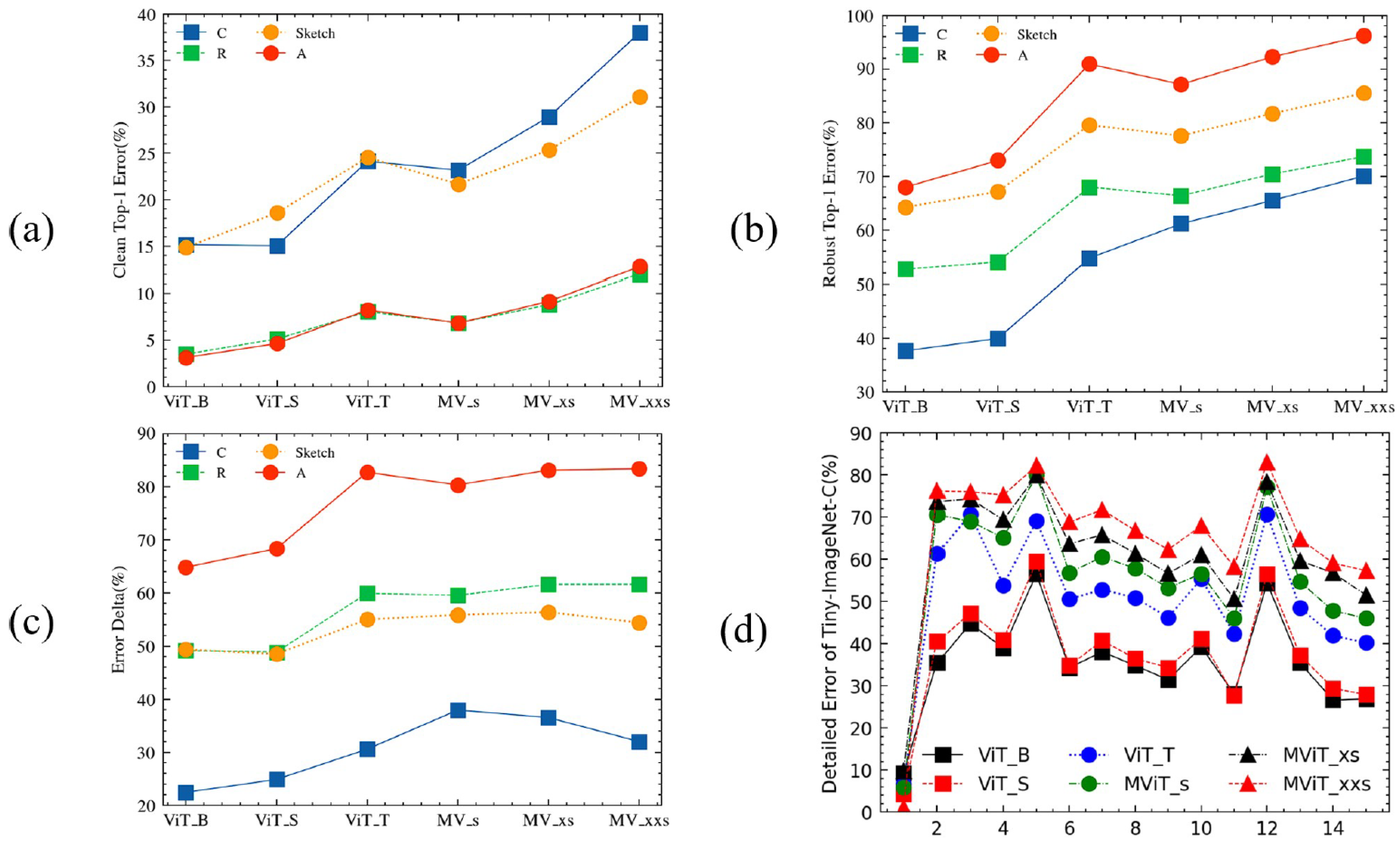
This study primarily utilizes adversarial training to strengthen the adversarial robustness of lightweight Transformer models. During the experimental phase, it was found that traditional adversarial attack methods, such as FGSM and PGD, which generate adversarial examples and mix them with clean samples for training, are not entirely suitable for lightweight Transformer models. The reason for this is that lightweight Transformer models exhibit training instability during traditional adversarial training, such as overfitting, rapid loss increase, and gradient explosion. To mitigate this issue, various stabilization techniques were applied to standard adversarial training frameworks. Furthermore, to improve the adversarial robustness of lightweight Transformer architectures following stabilization, two decision boundary optimization-based adversarial training strategies were employed.
4.1.1. Preliminary Robustness Enhancement Through Stabilized Adversarial Training
1. Static Parameter Adjustment
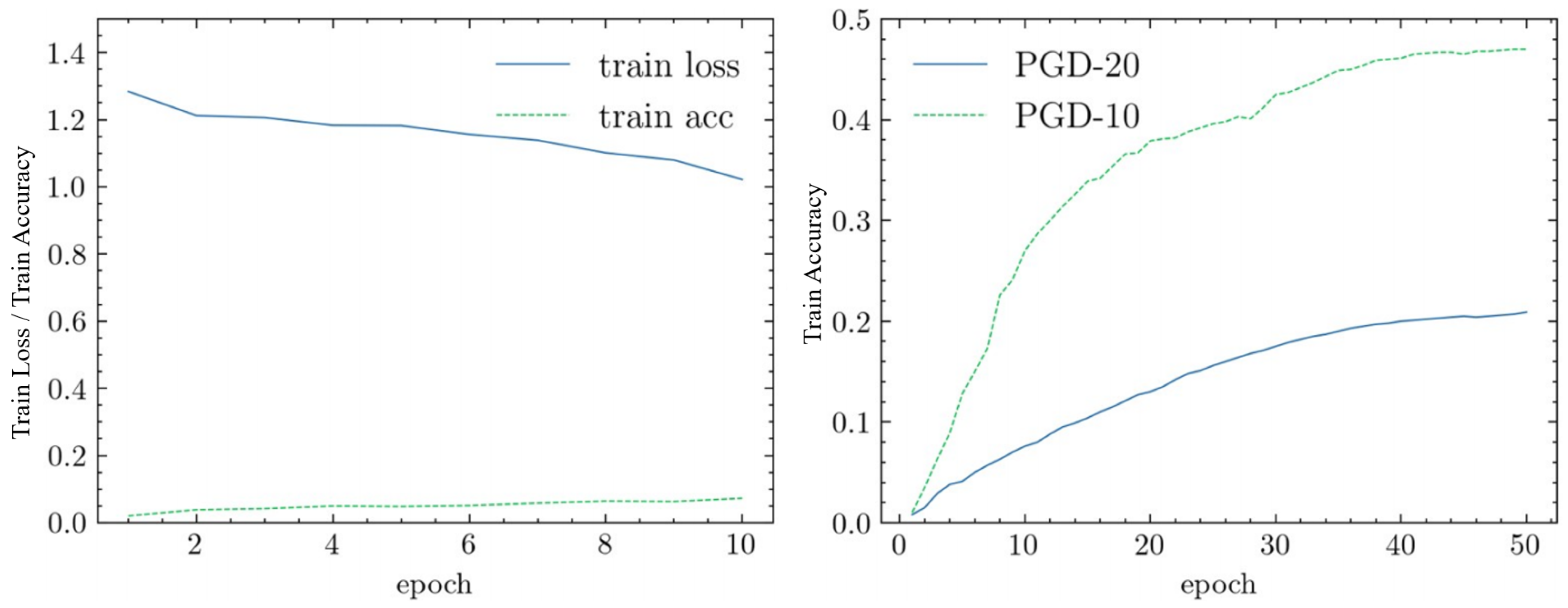
To address the issue of slow accuracy improvement and slow convergence in lightweight Transformer models during traditional adversarial training, this study adopted static parameter adjustment to enhance training efficiency. Specifically, based on traditional adversarial training, suitable values were set for the momentum and weight decay parameters of the SGD optimizer. Additionally, for the learning rate, the fixed learning rate was optimized by performing a warm-up in the early stages of adversarial training, followed by cosine annealing to cyclically adjust the learning rate based on the cosine function. This strategy better balances global and local search, improving adversarial robustness as well as the model’s performance and convergence speed during adversarial training. Furthermore, the study set appropriate PGD iteration steps and perturbation thresholds for the lightweight Transformer model to prevent the generation of low-quality adversarial examples. The model training curves before and after static parameter adjustment are shown in
Figure 5.
The static parameter adjustment strategy was applied to solve the problem of slow accuracy growth and convergence during traditional adversarial training of lightweight Transformer models. Specifically, suitable values for the momentum and weight decay parameters of the SGD optimizer were set. For learning rate adjustment, a cyclical strategy was adopted to more effectively control the training process. At the start of adversarial training, a warm-up was performed by setting a small learning rate and gradually increasing it to a pre-set threshold to avoid issues with non-convergence due to an excessively high learning rate in the early stages. Subsequently, cosine annealing was employed to periodically adjust the learning rate according to the cosine function, maintaining an appropriate adjustment range during training. This strategy better balances global and local search, improving both adversarial robustness and the model’s performance and convergence speed during adversarial training. Additionally, for lightweight Transformer models, moderate PGD iterations and perturbation thresholds were set to prevent the generation of low-quality adversarial examples. After the static parameter adjustment, the convergence speed was significantly improved, accelerating model training. The model training curves are shown in
Figure 5.
2. Dynamic Parameter Optimization
To address issues such as sudden increases in loss and gradient explosion during traditional adversarial training of lightweight models, this study employs dynamic parameter optimization. Specifically, gradient clipping is used to constrain the gradient updates within a reasonable range, preventing issues such as excessively large (gradient explosion) or excessively small (gradient vanishing) gradients during training. This approach ensures a more stable adversarial training process for lightweight Transformer models.
Using gradient clipping, the gradient descent process can be reformulated as shown in Equations (
1) and (
2). Given the objective function
and the learning rate
, the parameter
is iteratively adjusted at each step
t. Let the clipping threshold be denoted by
.
Under the influence of the gradient clipping algorithm, the model parameter
undergoes gradient descent, where each step’s descent direction is scaled by a factor of
. The product of these two parameters determines the step size. The operation of gradient clipping can be viewed as the process shown in Equation (
3):
During gradient descent, the gradient clipping strategy effectively limits the negative impact of excessively large gradients on model performance. By restricting the maximum range of gradients, it ensures the stability of the training process, thereby helping to improve the model’s convergence speed and final performance [
42].
3. Staged Model Parameter Update
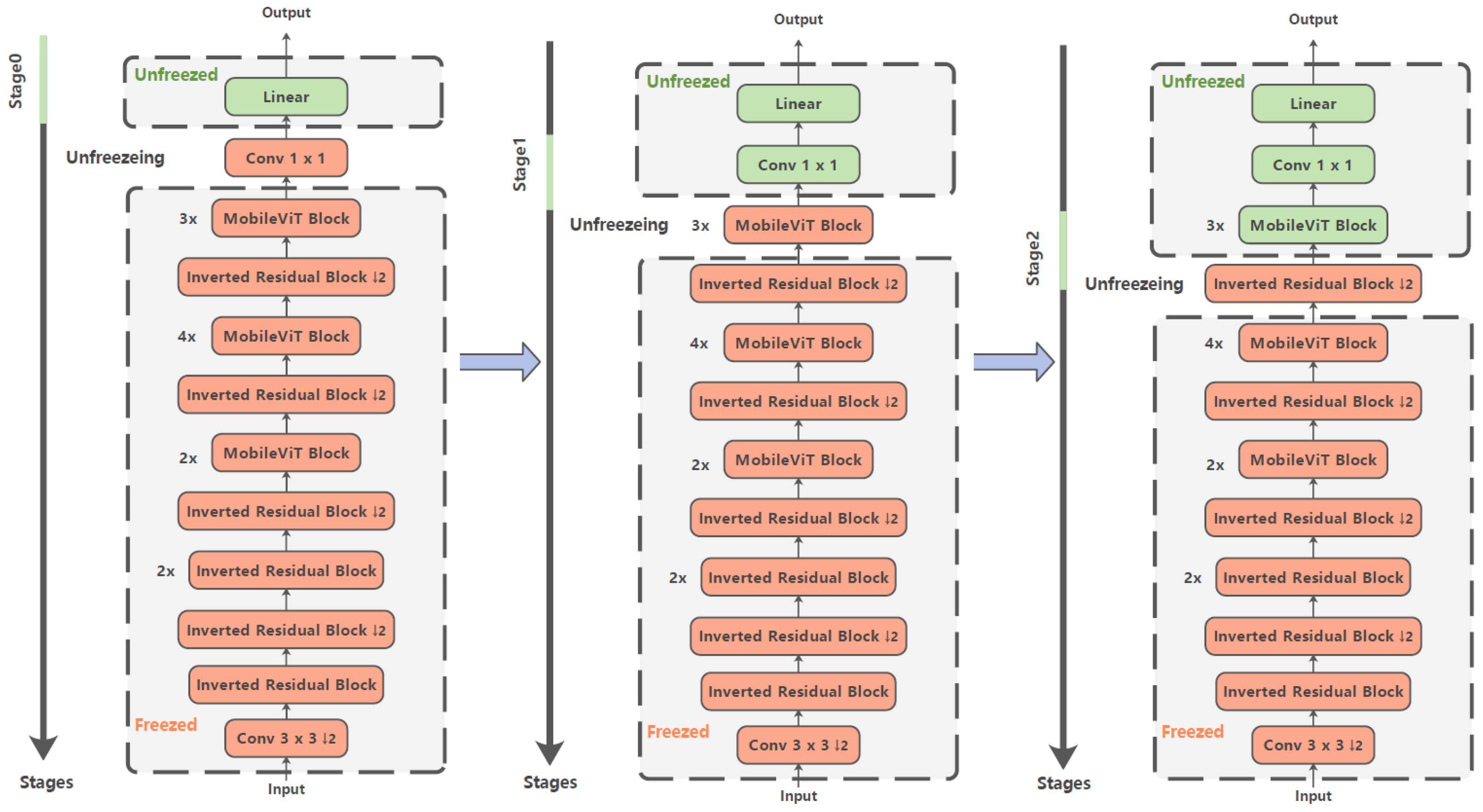
To address issues such as unstable loss convergence and overfitting during adversarial training of lightweight Transformer models, this study adopts a staged layer-wise unfreezing strategy. Initially, all layers of the model except the final layer are frozen. As training progresses, the layers are gradually unfrozen one by one. This approach helps mitigate the risk of overfitting and reduces computational cost.
The concept of layer-wise staged unfreezing was first proposed by Howard et al. [
43] in the context of fine-tuning in natural language processing tasks. Inspired by this principle, our study applies it to lightweight Transformer models for visual classification tasks. By using the learning period as a unit, layers are progressively unfrozen from back to front. This method is applied to a representative lightweight Transformer model, MobileViT, as illustrated in
Figure 6.
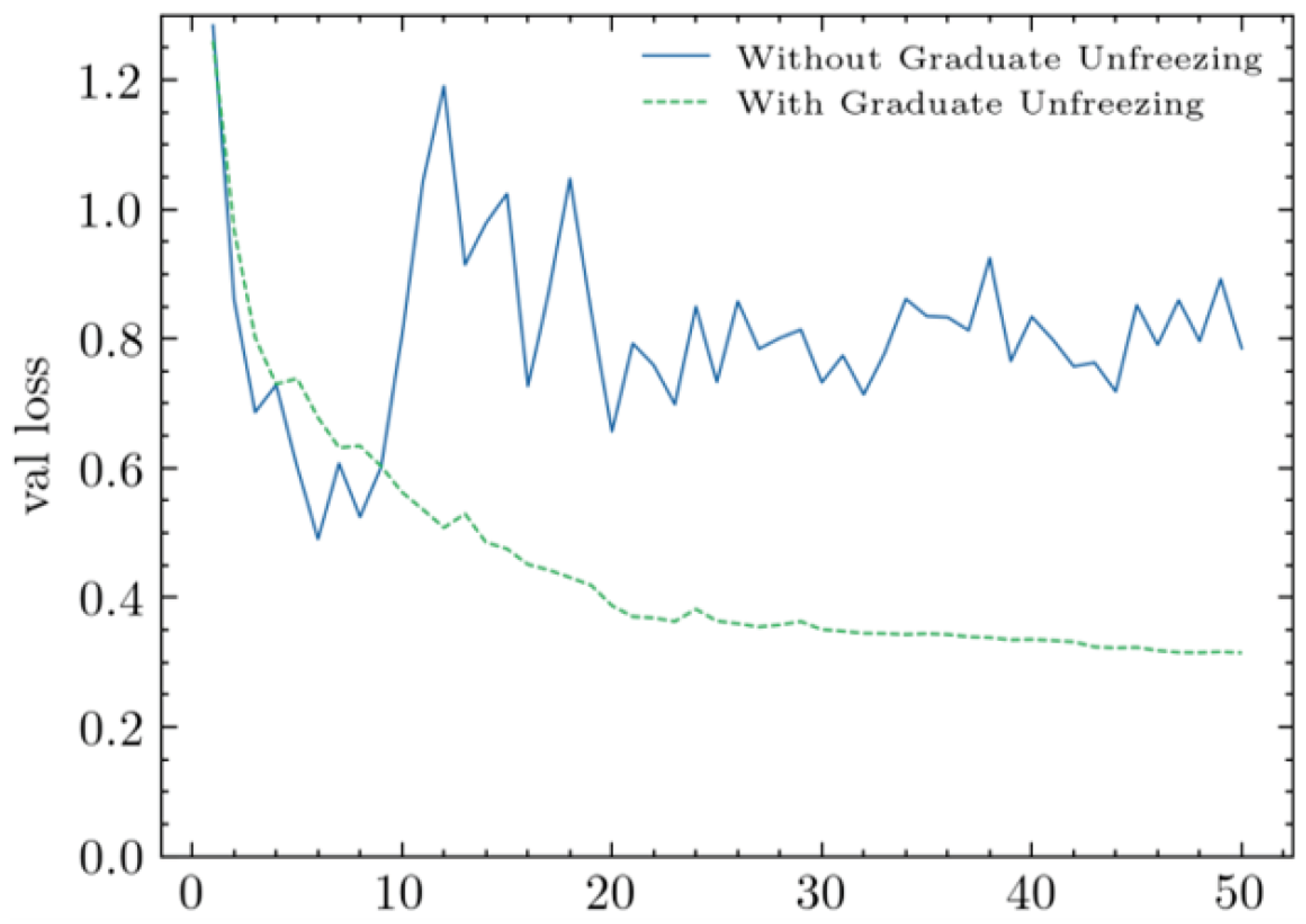
The layer-wise unfreezing method effectively alleviates issues of unstable validation loss convergence and overfitting during adversarial training of lightweight Transformer models. As shown in
Figure 7, the progressive unfreezing strategy leads to smoother loss variations and eventual convergence during PGD-10 adversarial training.
4.1.2. Adversarial Training Strategy Oriented Toward Decision Boundary Optimization
1. Decision Boundary Optimization Based on TRADES
Tsipras et al. [
44,
45] proposed from a theoretical perspective in 2019 that constructing adversarial samples during training may degrade classification accuracy on clean examples. Therefore, there is a need to balance robustness and accuracy in adversarial training. TRADES [
40,
41] is a technique that improves the balance between accuracy and robustness through decision boundary optimization. Compared with conventional adversarial training, it attains a more favorable compromise between robustness and accuracy, thereby facilitating more balanced learning in machine learning models. As noted by Zhang et al. [
46], the robust error (
) is generally composed of two elements: the natural error (
), measured on clean data, and the boundary error (
), caused by adversarial perturbations. Thus, the total robust error can be expressed as the combination of these two sources of error, as shown in Equation (
4).
The core idea of the TRADES method is to minimize the natural error and robust error during training. While natural error reflects the model’s performance on clean samples, boundary error reflects its robustness to adversarial perturbations. By optimizing this trade-off loss, TRADES can maintain model accuracy while improving adversarial robustness.
TRADES introduces a novel loss function that jointly accounts for the classification loss on clean inputs and the robustness objective concerning adversarial examples. Specifically, the TRADES loss comprises two main components:
Cross-entropy loss: This term targets clean data and is designed to maximize the model’s classification accuracy.
Adversarial loss: This term evaluates how well the model maintains performance when exposed to adversarially perturbed inputs.
In TRADES, the Kullback–Leibler (KL) divergence is employed to measure discrepancies between the predicted distributions of clean and adversarial inputs. Minimizing this divergence helps the model improve its robustness against adversarial perturbations. During training, model parameters are iteratively optimized by reducing the TRADES loss through gradient descent. At each step, adversarial examples are crafted using the PGD method, followed by loss computation and parameter updates. This process is repeated over the training set until the model converges.
In this study, we adopt the TRADES framework by decomposing the adversarial training loss
into natural loss
and adversarial loss
. The adversarial training loss function is defined as shown in Equation (
5):
Here,
serves as a hyperparameter that controls the trade-off between the standard classification loss and the adversarial component. The adversarial loss, introduced in Equation (
5), is formulated using the KL divergence, as detailed in Equation (
6).
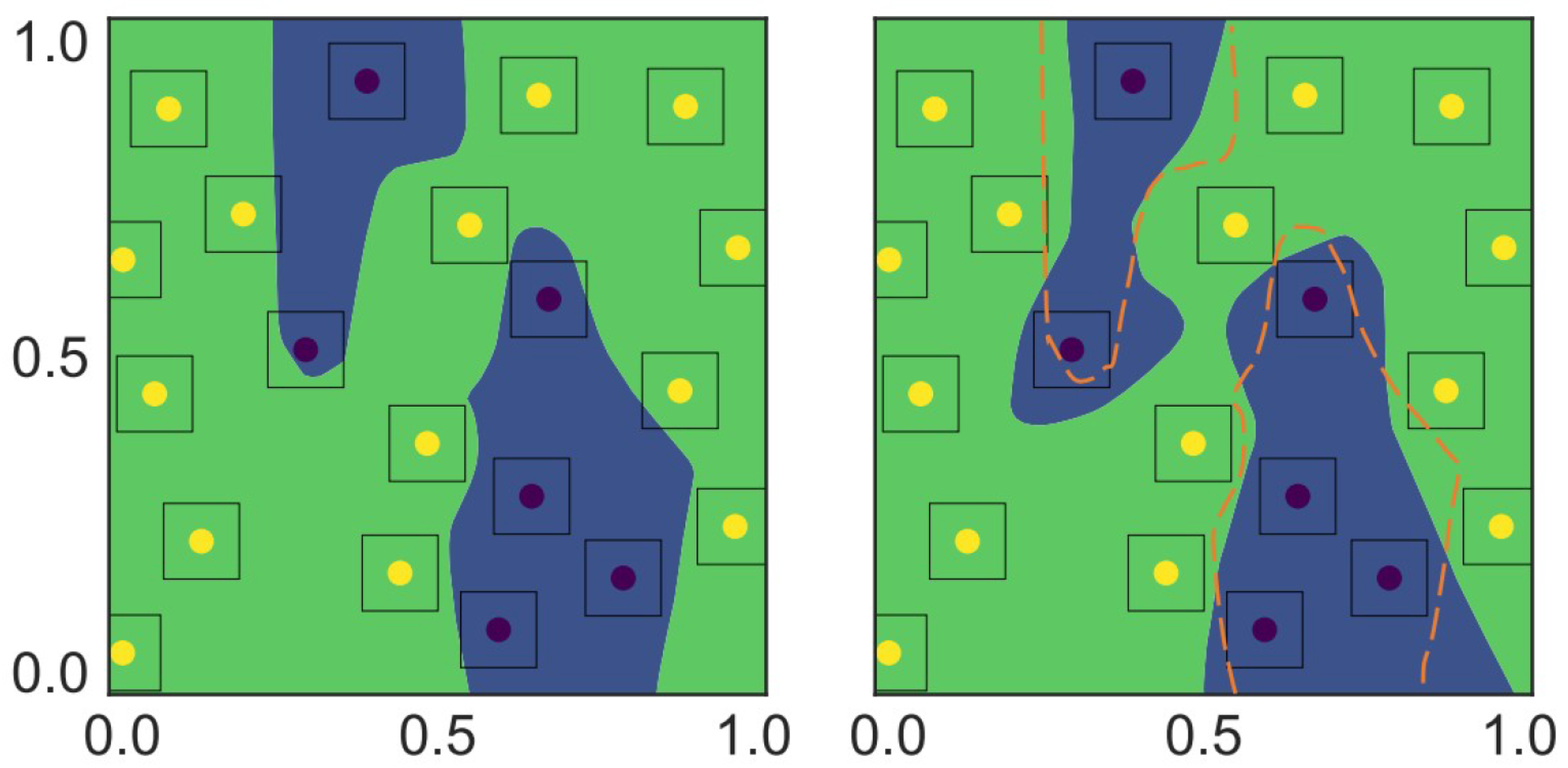
As shown in
Figure 8, the image on the left represents the decision boundary trained on clean samples, while the image on the right illustrates the decision boundary obtained through the TRADES method. Although both boundaries achieve zero classification error on natural samples, TRADES achieves a more robust decision boundary by balancing robustness on clean samples and adversarial samples.
2. Decision Boundary Smoothing Based on the SMART Method
SMART [
47] is a shorthand for Smoothness-inducing Adversarial Regularization and BRegman pRoximal poinT optTimization (
SMART3). Proposed by Jiang et al. in 2020, SMART is a regularization method originally designed for fine-tuning NLP models. This study builds on the core concept of SMART and extends its application to the computer vision domain. We refer to our adapted version as SMART+, applying it to generate adversarial samples and conduct adversarial training to improve the robustness of lightweight Transformer models.
The core idea of SMART+ mainly consists of the following component:
(1) Smoothness-Inducing Adversarial Regularization
To address the issue of model overfitting and poor generalization due to the complexity of task-specific and domain-specific pretraining, the Smoothness-Inducing Adversarial Regularization (SIAR) method aims to solve the optimization problem defined in Equation (
7):
where
denotes the conventional loss function, as specified in Equation (
8).
In Equation (
7),
is a hyperparameter, and the regularization term
is defined in Equation (
9):
In Equation (
9),
denotes the radius under the
norm, which defines the perturbation range. To minimize the objective function, it encourages the function
f to vary as smoothly as possible within the
-ball around each input. This smoothness helps prevent model overfitting and enhances generalization. The term
in Equation (
9) typically adopts symmetric KL divergence, as defined in Equation (
10):
This method introduces a smoothness-inducing regularization step during fine-tuning, which effectively controls model complexity. Moreover, by incorporating adversarial samples and comparing the classifier output distributions of adversarial and clean samples, the method enables the model to acquire a certain level of robustness against adversarial examples.
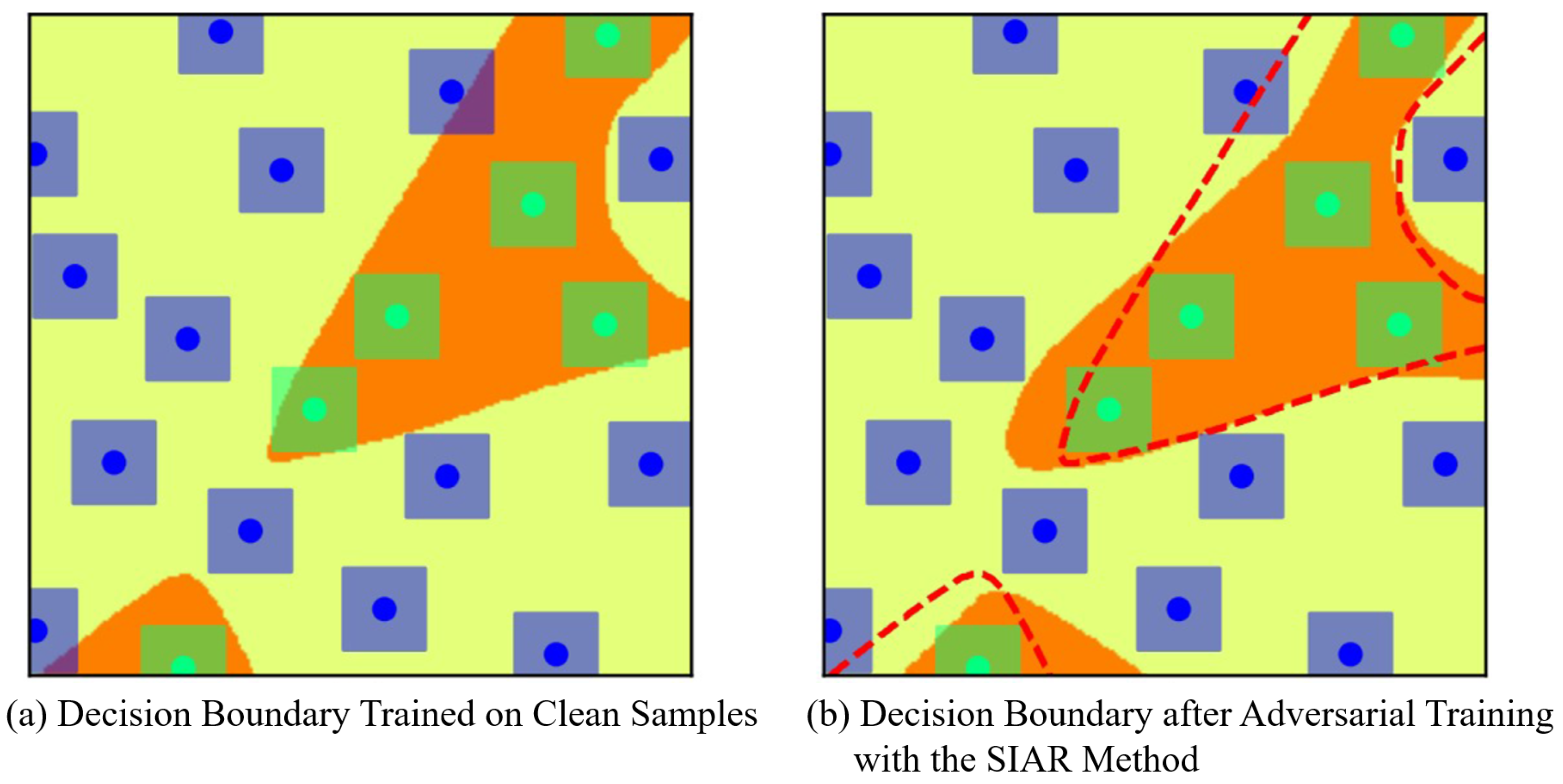
As shown in
Figure 9, the left image depicts the decision boundary trained on clean samples, while the right image shows the decision boundary after applying adversarial training with the SIAR method. It can be observed that the SIAR method smooths the decision boundary during adversarial training, thereby enhancing the model’s discriminative capability. Moreover, for two similar input samples, a smoother decision boundary leads to more consistent prediction results.
(2) Bregman Proximal Point Optimization
To solve the optimization problem in Equation (
7), the SMART+ method introduces trust region optimization based on the traditional Bregman Proximal Point method by incorporating a momentum-like prior. In this study, we define the pretrained initialization model as
. At the
-th iteration, the parameters are updated using the traditional Bregman Proximal Point method as shown in Equation (
11):
In Equation (
11),
is a hyperparameter, and
denotes the Bregman divergence, defined in Equation (
12):
The Bregman divergence in the traditional Bregman Proximal Point method serves as a regularization term during each iteration, preventing the model’s parameters from drifting too far from those of the previous iteration. Therefore, the method effectively preserves the knowledge learned during pretraining, particularly knowledge derived from out-of-distribution (OOD) data.
Since the optimization problem in Equation (
11) does not have a closed-form solution, we adopt the ADAM optimizer to solve it using stochastic gradient descent. Instead of solving Equation (
11) until convergence in each iteration, we only perform a few update steps to generate a reliable initialization for the next subproblem.
Building upon the traditional Bregman Proximal Point framework, the SMART+ method accelerates optimization by introducing a momentum-based iterative update scheme, as shown in Equation (
13):
In Equation (
13),
, where
represents the exponential moving average, and
is a momentum parameter in the interval
.
During adversarial training, the SMART+ method utilizes a local smoothness regularization term to generate adversarial examples. This regularization term computes the output difference between clean and adversarial inputs, encouraging the model to produce similar outputs for nearby inputs. In each training iteration, the SMART+ method updates the model parameters by minimizing this regularized loss function.
The adversarial training process adopts the ADAM optimizer to update model parameters, performing
T rounds of updates in total. The specific training process is shown in Algorithm 1.
| Algorithm 1 SMART+: Adversarial Training Strategy Combining Smoothness-Inducing Regularization and Momentum-Accelerated Bregman Proximal Optimization |
Require: Number of iterations T, dataset , pretrained model parameters , Gaussian noise variance , learning rate , momentum parameter , batch size Ensure: Model parameters after T iterations - 1:
- 2:
for to T do - 3:
- 4:
Randomly sample a batch of size from - 5:
for to do - 6:
▹ - 7:
- 8:
- 9:
▹ denotes projection onto set A - 10:
end for - 11:
Feed adversarial samples into the model - 12:
Update using Adam: - 13:
- 14:
- 15:
end for
|
In the above process, this study adopts a smoothness-inducing regularization approach to generate adversarial samples, which are constrained within an
-neighborhood of the clean samples. To solve the optimization problem in Equation (
7), this study further employs the Bregman Proximal Point method.
In addition, momentum is introduced, and the exponential moving average method is used to accelerate the iterative optimization process across multiple updates.
4.1.3. Hyperparameter Ablation
To determine the optimal number of iterations T for adversarial sample generation in the SMART+ method, we designed systematic ablation experiments. Under fixed values for other hyperparameters (, , ), we conducted comparative evaluations for . The experiments were conducted on the MobileViT-s model and the CIFAR-10 validation set, using two key indicators:
(1) Training Stability: Validation loss curve under PGD-10 attack.
(2) Robustness Improvement: Classification accuracy on adversarial samples.
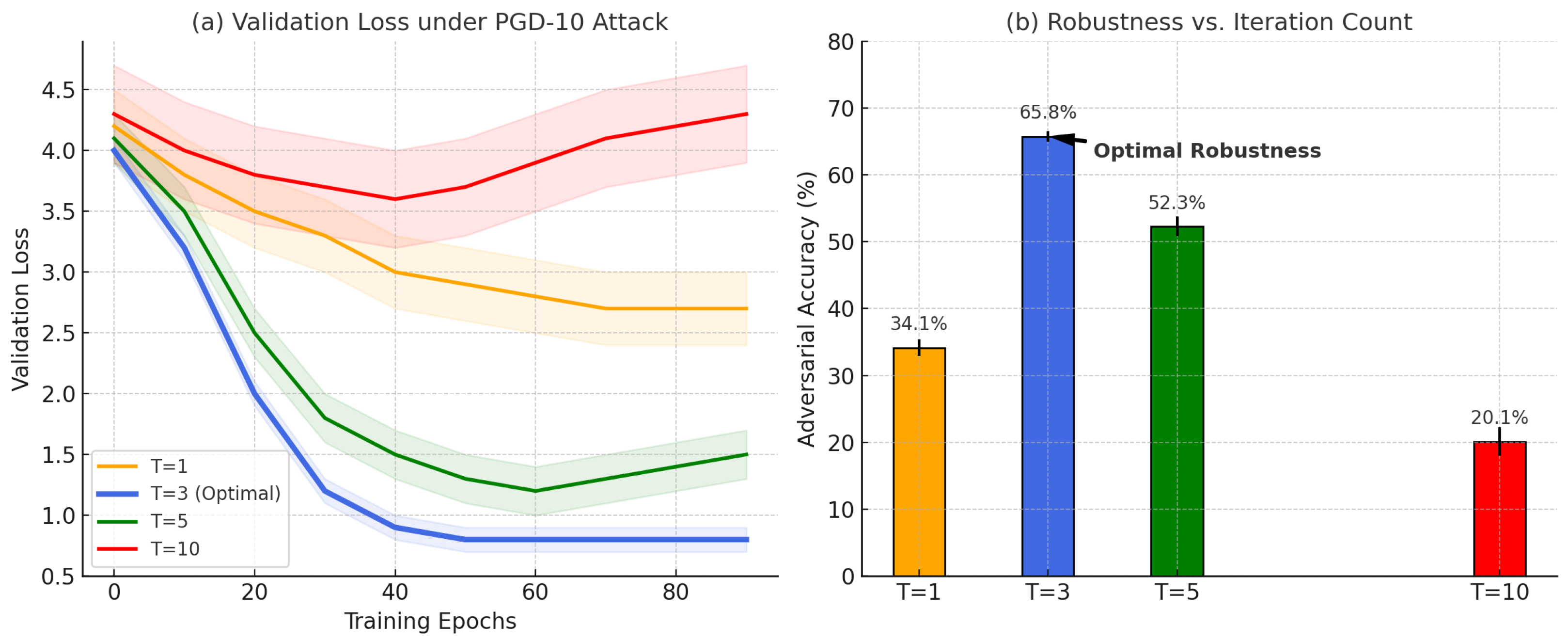
Experimental results are shown in
Figure 10, and the results show the following: (1)
: The validation loss exhibits severe oscillation (orange curve), indicating insufficient adversarial sample generation and inadequate decision boundary smoothing (corresponding robust accuracy is only 34.15%). (2)
: The loss curve converges smoothly to the lowest value (blue curve), and robust accuracy reaches its peak at 65.77%. (3)
: The loss curve shows a trend of dispersion (red/purple curves), and for
, robust accuracy drops sharply to 20.12%, demonstrating that excessive iterations lead to overfitting.
Due to the limited capacity of lightweight models (e.g., MobileViT-s with only 5.5 M parameters), when
, multiple iterative updates cause adversarial samples to move outside the effective perturbation region (
-ball); the generated samples deviate excessively from the distribution of real data, violating the local smoothing assumption (Equation (9)); and the model overfits to invalid perturbations, undermining its regularization ability (Equation (
7),
fails).
Therefore, achieves the optimal balance between decision boundary smoothing and training efficiency, which is especially suitable for resource-constrained scenarios.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}