
ISVD-Based Advanced Simultaneous Localization and Mapping (SLAM) Algorithm for Mobile Robots


Abstract
:1. Introduction
2. Related Work
3. Experimental Setup
- Two layer architecture leaves enough space for the electronics and controlling laptop;
- Driving wheels with 2 DC motor encoder;
- 4 inflated tire with air;
- Two 12V accumulator;
- 5 distance sensor;
- Integrated control electronics;
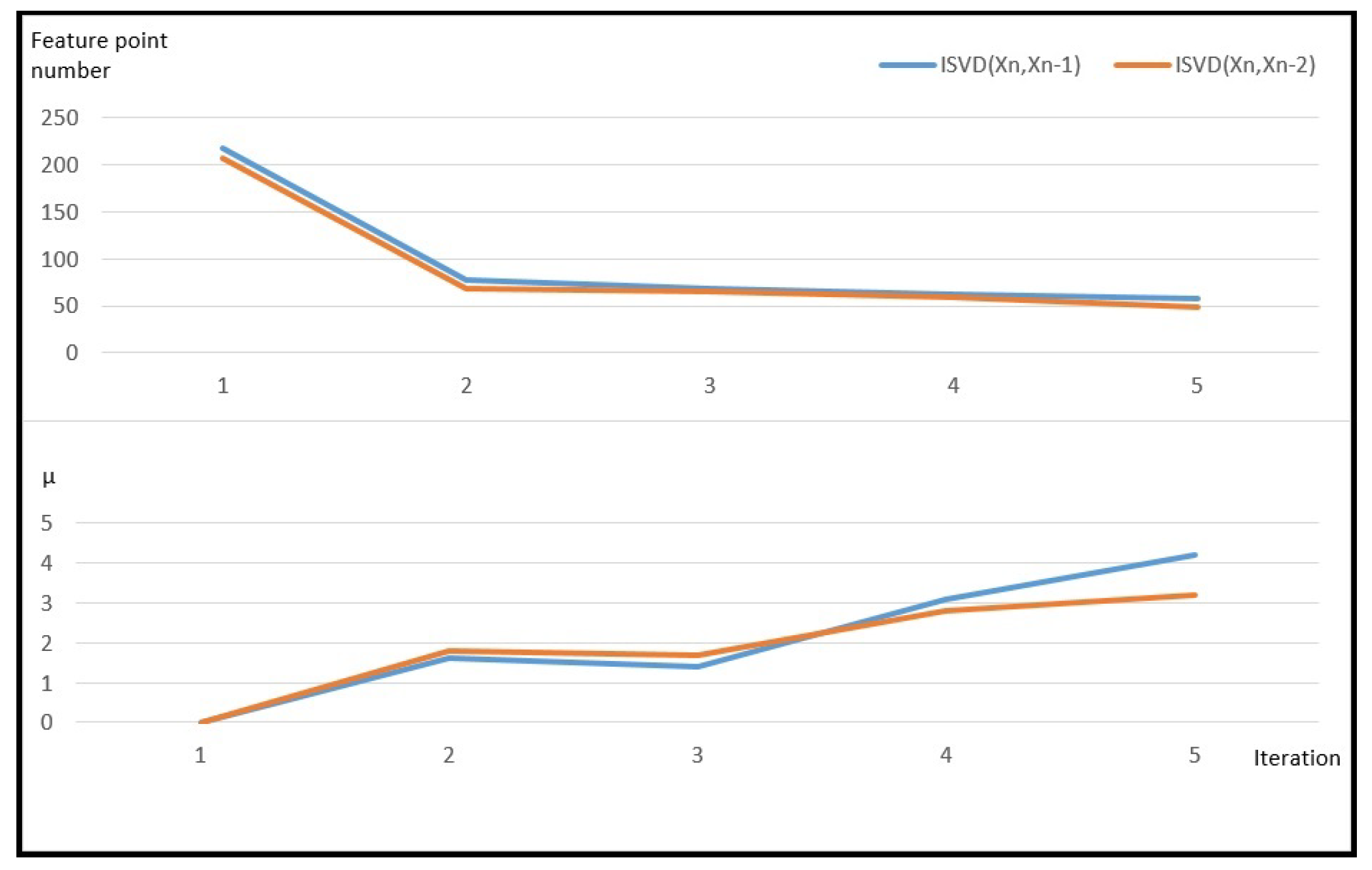
4. Methodology
| Algorithm 1 The proposed multistage three dimensional point cloud matcher (ISVD) |
procedure ISVD(D, S, , , ) for do for do if then end if end for if then Return else = end if end for end procedure |
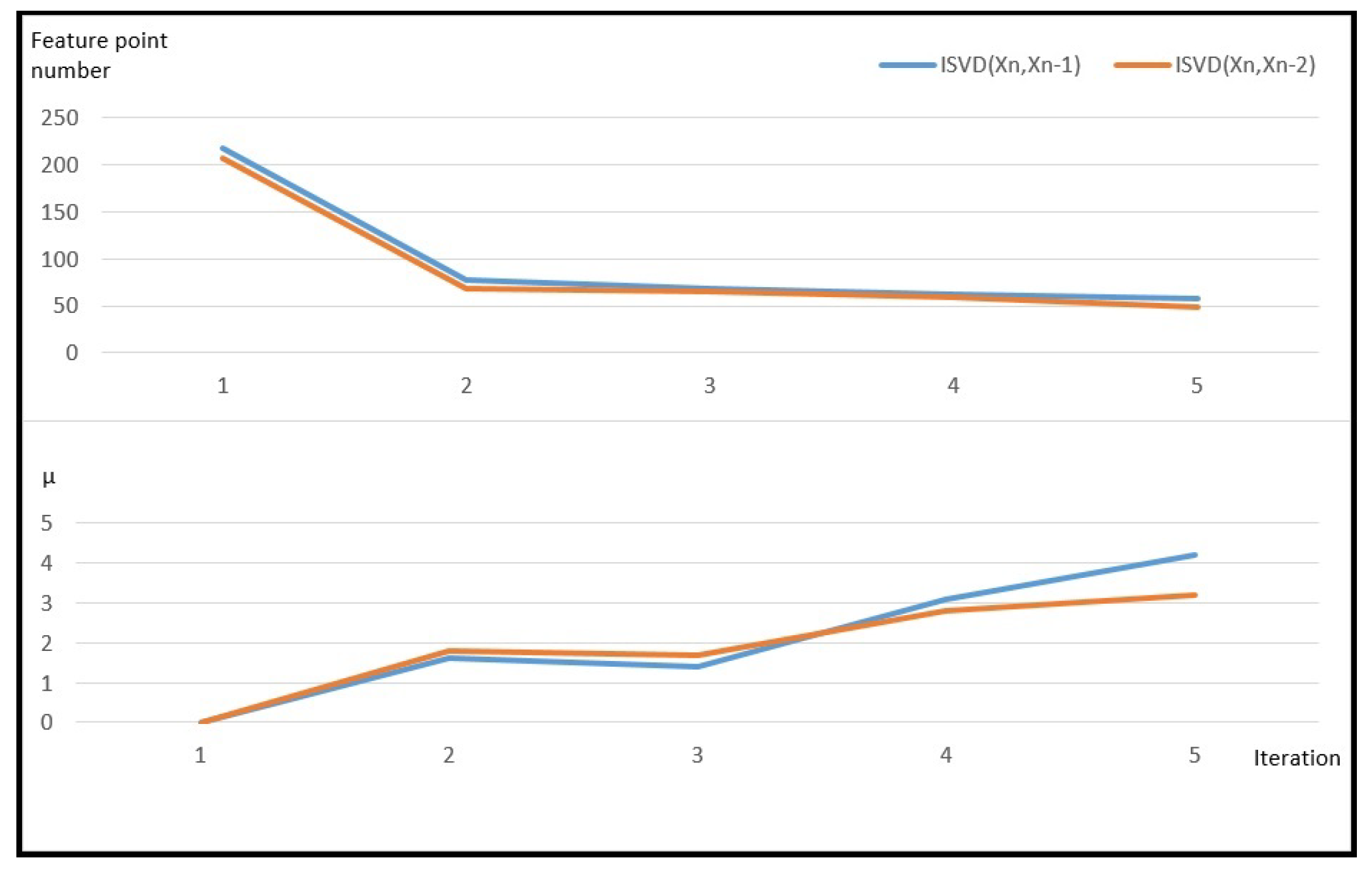
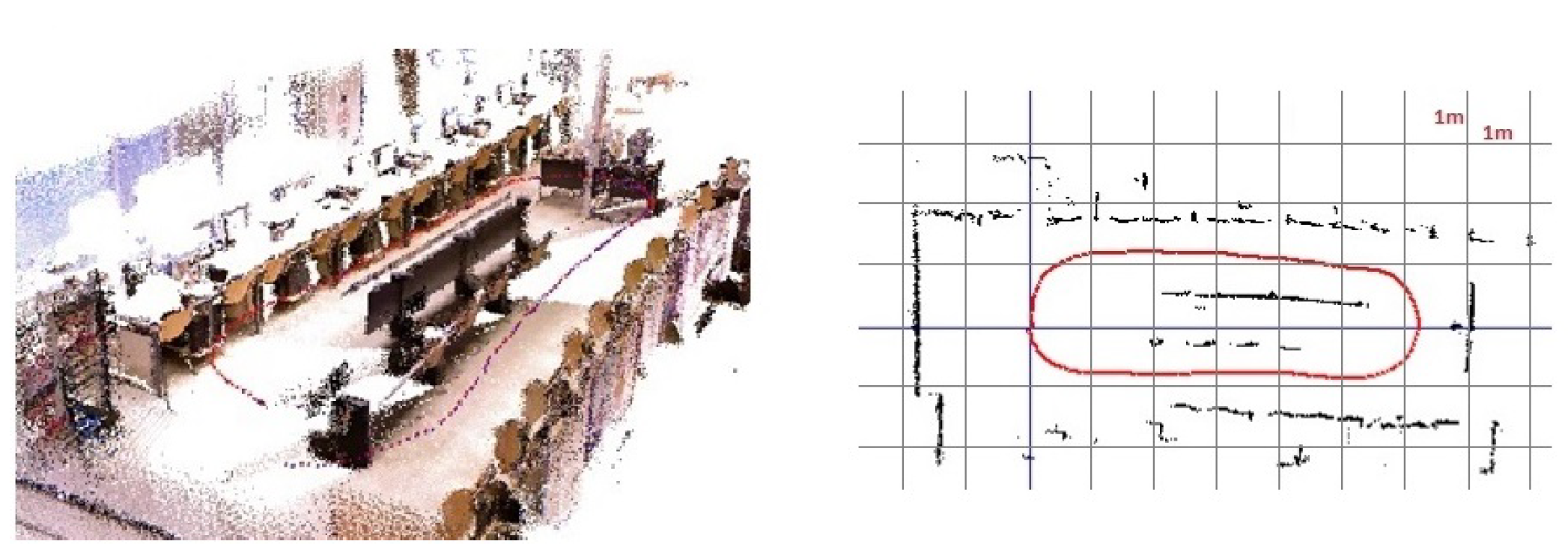
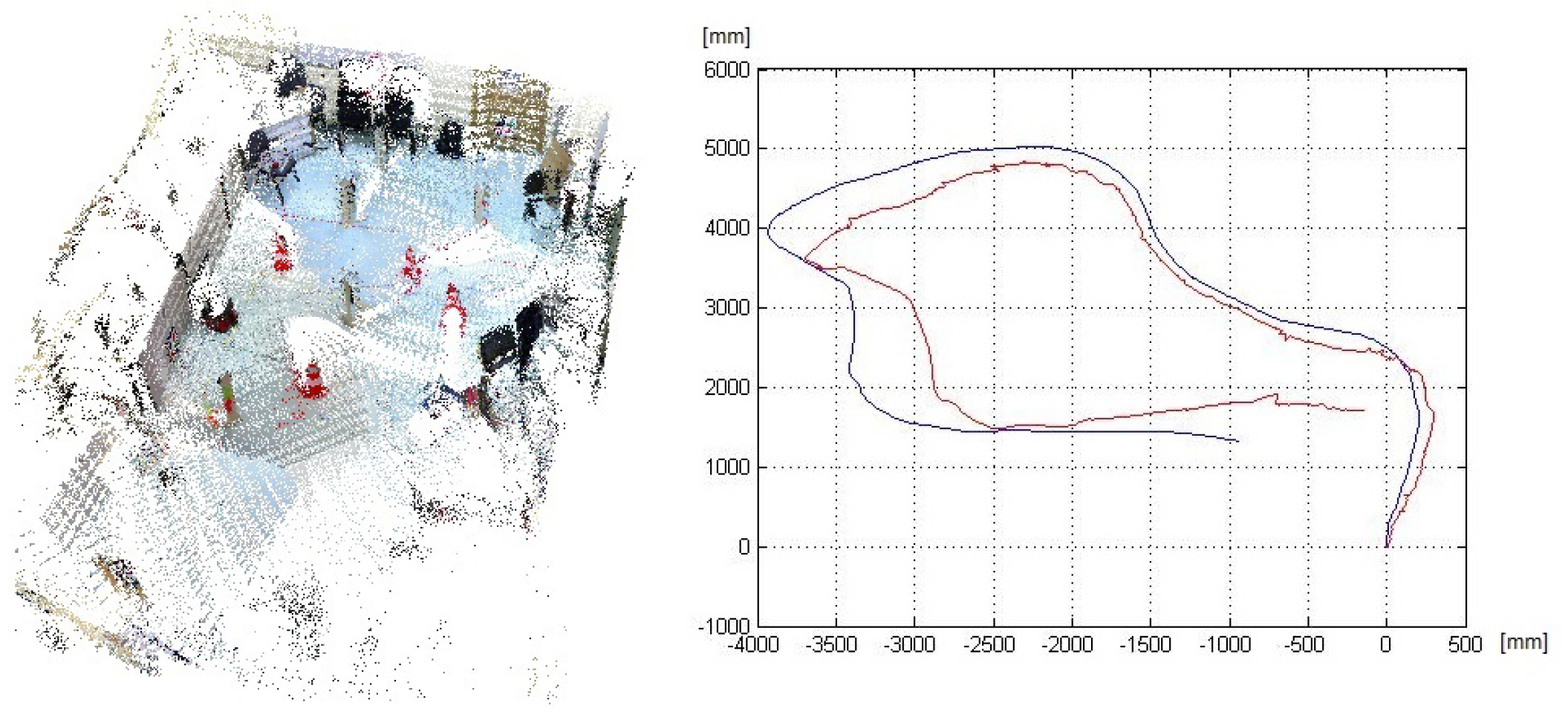
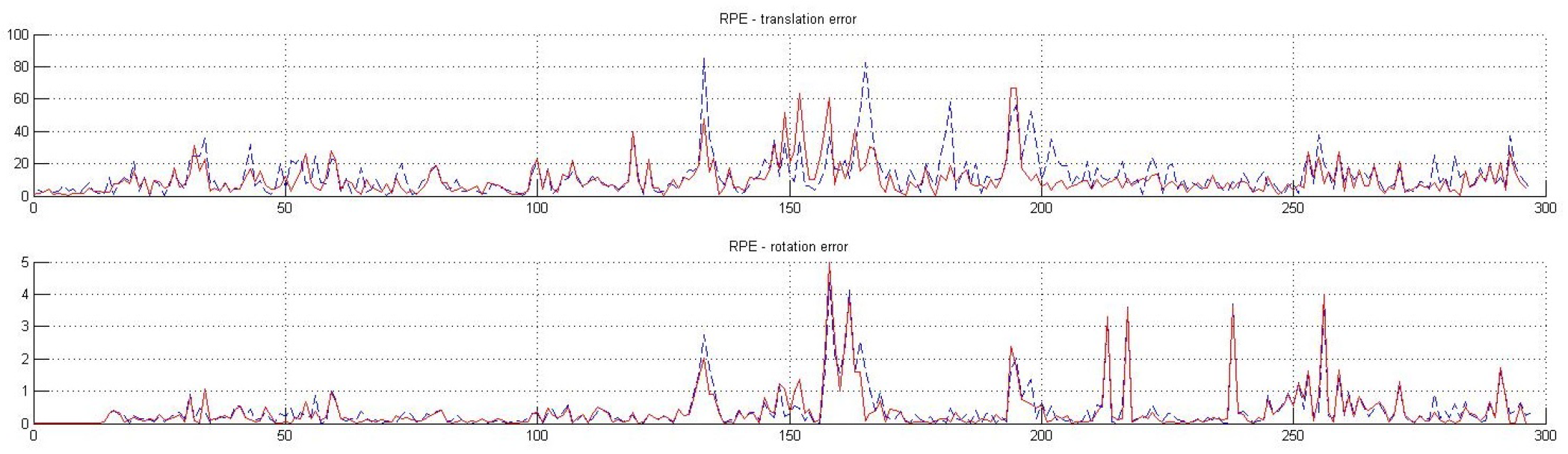
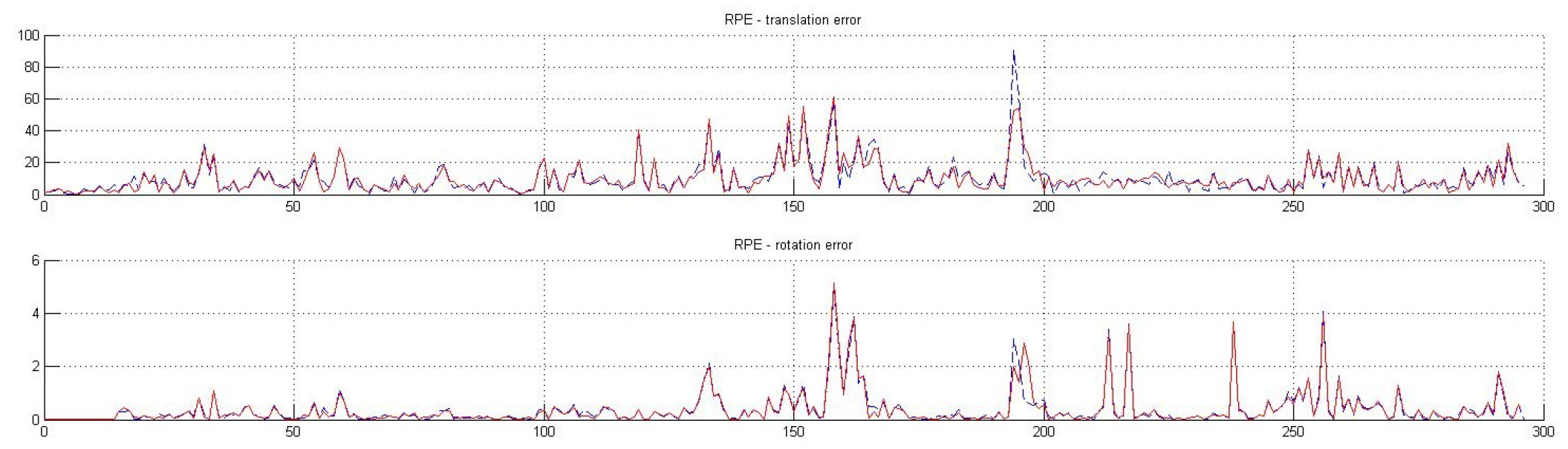
5. Evaluation and Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATE | Absolute Trajectory Error |
| FAST | FAST Feature Detector |
| GPS | Ground Positioning System |
| ICP | Iterative Closest Point |
| IMU | Inertial Movement Unit |
| ISVD | Iterative SVD |
| LC | Loop Closure |
| LIDAR | Light Detection and Ranging |
| ORB | Oriented FAST and Rotated BRIEF |
| PC | Personal Computer |
| PCA | Principal Component Analysis |
| QR | Quick Response Code |
| RGB | Red Green Blue Color Representation |
| RGBD | RGB+Depth Sensor |
| RMSE | Root Mean Square Error |
| RPE | Relative Pose Error |
| SIFT | Scale-Invariant Feature Transform |
| SLAM | Simultaneous Localization and Mapping |
| SURF | Sped-Up Robust Features |
| SVD | Singular Value Decomposition |
| UAV | Unmanned Aerial Vehicle |
| VO | Visual Odometry |
References
- Filipenko, M.; Afanasyev, I. Comparison of various slam systems for mobile robot in an indoor environment. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; pp. 400–407. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F. Visual odometry [tutorial]. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Ross, R.; Hoque, R. Augmenting GPS with geolocated fiducials to improve accuracy for mobile robot applications. Appl. Sci. 2019, 10, 146. [Google Scholar] [CrossRef] [Green Version]
- Szénási, S.; Kertész, G.; Felde, I.; Nádai, L. Statistical accident analysis supporting the control of autonomous vehicles. J. Comput. Methods Sci. Eng. 2021, 21, 85–97. [Google Scholar] [CrossRef]
- Cristinacce, D.; Cootes, T.F. Feature Detection and Tracking with Constrained Local Models. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006; BMVA Press: Swansea, UK, 2006; pp. 95.1–95.10. [Google Scholar] [CrossRef] [Green Version]
- Kobayashi, H. A new proposal for self-localization of mobile robot by self-contained 2d barcode landmark. In Proceedings of the 2012 of SICE Annual Conference (SICE), Akita, Japan, 20–23 August 2012; pp. 2080–2083. [Google Scholar]
- Elayaraja, D.; Ramabalan, S. Investigation in autonomous line follower robot. J. Sci. Ind. Res. 2017, 76, 212–216. [Google Scholar]
- Yildiz, H.; Korkmaz Can, N.; Ozguney, O.C.; Yagiz, N. Sliding mode control of a line following robot. J. Braz. Soc. Mech. Sci. Eng. 2020, 42, 1–13. [Google Scholar] [CrossRef]
- Goyal, N.; Aryan, R.; Sharma, N.; Chhabra, V. Line Follower Cargo-Bot For Warehouse Automation. Int. Res. J. Eng. Technol. 2021, 8, 1–8. [Google Scholar]
- Csaba, G.; Somlyai, L.; Vámossy, Z. Differences between Kinect and structured lighting sensor in robot navigation. In Proceedings of the 2012 IEEE 10th International Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 26–28 January 2012; pp. 85–90. [Google Scholar]
- Wasenmüller, O.; Meyer, M.; Stricker, D. CoRBS: Comprehensive RGB-D benchmark for SLAM using Kinect v2. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar]
- Kuan, Y.W.; Ee, N.O.; Wei, L.S. Comparative study of intel R200, Kinect v2, and primesense RGB-D sensors performance outdoors. IEEE Sens. J. 2019, 19, 8741–8750. [Google Scholar] [CrossRef]
- Zhou, T.; Fan, D.P.; Cheng, M.M.; Shen, J.; Shao, L. RGB-D salient object detection: A survey. Comput. Vis. Media 2021, 7, 37–69. [Google Scholar] [CrossRef]
- Tadic, V.; Toth, A.; Vizvari, Z.; Klincsik, M.; Sari, Z.; Sarcevic, P.; Sarosi, J.; Biro, I. Perspectives of RealSense and ZED Depth Sensors for Robotic Vision Applications. Machines 2022, 10, 183. [Google Scholar] [CrossRef]
- Zhou, Y.; Gallego, G.; Shen, S. Event-based stereo visual odometry. IEEE Trans. Robot. 2021, 37, 1433–1450. [Google Scholar] [CrossRef]
- Kostavelis, I.; Boukas, E.; Nalpantidis, L.; Gasteratos, A. Stereo-based visual odometry for autonomous robot navigation. Int. J. Adv. Robot. Syst. 2016, 13, 21. [Google Scholar] [CrossRef] [Green Version]
- Dieterle, T.; Particke, F.; Patino-Studencki, L.; Thielecke, J. Sensor data fusion of LIDAR with stereo RGB-D camera for object tracking. In Proceedings of the 2017 IEEE Sensors, Glasgow, UK, 29 October–1 November 2017; pp. 1–3. [Google Scholar]
- Qi, X.; Wang, W.; Liao, Z.; Zhang, X.; Yang, D.; Wei, R. Object semantic grid mapping with 2D LiDAR and RGB-D camera for domestic robot navigation. Appl. Sci. 2020, 10, 5782. [Google Scholar] [CrossRef]
- Vokhmintcev, A.; Timchenko, M. The new combined method of the generation of a 3d dense map of evironment based on history of camera positions and the robot’s movements. Acta Polytech. Hung. 2020, 17, 95–108. [Google Scholar] [CrossRef]
- Amanatiadis, A.; Henschel, C.; Birkicht, B.; Andel, B.; Charalampous, K.; Kostavelis, I.; May, R.; Gasteratos, A. Avert: An autonomous multi-robot system for vehicle extraction and transportation. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1662–1669. [Google Scholar]
- Chen, X.; Läbe, T.; Milioto, A.; Röhling, T.; Vysotska, O.; Haag, A.; Behley, J.; Stachniss, C. OverlapNet: Loop closing for LiDAR-based SLAM. arXiv 2021, arXiv:2105.11344. [Google Scholar]
- Kostavelis, I.; Gasteratos, A. Learning spatially semantic representations for cognitive robot navigation. Robot. Auton. Syst. 2013, 61, 1460–1475. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Mac, T.T.; Lin, C.Y.; Huan, N.G.; Duc, L.; Nhat, P.C.H.; Hai, H.H. Hybrid SLAM-based exploration of a mobile robot for 3D scenario reconstruction and autonomous navigation. Acta Polytech. Hung 2021, 18, 197–212. [Google Scholar]
- Hana, X.F.; Jin, J.S.; Xie, J.; Wang, M.J.; Jiang, W. A comprehensive review of 3D point cloud descriptors. arXiv 2018, arXiv:1802.02297. [Google Scholar]
- Renò, V.; Nitti, M.; di Summa, M.; Maglietta, R.; Stella, E. Comparative analysis of multimodal feature-based 3D point cloud stitching techniques for aeronautic applications. In Proceedings of the 2020 IEEE 7th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Pisa, Italy, 22–24 June 2020; pp. 398–402. [Google Scholar]
- Xu, T.; An, D.; Jia, Y.; Yue, Y. A review: Point cloud-based 3d human joints estimation. Sensors 2021, 21, 1684. [Google Scholar] [CrossRef]
- Fernandes, D.; Silva, A.; Névoa, R.; Simoes, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf. Fusion 2021, 68, 161–191. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using depth cameras for dense 3D modeling of indoor environments. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 477–491. [Google Scholar]
- Ho, K.L.; Newman, P. Loop closure detection in SLAM by combining visual and spatial appearance. Robot. Auton. Syst. 2006, 54, 740–749. [Google Scholar] [CrossRef]
- Kiss, D.; Stojcsics, D. Eigenvector based segmentation methods of high resolution aerial images for precision agriculture. In Proceedings of the 5th ICEEE-2014 International Conference: Global Environmental Change and Population Health: Progress and Challenges, Budapest, Hungary, 19–21 November 2014; pp. 155–162. [Google Scholar]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2017; pp. 235–252. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Nowicki, M.; Skrzypezyński, P. Combining photometric and depth data for lightweight and robust visual odometry. In Proceedings of the 2013 European Conference on Mobile Robots, Barcelona, Spain, 25–27 September 2013; pp. 125–130. [Google Scholar]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1691–1696. [Google Scholar]
- Laidlow, T.; Bloesch, M.; Li, W.; Leutenegger, S. Dense RGB-D-inertial SLAM with map deformations. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6741–6748. [Google Scholar]
- Deng, X.; Jin, G.; Wang, M.; Li, J. Robust 3D-SLAM with tight RGB-D-inertial fusion. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 4389–4396. [Google Scholar]
- Somlyai, L.; Vámossy, Z. Map building with rgb-d camera for mobil robot. In Proceedings of the 2012 IEEE 16th International Conference on Intelligent Engineering Systems (INES), Lisbon, Portugal, 13–15 June 2012; pp. 489–493. [Google Scholar]
- Juan, L.; Gwun, O. A comparison of sift, pca-sift and surf. Int. J. Image Process. (IJIP) 2009, 3, 143–152. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-squares fitting of two 3-D point sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 698–700. [Google Scholar] [CrossRef] [Green Version]
- Seeger, S.; Laboureux, X.; Häusler, G. An accelerated ICP-algorithm. In Lehrstuhl für Optik; Annual Report; Springer: Berlin/Heidelberg, Germany, 2001; p. 32. [Google Scholar]
- Schmidt, A.; Fularz, M.; Kraft, M.; Kasiński, A.; Nowicki, M. An indoor RGB-D dataset for the evaluation of robot navigation algorithms. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Poznań, Poland, 28–31 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 321–329. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Somlyai, L.; Csaba, G.; Vámossy, Z. Benchmark system for novel 3D SLAM algorithms. In Proceedings of the 2018 IEEE 16th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Kosice and Herlany, Slovakia, 7–10 February 2018; pp. 000131–000136. [Google Scholar]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Li, R.; Hu, H.; Gu, D. Building semantic maps for blind people to navigate at home. In Proceedings of the 2016 8th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 28–30 September 2016; pp. 12–17. [Google Scholar]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2013, 30, 177–187. [Google Scholar] [CrossRef]
- Stückler, J.; Behnke, S. Multi-resolution surfel maps for efficient dense 3D modeling and tracking. J. Vis. Commun. Image Represent. 2014, 25, 137–147. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.W. Role of deep learning in loop closure detection for visual and lidar SLAM: A survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surf8 [47] | Surf4 | Surf4+LC | Whelan et al. [48] | Qiang et al. [49] | RGBD SLAM [50] | MRSMap [51] | |
|---|---|---|---|---|---|---|---|
| ATE | 0.0907 | 0.082 | 0.0628 | 0.037 | 0.064 | 0.026 | 0.043 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Somlyai, L.; Vámossy, Z. ISVD-Based Advanced Simultaneous Localization and Mapping (SLAM) Algorithm for Mobile Robots. Machines 2022, 10, 519. https://doi.org/10.3390/machines10070519
Somlyai L, Vámossy Z. ISVD-Based Advanced Simultaneous Localization and Mapping (SLAM) Algorithm for Mobile Robots. Machines. 2022; 10(7):519. https://doi.org/10.3390/machines10070519
Chicago/Turabian StyleSomlyai, László, and Zoltán Vámossy. 2022. "ISVD-Based Advanced Simultaneous Localization and Mapping (SLAM) Algorithm for Mobile Robots" Machines 10, no. 7: 519. https://doi.org/10.3390/machines10070519
APA StyleSomlyai, L., & Vámossy, Z. (2022). ISVD-Based Advanced Simultaneous Localization and Mapping (SLAM) Algorithm for Mobile Robots. Machines, 10(7), 519. https://doi.org/10.3390/machines10070519