
Evaluation of Machine Learning and Web-Based Process for Damage Score Estimation of Existing Buildings





Abstract
:1. Introduction
2. Background of the Study
2.1. Rapid Visual Screening
2.2. Machine Learning in Seismic Vulnerability Assessment
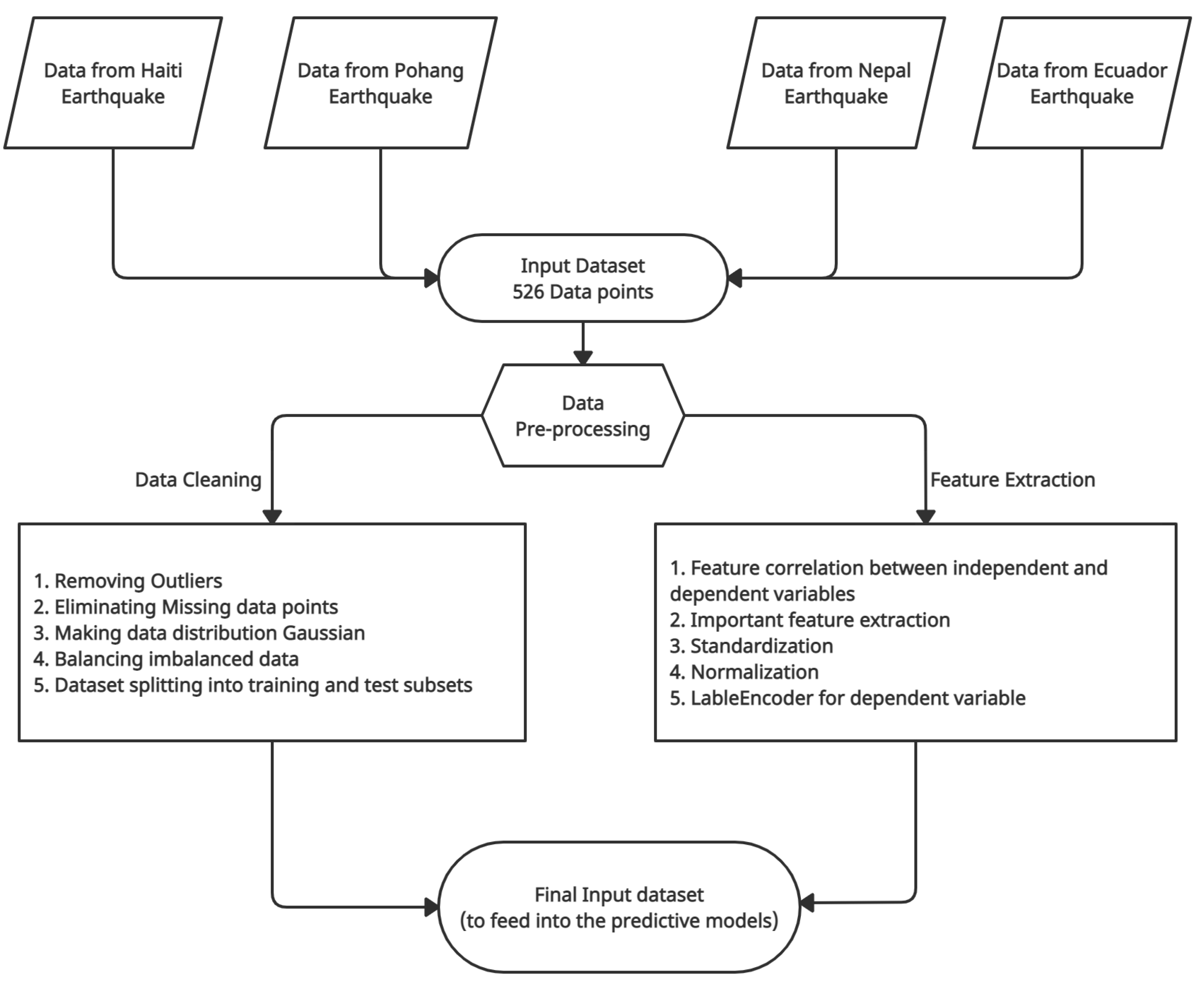
3. Data and Methodology
3.1. Input Data Source
3.2. Data Preprocessing
3.2.1. Data Preparation
- Outlier detection—An outlier is a data point that is unlike the other data points. They are rare, discrete, or do not belong in some way. There is no definite technique to distinguish and recognize outliers as usual because of the specifics of each dataset. However, a domain expert can interpret the raw observations and verify if any given data are outliers or not. Identifying outliers can be tricky even after a thorough comprehension of the data. Proper attention should be taken not to eliminate or replace values rashly, specifically when the sample size is small [58].The input dataset for the study is medium size, so detecting the outliers on the basis of extreme value analysis was possible. There were few data points which were not in the range and distribution of attribute values. Those data points were eliminated to avoid creating any unforeseen circumstance to control the predicting model inaccurately.
- Missing data elimination—Major ML algorithms utilize numeric-type input data values arranged in rows and columns in a given dataset. Missing values in a dataset can create problems for the algorithms to function optimally. Therefore, it is a common practice to identify the missing values and substitute them with a corresponding numerical value. The method is known as missing data imputation or data imputing.A known approach for data imputation is replacing all missing values for that column with the respective column’s mean or median value. - library provides a with a mean or median strategy for missing value elimination. The input dataset for this study is moderately tiny with only 526 values; however, there were 3 NaN (Not a Number) data points raising errors while processing the algorithms. Therefore, using the conventional strategy, those NaN were replaced by the mean value of their respective columns.
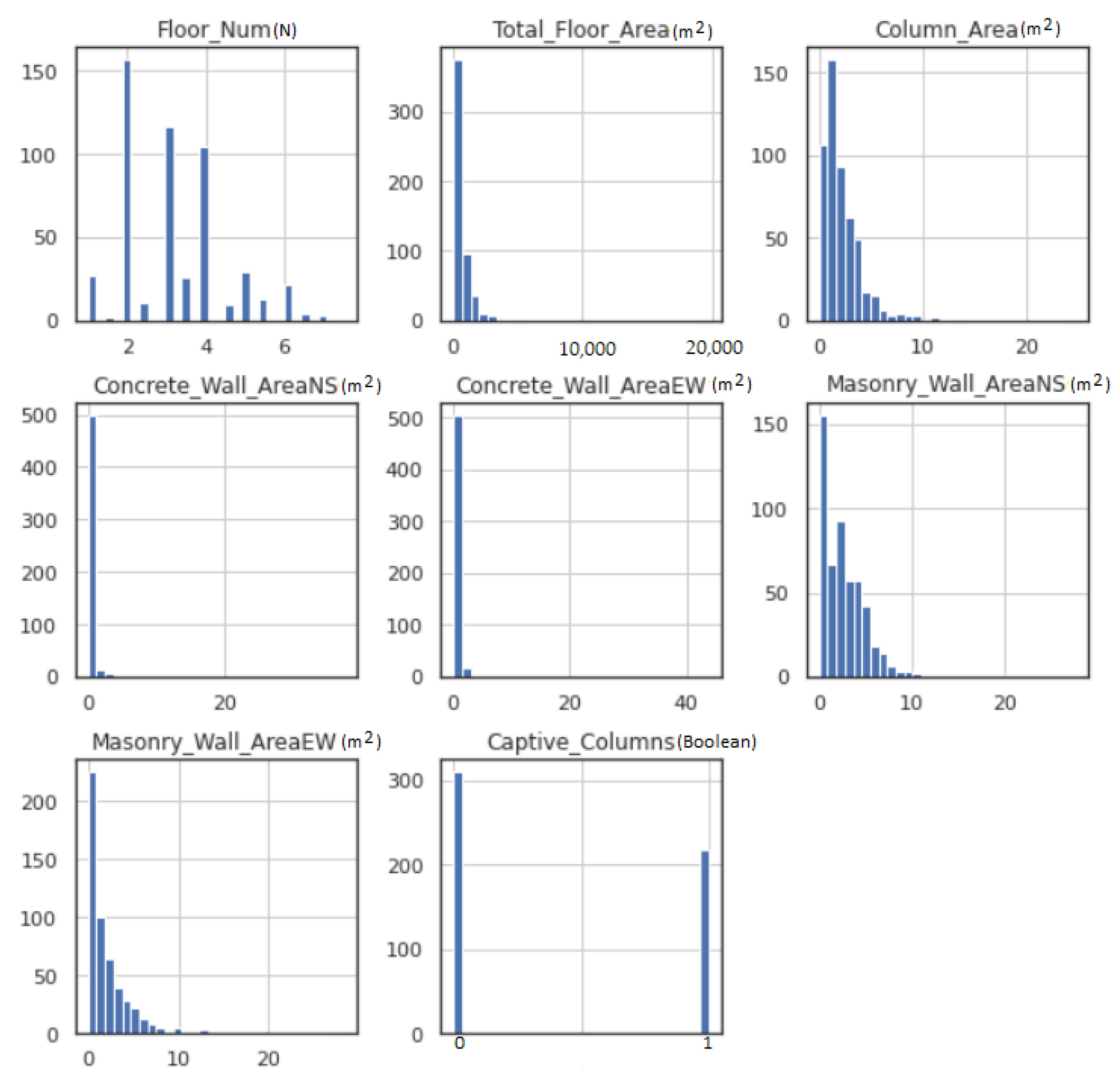
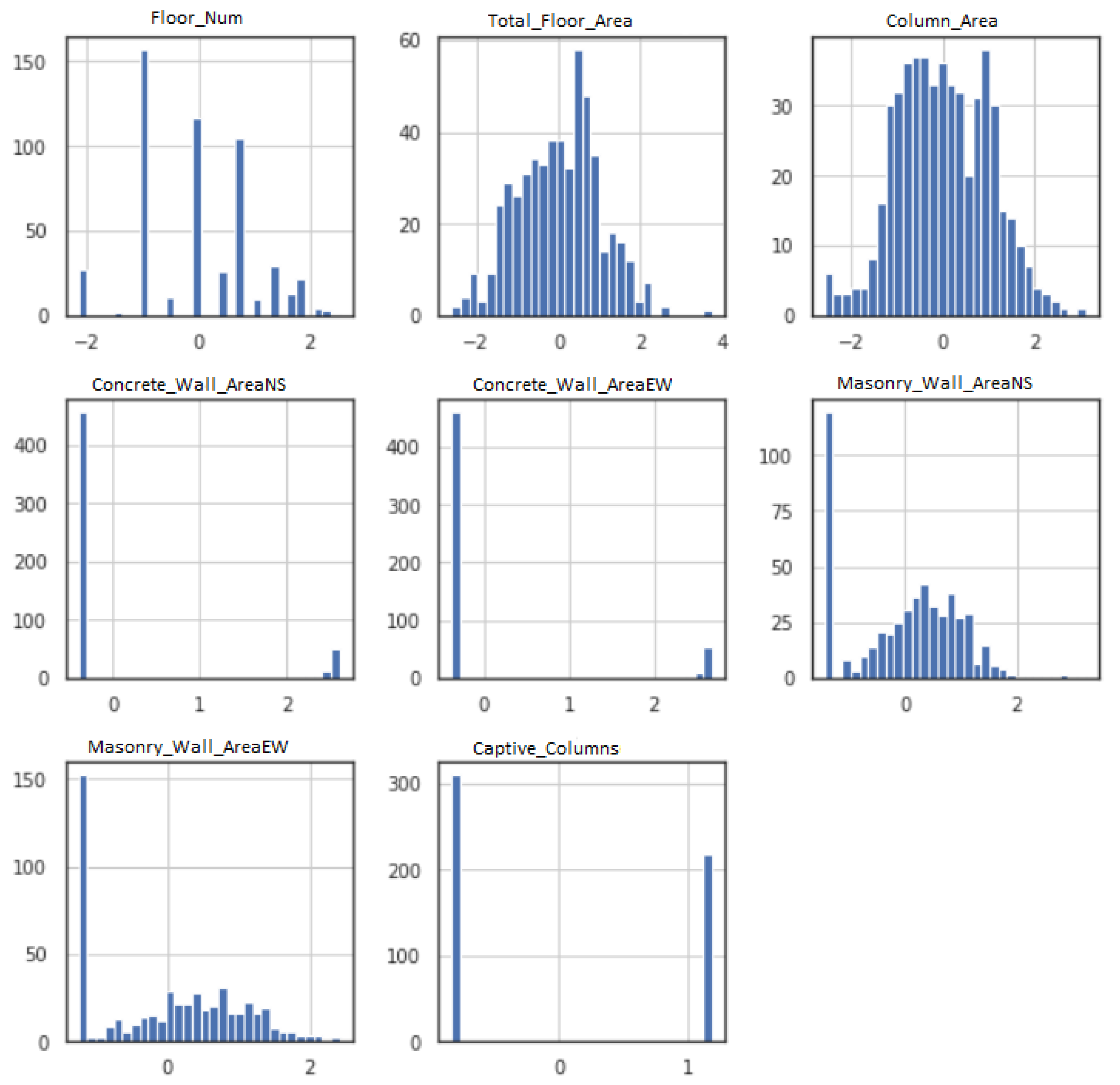
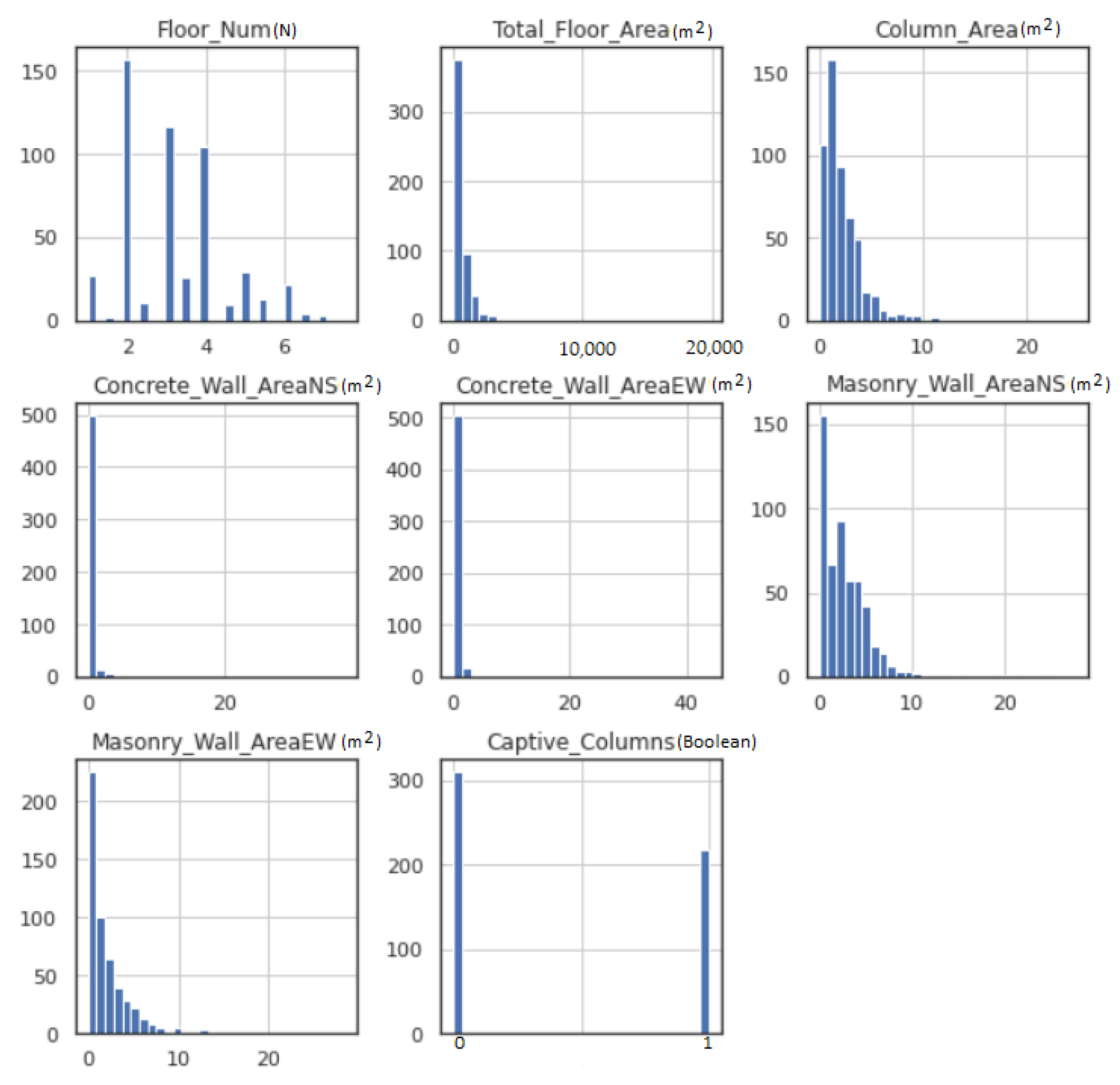
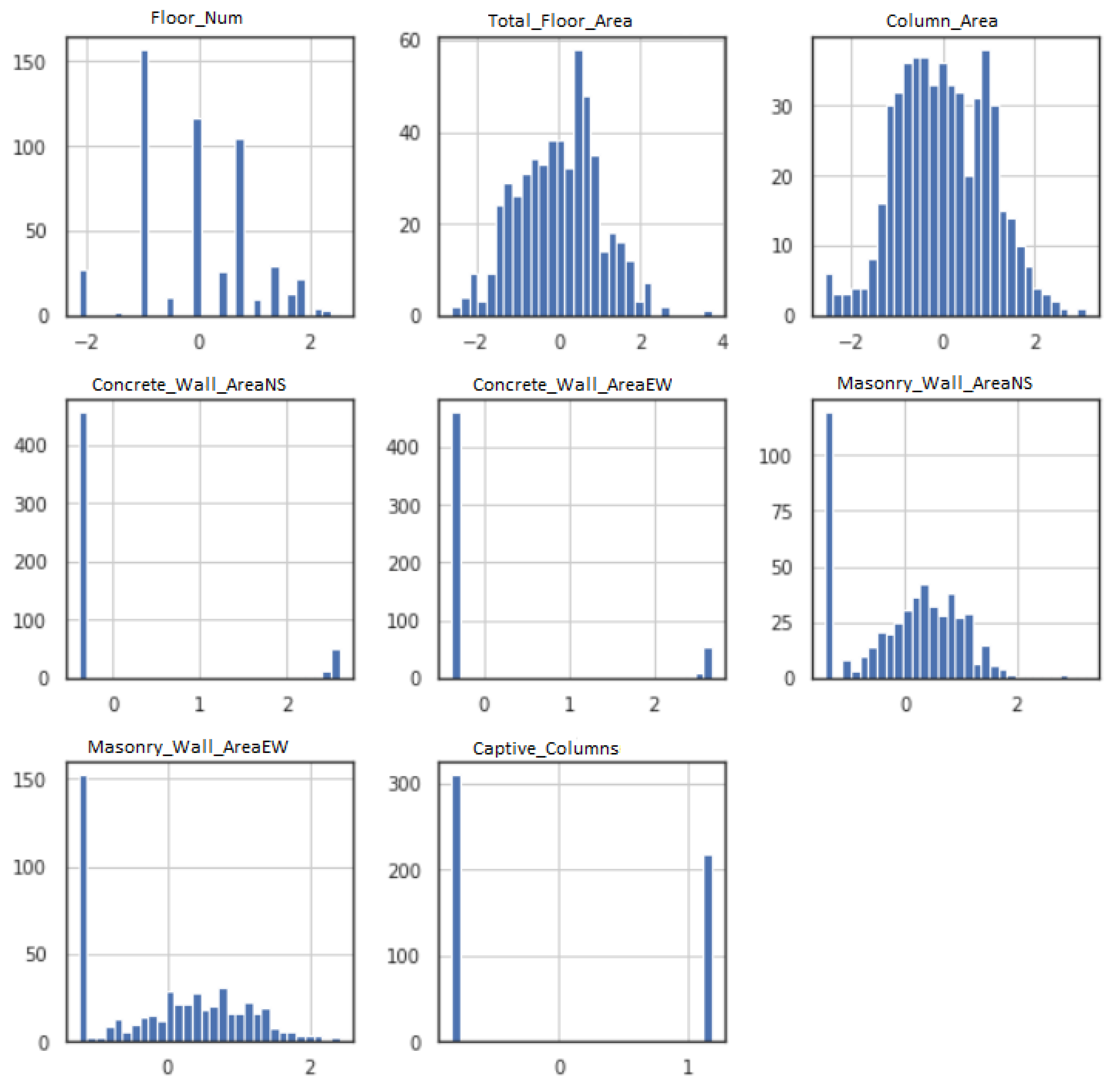
- Gaussian data—ML models function better when the data have Gaussian distribution. The Gaussian is a standard distribution with the familiar bell shape. Data fitting techniques can modify each variable to make the distribution Gaussian, or if not Gaussian, then more Gaussian-like. These transforms are most efficient when the data population is nearly Gaussian, to begin with, and is skewed or affected by outliers. Figure 2 shows the histogram for each feature input variable. Floor number has Gaussian-like distribution of the data points, whereas most of the features are skewed toward the left. The captive column obtained a binomial value (0 or 1); therefore, the data distribution is discrete.Figure 3 illustrates the data distribution for each feature input after employing Power-Transformer class from - library. Total floor area and column area show a better Gaussian bell shape, whereas masonry wall area NS and masonry wall area EW have some skewness on the left side. Due to very few non-zero data points, the area of concrete wall area NS and concrete wall area EW did not show any significant improvement.
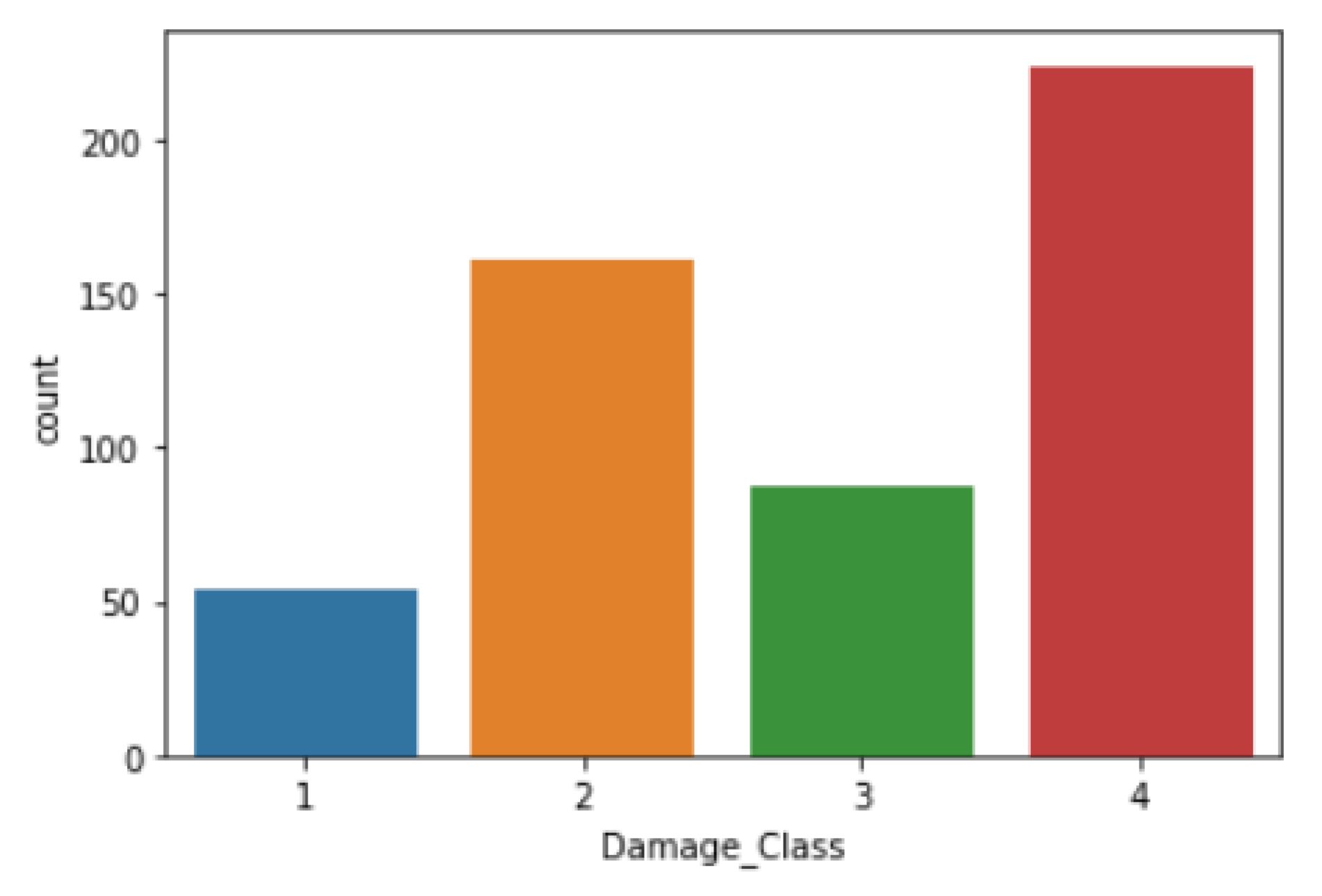
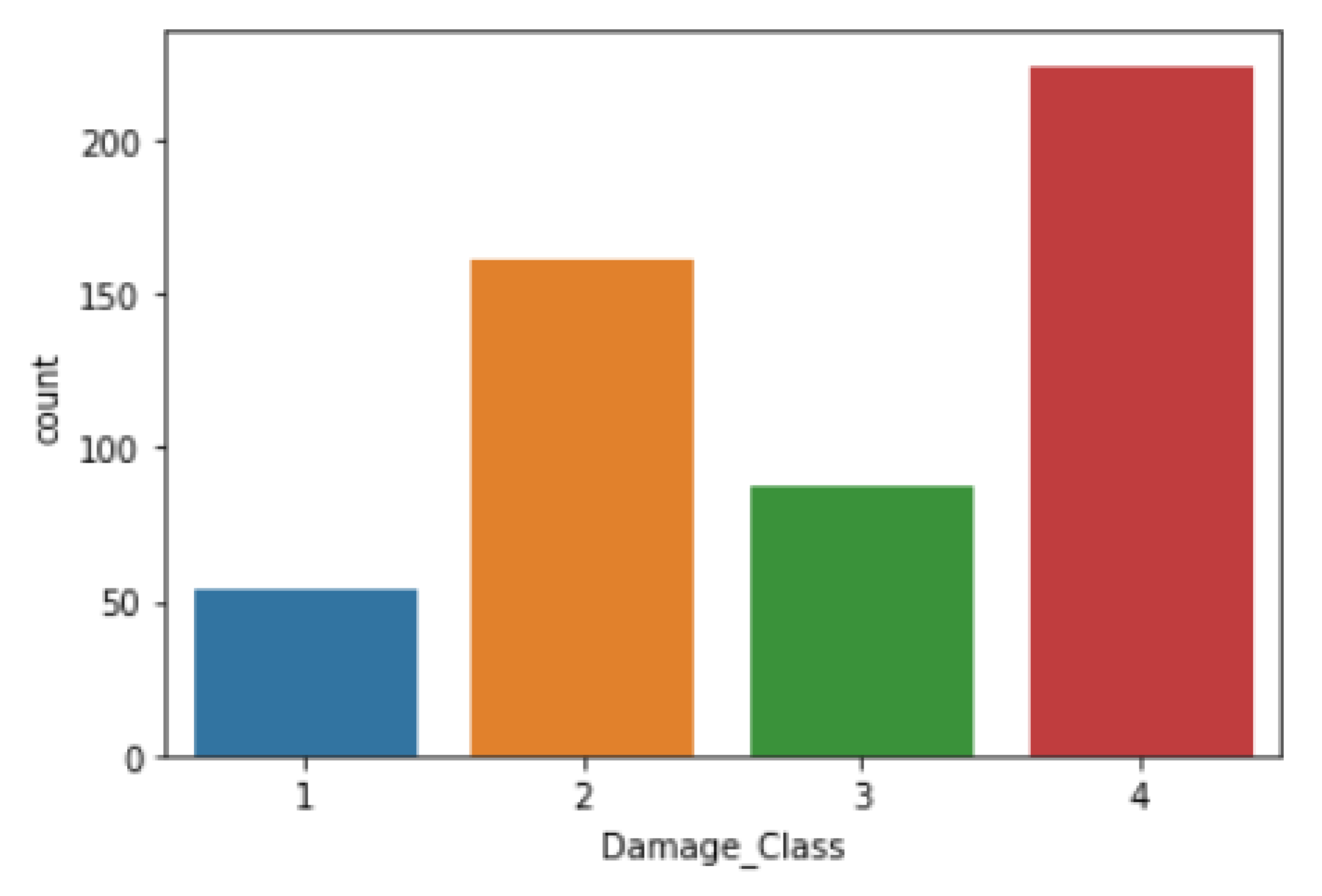
- Imbalanced Data—An imbalance in data distribution for each input feature creates objections for predictive modeling. In real-world cases, the dataset contains irregular data sharing several times, affecting the model prediction’s performance. Figure 4 depicts that the input dataset contains an asymmetric distribution of feature data which resulted in imbalanced data in each output class. For example, damage class 4 has the highest number of samples, whereas damage class 1 has the least. This kind of data distribution prevents the model from performing optimally. Synthetic Minority Oversampling Technique (SMOTE) [59] generates synthetic data for the minority class, therefore producing symmetry for majority of classes. Table 3 illustrates that, using SMOTE, the imbalanced state of data distribution in the target variable is balanced.
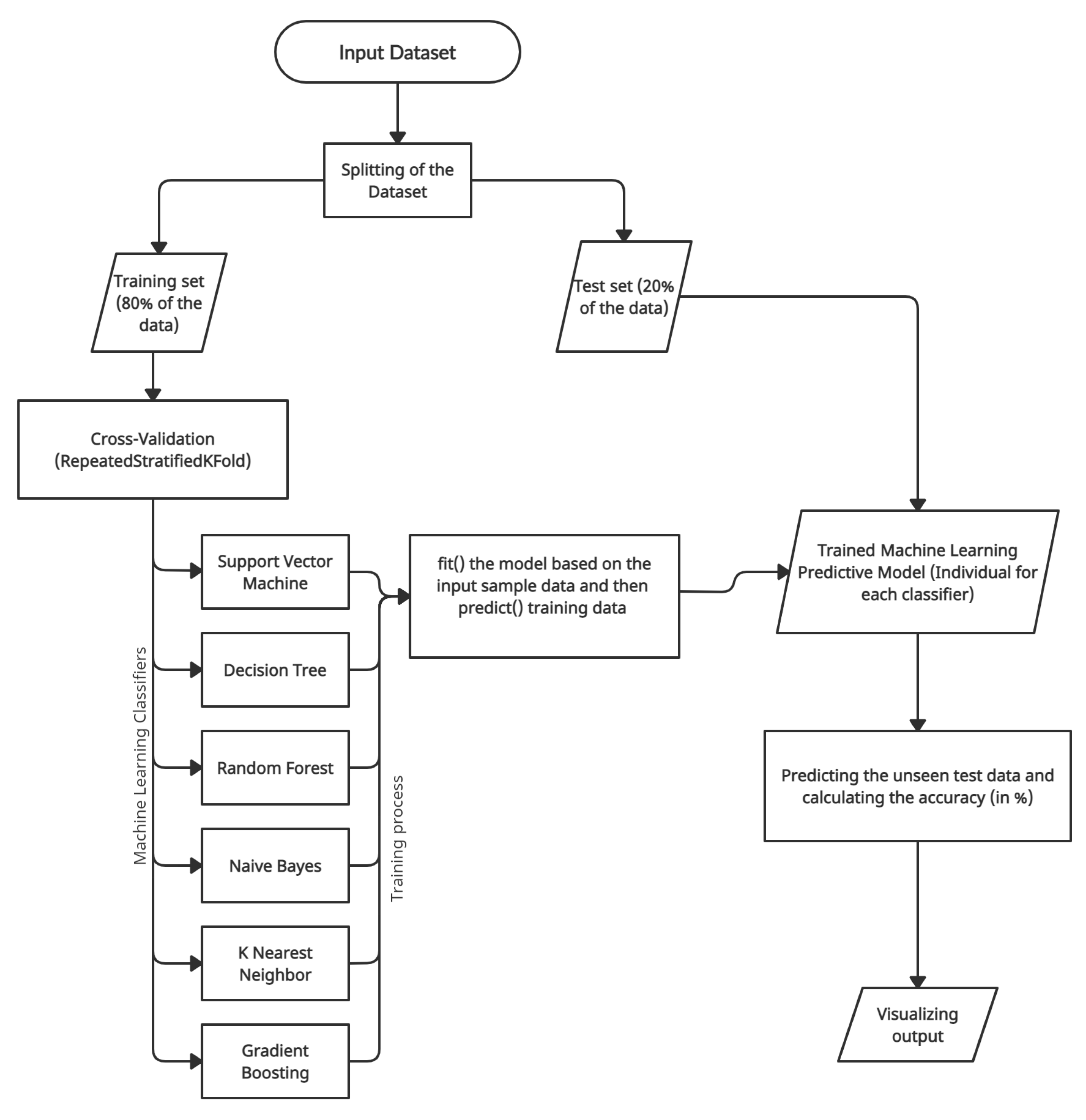
- Dataset splitting—The suitable approach for performing data preparation with a train–test split evaluation is to fit the data preparation on the training set, then apply the transform to the train and test sets. Therefore, the input dataset was split into (80–20%) into the training set and testing set using function -- from - module in -.
- Cross-Validation—As a good practice, ML models should evaluate the dataset using k-fold cross-validation, particularly in small to medium-sized datasets. Cross-validation aims to examine the model’s worth to predict unseen data, check issues such as model overfitting, or biasedness to give an insight into the model behavior against an independent dataset. The study implemented repeated stratified 10-fold cross-validation using the function RepeatedStratifiedKFold from module ensemble in -.
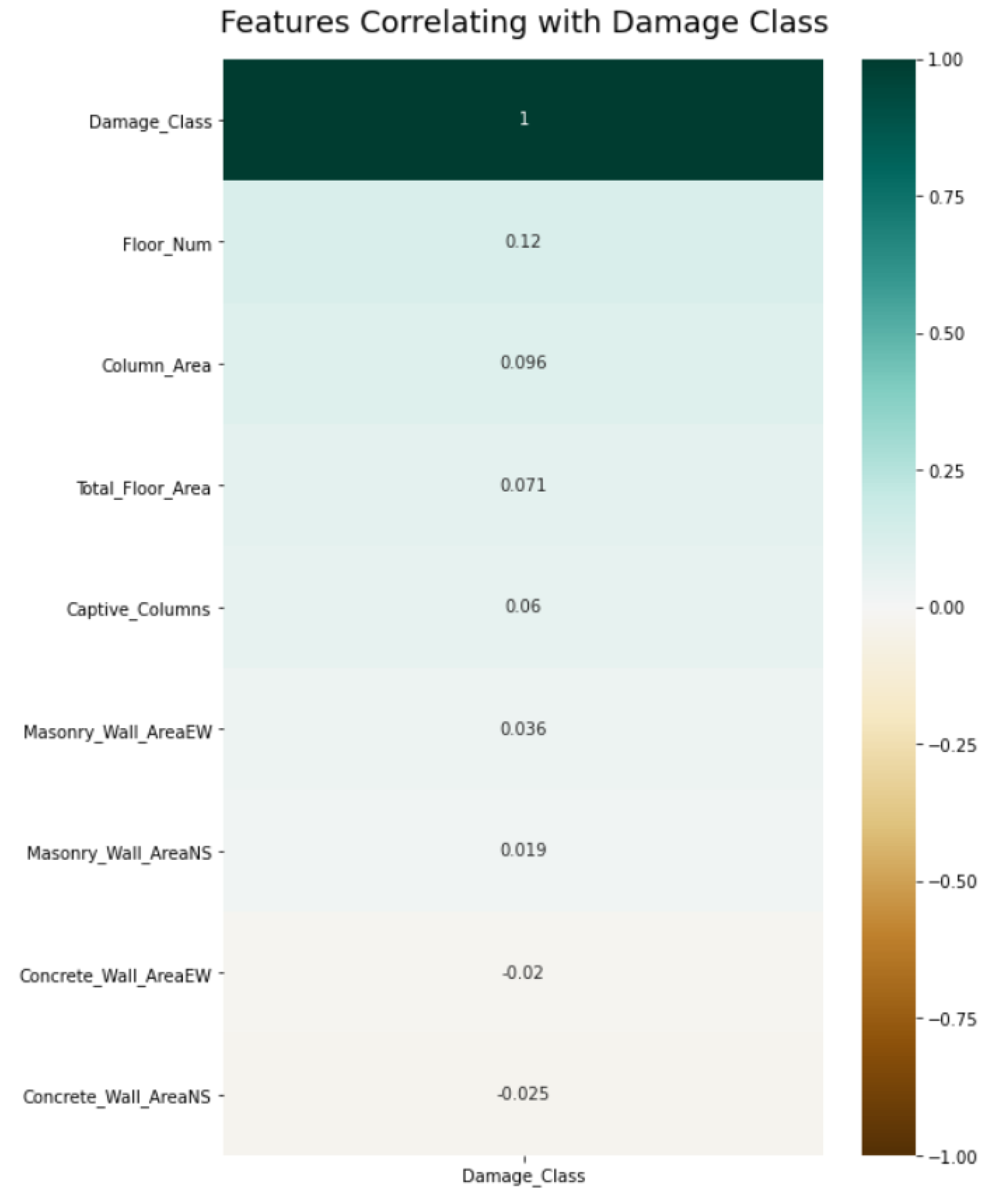
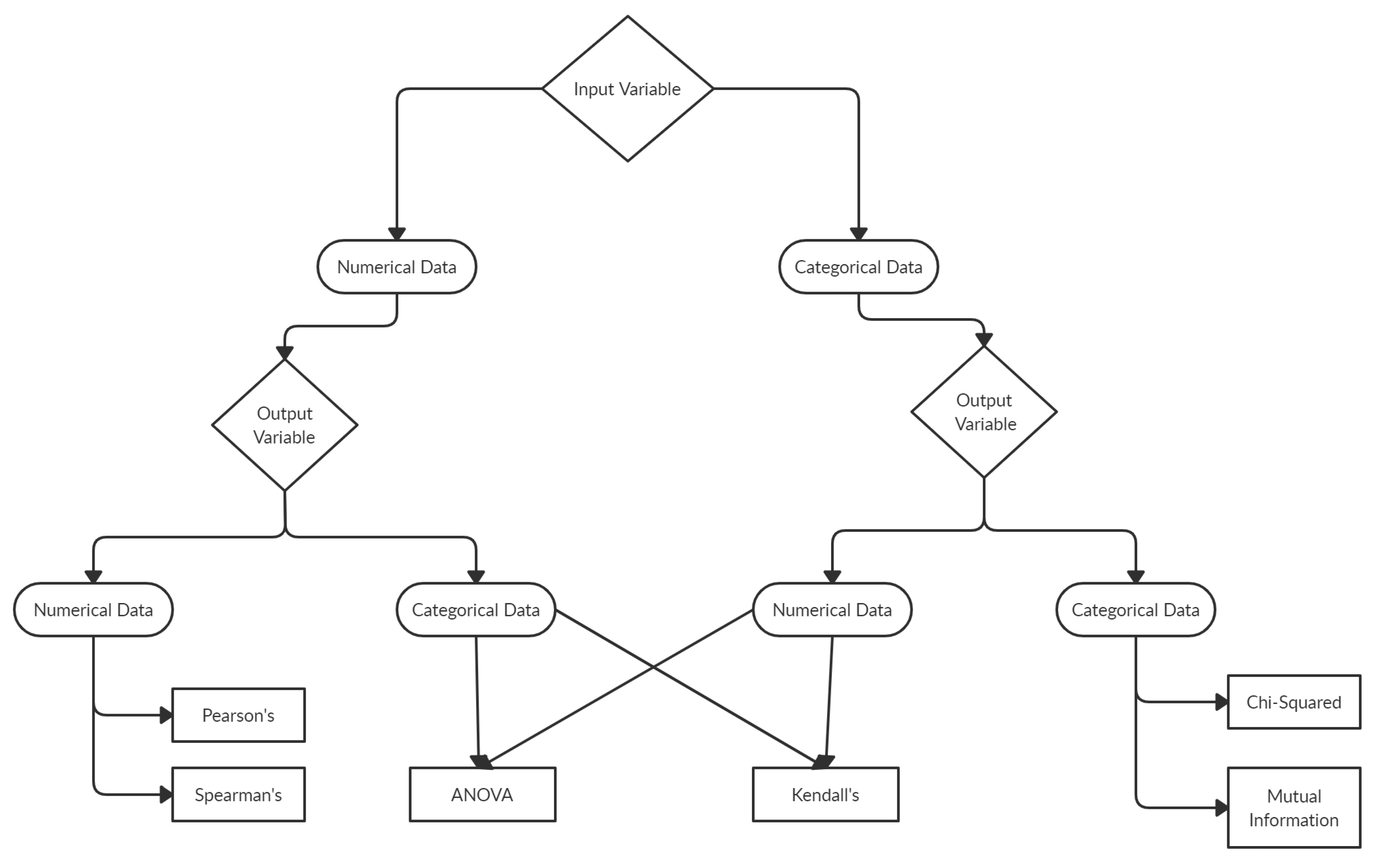
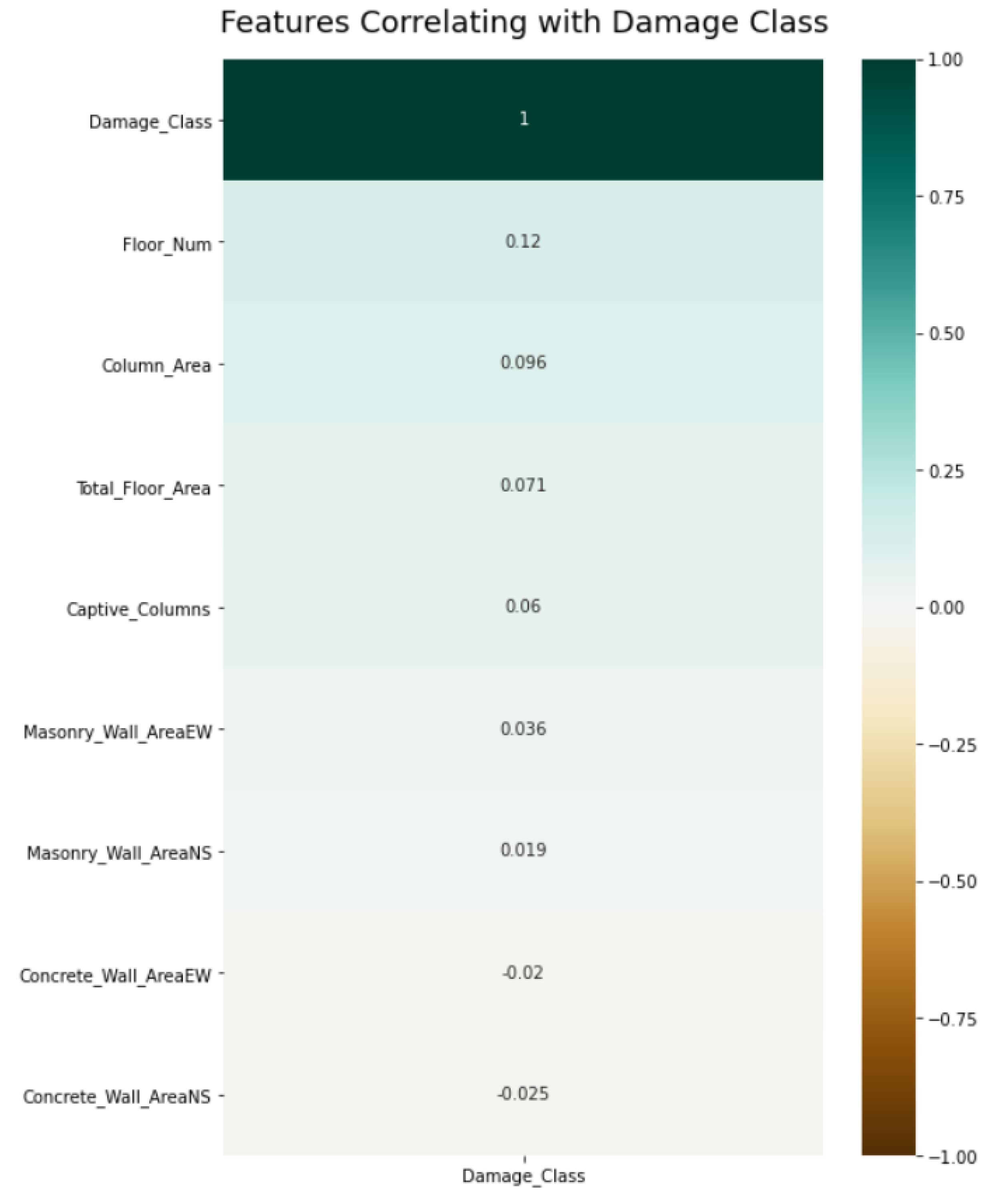
3.2.2. Feature Selection
3.2.3. Data Transformation
- Standardization—Standardization of a dataset includes re-scaling the spread of values such that the mean of observed values is 0 and the standard deviation is 1. The method is offered by a function called available in the module of - library. Deducing the mean value from the given data is known as centering, and dividing the data by the standard deviation is known as scaling. The method is also referred to as center-scaling.
- Normalization—Data points in any dataset may scale differently from variable to variable. Often ML predictive models perform better if the variables are scaled in a standard range, for example, in the range between 0 and 1. The scaling of all variables in the range between 0 and 1 is known as Normalization. Class from module in - library normalizes the input variable.
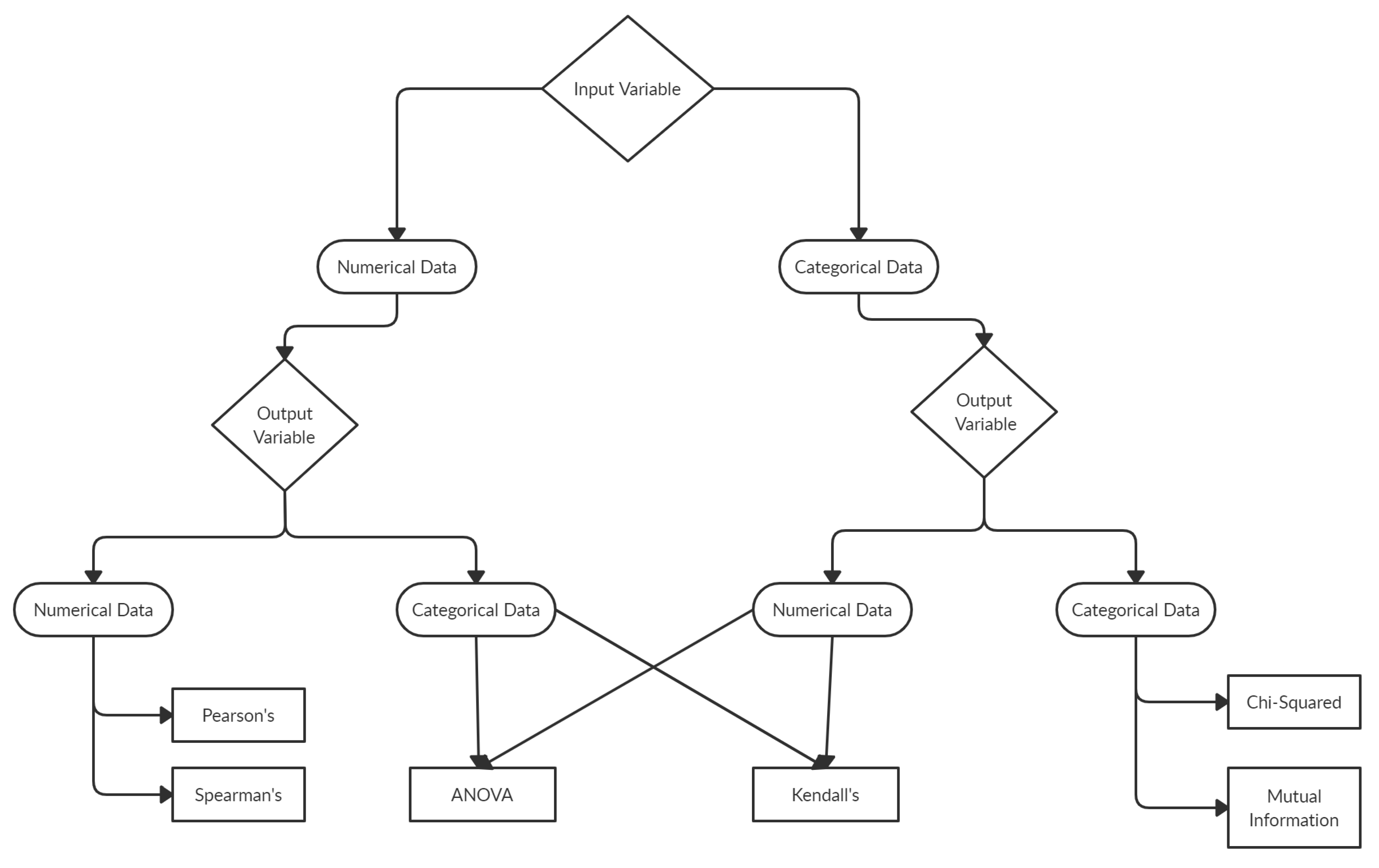
- Label Encoder—ML predictive models assume all the provided input and output variables to be numeric. Numerical data include data points that comprise numbers, such as integer or floating-point values. Categorical data involve label values instead of numerical. Categorical variables are frequently known as nominal. - library also has this requirement which implies that all categorical data must be transformed to numerical values.For the dataset applied in this study, the target variable is in the categorical form: the different damage classes assigned to the earthquake-affected RC buildings. With the one-hot encoding method, the categorical output variable can be changed to an ordinal numerical form. The ordinal encoding transform is available in the - library via the class.
3.3. Predictive Model Building
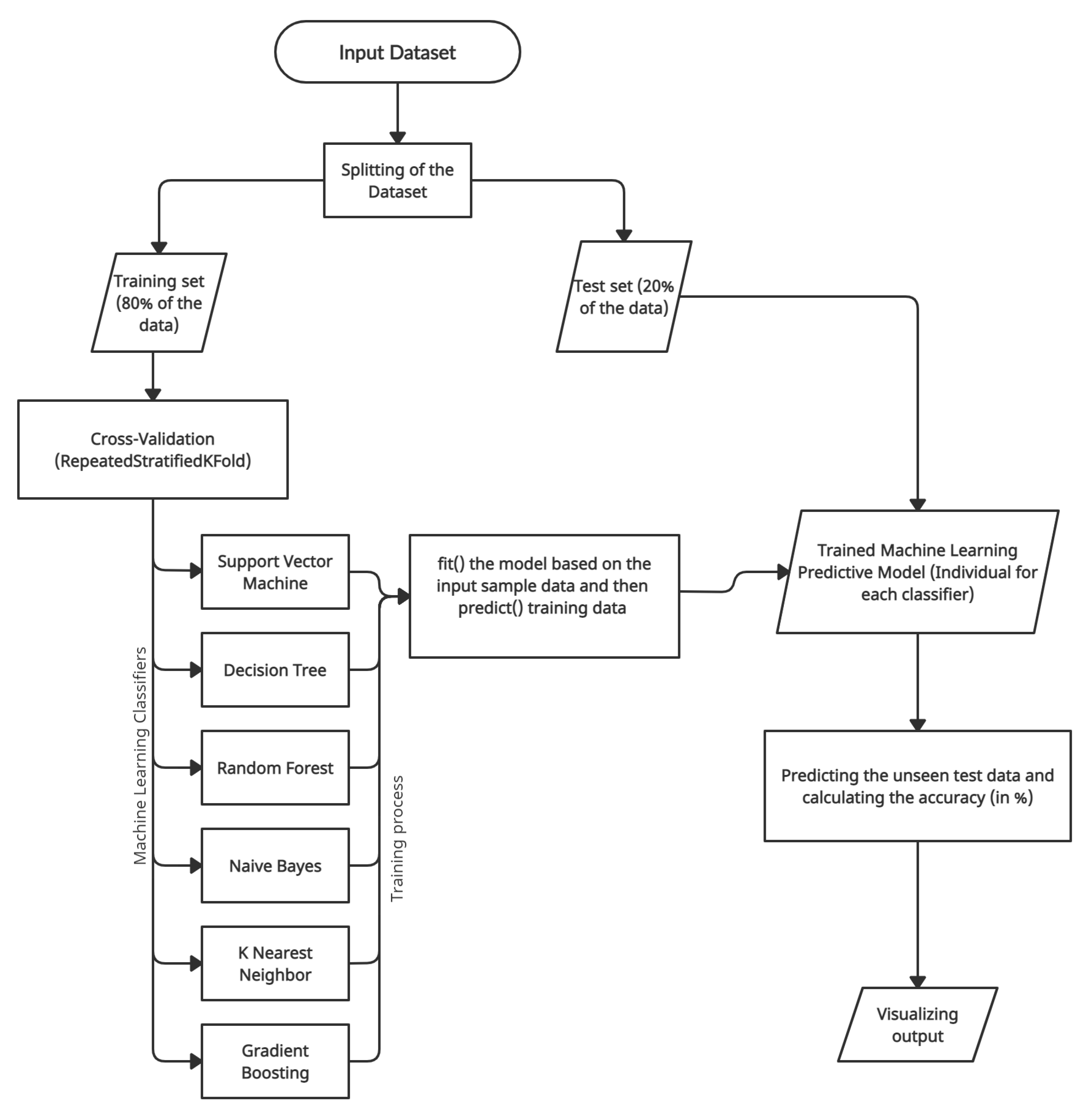
3.3.1. Support Vector Machine
3.3.2. Decision Tree Classifier
3.3.3. Naive Bayes
3.3.4. K-Nearest Neighbor
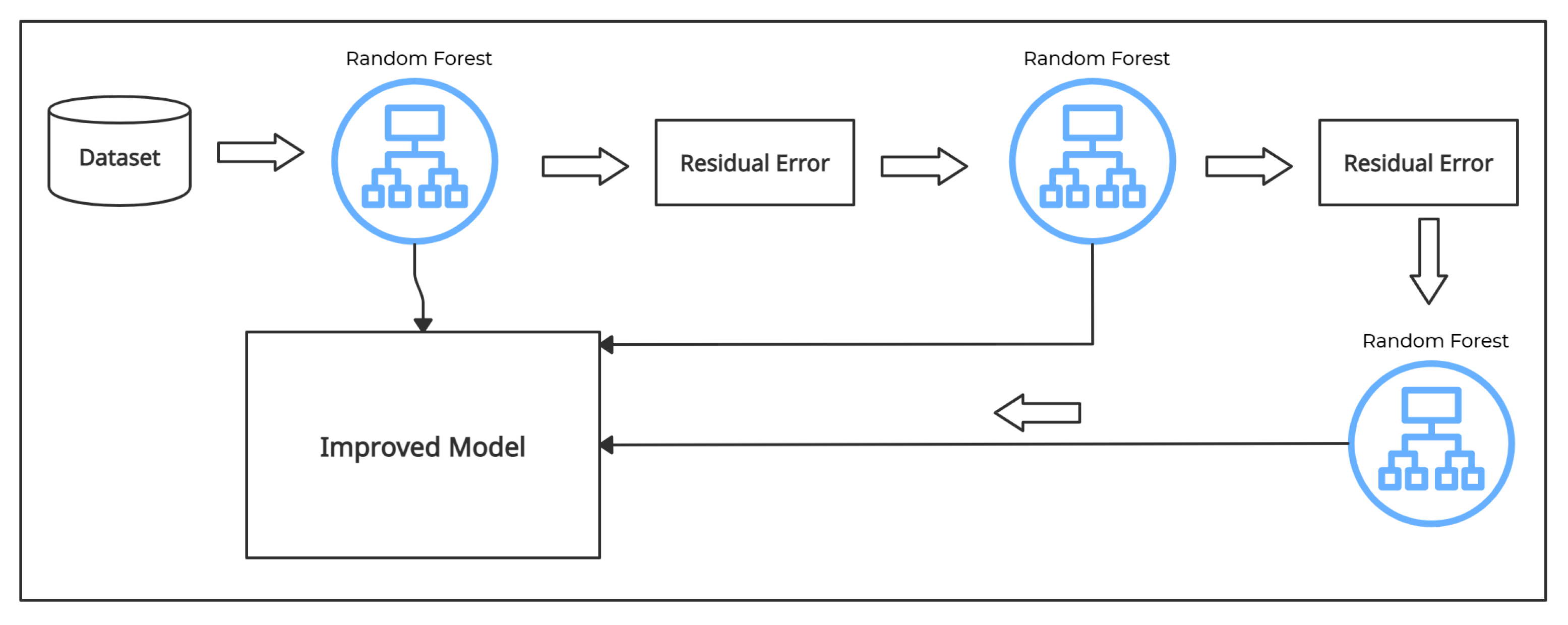
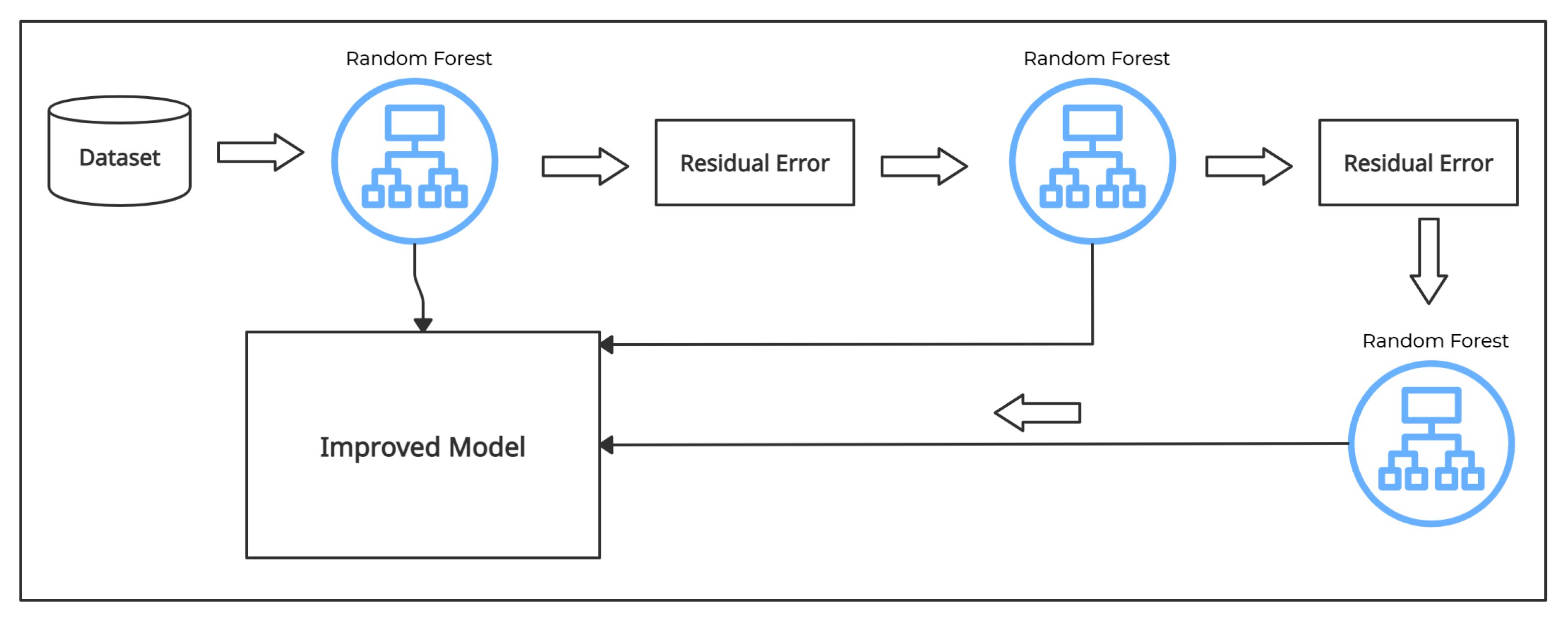
3.3.5. Random Forest
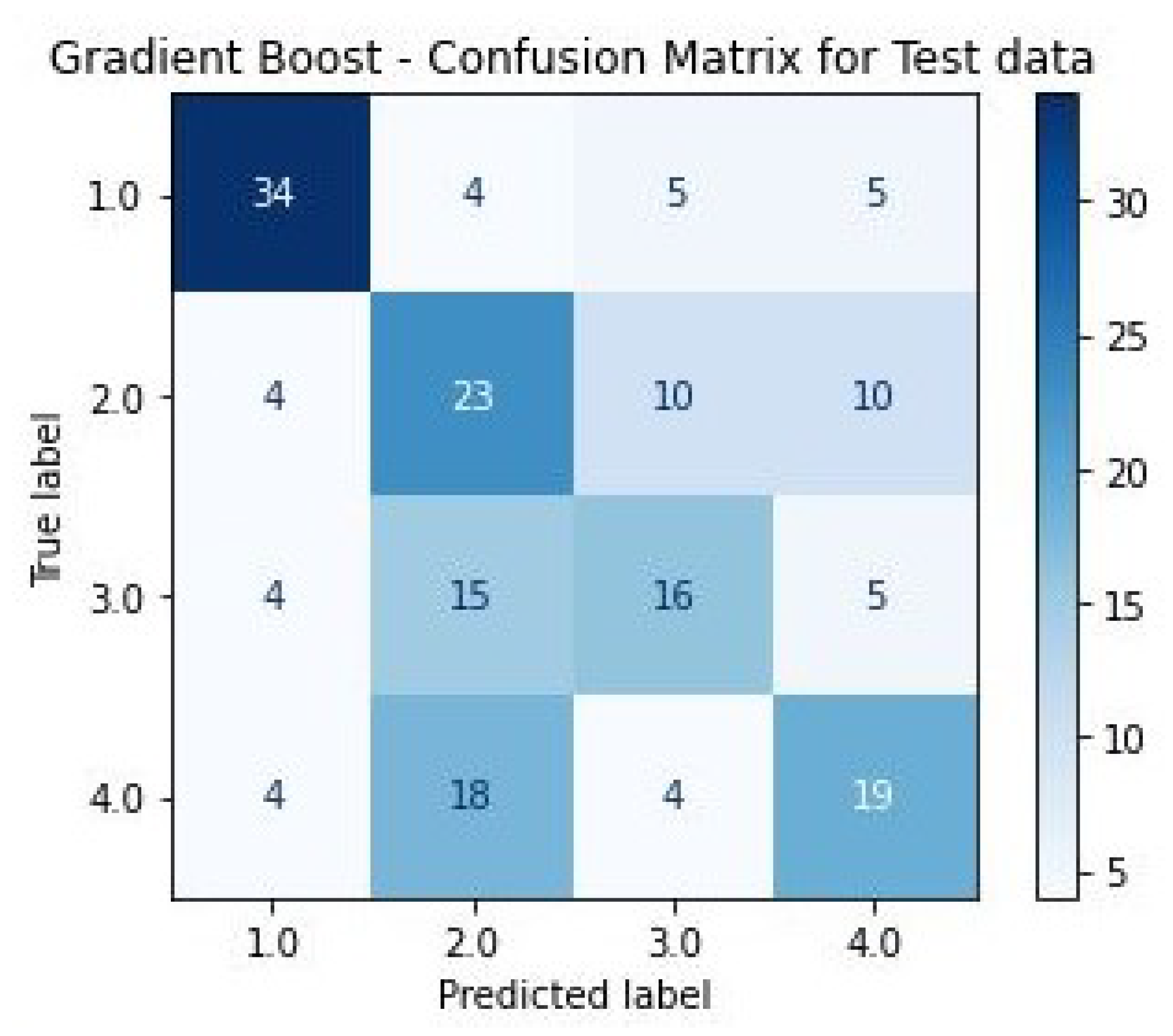
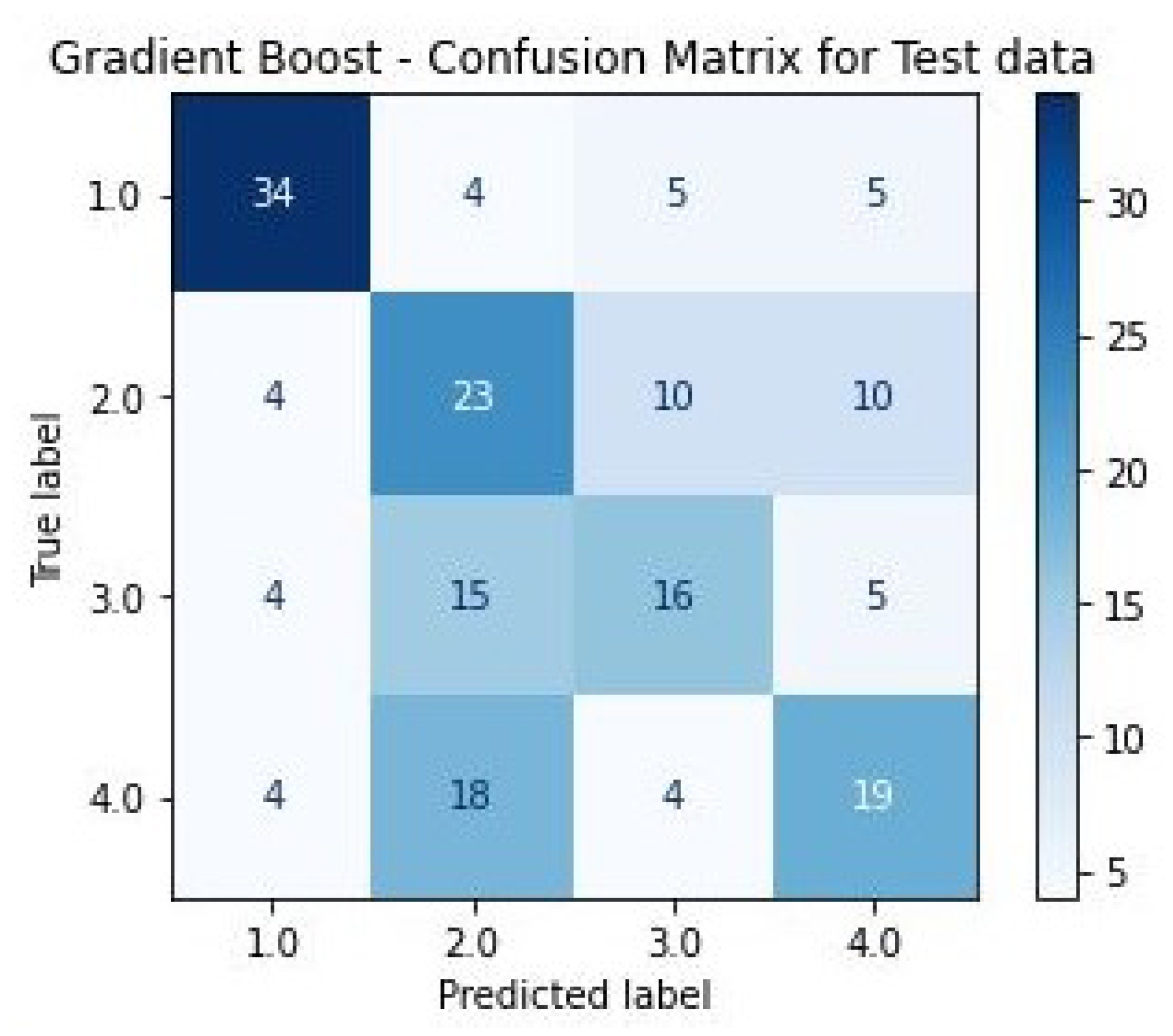
3.3.6. Gradient Boost
3.4. Selection of ML Classifier
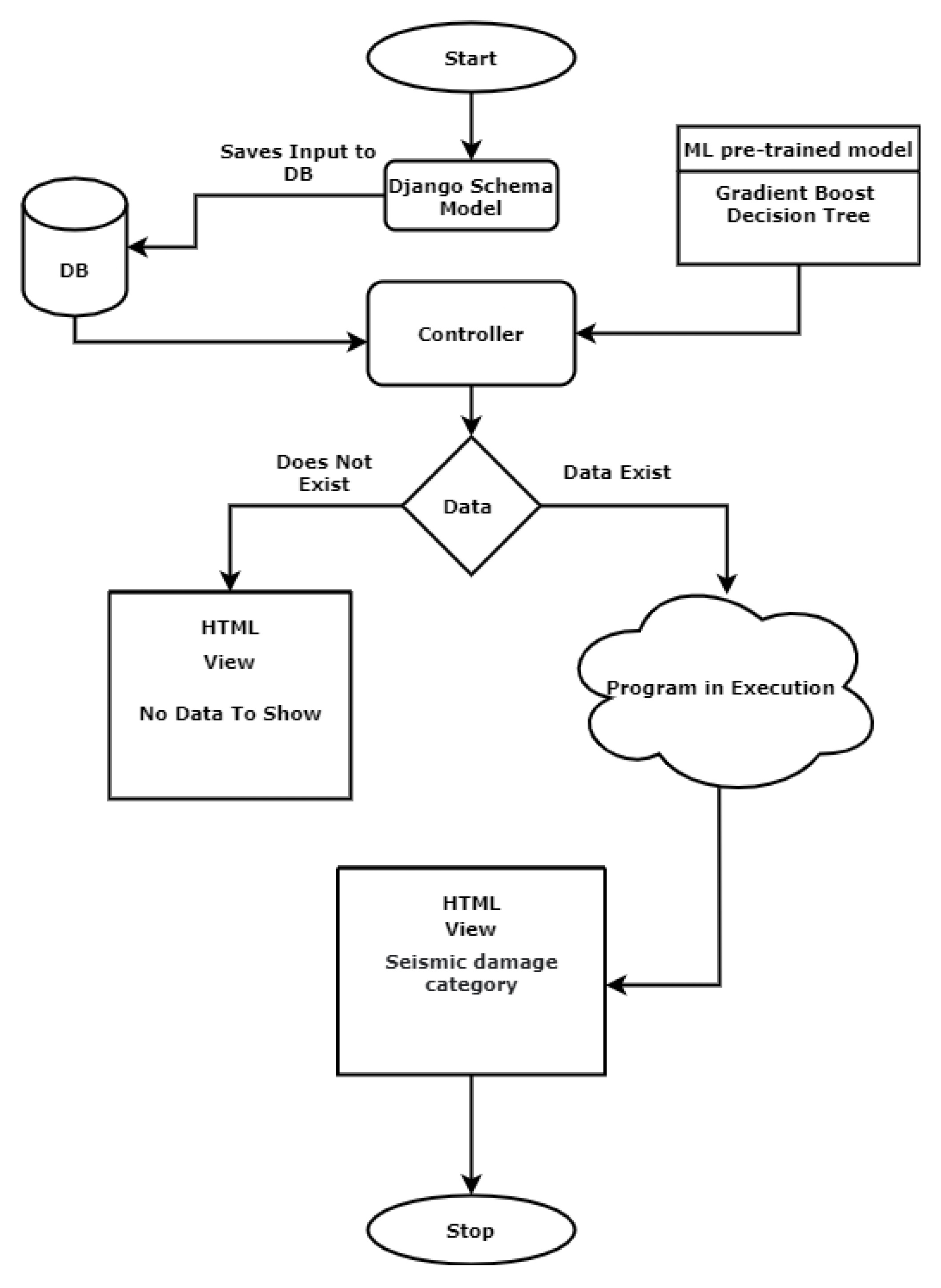
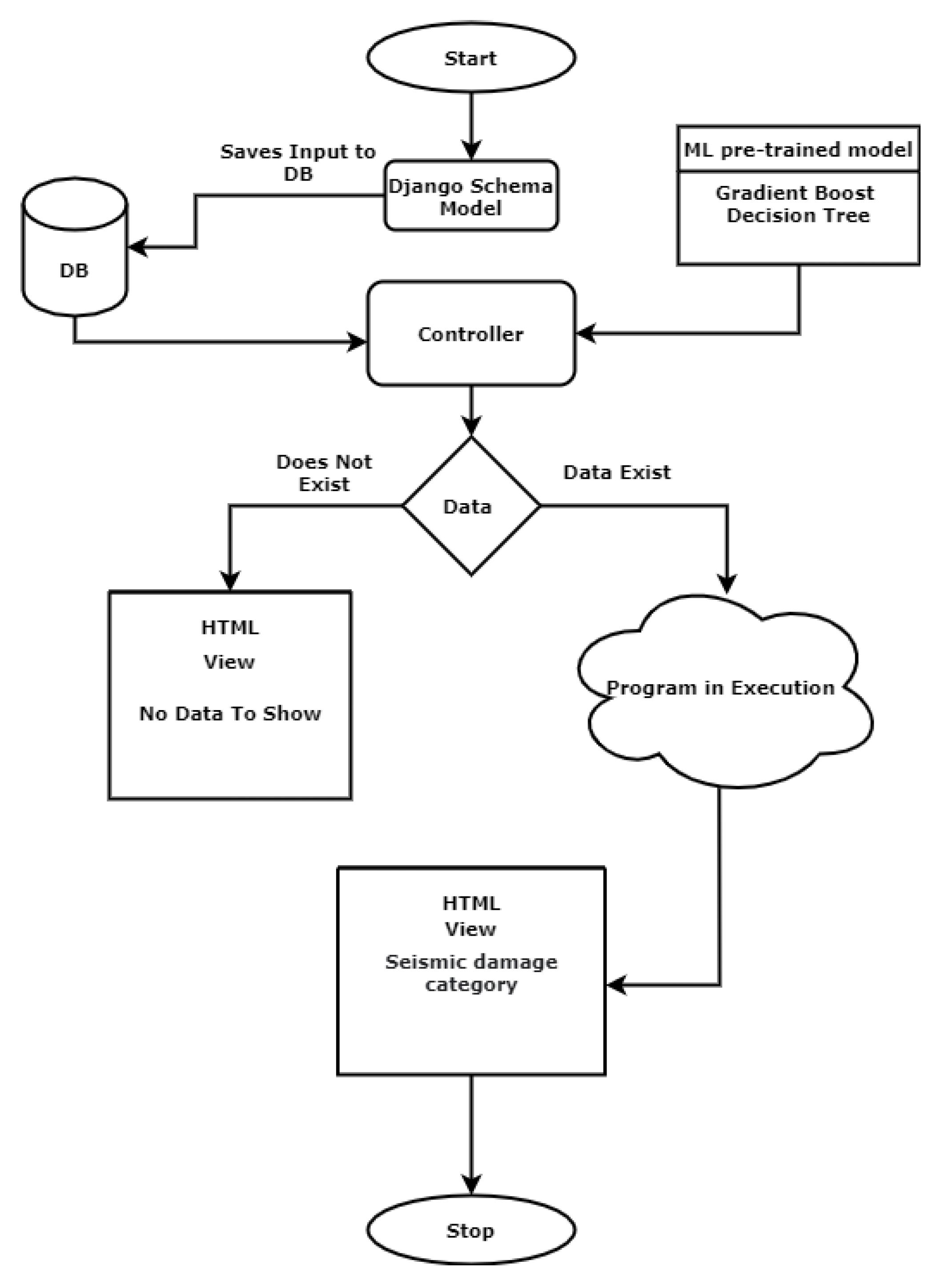
3.5. Web-Development Using ML Model
3.5.1. Design Approach
3.5.2. Project Structure
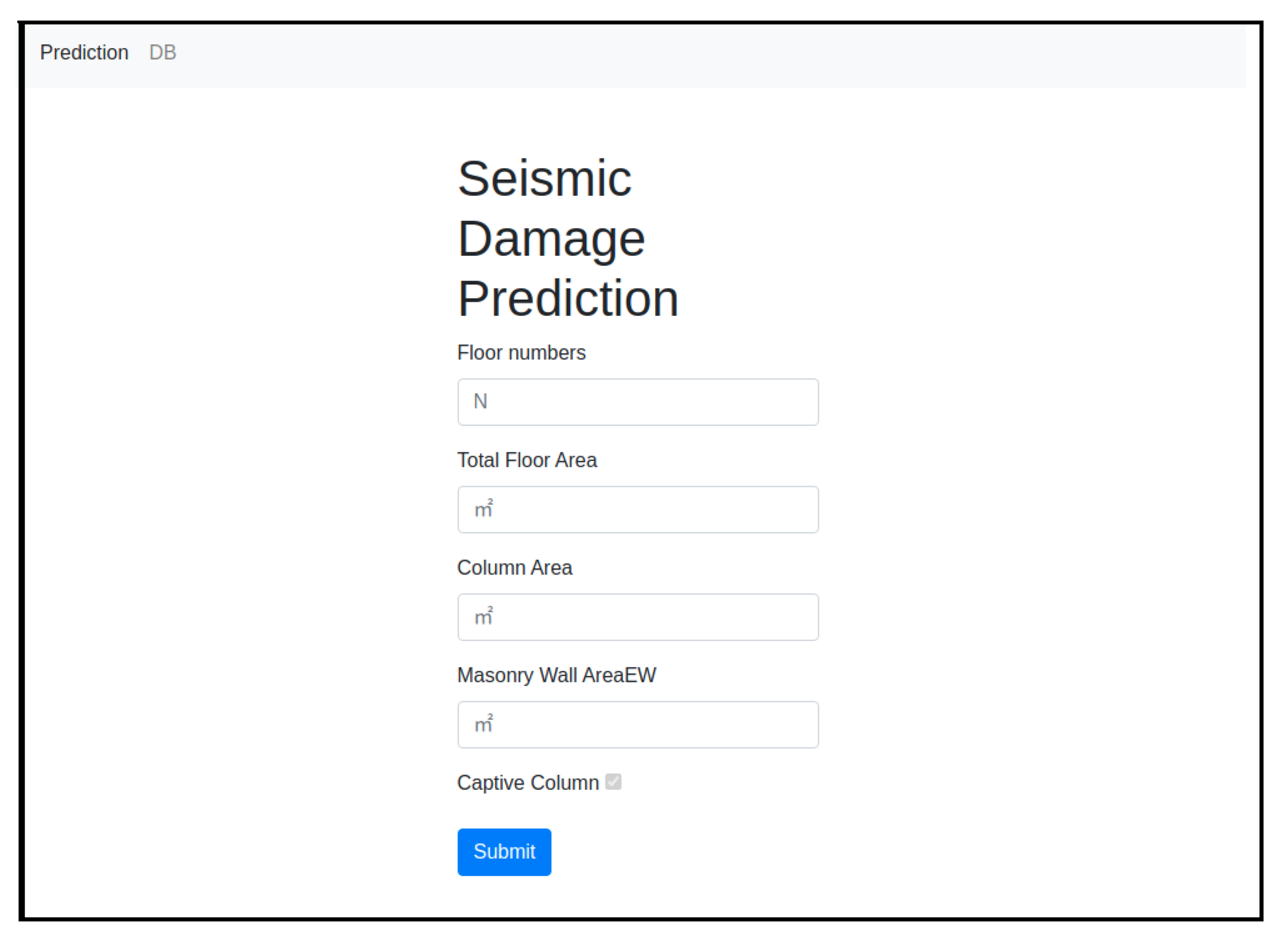
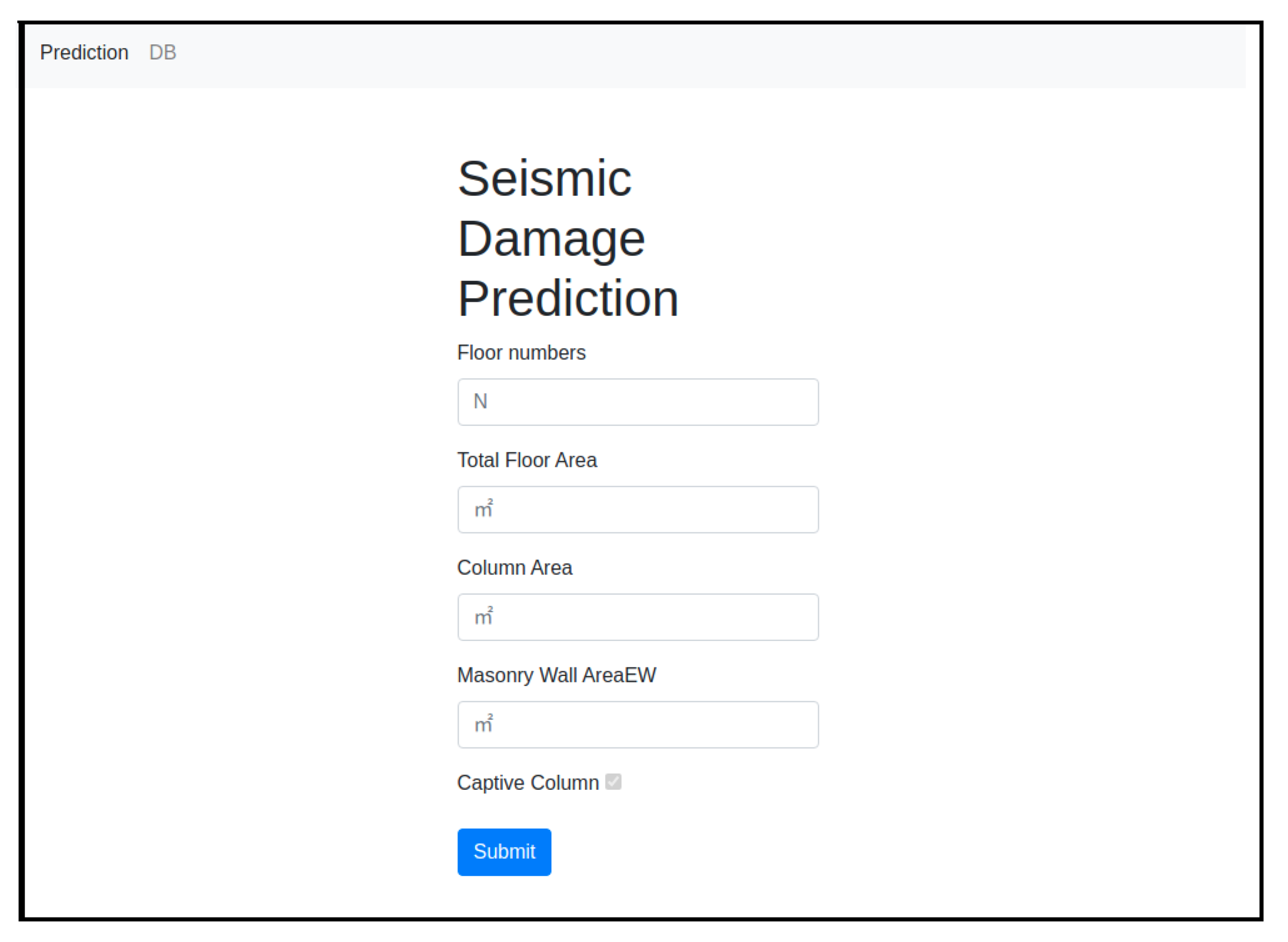
- Home Page: This application provides the basic home view of the project. The user can see the blank input fields to fill the values of required attributes.
- Predictor: The Submit button will have the functionality to use the ML model and to generate predictions.
- Database (DB): The database or DB button on the home page will connect to another page where all the user-inserted inputs with their predicted values will be saved. In case of no data, the database table will show a blank page.
4. Results and Discussion
5. Conclusions
Future Recommendations
- Future studies should consider additional data taking into account the structural system, scale, and damage classifications. In addition, the overall accuracy and robustness of prediction models can be enhanced in future research by adding more extensive datasets (e.g., numerous incidents) and additional site- (e.g., soil conditions) and building-specific predictor variables.
- Concept drift [83] is an ML phenomenon that focuses on data changes, resulting in the ML model’s testing performance to deteriorate over time. Finally, in the case of RVS, a model’s incorrect forecast might be dangerous as, over time, its performance may decrease. However, this effect can be checked by constantly updating the model and periodically re-fitting the model with new data. Therefore, in the long term, the effect of the concept drift needs to be addressed in any ML-based methodology.
- The web-based application is built in a test-driven development environment. The application is based on the Django framework and uses an internal WSGI gateway and an SQLite3 database. The server and database must be uploaded to the proper server and databases expressly developed for production environments. For heavy-load traffic settings, open-source servers such as Apache and Nginx can be utilized. Other open-source databases, such as MySQL, offer greater security and a broader range of features in a production setting. These ideas will need further research and experimentation, which will be left to future projects.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANOVA | Analysis of Variance |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| CART | Classification and Regression Tree |
| CT | Classification Tree |
| CNN | Convolution Neural Network |
| DB | Database |
| DT | Decision Tree |
| FEMA | Federal Emergency Management Agency |
| FLDA | Fisher’s Linear Discriminant Analysis |
| FL | Fuzzy Logic |
| GB | Gradient Boost |
| GBDT | Gradient Boost Decision Tree |
| K | Kernel |
| KNN | K-Nearest Neighbor |
| ML | Machine Learning |
| MISDR | Maximum Inter-Story Drift Ratio |
| MFPN | Multilayer Feedforward Perceptron Networks |
| MLP-NN | Multilayer Perceptron Neural Network |
| MVC | Model-View-Controller |
| MVT | Model-View-Template |
| NB | Naive Bayes |
| NCREE | National Center for Research on Earthquake Engineering |
| NN | Neural Network |
| PLS-DA | Partial Least Squares Discriminant |
| RBF | Radial basis function |
| RF | Random Forest |
| RVS | Rapid Visual Screening |
| RC | Reinforced Concrete |
| SVM | Support Vector Machine |
| SMOTE | Synthetic Minority Oversampling Technique |
| UI | User Interface |
| WSGI | Web Server Gateway Interface |
References
- Dixit, A.; Shrestha, S.; Parajuli, Y.; Thapa, M. Preparing for a Major Earthquake in Nepal: Achievements and Lessons. In Proceedings of the 12th World Conference on Earthquake Engineering, Lisbon, Portugal, 24–28 September 2012. [Google Scholar]
- Emami, M.J.; Tavakoli, A.R.; Alemzadeh, H.; Abdinejad, F.; Shahcheraghi, G.; Erfani, M.A.; Mozafarian, K.; Solooki, S.; Rezazadeh, S.; Ensafdaran, A.; et al. Strategies in evaluation and management of Bam earthquake victims. Prehospital Disaster Med. 2005, 20, 327–330. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doocy, S.; Daniels, A.; Aspilcueta, D.; Zambrano, P.; Rodriguez, S.; Hanif, H.; Shepard, S.H.; Milch, K.; Diaz, A.; Gorokhovich, Y.; et al. Mortality and injury following the 2007 Ica earthquake in Peru. Am. J. Disaster Med. 2009, 4, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Nie, H.; Tang, S.Y.; Lau, W.B.; Zhang, J.C.; Jiang, Y.W.; Lopez, B.L.; Ma, X.L.; Cao, Y.; Christopher, T.A. Triage during the week of the Sichuan earthquake: A review of utilized patient triage, care, and disposition procedures. Injury 2011, 42, 515–520. [Google Scholar] [CrossRef] [PubMed]
- Gamulin, A.; Villiger, Y.; Hagon, O. Disaster medicine: Mission Haiti. Rev. Med. Suisse 2010, 6, 973–977. [Google Scholar]
- Stein, S.; Geller, R.J.; Liu, M. Why earthquake hazard maps often fail and what to do about it. Tectonophysics 2012, 562, 1–25. [Google Scholar] [CrossRef]
- Federal Emergency Management Agency. Rapid Visual Screening of Buildings for Potential Seismic Hazards: Supporting Documentation; Government Printing Office: Washington, DC, USA, 2015.
- Ozcebe, G.; Yucemen, M.S.; Aydogan, V. Statistical seismic vulnerability assessment of existing reinforced concrete buildings in Turkey on a regional scale. J. Earthq. Eng. 2004, 8, 749–773. [Google Scholar] [CrossRef]
- Alvanitopoulos, P.; Andreadis, I.; Elenas, A. Neuro-fuzzy techniques for the classification of earthquake damages in buildings. Measurement 2010, 43, 797–809. [Google Scholar] [CrossRef]
- Xie, Y.; Ebad Sichani, M.; Padgett, J.E.; DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 2020, 36, 1769–1801. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Vasiliadis, L.K. Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms. Appl. Sci. 2022, 12, 3845. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Use of Artificial Neural Networks in the R/C Buildings’ Seismic Vulnerabilty Assessment: The Practical Point of View. In Proceedings of the 7th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete, Greece, 24–26 June 2019; pp. 24–26. [Google Scholar]
- Yong, C.; Ling, C.; Güendel, F.; Kulhánek, O.; Juan, L. Seismic hazard and loss estimation for Central America. Nat. Hazards 2002, 25, 161–175. [Google Scholar] [CrossRef]
- Bilgin, H.; Shkodrani, N.; Hysenlliu, M.; Ozmen, H.B.; Isik, E.; Harirchian, E. Damage and performance evaluation of masonry buildings constructed in 1970s during the 2019 Albania earthquakes. Eng. Fail. Anal. 2022, 131, 105824. [Google Scholar] [CrossRef]
- Anbarci, N.; Escaleras, M.; Register, C.A. Earthquake fatalities: The interaction of nature and political economy. J. Public Econ. 2005, 89, 1907–1933. [Google Scholar] [CrossRef]
- Rashid, M.; Ahmad, N. Economic losses due to earthquake-induced structural damages in RC SMRF structures. Cogent Eng. 2017, 4, 1296529. [Google Scholar] [CrossRef]
- Işık, E.; Harirchian, E.; Büyüksaraç, A.; Ekinci, Y.L. Seismic and structural analyses of the eastern anatolian region (Turkey) using different probabilities of exceedance. Appl. Syst. Innov. 2021, 4, 89. [Google Scholar] [CrossRef]
- Mandas, A.; Dritsos, S. Vulnerability assessment of RC structures using fuzzy logic. WIT Trans. Ecol. Environ. 2004, 77, 1–10. [Google Scholar] [CrossRef]
- Demartinos, K.; Dritsos, S. First-level pre-earthquake assessment of buildings using fuzzy logic. Earthq. Spectra 2006, 22, 865–885. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Saatcioglu, M. Risk-based seismic evaluation of reinforced concrete buildings. Earthq. Spectra 2008, 24, 795–821. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T. Improved Rapid Assessment of Earthquake Hazard Safety of Structures via Artificial Neural Networks. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 897, p. 012014. [Google Scholar]
- Riedel, I.; Guéguen, P.; Dalla Mura, M.; Pathier, E.; Leduc, T.; Chanussot, J. Seismic vulnerability assessment of urban environments in moderate-to-low seismic hazard regions using association rule learning and support vector machine methods. Nat. Hazards 2015, 76, 1111–1141. [Google Scholar] [CrossRef]
- Shah, M.F.; Ahmed, A.; Kegyes-B, O.K. A Case Study Using Rapid Visual Screening Method to Determine the Vulnerability of Buildings in two Districts of Jeddah, Saudi Arabia. In Proceedings of the 15th International Symposium on New Technologies for Urban Safety of Mega Cities in Asia, Tacloban, Philippines, 7–9 November 2016. [Google Scholar]
- Calvi, G.M. A displacement-based approach for vulnerability evaluation of classes of buildings. J. Earthq. Eng. 1999, 3, 411–438. [Google Scholar] [CrossRef]
- Fäh, D.; Kind, F.; Lang, K.; Giardini, D. Earthquake scenarios for the city of Basel. Soil Dyn. Earthq. Eng. 2001, 21, 405–413. [Google Scholar] [CrossRef]
- Harirchian, E.; Hosseini, S.E.A.; Jadhav, K.; Kumari, V.; Rasulzade, S.; Işık, E.; Wasif, M.; Lahmer, T. A review on application of soft computing techniques for the rapid visual safety evaluation and damage classification of existing buildings. J. Build. Eng. 2021, 43, 102536. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Seismic parameters’ combinations for the optimum prediction of the damage state of R/C buildings using neural networks. Adv. Eng. Softw. 2017, 106, 1–16. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Approaches to the rapid seismic damage prediction of r/c buildings using artificial neural networks. Eng. Struct. 2018, 165, 120–141. [Google Scholar] [CrossRef]
- Tesfamariam, S.; Liu, Z. Earthquake induced damage classification for reinforced concrete buildings. Struct. Saf. 2010, 32, 154–164. [Google Scholar] [CrossRef]
- Zhang, Y.; Burton, H.V.; Sun, H.; Shokrabadi, M. A machine learning framework for assessing post-earthquake structural safety. Struct. Saf. 2018, 72, 1–16. [Google Scholar] [CrossRef]
- Allali, S.A.; Abed, M.; Mebarki, A. Post-earthquake assessment of buildings damage using fuzzy logic. Eng. Struct. 2018, 166, 117–127. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.; Dai, F. Landslide susceptibility mapping based on support vector machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Esteban, M.; Valenzuela, V.P.; Yun, N.Y.; Mikami, T.; Shibayama, T.; Matsumaru, R.; Takagi, H.; Thao, N.D.; De Leon, M.; Oyama, T.; et al. Typhoon Haiyan 2013 evacuation preparations and awareness. Int. J. Sustain. Future Hum. Secur. 2015, 3, 37–45. [Google Scholar] [CrossRef]
- Tripathi, S.; Srinivas, V.; Nanjundiah, R.S. Downscaling of precipitation for climate change scenarios: A support vector machine approach. J. Hydrol. 2006, 330, 621–640. [Google Scholar] [CrossRef]
- Harirchian, E.; Lahmer, T.; Kumari, V.; Jadhav, K. Application of Support Vector Machine Modeling for the Rapid Seismic Hazard Safety Evaluation of Existing Buildings. Energies 2020, 13, 3340. [Google Scholar] [CrossRef]
- Gilan, S.S.; Ali, A.M.; Ramezanianpour, A.A. Evolutionary fuzzy function with support vector regression for the prediction of concrete compressive strength. In Proceedings of the 2011 UKSim 5th European Symposium on Computer Modeling and Simulation, Madrid, Spain, 16–18 November 2011; pp. 263–268. [Google Scholar]
- Sobhani, J.; Khanzadi, M.; Movahedian, A. Support vector machine for prediction of the compressive strength of no-slump concrete. Comput. Concr. 2013, 11, 337–350. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Adeli, H. Concept drift-oriented adaptive and dynamic support vector machine ensemble with time window in corporate financial risk prediction. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 801–813. [Google Scholar] [CrossRef]
- Zhang, Z.; Hsu, T.Y.; Wei, H.H.; Chen, J.H. Development of a data-mining technique for regional-scale evaluation of building seismic vulnerability. Appl. Sci. 2019, 9, 1502. [Google Scholar] [CrossRef] [Green Version]
- Cannizzaro, F.; Pantò, B.; Lepidi, M.; Caddemi, S.; Caliò, I. Multi-directional seismic assessment of historical masonry buildings by means of macro-element modelling: Application to a building damaged during the L’Aquila earthquake (Italy). Buildings 2017, 7, 106. [Google Scholar] [CrossRef] [Green Version]
- Fagundes, C.; Bento, R.; Cattari, S. On the seismic response of buildings in aggregate: Analysis of a typical masonry building from Azores. Structures 2017, 10, 184–196. [Google Scholar] [CrossRef]
- Casapulla, C.; Argiento, L.U.; Maione, A. Seismic safety assessment of a masonry building according to Italian Guidelines on Cultural Heritage: Simplified mechanical-based approach and pushover analysis. Bull. Earthq. Eng. 2018, 16, 2809–2837. [Google Scholar] [CrossRef]
- Greco, A.; Lombardo, G.; Pantò, B.; Famà, A. Seismic vulnerability of historical masonry aggregate buildings in oriental Sicily. Int. J. Archit. Herit. 2020, 14, 517–540. [Google Scholar] [CrossRef]
- Lin, P.C.; Tsai, K.C.; Wang, K.J.; Yu, Y.J.; Wei, C.Y.; Wu, A.C.; Tsai, C.Y.; Lin, C.H.; Chen, J.C.; Schellenberg, A.H.; et al. Seismic design and hybrid tests of a full-scale three-story buckling-restrained braced frame using welded end connections and thin profile. Earthq. Eng. Struct. Dyn. 2012, 41, 1001–1020. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning. Scholarpedia 2015, 10, 32832. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Qi, Y. Character based string kernels for bio-entity relation detection. In Proceedings of the 15th Workshop on Biomedical Natural Language Processing, Berlin, Germany, 12 August 2016; pp. 66–71. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, D.; Rueda-Plata, D.; Acevedo, A.B.; Duque, J.C.; Ramos-Pollan, R.; Betancourt, A.; Garcia, S. Automatic detection of building typology using deep learning methods on street level images. Build. Environ. 2020, 177, 106805. [Google Scholar] [CrossRef]
- Harirchian, E.; Kumari, V.; Jadhav, K.; Rasulzade, S.; Lahmer, T.; Raj Das, R. A Synthesized Study Based on Machine Learning Approaches for Rapid Classifying Earthquake Damage Grades to RC Buildings. Appl. Sci. 2021, 11, 7540. [Google Scholar] [CrossRef]
- Catlin, A.C.; HewaNadungodage, C.; Pujol, S.; Laughery, L.; Sim, C.; Puranam, A.; Bejarano, A. A cyberplatform for sharing scientific research data at DataCenterHub. Comput. Sci. Eng. 2018, 20, 49–70. [Google Scholar] [CrossRef]
- Shah, P.; Pujol, S.; Puranam, A.; Laughery, L. Database on Performance of Low-Rise Reinforced Concrete Buildings in the 2015 Nepal Earthquake; DEEDS, Purdue University Research Repository: Lafayette, IN, USA, 2015. [Google Scholar]
- Sim, C.; Laughery, L.; Chiou, T.; Weng, P.W. 2017 Pohang Earthquake: Reinforced Concrete Building Damage Survey; DEEDS, Purdue University Research Repository: Lafayette, IN, USA, 2018. [Google Scholar]
- Sim, C.; Villalobos, E.; Smith, J.P.; Rojas, P.; Pujol, S.; Puranam, A.Y.; Laughery, L.A. Performance of Low-Rise Reinforced Concrete Buildings in the 2016 Ecuador Earthquake; Purdue University Research Repository: Purdue, IN, USA, 2018. [Google Scholar] [CrossRef]
- Patton, J. Earthquake Report: 2010 Haiti M 7.0. Available online: http://earthjay.com/?p=9178 (accessed on 2 January 2022).
- Ilyas, I.F.; Chu, X. Data Cleaning; ACM: New York, NY, USA, 2019. [Google Scholar]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Volume 26. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Villalobos, E.; Sim, C.; Smith-Pardo, J.P.; Rojas, P.; Pujol, S.; Kreger, M.E. The 16 April 2016 Ecuador earthquake damage assessment survey. Earthq. Spectra 2018, 34, 1201–1217. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ohtsuki, T. Sentiment analysis: From binary to multi-class classification: A pattern-based approach for multi-class sentiment analysis in Twitter. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gärtner, T.; Flach, P.A.; Kowalczyk, A.; Smola, A.J. Multi-instance kernels. In Proceedings of the Nineteenth International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 2002; Volume 2, p. 7. [Google Scholar]
- Timofeev, R. Classification and Regression Trees (CART) Theory and Applications. Master’s Thesis, Humboldt University, Berlin, Germany, 2004; pp. 1–40. [Google Scholar]
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Fix, E. Discriminatory Analysis: Nonparametric Discrimination, Consistency Properties; USAF School of Aviation Medicine: Randolph Field, TX, USA, 1985; Volume 1. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Amit, Y.; Geman, D. Shape quantization and recognition with randomized trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef] [Green Version]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. Open Access J. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Li, P. Robust logitboost and adaptive base class (abc) logitboost. arXiv 2012, arXiv:1203.3491. [Google Scholar]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 521–530. [Google Scholar]
- Burges, C.J. From ranknet to lambdarank to lambdamart: An overview. Learning 2010, 11, 81. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Izquierdo, J.L.C.; Cabot, J. The role of foundations in open source projects. In Proceedings of the 40th International Conference on Software Engineering: Software Engineering in Society, Gothenburg, Sweden, 27 May–3 June 2018; pp. 3–12. [Google Scholar]
- Robenolt, M. Scaling Django to 8 Billion Page Views. 2013. Available online: https://blog.disqus.com/scaling-django-to-8-billion-page-views (accessed on 2 January 2022).
- Sathya, R.; Abraham, A. Comparison of supervised and unsupervised learning algorithms for pattern classification. Int. J. Adv. Res. Artif. Intell. 2013, 2, 34–38. [Google Scholar] [CrossRef] [Green Version]
- Ghahramani, Z. Unsupervised learning. In Summer School on Machine Learning; Springer: New York, NY, USA, 2003; pp. 72–112. [Google Scholar]
- Tsymbal, A. The Problem of Concept Drift: Definitions and Related Work; Computer Science Department, Trinity College Dublin: Dublin, Ireland, 2004; Volume 106, p. 58. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Unit | Type |
|---|---|---|
| No. of Stories | N (1, 2, …) | Integer |
| Total Floor Area | m | Integer |
| Column’s Cross-Sectional Area | m | Integer |
| Concrete Wall Area (Y) | m | Integer |
| Concrete Wall Area (X) | m | Integer |
| Masonry Wall Area (Y) | m | Integer |
| Masonry Wall Area (X) | m | Integer |
| Captive Columns | N (exist = yes = 1, absent = no = 0) | Binomial |
| Damage Scale | Risk Association |
|---|---|
| 1 | No visible damage to the structure. Safe to reoccupy. |
| 2 | Low damage. Hairline to wide cracks in the structural elements. Spalling of concrete may also be observed. |
| 3 | Significant loss. Failure of at least one element in the structure. |
| 4 | Severe damage. At least one floor slab or part of it loses its elevation. |
| Target Class | Imbalanced Data | Balanced Data |
|---|---|---|
| 1 | 54 | 224 |
| 2 | 161 | 224 |
| 3 | 87 | 224 |
| 4 | 224 | 224 |
| ML Classifier | Dataset (before Preprocessing) | Dataset (after Preprocessing) | ||
|---|---|---|---|---|
| Training Set(in %) | Test Set (in %) | Training Set (in %) | Test Set (in %) | |
| Decision Tree | 48 | 41 | 47 | 42 |
| Gradient Boost Decision Tree | 77 | 49 | 78 | 51 |
| K-Nearest Neighbor | 64 | 46 | 64 | 45 |
| Naive Bayes | 46 | 35 | 43 | 42 |
| Random Forest | 38 | 33 | 45 | 37 |
| Support Vector Machine | 57 | 45 | 52 | 47 |
| Target Class | Number of Data Predicted | Correctly Predicted Data | Accuracy (in %) |
|---|---|---|---|
| 1 | 7 | 2 | 28.57 |
| 2 | 7 | 4 | 57.14 |
| 3 | 7 | 2 | 28.57 |
| 4 | 7 | 5 | 71.40 |
| Target Class | Number of Data Predicted | Correctly Predicted Data | Accuracy (in %) |
|---|---|---|---|
| 1 | 7 | 3 | 42.85 |
| 2 | 7 | 4 | 57.14 |
| 3 | 7 | 1 | 14.28 |
| 4 | 7 | 4 | 57.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumari, V.; Harirchian, E.; Lahmer, T.; Rasulzade, S. Evaluation of Machine Learning and Web-Based Process for Damage Score Estimation of Existing Buildings. Buildings 2022, 12, 578. https://doi.org/10.3390/buildings12050578
Kumari V, Harirchian E, Lahmer T, Rasulzade S. Evaluation of Machine Learning and Web-Based Process for Damage Score Estimation of Existing Buildings. Buildings. 2022; 12(5):578. https://doi.org/10.3390/buildings12050578
Chicago/Turabian StyleKumari, Vandana, Ehsan Harirchian, Tom Lahmer, and Shahla Rasulzade. 2022. "Evaluation of Machine Learning and Web-Based Process for Damage Score Estimation of Existing Buildings" Buildings 12, no. 5: 578. https://doi.org/10.3390/buildings12050578
APA StyleKumari, V., Harirchian, E., Lahmer, T., & Rasulzade, S. (2022). Evaluation of Machine Learning and Web-Based Process for Damage Score Estimation of Existing Buildings. Buildings, 12(5), 578. https://doi.org/10.3390/buildings12050578