1. Introduction
The Nadarajah–Haghighi (NH) distribution, proposed by Nadarajah and Haghighi [
1], has a density shape that can be growing or unimodal as well as a hazard rate that can be increasing, decreasing, or constant. Recently, as a new weighted version of the NH distribution, according to the idea of created weighted distributions, Khan et al. [
2] proposed the weighted Nadarajah–Haghighi (WNH) distribution as a competitive model to other lifetime models, such as gamma, exponentiated half-logistic, generalized-exponential, Weibull, etc. They also stated that the WNH distribution is suitable for modeling data from different areas; for example, reliability, survival analysis, forest, ecological, etc. Suppose that
X is a lifetime random variable of the test unit(s) following the two-parameter
distribution. Then, its probability density function (PDF)
and cumulative distribution function (CDF)
are given, respectively, as
and
where
and
are the shape and scale parameters, respectively. From (
1), Khan et al. [
2] showed that the WNH distribution could be considered an extended model of three common distributions, namely: NH, standard half-logistic and zero truncated weighted Weibull models, such as:
Further, the reliability function (RF)
and hazard function (HF)
at distinct time
t are
and
respectively. From (
2), where
, two lifetime models can be obtained by making a useful transformation, namely (i) standard half-logistic distribution when
and (ii) zero truncated weighted Weibull distribution when
.
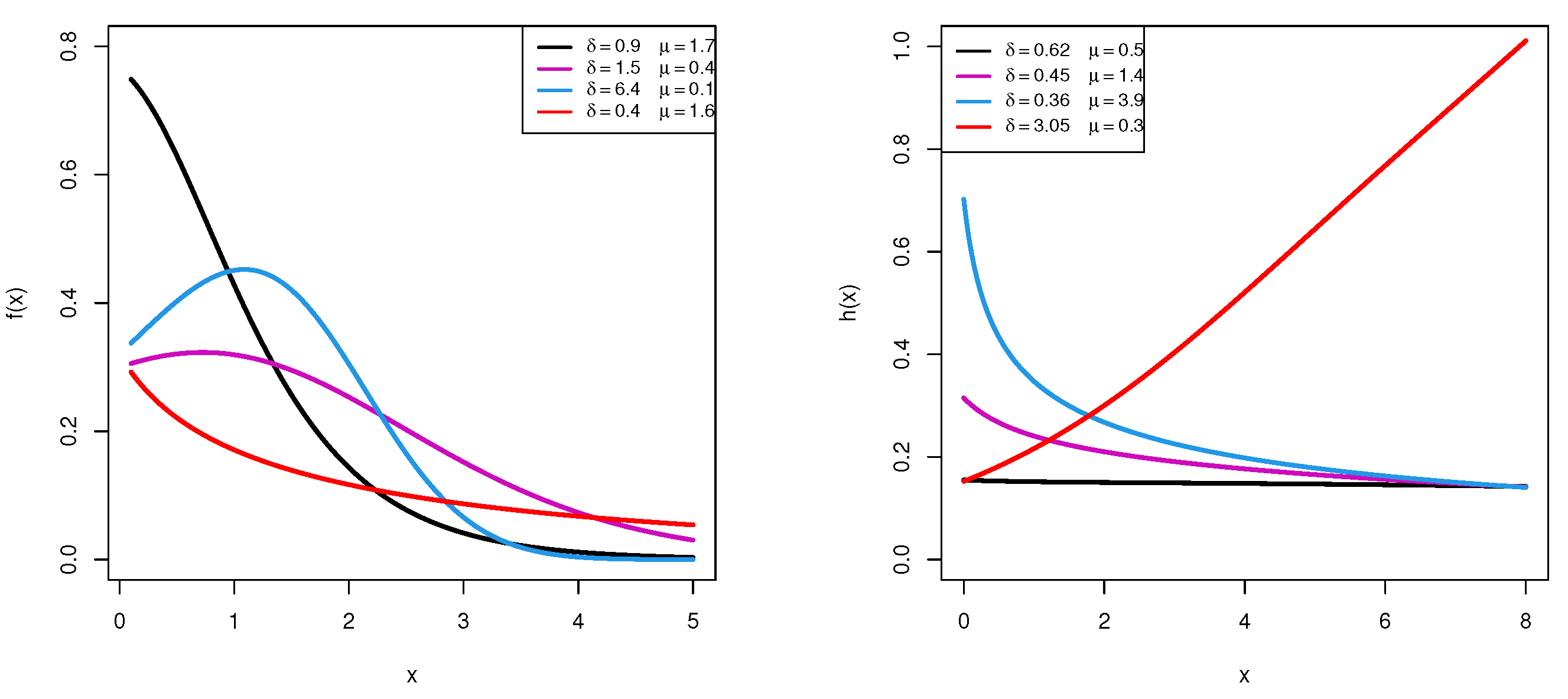
Figure 1 depicts the density and hazard rate shapes of the
distribution for several choices of its parameters. It reveals that the PDF (
1) is positively skewed while the HF (
4) has increasing, decreasing, and constant shapes.
In the past decade, researchers have favored dealing with progressive Type-II censoring (PCTII) over other censoring mechanisms because it (i) reduces the total testing time, (ii) reduces the cost of failed units, (iii) terminates the experiment rapidly, and (iv) allows the researcher to make use of the units removed during the experiment for use in other tests. Briefly, the PCTII can be described as: Suppose that n independent and identical units are subjected to a life-testing experiment at time zero, m is a fixed number of failures and the censoring scheme is also pre-specified. At the time that the first failure is observed (say ), survival units are randomly removed from the experiment. Following the second observed failure (say ), of survival units are randomly removed from units, and so on. This mechanism continues until the failure occurs and the experiment is stopped. At the same time, all remaining units are removed. Let be a PCTII sample of size m with censoring from a continuous population.
Then, the likelihood function of
, where
is the parameter vector, can be expressed as
where
.
Various studies on the NH distribution using censored data have been made in the literature, readers may refer to Mohie El-Din et al. [
3], Ashour et al. [
4], Wu and Gui [
5], Elshahhat et al. [
6], Elshahhat and Abu El Azm [
7], Dey et al. [
8], Almarashi et al. [
9], among others.
Although the NH distribution has received a lot of attention from several authors to the best of our knowledge, the problem of estimating the WNH parameters and/or the RF and HF via PCTII sampling has yet to be investigated. Therefore, this article offers an analysis of PCTII lifetime data when each test unit follows the WNH distribution. The maximum likelihood estimators (MLEs) with their Fisher information members are evaluated through the standard Newton–Raphson algorithm. The associated asymptotic normality of the MLE and log-MLE is used to construct the asymptotic confidence intervals (ACIs). Further, for all unknown quantities, bootstrap-p and bootstrap-t intervals are also obtained. Using the Lindley and Metropolis–Hastings (M-H) methods, the Bayes estimates against the squared-error loss (SEL) function can be easily approximated. Using Markov chain Monte Carlo (MCMC) steps, the Bayes credible interval (BCI) and the highest posterior density (HPD) interval for each unknown parameter are obtained. To compare two (or more) different progressive censoring plans, using their Fisher information, different optimality criteria are taken into account. To assess the performance of the proposed estimation methodologies, an extensive Monte Carlo simulation is performed. Lastly, three applications based on real-life engineering data are presented to show the superiority and flexibility of the WNH model over three weighted distributions (as competitors), namely: weighted exponential, weighted Gompertz, and weighted Lindley distributions. Additionally, the proposed applications aim to demonstrate the applicability of the acquired estimators in a real-life scenario.
The rest of the article is classified as:
Section 2 provides the likelihood inference. Two kinds of bootstrapping are presented in
Section 3. Bayes approximation techniques are discussed in
Section 4. Simulation results are provided in
Section 5. In
Section 6, a brief explanation of the optimum progressive censoring is presented. Three real applications are presented in
Section 7. In
Section 8, some conclusions are offered.
4. Bayes Estimators
The Bayes’ paradigm provides the possibility of incorporating prior information about the unknown parameter(s) of interest. To establish this method, the WNH parameters
and
are assumed to be random variables with some extra information included in their prior distributions. One of the most flexible priors is called the gamma conjugate density prior; see Kundu [
13]. Gamma density is fairly straightforward and flexible enough to cover a large variety of the experimenter’s prior beliefs. We, therefore, assumed that
and
, having independent gamma PDFs as
and
, where
are chosen to reflect prior knowledge about the
parameters. Thus, the joint gamma PDF of
and
becomes
where
and
are assumed to be known. On the other hand, the most widely used loss is called the SEL function,
, and is defined as
where
denotes the Bayes estimate of
.
From (
12), the target Bayes estimate is given by the posterior expectation of
. The joint posterior PDF, by combining (
11) with (
6), of
and
is
where
. However, using (
12), the Bayes estimator for any function of
and
, say
is given by
It is clear, based on (
14), that the Bayes estimate of
is derived in an expression of the ratio of double integrals.
Then, the Bayes solution for each unknown parameter is not available. We, therefore, propose to use both the Lindley and MCMC methods to approximate the Bayes estimates.
4.1. Lindley’s Approximation
In this subsection, following Lindley [
14], the closed expressions for the Bayes estimates
are obtained. However, setting
for simplicity, the approximated posterior expectation (say
) of
is given by
where all terms in (
15) are evaluated at their
and
,
,
,
,
,
,
,
,
,
,
,
, and
in the
element of the VCov matrix (
10).
From (
15), the Lindley’s estimators
and
of
and
, respectively, as
and
where
,
, and the items
(for
) are obtained and reported in
Appendix B.
Similarly, using (
15), the Lindley’s estimators of the reliability characteristic functions
and
of
and
are given (for
), respectively, by
and
where
is given in
Section 2.2 and
of
, and
are obtained and presented in
Appendix C.
Although the Lindley estimators of , , , and are expressed explicitly, the main problem of this approach is its disability to obtain an interval estimate. Consequently, to approximate the Bayes estimates and to construct their BCI and HPD interval estimates, the M-H algorithm is considered.
4.2. M-H Sampler
Since the joint posterior PDF cannot be reduced by analytical steps to any familiar form, the M-H algorithm (which is one of the effective MCMC techniques) is used, see Gelman et al. [
15].
First, from (
13), the conditional distribution of
and
must be obtained, respectively, as
and
As we anticipated, the conditional distributions (
16) and (
17) of
and
, respectively, cannot be reduced to any standard distribution.
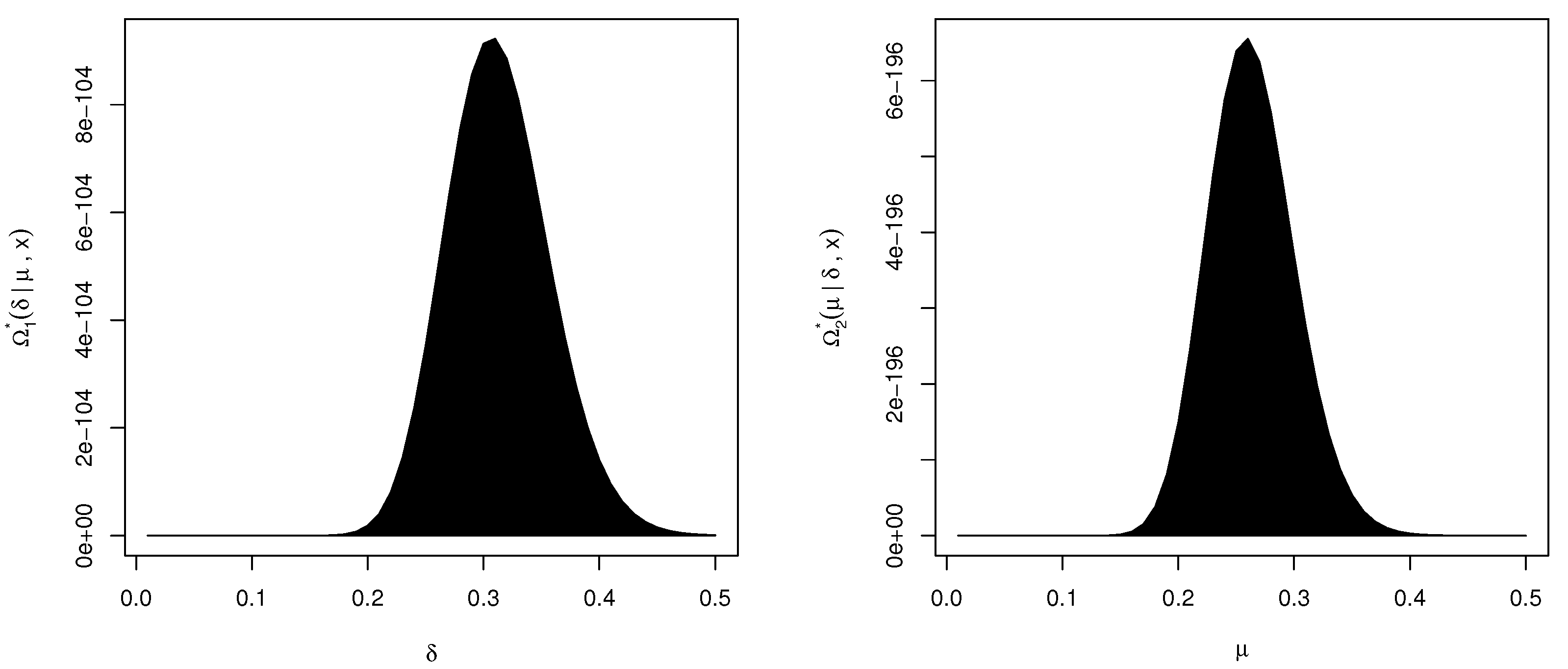
Figure 2 shows that the distributions (
16) and (
17) behave like a normal density. Therefore, to obtain the Bayes MCMC estimates along with their BCI and HPD intervals, we perform the generation process described in Algorithm 2.
| Algorithm 2 Markov Chain Monte Carlo Sampling: |
- Step 1:
Start with initial guesses and . - Step 2:
Set - Step 3:
Generate and from and , respectively. - Step 4:
Obtain and . - Step 5:
Generate sample variates and from the uniform distribution and set
- Step 6:
Obtain and , for by replacing and with their and , respectively. - Step 7:
Put . - Step 8:
Repeat Steps 3-7 times and obtain and for . - Step 9:
Compute the Bayes estimates of , , or (say ) under the SEL ( 12) as
where is burn-in. - Step 10:
Compute the BCI of by ordering as . Thus the BCI of is obtained as
- Step 11:
Compute the HPD interval of as
where is selected so that
|
5. Numerical Comparisons
To compare the efficiency of the proposed estimators of
,
,
, and
described in the preceding sections, based on 2000 PCTII samples generated from
via Algorithm 3, an extensive Monte Carlo simulation is conducted. At distinct time
, the corresponding actual values of
and
are taken as 0.935 and 0.012, respectively. Various combinations of the total sample size
n and effective sample size
m are also considered, such as
, and
m is taken as 50% and 80% for each
n. Three different progressive designs, where
means that 0 is repeated
times, are used, namely:
To draw a PCTII sample from the WNH distribution for pre-specified values of
n,
m, and
, we perform the following steps:
| Algorithm 3 Progressive Type-II Censored Sampling: |
- Step 1:
Create independent observations with size m as from uniform distribution. - Step 2:
For specific n, m, and , set . - Step 3:
Set for . - Step 4:
Set , is a PCTII sample from .
|
Using each simulated sample, the point estimators, such as maximum likelihood, Lindley, and MCMC, are compared using their mean absolute bias (MAB), and root mean squared error (RMSE) simulated values. Further, the 95% interval estimators, called ACI-NA, ACI-NL, Boot-p, Boot-t, BCI, and HPD intervals, are examined via their simulated average confidence length (ACL) and coverage probability (CP) values. Following Algorithm 1, the bootstrapping procedure of , , , and is repeated 10,000 times.
To compute the Bayes estimates and BCI/HPD intervals of
,
,
, or
, we repeat Algorithm 2 12,000 times and ignore the first 2000 times as burn-in. For both WNH parameters
and
, two different informative sets of the hyperparameters
are used, namely: Prior-1 (P1):
and Prior-2 (P2):
. These prior sets are specified based on two criteria called prior mean and prior variance in such a way that the prior mean becomes the plausible value of the corresponding unknown parameter. All numerical computations are carried out via
4.1.2 software utilizing two recommended packages, namely: ‘
’ and ‘
’ packages, as suggested by Plummer et al. [
16] and Henningsen and Toomet [
10], respectively.
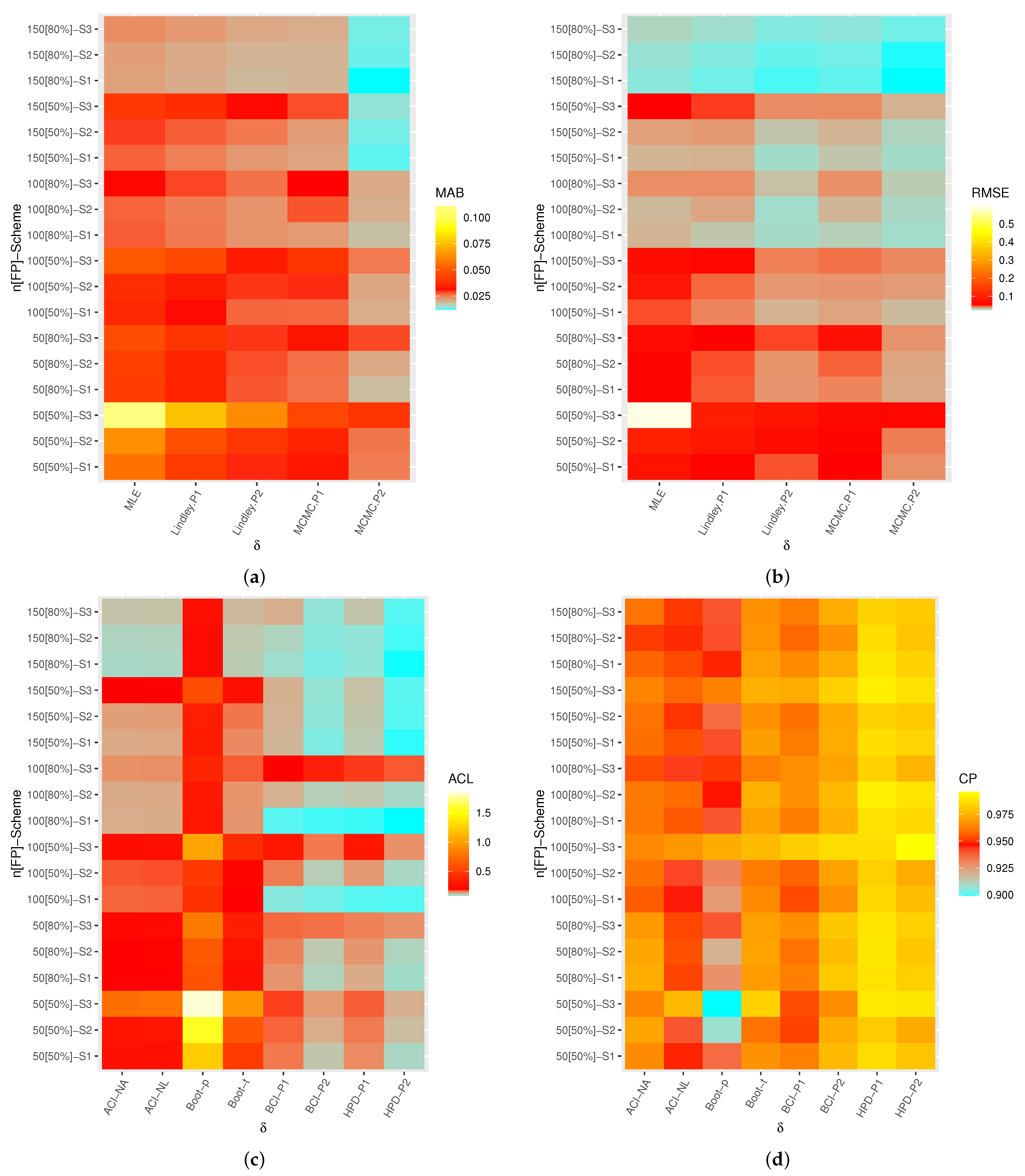
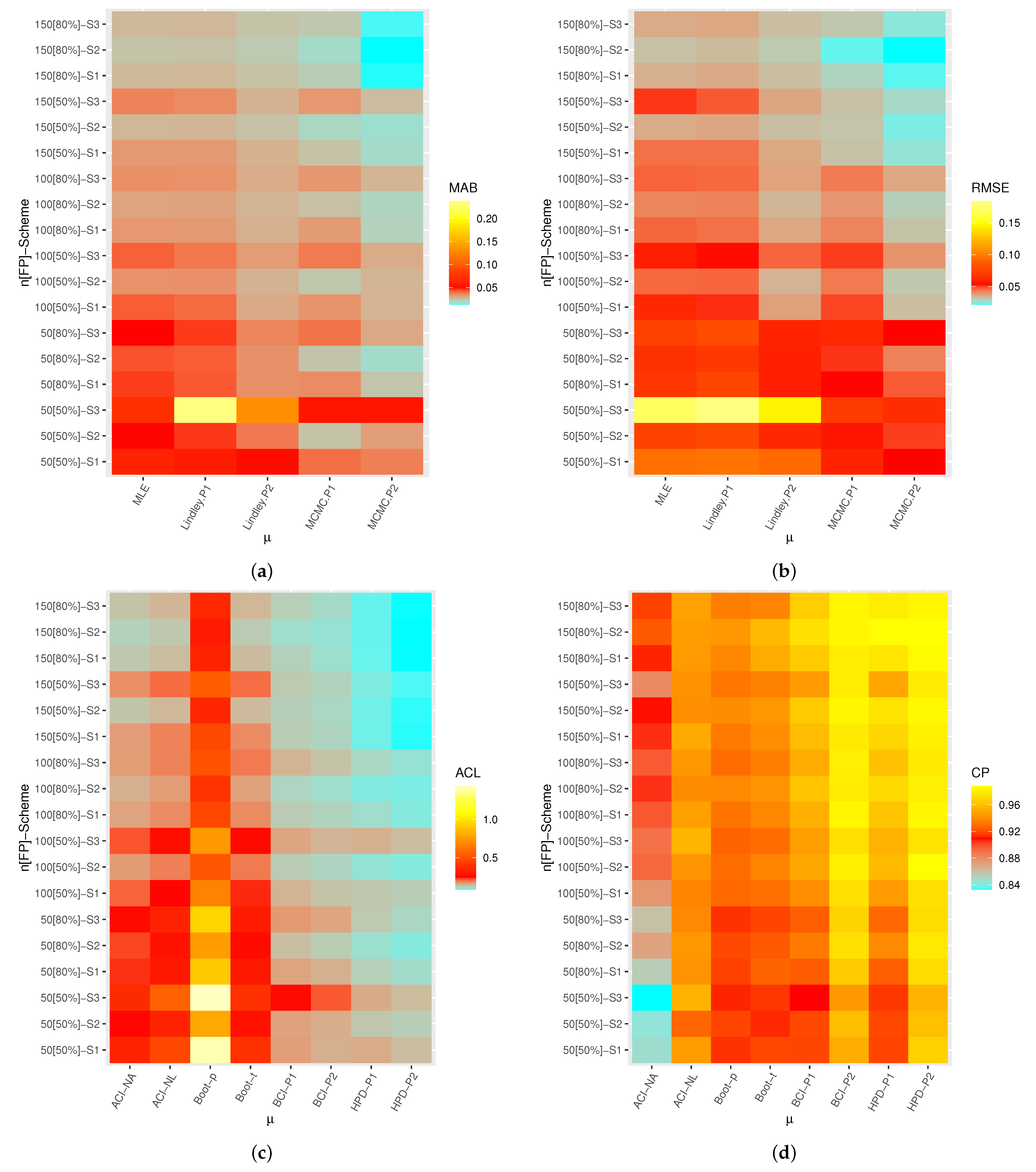
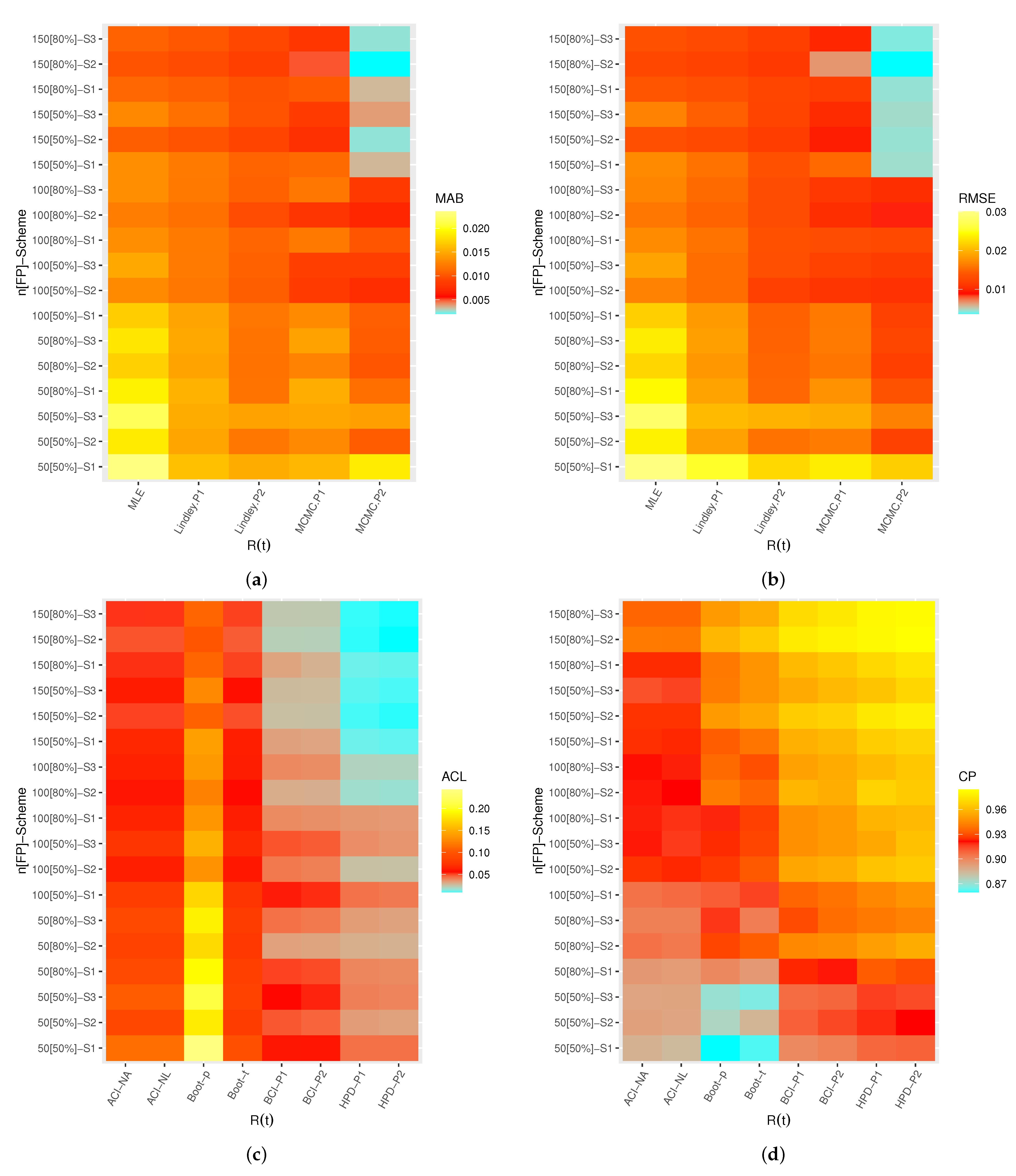
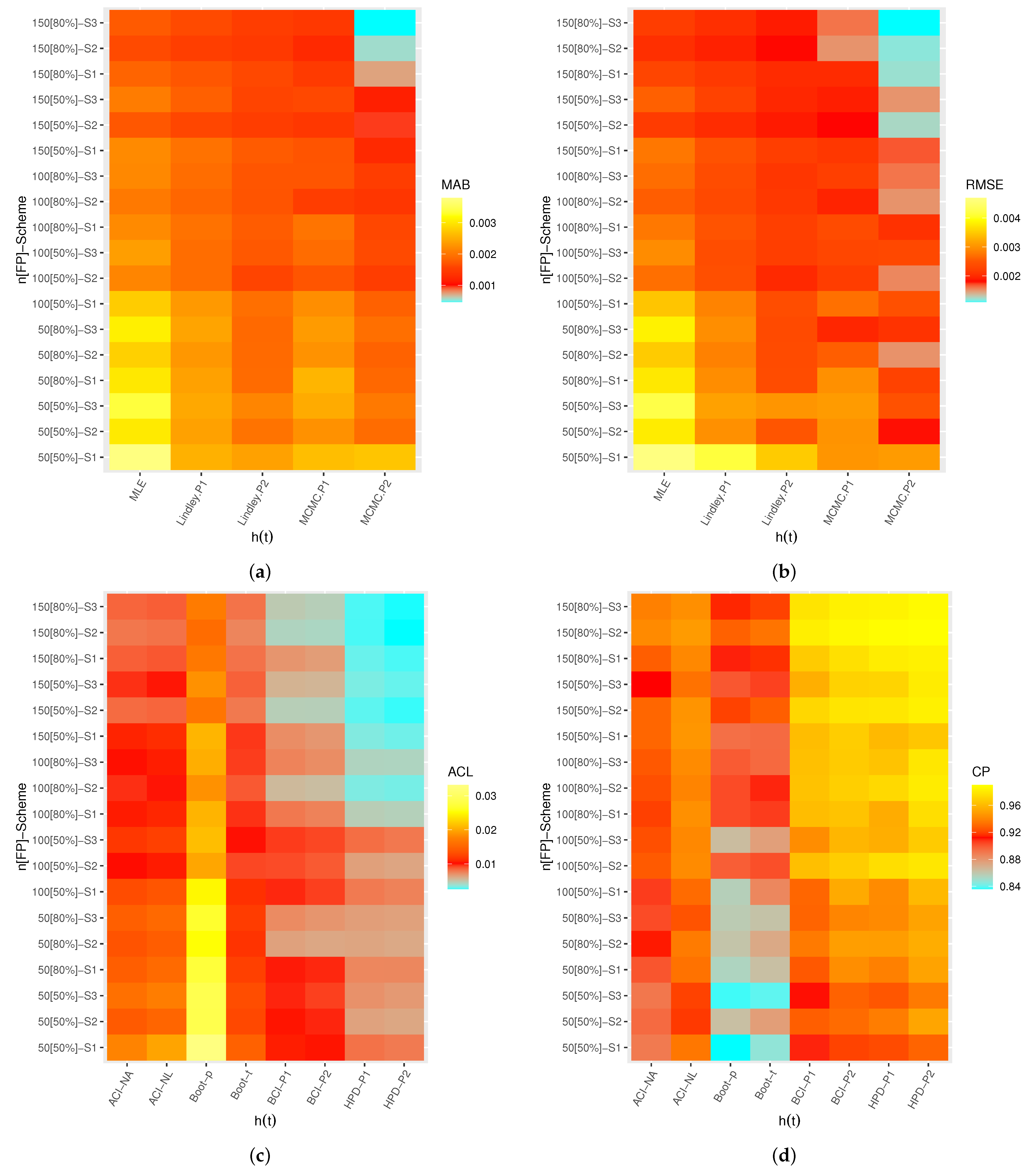
A heatmap is a graphical representation of numerical data used to show relationships between two variables of interest so that individual data points contained in a data set are represented via different colors. Therefore, by
software, the heatmap data tool is used to display the simulated results, including: MAB, RMSE, ACL, and CP values of
,
,
, and
, see
Figure 3,
Figure 4,
Figure 5 and
Figure 6, respectively. Each heatmap displays the proposed estimation methods and the specified test settings on the “
” and “
” lines, respectively. On the other hand, all simulation results of
,
,
, and
are also available in
Table 1,
Table 2,
Table 3 and
Table 4.
Overall, the Bayes MCMC estimates of all unknown parameters perform better than the MLEs in terms of the smallest values of MABs, RMSEs, and ACLs, as well as the highest CP values.
As n (or m) increases, the MABs, RMSEs, and ACLs tend to decrease (except CPs increase), which infers that the proposed estimates are asymptotically unbiased and consistent. This result is also reached when the total number of progressive items, , decreases.
Comparing the proposed point estimation methods on the basis of the smallest MABs and RMSEs, it is clear that the performance of MCMC estimates of all unknown parameters is highly recognizable compared to those obtained based on the Lindley approach, and both exhibit reasonably good performance compared to the likelihood method. It is an anticipated result because the calculated MCMC estimates included additional prior information.
Comparing the proposed interval estimation methods in terms of the smallest ACLs and highest CPs, it is observed that (i) ACI-NA performs better than ACI-NL, (ii) Boot-t performs better than Boot-p, and (iii) the HPD interval performs better than BCI. This conclusion holds for all unknown parameters. It is also clear, in most cases, that the CPs of classical (or Bayes) interval estimates are mostly close to (or below) the specified nominal level.
In particular, based on the ACL and CP criteria, it is also noted that the HPD interval of all unknown parameters provides the best bounds compared to its competitive intervals.
Since the variance in P2 is smaller than the variance in P1, consequently, the Bayes estimates (or BCI/HPD intervals) perform better based on P2 than the others.
Comparing the proposed censoring schemes, both point and interval estimation methods of provide good behavior under (where the survival units are removed in the first stage) compared with other competing schemes. Moreover, both point and interval estimation methods of , , and provide good behavior under (where the survival units are removed in the middle stage) compared to others.
Lastly, to evaluate the unknown parameter(s) of the WNH lifetime model in the presence of data collected from Type-II progressive censoring, the Bayes MCMC methodology is recommended.
6. Optimum PCTII Fashions
The issue of determining the optimum progressive censoring (removal pattern design
) from a group of all possible plans is a great challenge for any practitioner. In this context, independently, Balakrishnan and Aggarwala [
17] and Ng et al. [
18] first studied this issue through various setups. The main idea of optimal progressive censoring is, for fixed
n and
m, that the experimenter chooses the scheme
in the sense it provides a significant amount of information of the unknown parameter(s) under study. According to the experimenter’s knowledge about the availability of test items, experimental sources, and test cost, the best censoring plan is selected.
In the literature, for different lifetime models, various works have investigated the problem of optimum censoring; see, for example, Pradhan and Kundu [
19], Elshahhat and Nassar [
20], Elshahhat and Abu El Azm [
7], among others. In
Table 5, to select the optimal PCTII plan, several criteria are listed.
From
Table 5; regarding criterion 1, the experimenter aims to increase the main diagonal values of the observed Fisher information. Further, regarding criteria 2 and 3, the experimenter aims to reduce the trace and determinant values of the estimated VCov matrix. Under criterion 4, the experimenter aims to minimize the estimated variance in the logarithm of the MLE of
th quantile,
for
.
The optimized censoring should coincide with the largest value of criterion 1 and the smallest value of the other criteria. According to criterion 4, using the delta method, the variance of
is given by
where
7. Three Engineering Applications
To show the applicability of the proposed estimation methodologies to real phenomena, we will analyze three different actual data sets. The first data set (say Data A), reported by Mann [
21] and re-analyzed by Alotaibi et al. [
22], consists of the number of vehicle fatalities for 39 counties in South Carolina in 2012. The second data set (say Data B), given by Wang [
23] and discussed earlier by Elshahhat and Abu El Azm [
7], represents the times to failure of eighteen electronic devices. The last data set (say Data C), taken from Lawless [
24] and Mohammed et al. [
25], represents the failure times (in minutes) of fifteen electronic components in an accelerated life test. These data sets are reported in
Table 6.
To highlight the flexibility and adaptability of the proposed model, based on different criteria, the WNH distribution is compared with three weighted distributions as competitors, namely: weighted exponential (WE) by Gupta and Kundu [
26], weighted Gompertz (WG) by Bakouch et al. [
27] and new weighted Lindley (WL) by Asgharzadeh et al. [
28] distributions. The respective PDFs of the compared WE, WG, and WL distributions (for
and
) are:
For each data set, the parameter estimates of
and
with their standard errors (SEs) of each competing model are evaluated by the ML method. Moreover, the estimated values of the negative log-likelihood (NL), Akaike information (AI), consistent Akaike information (CAI), Bayesian information (BI), Hannan–Quinn information (HQI) and the Kolmogorov–Smirnov statistic with its
P-value are computed and reported in
Table 7.
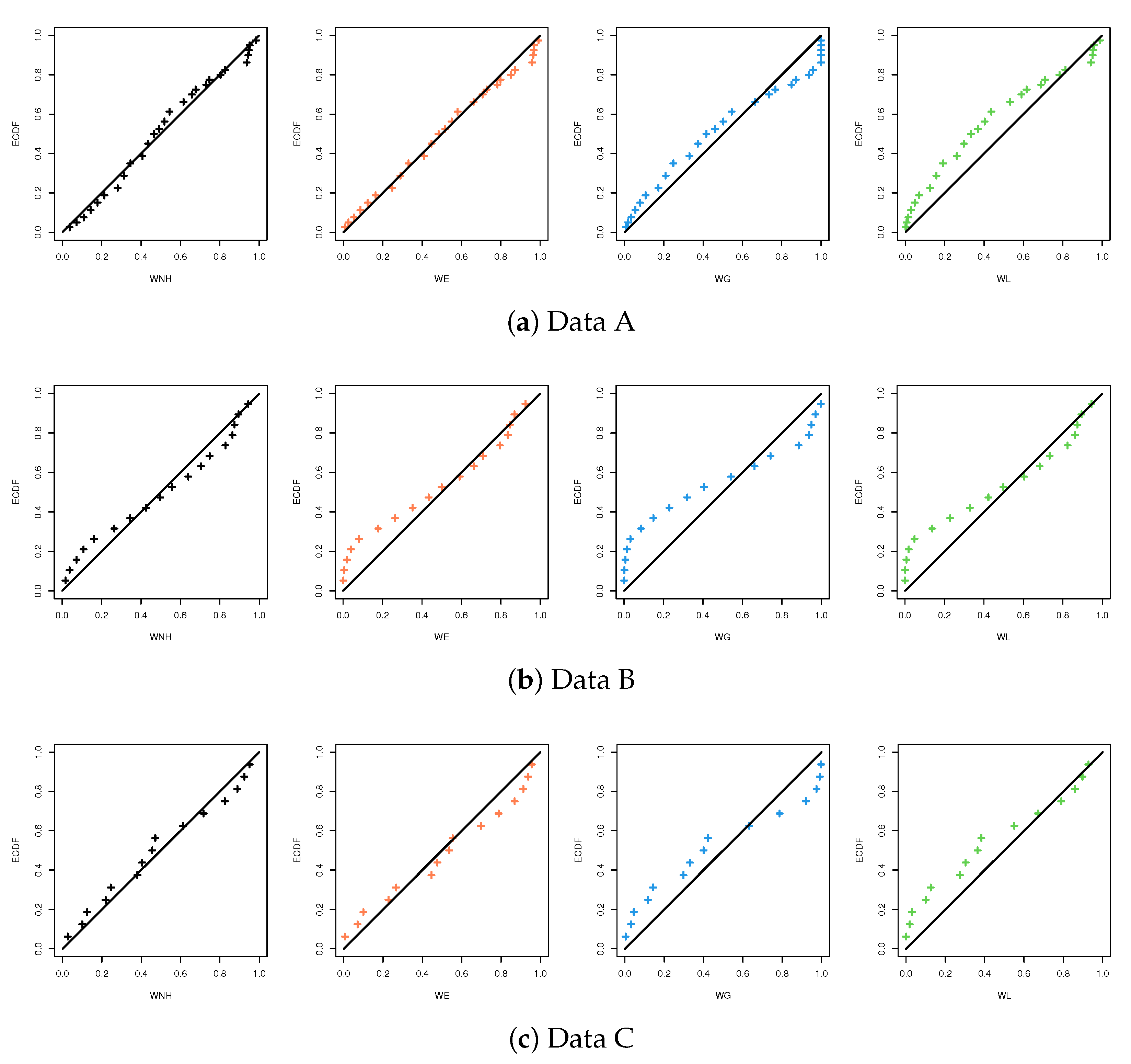
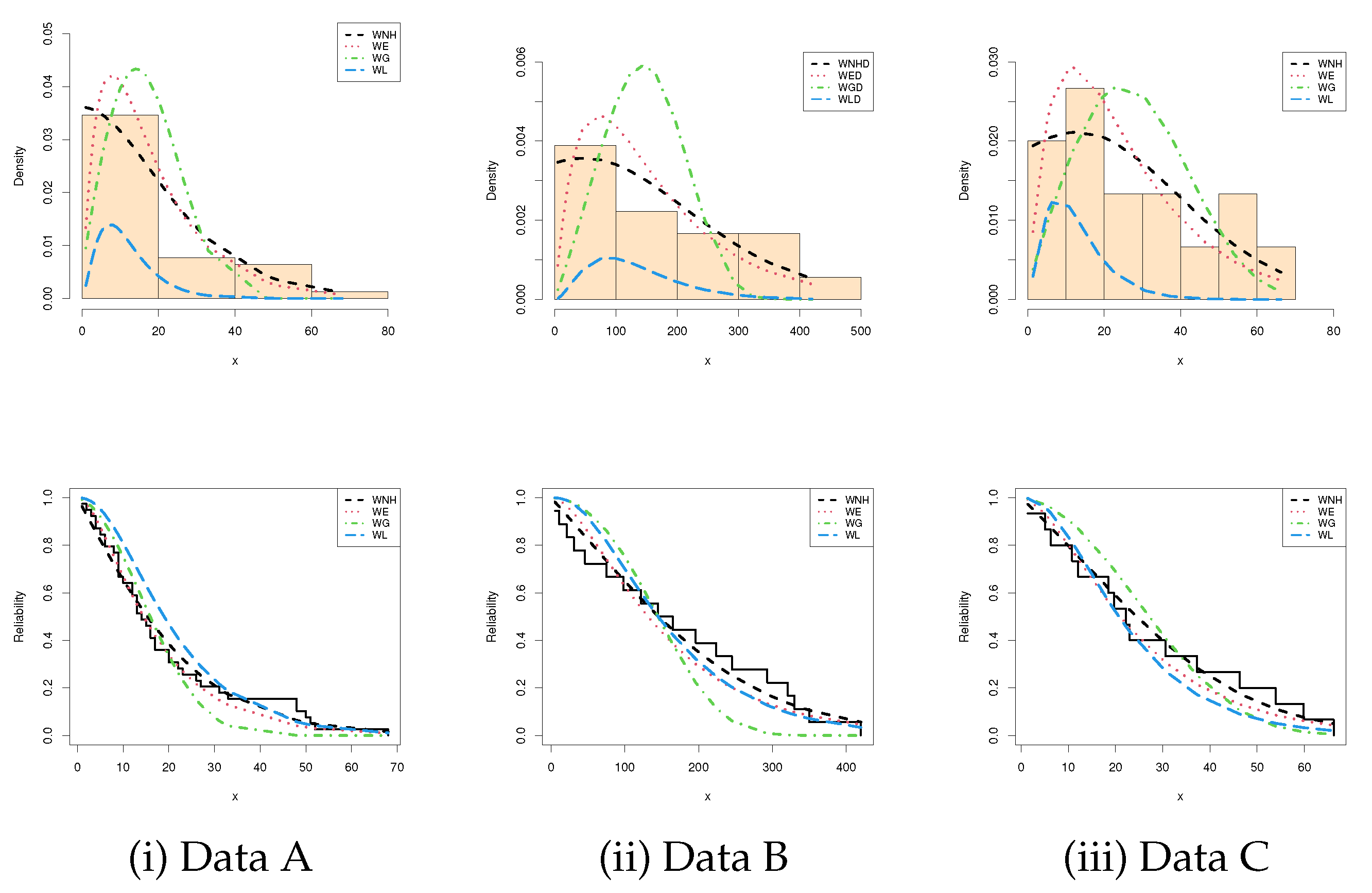
Figure 7 represents the probability-probability (PP) plots of the WNH, WE, WG and WL distributions. It indicates that the plotted points of the fitted WNH distribution based on each data set are quite close to the empirical distribution line. It also confirms the same findings in
Table 7. Moreover,
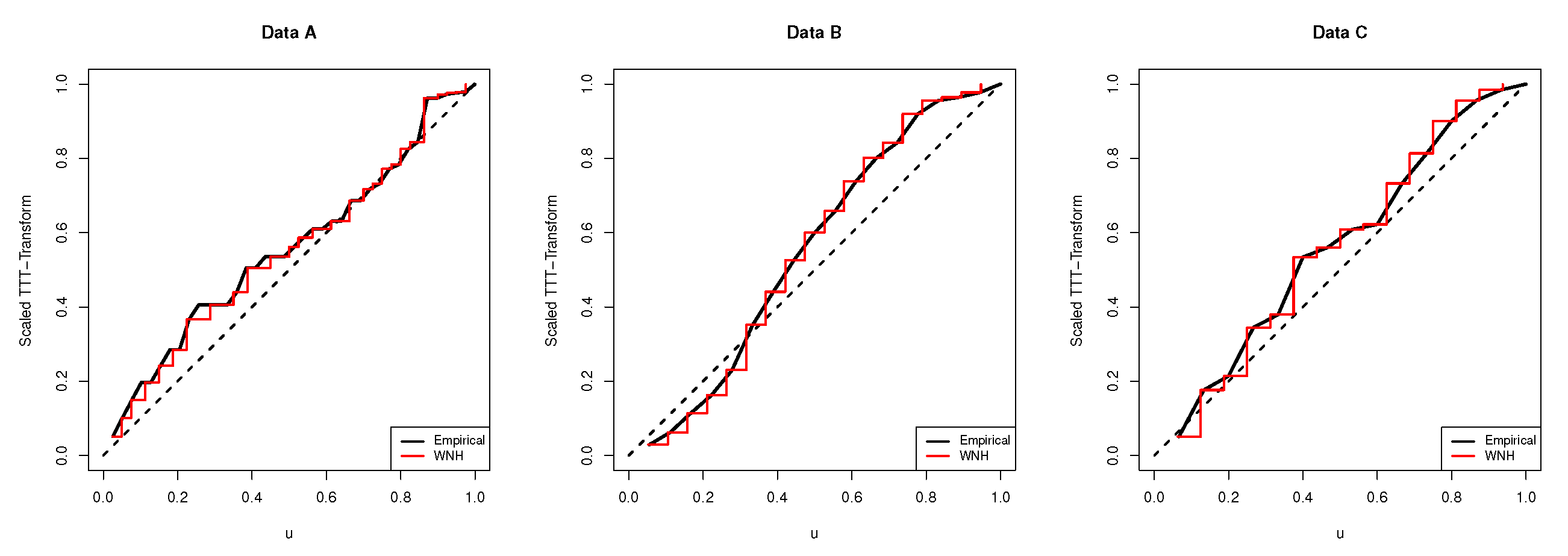
Figure 8 displays the estimated PDFs with their histograms as well as the estimated RFs for the compared distributions under the three data sets. It is clear that the fitted WNH density captures the empirical histograms well. To sum up, we concluded that the WNH distribution has a favorable superiority over other weighted distributions because it has the smallest values of the fitting criteria based on the given data sets. For more illustration, for each real data set, the empirical/estimated TTT transform plot of the WNH distribution is provided in
Figure 9. It exhibits that the given real data sets have a constant hazard rate function.
Next, using various choices of
m and
, three different PCTII samples from each complete real data set are generated and listed in
Table 8. For each PCTII sample in
Table 8, the theoretical results of
,
,
, and
are evaluated numerically via
software. The point estimates (including: MLEs, Lindley, and MCMC) with their SEs as well as the 95% interval estimates (including: ACI-NA, ACI-NL, Boot-
p, Boot-
t, BCI, and HPD) of
,
,
, and
(at
) are presented in
Table 9 and
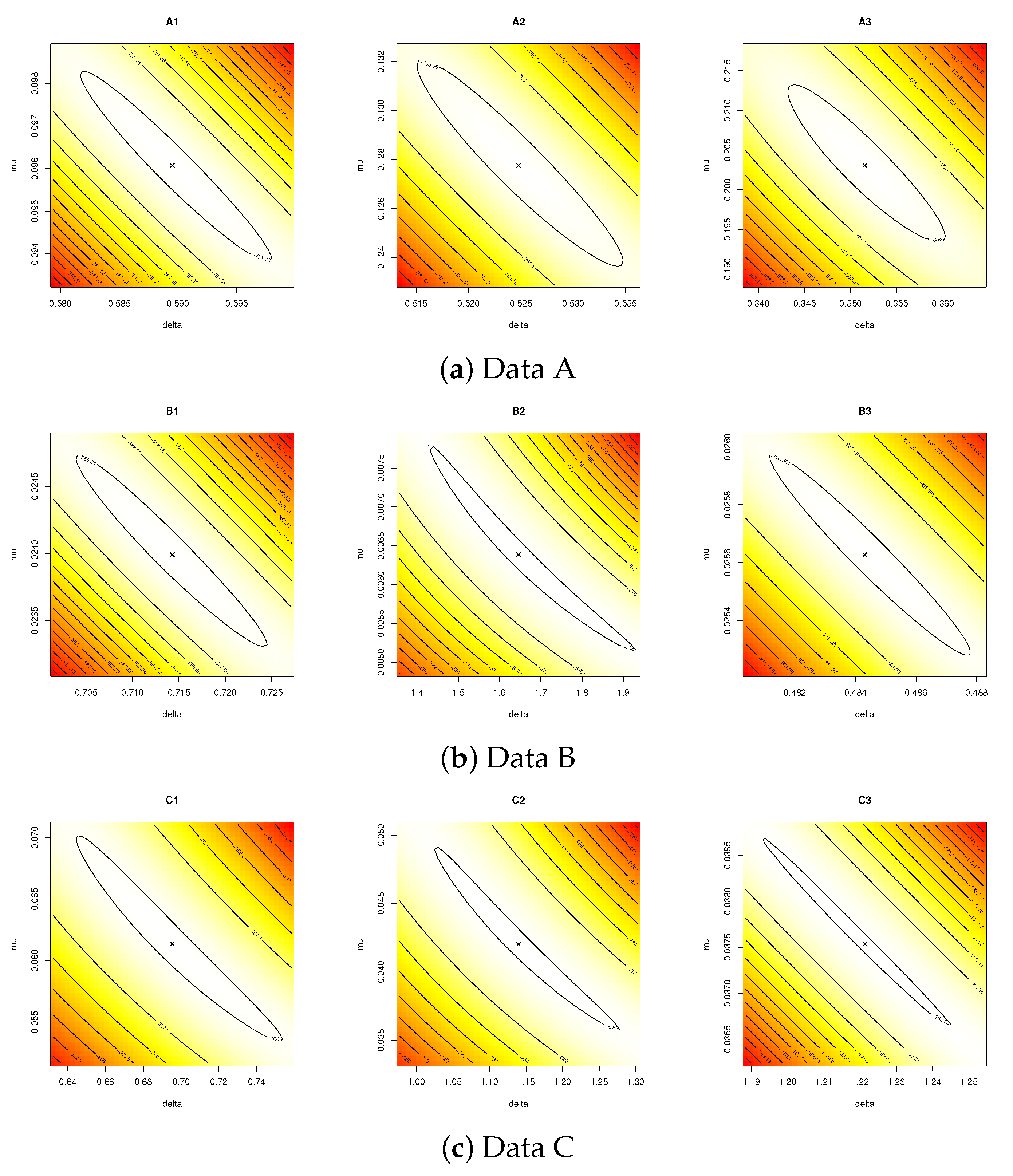
Table 10, respectively. To examine the uniqueness and existence of the MLEs of
and
for A
i, B
i, and C
i for
samples, the contour plots of the log-likelihood function (
7) are shown in
Figure 10. It shows that all acquired estimates of
and
exist and are unique. For obtaining the Bayes MCMC estimates along with their BCI/HPD intervals based on noninformative gamma prior, the M-H algorithm proposed in
Section 4.2 is repeated 30,000 times, and the first 5000 draws are thrown out. From
Table 9 and
Table 10, in terms of minimum standard errors and interval lengths, it can be seen that the MCMC estimates are more precise than the classical estimates. Moreover, the two interval bounds obtained by asymptotic, bootstrap, and credible intervals are close to each other.
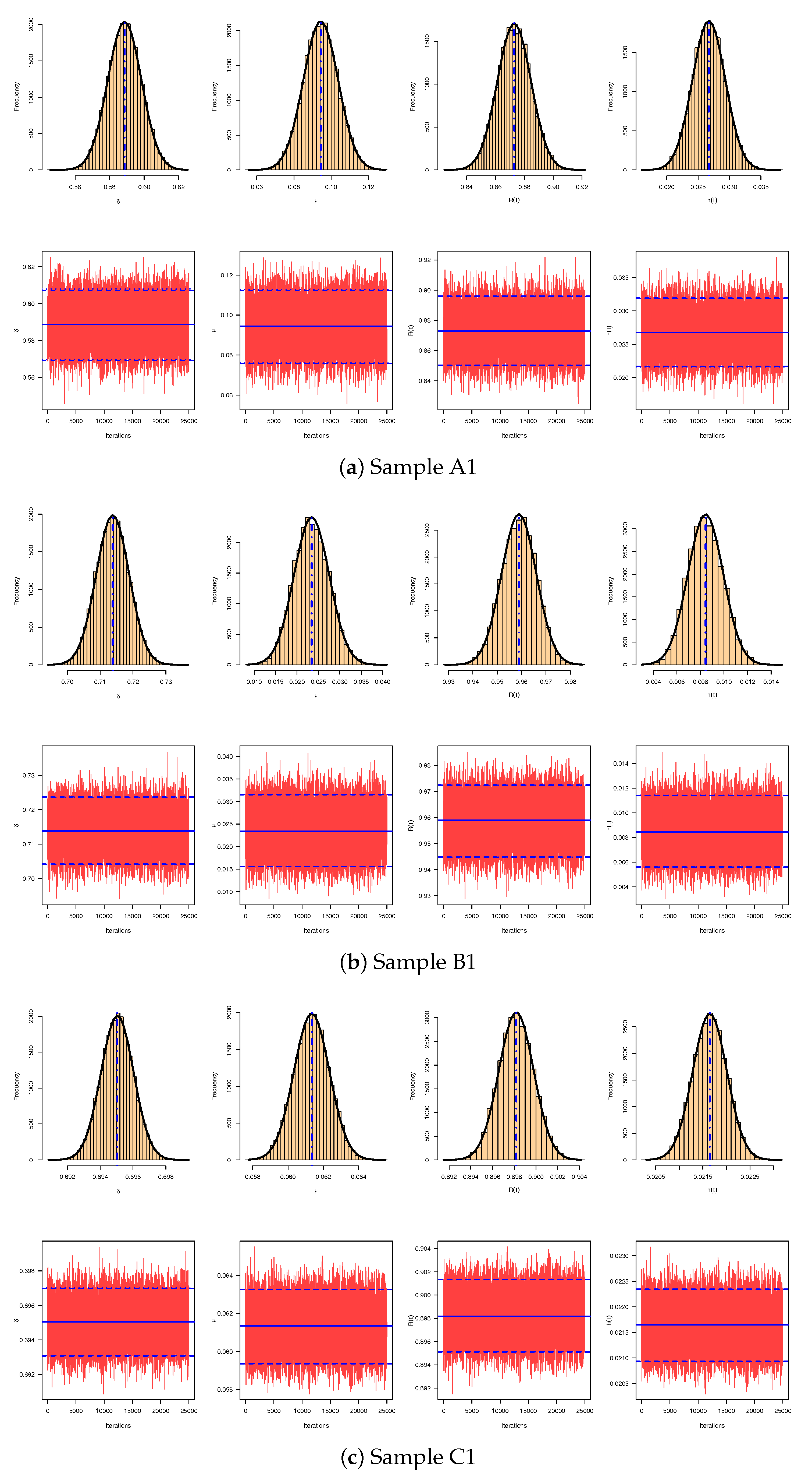
In
Figure 11, based on samples A1, B1, and C1 (as an example), the simulated estimates with their histograms for the marginal posterior distribution functions of
,
,
, and
are plotted with the Gaussian line. It is evident that the MCMC estimates behave appropriately with the normal distribution, where (:) represents the mean sample line. In addition, trace plots using A1, B1, and C1 of the same parameters are displayed in
Figure 11 where the sample mean, and
BCI/HPD intervals are shown with solid (—), dotted (…), and dashed (- - -) horizontal lines, respectively. It shows that the MCMC iterations based on each generated PCTII sample are mixed well.
Using the generated PCTII samples in
Table 8, the optimal progressive censoring plans, with respect to different criteria reported in
Table 5, are obtained and reported in
Table 11. It is noted, from
Table 11, that
For Data A; the censoring schemes used in samples A1 (with respect to criteria 1 and 3) and A3 (with respect to criteria 2 and 4) are the optimum plans.
For Data B; the censoring schemes used in samples B1 (with respect to criterion 3), B2 (with respect to criterion 1), and B3 (with respect to criteria 2 and 4) are the optimum plans.
For Data C; the censoring schemes used in samples C1 (with respect to criteria 2 and 3), C2 (with respect to criterion 1) and C3 (with respect to criterion 4) are the optimum plans.
Table 11 also supports the same results of the proposed censoring plans (S
) discussed in the simulation section. Briefly, we concluded that the WNH lifetime model provides a good and adequate explanation of the proposed censoring plan for all given real data sets.
8. Concluding Remarks
This article derives both point and interval estimators of the parameters, reliability, and hazard functions of the new, two-parameter weighted Nadarajah–Haghighi distribution based on Type-II progressive censored sample via the maximum likelihood and Bayesian estimation methods. Further, two parametric bootstrap confidence intervals of the same unknown parameters have been derived. Since the Bayes estimators cannot be written in closed forms, Lindley and MCMC approximations have been investigated. Numerical comparisons have been performed to judge the behavior of the proposed estimators, and they showed that the Bayes estimates using the Metropolis–Hastings algorithm behave well compared to Lindley’s procedure, and both behave much better than the frequentist estimates. Three real data sets taken from several areas, namely: insurance, reliability, and accelerated life testing, have been analyzed to show the usefulness of the proposed model in real practice. All theoretical results have been evaluated utilizing two useful packages in software, namely: ‘’ and ‘’ packages. As a result, the Bayes MCMC paradigm is recommended to estimate the model parameters and/or the reliability characteristic of the weighted Nadarajah–Haghighi model in the presence of a sample obtained from Type-II progressive censoring. As a future work, one can extend the results and methodologies discussed here to accelerate life tests or other censoring plans. We also hope that the proposed methodologies will be beneficial to researchers and reliability practitioners.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}