

Symmetrical Resilience: Detection of Cyberattacks for SCADA Systems Used in IIoT in Big Data Environments


Abstract
1. Introduction
- Providing detailed information about frequently occurring attacks in SCADA systems to shed light on developers working in this field;
- The dataset used in the developed model is obtained from IIoT devices used in SCADA, making the model applicable to both the SCADA and IIoT domains for detecting attacks;
- Increasing the number of applications in the field by using artificial intelligence technology, unlike the traditional attack detection methods;
- Comparing the results with other studies in the field, demonstrating the superior performance of the proposed approach;
- Providing a different perspective to experts in this field in terms of applying not only machine learning but also deep learning and hybrid models;
- Comparing the results by applying different hyperparameters to all the models, laying the foundation for future studies;
- Investigating the vulnerabilities and threats faced by SCADA systems in the Industrial Internet of Things (IIoT) emphasizes the critical aspect of safeguarding against cyberattacks. The focus of this study on detecting and mitigating these threats aligns with the journal’s emphasis on cybersecurity measures in modern technological frameworks;
- The inclusion of big data environments signifies the handling and analysis of substantial volumes of data generated by SCADA systems. This involves employing advanced analytics to derive meaningful insights, which resonates with the journal’s interest in big data applications and analytics techniques;
- The utilization of artificial intelligence (AI) and machine learning in identifying patterns or anomalies within SCADA-generated data reflects an innovative approach to cyberthreat detection. This connection aligns with the journal’s focus on AI applications in various technological domains;
- The study inherently addresses concerns about information security, authentication mechanisms, and the technologies deployed to safeguard data and systems. This aspect directly corresponds to the journal’s interest in exploring cutting-edge technologies for ensuring information security;
- By examining cyberthreats within SCADA systems, an integral part of the broader IoT landscape, the study addresses the security challenges prevalent in interconnected devices, aligning with the journal’s focus on IoT-related concerns;
- The comprehensive nature of this study, which explores cyberattack detection in SCADA systems within the IIoT while navigating a big data environment, encapsulates a multidisciplinary approach. It seamlessly weaves together cybersecurity, big data analytics, AI, information security, and IoT-related challenges. This holistic coverage enriches the study’s relevance and establishes a direct link to the diverse interests of the journal’s readership, providing insights into critical areas of the technological advancements and security paradigms.
2. Literature Review
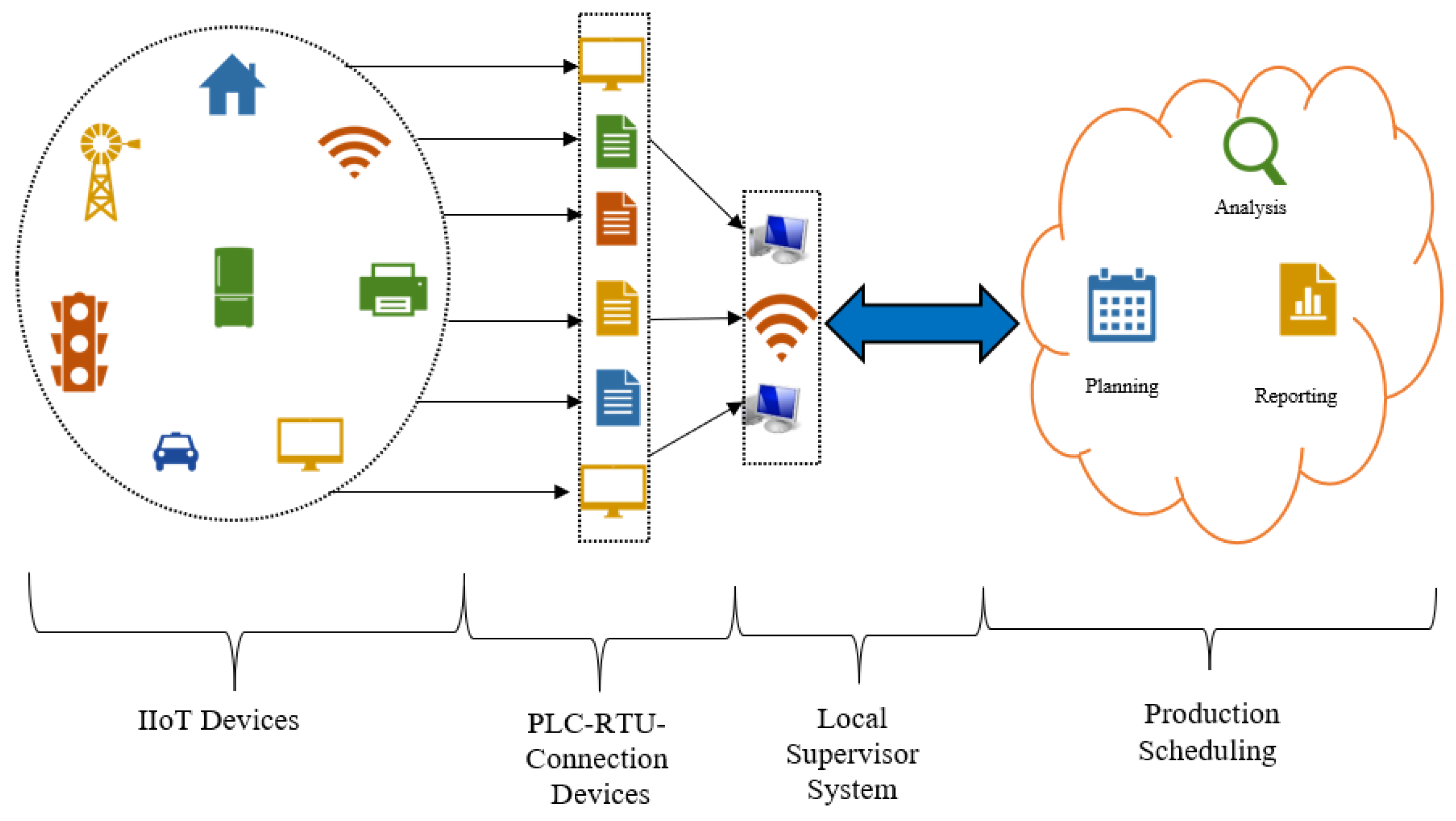
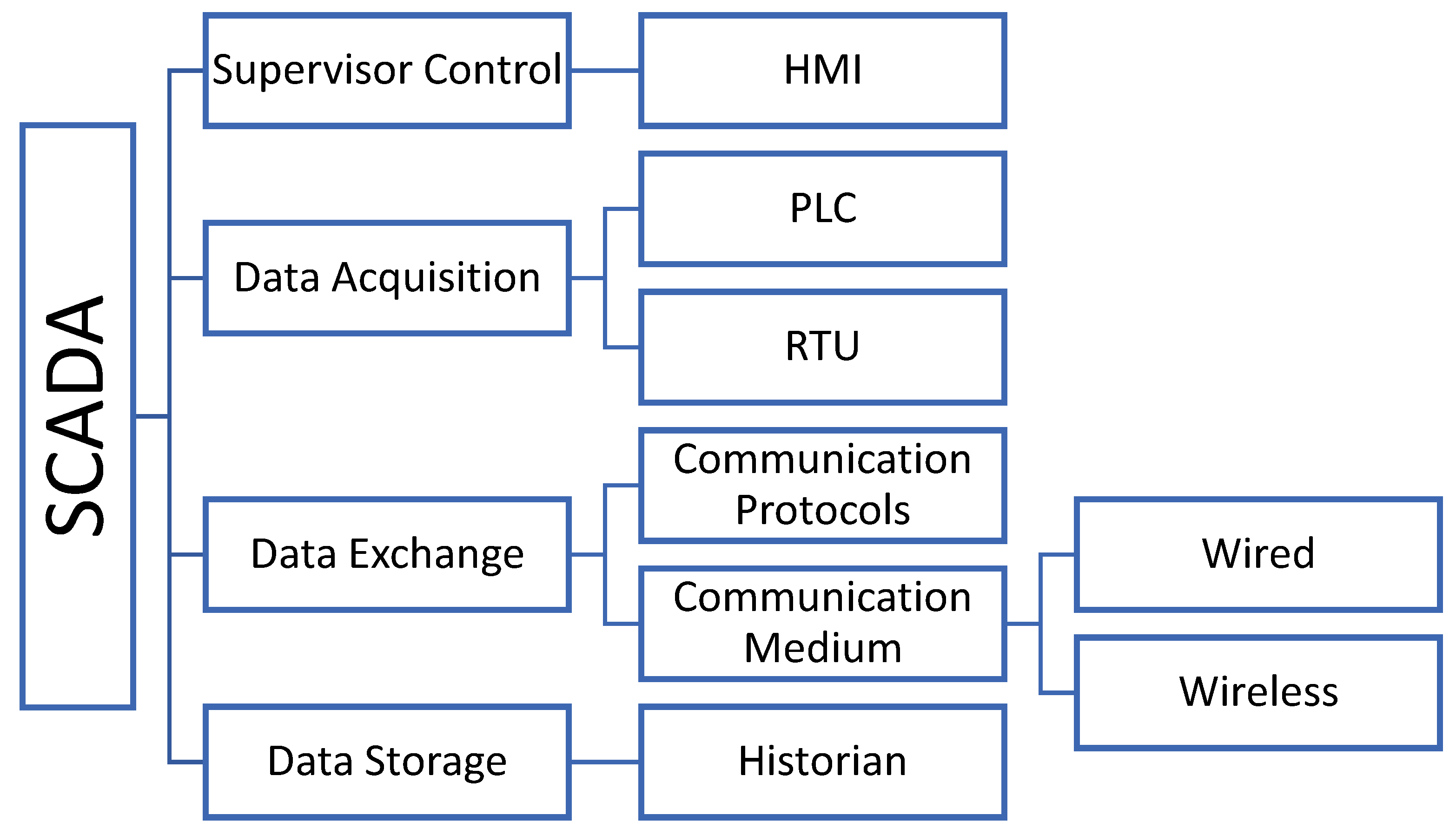
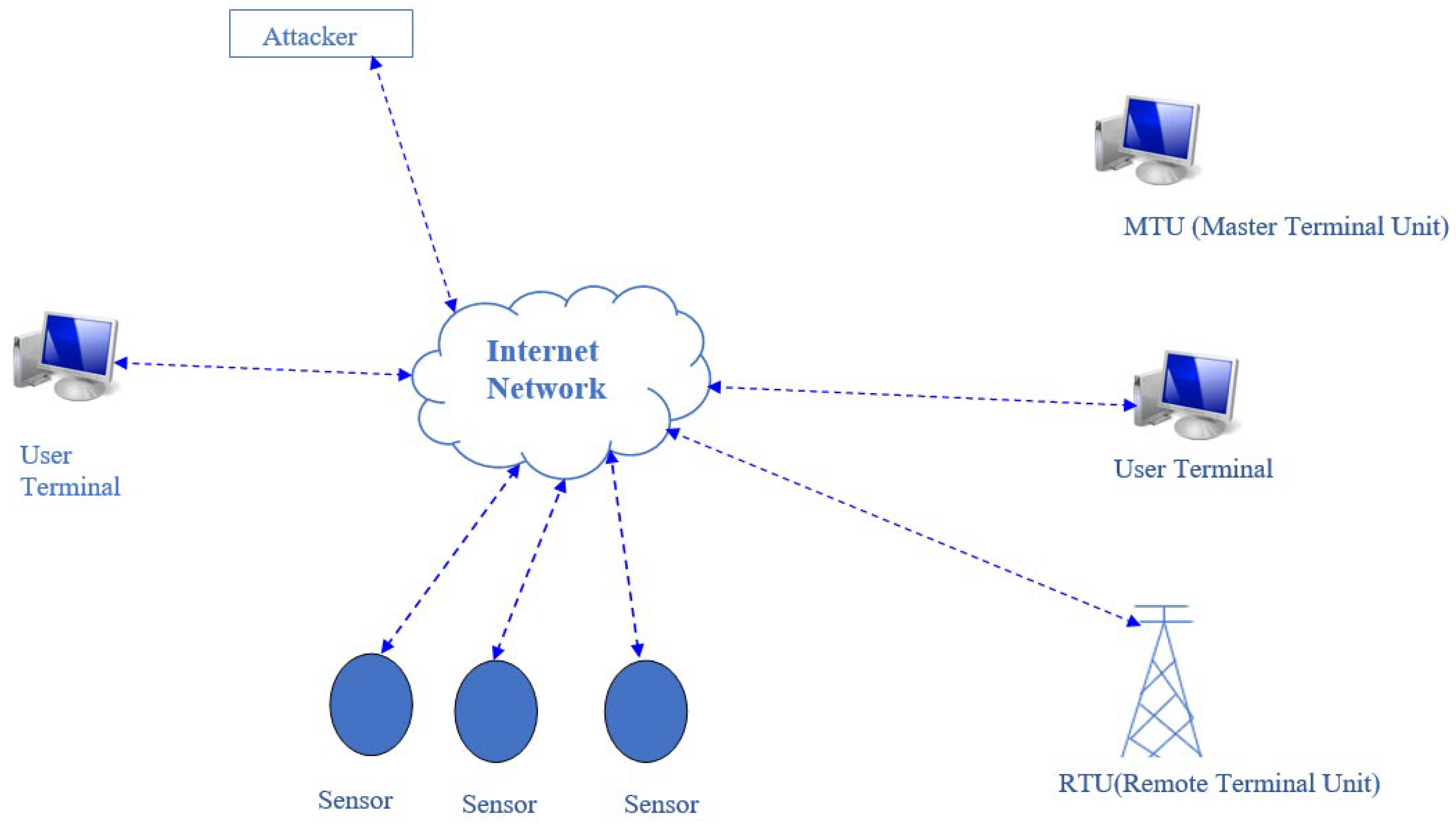
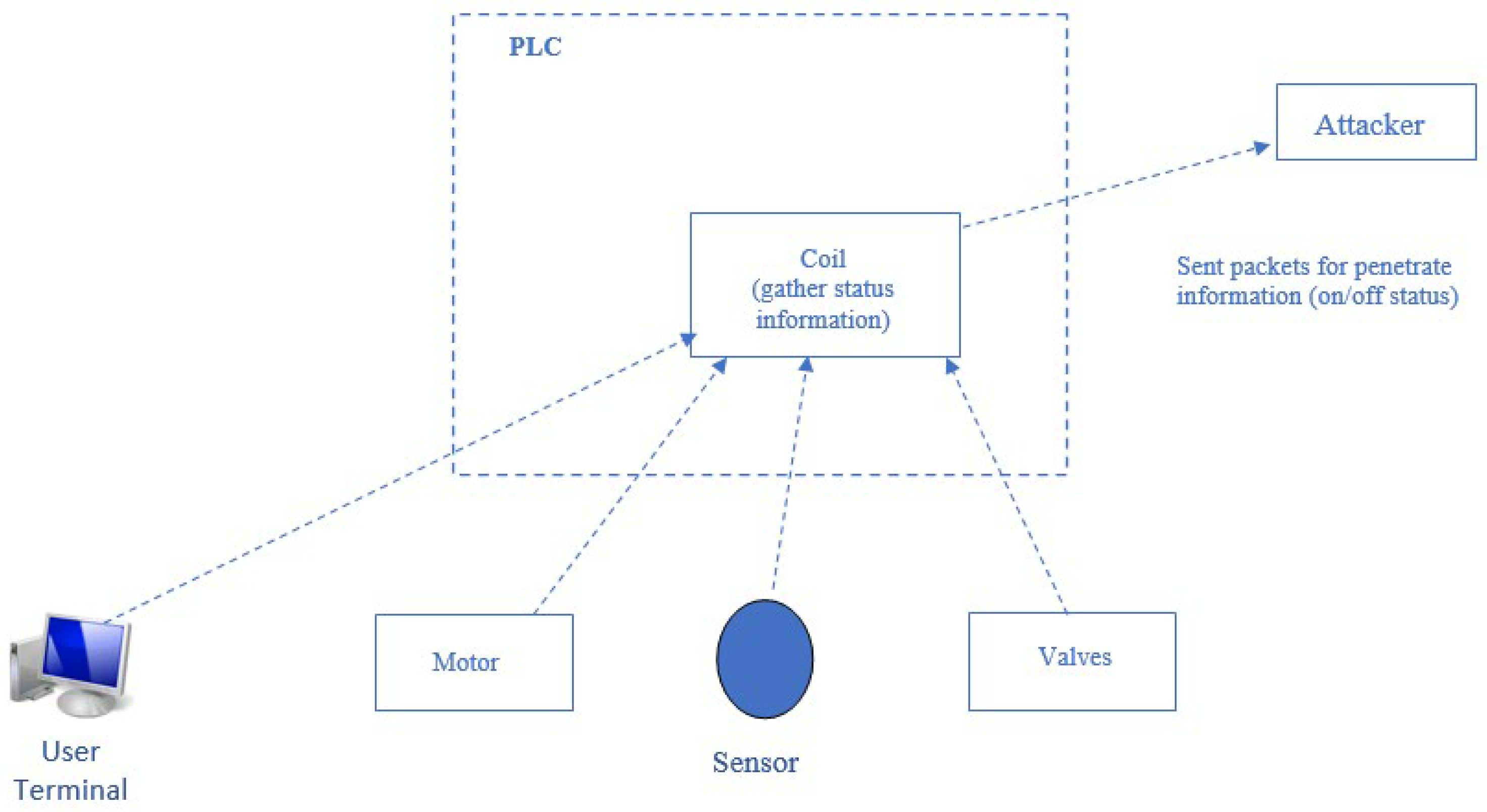
3. SCADA and Security
3.1. Port-Scanning Attack
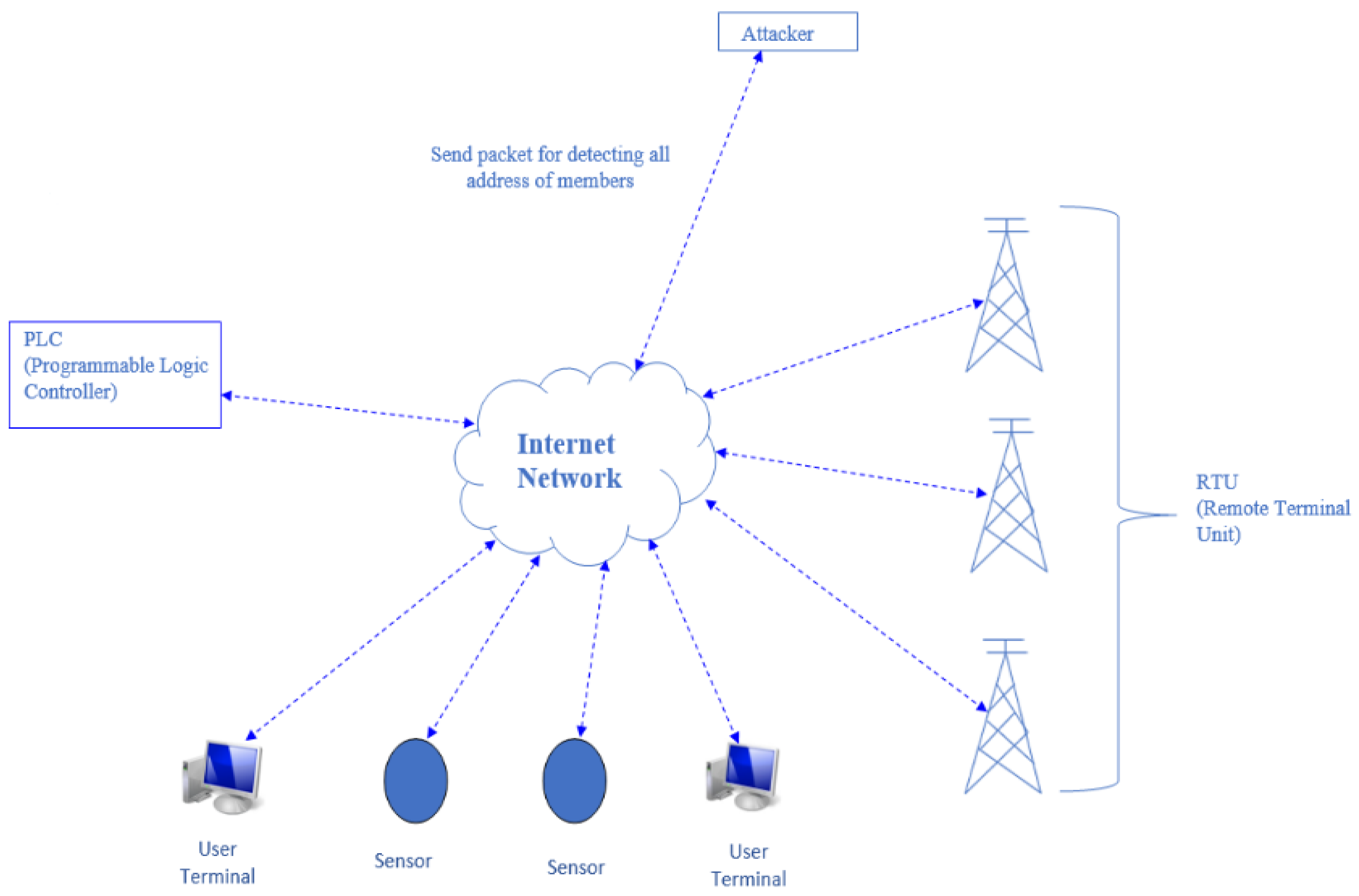
3.2. Address-Scanning Attack
3.3. Device Identification Attack
3.4. Device Identification Attack (Aggressive Mode)
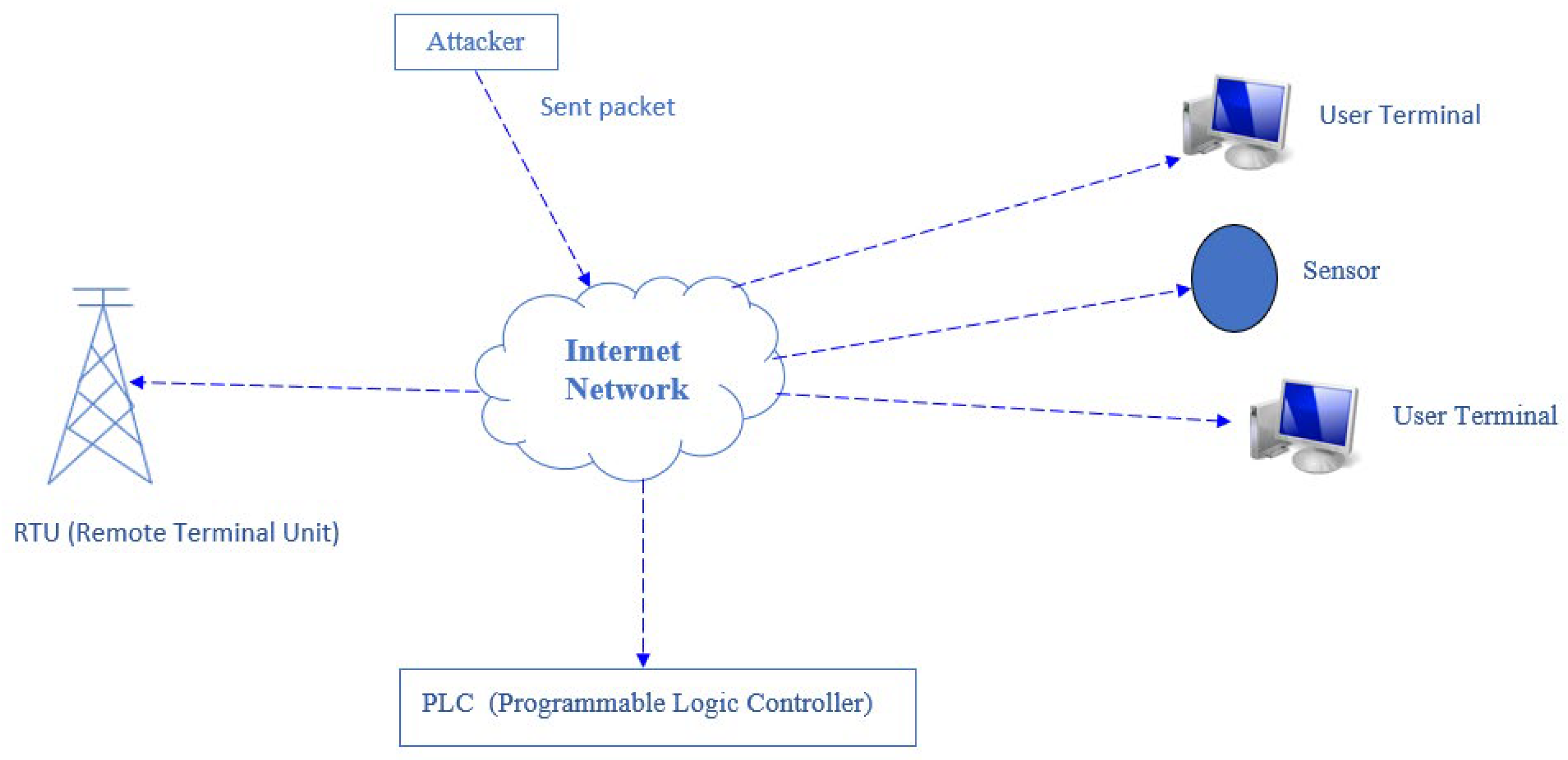
3.5. Exploit Attack
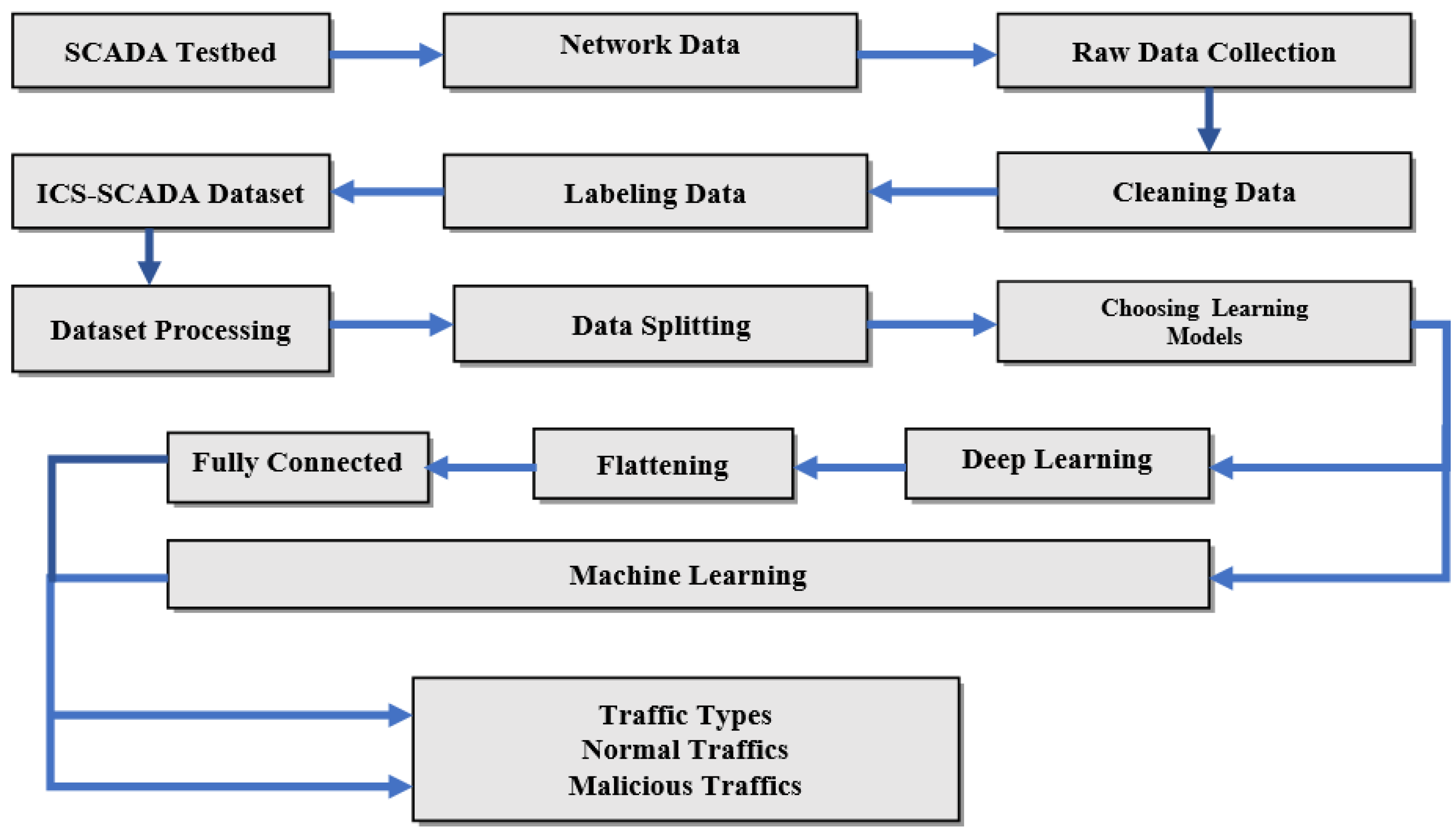
4. Materials and Methods
4.1. Dataset
4.2. Data Preprocessing
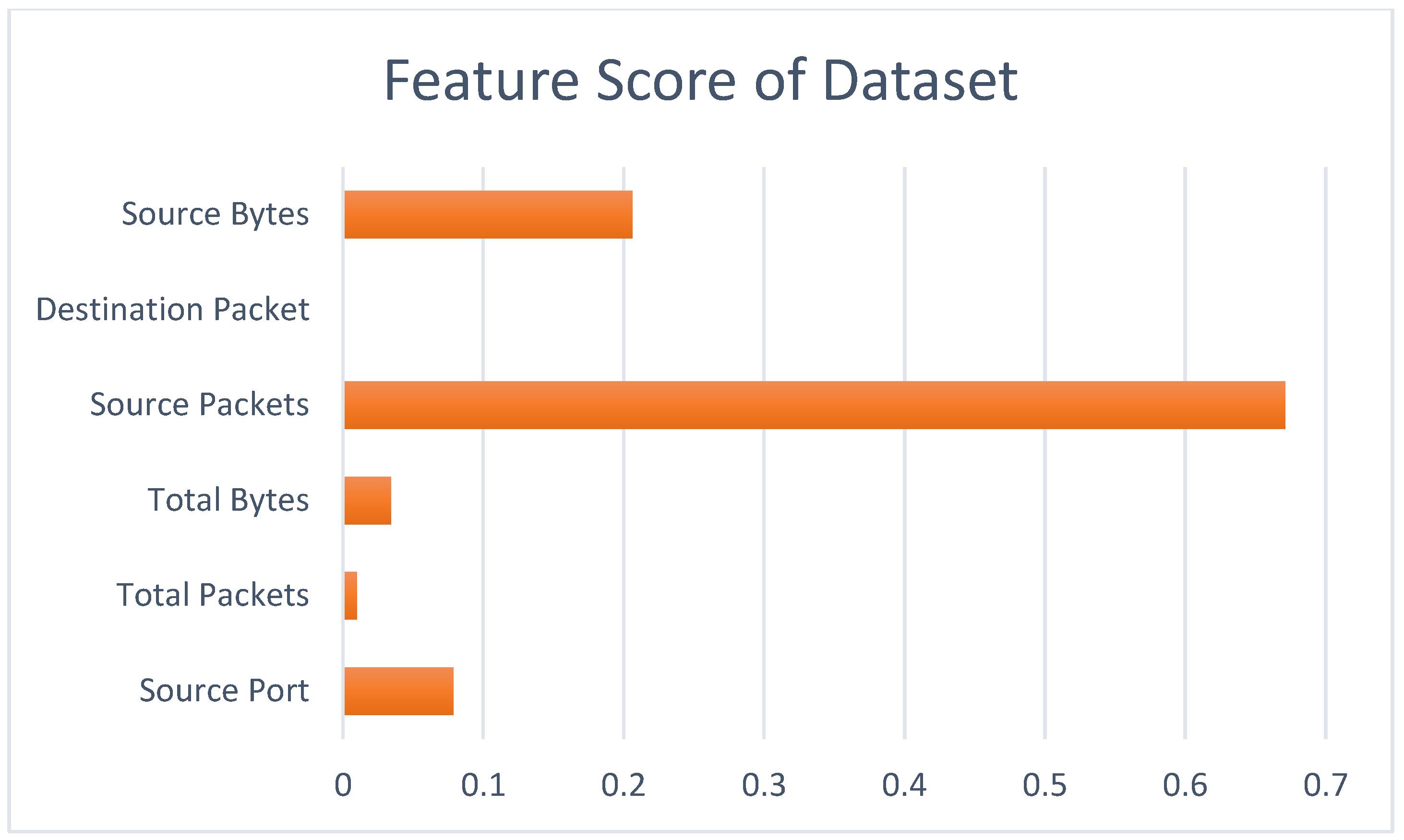
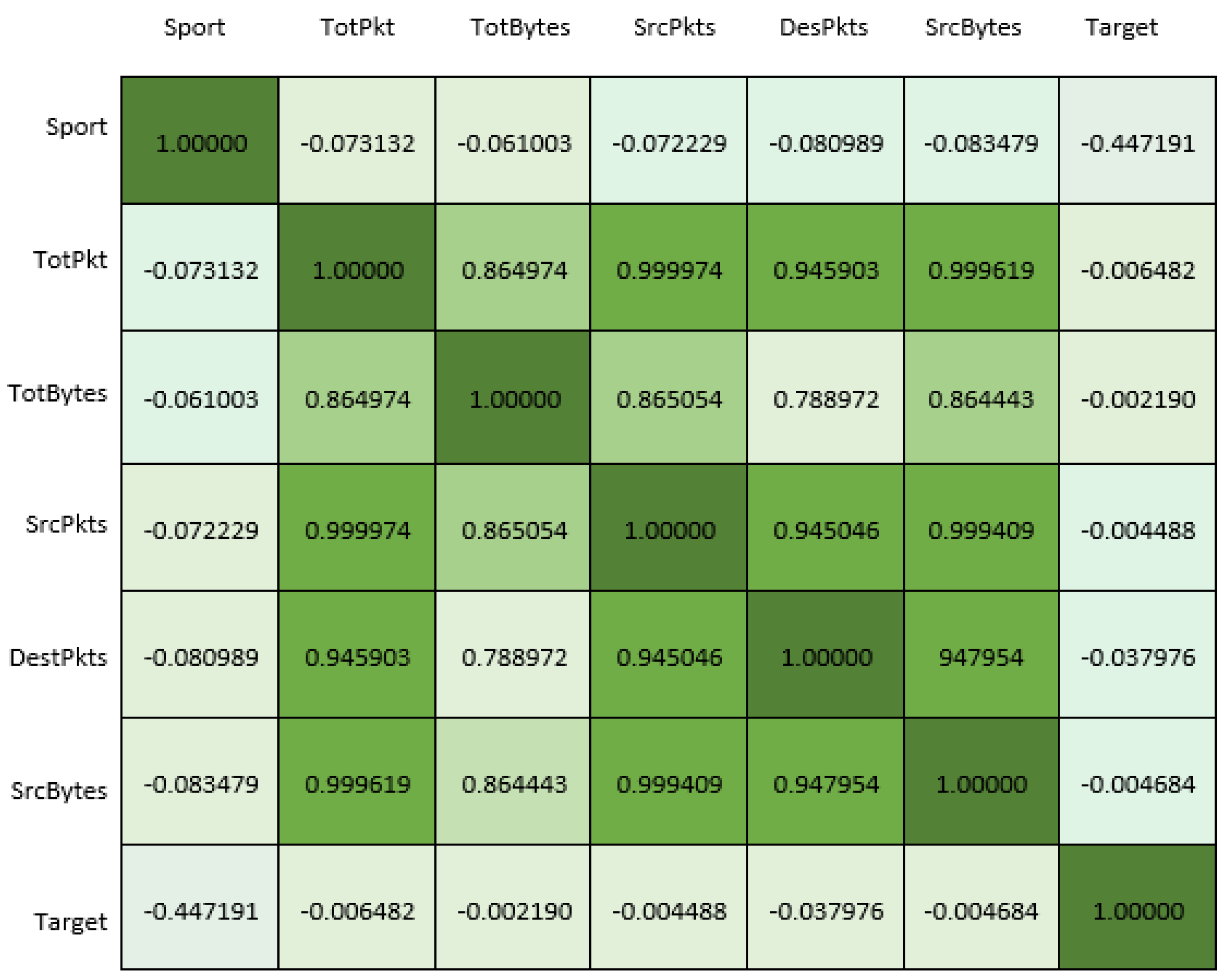
4.3. Feature Selection by Random Forest and PCA
5. Proposed Model
6. Experiments and Evaluations
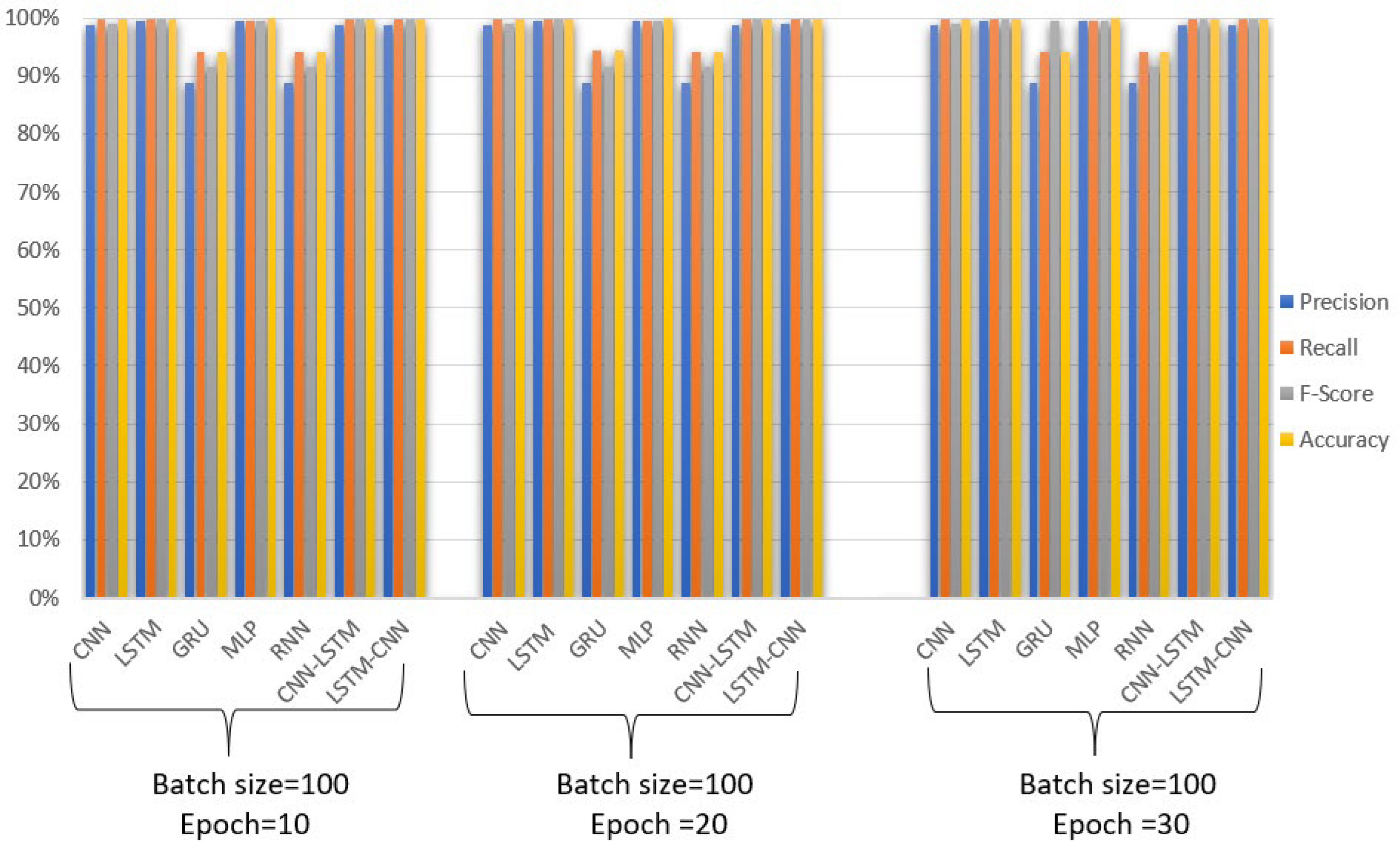
6.1. Model Parameters
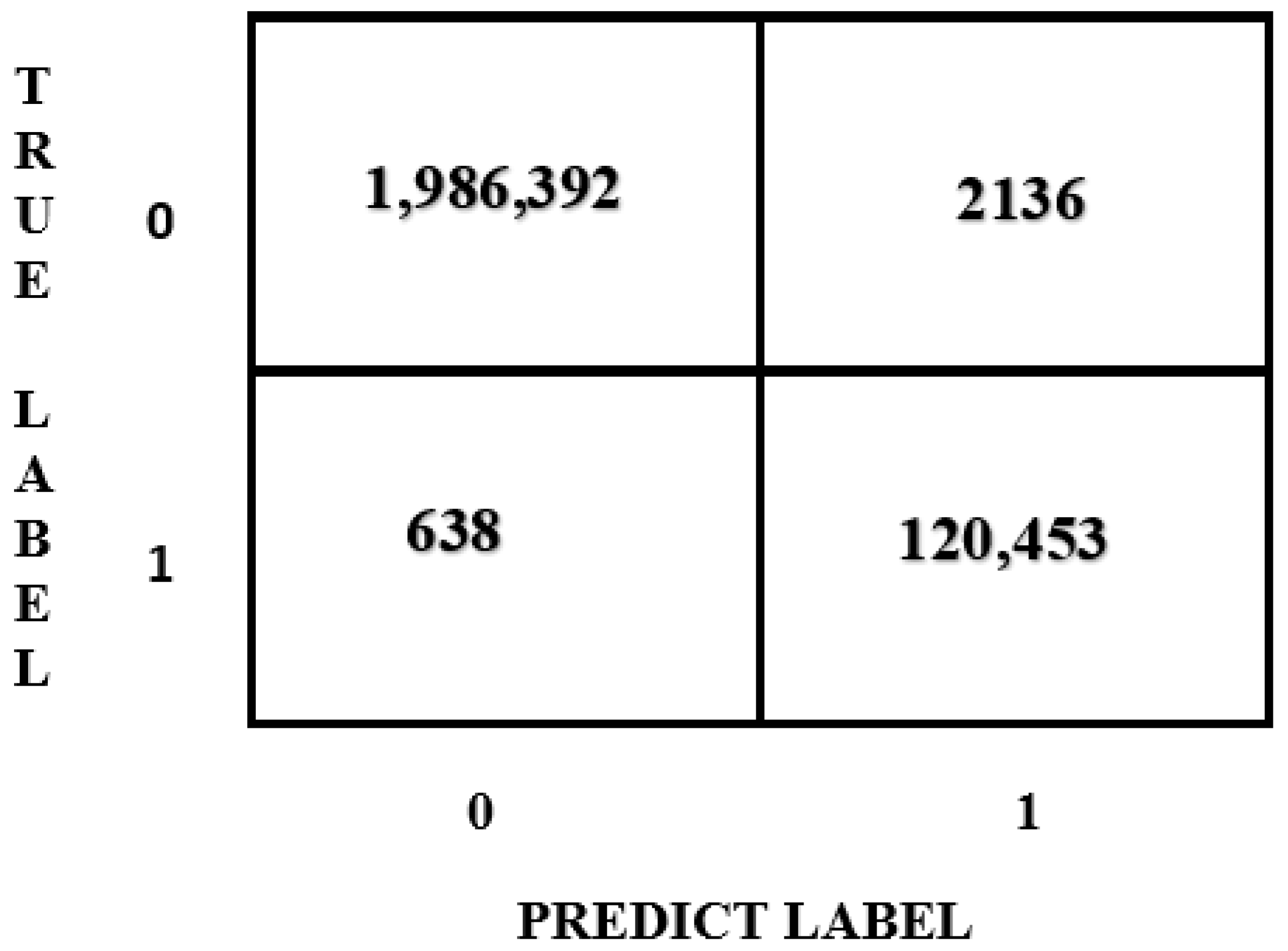
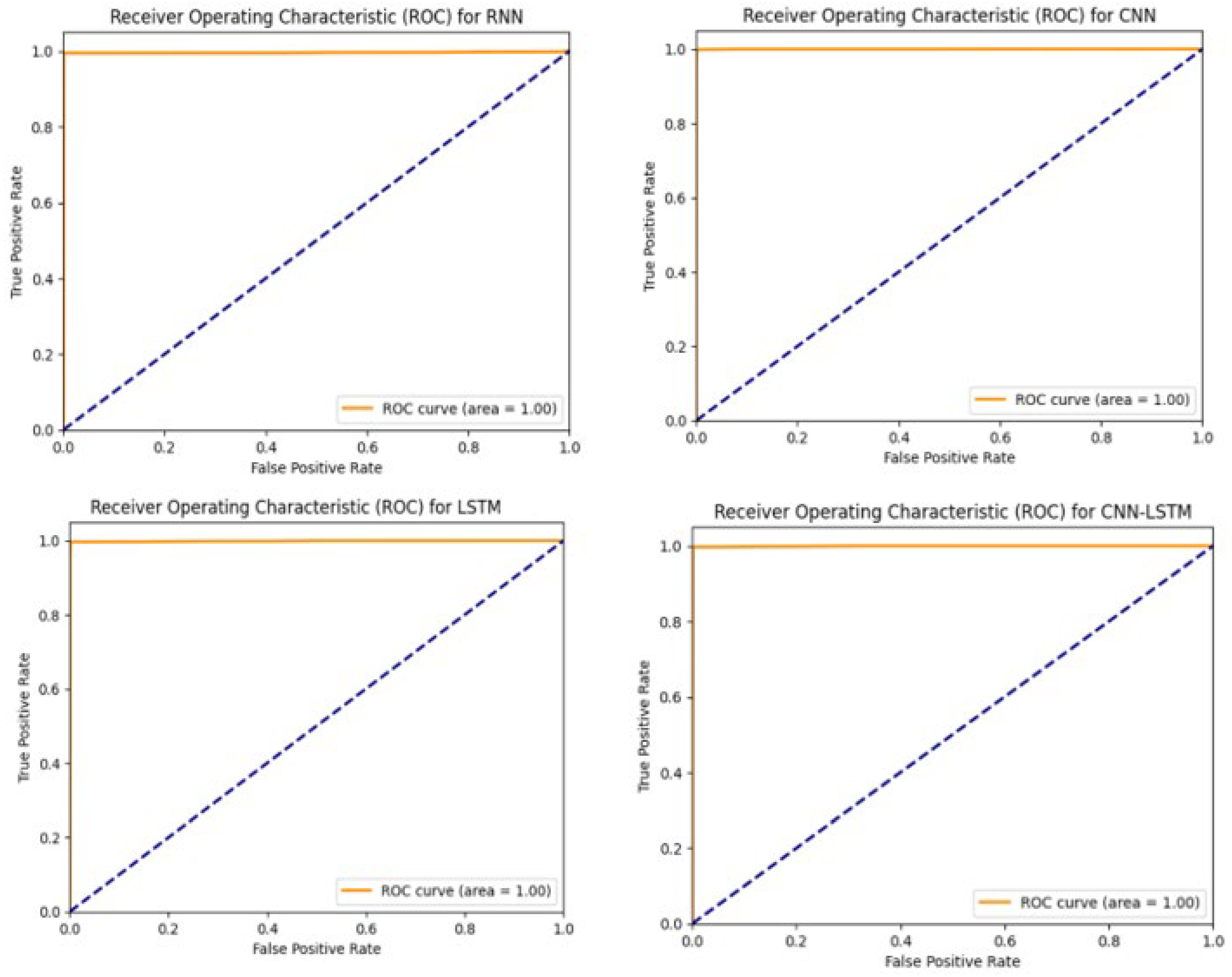
6.2. Results and Comparison
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tawalbeh, L.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and Security: Challenges and Solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Boyes, H.; Hallaq, B.; Cunningham, J.; Watson, T. The industrial internet of things (IIoT): An analysis framework. Comput. Ind. 2018, 101, 1–12. [Google Scholar] [CrossRef]
- Yu, X.; Guo, H. A Survey on IIoT Security. IEEE Access 2020, 8, 228659–228671. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M.R. Network intrusion detection using naive bayes. Int. J. Comput. Sci. Netw. Secur. 2007, 7, 258–263. [Google Scholar]
- Teixeira, M. IIOT-2018 Dataset for ICS (SCADA) Cybersecurity Research. WUSTL. Available online: https://www.cse.wustl.edu/~jain/iiot/index.html (accessed on 9 April 2024).
- Goetz, E.; Shenoi, S. Lessons Learned from the Maroochy Water Breach. In Critical Infrastructure Protection; Springer: New York, NY, USA, 2008. [Google Scholar]
- Analysis of the Cyber Attack on the Ukrainian Power Grid. Available online: https://www.researchgate.net/publication/378730818_Analysis_of_Ukraine_power_grid_cyber-attack_2015 (accessed on 9 April 2024).
- Cherdantseva, Y.; Burnap, P.; Blyth, A.; Eden, P.; Jones, K.; Soulsby, H.; Stoddart, K. A review of cyber security risk assessment methods for SCADA systems. In Proceedings of the IEEE International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Bristol, UK, 1–3 September 2022; pp. 1–8. [Google Scholar]
- Yadav, G.; Paul, K. Architecture and security of SCADA systems: A review. In Proceedings of the IEEE International Conference on Advanced Networks and Telecommunication Systems (ANTS), Janeiro, Brazil, 15–18 December 2015. [Google Scholar]
- Gregory, F.; Caldera, C.; Shrobe, H. IoT cyber security risk modeling for SCADA systems. IEEE Internet Things J. 2018, 5, 4486–4495. [Google Scholar]
- Igure, V.M.; Laughter, S.A.; Williams, R.D. Security issues in SCADA networks. Proc. IEEE 2003, 91, 944–961. [Google Scholar] [CrossRef]
- AL-Hawawreh, M.; Moustafa, N.; Sitnikova, E. Identification of malicious activities in industrial internet of things based on Deep Learning Models. J. Inf. Secur. Appl. 2018, 41, 1–11. [Google Scholar] [CrossRef]
- Binnar, P.; Bhiruda, S.; Kazi, F. Security analysis of cyber physical system using digital forensic incident response. Cyber Secur. Appl. 2024, 2, 100034. [Google Scholar] [CrossRef]
- Relan, N.G.; Patil, D.R. Implementation of network intrusion detection system using variant of decision tree algorithm. In Proceedings of the 2015 International Conference on Nascent Technologies in the Engineering Field (ICNTE), Navi Mumbai, India, 9–10 January 2015; pp. 1–5. [Google Scholar]
- Jayalaxmi, P.; Kumar, G.; Saha, R.; Conti, M.; Kim, T.-H.; Thomas, R. DeBot: A deep learning-based model for BOT detection in industrial internet-of-things. Comput. Electr. Eng. 2022, 102, 108214. [Google Scholar] [CrossRef]
- Priya, V.; Sumaiya Thaseen, I.; Gadekallu, T.R. Robust Attack Detection Approach for IIoT Using Ensemble Classifier. IEEE Access 2019, 7, 157100–157109. [Google Scholar]
- Vulfin, A.M.; Vasilyev, V.I.; Kuharev, S.N.; Homutov, E.V.; Kirillova, A.D. Algorithms for detecting network attacks in an enterprise industrial network based on data mining algorithms. IEEE Conf. Netw. Softwarization NetSoft 2018, 2001, 289–293. [Google Scholar] [CrossRef]
- Siddavatam, I.; Satish, S.; Mahesh, W.; Kazi, F. An Ensemble Learning for Anomaly Identification in SCADA System. In Proceedings of the 7th International Conference on Power Systems ICPS, Pune, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- Li, M.; Wang, S.; Fang, S.; Zhao, J. Anomaly Detection of Wind Turbines Based on Deep Small-World Neural Network. Appl. Sci. 2020, 10, 1243. [Google Scholar] [CrossRef]
- Yang, H.; Cheng, L.; Chuah, M.C. Deep-Learning-Based Network Intrusion Detection for SCADA Systems. In Proceedings of the 2019 IEEE Conference on Communications and Network Security CNS, Washington, DC, USA, 10–12 June 2019; pp. 1–6. [Google Scholar]
- Benisha, R.B.; Raja Ratna, S. Detection of interruption attack in the wireless networked closed loop industrial control systems. Telecommun. Syst. 2020, 73, 359–370. [Google Scholar] [CrossRef]
- Lai, Y.; Zhang, J.; Liu, Z. Industrial Anomaly Detection and Attack Classification Method Based on Convolutional Neural Network. Secur. Commun. Netw. 2019, 2019, 1–11. [Google Scholar] [CrossRef]
- Naseer, S.; Faizan, R.; Dominic, P.D.D.; Saleem, Y. Learning Representations of Network Traffic Using Deep Neural Networks for Network Anomaly Detection: A Perspective towards Oil and Gas IT Infrastructures. Symmetry 2020, 12, 1882. [Google Scholar] [CrossRef]
- Gao, J.; Gan, L.; Buschendorf, F.; Zhang, L.; Liu, H.; Li, P.; Dong, X. Omni SCADA Intrusion Detection Using Deep Learning Algorithms. IEEE Internet Things J. 2021, 8, 1321–1332. [Google Scholar] [CrossRef]
- Alqurashi, S.; Shirazi, H.; Ray, I. On the Performance of Isolation Forest and Multi-Layer Perceptron for Anomaly Detection in Industrial Control Systems Networks. IEEE Trans. Ind. Inform. 2021, 17, 3485–3493. [Google Scholar]
- Chen, L.; Ye, Z.; Jin, S. A Security, Privacy, and Trust Methodology for IIoT. IEEE Access 2021, 9, 62036–62049. [Google Scholar]
- Khan, M.A.; Alghamdi, N.S. A neutrosophic WPM-based machine learning model for device trust in industrial internet of things. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 3003–3017. [Google Scholar] [CrossRef]
- Guezzaz, A.; Azrour, M.; Benkirane, S.; Mohy-Eddine, M.; Attou, H.; Douiba, M. A Lightweight Hybrid Intrusion Detection Framework using Machine Learning for Edge-Based IIoT Security. Int. Arab. J. Inf. Technol. 2022, 19, 573–580. [Google Scholar] [CrossRef]
- de Elias, E.M.; Carriel, V.S.; De Oliveira, G.W.; Dos Santos, A.L.; Nogueira, M.; Junior, R.H.; Batista, D.M. A Hybrid CNN-LSTM Model for IIoT Edge Privacy-Aware Intrusion Detection. In Proceedings of the 2022 IEEE Latin-American Conference on Communications (LATINCOM), Rio de Janeiro, Brazil, 30 November–2 December 2022; pp. 1–6. [Google Scholar]
- Aboelwafa, M.M.N.; Seddik, K.G.; Eldefrawy, M.H.; Gadallah, Y.; Gidlund, M. A Machine-Learning-Based Technique for False Data Injection Attacks Detection in Industrial IoT. IEEE Internet Things J. 2020, 7, 8362–8372. [Google Scholar] [CrossRef]
- Silva Oliveira, G.A.; Lima, P.S.S.; Kon, F.; Terada, R.; Batista, D.M.; Hirata, R., Jr.; Hamdan, M. A Stacked Ensemble Classifier for an Intrusion Detection System in the Edge of IoT and IIoT Networks. In Proceedings of the 2022 IEEE Latin-American Conference on Communications LATINCOM, Rio de Janeiro, Brazil, 30 November–2 December 2022; pp. 1–6. [Google Scholar]
- Chkirbene, Z.; Erbad, A.; Hamila, R.; Gouissem, A.; Mohamed, A.; Guizani, M.; Hamdi, M. A Weighted Machine Learning-Based Attacks Classification to Alleviating Class Imbalance. IEEE Syst. J. 2021, 15, 4372–4381. [Google Scholar] [CrossRef]
- Mohy-eddine, M.; Guezzaz, A.; Benkirane, S.; Azrour, M. An effective intrusion detection approach based on ensemble learning for IIoT edge computing. J. Comput. Virol. Hacking Tech. 2022, 19, 469–481. [Google Scholar] [CrossRef]
- Tien, C.W.; Huang, T.Y.; Chen, P.C.; Wang, J.H. Automatic Device Identification and Anomaly Detection with Machine Learning Techniques in Smart Factories. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Chengdu, China, 10–13 April 2020; pp. 3003–3017. [Google Scholar]
- Lakshmanna, K.; Kavitha, R.; Geetha, B.T.; Nanda, A.K.; Radhakrishnan, A.; Kohar, R. Deep Learning-Based Privacy-Preserving Data Transmission Scheme for Clustered IIoT Environment. Comput. Intell. Neurosci. 2022, 2022, 8927830. [Google Scholar] [CrossRef]
- Yao, H.; Gao, P.; Zhang, P.; Wang, J.; Jiang, C.; Lu, L. Hybrid Intrusion Detection System for Edge-Based IIoT Relying on Machine-Learning Aided Detection. IEEE Netw. 2019, 33, 75–81. [Google Scholar] [CrossRef]
- Zolanvari, M.; Teixeira, M.; Jain, R. Effect of Imbalanced Datasets on Security of Industrial IoT Using Machine Learning. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Toronto, ON, Canada, 22–25 July 2018; pp. 1–6. [Google Scholar]
- Jadidi, Z.; Pal, S.; Nayak, N.; Selvakkumar, A.; Chang, C.-C.; Beheshti, M.; Jolfaei, A. Security of Machine Learning-Based Anomaly Detection in Cyber Physical Systems. In Proceedings of the 2022 International Conference on Computer Communications and Networks ICCCN, Honolulu, HI, USA, 25–28 July 2021; pp. 1–6. [Google Scholar]
- Khoda, M.E.; Imam, T.; Kamruzzaman, J.; Gondal, I.; Rahman, A. Robust Malware Defense in Industrial IoT Applications Using Machine Learning with Selective Adversarial Samples. IEEE Trans. Ind. Appl. 2020, 56, 4415–4426. [Google Scholar] [CrossRef]
- Hashemi, S.M.; Hashemi, S.A.; Botez, R.M. Reliable Aircraft Trajectory Prediction Using Autoencoder Secured with P2P Blockchain. In Proceedings of the International Symposium on Unmanned Systems and the Defense Industry, Madrid, Spain, 18 October 2023. [Google Scholar]
- Hashemi, S.M.; Botez, R.M.; Grigorie, T.L. New Reliability Studies of Data-Driven Aircraft Trajectory Prediction. Aerospace 2020, 7, 145. [Google Scholar] [CrossRef]
- Wang, W.; Harrou, F.; Bouyeddou, B.; Senouci, S.M.; Sun, Y. Cyber-attacks detection in industrial systems using artificial intelligence-driven method. IEEE Trans. Ind. Inform. 2020, 16, 2505–2513. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference No. | Year | Authors | Dataset | Models | Parameter Result |
|---|---|---|---|---|---|
| [16] | 2019 | V. Priya et al. | WUSTL-2018 N-BaIoT BoT_IoT | Decision Tree SVM Naive Bayes | Accuracy: 96% |
| [17] | 2018 | M. Vulfin et al. | WUSTL-2018 | Random Forest Logistic Regression Multilayer Perceptron | F-score: 91–95% |
| [18] | 2017 | I. Siddavatam, S. Satish, W. Mahesh, F. Kazi | SCADA testbed | Random Forest | Accuracy: 99.81% |
| [19] | 2018 | S.Wang et al. | SCADA testbed | XGBoost | Accuracy: 98.86% |
| [20] | 2019 | H. Yang, L. Cheng, M. Chuah | SCADA testbed | CNN | Accuracy: 99.84% |
| [21] | 2017 | R. Benisha R. Ratna | --------- | DL-NN | Accuracy: 78.69% |
| [22] | 2019 | Y. Lai, J Zhang, Z. Liu | SCADA testbed KDD NSL-KDD DARPA | CNN | Accuracy: 99.30% |
| [23] | 2019 | S. Naseer et al. | ISCX-2012 | CNN RNN-LSTM Autoencoder | Accuracy: 99–100% |
| [24] | 2021 | J. Gao et al. | SCADA testbed KDD’99 | LSTM FNN FNN-LSTM | F-score: 99.68% |
| [25] | 2021 | S. Alqurashi, H Shirazi, I. Ray | SwaT | DNN MLP SVM | Accuracy: 99% |
| [26] | 2021 | M. Alani E. Damiani U. Ghosh | WUSTL-2021 | CNN-LSTM | Accuracy: 99% |
| [27] | 2021 | M. Khan, N Alghamdi | ----------- | Neutrosophic SVM | Accuracy: 100% |
| [28] | 2022 | A. Guezzaz et al. | NSL-KDD BoT-IoT | KNN PCA | Accuracy: 99.10% |
| [29] | 2022 | M Elias et al. | Edge-IIoTset | CNN-LSTM | Accuracy: 97.85% |
| [30] | 2020 | N. Aboelwafa et al. | Tesbed | Autoencoders | Mean-squared error: Case 1: 0.0064 Case 2: 0.0051 |
| [31] | 2022 | S. Oliveira et al. | TON_IoT | SE-DNN | Precision: 99.7% F-score: 99.7% Recall: 99.7% Accuracy: 99.7% |
| [32] | 2021 | Zina Chkirbene | UNSW and NSL-KDD | Decision Tree | Accuracy: 94% |
| [33] | 2022 | M. Mohy-eddin A. Guezzaz S. Benkirane M. Azrour | Bot-IoT and the wustl_iiot_2021 | Random Forest | Accuracy: 99.99% |
| [34] | 2020 | W. Tien et al.l. | Real environments | Decision Tree | Accuracy: 99.99% |
| [35] | 2022 | K.Lakshmanna et al. | ----------- | BDL-PPDT | Accuracy: 98.15% |
| [36] | 2019 | H. Yao et al. | ----------- | Light GBM | Accuracy: 93.2% |
| [37] | 2019 | M. Zolanvari, M. A. Teixeira and R. Jain | ----------- | Random Forest | Accuracy: 99.99% |
| [38] | 2022 | Zahra Jadidi et al. | Modbus | FGSM-ANN | Precision: 83.06% Recall: 99.49% F-score: 90.53% |
| [39] | 2020 | M. Khod et al. | Malware dataset | SVM | Accuracy: 98.5% |
| [40] | 2023 | S. Hashemi et al. | Trajectory datasets | LSTM GAN GAN-BLT | Fooling rate: 2.8% |
| [41] | 2020 | S. Hashemi et al. | Trajectory datasets | --- |
68.97% Accuracy: |
| Feature | Value |
|---|---|
| Duration of capture | 25 h |
| Dataset size | 627 MB |
| Number of observations | 7,049,989 |
| Percentage of port-scanning attacks | 0.0003% |
| Percentage of address-scanning attacks | 0.0075% |
| Percentage of device identification attacks | 0.0001% |
| Percentage of device identification attacks (aggressive mode) | 4.9309% |
| Percentage of exploiting attacks | 1.1312% |
| Percentage of all attacks (total) | 6.07% |
| Percentage of normal traffic | 93.93% |
| Source Port | Total Packets | Total Bytes | Source Packets | Destination Packet | Source Bytes | Target (Class) |
|---|---|---|---|---|---|---|
| 54,966 | 18 | 1152 | 10 | 8 | 644 | 0 |
| 50,963 | 4 | 248 | 2 | 2 | 124 | 1 |
| 137 | 14 | 1316 | 14 | 0 | 1316 | 0 |
| 64,807 | 18 | 1152 | 10 | 8 | 644 | 0 |
| 64,809 | 20 | 1276 | 10 | 10 | 644 | 0 |
| 44,292 | 4 | 276 | 2 | 2 | 152 | 1 |
| 64,816 | 30 | 1960 | 16 | 14 | 1064 | 0 |
| 1740 | 354 | 9087 | 2 | 204 | 150 | 0 |
| 7,249,319 | 12 | 78 | 0 | 8 | 4 | 0 |
| 55,060 | 4 | 276 | 2 | 2 | 152 | 1 |
| 42,050 | 2 | 152 | 2 | 0 | 152 | 1 |
| 41,618 | 4 | 276 | 2 | 2 | 152 | 1 |
| 56,699 | 20 | 1276 | 10 | 10 | 644 | 0 |
| 56,647 | 2 | 136 | 2 | 0 | 136 | 0 |
| Label Number | Type of Traffic |
|---|---|
| 0 | Normal network traffic |
| 1 | Attack traffic |
| Feature Name | Feature Score |
|---|---|
| Source Port | 0.219584636 |
| Total Packets | 0.02156103 |
| Total Bytes | 0.121049478 |
| Source Packets | 0.347070595 |
| Destination Packet | 0.001457459 |
| Source Bytes | 0.289276802 |
| Feature Name | Feature Score |
|---|---|
| Source Port | 0.0786986 |
| Total Packets | 0.0099080 |
| Total Bytes | 0.0339848 |
| Source Packets | 0.6710430 |
| Destination Packet | 0.0000771 |
| Source Bytes | 0.2062886 |
| Model Name | Precision | Recall | F-Score | Accuracy |
|---|---|---|---|---|
| CART | 96.51% | 98.63% | 97.22% | 98.63% |
| Decision Tree | 96.83% | 98.83% | 98.18% | 98.83% |
| KNN | 95.62% | 98.66% | 97.67% | 98.66% |
| Logistic Regression | 85.88% | 96.88% | 89.88% | 96.88% |
| Naive Bayes | 88.85% | 94.26% | 91.48% | 94.26% |
| Random Forest | 97.17% | 99.44% | 98.11% | 99.44% |
| SVM | 98.35% | 99.31% | 99.07% | 99.31% |
| XGBoost | 95.91% | 97.82% | 96.86% | 97.82% |
| CNN | 98.77% | 99.87% | 98.97% | 99.87% |
| GRU | 88.87% | 94.27% | 91.50% | 94.27% |
| LSTM | 99.59% | 99.87% | 99.86% | 99.87% |
| MLP | 99.63 | 99.49 | 99.56 | 99.95 |
| RNN | 88.86% | 94.26% | 91.48% | 94.26% |
| CNN-LSTM | 98.87% | 99.87% | 99.66% | 99.87% |
| LSTM-CNN | 98.87% | 99.87% | 99.75% | 99.87% |
| Model Name | Epoch | Batch Size | Precision | Recall | F-Score | Accuracy |
|---|---|---|---|---|---|---|
| CNN | 10 | 100 | 98.764% | 99.755% | 98.965% | 99.755% |
| 20 | 98.771% | 99.870% | 98.974% | 99.870% | ||
| 30 | 98.769% | 99.862% | 98.983% | 99.862% | ||
| LSTM | 10 | 100 | 99.572% | 99.862% | 99.861% | 99.862% |
| 20 | 99.589% | 99.868% | 99.858% | 99.868% | ||
| 30 | 99.575% | 99.864% | 99.844% | 99.864% | ||
| GRU | 10 | 100 | 88.866% | 94.269% | 91.488% | 94.269% |
| 20 | 88.867% | 94.272% | 91.495% | 94.272% | ||
| 30 | 88.865% | 94.269% | 99.488% | 94.269% | ||
| MLP | 10 | 100 | 99.617% | 99.482% | 99.550% | 99.946% |
| 20 | 99.630% | 99.497% | 99.562% | 99.950% | ||
| 30 | 99.625% | 99.490% | 99.557% | 99.949% | ||
| RNN | 10 | 100 | 88.856% | 94.263% | 91.480% | 94.263% |
| 20 | 88.856% | 94.263% | 91.480% | 94.263% | ||
| 30 | 88.856% | 94.263% | 91.480% | 94.263% | ||
| CNN-LSTM | 10 | 100 | 98.864% | 99.870% | 99.864% | 99.870% |
| 20 | 98.866% | 99.871% | 99.856% | 99.871% | ||
| 30 | 98.862% | 99.869% | 99.861% | 99.869% | ||
| LSTM-CNN | 10 | 100 | 98.862% | 99.869% | 99.669% | 99.869% |
| 20 | 98.871% | 99.874% | 99.751% | 99.874% | ||
| 30 | 98.868% | 99.865% | 99.660% | 99.865% |
| Hyperparameters | Values |
|---|---|
| Activation function | ReLU, Sigmoid |
| Number of epochs | 20 |
| Units | 64, 128, 256, 1 |
| Optimizer | Adam |
| Loss | Binary Cross-Entropy |
| Hidden layer | 3 |
| Accuracy | 99.950% |
| Recall | 99.497% |
| Precision | 99.630% |
| F-score | 99.562% |
| Specific | 99.881% |
| Training time | 2838.377 s |
| Total parameter | 128.452 (501.77 KB) |
| Model Name | Epoch | Batch Size | Precision | Recall | F-Score | Accuracy |
|---|---|---|---|---|---|---|
| CNN | 20 | 100 | 98.860% | 99.266% | 99.183% | 99.266% |
| LSTM | 20 | 100 | 99.769% | 99.868% | 99.859% | 99.868% |
| MLP | 20 | 100 | 98.582% | 99.944% | 99.917% | 99.948% |
| RNN | 20 | 100 | 88.937% | 94.307% | 91.543% | 94.307% |
| CNN-LSTM | 20 | 100 | 99.674% | 99.872% | 99.793% | 99.872% |
| LSTM-CNN | 20 | 100 | 99.367% | 99.869% | 99.488% | 99.869% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Okur, C.; Dener, M. Symmetrical Resilience: Detection of Cyberattacks for SCADA Systems Used in IIoT in Big Data Environments. Symmetry 2025, 17, 480. https://doi.org/10.3390/sym17040480
Okur C, Dener M. Symmetrical Resilience: Detection of Cyberattacks for SCADA Systems Used in IIoT in Big Data Environments. Symmetry. 2025; 17(4):480. https://doi.org/10.3390/sym17040480
Chicago/Turabian StyleOkur, Celil, and Murat Dener. 2025. "Symmetrical Resilience: Detection of Cyberattacks for SCADA Systems Used in IIoT in Big Data Environments" Symmetry 17, no. 4: 480. https://doi.org/10.3390/sym17040480
APA StyleOkur, C., & Dener, M. (2025). Symmetrical Resilience: Detection of Cyberattacks for SCADA Systems Used in IIoT in Big Data Environments. Symmetry, 17(4), 480. https://doi.org/10.3390/sym17040480