
A Deep Learning Model Based on Capsule Networks for COVID Diagnostics through X-ray Images


Abstract
:1. Introduction
2. Materials and Methods
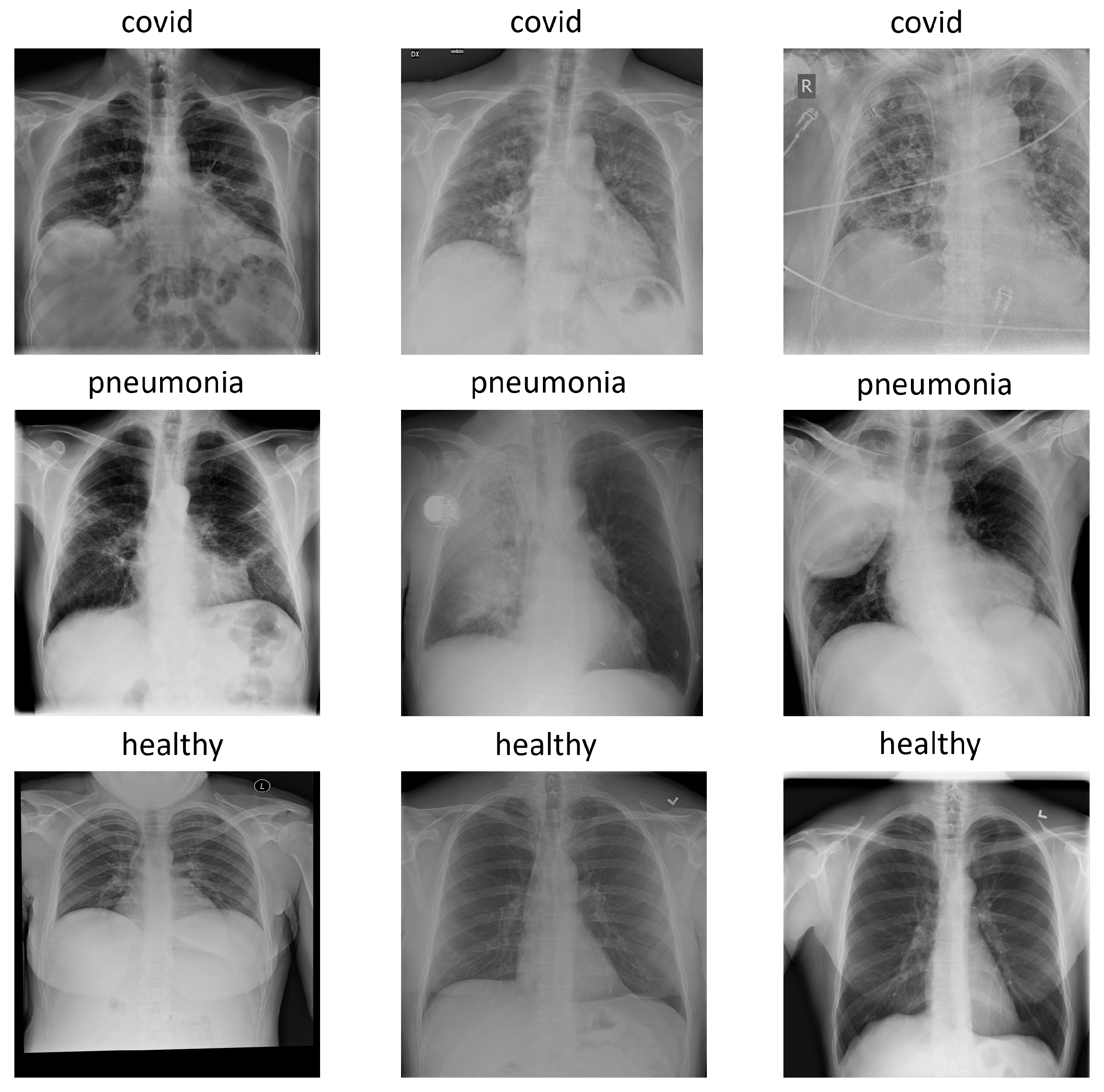
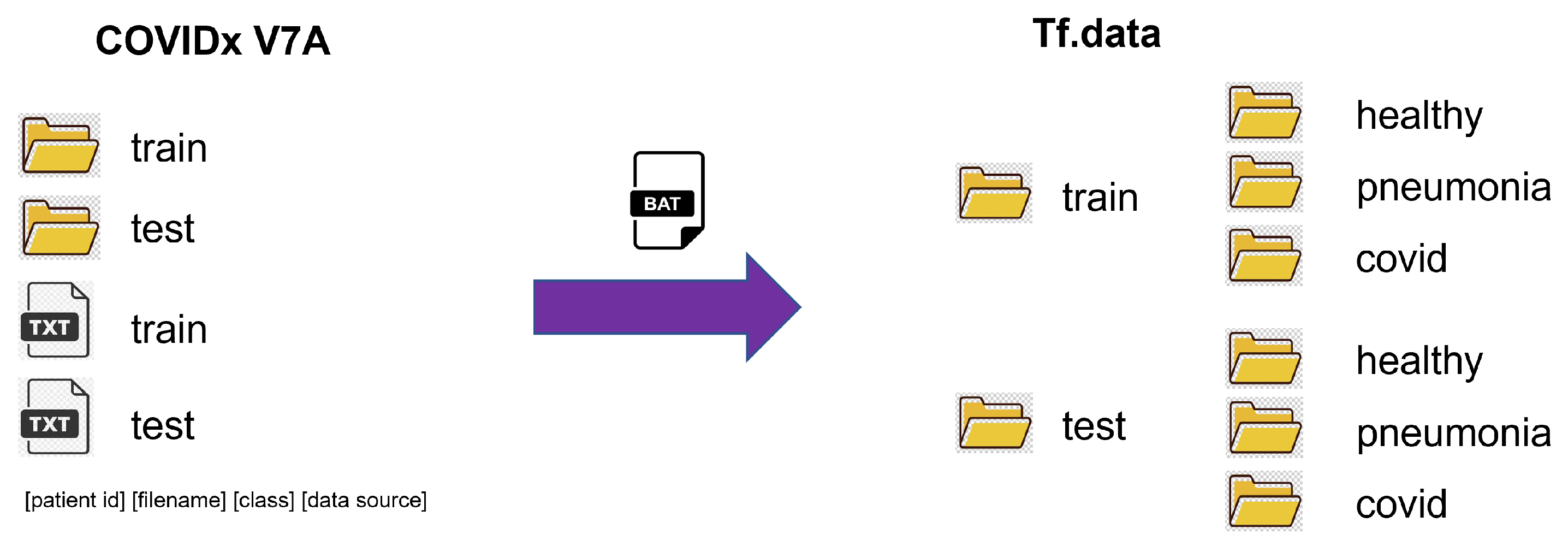
2.1. COVIDx Dataset
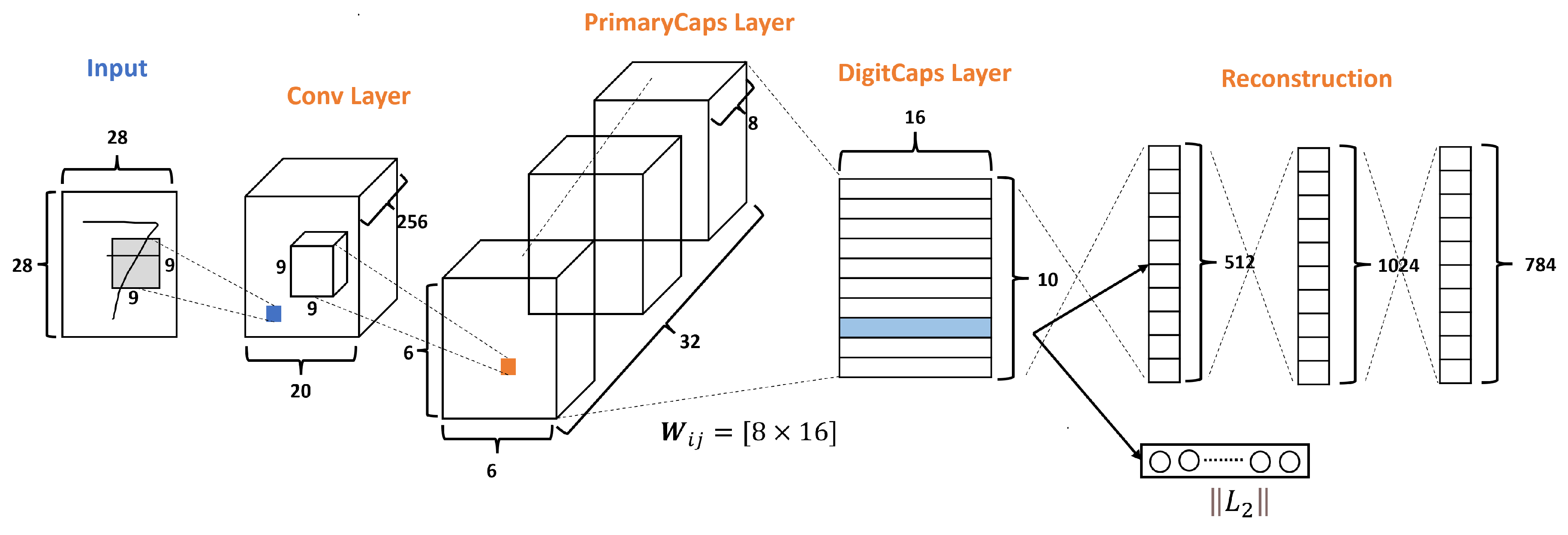
2.2. Capsnet Baseline
| Algorithm 1: Routing Algorithm, according to Sabour et al. [23] |
|
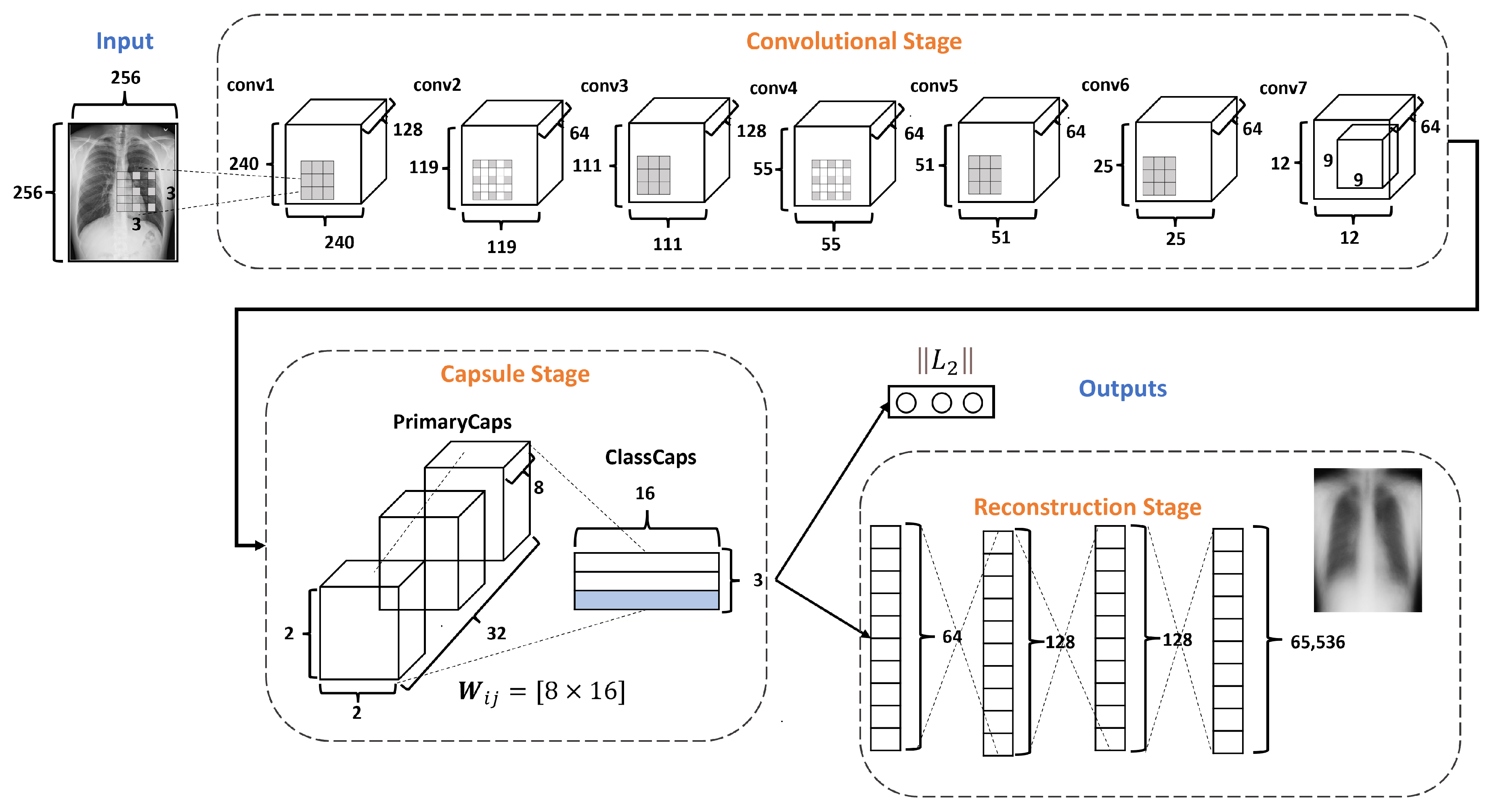
2.3. DRCaps Model
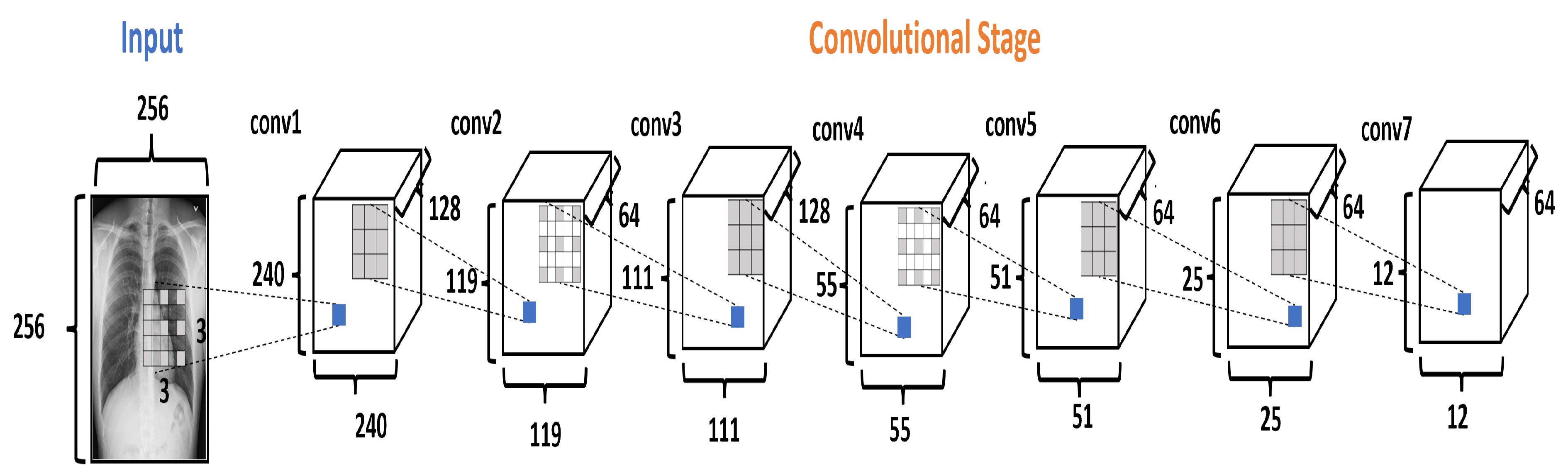
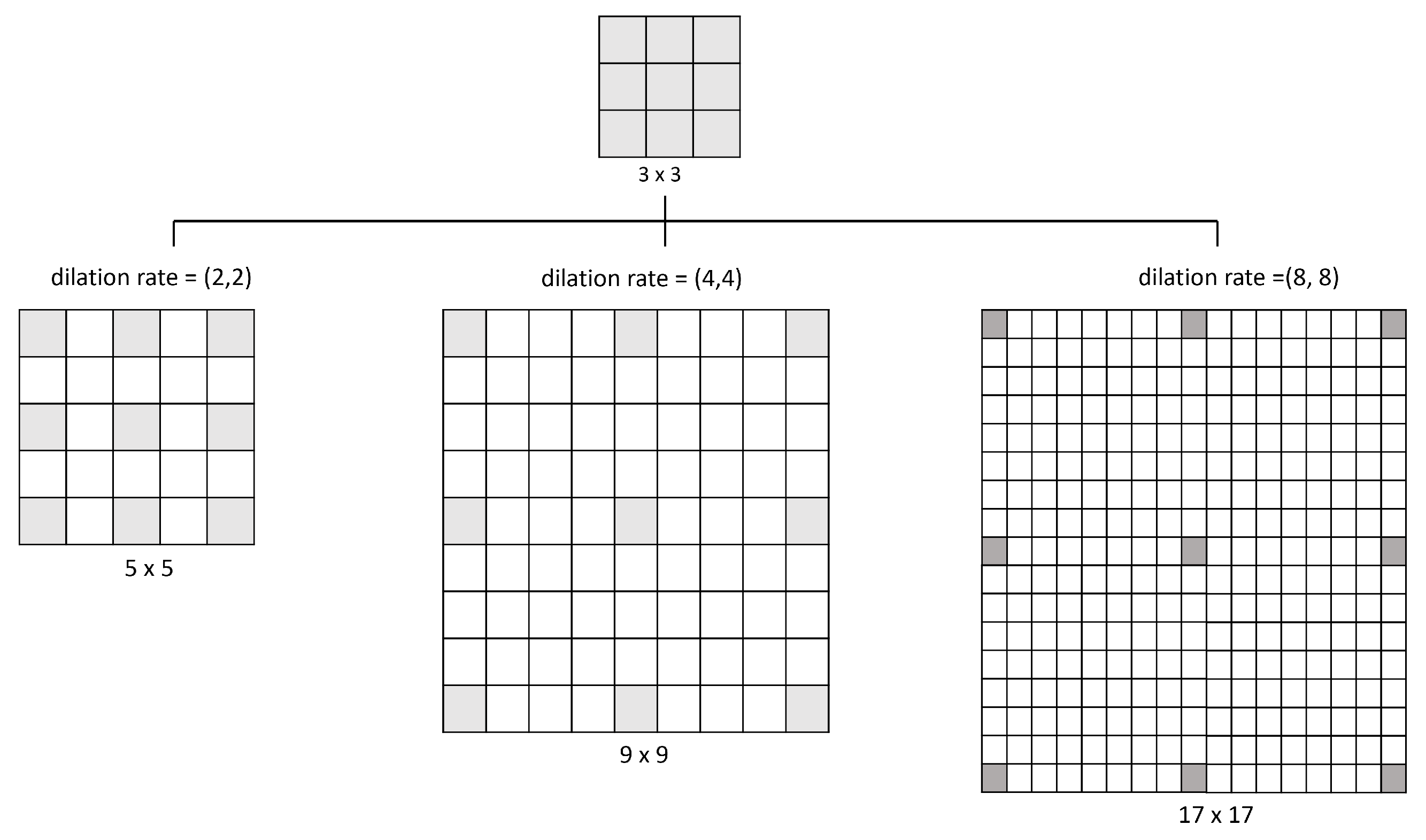
2.3.1. Convolution Stage
2.3.2. Capsule Stage
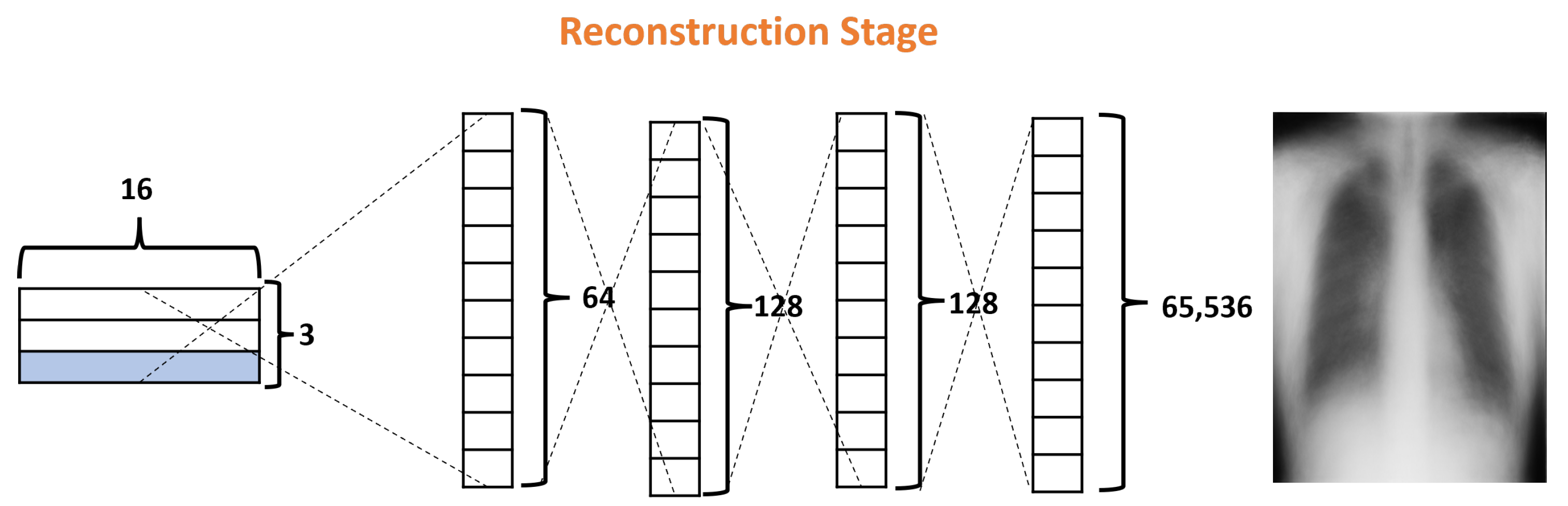
2.3.3. Reconstruction Stage
2.3.4. Loss Functions
Margin Loss
Reconstruction Loss
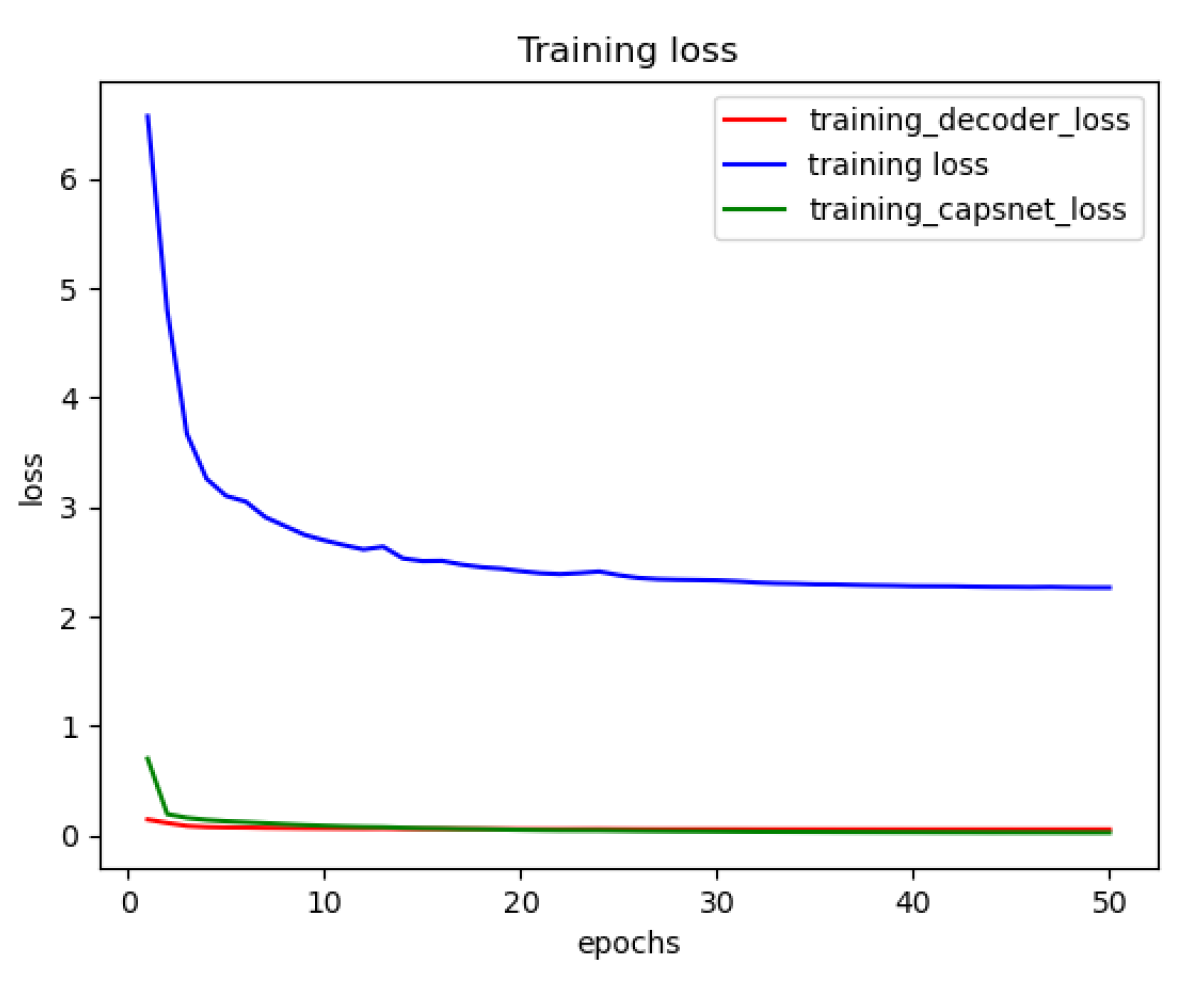
2.4. Training the DRCaps Model
2.5. Experimental Platform
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| CapsNets | Capsule Networks |
| CT | Computed Tomography |
| CC | Compute Capability |
| MRI | Magnetic Resonance Imaging |
| CS | Convolutional Stage |
| CaS | Capsule Stage |
| RS | Reconstruction Stage |
| PCR | Polymerase chain reaction |
| DL | The Deep Learning |
| COVID | Coronavirus Disease |
| GAN | Generative Adversarial Networks |
| ReLU | Rectified Linear Unit |
References
- Cellina, M.; Cè, M.; Irmici, G.; Ascenti, V.; Caloro, E.; Bianchi, L.; Pellegrino, G.; D’Amico, N.; Papa, S.; Carrafiello, G. Artificial Intelligence in Emergency Radiology: Where Are We Going? Diagnostics 2022, 12, 3223. [Google Scholar] [CrossRef] [PubMed]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Acharya, U.R. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef] [PubMed]
- Aboughazala, L.M. Automated detection of COVID-19 coronavirus cases using deep neural networks with X-ray images. Al-Azhar Univ. J. Virus Res. Stud. 2020, 2, 1–12. [Google Scholar]
- Khanna, M.; Agarwal, A.; Singh, L.K.; Thawkar, S.; Khanna, A.; Gupta, D. Radiologist-level two novel and robust automated computer-aided prediction models for early detection of COVID-19 infection from chest X-ray images. Arab. J. Sci. Eng. 2023, 48, 11051–11083. [Google Scholar] [CrossRef] [PubMed]
- Aljawarneh, S.A.; Al-Quraan, R. Pneumonia Detection Using Enhanced Convolutional Neural Network Model on Chest X-Ray Images. Big Data 2023. online ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Mobiny, A.; Cicalese, P.A.; Zare, S.; Yuan, P.; Abavisani, M.; Wu, C.C.; Ahuja, J.; de Groot, P.M.; Van Nguyen, H. Radiologist-level COVID-19 detection using ct scans with detail-oriented capsule networks. arXiv 2020, arXiv:2004.07407. [Google Scholar]
- Mobiny, A.; Van Nguyen, H. Fast capsnet for lung cancer screening. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018; Proceedings, Part II 1. Springer: Berlin/Heidelberg, Germany, 2018; pp. 741–749. [Google Scholar]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain tumor type classification via capsule networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: New York, NY, USA, 2018; pp. 3129–3133. [Google Scholar]
- Kruthika, K.; Maheshappa, H.; Alzheimer’s Disease Neuroimaging Initiative. CBIR system using Capsule Networks and 3D CNN for Alzheimer’s disease diagnosis. Inf. Med. Unlocked 2019, 14, 59–68. [Google Scholar] [CrossRef]
- Dammu, H.; Ren, T.; Duong, T.Q. Deep learning prediction of pathological complete response, residual cancer burden, and progression-free survival in breast cancer patients. PLoS ONE 2023, 18, e0280148. [Google Scholar] [CrossRef]
- Nasser, M.; Yusof, U.K. Deep Learning Based Methods for Breast Cancer Diagnosis: A Systematic Review and Future Direction. Diagnostics 2023, 13, 161. [Google Scholar] [CrossRef]
- Stumpe, M.; Mermel, C. Applying Deep Learning to Metastatic Breast Cancer Detection. Available online: https://ai.googleblog.com/2018/10/applying-deep-learning-to-metastatic.html (accessed on 26 July 2023).
- Gurovich, Y.; Hanani, Y.; Bar, O.; Nadav, G.; Fleischer, N.; Gelbman, D.; Basel-Salmon, L.; Krawitz, P.M.; Kamphausen, S.B.; Zenker, M.; et al. Identifying facial phenotypes of genetic disorders using deep learning. Nat. Med. 2019, 25, 60–64. [Google Scholar] [CrossRef]
- DARPA. Learning with Less Labels (LwLL); Technical Report; Defense Advanced Research Projects Agency: Arlington, VI, USA, 2018. [Google Scholar]
- Mitchell, T.M. Machine Learning, 1st ed.; McGraw-Hill, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Sundaram, D.M.; Loganathan, A. FSSCaps-DetCountNet: Fuzzy soft sets and CapsNet-based detection and counting network for monitoring animals from aerial images. J. Appl. Remote Sens. 2020, 14, 026521. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, F. DA-CapsNet: Dual attention mechanism capsule network. Sci. Rep. 2020, 10, 11383. [Google Scholar] [CrossRef] [PubMed]
- Phaye, S.S.R.; Sikka, A.; Dhall, A.; Bathula, D. Dense and diverse capsule networks: Making the capsules learn better. arXiv 2018, arXiv:1805.04001. [Google Scholar]
- Yang, S.; Lee, F.; Miao, R.; Cai, J.; Chen, L.; Yao, W.; Kotani, K.; Chen, Q. RS-CapsNet: An Advanced Capsule Network. IEEE Access 2020, 8, 85007–85018. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial attacks and defenses in deep learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, California, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3856–3866. [Google Scholar]
- Rajasegaran, J.; Jayasundara, V.; Jayasekara, S.; Jayasekara, H.; Seneviratne, S.; Rodrigo, R. DeepCaps: Going Deeper with Capsule Networks. arXiv 2019, arXiv:1904.09546. [Google Scholar]
- Jayasundara, V.; Jayasekara, S.; Jayasekara, H.; Rajasegaran, J.; Seneviratne, S.; Rodrigo, R. TextCaps: Handwritten Character Recognition With Very Small Datasets. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: New York, NY, USA, 2019; pp. 254–262. [Google Scholar]
- Frosst, N.; Sabour, S.; Hinton, G. DARCCC: Detecting adversaries by reconstruction from class conditional capsules. arXiv 2018, arXiv:1811.06969. [Google Scholar]
- Hinton, G.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, CO, Canada, 30 April–3 May 2018. [Google Scholar]
- Jaiswal, A.; AbdAlmageed, W.; Wu, Y.; Natarajan, P. Capsulegan: Generative adversarial capsule network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Jia, B.; Huang, Q. DE-CapsNet: A Diverse Enhanced Capsule Network with Disperse Dynamic Routing. Appl. Sci. 2020, 10, 884. [Google Scholar] [CrossRef]
- Wang, A.; Wang, M.; Wu, H.; Jiang, K.; Iwahori, Y. A Novel LiDAR Data Classification Algorithm Combined CapsNet with ResNet. Sensors 2020, 20, 1151. [Google Scholar] [CrossRef] [PubMed]
- Xiang, H.; Huang, Y.S.; Lee, C.H.; Chien, T.Y.C.; Lee, C.K.; Liu, L.; Li, A.; Lin, X.; Chang, R.F. 3-D Res-CapsNet convolutional neural network on automated breast ultrasound tumor diagnosis. Eur. J. Radiol. 2021, 138, 109608. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Kumar, D.; Mittal, M.; Saba, T.; Abunadi, I.; Rehman, A.; Roy, S. Detecting pneumonia using convolutions and dynamic capsule routing for chest X-ray images. Sensors 2020, 20, 1068. [Google Scholar] [CrossRef] [PubMed]
- Afshar, P.; Heidarian, S.; Naderkhani, F.; Oikonomou, A.; Plataniotis, K.N.; Mohammadi, A. Covid-caps: A capsule network-based framework for identification of COVID-19 cases from X-ray images. Pattern Recognit. Lett. 2020, 138, 638–643. [Google Scholar] [CrossRef] [PubMed]
- Toraman, S.; Alakus, T.B.; Turkoglu, I. Convolutional capsnet: A novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 2020, 140, 110122. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lin, Z.Q.; Wong, A. COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Rahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Kashem, S.B.A.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S.; et al. Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al Emadi, N.; et al. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Tsai, E.B.; Simpson, S.; Lungren, M.P.; Hershman, M.; Roshkovan, L.; Colak, E.; Erickson, B.J.; Shih, G.; Stein, A.; Kalpathy-Cramer, J.; et al. The RSNA International COVID-19 Open Radiology Database (RICORD). Radiology 2021, 299, e204–e213. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Cortes, C.; Yann, C.J.B. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist (accessed on 26 July 2023).
- TensorFlow Datasets. A Collection of Ready-to-Use Datasets. Available online: https://www.tensorflow.org/datasets (accessed on 26 July 2023).
- Filippas, D.; Nicopoulos, C.; Dimitrakopoulos, G. Streaming Dilated Convolution Engine. IEEE Trans. Very Large Scale Integr. Syst. 2023, 31, 401–405. [Google Scholar] [CrossRef]
- Rosario, V.M.D.; Borin, E.; Breternitz, M., Jr. The Multi-Lane Capsule Network (MLCN). arXiv 2019, arXiv:1902.08431. [Google Scholar]
- LaLonde, R.; Bagci, U. Capsules for object segmentation. arXiv 2018, arXiv:1804.04241. [Google Scholar]
- Ali, M.U.; Kallu, K.D.; Masood, H.; Tahir, U.; Gopi, C.V.; Zafar, A.; Lee, S.W. A CNN-Based Chest Infection Diagnostic Model: A Multistage Multiclass Isolated and Developed Transfer Learning Framework. Int. J. Intell. Syst. 2023, 2023, 6850772. [Google Scholar] [CrossRef]
- Sarki, R.; Ahmed, K.; Wang, H.; Zhang, Y.; Wang, K. Automated detection of COVID-19 through convolutional neural network using chest x-ray images. PLoS ONE 2022, 17, e0262052. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Dataset | Combination | Ref. |
|---|---|---|---|
| DA-CapsNet | MNIST, CIFAR10, FashionMNIST, SVHN, smallNORB and COIL-20 | Attention layers + CapsNet | [18] |
| FSSCaps-DetCountNet | The aerial elephant and The livestock | FSS classifier + CapsNet | [17] |
| DE-CapsNet | CIFAR-10, Fashion MNIST | SGE + CapsNet + DCNet++ | [30] |
| RS-CapsNet | CIFAR10, CIFAR100, SVHN, FashionMNIST, and AffNIST | Res2Net + SE + CapsNet | [20] |
| ResCapsNet | LiDAR | ResNet + CapsNet | [31] |
| Folder | Pneumonia | Healthy | COVID | Total |
|---|---|---|---|---|
| train | 5474 | 7966 | 1670 | 15,111 |
| test | 594 | 885 | 100 | 1579 |
| Layer | Filters | Kernel Size | Stride | Dilation Rate | Output Size | Parameters |
|---|---|---|---|---|---|---|
| conv1 | 128 | 3 × 3 | 1 | (8,8) | 240 × 240 | 1280 |
| conv2 | 64 | 3 × 3 | 2 | (1,1) | 119 × 119 | 73,792 |
| conv3 | 128 | 3 × 3 | 1 | (4,4) | 111 × 111 | 73,856 |
| conv4 | 64 | 3 × 3 | 2 | (1,1) | 55 × 55 | 73,792 |
| conv5 | 64 | 3 × 3 | 1 | (2,2) | 51 × 51 | 36,928 |
| conv6 | 64 | 3 × 3 | 2 | (1,1) | 25 × 25 | 36,928 |
| conv7 | 64 | 3 × 3 | 2 | (1,1) | 12 × 12 | 36,928 |
| Layer | Hyperparameters | |
|---|---|---|
| Input | Image size = (256, 256) channels = 1 | |
| Convolutional | # Layers = 7 # Channels = 64,128 # filters = 7 filter size = 3,3 parameters = 333, 504 | stride = 1,2 padding = valid dilation rate = (8,8),(4,4),(2,2) activation = ReLU |
| PrimaryCaps | # Capsules = 128 Capsule depth = 8 # Caps Layers = 32 parameters = 1, 327, 360 | stride = 2 padding = valid filter size = 9 |
| ClassCaps | # clases = 3 # Instantiation parameters = 16 parameters = 49, 152 | |
| Reconstruction | # layers = 3 # layer sizes = 64,128,128,65536 activation = ReLU parameters = 8, 482, 112, |
| Arguments | Compile | Train |
|---|---|---|
| epochs = 50 | optimizer = Adam | train images = 12,089 (80%) |
| learning rate = 0.001 | learning rate = 0.001 | validation images = 3022 (20%) |
| img width = 256 | prediction loss = margin loss | batch size = 32 |
| img height = 256 | reconstruction loss = mae | steps per epoch = 378 |
| lr decay = 0.9 | metrics = accuracy | test images = 1579 |
| routings = 3 | ||
| recon = 32.768 |
| Server | OS | TensorFlow | Keras | GPU | CC |
|---|---|---|---|---|---|
| Tinieblas | Linux | 2.5.0 | 2.5.0 | RTX 2080 Ti | 7.5 |
| Network | Dataset | Image Size | Depth | Dilation Rate | Stride | Capsules | RS | Parameters | Acc. | |
|---|---|---|---|---|---|---|---|---|---|---|
| CapsNet baseline | MNIST | 28 × 28 | 1 | no | 2 | 1152 | 0.392 | 5,121,024 | 8,215,568 | 98.5 |
| CapsNet V2 | MNIST | 28 × 28 | 1 | (2,2) | no | 128 | 0.392 | 5,121,024 | 6,904,848 | 99.2 |
| CapsNet V3 | MNIST | 28 × 28 | 1 | (2,2), (4,4) | no | 288 | 0.392 | 5,121,024 | 7,458,320 | 99.6 |
| CapsNet V3 | COVIDx | 256 × 256 | 3 | (2,2), (4,4) | no | 438,048 | 0.392 | 5,121,024 | 375,963,520 | - |
| CapsNet V3 | COVIDx | 256 × 256 | 1 | (2,2), (4,4) | no | 438,048 | 0.392 | 5,121,024 | 241,613,568 | - |
| CapsNet V4 | COVIDx | 256 × 256 | 3 | no | 2 | 512 | 0.392 | 64,128,128 | 28,612,288 | 80.0 |
| CapsNet V4 | COVIDx | 256 × 256 | 3 | no | 2 | 512 | 32.768 | 64,128,128 | 28,612,288 | 82.5 |
| CapsNet V5 | COVIDx | 256 × 256 | 1 | no | 2 | 512 | 0.392 | 64,128,128 | 11,702,848 | 78.0 |
| CapsNet V5 | COVIDx | 256 × 256 | 1 | no | 2 | 512 | 32.768 | 64,128,128 | 11,702,848 | 86.2 |
| DRCaps V1 | COVIDx | 256 × 256 | 1 | (8,8), (4,4), (2,2) | 1,2 | 128 | 32.768 | 64,128,128 | 10,192,128 | 88.0 |
| DRCaps V2 | COVIDx | 256 × 256 | 1 | (8,8), (4,4), (2,2) | 1,2 | 128 | 40 | 64,128,128 | 10,192,128 | 90.0 |
| DRCaps V3 | COVIDx | 256 × 256 | 1 | (8,8), (4,4), (2,2) | 1,2 | 128 | 80 | 64,128,128 | 10,192,128 | 85.0 |
| DRCaps V4 | COVIDx | 256 × 256 | 1 | (8,8), (4,4), (2,2) | 1,2 | 128 | 0.392 | 64,128,128 | 10,192,128 | 10.0 |
| Study | Model | Data | Input | Channels | Capsules | Classes | Decoder | Recons. | Max-Pooling | Data Aug. | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ali et al. [47] | 19-layers CNN | X-ray | 227 × 227 | 3 | nm | 2 | nm | no | yes | no | 98.5 |
| Mittal et al. [33] | ECC | X-ray | 100 × 100 | 1 | 36,864 | 2 | 2 | yes | no | no | 95.9 |
| Afshar et al. [34] | COVID-CAPS | X-ray | 224 × 224 | 3 | nm | 2 | nm | no | yes | no | 95.7 |
| Kruthika et al. [9] | CapsNets | MRI | 64 × 64 | 1 | 18,432 | 3 | 3 | yes | no | no | 94.0 |
| this | DR CapsNet | CT | 226 × 226 | 1 | 128 | 3 | 3 | yes | no | no | 90.0 |
| Mobiny and Van Nguyen [7] | Fast CapsNet | CT | 32 × 32 | 1 | 2048 | 2 | nm | yes | no | no | 88.5 |
| Khanna et al. [4] | DECAPS | CT | 448 × 448 | nm | nm | 2 | nm | no | no | yes | 87.6 |
| Sarki et al. [48] | VGG-16 CNN | X-ray | 224 × 224 | 3 | nm | 3 | nm | no | yes | no | 87.5 |
| Afshar et al. [8] | CapsNets | MRI | 64 × 64 | 1 | 18,432 | 3 | 3 | yes | no | no | 86.5 |
| Xiang et al. [32] | 3-D ResCapsNet | ABUS | 128 × 128 | nm | nm | 2 | nm | no | no | nm | 84.9 |
| Toraman et al. [35] | CapsNets | CT | 128 × 128 | 1 | 8192 | 3 | 4 | yes | yes | yes | 84.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rangel, G.; Cuevas-Tello, J.C.; Rivera, M.; Renteria, O. A Deep Learning Model Based on Capsule Networks for COVID Diagnostics through X-ray Images. Diagnostics 2023, 13, 2858. https://doi.org/10.3390/diagnostics13172858
Rangel G, Cuevas-Tello JC, Rivera M, Renteria O. A Deep Learning Model Based on Capsule Networks for COVID Diagnostics through X-ray Images. Diagnostics. 2023; 13(17):2858. https://doi.org/10.3390/diagnostics13172858
Chicago/Turabian StyleRangel, Gabriela, Juan C. Cuevas-Tello, Mariano Rivera, and Octavio Renteria. 2023. "A Deep Learning Model Based on Capsule Networks for COVID Diagnostics through X-ray Images" Diagnostics 13, no. 17: 2858. https://doi.org/10.3390/diagnostics13172858
APA StyleRangel, G., Cuevas-Tello, J. C., Rivera, M., & Renteria, O. (2023). A Deep Learning Model Based on Capsule Networks for COVID Diagnostics through X-ray Images. Diagnostics, 13(17), 2858. https://doi.org/10.3390/diagnostics13172858