1. Introduction
As cloud computing services become prevalent, distributed file systems (DFSs), the core technology of the service, are in the spotlight. DFSs’ characteristics, such as user transparency and efficient I/O processing, make it easy for users to utilize cloud computing services. DFSs can be divided in two categories based on the presence of a metadata server: centralized and decentralized file systems.
Centralized file systems, such as the Hadoop Distributed File System (HDFS) [
1] and Lustre [
2], have separate servers for processing metadata and the data themselves. I/O requests from clients are first sent to metadata servers to handle the metadata operations of the file. The file systems use the results from the metadata server to process the actual read or write operations on the data server. Thus, when the number of requests for metadata increases in the metadata servers, the servers have a higher load than the clients, and users suffer low I/O performance caused by asymmetry between server nodes [
3].
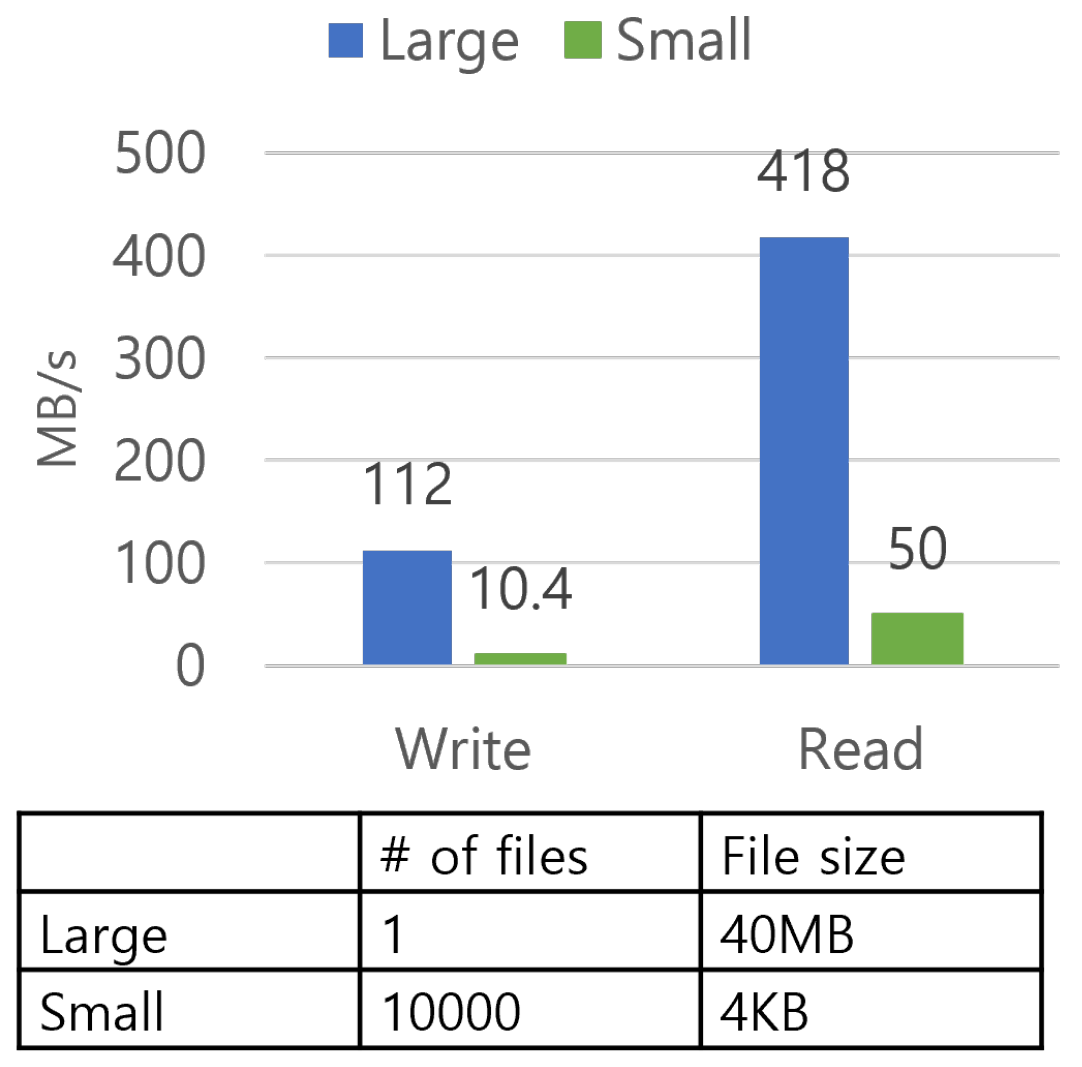
In addition, more than 60% of files used in Big Data processing are becoming smaller than 64 KB [
4,
5]. The phenomenon worsens the I/O performances by increasing the already high overheads in centralized file systems’ metadata servers.
To overcome the limitations of centralized file systems, decentralized file systems, such as the Gluster file system [
6] and Swift [
7], process metadata and data operations on the same servers. This results in I/O processing being performed in a client-driven manner [
8] and creates little performance degradation caused by metadata overheads in metadata servers. As a result, decentralized metadata file systems become more scalable and suitable for dealing with large amounts of I/O requests.
Since distributed file systems drive multiple computer nodes that are physically separated, clients and servers communicate via the Remote Procedure Call (RPC) protocol, and the RPC overheads created by the communications are inevitable. Especially in the case of decentralized file systems, where there are no separated metadata servers, even more RPC requests for metadata are exchanged between clients and servers. Thus, RPC overheads in decentralized file systems increase under metadata-intensive small-sized I/Os, and I/O performance degradation is not solved even in decentralized file systems. Additionally, since each server node handles different I/O patterns, a performance bottleneck occurs in some nodes with small-sized I/O requests, resulting in performance imbalance between nodes. The imbalance problem in the metadata server of centralized file systems is solved, but the load asymmetry between nodes due to RPC overheads remains, resulting in broken symmetry and reduced scalability.
Some researchers mitigate the I/O performance degradation by modifying the software stacks for processing I/O requests [
9,
10,
11,
12]. However, the fundamental RPC overheads remain to be addressed by these researchers. RPC requests are stored in the I/O queue in the order requested, and the next request is sent only after the completion requests of the previous RPC request arrives. In other words, RPC requests are not processed in parallel; instead, they must wait for processing time in server nodes and the network latency of the previous requests. In addition, the number of RPC requests transmitted between nodes is not changed, and the processing time for RPC requests is considerable. Other researchers have handled RPC requests faster using modified network protocols with advanced hardware [
13,
14,
15,
16,
17]. However, it is too costly to utilize all the high-spec devices in large-scale storage. Due to these reasons, a new software-level RPC protocol is needed, one that addresses the fundamental RPC overheads without any hardware supports.
In this paper, we propose a method to reduce RPC overheads, improve performance, and resolve I/O loads’ asymmetry in decentralized file systems by merging multiple RPC requests, then sending them at once to servers. We applied the I/O merging method on the Gluster file system, a well-known decentralized file system. We also evaluated the proposed method using the FIO benchmark and Small-File benchmark. The evaluated results showed that our proposed scheme outperforms the original file system by up to 16% and 13% in read and write performance, respectively, distributing I/O loads across nodes.
The rest of the paper is organized as follows.
Section 2 shows the related works concerning various methods, such as modifying network stacks and adapting new network topologies, to reduce network traffic.
Section 3 explains the basic architecture and I/O flow of the GlusterFS and identifies the cause of the RPC overheads in the file system.
Section 4 presents the design and the implementation of the proposed I/O merging method.
Section 5 compares the performance between the original GlusterFS and the proposed method. We discuss various factors that affect the performance of the merging method in
Section 6.
Section 7 explains the future work and concludes the paper.
2. Related Work
Warehouse-scale computing systems (WSCs) are systems where every computer node is connected via a network [
18]. Over the years, hardware resources used for WSCs have improved gradually, increasing the parallelism in processing. However, network traffic between each node soars drastically and becomes unpredictable, causing a bottleneck. Studies and research continue to be performed to reduce network bottlenecks and maximize the throughput.
The field of networks has been actively researched to maximize network performance by adapting larger frames and modifying the protocol stack. Some research has conducted experiments to maximize network throughput usages by recovering partial packets of jumbo frames in wireless LAN communication [
19]. Others have modified above and below the TCP protocol stack with a variety of optimizations, delivering up to 2 Gb/s of end-to-end TCP bandwidth [
20]. Studies have built a new transport protocol for a high volume of short messages, which employs a receiver-managed priority queue, giving round-trip times of less than 15 us [
21]. However, the RPC waiting problem mentioned throughout the paper still lies even with the efficient network protocols.
Researchers have utilized extra network hardware to improve the performances by shortening the processing time. ALTOCUMULUS uses a software–hardware co-designed NIC to schedule RPCs at nanosecond scales, replacing under-performing existing RPC schedulers [
13]. FPGA-based re-configurable RPC stack integrated into near-memory NICs are designed for delivering 1.3–3.8× higher throughput while accommodating a variety of microservices [
14].
Remote direct memory access (RDMA) is also redesigned or merged with various methodologies for better resource usage and low RPC latency. FaSST remodels the original one-sided RDMA primitives to two-sided datagrams. The system outperforms other designs by two-fold while using half the hardware resources [
15]. Researchers have presented a new RPC framework that integrates RPC processing with network processing in the user space by using RDMA, coordinating the distribution of resources for both processings within a many-core system [
16]. Another framework is designed based on Apache Thrift over RDMA with a hierarchical hint scheme optimizing heterogeneous RPC services and functions, showing up to 55% performance improvement [
17]. However, the above research not only requires high-spec hardware supports, but also needs a modification of the software stacks related to the network. Furthermore, the number of RPC requests does not change, leaving the RPC bottleneck unresolved.
Other studies have reduced the latency with an efficient metadata service for large-scale distributed file systems. InifiniFS uses a service that resolves metadata bottlenecks, such as long path resolution and poor locality, in large-scale file systems [
22]. The system utilizes access-content-decoupled partitioning, speculative path resolution, and an optimistic access metadata cache method to deliver high-performance metadata operations. Researchers have addressed challenging metadata management in centralized file system, such as Hadoop, by creating metadata access graphs based on historical access values, minimizing the latency [
23]. There are also studies in the field of file systems that drop network overheads by reducing the operations per an RPC request. The network file system (NFS) flows through the VFS and utilizes the POSIX file system API. Due to the limitation of the low-level POSIX file system, numerous RPC requests are sent in small units, which creates overheads. Detouring the VFS layer and implementing the system at the user level, a team built their own API to resolve the bottleneck from the POXIS level in the NFS [
24]. The API merges as much operations it can handle and sends the stacked RPC requests to reduce the RPC overhead. However, as vNFS is reconstructed from the kernel-level NFS to the user level, there is a limitation that the users need to re-implement the applications, using the API. The research has reduced the I/O processing time by adopting the modified metadata processing procedure and file systems, but, there are still problems regarding the huge amount of RPC requests exchanged between nodes and the performance bottleneck caused by waits among RPC requests.
4. Design and Implementation
To resolve metadata RPC overheads under metadata-intensive I/Os, we merge multiple RPC requests into larger RPC requests within the global queue, then send them to the server at once.
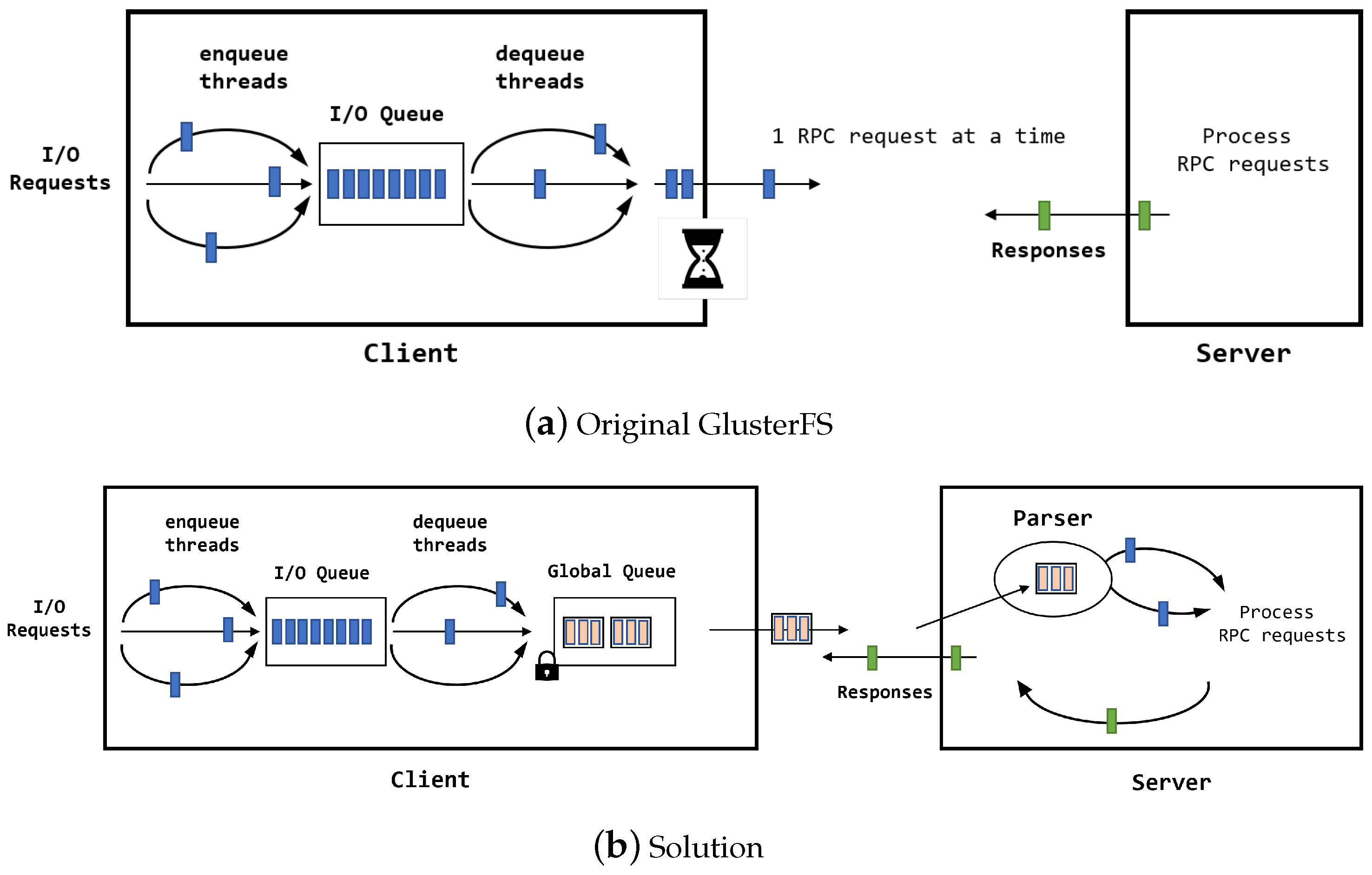
Figure 6a depicts the enqueue and dequeue flow of RPC requests in the original GlusterFS. On the client side, an I/O request is dequeued from the I/O thread queue, translated by the translator according to the option, and stays in the queue as an RPC request waiting its preceding RPC request to be processed. The delays between translation and transmission become the bottleneck.
Due to the bottleneck caused by the limitation of the RPC protocol, workloads executing I/Os suffer poor performances. We designed the global queue where multiple RPC requests are merged into a single request to overcome the limitation.
Figure 6b and
Figure 7 illustrate the implementation and the flowchart of the proposed solution.
The sender thread checks the queue periodically to see whether the number of requests has reached the predetermined water mark. If it has reached the mark, the merger thread serializes the RPC requests in a single packet and transmits it to the server. We provide the mutex lock in the queue for synchronization and preventing race conditions as multiple threads are accessing the same global queue. After receiving the packet, the server calls the parsing function, and the POSIX system calls for the corresponding I/O, then sends the result back to the client. The client checks the call ID of the received data and matches them with the requests.
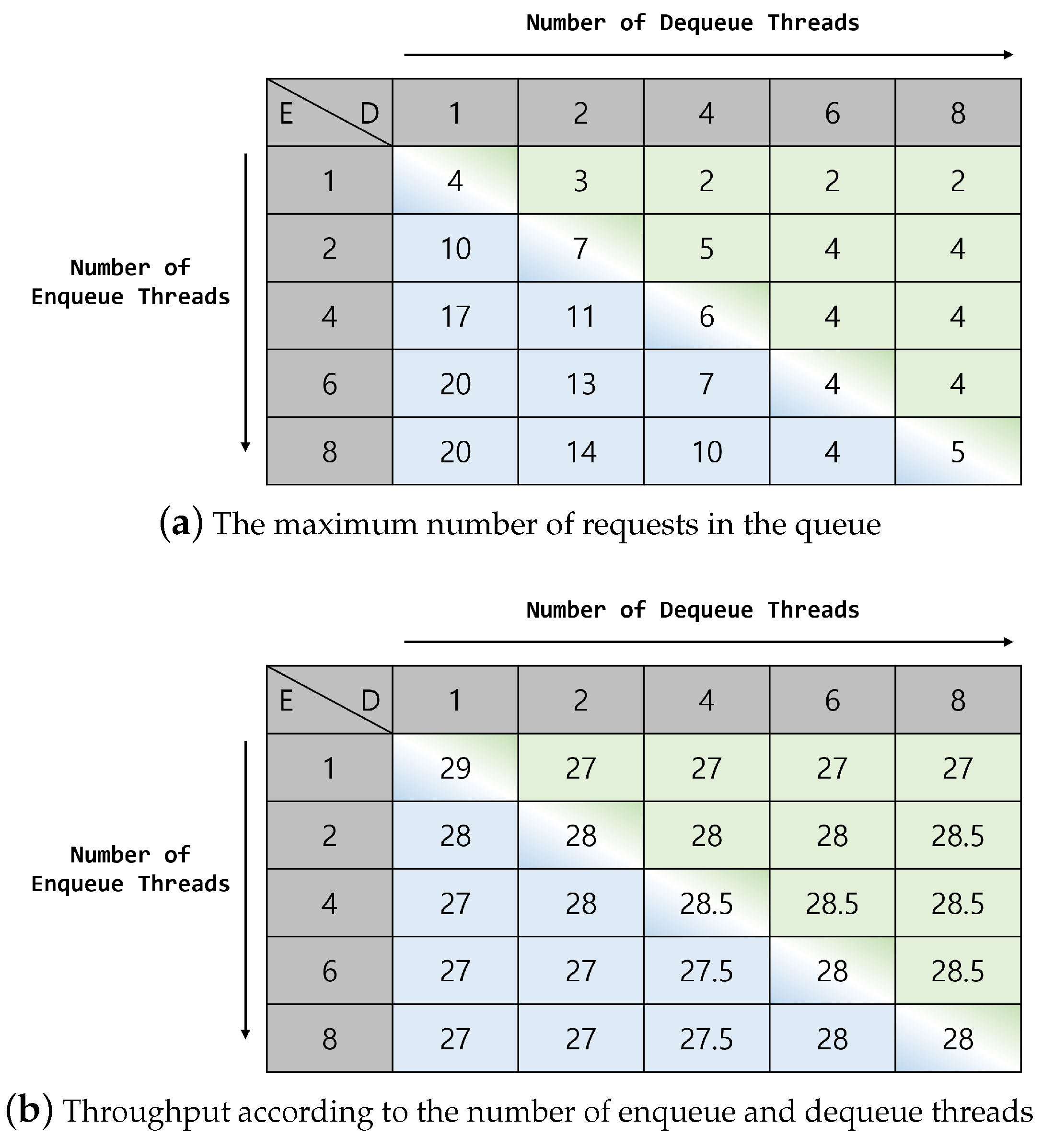
We discuss the optimal number of requests to merge depending on the specs and environment of the server in
Section 6.2.
RPC requests used in the GlusterFS are sent over the network since the server nodes are physically separated. Therefore, the network environment affects the performance. Even if we merge multiple RPC requests using the proposed method, the new RPC request might be divided into a few pieces to fit the size of the maximum transmission unit (MTU), or the network bandwidth is wasted if the merged request is smaller than the MTU. We used the jumbo frame [
25], which is the 9000 bytes-sized MTU, under 10 Gbps Ethernet, and merged as many requests as possible to utilize the maximum network bandwidth.
5. Evaluation
5.1. Environmental Setup
We measured the read and write performances over our solution using the Small-File benchmark and FIO benchmark on the machines shown in
Figure 8.
The evaluations were performed on two different client-to-server setups: one-to-one (a single client node connected to a single server node) and one-to-two (a single client node connected to two server nodes). As a request is sent only to one server in read processing, there are no differences between sending the requests to single and multiple servers. Thus, they were tested only on the one-to-one server setup for read I/O performances. For write requests, we used one-to-one and one-to-two client-to-server setups. The two nodes used in one-to-two setup are in replication mode.
The following subsections demonstrate and compare the performance of the proposed method with the original GlusterFS under the Small-File [
26] benchmark and FIO [
27] benchmark.
5.2. Performance of Merging Read Requests
Figure 9 depicts the throughput and execution time of the original GlusterFS and the proposed method according to the number of read requests merged in the global queue. Read I/O throughput on 30,000 4 KB-sized files using the Small-File benchmark is shown in
Figure 9a. The original GlusterFS shows a 27 MB/s throughput. The throughput of our method increases as the number of RPC requests merged increases, showing 29 MB/s, 30 MB/s, and 31.5 MB/s for 2, 3, and 4–6 requests merged, respectively.
The read I/O throughput on 10,000 4 KB-sized files using the FIO benchmark is shown in
Figure 9b. The performance tendency along the number of requests merged is the same as the result of the Small-File benchmark.
The right graphs in each subfigure represent the total execution time in the Small-File benchmark and FIO benchmark. Since RPC requests have to wait for their preceding requests, the total amount of time that requests wait between each request affects the execution time. It takes longer to execute I/O operations with more RPC requests to send. Merging multiple requests, therefore, shortens the execution time as it reduces the time requests waiting in the queue. Consequently, our method outperforms the original by up to 16% in both the execution time and read I/O throughput.
We present the throughputs evaluated on the eight-core machine in
Figure 10. As the processing speed becomes faster with more cores and better specs, the performance bounds at 5 requests in the 8-core machine, whereas it bounds at 4 requests in the 4-core machine. Improving the throughput by 17% compared to the original, the performance itself is better than the 4-core machine because the 8-core machine merges five requests at once.
However, because of the overhead inherent to merging itself, simply increasing the number of RPC requests to merge does not improve the performance. If we choose to merge too many requests at once, overheads occur from holding the lock and serializing them in the queue. It also becomes a heavy burden for the servers to parse large serialized RPC requests, which causes more overheads. Hence, both throughput and execution time converge as we merge more requests.
5.3. Performance of Merging Write Requests
The evaluations on write I/O throughput using the scheme give similar results to that of read requests.
Figure 11 depicts the throughput and the execution time according to the number of write requests merged in the global queue. We use 10,000 4 KB-sized files using the Small-File benchmark for the evaluation, shown in
Figure 11a. The throughput of our method increases as more RPC requests are merged, showing 27.5 MB/s, 28.3 MB/s, and 29.3 MB/s for 2, 3, and 4–6 requests merged each, while the original shows a 26 MB/s throughput. There is up to a 13% improvement in the performance compared to the original.
Write I/O throughput on 10,000 4 KB-sized files using the FIO benchmark is shown in
Figure 11b. The result resembles the Small-File benchmark as in
Section 5.2, as does the result of the execution time.
Write I/O performance does not gain benefits in performance as much as read I/O performance with the solution. Because we must attach the user data on write requests, the requests become larger in size than read RPC request. Larger requests take longer for the client to enqueue them in the global queue, as well as for the server to parse the packets due to the size, causing less improvement in the performance.
Figure 12 shows the result conducted on two server nodes, both nodes set as the replication mode, depicting a maximum 12.4% increment in the throughput for the Small-File benchmark. This is even a smaller increment of the performance compared with the above. As the client has to prepare the RPCs to be sent to the two server nodes, it gives heavier loads to the clients, leading to less improvements.
7. Conclusions
In this paper, we proposed a new software-level RPC protocol by merging requests without any hardware support. With this method, we resolved the performance degradation and I/O load asymmetry created under metadata-intensive workloads in decentralized file systems. Each RPC request between servers and clients has to wait for its preceding requests before being sent, causing a bottleneck. To handle this fundamental RPC overhead, our solution merges multiple RPC requests and sends them at once. We created a lock-synchronized global queue to collect the requests and modified dequeue threads to send the merged one. With the proposed method, we eliminated waits between RPC requests and multiple RPC requests are processed in parallel, distributing the imbalanced loads and improving the performance. The proposed method was evaluated with the GlusterFS and outperformed the original one by up to 16% and 13% in read and write I/O processing, resolving the asymmetry. We also explored factors that affect the utilization of the merging method with various experimental environments.
Future Work We only designed a software-level RPC protocol to handle the degradation in decentralized file systems by merging multiple RPC requests in a single RPC request. In the future, we will devise a way to merge multiple I/O metadata’s processing through multiple software layers in a single one such that it removes redundant RPC requests, reducing the number of requests themselves. Furthermore, we are planning to devise system-level optimization, such as cache and memory management.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













