
Prediction Intervals: A Geometric View



Abstract
1. Introduction
- -
- A geometric approach for interval forecasts is proposed;
- -
- A review of PI methods based on a geometric view was carried out;
- -
- A new approach to the construction of robust output models is proposed.
2. Prediction Intervals: Review
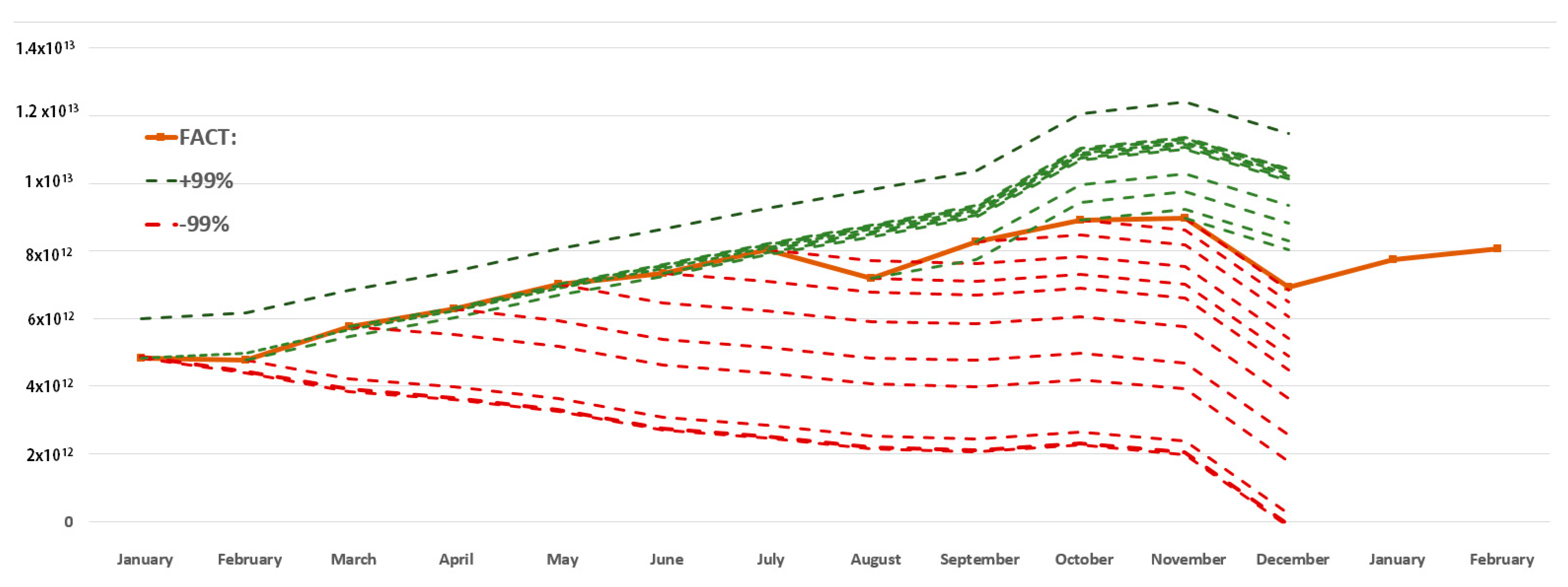
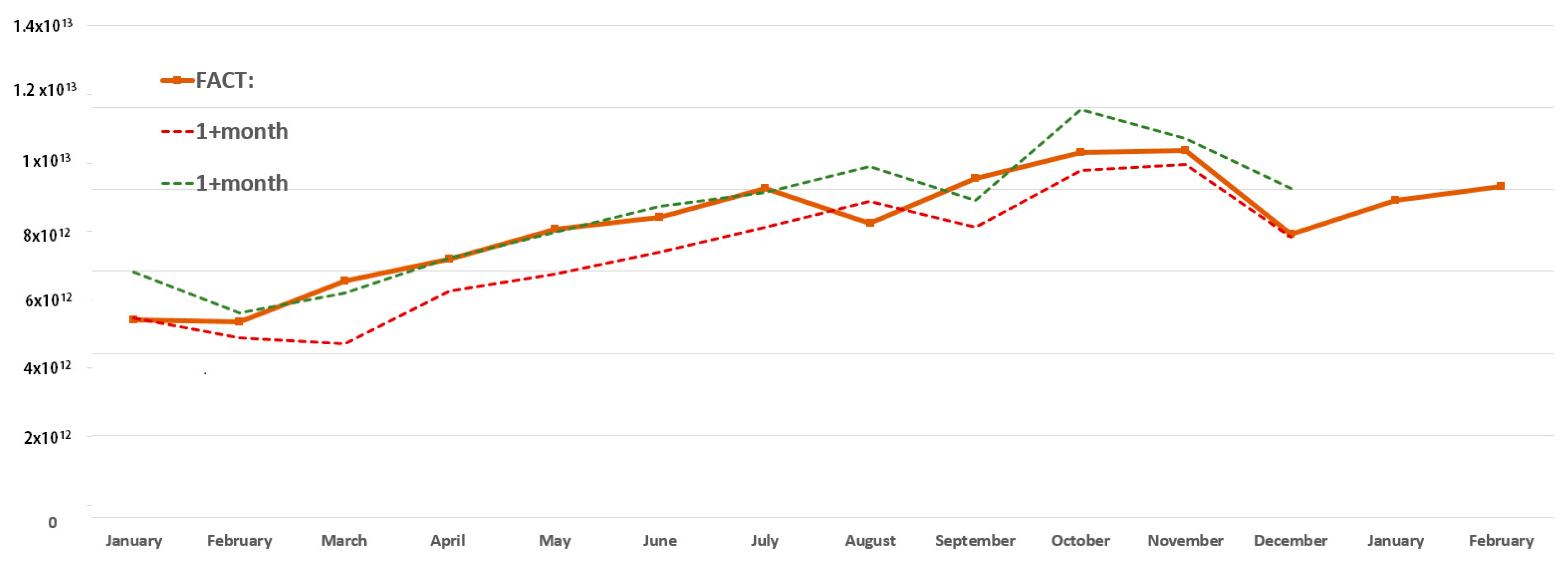
3. Criteria for Evaluating and Choosing the Optimal Width of the Prediction Intervals
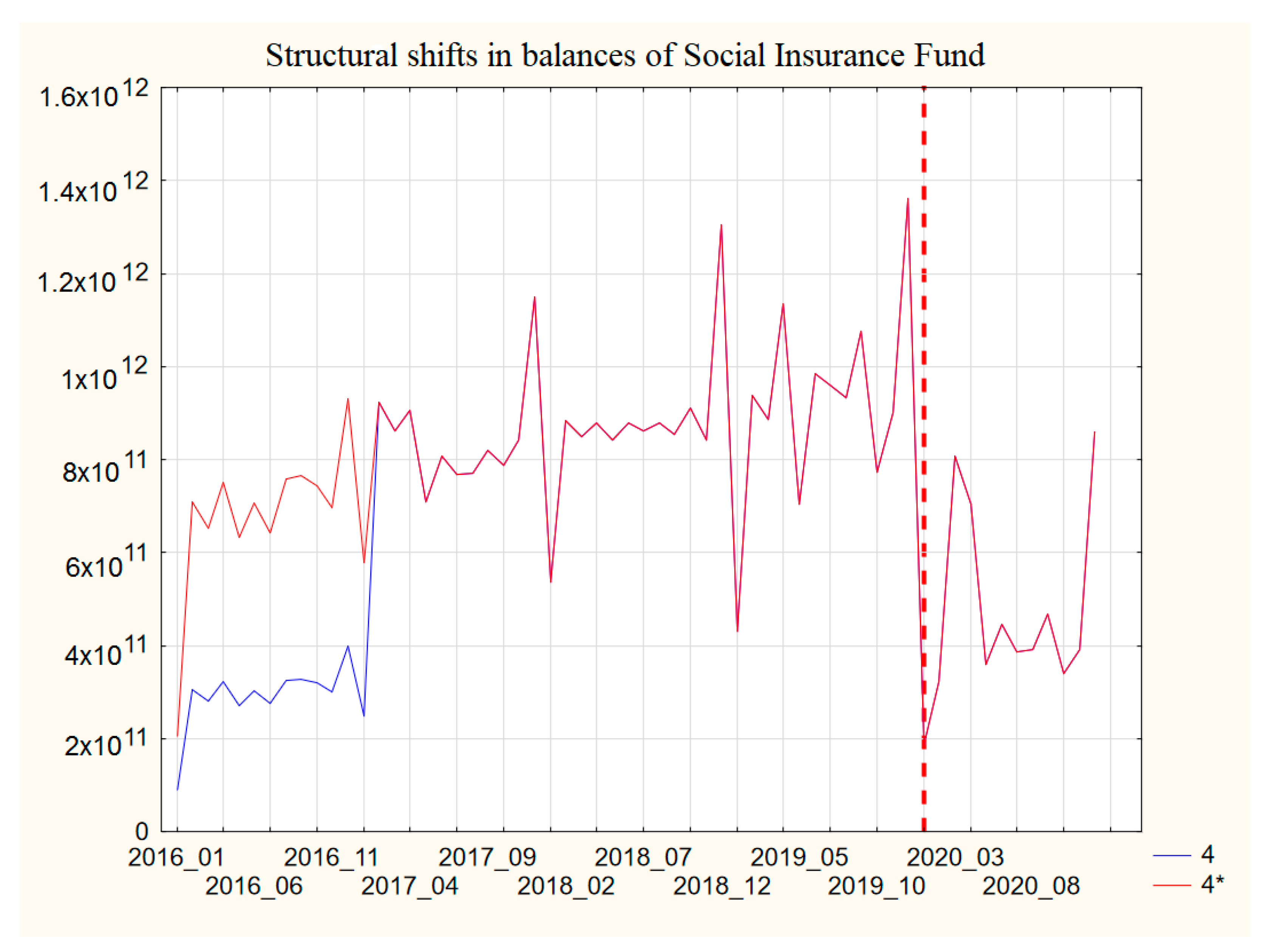
4. New Approach
- -
- We can add them according to the rules of addition of interval analysis;
- -
- We can build probabilistic models and take probabilistic characteristics at each point of the time series and can add them according to the rules of histogram arithmetic;
- -
- We can introduce fuzzy logic into the interval and add intervals according to the rules for adding fuzzy numbers;
- -
- The use of fixed intervals;
- -
- We can calculate the value of the intervals as a solution to some optimization problems, and so on.
- (1)
- The weighted average;
- (2)
- Triple exponential smoothing (Holt–Winters);
- (3)
- ARIMA (Box–Jenkins);
- (4)
- Linear regression.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| ARIMA | Autoregressive integrated moving average model |
| ARMA | Autoregressive moving average model |
| LSTM | Long short-term memory |
| LUBE | Lower upper bound estimation |
| MAPE | Mean absolute percentage error |
| PICP | Prediction interval coverage probability |
| PINAW | Prediction interval normalized average width |
| PI | Prediction interval |
References
- Zeng, Z.; Li, M. Bayesian median autoregression for robust time series forecasting. Int. J. Forecast. 2021, 37, 1000–1010. [Google Scholar] [CrossRef]
- Jeon, Y.; Seong, S. Robust recurrent network model for intermittent time-series forecasting. Int. J. Forecast. 2022, 38, 1415–1425. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, J. A robust time series prediction method based on empirical mode decomposition and high-order fuzzy cognitive maps. Knowl. Based Syst. 2020, 203, 106105. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Feizollahi, M.J.; Modarres, M. The robust deviation redundancy allocation problem with interval component reliabilities. IEEE Trans. Reliab. 2012, 61, 957–965. [Google Scholar] [CrossRef]
- Bochkov, A.V.; Lesnykh, V.V.; Zhigirev, N.N. Dynamic multi-criteria decision making method for sustainability risk analysis of structurally complex techno-economic systems. Reliab. Theory Appl. 2012, 7, 36–42. [Google Scholar]
- Zhou, M.; Wang, B.; Guo, S.; Watada, J. Multi-objective prediction intervals for wind power forecast based on deep neural networks. Inf. Sci. 2021, 550, 207–220. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, L.; Qin, H.; Liu, Y.; Li, J. Wind speed prediction method using shared weight long short-term memory network and Gaussian process regression. Appl. Energy 2019, 247, 270–284. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Wang, H.; Al-Musaylh, M.S.; Casillas-Pérez, D.; Salcedo-Sanz, S. Stacked LSTM sequence-to-sequence autoencoder with feature selection for daily solar radiation prediction: A review and new modeling results. Energies 2022, 15, 1061. [Google Scholar] [CrossRef]
- Jiang, F.; Zhu, Q.; Tian, T. An ensemble interval prediction model with change point detection and interval perturbation-based adjustment strategy: A case study of air quality. Expert Syst. Appl. 2023, 222, 119823. [Google Scholar] [CrossRef]
- Guan, Y.; Li, D.; Xue, S.; Xi, Y. Feature-fusion-kernel-based Gaussian process model for probabilistic long-term load forecasting. Neurocomputing 2021, 426, 174–184. [Google Scholar] [CrossRef]
- Zhang, W.; Quan, H.; Srinivasan, D. Parallel and reliable probabilistic load forecasting via quantile regression forest and quantile determination. Energy 2018, 160, 810–819. [Google Scholar] [CrossRef]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic forecasting of wind power generation using extreme learning machine. IEEE Trans. Power Syst. 2014, 29, 1033–1044. [Google Scholar] [CrossRef]
- Marín, L.G.; Cruz, N.; Sáez, D.; Sumner, M.; Núñez, A. Prediction interval methodology based on fuzzy numbers and its extension to fuzzy systems and neural networks. Expert Syst. Appl. 2019, 119, 128–141. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Jiang, M.; Yuan, Y. Prediction interval of wind power using parameter optimized beta distribution based LSTM model. Appl. Soft. Comput. 2019, 82, 105550. [Google Scholar] [CrossRef]
- van der Meer, D.W.; Shepero, M.; Svensson, A.; Widén, J.; Munkhammar, J. Probabilistic forecasting of electricity consumption, photovoltaic power generation and net demand of an individual building using Gaussian Processes. Appl. Energy 2018, 213, 195–207. [Google Scholar] [CrossRef]
- Shepero, M.; van der Meer, D.W.; Munkhammar, J.; Widén, J. Residential probabilistic load forecasting: A method using Gaussian process designed for electric load data. Appl. Energy 2018, 218, 159–172. [Google Scholar] [CrossRef]
- van der Meer, D.W.; Munkhammar, J.; Widén, J. Probabilistic forecasting of solar power, electricity consumption and net load: Investigating the effect of seasons, aggregation and penetration on prediction intervals. Sol. Energy 2018, 171, 397–413. [Google Scholar] [CrossRef]
- Serrano-Guerrero, X.; Briceño-León, M.; Clairand, J.M.; Escrivá-Escrivá, G. A new interval prediction methodology for short-term electric load forecasting based on pattern recognition. Appl. Energy 2021, 297, 117173. [Google Scholar] [CrossRef]
- He, Y.; Liu, R.; Li, H.; Wang, S.; Lu, X. Short-term power load probability density forecasting method using kernel-based support vector quantile regression and Copula theory. Appl. Energy 2017, 185, 254–266. [Google Scholar] [CrossRef]
- He, Y.; Zheng, Y. Short-term power load probability density forecasting based on Yeo-Johnson transformation quantile regression and Gaussian kernel function. Energy 2018, 154, 143–156. [Google Scholar] [CrossRef]
- Zhang, H.; Zimmerman, J.; Nettleton, D.; Nordman, D.J. Random forest prediction intervals. Am. Stat. 2020, 74, 392–406. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.; Mo, L.; Feng, K.; Liu, G.; He, Z. Day-ahead short-term load probability density forecasting method with a decomposition-based quantile regression forest. Appl. Energy 2019, 262, 114396. [Google Scholar] [CrossRef]
- Liu, F.; Li, C.; Xu, Y.; Tang, G.; Xie, Y. A new lower and upper bound estimation model using gradient descend training method for wind speed interval prediction. Wind. Energy 2021, 24, 290–304. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.W. ANN-based interval forecasting of streamflow discharges using the LUBE method and MOFIPS. Eng. Appl. Artif. Intell. 2015, 45, 429–440. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. Learn. Syst. 2011, 22, 337–346. [Google Scholar] [CrossRef]
- Quan, H.; Srinivasan, D.; Khosravi, A. Short-term load and wind power forecasting using neural network-based prediction intervals. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 303–315. [Google Scholar] [CrossRef]
- Zhang, G.; Wu, Y.; Wong, K.P.; Xu, Z.; Dong, Z.Y.; Iu, H.H.C. An advanced approach for construction of optimal wind power prediction intervals. IEEE Trans. Power Syst. 2014, 30, 2706–2715. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.; Li, H. Multi-objective algorithm for the design of prediction intervals for wind power forecasting model. Appl. Math. Model. 2019, 67, 101–122. [Google Scholar] [CrossRef]
- Ak, R.; Vitelli, V.; Zio, E. An interval-valued neural network approach for uncertainty quantification in short-term wind speed prediction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2787–2800. [Google Scholar] [CrossRef]
- Shrivastava, N.A.; Lohia, K.; Panigrahi, B.K. A multiobjective framework for wind speed prediction interval forecasts. Renew. Energy 2016, 87, 903–910. [Google Scholar] [CrossRef]
- Galván, I.M.; Valls, J.M.; Cervantes, A.; Aler, R. Multi-objective evolutionary optimization of prediction intervals for solar energy forecasting with neural networks. Inf. Sci. 2017, 418, 363–382. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, H.; Dinavahi, V. Direct interval forecast of uncertain wind power based on recurrent neural networks. IEEE Trans. Sustain. Energy 2018, 9, 1177–1187. [Google Scholar] [CrossRef]
- Chen, X.; Lai, C.S.; Ng, W.W.; Pan, K.; Lai, L.L.; Zhong, C. A stochastic sensitivity-based multi-objective optimization method for short-term wind speed interval prediction. Int. J. Mach. Learn. Cybern. 2021, 12, 2579–2590. [Google Scholar] [CrossRef]
- Cao, Z.; Wan, C.; Zhang, Z.; Li, F.; Song, Y. Hybrid ensemble deep learning for deterministic and probabilistic low-voltage load forecasting. IEEE Trans. Power Syst. 2019, 35, 1881–1897. [Google Scholar] [CrossRef]
- Yao, Z.; Wann, J.; Chen, J. Generalized maximum entropy based identification of graphical ARMA models. Automatica 2022, 141, 110319. [Google Scholar]
- Entezami, A.; Sarmadi, H.; Behkamal, B.; Mariani, S. Big data analytics and structural health monitoring: A statistical pattern recognition-based approach. Sensors 2020, 20, 2328. [Google Scholar] [CrossRef]
- Shi, Q.; Yin, J.; Cai, J.; Cichocki, A.; Yokota, T.; Chen, L.; Zeng, J. Block Hankel tensor ARIMA for multiple short time series forecasting. Proc. AAAI Conf. Artif. Intell. 2020, 34, 5758–5766. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. Wind power forecasting using neural network ensembles with feature selection. IEEE Trans Sustain. Energy 2015, 6, 1447–1456. [Google Scholar] [CrossRef]
- Luo, X.; Sun, J.; Wang, L.; Wang, W.; Zhao, W.; Wu, J.; Zhang, Z. Short-term wind speed forecasting via stacked extreme learning machine with generalized correntropy. IEEE Trans. Ind. Inform. 2018, 14, 4963–4971. [Google Scholar] [CrossRef]
- Jahangir, H.; Golkar, M.A.; Alhameli, F.; Mazouz, A.; Ahmadian, A.; Elkamel, A. Short-term wind speed forecasting framework based on stacked denoising auto-encoders with rough ANN. Sustain. Energy Technol. Assess. 2020, 38, 100601. [Google Scholar] [CrossRef]
- Messina, A.R.; Vittal, V. Nonlinear, non-stationary analysis of interarea oscillations via Hilbert spectral analysis. IEEE Trans. Power Syst. 2006, 21, 1234–1241. [Google Scholar] [CrossRef]
- Leung, T.; Zhao, T. Financial time series analysis and forecasting with Hilbert–Huang transform feature generation and machine learning. Appl. Stoch. Model. Bus. Ind. 2021, 37, 993–1016. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Zhang, L.; Niu, X. A combined forecasting model for time series: Application to short-term wind speed forecasting. Appl. Energy 2020, 259, 114137. [Google Scholar] [CrossRef]
- Ahmadi, G.; Teshnehlab, M. Designing and implementation of stable sinusoidal rough-neural identifier. IEEE Trans. Neural. Netw. Learn. Syst. 2017, 28, 1774–1786. [Google Scholar] [CrossRef]
- Jiang, P.; Li, R.; Li, H.J. A combined model based on data preprocessing strategy and multi-objective optimization algorithm for short-term wind speed forecasting. Appl. Energy 2019, 241, 519–539. [Google Scholar]
- Alsharekh, M.F.; Habib, S.; Dewi, D.A.; Albattah, W.; Islam, M.; Albahli, S. Improving the Efficiency of Multistep Short-Term Electricity Load Forecasting via R-CNN with ML-LSTM. Sensors 2022, 22, 6913. [Google Scholar] [CrossRef]
- Kabir, H.D.; Khosravi, A.; Hosen, M.A.; Nahavandi, S. Neural network-based uncertainty quantification: A survey of methodologies and applications. IEEE Access 2018, 6, 36218–36234. [Google Scholar] [CrossRef]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Pluzhnik, E.; Nikulchev, E. Virtual laboratories in cloud infrastructure of educational institutions. In Proceedings of the 2014 2nd 2014 2nd International Conference on Emission Electronics (ICEE), Saint-Petersburg, Russia, 30 June–4 July 2014; pp. 1–3. [Google Scholar]
- Nikulchev, E.V. Simulation of robust chaotic signal with given properties. Adv. Stud. Theor. Phys. 2014, 8, 939–944. [Google Scholar] [CrossRef]
- Nikulchev, E. Robust chaos generation on the basis of symmetry violations in attractors. In Proceedings of the 2014 2nd International Conference on Emission Electronics (ICEE), Saint-Petersburg, Russia, 30 June–4 July 2014; pp. 1–3. [Google Scholar]
- Koppe, G.; Toutounji, H.; Kirsch, P.; Lis, S.; Durstewitz, D. Identifying nonlinear dynamical systems via generative recurrent neural networks with applications to fMRI. PLoS Comput. Biol. 2019, 15, e1007263. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv 2020, arXiv:2002.09545. [Google Scholar]
- Rathnayaka, R.K.T.; Seneviratna, D.M.K.N. Taylor series approximation and unbiased GM (1, 1) based hybrid statistical approach for forecasting daily gold price demands. Grey Syst. Theory Appl. 2019, 9, 5–18. [Google Scholar] [CrossRef]
- Chaudhary, P.K.; Pachori, R.B. Automatic diagnosis of glaucoma using two-dimensional Fourier-Bessel series expansion based empirical wavelet transform. Biomed. Signal Process. Control. 2021, 64, 102237. [Google Scholar] [CrossRef]
- Son, J.H.; Kim, Y. Probabilistic time series prediction of ship structural response using Volterra series. Mar. Struct. 2021, 76, 102928. [Google Scholar] [CrossRef]
- Wu, S.; Xiao, X.; Ding, Q.; Zhao, P.; Wei, Y.; Huang, J. Adversarial sparse transformer for time series forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17105–17115. [Google Scholar]
- Montagnon, C.E. Forecasting by splitting a time series using Singular Value Decomposition then using both ARMA and a Fokker Planck equation. Phys. A Stat. Mech. Its Appl. 2021, 567, 125708. [Google Scholar] [CrossRef]
- Khan, S.; Alghulaiakh, H. ARIMA model for accurate time series stocks forecasting. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 524–528. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An experimental review on deep learning architectures for time series forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Meisenbacher, S.; Turowski, M.; Phipps, K.; Rätz, M.; Müller, D.; Hagenmeyer, V.; Mikut, R. Review of automated time series forecasting pipelines. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1475. [Google Scholar] [CrossRef]
- Astakhova, N.N.; Demidova, L.A.; Nikulchev, E.V. Forecasting of time series’ groups with application of fuzzy c-mean algorithm. Contemp. Eng. Sci. 2015, 8, 1659–1677. [Google Scholar] [CrossRef]
- Samokhin, A.B. Methods and effective algorithms for solving multidimensional integral equations. Russ. Technol. J. 2022, 10, 70–77. [Google Scholar] [CrossRef]
- Petrushin, V.N.; Nikulchev, E.V.; Korolev, D.A. Histogram Arithmetic under Uncertainty of Probability Density Function. Appl. Math. Sci. 2015, 9, 7043–7052. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, H.; Dinavahi, V. Wavelet neural network based multiobjective interval prediction for short-term wind speed. IEEE Access 2018, 6, 63352–63365. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Construction of optimal prediction intervals for load forecasting problems. IEEE Trans. Power Syst. 2010, 25, 1496–1503. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Xie, L.; Shen, Y.; Zhang, K. Direct interval forecasting of wind speed using radial basis function neural networks in a multi-objective optimization framework. Neurocomputing 2016, 205, 53–63. [Google Scholar] [CrossRef]
- Arora, P.; Jalali, S.M.J.; Ahmadian, S.; Panigrahi, B.K.; Suganthan, P.; Khosravi, A. Probabilistic wind power forecasting using optimised deep auto-regressive recurrent neural networks. IEEE Trans. Autom. Sci. Eng. 2023, 20, 271–284. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.; Zhang, H.; Wang, Y. A deep-learning wind speed interval forecasting architecture based on modified scaling approach with feature ranking and two-output gated recurrent unit. Expert Syst. Appl. 2023, 211, 118419. [Google Scholar] [CrossRef]
- Yeung, D.S.; Li, J.; Ng, W.W.Y.; Chan, P.P.K. MLPNN training via a multiobjective optimization of training error and stochastic sensitivity. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 978–992. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Class | Model Type | Advantages | Disadvantages |
|---|---|---|---|
| Direct modeling methods | 1.1. Engineering physical models | - Can model any physical system | They are complex and require detailed knowledge of the physical properties of the simulated process or device. Often unjustified high complexity |
| 2.2. Parametric identification of dynamical systems [53] | - Model parameters can be calculated from the initial data | - For non-linear systems, knowledge of non-linearities is required. High sensitivity to variations in variables | |
| Robust models | - Insensitivity to small changes | Ambiguity of decisions | |
| Inverse methods (time series modeling) | Series or expansions (Fourier series [54], Taylor series [55], Bessel series [56], Volterra functional expansion [57], etc.) | Fast calculations and ease of use | There are no criteria for how many members of the series must be used. Demonstrates sensitivity to the types of non-linearities in dynamics |
| Regression methods Linear regression, exponential regression [58], Box Jenkins (autoregressive moving average (ARMA) [59], autoregressive integrated moving average (ARIMA) [60]; Holt and Winters | Fast calculations | Poor prediction due to multiple seasonality of data. The art of choosing the right type of model is required | |
| Stochastic models (Bayesian models, Gaussian models; beta distribution) | Ease of use | Tied to a distribution type | |
| Machine learning [61,62,63,64] Neural networks, deep learning, evolutionary algorithms [65], etc. | High precision and adaptability | High dependence on the amount of training data | |
| Combined deterministic and non-deterministic models | A good criterion in choosing models improves predictions. They support physical interpretations without the need for a very detailed or complex mathematical model | An expert is required to select the parameters of non-deterministic models. Implementation can be difficult | |
| Prediction interval | Combined methods, integral equations [66], histogram arithmetic [67]; methods for constructing intervals [68] | Can use any of the above models | One is required to solve the problem of choosing the width of the interval |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikulchev, E.; Chervyakov, A. Prediction Intervals: A Geometric View. Symmetry 2023, 15, 781. https://doi.org/10.3390/sym15040781
Nikulchev E, Chervyakov A. Prediction Intervals: A Geometric View. Symmetry. 2023; 15(4):781. https://doi.org/10.3390/sym15040781
Chicago/Turabian StyleNikulchev, Evgeny, and Alexander Chervyakov. 2023. "Prediction Intervals: A Geometric View" Symmetry 15, no. 4: 781. https://doi.org/10.3390/sym15040781
APA StyleNikulchev, E., & Chervyakov, A. (2023). Prediction Intervals: A Geometric View. Symmetry, 15(4), 781. https://doi.org/10.3390/sym15040781