

Dynamic Value at Risk Estimation in Multi-Functional Volterra Time-Series Model (MFVTSM)


Abstract
1. Introduction
2. Methodology
2.1. Multifunctional Data Framework
2.2. Model and Estimation
3. The Mathematical Foundation of the Estimation
3.1. Assumptions
- (As1)
- The functions are differentiable in and satisfy the following:
- (As2)
- The function is a Holder continuous kernel such that
- (As3)
- For all , and we suppose that and for all ,
- (As4)
- There exist , such that
- (As5)
- The function has a support and satisfies
Some Comments
3.2. Asymptotic Result
4. Empirical Analysis
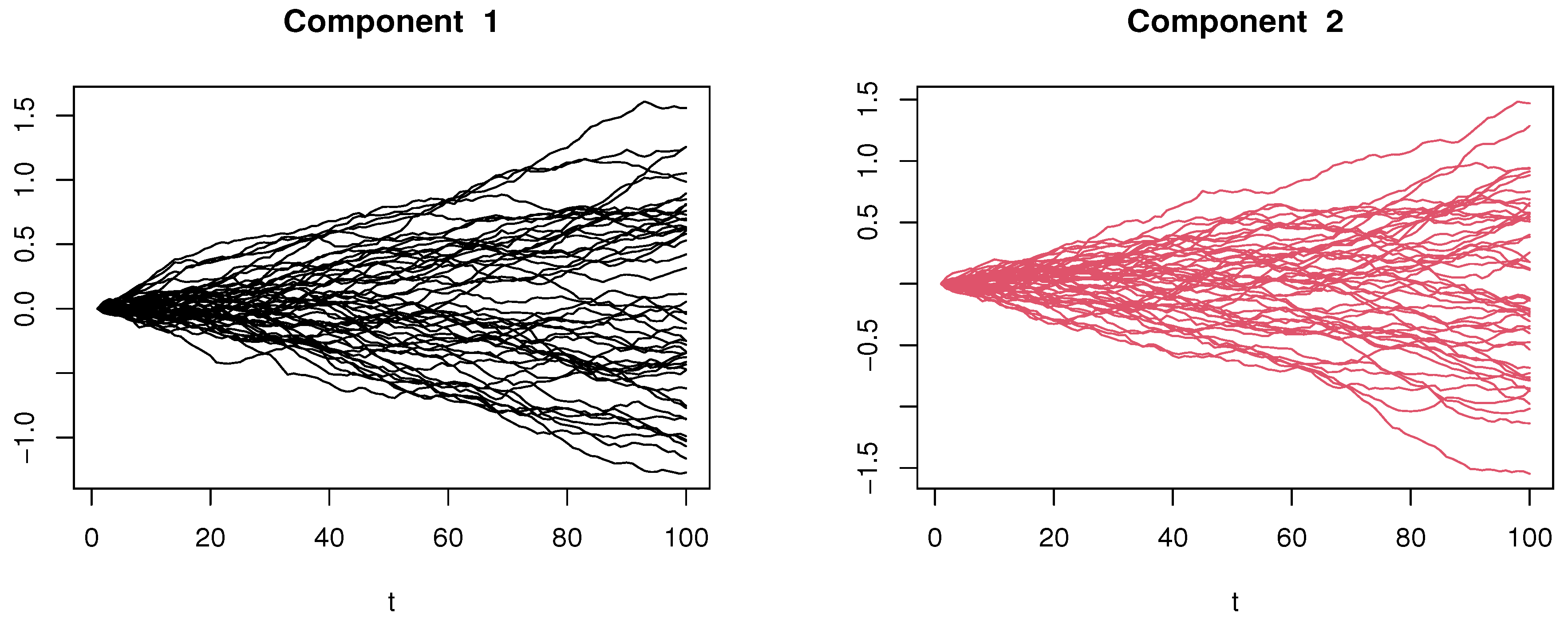
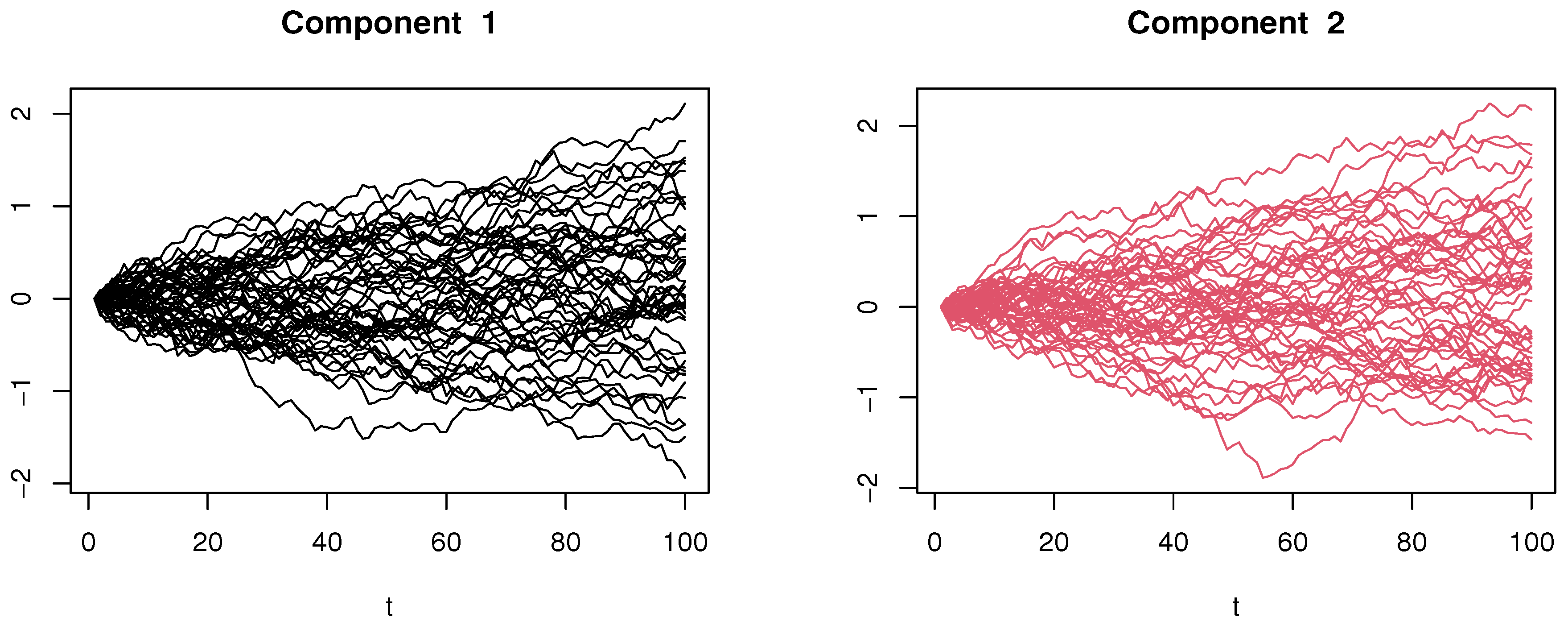
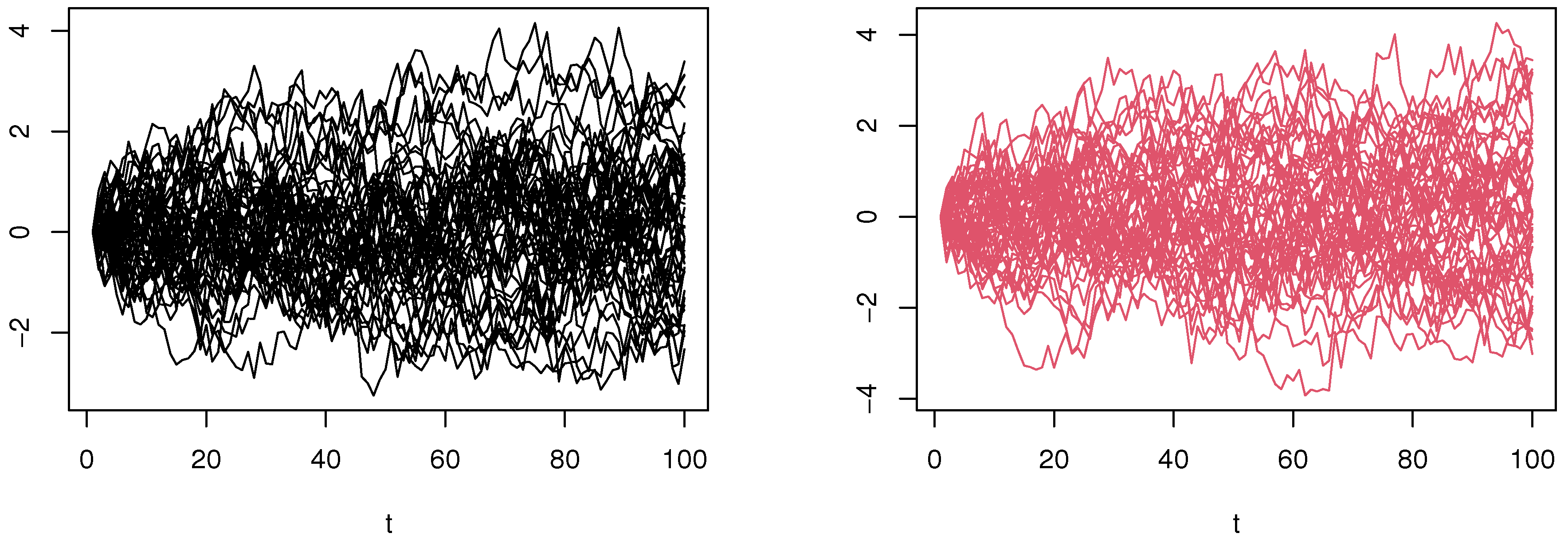
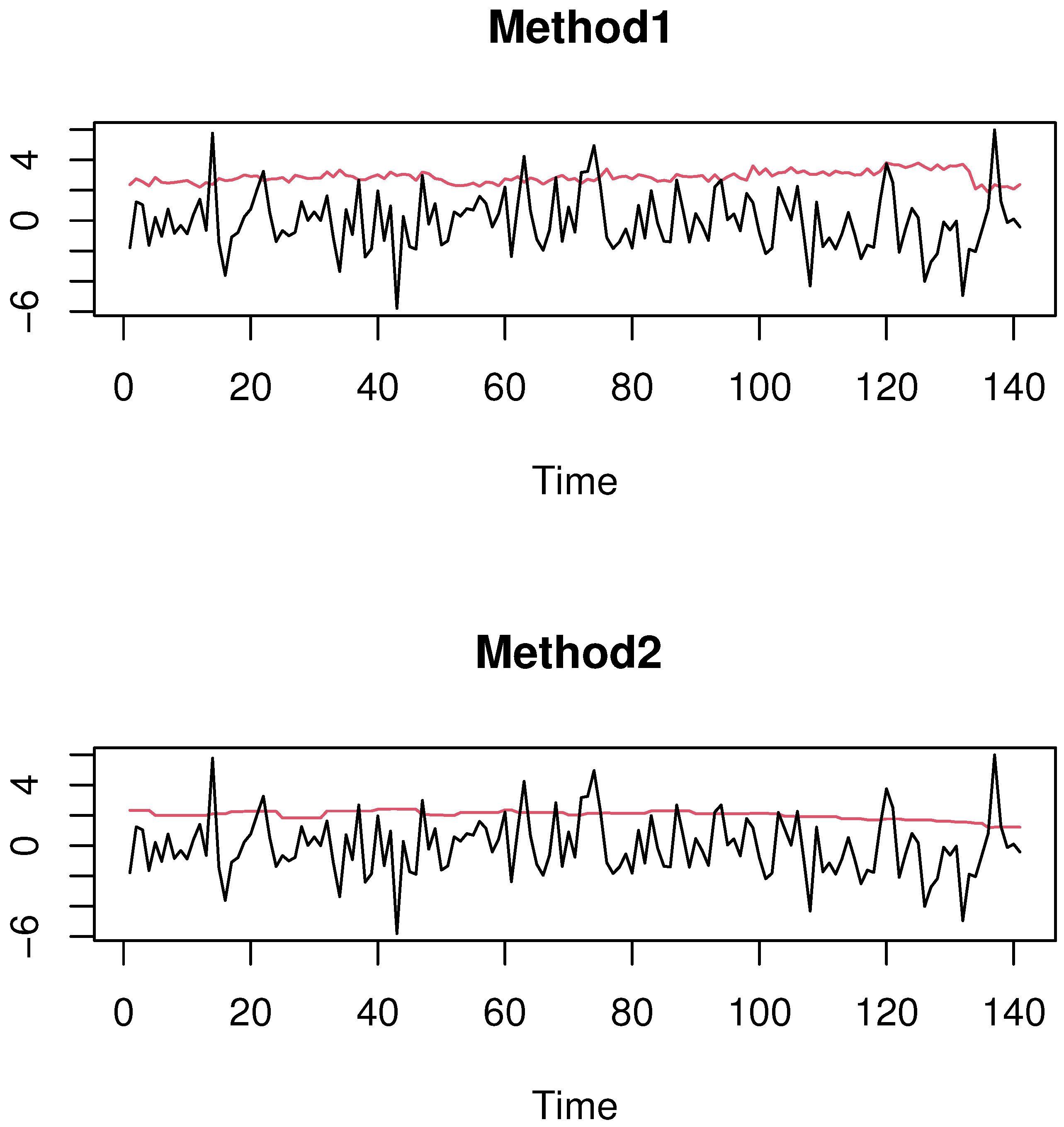
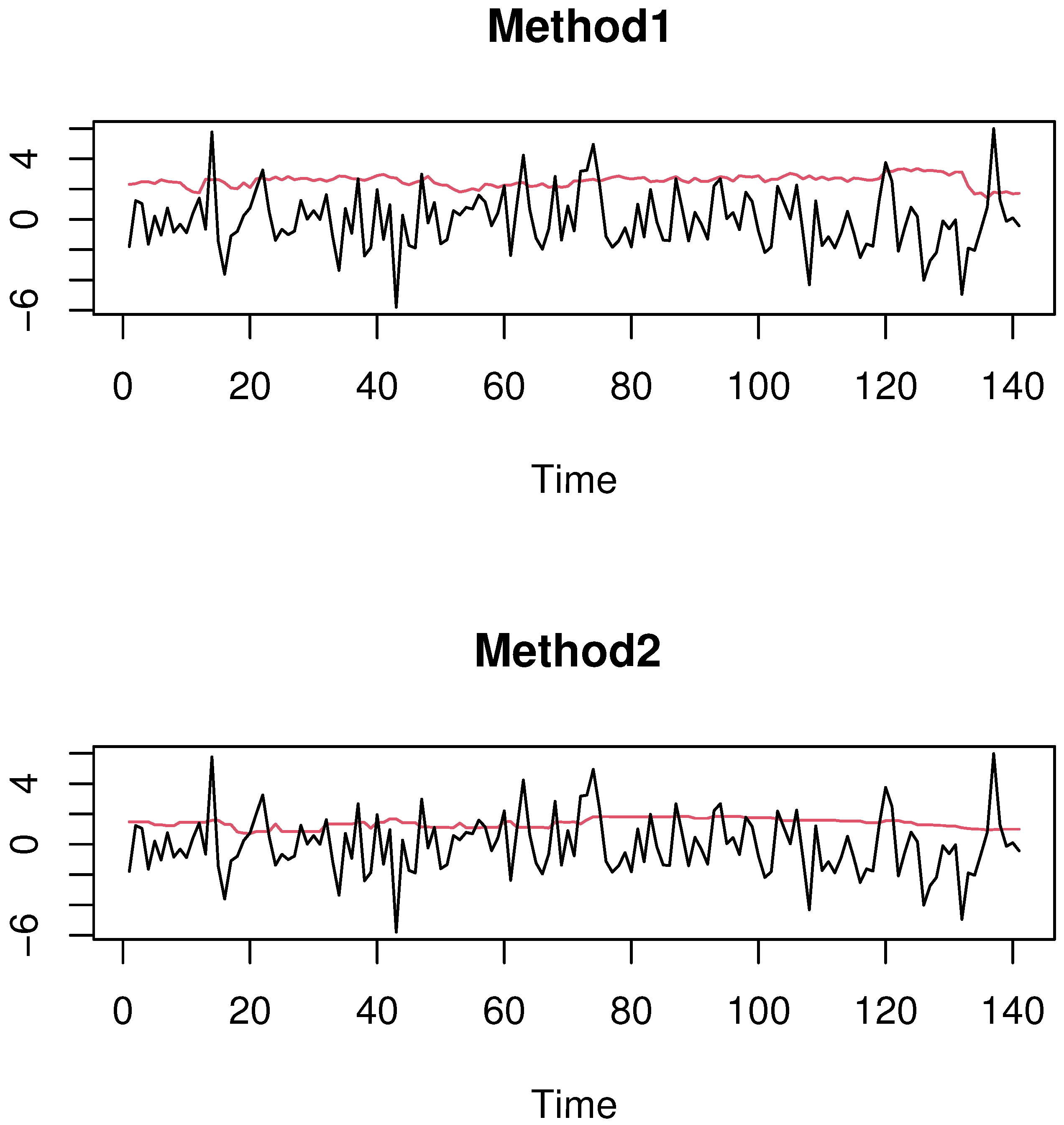
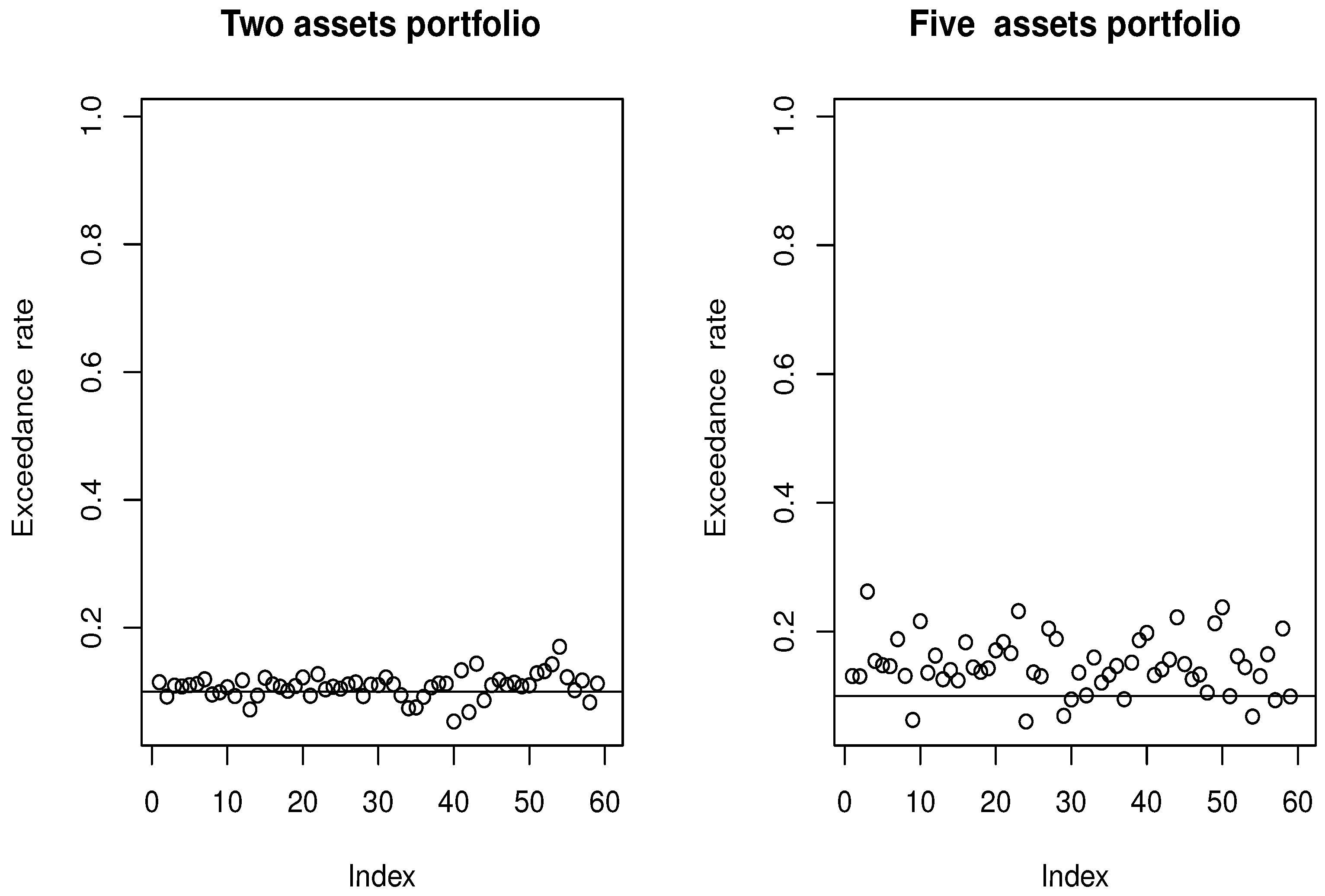
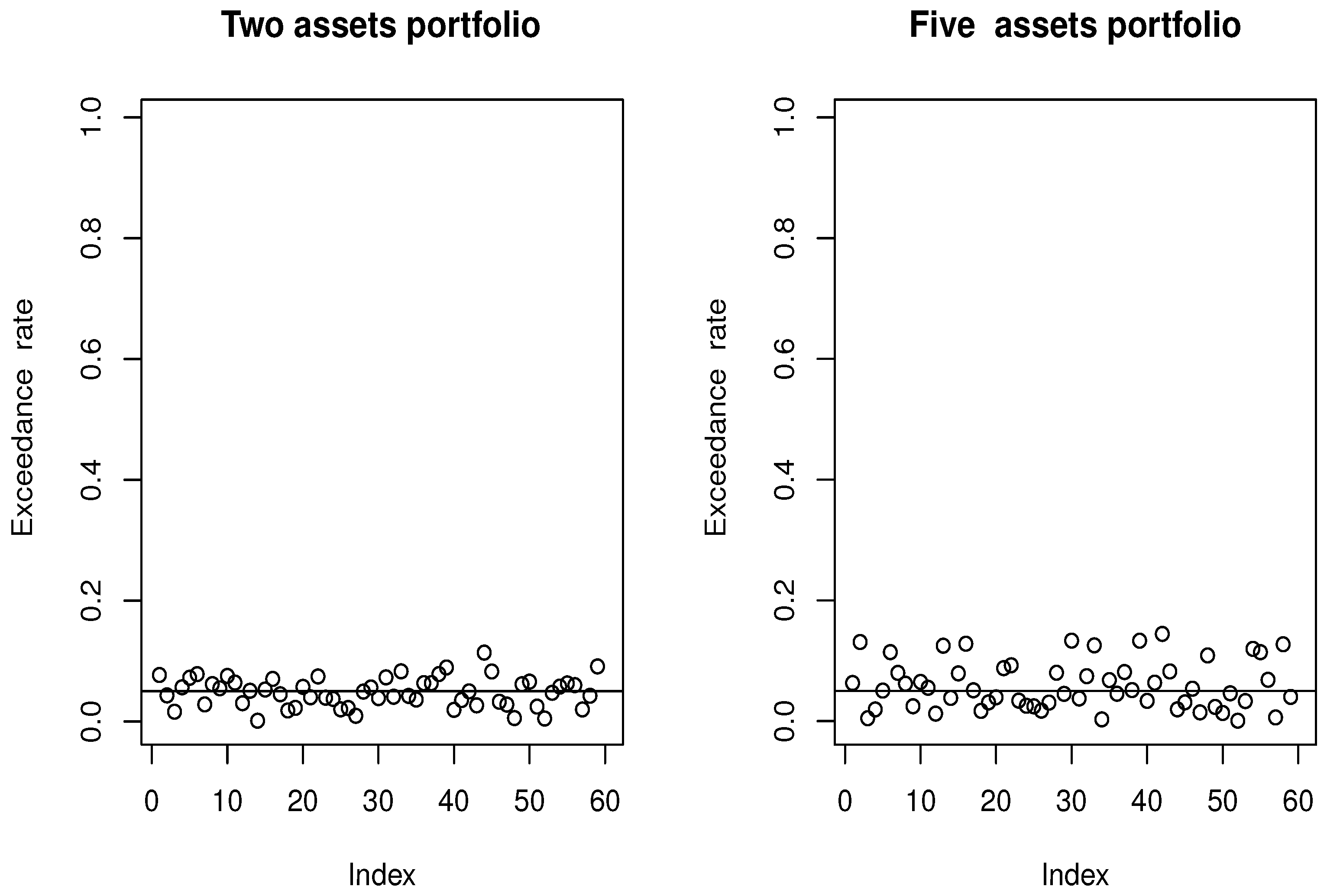
4.1. Simulated Financial Time-Series Analysis
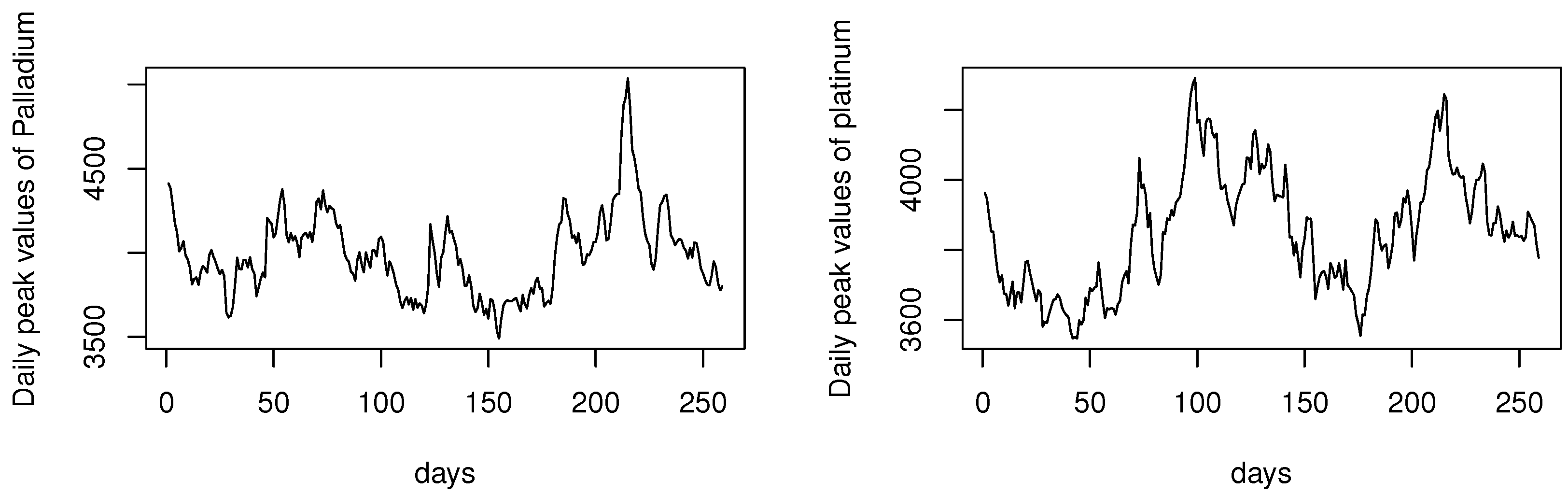
4.2. Real-World Financial Time Series
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Combining (As4) and (As5) to
References
- Comte, F.; Renault, E. Long memory in continuous-time stochastic volatility models. Math. Financ. 1998, 8, 291–323. [Google Scholar] [CrossRef]
- Alòs, E.; León, J.A.; Vives, J. On the short-time behavior of the implied volatility for jump-diffusion models with stochastic volatility. Financ. Stoch. 2007, 11, 571–589. [Google Scholar] [CrossRef]
- Fouque, J.P.; Papanicolaou, G.; Sircar, K.R. Derivatives in Financial Markets with Stochastic Volatility; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Tankov, P. Financial Modelling with Jump Processes; Chapman and Hall/CRC: Boca Raton, FL, USA, 2003. [Google Scholar]
- Engle, R.F.; Manganelli, S. CAViaR: Conditional autoregressive value at risk by regression quantiles. J. Bus. Econ. Stat. 2004, 22, 367–381. [Google Scholar] [CrossRef]
- Kuester, K.; Mittnik, S.; Paolella, M.S. Value-at-risk prediction: A comparison of alternative strategies. J. Financ. Econ. 2006, 4, 53–89. [Google Scholar] [CrossRef]
- Sun, P.; Lin, F.; Xu, H.; Yu, K. Estimation of value-at-risk by Lp quantile regression. Ann. Inst. Stat. Math. 2025, 77, 25–59. [Google Scholar] [CrossRef]
- Lux, M.; Härdle, W.K.; Lessmann, S. Data driven value-at-risk forecasting using a SVR-GARCH-KDE hybrid. Comput. Stat. 2020, 35, 947–981. [Google Scholar] [CrossRef]
- Herrera, R.; Schipp, B. Value at risk forecasts by extreme value models in a conditional duration framework. J. Empir. Financ. 2013, 23, 33–47. [Google Scholar] [CrossRef]
- Huang, J.-J.; Lee, K.-J.; Liang, H.; Lin, W.-F. Estimating value at risk of portfolio by conditional copula-GARCH method. Insur. Math. Econ. 2009, 45, 315–324. [Google Scholar] [CrossRef]
- Stone, C.J. Consistent Nonparametric Regression. Ann. Statist. 1977, 5, 595–620. [Google Scholar] [CrossRef]
- Stute, W. Conditional empirical processes. Ann. Statist. 1986, 14, 638–647. [Google Scholar] [CrossRef]
- Koenker, R. Quantile regression: 40 years on. Annu. Rev. Econ. 2017, 9, 155–176. [Google Scholar] [CrossRef]
- Cardot, H.; Crambes, C.; Sarda, P. Quantile regression when the covariates are functions. J. Nonparametric Stat. 2005, 17, 841–856. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Messaci, F.; Nemouchi, N.; Ouassou, I.; Rachdi, M. Local polynomial modelling of the conditional quantile for functional data. Stat. Methods Appl. 2015, 24, 597–622. [Google Scholar] [CrossRef]
- Ling, N.; Yang, Y.; Peng, Q. Partial linear quantile regression model with incompletely observed functional covariates. J. Nonparametric Stat. 2025, 1–27. [Google Scholar] [CrossRef]
- Mutis, M.; Beyaztas, U.; Karaman, F.; Lin Shang, H. On function-on-function linear quantile regression. J. Appl. Stat. 2025, 52, 814–840. [Google Scholar] [CrossRef] [PubMed]
- Beyaztas, U.; Tez, M.; Shang, H.L. Robust scalar-on-function partial quantile regression. J. Appl. Stat. 2024, 51, 1359–1377. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, G.; Sun, Y. Bivariate Functional Quantile Envelopes with Application to Radiosonde Wind Data. Technometrics 2020, 63, 199–211. [Google Scholar] [CrossRef]
- Lim, K.P.; Brooks, R.D.; Kim, J.H. Financial crisis and stock market efficiency: Empirical evidence from Asian countries. Int. Rev. Financial Anal. 2008, 17, 571–591. [Google Scholar] [CrossRef]
- Laksaci, A.; Lemdani, M.; Ould-Saïd, E. A generalized L1-approach for a kernel estimator of conditional quantile with functional regressors: Consistency and asymptotic normality. Stat. Probab. Lett. 2009, 79, 1065–1073. [Google Scholar] [CrossRef]
- Rachdi, M.; Vieu, P. Nonparametric regression for functional data: Automatic smoothing parameter selection. J. Stat. Plan. Inference 2007, 137, 2784–2801. [Google Scholar] [CrossRef]
- Alkhaldi, S.H.; Alshahrani, F.; Alaoui, M.K.; Laksaci, A.; Rachdi, M. Multifunctional Expectile Regression Estimation in Volterra Time Series: Application to Financial Risk Management. Axioms 2025, 14, 147. [Google Scholar] [CrossRef]
- Doukhan, P.; Neumann, M.H. Probability and moment inequalities for sums of weakly dependent random variables, with applications. Stoch. Process. Their Appl. 2007, 117, 878–903. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | h | N | |||
|---|---|---|---|---|---|
| 0.2 | 50 | 1.89 | 1.76 | 1.59 | |
| 150 | 1.12 | 1.02 | 1.07 | ||
| 250 | 0.81 | 0.64 | 0.73 | ||
| 0.6 | 50 | 1.57 | 1.41 | 1.61 | |
| 150 | 0.96 | 0.85 | 0.72 | ||
| 250 | 0.31 | 0.23 | 0.28 | ||
| 0.9 | 50 | 1.18 | 1.17 | 1.23 | |
| 150 | 1.02 | 1.09 | 1.11 | ||
| 250 | 0.18 | 0.25 | 0.33 | ||
| CVaR | 0.2 | 50 | 1.19 | 1.23 | 1.25 |
| 150 | 1.07 | 1.12 | 1.26 | ||
| 250 | 0.97 | 0.74 | 0.83 | ||
| 0.6 | 50 | 1.85 | 1.91 | 1.71 | |
| 150 | 1.11 | 1.03 | 1.12 | ||
| 250 | 0.71 | 0.46 | 0.53 | ||
| 0.9 | 50 | 2.20 | 2.21 | 2.33 | |
| 150 | 2.14 | 2.19 | 2.081 | ||
| 250 | 1.078 | 1.05 | 0.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almulhim, F.A.; Alamari, M.B.; Laksaci, A.; Rachdi, M. Dynamic Value at Risk Estimation in Multi-Functional Volterra Time-Series Model (MFVTSM). Symmetry 2025, 17, 1207. https://doi.org/10.3390/sym17081207
Almulhim FA, Alamari MB, Laksaci A, Rachdi M. Dynamic Value at Risk Estimation in Multi-Functional Volterra Time-Series Model (MFVTSM). Symmetry. 2025; 17(8):1207. https://doi.org/10.3390/sym17081207
Chicago/Turabian StyleAlmulhim, Fatimah A., Mohammed B. Alamari, Ali Laksaci, and Mustapha Rachdi. 2025. "Dynamic Value at Risk Estimation in Multi-Functional Volterra Time-Series Model (MFVTSM)" Symmetry 17, no. 8: 1207. https://doi.org/10.3390/sym17081207
APA StyleAlmulhim, F. A., Alamari, M. B., Laksaci, A., & Rachdi, M. (2025). Dynamic Value at Risk Estimation in Multi-Functional Volterra Time-Series Model (MFVTSM). Symmetry, 17(8), 1207. https://doi.org/10.3390/sym17081207