1. Introduction
Identifying influential nodes [
1,
2,
3,
4,
5,
6] in complex networks [
7,
8,
9] remains a persistent challenge, with critical applications spanning targeted advertising on social platforms, source localization in rumor propagation, and the selection of high-impact researchers.
In the context of various methods for assessing scientific influence, one prominent metric is the
H-index [
10], which has emerged as a widely adopted metric to quantify both the quality and productivity of the research output. Originally proposed by J. E. Hirsch to characterize individual scientific contributions, the
H-index has since been extended to evaluate academic institutions and journals [
11]. By integrating measures of publication quality (impact factor) and quantity (publication count), it addresses the limitations of traditional metrics that prioritize only one dimension.
Over the past two decades, the
H-index has attracted significant attention from scientometrics researchers proposing various improvements in different perspectives [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. These advancements fall into three primary categories: (I) Normalization and Averaging: Methods such as normalizing the H-index by the number of authors [
14], by the publication year [
15], and by the disciplinary field [
16], as well as by averaging with citation counts [
17] or geometric mean [
18]. (II) Incorporation of Additional Information: Approaches that integrate auxiliary data, including the author’s position in bylines [
19], the shape of citing functions [
20], subdomain distributions within a scientist’s citation profile [
21], the collaboration distance between citing and cited authors [
22], excess citations beyond
citations for papers [
23], and the inclusion of uncited papers [
24]. (III) Temporal Evolution Analysis: Studies examining the H-index’s trajectory over a researcher’s career, such as predictive models via regression analysis [
25,
26] and time window evaluations [
27].
These improvements, though valuable, are closely tied to the intrinsic properties of papers and authors, making generalization to broader complex networks challenging.
Notably, the
H-index has also captured the interest of scholars in complex networks since Lü et al. [
28] revealed the
H-index’s relationship to degree and coreness. Specifically, Lü et al. [
28] defined an
H-operator on a group of numbers via the
H-index. They proved that the coreness—a centrality measure introduced by Kitsak et al.—is the limit of the iteration of the
H-operator. This seminal work [
28] has sparked widespread attention. On the one hand, it has been extended to directed networks [
29] and weighted networks [
30]. On the other hand, it has reinvigorated interest in coreness, a computationally efficient centrality metric. Despite its utility, coreness has inherent limitations, such as limited discrimination power and coarse-grained resolution, which can hinder its application in certain contexts. To address these, several refinements have been proposed, including mixed degree [
31], shortest distance-based coreness [
32], community-based coreness [
33], coreness without redundant links [
34], and two-step coreness [
35].
This paper investigates the limitations of the H-index in capturing the influence of weak nodes—nodes with small degrees but high-degree neighbors. Our analysis is driven by the observation that the H-index, which counts neighbors’ degrees, underestimates the influence of weak nodes. For example, consider two nodes: Node u has neighbors with degrees , yielding and highlighting that it is indeed a weak node. Node v has neighbors with degrees , also yielding . Although node v is a weak node (low degree but surrounded by high-degree neighbors), it is more influential in information propagation than node v. This illustrates a critical shortcoming of the H-index: specifically, it assigns equal influence to nodes with structurally distinct neighbor sets.
The k-core decomposition, derived by iteratively applying the H-index to a node’s neighbors, exacerbates this bias. Weak nodes are systematically underestimated in k-core analyses due to their low intrinsic degrees, despite their high-degree neighbors.
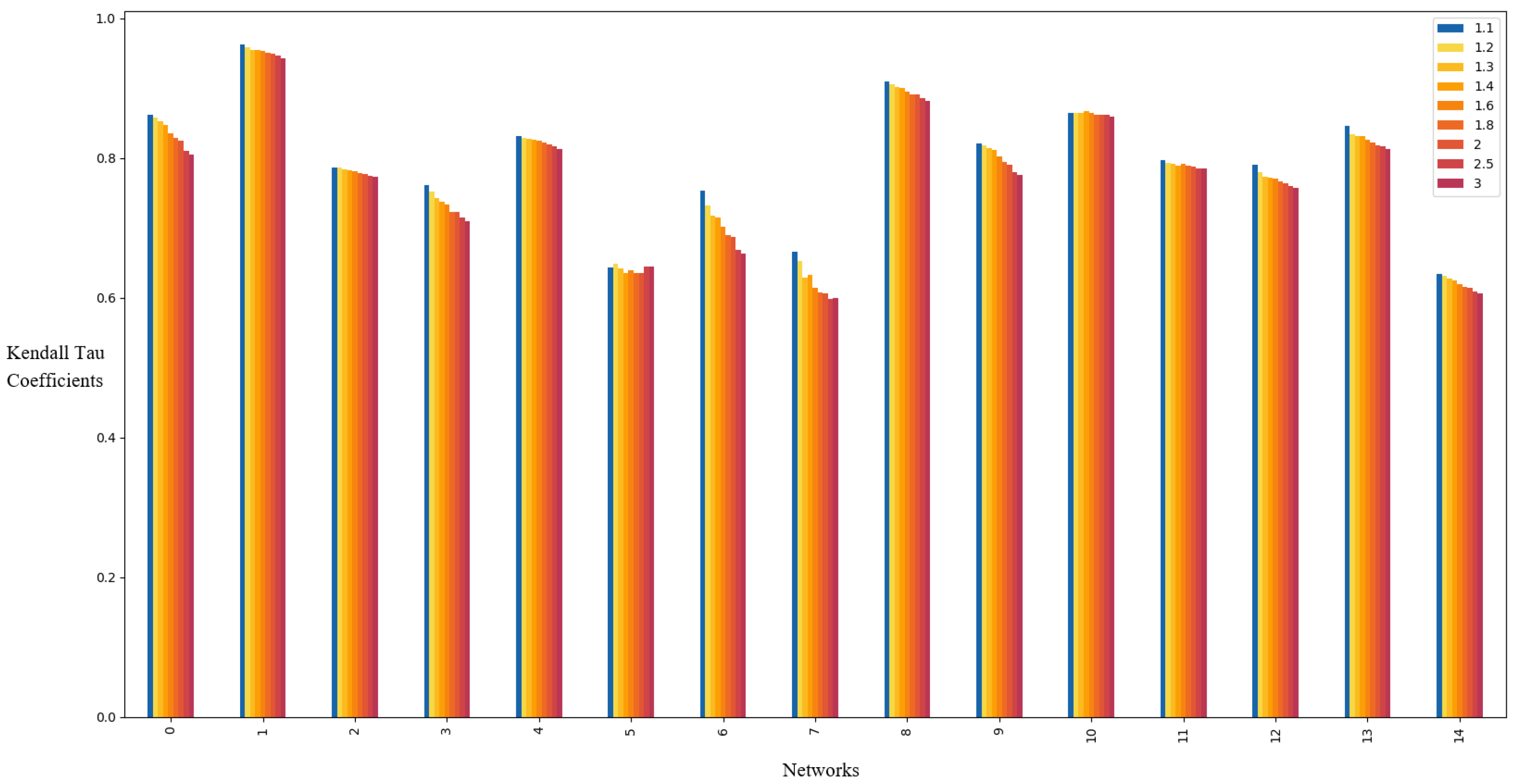
To estimate the influence of weak nodes during information spreading, we propose a new centrality, the -index, which is the maximum number of neighbors with at least times the node’s degree. This formulation emphasizes relative neighbor quality (via ) over absolute degree thresholds, enabling nuanced influence quantification.
Building on the -index, we define the g-core, a hierarchical decomposition that partitions the network based on -index values. This method better captures the influence of weak nodes compared to the traditional k-core.
The rest of the paper is organized as follows:
Section 2 provides the theoretical background on the
H-index, k-core, and collective influence centrality.
Section 3 introduces the
-index, the
g-core, and the local
g-core.
Section 4 presents experiments validating the superiority of the
-index and
g-core.
Section 5 discusses future research directions.
2. Classical Centrality
2.1. Notations
Let denote an undirected symmetric network, where V and E represent the set of nodes and the set of edges in G, respectively. The adjacency matrix encodes connectivity, where is the number of nodes in G and if nodes u and v are connected, i.e., , and otherwise. The neighborhood of the node v is defined as the set of nodes directly connected to v. For a node v, let denote its degree, i.e., .
2.2. H-Index Centrality
Definition 1. Let be a finite non-empty set of positive real numbers. Define the subset as The H-operator, denoted as , is the maximum value y such that . Definition 2. Let v be a node in the graph G, and let denote its neighborhood. The H-index of v, denoted as , is defined aswhere is the degree of node u. 2.3. Coreness Centrality
Coreness centrality is a network topological measure derived from k-core decomposition. It evaluates a node’s importance based on its position within the hierarchical core structure of a network. Nodes with higher coreness values occupy denser, more central regions of the network, playing critical roles in maintaining global connectivity and influence.
The k-core is obtained through iterative degree-based pruning:
- (1).
Start with the original graph .
- (2).
Iteratively remove all nodes with a degree less than k along with their incident edges.
- (3).
Repeat until no nodes with a degree less than k remain.
The resulting subgraph is the k-core. The node v is assigned a coreness of if it belongs to the k-core but not the -core. This hierarchical decomposition ensures that nodes in higher k-cores are more deeply embedded within the network’s core structure.
2.4. Closeness Centrality
Closeness centrality measures a node’s centrality based on its average distance to all other nodes in the network. It quantifies how quickly a node can reach others, reflecting its efficiency in spreading information or influence. Nodes with high closeness centrality are “close” to others, meaning that they have short average path lengths to all nodes.
The closeness centrality
of the node
v in the connected graph
with
n nodes is defined as
where
is the shortest path length between nodes
u and
v and
normalizes the measure to account for the number of other nodes in the network.
2.5. Collective Influence Centrality
Collective influence (CI) is a method developed by Morone and Makse [
36] for identifying highly influential nodes in complex networks. CI quantifies a node’s influence by measuring the extent of damage inflicted on the network’s giant connected component upon the node’s removal. The formal definition of CI is given by
where
represents the degree of node
i,
denotes the set of nodes at a
l-hop distance from node
u, and
is the degree of node
j.
2.6. Betweenness Centrality
Betweenness centrality is a measure of a node’s centrality in a network based on the extent to which it lies on the shortest paths between pairs of other nodes. It quantifies a node’s role as a “bridge” or intermediary in facilitating communication, information flow, or interactions across the network. Nodes with high betweenness centrality are critical for maintaining connectivity and controlling the flow of resources, as their removal can significantly disrupt network interactions.
The betweenness centrality
of the node
u in graph
with
n nodes is defined as
where
is the total number of shortest paths from node
s to node
t and
is the number of those shortest paths that pass through node
u.






{kind=link}
{kind=link}
{kind=link}
{kind=link}