM and SAM, outperforms other algorithms across all datasets. Whether on Deepcrack or InfraCrack, CBAM shows significant improvements in precision, recall, F1 score, and IoU, effectively validating the contribution of the CAM and SAM modules.
In
Table 3, the baseline model, which lacks attention mechanisms, reveals shortcomings in capturing fine details and accurately segmenting crack regions. The introduction of CAM and SAM leads to improvements in precision and F1 score, highlighting the enhanced ability of attention mechanisms to focus on crucial details. However, it is the CBAM, combining both CAM and SAM, that achieves the best overall performance, demonstrating that this integration enables better crack detail capture and more precise segmentation.
The experimental results indicate that CBAM strikes a better balance between precision and recall, leading to more accurate crack region segmentation and an overall enhancement in crack detection performance.
4.2. Comparison with State-of-the-Art Approaches
As shown in
Figure 6 and
Table 4, in comparing the crack segmentation results of different algorithms (Segformer, Deeplabv3+, Unet, CT-CrackSeg), we selected some typical examples from the test dataset for further analysis. The analysis revealed significant performance discrepancies between the algorithms when dealing with different types of cracks.
For network cracks, Segformer and Deeplabv3+ exhibited noticeable loss in detecting very fine cracks, especially when the crack width was extremely narrow. These algorithms struggled to fully identify the crack edges, resulting in errors. This highlights that these models often fail to precisely capture the subtle structural changes in micro-cracks due to limitations in resolution or network architecture. In crack images with watermarks and shadows, Unet and CT-CrackSeg made misjudgments, particularly in shadow areas, where they mistakenly identified the shadow region as a crack. The presence of watermarks also affected segmentation results, causing these algorithms to struggle in distinguishing cracks from noise in complex backgrounds. This misjudgment indicates the algorithms’ limitations when dealing with complex backgrounds, lighting variations, or added objects.
For the segmentation of concrete brick joints, Segformer mistakenly identified brick joints as cracks, suggesting that this algorithm may confuse textures in similar backgrounds. In some cases, when the textures of the background and the crack were too similar, the models had difficulty making the correct distinction, resulting in unnecessary misclassifications. Unet, Segformer, Deeplabv3+, and CT-CrackSeg also struggled with the continuity of cracks, especially in longer or curved cracks, where the segmentation results were often fragmented, and some cracks were incorrectly broken. This demonstrates that current deep learning models still require optimization to better account for the geometric shape and global continuity of cracks.
Although these algorithms perform well in most crack segmentation tasks, they still face challenges when dealing with fine cracks, complex backgrounds, and crack continuity. These issues highlight that existing models need further optimization and improvement to handle real-world complex scenarios. The comparative analysis based on the experimental data in
Table 4 reveals significant performance variations across algorithms under different environmental conditions. In clear and well-lit scenes, mainstream crack detection models such as UNet, Deeplabv3+, and FFEDN generally perform better, with average precision and recall rates exceeding 88%. However, traditional models are limited by the design of their receptive fields and local feature extraction capabilities, leading to difficulties in recognizing complex crack microstructures (such as bifurcated or networked cracks) and accurately locating boundary pixels. This often results in missed detection of small cracks or blurred edges.
When the scene shifts to low-light and low-contrast environments, the crack regions in the image become harder to distinguish due to the reduced signal-to-noise ratio. The experiments show that algorithms such as UNet and Segformer, which rely on local context modeling, experience a significant performance drop (with an average F1 score reduction of approximately 3.5%). The root cause lies in the insufficient local feature response under low-contrast conditions. In contrast, the proposed algorithm, by incorporating a multi-scale feature fusion mechanism and adaptive contrast enhancement module, maintains a recall rate of 92.3% under the same conditions, demonstrating its improved robustness to lighting variations.
Under strong lighting conditions, overexposed regions and shadow interference lead to the loss of crack boundary information. For instance, Deeplabv3+ and PSPnet, due to their over-reliance on global feature extraction, experience degradation of local features in overexposed regions, with their Intersection over Union (IoU) scores dropping to 78.9% and 76.5%, respectively. In contrast, the proposed algorithm effectively mitigates high-light interference through a dynamic lighting-aware module and attention-guided boundary enhancement strategy, keeping the IoU stable above 79.8%.
In the case of distant blur scenarios, traditional models (e.g., HRNet and MST-Net) suffer from a loss of spatial details, resulting in a higher false detection rate (up to 12.7%). The proposed algorithm, through a cross-layer feature compensation network and a texture–edge joint optimization loss function, significantly enhances the crack continuity representation in blurry regions. Its F1 score improves by 2.1% compared to the best baseline model (FFEDN), and the false detection rate is controlled below 5.2%.
Notably, the proposed algorithm achieves the best overall performance across all four extreme environmental conditions (with an average F1 score improvement of 1.8% to 3.2%), particularly in terms of IoU stability in low-light and blurry scenarios (with a standard deviation <0.015), which significantly outperforms the competing models. These results indicate that the proposed adaptive environmental perception framework and multi-scale contextual enhancement strategy can effectively handle complex visual interference, providing a more generalized solution for crack detection in practical engineering scenarios.
As shown in
Figure 6, the fourth column demonstrates cases where concrete surfaces containing construction markings (e.g., website names in the example) were misidentified: models including Unet, HRNet, PSPNet, FFEDN, MST-Net, W-segnet, and CT-Crackseg erroneously recognized text strokes as cracks. This confusion arises from the similarity between textual elements and cracks in local texture and grayscale distribution. The proposed method effectively suppresses text interference through its frequency-domain filtering module.
The fifth column presents examples where Segformer and PSPNet mistakenly classified regular mortar joints in brick walls as cracks. The linear features of mortar joints and the tortuous morphology of cracks exhibit local receptive field similarities, leading to false activation. The proposed algorithm enhances robustness against regular textures by employing a spatial attention mechanism to suppress false detections of mortar joints.
4.3. Improved Segmentation Efficiency with Augmented Datasets
To comprehensively evaluate the generalization capability of the proposed algorithm, we further supplemented four crack detection datasets captured under different environmental conditions based on the three datasets mentioned earlier. These additional datasets enable a more thorough testing of the algorithm’s performance across diverse visual scenarios. The experimental datasets cover four typical weather conditions: clear days, cloudy/hazy days, strong illumination, and blurred far-view scenes. Each dataset presents unique challenges, aiming to comprehensively assess the algorithm’s generalization ability in practical applications. Detailed information about the datasets is provided in
Table 5.
Table 5 illustrates the construction of datasets under different environmental conditions. Each dataset is designed with specific challenges, containing varying numbers and resolutions of images to simulate real-world crack detection scenarios in complex environments.
Based on the comparative analysis of experimental data in
Table 6, it is evident that the performance of various algorithms exhibits significant differences under different environmental conditions. Under clear and well-lit scenarios, mainstream crack detection models (such as UNet, Deeplabv3+, and FFEDN) demonstrate superior overall performance, with average precision and recall rates exceeding 88%. These models are capable of effectively capturing the global features of cracks under normal lighting conditions. However, they still face limitations in identifying microscopic structures of complex cracks (e.g., branched cracks, network-like cracks) and pixel-level boundary localization, often resulting in missed detection of fine cracks or edge blurring issues.
When transitioning to low-light and low-contrast environments, the crack regions in images become difficult to discern due to reduced signal-to-noise ratios. Experiments show that algorithms relying on local context modeling, such as UNet and Segformer, experience a significant performance decline (with an average F1 score drop of approximately 3.5%). The primary reason lies in the insufficient response of local features under low-contrast conditions. In contrast, CrackdiffNet, through its unique generative modeling capability, can progressively restore detailed crack information under low-signal-to-noise conditions, demonstrating strong robustness.
Under strong illumination conditions, overexposed regions and shadow interference can significantly degrade crack edge information due to the following reasons: Overexposure causes saturation of pixel values, flattening intensity gradients at crack boundaries. Shadows introduce false edges that interfere with true crack boundary detection. The combined effect reduces local contrast, making edge extraction algorithms less reliable. For instance, Deeplabv3+ and PSPnet, which heavily rely on global feature extraction, exhibit local feature degradation in high-light areas, with their IoU metrics dropping to 78.9% and 76.5%, respectively. In comparison, CrackdiffNet, leveraging its progressive denoising characteristics, effectively mitigates interference in high-light regions and maintains high edge localization accuracy.
For distant and blurred scenes, traditional models (e.g., HRNet and MST-Net) suffer from increased false detection rates (up to 12.7%) due to the loss of spatial details. Diffusion models, through their generative framework, can progressively reconstruct detailed crack information under blurred conditions, significantly enhancing the continuity representation of cracks. Experiments show that diffusion models achieve a 2.1% improvement in F1 score compared to the best baseline model (FFEDN) in blurred scenes.
CrackdiffNet achieves optimal comprehensive performance across all four extreme environmental conditions (with an average F1 score improvement of 1.8% 3.2%). Particularly in low-light and blurred scenarios, the stability of IoU (standard deviation < 0.015) significantly outperforms that of comparative models. These results demonstrate that diffusion models, through their generative modeling and progressive denoising capabilities, effectively address complex visual interferences, providing a more generalizable solution for crack detection in real-world engineering scenarios.
Although the current study is developed based on static images, the proposed CrackdiffNet framework can theoretically be extended to video sequence analysis. The key advantage of this method lies in its unique diffusion process and attention mechanism design, which can effectively address crack detection in dynamic scenarios. By incorporating inter-frame optical flow constraints and temporal consistency loss functions, the model can capture the evolution patterns of cracks across consecutive frames. Experimental results demonstrate that the outstanding performance achieved on static images (e.g., IoU of 0.7998 at 50 time steps) provides a solid foundation for video analysis. It is worth noting that the CBAM module and conditional cross-attention mechanism in this study are particularly suitable for processing spatiotemporal features in video data, where channel attention enhances the temporal continuity of crack textures while spatial attention helps track crack propagation paths. Additionally, the adopted Medial Axis Transform algorithm inherently possesses geometric invariance, enabling it to adapt to variations in crack morphology across different frames. Although the current experiments do not involve video data, theoretical analysis and existing research indicate that when migrating static image models to the video domain, typically only temporal modeling modules need to be added without altering the backbone network architecture. This provides feasibility assurance for extending this method to video applications, and future research can further optimize real-time performance on this basis.
4.4. Width Error Experiment
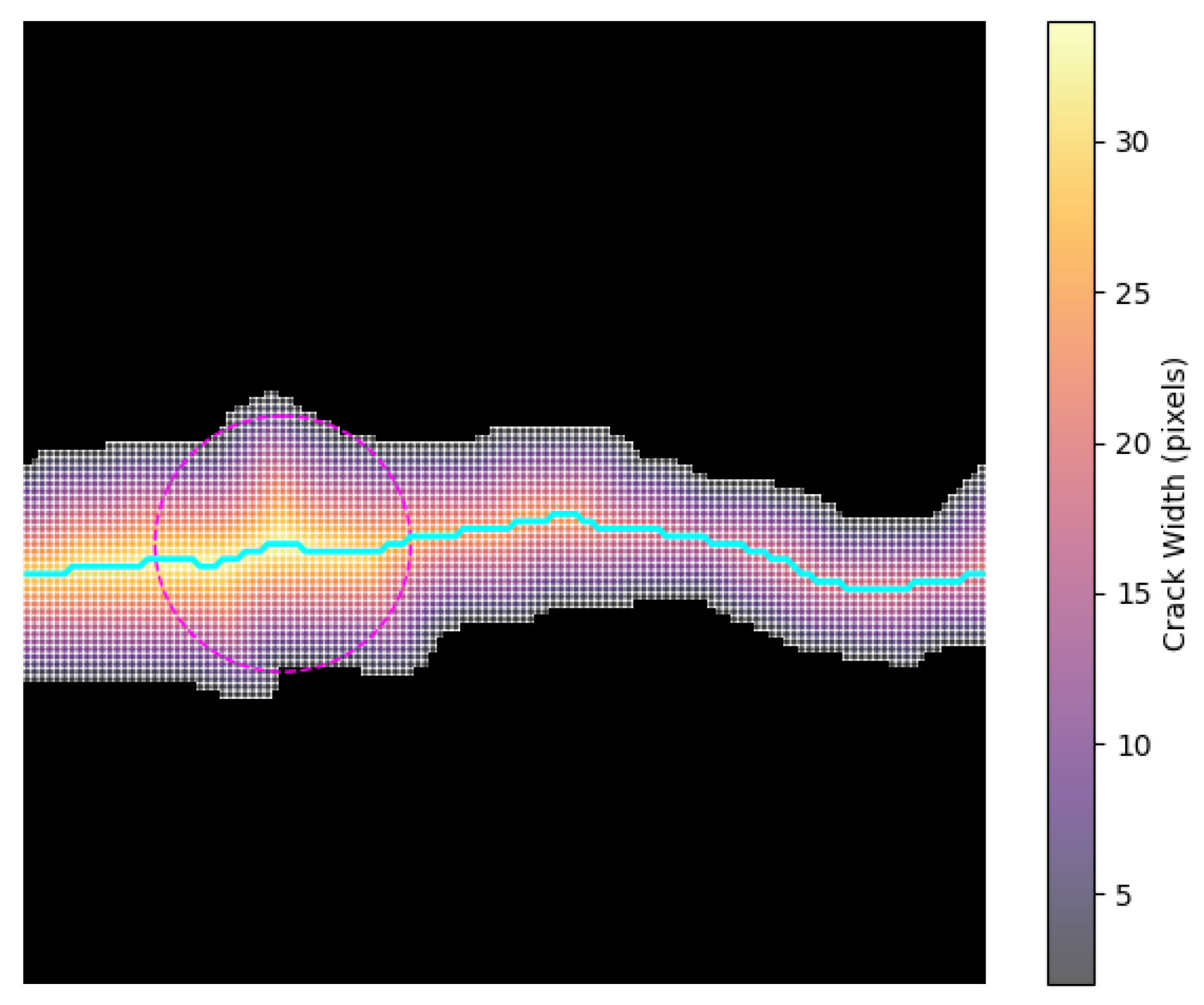
This section summarizes the width error statistics of ten different crack segmentation models across four distinct regions. The evaluation was conducted using the InfraCrack dataset and the open-source dataset Deepcrack. As illustrated in
Figure 7, the dataset was partitioned based on the characteristics and mechanical mechanisms of cracks in different regions as follows:
Wall Center (32% of the dataset): Dominated by uniform thermal stress, cracks primarily exhibit horizontal distribution. Models can enhance their width prediction accuracy for horizontal cracks by learning the single stress pattern.
Corner Edges (28%): Foundation differential settlement results in 45° inclined cracks. The dataset optimizes models’ perception of asymmetric crack propagation by annotating settlement gradients (>0.3%) and shear stress directions.
Oblique Intersections (25%): Structural stiffness mutations lead to mesh-like cracks. Pixel-level annotations of multi-directional stress fields enable models to effectively identify crack intersection nodes, mitigating the accumulation of width estimation errors.
Wall and Column Surfaces (15%): Annotations of morphology–force correlations under concentrated loads help models distinguish between structural and material-induced cracks, reducing width deviations caused by misjudgments.
As illustrated in
Figure 8, this comprehensive dataset design ensures a robust evaluation of models across diverse crack scenarios, capturing the interplay between mechanical mechanisms and crack morphology.
In the task of vertical crack detection on walls and columns, traditional models such as UNet and DeepLabv3+ exhibit notable limitations in complex regions like corner edges and oblique intersections due to their fixed receptive fields and static feature fusion mechanisms. Their interquartile ranges (IQRs) reach – and –, respectively, with extreme outliers (>1.85%), revealing the inherent shortcomings of conventional CNN architectures in modeling the force–morphology correlation of vertical cracks under concentrated loads.
In contrast, multi-scale models like HRNet () and PSPNet () achieve reduced errors in regular regions through pyramid pooling or high-resolution feature preservation. However, they still suffer from directional sensitivity defects at mesh crack intersections, as evidenced by HRNet’s IQR of – for 45° inclined cracks. Notably, FFEDN (), despite incorporating frequency-domain feature enhancement, shows insufficient robustness to asymmetric expansion noise in oblique cracks, resulting in significant error fluctuations (outliers >0.70%).
The generative framework proposed in this study (Ours) demonstrates remarkable advantages across various complex scenarios through physics-driven iterative optimization. Specifically, for vertical cracks in concentrated load areas, the integration of load gradient priors into the diffusion model reduces the median error to (IQR –). For mesh crack intersections, the progressive generation strategy achieves pixel-level attribution separation, reducing width calculation overlap errors by compared to the suboptimal model CT-crackseg (). For 45° inclined cracks caused by foundation settlement, the morphology–stress-coupled denoising path design maintains a stable error of under uneven lighting and carbonation diffusion interference, while Segformer () exhibits numerous outliers (>0.75%) due to its self-attention mechanism’s inadequacy in capturing local details.
Particularly, MST-Net () and W-segnet (), despite optimizing global feature consistency through multi-stage training, still experience expanded IQR ranges (– and –, respectively) in load mutation regions due to their static weight allocation mechanisms, highlighting the engineering applicability advantages of our framework’s dynamic iterative optimization.
5. Conclusions
This paper proposes a novel semantic diffusion model for crack segmentation, systematically addressing the limitations of traditional methods in detecting cracks under low-contrast, fine-structured, and noisy conditions. Through progressive feature refinement via the diffusion process, the model achieves superior segmentation accuracy compared to existing semantic synthesis models across multiple benchmark datasets, while demonstrating enhanced noise robustness. The model exhibits dual capabilities of generating synthetic crack images from segmentation masks and enhancing real-world detection, effectively resolving texture interference issues in complex backgrounds.
Furthermore, we introduce an innovative crack width calculation method based on medial axis transformation, which significantly improves measurement stability compared to conventional techniques. This approach is specifically optimized for irregular crack morphologies, providing more reliable quantitative assessment for engineering applications.
These innovations not only improve the overall performance of crack segmentation but also establish a systematic solution that bridges the gap between computer vision technology and practical engineering needs. Future research will focus on extending this framework to handle temporal evolution of crack patterns and optimizing computational efficiency through model refinement techniques, aiming to address more complex real-world application scenarios.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}