
MCPANet: Multiscale Cross-Position Attention Network for Retinal Vessel Image Segmentation


Abstract
:1. Introduction
- A new multi-scale cross-position attention mechanism for the retinal vessel segmentation framework is proposed, and the residual connection is used in the network to improve the feature extraction ability of the network structure and reduce the noise in the segmentation. The use of pooling operations at different scales to expand the receptive field results in a significant reduction in the loss of information about tiny vessel features.
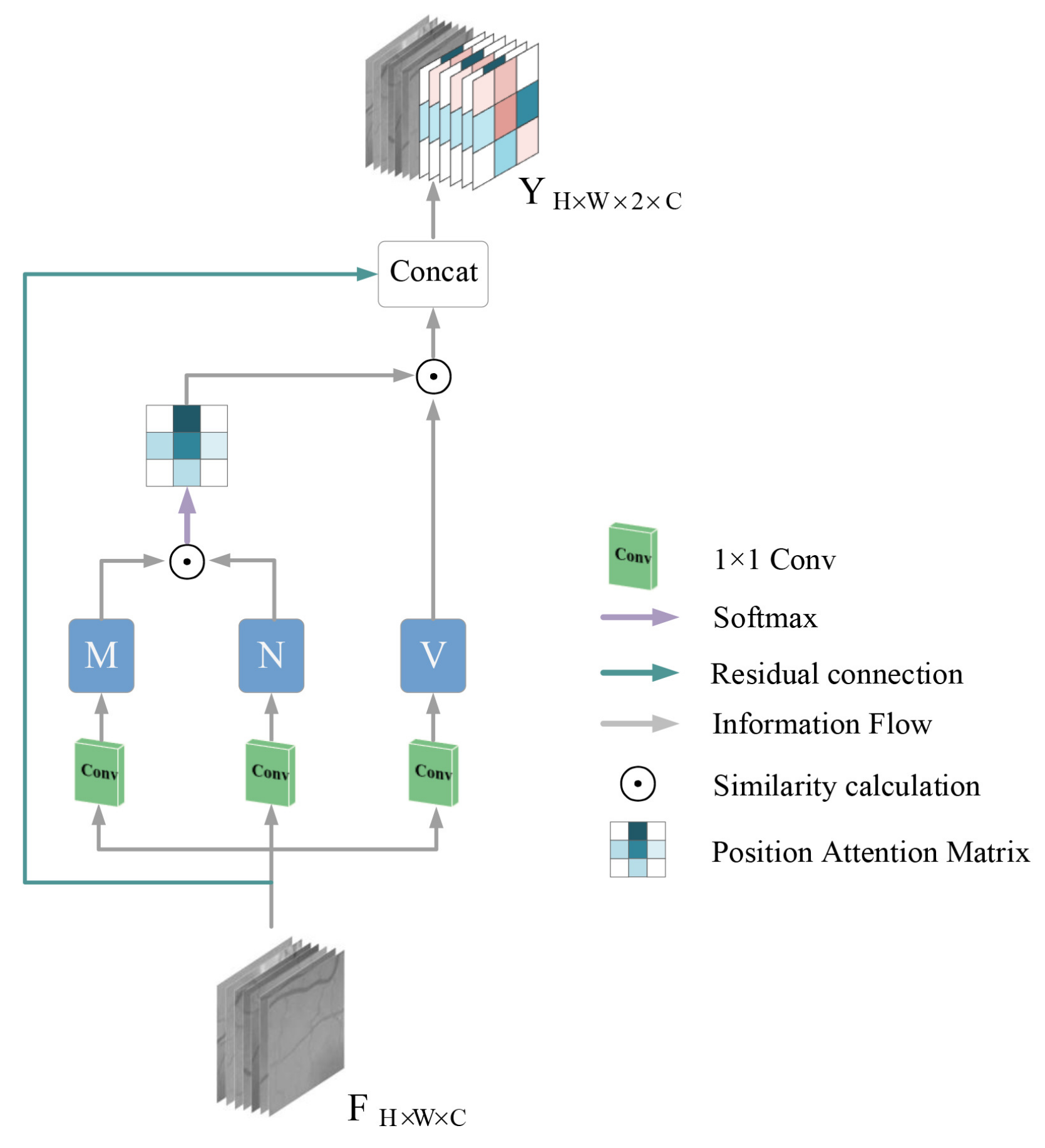
- A cross-position attention module is proposed to obtain the contextual information of pixels and build a relational model with the contextual information associated with them on local detail features, which not only operates on the whole image but also focuses on finer details present in local blocks. It also reduces the computation and memory usage in non-local blocks, and our model has only a small number of parameters.
- Trained and validated on three publicly available retinal datasets, DRIVE, CHASE, and STARE, our model performs well in terms of performance and segmentation results.
2. Methods
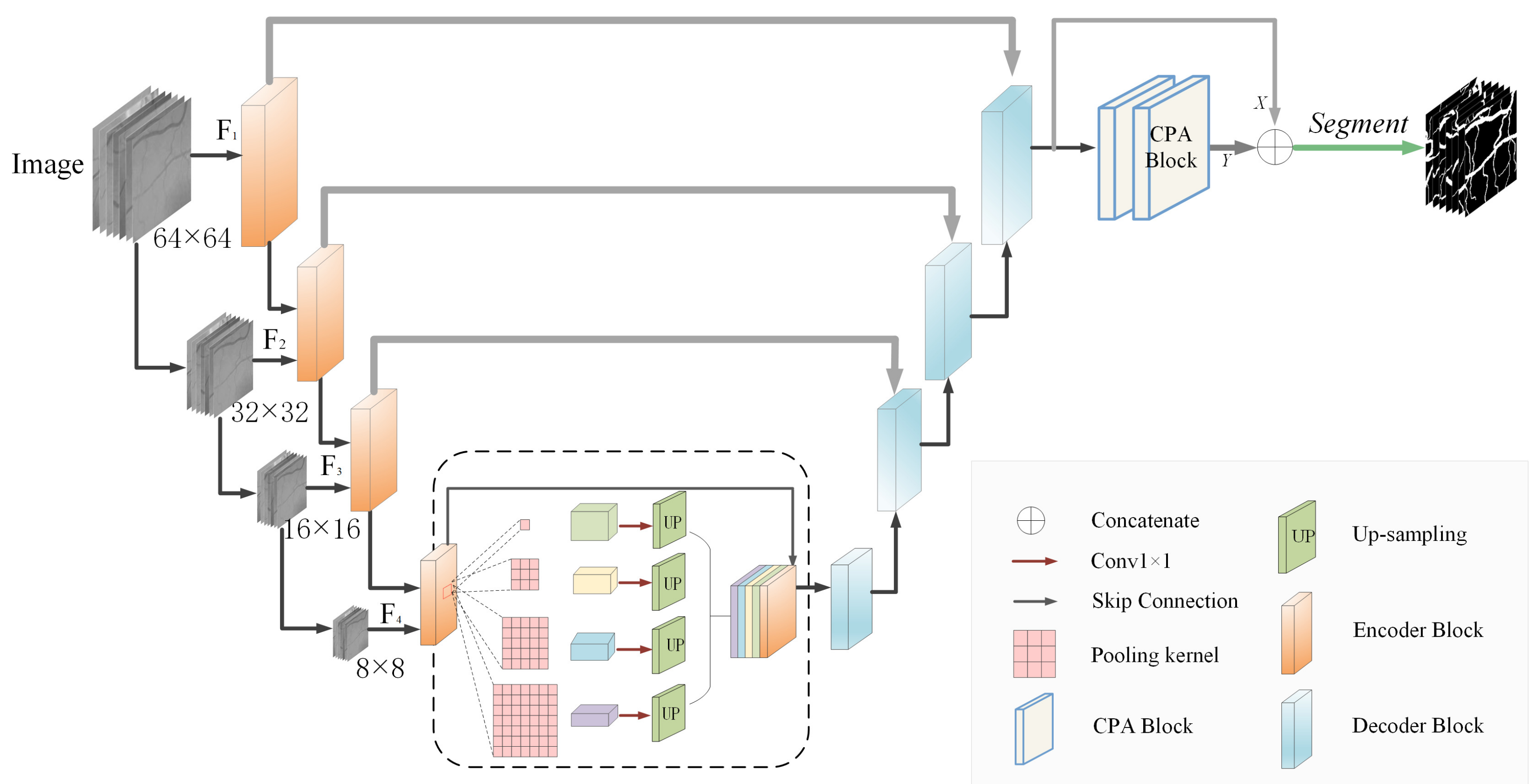
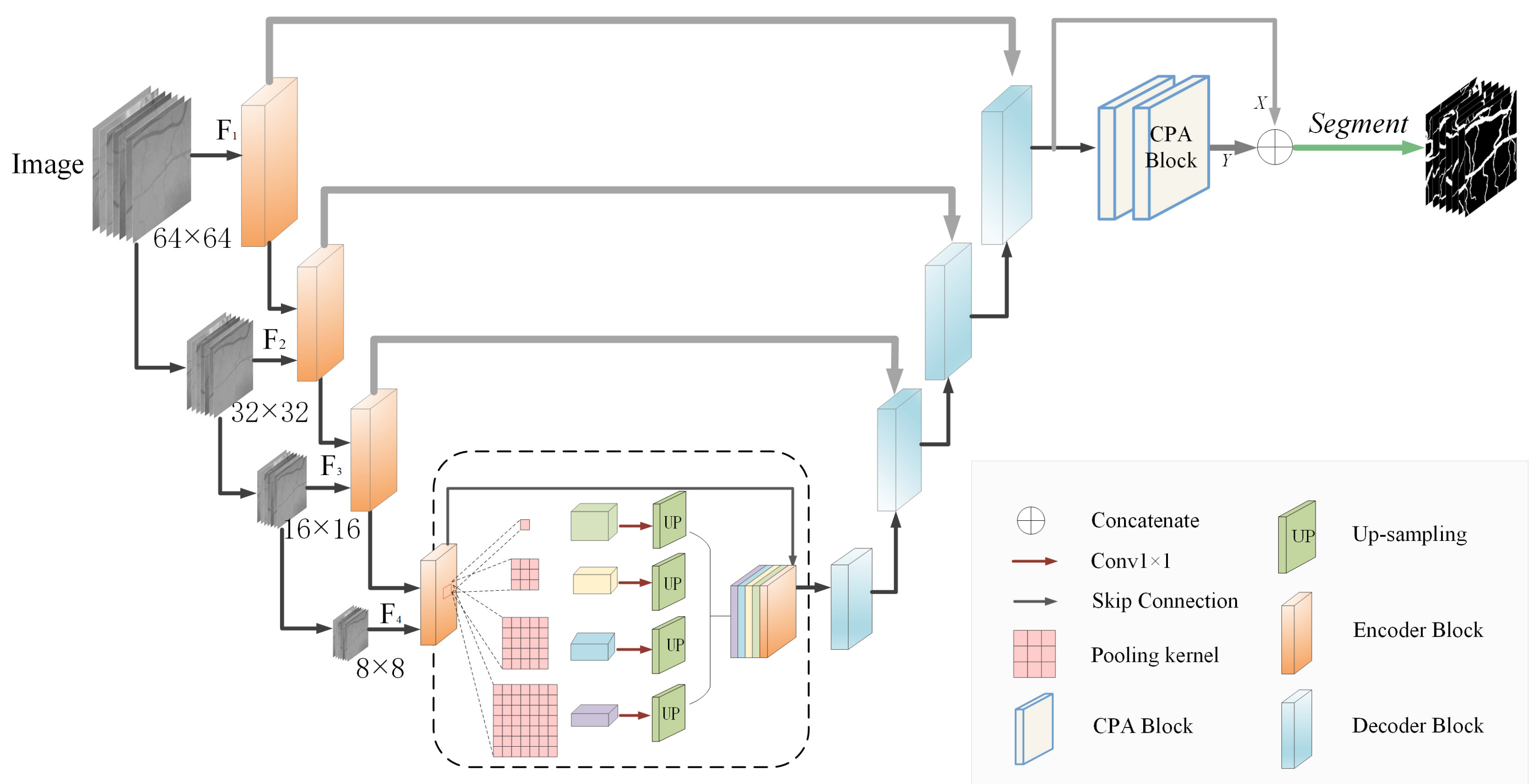
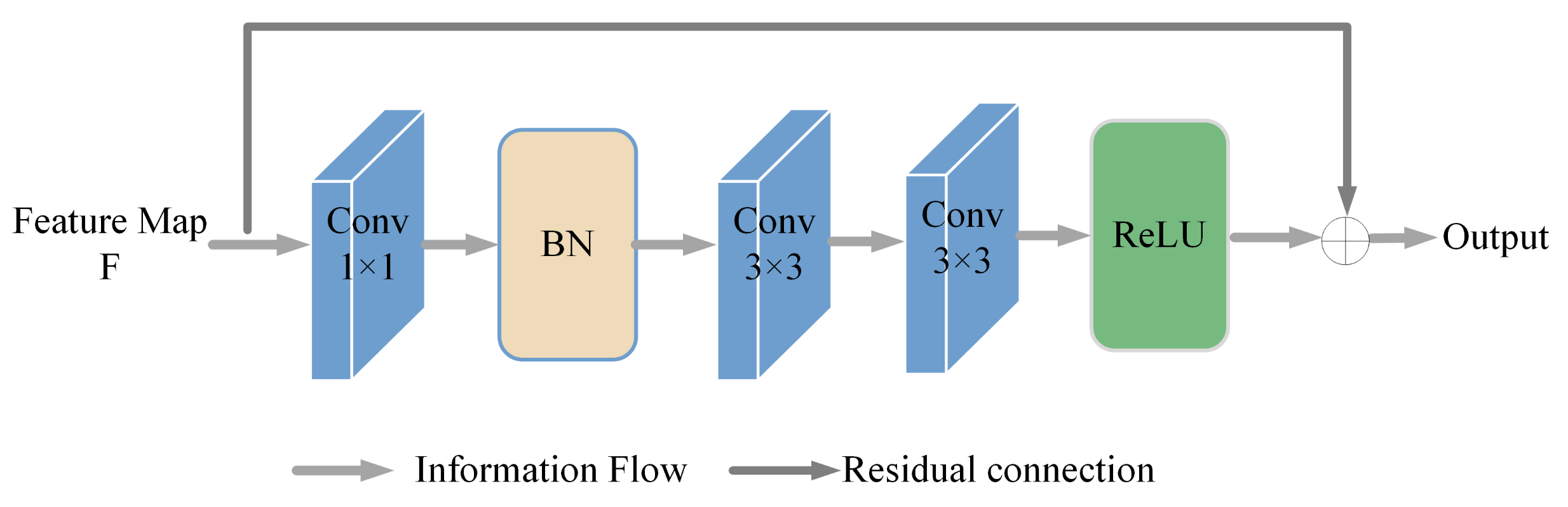
2.1. Network Architecture
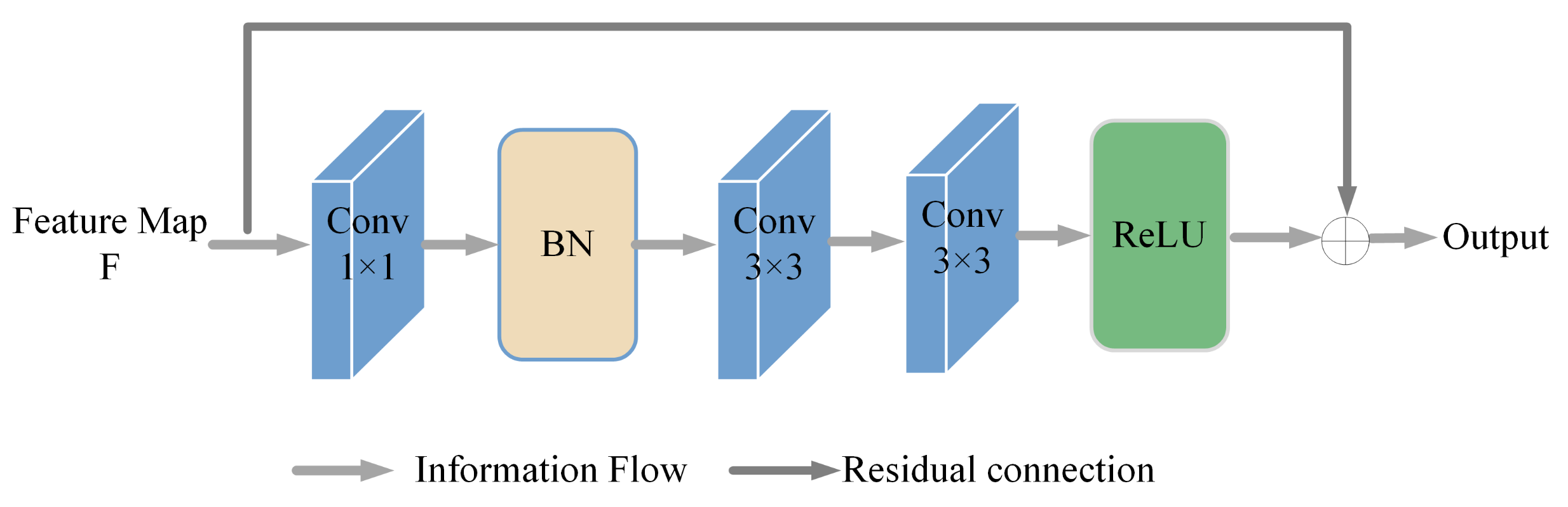
2.2. Encoder and Decoder Structure
2.3. Cross-Positional Attention Module
2.4. Loss Function
3. Dataset and Evaluation Metrics
3.1. Experimental Environment and Parameters
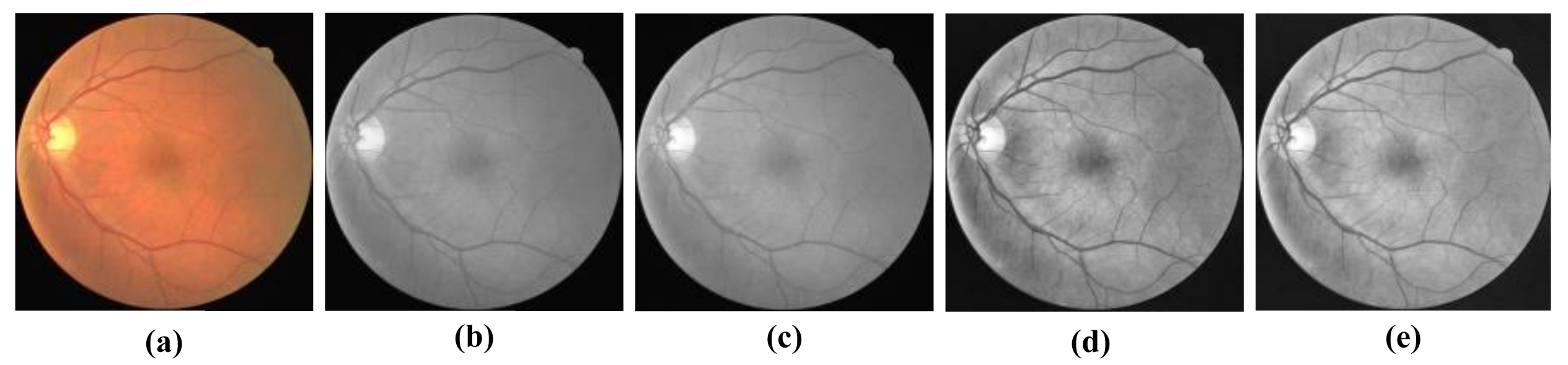
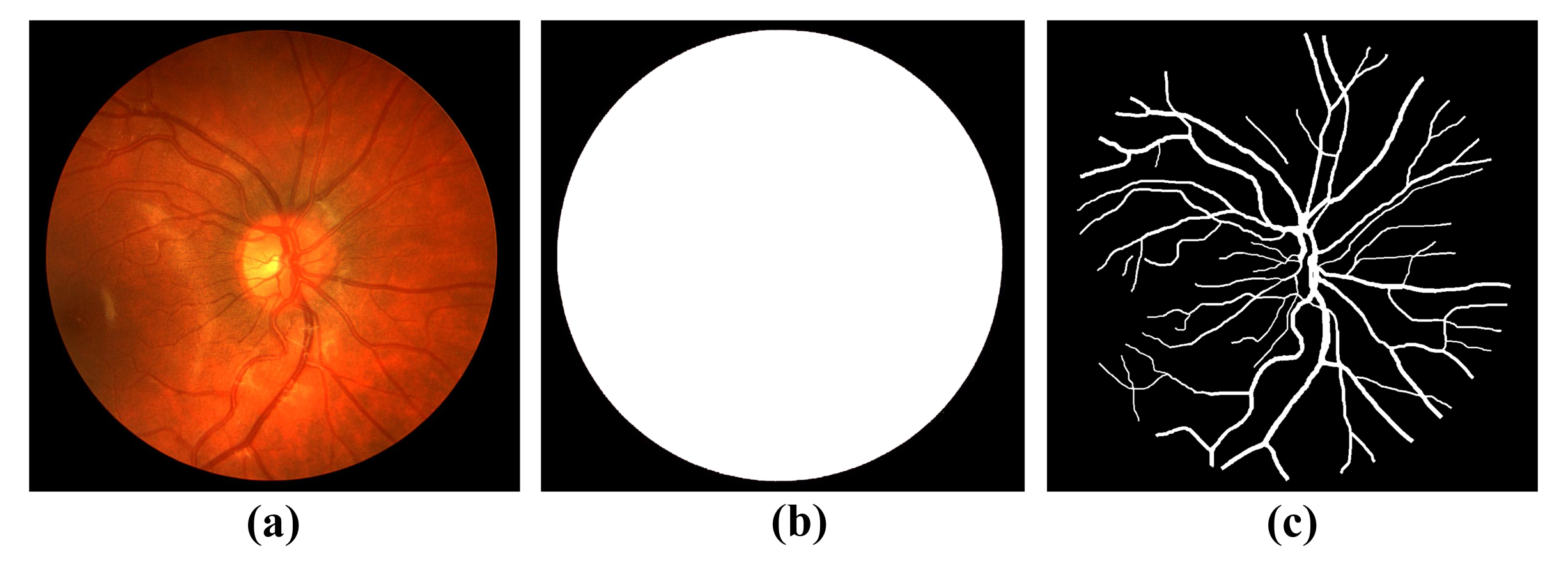
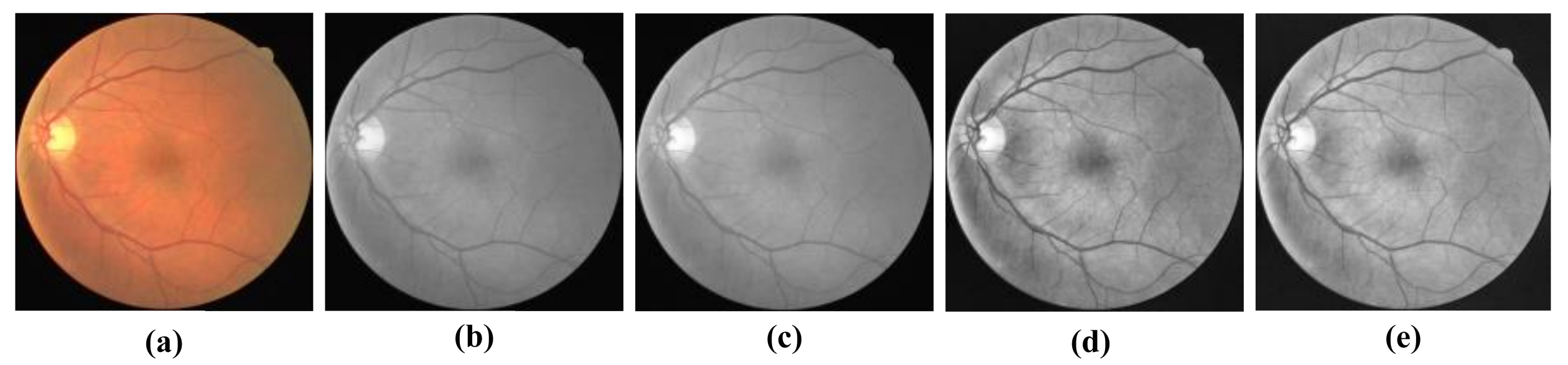
3.2. Datasets
3.3. Experimental Evaluation Metrics
4. Experimental Results and Analysis
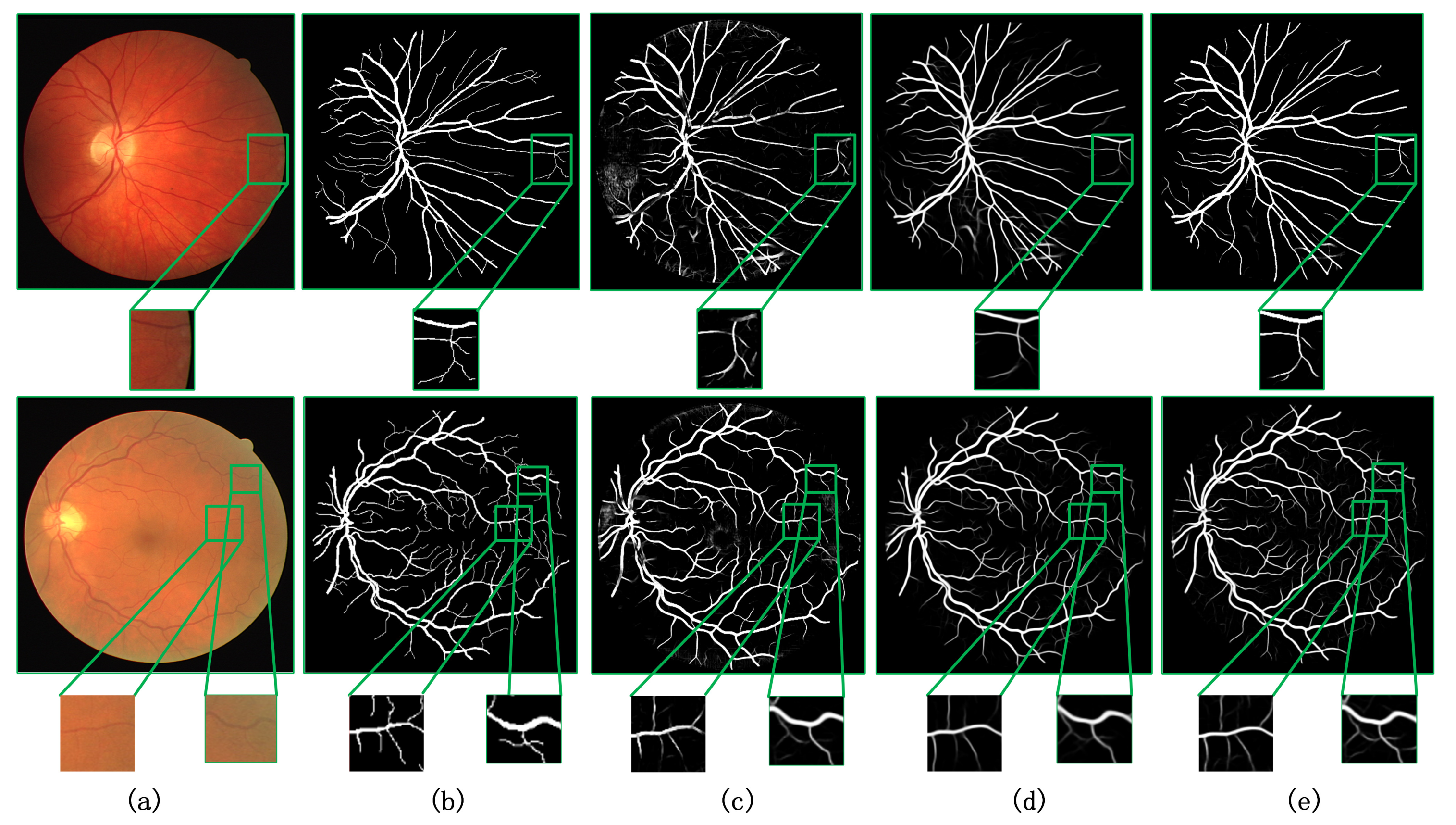
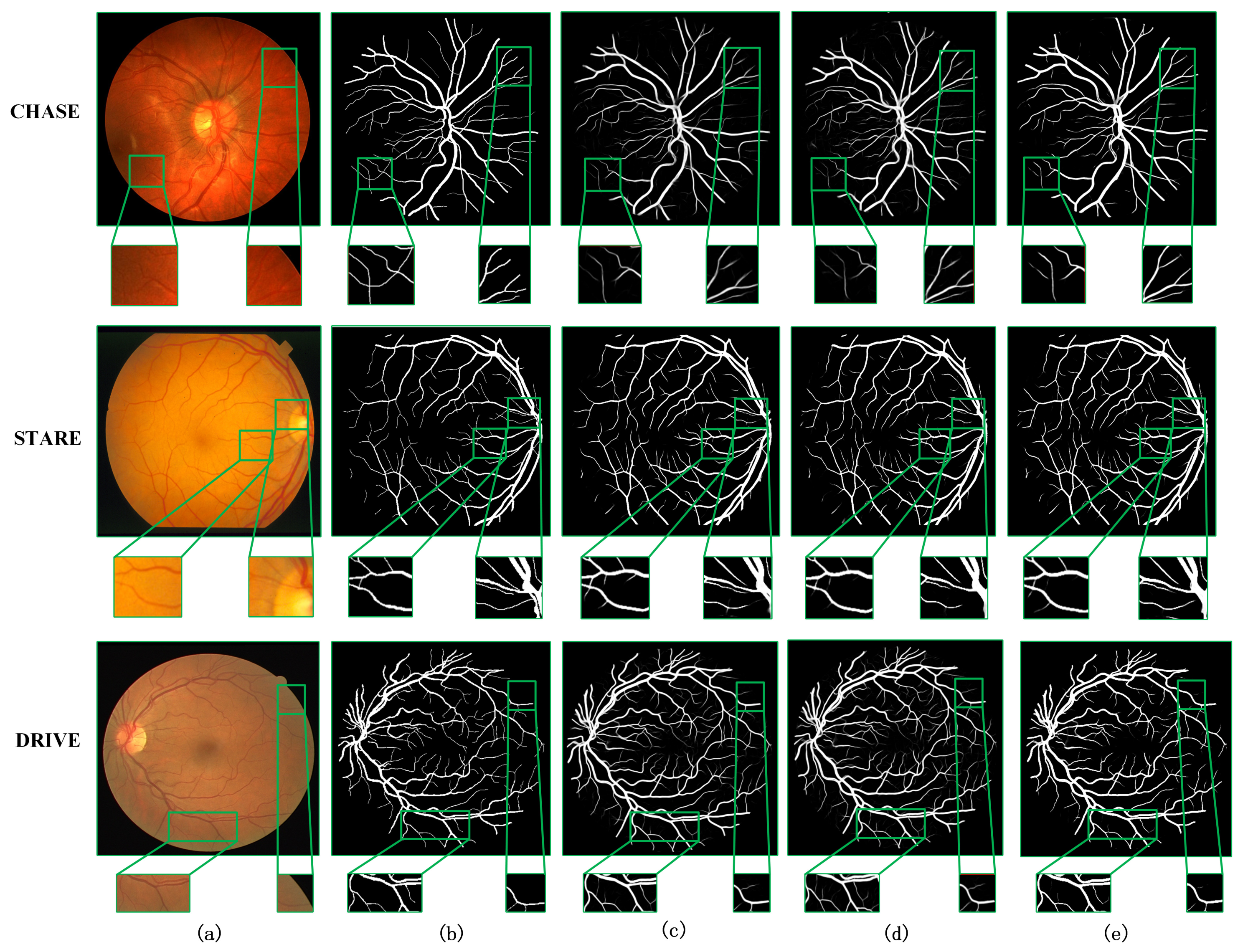
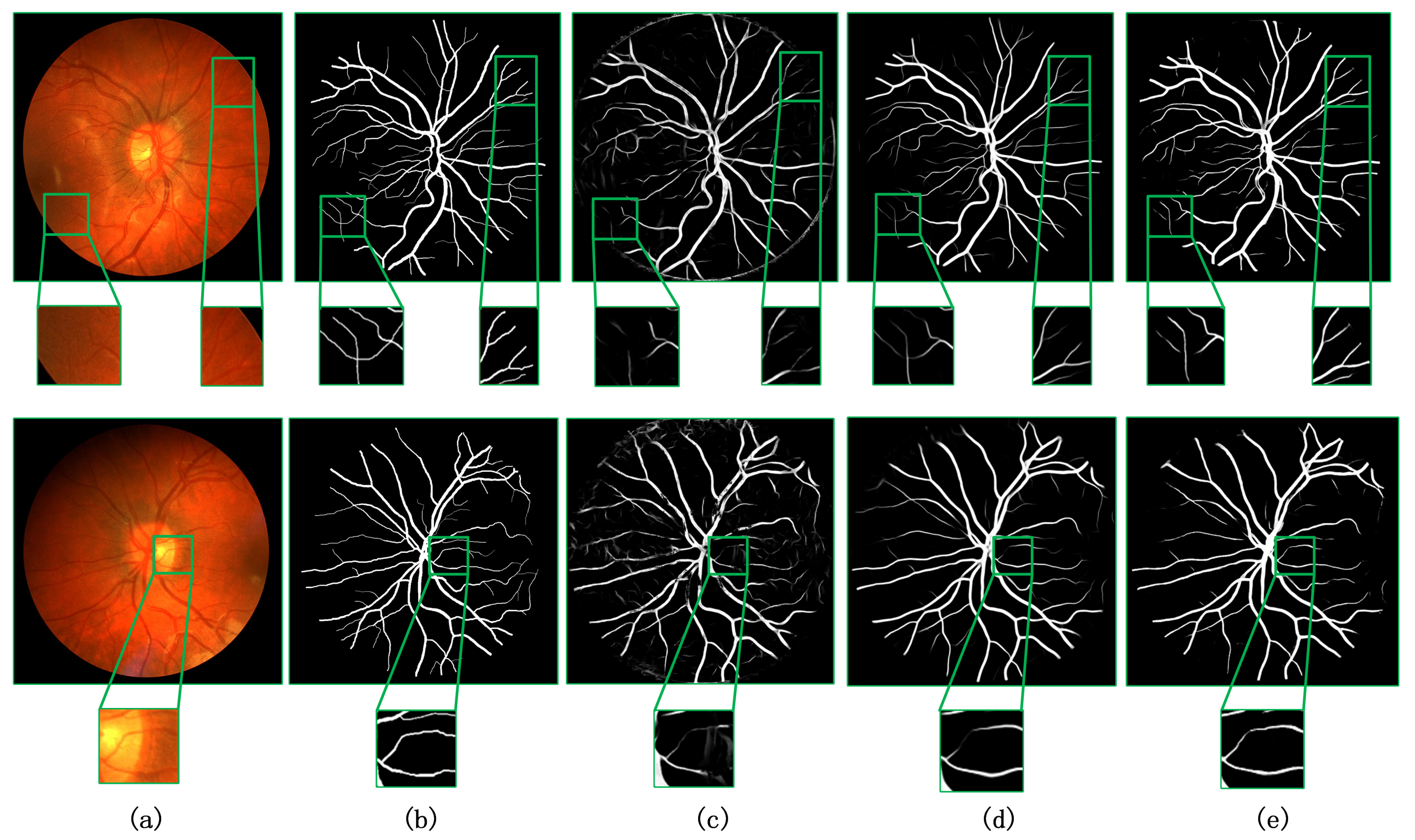
4.1. Comparison of the Results before and after Model Improvement
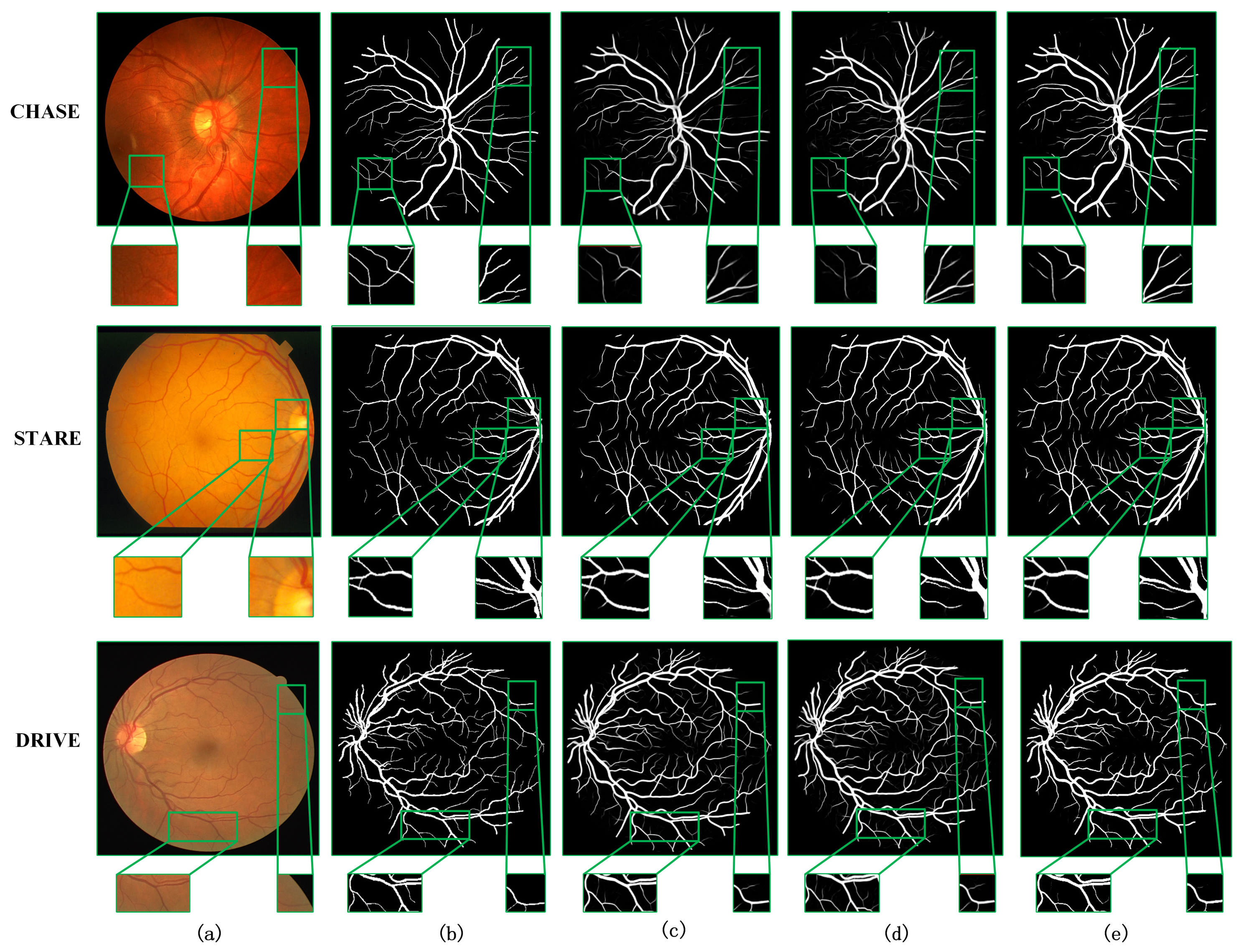
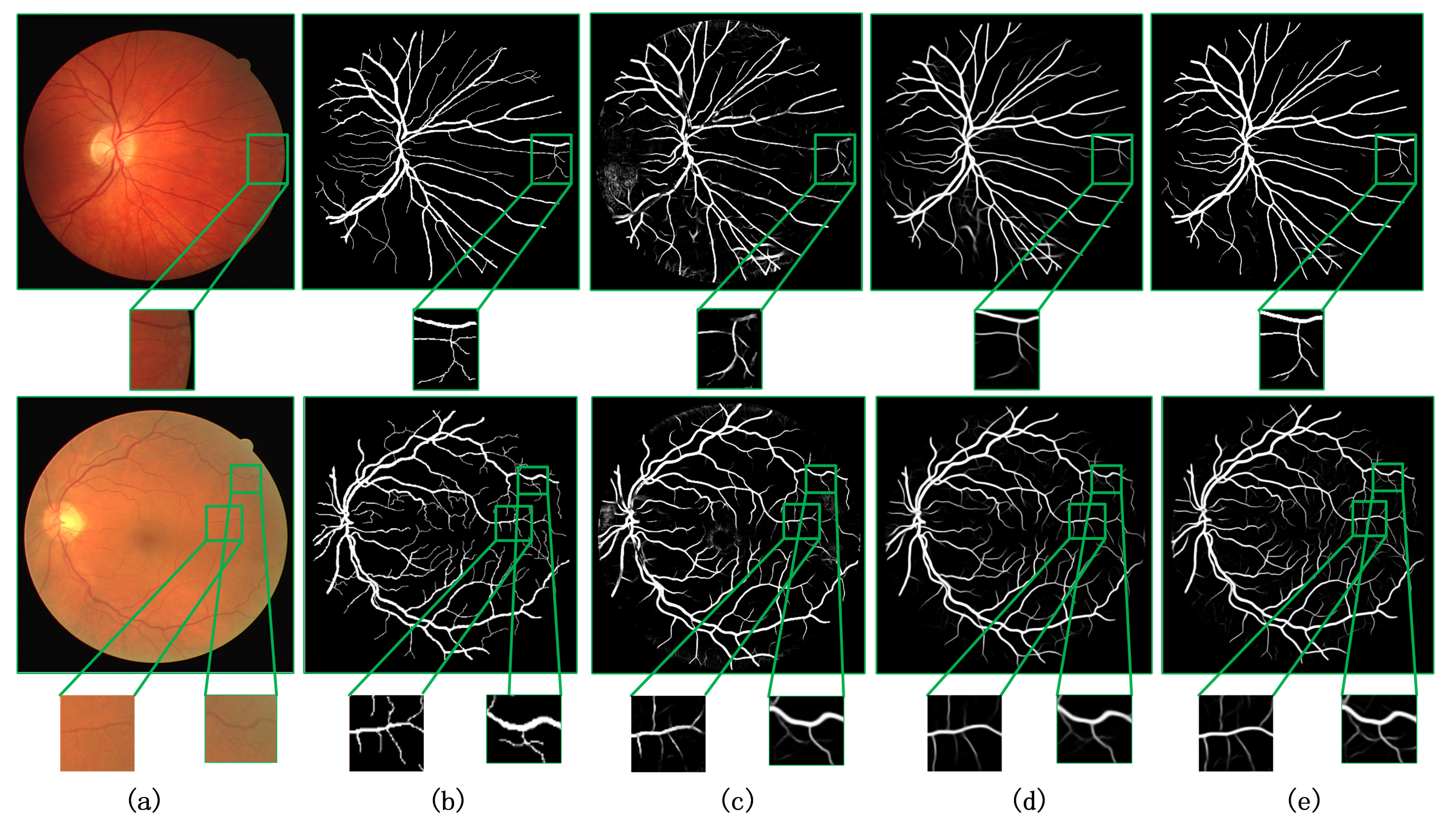
4.2. Comparison with Other Methods
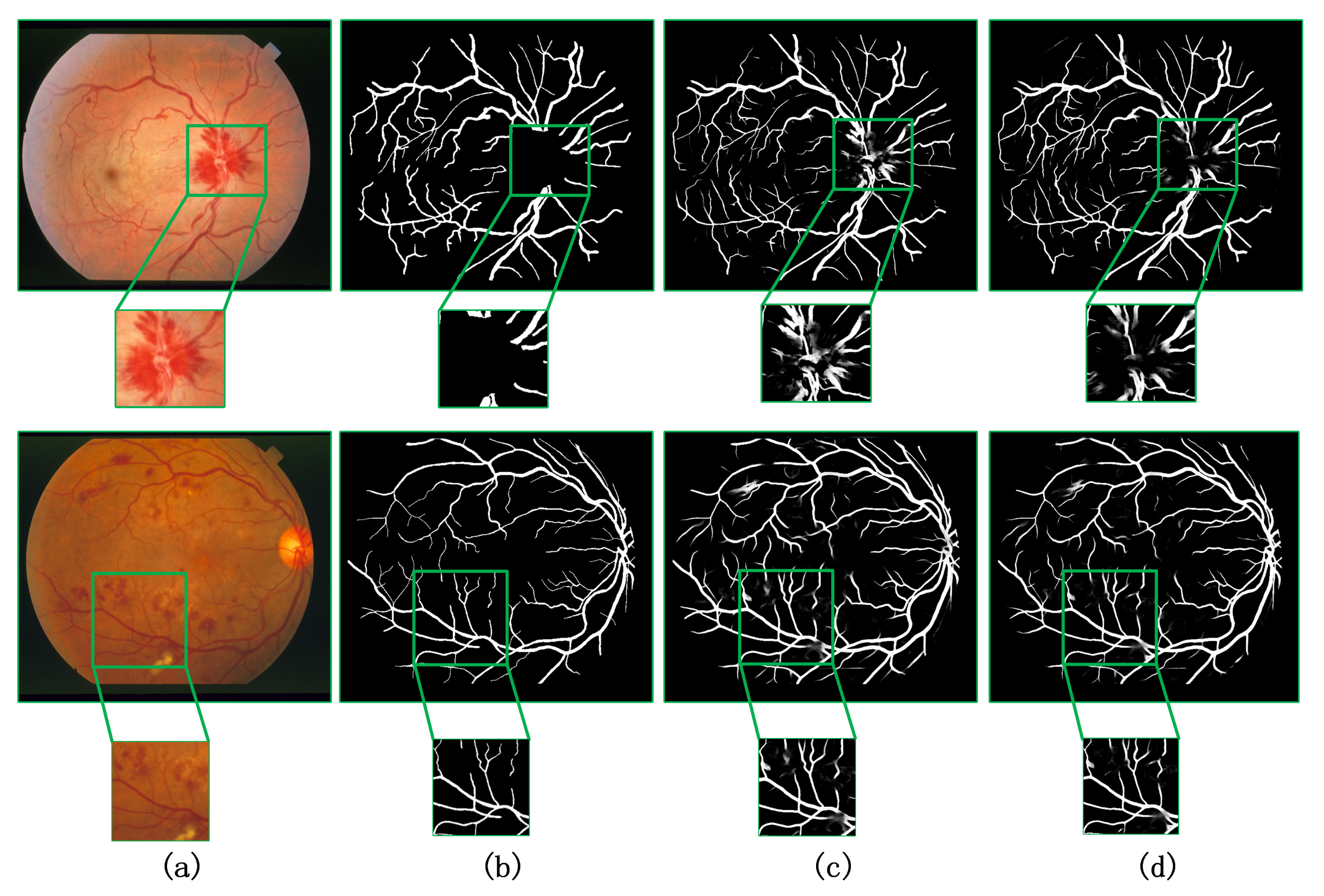
4.3. Generalization Verification of the Model
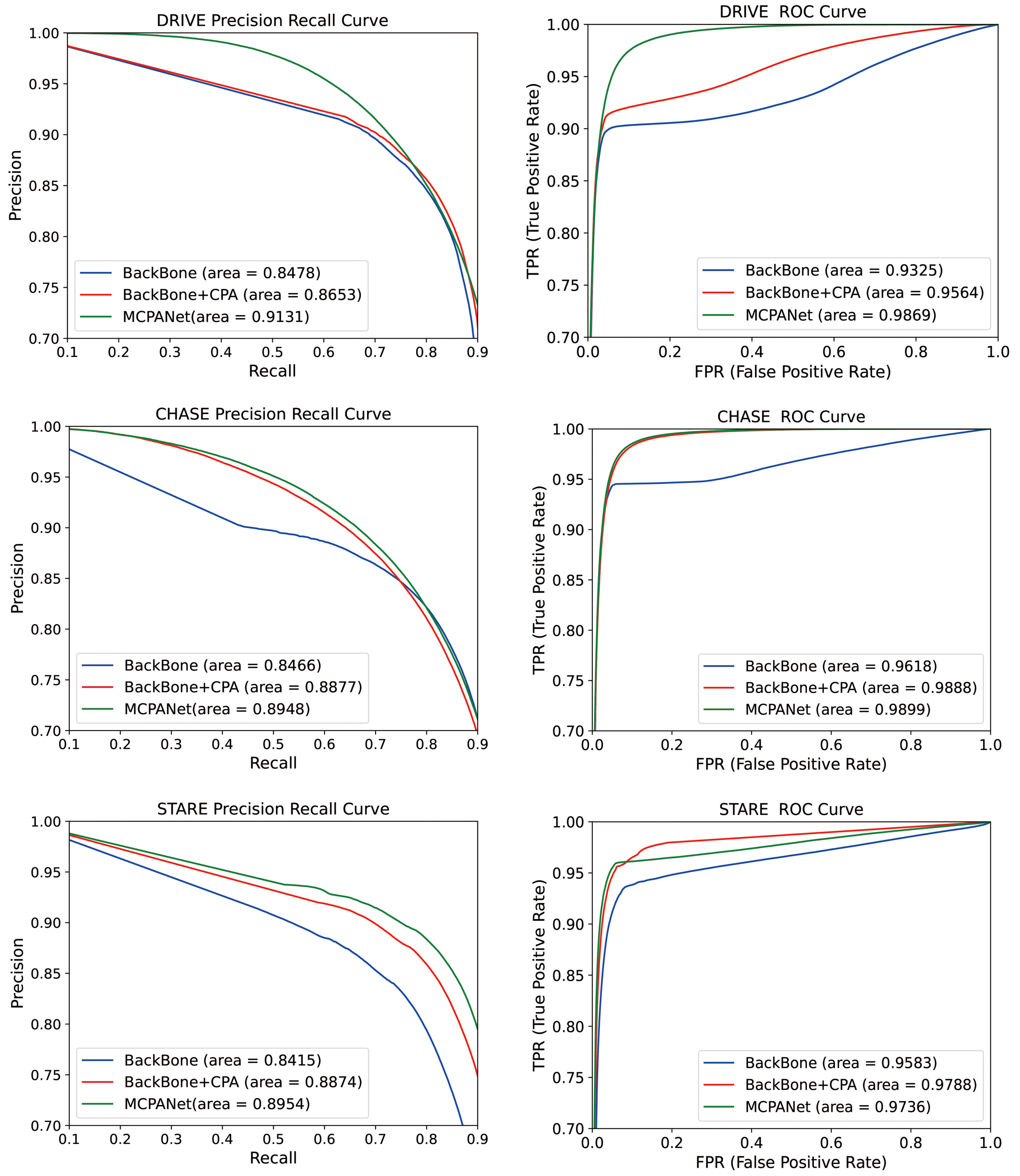
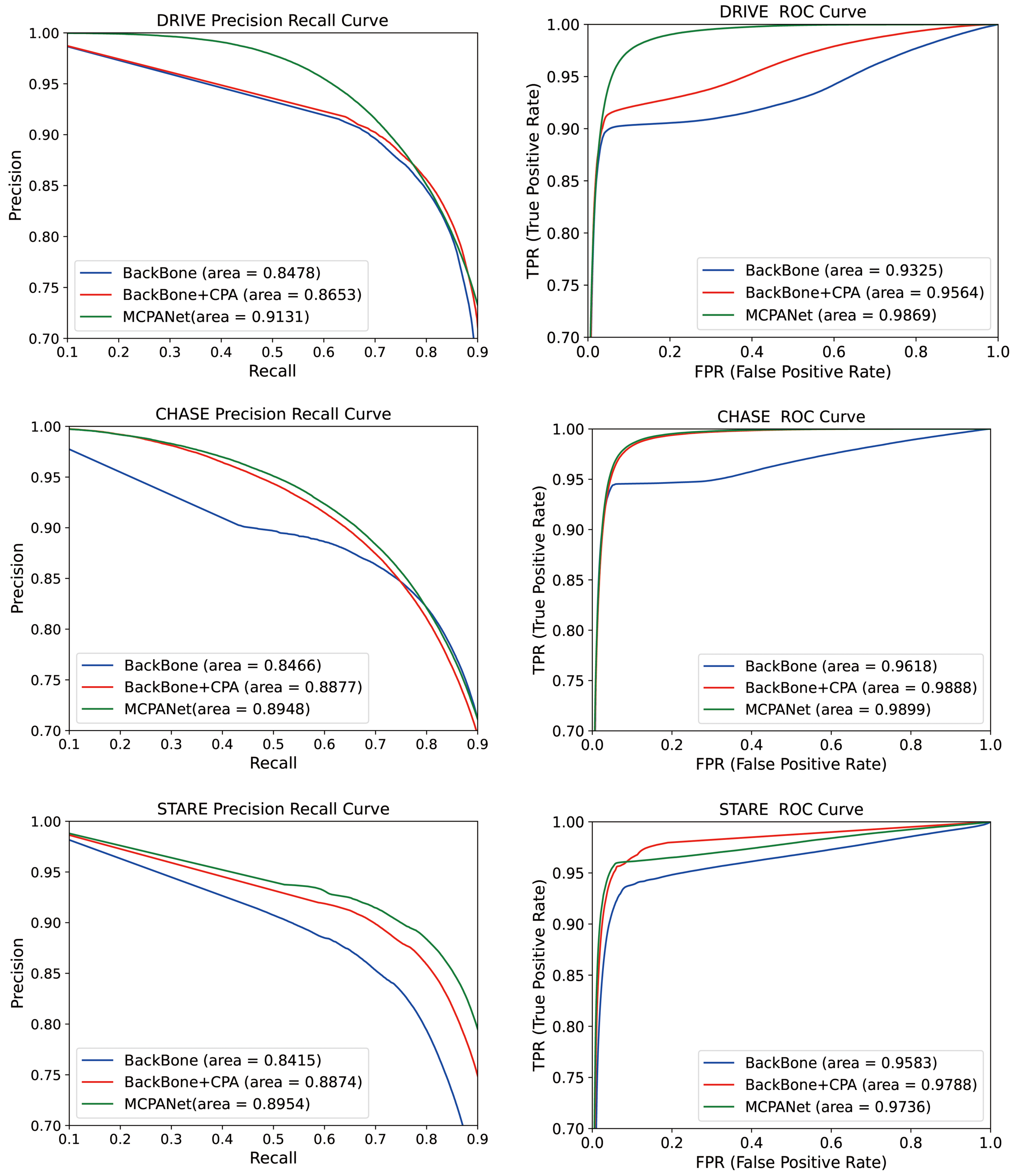
4.4. Number of Model Parameters and ROC Curve Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oshitari, T. Diabetic retinopathy: Neurovascular disease requiring neuroprotective and regenerative therapies. Neural Regen. Res. 2022, 17, 795. [Google Scholar] [CrossRef] [PubMed]
- Mookiah, M.R.; Hogg, S.; MacGillivray, T.J.; Prathiba, V.; Pradeepa, R.; Mohan, V.; Anjana, R.M.; Doney, A.S.; Palmer, C.N.; Trucco, E. A review of machine learning methods for retinal blood vessel segmentation and artery/vein classification. Med. Image Anal. 2020, 68, 101905. [Google Scholar] [CrossRef] [PubMed]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE J. Biomed. Health Inform. 2014, 19, 1118–1128. [Google Scholar]
- Oliveira, A.; Pereira, S.; Silva, C.A. Retinal vessel segmentation based on fully convolutional neural networks. Expert Syst. Appl. 2018, 112, 229–242. [Google Scholar] [CrossRef] [Green Version]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E.; Parv, B. Multi-Objective retinal vessel localization using flower pollination search algorithm with pattern search. Adv. Data Anal. Classif. 2017, 11, 611–627. [Google Scholar] [CrossRef]
- Neto, L.C.; Ramalho, G.L.; Neto, J.F.; Veras, R.M.; Medeiros, F.N. An unsupervised coarse-to-fine algorithm for blood vessel segmentation in fundus images. Expert Syst. Appl. 2017, 78, 182–192. [Google Scholar] [CrossRef]
- Jainish, G.R.; Jiji, G.W.; Infant, P.A. A novel automatic retinal vessel extraction using maximum entropy based EM algorithm. Multimed. Tools Appl. 2020, 79, 22337–22353. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 699–711. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Mo, J.; Zhang, L. Multi-Level deep supervised networks for retinal vessel segmentation. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 2181–2193. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted res-unet for high-quality retina vessel segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 9–21 October 2018; pp. 327–331. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginneken, B. Ridge-Based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Owen, C.G.; Rudnicka, A.R.; Mullen, R.; Barman, S.A.; Monekosso, D.; Whincup, P.H.; Ng, J.; Paterson, C. Measuring retinal vessel tortuosity in 10-year-old children: Validation of the computer-assisted image analysis of the retina(CAIAR) program. Investig. Ophthalmol. Vis. Sci. 2009, 50, 2004–2010. [Google Scholar] [CrossRef] [Green Version]
- Hoover, A.D.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched 691filter response. IEEE Trans. Med. Imaging 2000, 19, 203–210. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zhang, H.; Tan, N.; Chen, L. Automatic retinal blood vessel segmentation based on fully convolutional neural networks. Symmetry 2019, 11, 1112. [Google Scholar] [CrossRef] [Green Version]
- Azzopardi, G.; Strisciuglio, N.; Vento, M.; Petkov, N. Trainable COSFIRE filters for vessel delineation with application to retinal images. Med. Image Anal. 2015, 19, 46–57. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Chen, M.; Li, J.; Zhang, E. Retina image vessel segmentation using a hybrid CGLI level set method. Biomed. Res. Int. 2017, 2017, 1263056. [Google Scholar] [CrossRef]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Tong, H.; Fang, Z.; Wei, Z.; Cai, Q.; Gao, Y. SAT-Net: A side attention network for retinal image segmentation. Appl. Intell. 2021, 51, 5146–5156. [Google Scholar] [CrossRef]
- Tian, C.; Fang, T.; Fan, Y.; Wu, W. Multi-Path convolutional neural network in fundus segmentation of blood vessels. Biocybern. Biomed. Eng. 2020, 40, 583–595. [Google Scholar] [CrossRef]
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl.-Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Ma, H.; Li, J.; Liu, S. Attention guided u-net with atrous convolution for accurate retinal vessels segmentation. IEEE Access 2020, 8, 32826–32839. [Google Scholar] [CrossRef]
- Wang, W.; Zhong, J.; Wu, H.; Wen, Z.; Qin, J. Rvseg-Net: An efficient feature pyramid cascade network for retinal vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Cham, Switzerland, 2020; pp. 796–805. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Zhou, W.; Bian, H. Residual Spatial Attention Network for Retinal Vessel Segmentation. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; Springer: Cham, Switzerland, 2020; pp. 509–519. [Google Scholar]
- Yang, J.; Dong, X.; Hu, Y.; Peng, Q.; Tao, G.; Ou, Y.; Cai, H.; Yang, X. Fully automatic arteriovenous segmentation in retinal images via topology-aware generative adversarial networks. Interdiscip. Sci. Comput. Life Sci. 2020, 12, 323–334. [Google Scholar] [CrossRef]
- Park, K.B.; Choi, S.H.; Lee, J.Y. M-Gan: Retinal blood vessel segmentation by balancing losses through stacked deep fully convolutional networks. IEEE Access 2020, 8, 146308–146322. [Google Scholar] [CrossRef]
- Wu, H.; Wang, W.; Zhong, J.; Lei, B.; Wen, Z.; Qin, J. SCS-Net: A Scale and Context Sensitive Network for Retinal Vessel Segmentation. Med. Image Anal. 2021, 70, 102025. [Google Scholar] [CrossRef]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-Unet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1236–1242. [Google Scholar]
- Arsalan, M.; Haider, A.; Lee, Y.W.; Park, K.R. Detecting retinal vasculature as a key biomarker for deep Learning-based intelligent screening and analysis of diabetic and hypertensive retinopathy. Expert Syst. Appl. 2022, 200, 117009. [Google Scholar] [CrossRef]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-Net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Specificity | Sensitivity | Accuracy | Dice | AUC_ROC |
|---|---|---|---|---|---|
| BackBone | 0.9849 | 0.8281 | 0.9706 | 0.8130 | 0.9622 |
| BackBone + CPA | 0.9854 | 0.8167 | 0.9704 | 0.8280 | 0.9747 |
| MCPANet | 0.9836 | 0.8356 | 0.9705 | 0.8315 | 0.9871 |
| Model | Specificity | Sensitivity | Accuracy | Dice | AUC_ROC |
|---|---|---|---|---|---|
| BackBone | 0.9862 | 0.8155 | 0.9762 | 0.8122 | 0.9769 |
| BackBone + CPA | 0.9855 | 0.8328 | 0.9757 | 0.8123 | 0.9896 |
| MCPANet | 0.9849 | 0.8416 | 0.9758 | 0.8148 | 0.9898 |
| Model | Specificity | Sensitivity | Accuracy | Dice |
|---|---|---|---|---|
| MCPANet + Cross-entropy | 0.9836 | 0.8343 | 0.9703 | 0.8305 |
| MCPANet + Dice | 0.9836 | 0.8356 | 0.9705 | 0.8315 |
| Model | Specificity | Sensitivity | Accuracy | Dice |
|---|---|---|---|---|
| MCPANet + Cross-entropy | 0.9859 | 0.8297 | 0.9759 | 0.8131 |
| MCPANet + Dice | 0.9849 | 0.8416 | 0.9758 | 0.8148 |
| Image | Accuracy | Specificity | Sensitivity | Dice | AUC_ROC |
|---|---|---|---|---|---|
| 0 | 0.9722 | 0.9833 | 0.8478 | 0.8288 | 0.9781 |
| 1 | 0.9776 | 0.9900 | 0.8184 | 0.8297 | 0.9684 |
| 2 | 0.9807 | 0.9864 | 0.8909 | 0.8468 | 0.9812 |
| 3 | 0.9714 | 0.9870 | 0.7767 | 0.8010 | 0.9715 |
| 4 | 0.9668 | 0.9824 | 0.8090 | 0.8148 | 0.9531 |
| 5 | 0.9780 | 0.9843 | 0.8915 | 0.8488 | 0.9854 |
| 6 | 0.9748 | 0.9776 | 0.9420 | 0.8567 | 0.9858 |
| 7 | 0.9757 | 0.9774 | 0.9540 | 0.8544 | 0.9925 |
| 8 | 0.9822 | 0.9857 | 0.9401 | 0.8923 | 0.9919 |
| 9 | 0.9737 | 0.9780 | 0.9237 | 0.8494 | 0.9858 |
| 10 | 0.9797 | 0.9864 | 0.8917 | 0.8621 | 0.9887 |
| 11 | 0.9807 | 0.9824 | 0.9603 | 0.8848 | 0.9914 |
| 12 | 0.9800 | 0.9874 | 0.9037 | 0.8894 | 0.9854 |
| 13 | 0.9803 | 0.9896 | 0.8869 | 0.8907 | 0.9879 |
| 14 | 0.9780 | 0.9867 | 0.8857 | 0.8741 | 0.9800 |
| 15 | 0.9682 | 0.9875 | 0.7989 | 0.8370 | 0.9708 |
| 16 | 0.9760 | 0.9882 | 0.8567 | 0.8641 | 0.9767 |
| 17 | 0.9866 | 0.9940 | 0.8455 | 0.8642 | 0.9710 |
| 18 | 0.9827 | 0.9877 | 0.8728 | 0.8130 | 0.9774 |
| 19 | 0.9710 | 0.9830 | 0.8408 | 0.7867 | 0.9738 |
| Average | 0.9768 | 0.9853 | 0.8799 | 0.8505 | 0.9798 |
| Model | Specificity | Sensitivity | Accuracy | Dice | AUC_ROC |
|---|---|---|---|---|---|
| BackBone | 0.9821 | 0.8594 | 0.9722 | 0.8256 | 0.9791 |
| BackBone + CPA | 0.9837 | 0.8661 | 0.9748 | 0.8371 | 0.9796 |
| MCPANet | 0.9853 | 0.8799 | 0.9768 | 0.8505 | 0.9798 |
| Type | Methods | Year | Accuracy | Sensitivity | Specificity | Dice |
|---|---|---|---|---|---|---|
| Unsupervised method | Azzopardi et al. [24] | 2015 | 0.9442 | 0.7655 | 0.9704 | - |
| Chen et al. [25] | 2017 | 0.9390 | 0.7358 | 0.9680 | - | |
| Tian et al. [28] | 2019 | 0.9580 | 0.8639 | 0.9690 | - | |
| Jainish et al. [7] | 2020 | 0.9657 | 0.9890 | 0.7900 | - | |
| Supervised Method | U-Net [10] | 2015 | 0.9531 | 0.7537 | 0.9820 | 0.8142 |
| R2U-Net [26] | 2018 | 0.9556 | 0.7792 | 0.9813 | 0.8171 | |
| DUNet [29] | 2019 | 0.9566 | 0.7963 | 0.9800 | 0.8237 | |
| AG-UNet [30] | 2020 | 0.9558 | 0.7854 | 0.9810 | 0.8216 | |
| CA-Net [9] | 2020 | 0.9605 | 0.7727 | 0.9788 | 0.7733 | |
| RVSeg-Net [31] | 2020 | 0.9681 | 0.8107 | 0.9845 | - | |
| Guo et al. [32] | 2020 | 0.9691 | 0.8149 | 0.9839 | 0.8222 | |
| topGAN [33] | 2020 | 0.9430 | 0.9180 | 0.9300 | - | |
| M-GAN [34] | 2020 | 0.9706 | 0.8346 | 0.9836 | 0.8324 | |
| Tong et al. [27] | 2021 | 0.9684 | 0.8117 | 0.9870 | 0.8174 | |
| SCS-Net [35] | 2021 | 0.9697 | 0.8289 | 0.9838 | 0.8189 | |
| SA-Net [36] | 2021 | 0.9569 | 0.8252 | - | - | |
| PLRS-Net [37] | 2022 | 0.9682 | 0.8269 | 0.9817 | - | |
| Ours | 2022 | 0.9705 | 0.8356 | 0.9836 | 0.8315 |
| Type | Methods | Year | Accuracy | Sensitivity | Specificity | Dice |
|---|---|---|---|---|---|---|
| Unsupervised method | Azzopardi et al. [24] | 2015 | 0.9387 | 0.7585 | 0.9587 | - |
| Tian et al. [28] | 2019 | 0.9601 | 0.8778 | 0.9680 | - | |
| Supervised Method | U-Net [10] | 2015 | 0.9578 | 0.8288 | 0.9701 | 0.7783 |
| R2U-Net [26] | 2018 | 0.9634 | 0.7756 | 0.9820 | 0.7928 | |
| DUNet [29] | 2019 | 0.9610 | 0.8155 | 0.9752 | 0.7883 | |
| AG-UNet [30] | 2020 | 0.9752 | 0.8110 | 0.9870 | 0.8116 | |
| RVSeg-Net [31] | 2020 | 0.9726 | 0.8069 | 0.9836 | - | |
| Guo et al. [32] | 2020 | 0.9751 | 0.8486 | 0.9836 | 0.8111 | |
| CA-Net [9] | 2020 | 0.9645 | 0.8120 | 0.9749 | 0.7409 | |
| M-GAN [33] | 2020 | 0.9736 | - | - | 0.8110 | |
| Tong et al. [27] | 2021 | 0.9739 | 0.8340 | 0.9868 | 0.7911 | |
| SCS-Net [35] | 2021 | 0.9744 | 0.8365 | 0.9839 | - | |
| PLRS-Net [37] | 2022 | 0.9731 | 0.8301 | 0.9839 | - | |
| Ours | 2022 | 0.9758 | 0.8416 | 0.9849 | 0.8148 |
| Type | Methods | Year | Accuracy | Sensitivity | Specificity | Dice |
|---|---|---|---|---|---|---|
| Unsupervised Method | Azzopardi et al. [24] | 2015 | 0.9387 | 0.7585 | 0.9587 | - |
| Tian et al. [28] | 2019 | 0.9601 | 0.8778 | 0.9680 | - | |
| U-Net [10] | 2015 | 0.9690 | 0.8270 | 0.9842 | 0.8373 | |
| Supervised Method | R2U-Net [26] | 2018 | 0.9712 | 0.8298 | 0.9862 | 0.8475 |
| Iter-Net [38] | 2020 | 0.9782 | 0.7715 | 0.9919 | 0.8146 | |
| M-GAN [35] | 2020 | 0.9876 | 0.8324 | 0.9938 | 0.8370 | |
| Tong et al. [27] | 2021 | 0.9805 | 0.8072 | 0.9927 | 0.8270 | |
| SCS-Net [35] | 2021 | 0.9736 | 0.8207 | 0.9839 | - | |
| PLRS-Net [37] | 2022 | 0.9715 | 0.8635 | 0.9803 | - | |
| Ours | 2022 | 0.9768 | 0.8799 | 0.9853 | 0.8505 |
| Methods | Year | Accuracy | Sensitivity | Specificity | Dice |
|---|---|---|---|---|---|
| U-Net [10] | 2015 | 0.9466 | 0.9594 | 0.9401 | 0.8212 |
| Attention U-Net [39] | 2018 | 0.9440 | 0.9508 | 0.9375 | 0.8181 |
| CE-Net [40] | 2019 | 0.9501 | 0.9569 | 0.9435 | 0.8307 |
| CA-Net [9] | 2020 | 0.9422 | 0.9489 | 0.9357 | 0.8099 |
| Ours | 2022 | 0.9521 | 0.9591 | 0.9453 | 0.8374 |
| Model (Params) | DRIVE (10,000 Pathcs) | CHASE_DB1 (10,000 Pathcs) | STARE (38,000 Patchs) |
|---|---|---|---|
| BackBone (7.42 M) | 1.29 s | 6.37 s | 7.05 s |
| BackBone + CPA (7.43 M) | 1.51 s | 7.37 s | 1.51 s |
| CA-Net (2.8 M) | 2.7 s | 3.77 s | 2.28 s |
| AG-UNet (28.3 M) | 6.21 s | 21.01 s | 15.89 s |
| MCPANet (7.46 M) | 0.83 s | 10.24 s | 1.02 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Liang, J.; Cheng, T.; Zhang, Y.; Lin, X.; Dong, J. MCPANet: Multiscale Cross-Position Attention Network for Retinal Vessel Image Segmentation. Symmetry 2022, 14, 1357. https://doi.org/10.3390/sym14071357
Jiang Y, Liang J, Cheng T, Zhang Y, Lin X, Dong J. MCPANet: Multiscale Cross-Position Attention Network for Retinal Vessel Image Segmentation. Symmetry. 2022; 14(7):1357. https://doi.org/10.3390/sym14071357
Chicago/Turabian StyleJiang, Yun, Jing Liang, Tongtong Cheng, Yuan Zhang, Xin Lin, and Jinkun Dong. 2022. "MCPANet: Multiscale Cross-Position Attention Network for Retinal Vessel Image Segmentation" Symmetry 14, no. 7: 1357. https://doi.org/10.3390/sym14071357
APA StyleJiang, Y., Liang, J., Cheng, T., Zhang, Y., Lin, X., & Dong, J. (2022). MCPANet: Multiscale Cross-Position Attention Network for Retinal Vessel Image Segmentation. Symmetry, 14(7), 1357. https://doi.org/10.3390/sym14071357