
Semantic Textual Similarity with Constituent Parsing Heterogeneous Graph Attention Networks


Abstract

1. Introduction
- This paper utilizes constituent parsing to construct heterogeneous graphs and employs a graph attention mechanism to propagate information.
- This paper designs different message propagation paths.
- This paper augments the dataset by establishing corresponding links between noun phrases and verb phrases within the syntax tree.
2. Related Work
2.1. The Application of Graph Attention Network in Field of NLP
2.2. Fusion Syntax Model
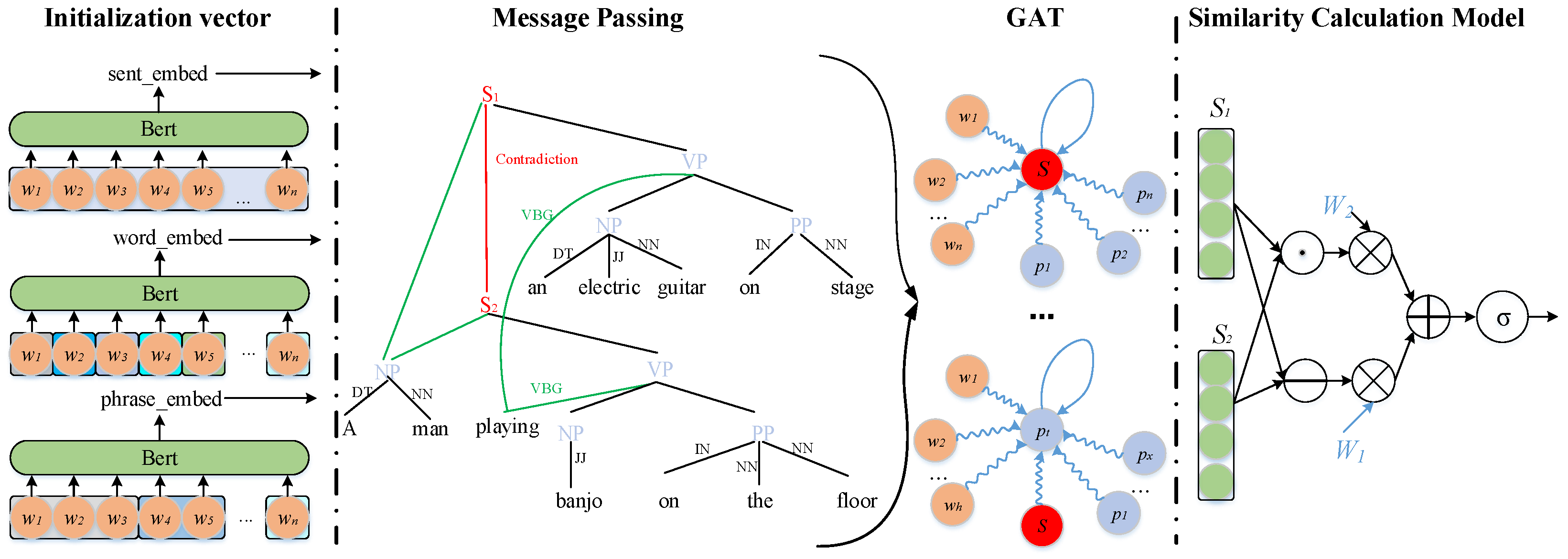
3. Methodology
3.1. Graph Attention Network
3.2. Heterogeneous Graph Neural Network (HGNN)
3.3. Model Overview
3.3.1. Graph Construction
3.3.2. Graph Attention Layer
3.3.3. Message Propagation
3.3.4. Similarity Calculation Model
4. Experiments
4.1. Tasks and Datasets
4.1.1. Sentences Involving Compositional Knowledge (SICK) Dataset
4.1.2. STS Benchmark Dataset
4.1.3. The Stanford Natural Language Inference (SNLI) Dataset
4.2. Experimental Details and Hyperparameters
4.3. Results on SICK Dataset
4.4. Results on STS Benchmark Dataset
4.5. Results on SLNI
4.6. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| STS | Semantic Textual Similarity |
| NLP | Natural Language Processing |
| MT | Machine Translation |
| LSTM | Long Short-Term Memory |
| HGAT-CP | Heterogeneous Graph Attention Network that Integrates Constituent Parsing |
| BERT | Bidirectional Encoder Representations from Transformers |
| GAT | Graph Attention Network |
| NP | Noun Phrase |
| VP | Verb Phrase |
| HGAT | Heterogeneous Graph Attention Network |
| SICK | Sentences Involving Compositional Knowledge |
| SNLI | Stanford Natural Language Inference |
| MSRVID | Microsoft Video Paraphrase Dataset |
References
- Wang, M.; Smith, N.A.; Mitamura, T. What is The Jeopardy Model? A Quasi-Synchronous Grammar for QA. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; pp. 22–32. [Google Scholar]
- Yang, Y.; Yih, W.T.; Meek, C. WikiQA: A Challenge Dataset for Open-Domain Question Answering. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2013–2018. [Google Scholar]
- Santos, J.; Alves, A.; Gonçalo Oliveira, H. Leveraging on Semantic Textual Similarity for Developing a Portuguese Dialogue System. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Evora, Portugal, 2–4 March 2020; pp. 131–142. [Google Scholar]
- Yin, W.; Schütze, H. Convolutional Neural Network for Paraphrase Identification. In Proceedings of the Human Language Technologies: The 2015 Annual Conference of the North American Chapter of the ACL, Denver, CO, USA, 31 May–5 June 2015; pp. 901–911. [Google Scholar]
- He, H.; Wieting, J.; Gimpel, K.; Rao, J.; Lin, J. UMD-TTIC-UW at SemEval-2016 Task 1: Attention-Based Multi-Perspective Convolutional Neural Networks for Textual Similarity Measurement. In Proceedings of the SemEval-2016, San Diego, CA, USA, 16–17 June 2016; pp. 662–667. [Google Scholar]
- Richardson, R.; Smeaton, A.F. Using Wordnet in a Knowledge-Based Approach to Information Retrieval; Dublin City University, School of Computer Applications: Dublin, Ireland, 1995. [Google Scholar]
- Niwattanakul, S.; Singthongchai, J.; Naenudorn, E.; Wanapu, S. Using of Jaccard Coefficient for Keywords Similarity. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2013; Volume 1, pp. 380–384. [Google Scholar]
- Opitz, J.; Daza, A.; Frank, A. Weisfeiler-Leman in the BAMBOO: Novel AMR Graph Metrics and a Benchmark for AMR Graph Similarity. Trans. Assoc. Comput. Linguist. 2021, 9, 1425–1441. [Google Scholar]
- Wang, H.; Yu, D. Going Beyond Sentence Embeddings: A Token-Level Matching Algorithm for Calculating Semantic Textual Similarity. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 2: Short Papers, pp. 563–570. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings using Compositional N-gram Features. In Proceedings of the NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; pp. 528–540. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Volume 32 (ICML’14), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- He, H.; Gimpel, K.; Lin, J. Multi-Perspective Sentence Similarity Modeling with Convolutional Neural Network. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1576–1586. [Google Scholar]
- Mueller, J.; Thyagarajan, A. Siamese Recurrent Architectures for Learning Sentence Similarity. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2786–2792. [Google Scholar]
- Ranasinghe, T.; Orǎsan, C.; Mitkov, R. Semantic Textual Similarity with Siamese Neural Networks. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 1004–1011. [Google Scholar]
- Miller, G.A. Wordnet: A Lexical Database for English. Commun. ACM 1992, 38, 22–32. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the EMNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. Simcse: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6894–6910. [Google Scholar]
- Chuang, Y.S.; Dangovski, R.; Luo, H.; Zhang, Y.; Chang, S.; Soljačić, M.; Li, S.W.; Yih, W.T.; Kim, Y.; Glass, J. Diffcse: Difference-Based Contrastive Learning for Sentence Embeddings. In Proceedings of the NAACL 2022: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4207–4218. [Google Scholar]
- Zhang, D.; Xiao, W.; Zhu, H.; Ma, X.; Arnold, A.O. Virtual Augmentation Supported Contrastive Learning of Sentence Representations. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 2430–2440. [Google Scholar]
- Nguyen, X.P.; Joty, S.; Hoi, S.C.; Socher, R. Tree-Structured Attention with Hierarchical Accumulation. arXiv 2019, arXiv:2002.08046. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. Sg-net: Syntax-Guided Machine Reading Comprehension. Aaai Conf. Artif. Intell. 2020, 34, 9636–9643. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations from Tree-Structured Long Short-Term Memory Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 1556–1566. [Google Scholar]
- Li, Z.; Zhou, Q.; Li, C.; Xu, K.; Cao, Y. Improving BERT with Syntax-aware Local Attention. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 645–653. [Google Scholar]
- Xu, Z.; Guo, D.; Tang, D.; Su, Q.; Shou, L.; Gong, M.; Zhong, W.; Quan, X.; Duan, N.; Jiang, D. Syntax-Enhanced Pre-trained Model. In Proceedings of the ACL 2021, Online, 1–6 August 2021; pp. 5412–5422. [Google Scholar]
- Bai, J.; Wang, Y.; Chen, Y.; Yang, Y.; Bai, J.; Yu, J.; Tong, Y. Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees. arXiv 2021, arXiv:2103.04350. [Google Scholar]
- Wang, R.; Tang, D.; Duan, N.; Wei, Z.; Huang, X.; Cao, G.; Jiang, D.; Zhou, M. K-adapter: Infusing Knowledge into Pre-trained Models with Adapters. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1405–1418. [Google Scholar]
- Liang, S.; Wei, W.; Mao, X.L.; Wang, F.; He, Z. BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1835–1848. [Google Scholar]
- Ahmad, W.U.; Peng, N.; Chang, K.W. Gate: Graph Attention Transformer Encoder for Crosslingual Relation and Event Extraction. Proc. AAAI Conf. Artif. Intell. 2021, 35, 12462–12470. [Google Scholar] [CrossRef]
- Devianti, R.; Miyao, Y. Transferability of Syntax-Aware Graph Neural Networks in Zero-Shot Cross-Lingual Semantic Role Labeling. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 20–42. [Google Scholar]
- Zhang, P.; Chen, J.; Shen, J.; Zhai, Z.; Li, P.; Zhang, J.; Zhang, K. Message Passing on Semantic-Anchor-Graphs for Fine-grained Emotion Representation Learning and Classification. In Proceedings of the 2024 Confere.nce on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 2771–2783. [Google Scholar]
- Xu, H.; Bao, J.; Liu, W. Double-Branch Multi-Attention based Graph Neural Network for Knowledge Graph Completion. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 15257–15271. [Google Scholar]
- Zhang, D.; Chen, F.; Chen, X. DualGATs: Dual Graph Attention Networks for Emotion Recognition in Conversations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 7395–7408. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2015; pp. 2022–2032. [Google Scholar]
- Chen, H.; Hong, P.; Han, W.; Majumder, N.; Poria, S. Dialogue Relation Extraction with Document-Level Heterogeneous Graph Attention Nnetworks. Cogn. Comput. 2023, 15, 793–802. [Google Scholar]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. HGAT: Heterogeneous Graph Attention Networks for Semi-Supervised Short Text Classification. Acm Trans. Inf. Syst. (Tois) 2021, 39, 4821–4830. [Google Scholar]
- You, J.; Li, D.; Kamigaito, H.; Funakoshi, K.; Okumura, M. Joint Learning-based Heterogeneous Graph Attention Network for Timeline Summarization. J. Nat. Lang. Process. 2023, 30, 184–214. [Google Scholar]
- Chen, S.; Feng, S.; Liang, S.; Zong, C.C.; Li, J.; Li, P. CACL: Community-Aware Heterogeneous Graph Contrastive Learning for Social Media Bot Detection. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; Volume 30, pp. 10349–10360. [Google Scholar]
- Ye, X.; Sun, Y.; Liu, D.; Li, T. A Multisource Data Fusion-based Heterogeneous Graph Attention Network for Competitor Prediction. Acm Trans. Knowl. Discov. Data 2024, 18, 1–20. [Google Scholar] [CrossRef]
- Yang, Y.; Tong, Y.; Ma, S.; Deng, Z.H. A Position Encoding Convolutional Neural Network based on Dependency Tree for Relation Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 65–74. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying Relations via Long Short Term Memory Networks Along Shortest Dependency Paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Jiang, X.; Li, Z.; Zhang, B.; Zhang, M.; Li, S.; Si, L. Supervised Treebank Conversion: Data and Approaches. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2706–2716. [Google Scholar]
- Shen, Y.; Lin, Z.; Huang, C.W.; Courville, A. Neural Language Modeling by Jointly Learning syntax and Lexicon. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Shen, Y.; Tan, S.; Sordoni, A.; Courville, A. Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sachan, D.S.; Zhang, Y.; Qi, P.; Hamilton, W. Do Syntax Trees Help Pre-trained Transformers Extract Information? In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Online, 19–23 April 2021; pp. 2647–2661. [Google Scholar]
- Bao, X.; Jiang, X.; Wang, Z.; Zhang, Y.; Zhou, G. Opinion Tree Parsing for Aspect-based Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 7971–7984. [Google Scholar]
- Tang, A.; Deleger, L.; Bossy, R.; Zweigenbaum, P.; Nédellec, C. Do Syntactic Trees Enhance Bidirectional Encoder Representations from Transformers (BERT) models for chemical–drug relation extraction? Database 2022, 2022, baac070. [Google Scholar] [CrossRef] [PubMed]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Marelli, M.; Bentivogli, L.; Baroni, M.; Bernardi, R.; Menini, S.; Zamparelli, R. SemEval-2014 task 1: Evaluation of Compositional Distributional Semantic Models on Full Sentences Through Semantic Relatedness and Textual Entailment. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A. SemEval-2012 task 6: A Pilot on Semantic Textual Similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics, Montreal, QC, Canada, 7–8 June 2012; pp. 385–393. [Google Scholar]
- Socher, R.; Karpathy, A.; Le, Q.V.; Manning, C.D.; Ng, A.Y. Grounded Compositional Semantics for Finding and Describing Images with Sentences. Trans. Assoc. Comput. Linguist. 2014, 2, 207–218. [Google Scholar] [CrossRef]
- Shao, Y. Hcti at semeval-2017 task 1: Use Convolutional Neural Network to Evaluate Semantic Textual Similarity. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 130–133. [Google Scholar]
- Yang, Y.; Yuan, S.; Cer, D.; Kong, S.Y.; Constant, N.; Pilar, P.; Ge, H.; Sung, Y.H.; Strope, B.; Kurzweil, R. Learning Semantic Textual Similarity from Conversations. In Proceedings of the 3rd Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; pp. 164–174. [Google Scholar]
- Maillard, J.; Clark, S.; Yogatama, D. Jointly Learning Sentence Embeddings and Syntax with Unsupervised Tree-LSTMs. Nat. Lang. Eng. 2019, 25, 433–449. [Google Scholar]
- Choi, J.; Yoo, K.M.; Lee, S.G. Learning to Compose Task-Specific Tree Structures. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence: Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 7. [Google Scholar]

{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Word Embedding Dimension | 300 |
| Phrase Embedding Dimension | 300 |
| Sentence Embedding Dimension | 300 |
| Multi-head Attention Number | 10 |
| Learning Rate | 0.0003 |
| Batch Size | 32 |
| Optimizer | adam |
| Learning Rate Decay | 0.9 |
| Dropout | 0.5 |
| Methods | Pearson × 100 | Spearman × 100 | MSE |
|---|---|---|---|
| Not-use syntactic structure | |||
| Mean vectors | 76.24 | 70.31 | 0.4321 |
| LSTM | 84.32 | 78.27 | 0.2866 |
| BiLSTM | 85.68 | 79.45 | 0.2756 |
| BERT-Sent2vec [11] | 81.43 | 77.35 | 0.2886 |
| CNN [12] | 86.86 | 80.47 | 0.2606 |
| BERT [16] | ∖ | 42.63 | ∖ |
| SRoBERTa [19]) | ∖ | 74.46 | ∖ |
| SBERT [19] | ∖ | 72.91 | ∖ |
| SimCSE-RoBERTa base [20] | ∖ | 80.50 | ∖ |
| SimCSE-RoBERTa large [20] | ∖ | 81.95 | ∖ |
| Use syntactic structure | |||
| DT-RNN [55] | 79.23 | 73.19 | 0.3822 |
| SDT-RNN [55] | 79.00 | 73.04 | 0.3848 |
| Const.LSTM [26] | 85.82 | 79.66 | 0.2734 |
| Dep. LSTM [26] | 86.76 | 80.83 | 0.2532 |
| HGAT_W-S | 86.31 | 79.51 | 0.2712 |
| HGAT_CP | 86.92 | 80.43 | 0.2582 |
| HGAT_CP(NP, VP) | 87.73 * | 82.34 * | 0.2343 * |
| Models | Pearson × 100 |
|---|---|
| Not-use syntactic structure | |
| Mean vectors | 62.31 |
| LSTM | 72.36 |
| BiLSTM | 73.82 |
| HCTI [56] | 78.40 |
| Reddit tuned [57] | 78.10 |
| BERT [16] | 84.30 |
| SRoBERTa [19] | 84.92 |
| SBERT [19] | 84.67 |
| SimCSE-RoBERTa base [20] | 85.83 |
| SimCSE-RoBERTa large [20] | 86.70 * |
| Use syntactic structure | |
| Dependency Tree-LSTM | 71.20 |
| Constituency Tree-LSTM | 71.90 |
| HGAT_W-S | 79.31 |
| HGAT_CP | 80.23 |
| HGAT_CP(NP, VP) | 81.35 |
| Models | Accuracy × 100 |
|---|---|
| 100D Latent Syntax Tree-LSTM [58] | 80.5 |
| 100D CYK Tree-LSTM [58] | 81.6 |
| 600D Gumbel Tree-LSTM [59] | 86.0 |
| 300D Gumbel Tree-LSTM [59] | 85.6 |
| BERT_base [16] | 90.9 |
| BERT_large [16] | 91.0 * |
| HGAT_W-S | 86.3 |
| HGAT_CP | 89.6 |
| HGAT_CP(NP, VP) | 90.5 |
| SICK | Length > 13 | Length < 6 | STS Benchmark | Length > 13 | Length < 6 |
|---|---|---|---|---|---|
| Method | Pearson × 100 | Pearson × 100 | Method | Pearson × 100 | Pearson × 100 |
| Mean vectors | 62.75 | 82.37 | Mean vectors | 48.26 | 72.37 |
| LSTM | 75.74 | 87.82 | LSTM | 60.74 | 85.47 |
| BiLSTM | 77.38 | 87.96 | BiLSTM | 62.13 | 86.18 |
| HGAT_W-S | 77.72 | 88.36 | HGAT_W-S | 61.94 | 86.81 |
| HGAT_CP | 79.53 | 89.33 | HGAT_CP | 64.87 | 88.13 |
| HGAT_CP(NP, VP) | 80.07 * | 89.46 * | HGAT_CP(NP, VP) | 65.61 * | 88.62 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Huang, D.; Lin, X. Semantic Textual Similarity with Constituent Parsing Heterogeneous Graph Attention Networks. Symmetry 2025, 17, 486. https://doi.org/10.3390/sym17040486
Wu H, Huang D, Lin X. Semantic Textual Similarity with Constituent Parsing Heterogeneous Graph Attention Networks. Symmetry. 2025; 17(4):486. https://doi.org/10.3390/sym17040486
Chicago/Turabian StyleWu, Hao, Degen Huang, and Xiaohui Lin. 2025. "Semantic Textual Similarity with Constituent Parsing Heterogeneous Graph Attention Networks" Symmetry 17, no. 4: 486. https://doi.org/10.3390/sym17040486
APA StyleWu, H., Huang, D., & Lin, X. (2025). Semantic Textual Similarity with Constituent Parsing Heterogeneous Graph Attention Networks. Symmetry, 17(4), 486. https://doi.org/10.3390/sym17040486