1. Introduction
The rapid expansion of marine economies and increasingly sophisticated maritime security challenges have intensified demands for advanced sea area monitoring and vessel identification technologies. With the accelerated development of marine wireless sensor networks and edge computing technologies, the construction efficient real-time maritime wireless surveillance networks has emerged as a critical direction that imposes heightened requirements on the computational efficiency and detection accuracy of ship detection algorithms. Ship target detection serves as a cornerstone technology for marine surveillance systems and demonstrates substantial practical value across maritime traffic management, illegal fishing monitoring, search and rescue operations, marine security maintenance, and ocean resource protection [
1]. Nevertheless, marine environments present formidable obstacles, including varying illumination conditions, sea surface reflections, wave interference, foggy weather, intricate backgrounds, and dense vessel distributions. Notably, marine environments encompass abundant symmetrical characteristics: ship targets exhibit distinct structural symmetry, while ocean waves display periodic symmetric patterns, which provide crucial prior information for target detection. However, conventional detection algorithms frequently overlook effective utilization of these symmetrical characteristics and demonstrate inadequate performance when processing complex interactions between symmetric targets and asymmetric backgrounds, failing to fully exploit discriminative features within symmetrical information while struggling to meet real-time detection requirements in marine wireless network environments.
To precisely characterize the complexity of maritime environments, we define complex environments as scenarios exhibiting three concurrent challenge dimensions that traditional detection methods struggle to address simultaneously. First, the complexity of environmental interference includes atmospheric disturbances such as fog, precipitation, and dynamic changes in illumination, which create time-varying visual occlusions and alterations in surface reflectance. Second, geometric complexity arises from the spatial interaction between vessel structural symmetry and irregular background patterns, in which symmetric ship features become entangled with wave textures, coastal infrastructure, and surface reflections, creating ambiguous feature spaces that confound conventional detection algorithms. Third, scale complexity manifests through dramatic target-size variations within single surveillance frames, ranging from small fishing vessels appearing as mere pixel objects to large cargo ships spanning significant image portions, each requiring different feature extraction strategies. Consequently, developing efficient ship detection algorithms capable of thoroughly leveraging symmetrical features holds profound significance for the construction of high-performance maritime wireless surveillance networks and in enhancing maritime situational awareness [
2].
Traditional ship detection methodologies primarily rely on manually designed feature extractors, achieving detection through the development of ship-specific feature descriptors [
3]. Early approaches utilizing HOG features, SIFT features, and LBP texture features demonstrated reasonable performance in simplified scenarios. Recent advances in multi-feature extraction have shown promising results in remote sensing applications, where researchers have successfully combined texture features extracted via a Gray-Level Co-occurrence Matrix (GLCM) with distance-based similarity measures to construct comprehensive feature representations for dimensionality reduction tasks [
4]. However, as image characteristics have become increasingly diverse, the design of handcrafted features has grown progressively complex. Particularly when dealing with high-resolution optical remote sensing images characterized by intricate features, conventional detection methods encounter numerous difficulties, including complex marine environments, dense distributions, and rotational variations, rendering traditional approaches inadequate for the complex scenarios encountered in actual marine environments [
5].
Recent years have witnessed breakthrough advances in deep learning technologies in the computer vision domain. Deep learning-based ship detection approaches can be broadly categorized into two classes: two-stage detection methods and single-stage detection methods. Two-stage detection frameworks, such as R-CNN, Fast R-CNN, and Faster R-CNN, have demonstrated superior detection accuracy in marine monitoring applications [
6]. Zhang et al. [
7] discovered that Faster R-CNN exhibits enhanced precision and recall rates for ship detection in marine environments, albeit with slower computational speed. Conversely, single-stage detection methods, including SSD and the YOLO series, have gained widespread attention in practical applications due to their real-time capabilities and computational efficiency [
8].
Object detection technology, which stands as one of the basic undertakings in computer vision, has reached a high level of development. In the fields of remote sensing image and video monitoring, object recognition methods have shown excellent real-time capabilities and precision, offering strong backing for ship detection applications [
9]. As deep learning has progressed, object detection algorithms have made substantial enhancements in detection precision, velocity, and stability. This has laid a firm groundwork for ship detection in intricate situations [
10]. Consequently, this study employs an approach based on object detection, capitalizing on the benefits of deep learning to tackle the difficulties of ship detection in complex maritime settings.
Despite the outstanding performance of YOLO-series algorithms in object detection, ship detection in complex marine environments continues to face three core challenges: First, factors such as sea surface reflections, wave fluctuations, and adverse weather conditions severely impact image quality, leading to blurred or distorted ship features, with detection performance particularly degrading under low-light conditions. Second, ship sizes range from several meters to hundreds of meters, and ships frequently appear in dense distributions within port areas, causing YOLO11 to exhibit obvious missed detections and false positives when handling such extreme scale variations and dense targets. Finally, background elements such as coastal buildings and marine buoys share similar shapes with ships, easily leading to false detections, while existing attention mechanisms struggle to effectively distinguish ships from interference objects.
To address these challenges, we propose YOLO-StarLS, a wavelet transform and multi-scale feature extraction algorithm designed for ship detection in complex environments. Our approach fundamentally reconceptualizes traditional object detection pipelines by strategically integrating frequency-domain analysis with spatial attention mechanisms specifically tailored for maritime surveillance scenarios. The main contributions of this work are outlined as follows:
(1) To address the inefficiency of traditional networks in multi-scale feature extraction, we introduce the Wavelet-based Multi-scale Feature Extraction Network (WMFEN). This network utilizes the inherent frequency–spatial collaborative properties of wavelet decomposition to simultaneously preserve fine-grained vessel details and capture global structural patterns. Unlike conventional backbone architectures that suffer from information loss during downsampling operations, WMFEN employs adaptive Haar wavelet transforms to decompose input features into multiple frequency components. This approach ensures the preservation of critical high-frequency information, which is essential for detecting small-scale maritime targets, while maintaining computational efficiency.
(2) To address the challenge of distinguishing ships from interfering objects in complex backgrounds, we propose the Cross-axis Spatial Attention Refinement (CSAR) mechanism. This mechanism addresses the geometric asymmetry characteristic of ship targets by employing a dual-pathway attention strategy that processes horizontal and vertical spatial dependencies independently. By integrating the star structure topology with cross-axis attention computations, CSAR significantly enhances the model’s spatial perception capabilities for ship targets, effectively mitigating false positives caused by wave patterns, coastal infrastructure, and other maritime interference objects.
(3) To enhance the detail preservation capabilities of detection heads, we design the Efficient Detail-Preserving Detection (EDPD) head. This detection head surpasses the limitations of traditional detection architectures, which depend on separate convolutional branches for multi-scale processing. EDPD employs a shared convolutional structure in conjunction with differential convolution operations, enabling enhanced extraction of ship target edge and texture features through the coordinated fusion of differential convolution and shared convolution structures. This design significantly reduces computational overhead while improving detection precision for vessels with complex geometric configurations.
The remainder of this paper proceeds as follows.
Section 2 reviews related work on object detection algorithms and lightweight model architectures.
Section 3 presents our proposed methodology, detailing the WMFEN backbone, CSAR mechanism, and EDPD head, along with their mathematical formulations.
Section 4 provides a comprehensive experimental evaluation that includes ablation studies and comparative analysis against state-of-the-art methods.
Section 5 concludes with our findings and future research directions.
3. Methodology
The methodology presented in this work was developed to address the fundamental limitations of existing object detection frameworks when applied to maritime surveillance scenarios. Our approach focuses on the development of a comprehensive detection pipeline that systematically tackles the multi-faceted challenges inherent in ship detection tasks. We designed YOLO-StarLS as an integrated framework that combines frequency-domain feature analysis with spatial attention mechanisms specifically engineered to handle the complex interference patterns and scale variations encountered in marine environments. The methodology was structured around three interconnected innovations: a wavelet-based backbone network for enhanced multifaceted feature extraction, a cross-axis attention mechanism for improved spatial discrimination, and an efficient detection head optimized for detail preservation. Each component was designed to work synergistically, creating a robust detection system capable of maintaining high accuracy while meeting the computational constraints typical of real-world maritime applications.
3.1. Network Overview
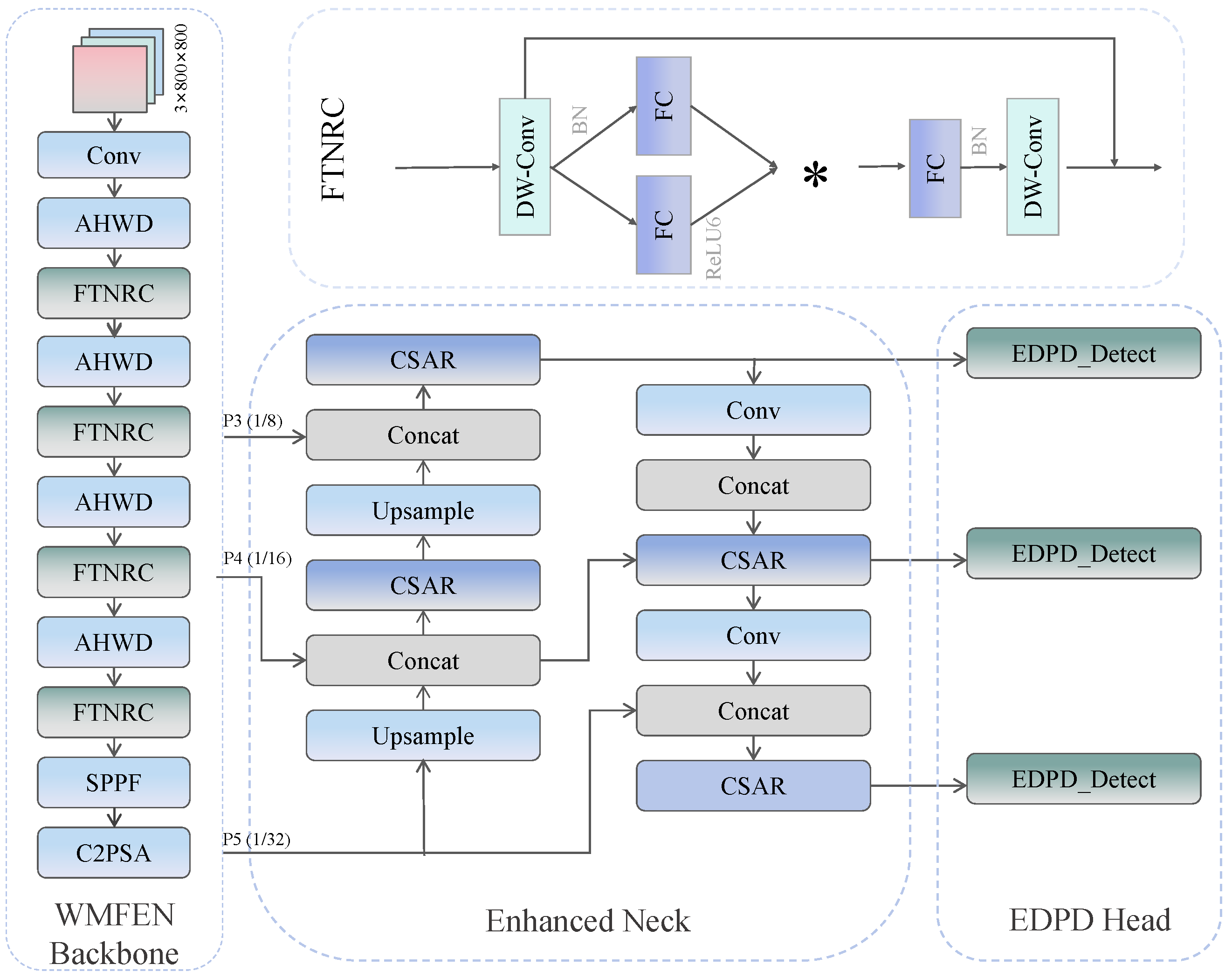
In this study, we propose the YOLO-StarLS detection framework for ship target detection in complex marine environments. As shown in
Figure 1, YOLO-StarLS consists of three core components: the WMFEN, leveraging the frequency-domain symmetry of wavelet transforms and the radial symmetry of star-shaped structures; the CSAR module, employing cross-axis attention mechanisms to strengthen perceptual capabilities for symmetric ship structures; and the EDPD head, adopting a differential convolution design for precise capture of ship-edge symmetry features. This design enables effective processing of symmetric interference from sea surface reflections and symmetric confusion in dense target scenarios while ensuring real-time requirements of marine wireless networks through lightweight implementation. Next, we provide detailed descriptions of the three key innovations.
3.2. Wavelet-Based Multi-Scale Feature Extraction Network (WMFEN)
Traditional YOLO-series object detection algorithms employ backbone networks that primarily rely on simply stacked convolutional layers and residual connections. However, conventional convolutions are inefficient for multi-scale feature extraction, struggling to simultaneously capture both the fine structures and overall contours of ships. Additionally, traditional downsampling operations often result in high-frequency information loss, severely degrading features of small vessels. Furthermore, simplistic feature fusion methods cannot effectively address target interference issues in complex maritime backgrounds. To tackle these challenges, we propose the WMFEN backbone architecture, as illustrated in
Figure 2. This architecture effectively resolves the problems of insufficient detection accuracy, blurred vessel edges, and similar-target confusion in complex sea conditions through the introduction of adaptive wavelet transforms and star-shaped feature extraction modules, providing a solid feature foundation for high-precision ship detection.
The core innovations of the WMFEN backbone lie in its unique frequency–spatial collaborative feature extraction mechanism and efficient star-shaped connection topology, as shown in
Figure 3. Unlike the linear stacking approach of traditional networks, each stage of this architecture first leverages the symmetry properties of wavelet transforms to decompose and reduce features in the frequency domain through the Adaptive Haar Wavelet Downsampler (AHWD) module, preserving symmetry-discriminative information from different frequency bands. Subsequently, spatial-domain feature refinement is performed through multiple Feature Transformation Networks with Radial Connections (FTNRCs), establishing more flexible feature transformation pathways. Particularly for densely distributed, multi-scale ship targets, WMFEN provides more robust symmetry-aware feature representations, effectively mitigating the negative impacts of background interference and target occlusion.
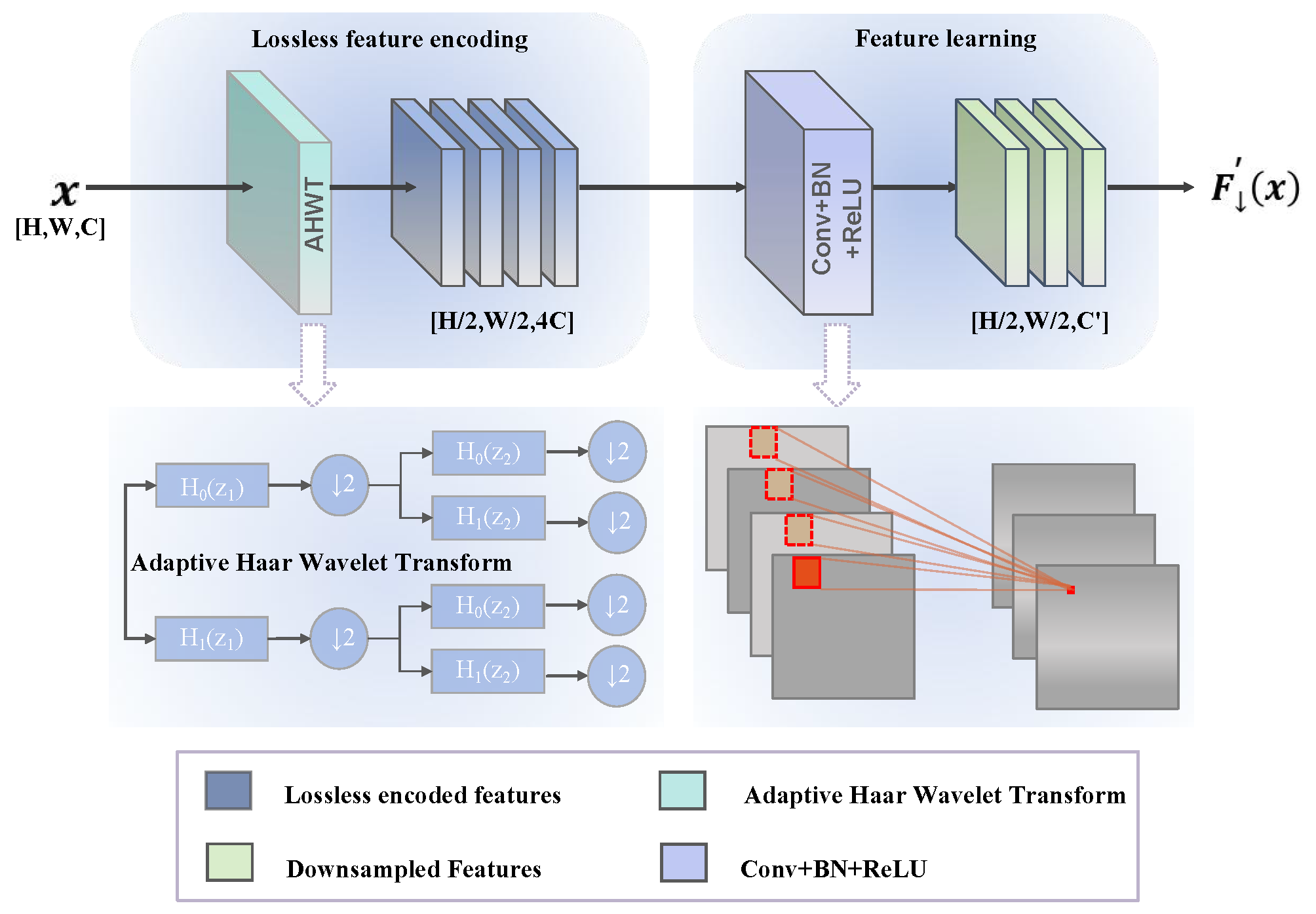
The AHWD module is the core component in the WMFEN architecture responsible for frequency domain feature extraction and dimensionality reduction. Given an input feature map (
), AHWD first applies Haar wavelet transform to perform two-dimensional discrete wavelet decomposition, yielding a low-frequency approximation component and three directional high-frequency detail components:
where
represents the low-frequency approximation component preserving the main structure and global morphological information of ship targets;
,
, and
represent high-frequency detail components in the horizontal, vertical, and diagonal directions, respectively, encoding discriminative features such as edges, textures, and corner points of ships. Subsequently, AHWD concatenates these four components along the channel dimension and applies a 1 × 1 convolution for adaptive feature fusion:
where
denotes the channel-wise concatenation operation,
represents the parameterized 1 × 1 convolution mapping function, and
is the number of output channels. Through this wavelet-based frequency-domain decomposition and fusion mechanism, the AHWD module can preserve rich multi-scale features while reducing spatial dimensions, providing a more comprehensive information foundation for subsequent feature refinement.
The FTNRC serves as the basic building block of WMFEN, employing an innovative star-shaped connection topology and adaptive feature transformation mechanism. As illustrated in
Figure 2, the FTNRC processing flow first models symmetry-aware spatial context through depthwise separable convolutions on the input features:
where
represents the convolution kernel for the corresponding channel, ⊛ denotes the depthwise convolution operation, and
represents batch normalization. Subsequently, FTNRC introduces a dual-path feature transformation and adaptive gating mechanism, implementing dynamic adjustment of feature channel importance:
where
and
are feature mapping functions implemented by 1 × 1 convolutions,
represents the ReLU6 activation function, and ⊙ denotes the Hadamard product. Through this gating mechanism, the network can adaptively enhance the feature representation of key regions of ships while suppressing interference from background and redundant information. Finally, FTNRC integrates the original features with the transformed features through residual connections, forming a richer representation:
where
represents a channel dimensionality reduction projection function and
represents the second depthwise separable convolution.
The proposed WMFEN backbone architecture, through the organic combination of AHWD modules and FTNRC, achieves three significant innovations: First, wavelet transform-based multi-scale frequency-domain analysis enhances the network’s capability to extract multi-level features of ship targets. Second, the star-shaped connection topology and adaptive gating mechanism optimize feature transformation pathways, improving model robustness to complex sea conditions and lighting variations. Finally, the lightweight design and efficient computation strategy of the overall architecture significantly reduce parameter count and computational complexity, meeting the efficiency requirements of real-time systems while maintaining high detection accuracy.
3.3. Cross-Axis Spatial Attention Refinement (CSAR)
Traditional C3k2 modules serve as core components in YOLO series networks and demonstrate excellent performance in general object detection tasks. However, they exhibit significant limitations in specialized scenarios such as ship target detection. First, the standard convolution structure of C3k2 proves unable to effectively exploit the symmetric geometric structures of ship targets, making it inefficient in capturing long-range spatial dependencies of ship targets, resulting in incomplete feature capture for large vessels and elongated hulls. Second, the lack of effective feature enhancement mechanisms makes it difficult to accurately separate foreground from background under complex sea surface interference. To address these issues, we proposed CSAR, which effectively improves model detection accuracy and robustness for ship targets in complex marine environments through the integration of the symmetric feature transformation capabilities of star structures and the directional feature enhancement capabilities of the Cross-Axis Attention Module (CAAM).
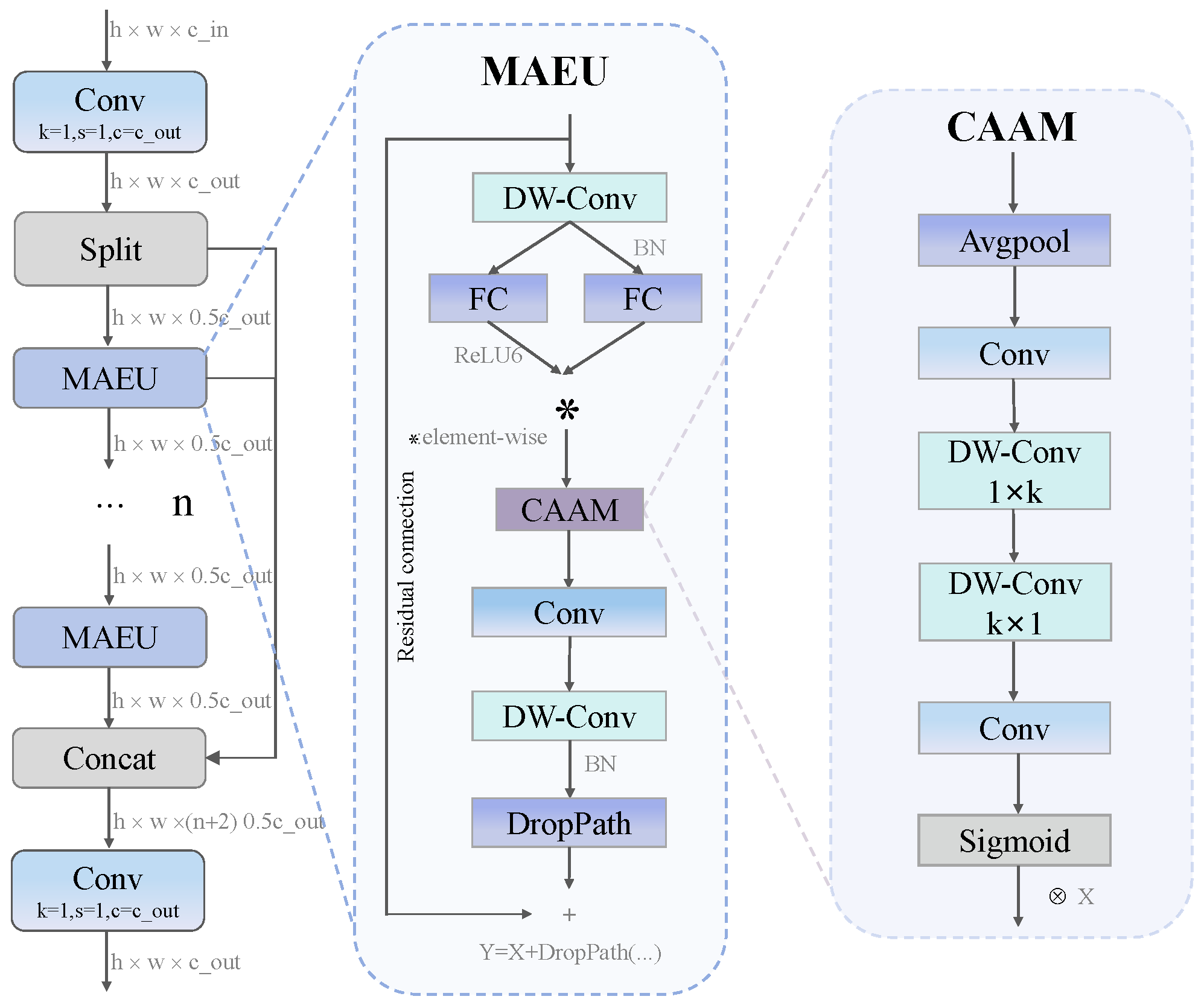
The CSAR module retains the branching architecture concept of CSP networks while significantly improving their feature extraction capabilities. As shown in
Figure 4, the module first splits input features into two pathways through
convolution, then cascades multiple Multi-directional Attention Enhancement Units (MAEUs) in the main pathway for deep feature extraction, while the bypass pathway preserves original features to prevent information loss. Finally, feature fusion integrates multi-pathway information. The mathematical expression of the entire module can be summarized as follows:
where
and
represent the two pathways after initial feature splitting,
denotes the
i-th MAEU module, and
indicates the final feature fusion layer. This structural design ensures information flow diversity while enhancing feature representation through the nonlinear transformation capabilities of MAEU modules, making it particularly suitable for capturing complex structural features of ship targets. During inference, CSAR significantly improves computational efficiency through parallel computation and feature reuse while maintaining powerful feature extraction capabilities.
MAEU serves as the core computational unit of CSAR, integrating spatial feature enhancement and attention mechanisms. The module first applies
depthwise separable convolution to expand the receptive field, then generates complementary feature mappings through two parallel
convolutions and employs gating mechanisms for feature activation. This process can be expressed as follows:
where
represents the
depthwise convolution operation,
and
denote two parallel
convolution weight matrices, and ⊙ indicates the Hadamard product. This gating mechanism enables the module to adaptively suppress irrelevant features and enhance key features, which proves particularly important for the suppression of complex backgrounds in ship detection.
Subsequently, after features are enhanced through the CAAM attention module, they undergo a series of transformations to obtain the final output:
where
represents the cross-axis attention operation,
denotes the feature dimensionality reduction
convolution,
indicates the second depthwise convolution, and DropPath serves as the regularization operation. This design enhances feature expressiveness while maintaining computational efficiency and gradient flow through residual connections and multi-level feature transformations, making it particularly suitable for capturing multi-scale features of ship targets.
The CAAM constitutes an efficient attention mechanism designed specifically for ship target aspect-ratio characteristics, focusing on capturing long-range dependencies in horizontal and vertical directions. The CAAM first compresses input features through
average pooling, then extracts directional features along horizontal and vertical axes through a series of convolution operations. The entire process can be expressed as follows:
where
represents the average pooling operation;
and
denote the front and rear convolutions for feature transformation, respectively;
and
represent depthwise separable convolutions in the horizontal
and vertical
directions, respectively;
indicates the Sigmoid activation function; and ⊗ denotes broadcast multiplication. This design enables the model to simultaneously focus on horizontal symmetric structures and vertical symmetric features of ships, significantly improving symmetry recognition capabilities for ships at different angles and poses. The CAAM effectively captures directional features of ship targets under low computational complexity, providing crucial spatial contextual information for detection.
The CSAR module successfully addresses multiple challenges of traditional C3k2 in ship target detection through deep integration of star structures and cross-axis attention mechanisms. This module significantly enhanced the model’s spatial perception and feature extraction capabilities for ship targets, enabling more accurate identification of ships in complex marine environments. It demonstrates obvious advantages, particularly in handling extreme situations such as distant small targets, occluded targets, and illumination changes. Theoretical analysis indicates that CSAR improves feature representation diversity and robustness while maintaining computational efficiency; the introduction of cross-axis attention mechanisms enables the model to adaptively focus on key features in different directions, effectively suppressing background interference such as sea surface reflections and wave textures.
3.4. Efficient Detail-Preserving Detection (EDPD)
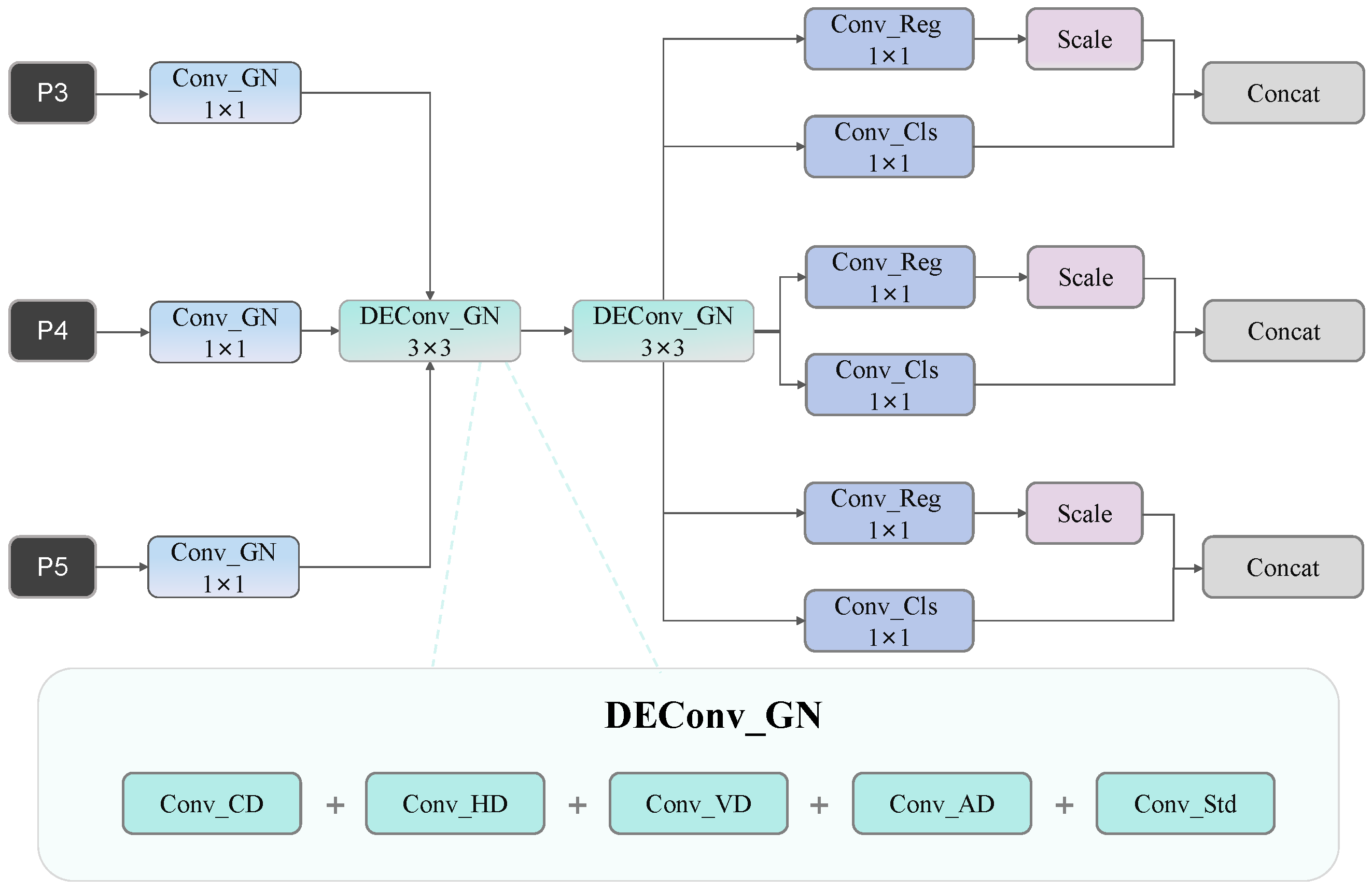
Traditional object detection networks typically employ independent convolutional layers in their detection heads for feature extraction and prediction, leading to parameter redundancy and computational inefficiency. For ship targets characterized by complex structures and intricate edges, conventional detection heads struggle to effectively extract and preserve crucial symmetric contour information, resulting in limited detection accuracy. Moreover, traditional detection heads often rely on independent convolutional branches when processing multi-scale features, lacking effective symmetric feature-sharing mechanisms and failing to capture consistent features of ship targets across different resolutions. To address these limitations, we propose an EDPD head that innovatively integrates differential convolution and shared convolution structures, enhancing the extraction capability for ship target edges and texture features while significantly reducing model parameters and computational complexity, thereby improving both detection accuracy and efficiency. As illustrated in
Figure 5, EDPD employs group normalization instead of batch normalization, reducing sensitivity to batch size and making it more suitable for deployment on resource-constrained platforms.
The core innovation of the EDPD detection head lies in its Detail Enhancement Convolution with Group Normalization (DEConv_GN) and shared convolution architecture. The detection head first receives multi-scale feature maps (P3, P4, and P5) from the backbone network and adjusts channel dimensions through
convolutions:
where
represents the original feature map of the
i-th detection layer,
denotes the channel-adjusted feature map, Conv_GN indicates a convolution operation with group normalization, and
represents the number of detection layers.
Subsequently, feature maps from all scales undergo processing through a shared DEConv_GN module, which can be expressed as a cascaded operation:
where
represents the shared convolution function with parameters (
) and ∘ denotes function composition.
The DEConv_GN module constitutes the key innovation of EDPD, integrating five distinct convolution operations: Central Difference convolution (CD), Horizontal Difference convolution (HD), Vertical Difference convolution (VD), Angular Difference convolution (AD), and standard convolution. The mathematical expression is formulated as follows:
This multi-differential convolution fusion employs a symmetric design that enables the network to simultaneously capture edge symmetry and texture symmetry information across different orientations, proving particularly effective for extracting contour symmetry and structural symmetry features of ship targets. Specifically, horizontal and vertical differential convolutions are designed to capture the main symmetric axis features of ships, angular differential convolutions handle symmetry variations at tilted angles, and central differential convolution enhances local symmetry details. Furthermore, the DEConv_GN module utilizes group normalization instead of batch normalization, reducing dependency on batch size and enhancing training stability.
Following shared convolution processing, feature maps generate final outputs through two parallel convolution branches:
where
and
represent convolution operations for bounding-box regression and classification prediction, respectively, and
denotes the learnable scale factor function for the
i-th detection layer, balancing prediction contributions across different scales. Finally, predicted bounding-box parameters are decoded through Distribution Focal Loss (DFL), combined with pre-computed anchors and strides to achieve high-precision target localization and classification results.
The introduction of the EDPD detection head significantly enhances YOLO11-based ship target detection performance. Compared to traditional detection heads, EDPD strengthens perception capabilities for ship target edge symmetry and texture symmetry through differential convolution mechanisms, particularly improving contour extraction accuracy under complex sea conditions and low-contrast environments. The shared convolution structure not only reduces the parameter count and computational complexity but also facilitates effective fusion of multi-scale features, improving detection consistency for ship targets of varying sizes. Additionally, the application of group normalization enhances model stability during small-batch training, making deployment on edge computing devices more reliable. Overall, EDPD maintains low computational cost while significantly improving ship target detection accuracy and robustness, providing more dependable technical support for maritime target monitoring and intelligent navigation systems.
5. Conclusions
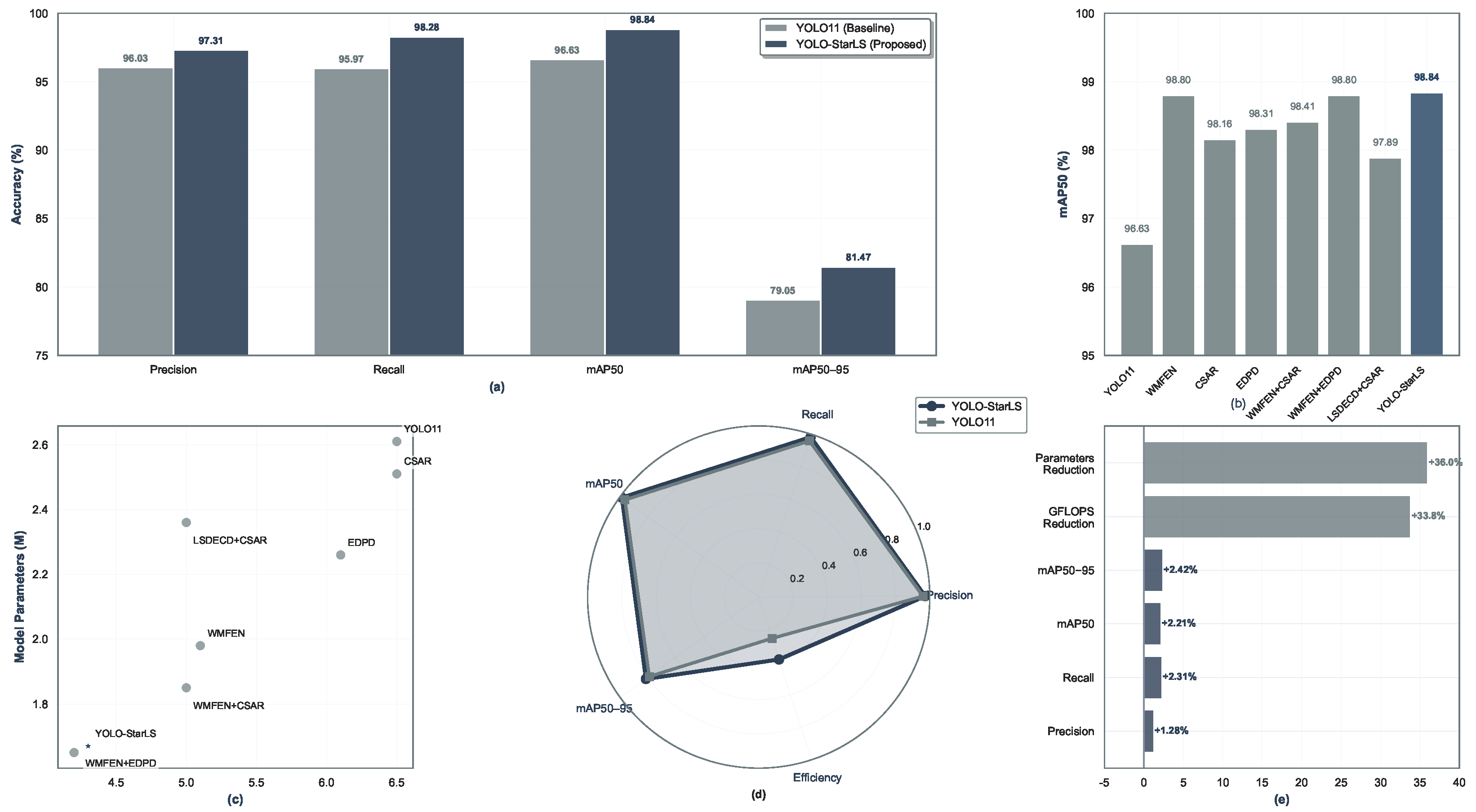
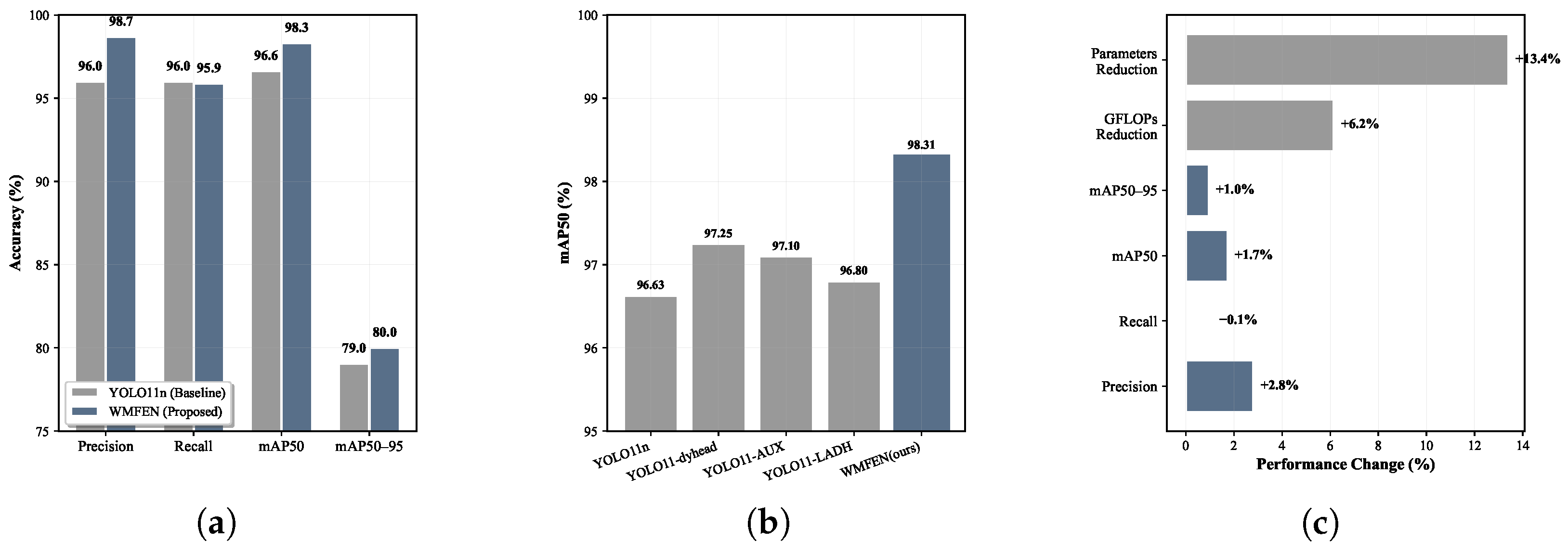
This work has developed YOLO-StarLS, a deep learning framework that successfully addresses ship detection challenges in complex maritime environments. Our approach, which integrates wavelet-based multi-scale feature extraction, cross-axis spatial attention refinement, and efficient detail-preserving detection mechanisms, achieved superior performance on the SeaShips dataset, surpassing the YOLO11 baseline by 2.21% and 2.42% for mAP50 and mAP50–95, respectively.
The experimental analysis revealed the effectiveness of leveraging symmetry characteristics inherent in wavelet transformations to handle complex interference patterns, particularly to mirror symmetry from sea surface reflections and periodic wave textures. Our cross-axis attention mechanism proved capable of enhancing spatial perception of vessel symmetry features while suppressing symmetric background noise. Additionally, the lightweight architecture achieved substantial efficiency improvements, reducing parameters by 36% to 1.67 M and computational overhead by 34% to 4.3 GFLOPs, making real-time deployment feasible for maritime wireless networks. Performance comparisons with eight contemporary algorithms confirmed the superior detection capabilities of our approach. Ablation studies provided empirical support for the symmetry-based design principles underlying the framework. The results indicate that YOLO-StarLS constitutes a practical solution for maritime surveillance, autonomous navigation, and oceanic security systems.
Future work will investigate the generalization potential of symmetry-based features across varied maritime conditions and explore extensions to multimodal fusion architectures for comprehensive wireless network monitoring applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}