1. Introduction
1.1. Importance and Motivation
As edge control technology evolves, the implementation of intelligent manufacturing in smart factories becomes critically dependent on cyber-physical systems (CPSs) adoption [
1,
2,
3]. Numerous cases underscore the pivotal role of optimized intelligent decision-making processes within CPSs [
4,
5]. This involves perceiving system states, forecasting future developments, setting goals, and planning actions [
6]. Meanwhile, optimizing the processing of local data at the edge side significantly improves system performance, efficiency, and reliability. Job shop scheduling with shared resource constraints represents a key challenge in intelligent decision making. This problem has gained growing attention in industrial systems due to its significant impact on production scheduling efficiency [
7,
8].
In CPSs, the edge controller becomes an integral part. Adding algorithms to edge controllers gives them a certain level of intelligence, which can greatly improve the overall efficiency of the system from the device level. With the development of manufacturing automation, edge controllers with algorithms can replace human decision making to greatly reduce waiting time and improve productivity. However, different algorithms are applicable to different areas. If the algorithm execution time is too long, it will also reduce productivity. Therefore, reducing the execution time of the algorithm is also a necessary part of optimizing efficiency.
1.2. Literature Review
Prior to conducting the work presented in this study, the authors utilized Petri nets to model and analyze the processes of CPSs [
2,
9]. As a graphical–mathematical modeling tool, Petri nets uniquely integrate diagrammatic representation with algebraic formalism. This synthesis allows for precise characterization of the scheduling complexities, including but not limited to process discreteness, operational conflicts, asynchronous behaviors, concurrency patterns, and system deadlocks. [
10,
11]. Consequently, they have emerged as one of the mainstream technologies for CPS modeling and analysis [
12,
13]. This advantage has led to their widespread application in the industrial manufacturing sector [
14,
15,
16]. Petri nets are gradually becoming a promising method for optimizing the job scheduling problem and have been thoroughly studied by a wide range of scholars. Based on timed Petri nets (TPNs), Cui [
17] designed an algorithm combining genetic algorithms and particle swarm optimization to optimize scheduling problems. Similarly, Wu [
18] devised an algorithm combining ant colony optimization (ACO) to optimize process control that was also based on TPNs. However, both approaches employ action fragmentation by dividing a single operation into two discrete phases: an initiation phase modeled through timed transition and a termination phase represented by immediate transition. This dual-representation paradigm inevitably leads to network structure inflation (increased node count) and consequently diminishes algorithmic efficiency. Although Petri nets are capable of modeling CPSs, they are predominantly used for system analysis [
13,
19]. Few cases directly guide industrial processes to improve efficiency, leading to a disconnect between the established models and practical problem solving.
With the advancement of computer performance, neural networks have begun to make significant strides across various fields, including reinforcement learning and deep learning. Compared to heuristic methods, neural networks rely less on domain knowledge and demonstrate strong capabilities in learning complex patterns and processing large datasets. They have also been proven successful in the field of task scheduling [
20,
21,
22]. Neural networks can be combined with Petri nets to retain the inherent advantages of Petri nets in modeling discrete event dynamic systems. For example, Lassoued [
23] developed the PetriRL framework by synergizing Petri nets with deep reinforcement learning. This integrated approach demonstrates strong generalization capabilities across varying instance scales. Kim [
24] developed Look-Ahead Reinforcement Learning (LARL) to enhance Petri net model exploration. This method trains Q-networks through deep Q-learning on existing instances and then applies anticipatory search strategies for new scenarios. Experimental validation confirmed LARL’s effectiveness.
However, deep learning models are often viewed as “black boxes”, lacking interpretability. In CPSs, scheduling decisions require clear logic and traceability to meet safety and compliance requirements. Furthermore, deep learning typically necessitates a large amount of training data, which is often difficult to obtain in the field. Training on public datasets may not yield satisfactory generalization performance. In CPS environments, scheduling decisions frequently depend on real-time data. That exposes models to risks of data scarcity and rapid environmental dynamics.
Deep learning model training and inference require intensive computation on both developer workstations and CPS edge controllers. However, real-time processing needs and limited resources often restrict their effectiveness. These factors limit their widespread application in the industrial sector.
Heuristic algorithms are widely adopted in industrial settings due to their operational simplicity. A prime example is the Proportional–Integral–Derivative (PID) method. These algorithms require minimal computational resources compared to exact optimization approaches. Their design inherently balances system stability needs with hardware limitations. This combination makes them particularly suitable for process control applications. Conversely, the tradeoff for these simplification is suboptimal scheduling and significant reliance on domain knowledge, hindering their generalization. Some metaheuristic methods draw inspiration from nature, such as genetic algorithms and ACO. Although these methods are not problem-specific and can be applied to a wide range of problems, they are highly sensitive to initial conditions, necessitating extensive tuning of hyperparameters.
1.3. Contribution
The problem of algorithm efficiency has been widely explored by researchers. However, with increasing arithmetic power nowadays, the execution time problem of algorithms is easily ignored. In particular, algorithms running on edge controllers, which are small computing power devices, are constrained by arithmetic power. Thus, the algorithms need to be optimized to be more relevant. Therefore, this study aims to address the barriers between Petri nets and heuristic intelligence algorithms in scheduling optimization, with a view to achieving better results and improving algorithmic efficiency in a less arithmetic environment. Furthermore, whether heuristic algorithms can achieve further efficiency improvements based on Petri nets is also a noteworthy question.
Based on this, the authors conducted research on scheduling efficiency issues and devised a method named Petri-net-adaptive ant colony optimization (PN-AACO). The PN-AACO algorithm eliminates the information barrier between Petri net modeling and heuristic algorithms, thus enhancing the efficiency of heuristic algorithms in Petri net modeling. However, the algorithm’s pheromone index mechanism includes states, which imposes certain limitations on PN-AACO. When facing a small number of states, PN-AACO can quickly solve the optimization execution sequence. However, the actual process also exists in a complex Petri net process with a large number of states, and traversing the pheromone size will become slower and slower. That will lead to slower execution of the algorithm. The slow execution of the PN-AACO algorithm based on the number of Petri net states also slows down the operation efficiency of the whole system. To address the issue of slow execution speed of the PN-AACO algorithm when facing a large number of states, this study proposes a pheromone index mechanism based on transition–transition and fixes the count of pheromones to ( is the count of transition set, and is the count of the transition set that can fire in initial markings). The improved PN-AACO (iPN-AACO) algorithm is able to optimize the workflow by finding the current best known scheduling comparable to other heuristic algorithms in a smaller computing power environment. It also has an advantage over PN-AACOs when dealing with optimization problems for tasks with more states, wherein the more pheromones there are, the more obvious the advantage becomes.
1.4. Organization
The remaining sections of this paper are organized as follows: Due to the PN-AACO algorithm proposed in previous work not yet being published, a brief introduction of the PN-AACO algorithm is provided in
Section 2.
Section 3 presents the improvements made to the PN-AACO algorithm. The process of the iPN-AACO algorithm is described in
Section 4.
Section 5 conducts simulation verification on the iPN-AACO algorithm. Finally, conclusions are drawn in
Section 6.
2. PN-AACO Algorithm
The PN-AACO algorithm mainly comprises Petri net modeling, the global timing mechanism of key time points, the pheromone index mechanism for marking–transition, and adaptive pheromone update mechanisms. This algorithm establishes a six-tuple TPN model for the task scheduling process of a CPS:
where
is the place set (In this study,
represents the number of elements in
X set);
is the transition set;
F is the flow relationship, which is represented by an ordered pair such as
that means from
to
; and
W is the weight function, which represents the number of tokens required when the transition occurs. By default, it is 1 when not marked;
is the initial marking;
is the firing time set, and
represents the firing time of
. Because the average firing rates of transition are defined as
, there is a set of the average firing rates of transitions
. It defines the average number of firings per unit time when enabled. The unit is the number of times per unit time.
The model allows for the determination of the input matrix and output matrix , as well as other variables required by the algorithm. Subsequently, the task objective is defined as finding a transition sequence that minimizes the execution time of the sequence.
The traditional ACO algorithm is typically implemented for traveling salesman problem (TSP) scenarios with fixed city counts, where pheromone matrices maintain city-to-city indexing, and ants initiate exploration from randomly assigned urban nodes. While this architecture effectively addresses static TSP configurations, its reliance on predetermined topological constraints poses challenges in dynamic environments requiring real-time adaptability. Unlike the traveling salesman problem, the number of ordinal couples recorded in marking–transition is not a fixed value.
At the initial time,
m ants are placed at the marking
. The initial pheromone levels on each path of the first travel are equal.
is the initial pheromone level, where
is the ordinal labeling of some marking
M, and
is the ordinal labeling of the timed transitions
t. The probability that an ant
chooses the next transition among the enabled transitions according to a randomized proportionality rule among the feasible transitions is
where
is the pheromone level from
to
;
is the pheromone factor;
is the average firing rates of
; and
is the same.
is the heuristic factor, and
is the transition set that the
k-th ant will enable next.
Upon reaching the end marking , ants cease their traversal, calculating the sequence execution time traveled by each ant. The shortest sequence execution time is then saved, and the pheromone levels on all paths are updated simultaneously.
Following this, a method for recording pheromones for key time points and marking–transition was designed (key time points and marking–transition were collectively called the KTMT method) to store and connect the ACO method. In the key time points method, the time before and after the transition is finely divided, and the entire system shares a single global timeline. Each key time point represents an instance in time and can be viewed as a structure. This structure includes the current time , the pretransition marking array , the ending transition set , the current marknig array M, the preceding transition set , and the post-transition marking array . The internal variables of key time points can be represented using or based on the index sequences or time markers. Additionally, since a marking in the Petri net may be reached by different transitions, unlike two cities in analogy, the marking–transition is used as an atomic index to define the pheromones. Pheromones are updated offline, meaning that after all ants have completed their traversal, and a round of pheromone updates occurs.
Pheromone updates mainly consist of two components: pheromone evaporation and the deposition of pheromones by ants along the paths they traverse. The traditional method for updating pheromones is as follows:
where
denotes the current iteration count;
represents the pheromone level for the next iteration;
stands for the pheromone evaporation coefficient, where
; and
denotes the persistence coefficient of the pheromones. Additionally,
signifies the pheromone levels for the current iteration, and
indicates the pheromone levels deposited by the
k-th ant along its path, which are defined as
where
Q is the pheromone increase factor;
is the sequence execution time of the current iteration number
k-th ant that has completed traveling; and
is the occurrence sequence that the
k-th ant has searched for. According to Equation (
4), it is evident that traditional ACO algorithms exhibit significant variations in sequence execution times when applied to different tasks. This necessitates constant adjustments to the
Q value to attain the suitable pheromone. Moreover, within the same task, the impact of the sequence execution time on the pheromone levels is relatively minor, potentially resulting in slower convergence rates. These limitations will be addressed in the subsequent parts by improving the pheromone updating mechanism.
Therefore, an adaptive ant colony algorithm (AACO) was designed to optimize the search efficiency of the traditional ant colony algorithm using the Petri net model. The method updates the increment of pheromones
as follows:
where the subscripts
i and
j represent that the pheromone levels are from
to
;
is the path influence factor;
stands for the minimum global sequence execution time; and
represents the maximum sequence execution time traveled by all ants in the current iteration. The proposed algorithm achieves good results in small, low-batch tasks.
To facilitate the description of the scheduling decision problem, let us define it within a Petri net framework as follows:
represents a set of jobs, such as those in a production line. Each job is further divided into different operations.
denotes a set of resources, such as operators, machines, or tools. These resources belong to the place set and are shared among various operations.
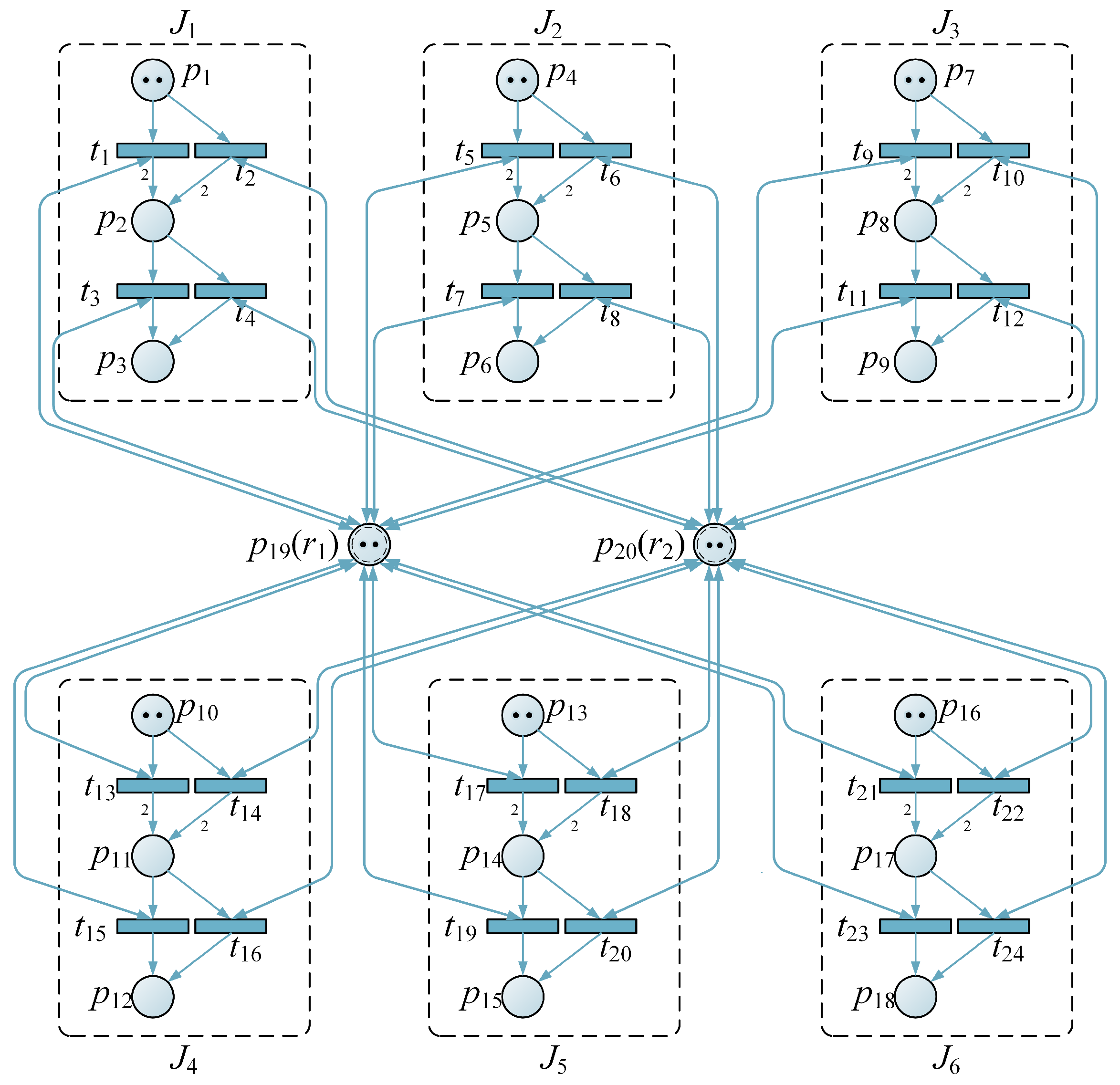
3. iPN-AACO Algorithm
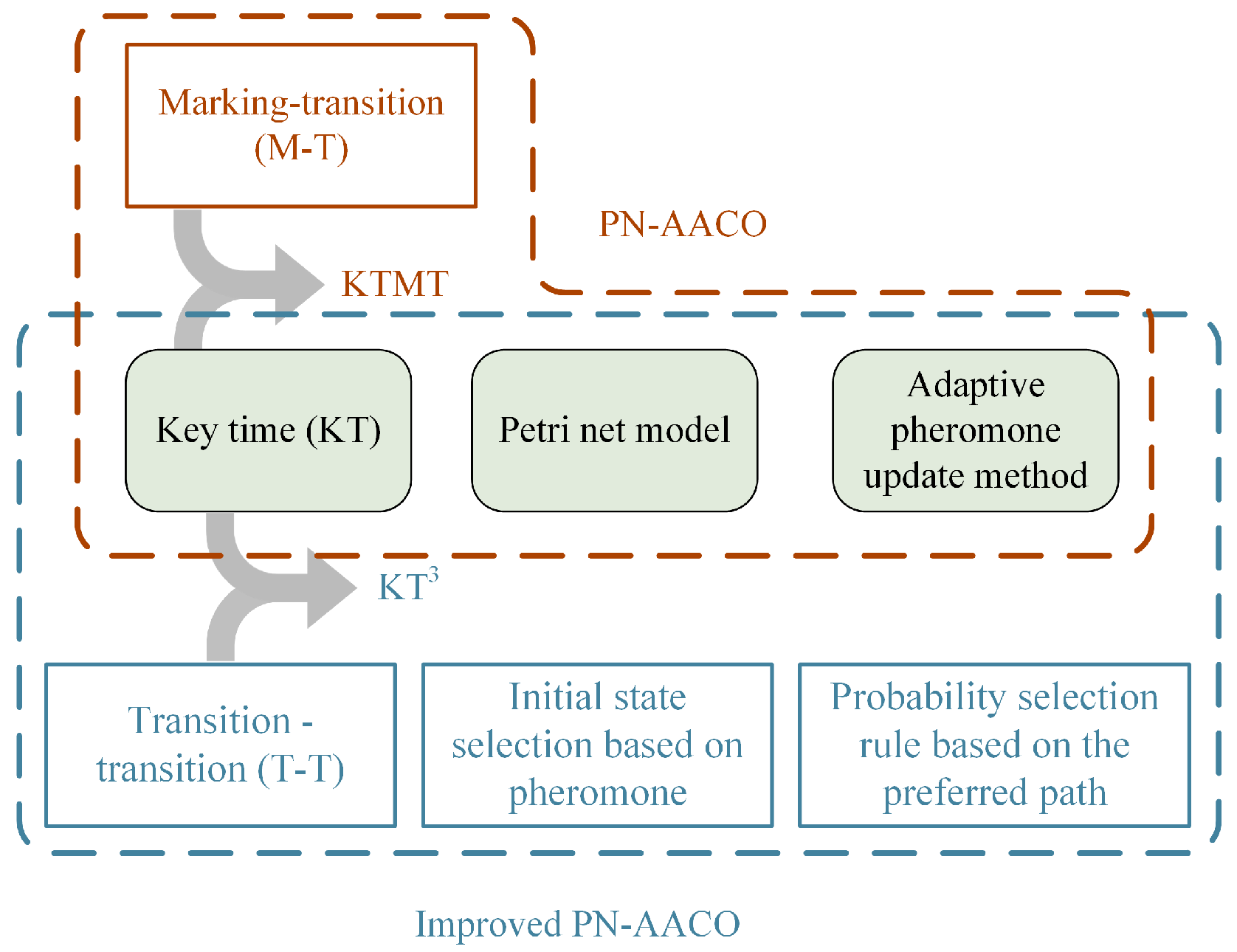
The improved algorithm primarily improves the initial state selection method, recording method, and update method of the pheromones, as shown in
Figure 1 when compared with the original algorithm.
As has been explained in
Section 1.2, Petri nets have their advantages for describing discrete event dynamic systems such as task scheduling and are widely used; the key time point approach can describe the Petri operation process on a global timeline. Therefore, in
Figure 1, the iPN-AACO algorithm follows the Petri net model of the original algorithm and the time description of the key time point. The iPN-AACO algorithm changes the original marking–transition (M-T) pheromone index mechanism to transition–transition (T-T) with the size of
and recollectively with the key time point method as KT
3. The benefit of the T-T-based recording method is that it is not affected by the number of Petri net reachable markings, and it does not affect the size of the pheromone recording as the number of states increases. However, this also brings a disadvantage because the indexing of the pheromone markings has an uncertainty, i.e., the markers may be different between the same two transitions. To solve this problem, a probabilistic selection rule based on the best konwn paths was proposed. It makes the algorithm converge according to a heuristic rule. Since the T-T recording method cannot affect the initial selection probability as much as the initial state, a pheromone-based initial state selection method was also proposed. The details are developed and described in the following sections.
3.1. KT3 Method
The key time points serve as a bridge between the Petri net and the algorithm, enabling the optimization of scheduling through these points. The algorithm updates the pheromone levels in each iteration, and how to record pheromones is a crucial optimization issue. In this study, process transitions are analogized to cities in the traveling salesman problem, where each transition serves as a node to record pheromones, resulting in a fixed count of pheromones. This pheromone recording table is referred to as the table Eta.
The final sequence formed by the Petri net is actually a finite occurrence sequence
. The objective is to find a transition sequence
. It is evident that
is a simplification of
, which is obtained by removing states from
. If we directly seek
, the marking between any two transitions ordered pair in
in different initial markings is indeterminate. Therefore, using the transition–transition pheromone index mechanism does not uniquely describe the states in principle, but only reflects the “distance” between transitions locally. This leads to the ant’s selection based on the pheromones recorded by transition–transition being local. In
Section 3.3, we will discuss incorporating the influence of the entire path into the ant’s probability selection.
3.2. Initial State Selection Based on Pheromone
Unlike the random selection of the initial route, the convergence ability of the algorithm will be reduced if the route is influenced by the best known route and the initial selection is still random. So, the first transition from each job
is extracted to form the initial variation set
. Simultaneously, maintain a table Zeta of size
to record the initial pheromone levels. At the beginning of each ant’s traversal, the
k-th ant (where
) selects the initial city according to a random proportion rule. The probability of selecting a particular transition is designed as follows:
where
represents the pheromone level on transition
selected in the initial marking
.
3.3. Probabilistic Selection Rules Based on Best Known Paths
In Equation (
2), the factor
is only the time-consuming impact of local transition. Obviously, it is inappropriate to have only the local transition time affecting the selection probability in the whole path, and the path selection of ants should take into account the path impact of the shortest time-consuming path in each round. After each iteration
is completed, the shortest path
with the least execution time is retained. When
, the probability selection of each ant is influenced by the global best known path. The rule for designing probability selection is as follows:
where
is the global best known path influence component, which is designed to influence as follows:
where
is the maximum count of iterations;
represents the overlap between the current path and the best known path; and Algorithm 1 shows how to compute
.
| Algorithm 1 Compute . |
| Require: transition sequence of current path , transition sequence set of global best known path .
|
| Ensure: ; |
| 1: for ; ; do |
| 2: if begin with then |
| 3: Compute ;▹ denotes the number of transitions in the sequence |
| 4: break; |
| 5: end if |
| 6: end for |
| 7: return ;
|
is the overlap compensation coefficient, and z is the overlap influence coefficient. The factor is to present the effect of the best known path at the first iteration, where only the first round of paths are traveled, and the path with the shortest time to execute the sequence occurs. The factor is applied to allow the ant colony to accelerate the rate of convergence as the count of iterations increases. The influence of the real best known path on the ant selection probability is the factor . After many tests, it was summarized that it would be more appropriate to take and in this study.
4. Improved Algorithmic Flow
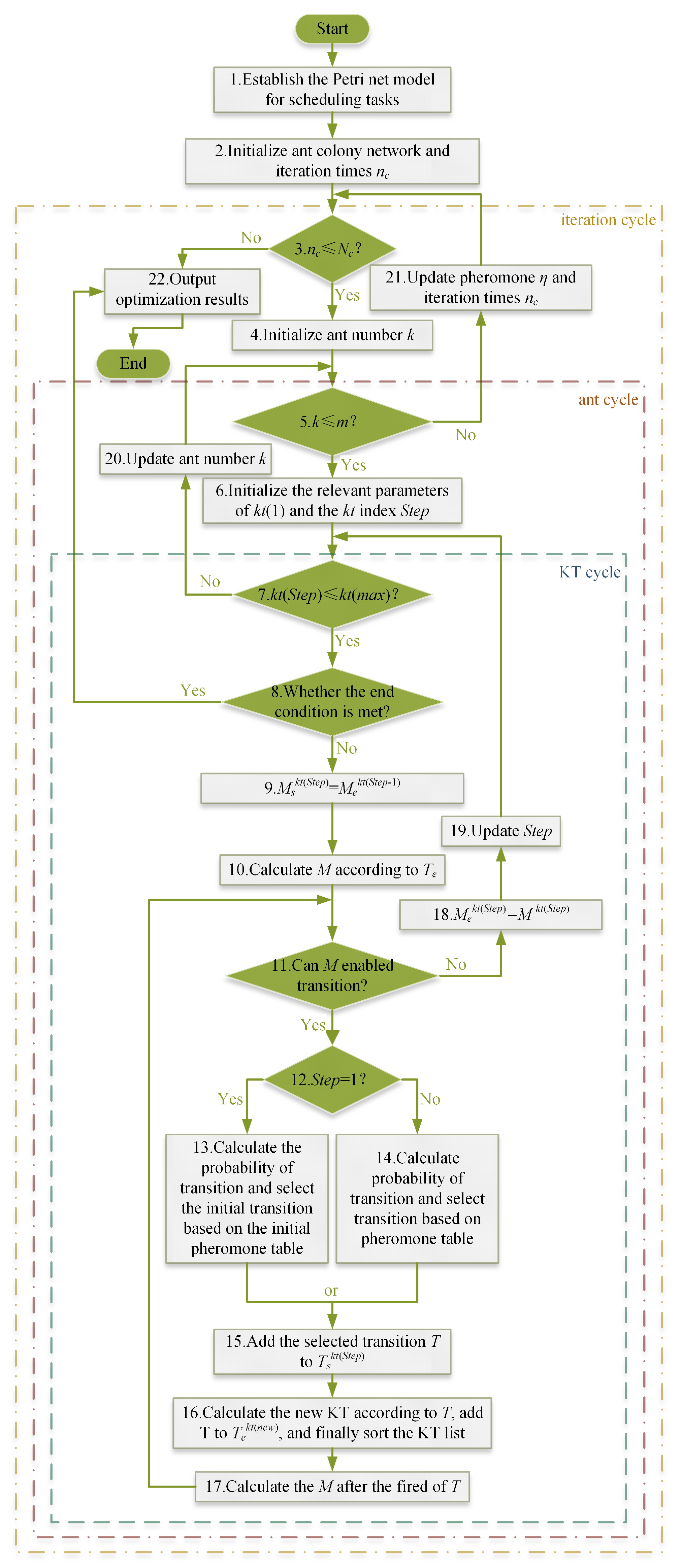
The original PN-AACO algorithm process maintained two tables: the table KT and the pheromone table Eta. The iPN-AACO algorithm also includes an additional table: the initial pheromone table Zeta. The improved algorithm achieves optimization through an iteration cycle, ant cycle, and KT cycle, as illustrated in the
Figure 2.
From
Figure 2, it can be observed that the algorithm process mainly consists of three stages: model building, initialization, and cycle body.
Modeling of the Petri net for scheduling tasks in done in step 1. Find using a method where each job is completed individually and sequentially to ensure that is reachable. The scheduling process is described in the Petri net model to determine data such as P, T, , , , , , etc., to prepare the data input for the next ACO algorithm.
Step 2 is ACO algorithm initialization. In this step, some parameters are defined, including m, , , , , Q, and . Then, create the table KT, table Eta, table Zeta, and tables for some intermediate parameters. Finally, set the iteration times to 1 and prepare the first iteration.
The three-layer cycle is described as follows: The three cycles are, in order from outside to inside, the iteration cycle, the ant cycle and the KT cycle. First, outside the cycle, initialize the iterations
. After entering the iteration cycle, i.e., step 3, first determine whether the current iteration count is less than or equal to the specified count of cycles; if not, enter step 22—output the result and end the cycle. If yes, enter step 4—initialize the ant number
, and enter the ant cycle, i.e., step 5. In the ant cycle, the count of ants is
m. If all ants are traveled, enter step 21—the pheromone level is updated according to Equations (
3) and (
5) and
increases itself by one to the next iteration cycle; if not traveled completely, enter step 6—initialize
,
,
, and prepare to enter the KT cycle, where
is the index of KT; initialize index
.
Enter the KT cycle, i.e., step 7, to determine whether the current is the last key time point of the table KT. If yes, then enter step 20—jump out of the KT cycle to update the ant index number to travel the new ant; if not, then enter the KT cycle body, i.e., step 8. Because each ant does not necessarily travel through the same number of key time points, the ant cycle is in the outer layer of the KT cycle. The KT cycle needs to traverse all key time points on the global timeline, and the key time points are dynamically increasing. After entering the KT cycle, it first determines whether the end condition is satisfied in step 8, and the end condition can determine whether the end marking
is reached. Output the optimization result in step 22 if the end state is satisfied; if not, continue the KT cycle, i.e., step 9. When traveling to
, the following is satisfied:
Then, enter step 10 according to the following:
Compute the
values, where
is a vector of which the ordinal labeling set is the transition set
. The element of
is the fired count of the transition corresponding to the same ordinal labeling. For example, if the count of a transition set is
, then
. Then,
. After calculating
, enter step 11: Determine what transition can fire in
. The basis on which the transition
can fire is
where
is a vector,
denotes the
i-th element of
, and similarly,
denotes the
i-th row and
j-th column of matrix
. If Equation (
11) is satisfied, then the transition can fire. Temporary transitions that can occur are stored, and the process proceeds to step 12. If
, then proceed to step 13, where the probabilities are computed based on Equation (
6), and an initial transition is randomly selected. Otherwise, proceed to step 14, where computations and selections are made according to Equation (
7). Assuming that the chosen transition is
, then a new element
is added to
in step 15, i.e.,
where “′” represents the new value. Once it is added, go to step 16. If
does not exist in the table KT, add
to the table KT and sort by
. Also, update the member variable
of the table KT for the new moment:
Next, enter step 17: Calculate the new
after the transition has fired. It is defined as follows:
where
is a vector with the transition
as the ordinal labeling set. After calculating the new
, we again determine whether
can fire the transition or not. Until
is unable to fire, enter step 18. Throughout the process from step 11 to step 17, the tokens always satisfy the selected transition first, and after the current transition has consumed the tokens, the remaining tokens are judged to determine whether a new transition can still fire. This process can effectively prevent the deadlock phenomenon caused by resource grabbing. Next is step 19:
is updated, while
increments itself by one and goes to the next KT cycle.
6. Train Loading Application
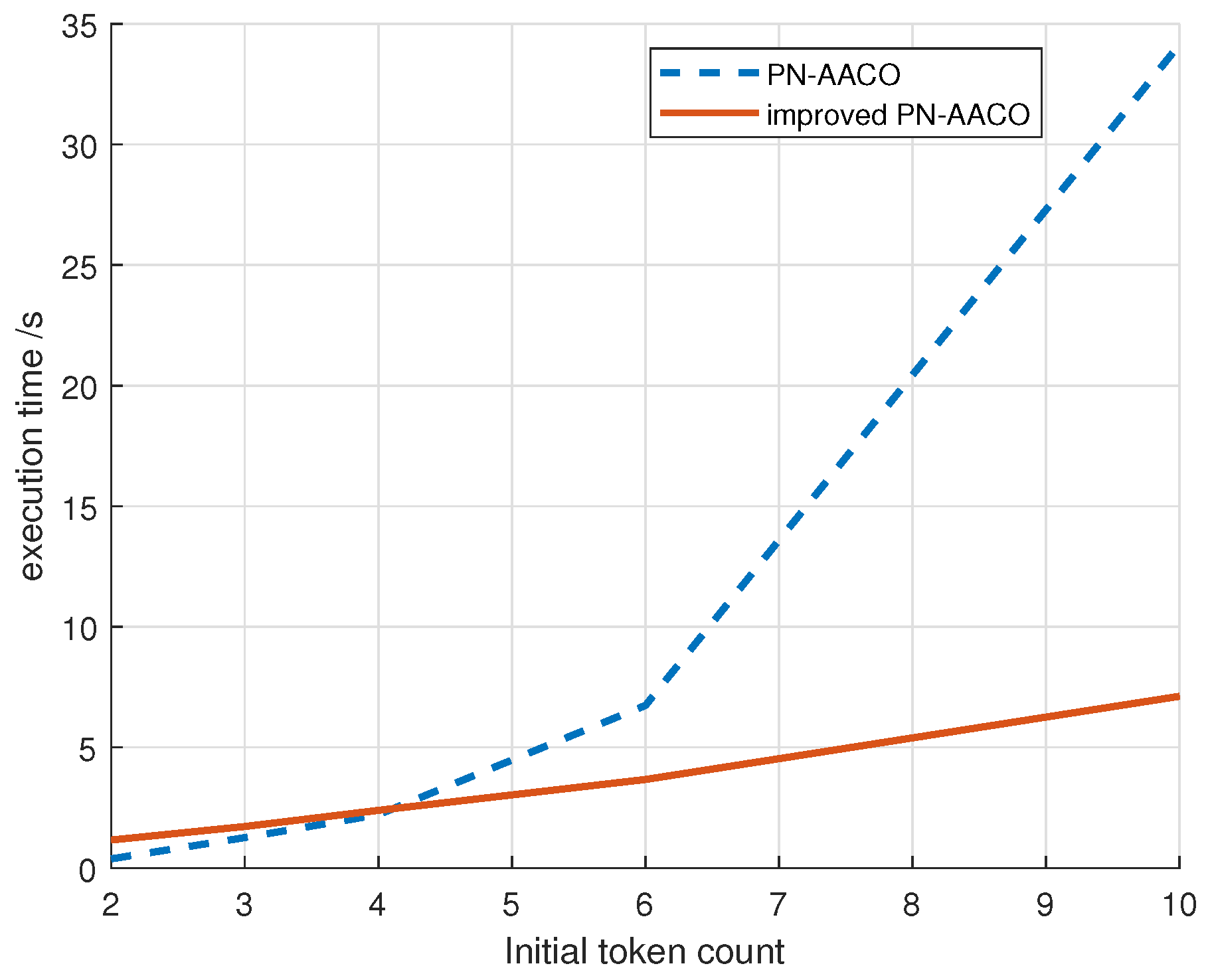
To validate the feasibility of the iPN-AACO algorithm, this study conducted a simulation using the task of coiling carbon steel sheets in the 2# warehouse area of the Finished Product Service Branch of Gansu Jiuquan Iron and Steel Group Hongxing Iron and Steel Co., Ltd., Jiayuguan, China. The simulation aimed to obtain a scheduling solution for minimizing the completion time of work in this system. Specifically, the goal was to find the shortest transition sequence that minimized the completion time . The simulation employed both the PN-AACO algorithm and the iPN-AACO algorithm for this purpose.
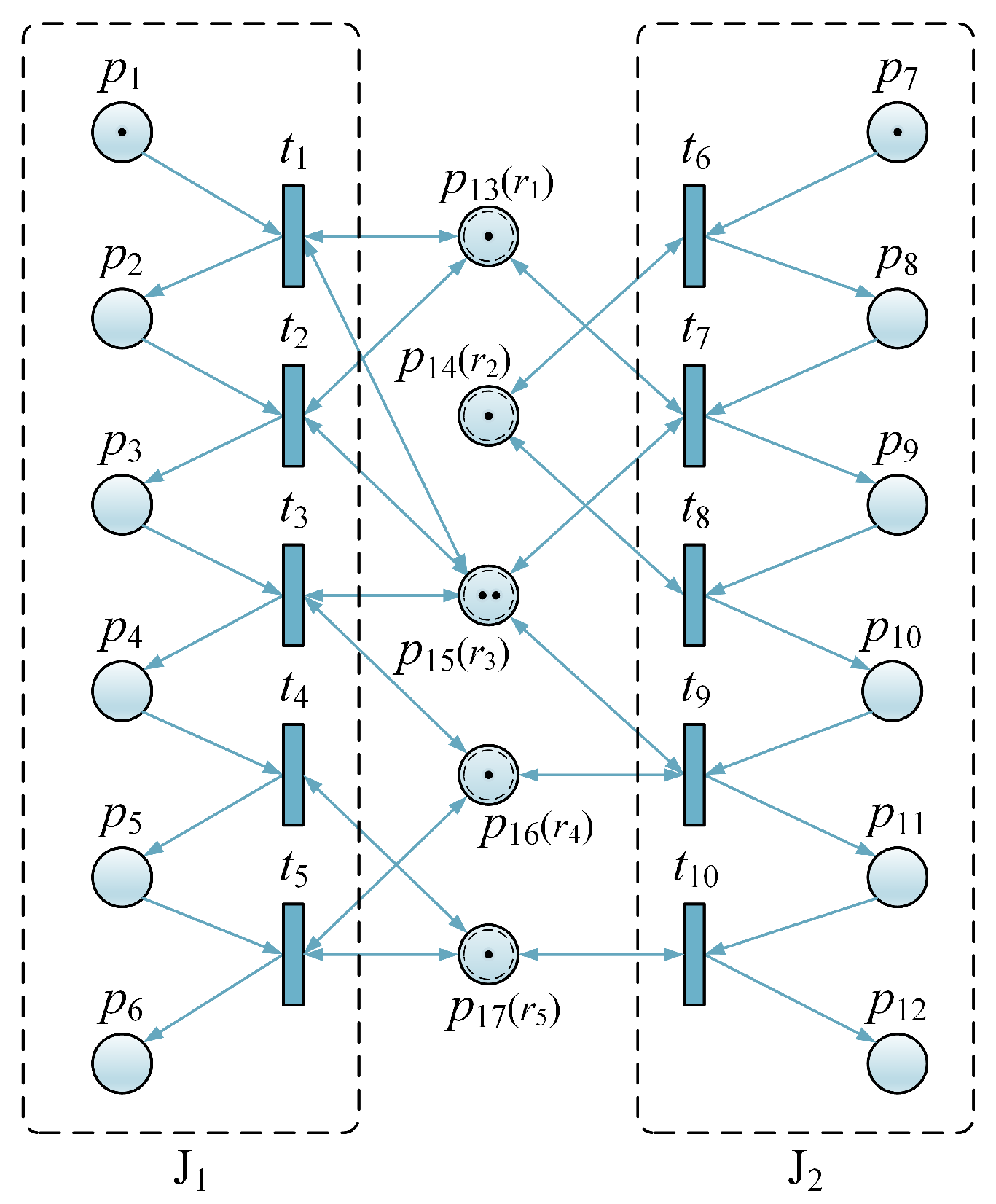
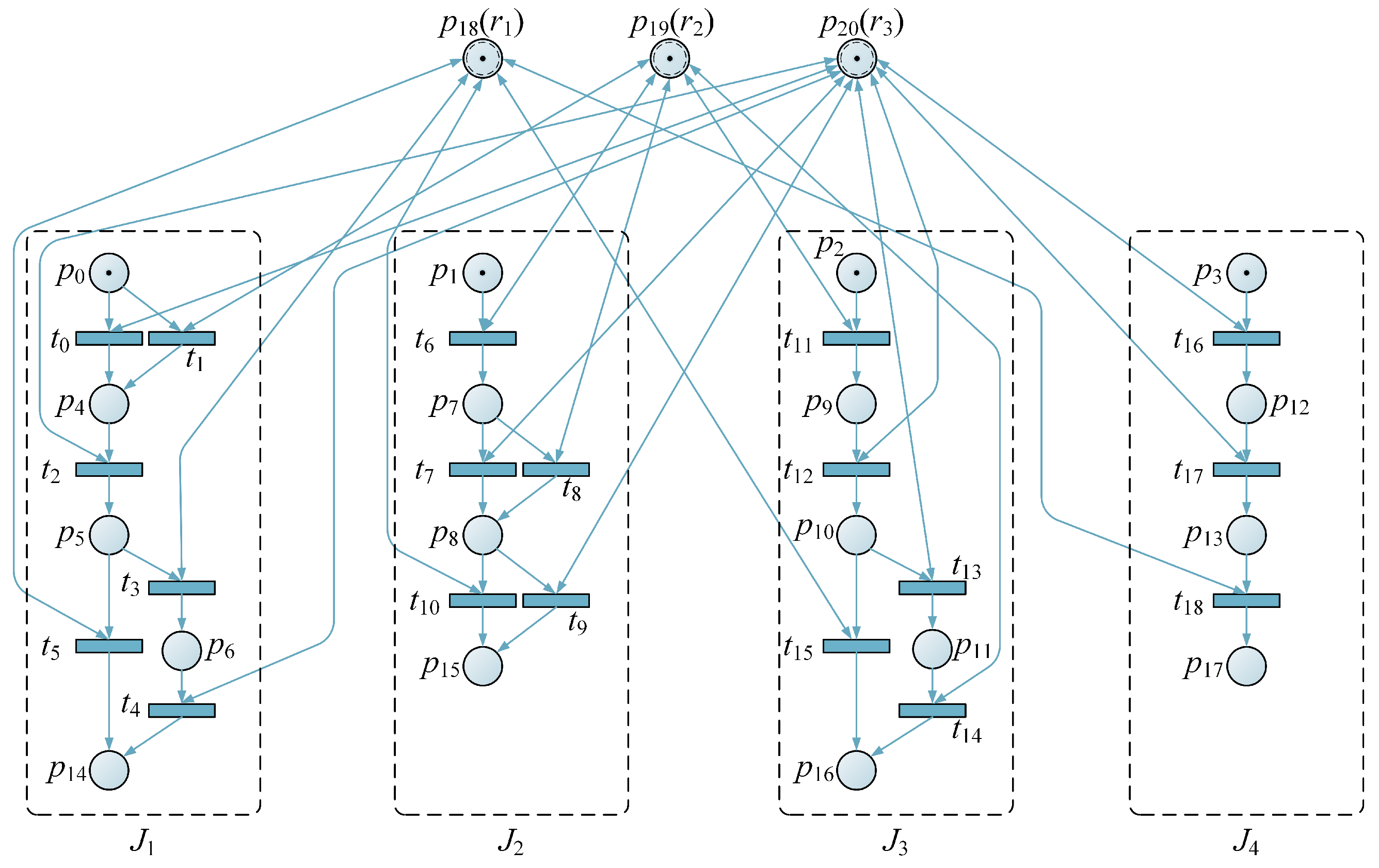
There are two double-girder overhead traveling cranes and two forklifts for transporting steel coils in the cold rolled carbon steel sheet 2# storage area. And there is one railroad loading and unloading line with access to the warehouse area with six carriages, one carriage for two steel brackets and one steel bracket for two steel coils. The task was to optimize the deployment of cranes and forklifts in such a way that the shortest possible time was required for loading the six carriages of steel coils that were driven into the storage area. This study did not take into account the mutual interference between cranes, and it assumed that the storage capacity is much greater than the capacity of the six carriages. Additionally, it did not consider the time taken for the train to transport coils to the next empty train position. The loading problem was simplified to model the Petri net, as shown in
Figure 8.
The algorithm parameters were the same as in test task. In the iPN-AACO algorithm,
. Our target was to find an
that minimizes the
when the train drives into the warehouse area. The PN-AACO and iPN-AACO algorithms were used, where the PN-AACO algorithm had a execution time of 36.1 s, and the iPN-AACO algorithm had a execution time of 5.1 s. Both algorithms searched for the best known path, and the
of
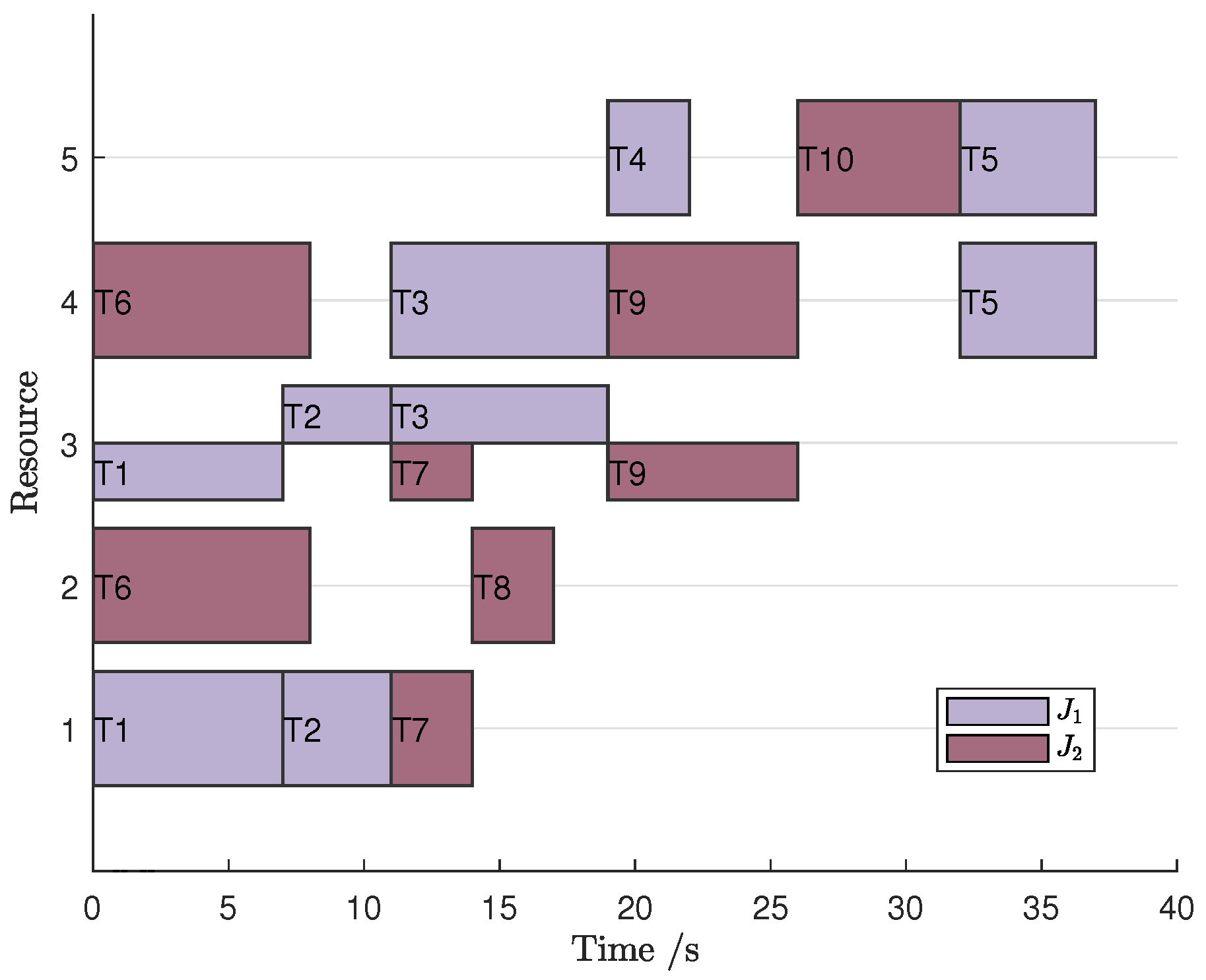
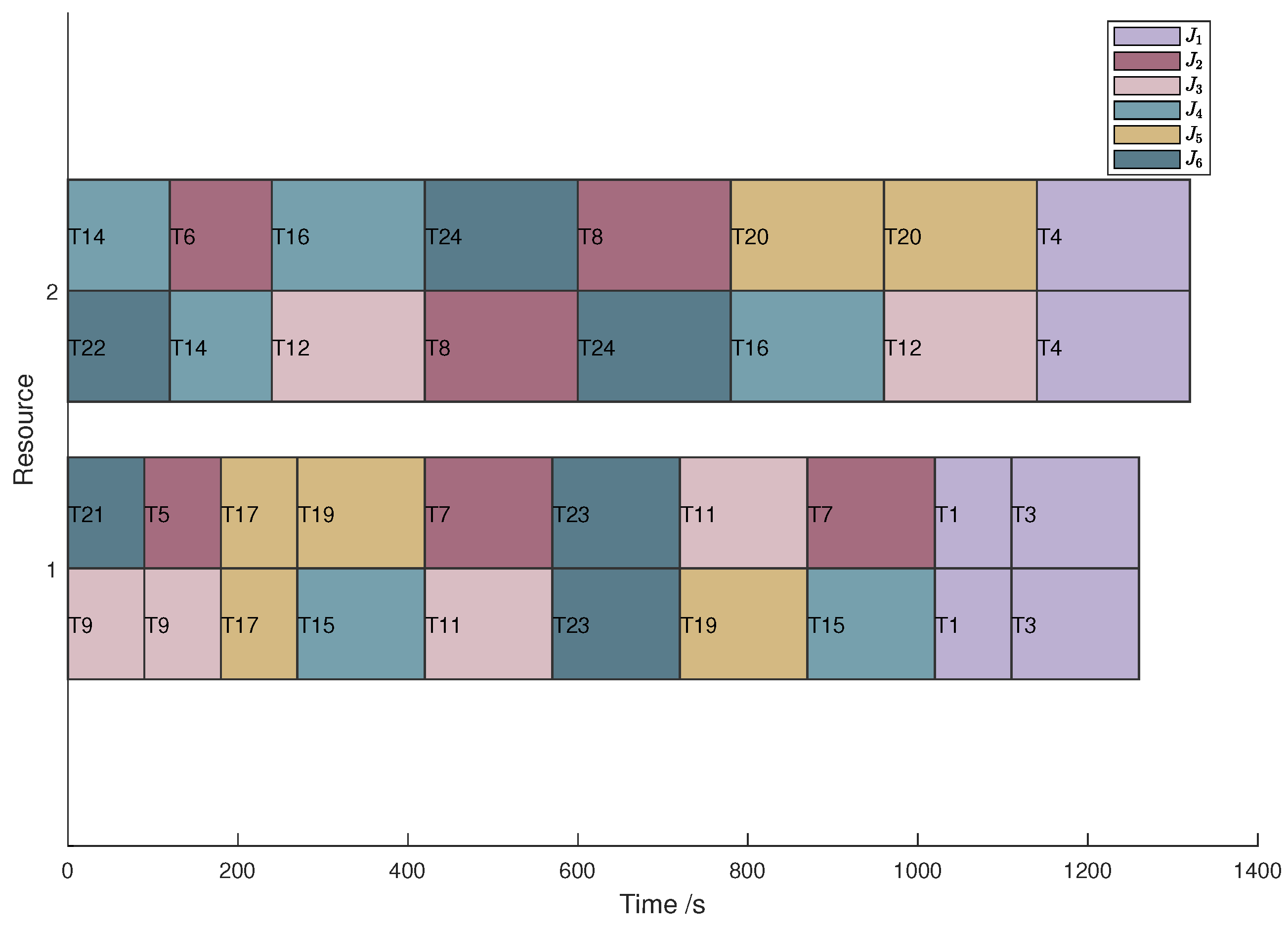
came out ot 1320 s. It can be seen from the algorithms that there is more than one best known path, and the scheduling Gantt chart is shown in
Figure 9 for example
.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}