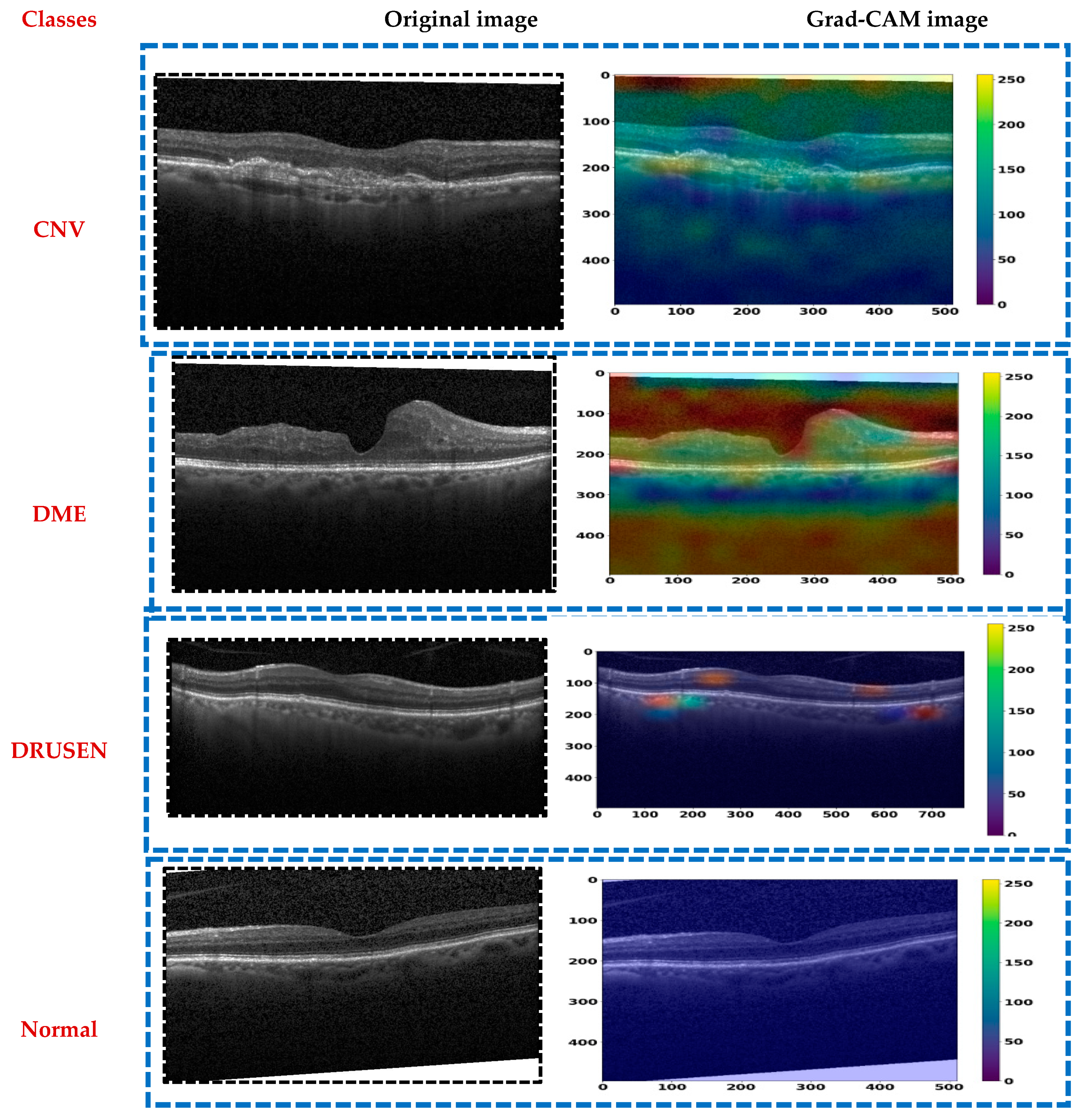
In this section, we describe the evaluation metrics utilized to assess the proposed model. We will cover the overall classification performance, conduct statistical analysis, present ablation studies and visual explanations via Grad-CAM, and compare our findings with previous work.
4.2. The CDResNet101-V2 Model Evaluation
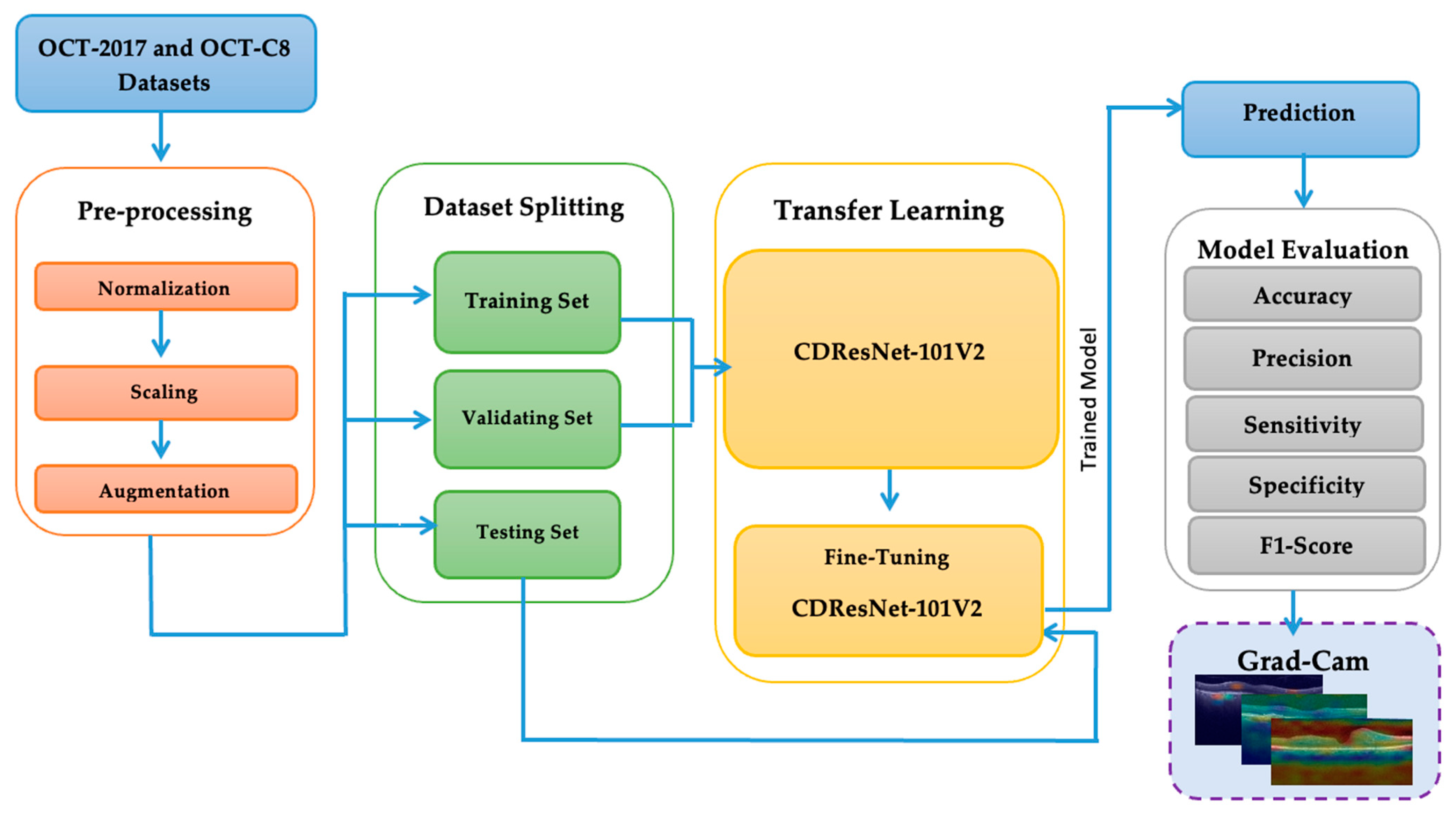
In this study, we conducted two experiments using the OCT-2017 and OCT-C8 datasets for multiclass classification in the Kaggle environment. The experiments were performed on a system equipped with an Intel Core i9-13900K CPU operating at 64 GB DDR5 RAM. We utilized Python version 3 and the TensorFlow library, which is a well-known DL framework developed by Google. TensorFlow is commonly used for building and deploying DL and ML models, particularly in the fields of DL and AI.
The OCT-2017 dataset was split into three sections: The training set had 83,484 images, the test set included 968 images, and the validation set contained 32 images. The OCT-C8 dataset was also divided into three parts: The training set consisted of 18,400 images, with both the test and validation sets each containing 2800 images. We conducted two experiments focusing on transfer learning to pre-train six DL models. In the initial transfer learning phase, we performed supervised pre-training using the ImageNet dataset to train these six DL models. Subsequently, we carried out the fine-tuning phase using the training sets from the two OCT datasets. At the end of the experiment, we employed evaluation metrics (as specified in Equations (1)–(7)) to evaluate the performance of the six DL models.
In
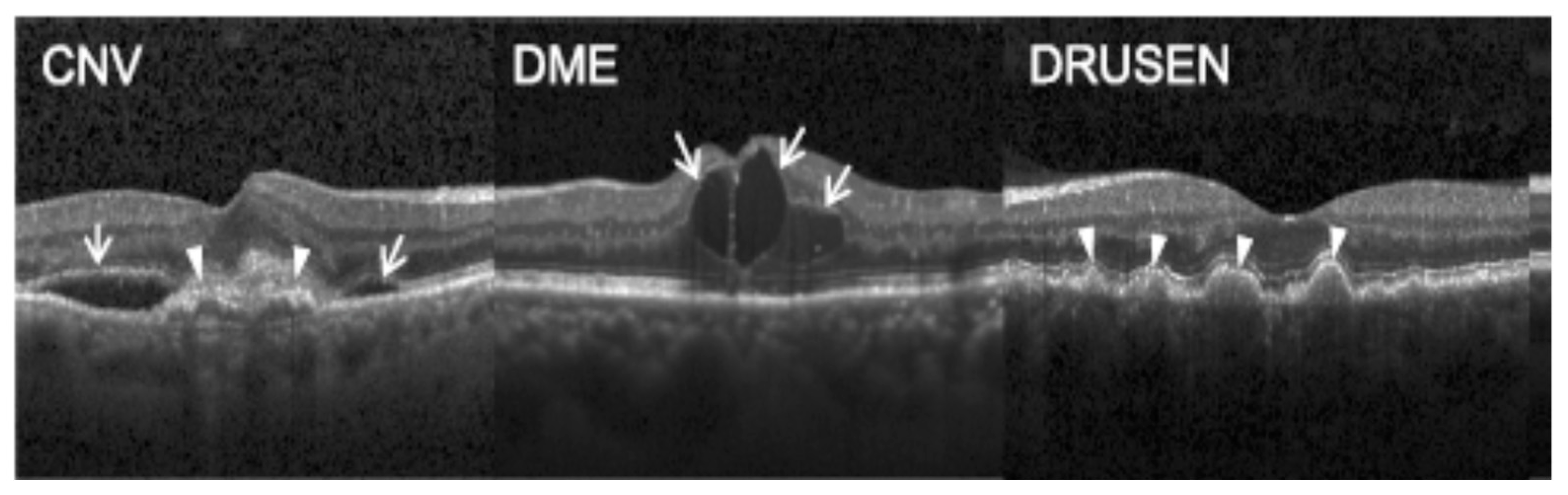
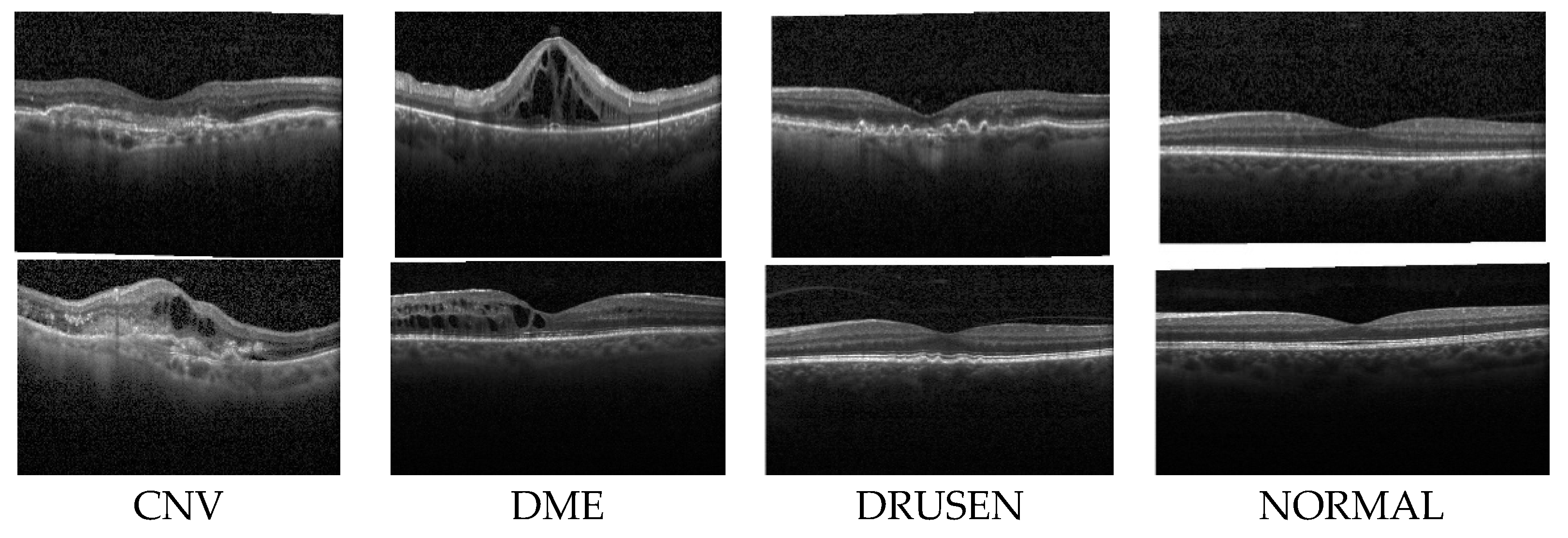
the first experiment, we conducted a multiclass classification of EDs using the OCT-2017 dataset. This dataset consists of four classes: normal, CNV, DME, and drusen.
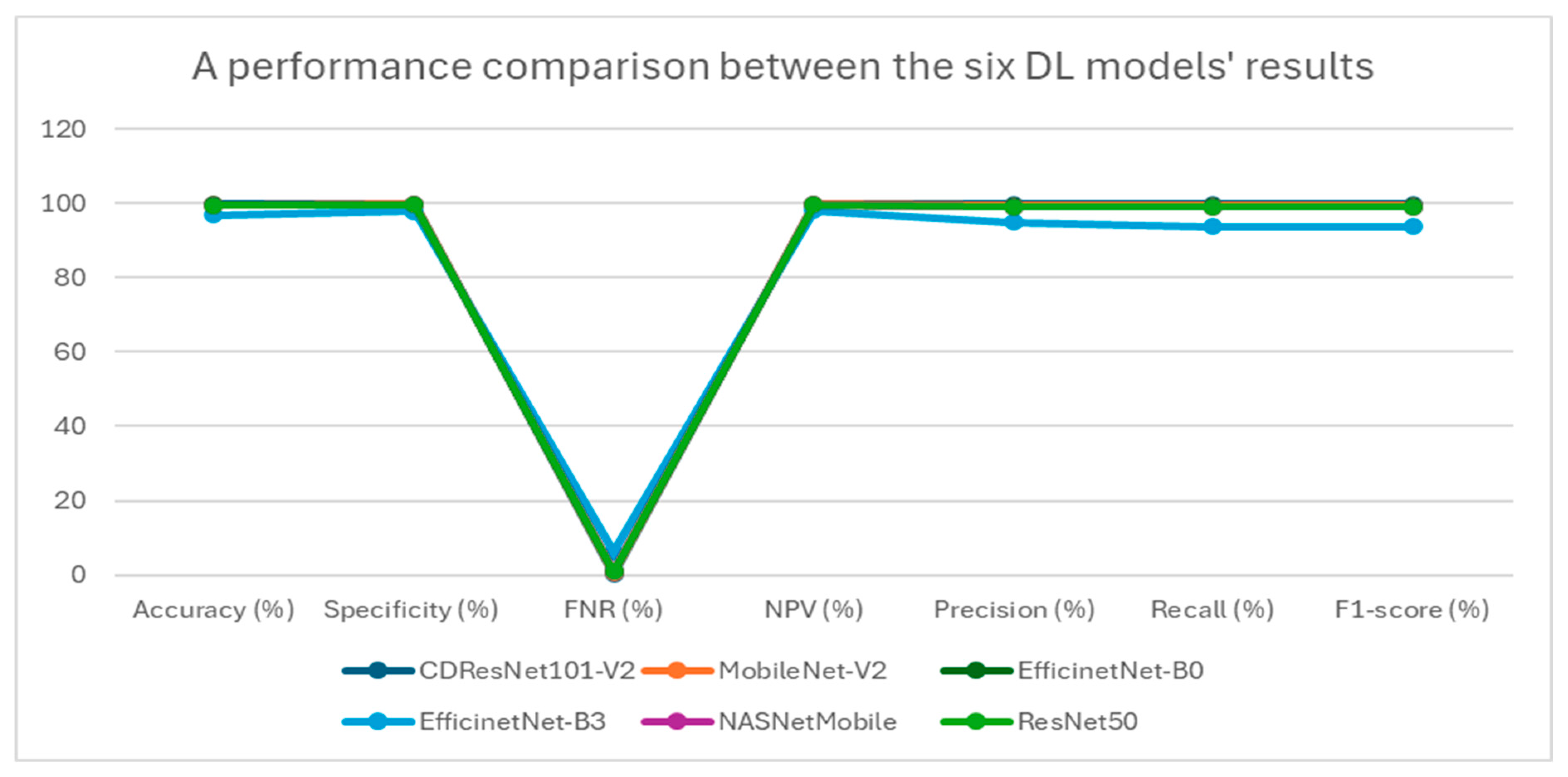
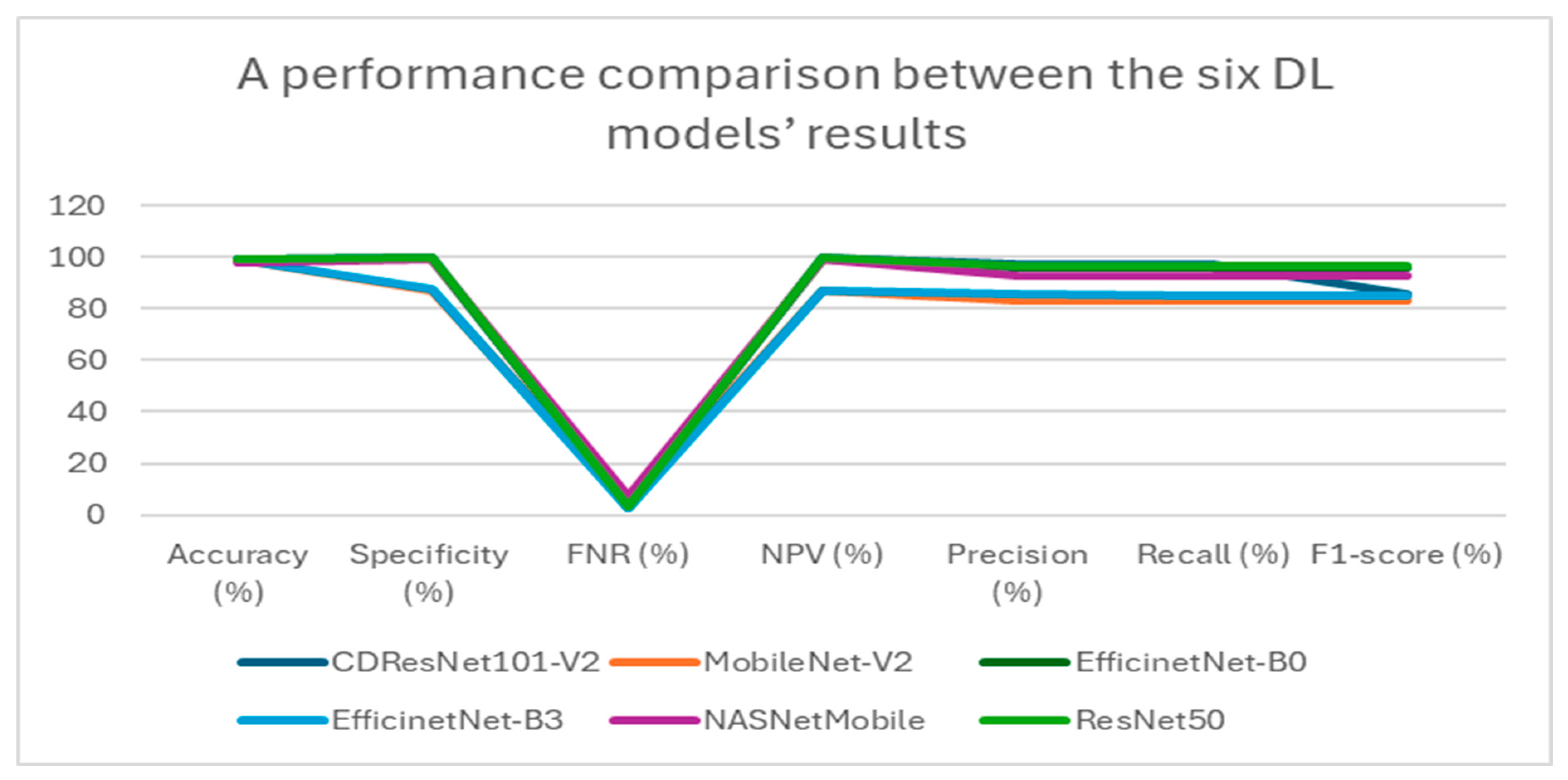
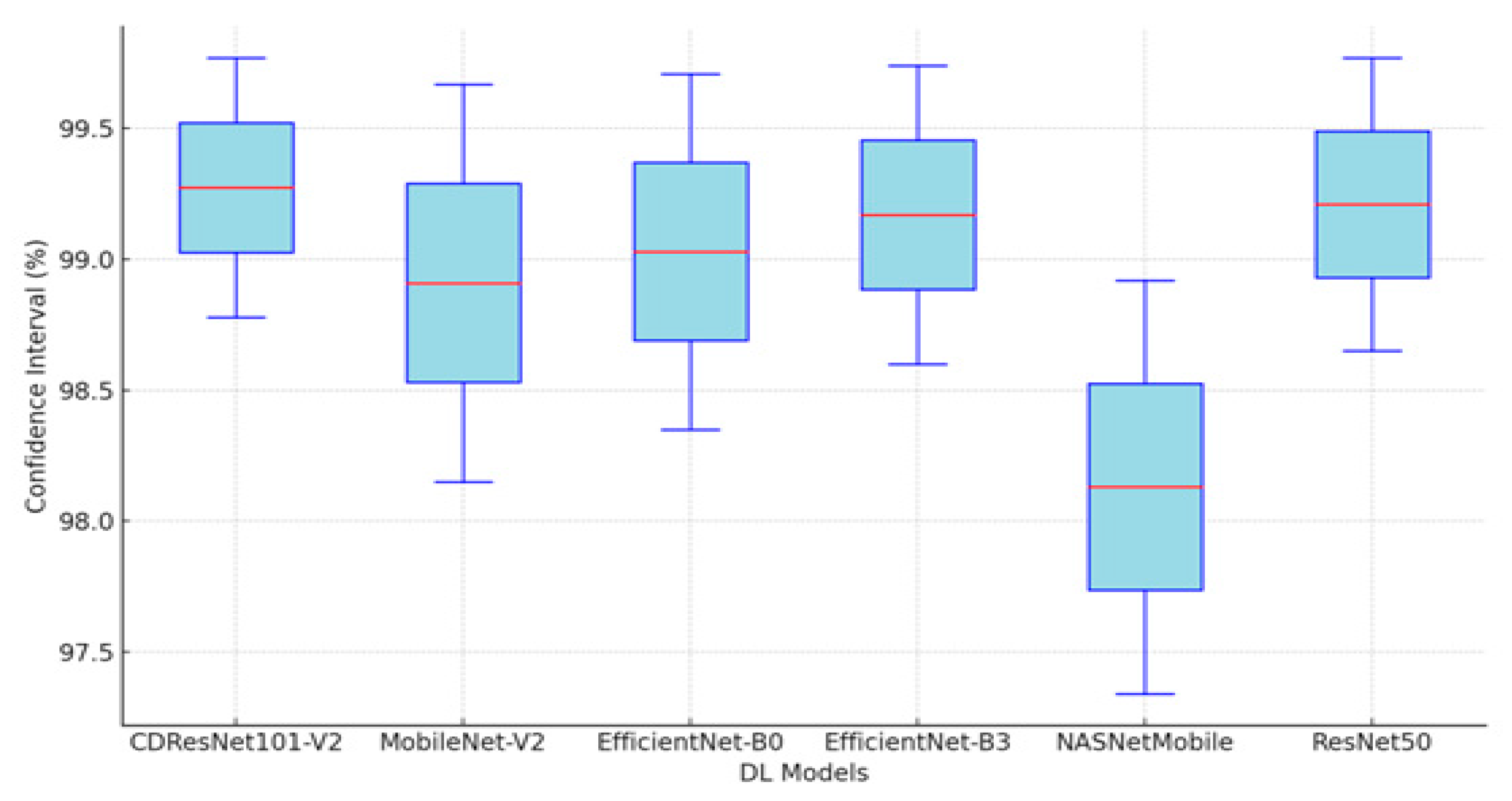
Table 5 presents a summary of the performance metrics for the following models: CDResNet101-V2, MobileNet-V2, EfficinetNet-B0, EfficinetNet-B3, NASNetMobile, and ResNet50. The metrics include accuracy, specificity, FNR, NPV, precision, recall, and F1-score.
Table 5 and
Figure 11 display the performance metrics for the six DL models. The CDResNet101-V2 model achieved the highest accuracy rate of 99.90%, with a specificity of 99.93% and an F1-score of 99.79%. Importantly, it also recorded the lowest FNR at 0.21%, highlighting its exceptional detection capability. Furthermore, the precision of 99.80% and recall of 99.79% illustrate its balanced performance in identifying true positives.
MobileNet-V2 achieved an accuracy of 99.69%, which is marginally lower than that of CDResNet101-V2. The FNR was recorded at 0.62%, with a specificity of 99.79% and a NPV of 99.80%. The F1-score was noted at 99.38%, indicating strong performance, although it was slightly less effective compared to CDResNet101-V2.
EfficientNet-B0 achieved an accuracy of 99.59% and demonstrated a specificity of 99.72% along with an F1-score of 99.18%. The FNR was recorded at 0.83%, indicating a slightly higher error rate than the leading models.
EfficientNet-B3 had the lowest accuracy at 96.85%, with the highest FNR of 6.30%, highlighting a significant performance gap. Its F1-score was 93.79%, and specificity was 97.90%, which was the lowest among the models compared.
NASNetMobile achieved an accuracy of 99.48%, with a specificity of 99.66% and an F1-score of 98.97%. The FNR was noted at 1.03%, suggesting a relatively higher level of misclassification compared to MobileNet-V2 and CDResNet101-V2.
ResNet50 achieved an accuracy of 99.54% and a specificity of 99.69%, with an FNR of 0.93%. Its F1-score was 99.07%, indicating a strong performance, though slightly lower than that of MobileNet-V2.
In summary, CDResNet101-V2 consistently outperformed the other models across nearly all metrics, showcasing greater effectiveness and reliability. In contrast, EfficientNet-B3 exhibited significant performance limitations.
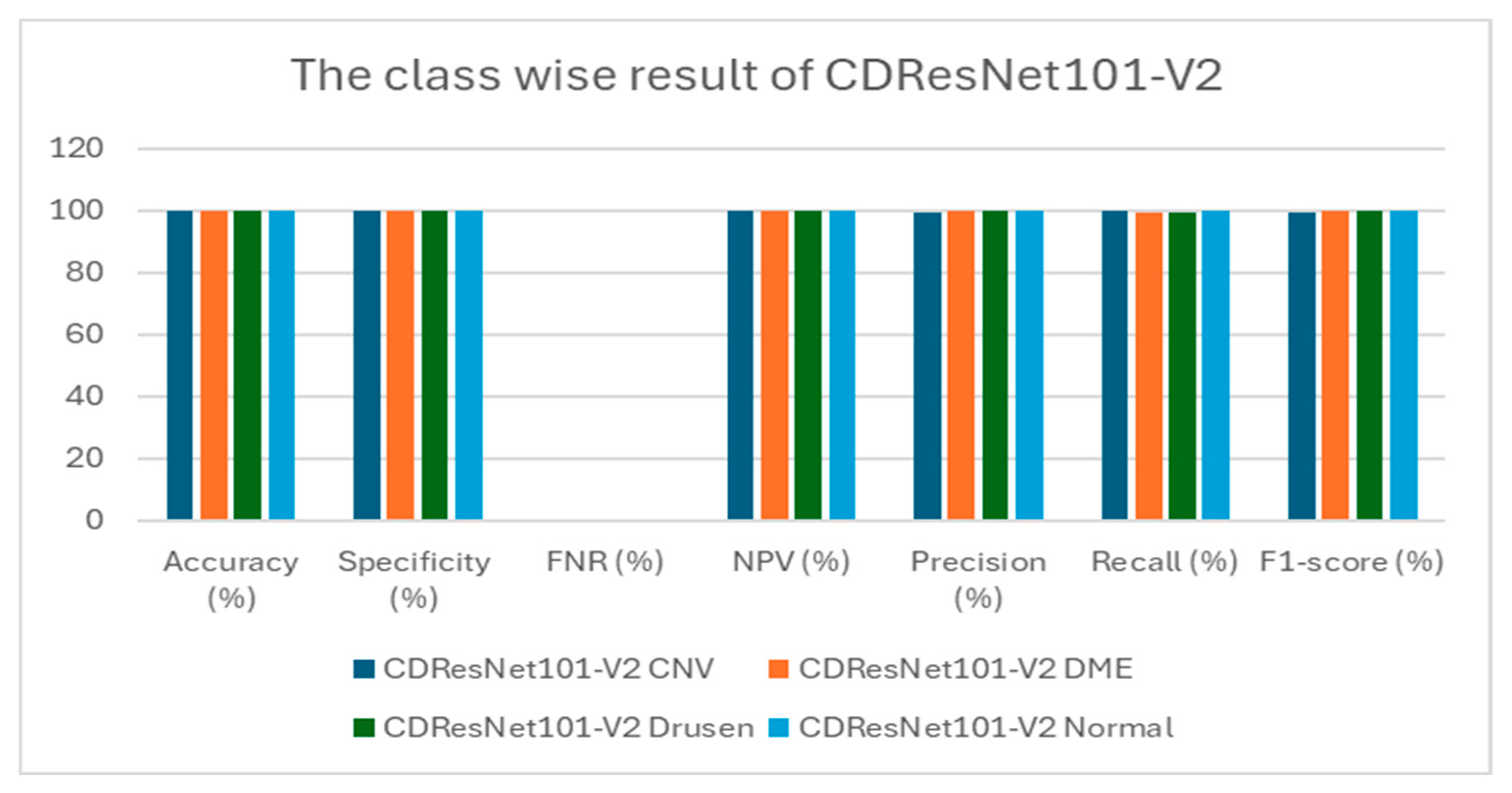
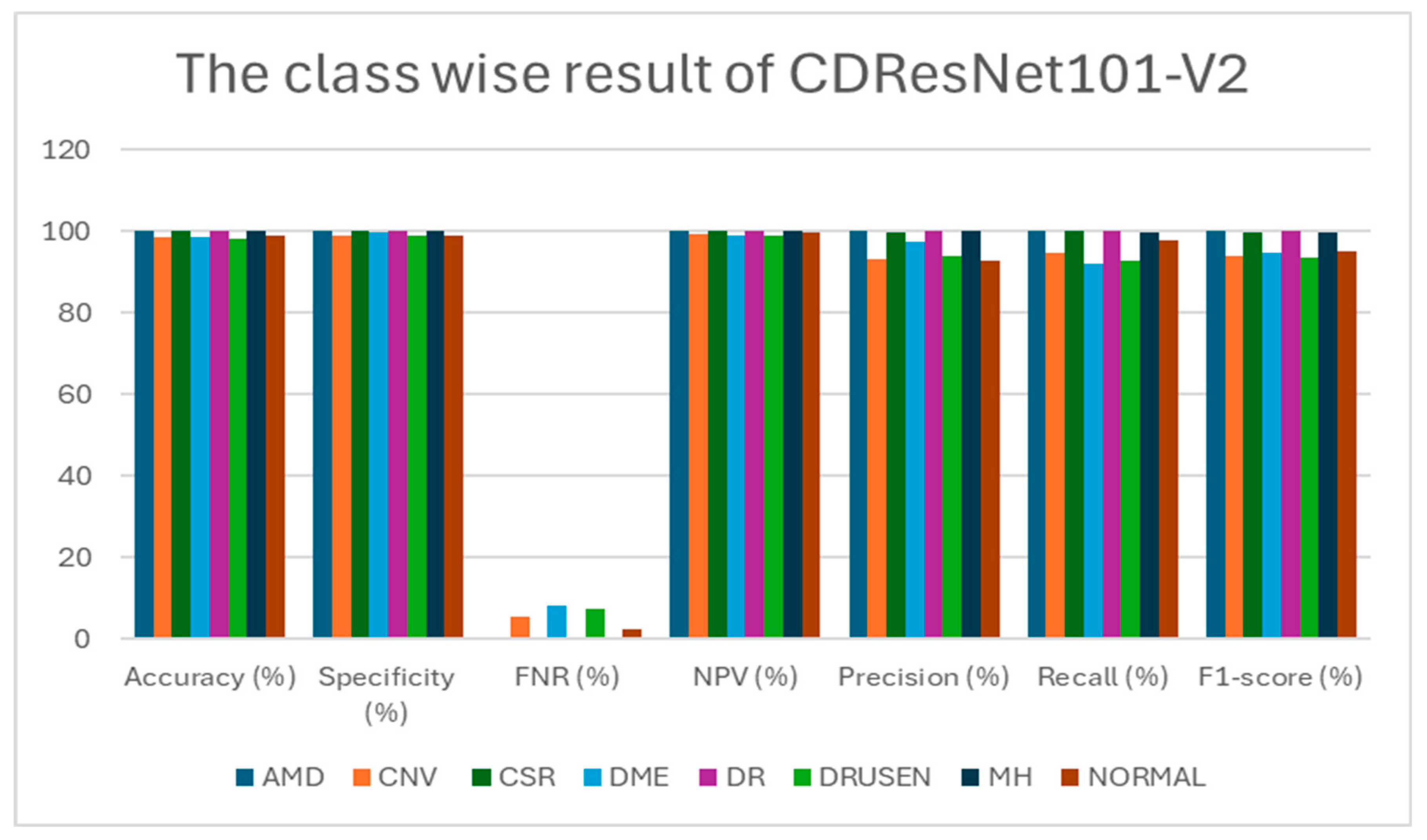
Table 6 presents class-wise evaluation metrics for the six DL models on the test set of the OCT-2017 dataset that contains four classes: CNV, DME, drusen, and normal. In
Table 6 and
Figure 12,
for the CNV class, CDResNet101-V2 achieved an accuracy of 99.79% and a specificity of 99.72%. Notably, it recorded an FNR of 0.00%, indicating that there were no missed true positive cases. The precision was 99.18%, and recall was perfect at 100%, resulting in an F1-score of 99.59%. This indicates that the model was highly reliable in detecting CNV without missing any true positive cases.
For the DME class, it demonstrated an impressive accuracy of 99.90% and a specificity of 100%. The FNR was minimal at 0.41%. With precision at 100% and recall reaching 99.59%, the F1-score was calculated at 99.79%. The model exhibited an excellent balance between sensitivity and specificity for DME detection.
For the drusen class, CDResNet101-V2 was similar to DME; it achieved an accuracy of 99.90%, with a specificity of 100% and an FNR of 0.41%. Both precision and recall were 100% and 99.59%, respectively, yielding an F1-score of 99.79%. The results demonstrated that the model was equally effective in detecting drusen with minimal false negatives.
For the normal class, CDResNet101-V2 performed flawlessly for normal images, achieving 100% in accuracy, specificity, NPV, precision, recall, and F1-score, with an FNR of 0.00%. This suggests perfect classification of normal retinal images, with no false positives or negatives.
MobileNet-V2 reached an accuracy of 99.38%, with an F1-score of 98.78% and 100% recall for the CNV class. It performed excellently in the DME class, achieving perfect scores across all categories (100%). However, for the drusen class, it recorded an accuracy of 99.38%, with a higher FNR of 2.48% and an F1-score of 98.74%, indicating a slight decrease in performance. The normal class also displayed perfect metrics (100%).
EfficientNet-B0 achieved an accuracy of 99.17% for the CNV class, with an F1-score of 98.37% and 100% recall. In the DME class, it scored 99.79% accuracy, boasting 100% specificity and an F1-score of 99.59%. For the drusen class, it attained an accuracy of 99.38%, accompanied by a higher FNR of 2.48% and an F1-score of 98.74%. The normal class demonstrated perfect metrics (100%).
EfficientNet-B3 showed a lower accuracy of 93.90% for the CNV class, with relatively low precision at 80.40% and an F1-score of 89.13%. In the DME class, it achieved 97.93% accuracy, with a higher FNR of 8.26% and an F1-score of 95.69%. For the drusen class, its accuracy was 95.76%, with a significantly high FNR of 16.94% and an F1-score of 90.74%. The normal class exhibited near-perfect performance, with an F1-score of 99.59%.
NASNetMobile recorded an accuracy of 98.97%, with 100% recall and an F1-score of 97.98% for the CNV class. It performed excellently in the DME class, with perfect metrics across all categories (100%). For the drusen class, it achieved an accuracy of 99.07%, with an FNR of 3.72% and an F1-score of 98.11%. It also demonstrated perfect performance in the normal class (100%).
ResNet50 attained an accuracy of 99.17%, with an F1-score of 98.37% and 100% recall for the CNV class. In the DME class, it scored 99.48% accuracy, with an F1-score of 98.96% and an FNR of 2.07%. For the drusen class, its accuracy was 99.59%, yielding an F1-score of 99.17%. In the normal class, it achieved nearly perfect results, with an F1-score of 99.79%.
In conclusion, CDResNet101-V2 exhibited the best overall performance, achieving the highest metrics across all classes. Conversely, EfficientNet-B3 faced the most challenges, particularly in the drusen and DME classes, highlighting its limitations. Other models like MobileNet-V2 and NASNetMobile demonstrated consistent and reliable performance, although they did not reach the exceptional results of CDResNet101-V2.
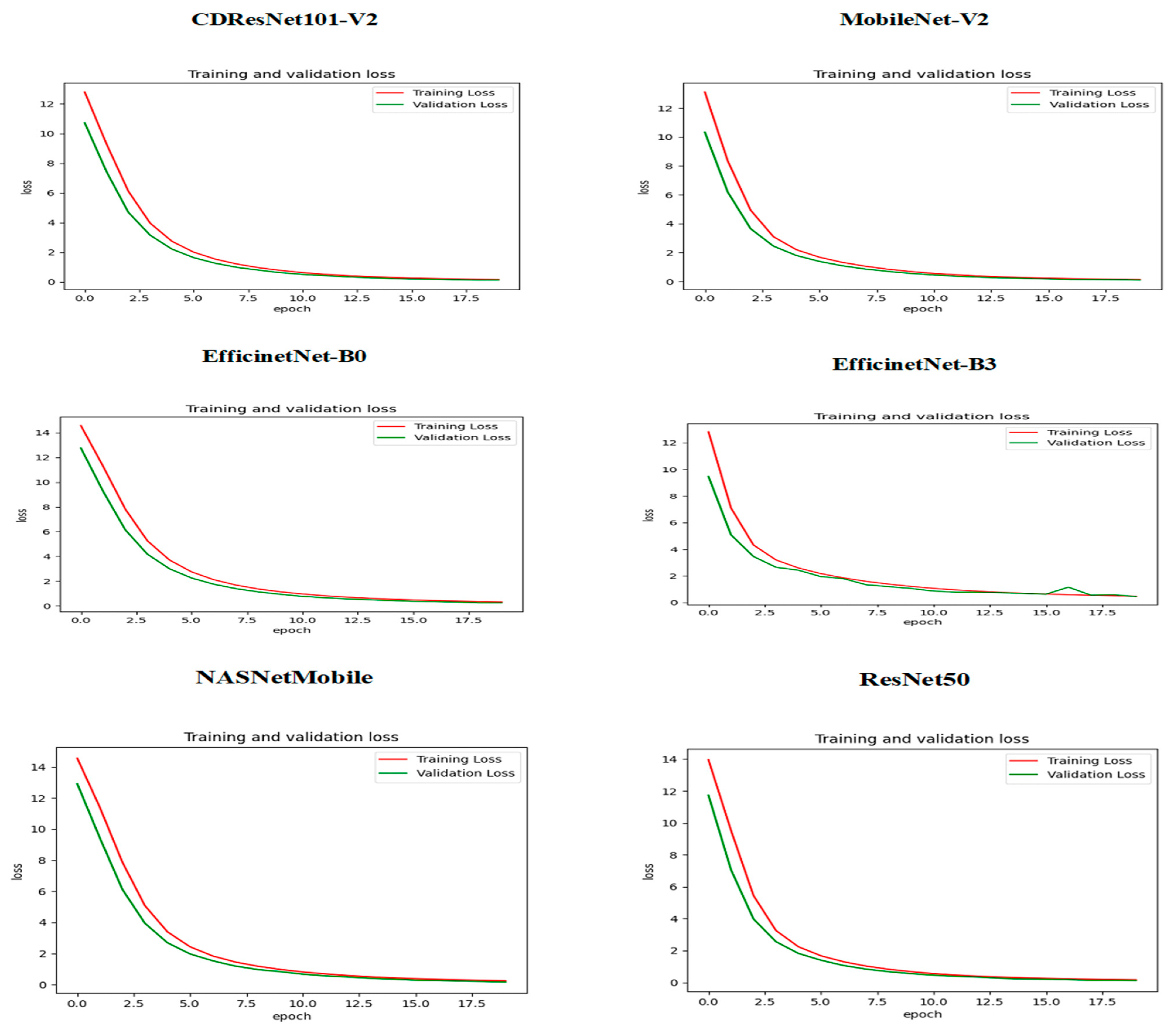
Figure 13 illustrates how the training and validation loss changed over epochs while training six DL models. At the beginning, specifically at epoch 0, the training loss was significantly high, indicating that the models were not initially well-fitted to the data. The validation loss was also high but slightly lower than the training loss. As the training progressed, a steady decline in both losses was observed, suggesting that the models were improving their learning and reducing errors over time. By approximately epoch 15, both the training and validation losses approached zero, signaling that the models had achieved a robust fit to the data. The closeness of the training and validation curves indicated a low risk of overfitting, as they displayed similar trends throughout the training period. The small gap between the training loss (shown by the red curve) and validation loss (represented by the green curve) in the later epochs highlighted the models’ capacity to generalize effectively to new, unseen data. In conclusion,
Figure 13 demonstrates that the training of the six DL models successfully reduced both training and validation losses, reaching convergence with minimal signs of overfitting.
Figure 14 shows the relationship between training and validation accuracy and the number of epochs during the training of six DL models. At the beginning of the training (epoch 0) for the CDResNet101-V2, MobileNet-V2, EfficinetNet-B0, NASNetMobile, and ResNet50 models, the training accuracy (shown by the red curve) was low, indicating that the model’s initial performance was not very good. In contrast, the validation accuracy (shown by the green curve) started at a higher level than the training accuracy, suggesting better initial performance on the validation dataset. As the epochs progressed, the training accuracy steadily increased. The validation accuracy experienced some fluctuations but remained relatively high throughout the training process. By around epoch 15, the training accuracy approached 100%, indicating that the model fit the training data very well. The validation accuracy also stayed close to 100% over the epochs, with only slight variations, demonstrating that the model had strong generalization capabilities on the validation dataset.
The training and validation accuracy curves in
Figure 14 showed minimal divergence, indicating that the model effectively avoided overfitting and maintained a good balance between training and validation performance. Overall, the plot illustrated that the model successfully improved its training accuracy while keeping consistently high validation accuracy, showcasing its strong learning and generalization abilities.
In the initial epoch (epoch 0) of the EfficientNet-B3 model, training accuracy was relatively low, suggesting that the model struggled to perform well on the training dataset at the beginning. Conversely, validation accuracy started at a higher level than training accuracy but displayed significant variations in the early epochs. As training progressed, there was a consistent increase in training accuracy, indicating effective learning and improvement. However, validation accuracy showed notable fluctuations, with occasional spikes and declines, reflecting variability in the model’s generalization ability. In the middle to later epochs, validation accuracy experienced sharp declines at certain points, diverging from the steadily increasing training accuracy. This divergence hinted at potential overfitting or sensitivity to the validation dataset. By the end of the training, training accuracy approached 90%, signifying strong performance on the training data. Meanwhile, validation accuracy stabilized around 90% but continued to exhibit variability, highlighting inconsistencies in generalization. In conclusion, despite the model’s progress on the training dataset, the fluctuations observed in validation accuracy suggested possible overfitting or sensitivity to the characteristics of the validation dataset.
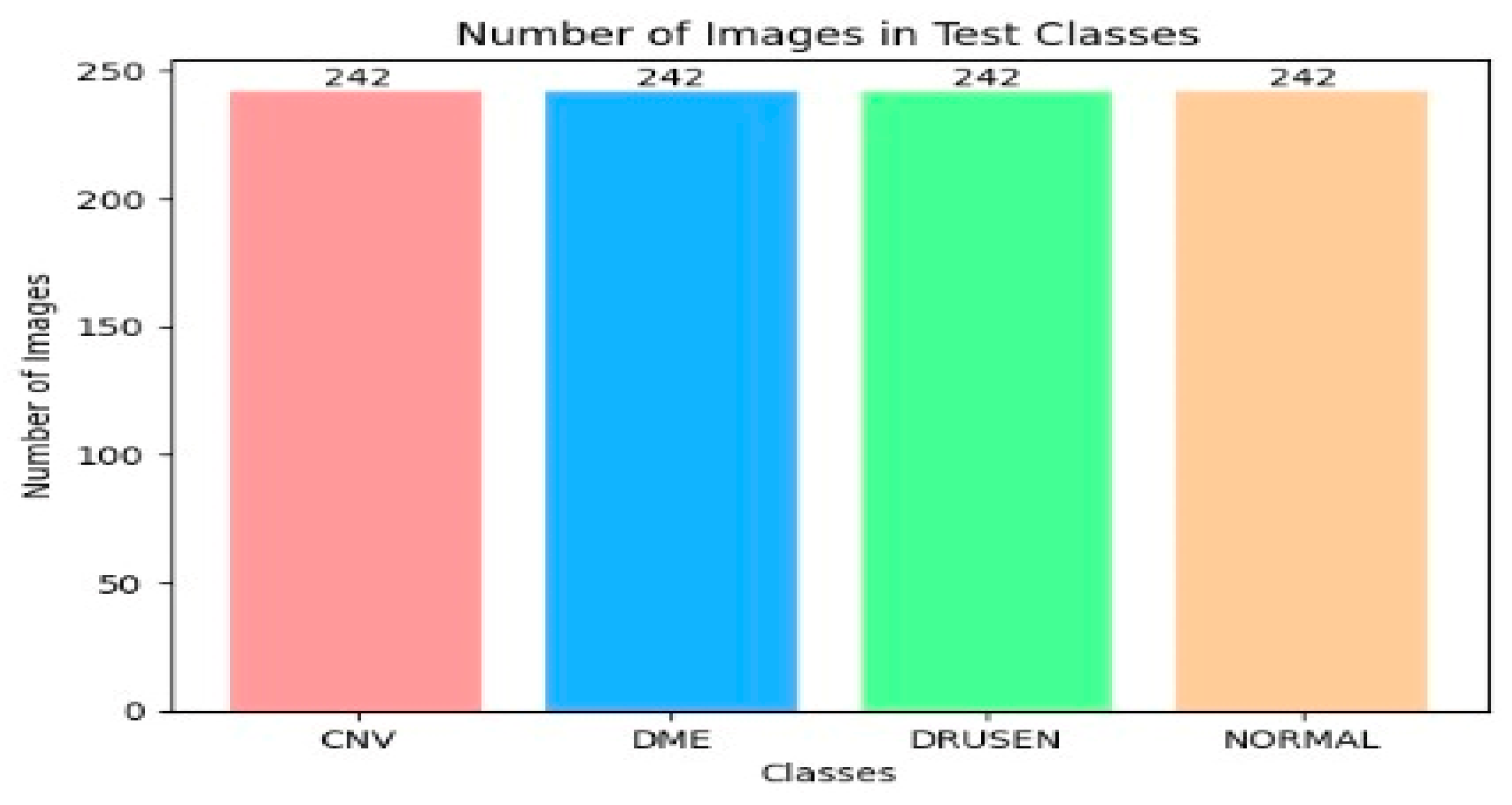
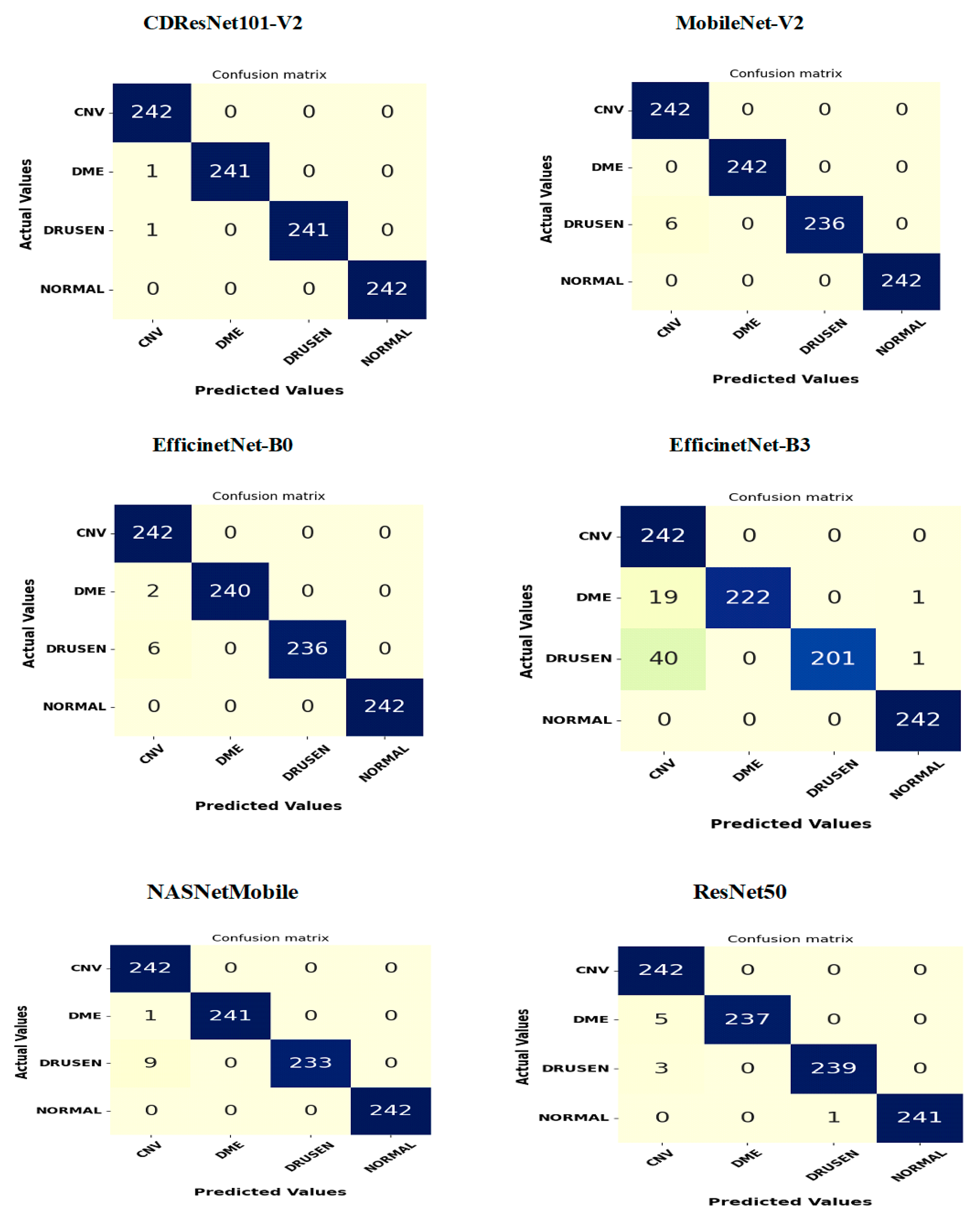
Figure 15 shows the confusion matrices for six DL models tested on the OCT-2107 dataset, consisting of 242 samples categorized into four groups: CNV, DME, drusen, and normal. The CDResNet101-V2 model demonstrated exceptional performance in both the CNV and normal categories, achieving an impressive accuracy of 100%. It accurately classified almost all instances, with only two misclassifications: one CNV instance was incorrectly identified, and one drusen instance was misclassified as CNV. Overall, the CDResNet101-V2 model effectively categorized all four classes of EDs.
The MobileNet-V2 model also achieved a high accuracy of 100% for the CNV, DME, and normal categories, successfully classifying all instances. However, it misclassified six drusen instances as CNV, resulting in an overall accuracy of 97.5% for that category.
The EfficientNet-B0 model accurately identified all 242 actual instances of CNV and normal, both achieving perfect accuracy of 100%. It correctly classified 240 out of 242 DME instances, resulting in an accuracy of 99.17%, with two DME instances misclassified as CNV. Additionally, it accurately classified 236 drusen instances, but six were incorrectly predicted as CNV, leading to a 97.5% accuracy for that class. The model performed exceptionally well with CNV and normal while showing only minor misclassifications in DME and drusen.
The EfficientNet-B3 model also achieved perfect predictions for all 242 actual CNV and normal instances. Among the DME instances, it correctly classified 222, while 19 were misclassified as CNV and one as normal. For drusen, 201 instances were correctly classified, but 40 were misidentified as CNV and one as normal. This model excelled in classifying CNV and normal but showed some confusion between DME and CNV, as well as drusen and CNV, with a few isolated misclassifications of DME and drusen as normal.
The NASNetMobile model performed excellently, accurately classifying all 242 actual CNV and normal instances. It correctly identified 241 DME instances, but one was misclassified as CNV. For drusen, 233 instances were accurately classified, but nine were misidentified as CNV. Overall, this model achieved perfect classification for CNV and normal, with slight misclassifications in DME and drusen.
Lastly, the ResNet50 model accurately classified all 242 actual CNV instances. It correctly predicted 237 DME instances while misclassifying five as CNV. For drusen, 239 instances were correctly classified, while three were incorrectly labeled as CNV. The model also correctly identified 241 normal instances, with one misclassified as drusen. In summary, ResNet50 demonstrated high accuracy across CNV, DME, and normal categories, with only a few misclassifications, mostly affecting DME and drusen.
In the second experiment, we conducted a multiclass classification of EDs using the OCT-C8 dataset. This dataset consists of eight classes: AMD, CNV, CSR, DME, DR, drusen, MH, and normal.
Table 7 and
Figure 16 present a summary of the performance metrics for the following models: CDResNet101-V2, MobileNet-V2, EfficinetNet-B0, EfficinetNet-B3, NASNetMobile, and ResNet50. The metrics include accuracy, specificity, FNR, NPV, precision, recall, and F1-score.
Table 7 displays the performance metrics for six DL models. CDResNet101-V2 model achieved remarkable results, with an accuracy of 99.28% and a specificity of 99.59%. It had a low FNR of 2.89%, demonstrating strong classification ability across various categories. Its precision was 97.14%, and recall stood at 97.11%, resulting in an impressive F1-score of 85.55%.
MobileNet-V2, achieving an accuracy of 98.91%, had a significantly lower specificity of 87.00% compared to others. It recorded an FNR of 4.36% and an NPV of 87.00%, indicating areas for improvement. The precision was 83.33%, with a recall of 83.27%, leading to a lower F1-score of 83.27%. Inconsistent management of class imbalances was noted.
EfficientNet-B0 achieved a strong overall performance, with an accuracy of 99.04% and a specificity of 99.45%. It maintained a low FNR of 3.86% and a high NPV of 99.45, reflecting reliability in negative predictions. The precision recorded was 96.22%, with a recall at 96.14%, culminating in an F1-score of 96.14%. It demonstrated stable and dependable performance across various categories.
EfficientNet-B3 had an accuracy of 99.18%. Its specificity was slightly lower at 87.31% compared to EfficientNet-B0. It maintained a low FNR of 2.90%, while the NPV at 87.21% was comparable to its specificity. The precision was 85.39%, and recall was 84.73%, resulting in a slightly lower F1-score of 85.05%.
NASNetMobile achieved an accuracy of 98.13% and a specificity of 98.93%, which were respectable but slightly lower than some other models. However, it recorded the highest FNR at 7.46%, impacting on its overall reliability. The precision was strong at 93.01%, and the recall was 92.54%, resulting in an F1-score of 92.54%. While performing well, it faced challenges due to a higher rate of false negatives.
ResNet50 achieved excellent results, with an accuracy of 99.21% and a specificity of 99.55%. It maintained a low FNR of 3.14% and a high NPV of 99.55%, ensuring robust classification. With precision at 96.93% and recall at 96.86%, it produced an F1-score of 96.85%. This model exhibited consistent and reliable performance across all metrics.
In conclusion, CDResNet101-V2 and ResNet50 demonstrated the most reliable and high-performing metrics overall. EfficientNet-B0 closely followed, with slightly lower performance in certain areas. MobileNet-V2 and EfficientNet-B3 showed variability, especially in specificity and precision under certain conditions. NASNetMobile, while delivering competitive outcomes, was impacted by a higher FNR, affecting its overall reliability.
Table 8 presents class-wise evaluation metrics for six DL models tested on the OCT-C8 dataset, which includes eight classes: AMD, CNV, CSR, DME, DR, drusen, MH, and normal. In
Table 8 and
Figure 17, The CDResNet101-V2 model showed exceptional performance, achieving 100% accuracy, specificity, and F1-score for the AMD, CSR, DR, and MH classes. However, the CNV, DME, and drusen classes saw a slight decrease in precision and recall, with the highest FNR for DME at 8%. The normal class demonstrated high accuracy at 98.79% and precision at 92.93%, although its recall was slightly lower at 97.71%. On average, the model achieved an impressive accuracy of 99.28% and an F1-score of 97.10%, indicating strong overall effectiveness.
MobileNet-V2 also achieved perfect scores (100%) in the AMD, CSR, and MH categories. However, the CNV and drusen classes had the highest FNRs at 11.43% and 9.43%, respectively, leading to lower F1-scores of 91.18% and 88.92%. While the DME and normal categories maintained high accuracy, they experienced slight reductions in both recall and precision compared to other classes. The average F1-score for this model was slightly lower than that of CDResNet101-V2, at 95.65%.
EfficientNet-B0 maintained consistently high performance across all classes, achieving perfect or near-perfect results for the AMD, CSR, DR, and MH categories. The CNV and drusen classes showed decreased precision (93.45% and 90.26%) and F1-scores (91.55% and 90.13%) due to higher FNRs. The normal category achieved commendable metrics, although its recall was slightly lower at 98.86%. Overall, the performance was competitive but slightly below that of CDResNet101-V2, with an F1-score of 96.14%.
EfficientNet-B3 produced outstanding results, achieving perfect scores for AMD, CSR, and MH. Although the CNV and DME categories saw reduced recall, their precision remained strong, resulting in F1-scores of 93.41% and 94.32%, respectively. The drusen and normal categories showed slight variability but maintained strong overall metrics. The average F1-score for this model was 96.72%, reflecting excellent performance across most classes.
NASNetMobile, while competitive, recorded the lowest overall performance among the tested models. The AMD and MH categories achieved near-perfect metrics, but the CNV and DME classes experienced significant drops in recall and F1-scores (82.00% and 84.00%). The drusen class recorded the lowest precision (80.55%) across all models, negatively impacting its F1-score. On average, this model achieved a respectable F1-score of 92.54%, although lower than the others.
ResNet50 achieved flawless results in the AMD, CSR, DR, and MH classes. The CNV and drusen categories displayed lower precision (89.87% and 96.23%) and higher FNRs compared to the leading models. The DME and normal classes maintained strong metrics, with only minimal declines in precision and recall. The average F1-score for ResNet50 was 96.85%, indicating excellent overall performance, though slightly behind CDResNet101-V2.
In conclusion, CDResNet101-V2 emerged as the top performer, consistently achieving high metrics across all classes. MobileNet-V2 and EfficientNet-B3 closely followed, although with slightly lower metrics in certain categories. In contrast, NASNetMobile exhibited the least favorable performance, with significant variability in F1-scores across the various classes.
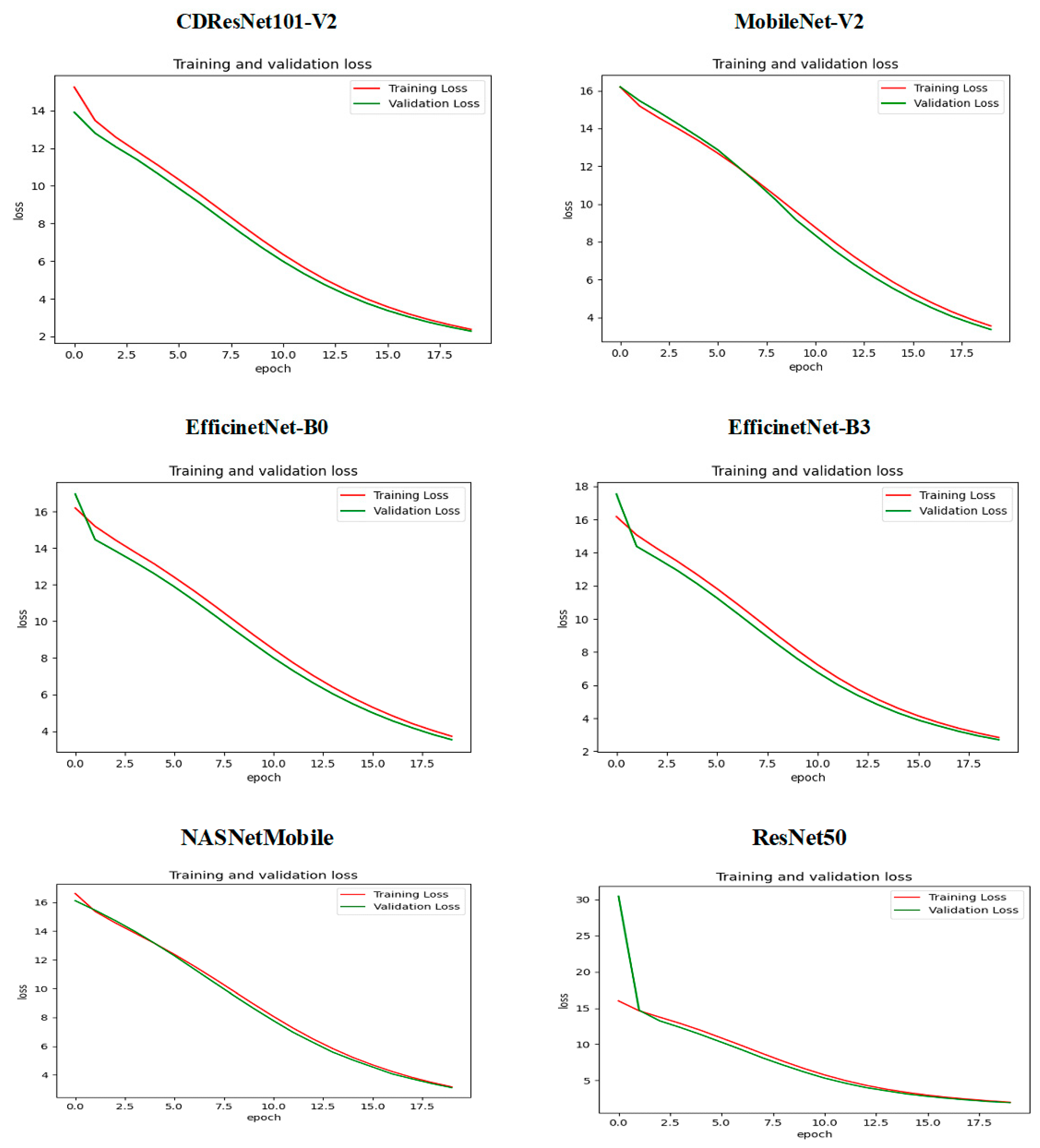
Figure 18 presents the training and validation loss over 18 epochs for the six DL models. The x-axis denotes the number of epochs, while the y-axis represents the loss values. For the CDResNet101-V2 model, the training loss (in red) started at approximately 14 and consistently decreased throughout the training process, nearing 2 by the 18th epoch. The validation loss (in green) followed a similar trend, starting around 14 and steadily declining to stabilize near 2 by the training’s conclusion. The close alignment between the training and validation loss curves indicates that the model effectively reduced loss during training without overfitting. Both curves maintained a continuous downward trend, demonstrating the model’s ability to generalize well to the data.
In the case of MobileNet-V2, EfficientNet-B0, EfficientNet-B3, and NASNetMobile, the training loss began at about 16 and gradually decreased, ultimately reaching around 4 by the 18th epoch. The validation loss mirrored this pattern, also starting near 16 and consistently declining to stabilize around 4 by the final epoch. The strong correlation between the training and validation loss curves suggests that these models effectively minimized loss during training without overfitting, with both curves reflecting a steady downward trajectory indicative of their generalization capabilities across the data.
For the ResNet50 model, the training loss commenced at a notably higher value of about 25 and steadily decreased over the epochs, stabilizing at around 5 by the end of the training. Interestingly, the validation loss began even higher than the training loss, peaking at approximately 30 before sharply declining and closely aligning with the training loss. By the final epochs, the validation loss also stabilized around 5. The consistent reduction in both training and validation loss indicates that the model successfully minimized loss during training. The convergence of the two curves suggests that the model generalized well to unseen data without overfitting. However, the initial spike in validation loss may imply early instability, which was addressed in the subsequent epochs.
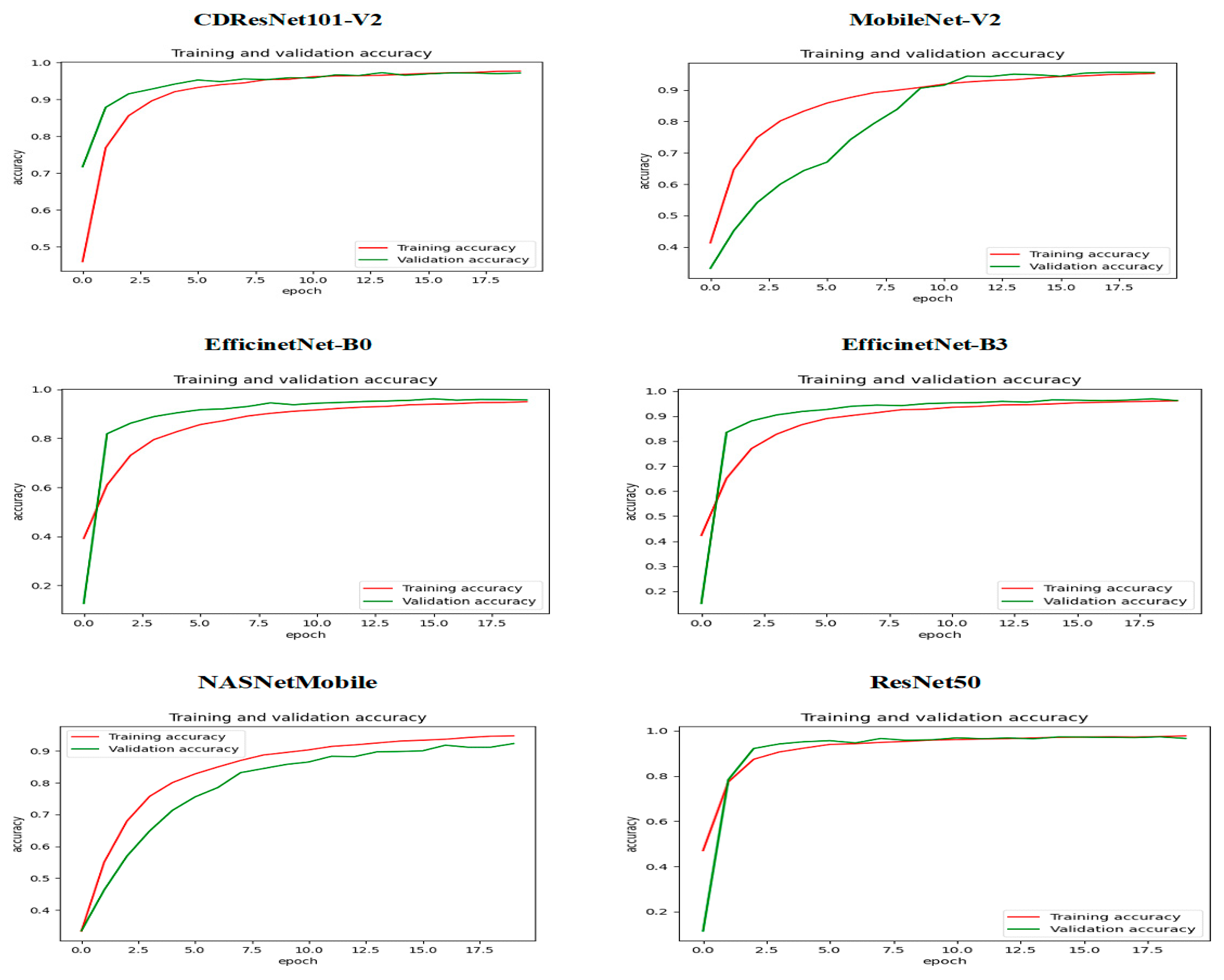
Figure 19 displays the training and validation accuracy of six DL models across various epochs. The red line illustrates the training accuracy, while the green line shows the validation accuracy. For the CDResNet101-V2 model, the validation accuracy rose sharply at the beginning, surpassing the training accuracy in the early epochs. This phenomenon may be attributed to regularization effects or dropout techniques. As training continued, both accuracy metrics began to converge, suggesting effective model learning with minimal signs of overfitting. By the end of the training, the accuracy values for both training and validation were nearly identical, indicating a well-trained model with balanced performance.
In the case of MobileNet-V2, the training accuracy increased rapidly, exceeding 80% within the first five epochs. The validation accuracy followed a similar upward trend but was slightly behind. Around the 10th epoch, both the training and validation accuracies converged at approximately 90%. Following this point, there were only minor improvements, and both metrics stabilized, showing no signs of overfitting. This pattern suggested that the model achieved balanced and optimal performance on both training and validation datasets.
For EfficientNet-B0, EfficientNet-B3, and ResNet50, the validation accuracy also displayed a significant increase early on, outpacing the training accuracy within the first few epochs. Afterward, both metrics improved steadily, with training accuracy catching up to validation accuracy midway through the training process. By the later epochs, both the training and validation accuracies converged at high values, approaching 100%. This outcome indicated that the model learned effectively without significant overfitting, as the validation performance closely matched the training performance.
For NASNetMobile, as training progressed, the training accuracy exhibited a steady increase, reaching approximately 0.93 by the end of the 20th epoch. The validation accuracy also improved over time, but at a slower rate, achieving about 0.90. Initially, the training accuracy rose more rapidly than the validation accuracy, indicating that the model was proficient at identifying patterns in the training dataset. However, the gap between the two curves suggested a slight level of overfitting, as the training accuracy consistently exceeded the validation accuracy throughout the training process.
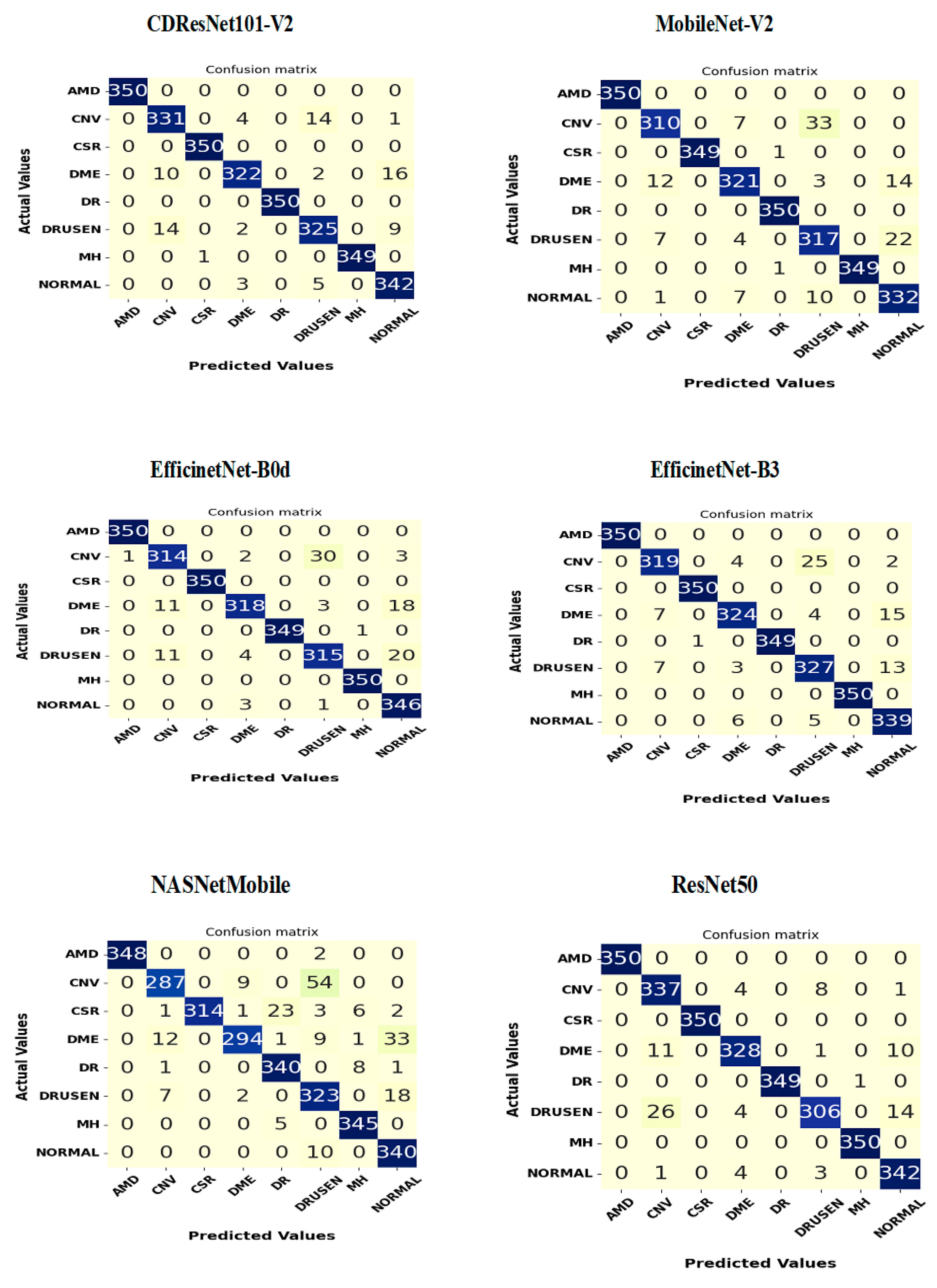
Figure 20 presents a confusion matrix for the six classification models, highlighting the relationship between actual and predicted class labels for the OCT-C8 test set of ED images. This test set consists of 2800 samples categorized into eight classes: AMD, CNV, CSR, DME, DR, drusen, MH, and normal, with each class containing 350 samples.
In the CDResNet101-V2 model, the diagonal entries of the classification matrix indicate the number of instances accurately classified for each category. There were 350 instances of AMD, CSR, and DR that were correctly identified as AMD, CSR, and DR, resulting in an accuracy of 100%. Additionally, 331 instances of CNV were accurately classified as CNV, achieving an accuracy of 94.5%. Furthermore, 322 instances of DME were correctly classified as DME, yielding an accuracy of 92%. For drusen, 325 instances were accurately classified, resulting in an accuracy of 92.85%. The model also correctly identified 349 instances of MH as MH, achieving an accuracy of 99.7%. Lastly, 342 instances of normal were correctly identified as normal, reaching an accuracy of 97.7%.
The off-diagonal entries in the matrix represent misclassifications. Specifically, 4 instances of CNV were incorrectly classified as DME, 14 as drusen, and 1 as normal. Additionally, 10 instances of DME were misidentified as CNV, while 16 instances of DME were mistakenly categorized as normal. These statistics highlight the model’s misclassifications and emphasize the classes that are often confused with one another. Overall, the model exhibited strong performance, with most categories showing high classification accuracy, though slight errors occurred for certain labels such as drusen and DME.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}