5.1. Datasets
Smart contract vulnerability detection is a relatively niche and emerging research area, and currently, there are no official or widely recognized third-party datasets available. Therefore, for the experiments in this paper, we synthesized data from various sources. A total of 2307 contracts containing 6744 functions were collected. Among these, 1180 contracts involving vulnerabilities contain 3017 unique functions, while 1127 contracts not involving vulnerabilities contain 3837 functions. Part of the dataset is pre-labeled and includes three types of vulnerabilities: reentrancy, timestamp, and integer overflow, with a total of 1093 contracts and 1173 functions. The remaining data were selected from a larger dataset of over 12,000 Ethereum contracts, which cover eight types of vulnerabilities. From this larger dataset, we extracted the three types of vulnerabilities (reentrancy, timestamp, and integer overflow), de-weighted the data, cleaned it, and labeled it accordingly. Ultimately, 1214 contracts containing 5681 functions were selected. Before conducting the experiments, each subset of the dataset was partitioned into a training set and a validation set, with 80% of the data allocated for training and 20% reserved for validation. All data were derived from real contracts deployed on the Ethereum network, ensuring both the diversity and real-world relevance of the data. This, in turn, supports the generalization ability of the subsequent training models.
Table 2 clearly presents the composition of the dataset used in this paper.
5.3. Evaluation Metrics
In this experiment, we use several common evaluation metrics to assess the performance of the model in the smart contract vulnerability detection task. These metrics include accuracy, precision, recall, and F1 score.
Accuracy: This metric indicates the percentage of samples for which the model predicts the correct result.
Precision: This metric indicates the percentage of true positive categories (i.e., vulnerabilities) that are correctly predicted as positive by the model. The magnitude of the precision value reflects the false alarm rate of the detection task.
Recall: This metric indicates the ratio of samples correctly predicted as positive among all samples that are truly positive (i.e., those containing vulnerabilities). Increasing the recall rate ensures that more vulnerabilities are detected.
Precision and recall both influence the value of the F1 score, which serves as a comprehensive measure of the model’s performance, particularly in addressing the class imbalance problem present in the dataset of this paper.
5.4. Results and Analysis
In this subsection, we compare the BGMF detection method with nine other detection methods across three types of vulnerabilities: reentrancy, timestamp, and integer overflow, and carefully analyze the experimental results. Among these ten detection methods, there are three categories of detection methods:
Traditional detection methods: Tools such as Mythril, Manticore, Oyente [
41], and Slither primarily rely on static analysis and symbolic execution. These methods are effective for detecting well-established vulnerabilities and offer high computational efficiency. However, their reliance on predefined rules and models limits their ability to detect new or intricate vulnerabilities, particularly those that deviate from known patterns.
Deep learning approaches: Methods such as CNN, LSTM, Degree-Free Graph Convolutional Networks (DR_GCN), and Message Propagation Networks (TMP) leverage neural network models trained on extensive datasets. These approaches are adept at capturing complex patterns of vulnerabilities that might not be readily identifiable by traditional methods. They excel particularly in scenarios where the analysis requires the understanding of structured information within smart contracts or the temporal dependencies inherent in contract execution.
Large model approaches: Recent advancements in deep learning have introduced large model-based approaches, such as BERT and SmartBugBert, which utilize pre-trained models to deeply understand the logic of contract code in context. These models are capable of identifying potential vulnerabilities by leveraging their ability to process complex contract structures and semantic relationships. The strength of large models lies in their superior generalization capabilities, allowing them to recognize previously unseen vulnerabilities and adapt to a variety of contract structures.
In this paper, the implementation of all comparative experiments is divided into three scenarios:
When the source code is provided: If the article provides the source code, we will replicate the original code, utilize our own dataset, and preprocess the data according to the methods described in the paper. Experimental results will then be recorded based on the evaluation metrics.
When the source code is not provided: If the article does not publicly release the source code, we will contact the authors via email to inquire whether they can provide the source code for the purpose of conducting comparative experiments.
When no response is received: If no response is received after emailing the authors, we will independently implement the algorithm based on the descriptions in the paper and perform the comparative experiments.
Additionally, we conducted ablation experiments on the two modules involved in the BGMF model and carefully analyzed the results. Due to the data imbalance in this experiment and the need to balance between minimizing misses and reducing false positives, we focus on the F1 score and recall values.
Table 5 presents the comparison results between the nine smart contract vulnerability detection methods and our method for detecting reentrancy vulnerabilities. From the table, it is evident that the performance of traditional detection tools is generally low, especially with Mythril and Manticore, which have low F1 values and accuracy rates. This indicates a high false-positive rate, as both methods predict potential vulnerabilities from the source code, while some reentrancy vulnerabilities occur during external calls, state changes, or contract interactions. This dynamic behavior results in some vulnerabilities not being correctly identified. However, Slither performs better and significantly outperforms other traditional detection methods in all metrics.In comparison with traditional detection methods, the overall performance of deep learning detection methods shows significant improvement. The difference in F1 scores between the worst-performing deep learning method and the best-performing traditional method is nearly 8 percentage points, indicating that deep learning methods have clear advantages in detecting reentrancy vulnerabilities. The BERT, a detection method derived from traditional deep learning, does not perform as well, with an F1 score of only 83.01%. This is because BERT is primarily designed for language modeling and text-based tasks, requiring more pre-training and fine-tuning for smart contract detection. The BGMF model presented in this paper overcomes this limitation by pre-training on a specific dataset, achieving superior performance across all metrics. It achieves an accuracy of 96.40%, an F1 score of 93.23%, and the best balance, demonstrating the robustness and practicality of the model.
Table 6 presents the detailed detection results for timestamp vulnerability detection across different methods. Among the traditional detection tools, Mythril performs relatively poorly, with an accuracy of 52.34%, a precision of 53.45%, and a recall as low as 33.56%, resulting in an F1 score of only 40.78%. This ineffective detection is primarily due to the static analysis methods, which are unable to effectively capture the dynamic behavior of timestamp vulnerabilities. Manticore and Oyente show improved performance, especially in terms of recall. Slither performs relatively well, achieving an F1 score of 56.78%, although it still falls short of the performance of deep learning methods. Among the deep learning methods, CNN and LSTM outperform traditional detection methods, with F1 scores of 78.53% and 81.32%, respectively, indicating a better balance between precision and recall. The BERT model further enhances the overall performance compared with traditional deep learning methods, demonstrating the significant potential of large models for smart contract vulnerability detection. The method presented in this paper more effectively mines the deep semantic features of the code, achieving an F1 score of 93.56% in the timestamp vulnerability detection task. This represents a 5.22% improvement over the best existing method and far surpasses the performance of other smart contract detection methods.
Table 7 presents the detection results for integer overflow vulnerability across ten different models. From the data, it is evident that deep learning methods outperform traditional detection tools, with the method proposed in this paper achieving the most outstanding results. It demonstrates an accuracy rate close to 100%, efficiently detecting vulnerabilities with almost no false positives. Furthermore, previous experiments on integer overflow vulnerability detection have been limited, and our work addresses these gaps, significantly advancing the field of integer overflow vulnerability detection.
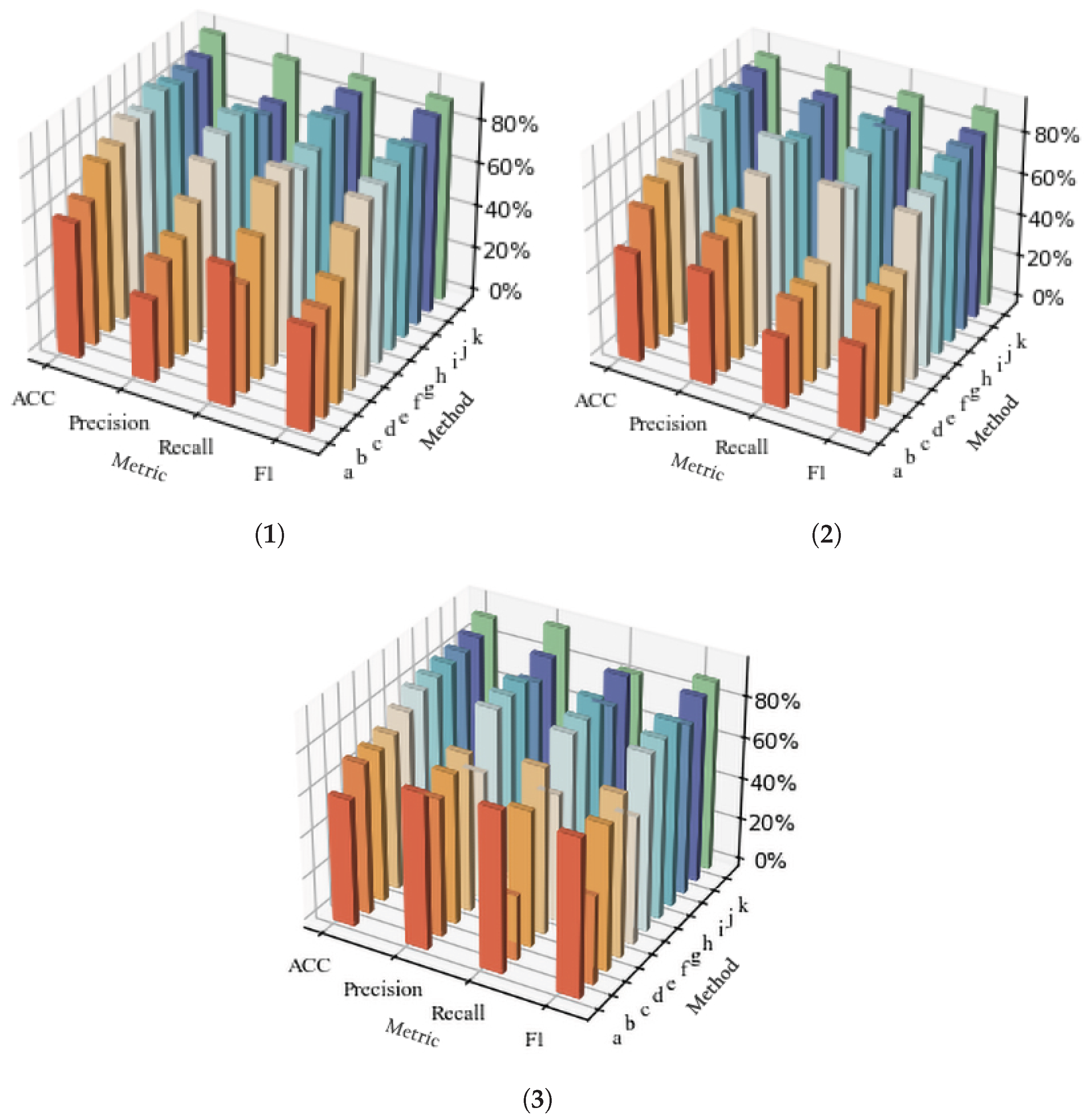
The comparative experimental data on reentrancy, timestamp, and integer overflow vulnerabilities presented above indicate that most traditional tools still exhibit certain limitations compared with deep learning approaches. Our method combines the advantages of previous research, addresses its shortcomings, and introduces innovations that improve the original model. As a result, it outperforms the best-performing previous methods for each of the vulnerabilities discussed in this paper. The three graphs in
Figure 10 further visualize the detection results of the ten detection methods for reentrancy, timestamp, and integer overflow vulnerabilities. It is clearly evident that our method outperforms all other methods. (In the figures, (a–j) represent Mythril, Manticore, Oyente, Slither, CNN, LSTM, DR_GCN, TMP, BERT, and our method, respectively).
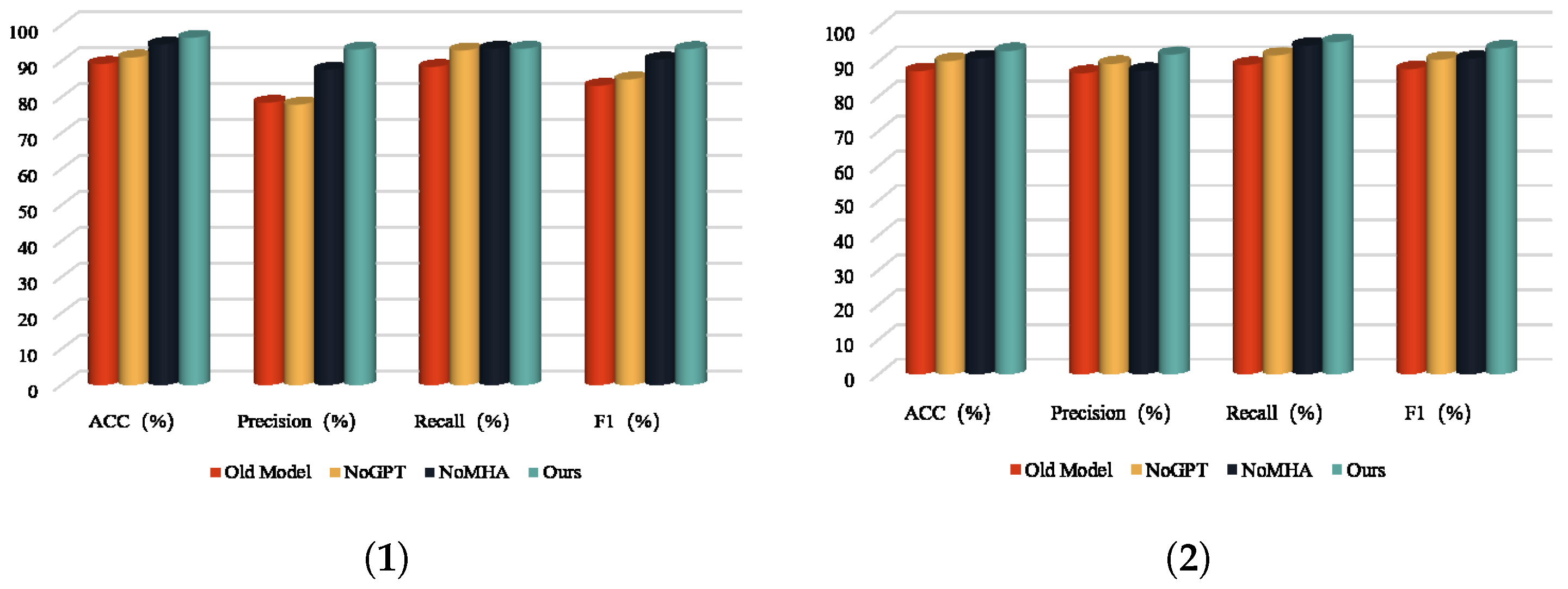
To demonstrate the effectiveness of the improved method proposed in this paper, we conducted ablation experiments. This paper conducts a comparative analysis of the following models:
Old Model: This model represents the original detection method, serving as a baseline for performance comparison. Its performance reflects the detection capability without the inclusion of the innovative modules proposed in this paper.
NoGPT: This model removes the generative semantic feature extraction module introduced in this paper while retaining the multi-head attention mechanism module. It is designed to evaluate the performance of smart contract vulnerability detection using a single semantic feature, where only the original semantics are retained.
NoMHA: This model removes the multi-head attention mechanism module proposed in this paper while keeping the generative semantic feature extraction module. It aims to assess the performance of smart contract vulnerability detection without the feature fusion step.
Ours: This model represents the fully improved approach proposed in this paper, incorporating both the generative semantic feature extraction module and the multi-head attention mechanism module. Its performance demonstrates the optimal detection capability resulting from the synergy of all the proposed enhancements.
Table 8 and
Table 9 present the performance of each module of the improved method compared with the original detection method. In the detection of reentrancy vulnerabilities, our improved method shows significant improvements across all metrics, with the F1 score being 10.22% higher than that of the original method. As shown in the data in
Table 9, both the generative semantic extraction module and the multi-head attention mechanism module enhance the original model, with the generative semantic module providing the most noticeable improvement. This clearly demonstrates the effectiveness of the proposed improvements. For timestamp vulnerabilities, our improved method achieves a 5.89% increase in F1 score compared with the original method, indicating that the added modules are more effective in detecting timestamp vulnerabilities.
Figure 11 visualizes the effectiveness of the improved modules.




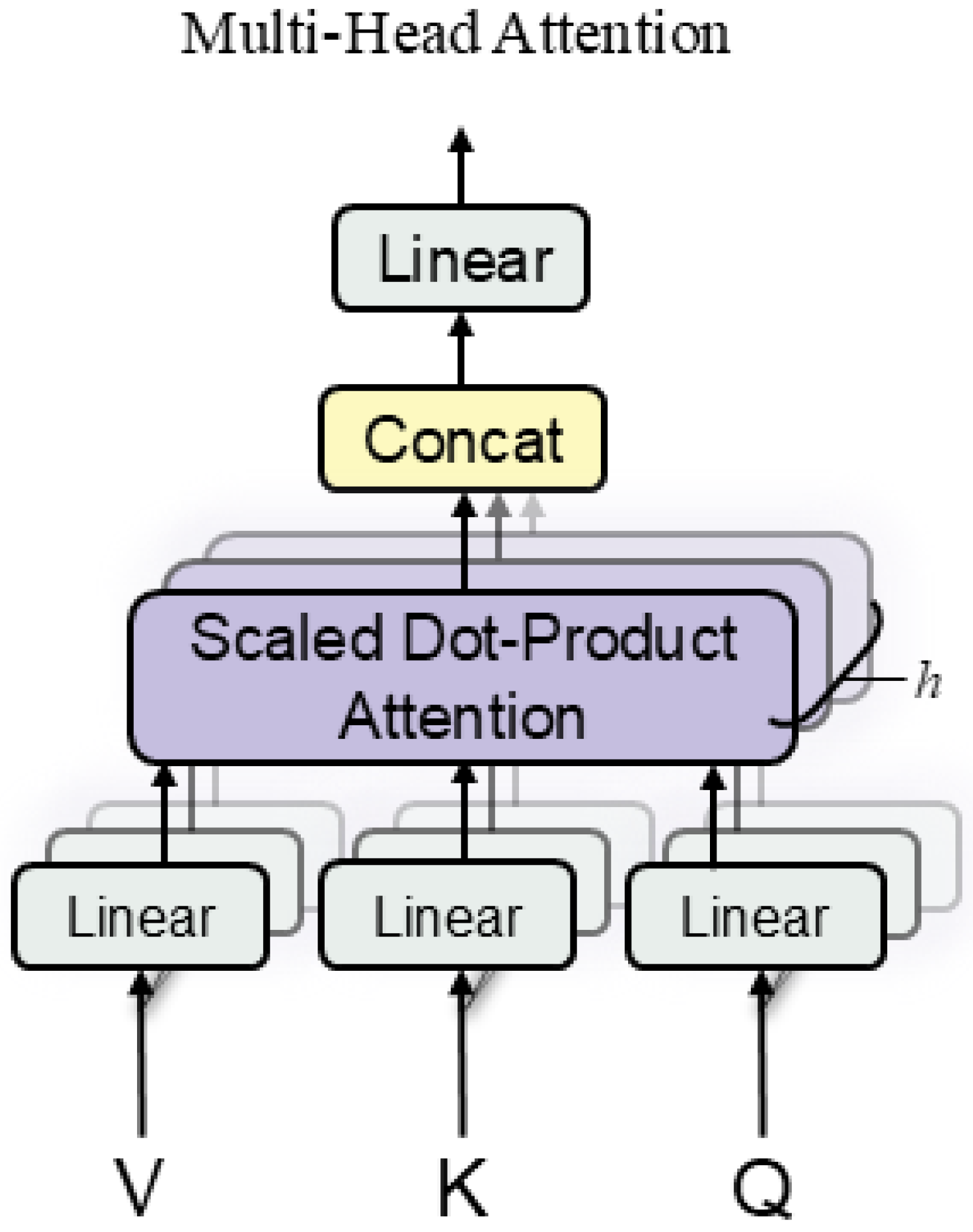





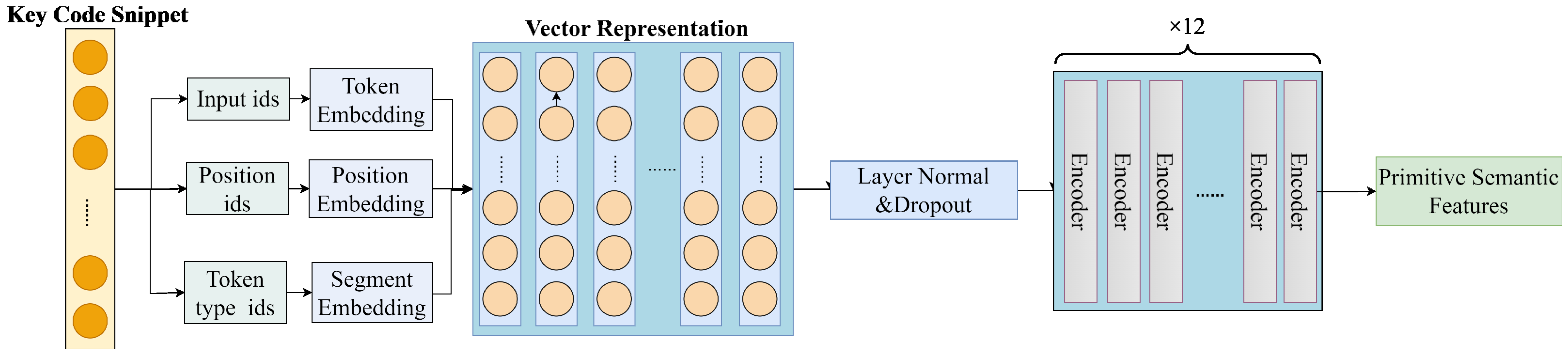
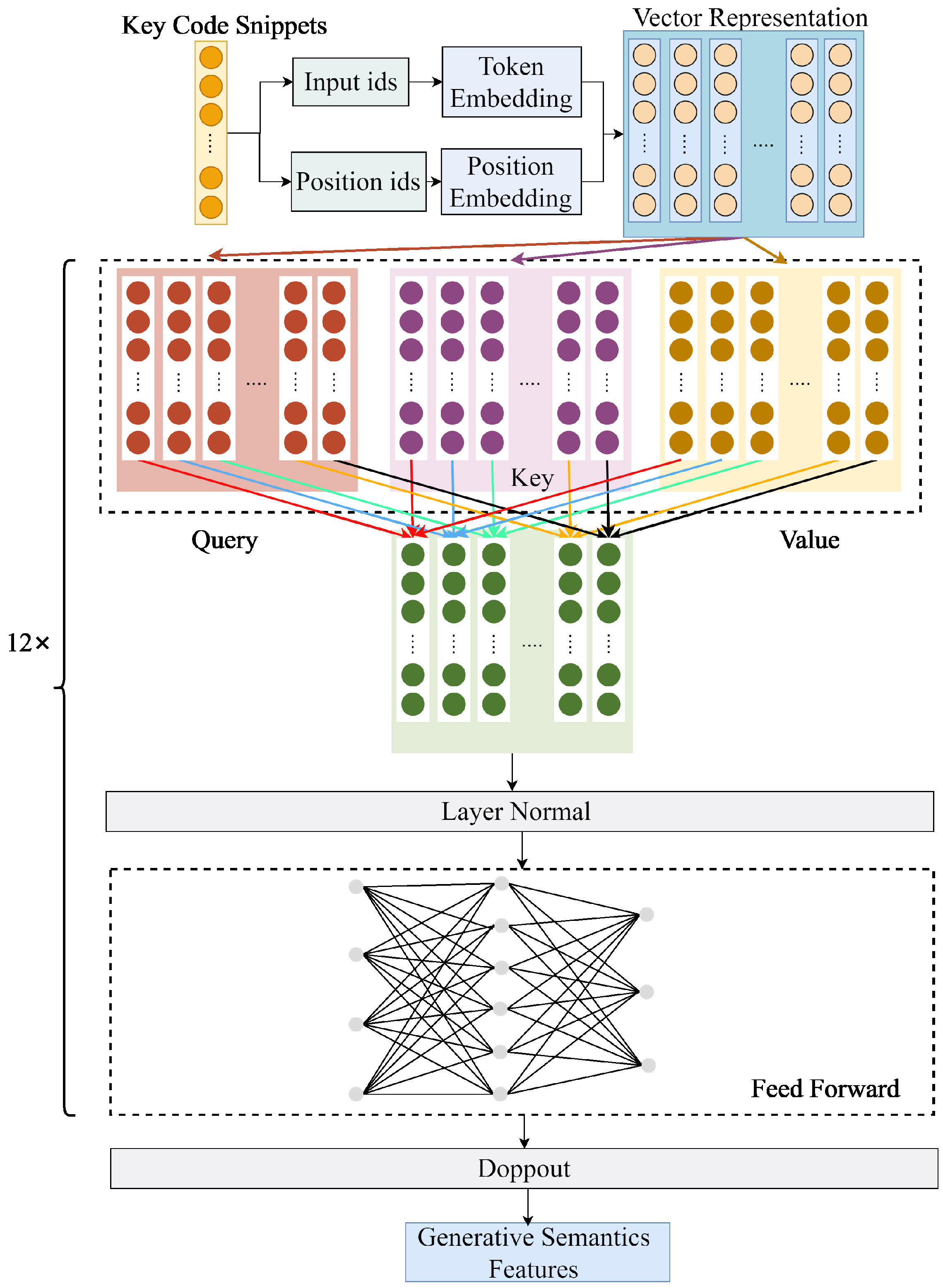
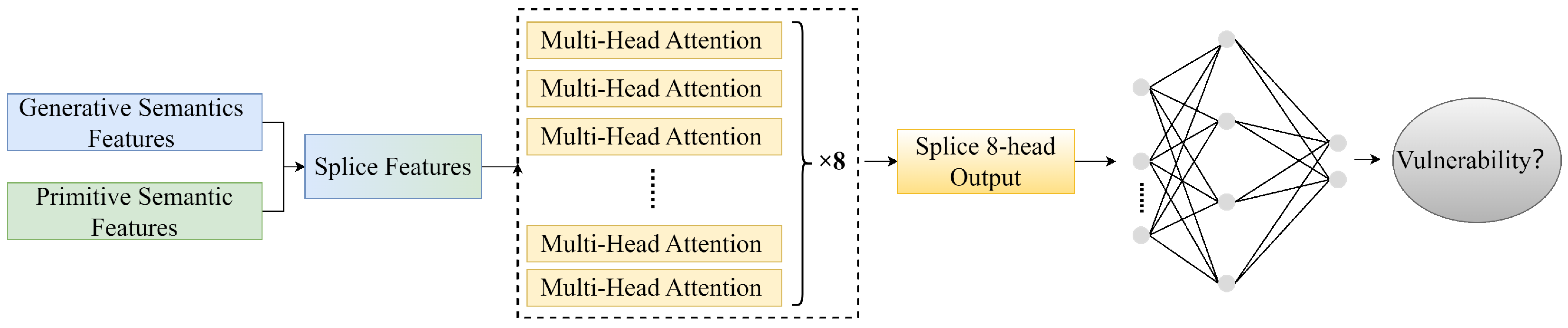

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}