Abstract
The lack of gas turbine field data, especially faulty engine data, and the complexity of fault embedding into gas turbines on test benches cause difficulties in representing healthy and faulty engines in diagnostic algorithms. Instead, different gas turbine models are often used. The available models fall into two main categories: physics-based and data-driven. Given the models’ importance and necessity, a variety of simulation tools were developed with different levels of complexity, fidelity, accuracy, and computer performance requirements. Physics-based models constitute a diagnostic approach known as Gas Path Analysis (GPA). To compute fault parameters within GPA, this paper proposes to employ a nonlinear data-driven model and the theory of inverse problems. This will drastically simplify gas turbine diagnosis. To choose the best approximation technique of such a novel model, the paper employs polynomials and neural networks. The necessary data were generated in the GasTurb software for turboshaft and turbofan engines. These input data for creating a nonlinear data-driven model of fault parameters cover a total range of operating conditions and of possible performance losses of engine components. Multiple configurations of a multilayer perceptron network and polynomials are evaluated to find the best data-driven model configurations. The best perceptron-based and polynomial models are then compared. The accuracy achieved by the most adequate model variation confirms the viability of simple and accurate models for estimating gas turbine health conditions.
1. Introduction
Reliable gas turbine health information is essential for successful the implementation of condition-based maintenance [1] Gas-path diagnostic techniques provide such information by analyzing engine performance and early identifying potential faults before they develop into serious accidents [2]. Many maintenance actions are based on these diagnostic judgments resulting in maximal asset profitability, reliability, and availability and minimal life cycle costs [3]. To get information about engine operation and possible faults, the diagnostic algorithms employ recorded data and different models. According to the utilization of the data and the models, the gas-path diagnostics can be split into two main approaches.
The first approach, called a Gas Path Analysis (GPA), relies on a nonlinear physics-based engine model. Such a model, also known as a thermodynamic model, involves thermodynamic and other physical relationships to compute gas path variables for given engine operating conditions and health parameters. Engine components (compressor, turbine, burner, etc.) are presented in the model by experimental component performance maps initially corresponding to a new engine. As with real faults that change component performances, the health parameters can slightly shift component performance maps to simulate different degradation mechanisms. Typically, the flow capacity and efficiency performances of each component are corrected [4]. GPA can also employ a linear model, however, to compute the necessary fault influence coefficient matrix, the thermodynamic model is still used.
Known thermodynamic model programs include but are not limited to Gas turbine Simulation Program (GSP), Numerical Propulsion System Simulation (NPSS), Propulsion Object-Oriented Simulation Software (PROOSIS), and GasTurb [3,5]. The latter software was developed by Kurzke [6] and offers nonlinear simulation for many configurations of different gas turbine engines [3]. A nonlinear thermodynamic model enables the creation of different simplified models. The most known of them is a linear model that relates small changes of health parameters to the corresponding changes of monitoring variables through a so-called influence coefficient matrix.
The described nonlinear and linear models present a direct mathematical problem, in which operating conditions and health parameters are independent quantities and monitored variables present dependent quantities. The considered diagnostic approach aims to solve an inverse problem [7] that allows estimating unmeasured parameters through the measured variables and knowledge of the physical processes of the system, making inferences from data [8]. A difficulty of inverse problems on multidimensional space is the instability of their solutions, in other words, small errors in measurements can cause large errors in the estimated parameters. There exist many methods to solve inverse problems, among them, regularization, Truncated Singular Value Decomposition (TSVD), interactive methods, discretization, the maximum entropy method, Algebraic Reconstruction Technique (ART), and the Backus Gilbert method [7].
In the case of GPA, an inverse problem consists in evaluating the conditions of engine components through estimating health parameters using measured operating conditions and monitored variables [9]. In this way, a general fleet-average model is adapted to a particular real engine, and this adaption problem belongs to the area of system identification. When diagnostic algorithms employ the linear model, diagnostic matrixes [9] are computed, for example, by the least squares method [9,10]. Study [11] reveals that linearization significantly increases the errors of estimated parameters. If engine diagnosis relies on a nonlinear thermodynamic model, different iterative procedures of the model identification are applied to estimate health parameters. For example, the authors of paper [12] propose and employ the approach called adaptive modeling, paper [13] performs the nonlinear model identification using a genetic algorithm, paper [14] proposes multicriteria identification, and paper [15] presents a strategy for automatic adaption of an identification scheme in the case of sensor malfunctions.
The second main diagnostic approach called data-driven relies on available real data and pattern recognition techniques. This approach consists of three stages: data acquisition, preliminary data processing or feature extraction, and a diagnostic process itself. Data can be acquired in three ways: field data recording, experimental test bed data acquisition, and data generation by an engine model. The field recordings suffer the data with engine fault manifestations, and physical fault embedding in real engines in test beds is too expensive [16]. Therefore, the simulation of faults-affected engine data is an effective and widely used option.
The stage of feature extraction determines the features that are sensitive to engine faults. Typically, deviations of measured values of monitored variables from baseline values corresponding to a healthy engine are computed. Given that the engine variables depend on an operating point, a baseline model is determined through the approximation of available healthy engine data at different operating points. Such a model can be called data-driven or “black box”. It does not need detailed knowledge of engine functioning and can be easily created by gas turbine operators using, for example, polynomial regression [1] or multilayer perceptron [17] as approximation functions.
Deviations of monitored variables form a feature vector, which is a pattern to be recognized. From such patterns a classification is created, in which each class is presented by numerous patterns corresponding to a specific fault. The classification data allow learning a recognition technique, mostly one of artificial neural networks.
The present paper proposes and proves a new simulation methodology for the GPA that originally presents a physics-based approach. The nonlinear thermodynamic model is accurate but complex and critical to computer resources. On the other hand, the linear model is fast but inaccurate because of linearization errors, which significantly intensify in the inverse procedure of estimating health parameters. It is proposed to consolidate the advantages of these models by creating a new nonlinear data-driven model that computes health parameters using measured operating conditions and monitored variables as inputs. Because of its nonlinear nature, such an inverse diagnostic model can conserve the accuracy of the underlying thermodynamic model. On the other hand, it will be fast due to simple data-driven functions involved and no need in inverse procedures to diagnose an engine. Furthermore, the new model will be by far more stable and reliable because during iterative computing of the thermodynamic model an engine operating point can go beyond components performance maps resulting in the loss of convergence and even abnormal program termination. The proposed inverse nonlinear data-driven model and the corresponding mode to diagnose gas turbines present a hybrid approach because the original GPA is now based on a data-driven model. Such an approach to engine modeling and diagnosis is not mentioned in extensive reviews on gas turbine diagnostics [2,3], and to our knowledge, it is novel.
To realize and prove the proposed approach, this paper employs two aircraft engines of different types, namely, turbo shaft and turbo fan. For each engine, polynomial-based and multilayer perceptron-based variations of the inverse model were created. The necessary data to build and test the models were generated by the software GasTurb that offers a nonlinear thermodynamic simulation of main gas turbine types. The use of this well-known and commercially available software in the present study allows every researcher to repeat the investigation and verify its results. For such a verification the paper provides all necessary details of the calculations performed.
2. Gas Turbine Simulation Techniques
2.1. Thermodynamic Model
As it follows from the previous section, the data required to create the inverse nonlinear models are generated in GasTurb by gas turbine thermodynamic models of the corresponding test-case engines. Each gas turbine component is presented in a thermodynamic model by a component performance map. Using known thermodynamic relations and mechanical laws, this model relates gas path variables to component performances and engine steady-state operating points. The process of computing gas path variables is organized as the solution of a system of nonlinear algebraic equations reflecting a balance of mass, heat, and energy in those components at steady states. The system is usually solved by the Newton–Raphson method, aka Newton’s method. The computation is complex and includes some iterative cycles. The model software is considerably complex and comprises dozens of subprograms. As a result of the computation, the model determines gas path quantities including an [m × 1]-vector of monitored variables as a function of an [n × 1]-vector of operating conditions (power set and ambient variables) and an [r × 1]-vector of special health parameters. Thus, the thermodynamic model can be presented by the following mathematical expression [18]:
The health parameters can be presented by an expression . A vector corresponds to a healthy engine and nominal component performances, while a vector of fault parameters allows shifting performance maps to simulate different scenarios of engine deterioration with varying severity.
2.2. Multilayer Perceptron
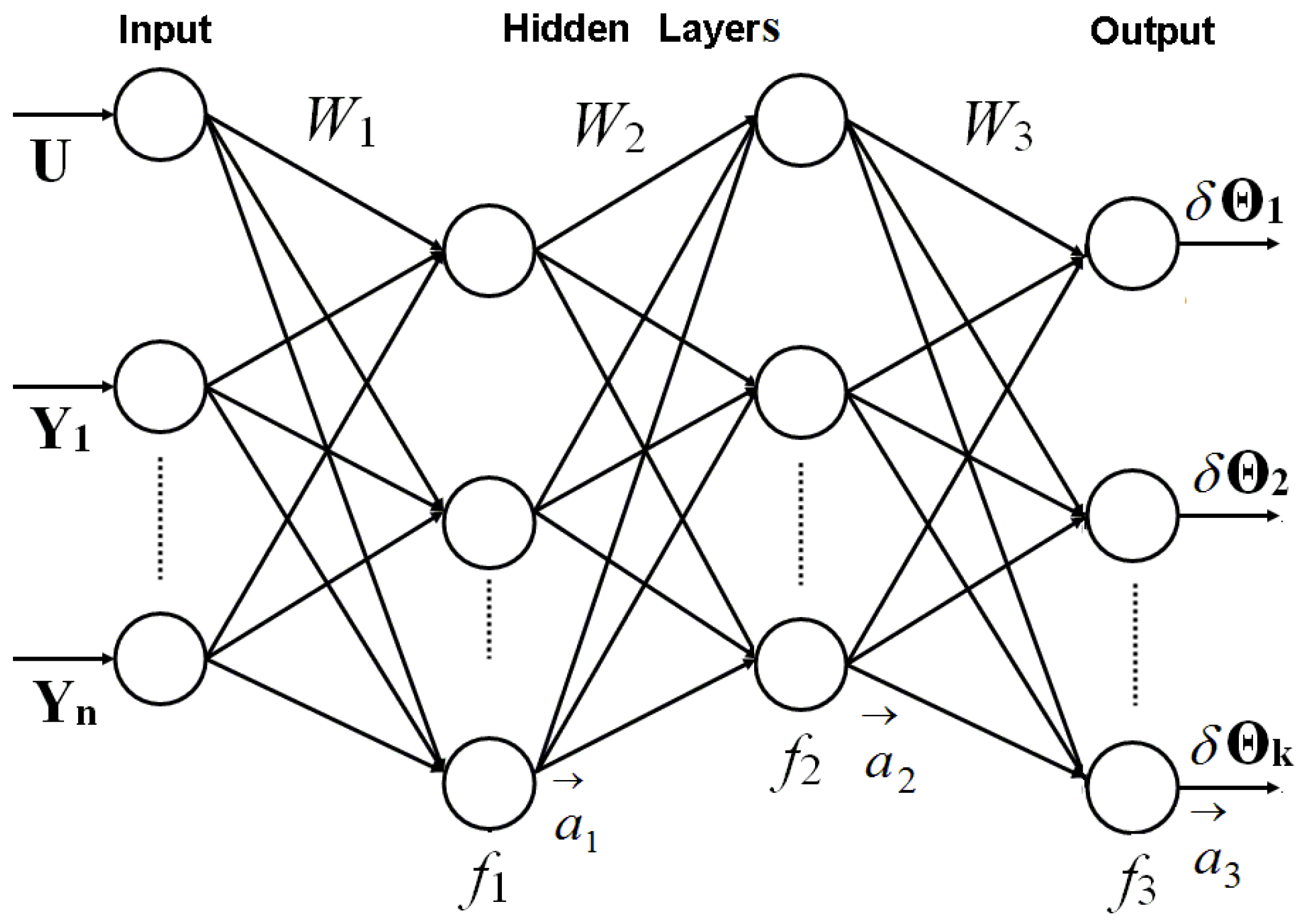
The multilayer perceptron (MLP) is known as an artificial neural network capable to solve both classification and approximation problems. As an approximation technique, it is employed in gas turbine diagnostics for building a gas turbine baseline model [17] that computes monitored variables as a function of operating conditions. Figure 1 illustrates the structure and operation of the MLP [19,20] proposed to develop the diagnostic models for the present study. MLP includes three types of layers. The input layer is represented by operating conditions and monitored variables and is followed by two hidden layers and an output layer of the health parameters.
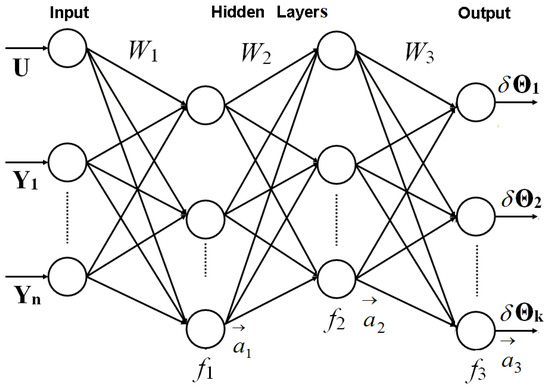
Figure 1.
Two hidden layers MLP proposed to develop the GasTurb diagnostic models.
The perceptron presents a feed-forward network in which all signals go from the input to the output. In this network, all nodes of adjacent layers are connected. Each connection has a weight coefficient. The coefficient of one layer constitute the corresponding matrix W1, W2, or W3. All the signals of one layer multiplied by its weight coefficients and summed to form an input to each node of the subsequent layer. A transfer function f1, f2, or f3 transforms this input into a node output. The outputs of all the layer nodes constitute a vector , , or . Then these operations are repeated for the next layer, and so on. Finally, output signals are computed. The described procedure can be written by the following expressions , , and , where is a network input vector constituted by operating conditions U and monitored variables Y.
To find unknown weight coefficients, the perceptron undergoes multiple iterations (epochs) of a back-propagation learning algorithm that minimizes the total error of the network output. In every epoch, the coefficients are corrected in the direction that reduces the output error. The epochs are repeated unless the algorithm finds the error minimum. Before estimating waiting coefficients, network hyperparameters should be determined, namely, the number of hidden layers, numbers of neurons on each hidden layer, type of activation functions, and number of epochs. This is an optimization process [21] usually conducted through manual trial-and-error methods [22].
2.3. Polynomials
The research conducted by Loboda et al. [23] successfully applies second-order polynomials to create a gas turbine baseline model. Hence, this type of polynomials was chosen as a candidate technique in the present study.
As described in Section 1, the proposed inverse diagnostic model has structure . The model was created on the data corresponding to standard ambient conditions. Therefore, within the vector the model uses only one element, a power set variable. To use the model for other ambient conditions, the input variables and U should be corrected to the standard conditions using known correction relations [24]. Given the above explanation, the second-order polynomial model for one fault parameter δΘ takes a form:
This equation can be rewritten in a vector form as . Where is a k × 1 vector of the coefficients, and presents a k × 1 vector of products of Y and U multiplied by the corresponding coefficients in Equation (2).
The polynomials for all fault parameters δ are presented in a generalized form by the following expression:
where a k × r matrix A includes unknown coefficients for all r health parameters. Given that a single operating point is not sufficient to compute all the coefficients, the data used to estimate the coefficients incorporate t operating points with different operating and health conditions. Let the totality of the health parameters values be a t × r matrix δΘ and the set of all the values of Y and U products be a t × k matrix V. A linear system of equations for parameters δΘ will take a form δΘ = VA then.
For the sake of high accuracy of estimates δΘ, a great volume of the input data is engaged, and a widespread solution
is drawn by the least-squares method.
The input data were generated by the software GasTurb for turbo shaft and turbo fan engines. The turbo shaft is set as a primary test case engine and has great volume of generated data, on which, many influencing factors are studied. The turbo fan is a secondary test case engine with smaller volume of data to verify a general viability of diagnostic models proposed.
3. Turbo Shaft Diagnostic Models
3.1. Input Data
For the turbo shaft, GasTurb simulates the following variables that are usually measured in real engines and can be used for engine monitoring: temperatures and pressures at the outlet of each compressor and turbine and fuel flow. Among the operating conditions, a compressor spool speed, ambient temperature, and ambient pressure are simulated. The present study uses the spool speed as a model input variable while the ambient temperature and pressure have constant standard values. The available and chosen fault parameters are those that correct capacity and efficiency performances of the compressor and turbines. Table 1 specifies all these quantities.

Table 1.
Turbo shaft simulated quantities.
The multidimensional space of the chosen fault parameters causes the need for a large amount of simulated data to fully cover this space. Therefore, each of the six fault parameters ΔCC, ΔCE, ΔHPTC, ΔHPTE, ΔPTC, and ΔPTE had the same 6 levels of values: 0%, 1%, 2%, 3%, 4%, and 5%. These fixed levels were introduced to better see the influence of degradation severity on simulation errors. Five operating regimes were set by different spool speed values. For each regime, the simulated data include the necessary Y and U variables at 1458 operating points with different combinations of the fault parameters and their levels. In total for all operating regimes, the data embrace 7290 operating points. They are divided into a learning set embracing 85% of data from each regime and a validation set with the rest of the data.
For additional model verification, a testing set was also generated. At each operating regime it has 150 points with a random distribution of the fault parameters in the interval (0%, −5%), resulting in a total of 750 points for the 5 regimes. This uniform random parameter distribution allows fully covering a simulation area and therefore is favorable to accurate data approximation. The chosen parameter interval corresponds to the recommendations of the extensive study carried out by Fentaye et al. [2] on different degradation mechanisms and engine performance losses that they cause.
3.2. Perceptron Configuration
Perceptron with one hidden layer architecture is sufficient for any classification problem, and several studies confirm it [25]. However, for a continuous function approximation problem, one hidden layer did not prove to be better than a second-degree polynomial [23]. Based on this reasoning and studies on noise filtering [26,27] which recommend a two hidden layers perceptron, configurations with one and two layers were chosen for the proposed diagnostic models. In these models, the monitored variables and the operating condition U are inputs, and the fault parameters are outputs. Kolmogorov’s theorem is a notable reference for an initial perceptron configuration, proposing that the number of neurons in the hidden layer of an ANN should not be greater than [28], where n denotes the number of inputs. The perceptron is learned using the variations of a back-propagation algorithm [29] available in Matlab.
3.3. One Regime Diagnostic Model
To gain better understanding of the influence of the arguments on model accuracy, a simplified model for diagnosing on one fixed regimen is first created. The MLP network employed for this model has the monitored variables as inputs and the fault parameters as outputs. Different configurations of one and two hidden layers were tested, using all the 18 training methods available in Matlab. For each method, the learning was performed with different numbers of training epochs to choose the optimal number for the method. The comparison criterion for the analyzed methods was the root mean square error (RMSE) between the true values used in GasTurb and the values simulated by the network. Table 2 shows the results of the best final configurations of the network with one hidden layer (ANN 1) and the network with two hidden layers (ANN 2). The operating regime is set here by a relative spool speed of 1.0 that corresponds to the maximum power of 100%. One can see that, according to the average accuracy shown in the last row, ANN 2 trained by the trainbr Matlab function (Bayesian Regulation) is the best configuration.
Table 2.
RMSE for MLP configurations of one regime diagnostic model (turbo shaft, relative spool speed 1.0).
After the demonstration of the high accuracy of the two hidden layers MLP, tests were performed to determine the number of neurons in the second hidden layer. Different numbers were tested keeping constant the regime (100%), eight neurons in the first hidden layer, the method (Bayesian Regulation), and the training epochs (500). Table 3 shows the results, which allow pointing out that increasing the neurons number generally enhances the accuracy, and the best network configuration has 28 hidden neurons.
Table 3.
Selection of optimal neurons number (turbo shaft, relative spool speed 1.0).
Once the number of neurons in the second hidden layer was defined, the MLP was also tested at the other 4 operating regimes given by relative spool speed values 0.9 (90%), 0.8, 0.7, and 0.6. The results for all 5 regimes presented in Table 4 show that an accuracy level remains high for all the regimes.
Table 4.
RMSE for 5 operating regimes.
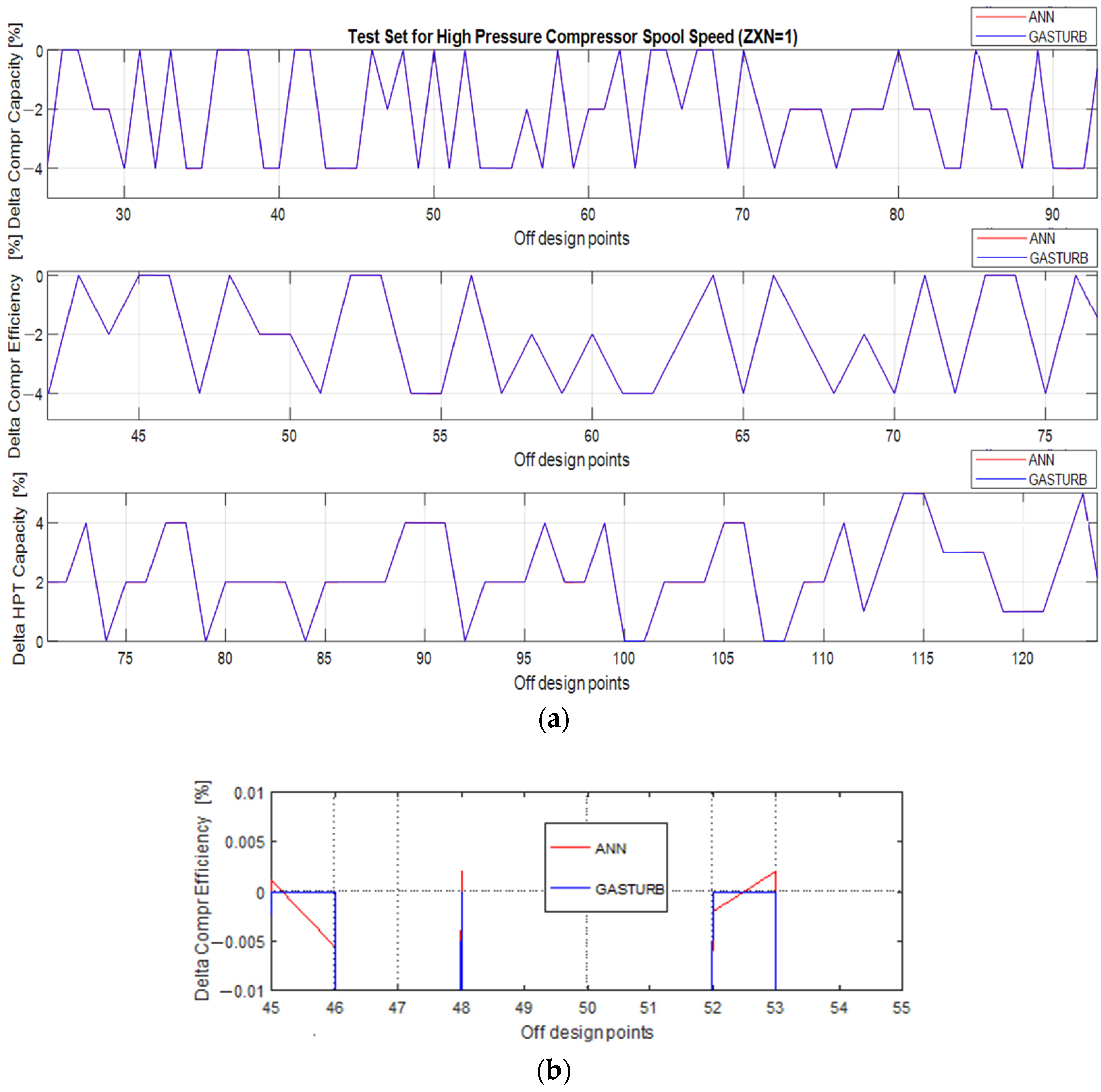
Figure 2 confirms a high degree of approximation accuracy achieved by the MLP network. Figure 2a shows three fault parameters used in GasTurb in comparison with the same parameters simulated by MLP. Both curves practically coincide in the figure for all parameters in all points. Enlarged scale plot of the second parameter in Figure 2b shows that maximal difference between original and MLP values is about 0.005%. It is 200 times smaller than 1% that is usually considered as the minimal value of the changes induced by engine faults. Thus, one can state that the MLP-based model of fault parameters is accurate enough and useful for diagnosing engines.
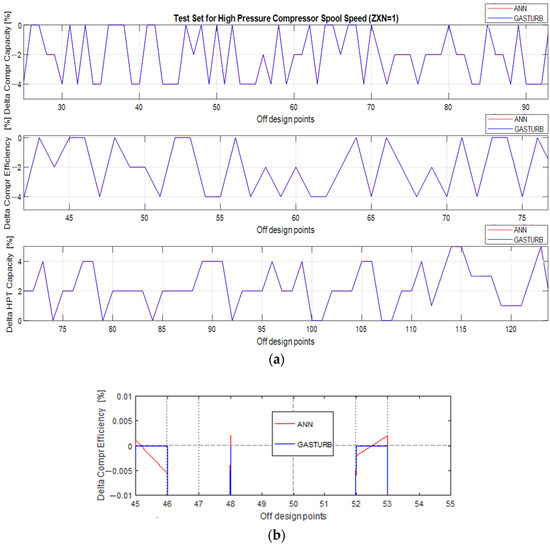
Figure 2.
Original fault parameters and parameters simulated by ANN-based one regime diagnostic model ((a) 3 parameters, normal scale; (b) compressor efficiency parameter, enlarged scale).
3.4. Extended Diagnostic Model
The model studied in the previous subsection is intended for diagnosing on a fixed regime. To make the model more universal and useful, it is extended by adding a spool speed variable to the model inputs. Such a model will have a structure . In contrast to the previous subsection, where each model was determined with an individual data set generated at one of the 5 regimes, the new model will be learned with all data sets available from different regimes. Since the model change is small, from 9 to 10 inputs with the same outputs, the same MLP configurations were verified. The one- and two-hidden-layers MLP were again tested with a wide variety of neuron numbers, epochs, and training methods. Table 5 shows the test results for two network configurations and two learning functions. As before, two hidden layer networks learned by the Bayesian training method expose the best accuracy.
Table 5.
RMSE for best MLP configurations of extended diagnostic model.
Having demonstrated the greater precision of the two-hidden-layer MLP, tests were carried out to determine the number of neurons in the second layer, keeping constant the training method and epochs number. Based on previous experience with the one-regime model, 19 to 31 neurons were probed in the second hidden layer. Table 6 shows the test set results, namely RMSE of health parameters for each node number. As can be seen, the configuration with 27 neurons in the second hidden layer is the most accurate.
Table 6.
Selection of the optimal neurons number (turbo shaft, extended model).
In comparison with the one-regime models that have very low approximation errors, the extended model errors are significantly greater. According to Table 4 and Table 6, the errors have increased 5–10 times. Even with this loss of accuracy, the network proposed appears capable of diagnosing. Against the background of fault parameter values that vary from 1% to 5%, the average error will be only 0.0534% i.e., 20 times lower than the smallest parameter value.
3.5. Comparison between Approximation Functions for the Extended Model
Loboda et al. [23] compared the approximation capabilities of the second-degree polynomials and a typical single hidden layer MLP in the application to a baseline model. The MLP showed a better data approximation in the training sets, however, in the test sets it lost accuracy, although the authors expected the superiority of the network. They pointed out very similar performances of both tools with slight dominance of the polynomials and abandoned the idea of the superiority of MLP.
The above-cited work inspired us to develop a polynomial-based extended model and compare it with the network-based model to choose the best one. Both turbo shaft models were trained on the learning set and applied to the validation and testing sets described in the subsection “Input data”.
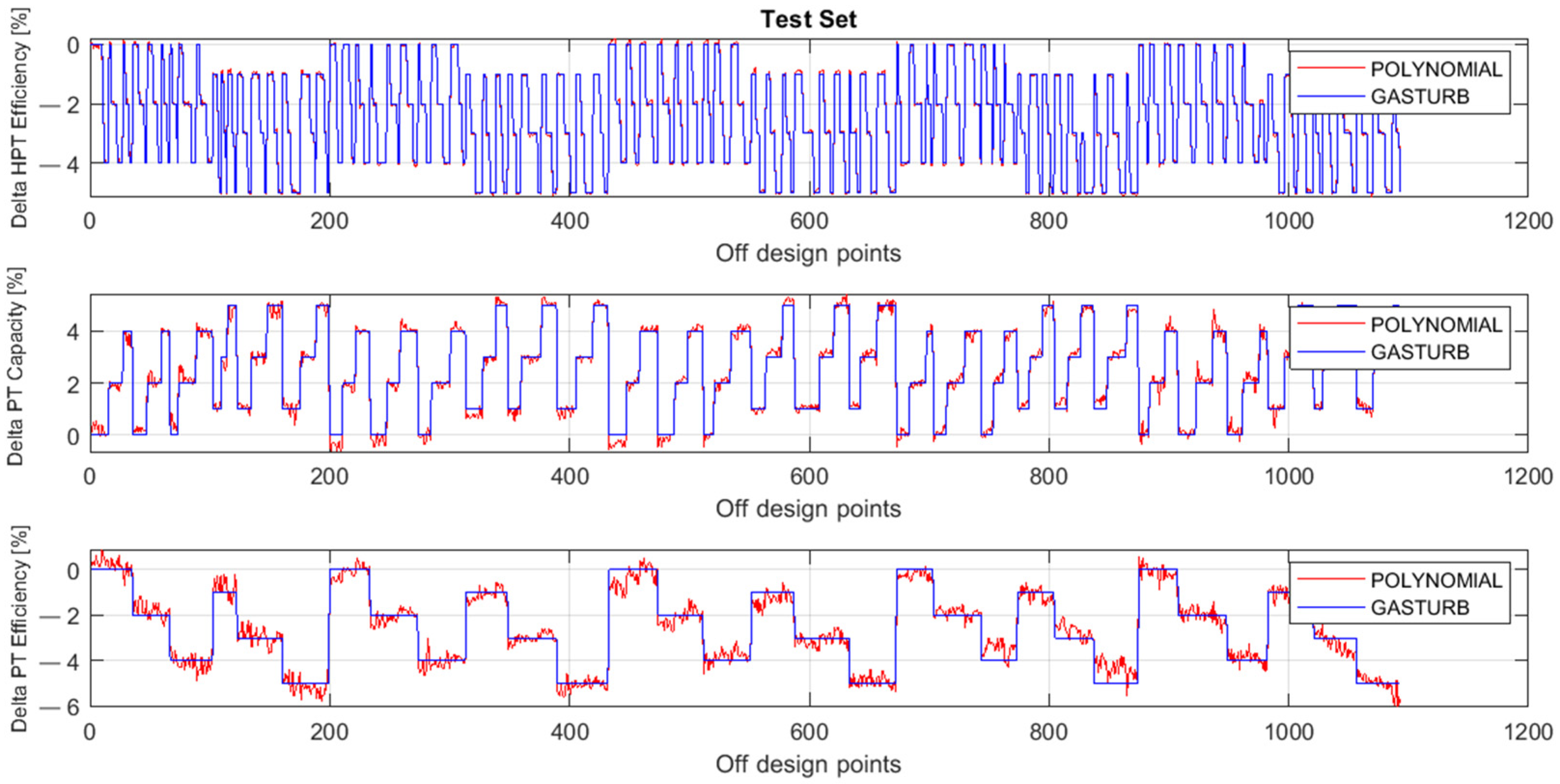
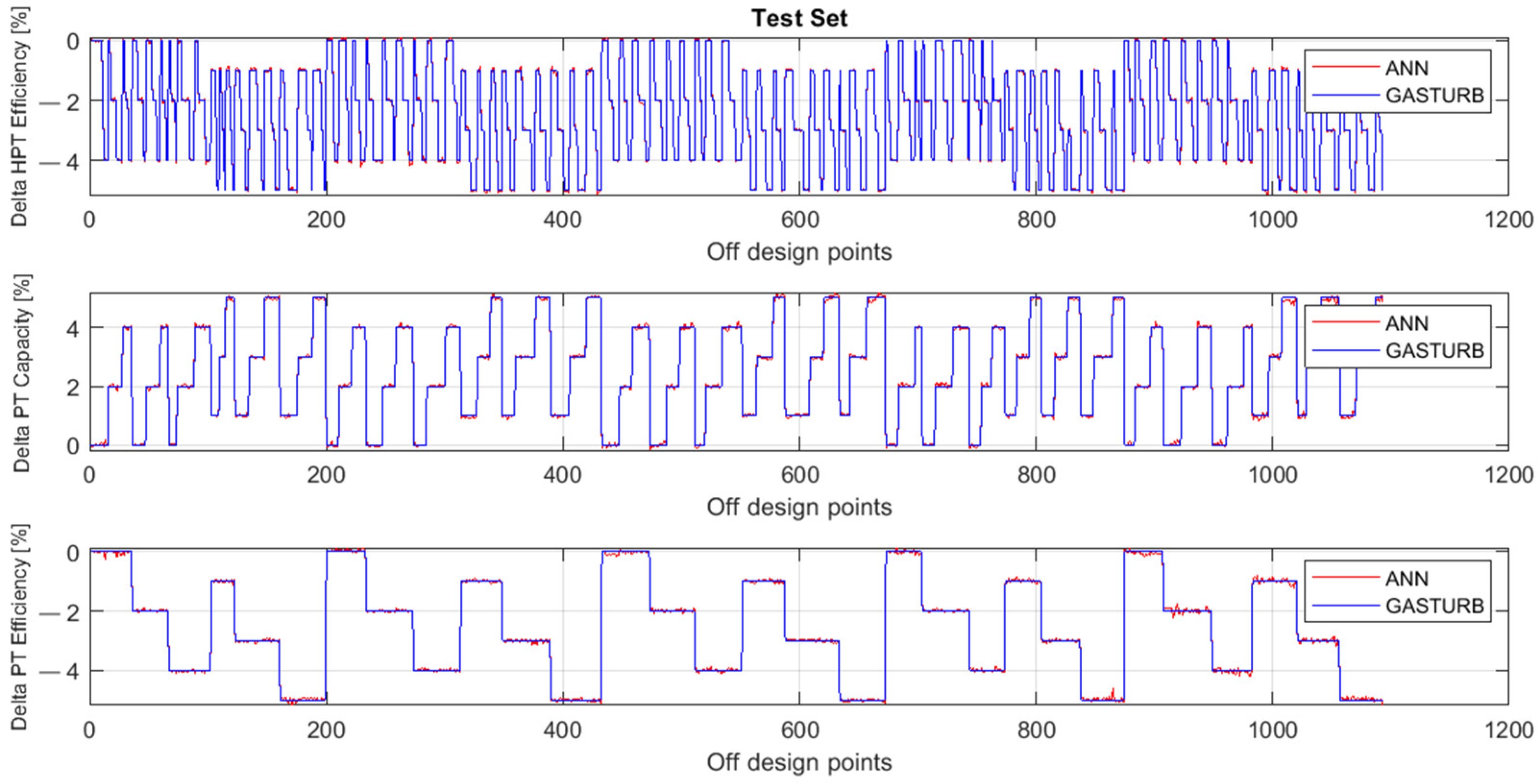
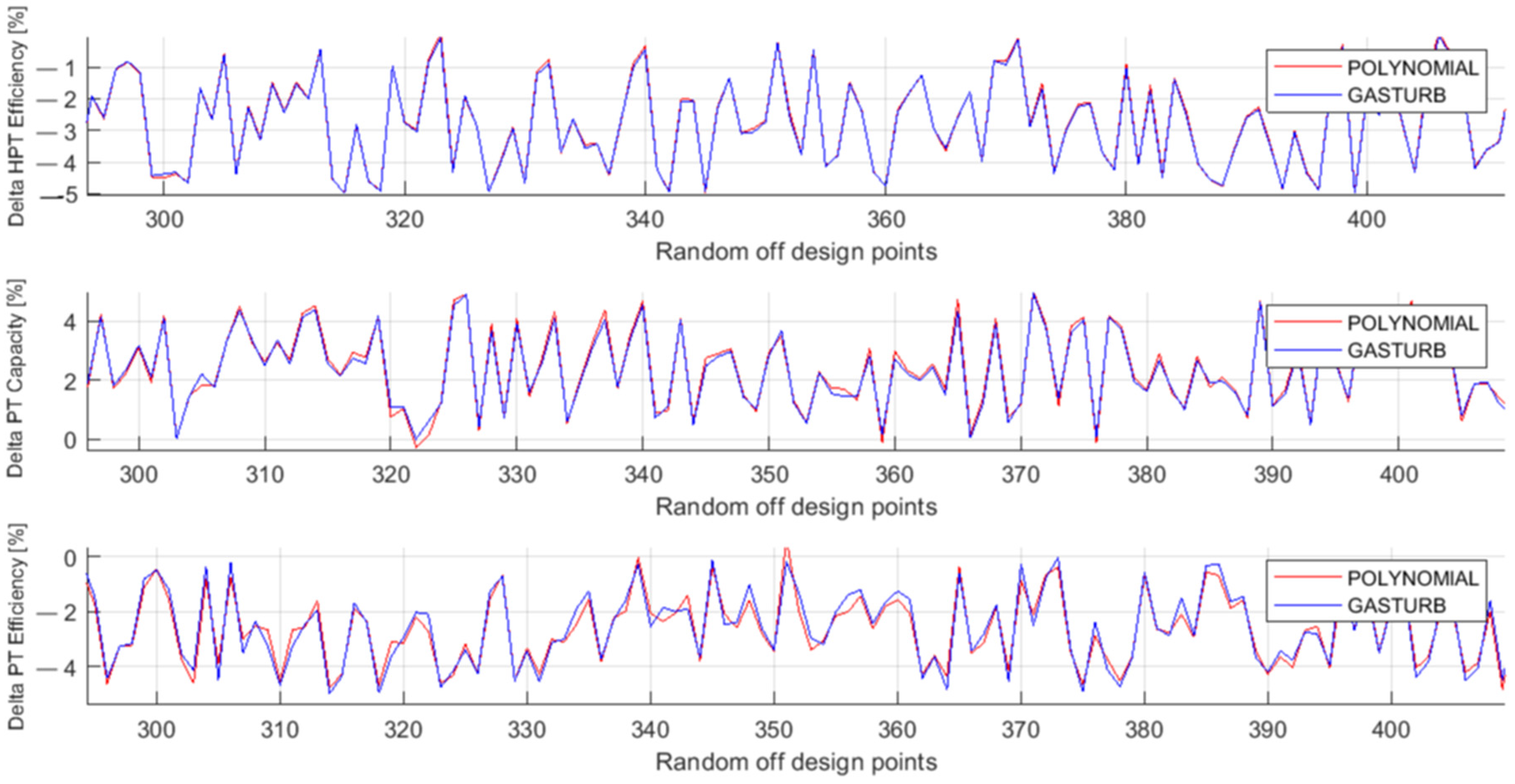
Figure 3 presents the fault parameters ΔHPTE, ΔPTC, and ΔPTE employed in GasTurb and simulated by second-degree polynomials. All the data plotted in the figure are from the validation set. Figure 4 shows the same parameters, but the simulation was performed by the two-hidden-layer MLP. Comparing these figures separately for each fault parameter, the MLP simulation is much closer to the true values than the polynomial simulation for all the parameters presented.
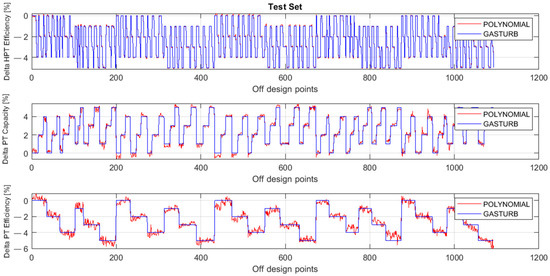
Figure 3.
Fault parameters ΔHPTE, ΔPTC, and ΔPTE, true and simulated by polynomials (validation set).
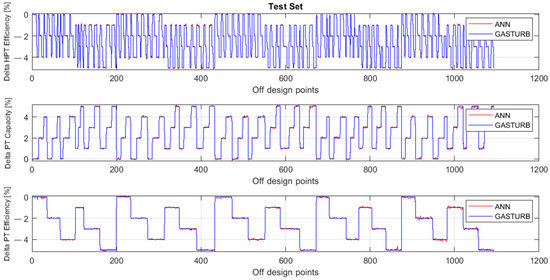
Figure 4.
Fault parameters ΔHPTE, ΔPTC, and ΔPTE, true and simulated by MLP (Validation set).
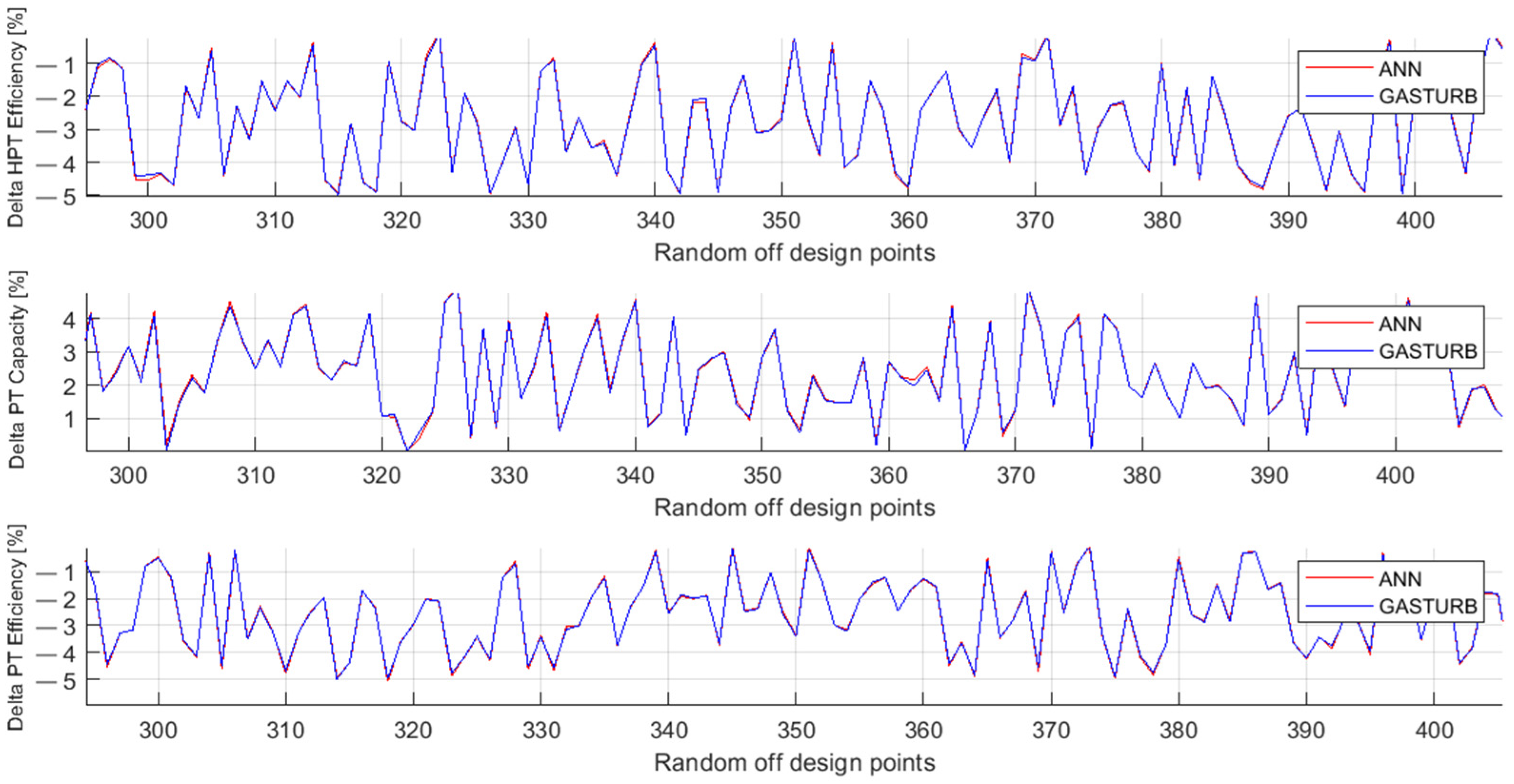
Figure 5 and Figure 6 illustrate the behavior of the same parameters as Figure 3 and Figure 4, but the parameters are now computed for the testing set. The comparison of these figures confirms the previous conclusion that the MLP-based model has higher accuracy.
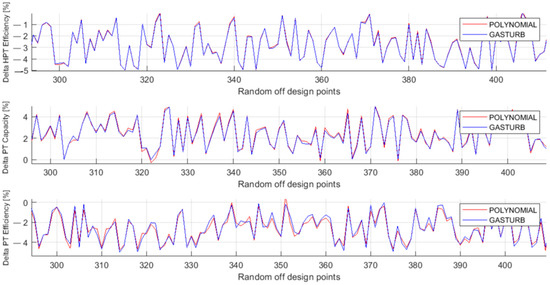
Figure 5.
Fault parameters ΔHPTE, ΔPTC, and ΔPTE, true and simulated by polynomials (Testing set).
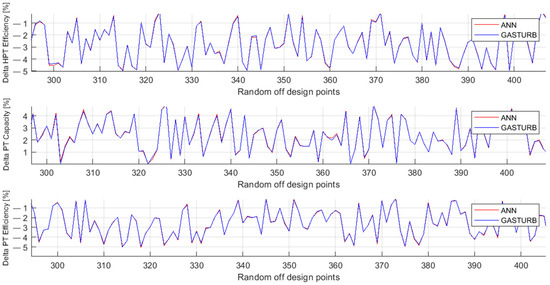
Figure 6.
Fault parameters ΔHPTE, ΔPTC, and ΔPTE, true and simulated by MLP (Testing set).
In addition to the qualitative analysis of Figure 3, Figure 4, Figure 5 and Figure 6, Table 7 helps us to make a quantitative comparison of the polynomials- and the MLP-based models. The table includes mean fault parameter errors of both techniques on the data of the learning, validation, and testing sets. Each data set shows that the MLP-based model is by far more accurate for each parameter and in general.
Table 7.
Fault parameter RMSE of polynomials and MLP.
To validate the results obtained for the turbo shaft, the turbo fan was chosen as the second motor due to its wide use as a power plant for passenger and cargo aircrafts.
4. Diagnostic Models of the Turbo Fan
4.1. Input Data
As with the turbo shaft, to develop turbo fan diagnostic models, data with different fault and operating conditions were generated by GasTurb. The following variables were simulated and recorded. An engine operating regime is set in GasTurb by an HPC spool speed variable. Among simulated gas path quantities, seven variables usually used for monitoring were chosen. As to fault parameters, their number was increased from six to eight because the turbo fan has a greater complexity and more components that need estimating their health condition. Table 8 specifies all these quantities.
Table 8.
Simulated quantities of turbo fan.
Given that the turbo fan presents a secondary test case aimed to confirm the general viability of the proposed diagnostic model, and that the work with GasTurb is mostly manual, the total volume of generated data is smaller. For each of the 5 regimes, the data include 700 operating points with different fault parameters randomly distributed within the range of 0% to ±5%. In this way, the total data include 3500 operating points. A learning set, which is used to determine turbo fan diagnostic models, embraces 85% of data from each regime. The rest of the data form a validation set intended for the model verification. All the indicators of models’ accuracy illustrated in the below subsections were obtained on the validation data.
4.2. Extended MLP-Based Turbo Fan Diagnostic Model
Since one regime models of the turbo shaft were intermediate and not intended for a diagnostic application, these models were not created for the turbo fan. The extended models were only formed, and the methodology used to build and verify the turbo shaft models was conserved. As the first step, all available MLP training methods were probed, resulting in choosing the method of Bayesian regularization as the most accurate. Then, different network configurations with a varying number of neurons were tested. The RMSEs for these configurations are placed in Table 9. Comparing it with Table 6, one can observe a general error increase. It is more significant for the first two health parameters. This fact will be further analyzed. As to the influence of a neuron number, it is not strong now: the average RSME changes from 0.4024 to 0.4122, and the lowest error corresponds to 19 neurons.
Table 9.
Selection of optimal neurons number (turbo fan, extended model).
4.3. Comparison between MLP- and Polynomials-Based Models
To find the best model and clarify whether the described above accuracy loss is related to the used network or is a common problem, a polynomial-based turbo fan diagnostic model was also developed. Table 10 shows the RMSEs of both models. The polynomials have the same accuracy problem. Moreover, their errors are greater for all fault parameters and almost double on average in comparison with MLP.
Table 10.
Fault parameter RMSEs of MLP and polynomials (turbo fan).
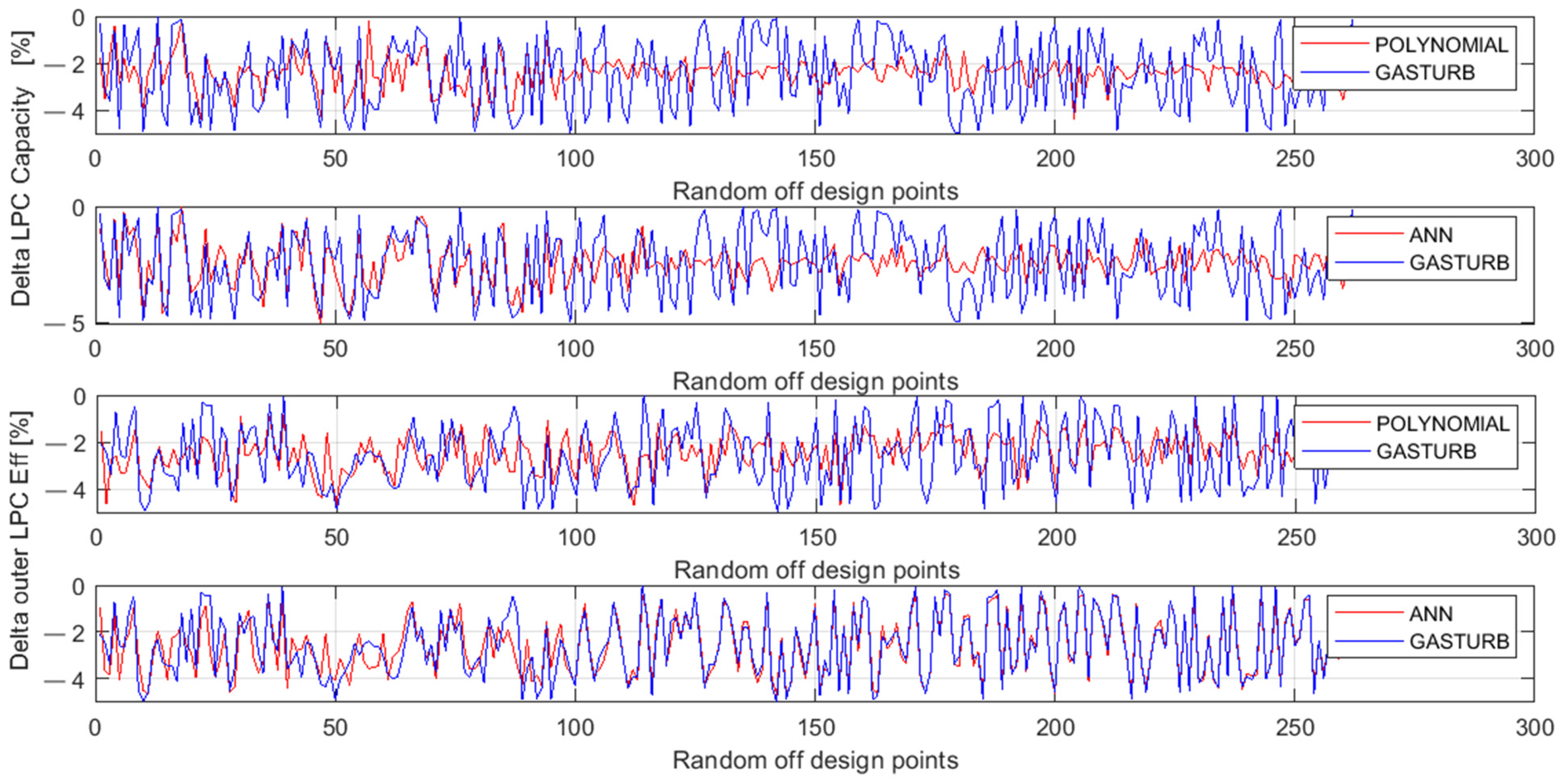
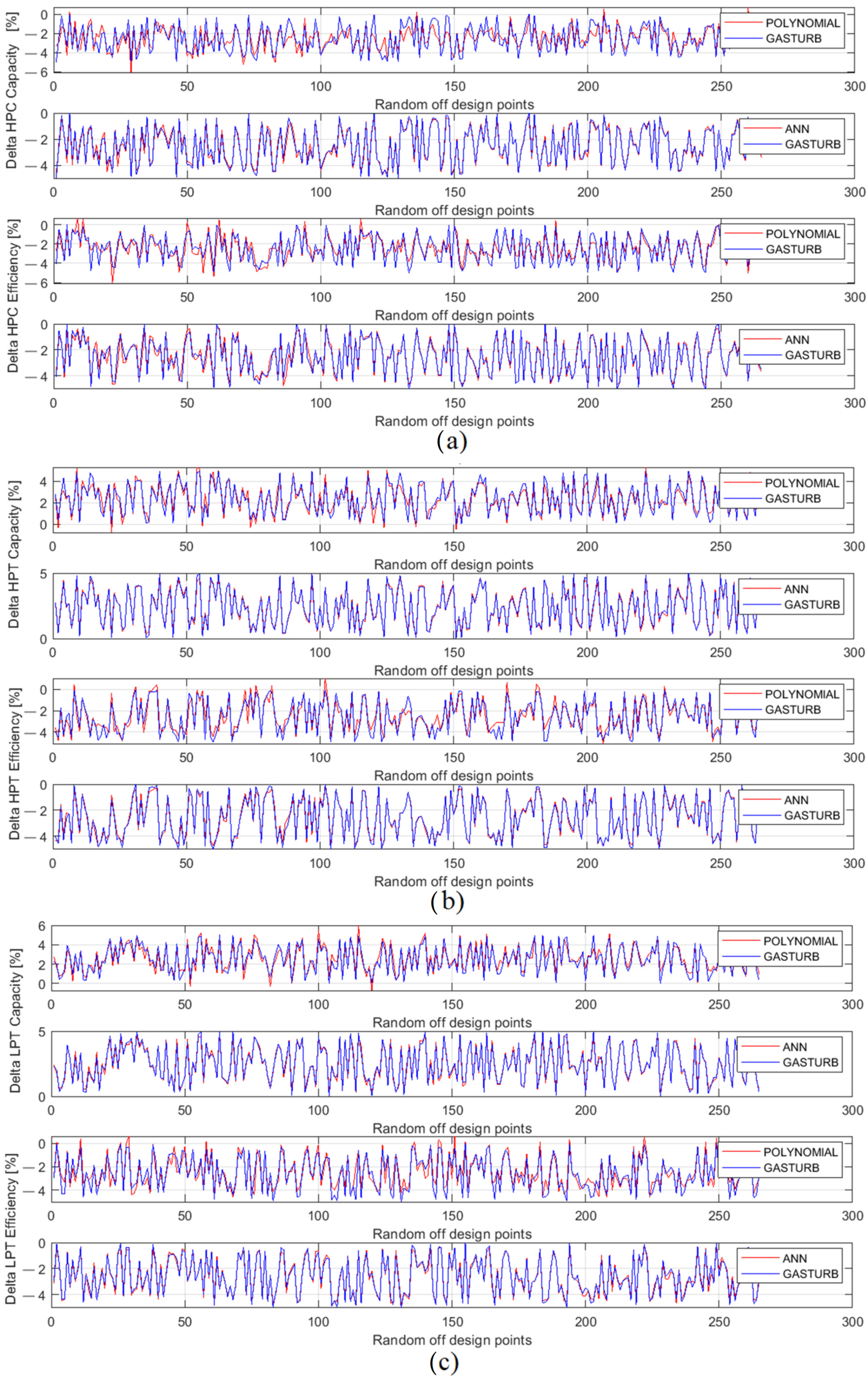
To gain a better understanding of fault parameter behavior and errors, the below analysis uses a graphical mode. Since the first two fault parameters corresponding to a ventilator expose greater errors, Figure 7 presents them separately and Figure 8 illustrates the parameters of the other components, namely, HPC, HPT, and LPT. These figures plot three quantities for each parameter: original values generated by Gas Turb, MLP simulations, and polynomials simulations.
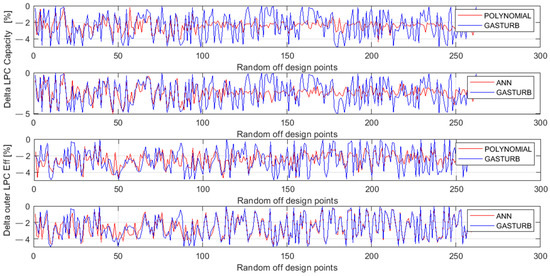
Figure 7.
Ventilator fault parameters generated by GasTurb and approximated by the polynomials and MLP.
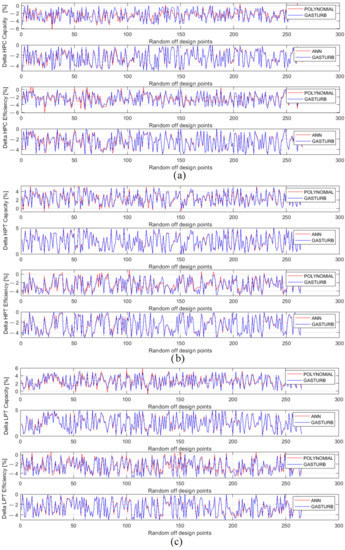
Figure 8.
HPC, HPT, and LPT fault parameters generated by GasTurb and approximated by polynomials and MLP: (a) high pressure compressor parameters, (b) high pressure turbine parameters, (c) power turbine parameters).
One can see in Figure 7 that there are visible differences (errors) between true and simulated values for both parameters and both models. The first parameter of Delta LPC Capacity has greater errors for both models, while for the second parameter MLP is more accurate. Additionally, the plots show that the simulation of the first parameter by both models becomes worse after point 100 where an operating regime changes.
Figure 8 helps to analyze the behavior of the rest of the fault parameters. A general impression of the plots presented here is that the simulated values satisfactorily follow original ones. All errors are significantly lower than those of the ventilator parameters. The only exception is the first parameter “Delta HPC Capacity” inaccurately simulated by polynomials. Moreover, for each of the parameters presented, polynomials yield to MLP.
The comparison of the two engine models shows that the turbo fan model accuracy is mostly acceptable but has worsened for both the MLP- and polynomials-based models in comparison with the turbo shaft models. This worsening is primarily related with great simulation errors of the ventilator fault parameters. Since these errors take place for both approximation techniques, they are not a particular technique problem and rather present a common estimation problem. Probable explanations are the low influence of these parameters on monitored variables and the increase of the total number of estimated parameters (from 6 for the turbo shaft to 8). Additional negative factors are the decrease of the number of monitored variables from 8 to 7 and the considerable reduction of learning data from about 6200 to 3000 operating points.
To solve this error problem, it is natural to exclude LPC fault parameters from the estimated quantities because LPC is a ventilator that is open to a visual inspection. Another way is a multipoint diagnostic option. Within this option, a diagnostic model will get the measurements from different operating points for estimating a single fault parameter vector. Such an increase of input information will yield significant improvement of estimation accuracy.
5. Conclusions
Inverse gas turbine models were developed and tested in the present paper. These diagnostic models compute unknown fault parameters of each engine component and in this way provide useful information about component health conditions. Since the goal of the GPA diagnostic approach is reached, the developed models present a complete method to diagnose gas turbines.
To obtain more general and reliable results, two alternative approximation techniques, artificial neural networks (namely, MLP) and polynomials, were chosen and applied to create the models of two different engines, turbo shaft and turbo fan. In general for all cases considered, it was found that the accuracy of fault parameters was sufficient for successful engine diagnosis. Although the turbo fan models have greater approximation errors, these errors remain significantly lower than the true values of the fault parameters. This allows correct evaluation of the health of engine components. As to the approximation techniques, a two hidden layers MLP was found to be the best and is recommended for further use.
In contrast to an original nonlinear GPA that employs a physics-based nonlinear model and an iterative adaption procedure for estimating fault parameters, the new data-driven models do the same job, but by far faster and more reliably. Since the developed models present simple, fast, and reliable diagnostic algorithms and have high accuracy, they can receive a wide application in real online diagnostic systems.
Author Contributions
Conceptualization, I.G.C. and I.L.; methodology, I.G.C. and I.L.; software, I.G.C.; validation, and J.L.P.R.; formal analysis, I.G.C.; investigation, I.G.C.; resources, I.G.C. and I.L.; data curation, J.L.P.R.; writing—original draft preparation, I.G.C.; writing—review and editing, I.L.; visualization, I.G.C.; supervision, I.L.; project administration, I.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknoledgements
The authors had the support of the Instituto Politécnico Nacional (México) and UNAM-DGAPA through the Postdoctoral fellowship program.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Borguet, S.; Léonard, O.; Dewallef, P. Regression-Based Modelling of a Fleet of Gas Turbine Engines for Performance Trending. In Proceedings of the ASME Turbo Expo 2015: Turbine Technical Conference and Exposition GT-2015, Montréal, QC, Canada, 15–19 June 2015. [Google Scholar]
- Fentaye, A.D.; Baheta, A.T.; Gilani, S.I.; Kyprianidis, K.G. A Review on Gas Turbine Gas-Path Diagnostics: State of the Art Methods, Challenges and Opportunities. Aerospace 2019, 6, 83. [Google Scholar] [CrossRef] [Green Version]
- Tahan, M.; Tsoutsanis, E.; Muhammad, M.; Abdul Karima, Z.A. Performance based health monitoring, diagnostics and prognostics for condition based maintenance of gas turbines: A review. Appl. Energy 2017, 198, 122–144. [Google Scholar] [CrossRef] [Green Version]
- Ogaji, S.; Sampath, S.; Singh, R.; Probert, S.D. Parameter selection for diagnosing a gas-turbine’s performance-deterioration. Appl. Energy 2002, 73, 25–46. [Google Scholar] [CrossRef]
- Sielemann, M.; Thorade, M.; Claesson, J.; Nguyen, A.; Zhao, X.; Sahoo, S.; Kyprianidis, K. Modelica and Functional Mock-up Interface: Open Standards for Gas Turbine Simulation. In Proceedings of the ASME Turbo Expo 2019: Turbine Technical Conference and Exposit, Chennai, India, 17–21 June 2019. [Google Scholar]
- GasTurb GmbH. GasTurb. 2020. [En línea]. Available online: http://www.gasturb.de/ (accessed on 16 December 2021).
- Groetsch, C.W. Inverse Problems in the Mathematical Sciences; Vieweg: Berlin, Alemania, 1993. [Google Scholar]
- Mosegaard, K.; Tarantola, A. Monte Carlo sampling of solutions to inverse problems. J. Geophys. Res. Solid Earth 1995, 100, 12431–12447. [Google Scholar] [CrossRef]
- Volponi, A.J. Gas Turbine Condition Monitoring and Fault Diagnostics I. In Gas Turbines; Von Karman Institute for Fluid Dynamics: Sint-Genesius-Rode, Belgium, 2003; (Lecture Series 2003-01). [Google Scholar]
- Doel, D.L. Interpretation of weighted-least-squares gas path analysis results. J. Eng. Gas Turbines Power Julio 2003, 125, 624–633. [Google Scholar] [CrossRef]
- Kamboukos, P.; Mathioudakis, K. Comparison of Linear and Non Linear Gas Turbine Performance Diagnostics. J. Eng. Gas Turbines Power 2005, 127, 49–56. [Google Scholar] [CrossRef]
- Stamatis, A.; Mathioudakis, K.; Smith, M.; Papaili, K. Gas turbine component fault identification by means of adaptive performance modeling. In Gas Turbine and Aeroengine Congress and Exibition; ASME Digital Collection: Brussels, Belgium, 1990. [Google Scholar]
- Gatto, E.L.; Li, Y.; Pilidis, P. Gas turbine off-design performance adaptation using a genetic algorithm. In IGTI/ASME Turbo Expo 2006; ASME Digital Collection: Barcelona, Spain, 2006. [Google Scholar]
- Khustochka, O.; Yepifanov, S.; Zelenskyi, R.; Przysowa, R. Estimation of Performance Parameters of Turbine Engine Components Using Experimental Data in Parametric Uncertainty Conditions. Aerospace 2020, 7, 6. [Google Scholar] [CrossRef] [Green Version]
- Stenfelt, M.; Zaccaria, V.; Kyprianidis, K. Automatic gas turbine matching scheme adaptation for robust GPA diagnostics. In Proceedings of the ASME Turbo Expo 2019, Phoenix, AZ, USA, 17–21 June 2019. [Google Scholar]
- Misté, G.A.; Benini, E. Turbojet Engine Performance Tuning With a New Map Adaptation Concept. J. Eng. Gas Turbines Power 2014, 136, 071202. [Google Scholar] [CrossRef]
- Fast, M.; Assadi, M.; De, S. Condition based maintenance of gas turbines using simulation data and artificial neural network: A demonstration of feasibility. In Proceedings of the IGTI/ASME Turbo Expo 2008, Berlin, Germany, 9–13 June 2008. [Google Scholar]
- Saravanamuttoo, H.I.H.; MacIsaac, B.D. Thermodynamic Models for Pipeline Gas Turbine Diagnostics. ASME J. Eng. Power 1983, 105, 875–884. [Google Scholar] [CrossRef]
- Duda, R.O. Pattern Classification; Wiley-Interscience: New York, NY, USA, 2001. [Google Scholar]
- Haykin, S. Neural Networks; Macmillan College Publishing Company: New York, NY, USA, 1994. [Google Scholar]
- Thomas, A.J.; Petridis, M.; Walters, S.D. On Predicting the Optimal Number Hidden Nodes. In Proceedings of the International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 7–9 December 2015. [Google Scholar]
- Ojha, V.; Snasel, V.; Abraham, A. Metaheuristic Design of Feedforward Neural Networks: A Review of Two Decades of Research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar] [CrossRef] [Green Version]
- Loboda, I.; Feldshteyn, Y. Polynomials and Neural Networks for Gas Turbine Monitoring: A Comparative Study. Int. J. Turbo Jet Engines 2011, 28, 227–236. [Google Scholar] [CrossRef]
- Volponi, A.J. Gas turbine parameter corrections. In International Gas Turbine & Aeroengine Congress & Exhibition; ASME Digital Collection: Stockholm, Sweden, 1998. [Google Scholar]
- Eswaran, K.; Singh, V. Some Theorems for Feed Forward Neural Networks. Int. J. Comput. Appl. 2015, 130, 1–17. [Google Scholar] [CrossRef]
- Castillo, I.G.; Loboda, I.; Díaz, J.G. Perceptrón Multicapa para Filtración de Datos de Entrada en el Diagnóstico de Turbinas de Gas. In Memorias del Congreso Internacional de Ingeniería Electromecánica y de Sistemas CIIES 2014; CD Publishing: Ciudad de México, Mexico, 2014. [Google Scholar]
- Lu, P.; Zhang, M.; Hsu, T.C.; Zhang, J. An Evaluation of Engine Faults Diagnostics Using Artificial Neural Networks. J. Eng. Gas Turbines Power 2001, 123, 340–346. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Kolmogorov’s mapping neural network existence theorem. In Proceedings of the International Conference on Neural Networks, San Diego, CA, USA, 21–24 June 1987. [Google Scholar]
- Demuth, H.; Beale, M. Neural Network Toolbox for Use with Matlab, User’s Guide; The MathWorks: Natick, MA, USA, 2002. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).