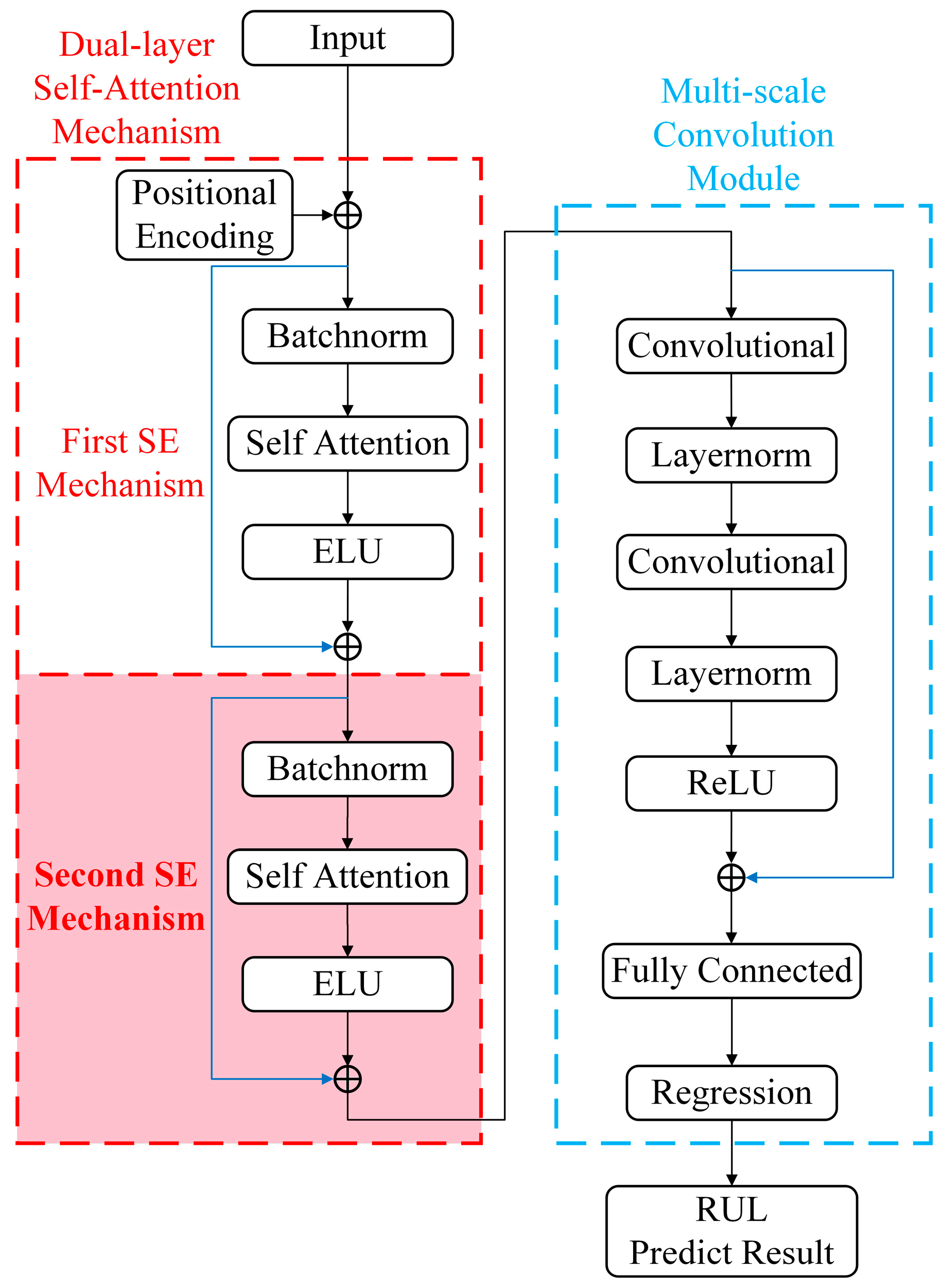
3.2.1. Bottom-Level Network
The proposed bottom-level network consists of the input layer, positional encoding layer, and self-attention mechanism module. (
Figure 1 red dashed box)
This layer is responsible for accepting the multi-domain and multi-class feature sets of rolling bearing vibration, and the feature set comes from the bearing vibration signal information in the time domain, frequency domain, and time-frequency domain.
- 2.
Positional encoding layer
The positional encoding can save the time sequence for each time step; the calculation formula is as follows:
where
represents the position of the feature vector,
represents the dimension of the positional encoding, and
represents the dimension of the feature vector.
- 3.
Residual connection
Residual connections preserve the original input information and allow information to flow directly from the input layer to the subsequent layers, adding the input of one layer directly to the output of that layer. The output of the network can then be represented as a nonlinear transformation of the input and a linear superposition, that is,
. This alleviates the problem of difficult information transfer in deep networks and helps maintain a more direct flow of information. This not only provides a direct propagation path for the gradient, alleviates the problem of gradient vanishing or exploding in deep network training, but also prevents the model from overfitting, enables the model to learn the general feature law, and enhances the generalization ability of new data. Residual connection is used in dual-layer self-attention mechanism and multi-scale convolution module in TransCN (as shown by the blue line in
Figure 1).
- 4.
Attention mechanism module
The proposed attention mechanism module consists of batch normalization, self-attention mechanism, and ELU.
Self-attention connects two sequence positions to capture long-term dependencies in time series data. However, single-layer self-attention struggles to extract key degraded features from complex data. Thus, this study adds a second self-attention layer (pink shading in
Figure 1) after the original in the transformer network. Batch normalization is applied to the input data to enhance model convergence and generalization, calculated as follows.
where
is the feature vector of the input and
is a small value that prevents division by zero. The parameters
and
are trainable.
The self-attention layer captures the global degradation trend of rolling bearing life from a global perspective, aiding the model in understanding bearing state evolution and providing critical information for life prediction. The formula is as follows:
The input feature matrix is
, and Query, Key, and Value matrices are generated by three sets of linear transformations.
where
,
and
are trainable parameter matrices.
Attention weights are calculated by the dot product of Query and Key:
where
is the dimension of
and
matrices.
To capture attention for different features, a multi-head mechanism is used for parallel computation:
where
is the number of attention heads,
is the output transformation matrix. It should be noted that the algorithms of each self-attention in the proposed dual-layer self-attention mechanism are the same.
To introduce nonlinearity and enhance convergence, the self-attention output is activated by ELU. The formula is as follows:
where
is a hyperparameter which usually takes the value 1.
The dual-layer self-attention mechanism offers significant advantages. First, the first layer captures basic state evolution features of rolling bearings (trends and periods), while the second layer extracts deeper features (subtle changes and irregular patterns). This structure enables the model to handle more complex inputs. Secondly, the second layer refines the first layer’s output, enhancing focus on key fatigue features. For instance, in monitoring tasks, more accurately identifying fatigue features under different working conditions while suppressing less relevant noise. This targeted feature selecting enhances the model’s effectiveness in dynamic behavior modeling, improves adaptability, meets diverse data analysis needs, boosts generalization, and ensures robust performance in complex industrial environments.
3.2.2. Top-Level Network
The proposed top-level network includes a convolutional layer, layer normalization, ReLU, fully connected layer and a regressive layer. (
Figure 1 blue dashed box)
To take into account the local information of fatigue data of rolling bearings, this paper proposes that after the dual-layer self-attention mechanism, a one-dimensional same convolution layer with two layers of different convolution kerns is used to extract and merge the feature of bearing vibration signals at different scales to learn the complex nonlinear relationship between bearing vibration signals and their life course more effectively.
The one-dimensional same convolutional layer can flexibly control the receptive field by adjusting the size and step size of the convolution kernel while maintaining a low computational burden. Without increasing the difficulty of calculation, the design further introduces more nonlinearities by deepening the number of network layers to improve the expression ability of the model. In this paper, two same convolution layers can be used to further simplify the model structure and independently adjust the convolution kernel size and step size to adapt to different sequence lengths and feature extraction requirements, which helps to reduce the complexity of the model, reduce the risk of overfitting, and improve the generalization ability of the model, and extracting higher-level features layer by layer and fusion to improve the richness of feature expression. The model can capture and utilize the patterns in the data more effectively, which can further improve the accuracy of life prediction. The formula is as follows:
where
is the input signal,
is the convolution kernel,
represents the convolution operation,
is the integral variable used for the displacement in the convolution operation, and
is the result of the convolution operation, that is, the feature extracted by the convolution operation.
- 2.
Layer normalization
To reduce the influence of input distribution variation between layers, this paper performs layer normalization on input data to improve the training efficiency and stability of the model. Layer normalization utilizes the statistical information of a single sample and can maintain a stable gradient update effect when dealing with time series data. It is calculated as follows.
where
is the feature vector of the input and
is a small value that prevents division by zero. The parameters
and
are trainable.
After normalization, the ReLU function is activated, and the life prediction value of the rolling bearing is obtained through the output of the regressive layer.
The primary purpose of the first convolution layer is to extract preliminary local features from the sequence. This layer is capable of capturing short-term patterns and trends in the sequence, and local features are crucial for understanding the real-time state of bearings, as they can reveal the dynamic changes in bearings at the microscopic level. The second convolution layer further refines the feature extraction process. This layer uses a different convolutional kernel configuration and is designed to capture more complex local features that are associated with a specific degradation pattern of the bearing. The introduction of the second convolutional layer enables the model to understand the bearing degradation process from a more fine-grained perspective, thereby enhancing the model’s ability to identify subtle changes in the bearing degradation process. By convolving the two layers in series, the model can capture local features on multiple scales, thereby providing a more comprehensive understanding of the bearing degradation process. This multi-scale feature extraction method helps the model capture the dynamic changes in bearings on different time scales, thus improving the accuracy and robustness of the prediction. The concatenation of two layers of convolution not only enhances the expression ability of the feature but also improves the recognition ability of complex degenerated patterns through the fusion of features at different scales. To stabilize the training process and accelerate convergence, after each convolution operation, layer normalization is added. Layer normalization reduces internal covariate offsets by normalizing feature values for each sample, which helps prevent gradient vanishing or exposing problems, thus making deep network training more stable. Therefore, the model can adapt to the distribution change in data faster, thereby improving the training efficiency and model performance. Finally, the ReLU activation function is used to introduce nonlinearity, which enables the model to identify and use the nonlinearity feature in the data to more accurately simulate the complex process of bearing degradation.
In summary, the life prediction model of rolling bearing proposed in this paper mainly has the following steps:
Step 1: the vibration signals of multiple bearings in the whole life cycle are collected, and the different bearings are divided into the training set and a test set.
Step 2: extract the multi-domain feature of the vibration signal, normalize the set of multi-domain features, and label it with a lifetime (Equations (18) and (35)).
Step 3: Build a dual-layer self-attention mechanism transformer encoding layer (Equations (24)–(29)). The first layer of attention captures the basic feature of the rolling bearing state, and the series structure of the second layer of attention forms the self-iteration of the attention mechanism to further extract the feature of the depth state.
Step 4: Construct the multi-scale convolution module (Equation (31)). The local feature of rolling bearing vibration signals in different time scales is extracted and fused.
Step 5: the output results of the model are smoothed (Equation (36)) to obtain the life prediction results.
As shown in
Figure 2, the self-attention mechanism of the bottom-level network in the proposed model enables the model to identify and exploit long-term trends in the time series. Through the serial connection of self-attention mechanism, the feature is gradually extracted from the model at different abstraction levels. These features contain the global information of time series, providing a more comprehensive representation of time features for the proposed model, and laying a high-quality data foundation for further processing of subsequent top-level network. The top-level network uses the multi-scale convolution module to capture and fuse local features on different time scales, which enhances the sensitivity of the proposed model to regional changes in time series. Through convolution operation, the model can further refine and enhance the features transmitted from the bottom-level network, making the feature expression more abundant and accurate. By using this kind of division and cooperation mode of the top and bottom-level network series structure, the model can predict the life of the rolling bearing by using the global and local features at the same time and enhance the understanding ability of the model to the information of the bearing life process.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}