1. Introduction
The next generation mobile communication technology (6G) aims to realize the full connection between terrestrial communication networks and nonterrestrial communication networks, so as to achieve seamless global coverage and allow network signals to reach any remote area [
1,
2]. The wireless communication technology assisted by unmanned aerial vehicles (UAVs) including blimps, balloons, and fixed-wing and rotary-wing UAVs is getting more and more attention from scholars [
3,
4,
5,
6], and is expected to become an indispensable part of 6G [
7,
8,
9,
10,
11]. Compared with terrestrial networks, flying ad hoc networks (FANETs) have more flexible nodes and communication links, so the latter can give play to their asymmetric advantages compared with the former to achieve auxiliary data transmission or emergency communication. FANETs based on UAVs are capable of improving the coverage of ground wireless service as well as providing reliable communications for ground devices [
12,
13].
Routing technology aims to ensure that the control and business data in the network can be delivered to the destination quickly, stably, and completely [
14,
15,
16,
17,
18]. FANETs differ from traditional ground communication networks in terms of connectivity, mobility, applications areas, etc. In this case, the routing algorithms specifically proposed for fixed topology characteristics of ground networks may not apply well to FANETs, as the topology of the latter is in a process of continuous change. Meanwhile, this situation makes location-based algorithms become the main development direction of FANETs’ routing technology [
19].
A lot of research efforts have been devoted into routing technology in FANETs, for which some effective and robust algorithms have been presented [
20,
21,
22,
23,
24,
25,
26,
27,
28]. In [
20], a bidirectional Q-learning routing strategy was proposed on the basis of the Ad Hoc On-Demand Distance Vector Routing (AODV) method, which could obviously accelerate the convergence speed of the Q-learning process. The particle swarm optimization was adopted in [
21] to address the suboptimal choice problem of greedy forwarding. Relying on the cooperation between ground equipment and UAV nodes, S. Jiang et al. [
22] proposed a method that integrated fuzzy logic and a depth-first search to construct a Q-value routing table with well convergence performance. In [
23], a routing strategy dominated by upper UAV nodes participating in multilayer FANETs was proposed, which was based on information such as node location and network connectivity. P. K. Deb et al. [
24] introduced LEO satellites into FANETs and adopted Q-learning to adapt routing decision, so as to improve the efficiency of the network providing services to the ground in a 6G scenario. An improved Optimized Link State Routing (OLSR) protocol based on dynamic topology was presented in [
25], which could adaptively adjust the sending period of HELLO packets according to the dynamics of the network topology. In [
26], the distance factor and link lifetime factor were mainly considered, and the routing problem was effectively solved by linear programming. Taking into account the deviation angle, node spacing, and link lifetime factors, the authors in [
27] designed an optimal virtual routing model to select the neighboring relay node. K. Zhu et al. [
28] utilized the ant colony optimization approach for calculating the route in UAV-assisted massive machine-type communications networks to reduce the energy consumption and prolong the network lifetime.
The UAV nodes in FANETs are symmetrical, and each node is responsible for data collection and packet forwarding, which also limits the application of central routing algorithms in FANETs. It is worth noting that these aforementioned routing mechanisms have all or part of the following problems: (1) the decision-making method is central rather than distributed, thus the decision-making process may consume large communication resources and bring large time delay; (2) the proposed method does not take the mobile characteristics of nodes in FANETs into account, so the method may not be applicable; (3) information of only one-hop neighboring nodes is obtained, which leads to the method being merely able to obtain a local optimal solution with limited performance; (4) Q-learning is adopted to record and update the routing table, but the table becomes cumbersome and inefficient due to the topology dynamics of FANETs.
This paper focuses on exploring and proposing an intelligent decentralized routing method that mainly uses the state information of nodes in two hops. Moreover, the location, moving speed, load degree, and link quality of the nodes are utilized flexibly to build the supporting elements of the method. The proposed method does not need to predict the state of links/nodes or set classification thresholds. The remainder of this paper is organized as follows. The system model is introduced in
Section 2.
Section 3 gives an introduction to reinforcement learning. The proposed intelligent routing method is detailed in
Section 4.
Section 5 and
Section 6 separately cover the performance verification for the proposed method and the conclusion.
Notation: Throughout the paper, scalars are denoted by a nonboldface type, while vectors and matrices are denoted by a boldface type. and , respectively, signify matrix transpose and statistical expectation. Furthermore, represents the ith entry of the vector .
2. System Model
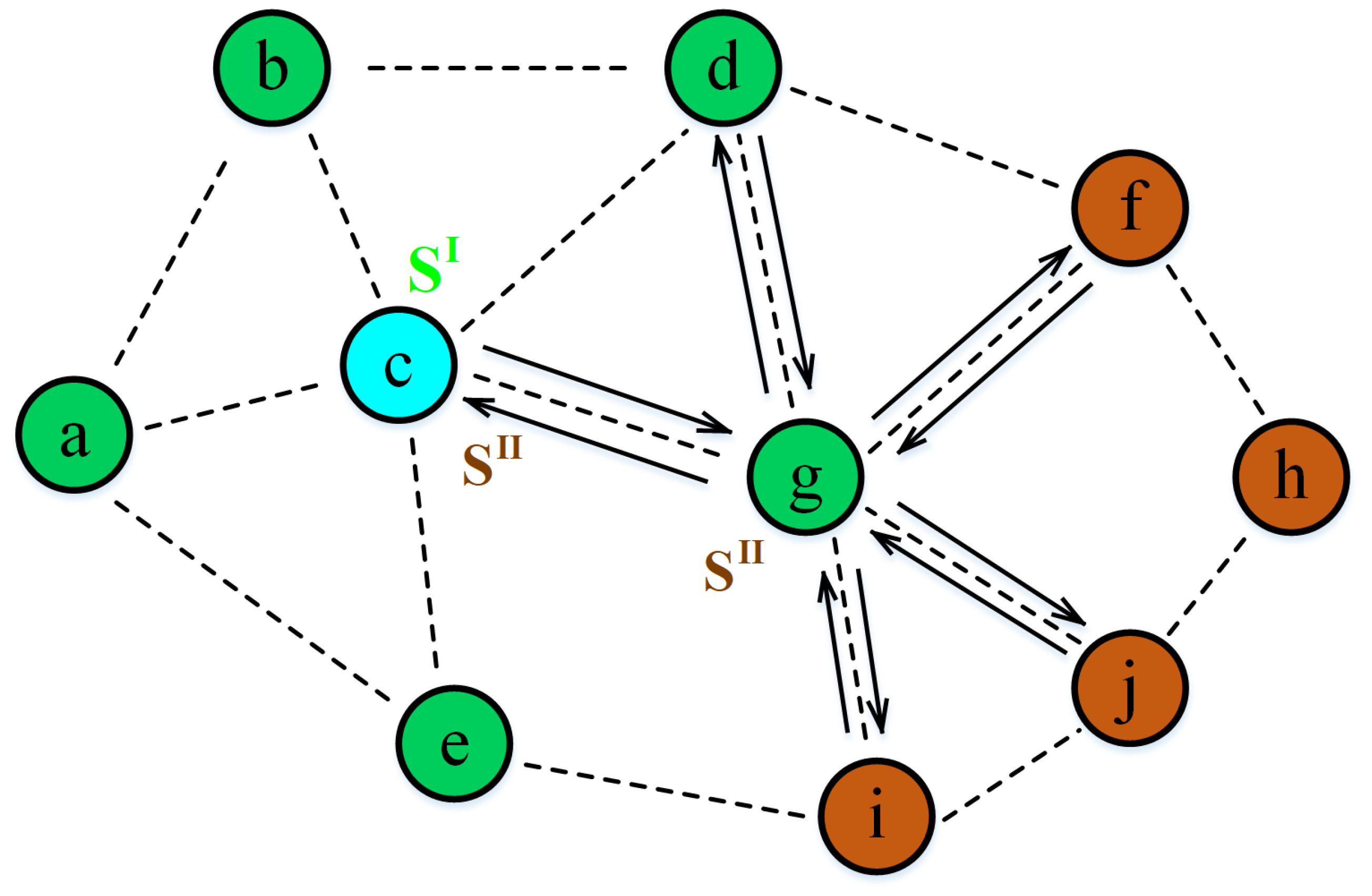
Figure 1 illustrates the routing scenario in the FANET, where the blue, green, and brown circles represent the current node, one-hop neighboring nodes, and two-hop neighboring nodes, respectively, while
and
separately denote the state information matrix of one-hop neighboring nodes and two-hop neighboring nodes. As aforementioned, the purpose of routing in the scenario is to select a neighboring one-hop node for the current UAV node, so as to transmit the data to the final destination in a timely and complete manner.
This paper considered the information of two-hop nodes in order to provide a rich reference for routing decision-making. We assumed that the set of one-hop neighboring nodes and two-hop neighboring nodes for the current node c are and , respectively. Then, and separately represented the number of one-hop neighboring nodes and two-hop neighboring nodes. Each UAV node in the FANET was equipped with the positioning system and thus could obtain its own position, movement speed, and direction. Without losing generality, this paper set the effective communication distance of each node as R. Meanwhile, it was assumed that the current node and the one-hop neighboring node could acquire or estimate the load and link quality of each of the neighboring nodes by communication interaction, e.g., by exchanging HELLO packages.
On the basis of this information, the method proposed in this paper conducted further processing, the intelligent output of the method was obtained by relying on the reasonable design of the related parameters, and the output could then provide a recommendation for the selection among the one-hop neighboring (i.e., the candidate) nodes. It is worth noting that the current node did not require the information of all nodes within its two hops in the proposed method, and too-strict requirements may make the method infeasible due to the failure of some links. We introduce the details of the proposed decentralized and intelligent routing method in
Section 4.
3. Reinforcement Learning
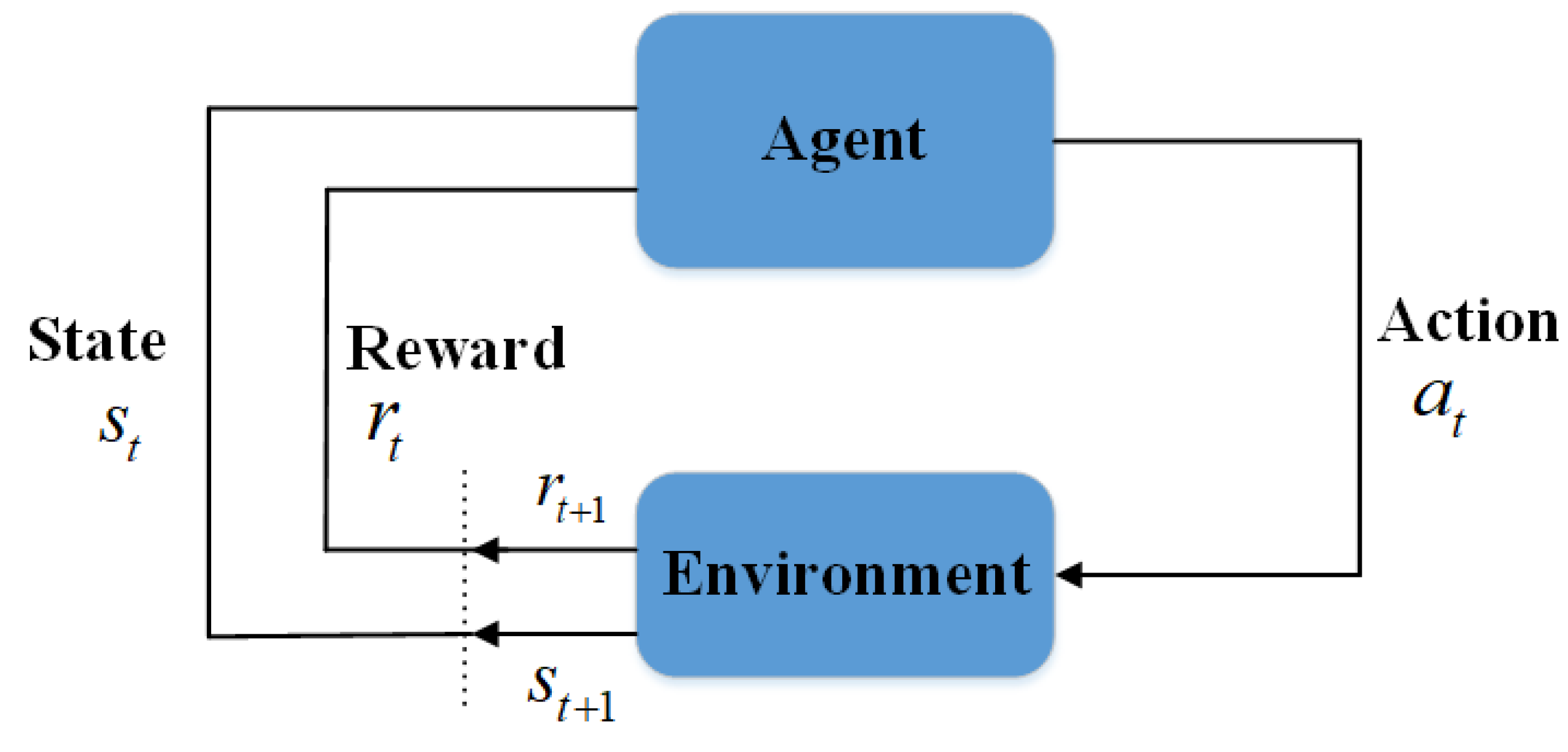
Reinforcement learning is different from other machine learning methods in the process of model training [
29,
30,
31,
32]. Its agent relies on the interactive process with the environment to update the evaluation of decision-making actions under different environmental states (see
Figure 2). The optimal strategy
can be acquired in a process of continuous interaction, with which the reward
R is maximized, i.e.,
where
and
, respectively, denote the instantaneous reward and decay value of the future reward at time
t. Among the RL algorithms, Q-learning is commonly utilized. The action-value function of Q-learning can be mathematically expressed as [
29,
33]
where
s and
a are, respectively, the current state and action, while
and
denote the next state and action, respectively. Therefore,
can be understood as the expected reward when taking action
a under state
s.
Considering that it is difficult to obtain the optimal strategy
straightforwardly, the optimal strategy
is obtained through updating the action-value function
continuously in Q-learning. Concretely, the following rule is utilized to update the Q-table which stores the action-value function
where
denotes the reward for performing action
a under state
s,
represents the learning rate, and
means the max
Q value under the next state
s. To balance the exploration and exploitation processes in the continuously interactive Q-learning method, and to avoid the learning process obtaining a suboptimal solution with unsatisfactory performance, the
-greedy algorithm is commonly adopted, which can be described as
Although the Q-learning method based on a Q-table has the advantages of an intuitive principle logic, simplicity, and effectiveness, the method becomes extremely inefficient when the state space or action space is huge, as the increase of storage entries significantly reduces the efficiency of reading from and saving to the table. The deep reinforcement learning (DRL) [
34] avoids this problem to a great extent, it introduces a deep learning that is based on a deep neural network (i.e., Deep Q Network, DQN) to perceive the logical relationship between the environmental state and agent action, which ensures that DRL does not need to traverse all state–action pairs as in Q-learning. The typical realization of DRL is the DQN algorithm that updates the action-value function through
where
denotes the parameter matrix of the neural network. In order to avoid the performance turbulence of the DQN in the training process, both the main network and the target network are adopted. Moreover, with Equations (
3) and (
5), the following objective function is utilized to update
, i.e.,
where
and
separately represent the parameter of the main network and the target network.
4. Proposed Intelligent Routing Method
The rationality of the setting of supporting elements related to reinforcement learning can greatly affect the effectiveness of the method. In this section, the detailed content of the proposed DRL-based FANETs’ intelligent routing (DRL-FIR) strategy, including the description of the state space, action space, and reward settings, is introduced.
4.1. State Space
As the input of the DRL model, the state should be able to objectively and comprehensively reflect the environment of the agent (i.e., the current UAV). In order to enable the agent to grasp more information about the environment, this paper adopted four routing-related parameters of neighboring nodes within two hops of the current node as the composition of the state space, which are introduced below.
The signal-to-interference-noise ratio (SINR) can well reflect the quality of the channel, and this paper utilized
and
to represent the SINR of the channel between the current node
c and one-hop node
i, and the SINR of the channel between one-hop node
i and two-hop node
j at time
t, respectively. We have:
where
and
denote the average channel gain of the two links (i.e.,
and
), respectively,
and
are the transmission power of node
c and node
i, respectively, while
and
represent the variance of a Gaussian white noise at routing node
i and node
j, respectively. For the sake of clarity, the time identification in the equations is omitted in the following part of this paper. We could then acquire the channel capacity by the Shannon formula
with
and
denoting the available bandwidth of the two links, respectively. In order to fairly compare the potential of different candidate nodes, we took the channel capacity ratio as the part of the state, which could be, respectively, denoted as
where
represents the set of one-hop neighboring nodes for node
i, which is a single-hop neighbor node of
c, while
means the cardinality of set “·”. Note that those nodes simultaneously belonging to one hop were excluded when calculating the ratio of two-hop nodes.
The second element of the state set in the proposed method was distance, which plays a key role in almost all location-based routing algorithms. With the positioning ability, the distance between nodes could be easily calculated. The following distance ratios were adopted in DRL-FIR:
where
and
denote the distance between the current node
c and the one-hop node
i, and the distance between node
i and the two-hop node
j, respectively.
Considering that the business load of nodes can greatly affect the performance of the routing process in terms of delay and packet loss rate, this paper also took into account the load ratio of nodes within two hops in the setting of the state, which can be expressed as
where
and
represent the queue length in the MAC layer of nodes
i and
j, respectively.
Furthermore, we note that the mobility characteristics of nodes should also be considered, as they can affect the life of links to a great extent, and then affect the reliability of routing. The lifetime of the link between nodes
i and
j (i.e.,
) can be calculated by solving the following formula
where
and
denote the position and velocity vector of node
a, respectively. The link lifetime ratios were then set in the state of the proposed method, which can be expressed as
with
and
, respectively, denoting the lifetime of links
and
.
Finally, the state of the DRL-FIR method can be written as matrix with and .
4.2. Action Space
Intuitively, the selection of actions in the action space corresponds to the choice of the next hop node. Unlike Q-learning, which updates the Q value of each neighboring node online, DRL-FIR belongs to the type of offline learning mode. The size of the action space thus should be set in advance to be equal to the number of one-hop nodes in the state space. Mathematically, we have , where means that the next routing node is node * for the current node c.
4.3. Reward
The proposed method aimed to realize the reliability, stability, and integrity of data transmission through node selection. Under the guidance of this goal, if the next hop is the destination node, the agent should obtain the maximum reward, and then we have
Meanwhile, we note that the selection of ordinary relay nodes should also be rewarded in order to guide the convergence of the routing process. Therefore, the above four factors were taken into account in the setting of rewards. Specifically, denote
and
, respectively, as the channel capacity and the link lifetime between the current node and the selected next node
j, and
and
as the distance to the destination and the MAC queue length of
j. In the proposed method, the reward was set as
where
,
,
, and
, respectively, represent the maximum channel capacity, link lifetime, distance to the destination, and MAC queue length among the neighboring one-hop nodes, while
is the weight factor, and we have
.
4.4. Other Details
The Residual Network (ResNet) which can effectively avoid the problem of degradation of traditional network structures was adopted in the proposed DRL-FIR. The Q values were estimated by an 8-layer ResNet. Moreover, the Adam optimizer and Relu activation function were employed in the training process of the ResNet. The input and outputs of the network, respectively, corresponded to the summative state of the current node and the Q values of the one-hop nodes.
Algorithm 1 summarizes the proposed intelligent routing strategy. The algorithm mainly shows the training process of the model of the proposed method. In order to avoid violent fluctuations in the process of training, the algorithm adopted the dual neural network (Step 12), replay memory (Step 9), and small batch learning (Step 11) approaches. It is worth noting that the complexity of the proposed strategy is mainly in the training stage of the model, while the complexity of the testing or application stage is quite low, as the method only needs relatively simple forward linear and nonlinear calculations in these stages. Considering that the training of the proposed method can be carried out by ground equipment, and the UAV nodes should only record the historical status and action decisions, thus, the method is computationally feasible for FANETs.
We note that the proposed DRL-FIR method is forward-compatible, which means that the model of the method can be applied to other scenes that are more simplified than the corresponding scene during training. For the latter, it only needs to set the parameters of the model to zero or replace them with simple values. Meanwhile, it is worth adding that the proposed method does not require the information of all the two-hop nodes around it, as the state set by the method contains relative values rather than absolute values. This ensures the practicality of the method to a great extent, considering that the link sustainability between nodes may be unstable in the dynamic FANETs. The method proposed in this paper is applicable to all nodes in FANETs. The current node obtains and calculates the asymmetry information of surrounding nodes for rapid decision-making, and then sends data packets to the next symmetric node until the data routing process is completed.
| Algorithm 1: The proposed DRL-FIR strategy. |
- 1:
Input: state , action , learning rate , discount factor , update frequency of the target network , the source UAV node, and the destination UAV node. - 2:
Initialize replay memory , main network with random weights Q(s,a|θ’) θ’ = θ, ε, εdecay, εmin Zs, n = 0 , r_ = 0.
|
- 3:
ForDo - 4:
if ε > εmin then - 5:
For Do - 6:
Generate a random number p from 0 to 1;
- 7:
;
- 8:
Take action a and make state transition ; calculate;
- 9:
Save into replay memory ; ;
- 10:
if then - 11:
- 12:
if then, - 13:
if is the destination then Save into action list.
- 14:
End - 15:
End
|
5. Simulation and Performance Analysis
This paper utilized Keras as the platform of deep learning for training the model of the proposed DRL-FIR method. The simulation area of the FANET was set as 1000 m × 1000 m, including 45 UAV nodes with randomly generated positions. The packet size and the transmission range of each node were, respectively, set as 512 Byte and 120 m. The available bandwidth, SINR, queue length, and moving speed factors were separately generated randomly, and the generated data obeyed a uniform distribution. The source node and the destination node were randomly selected, and the simulation set so that a node continued to move in the direction of reflection when it moved to the boundary of the region. The simulation parameters including the model-related parameters are summarized in
Table 1. Meanwhile, this paper randomly generated a large number of samples (i.e., snapshots) for model training, and adopted the same method to generate the test set to verify the performance of the model (see
Figure 3). For each snapshot in the training set, the model was trained 1000 times.
To demonstrate the performance of the proposed method, four algorithms were adopted as comparison methods, which are shown below (It should be noted that most of the existing methods belong to the type of central decision-making, or their applicable scenarios are different from the scenarios considered in this paper in topology. Therefore, the comparison methods considered in this paper are variations of the proposed method or the typical distributed routing method.)
FIR-OH: This method considers only the information of one-hop neighboring nodes. Note that the performance of this method can basically correspond to the results of some existing Q-learning based methods, e.g., [
20].
GPSR: A classical distributed routing algorithm proposed in [
35]. Many methods have been improved on this method [
19], and this method is often used for performance comparison.
W-GPCR: The weighted greedy perimeter coordinator routing method proposed in [
36]. We modified this method so that it could be used in this paper. We set this method to consider a Euclidean distance, channel capacity, and link lifetime with the same weight.
FIR-CD: a variant of the proposed DRL-FIR method. This method only considers the channel capacity and distance factors in Equations (
11)∼(
Section 4.1). Ignoring factors such as MAC queue length and link lifetime may cause the method to not be well applicable to the dynamics of FANETs.
FIR-DLT: a variant of the proposed DRL-FIR method. This method only considers the distance, MAC queue length, and link lifetime factors in Equations (
12)∼(
Section 4.1). This method is similar to [
27] in terms of factors considered, although the lifetime factor of candidate links is not predicted in the former.
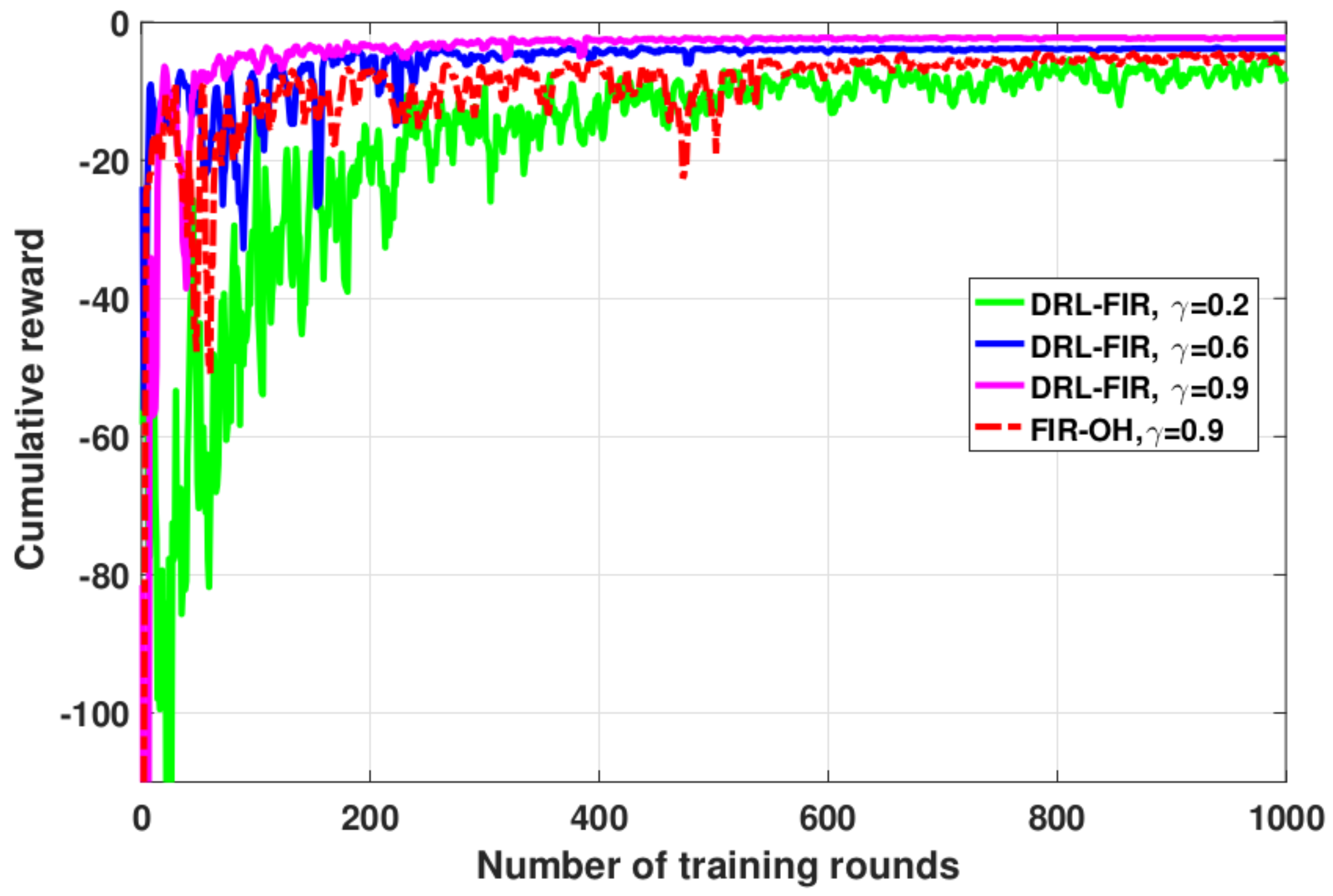
We first show the convergence performance of the proposed DRL-FIR method with different decay values in
Figure 4. The decay value
can reflect the preference of the model for present and future rewards in the training process. As can be seen, both the proposed method and FIR-OH can converge under different parameter configurations. This reflects the effectiveness of the proposed method. We could observe that the proposed method has the best performance when
, which is consistent with the feature that the data need to be finally transferred to the destination in the routing scenario. Since DRL-FIR is capable of perceiving the regional dynamics of the node’s environment more comprehensively compared to FIR-OH, the performance after convergence of the former is better than that of the latter under the same configuration. More specifically, the information about the channel state, link lifetime, spatial location, and MAC queue length of the neighboring nodes within the two hops rather than the one hop enables the DRL-FIR method to determine a better next hop than the FIR-OH method, so as to obtain greater rewards. In the subsequent simulation, we set the decay value as 0.9.
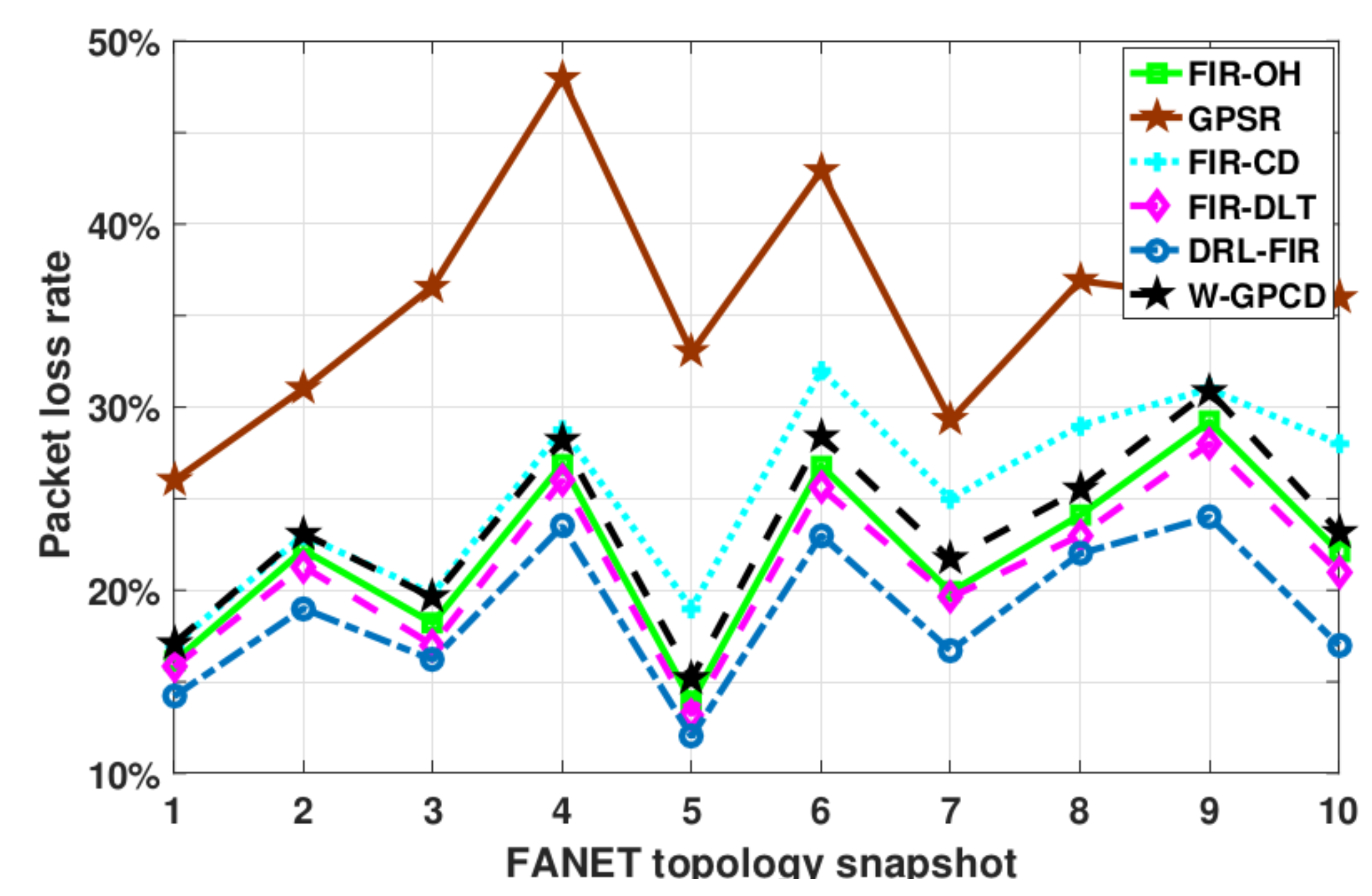
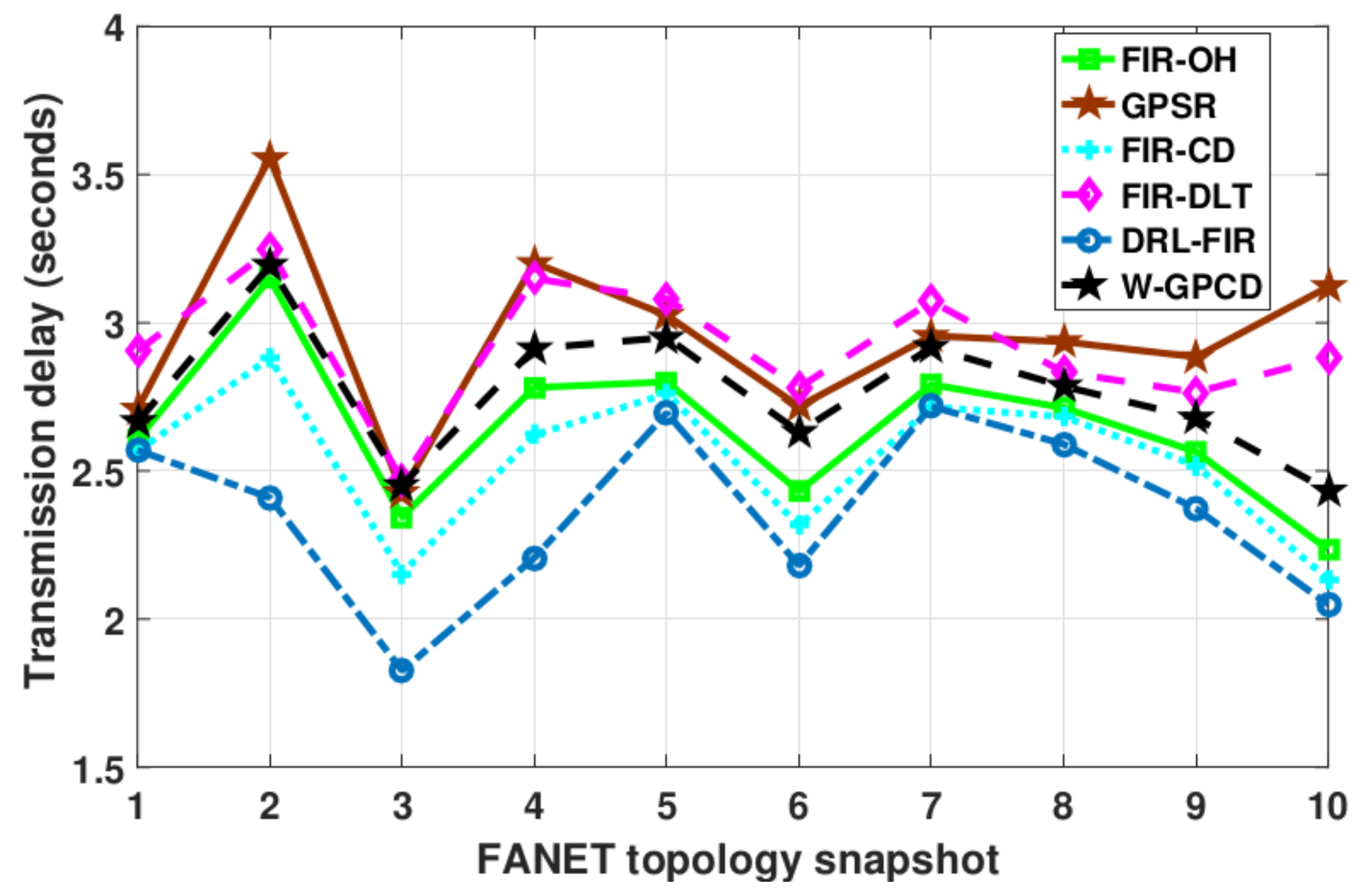
In order to intuitively show the performance of the proposed DRL-FIR in this paper, the packet loss rate (PLR) and delay performance of methods for random FANET topology snapshots are shown in
Figure 5 and
Figure 6, respectively. It can be observed that the methods show obvious differences in their performance in terms of PLR. It should be noted that compared with factors such as channel capacity and spatial location, the PLR performance is closely related to the link lifetime and MAC queue length, as these two can greatly affect the reliable reception of data packets. In contrast, the delay performance is more concerned with channel capacity and spatial location factors.
The performance of FIR-DLT is slightly better than that of FIR-OH; this is because the PLR has little to do with the capacity status of the channel, and FIR-DLT can give play to the advantage of a multihop node environment perception without considering it. Meanwhile, the PLR performance of the FIR-CD method deteriorates as the relevant queuing and link lifetime factors have not been considered. GPSR has the worst performance because it only considers the distance between each surrounding one-hop node and the destination node. The PLR performance of W-GPCD is significantly better than that of GPSR due to the more abundant influence factors considered. As the link lifetime parameter is referenced in the decision-making, its PLR is also lower than that of FIR-CD.
It is worth noting that the performance of the methods in terms of transmission delay changes significantly. Since the distance and channel capacity factors have the greatest relationship with the transmission delay, the performance of the FIR-CD method is better than that of the FIR-OH, W-GPCD, and FIR-DLT methods. For the same reason, the FIR-DLT and GPSR methods basically show similar performance without considering the channel capacity factor. By observing the two figures, it can be concluded that the performance of DRL-FIR is better because it considers more comprehensive influencing factors.
Finally, the average performance of the methods for 1000 randomly generated FANET topology snapshots is summarized in
Table 2. It can be seen that GPSR shows the worst performance in terms of both PLR and transmission delay. This is because the factors it considers are too limited or single in area size and node state. FIR-OH performs moderately well in several methods based on DQN, while the FIR-CD and FIR-DLT methods show their respective advantages in two aspects of performance because they have their own emphasis on the factors considered. The performance of W-GPCD is similar to that of FIR-OH on the whole, but there is still a certain gap, as the latter is more comprehensive in its consideration of factors and adaptive decision-making ability. Since the key factors are taken into account, the proposed DRL-FIR method has the lowest PLR and transmission delay among all methods.
6. Future Work
Suitable routing algorithms are quite important for FANETs, the proposed method based on deep reinforcement learning in this paper can be well applied to FANETs with topological dynamic characteristics by considering multiple states of nodes in a local region. Furthermore, it is not mandatory to obtain the information of all the nodes within the two hops, which also makes the method feasible in reality. Compared with several utilized comparison methods, the main disadvantage of the proposed method is its high complexity, as it needs to obtain more information and carry out the corresponding preprocessing, but the calculation of the proposed method consumes very few resources, which is completely affordable for UAV nodes.
It should be noted that although central routing algorithms cannot solve the dynamic problem of the FANETs well, their global planning process may have some advantages over the distributed algorithm in some respects. Therefore, a routing algorithm combining central and distributed modes may have better performance, which can be taken as a further direction for researchers. Meanwhile, the types of messages will also become increasingly abundant with the rapid development of wireless communication networks. It is expected to be able to provide users with required services more flexibly and efficiently by considering the different performance requirements of various message types in the design of a routing algorithm.
7. Conclusions
This paper considered the routing problem in FANETs. A distributed adaptive routing strategy based on deep reinforcement learning was proposed to adapt to node mobility and network topology dynamics. The state parameter of the method was reasonably designed to reflect the local characteristics of the network as completely and comprehensively as possible. It integrated the moving speed, location, link quality, load, and link life of nodes within two hops. Simulation results showed that the proposed strategy possessed significantly better performance than commonly utilized methods.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}