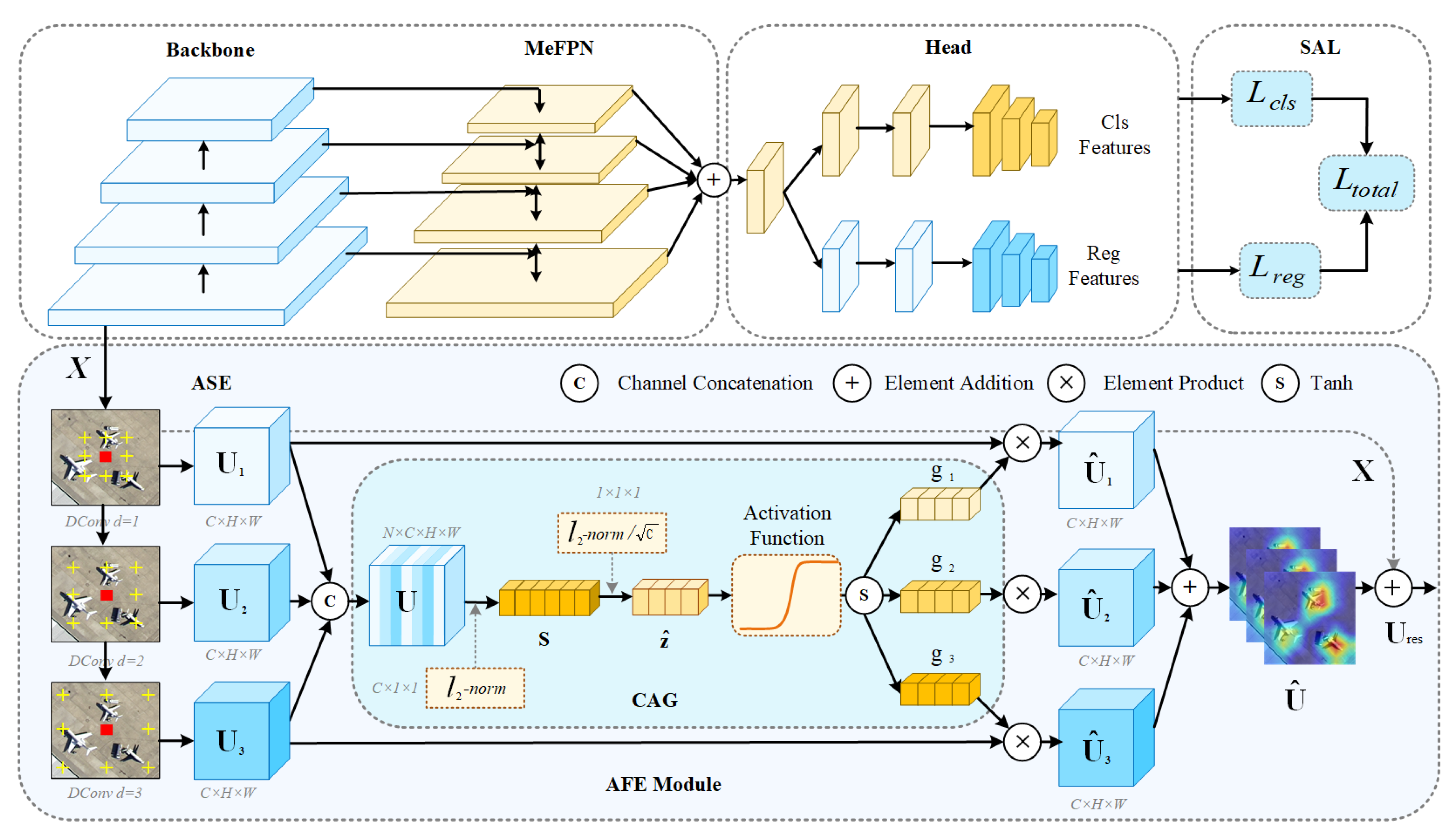
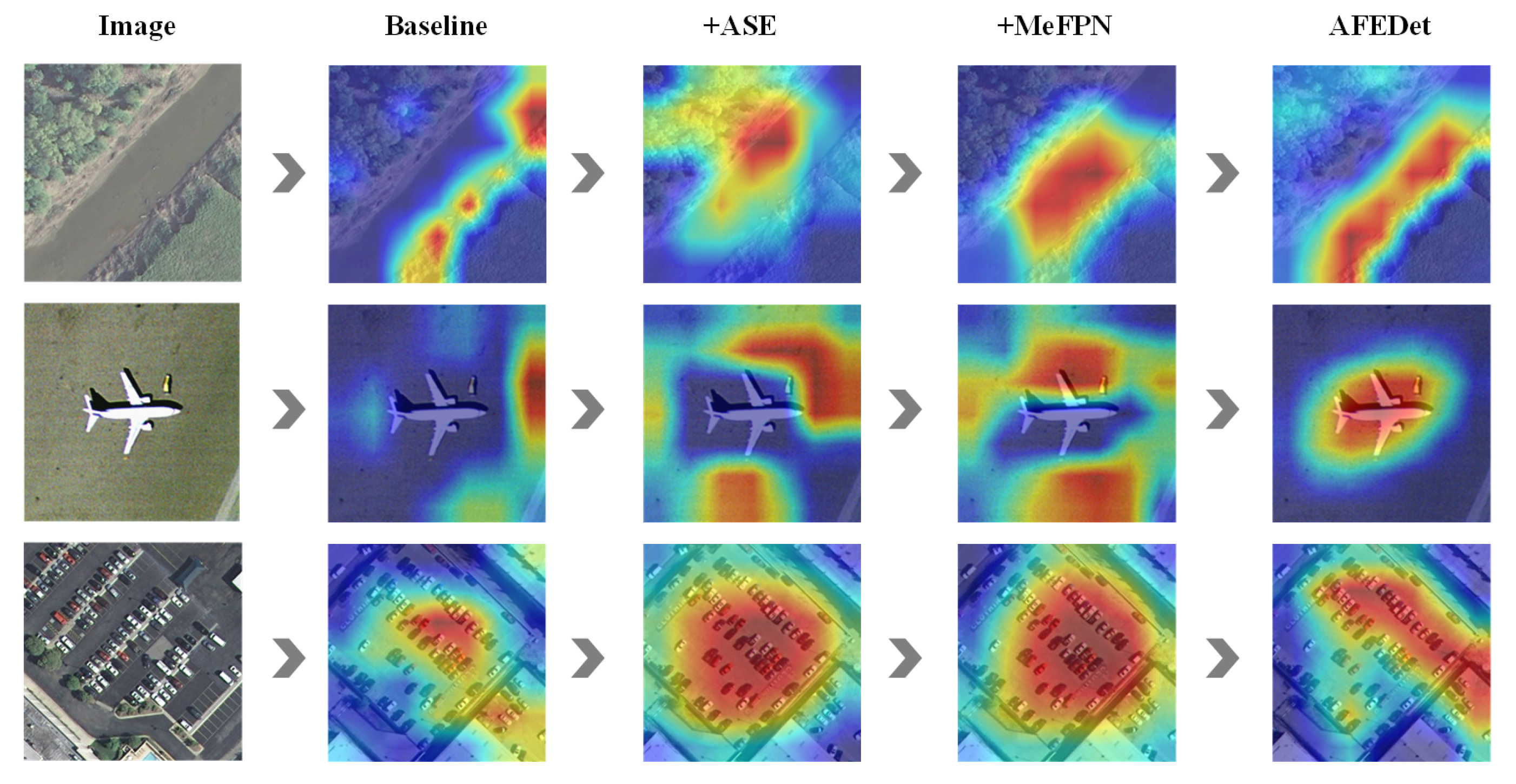
3.1. Adaptive Feature Extraction Module
Traditional object detection methods use fixed-sized convolution kernels and a single network structure. When dealing with objects of different scales, it is difficult for them to adapt to scale changes and they cannot effectively extract comprehensive features.
Parallel Dilated Convolution Sequence: AFE adopts a parallel dilated convolution sequence. This design expands the receptive field without extra parameters and excels in tasks like image recognition requiring a good grasp of data spatial relationships. The pseudocode of this module is shown in
Table 1. Assume that the input feature map is denoted as
, and the output of each branch can be formulated as follows:
where
d represents the dilation rate, which determines the interval of skipping pixels during the convolution process of the convolutional kernel, and
is the kernel function that describes the specific operation rules of the convolution operation.
The receptive fields of different branches can be expressed as
Here, k denotes the kernel size, stands for the receptive field of the preceding layer, and is the dilation rate of the current layer. The dilation rates of various layers can be configured based on practical requirements. By doing so, the network is able to flexibly modify the size of the receptive field to meet the feature extraction needs of objects at different scales.
All branch outputs are combined in the channel dimension, with the following formula representing this process:
where
n represents the number of branches, and
represents the concatenation operation along the channel. Through this concatenation method, the features with different receptive fields extracted by different branches are fused to obtain more abundant feature information.
Channel Attention Gating Module: Selective kernel network (SKNet) [
33] uses global average pooling (GAP) and fully connected layers to perceive the relationships between channels and assign channel importance. However, for normalized inputs, its output lacks discrimination among different samples. Moreover, global average pooling is insensitive to noise and outliers, and these will be averaged into the final result, affecting the model’s stability. To resolve these issues, the present paper employs the normalized CAG. For the features of each branch, the
-norm [
34] is calculated along the channel dimension. Unlike average pooling and max pooling, which select the maximum or average value within the pooling window as output, the
-norm, computed as
, can preserve richer feature information. This enables the extraction of more detailed features during the feature extraction phase. The formula for the
-norm is as follows:
Here, is a learnable weight parameter used to adjust the importance of each channel’s feature, and is assigned a value of to prevent division-by-zero errors during the computation.
The feature vector of each channel is processed through a parameter-free normalization technique based on
-norm scaling, and the formula is as follows:
The scalar
is introduced to adjust the scale of
, preventing its value from being too small when the number of channels
C is large, and ensuring the comparability of features of different channels in subsequent calculations. Subsequently, the activation function
is used to dynamically adjust the contribution of features, and the formula is
Here, represents the normalized scale vector, while and denote the gating weight and bias, respectively. These are employed to adaptively regulate the scale of each channel within the feature map. The output of the function lies within the range of . This property can effectively preserve numerical stability throughout the training process and permits the adjustment of feature contributions in both positive and negative directions. As a result, the model can better adapt to diverse feature distributions.
3.2. Multi-Scale Enhanced Feature Pyramid Network
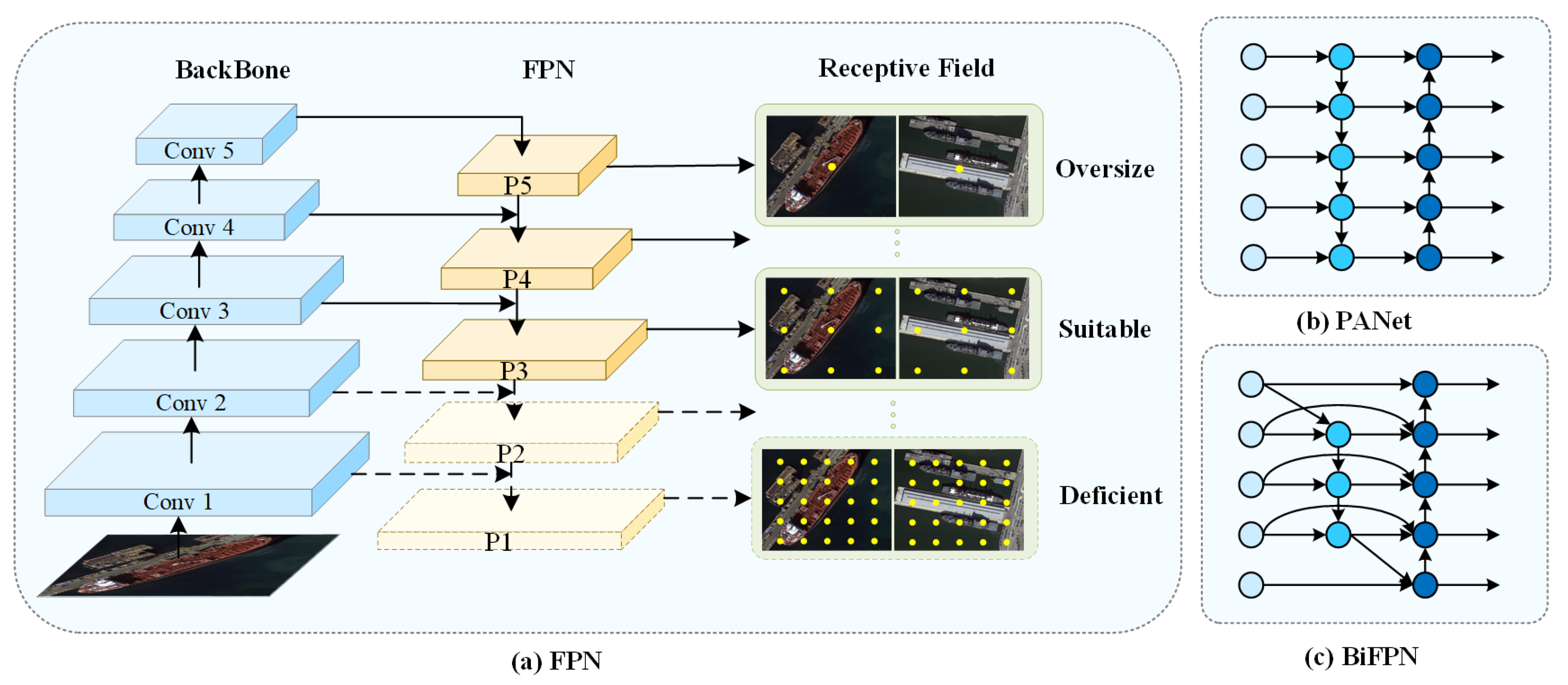
Previously, in the realm of feature fusion, numerous methodologies frequently resorted to straightforward techniques like feature concatenation or direct addition to integrate multi-level features, as depicted in
Figure 3b. This approach overlooks the disparities in scale and semantics among features at various levels. Consequently, it readily leads to information loss or semantic ambiguity in the fused features, making it arduous to fully harness the merits of features at each layer during object detection.
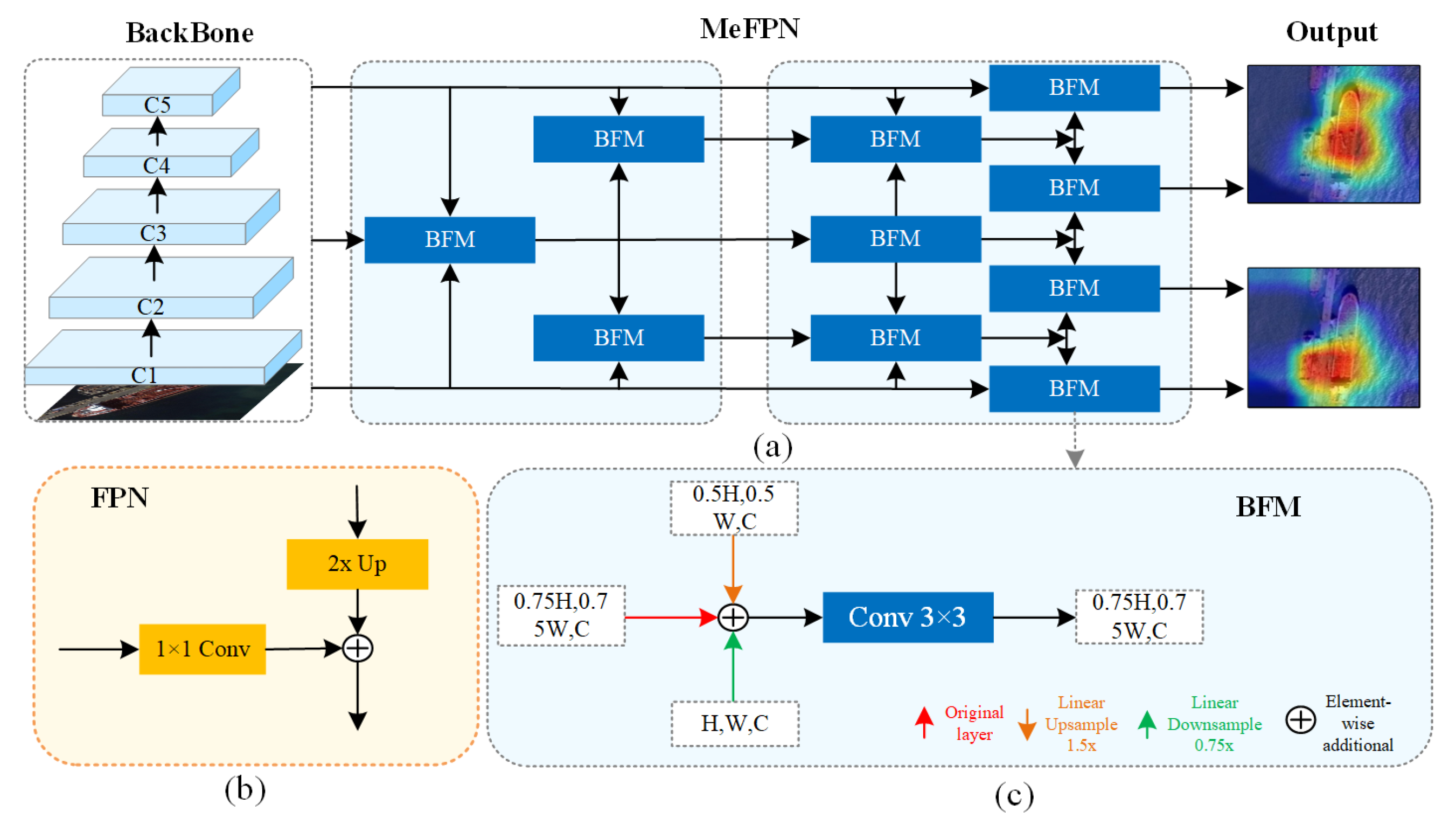
To effectively utilize multi-level features, MeFPN integrates a BFM based on structural symmetry, as illustrated in
Figure 3a. Within the BFM (
Figure 3c), a linear scale transformation is applied to align features from different levels to a common intermediate scale. This ensures that features from various levels can be fused at a unified scale, facilitating the efficient integration of high-level semantic cues with low-level fine-grained details. The formula for linear scale transformation is as follows:
Here,
and
represent the scaling factors for upsampling and downsampling, respectively. We employ bilinear interpolation to upscale higher-level feature maps, bringing their scales closer to the intermediate level in upsampling.The upsampling factor
, and the new pixel value is computed as a weighted average of four neighboring pixels:
Here, is the upsampled feature map, denotes the weight coefficient determined by the relative position of the new coordinate and neighboring pixels, and represents the pixel values in the higher-level feature map.
We employ convolution-based downsampling with a fixed stride to adjust lower-level feature maps. Specifically, a convolution kernel slides over the lower-level feature map with a downsampling factor
, following the equation
Here, is the downsampled feature map, K represents the convolution kernel value at position , denotes the corresponding pixel value in the original lower-level feature map, and k is the kernel size. The stride s is determined by the downsampling factor .
To enhance the feature representation, the scaled features are combined with the original layer features in an element-wise manner. The corresponding formula is presented below:
where
represents the features of the original layer. This preserves the advantages of each layer while enriching the overall feature set.
Finally, further feature extraction and fusion are carried out through a convolution operation to achieve more in-depth feature extraction. The formula for the fusion layer is
Here, K is a convolution kernel, and the convolution operation. The convolution screens and integrates fused features to extract more representative ones, boosting the model’s multi-scale object detection ability.
Therefore, the BFM design of MeFPN not only maintains high-efficiency feature fusion but also enhances the feature representation and discriminative ability through precise scale alignment and a two-way fusion mechanism. It achieves more flexible and accurate feature capture of multi-scale objects with lower computational complexity. The pseudocode of it is shown in
Table 2. By stacking multiple BFMs, features at different levels can be combined more fully, further enhancing the feature representation ability.
3.3. Scale-Aware Loss Function
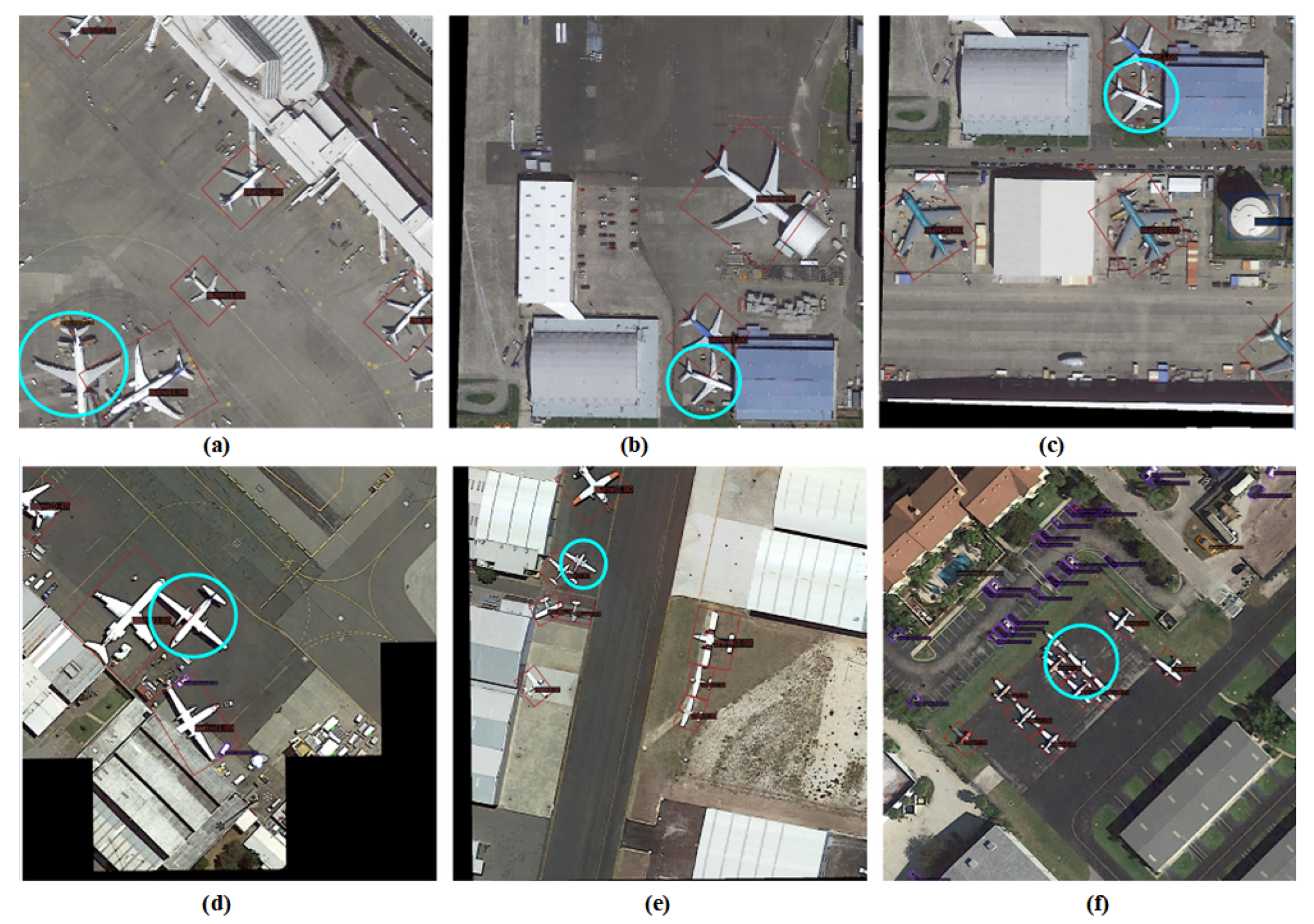
In remote sensing images, detection difficulty varies greatly by object scale. Small objects are harder to detect due to small pixel proportion and vague features [
35]. Traditional loss functions treat all-scale objects alike when computing losses, causing the network to struggle to improve small-object detection accuracy during training and thus affecting overall performance.
To balance detection difficulty differences, we introduce a scale-sensitive loss function that adjusts loss weights by object scale. Specifically, a scale weight
is added to the classification loss function:
Here, the relative scale of an object is given by
, where
,
,
, and
are object and image width-height values, respectively. Trainable parameters
and
are vital for regulating adjustment speed and maintaining scale-weight balance. Their values generally range for
from
to 10 (increased for datasets with many small objects), and
is selected around the average relative scale
based on target scale statistics. In actual training, random initialization and gradient descent are combined to fine tune them. In the DOTA [
36] dataset experiment, with dense small objects, multiple comparative tests show the model performs well when
and
. The classification loss function is expressed as
Here, is a balance factor for sample balancing, adjusting sample weights in loss calculation, and is the model’s predicted probability. The focusing parameter b is usually 2, reducing the loss weight of easy-to-classify samples so the model focuses on hard-to-classify ones. For small objects, is small, increasing classification loss and making the model focus on them. For large objects, is near 1, with no obvious increase in classification loss, ensuring stable detection.
The intersection over union (IoU) [
37] is commonly employed as a metric for evaluating regression loss. Nevertheless, IoU comes with certain limitations. Take the situation where there is no overlap between the ground-truth box (GT) and the anchor box, for instance; in such a case, the IoU value drops to 0, potentially resulting in the vanishing gradient problem. Moreover, when the anchor box is entirely enclosed within the GT box, IoU fails to precisely assess the positioning status.
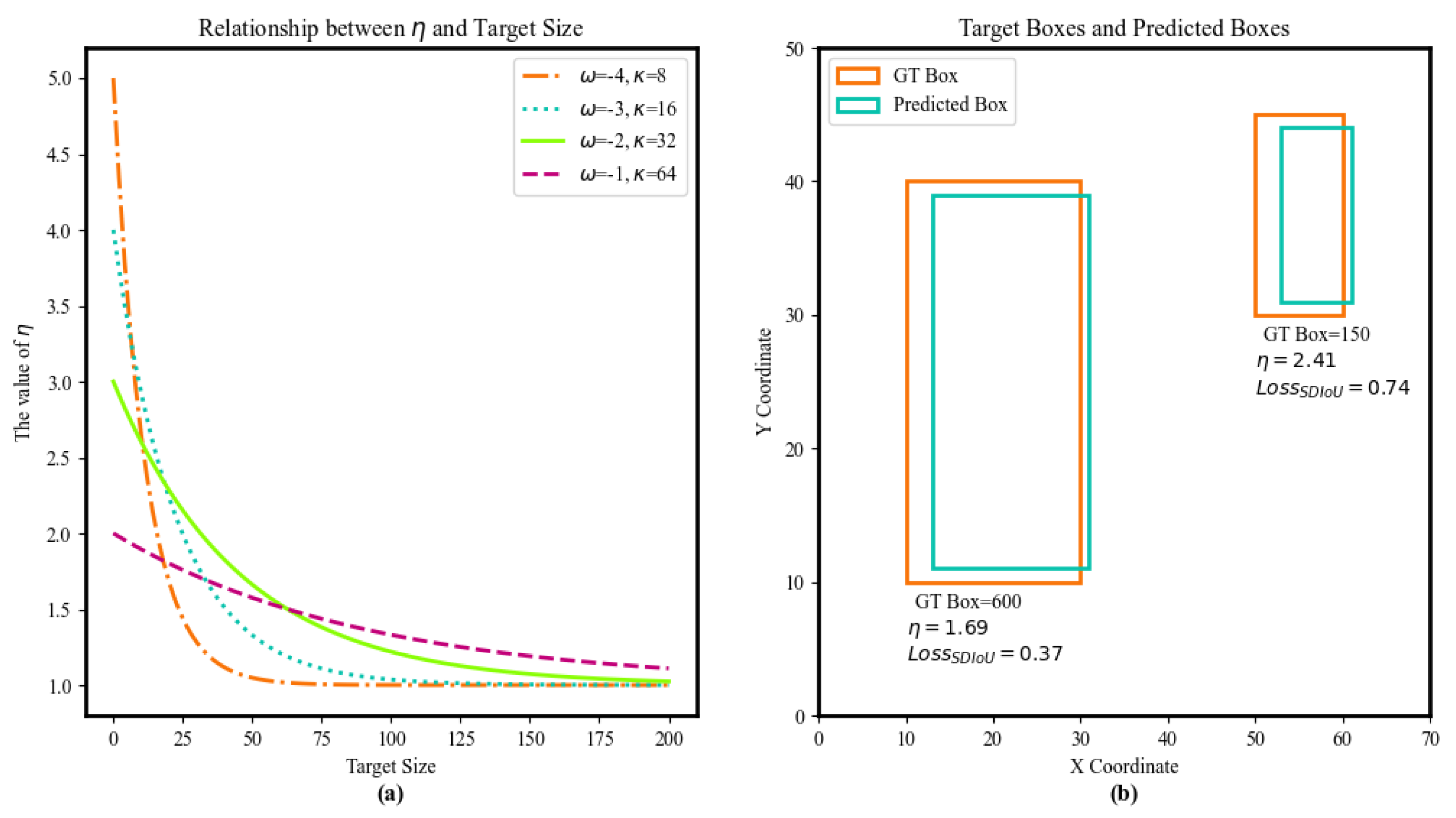
To address these issues, this paper proposes the scale-aware intersection over union (SDIoU), which balances the loss contribution of objects of different sizes through the scale weight
. As shown in
Figure 4, the GT box is
and the anchor box is
. The SDIoU is defined as follows:
Here, d is the Euclidean distance between the GT box and anchor box centers, c is the diagonal of their smallest enclosing box, is the scale weight, adjusts small-object scaling, and determines large-object’s return rate to standard IoU. Multiple tests show the model gets best accuracy for different-scale objects when and . In practice, these two parameters are fine tuned based on dataset features and task requirements.
The SAL integrates the
and the
to formulate an overall loss function:
where
and
are the weights of the classification and regression error terms, respectively. In the experiments, their values are set to
and
. The determination of these two weights is obtained through comparative experiments on multiple datasets, comprehensively considering indicators such as the precision and recall rate of the model in the detection of objects at different scales. By using scale-reciprocal loss weighting in the SAL function, these symmetric components collectively enhance the system’s robustness to scale variations while maintaining computational efficiency.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}