
Denoising and Dehazing an Image in a Cascaded Pattern for Continuous Casting

Abstract
:1. Introduction
- We analyze the atmospheric scattering model and additive noise from the perspective of combining them. We further expand this formula into a new denoising and dehazing algorithm that works in a cascading pattern.
- We propose CDDNet, a cascading two-stage U-Net for image denoising and dehazing.
- We provide in-depth experiments on both synthesized images and a real video from a continuous casting factory, which demonstrates that CDDNet achieves superior performance to other models.
2. Related Work
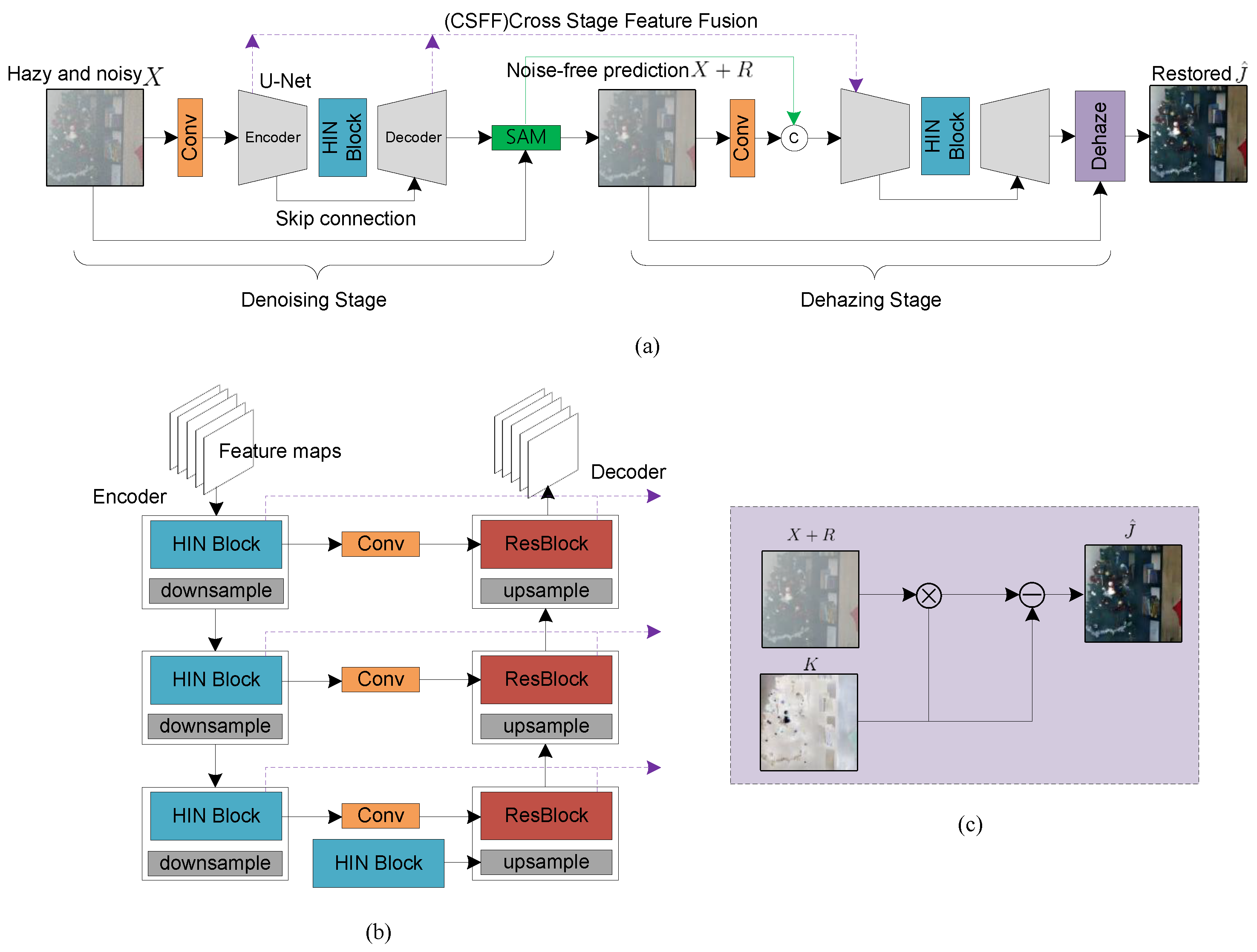
3. Method
3.1. Transformed Formula
3.2. CDDNet
4. Experiments
4.1. Implementation Details
4.2. Quantitative Results
4.3. Visual Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, H.; Huang, R.; Gao, L.; Wang, W.; Xu, A.; Yuan, F. Wear Debris Classification of Steel Production Equipment using Feature Fusion and Case-based Reasoning. ISIJ Int. 2018, 58, 1293–1299. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cheng, S.; Wang, Y.; Huang, H.; Liu, D.; Fan, H.; Liu, S. NBNet: Noise Basis Learning for Image Denoising with Subspace Projection. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half Instance Normalization Network for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar] [CrossRef]
- Mehri, A.; Ardakani, P.B.; Sappa, A.D. MPRNet: Multi-Path Residual Network for Lightweight Image Super Resolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021. [Google Scholar]
- Cox, L. Optics of the Atmosphere-Scattering by Molecules and Particles. Opt. Acta Int. J. Opt. 1977, 24, 779. [Google Scholar] [CrossRef]
- Narasimhan, S.; Nayar, S. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head Island, SC, USA, 15 June 2000; Volume 1, pp. 598–605. [Google Scholar] [CrossRef] [Green Version]
- Narasimhan, S.; Nayar, S. Vision and the Atmosphere. In International Journal of Computer Vision; Springer: Berlin/Heidelberg, Germany, 2002; pp. 233–254. [Google Scholar] [CrossRef]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009; pp. 1956–1963. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed] [Green Version]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buades, A.; Coll, B.; Morel, J.M. Non-Local Means Denoising. Image Process. OnLine 2011, 1, 208–212. [Google Scholar] [CrossRef] [Green Version]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Portilla, J.; Strela, V.; Wainwright, M.; Simoncelli, E. Image denoising using scale mixtures of Gaussians in the wavelet domain. IEEE Trans. Image Process. 2003, 12, 1338–1351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Matlin, E.; Milanfar, P. Removal of Haze and Noise from a Single Image; Electronic Imaging; International Society for Optics and Photonics: Bellingham, WA, USA, 2012. [Google Scholar]
- Liu, X.; Zhang, H.; Cheung, Y.M.; You, X.; Tang, Y.Y. Efficient single image dehazing and denoising: An efficient multi-scale correlated wavelet approach. Comput. Vis. Image Underst. 2017, 162, 23–33. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; Vleeschouwer, C.D. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images. arXiv 2018, arXiv:1804.05091v1. [Google Scholar]
- Wikipedia Contributors. Peak Signal-to-Noise Ratio—Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio (accessed on 5 January 2022).
- Wikipedia Contributors. Structural Similarity—Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Structural_similarity (accessed on 5 January 2022).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. 2017. Available online: http://xxx.lanl.gov/abs/1412.6980 (accessed on 5 January 2022).
- Chaudhury, S.; Yamasaki, T. Robustness of Adaptive Neural Network Optimization Under Training Noise. IEEE Access 2021, 9, 37039–37053. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:cs.LG/1608.03983. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | TestSet A | TestSet B | ||||||
|---|---|---|---|---|---|---|---|---|
| 0.05 | 0.1 | 0.2 | 0.3 | 0.05 | 0.1 | 0.2 | 0.3 | |
| DCP | ||||||||
| AODNet | ||||||||
| BM3D + DCP | ||||||||
| BM3D + AODNet | ||||||||
| CDDNet | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, W.; Zhang, Y.; Wei, H.; Gao, Q. Denoising and Dehazing an Image in a Cascaded Pattern for Continuous Casting. Metals 2022, 12, 126. https://doi.org/10.3390/met12010126
Su W, Zhang Y, Wei H, Gao Q. Denoising and Dehazing an Image in a Cascaded Pattern for Continuous Casting. Metals. 2022; 12(1):126. https://doi.org/10.3390/met12010126
Chicago/Turabian StyleSu, Wenbin, Yifei Zhang, Hongbo Wei, and Qi Gao. 2022. "Denoising and Dehazing an Image in a Cascaded Pattern for Continuous Casting" Metals 12, no. 1: 126. https://doi.org/10.3390/met12010126
APA StyleSu, W., Zhang, Y., Wei, H., & Gao, Q. (2022). Denoising and Dehazing an Image in a Cascaded Pattern for Continuous Casting. Metals, 12(1), 126. https://doi.org/10.3390/met12010126