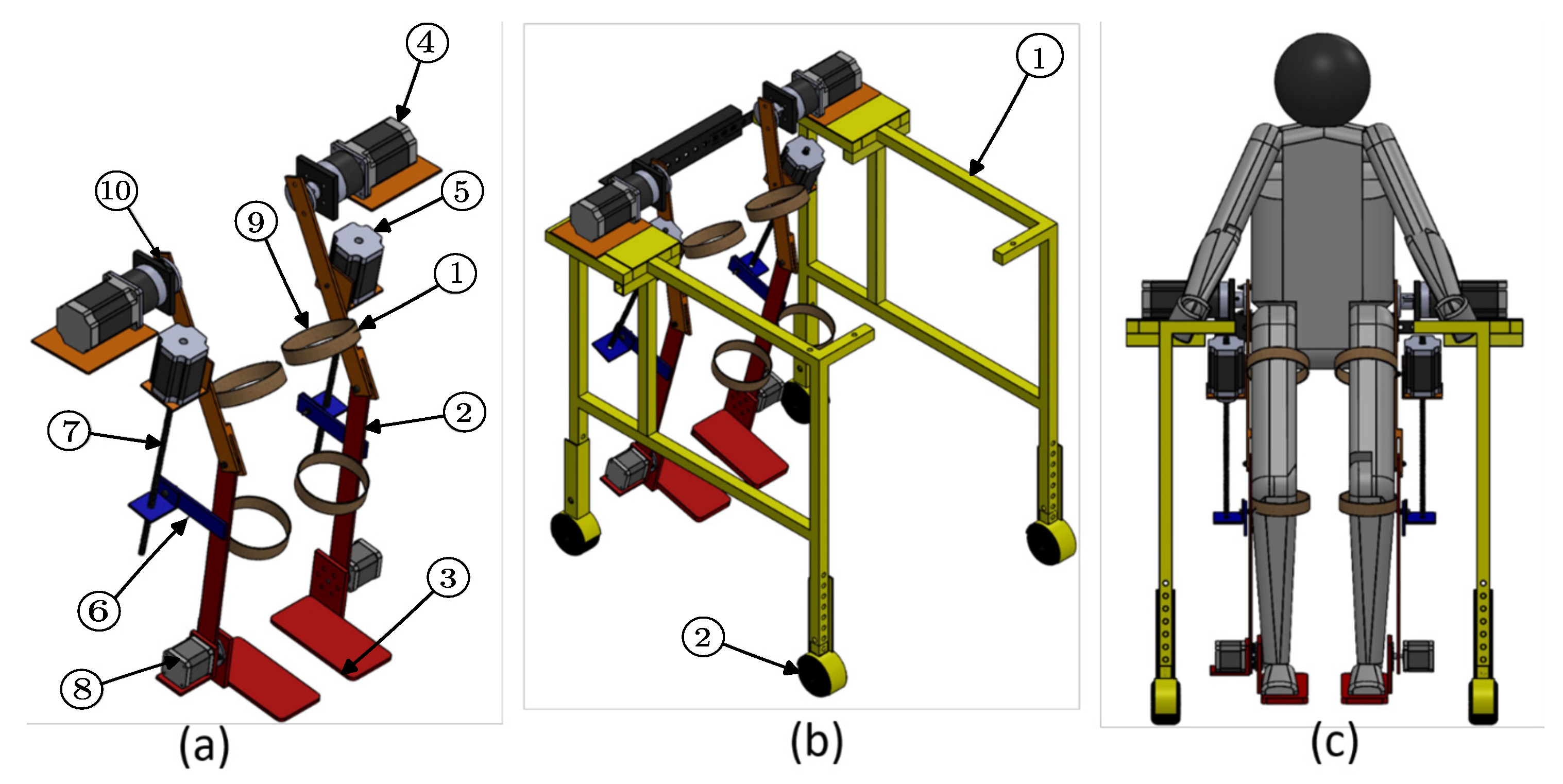
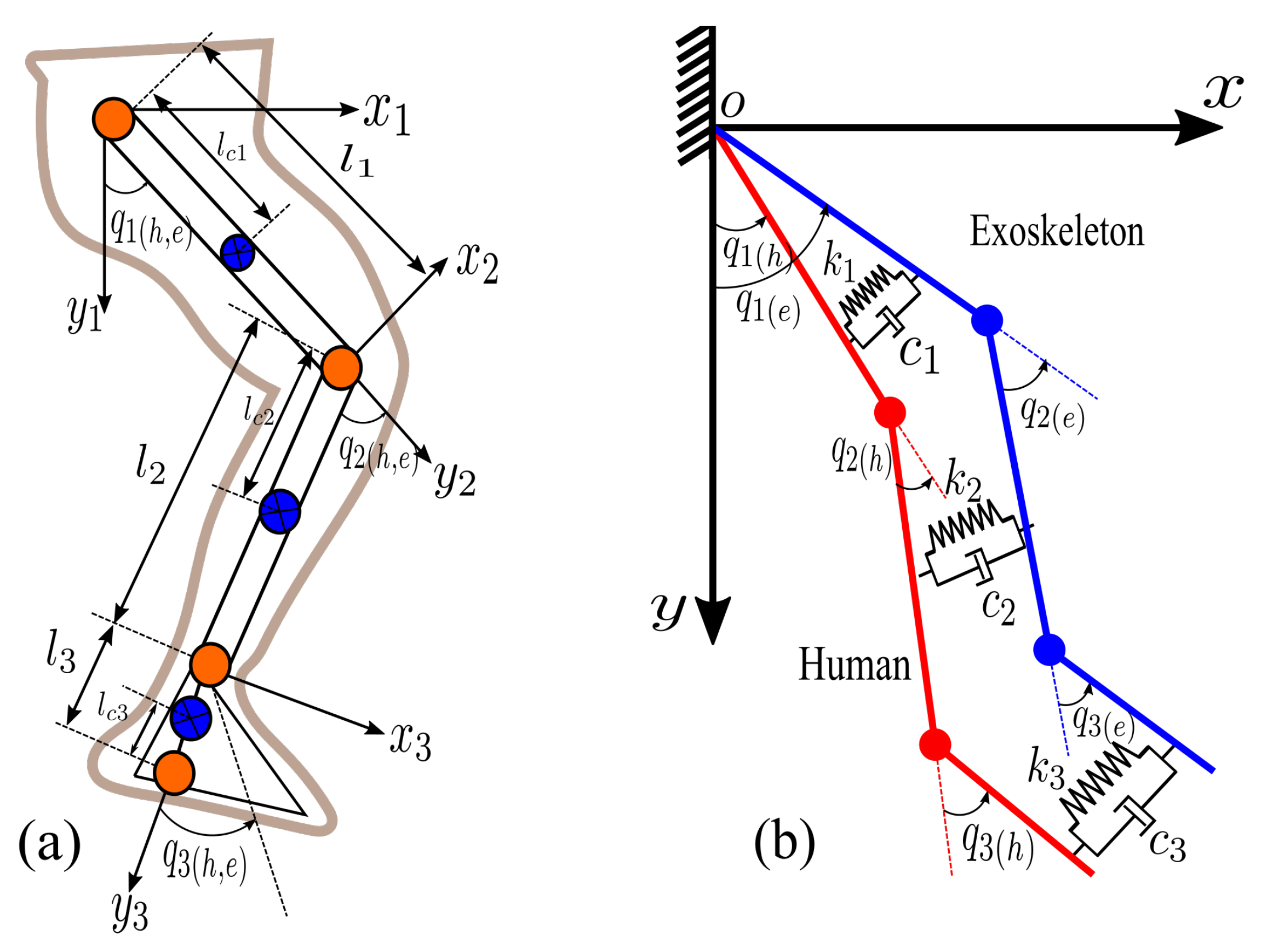
1. Introduction
Gait impairments, often arising from neurological conditions such as cerebral palsy, spinal cord injury, or stroke, affect millions of individuals globally, significantly reducing their mobility and quality of life [
1,
2]. These conditions are particularly challenging in pediatric populations, where the rapid changes in anthropometric parameters complicate rehabilitation efforts [
3]. Traditional therapeutic interventions, although effective, rely heavily on manual assistance, which is labor-intensive, costly, and difficult to scale [
4]. Consequently, robotic rehabilitation devices like lower-limb exoskeletons (LLEs) have emerged as transformative solutions for delivering repetitive task-oriented training that is essential for motor recovery [
5,
6]. LLEs offer two main assistance modes: passive assistance (PA), which uses position/trajectory control to drive limb motion, and active assistance (AA), which combines user muscle effort with admittance or impedance control—suitable for patients with residual limb strength.
While passive-assisted LLERs have been widely studied [
7], position control alone is inadequate for AA modes where patient muscle participation is essential. This has led to growing interest in combining admittance or impedance control with trajectory control, referred to as human-in-the-loop control, to promote active user involvement. Early work in [
8] introduced a method of generalized elasticities to diminish the interaction forces. However, the interaction forces should not be minimized in the case of AA training mode to increase the varying forms of assistance by the user. The researchers in [
9] presented a patient-human-in-the-loop control strategy for a single-degree-of-freedom (1-DOF) lower-limb exoskeleton system in which the dynamics of impedance is controlled using fuzzy logic, specifically aimed at reducing the interaction forces at the points of contact with the user. The researchers in [
10] introduced a fuzzy logic admittance control system for a 2-DOF ankle therapeutic device with varying levels of assistance or resistance. In related research on human-in-the-loop control, Chen et al. [
11] introduced an adaptive impedance control strategy to enable AA, using a disturbance observer to estimate interaction forces under cost constraints. More recently, Mosconi et al. [
12] conducted simulations to evaluate the effectiveness of impedance control in supporting lower-limb impairments during the swing phase.
Despite the human-in-the-loop control promise, exoskeleton control remains challenging due to nonlinear system dynamics, user variability, and unpredictable external disturbances such as involuntary muscle contractions [
3,
13]. Conventional trajectory feedback controllers like PD and PID are easy to implement but often fail under significant parameter variations or perturbations [
3]. Model-based strategies such as computed torque control (CTC) and sliding-mode control (SMC) offer robustness against uncertainties but typically rely on accurate system models and meticulous gain tuning. Recent examples include hierarchical torque control for active assistance [
14], time-delay robust CTC [
15], and adaptive SMC variants using fuzzy logic [
16], radial basis function compensators [
17], and fast terminal sliding modes for sit-to-stand transitions [
18]. While these methods have achieved high tracking performance in simulations and early prototypes, a shared limitation is their dependence on accurate modeling and manually tuned parameters.
To address this, reinforcement learning (RL) has gained traction as a model-free approach to adaptive control. Unlike classical controllers, RL enables agents to learn optimal policies directly from environment interactions, making it particularly valuable in human–exoskeleton systems where dynamics are uncertain and user-specific. Deep reinforcement learning (DRL), which uses neural networks as function approximators, has shown promise in continuous high-dimensional control tasks characteristic of lower-limb rehabilitation robotics. Early studies applied Q-learning and DDPG for mapping sensory inputs to control torques [
19,
20], while more recent efforts have used Proximal Policy Optimization (PPO) to dynamically adjust assistance levels [
21] and achieve robustness via domain randomization.
Hybrid control frameworks that combine the robustness of SMC with the adaptability of DRL have recently emerged as powerful alternatives. For instance, Hfaiedh et al. [
22] used a DDPG approach to adapt a non-singular terminal SMC for upper-limb exoskeleton control, achieving improved tracking and disturbance resilience. Similarly, Khan et al. [
23] integrated SMC with an Extended State Observer and DDPG to enhance multibody robot tracking, outperforming optimal PID and H-infinity controllers. Zhu et al. [
24] used PPO to tune a terminal SMC controller online, improving robustness to matched and mismatched disturbances. Notably, TD3 has become a preferred actor–critic algorithm in such contexts due to its delayed policy updates and clipped double-Q estimation, which mitigate overestimation bias and improve learning stability [
25,
26]. A notable example is the work by Sun et al. [
27], who proposed a reinforcement learning framework for soft exosuits that combines a conventional PID controller with a learned policy. This approach enables the system to adaptively modify assistive torques in response to user-specific gait variations, demonstrating improved performance and wearer comfort in both simulations and physical trials. Similarly, Li et al. [
28] applied TD3 to augment an active disturbance-rejection controller (ADRC) for lower-limb exoskeletons, achieving enhanced tracking and disturbance rejection in both simulated and experimental settings. These hybrid designs often outperform standalone SMC, PID, or neural approaches, especially under uncertainty and parameter drift [
29].
Building on these promising advances, further research is needed to translate hybrid DRL–model-based control frameworks into practical human-in-the-loop systems for pediatric gait rehabilitation. In AA modes, inner-loop controllers must not only provide robust trajectory tracking under disturbances and user variability but should also adapt safely and effectively to joint-specific dynamics and subject-specific behaviors. Achieving real-time gain adaptation in such nonlinear human-interactive systems remains challenging, particularly given the safety-critical nature of pediatric applications and the need to balance responsiveness with stability. Motivated by these challenges, this work proposes a novel human-in-the-loop control framework that integrates outer-loop admittance control with a TD3-tuned finite-time NSTSM inner-loop controller for gait tracking in pediatric exoskeletons. The key contributions are as follows:
- (i)
We introduce human-in-the-loop control with admittance control in the outer loop and finite-time sliding-mode control in the inner loop, improving robustness without requiring precise modeling of a pediatric exoskeleton system.
- (ii)
We introduce a TD3-based DRL approach to tune and adjust the gains of the NSTSM controller (TD3-NSTSM) online in the human-in-the-loop control.
- (iii)
We test the proposed human-in-the-loop control numerically for a gait trajectory of a healthy pediatric participant of age 12 years.
- (iv)
We compare the admittance control performance of the baseline NSTSM with that of the TD3-tuned admittance using standard tracking metrics: maximum absolute deviation (MAD), root mean square error (RMSE), and integral of absolute error (IAE).
3. Human-in-the-Loop Control
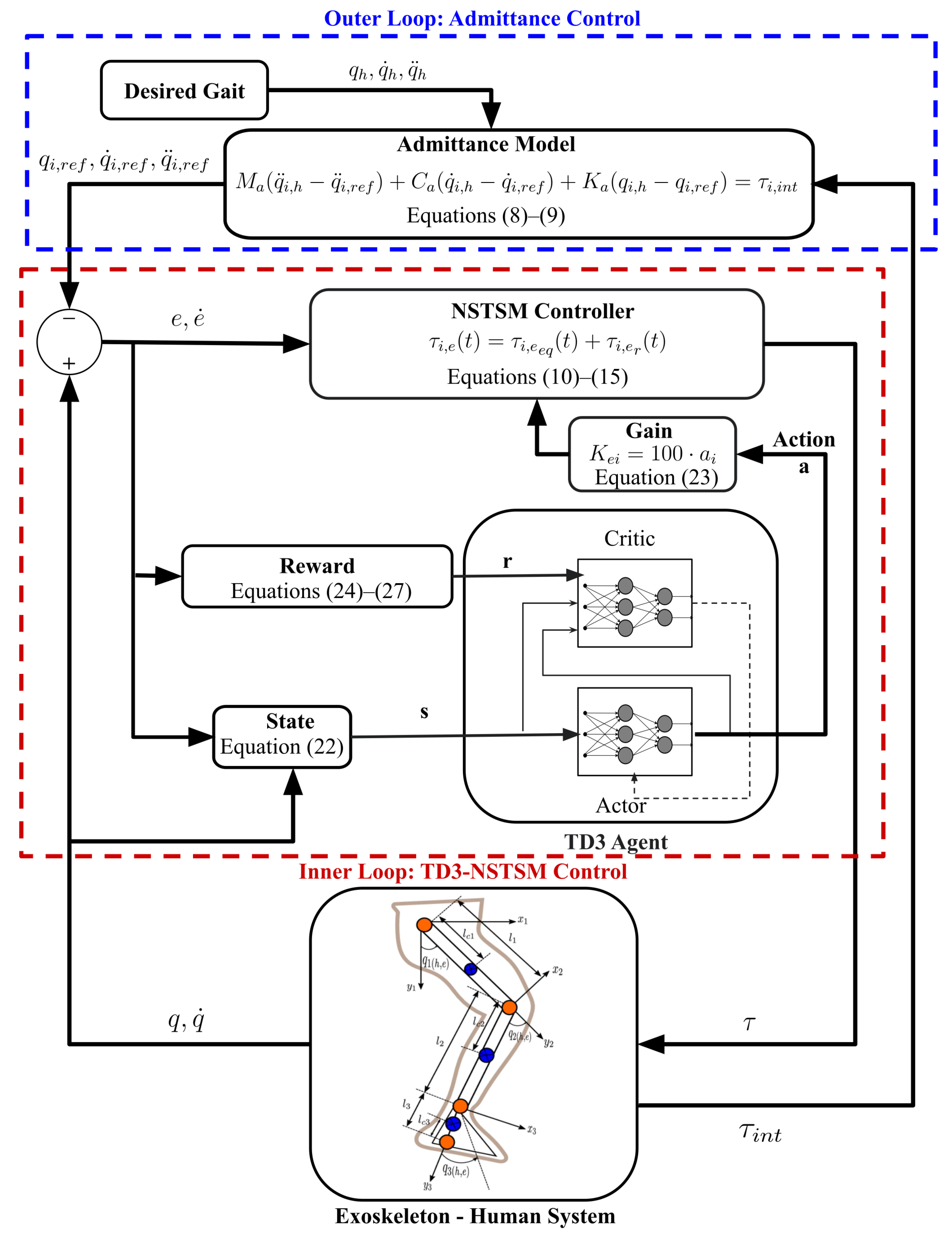
Human-in-the-loop control (see
Figure 3) is structured using a layered control approach that encourages active involvement from the user, as outlined earlier in the Introduction. In this study, the outer loop is designed using an admittance control strategy, which interprets interaction forces to adjust motion. Meanwhile, the inner loop implements a robust finite-time sliding-mode method to ensure precise gait tracking. The next subsections detail the development of the admittance controller, followed by the position control strategy tailored for the integrated pediatric exoskeleton system.
3.1. Admittance Control
In the admittance model, the exoskeleton robot can adjust its planned trajectory in reaction to the user’s applied force. Depending on how much the actual exoskeleton path differs from the original gait trajectory, the modified trajectory complies with the interaction force between the subject and the exoskeleton. The coupled subject–exoskeleton system uses a servo-level control scheme to regulate the reference trajectory it adapts. The following version of the admittance model can be applied if the reference trajectory,
, and the intended gait trajectory for a human,
, are provided.
In this context, , , and represent the inertial, damping, and stiffness components of the admittance model. In the AA mode explored here, the difference between the desired human motion and the reference trajectory is actively modeled to reflect human–robot interaction.
3.2. NSTSM Trajectory Tracking Control
In traditional terminal sliding-mode (TSM) control, the use of negative fractional powers introduces singularities, which can lead to unbounded control inputs and compromise the system’s performance. To address these issues, this section presents a novel design for a non-singular terminal sliding-mode (NSTSM) controller. The proposed approach offers the advantages of avoiding singularities and demonstrating robustness against parametric uncertainties as well as unmodeled or external disturbances. The discussion begins with a clear definition of the problem, considering the error dynamics, sliding surface, and the newly proposed control law. Following this, a Lyapunov stability analysis is conducted to confirm the finite-time convergence of the system states.
Let
represent the tracking error and
denote its derivative. The error dynamics can then be formulated in state-space representation as
In the absence of prior knowledge about the upper bounds of dynamic parameters, the following design approach can be utilized for this purpose [
39].
The parameters , , and are required to be positive, and along with must remain within defined limits to reduce the adverse impact of uncertainties and external disturbances.
Consider the exoskeleton dynamics described in Equation (
10), which satisfies the upper bound condition specified in Equation (
11) with known constants
,
, and
. If the NSTSM surface
is defined as
where
is a diagonal design matrix with
, and
a and
b are positive odd integers with
, the proposed control law is expressed as the combination of equivalent control law
and reaching control law
:
where
and
Here, the parameters satisfy , and is a small positive constant. The use of the function instead of the traditional function is intended to mitigate chattering effects. Under these conditions, the system’s gait tracking error is guaranteed to converge to zero within a finite time.
Stability Proof
Let us define the proposed Lyapunov function as follows:
By taking the time derivative of the above function and applying Equation (
12), the resulting expression can be obtained.
By replacing
as defined in Equation (
10) and subsequently applying the relations from Equation (
13) through Equation (
15),
i.e., using Equation (
11),
where
According to Lyapunov’s stability criteria, Equation (
19) guarantees that the system states asymptotically converge to the origin under the condition that
. Additionally, to demonstrate the finite-time convergence
, Equation (
19) can be reformulated utilizing Equation (
16) as follows:
Reorganizing the inequality and performing integration on both sides
Equation (
21) demonstrates that the gait tracking error diminishes to zero within a finite time frame, provided the sliding surface
also achieves zero convergence within the same finite duration.
3.3. TD3-Augmented NSTSM
To enhance the robustness and adaptability of the NSTSM controller, we integrate an RL framework based on the TD3 algorithm. In this TD3-NSTSM approach, the RL agent learns to adapt the gains of the diagonal design matrix in Equation (
12) in real time based on observed state dynamics and tracking errors. By replacing heuristic gains or fixed tuning rules with a learned policy, the controller continuously adapts to parameter variations, external disturbances, and subject-specific changes, thereby improving tracking accuracy and ensuring more reliable and effective gait rehabilitation assistance.
Remark 2. The reinforcement learning agent functions solely in inference mode during deployment, with all training conducted offline. NSTSM gains adapted by the TD3 agent remain within pre-defined safe bounds.
3.3.1. RL Environment
The environment is critical to any RL model. Here, the RL environment is designed to simulate the interaction between the lower-limb exoskeleton and its control system. It incorporates the aforementioned dynamics of the human–exoskeleton system and the NSTSM controller as part of the environment. The RL agent interacts with this environment by receiving observations and selecting actions that update control parameters to minimize tracking errors. The key components of the RL environment are described below.
State Space: The state space consists of continuous variables representing the system’s dynamic behavior and tracking performance, including joint angles and velocities to reflect the current state of the exoskeleton joints and position and velocity tracking errors that indicate deviations from the reference trajectory. Consequently, the state vector for each joint is five-dimensional and is defined as
where
is the reference position,
and
are current joint positions and velocities, and
and
are current position and velocity errors, as mentioned earlier.
Since there are three joints, the combined state vector has 15 dimensions. Each dimension is bounded to a realistic range of values based on the limits of the exoskeleton and the baseline performance of the NSTSM controller.
Action Space: The action space is a continuous 3-dimensional vector
a , corresponding to the hip, knee, and ankle joints. Each action component is used to adaptively tune the diagonal design matrix
of the NSTSM controller (see Equation (
12)). Specifically, the mapping is defined as
This results in effective gain values , allowing the RL agent to modulate the convergence behavior of each joint’s sliding surface independently. This formulation () ensures all actions remain within a physically meaningful and safe range for pediatric exoskeleton actuation. By varying these gains online, the controller can adapt to changing dynamics and user-specific characteristics without requiring manual gain tuning or precise system modeling. To further ensure safe and realistic control, actuator saturation limits were enforced during simulation. Torque outputs were clipped at 50 Nm for the hip, 20 Nm for the knee, and 5 Nm for the ankle, consistent with the rated capabilities of the LLES v2 exoskeleton actuators.
Reward Function: The reward function is designed to guide the RL agent toward achieving precise gait trajectory tracking. The reward starts with a default value of 1 and is reduced based on the deviation from the reference trajectory. At each time step
t, the reward
is defined as
where
and
are the weights of the combined position error reward
and combined velocity error reward
, respectively.
The combined position error reward
is given by
where
,
, and
are the weights for the position errors of the hip (
), knee (
), and ankle (
) joints, respectively.
Similarly, the combined velocity error reward
is given by
where
,
, and
are the weights for the velocity errors of the hip (
), knee (
), and ankle (
) joints, respectively.
The position/velocity error reward for each joint
j is calculated as
where
represents the position/velocity error for joint
i, and
is the maximum allowable error for that joint. This maximum is determined based on the expected errors regarding the baseline NSTSM performance, as well as the limits of the exoskeleton.
The weights in each equation are selected to uniformly sum to one. Consequently, the overall reward is bounded to help prevent numerical instability during training. This is particularly relevant for policy gradient algorithms where large reward values can lead to exploding gradients or overly aggressive updates.
3.3.2. Twin Delayed Deep Deterministic Policy Gradient (TD3)
TD3 is an actor–critic RL algorithm designed for continuous control tasks—such as exoskeleton control. It builds upon the deep deterministic policy gradient (DDPG) algorithm by addressing overestimation bias in value function approximation and improving stability during training [
40]. TD3 achieves these improvements through three key modifications: clipped double-
Q learning, target policy smoothing, and delayed policy updates.
In TD3, the state of the system at time t is represented as and the action as . The algorithm maintains two critic networks, and , parameterized by and , which approximate the state–action value function. The actor network, , parameterized by , maps the state to a deterministic action. A replay buffer stores transitions , enabling the algorithm to sample data uniformly for updates.
Clipped Double-Q Learning
To mitigate overestimation bias, TD3 uses two independent critic networks and takes the minimum of their value estimates when computing the target value [
40]:
where
is the discount factor, and
is the slowly updated target version of the
i-th critic network. The target action
is computed as
where
is the target actor network, and
is clipped Gaussian noise added to smooth the policy and improve robustness. The loss for each critic is given by
Delayed Policy Updates
TD3 updates the actor network less frequently than the critic networks to improve training stability. Specifically, after every
d updates to the critics, the actor is updated using the deterministic policy gradient [
40]:
The target networks for both actor and critics are updated using a soft update rule:
where
is the update rate (target smooth factor). Note that the symbol
is used here instead of the standard notation
since
represents torque in this work.
Target Policy Smoothing
To prevent overfitting and reduce variance in the target value estimate, noise
is added to the target action during critic updates. The noise is clipped to a small range
to ensure that the target remains near the learned policy [
40]:
This modification ensures that the learned policy is robust to small perturbations and avoids exploiting narrow peaks in the value function.
These enhancements make TD3 more robust and stable than the predecessor in DDPG for continuous control problems, addressing issues like overestimation bias and instability while maintaining efficient learning in high-dimensional action spaces.
3.3.3. Hyperparameter Tuning
The selection and tuning of hyperparameters play a crucial role in the training performance and stability of RL agents such as TD3. Key hyperparameters include the learning rates of the actor and critic networks ( and ), the target smooth factor (), the discount factor (), and the exploration noise parameters (), all of which can significantly influence the agent’s learning behavior.
The learning rates control how quickly the networks update their weights in response to gradient signals. Lower learning rates promote stable convergence but can result in slower learning, while higher rates accelerate learning at the risk of instability or suboptimal convergence. Proper selection ensures that the networks adapt efficiently to the exoskeleton control task without diverging or overfitting. The discount factor () determines the relative importance of future rewards compared to immediate rewards. A higher discount factor () encourages the agent to prioritize long-term performance, which can improve overall policy robustness but may introduce additional computational complexity. Conversely, a lower discount factor biases the agent toward short-term rewards, which can enhance responsiveness to real-time disturbances—a critical feature for practical exoskeleton control applications. Exploration noise parameters, particularly Gaussian noise in TD3, regulate the agent’s exploration of the action space during training. Appropriately tuned noise parameters ensure a balance between exploration and exploitation. Excessive exploration can delay convergence, while insufficient exploration may result in the agent becoming trapped in suboptimal policies. To address this, our training process employs an exploration schedule, where exploration is emphasized in early episodes and gradually reduced in later stages to encourage exploitation of the learned policy. Additional factors, such as batch size and the target network update frequency, also impact the training process. A larger batch size tends to stabilize policy updates by reducing variance, although at the expense of increased computational requirements. The target smooth factor () governs the rate of updates to the target networks; smaller values ensure gradual changes, which contribute to more stable learning.
3.4. Implementation and Training
The proposed human-in-the-loop control framework, with the novel TD3-NSTSM, is implemented using Simulink combined with MATLAB 2024b’s reinforcement learning Toolbox. This platform provides an intuitive interface for creating custom environments and for training and evaluating reinforcement learning agents. The control parameters used in the baseline NSTSM controller are summarized in
Table 3. For the TD3 agent, optimized for the exoskeleton control task, the training and model configurations are summarized in
Table 4. To fine-tune these hyperparameters, Bayesian optimization was employed, with the objective of maximizing episodic return. This method systematically explores the hyperparameter space, allowing for the identification of optimal settings.
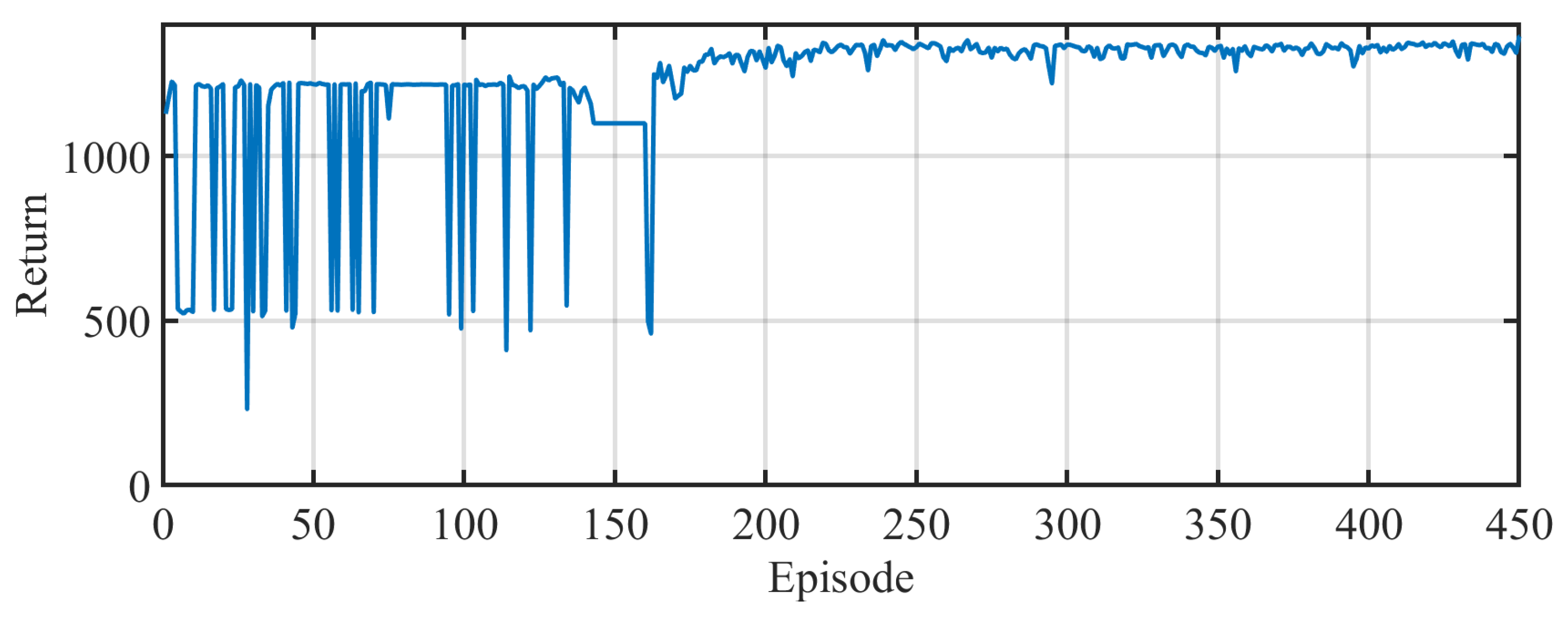
The training performance of the TD3 agent is illustrated in
Figure 4, which shows the learning curve over 450 episodes. The early phase (approx. episodes 0–200) is characterized by high variability in return, indicative of the agent’s exploratory behavior as it searched the action space to learn effective gain combinations. After this exploratory phase, the best-performing model was saved based on return and thus controller performance. In the subsequent phase (episodes 200–450), the agent was fine-tuned from this checkpoint, leading to a marked increase in return stability and convergence to a robust policy. This two-stage training strategy enabled efficient policy refinement and accelerated convergence toward optimal gain tuning.
3.5. Model Evaluation
The performance of the TD3-NSTSM controller within the wider human-in-the-loop control scheme is evaluated through numerical simulations conducted in MATLAB. The evaluation focuses on the controller’s tracking performance based on the following metrics:
4. Results
This section presents and compares the results for the proposed human-in-the-loop control framework with an inner-loop TD3-NSTSM controller against the same framework with a standalone NSTSM controller, highlighting the performance and adaptability of the RL framework. The uncertainty parameter and disturbance vector are defined as and , respectively. The analysis begins with a comparison of joint-space trajectory tracking performance, quantified by the RMSE, MAD, and IAE metrics. This is followed by an evaluation of Cartesian tracking accuracy. A torque analysis is then provided to assess the efficiency of the different control strategies. Finally, a gain analysis illustrates how the TD3 agent adapts the inner-loop NSTSM control parameters throughout the gait cycle.
4.1. Tracking Performance: Joint Space
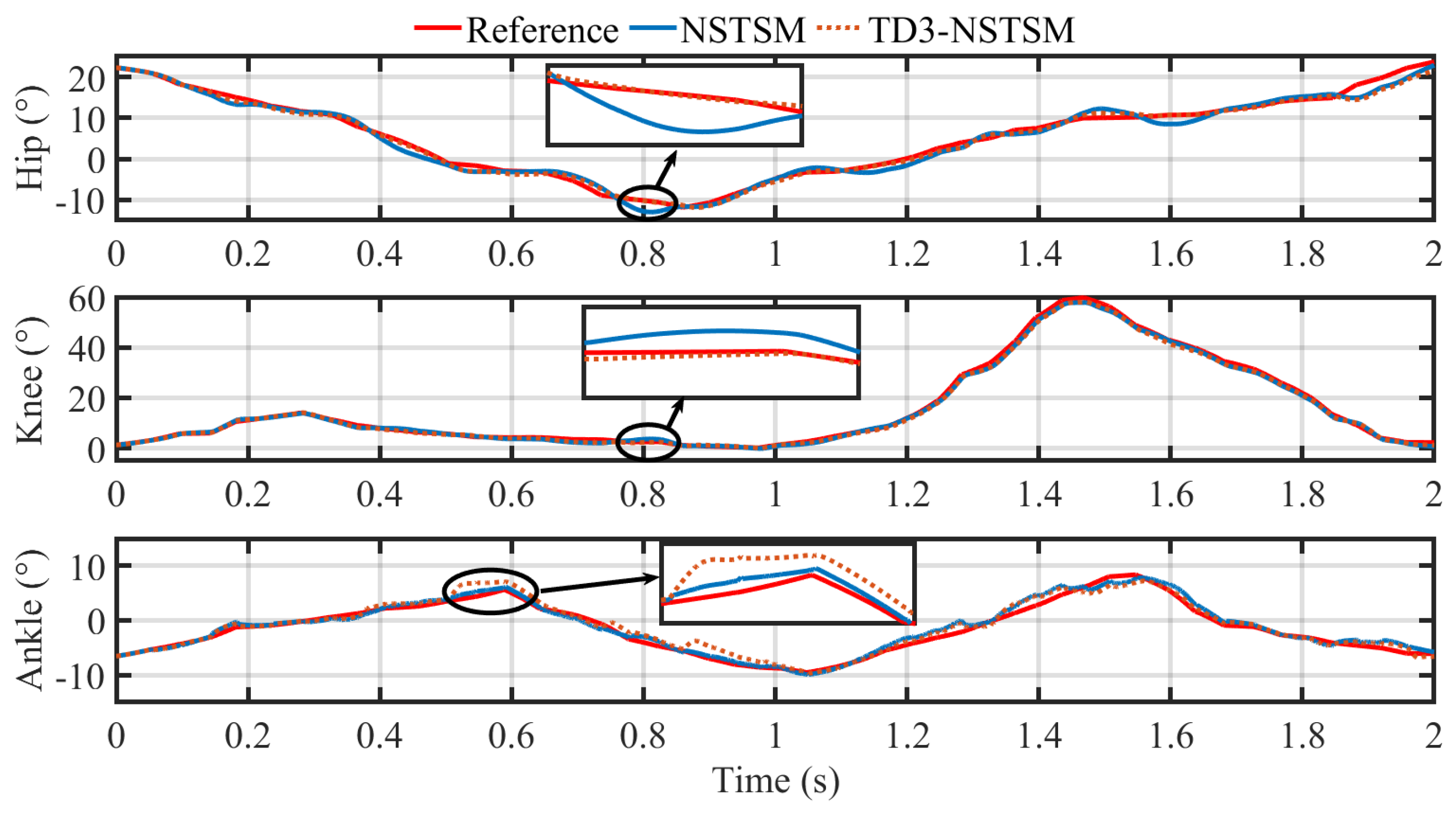
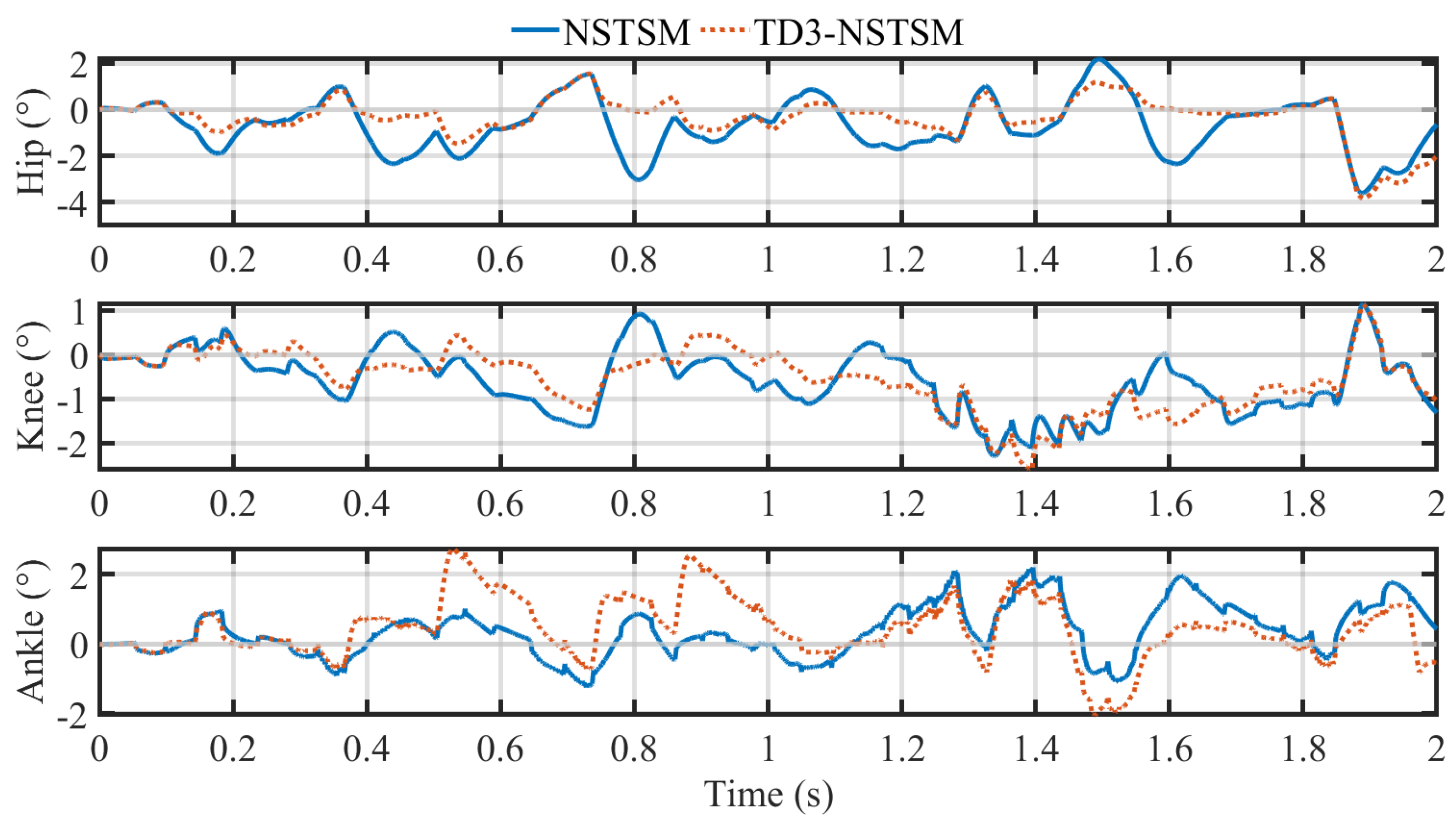
Figure 5 and
Figure 6 illustrate the joint-space tracking performance of the baseline NSTSM and the proposed TD3-NSTSM for the hip, knee, and ankle joints.
Figure 5 compares the reference trajectory (solid red) with the trajectories achieved by each controller, highlighting key regions where differences are most pronounced.
Figure 6 presents the corresponding tracking errors over time, showing how each controller responds throughout the gait cycle.
Table 5 complements the visual analysis by providing a quantitative summary of the maximum absolute deviation (MAD), root mean square error (RMSE), and integrated absolute error (IAE) for each joint, along with the percentage improvements achieved by TD3-NSTSM.
For the hip joint, TD3-NSTSM demonstrates clear improvement over the baseline NSTSM controller. The observed trajectory tracks the reference more closely, especially during transitions, as emphasized by the inset in
Figure 5. The error curve in
Figure 6 shows consistently lower deviations for TD3-NSTSM across most of the gait cycle. Quantitatively, TD3-NSTSM reduces the RMSE by 27.82% and IAE by 40.85%, although the MAD slightly increases by 6.09%, possibly due to brief overshoots in specific segments. For the knee joint, TD3-NSTSM also improves tracking accuracy across all the metrics.
Figure 5 shows better alignment with the reference trajectory, particularly during the mid-swing phase, while the error plot in
Figure 6 reveals reduced peak errors. TD3-NSTSM achieves a 5.43% reduction in RMSE and a 10.20% reduction in IAE, although the MAD again shows a modest increase of 13.04%, suggesting more frequent—but smaller—corrections over time. For the ankle joint, TD3-NSTSM does not show consistent improvements over the baseline. As seen in
Figure 5, both controllers follow the reference trajectory reasonably well, but TD3-NSTSM exhibits greater deviations during certain portions of the gait cycle. The error plot in
Figure 6 highlights larger fluctuations in the TD3-NSTSM error profile, particularly in the early and mid-stance phases. This is reflected quantitatively by increases in all three error metrics: MAD rises by 24.55%, RMSE by 19.75%, and IAE by 13.39%. These degradations may stem from the more complex dynamics and higher sensitivity of the ankle joint to rapid trajectory changes. Overall, the results demonstrate that TD3-NSTSM effectively enhances the tracking performance for the hip and knee joints, with moderate trade-offs at the ankle.
Furthermore, when comparing the performance of the TD3-NSTSM controller with other state-of-the-art approaches such as fuzzy adaptive sliding-mode control (FASMC) [
41], it appears that NSTSM shows considerably reduced MAD at both the hip (3.83° vs. 3.96°) and knee joints (2.60° vs. 2.94°). However, such a comparison is not fully justified as the FASMC [
41] was designed for an entirely different lower-limb exoskeleton design with varying system dynamics, uncertainties, and external perturbations. Moreover, the authors in [
41] did not account for human–exoskeleton interaction effects, which are explicitly addressed in our work.
4.2. Tracking Performance: Cartesian Space
Figure 7 presents the foot trajectory tracking performance in the Cartesian plane, comparing the reference trajectory with those generated by NSTSM and TD3-NSTSM. While both controllers approximate the target loop, TD3-NSTSM follows the trajectory more closely, especially during the terminal swing phase.
The inset highlights a region near the end of the gait cycle where TD3-NSTSM significantly reduces deviation compared to NSTSM, which exhibits more noticeable overshooting and undershooting. This improvement suggests that adaptive gain tuning enables more precise path following in two-dimensional space—crucial for maintaining smooth and symmetric gait patterns during gait rehabilitation.
4.3. Torque Analysis
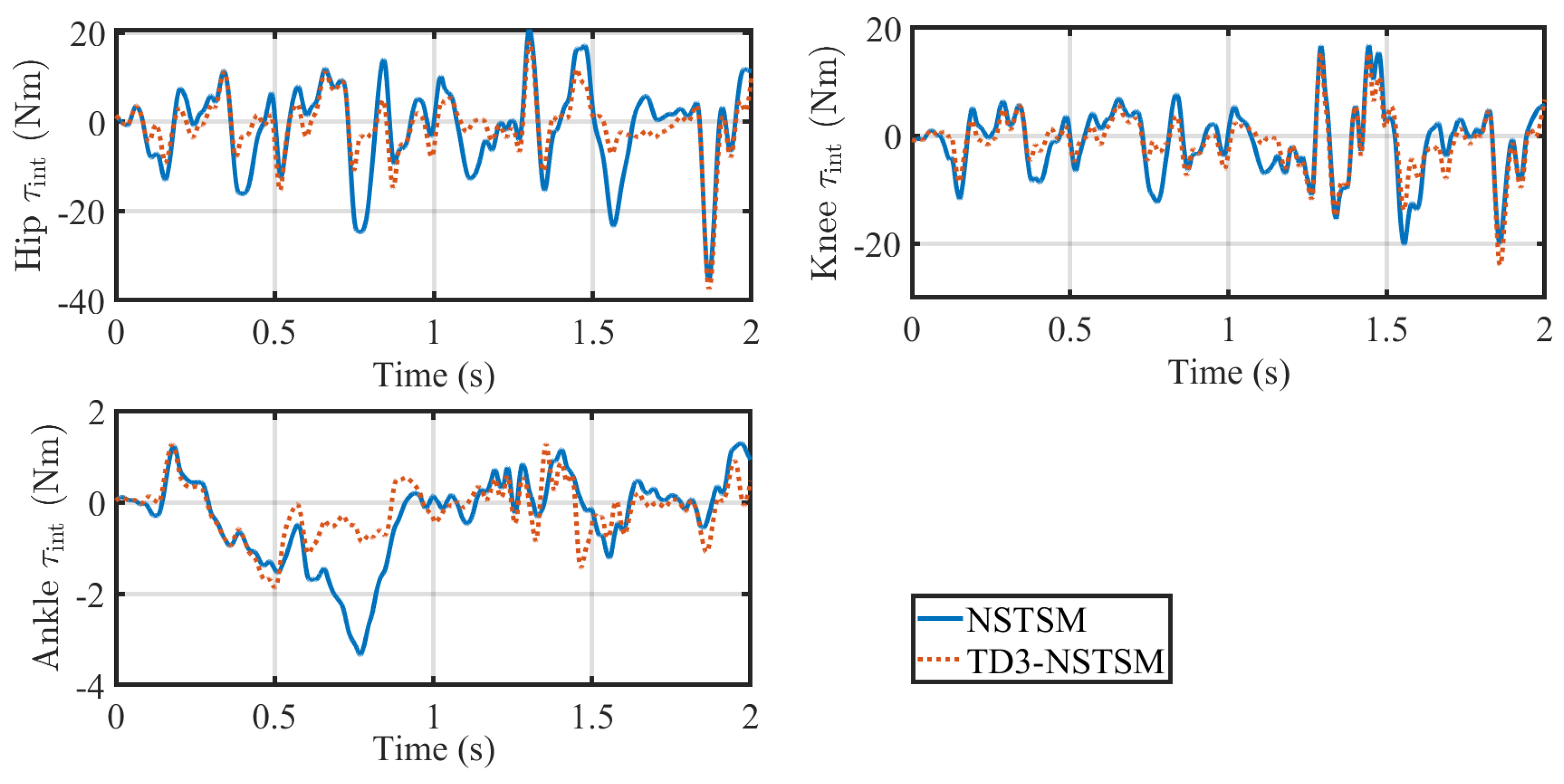
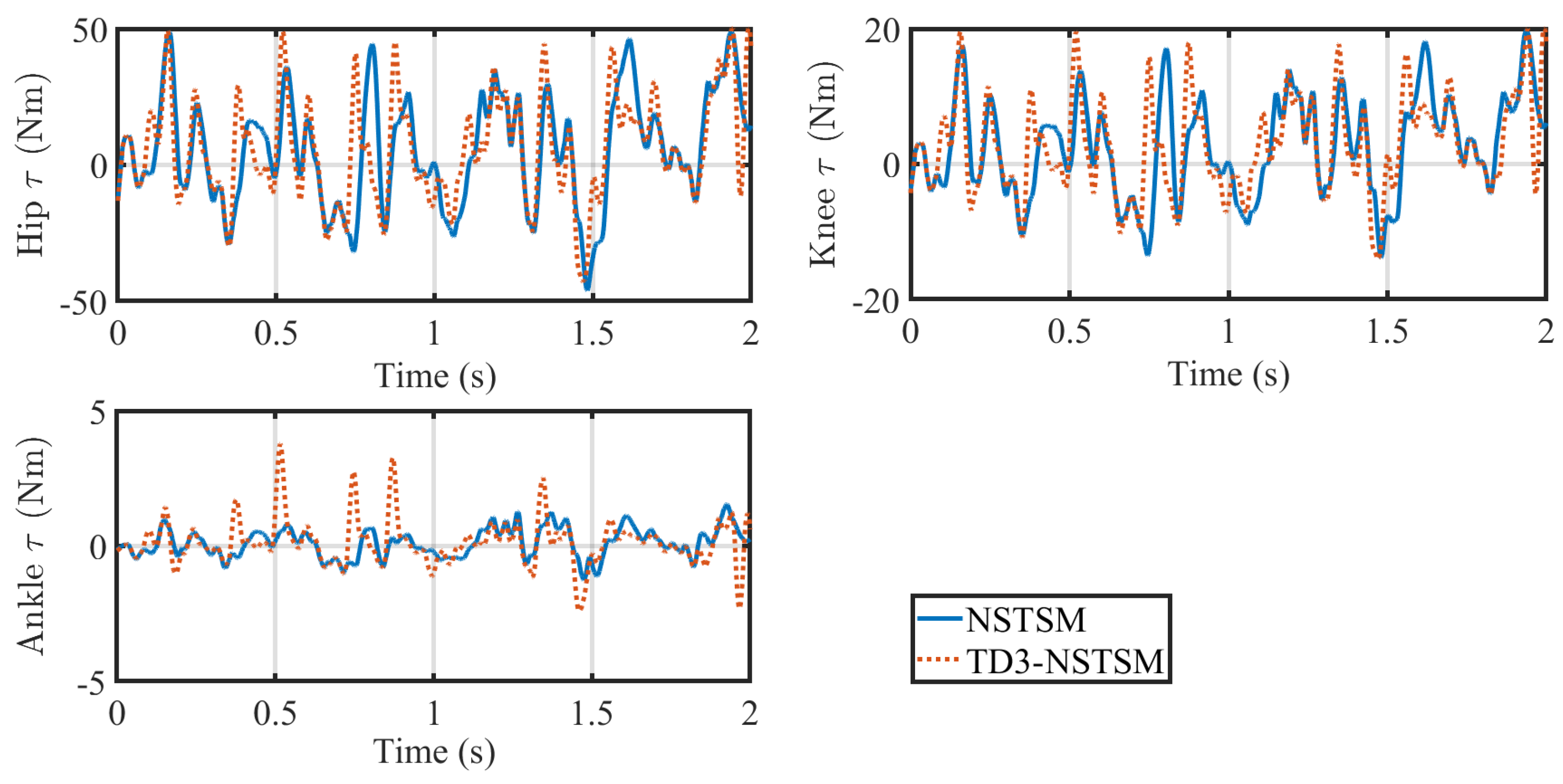
Figure 8 and
Figure 9 present the interaction torques and applied control torques for the hip, knee, and ankle joints under both NSTSM and TD3-NSTSM.
Figure 8 shows the measured interaction torques between the user and the exoskeleton, revealing significant joint-dependent variability across the gait cycle. At the hip joint, TD3-NSTSM generally reduces interaction torques compared to NSTSM, with typical reductions of about 5–15 Nm. However, near the end of the gait cycle, there is a notable peak where both controllers exhibit similar magnitudes. The knee joint shows reduced interaction torques under TD3-NSTSM for much of the gait cycle; however, after about
t = 1.25 s, the reduction becomes less consistent, with TD3-NSTSM at times producing higher interaction torques than NSTSM. For the ankle joint, TD3-NSTSM effectively reduces interaction torques during the first half of the gait cycle, particularly by mitigating a major spike; however, it shows less consistent behavior in the second half. These patterns suggest that TD3-NSTSM offers more compliant and comfortable assistance by better accommodating user movements and reducing user–exoskeleton conflict, although further refinement is needed to ensure consistent performance across all the gait phases.
Figure 9 compares the actuator torques generated by each controller. To improve visual clarity and emphasize the overall trends in
Figure 9, a moving average and a Savitzky–Golay filter were applied to smooth both NSTSM and TD3-NSTSM signals. Overall, both controllers produced periodic torque patterns, with TD3-NSTSM generally exhibiting sharper peaks and corrections. This behavior reflects the controllers’ adaptive gain adjustments, which respond more aggressively to tracking errors—particularly evident in the hip and knee joints. In contrast, at the ankle joint, the torque magnitude is lower and more stable for both controllers, although TD3-NSTSM displays slightly more high-frequency variability.
Table 6 quantifies the chattering behavior using the chattering index (CI) [
42]. Although chattering is characteristic of sliding-mode control, the NSTSM control avoids chattering by using a saturation function instead of the signum function, as mentioned in
Section 3.2. Moreover, in our proposed RL-NSTSM implementation, the reinforcement learning component helped to mitigate chattering by achieving a reduction of 2.49% at the hip and 3.1% at the knee through responsive tuning of the NSTSM gains. It is also pertinent to mention that the CI observed with NSTSM and TD3-NSTSM is significantly less compared to conventional sliding-mode control schemes, with a range of
–
[
42].
Overall, these results suggest that TD3-NSTSM not only delivers more assertive yet targeted control at high-load joints but also provides assistance that could enhance user comfort and engagement by minimizing unnecessary user–exoskeleton conflict.
4.4. Gain Analysis
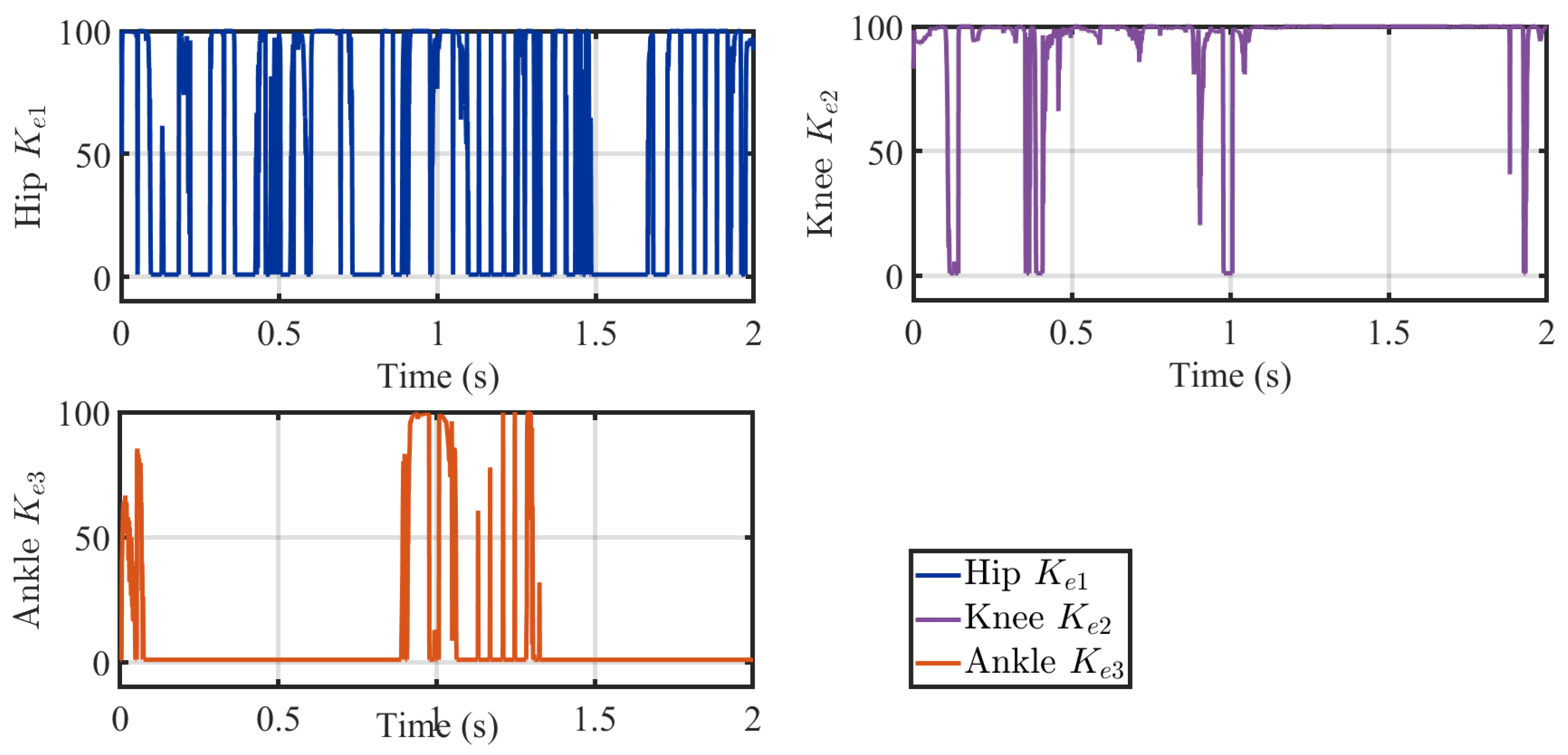
Figure 10 shows the time-varying gain values
,
, and
for the hip, knee, and ankle joints, respectively, as adapted by the TD3 agent during the gait cycle. The results highlight how the reinforcement learning policy modulates these gains in response to joint-specific dynamics and tracking demands. At the hip,
fluctuates frequently to provide rapid corrections during phases of high load transfer. The knee gain
exhibits periods of near-maximal values, suggesting stronger corrective effort during stance transitions, while the ankle gain
shows more sporadic activation, reflecting both the lower torque requirements and the agent’s less consistent tuning at this joint. These patterns demonstrate how TD3-NSTSM adaptively allocates control authority across joints, although the variability at the ankle indicates further refinement may be needed to achieve smoother gain modulation.
5. Discussion
The results of this study demonstrate that the proposed human-in-the-loop controller, comprising outer-loop admittance control and an inner-loop TD3-NSTSM controller, improves the gait tracking of a pediatric exoskeleton in AA mode. By integrating reinforcement learning with a model-based NSTSM control scheme, the hybrid controller achieved reduced tracking errors in both joint and Cartesian spaces, along with sharper and more responsive torque profiles in high-load joints such as the hip and knee. These findings suggest that real-time adaptation of control gains via deep reinforcement learning can compensate for modeling uncertainties and joint-specific dynamics in pediatric gait rehabilitation. TD3-NSTSM also reduced peak interaction torques compared to the baseline NSTSM controller, indicating more compliant assistance that may enhance user comfort, engagement, and motor learning.
This work advances the field in two primary directions: (i) improving robustness through model-based frameworks and (ii) enabling online adaptability using deep reinforcement learning. Traditional inner-loop controllers such as SMC and NSTSM control have shown strong robustness to disturbances and parameter variations [
18,
43] but rely on fixed gains or heuristic offline tuning, limiting their responsiveness to dynamic user-specific changes during gait. Recent efforts to introduce learning-based adaptivity have shown promise. Hfaiedh et al. [
22] used DDPG to tune gains in an NSTSM controller for upper-limb rehabilitation, while Luo et al. [
21] employed PPO to adjust assistance levels in lower-limb gait tasks. Sun et al. [
27] used a TD3-based residual reinforcement learning framework to fine-tune PID control for soft exosuits, achieving significant improvements in metabolic efficiency during real-world trials. Li et al. [
28] combined TD3 with an active disturbance-rejection controller (ADRC) for lower-limb exoskeletons, demonstrating enhanced tracking and robustness to disturbances in both simulation and experimental settings.
While Sun et al. [
27] applied TD3 to fine-tune PID gains, our method directly modulates the gains of an NSTSM controller—a more robust nonlinear framework with finite-time convergence and improved resilience to disturbances. The observed improvements in hip and knee tracking validate this deeper integration of learning with robust control. However, the ankle joint remains a challenge, likely due to its lower torque requirements, increased sensitivity to trajectory timing, or convergence to a suboptimal policy. These characteristics may necessitate joint-specific learning strategies or adaptive reward weighting to achieve more consistent performance.
Despite its advantages, the TD3-NSTSM controller has certain limitations. Although the simulation includes interaction torques to emulate user input and operates in AA mode, it remains an idealized environment that omits real-world complexities such as sensor noise, joint friction, and inference latency. Additionally, because the TD3 policy is deployed in inference mode without online learning, its effectiveness depends heavily on the quality and diversity of the offline training data. Furthermore, the inner loop NSTSM control can be improved by exploiting the latest disturbance-rejection controllers [
28,
44,
45]. On the other hand, exposure to a broader range of patient variability, including variations in effort, fatigue, engagement, and pathological gait patterns such as spasticity, is needed to improve generalization. Finally, while user effort is partially modeled, direct sensing of human intent (e.g., via EMG or force sensors) was not incorporated. These limitations must be addressed through hardware implementation and user-in-the-loop testing prior to clinical deployment.
6. Conclusions
This work introduced a human-in-the-loop control framework combining outer-loop admittance control with a novel TD3-NSTSM inner-loop controller for pediatric lower-limb exoskeletons. The system dynamically adapts both the reference trajectory and control gains in response to user interaction forces and gait tracking demands. The simulation results show that TD3-NSTSM reduced the RMSE at the hip and knee by 27.82% and 5.43%, respectively, and the IAE by 40.85% and 10.20%, while generating responsive control torques that better accommodate joint-specific dynamics. Although the ankle tracking performance was less consistent, the approach maintained stable adaptive control throughout the gait cycle, highlighting areas for further refinement. The reduction in peak interaction torques further indicates the potential of TD3-NSTSM to provide more comfortable and user-aligned assistance.
Future work should focus on real-time implementation of this layered control architecture on the LLES v2 exoskeleton, including robust safety mechanisms, to validate its robustness under unstructured conditions. Enhancing the outer loop with biosignal-based intent detection (e.g., EMG or force sensors) could further personalize assistance in line with assist-as-needed principles. To address the current limitations, researchers should conduct ablation studies to evaluate reward sensitivity and explore joint-specific learning strategies. Furthermore, improving the diversity of the offline dataset through variation in gait profiles, user dynamics, and simulated disturbances will help to ensure that the learned policy generalizes across a wide range of patient scenarios. Ultimately, clinical trials will be necessary to assess the therapeutic impact, usability, and long-term efficacy, ensuring that the proposed human-in-the-loop controller translates effectively into pediatric gait rehabilitation practice.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}