


STA-3D: Combining Spatiotemporal Attention and 3D Convolutional Networks for Robust Deepfake Detection

Abstract
1. Introduction
- We propose a novel framework named the Spatiotemporal Attention 3D Network (STA-3D), which integrates a lightweight spatiotemporal attention module with a 3D-CNN backbone for enhanced deepfake detection.
- We initialize our 3D-CNN backbone using weights pre-trained on action recognition tasks, reducing computational overhead through transfer learning. The design incorporates a plug-and-play multi-branch attention layer for analyzing correlations across temporal and spatial dimensions, a spatial pyramid pooling layer supporting variable-length frame sequences, and focal loss [34] to address class asymmetry issues during training.
- We conduct comprehensive experiments evaluating intra-dataset performance, cross-dataset generalization, and comparisons with multiple baselines. Our method demonstrates consistent performance across various testing scenarios.
2. Related Works
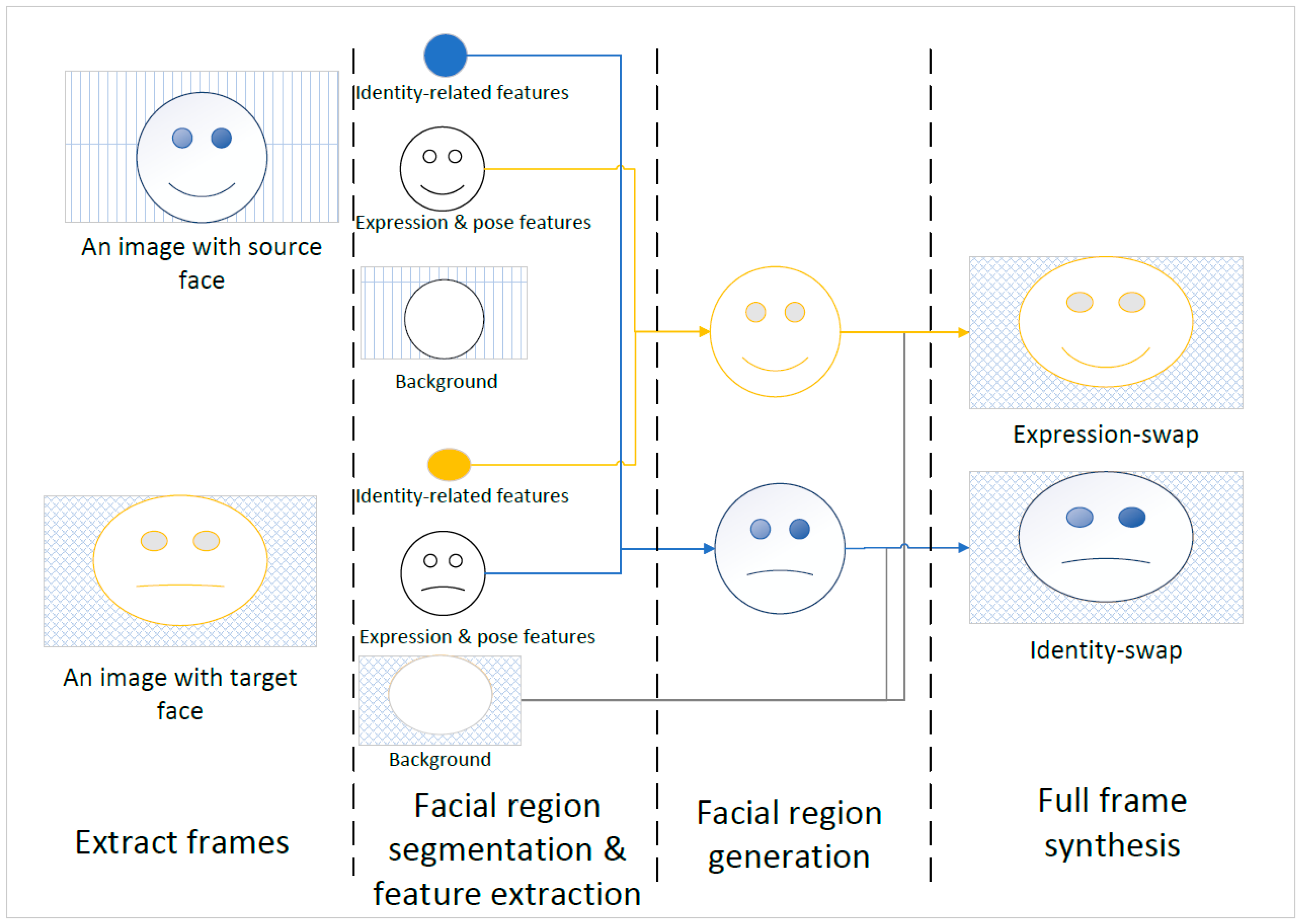
2.1. Deepfake Generation
2.2. Plug-and-Play Attention Mechanisms
2.3. 3D-CNN and Action Recognition
3. Methods
3.1. Overview
3.2. 3D-CNN Feature Extraction Module
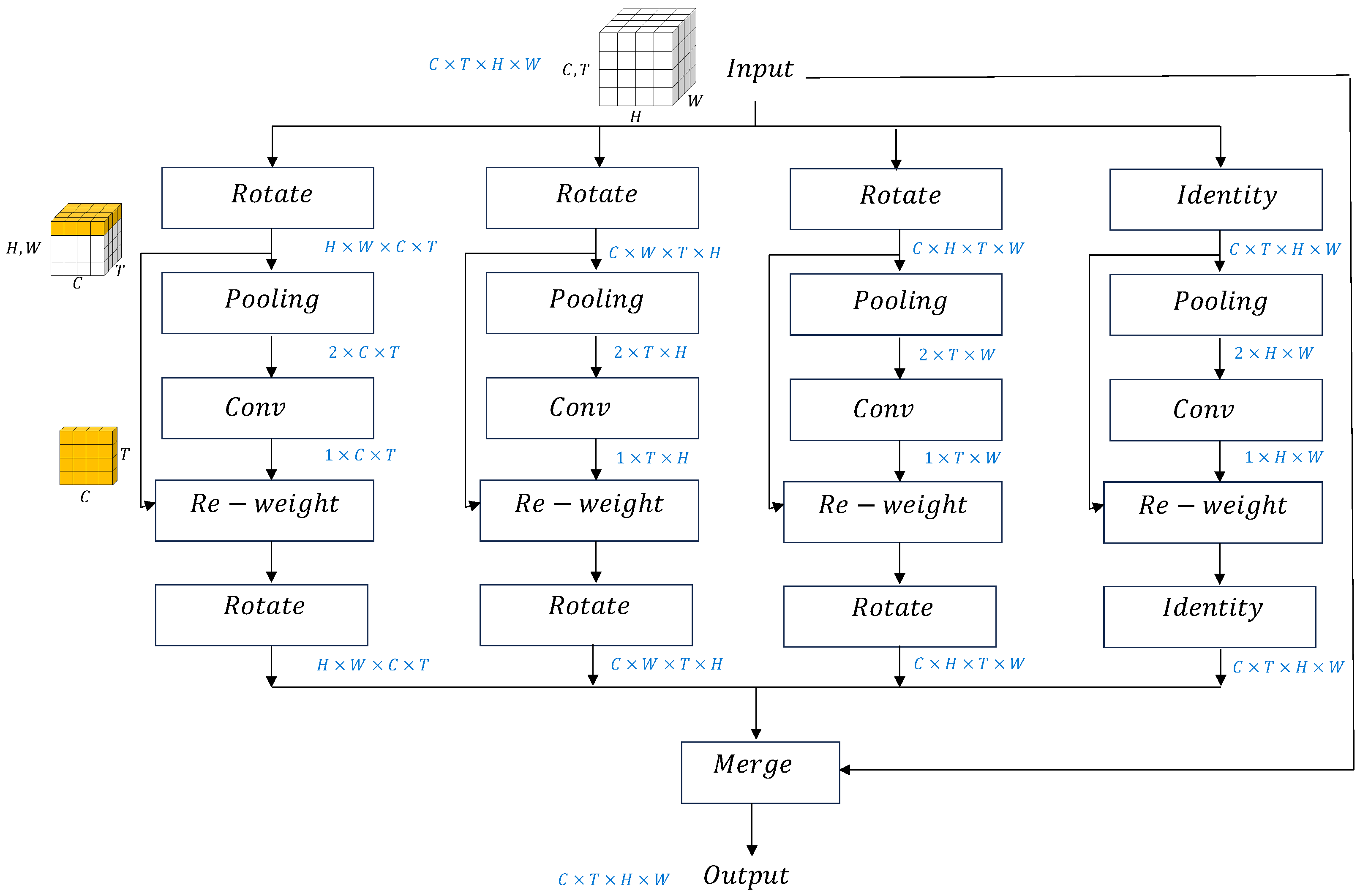
3.3. Attention Module
3.4. Loss Function Design for Class Imbalance
4. Results and Analysis
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Overall Model Parameters and Computational Cost
4.4. Comparison with Previous Methods
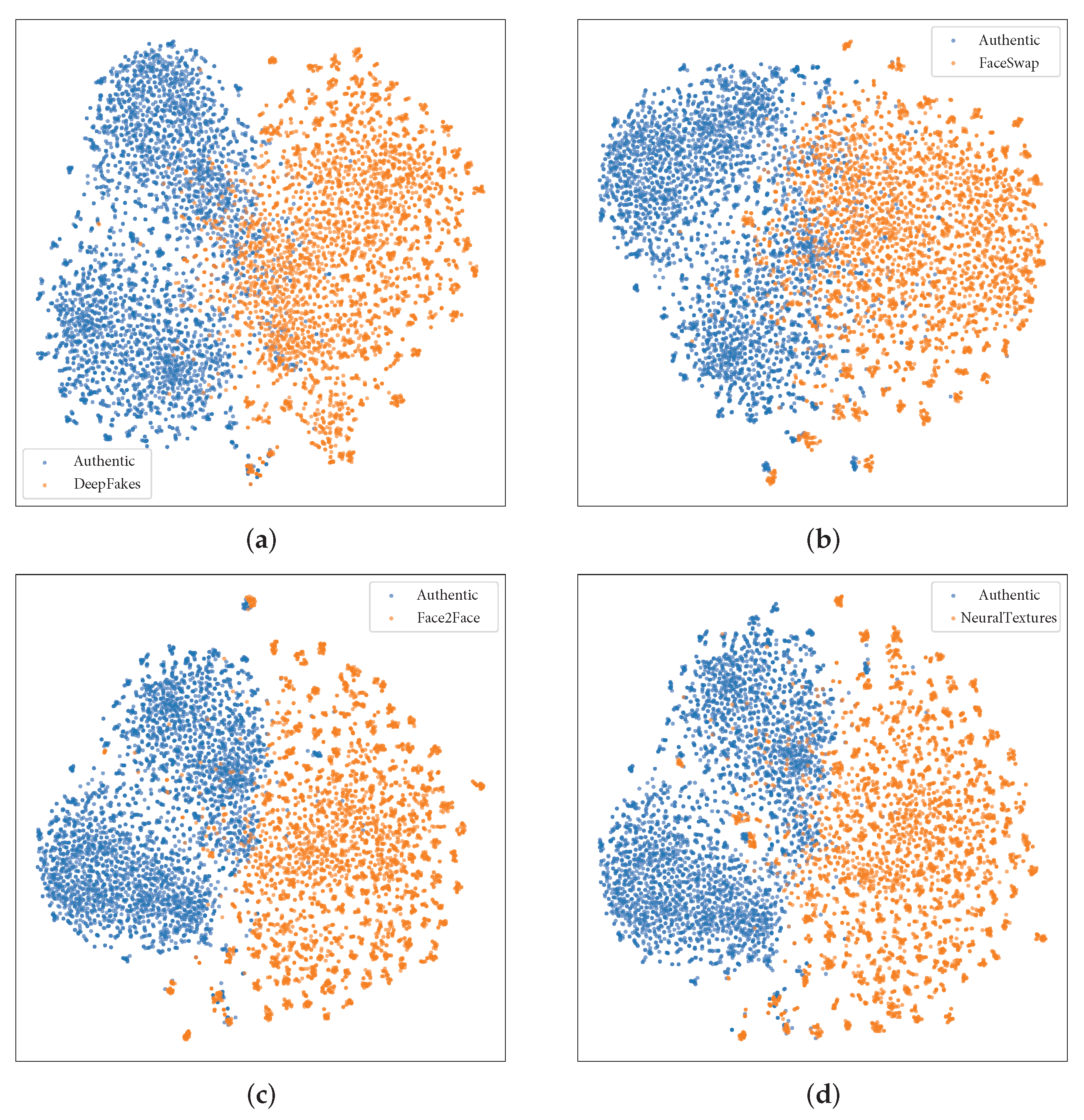
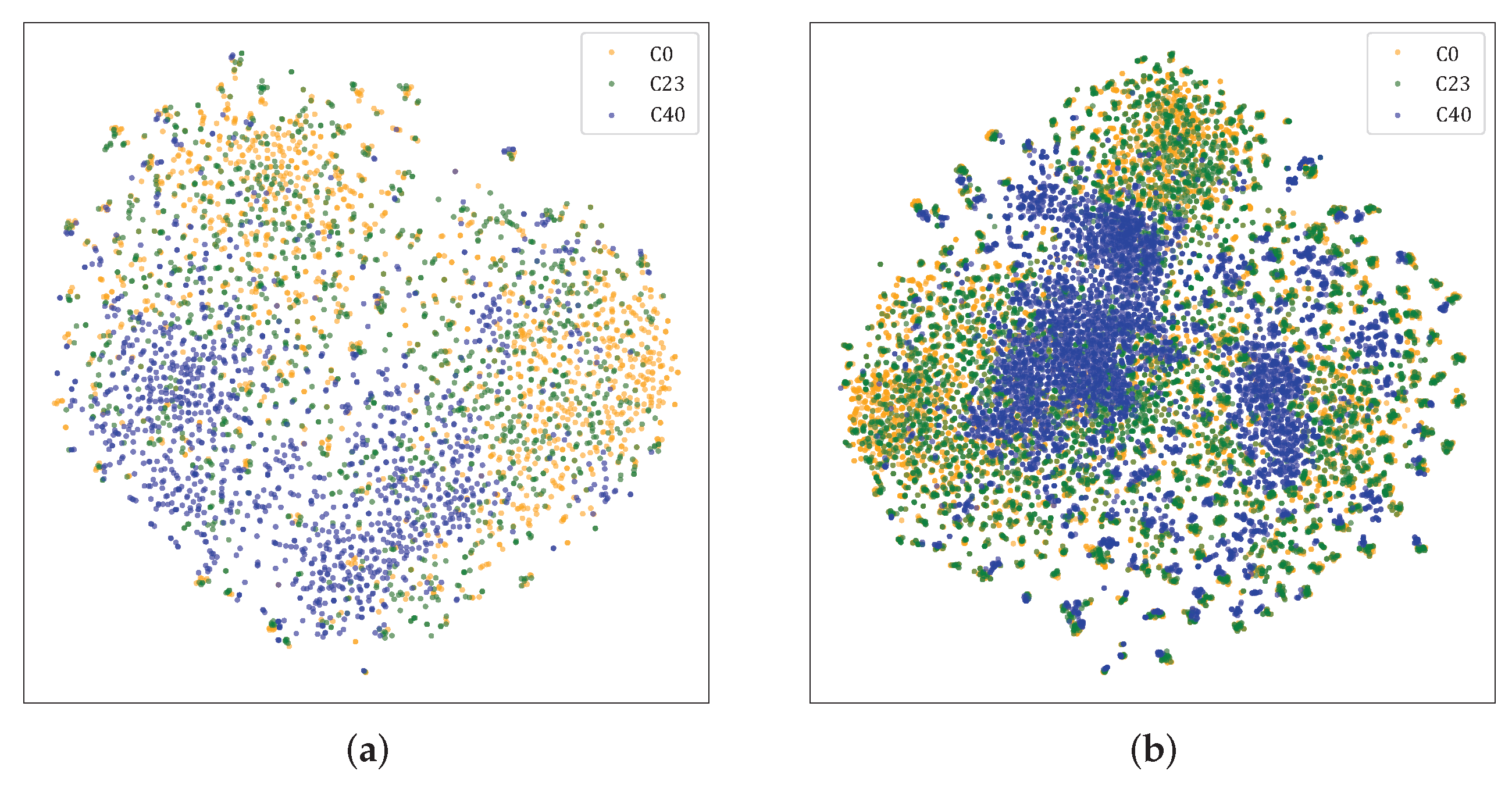
4.5. Visualization Analysis
4.6. Ablation Study
4.7. Generalization Ability

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Training Dataset | Testing Dataset | |
|---|---|---|---|
| DFDC-P | Celeb-DF | ||
| Meso-4 [3] | FF++ | 59.4 | 53.6 |
| HeadPose [95] | FF++ | 54.6 | |
| DSP [5] | FF++ | 67.9 | 73.7 |
| VA-LogReg [96] | FF++ | 55.1 | |
| Capsule-Forensics [97] | FF++ | 57.5 | |
| Multi-task [98] | FF++ | 54.3 | |
| D-FWA [6] | FF++ | 56.9 | |
| LRNet [99] | FF++ | 53.2 | |
| RATF [94] | FF++ | 69.1 | 76.5 |
| Ours | FF++ | 69.24 | 59.64 |
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D-CNNs | Three-dimensional convolutional neural networks |
| ViT | Vision Transformers |
| SPP | Spatial Pyramid Pooling |
| FF++ | FaceForensics++ |
| DFDC-P | Deepfake Detection Challenge Preview |
| Celeb-DF | Celeb-DeepFake |
| AUC | Area Under the Curve |
| CE | Cross Entropy |
| t-SNE | T-distributed Stochastic Neighbor Embedding |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
References
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Kumar, P.; Vatsa, M.; Singh, R. Detecting face2face facial reenactment in videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2589–2597. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 13–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 86–103. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Nguyen, D.; Mejri, N.; Singh, I.P.; Kuleshova, P.; Astrid, M.; Kacem, A.; Ghorbel, E.; Aouada, D. LAA-Net: Localized Artifact Attention Network for Quality-Agnostic and Generalizable Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–22 June 2024; pp. 17395–17405. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces (GUI) 2019, 3, 80–87. [Google Scholar]
- Vamsi, V.V.V.N.S.; Shet, S.S.; Reddy, S.S.M.; Rose, S.S.; Shetty, S.R.; Sathvika, S.; Supriya, M.; Shankar, S.P. Deepfake detection in digital media forensics. Glob. Transit. Proc. 2022, 3, 74–79. [Google Scholar] [CrossRef]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. Deepfake video detection through optical flow based cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Saikia, P.; Dholaria, D.; Yadav, P.; Patel, V.; Roy, M. A hybrid CNN-LSTM model for video deepfake detection by leveraging optical flow features. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5039–5049. [Google Scholar]
- Wu, J.; Zhu, Y.; Jiang, X.; Liu, Y.; Lin, J. Local attention and long-distance interaction of rPPG for deepfake detection. Vis. Comput. 2024, 40, 1083–1094. [Google Scholar] [CrossRef]
- Verkruysse, W.; Svaasand, L.O.; Nelson, J.S. Remote plethysmographic imaging using ambient light. Opt. Express 2008, 16, 21434–21445. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Peng, C.; Miao, Z.; Liu, D.; Wang, N.; Hu, R.; Gao, X. Where Deepfakes Gaze at? Spatial-Temporal Gaze Inconsistency Analysis for Video Face Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2024, 19, 4507–4517. [Google Scholar] [CrossRef]
- Zheng, Y.; Bao, J.; Chen, D.; Zeng, M.; Wen, F. Exploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15044–15054. [Google Scholar]
- Xu, Y.; Liang, J.; Jia, G.; Yang, Z.; Zhang, Y.; He, R. Tall: Thumbnail layout for deepfake video detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 22658–22668. [Google Scholar]
- Zhao, C.; Wang, C.; Hu, G.; Chen, H.; Liu, C.; Tang, J. ISTVT: Interpretable spatial-temporal video transformer for deepfake detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1335–1348. [Google Scholar] [CrossRef]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.F.; Paluri, M. Convnet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Turrisi, R.; Verri, A.; Barla, A. The effect of data augmentation and 3D-CNN depth on Alzheimer’s Disease detection. arXiv 2023, arXiv:2309.07192. [Google Scholar]
- De Lima, O.; Franklin, S.; Basu, S.; Karwoski, B.; George, A. Deepfake detection using spatiotemporal convolutional networks. arXiv 2020, arXiv:2006.14749. [Google Scholar]
- Liu, J.; Zhu, K.; Lu, W.; Luo, X.; Zhao, X. A lightweight 3D convolutional neural network for deepfake detection. Int. J. Intell. Syst. 2021, 36, 4990–5004. [Google Scholar] [CrossRef]
- Lu, C.; Liu, B.; Zhou, W.; Chu, Q.; Yu, N. Deepfake video detection using 3D-attentional inception convolutional neural network. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3572–3576. [Google Scholar]
- Ma, Z.; Mei, X.; Shen, J. 3D Attention Network for Face Forgery Detection. In Proceedings of the 2023 4th Information Communication Technologies Conference (ICTC), Nanjing, China, 17–19 May 2023; pp. 396–401. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Z.; Bao, J.; Zhou, W.; Wang, W.; Li, H. Altfreezing for more general video face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4129–4138. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- MarekKowalski. 3D Face Swapping Implemented in Python. 2021. Available online: https://github.com/MarekKowalski/FaceSwap (accessed on 15 January 2025).
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- DeepFakes. 2018. Available online: https://www.theverge.com/2018/2/7/16982046/reddit-deepfakes-ai-celebrity-face-swap-porn-community-ban (accessed on 15 January 2025).
- Shaoanlu. Faceswap-GAN. 2022. Available online: https://github.com/shaoanlu/faceswap-GAN (accessed on 15 January 2025).
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. Towards open-set identity preserving face synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6713–6722. [Google Scholar]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Faceshifter: Towards high fidelity and occlusion aware face swapping. arXiv 2019, arXiv:1912.13457. [Google Scholar]
- Zhu, Y.; Li, Q.; Wang, J.; Xu, C.Z.; Sun, Z. One shot face swapping on megapixels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4834–4844. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Kim, J.; Lee, J.; Zhang, B.T. Smooth-swap: A simple enhancement for face-swapping with smoothness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10779–10788. [Google Scholar]
- Rosberg, F.; Aksoy, E.E.; Alonso-Fernandez, F.; Englund, C. Facedancer: Pose-and occlusion-aware high fidelity face swapping. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 3454–3463. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. Acm Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Tripathy, S.; Kannala, J.; Rahtu, E. Icface: Interpretable and controllable face reenactment using gans. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3385–3394. [Google Scholar]
- Wang, Y.; Yang, D.; Bremond, F.; Dantcheva, A. Latent image animator: Learning to animate images via latent space navigation. arXiv 2022, arXiv:2203.09043. [Google Scholar]
- Pang, Y.; Zhang, Y.; Quan, W.; Fan, Y.; Cun, X.; Shan, Y.; Yan, D.M. Dpe: Disentanglement of pose and expression for general video portrait editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 427–436. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networkspark2018bam. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3531–3539. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Si, Y.; Xu, H.; Zhu, X.; Zhang, W.; Dong, Y.; Chen, Y.; Li, H. SCSA: Exploring the synergistic effects between spatial and channel attention. Neurocomputing 2025, 634, 129866. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, S.; Guo, S.; Huang, W.; Scott, M.R.; Wang, L. V4d: 4d convolutional neural networks for video-level representation learning. arXiv 2020, arXiv:2002.07442. [Google Scholar]
- Wu, W.; Zhao, Y.; Xu, Y.; Tan, X.; He, D.; Zou, Z.; Ye, J.; Li, Y.; Yao, M.; Dong, Z.; et al. Dsanet: Dynamic segment aggregation network for video-level representation learning. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1903–1911. [Google Scholar]
- Tian, Q.; Miao, W.; Zhang, L.; Yang, Z.; Yu, Y.; Zhao, Y.; Yao, L. MCANet: A lightweight action recognition network with multidimensional convolution and attention. Int. J. Mach. Learn. Cybern. 2025, 16, 3345–3358. [Google Scholar] [CrossRef]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ridnik, T.; Ben-Baruch, E.; Zamir, N.; Noy, A.; Friedman, I.; Protter, M.; Zelnik-Manor, L. Asymmetric loss for multi-label classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 82–91. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16. Springer: Cham, Switzerland, 2020. [Google Scholar]
- Kohli, A.; Gupta, A. Detecting deepfake, faceswap and face2face facial forgeries using frequency cnn. Multimed. Tools Appl. 2021, 80, 18461–18478. [Google Scholar] [CrossRef]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. C3D: Generic Features for Video Analysis. arXiv 2014, arXiv:1412.0767. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6202–6211. [Google Scholar]
- Liu, Z.; Luo, D.; Wang, Y.; Wang, L.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Lu, T. Teinet: Towards an efficient architecture for video recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11669–11676. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5781–5790. [Google Scholar]
- Pang, G.; Zhang, B.; Teng, Z.; Qi, Z.; Fan, J. MRE-Net: Multi-rate excitation network for deepfake video detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3663–3676. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Gu, Z.; Yao, T.; Chen, Y.; Yi, R.; Ding, S.; Ma, L. Region-Aware Temporal Inconsistency Learning for DeepFake Video Detection. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022; pp. 920–926. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar]
- Sun, Z.; Han, Y.; Hua, Z.; Ruan, N.; Jia, W. Improving the efficiency and robustness of deepfakes detection through precise geometric features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3609–3618. [Google Scholar]
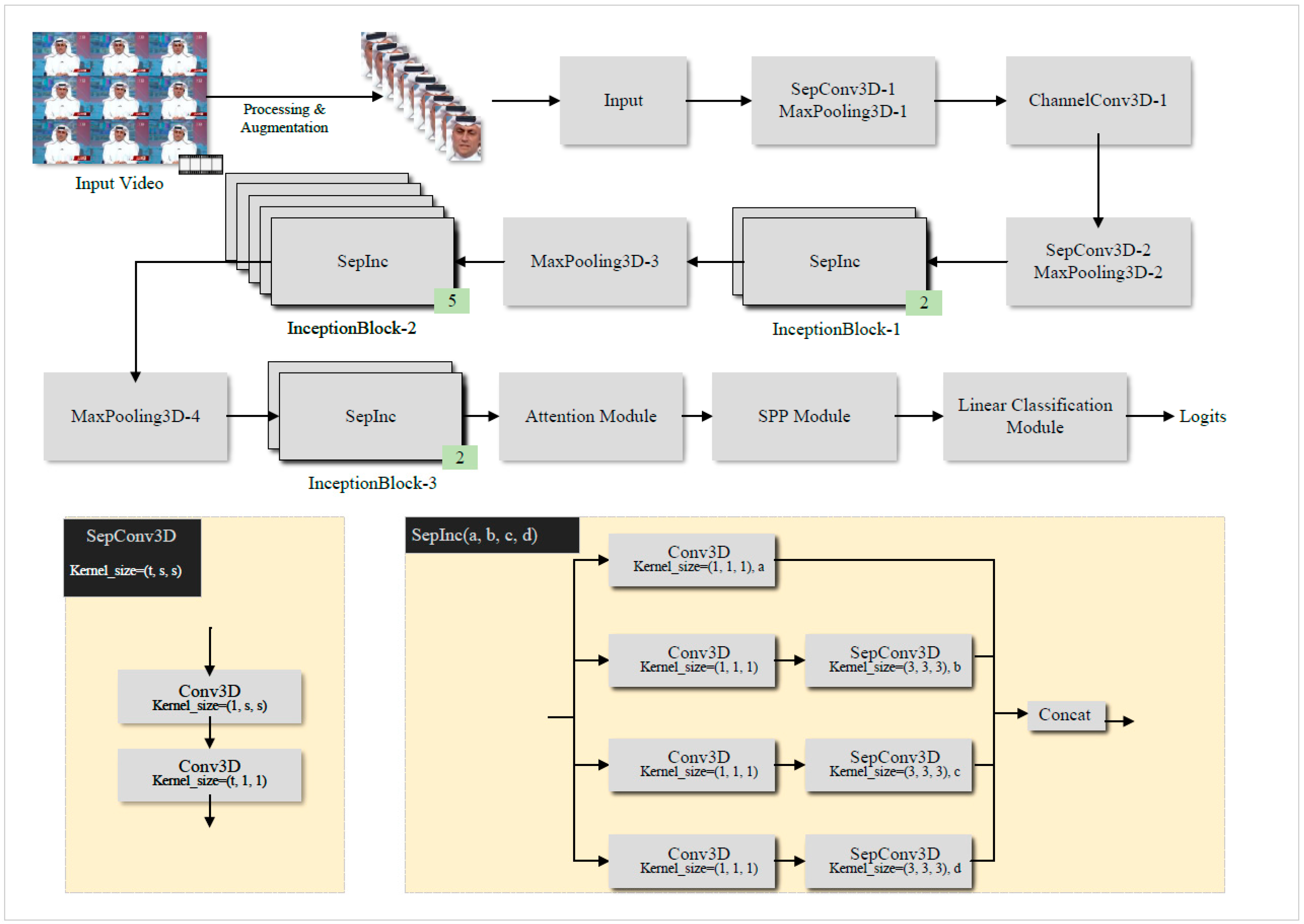


| Layers | Filter Configuration | Output Shape (Relative) | |
|---|---|---|---|
| Temporal | Spatial | ||
| Input | - | 1 | 1 |
| SepConv3D-1 | , 64 | ||
| MaxPooling3D-1 | , 64 | ||
| ChannelConv3D-1 | , 64 | ||
| SepConv3D-2 | , 192 | ||
| MaxPooling3D-2 | , 192 | ||
| InceptionBlock-1 | |||
| MaxPooling3D-3 | , 480 | ||
| InceptionBlock-2 | |||
| MaxPooling3D-4 | , 832 | ||
| InceptionBlock-3 | |||
| Method | Parameters Formula | Parameter Count |
|---|---|---|
| SE Block [52] | 131.07 K | |
| CBAM [30] | 131.17 K | |
| Proposed Attention Module | 96 |
| Dataset | Usage | Real/Fake Videos | Fake-to-Real Ratio |
|---|---|---|---|
| FaceForensics++ (FF++) | Train | 2160/10,800 | 5.00 |
| FaceForensics++ (FF++) | Test | 420/2100 | 5.00 |
| DFDC-Preview (DFDC-P) | Test | 276/501 | 1.82 |
| Celeb-DF | Test | 178/340 | 1.91 |
| Frames | Number of Trainable Parameters | GPU Memory Usage (MB) | Inference Time (s) | Computational Complexity (FLOPs) |
|---|---|---|---|---|
| 8 | 7.96 M | 1535 | 0.86 | 10.72 G |
| 16 | 3009 | 1.03 | 21.44 G | |
| 32 | 5958 | 1.75 | 42.88 G |
| Categories | Methods | C0 | C23 | C40 | (C23-C40) ↓ | Avg |
|---|---|---|---|---|---|---|
| Frame-based | Steg.Features [81] | 97.63 | 70.97 | 55.98 | 14.99 | 74.86 |
| ResNet-50 [82] | 98.04 | 91.61 | 6.43 | 94.83 | ||
| Meso-4 [3] | 96.4 | 96.4 | ||||
| MesoInception-4 [3] | 94.08 | 86.09 | 75.15 | 10.94 | 85.11 | |
| Frequency-based | Two-branchRN [84] | 96.43 | 86.34 | 10.09 | 91.39 | |
| F3-Net-Xception [7] | 99.95 | 97.52 | 90.43 | 7.09 | 95.97 | |
| fCNN [85] | 87.48 | 83.78 | 72.49 | 11.29 | 81.25 | |
| SPSL [86] | 91.5 | 81.57 | 9.93 | 86.54 | ||
| Spatial–temporal | C3D [87] | 90.72 | 86.79 | 3.93 | 88.75 | |
| I3D [66] | 93.13 | 86.88 | 6.25 | 90.00 | ||
| SlowFast [88] | 92.48 | 92.48 | ||||
| TEINet [89] | 96.79 | 92.77 | 4.02 | 94.78 | ||
| ADDNet-3D [90] | 86.70 | 79.47 | 7.23 | 83.08 | ||
| Ma et al. [29] | 98.79 | 95.92 | 91.49 | 4.43 | 95.40 | |
| Ours | 99.17 | 97.62 | 94.40 | 3.22 | 97.06 |
| Methods | C0 | C23 | C40 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DF | FS | F2F | NT | DF | FS | F2F | NT | DF | FS | F2F | NT | |
| [82] | 98.93 | 99.64 | 98.93 | 95.00 | 95.36 | 94.64 | 88.93 | 87.5 | ||||
| [3] 1 | 96.37 | 98.17 | 97.75 | 93.30 | ||||||||
| [3] 2 | 88.34 | 97.81 | 97.65 | 92.52 | 83.47 | 94.34 | 94.34 | 75.06 | 74.20 | 79.72 | 78.75 | 67.94 |
| [85] | 87.79 | 89.28 | 85.37 | 85.24 | 85.03 | 85.03 | 79.24 | 68.88 | 69.35 | |||
| [87] | 92.86 | 91.79 | 91.79 | 89.64 | 89.29 | 87.86 | 82.86 | 87.14 | ||||
| [66] | 92.86 | 96.43 | 96.43 | 90.36 | 91.07 | 91.43 | 86.43 | 78.57 | ||||
| [88] | 97.50 | 95.00 | 94.90 | 82.50 | ||||||||
| [89] | 97.86 | 97.50 | 97.50 | 94.29 | 95.00 | 94.64 | 91.07 | 90.36 | ||||
| [90] | 92.14 | 92.50 | 83.93 | 78.21 | 90.36 | 80.00 | 78.21 | 69.29 | ||||
| [29] | 99.60 | 98.84 | 99.12 | 97.58 | 98.43 | 94.34 | 94.34 | 93.45 | 96.97 | 90.63 | 93.80 | 84.54 |
| ours | 99.29 | 99.29 | 99.29 | 98.69 | 97.62 | 97.62 | 98.22 | 97.62 | 93.22 | 94.41 | 95.00 | 94.41 |
| C0 | C23 | C40 | Avg | ||||||
|---|---|---|---|---|---|---|---|---|---|
| w/ attn | w/o attn | w/ attn | w/o attn | w/ attn | w/o attn | w/ attn | w/o attn | ||
| Frames | 8 | 96.55 | 97.74 | 92.50 | 93.33 | 90.00 | 91.67 | 93.02 | 94.25 |
| 16 | 99.17 | 99.64 | 97.62 | 98.10 | 94.40 | 93.10 | 97.06 | 96.95 | |
| 32 | 99.64 | 99.40 | 98.33 | 97.26 | 92.86 | 91.07 | 96.94 | 95.91 | |
| Avg | 98.45 | 98.93 | 96.15 | 96.23 | 92.42 | 91.95 | – | – | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Lei, J.; Li, S.; Zhang, J. STA-3D: Combining Spatiotemporal Attention and 3D Convolutional Networks for Robust Deepfake Detection. Symmetry 2025, 17, 1037. https://doi.org/10.3390/sym17071037
Wang J, Lei J, Li S, Zhang J. STA-3D: Combining Spatiotemporal Attention and 3D Convolutional Networks for Robust Deepfake Detection. Symmetry. 2025; 17(7):1037. https://doi.org/10.3390/sym17071037
Chicago/Turabian StyleWang, Jingbo, Jun Lei, Shuohao Li, and Jun Zhang. 2025. "STA-3D: Combining Spatiotemporal Attention and 3D Convolutional Networks for Robust Deepfake Detection" Symmetry 17, no. 7: 1037. https://doi.org/10.3390/sym17071037
APA StyleWang, J., Lei, J., Li, S., & Zhang, J. (2025). STA-3D: Combining Spatiotemporal Attention and 3D Convolutional Networks for Robust Deepfake Detection. Symmetry, 17(7), 1037. https://doi.org/10.3390/sym17071037