
Object Detection by Attention-Guided Feature Fusion Network


Abstract
:1. Introduction
- The method of feature aggravation is intended for extracting more representative features in object detection.
- An effective attention mechanism Channel-Spatial Attention Module (CSAM) guides feature fusion to improve detection accuracy.
- The proposed Attention-guided Feature Fusion Network (AFFN) method is capable of reliably detecting objects of a wider range of sizes, outperforms YOLOv3 in both subjective and objective evaluations. Furthermore, we apply our work on helmet detection and achieve excellent results, which contributed to operation security.
2. Related Work
2.1. Object Detection in Convolution Neural Network
2.2. Feature Aggravation
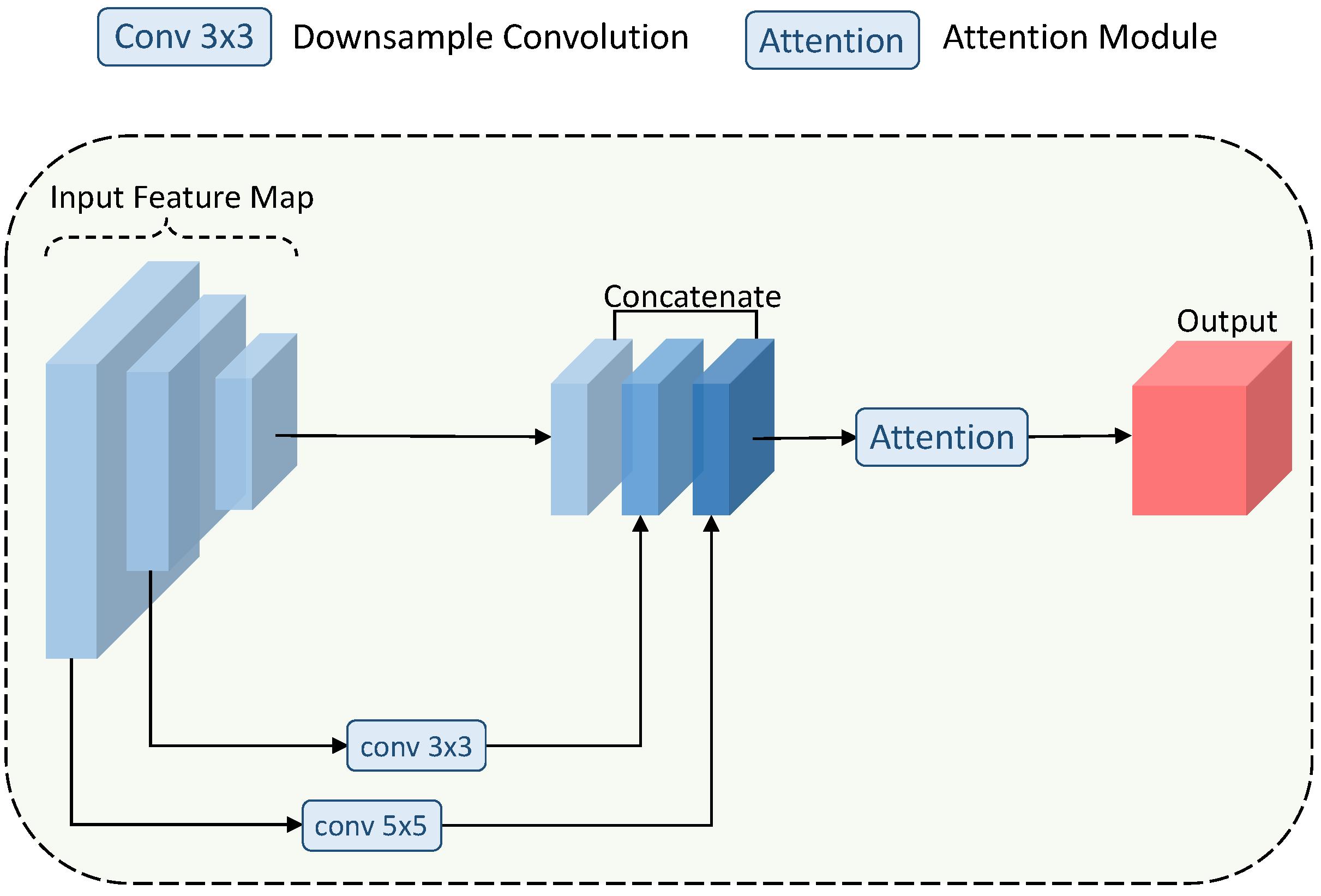
2.3. Attention Mechanism
3. Method
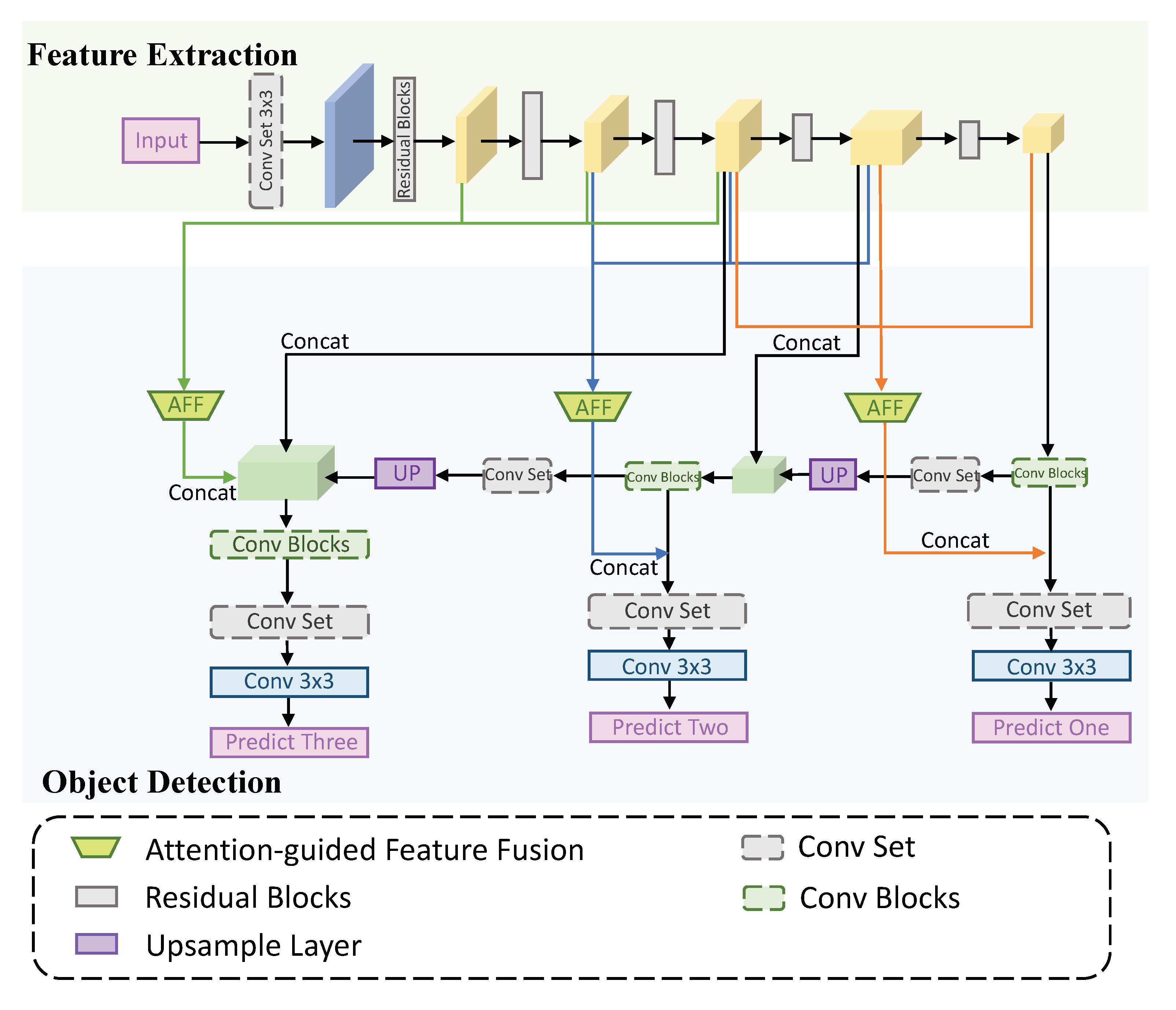
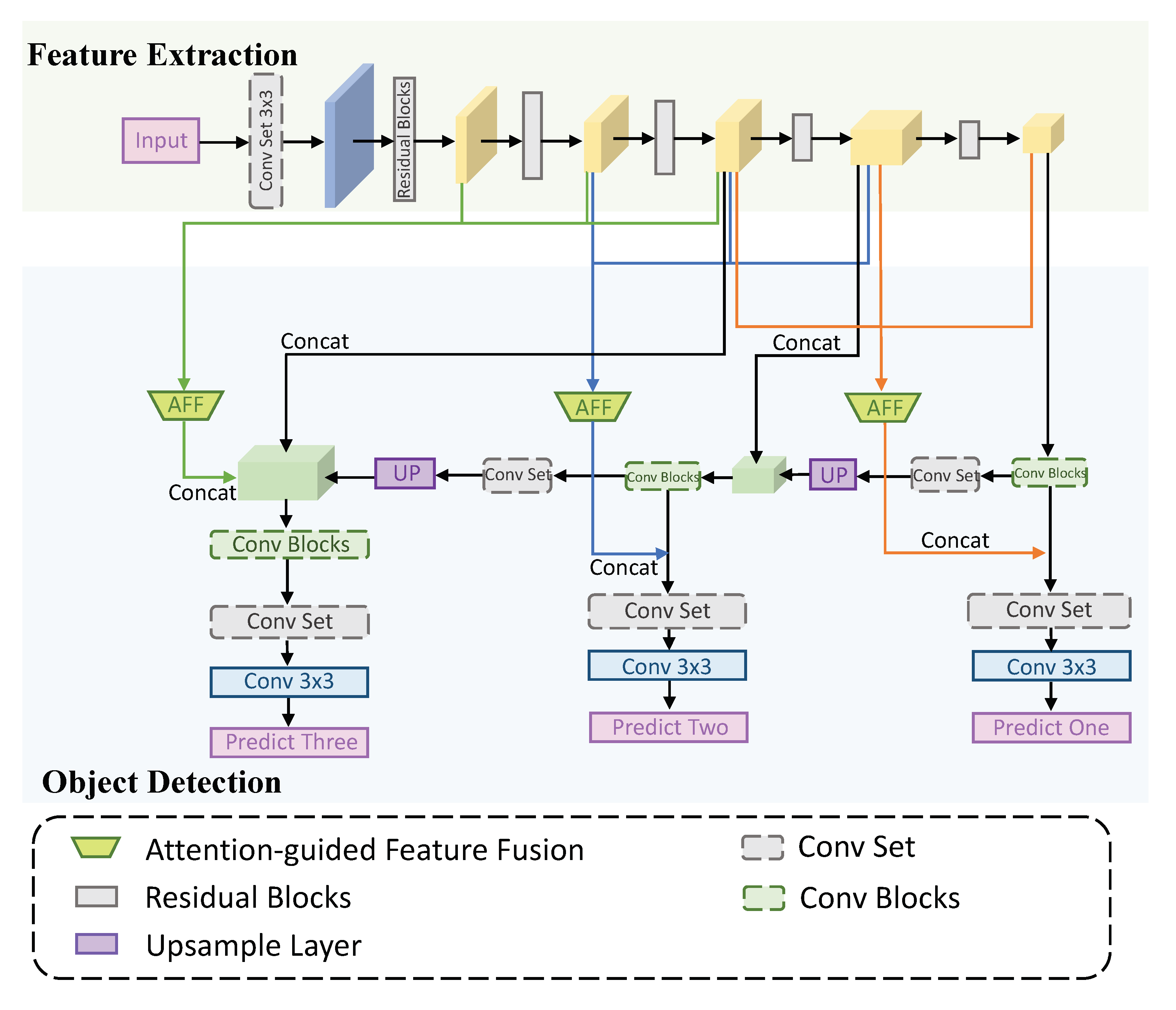
3.1. Overall Network
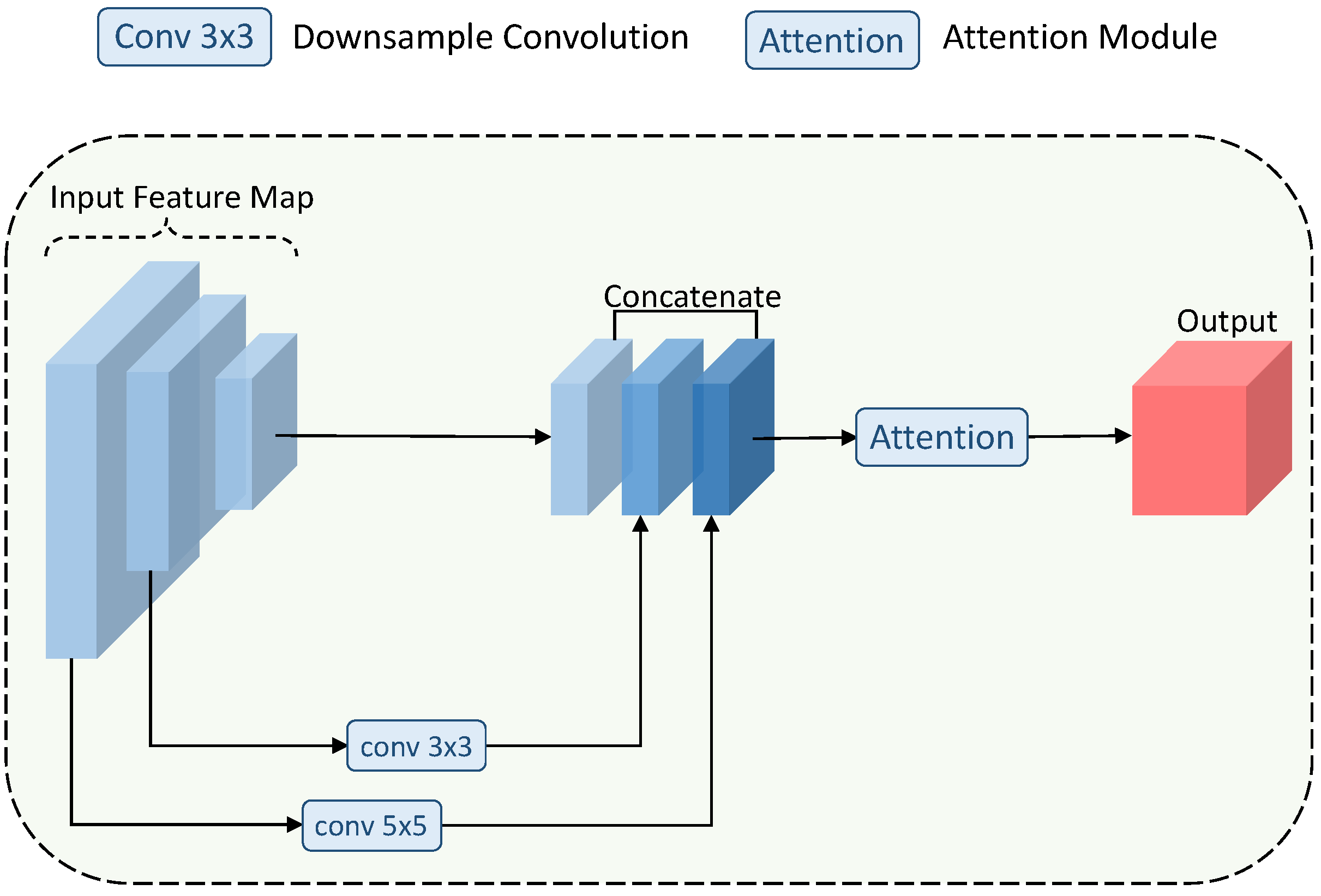
3.2. Attention-Guided Feature Fusion Module
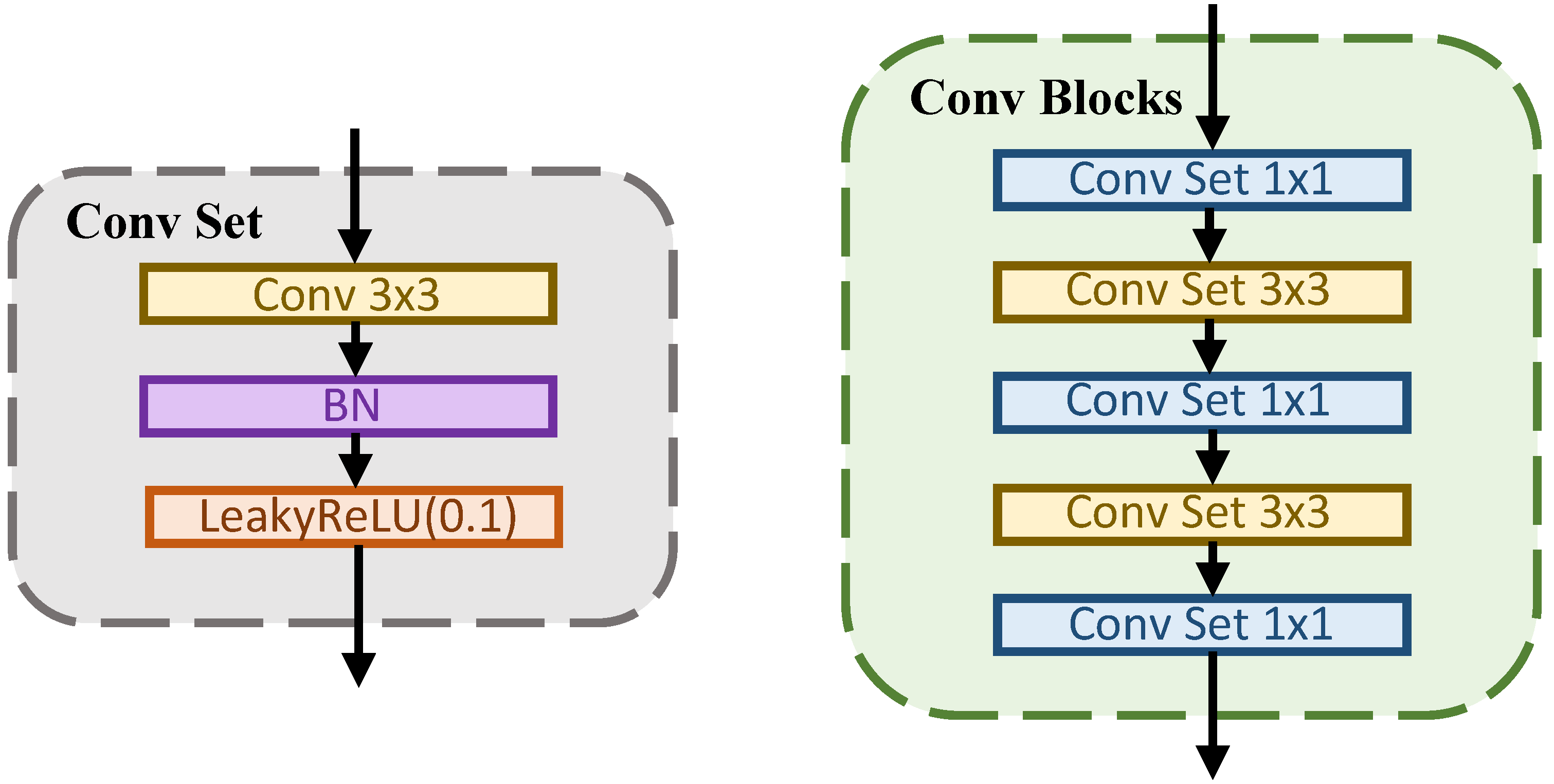
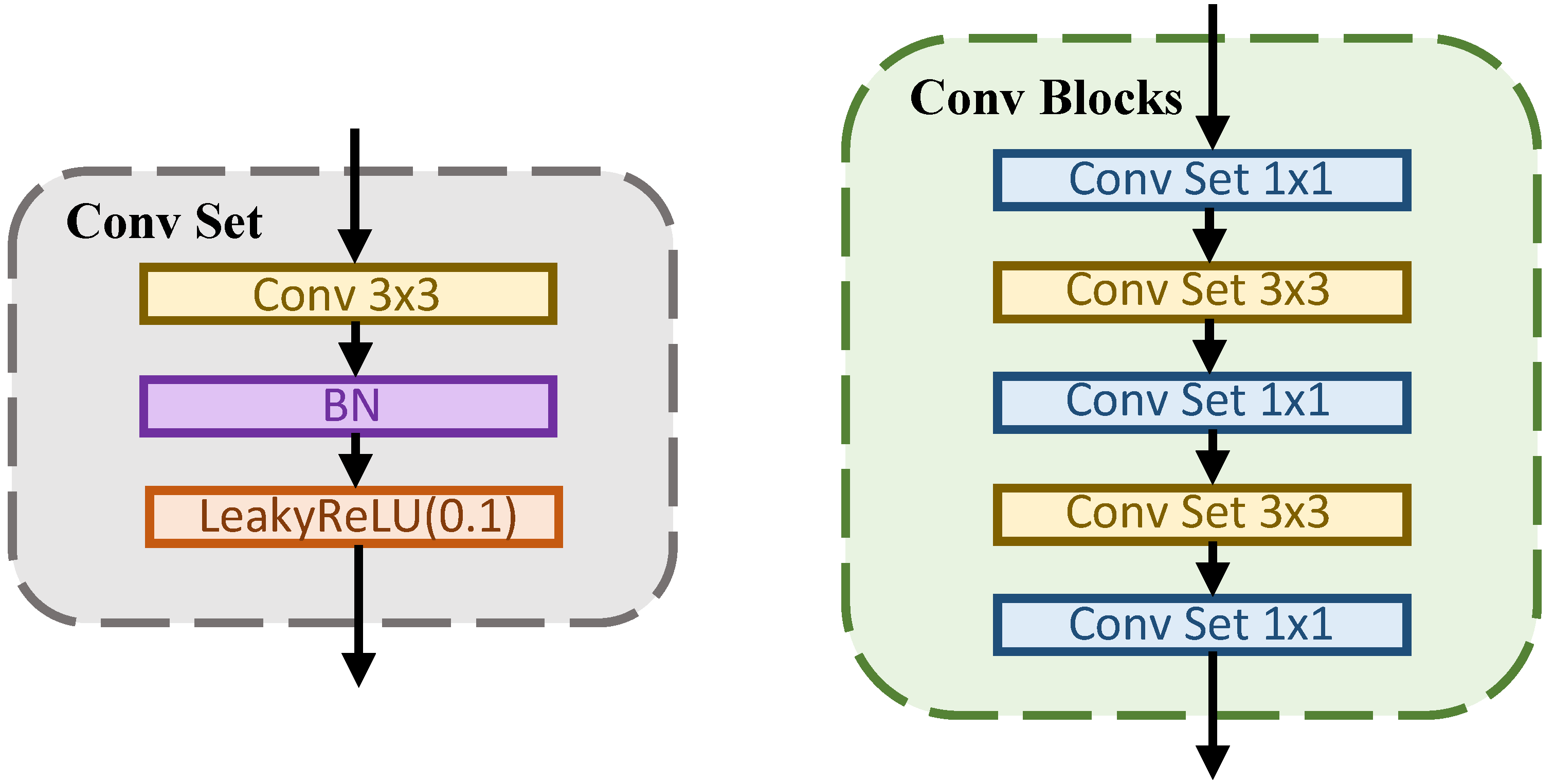
3.3. Implementation Detail
3.3.1. Network Structure
3.3.2. Loss Function
4. Experiments
4.1. Datasets
4.2. Experiment Setting
4.3. Comparison Methods
4.4. Results on Pascal VOC Datasets
4.4.1. Objective Results
4.4.2. Visual Comparison
4.5. Ablation Study
4.5.1. Effectiveness of Feature Aggravation and CSAM Attention Guidance
4.5.2. Influence of Different Number Feature Maps on AFFN
4.6. Application on Helmet Detection
4.6.1. Visual Comparison
4.6.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hurtik, P.; Molek, V.; Hula, J.; Vajgl, M.; Vlasanek, P.; Nejezchleba, T. Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3. Neural Comput. Appl. 2022, 27, 1–16. [Google Scholar] [CrossRef]
- OMOYİ, C.; OMOTEHİNSE, A. A Factorial Analysis of Industrial Safety. Int. J. Eng. Innov. Res. 2022, 4, 33–43. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2359–2368. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Wu, Y.H.; Liu, Y.; Xu, J.; Bian, J.W.; Gu, Y.C.; Cheng, M.M. MobileSal: Extremely efficient RGB-D salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Z.; Lin, Z.; Xu, J.; Jin, W.D.; Lu, S.P.; Fan, D.P. Bilateral attention network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 1949–1961. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4003–4012. [Google Scholar]
- Xu, G.; Xu, J.; Li, Z.; Wang, L.; Sun, X.; Cheng, M.M. Temporal modulation network for controllable space-time video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual. 19–25 June 2021; pp. 6388–6397. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 11863–11874. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 528–537. [Google Scholar]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. Couplenet: Coupling global structure with local parts for object detection. In Proceedings of the IEEE International Conference on COMPUTER Vision, Venice, Italy, 22–29 October 2017; pp. 4126–4134. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | BackBone | Test Images Size | Test Set | mAP@0.5 |
|---|---|---|---|---|
| Faster-RCNN [5] | VGG16 | 1000 × 1000 | VOC 2007 | 73.2 |
| Faster-RCNN [6] | ResNet101 | 1000 × 1000 | VOC 2007 | 76.4 |
| SSD [30] | VGG16 | 300 × 300 | VOC 2007 | 77.1 |
| DSSD [31] | ResNet-101 | 513 × 513 | VOC 2007 | 81.5 |
| STDN [32] | DenseNet-169 | 513 × 513 | VOC 2007 | 80.9 |
| RFBNet [34] | VGG-16 | 512 × 512 | VOC 2007 | 82.2 |
| CoupleNet [33] | ResNet-101 | 1000 × 1000 | VOC 2007 | 82.7 |
| YOLOv3 [4] | DarkNet-53 | 544 × 544 | VOC 2007 | 79.3 |
| YOLOv3 (Our) | DarkNet-53 | 544 × 544 | VOC 2007 | 84.3 |
| AFFN (Our) | DarkNet-53 | 544 × 544 | VOC 2007 | 85.3 |
| Backbone | Variant | Candidate | VOC2007test | ||
|---|---|---|---|---|---|
| FA | CSAM | mAP@0.5 | mAP@0.75 | ||
| DarkNet53 | A | 83.8 | 42.2 | ||
| B | √ | 84.8 | 44.1 | ||
| C | √ | 85.4 | 45 | ||
| D | √ | √ | 85.8 | 45.7 | |
| Number of Feature Maps | mAP@0.5 | mAP@0.75 |
|---|---|---|
| +2 | 83.93 | 43.08 |
| +3 | 85.80 | 45.70 |
| +4 | 83.88 | 43.05 |
| Algorithm | Backbone | Test Images Size | Test Set | mAP@0.5 |
|---|---|---|---|---|
| YOLOv3 | DarkNet-53 | 544 × 544 | Helmet test set | 61.5 |
| AFFN | DarkNet-53 | 544 × 544 | Helmet test set | 62.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Fan, Y.; Xu, S.; Gao, Y.; Gao, R. Object Detection by Attention-Guided Feature Fusion Network. Symmetry 2022, 14, 887. https://doi.org/10.3390/sym14050887
Shi Y, Fan Y, Xu S, Gao Y, Gao R. Object Detection by Attention-Guided Feature Fusion Network. Symmetry. 2022; 14(5):887. https://doi.org/10.3390/sym14050887
Chicago/Turabian StyleShi, Yuxuan, Yue Fan, Siqi Xu, Yue Gao, and Ran Gao. 2022. "Object Detection by Attention-Guided Feature Fusion Network" Symmetry 14, no. 5: 887. https://doi.org/10.3390/sym14050887
APA StyleShi, Y., Fan, Y., Xu, S., Gao, Y., & Gao, R. (2022). Object Detection by Attention-Guided Feature Fusion Network. Symmetry, 14(5), 887. https://doi.org/10.3390/sym14050887