A Novel Heterogeneous Federated Edge Learning Framework Empowered with SWIPT


Abstract
1. Introduction
1.1. State-of-the-Art
1.2. Motivations and Contributions
- We propose a SWIPT-enabled, asymmetry-tolerance training mechanism for FEEL with two key objectives: (1) alleviating the negative impact of device asymmetry through flexible training intensity and (2) utilizing SWIPT to mitigate training insufficiencies and wireless distortion issues arising from battery limitations, thus enabling FEEL applications on low-end devices. In this context, we acknowledge that, when edge devices operate under limited energy budgets, a critical trade-off may exist between heterogeneous local training intensity and wireless transmission quality. This indicates that local training intensity and wireless transmission strategies should be closely integrated, rather than entirely decoupled.
- To clarify this potential trade-off, we systematically derive the impact of device heterogeneous local training intensity and AirComp aggregation errors on the upper bound of FEEL convergence performance, theoretically revealing the key role of balancing training and transmission under energy-constrained conditions for system convergence efficiency. Our theoretical findings suggest that naively increasing local training intensity under limited energy budgets may inadvertently degrade final training performance. This contrasts with existing research, e.g., [5,12], which often views increasing local training intensity as an effective way to accelerate convergence without considering wireless aggregation distortion issues.
- To maximize system performance, we identify two critical optimization problems. The first problem is a SWIPT optimization problem aimed at maximizing the harvested power across all devices while ensuring successful decoding of global model information. The second problem is a joint learning–communication optimization problem that operates within the available energy of devices, guiding the joint design of uplink transmit beamforming for both devices and the BS, along with local training intensity. To tackle the non-convexity of these optimization problems, we propose an efficient alternating optimization (AO) strategy that combines successive convex approximation (SCA) with first-order Taylor expansion. The simulation results show that the proposed SWIPT-enabled FEEL heterogeneous training mechanism significantly enhances learning performance compared to baseline solutions.
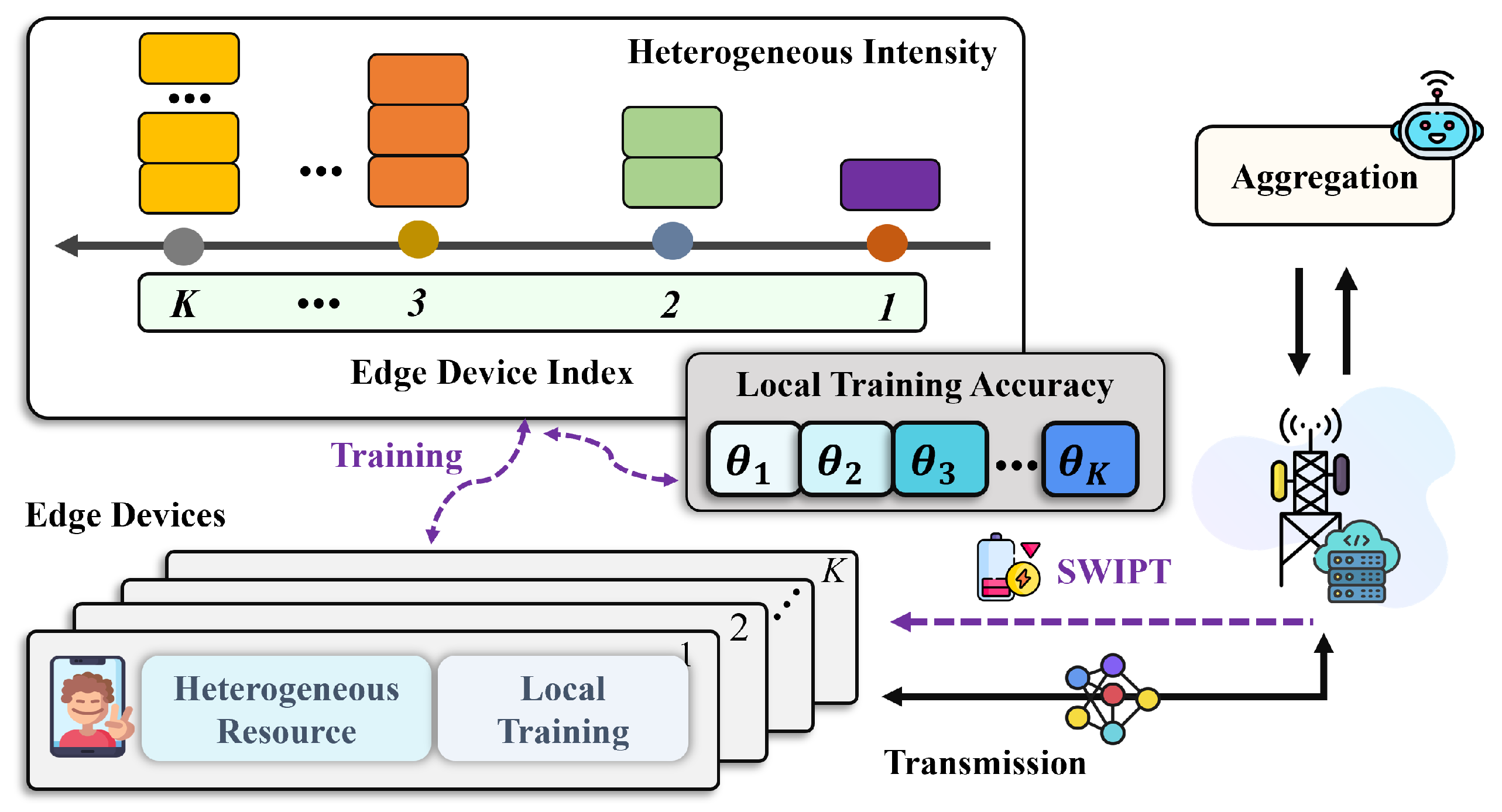
2. System Model
2.1. Federated Learning Framework
- Downlink model broadcast: The BS broadcasts the feedback information to all devices using SWIPT, which includes the global model parameters from the previous iteration and the aggregated gradient (as defined in Equations (5) and (6)). Subsequently, each device, integrated with a power splitter [28], receives the global parameters along with radio frequency energy from the BS.
- Heterogeneous local computation: Each device performs local training based on the following surrogate objective function:It can be observed that dynamically adjusts the optimization objective by incorporating and into , thereby better aligning with the convergence requirements of the global optimization process [5]. Considering the limitations of device computing capabilities in practical resource-constrained FEEL environments, this paper introduces an approximate solving strategy to achieve a reasonable balance between computational complexity and model training effectiveness. Specifically, each device obtains a feasible solution by approximately solving problem (3), which satisfies the following approximation condition:where represents the local training accuracy of device k, indicating the degree to which the device solves the local problem (3). Intuitively, signifies that the device can optimally solve the local problem (3); conversely, when , the device chooses to skip local optimization and directly sets . Therefore, from another perspective, a smaller can be interpreted as device k requiring a higher intensity of local training, and vice versa.
- Uplink model transmission: after completing local training, device transmits the local model update and the corresponding gradient to the BS via a wireless channel.
- Global Model Aggregation: Upon receiving the local model updates and the gradients sent via all devices , the BS aggregates them as follows:Subsequently, the BS broadcasts the updated model and the aggregated gradient to all edge devices. For any small constant , the convergence condition is satisfied whenindicating that the solution to problem (1) reaches convergence at the n-th iteration. Here, is the global optimal solution to problem (1).
2.2. Downlink Communication Model with SWIPT
2.3. Uplink AirComp Communication Model
2.4. Delay and Energy Model
3. Convergence Analysis and Problem Formulation
3.1. Basic Assumptions and Preliminaries
3.2. Convergence Analysis
3.3. Problem Formulation
4. Alternating Optimization
4.1. Max–Min Optimization of SWIPT
4.1.1. Given , Optimizing ()
4.1.2. Given (), Optimizing
| Algorithm 1 Alternating optimization for the SWIPT max–min problem |
|
4.2. Joint Learning–Communication Optimization
4.2.1. Wireless Transmission Design
4.2.2. Local Training Intensity Determination
| Algorithm 2 Joint Learning–Communication Optimization |
|
4.3. Computational Complexity
5. Numerical Results
5.1. Simulation Setup
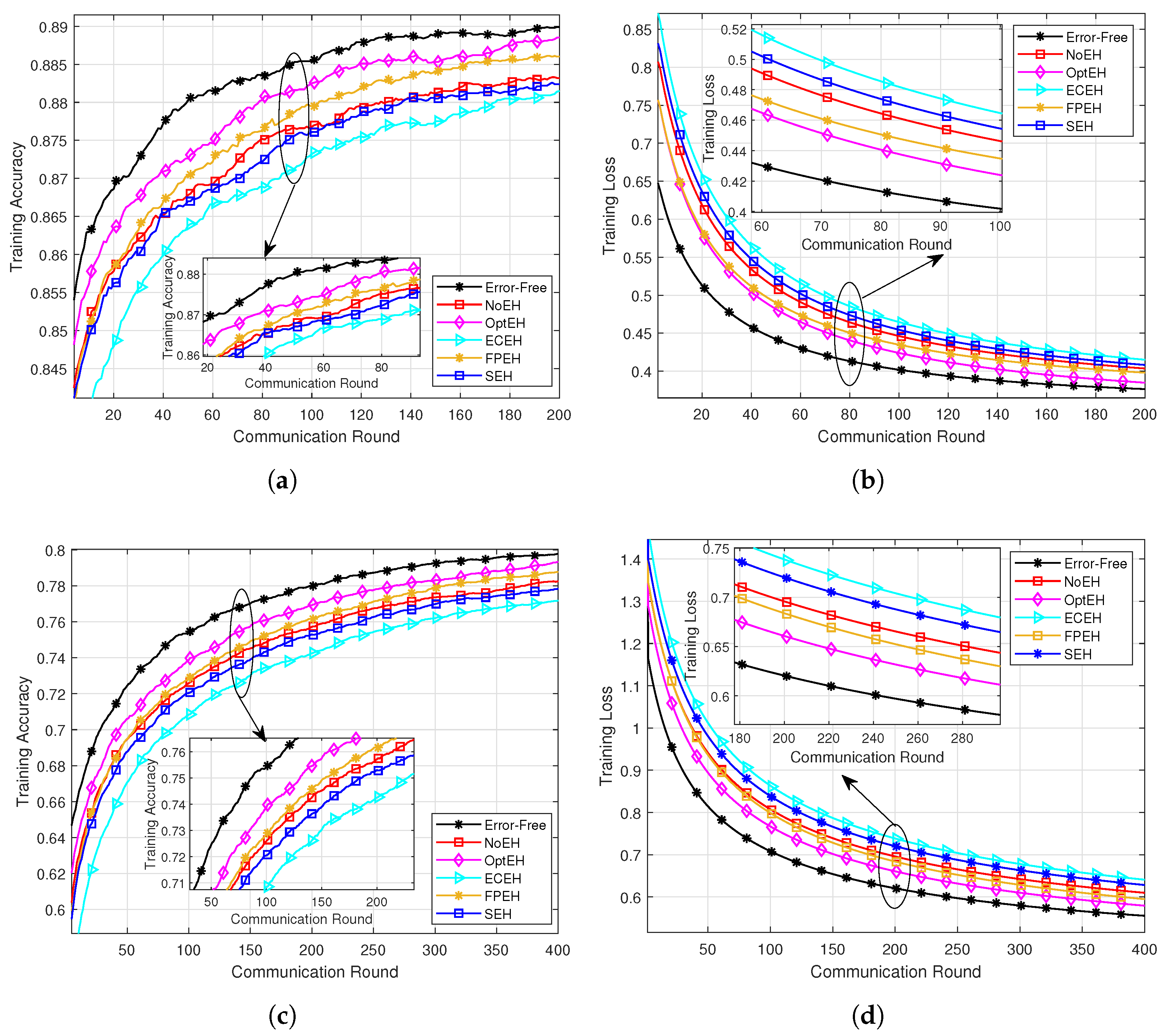
- NoEH [6]: In this approach, edge devices have only limited inherent energy and cannot replenish their energy during the FEEL processes.
- ECEH [5]: All devices adopt the same energy harvesting scheme and wireless communication strategy as OptEH, but they execute the same local training intensity, which is determined by the slowest device.
- FPEH [43]: This scheme implements a heuristic approach to SWIPT by employing a fixed power-splitting ratio. In this model, devices operate with a predetermined ratio for splitting power between energy harvesting and information decoding (we set ).
- SEH [44]: Devices are selected based on their channel gain to mitigate the “straggler” problem. Only those devices that achieve channel gains above a specified threshold are allowed to participate in the training process, while others are excluded from engagement in training.
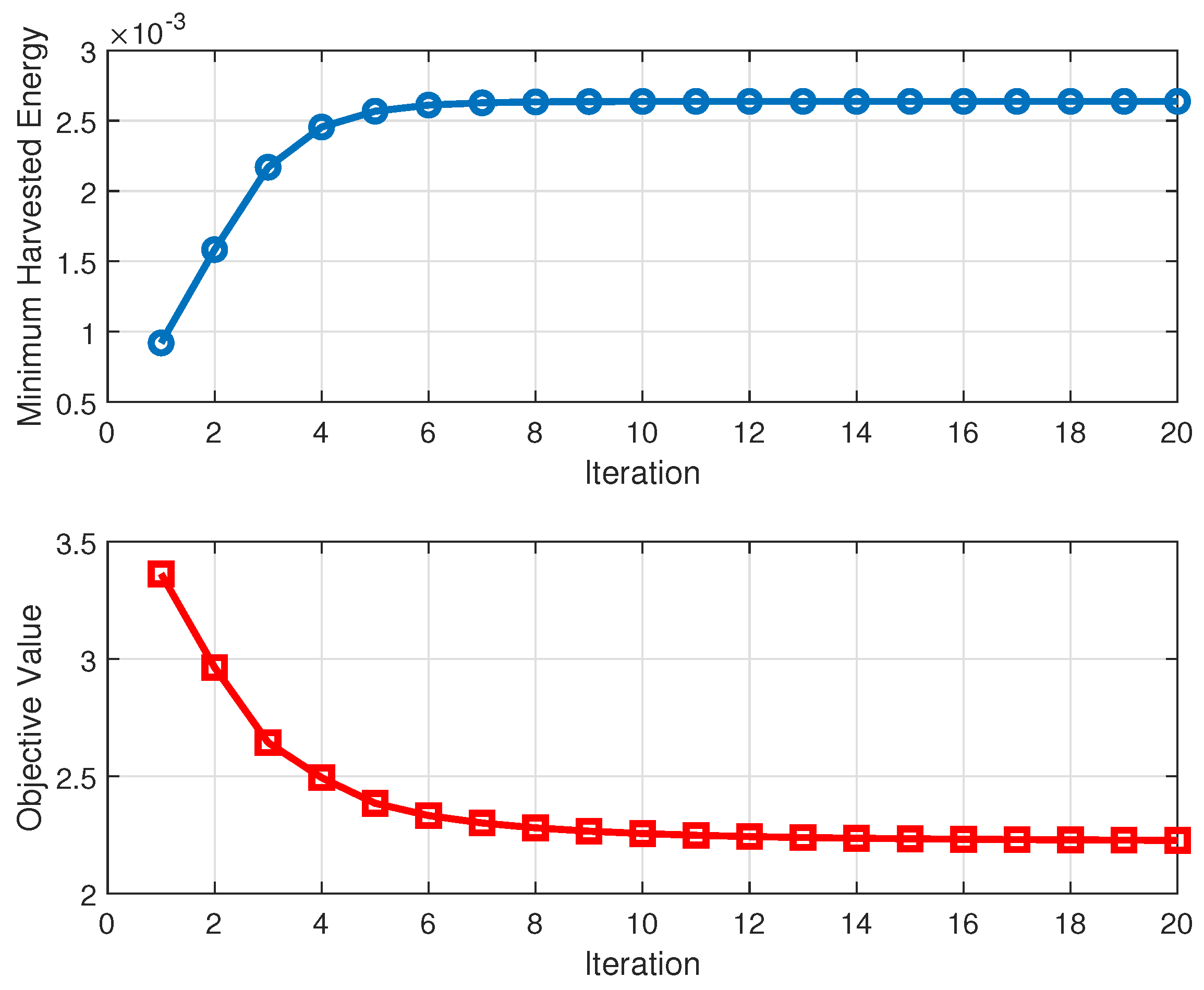
5.2. Convergence Behaviour of the Proposed Algorithms
5.3. Performance Comparison on Learning Convergence
5.4. Performance Versus the Number of BS Antennas
5.5. Performance Versus the Maximum Inherent Energy Budget
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SWIPT | Simultaneous wireless information and power transfer |
| FEEL | Federated edge learning |
| AirComp | Over-the-air computation |
| SCA | Successive convex approximation |
| MSE | Mean squared error |
| AO | Alternating optimization |
| BS | Base station |
| ID | Information decoding |
| EH | Energy harvesting |
Appendix A. Proof of Theorem 1
Appendix B. Proof of Lemma 3
References
- Lyu, X.; Ren, C.; Ni, W.; Tian, H.; Liu, R.P.; Dutkiewicz, E. Optimal Online Data Partitioning for Geo-Distributed Machine Learning in Edge of Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 2393–2406. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zhang, T.; Mao, S. Energy-Efficient Federated Learning With Intelligent Reflecting Surface. IEEE Trans. Green Commun. Netw. 2022, 6, 845–858. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; Singh, A., Zhu, J., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Dinh, C.T.; Tran, N.H.; Nguyen, M.N.H.; Hong, C.S.; Bao, W.; Zomaya, A.Y.; Gramoli, V. Federated Learning Over Wireless Networks: Convergence Analysis and Resource Allocation. IEEE/ACM Trans. Netw. 2021, 29, 398–409. [Google Scholar] [CrossRef]
- Li, H.; Wang, R.; Jiang, M.; Liu, J. STAR-RIS Empowered Heterogeneous Federated Edge Learning With Flexible Aggregation. IEEE Internet Things J. 2025, 12, 28374–28389. [Google Scholar] [CrossRef]
- Zhou, Y.; Pang, X.; Wang, Z.; Hu, J.; Sun, P.; Ren, K. Towards Efficient Asynchronous Federated Learning in Heterogeneous Edge Environments. In Proceedings of the IEEE INFOCOM 2024—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 20–23 May 2024; pp. 2448–2457. [Google Scholar]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Differentially Private Asynchronous Federated Learning for Mobile Edge Computing in Urban Informatics. IEEE Trans. Ind. Informatics 2020, 16, 2134–2143. [Google Scholar] [CrossRef]
- Kou, Z.; Ji, Y.; Yang, D.; Zhang, S.; Zhong, X. Semi-Asynchronous Over-the-Air Federated Learning Over Heterogeneous Edge Devices. IEEE Trans. Veh. Technol. 2025, 74, 110–125. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Z.; Tian, Y.; Yang, Q.; Shan, H.; Wang, W.; Quek, T.Q.S. Asynchronous Federated Learning Over Wireless Communication Networks. IEEE Trans. Wirel. Commun. 2022, 21, 6961–6978. [Google Scholar] [CrossRef]
- Chen, Z.; Yi, W.; Shin, H.; Nallanathan, A. Adaptive Semi-Asynchronous Federated Learning over Wireless Networks. IEEE Trans. Commun. 2024, 73, 394–409. [Google Scholar] [CrossRef]
- Xu, Y.; Liao, Y.; Xu, H.; Ma, Z.; Wang, L.; Liu, J. Adaptive Control of Local Updating and Model Compression for Efficient Federated Learning. IEEE Trans. Mob. Comput. 2023, 22, 5675–5689. [Google Scholar] [CrossRef]
- Ma, Z.; Xu, Y.; Xu, H.; Meng, Z.; Huang, L.; Xue, Y. Adaptive Batch Size for Federated Learning in Resource-Constrained Edge Computing. IEEE Trans. Mob. Comput. 2023, 22, 37–53. [Google Scholar] [CrossRef]
- Wang, L.; Xu, Y.; Xu, H.; Jiang, Z.; Chen, M.; Zhang, W.; Qian, C. BOSE: Block-Wise Federated Learning in Heterogeneous Edge Computing. IEEE/ACM Trans. Netw. 2024, 32, 1362–1377. [Google Scholar] [CrossRef]
- Liao, Y.; Xu, Y.; Xu, H.; Wang, L.; Qian, C. Adaptive Configuration for Heterogeneous Participants in Decentralized Federated Learning. In Proceedings of the IEEE INFOCOM 2023—IEEE Conference on Computer Communications, New York, NY, USA, 17–20 May 2023; pp. 1–10. [Google Scholar]
- Zeng, M.; Wang, X.; Pan, W.; Zhou, P. Heterogeneous Training Intensity for Federated Learning: A Deep Reinforcement Learning Approach. IEEE Trans. Netw. Sci. Eng. 2023, 10, 990–1002. [Google Scholar] [CrossRef]
- Li, H.; Wang, R.; Zhang, W.; Wu, J. One Bit Aggregation for Federated Edge Learning With Reconfigurable Intelligent Surface: Analysis and Optimization. IEEE Trans. Wirel. Commun. 2023, 22, 872–888. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A Joint Learning and Communications Framework for Federated Learning Over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 269–283. [Google Scholar] [CrossRef]
- Wen, D.; Bennis, M.; Huang, K. Joint Parameter-and-Bandwidth Allocation for Improving the Efficiency of Partitioned Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 8272–8286. [Google Scholar] [CrossRef]
- Li, H.; Wang, R.; Wu, J.; Zhang, W.; Soto, I. Reconfigurable Intelligent Surface Empowered Federated Edge Learning With Statistical CSI. IEEE Trans. Wirel. Commun. 2024, 23, 6595–6608. [Google Scholar] [CrossRef]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. Federated Learning via Over-the-Air Computation. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- Zhu, G.; Du, Y.; Gündüz, D.; Huang, K. One-Bit Over-the-Air Aggregation for Communication-Efficient Federated Edge Learning: Design and Convergence Analysis. IEEE Trans. Wirel. Commun. 2021, 20, 2120–2135. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, Q.; Zhu, G.; Jiang, H.; Eldar, Y.C.; Cui, S. Communication-and-Energy Efficient Over-the-Air Federated Learning. IEEE Trans. Wirel. Commun. 2025, 24, 767–782. [Google Scholar] [CrossRef]
- Zhang, Y.; You, C. SWIPT in Mixed Near- and Far-Field Channels: Joint Beam Scheduling and Power Allocation. IEEE J. Sel. Areas Commun. 2024, 42, 1583–1597. [Google Scholar] [CrossRef]
- Faramarzi, S.; Zarini, H.; Javadi, S.; Robat Mili, M.; Zhang, R.; Karagiannidis, G.K.; Al-Dhahir, N. Energy Efficient Design of Active STAR-RIS-Aided SWIPT Systems. IEEE Trans. Wirel. Commun. 2025, 24, 3209–3224. [Google Scholar] [CrossRef]
- He, Y.; Huang, F.; Wang, D.; Zhang, R. Outage Probability Analysis of MISO-NOMA Downlink Communications in UAV-Assisted Agri-IoT With SWIPT and TAS Enhancement. IEEE Trans. Netw. Sci. Eng. 2025, 12, 2151–2164. [Google Scholar] [CrossRef]
- Do, T.N.; da Costa, D.B.; Duong, T.Q.; An, B. Improving the Performance of Cell-Edge Users in MISO-NOMA Systems Using TAS and SWIPT-Based Cooperative Transmissions. IEEE Trans. Green Commun. Netw. 2018, 2, 49–62. [Google Scholar] [CrossRef]
- Zheng, G.; Fang, Y.; Wen, M.; Ding, Z. Novel Over-the-Air Federated Learning via Reconfigurable Intelligent Surface and SWIPT. IEEE Internet Things J. 2024, 11, 34140–34155. [Google Scholar] [CrossRef]
- Liu, H.; Yuan, X.; Zhang, Y.J.A. Reconfigurable Intelligent Surface Enabled Federated Learning: A Unified Communication-Learning Design Approach. IEEE Trans. Wirel. Commun. 2021, 20, 7595–7609. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, Y.; Shi, Y.; Zhuang, W. Interference Management for Over-the-Air Federated Learning in Multi-Cell Wireless Networks. IEEE J. Sel. Areas Commun. 2022, 40, 2361–2377. [Google Scholar] [CrossRef]
- Nadeem, Q.U.A.; Kammoun, A.; Chaaban, A.; Debbah, M.; Alouini, M.S. Intelligent reflecting surface assisted wireless communication: Modeling and channel estimation. arXiv 2019, arXiv:1906.02360. [Google Scholar]
- Liaskos, C.; Tsioliaridou, A.; Pitilakis, A.; Pirialakos, G.; Tsilipakos, O.; Tasolamprou, A.; Kantartzis, N.; Ioannidis, S.; Kafesaki, M.; Pitsillides, A.; et al. Joint compressed sensing and manipulation of wireless emissions with intelligent surfaces. In Proceedings of the IEEE International Conference on Distributed Computing in Sensor Systems, Santorini Island, Greece, 29–31 May 2019; pp. 318–325. [Google Scholar]
- Wang, Z.; Qiu, J.; Zhou, Y.; Shi, Y.; Fu, L.; Chen, W.; Letaief, K.B. Federated Learning via Intelligent Reflecting Surface. IEEE Trans. Wirel. Commun. 2022, 21, 808–822. [Google Scholar] [CrossRef]
- Ni, W.; Liu, Y.; Yang, Z.; Tian, H.; Shen, X. Integrating Over-the-Air Federated Learning and Non-Orthogonal Multiple Access: What Role Can RIS Play? IEEE Trans. Wirel. Commun. 2022, 21, 10083–10099. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, M.; Chen, M.; Yang, Z.; Shikh-Bahaei, M.; Poor, H.V.; Cui, S. Energy Minimization for Federated Learning with IRS-Assisted Over-the-Air Computation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3105–3109. [Google Scholar] [CrossRef]
- Zhou, S.; Li, G.Y. Federated Learning Via Inexact ADMM. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9699–9708. [Google Scholar] [CrossRef] [PubMed]
- Elgabli, A.; Park, J.; Issaid, C.B.; Bennis, M. Harnessing Wireless Channels for Scalable and Privacy-Preserving Federated Learning. IEEE Trans. Commun. 2021, 69, 5194–5208. [Google Scholar] [CrossRef]
- Nesterov, Y. Lectures on Convex Optimization; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 137. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. Graph implementations for nonsmooth convex programs. In Recent Advances in Learning and Control; Blondel, V., Boyd, S., Kimura, H., Eds.; Lecture Notes in Control and Information Sciences; Springer: Berlin/Heidelberg, Germany, 2008; pp. 95–110. [Google Scholar]
- Liu, Y.; Mu, X.; Xu, J.; Schober, R.; Hao, Y.; Poor, H.V.; Hanzo, L. STAR: Simultaneous Transmission and Reflection for 360° Coverage by Intelligent Surfaces. IEEE Wirel. Commun. 2021, 28, 102–109. [Google Scholar] [CrossRef]
- Lecun, Y.; Cortes, C. The Mnist Database of Handwritten Digits. 2005. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 October 2024).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Wu, Y.; Song, Y.; Wang, T.; Dai, M.; Quek, T.Q.S. Simultaneous Wireless Information and Power Transfer Assisted Federated Learning via Nonorthogonal Multiple Access. IEEE Trans. Green Commun. Netw. 2022, 6, 1846–1861. [Google Scholar] [CrossRef]
- Yao, J.; Xu, W.; Yang, Z.; You, X.; Bennis, M.; Poor, H.V. Wireless Federated Learning Over Resource-Constrained Networks: Digital Versus Analog Transmissions. IEEE Trans. Wirel. Commun. 2024, 23, 14020–14036. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | FEEL Scenario? | Heterogeneity Consideration? | Communication-Learning Design? | SWIPT? |
|---|---|---|---|---|
| [4,5] | ✓ | |||
| [7,8,9,10,12,13,14,15,16] | ✓ | ✓ | ||
| [18,19,20,21,22,23] | ✓ | ✓ | ||
| [24,25,26,27] | ✓ | |||
| This Work | ✓ | ✓ | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Shu, S.; Zhu, Y.; Li, H.; Rui, K. A Novel Heterogeneous Federated Edge Learning Framework Empowered with SWIPT. Symmetry 2025, 17, 1115. https://doi.org/10.3390/sym17071115
Fang Y, Shu S, Zhu Y, Li H, Rui K. A Novel Heterogeneous Federated Edge Learning Framework Empowered with SWIPT. Symmetry. 2025; 17(7):1115. https://doi.org/10.3390/sym17071115
Chicago/Turabian StyleFang, Yinyin, Sheng Shu, Yujun Zhu, Heju Li, and Kunkun Rui. 2025. "A Novel Heterogeneous Federated Edge Learning Framework Empowered with SWIPT" Symmetry 17, no. 7: 1115. https://doi.org/10.3390/sym17071115
APA StyleFang, Y., Shu, S., Zhu, Y., Li, H., & Rui, K. (2025). A Novel Heterogeneous Federated Edge Learning Framework Empowered with SWIPT. Symmetry, 17(7), 1115. https://doi.org/10.3390/sym17071115