1. Introduction
Linear mixed effect model (LME) is an important statistical model, which is widely used in various fields. The LME model includes the fixed effect and random effect. The fixed effect is used to represent the general characteristics of the sample population, and the random effect is used to depict the divergences between individuals and the correlation between multiple observations. The structure and property of this model reveal substantial differences compared to the general linear models and complete random coefficient linear models. Compared with other linear models, the inclusion of random effects in the mixed effects model captures the correlation between the observed variables.
Maximum likelihood and least square method are the classical methods of estimation used for the LME model. However, the least square method leads to biased estimates when the data with heavy-tailed distribution or significant heteroscedasticity. Koenker and Bassett (1978) [
1] considered the quantile regression to solve such problems by regressing covariates according to the conditional quantiles of response, and capture the regression models under the all quantiles. However, the sparsity of sample variable is an issue which can not be ignored when it involves the correction analysis of variables, that is not all variables have predictive roles on regression analysis. In practical applications, massive candidate variables can be used for modeling analysis and prediction. Retaining the incorrelated variables in the model for prediction is undesirable, where the retention of irrelevant variables will produce the large deviation and non-interpretability of the model. How to select variables effectively is a challenging topic for the linear mixed effects models. Similar to the general linear regression, replacing the different types of penalty terms in the quantile regression can achieve synchrosqueezing for coefficients to reach target of variable selection. For example, Tibshirani (1996) [
2] proposed a Lasso method with penalty terms, and selected variables by squeeze parameters sparsely in quantile regression. Quantile Lasso regression constraints some coefficients of irrelevant variables to 0 when the sum of absolute values of coefficients is less than a pre-specified constant, which not only can acquire a more simplified model and select variables simultaneously, also solve the problem of data with sparsity. Next, Zou (2006) [
3] gave the proof of the oracle properties of adaptive Lasso in generalized linear models. Biswas and Das (2021) [
4] proposed a Bayesian approach of estimating the quantiles of multivariate longitudinal data. Koenker (2004) [
5] proposed the
penalty quantile regression based on random effects, which can estimates parameter through weighting random effects information of multiple quantiles. Wang (2018) [
6] proposed a new semiparametric approach that uses copula to account for intra-subject dependence and approximates the marginal distributions of longitudinal measurements, given covariates, through regression of quantiles. Wu and Liu (2009) [
7] proposed the SCAD and adaptive Lasso penalized quantile regression method, and gave the oracle properties in the situation of variable number unchanged. For different types of data, Peng (2021) [
8] illustrated the practical utility of quantile regression in actual survival data analysis through two cases. Li (2020) [
9] constructed a double penalized quantile regression method, and used the Lasso algorithm to solve the parameters. It proved that the estimated accuracy of the double penalized quantile regression is better than the other quantile regression. And according to the article above, we find that double penalized quantile regression model lacks accuracy and stability in excluding inactive variables. And expectile regression can accurately reflect the tail characteristics of the distribution, the variables of the model can be accurately selected. Therefore, in order to excluding inactive variables more accurately, this paper cojoin the double penalty terms into the expectile regression to obtain the double penalized expectile regression model.
Newey and Powell (1987) [
10] replaced the
-norm loss function to
-norm loss function for weighted least-squares, and proposed expectile regression. It regresses the covariates based on the conditional expectile of the response to obtain the regression model under all expectiles level. Almanjahie et al. (2022) [
11] investigated the nonparametric estimation of the expectile regression model for strongly mixed function time series data. Gu (2016) [
12] proposed the regularized expectile regression to analysis heteroscedastictiy of high-dimensional data. Farooq and Steinwart (2017) [
13] analysed a support vector machine type approach for estimating conditional expectiles. Expectile and quantile are metric indicators that capture the tail behavior of data distribution. When covariates make different impacts on the distributions of different response, such as right or left skew, the two metrics can not only decrease the effects of outliers on statistical inference, but also provide a more comprehensive characteristics of entire distribution. Therefore, quantile and expectile regression provide a more comprehensive relation between the covariates and response.
Quantile regression is the generalization of median regression, and expectile regression is the generalization of mean regression, so expectile regression inherits the computational convenience and sensitivity to the observation values. Especially in the financial field, researchers need the sensity of expectile regression to data. For panel data, the model proposed by Schulze and Kauermann (2017) [
14] allows multiple covariates, and a semi-parametric approach with penalized splines is pursued to fit smooth expectile curves. For cross-sectional data, expectile regression models and its applications have been studied. Sobotha et al. (2013) [
15] discussed the expectile confidence interval based on large sample properties; Zhao and Zhao (2018) [
16] proposed the penalized expectile regression model with SCAD penalty with the proof of asymptotic property; Liao et al. (2019) [
17] proposed penalized expectile regression with adaptive Lasso and SCAD penalty for variable selection, and gave the proof of oracle properties under independent but different distributions of error terms. Waldmannetal et al. (2017) [
18] proposed a combined Bayesian method with weighted least squares to estimate complex expectile regression. Next, the newly proposed iterative Lasso-expectile regression algorithm is used to solve the estimation of parameters and variables selections. Xu and Ding (2021) [
19] combined the elastic network punishment with expectile regression and constructed the elastic network penalized expectile regression model. For the underlying optimization problem, Farooq and Steinwart (2017) [
20] proposed an efficient sequential-minimal-optimization-based solver and derived its convergence. For the model selection problem, Spiegel et al. (2017) [
21] introduced several approaches on selection criteria and shrinkage methods to perform model selection in semiparametric expectile regression. Expectile regression has also received attention in the economic and financial sector, particularly in actuarial and financial risk management. Daouia et al. (2020) [
22] derive joint weighted Gaussian approximations of the tail empirical expectile and quantile processes under the challenging model of heavy-tailed distributions. Ziegel (2013) [
23] applied expectile regression to the field of risk measurement.
Expectile regression is widely used in various fields. Including economic field [
11,
14,
17,
22,
23], biomedical field [
12,
19] and health field [
15,
18,
21] etc. Therefore, the study of expectile regression has many practical significances, and it is very necessary to study it.
To select the important variables into the model and the inactive variables excluded from the model more accurately, this paper combines the linear mixed effect model with the expectile regression model, and cojoin penalty terms into the estimation of random and fixed effects to construct the double penalized expectile regression for linear mixed effects model. And the iterative Lasso-Expectile regression algorithm is used to solve parameters. The asymptotic property of double penalized expectile regression estimation is proved. The simulation studies will analysis the results of coefficient estimation and variable selection of the method proposed in this paper under different conditions, and the robustness of this method in excluding inactive variables is mainly studied. Finally, based on the research on the real data of CD4 cells, the practical utility difference between the double penalized quantile regression and the double penalized expectile regression are compared.
The rest of this paper is organized as follows. We propose the double penalized expectile regression method and the iterative Lasso expectile regression algorithm in
Section 2. The convergence of the algorithm and the asymptotic properties of the model are given in
Section 3. In
Section 4, we present the simulation studies. And a real data example is illustrated in
Section 5. Moreover, this method is compared with the existing double penalized quantile regression method in parameter estimation and variable selection in simulation studies and real data analysis. In
Section 6, we give the conclusions. In Appendices, we show the proofs of lemmas and asymptotic properties, and some graphs and tables obtained by simulation studies.
4. Simulation Study
In this section, we illustrate the performance of the proposed double penalized expectile regression. In order to study the impact of the SIC criteria and the GACV criteria on double penalized Lasso expectile regression model and double penalized Lasso quantile regression model [
9]. Simulation 1 is used to compare the two methods with different expectile levels and signal-to-noise ratio. And briefly denoted as DLER-SIC, DLER-GACV, DLQR-SIC, and DLQR-GACV; To illustrate the robustness of the DLER method in excluding inactive variables, simulation 2 and simulation 3 are given to study the impact of random effects on the coefficient estimation, comparing the performance of DLER and DLQR under different random effects. As well as comparing the obtained experimental values at different error distributions and different model sparsity to illustrate the advantage of DLER in variable selection; in order to illustrate the advantage of the DLER method in high-dimensional data, simulation 4 compares the two methods when dimensions of covariate is larger than the sample size.
In order to evaluate the accuracy of model coefficient estimation, we use mean square error (MSE) as the evaluation index. MSE is defined as:
where
, and
is the estimator of
in the
simulation. SD stands for the 100-repetition Bootstrap standard deviation. Corr expresses the average proportion of important variables that were entered into the model correctly, and Incorr expresses the average proportion of inactive variables that were entered into the model incorrectly.
represent the total number of choosing each important variable into the model correctly and its bootstrap standard deviation respectively.
represent the total number of correctly excluded each redundant variable out of the model and its bootstrap standard deviation respectively. Int (
) represent the total number of choosing intercept into the model and its bootstrap standard deviation.
Simulation 1. The impact of “signal-to-noise ratio” on estimation.
We compared the effectiveness of the two tuning parameter criteria, SIC and GACV. The process for producing the model data listed below was rated as
We let , , ,
, and
are generated from
with correlation between
and
being
,
. This paper sets the random effects are iid from
, where
. And
,
. The error terms are iid from
, we set
, and
to compare the estimation methods. In every simulation, we consider the estimator of coefficients to be 0 if its absolute value is less than 0.1. We set
in the iterative Lasso algorithm of DLER as the same settings in the iterative algorithm of DLQR of Li (2020) [
8].
Table A1 and
Table A2 (in the
Appendix C) give the results of coefficient estimation and variable selection, respectively.
According to
Table A1, the estimation accuracy of the model is first analyzed. When
is fixed, the MSE of the two methods is almost reaches the minimum at
, the estimation accuracy of the two methods is better, while the accuracy at the other fractile is slightly worse, but the difference is not obvious, for example when
, MSE of DLER-SIC method is 0.292 at
, while at the other expectile levels are 0.306 and 0.374, respectively. In this case, this shows that the DLER method has the same accuracy as the DLQR method in parameter estimation. In addition, according to the results of the two tunning parameter criterions, the estimation accuracy under the SIC is better than the GACV whether the DLER model or the DLQR model.
Next, analyze the accuracy of variable selection. According to the SD of each variable estimation in
Table A1, when fixed
, with the increase of
, SD decreases gradually, and the accuracy of variable selection of the two models is gradually increased. For each important variable, according to
Table A2, the DLER method can select 99% of the important variables into the model. In addition, for each inactive variable, comparing the results in the table, shows that when
is fixed, with the increase of
, the SD is also increasing, indicating that the accuracy of DLQR method is gradually weakened in excluding inactive variables out of the model. For DLER method, the SD is the largest at
, DLER method has the low accuracy, it is still better than DLQR at this time, especially at
, the SD is the smallest, indicating that with the increase of signal-to-noise ratio, DLER method is better than DLQR method in excluding the redundant variables. Combined with the results of
Table A2, the same conclusion can be obtained.
Therefore, for the parameter estimation of the methods, when the signal-to-noise ratio with relatively large, the DLER method is better than the DLQR method. In terms of model variables selection, whether in SIC and GACV criteria, almost 99%of important variables can be selected in both methods. For the ability to exclude the redundant variables, the DLER method is more advantageous than the DLQR method. Therefore, in terms of the accuracy of parameter estimation, DLER method and DLQR method have the same effect. However, the DLER method is better than the DLQR method in terms of estimated stability and excluding inactive variables.
Simulation 2. The influence of random effects.
We use the simulation to show the influence of random effects on DLER-SIC, DLER-GACV, DLQR-SIC and DLQR-GACV. The data generation model is Equation (15) with the fixed
. And consider the covariance matrix of the random effect
with three forms:
With the increasing of random effects, we get the results of 100 repetitions simulations with
.
Table A3 and
Table A4 (in the
Appendix C) give the results of estimation and variable selection of different methods under different random effects at
.
According to
Table A3, with the increasing interference of random effects, although the estimation accuracy of the two methods is decreasing, and the accuracy of the fixed effect coefficient is decreasing, especially the first two important covariates interfered by random effects. However, in term of variable selection, DLER method has little change in the accuracy of variable selection, and almost all the important variables can be choosing into the model, and the ability to exclude the inactive variables is still better than DLQR method. In particular, the DLER-SIC method, combined with
Table A4, shows that the proportion of correctly choosing variables is 99%, and the accuracy of excluding the redundant variables is almost above 90%. In general, since the double penalized expectile regression takes into account the random effects while selecting fixed effects, it can be almost free from the interference of random effects in the accuracy of variables selection, but it will still be affected by random effects to a degree in the accuracy of fixed effect coefficient estimation. Therefore, in terms of the accuracy of parameter estimation, DLER method and DLQR method have the same effect. However, DLER is still more robust than DLQR in variable selection, even if the interference of random effects is added to the model.
Simulation 3. The case of different model sparsity and error distribution.
We compare DLQR and DLER under different model sparsity and error distribution. The data generation model is Equation (15), considering the fixed effect as the following three cases
- (1)
Dense
- (2)
Sparse
- (3)
High Sparse
We consider
,
,
, the distribution of error term respectively comes form
,
and
. Comparing the models DLER-SIC, DLER-GACV, DLQR-SIC and DLQR-GACV. Tables shows the results of the three models by 100 repetitions simulations.
Table A5 and
Table A6 show the results of coefficient estimation and variable selection under the dense model,
Table A7 and
Table A8 show the results under the sparse model,
Table A9 and
Table A10 show the results under the highly sparse model. (See
Appendix C for tables).
According to
Table A5. At this time, all variables are important variables. With the change of error distribution, MSE are increasing, and the estimation accuracy of the two methods are decreased. We find that DLER method and DLQR method have the same effect in term of the accuracy of parameter estimation. In addition, considering the accuracy of variable selection of the two methods. Although the two methods cannot completely choose all the important variables into the model, it can be known from
Table A6 that the average of the correct variables retained by them is more than 7.6, which is very close to the true value 8. Moreover, when the error term is adjusted from the normal distribution to the heavy-tailed distribution, the change of DLER is the smallest in all methods, so it is weak on the influence of different error distributions. In summary, DLER is robust to the change of error distribution on variable selection.
Next, the results of sparse model and highly sparse model are analyzed. Firstly, the estimation accuracy of DLER method and DLQR method is analyzed. The results are similar to the dense model, with the error distribution becoming more complex, MSE are increasing, and the estimation accuracy of the two methods is decreased. Next, considering the accuracy of the variable selection in model, according to
Table A7 and
Table A8, when the error obeys the normal distribution, for the sparse model, the two methods have little difference in the accuracy of excluding the inactive variables. However, when the error obeys distribution
or
, the DLER method is significantly better than DLQR. Especially in the highly sparse model with error distribution
, DLER excluding the inactive variables advantage is more obvious, especially DLER-SIC method. It shows that expectile regression is quite robust than quantile regression.
Simulation 4. The case of high dimensional data.
High-dimensional data is widely available in the stock exchange market, biomedicine, aerospace and other fields, so the modeling and analysis of high-dimensional data has very important practical significance. Next, we investigate the performance of the proposed model in the high-dimensional scenarios of selecting variables. The data generation model is still the Equation (15), we reduce the sample size to
,
, that is, the total sample size is 100. In addition, 102 independent noise variables
are added to the above sparse model, all variables are independent and identically distributed in
, thus the total number of variables is 110, larger than the total sample size, and
. There are three real important covariates and 107 redundant covariates. In addition, we set
,
.
Table A11 and
Table A12 (in the
Appendix C) show 100 repeated results of the two methods at
, where
(
) denote the average and bootstrap standard deviation of all redundant variables being correctly excluded out of the model.
Firstly, analyze the estimation precision of the two methods. According to
Table A11, in the situation of fixed quantile, when the dimension of covariates is larger than the sample size, the MSE is larger than the previous simulation, the change of the MSE value of the DLER method is less than DLQR, and the MSE of the DLQR method is significantly larger than the DLER, indicating that although the estimation accuracy of the two methods is decreasing, the DLER method is significantly better than the DLQR method, and the stability of the DLER method is better than the DLQR method. Next, analyze the accuracy of variable selection. According to
Table A11 and
Table A12, the DLER method can ensure that the proportion of excluding redundant variables is more than 95% under three expectile levels. When the expectile level is fixed, DLER method has absolute advantages over DLQR in excluding redundant variables, especially DLER-GACV method can exclude more than 97% of the inactive variables at
. Therefore, when the dimension of covariates is larger than the sample size, DLER method is superior to DLQR in terms of estimation accuracy and excluding the inactive variables both at median
and extreme expectile level
.
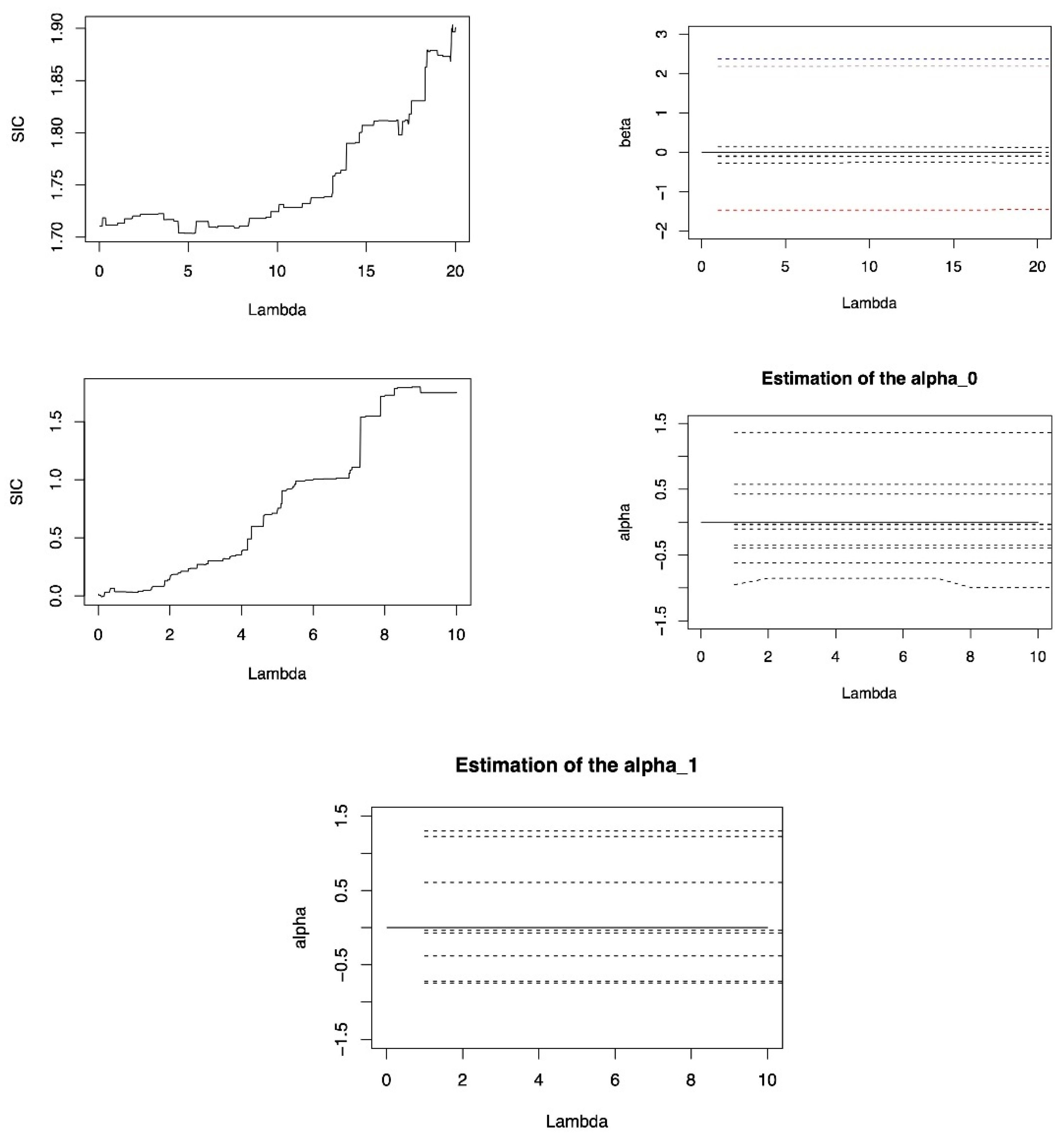
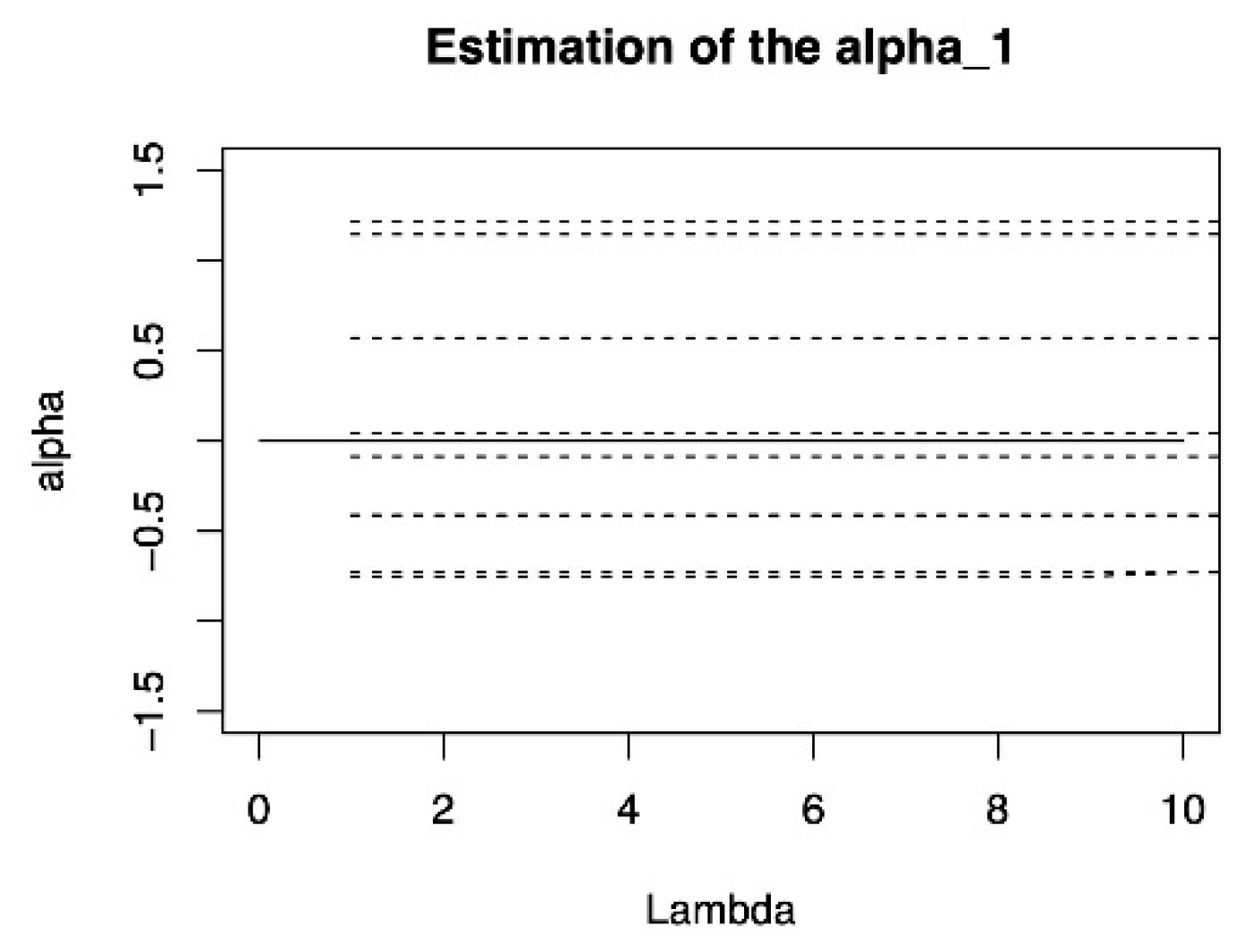
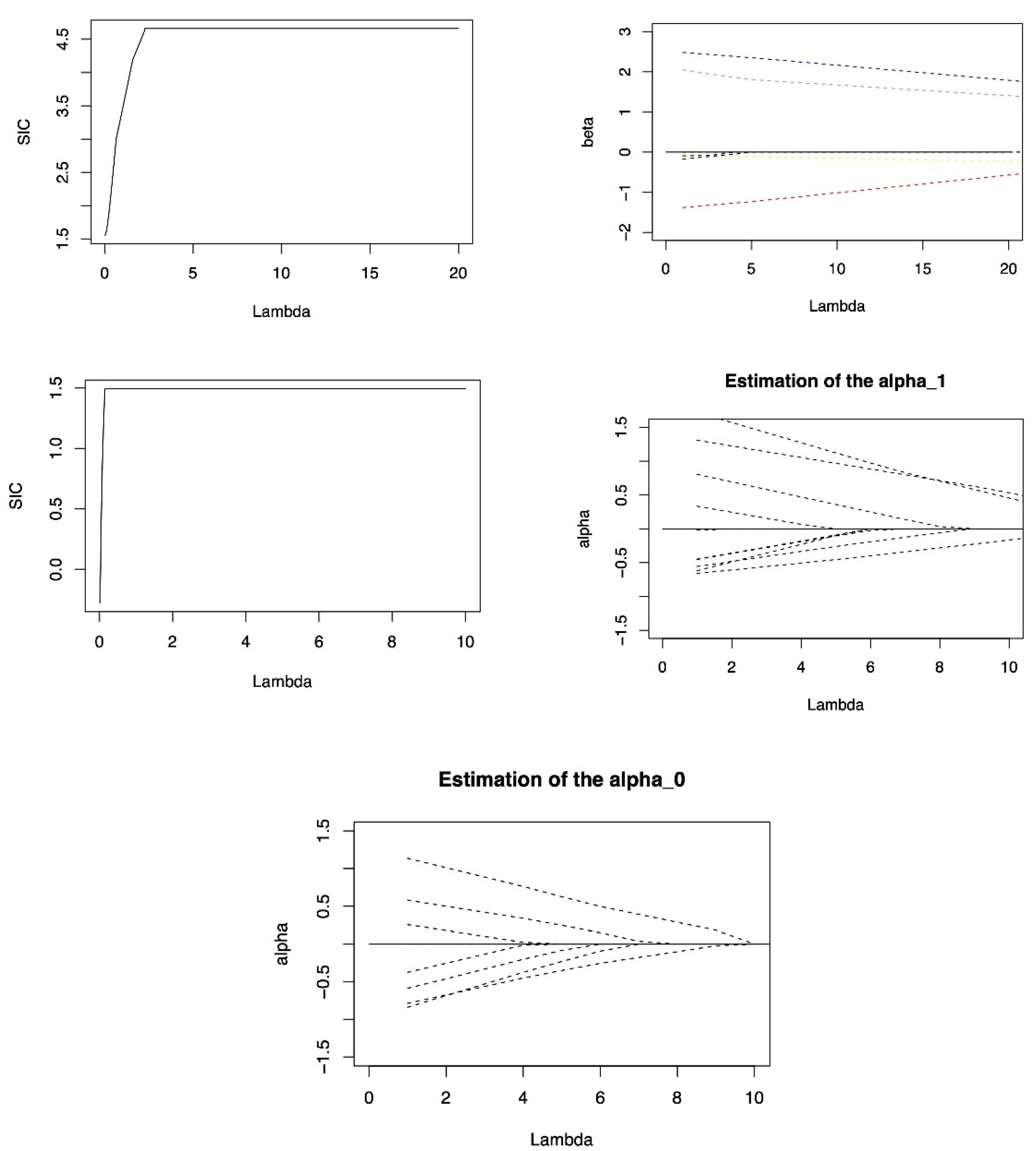
5. Application
CD4 cells play an important role in determining the efficacy of AIDS treatment and the immune function of patients, so excluding inactive variables is important for analyzing CD4 cell data. We applied the model to the real data of CD4 cell count. For a complete description of the data set, please refer to Diggle P.J’ s homepage:
https://www.lancaster.ac.uk/staff/diggle/, accessed on 30 June 2022, and we select a part of this data set. The response variable is the open-root conversion of CD4 cell count. The variables in the data set include the time of seroconversion (time), the age relative to a starting point (age), the smoking status depicted by the number of packets smoked (smoking), the number of sexual partners (sex partner), and the depression state and depression degree (depression). Choosing time, smoking, age and sex partner as important fixed effect to determine the CD4 cell numbers, where time and age are important random effects. On this basis, consider the following model:
where
is the
observation of the
ith individual,
is the observation of explanatory variables, and
is a subset of
. We set that the threshold of
is 0.05, and the threshold of
is 0.1.
Table A13 (in the
Appendix C) gives the results of the four methods at
.
From the results of
Table A13, the double penalized expectile regression method proposed can give the results of variable selection while estimating the coefficients. The variable with a value of 0 in the table indicates that it can be excluded from the model. It can be found that both estimation methods excluded variables
and
from the model. In the four variables, only time and smoking will affect CD4 cells. From the sign of coefficient estimation, the value of time is always less than 0, indicating that time has a negative influence on CD4 cells. The values of smoking are all larger than 0, indicating that smoking has a positive influence on CD4 cells.
Analysis of the numerical changes. For variable , under the SIC criterion, with the changes of expectile level, the DLER method fluctuates less, and the DLER is relatively stable. Indicating that the stability of the DLER-SIC method is slightly stronger. For variable , whether it is the SIC criteria or the GACV criteria, the numerical fluctuation of the DLER method is less than the DLQR method, indicating that the stability of DLER for estimation of variable is better than that of DLOR.
This shows that DLER method has strong practical utility for CD4 data in excluding inactive variables and analyzing its influencing factors.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}