
Daily Semiparametric GARCH Model Estimation Using Intraday High-Frequency Data


Abstract
1. Introduction
2. The Daily Semiparametric GARCH Model
2.1. The Semiparametric GARCH Model
2.2. The Semiparametric Volatility Proxy Model
3. Volatility Function Estimation
3.1. Estimation When Parameters Are Known
3.2. Estimating the Parameters
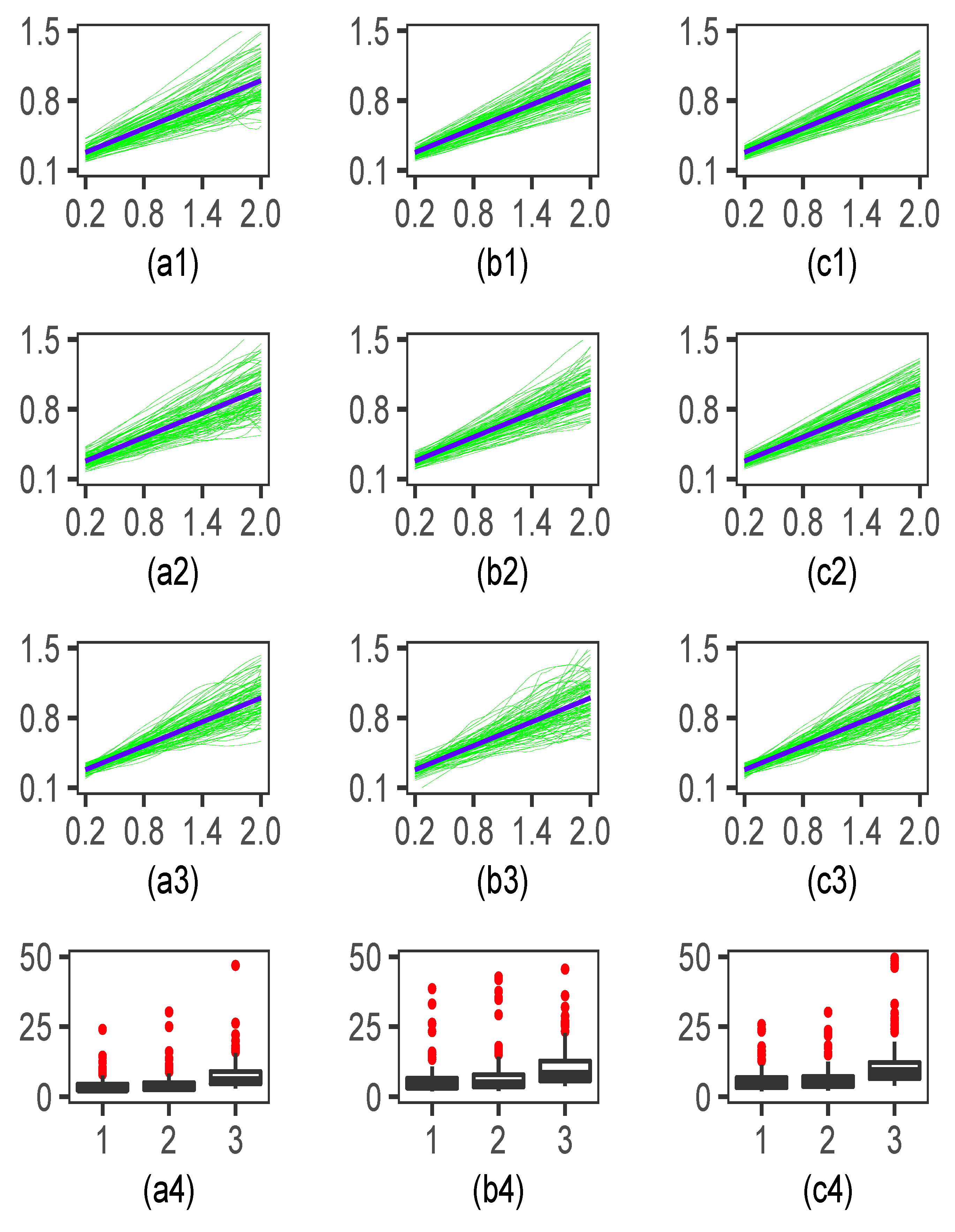
4. Simulation
5. Empirical Study
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Engle, R.F. Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. Inflation. Econometrica 1982, 50, 987–1008. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Engle, R.F.; Lilien, D.M.; Robbins, R.P. Estimating time varying risk premia in the term structure: The ARCH-M model. Econometrica 1987, 55, 391–407. [Google Scholar] [CrossRef]
- Nelson, D.B. Conditional heteroskedasticity in asset returns: A new approach. Economics 1991, 59, 347–370. [Google Scholar] [CrossRef]
- Glosten, L.R.; Jagannathan, R.; Runkle, D. On the relation between the expected value and the volatility of the nominal excess return on stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef]
- Engle, R.F.; Sokalska, M.E.; Chanda, A. High frequency multiplicative component GARCH. Comput. Econ. Financ. 2005, 409. [Google Scholar] [CrossRef]
- Liaqat, M.I.; Akgül, A.; De la Sen, M.; Bayram, M. Approximate and Exact Solutions in the Sense of Conformable Derivatives of Quantum Mechanics Models Using a Novel Algorithm. Symmetry 2023, 15, 744. [Google Scholar] [CrossRef]
- Hasan, A.; Akgül, A.; Farman, M.; Chaudhry, F.; Sultan, M.; De la Sen, M. Epidemiological Analysis of Symmetry in Transmission of the Ebola Virus with Power Law Kernel. Symmetry 2023, 15, 665. [Google Scholar] [CrossRef]
- Attia, N.; Akgül, A.; Alqahtani, R.T. Extension of the Reproducing Kernel Hilbert Space Method’s Application Range to Include Some Important Fractional Differential Equations. Symmetry 2023, 15, 532. [Google Scholar] [CrossRef]
- Farman, M.; Shehzad, A.; Akgül, A.; Baleanu, D.; De la Sen, M. Modelling and Analysis of a Measles Epidemic Model with the Constant Proportional Caputo Operator. Symmetry 2023, 15, 468. [Google Scholar] [CrossRef]
- Attia, N.; Akgül, A.; Seba, D.; Nour, A.; De la Sen, M. An Efficient Approach for Solving Differential Equations in the Frame of a New Fractional Derivative Operator. Symmetry 2023, 15, 144. [Google Scholar] [CrossRef]
- Engle, R.F.; Ng, V.K. Measuring and testing the impact of news on volatility. J. Financ. 1993, 48, 1749–1778. [Google Scholar] [CrossRef]
- Yang, L.; Härdle, W.; Nielsen, J. Nonparametric autoregression with multiplicative volatility and additive mean. J. Time Ser. Anal. 1999, 20, 597–604. [Google Scholar] [CrossRef]
- Hafner, C. Nonlinear Time Series Analysis with Applications to Foreign Exchange Rate Volatility; Physica-Verlag: Heidelberg, Germany, 1998. [Google Scholar]
- Carroll, R.; Härdle, W.; Mammen, E. Estimation in an additive model when the components are linked parametrically. Econom. Theory 2002, 18, 886–912. [Google Scholar] [CrossRef]
- Yang, L. Finite nonparametric GARCH model for foreign exchange volatility. Commun. Stat.-Theory Methods 2000, 5–6, 1347–1365. [Google Scholar] [CrossRef]
- Yang, L. Direct estimation in an additive model when the components are proportional. Stat. Sin. 2002, 12, 801–821. [Google Scholar]
- Visser, M.P. Garch parameter estimation using high-frequencydata. J. Financ. Econom. 2011, 9, 162–197. [Google Scholar]
- Huang, J.S.; Wu, W.Q.; Chen, Z.; Zhou, J.J. Robust M-estimate of GJR model with high frequency data. Acta Math. Appl. Sin. Engl. Ser. 2015, 31, 591–606. [Google Scholar] [CrossRef]
- Wang, M.; Chen, Z.; Wang, C.D. Composite quantile regression for GARCH models using high-frequency data. Econom. Stat. 2018, 7, 115–133. [Google Scholar] [CrossRef]
- Deng, C.; Zhang, X.; Li, Y.; Xiong, Q. Garch Model Test Using High-Frequency Data. Mathematics 2020, 8, 1922. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, R.; Li, Y.; SL, C. LADE-based inferences for autoregressive models with heavy-tailed G-GARCH(1, 1) noise. J. Econom. 2022, 227, 228–240. [Google Scholar] [CrossRef]
- Li, L.; Zhang, X.; Deng, C.; Li, Y. Quasi Maximum Exponential Likelihood Estimation of GARCH Model Based on High Frequency Data. Acta Math. Appl. Sin. Engl. Ser. 2022, 45, 652–664. [Google Scholar]
- Li, L.; Zhang, X.; Li, Y. Daily GARCH Model Estimation Using High Frequency Data. J. Guangxi Norm. Univ. (Nat. Sci. Ed.) 2021, 39, 68–78. [Google Scholar]
- Liang, X.; Zhang, X.; Li, Y.; Deng, C. Daily nonparametric ARCH(1) model estimation using intraday high frequency data. AIMS Math. 2021, 6, 3455–3464. [Google Scholar] [CrossRef]
- Yang, L. A semiparametric GARCH model for foreign exchange volatility. J. Econom. 2006, 130, 365–384. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation; Chapman & Hall: London, UK, 1986. [Google Scholar]
- Fan, J.; Yao, Q. Nonlinear Time Series: Nonparametric and Parametric Methods; Springer: New York, NY, USA, 2003. [Google Scholar]
- Härdle, W.; Tsybakov, A.B.; Yang, L. Nonparametric vector autoregression. J. Stat. Plan. Inference 1998, 68, 221–245. [Google Scholar]
- Yoshihara, K. Limiting behavior of U-statistics for stationary, absolutely regular processes. Probab. Theory & Relat. Fields 1976, 35, 237–252. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example | 1 | 2 | ||
|---|---|---|---|---|
| Proxy | ||||
| 0.4965 | 0.1030 | 0.1958 | 0.1013 | |
| 0.4865 | 0.1051 | 0.1991 | 0.0840 | |
| 0.4852 | 0.1055 | 0.2050 | 0.1051 | |
| Example | 1 | 2 | ||
|---|---|---|---|---|
| Proxy | ||||
| 0.5003 | 0.1061 | 0.1957 | 0.1112 | |
| 0.4950 | 0.1012 | 0.2097 | 0.0991 | |
| 0.4906 | 0.1147 | 0.2041 | 0.1143 | |
| Example | 1 | 2 | ||
|---|---|---|---|---|
| Proxy | ||||
| 0.5029 | 0.0969 | 0.1941 | 0.0973 | |
| 0.4983 | 0.1010 | 0.2027 | 0.1080 | |
| 0.5031 | 0.1034 | 0.1814 | 0.1013 | |
| Parameter | ||||
|---|---|---|---|---|
| 0.70 | 0.71 | 0.59 | 0.59 | |
| (0.1912) | (0.1431) | (0.1638) | (0.1907) | |
| 0.39 | 0.55 | 0.93 | 0.93 | |
| (0.0639) | (0.0210) | (0.0331) | (0.0528) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, F.; Li, Y.; Zhang, X.; Chen, Z. Daily Semiparametric GARCH Model Estimation Using Intraday High-Frequency Data. Symmetry 2023, 15, 908. https://doi.org/10.3390/sym15040908
Chai F, Li Y, Zhang X, Chen Z. Daily Semiparametric GARCH Model Estimation Using Intraday High-Frequency Data. Symmetry. 2023; 15(4):908. https://doi.org/10.3390/sym15040908
Chicago/Turabian StyleChai, Fangrou, Yuan Li, Xingfa Zhang, and Zhongxiu Chen. 2023. "Daily Semiparametric GARCH Model Estimation Using Intraday High-Frequency Data" Symmetry 15, no. 4: 908. https://doi.org/10.3390/sym15040908
APA StyleChai, F., Li, Y., Zhang, X., & Chen, Z. (2023). Daily Semiparametric GARCH Model Estimation Using Intraday High-Frequency Data. Symmetry, 15(4), 908. https://doi.org/10.3390/sym15040908