

VBTCKN: A Time Series Forecasting Model Based on Variational Mode Decomposition with Two-Channel Cross-Attention Network

Abstract

1. Introduction
2. Related Work
2.1. Traditional Methods
2.2. Machine Learning Methods
3. Methods
3.1. Problem Definition
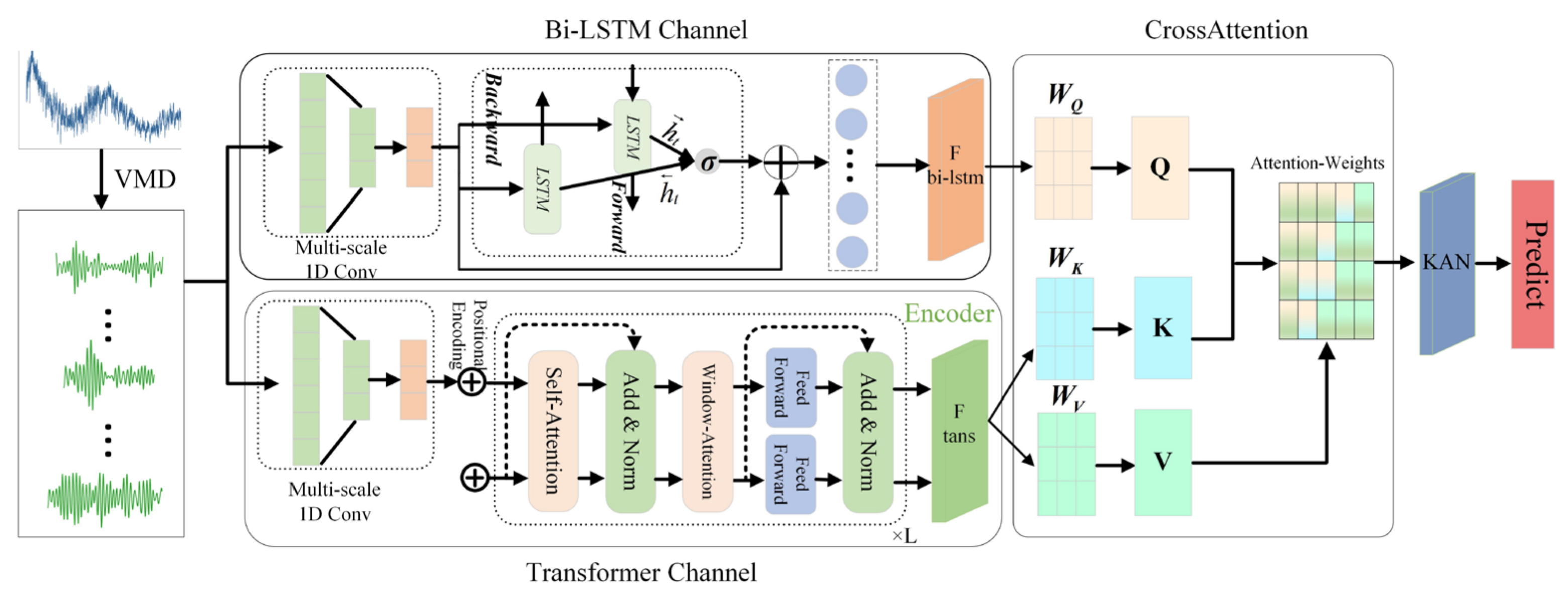
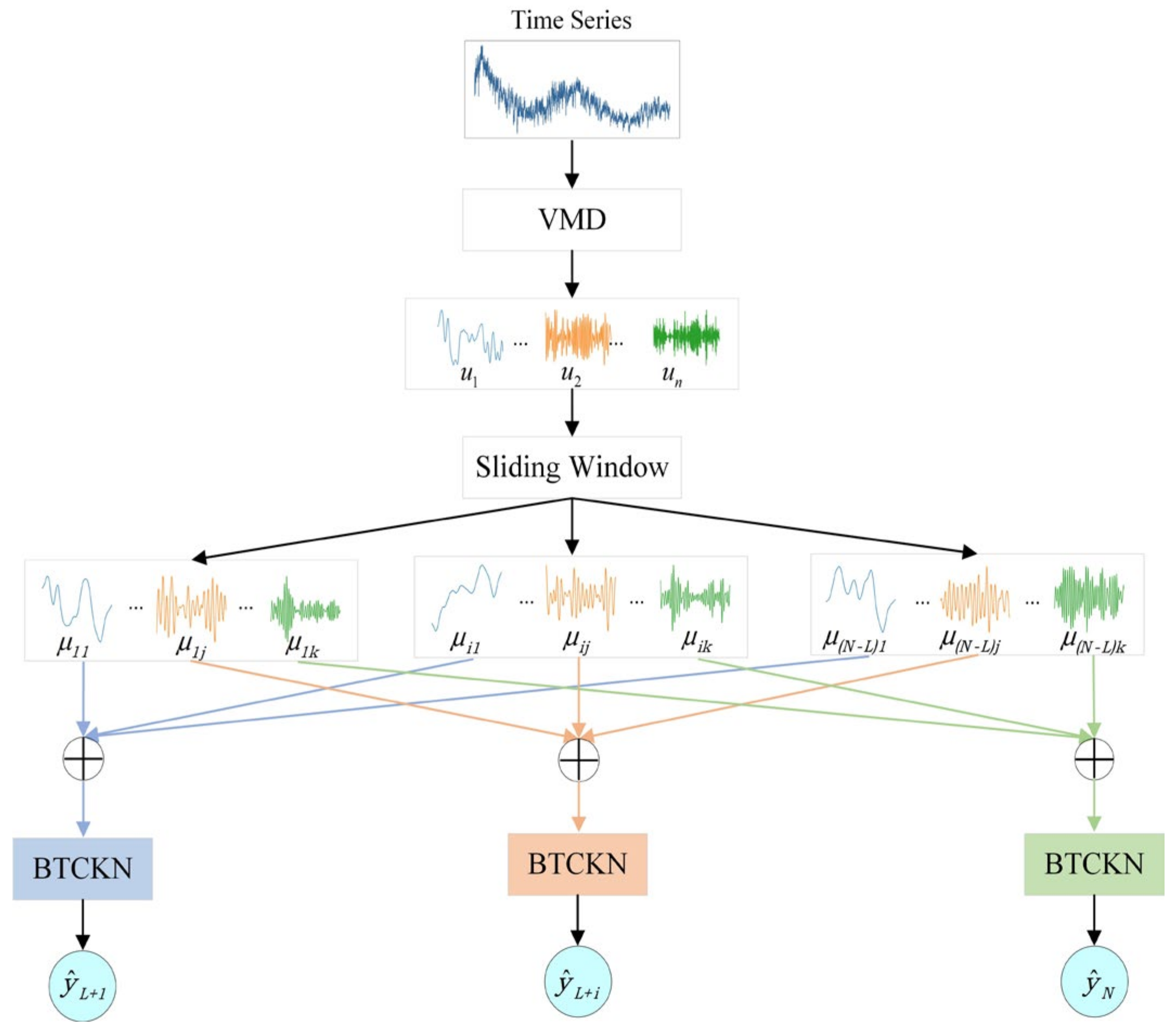
3.2. VBTCKN Model
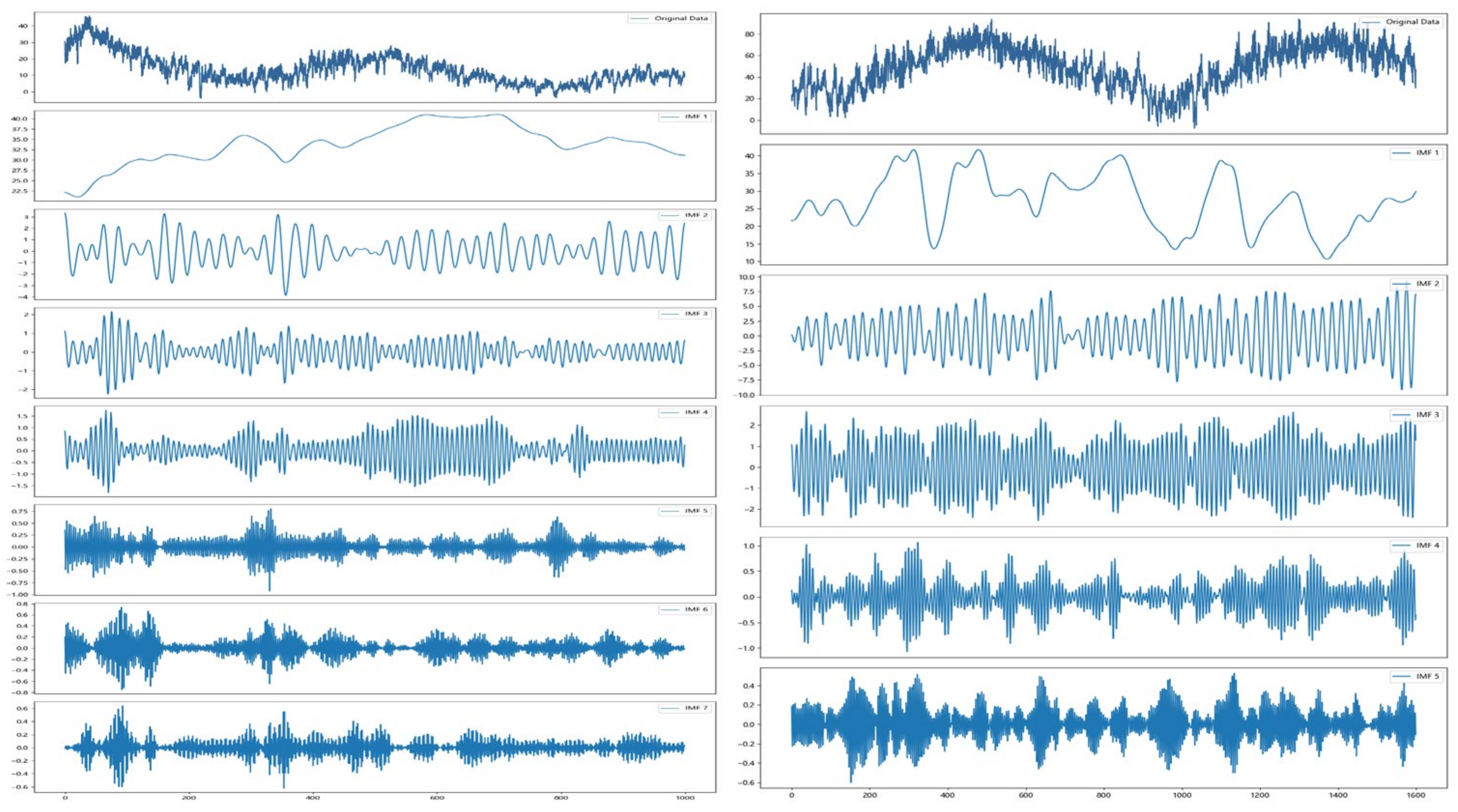
3.2.1. Variational Mode Decomposition
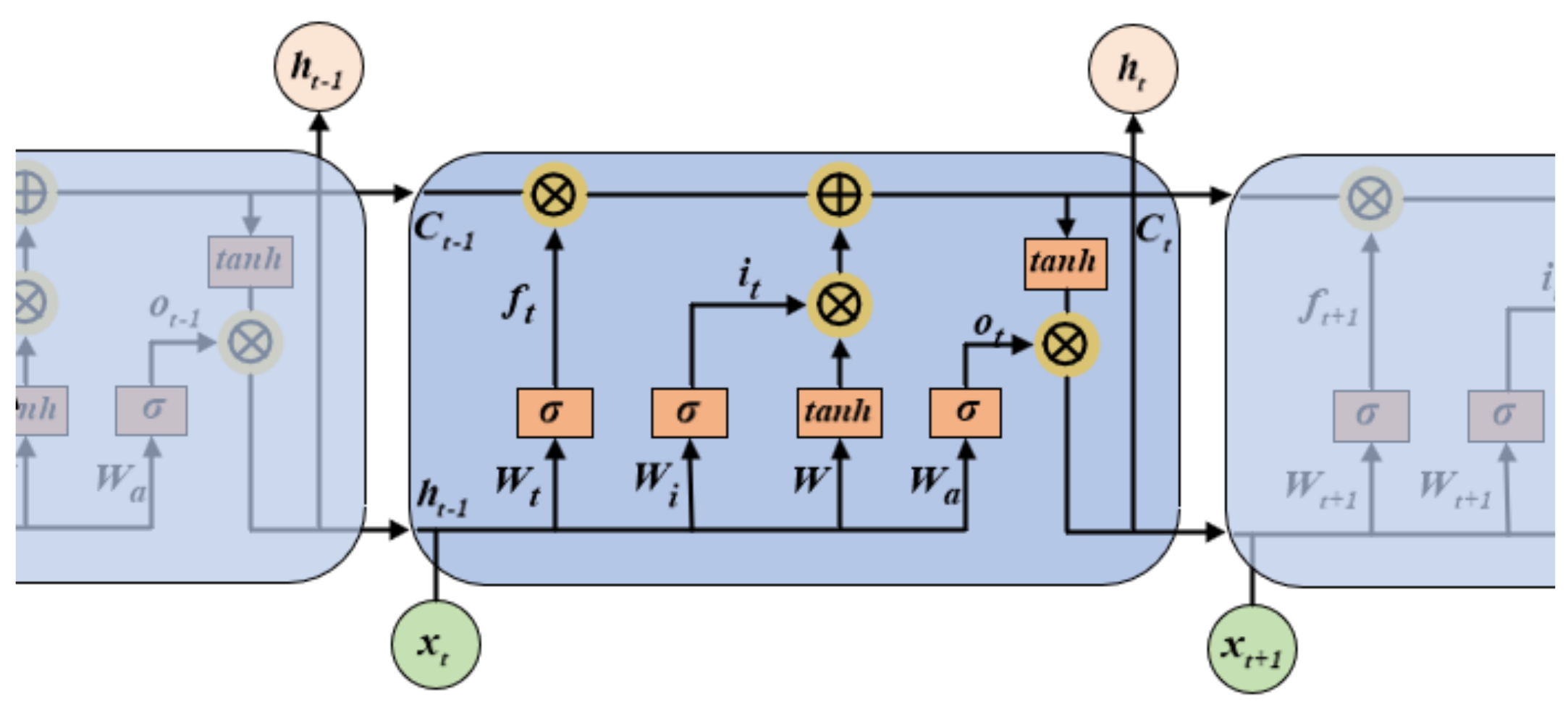
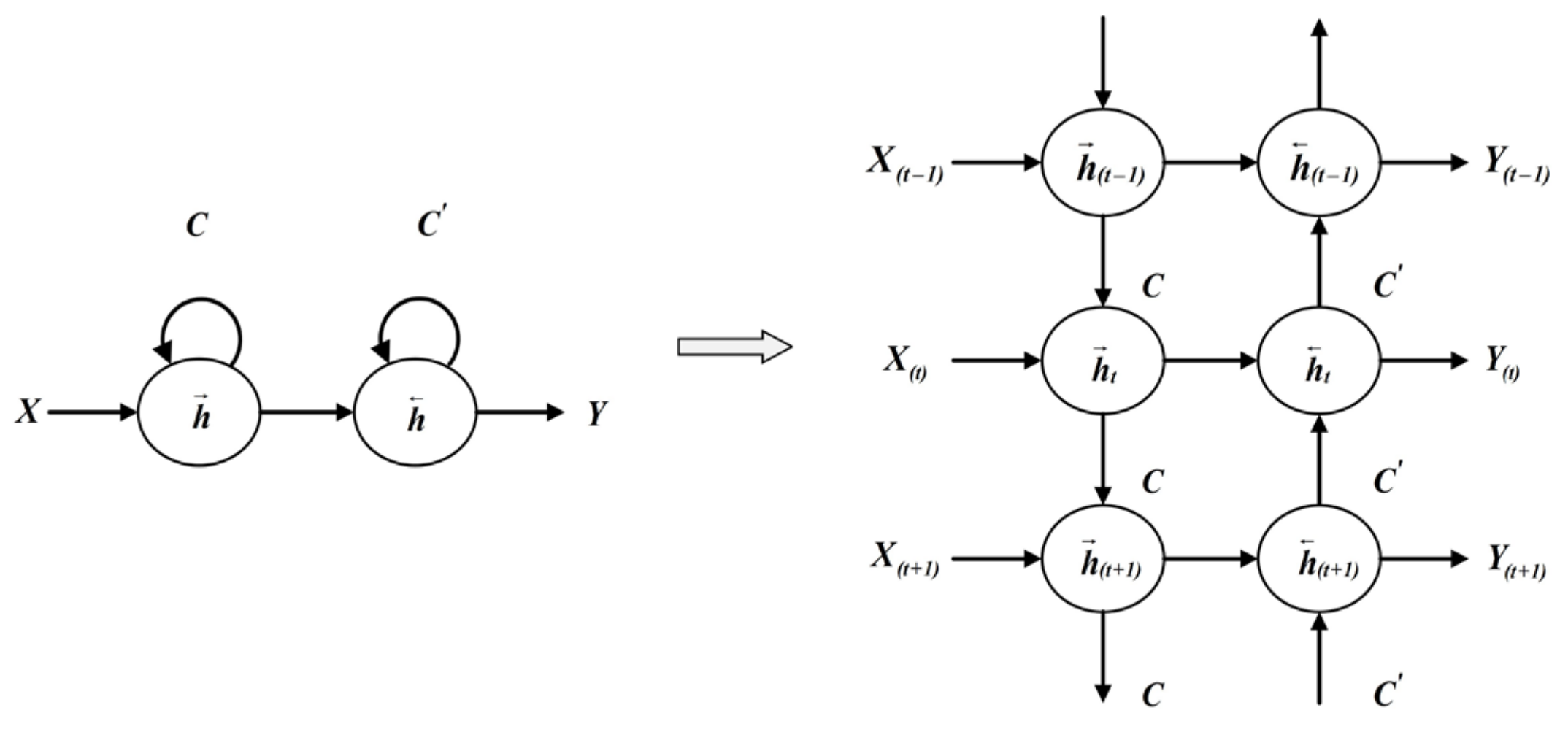
3.2.2. Bidirectional Long Short-Term Memory Network (BiLSTM)
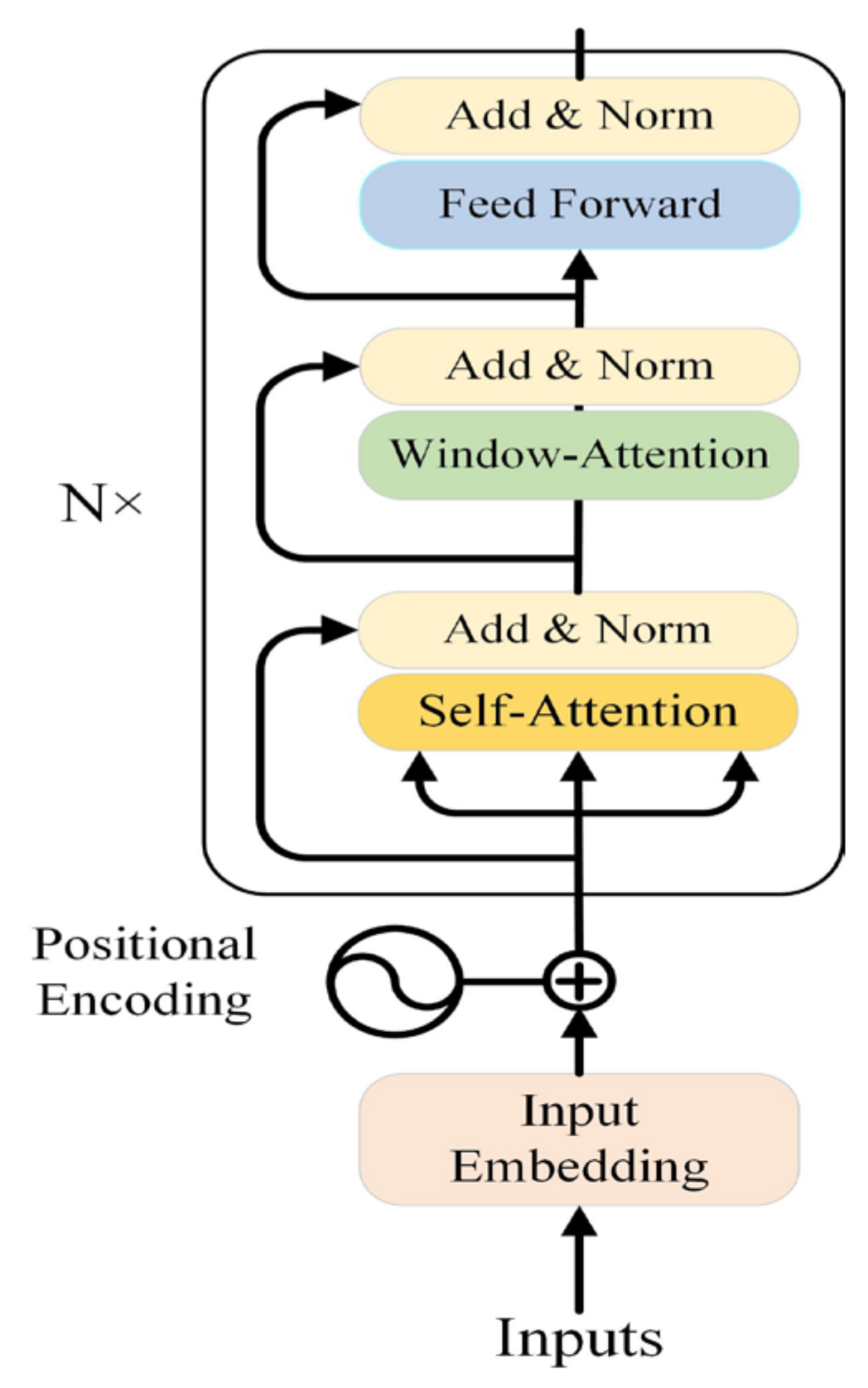
3.2.3. Transformer-Only Encoder
3.2.4. Cross-Attention Based Fusion Methods
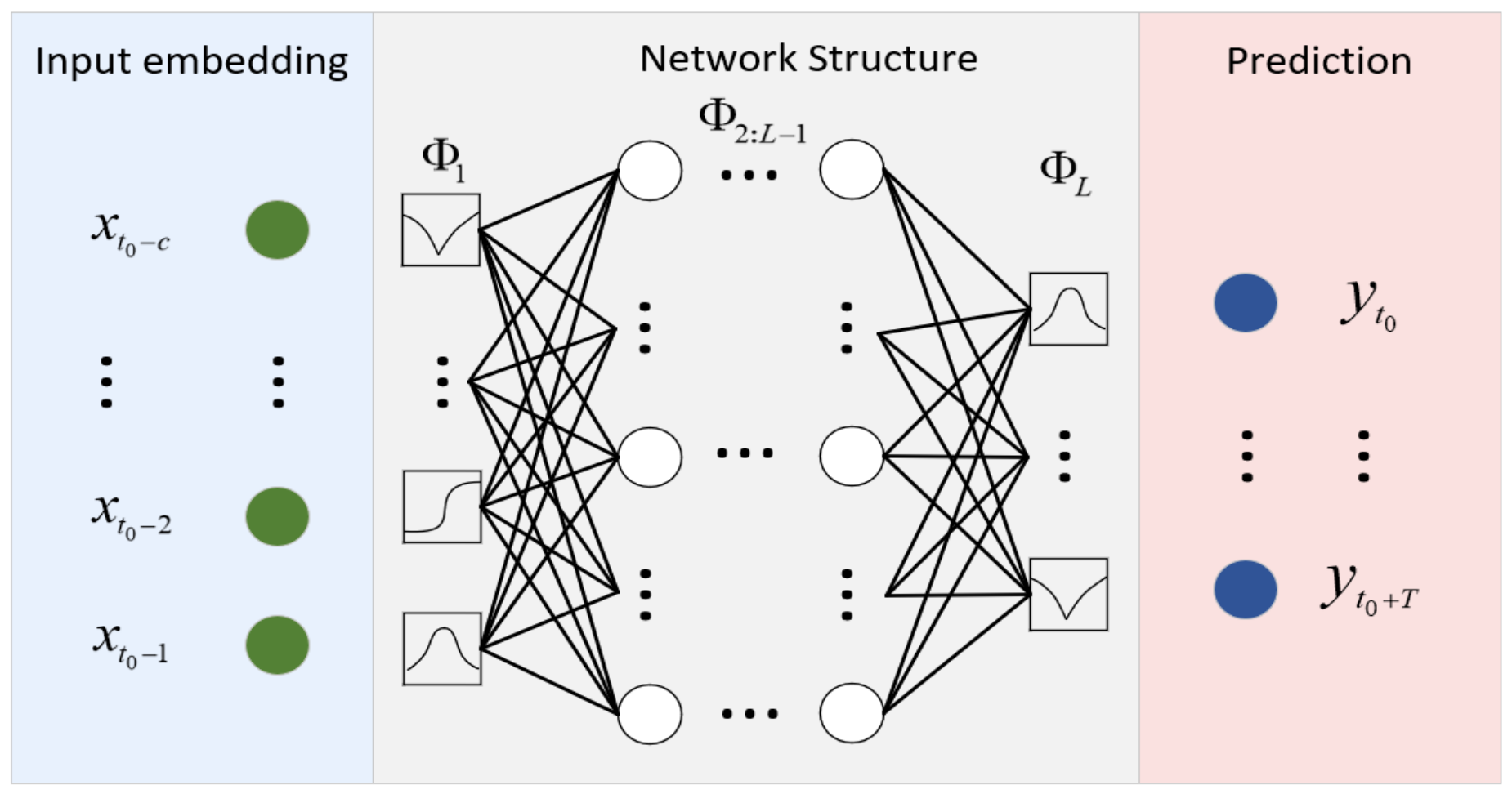
3.2.5. Kolmogorov–Arnold Networks (KAN)
3.2.6. VBTCKN Model Prediction Process
- VMD and Sliding Window
- 2.
- BiLSTM Channel
- 3.
- Transformer Channel
- 4.
- The predict of the model
| Algorithm 1 VBTCKN |
| Input: Time-series X = (X1, X2, X3, ..., Xt), Time-step L, Train-epoch n, vmd_params(K, α, τ), kernel_size k Output: Predict time-series Y = (Yt+1, Yt+2, Yt+3, ...,Yt+L), mean absolute error MAE, mean squared error MSE, root mean square error RMSE, Coefficient of Determination R2 |
| 1 X = vmd_decomposition (X, α, τ, K) 2 for t to n do: 3 for i to L do: 4 for j to L do: 5 bilstm channel calculate encoding vector hb←Xi 6 for s in k do: 7 Xs = conv1d = W × Xi + b 8 Xconv = concat(Xs) 9 10 11 12 dropout layer 13 LayerNormal layer 14 transformer channel calculate encoding vector ht←Xi 15 for s in k do: 16 Xs = conv1d = W × Xi + b 17 Xconv = concat(Xs) 18 a () 19 20 21 a ( ) 22 23 Feed Forward layer 24 dropout layer 25 LayerNormal layer 26 Cross-attention layer calculate decoding vector yi ←hb, ht 27 ; 28 29 30 KAN network layer predict Y = KAN( ) 31 end 32 end 33 end 34 calculate MAE MSE RMSE R2 35 return Y MAE MSE RMSE R2 |
4. Experiments
4.1. Model Performance Evaluation Indicators
- Mean absolute error
- 2.
- Mean square error
- 3.
- Root mean square error
- 4.
- Coefficient of determination
4.2. Datasets
4.2.1. Electricity Transformer Temperature Dataset
4.2.2. Weather Dataset
4.2.3. GEFCom2014-E Dataset
4.2.4. Solar-Energy Dataset
4.3. Data Preprocessing
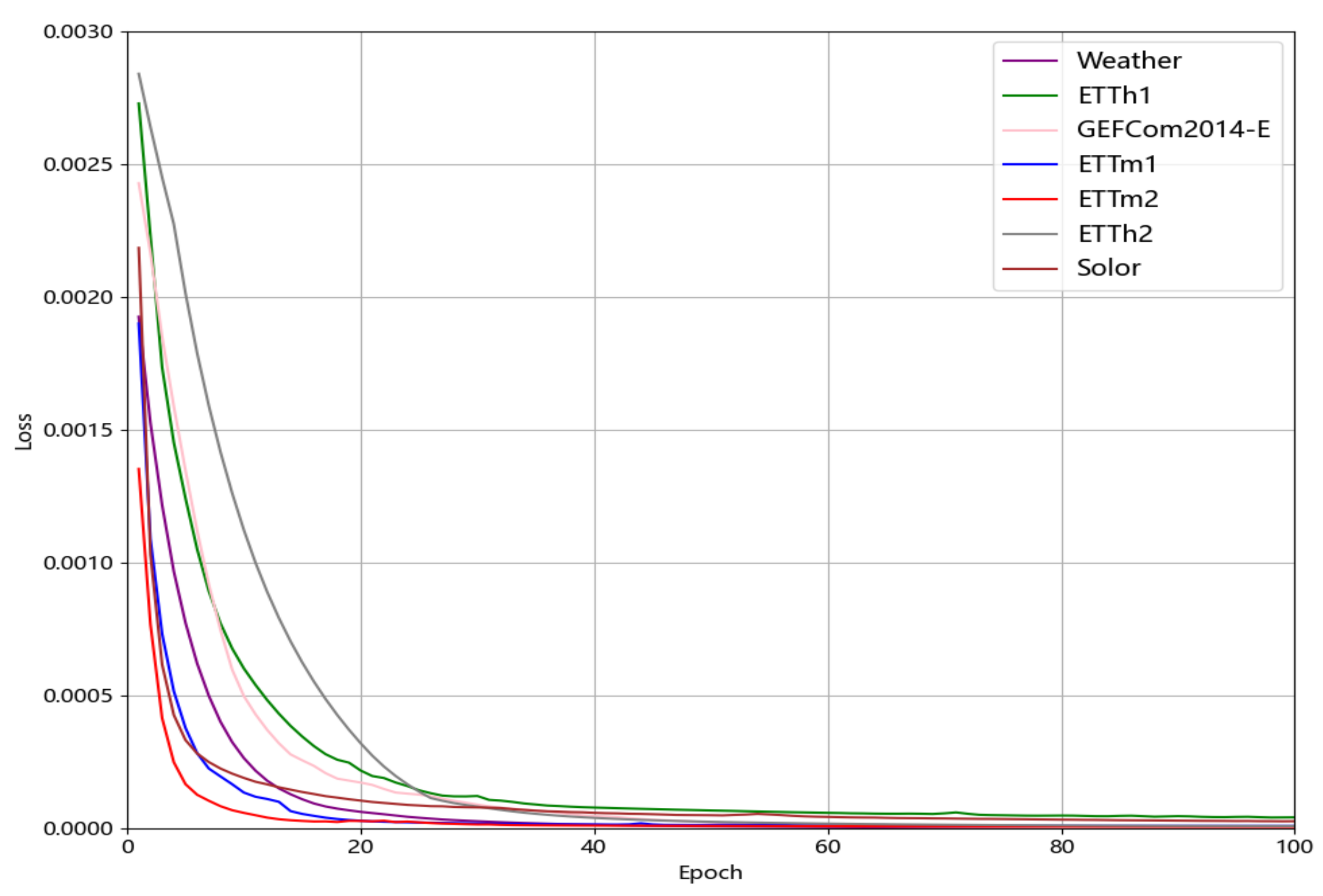
4.4. Experimental Setup
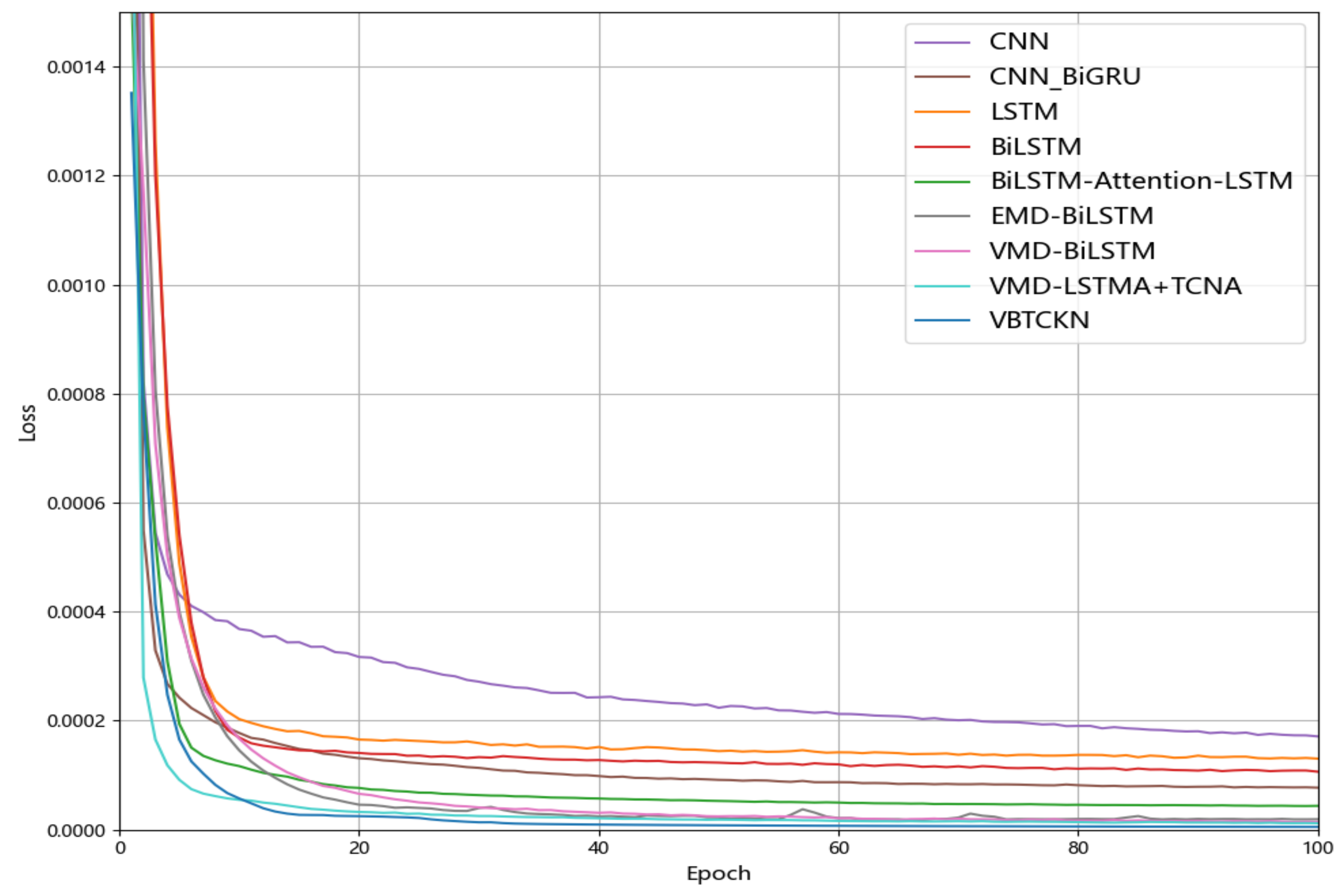
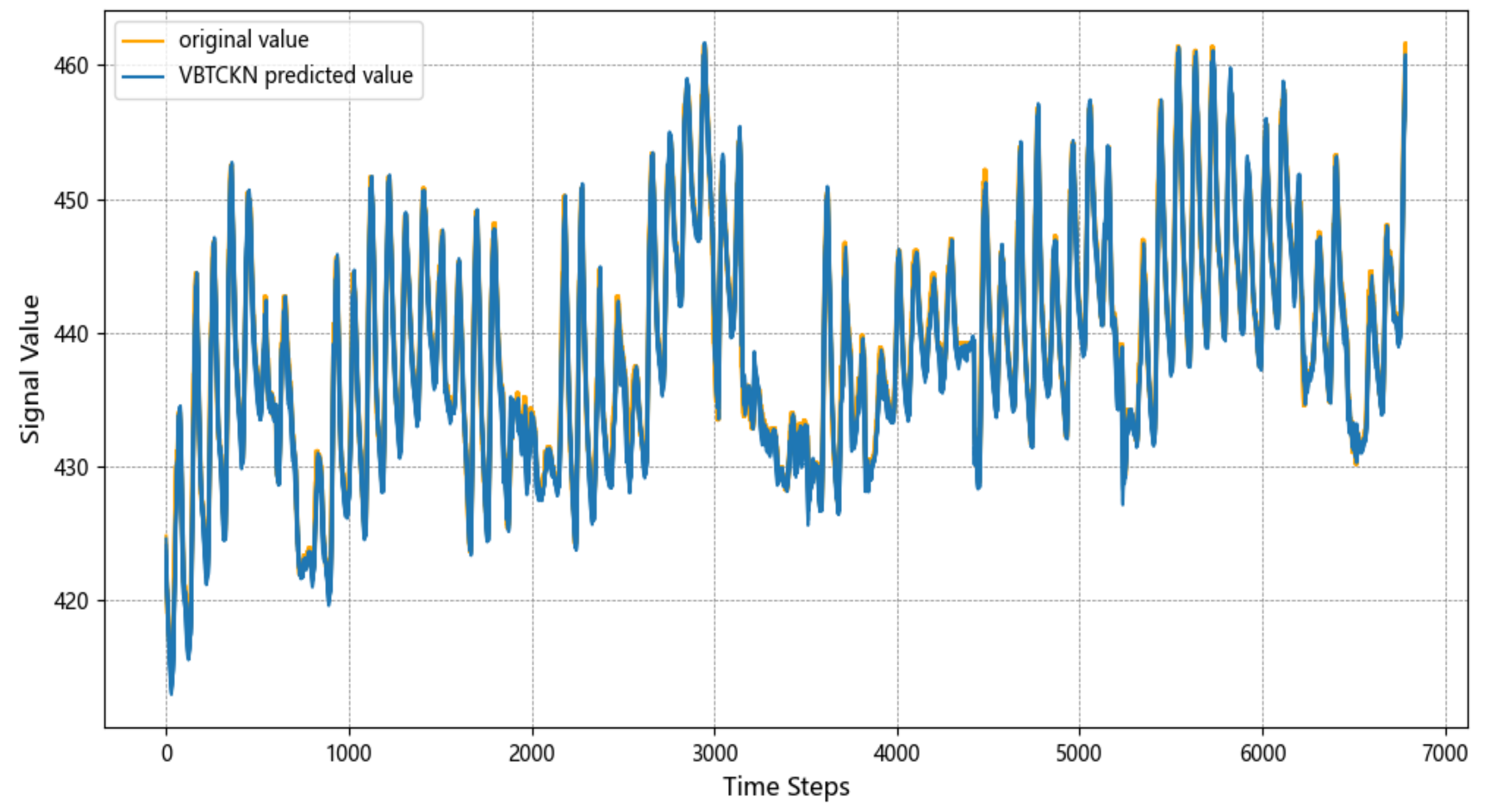
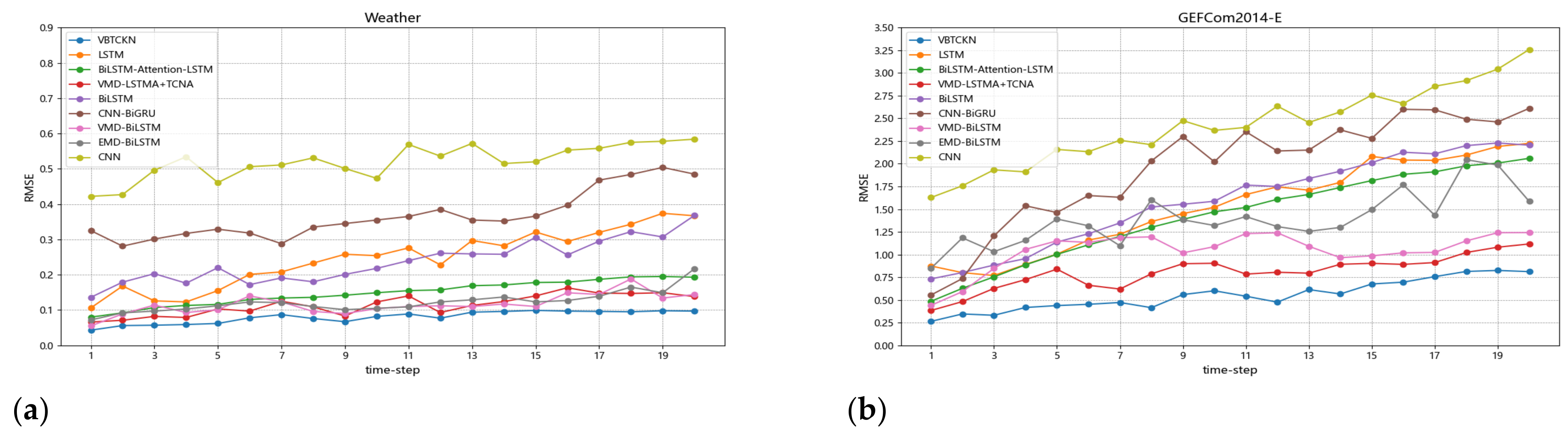
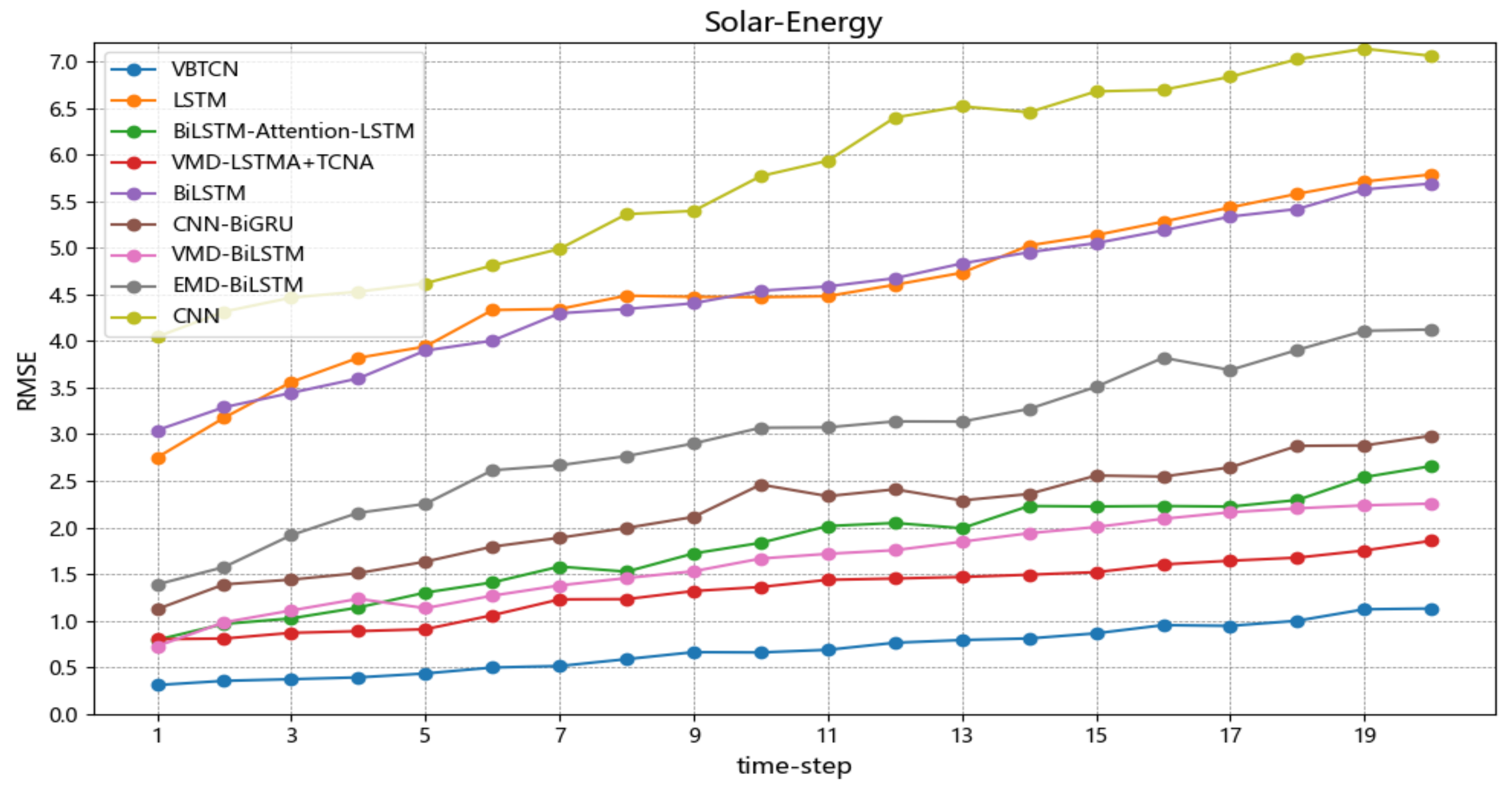
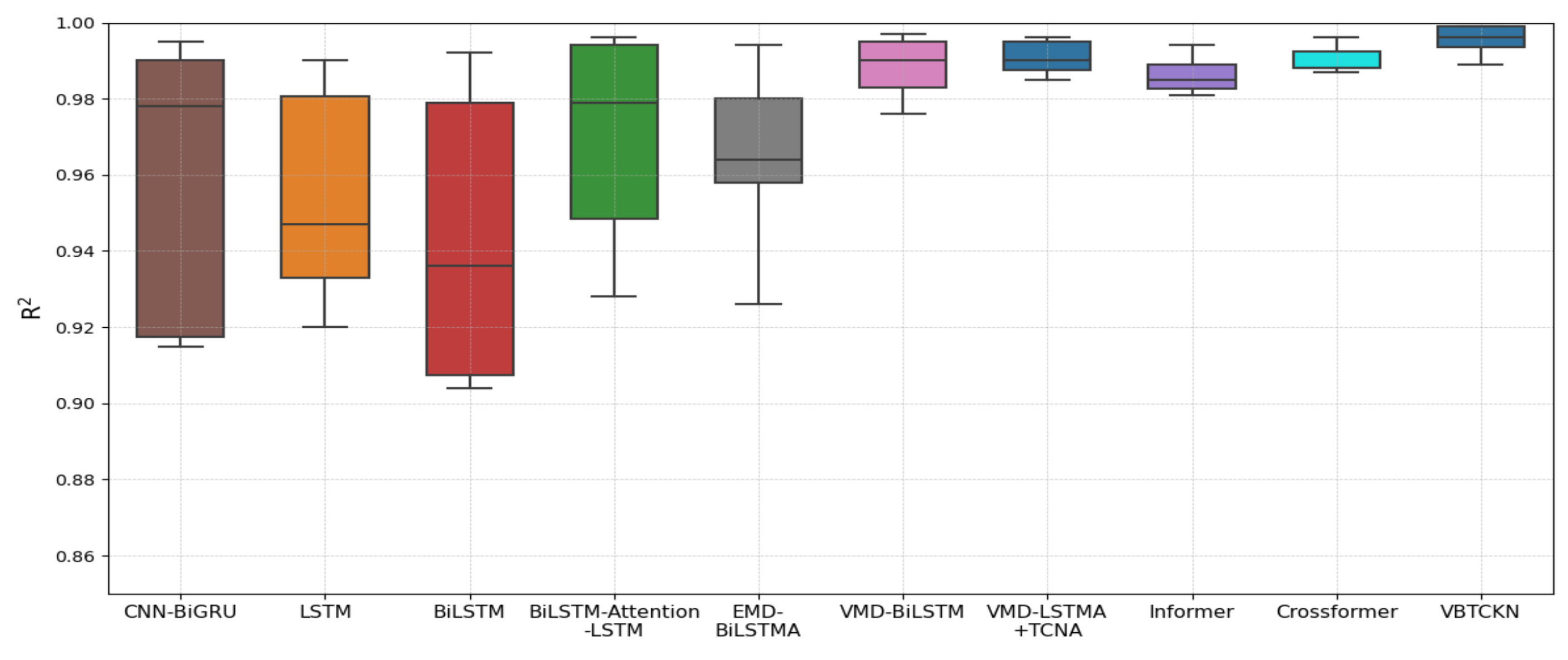
4.5. Experimental Results and Analysis
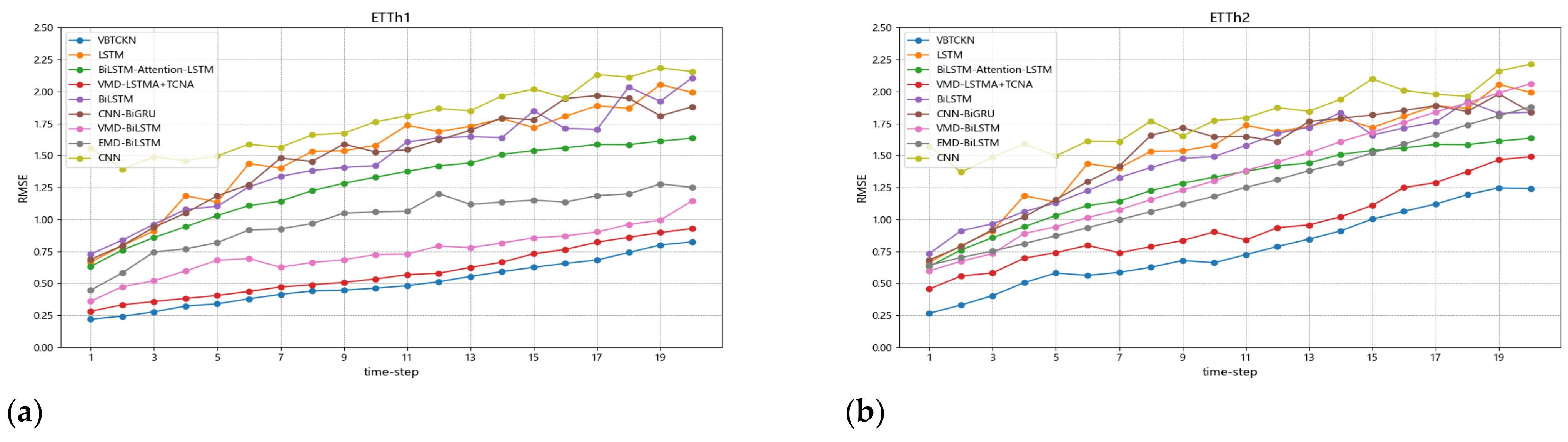
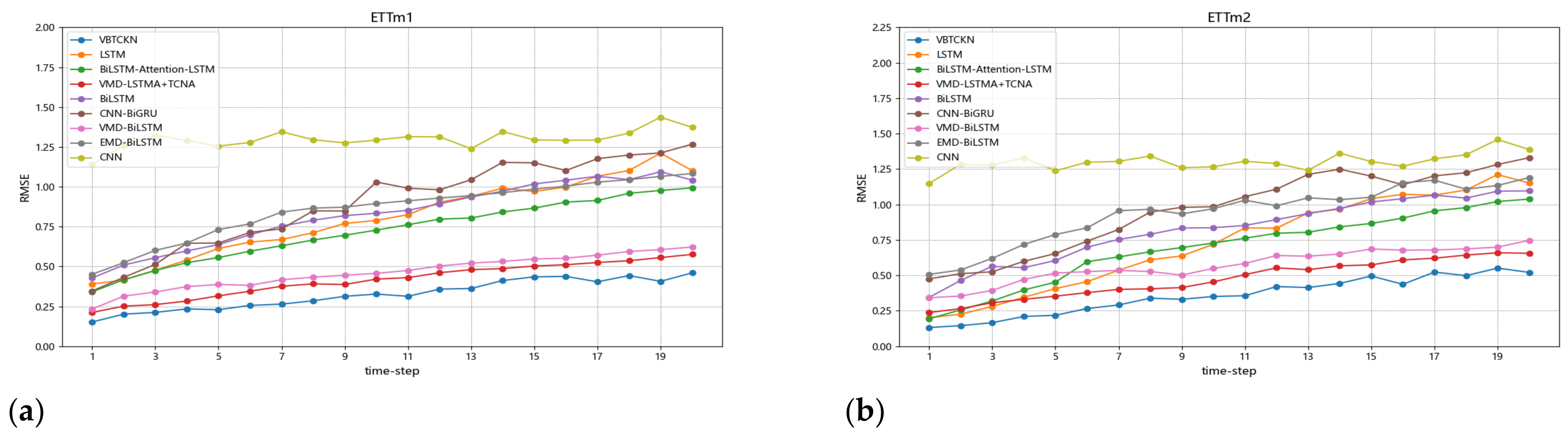
4.6. Comparison Experiments
4.7. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wen, X.; Li, W. Time series prediction based on LSTM-attention-LSTM model. IEEE Access 2023, 11, 48322–48331. [Google Scholar] [CrossRef]
- Zhao, C.; Hu, P.; Liu, X.; Lan, X.; Zhang, H. Stock market analysis using time series relational models for stock price prediction. Mathematics 2023, 11, 1130. [Google Scholar] [CrossRef]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Li, Z. Deep multi view spatial temporal network for taxi demand prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar] [CrossRef]
- Ullrich, T. On the Autoregressive Time Series Model Using Real and Complex Analysis. Forecasting 2021, 3, 716–728. [Google Scholar] [CrossRef]
- Tang, H. Stock Prices Prediction Based on ARMA Model. In Mathematical Problems in Engineering. In Proceedings of the 2021 International Conference on Computer, Blockchain and Financial Development (CBFD), Nanjing, China, 23–25 April 2021. [Google Scholar] [CrossRef]
- Elsaraiti, M.; Ali, G.; Musbah, H.; Merabet, A.; Little, T. Time Series Analysis of Electricity Consumption Forecasting Using ARIMA Model. In Proceedings of the 2021 IEEE Green Technologies Conference (GreenTech), Denver, CO, USA, 7–9 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 259–262. [Google Scholar] [CrossRef]
- Pongdatu, G.A.N.; Putra, Y.H. Seasonal Time Series Forecasting using SARIMA and Holt Winter’s Exponential Smoothing. IOP Conf. Ser. Mater. Sci. Eng. 2018, 407, 012153. [Google Scholar] [CrossRef]
- Durairaj, D.M.; Mohan, B.H.K. A convolutional neural network-based approach to financial time series prediction. Neural Comput. Appl. 2022, 34, 13319–13337. [Google Scholar] [CrossRef]
- Amalou, I.; Mouhni, N.; Abdali, A. Multivariate time series prediction by RNN architectures for energy consumption forecasting. Energy Rep. 2022, 8, 1084–1091. [Google Scholar] [CrossRef]
- Balti, H.; Ben Abbes, A.; Farah, I.R. A Bi-GRU-based encoder–decoder framework for multivariate time series forecasting. Soft Comput. 2024, 28, 6775–6786. [Google Scholar] [CrossRef]
- Yadav, H.; Thakkar, A. NOA-LSTM: An Efficient LSTM Cell Architecture for Time Series Forecasting. Expert Syst. Appl. 2024, 238, 122333. [Google Scholar] [CrossRef]
- Han, J.; Zeng, P. Residual BiLSTM based hybrid model for short-term load forecasting in buildings. J. Build. Eng. 2025, 99, 111593. [Google Scholar] [CrossRef]
- Aguilera-Martos, I.; Herrera-Poyatos, A.; Luengo, J.; Herrera, F. Local Attention Mechanism: Boosting the Transformer Architecture for Long-Sequence Time Series Forecasting. arXiv 2024, arXiv:2410.03805. [Google Scholar] [CrossRef]
- Dong, J.; Zhang, Y.; Hu, J. Short-term air quality prediction based on EMD-transformer-BiLSTM. Sci. Rep. 2024, 14, 20513. [Google Scholar] [CrossRef]
- Sun, H.; Yu, Z.; Zhang, B. Research on short-term power load forecasting based on VMD and GRU. PLoS ONE 2024, 19, e0306566. [Google Scholar] [CrossRef]
- Genet, R.; Inzirillo, H. TKAN: Temporal Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2405.07344. [Google Scholar] [CrossRef]
- Gardner, E.S. Exponential smoothing: The state of the art—Part II. Int. J. Forecast. 2006, 22, 637–666. [Google Scholar] [CrossRef]
- Wang, K.; Li, K.; Zhou, L.; Hu, Y.; Cheng, Z.; Liu, J.; Chen, C. Multiple convolutional neural networks for multivariate time series prediction. Neurocomputing 2019, 360, 107–119. [Google Scholar] [CrossRef]
- Gajamannage, K.; Park, Y.; Jayathilake, D.I. Real-time forecasting of time series in financial markets using sequentially trained dual-LSTMs. Expert Syst. Appl. 2023, 223, 119879. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Liang, J.; Liu, L. DAFA-BiLSTM: Deep autoregression feature augmented bidirectional LSTM network for time series prediction. Neural Netw. 2023, 157, 240–256. [Google Scholar] [CrossRef]
- Liu, W.; Mao, Z. Short-term photovoltaic power forecasting with feature extraction and attention mechanisms. Renew. Energy 2024, 226, 120437. [Google Scholar] [CrossRef]
- Mohammadi Farsani, R.; Pazouki, E. A transformer self-attention model for time series forecasting. J. Electr. Comput. Eng. Innov. 2020, 9, 1–10. [Google Scholar] [CrossRef]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Liu, Y.; Hu, T.; Zhang, H.; Wu, H.; Wang, S.; Ma, L.; Long, M. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. arXiv 2023, arXiv:2310.06625. [Google Scholar]
- Khan, A.A.A.; Ullah, M.H.; Tabassum, R.; Kabir, M.F. A transformer-BILSTM based hybrid deep learning approach for day-ahead electricity price forecasting. In Proceedings of the 2024 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 25–26 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Moudgil, V.; Sadiq, R.; Brar, J.; Hewage, K. Dual-channel encoded bidirectional LSTM for multi-building short-term load forecasting. J. Clean. Prod. 2025, 486, 144555. [Google Scholar] [CrossRef]
- Meng, Z.; Xie, Y.; Sun, J. Short-term load forecasting using neural attention model based on EMD. Electr. Eng. 2022, 104, 1857–1866. [Google Scholar] [CrossRef]
- Chen, H.; Lu, T.; Huang, J.; He, X.; Yu, K.; Sun, X.; Ma, X.; Huang, Z. An improved VMD-LSTM model for time-varying GNSS time series prediction with temporally correlated noise. Remote Sens. 2023, 15, 3694. [Google Scholar] [CrossRef]
- Zhang, Y.; Cui, L.; Yan, W. Integrating Kolmogorov–Arnold Networks with Time Series Prediction Framework in Electricity Demand Forecasting. Energies 2025, 18, 1365. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, S.; Tian, X.; Zhang, F.; Zhao, F.; Zhang, C. A stock series prediction model based on variational mode decomposition and dual-channel attention network. Expert Syst. Appl. 2024, 238, 121708. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Kim, J.; Moon, N. BiLSTM model based on multivariate time series data in multiple field for forecasting trading area. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1–10. [Google Scholar] [CrossRef]
- Wang, S. A Stock Price Prediction Method Based on BiLSTM and Improved Transformer. IEEE Access 2023, 11, 104211–104223. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, J.; Xie, Y.; Xie, S.; Chen, X. Dual Cross-Attention Transformer Networks for Temporal Predictive Modeling of Industrial Process. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2404.19756. [Google Scholar] [CrossRef]
- Hou, Y.; Zhang, D.; Wu, J.; Feng, X. A Comprehensive Survey on Kolmogorov Arnold Networks (KAN). arXiv 2024, arXiv:2407.11075. [Google Scholar] [CrossRef]
- Vaca-Rubio, C.J.; Blanco, L.; Pereira, R.; Caus, M. Kolmogorov-Arnold Networks (KANs) for Time Series Analysis. arXiv 2024, arXiv:2405.08790. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J.; Cui, Y. Short-term load forecasting based on LSTM networks considering attention mechanism. Int. J. Electr. Power Energy Syst. 2022, 137, 107818. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- He, T.; Liu, J.; Yang, F.; Yang, X.; Guo, S.; Sun, G. Short-term Prediction of Distribution Voltage Based on CNN-BiGRU. In Proceedings of the 2023 4th International Conference on Advanced Electrical and Energy Systems (AEES), Shanghai, China, 1–3 December 2023; pp. 361–365. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Casillas-Pérez, D.; Salcedo-Sanz, S. Electricity demand error corrections with attention bi-directional neural networks. Energy 2024, 291, 129938. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, T.; Du, P. Volatility forecasting of crude oil futures based on Bi-LSTM-Attention model: The dynamic role of the COVID-19 pandemic and the Russian-Ukrainian conflict. Resour. Policy 2024, 88, 104319. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Data Size | Variables | Train Size | Test Size |
|---|---|---|---|---|
| ETTh1 | 17,420 | 8 | 15,678 | 1742 |
| ETTh2 | 17,420 | 8 | 15,678 | 1742 |
| ETTm1 | 69,680 | 8 | 62,712 | 6968 |
| ETTm2 | 69,680 | 8 | 62,712 | 6968 |
| Weather | 52,696 | 22 | 47,426 | 5270 |
| GEFCom2014-E | 78,888 | 4 | 70,999 | 7889 |
| Solar-Energy | 52,560 | 137 | 23,911 | 2657 |
| Parameter/Dataset | ETT/Solar-Energy | Weather/GEFCom2014-E |
|---|---|---|
| epoch | 100 | 100 |
| batch_size | 128 | 128 |
| sliding window size | 60 | 60 |
| kan_layer | 2 | 2 |
| dropout | 0.3 | 0.3 |
| optimizer | Adam | Adam |
| loss function | huber-loss | huber-loss |
| activation function | relu | relu |
| learning rate | 1 × 10–3 | 1 × 10–3 |
| bilstm_Layer | 2 | 1 |
| transformerEncoder_Layer | 2 | 4 |
| heads | 2 | 8 |
| hidden_dim | 64 | 32 |
| Dataset | ETTh1 | ETTh2 | ETTm1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| 5 | 0.261 | 0.13 | 0.361 | 0.976 | 0.433 | 0.316 | 0.562 | 0.983 | 0.152 | 0.044 | 0.211 | 0.992 |
| 6 | 0.28 | 0.148 | 0.385 | 0.973 | 0.54 | 0.444 | 0.666 | 0.977 | 0.123 | 0.031 | 0.176 | 0.994 |
| 7 | 0.239 | 0.101 | 0.318 | 0.981 | 0.238 | 0.103 | 0.322 | 0.994 | 0.101 | 0.019 | 0.137 | 0.996 |
| 8 | 0.215 | 0.08 | 0.291 | 0.984 | 0.262 | 0.135 | 0.367 | 0.993 | 0.113 | 0.024 | 0.156 | 0.995 |
| 9 | 0.181 | 0.056 | 0.237 | 0.989 | 0.199 | 0.07 | 0.265 | 0.996 | 0.121 | 0.026 | 0.163 | 0.994 |
| 10 | 0.212 | 0.073 | 0.271 | 0.986 | 0.212 | 0.081 | 0.285 | 0.995 | 0.112 | 0.023 | 0.155 | 0.995 |
| Dataset | ETTm2 | Weather | GEFCom2014-E | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| 4 | 0.092 | 0.016 | 0.128 | 0.999 | 0.034 | 0.002 | 0.047 | 0.984 | 0.486 | 0.413 | 0.642 | 0.993 |
| 5 | 0.087 | 0.013 | 0.117 | 0.999 | 0.027 | 0.002 | 0.043 | 0.987 | 0.171 | 0.05 | 0.224 | 0.999 |
| 6 | 0.084 | 0.014 | 0.116 | 0.999 | 0.021 | 0.001 | 0.035 | 0.991 | 0.256 | 0.105 | 0.325 | 0.998 |
| 7 | 0.072 | 0.009 | 0.097 | 0.999 | 0.033 | 0.002 | 0.046 | 0.985 | 0.251 | 0.108 | 0.328 | 0.998 |
| 8 | 0.121 | 0.022 | 0.149 | 0.998 | 0.031 | 0.002 | 0.045 | 0.985 | 0.329 | 0.168 | 0.41 | 0.997 |
| Dataset | Solar-Energy | |||
|---|---|---|---|---|
| K | MAE | MSE | RMSE | R2 |
| 10 | 0.228 | 0.089 | 0.298 | 0.999 |
| 11 | 0.213 | 0.076 | 0.276 | 0.999 |
| 12 | 0.164 | 0.045 | 0.213 | 0.999 |
| 13 | 0.166 | 0.048 | 0.219 | 0.999 |
| 14 | 0.229 | 0.082 | 0.287 | 0.998 |
| Method Parameter | CNN | CNN-BiGRU | LSTM | BiLSTM | EMD-BiLSTM | VMD-BiLSTM | BiLSTM- Attention -LSTM | VMD- LSTMA +TCNA | Informer | Crossformer | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| learning _rate | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–3 | 1 × 10–4 | 1 × 10–4 | |
| hidden _dim | - | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 128 | |
| layer | 5 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | |
| dropout | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.05 | 0.2 | |
| heads | - | - | - | - | - | - | 8 | - | 8 | 8 | |
| Dataset | ETTh1 | ETTh2 | ETTm1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| CNN | 1.1 | 2.19 | 1.478 | 0.607 | 1.132 | 2.267 | 1.502 | 0.594 | 0.929 | 1.575 | 1.253 | 0.724 |
| CNN-BiGRU | 0.672 | 0.922 | 0.930 | 0.834 | 0.653 | 0.883 | 0.912 | 0.841 | 0.362 | 0.291 | 0.517 | 0.948 |
| LSTM | 0.675 | 0.945 | 0.937 | 0.831 | 0.674 | 0.945 | 0.937 | 0.83 | 0.302 | 0.253 | 0.487 | 0.955 |
| BiLSTM | 0.686 | 0.932 | 0.941 | 0.833 | 0.703 | 0.946 | 0.959 | 0.83 | 0.395 | 0.308 | 0.545 | 0.946 |
| BiLSTM-attention-LSTM | 0.575 | 0.748 | 0.844 | 0.866 | 0.575 | 0.748 | 0.844 | 0.865 | 0.293 | 0.228 | 0.462 | 0.959 |
| EMD-BiLSTM | 0.505 | 0.457 | 0.657 | 0.917 | 0.555 | 0.525 | 0.713 | 0.905 | 0.477 | 0.43 | 0.631 | 0.922 |
| VMD-BiLSTM | 0.394 | 0.29 | 0.525 | 0.947 | 0.579 | 0.613 | 0.757 | 0.967 | 0.247 | 0.113 | 0.33 | 0.977 |
| VMD-LSTMA +TCNA | 0.282 | 0.184 | 0.368 | 0.985 | 0.469 | 0.385 | 0.605 | 0.986 | 0.207 | 0.073 | 0.268 | 0.987 |
| Informer | 0.335 | 0.151 | 0.389 | 0.984 | 0.447 | 0.285 | 0.534 | 0.981 | 0.171 | 0.047 | 0.216 | 0.985 |
| Crossformer | 0.283 | 0.199 | 0.431 | 0.988 | 0.346 | 0.230 | 0.457 | 0.988 | 0.202 | 0.102 | 0.292 | 0.991 |
| VBTCKN | 0.255 | 0.114 | 0.331 | 0.989 | 0.324 | 0.192 | 0.416 | 0.99 | 0.140 | 0.035 | 0.184 | 0.992 |
| Dataset | ETTm2 | Weather | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| CNN | 0.931 | 1.58 | 1.255 | 0.723 | 0.371 | 0.215 | 0.468 | 0.322 |
| CNN-BiGRU | 0.422 | 0.308 | 0.543 | 0.984 | 0.245 | 0.096 | 0.311 | 0.535 |
| LSTM | 0.204 | 0.101 | 0.292 | 0.994 | 0.102 | 0.019 | 0.136 | 0.907 |
| BiLSTM | 0.392 | 0.269 | 0.506 | 0.986 | 0.139 | 0.034 | 0.183 | 0.834 |
| BiLSTM- attention-LSTM | 0.221 | 0.127 | 0.324 | 0.993 | 0.073 | 0.01 | 0.102 | 0.948 |
| EMD-BiLSTM | 0.482 | 0.417 | 0.634 | 0.925 | 0.064 | 0.009 | 0.095 | 0.954 |
| VMD-BiLSTM | 0.331 | 0.18 | 0.415 | 0.99 | 0.066 | 0.008 | 0.09 | 0.958 |
| VMD-LSTMA +TCNA | 0.233 | 0.091 | 0.298 | 0.996 | 0.056 | 0.006 | 0.08 | 0.985 |
| Informer | 0.207 | 0.062 | 0.251 | 0.994 | 0.046 | 0.004 | 0.063 | 0.981 |
| Crossformer | 0.155 | 0.066 | 0.244 | 0.996 | 0.071 | 0.005 | 0.092 | 0.988 |
| VBTCKN | 0.128 | 0.034 | 0.174 | 0.998 | 0.039 | 0.003 | 0.058 | 0.989 |
| Dataset | GEFCom2014-E | Solar-Energy | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| CNN | 1.478 | 3.573 | 1.877 | 0.946 | 3.211 | 18.36 | 4.245 | 0.867 |
| CNN-BiGRU | 0.853 | 1.379 | 1.099 | 0.979 | 1.074 | 2.051 | 1.249 | 0.985 |
| LSTM | 0.668 | 0.785 | 0.867 | 0.987 | 2.069 | 12.13 | 3.248 | 0.936 |
| BiLSTM | 0.7 | 0.854 | 0.902 | 0.987 | 2.201 | 12.35 | 3.344 | 0.925 |
| BiLSTM- attention-LSTM | 0.563 | 0.656 | 0.751 | 0.99 | 0.686 | 1.045 | 0.965 | 0.992 |
| EMD-BiLSTM | 0.822 | 1.127 | 1.018 | 0.983 | 1.312 | 2.526 | 1.685 | 0.981 |
| VMD-BiLSTM | 0.635 | 0.744 | 0.817 | 0.988 | 0.806 | 1.101 | 1.037 | 0.993 |
| VMD-LSTMA +TCNA | 0.479 | 0.405 | 0.611 | 0.993 | 0.604 | 0.741 | 0.854 | 0.995 |
| Informer | 0.321 | 0.165 | 0.406 | 0.989 | 0.248 | 0.117 | 0.348 | 0.989 |
| Crossformer | 0.311 | 0.158 | 0.393 | 0.987 | 0.238 | 0.111 | 0.325 | 0.999 |
| VBTCKN | 0.301 | 0.152 | 0.379 | 0.997 | 0.221 | 0.096 | 0.309 | 0.999 |
| Times-Step | 30-Step | 10-Step | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| CNN | 0.287 | 0.406 | 0.531 | 0.292 | 0.225 | 0.379 | 0.473 | 0.325 |
| CNN-BiGRU | 0.049 | 0.164 | 0.217 | 0.663 | 0.063 | 0.209 | 0.252 | 0.563 |
| LSTM | 0.06 | 0.165 | 0.227 | 0.586 | 0.065 | 0.195 | 0.254 | 0.688 |
| BiLSTM | 0.055 | 0.156 | 0.215 | 0.616 | 0.048 | 0.164 | 0.218 | 0.768 |
| BiLSTM- attention-LSTM | 0.052 | 0.174 | 0.228 | 0.749 | 0.022 | 0.107 | 0.149 | 0.891 |
| EMD-BiLSTM | 0.037 | 0.141 | 0.186 | 0.819 | 0.013 | 0.075 | 0.112 | 0.938 |
| VMD-BiLSTM | 0.021 | 0.104 | 0.141 | 0.851 | 0.011 | 0.076 | 0.104 | 0.947 |
| VMD-LSTMA +TCNA | 0.059 | 0.18 | 0.233 | 0.877 | 0.081 | 0.086 | 0.098 | 0.975 |
| Informer | 0.079 | 0.09 | 0.097 | 0.96 | 0.075 | 0.081 | 0.092 | 0.966 |
| Crossformer | 0.176 | 0.113 | 0.307 | 0.98 | 0.112 | 0.072 | 0.231 | 0.986 |
| VBTCKN | 0.009 | 0.065 | 0.091 | 0.981 | 0.052 | 0.062 | 0.078 | 0.987 |
| Times-Step | 30-Step | 10-Step | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| CNN | 11.95 | 2.743 | 3.44 | 0.821 | 5.639 | 1.861 | 2.368 | 0.916 |
| CNN-BiGRU | 9.185 | 2.285 | 2.931 | 0.863 | 4.384 | 1.572 | 2.022 | 0.935 |
| LSTM | 6.823 | 1.93 | 2.524 | 0.898 | 2.524 | 1.166 | 1.521 | 0.962 |
| BiLSTM | 6.683 | 1.9 | 2.484 | 0.9 | 2.703 | 1.22 | 1.587 | 0.96 |
| BiLSTM- attention-LSTM | 6.402 | 1.876 | 2.429 | 0.904 | 2.465 | 1.129 | 1.471 | 0.963 |
| EMD-BiLSTM | 3.468 | 1.428 | 1.821 | 0.948 | 1.779 | 1.063 | 1.32 | 0.973 |
| VMD-BiLSTM | 2.768 | 1.234 | 1.596 | 0.958 | 1.202 | 0.863 | 1.087 | 0.982 |
| VMD-LSTMA +TCNA | 2.428 | 1.071 | 1.424 | 0.962 | 0.915 | 0.847 | 0.904 | 0.984 |
| Informer | 0.701 | 0.544 | 0.831 | 0.978 | 0.399 | 0.242 | 0.501 | 0.981 |
| Crossformer | 0.659 | 0.664 | 0.811 | 0.991 | 0.386 | 0.257 | 0.499 | 0.989 |
| VBTCKN | 1.825 | 0.895 | 1.129 | 0.973 | 0.384 | 0.233 | 0.482 | 0.994 |
| Method | Model Parameters |
|---|---|
| CNN-BiGRU | 0.26 M |
| EMD-BiLSTM | 0.35 M |
| VMD-BiLSTM | 0.38 M |
| BiLSTM-Attention-LSTM | 0.51 M |
| VMD-LSTMA+TCNA | 0.86 M |
| Informer | 4.8 M |
| Crossformer | 19.1 M |
| VBTCKN | 1.18 M |
| Dataset | ETTm2 | GEFCom2014-E | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | R2 |
| BiLSTM | 2.422 | 1.113 | 1.461 | 0.878 | 10.77 | 2.37 | 3.016 | 0.841 |
| BiLSTM+Transformer | 2.001 | 0.972 | 1.364 | 0.902 | 8.147 | 2.06 | 2.69 | 0.879 |
| BiLSTM+Transformer +CrossAttention | 1.54 | 0.803 | 1.095 | 0.925 | 5.757 | 1.691 | 2.196 | 0.914 |
| BiLSTM+Transformer +CrossAttention +KAN | 1.352 | 0.747 | 1.054 | 0.936 | 5.294 | 1.625 | 2.099 | 0.921 |
| VMD+BiLSTM | 1.55 | 0.935 | 1.243 | 0.924 | 1.522 | 0.966 | 1.231 | 0.977 |
| VMD+Transformer | 1.157 | 0.748 | 1.064 | 0.943 | 2.429 | 1.199 | 1.53 | 0.964 |
| VBTCKN | 0.163 | 0.292 | 0.382 | 0.992 | 0.413 | 0.301 | 0.541 | 0.993 |
| Dataset | ETTm2 | GEFCom2014-E | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | MAE | MSE | RMSE | R2 | Parameter | MAE | MSE | RMSE | R2 | Parameter |
| VBTCKN (KAN = 2) | 0.163 | 0.292 | 0.382 | 0.992 | 1.189 M | 0.413 | 0.301 | 0.541 | 0.993 | 1.187 M |
| VBTCKN (MLP = 2) | 0.171 | 0.305 | 0.389 | 0.992 | 1.191 M | 0.461 | 0.351 | 0.582 | 0.992 | 1.189 M |
| VBTCKN (KAN = 3) | 0.176 | 0.311 | 0.391 | 0.992 | 1.199 M | 0.622 | 0.662 | 0.781 | 0.99 | 1.193 M |
| VBTCKN (MLP = 3) | 0.192 | 0.329 | 0.421 | 0.991 | 1.2 M | 0.707 | 0.838 | 0.911 | 0.987 | 1.194 M |
| Dataset | Solar-Energy | |||
|---|---|---|---|---|
| Layer | MAE | MSE | RMSE | R2 |
| 2 | 0.472 | 0.452 | 0.644 | 0.997 |
| 3 | 0.482 | 0.454 | 0.654 | 0.997 |
| 4 | 0.542 | 0.57 | 0.726 | 0.996 |
| 5 | 0.557 | 0.584 | 0.742 | 0.996 |
| Dataset | Solar-Energy | |||
|---|---|---|---|---|
| Hidden_Dim | MAE | MSE | RMSE | R2 |
| 32 | 0.478 | 0.458 | 0.652 | 0.997 |
| 64 | 0.468 | 0.448 | 0.639 | 0.997 |
| 128 | 0.508 | 0.512 | 0.697 | 0.996 |
| 256 | 0.511 | 0.536 | 0.714 | 0.996 |
| Dataset | Solar-Energy | |||
|---|---|---|---|---|
| Layer | MAE | MSE | RMSE | R2 |
| 2 | 0.478 | 0.463 | 0.651 | 0.997 |
| 4 | 0.494 | 0.496 | 0.682 | 0.996 |
| 6 | 0.534 | 0.559 | 0.717 | 0.996 |
| 8 | 0.544 | 0.584 | 0.729 | 0.996 |
| Dataset | Solar-Energy | |||
|---|---|---|---|---|
| Layer | MAE | MSE | RMSE | R2 |
| 2 | 0.476 | 0.457 | 0.649 | 0.997 |
| 4 | 0.519 | 0.528 | 0.701 | 0.996 |
| 6 | 0.526 | 0.531 | 0.704 | 0.996 |
| 8 | 0.531 | 0.553 | 0.715 | 0.996 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Z.; Li, C.; Hao, H.; Liang, S.; Shen, Q.; Li, D. VBTCKN: A Time Series Forecasting Model Based on Variational Mode Decomposition with Two-Channel Cross-Attention Network. Symmetry 2025, 17, 1063. https://doi.org/10.3390/sym17071063
Xiao Z, Li C, Hao H, Liang S, Shen Q, Li D. VBTCKN: A Time Series Forecasting Model Based on Variational Mode Decomposition with Two-Channel Cross-Attention Network. Symmetry. 2025; 17(7):1063. https://doi.org/10.3390/sym17071063
Chicago/Turabian StyleXiao, Zhiguo, Changgen Li, Huihui Hao, Siwen Liang, Qi Shen, and Dongni Li. 2025. "VBTCKN: A Time Series Forecasting Model Based on Variational Mode Decomposition with Two-Channel Cross-Attention Network" Symmetry 17, no. 7: 1063. https://doi.org/10.3390/sym17071063
APA StyleXiao, Z., Li, C., Hao, H., Liang, S., Shen, Q., & Li, D. (2025). VBTCKN: A Time Series Forecasting Model Based on Variational Mode Decomposition with Two-Channel Cross-Attention Network. Symmetry, 17(7), 1063. https://doi.org/10.3390/sym17071063