1. Introduction
At present, bearings are an essential component of machine manufacturing equipment. The good or bad running conditions of bearings directly affects the operation of the equipment. However, complex real environments, including abnormal humidity, temperatures and current magnitudes, cause different degrees of damage to the bearings, resulting in the occurrence of faults. This produces high maintenance costs as well as delays of production progress to the factory and even threatens the personal safety of personnel. Therefore, the safety of bearings has become a crucial concern. The research on the bearing fault diagnosis algorithm is of great significance to the safety of equipment [
1,
2].
Thus far, the traditional bearing fault diagnosis technology is to manually analyze the vibration signal obtained by the accelerometer [
3]. The corresponding methods are used to extract the characteristic information from the vibration signal, which mainly include fast Fourier transform (FFT) [
4], wavelet transformation (WT) [
5], empirical mode decomposition (EMD) [
6], short-time Fourier transform (STFT) [
7] and Wigner–Ville distribution (WVD) [
8]. Furthermore, the advent of Hilbert transformation (HT) [
9] made it possible to diagnose transient bearing faults. These methods have been shown to be effective in practice. In recent years, machine learning has been utilized in the study of bearing fault diagnosis.
The main methods are artificial neural networks (ANN) [
10], principal component analysis (PCA) [
11], K-Nearest Neighbors (K-NN) [
12] and support vector machines (SVM) [
13]. Machine learning as a branch of artificial intelligence is widely used in various fields. The use of machine learning has taught computers how to process data efficiently compared to traditional methods. The computer can find more subtle features to analyze, which improves the accuracy and intelligence of bearing fault diagnosis. However, with the rapid changes of current technology, the amount and types of data have also ushered in rapid growth. Feature selection, which we need to rely on experts to perform, becomes time-consuming and laborious. Deep learning not only has better accuracy and processing speed but also can solve problems end-to-end. Therefore, deep learning is gradually being widely adopted.
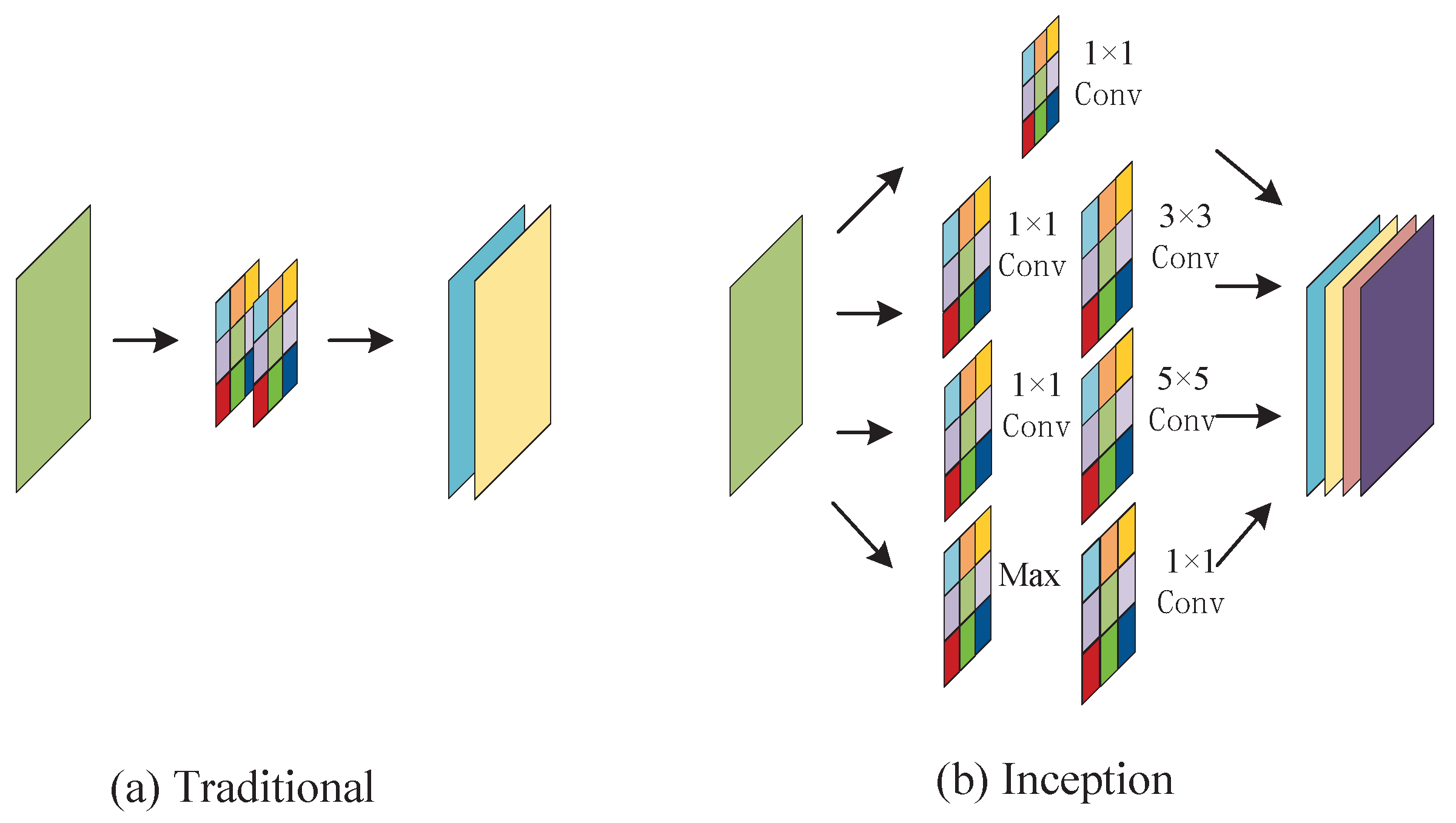
Deep learning has made great breakthroughs in the fields of computer vision, natural language and data mining. Typical methods, such as convolutional neural networks (CNN) [
14,
15], Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) [
16] and Generative Adversarial Networks (GAN) [
17], have obvious effects in dealing with problems in these fields. These methods simplify the step of feature extraction at the same time. Furthermore, deep learning has good application prospects in the field of bearing faults. Compared with the traditional diagnosis methods, the deep-learning method realizes the automatic extraction of features and has a good effect on the accuracy of diagnosis.
A fault diagnosis method based on CNN multi-sensor fusion was proposed in the literature [
18]. An automatic recognition architecture for rolling bearing fault diagnosis based on reinforcement learning was also proposed in the literature [
19]. With the use of real-life scenarios, the problem of insufficient training samples has been noticed and studied. In recent years, excellent progress has been made in the study of neural networks based on small samples [
20,
21]. Fang, Q. et al., proposed a denoised fault diagnosis algorithm with small samples that can solve the problem of bearing fault diagnosis under small samples [
22].
However, a model with complex structures often requires a large number of parameters. This leads to a higher level of operational equipment. Too many parameters make it far from practical in real world scenarios. Furthermore, this may also affect the computational speed. Hence, controlling the number of model parameters is extremely important in practical applications. Fang, H. et al. proposed a lightweight fault diagnosis model that can solve the problem of too many model parameters [
23]. However, it cannot perform fault diagnosis when there are insufficient samples. This shows that the recently proposed models are unable to achieve a better trade-off between accuracy and lightweight [
24,
25].
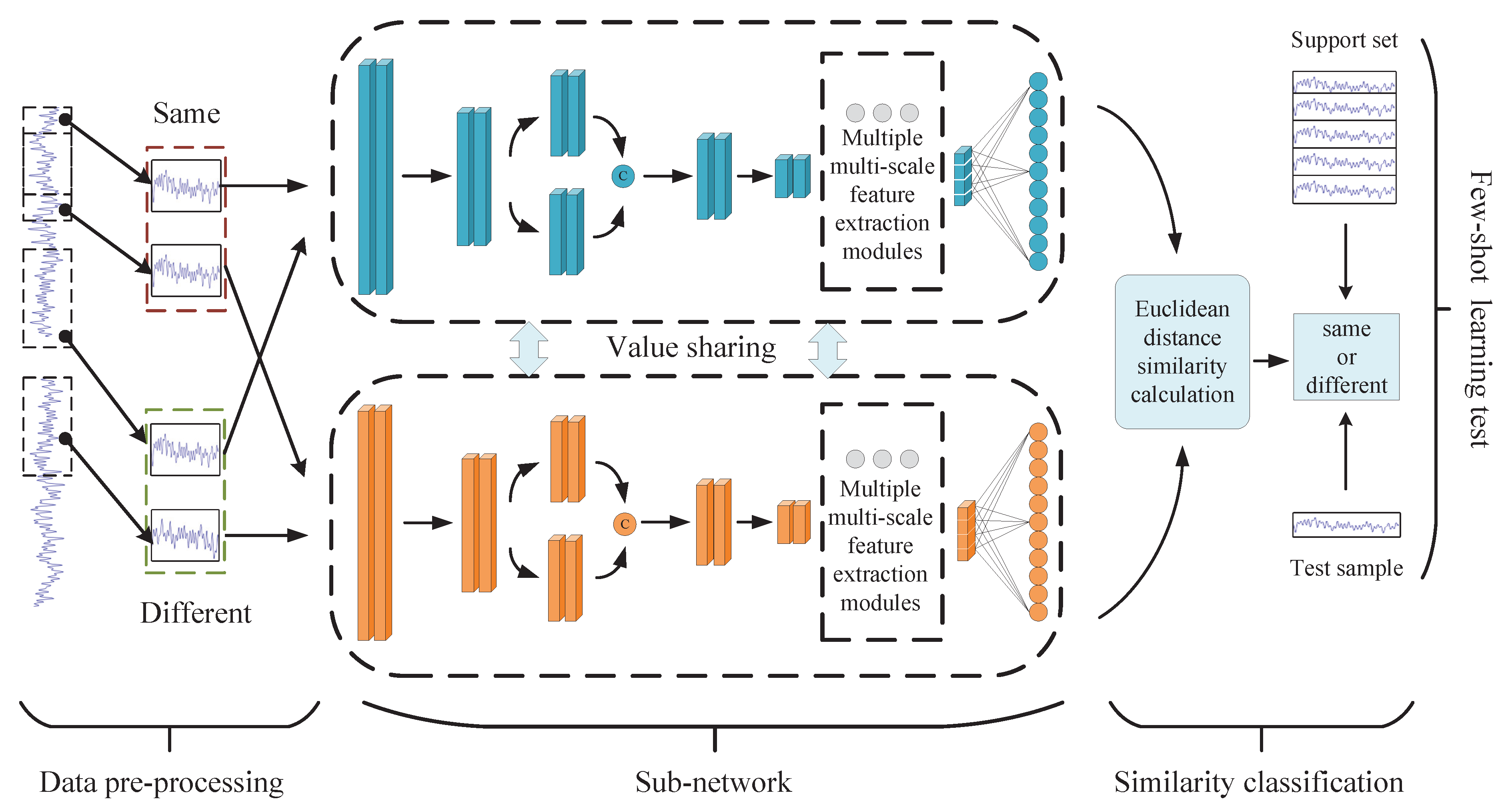
To overcome the problems of few samples and a huge amount of parameters, an end-to-end multi-scale and lightweight Siamese network with symmetrical architecture (MLS-net) is proposed in this paper. MLS-net not only maintains good accuracy in bearing fault diagnosis under small samples but also has fewer parameters to reduce resource consumption and a good generalization ability. The main contributions are summarized below.
We construct a novel fault diagnosis network architecture by combining an improved Siamese network and few-shot learning for the case of small samples.
A multi-scale feature extraction module is designed to improve the feature extraction capability of the model. Furthermore, we use the dimensionality reduction method to compress the parameters of the model to conserve device resources.
Extensive experiments are conducted on multiple datasets to demonstrate the efficiency and generalization of the proposed architecture.
The rest of the paper is organized as follows:
Section 2 introduces the mentioned basic theory.
Section 3 describes the proposed network structure.
Section 4 presents the details and results of the experiments.
Section 5 concludes the paper.
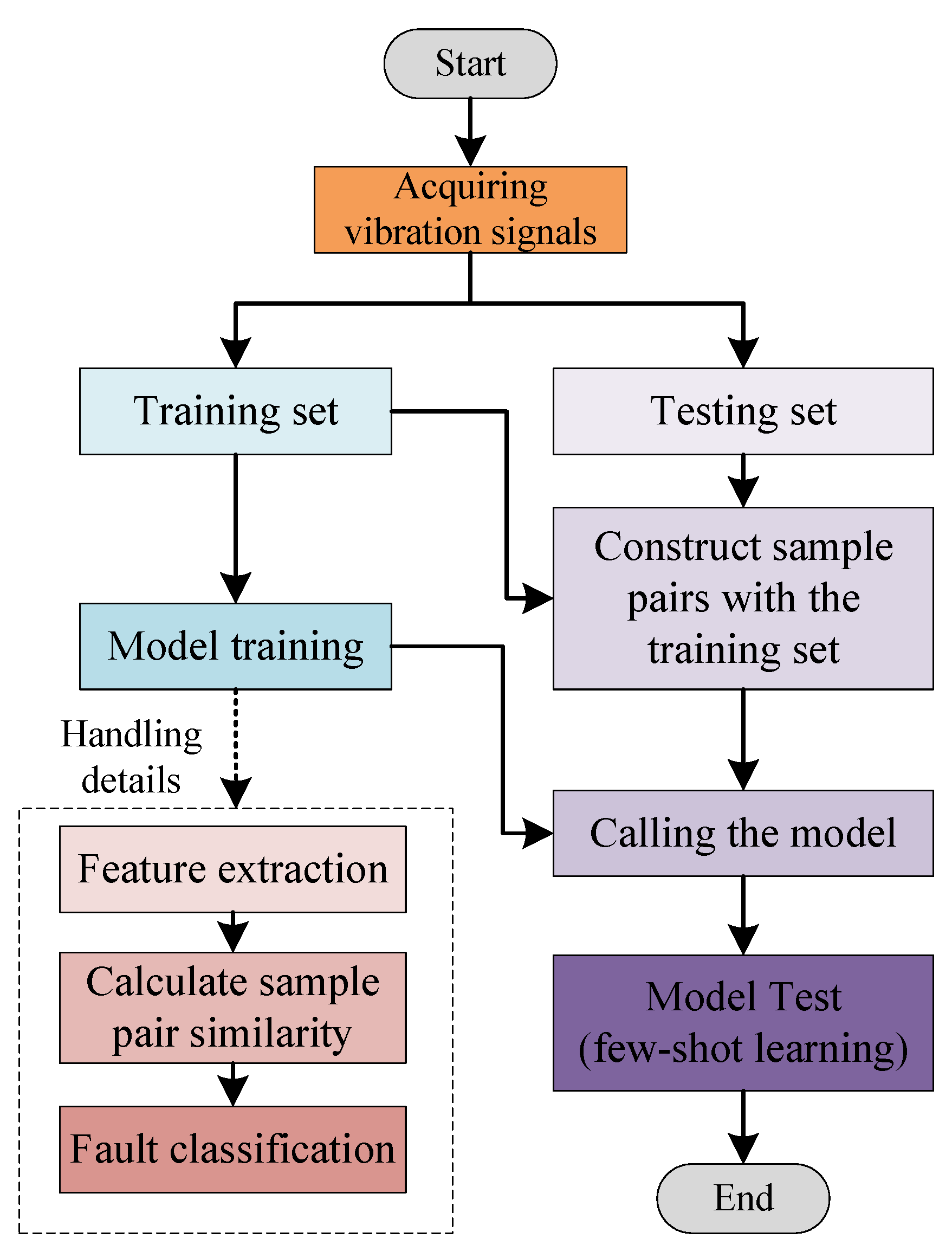
4. Experimentation and Analysis
4.1. Data Set Preparation
We must understand the performance of the proposed network structure in the case of insufficient samples. Three datasets are used for validation in this experiment. They are the Case Western Reserve University (CWRU) bearing fault dataset [
30], Mechanical fault Prevention Technology Institute (MFPT) bearing fault dataset [
31] and Laboratory simulated bearing fault dataset.
(1) CWRU bearing fault dataset
For this experiment, the 12 kHz bearing fault on the drive side from the Case Western Reserve University bearing dataset is used as the experimental data. The fault types are divided into four categories: normal, ball fault, inner ring fault and outer ring fault. Each fault, in turn, contains three fault categories of 0.007, 0.014 and 0.021 inch dimensions; therefore, the total number of fault categories is 10. The specific classification is in
Table 1.
(2) MFPT bearing fault dataset
The MFPT dataset is provided by the Mechanical Prevention Technology Association. The dataset contains data from the experimental bench and three real-world fault data. Fault types are divided into three categories: baseline conditions, outer race fault conditions and inner race fault conditions. The sampling frequency of the data set is 25 Hz. We selected seven types of data from MFPT to construct the experimental dataset. The fault types are classified into three categories: normal, outer ring fault and inner ring fault. Each fault class data is selected with load conditions of 50, 200 and 300 lbs. The total number of classes of the fault categories in the experimental dataset is seven. The specific classification is in
Table 2.
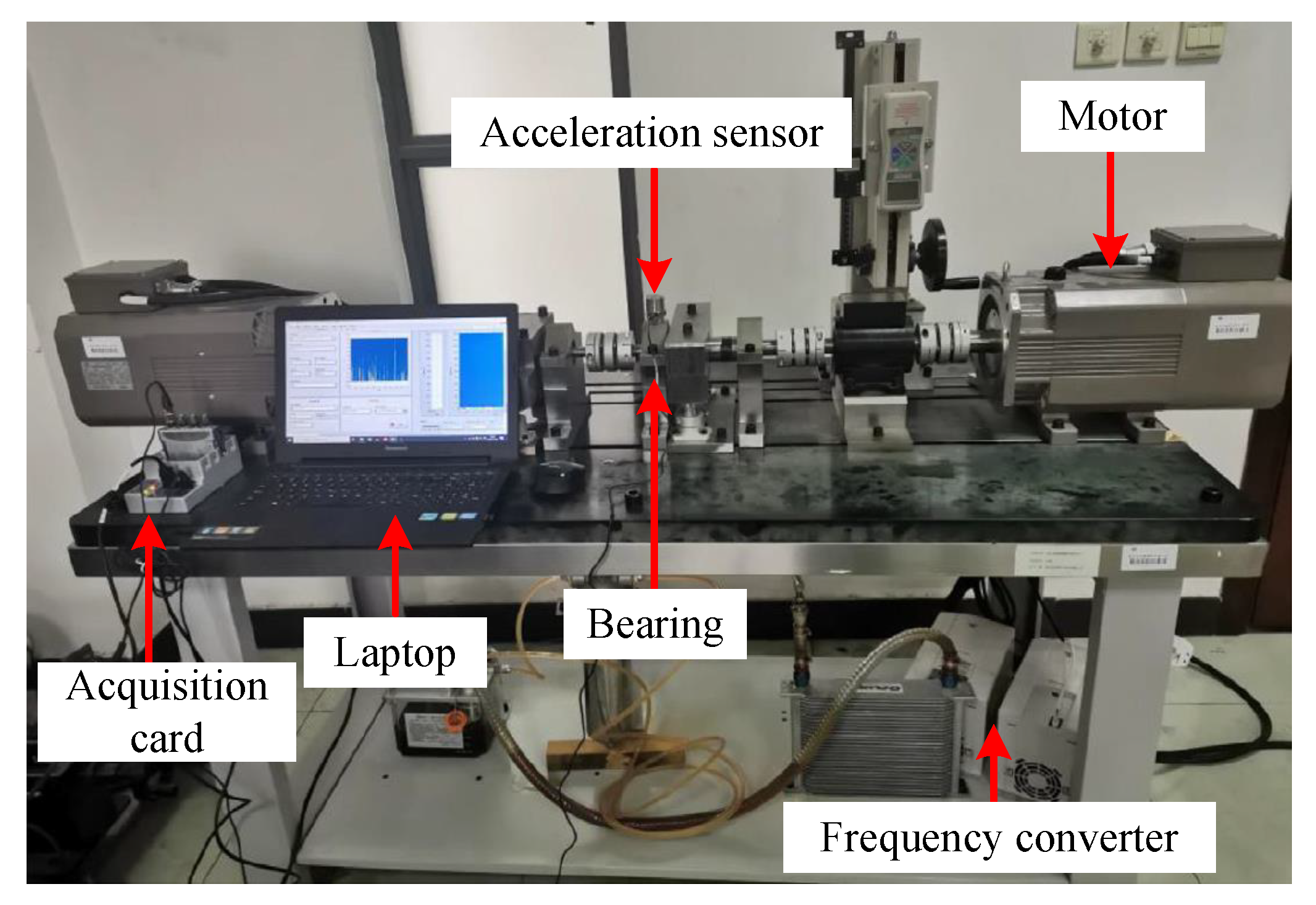
(3) Laboratory bearing fault dataset
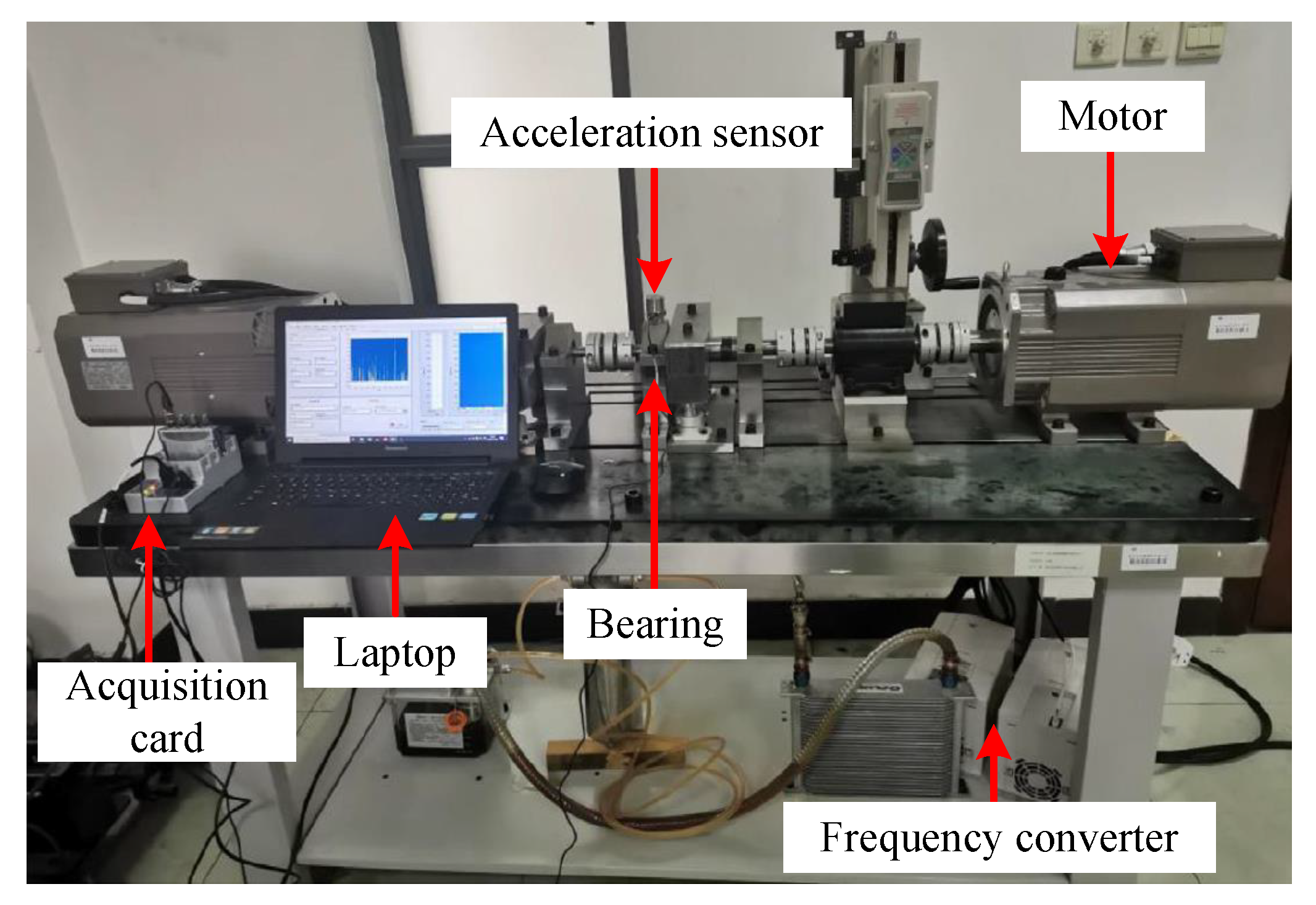
The main structure of the test bench is shown in the diagram below. The components are the following: accelerometer, bearings, motors, acquisition cards, frequency converter and external computers and other key devices. The positions of the individual devices are marked in
Figure 5. The entire experimental equipment is rotated by motors driving the bearing parts. The accelerometers collect the vibration signal in real time. The vibration signal is then transferred to the computer for storage and analysis by means of an acquisition card.
The experiments conducted in this case are set up for three fault situations. The faults are outer race fault, inner race fault and ball fault. All three faults are set as scratch faults. Three faults are set to penetrate in the axial. The width of the fault is 1.2 mm, and the depth is 0.5 mm. All three faults are tested twice at 1800 and 3000 r/min, respectively. Therefore, all fault categories are divided into six categories. Details of the corresponding health conditions are shown in the following
Table 3.
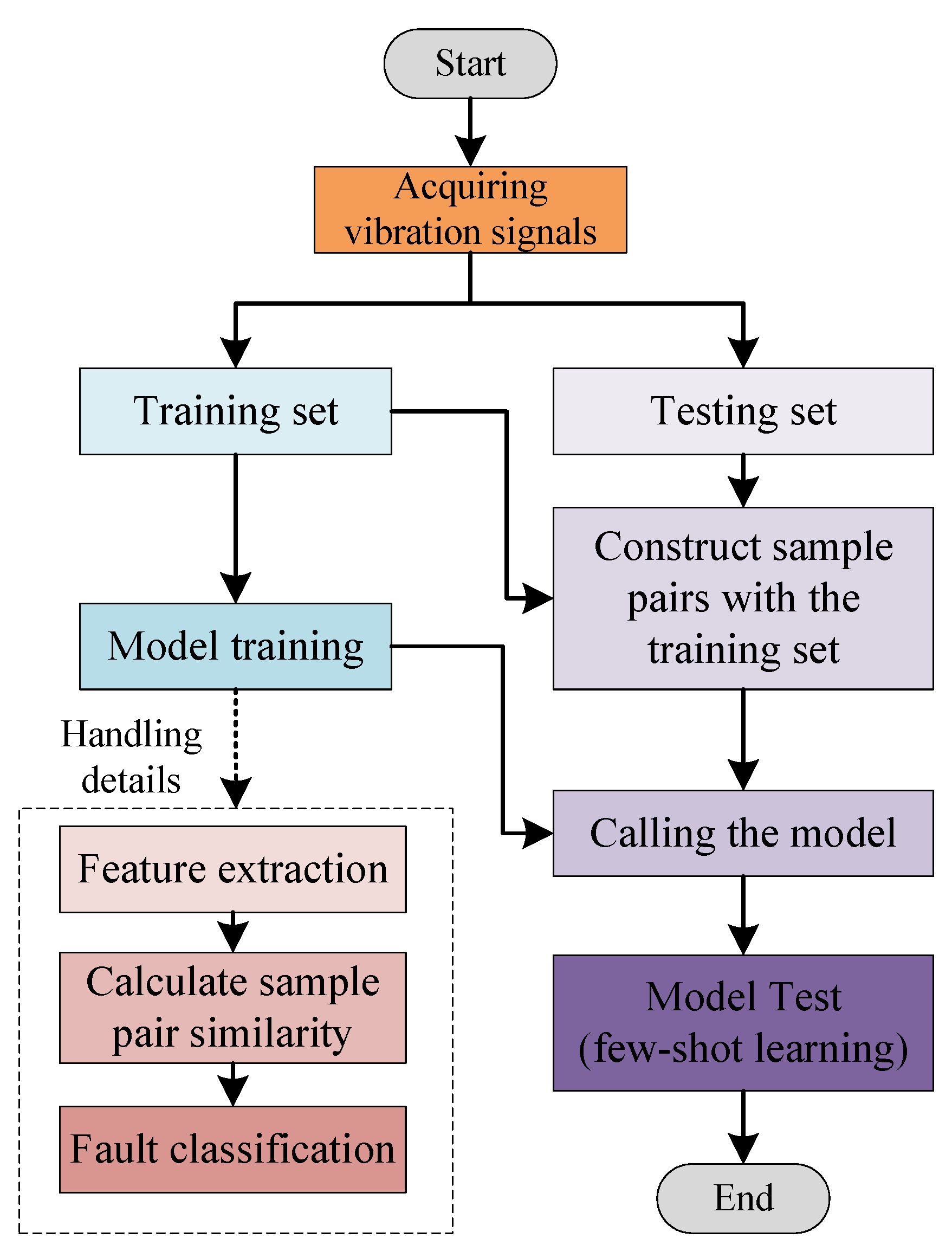
Each type of fault data is a vibration signal collected by an accelerometer. To ensure consistent conditions with the comparison schemes, the dataset is constructed based on the method in [
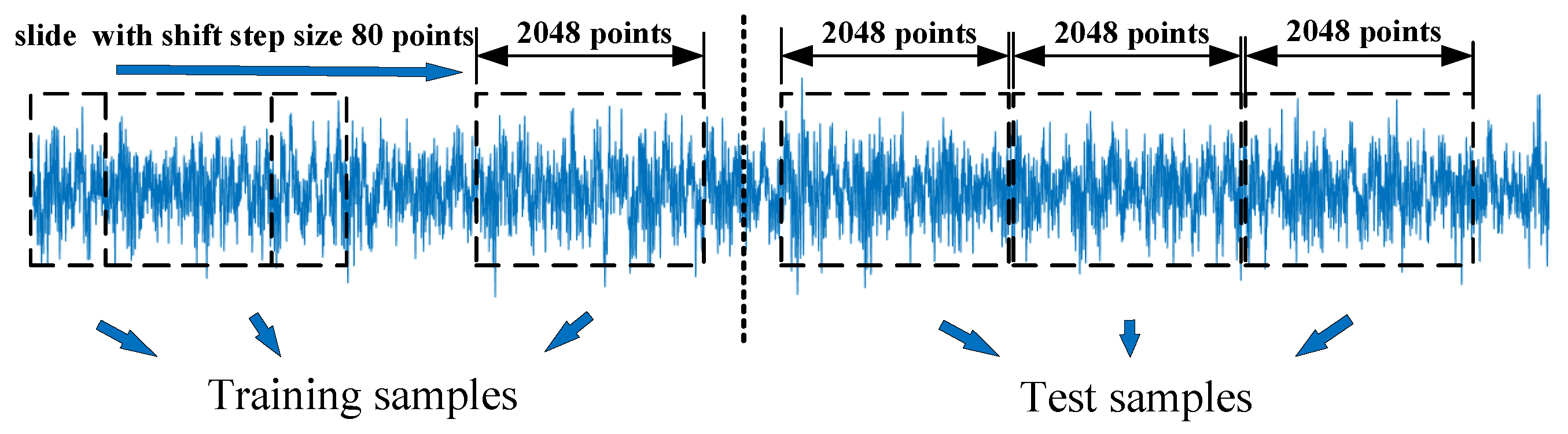
29]. The detailed schematic diagram for building the training and test sets is shown in
Figure 6. We build the training set from the first half of the vibration signal and the test set from the second. Each training sample is 2048 points in length. We use a sliding window with a step size of 80 to intercept the training samples sequentially backwards. The data intercepted by the sliding window is the training set. The second half of the vibration signal is divided into multiple non-overlapping test samples, and each test sample also contains 2048 points.
4.2. Experimental Setup
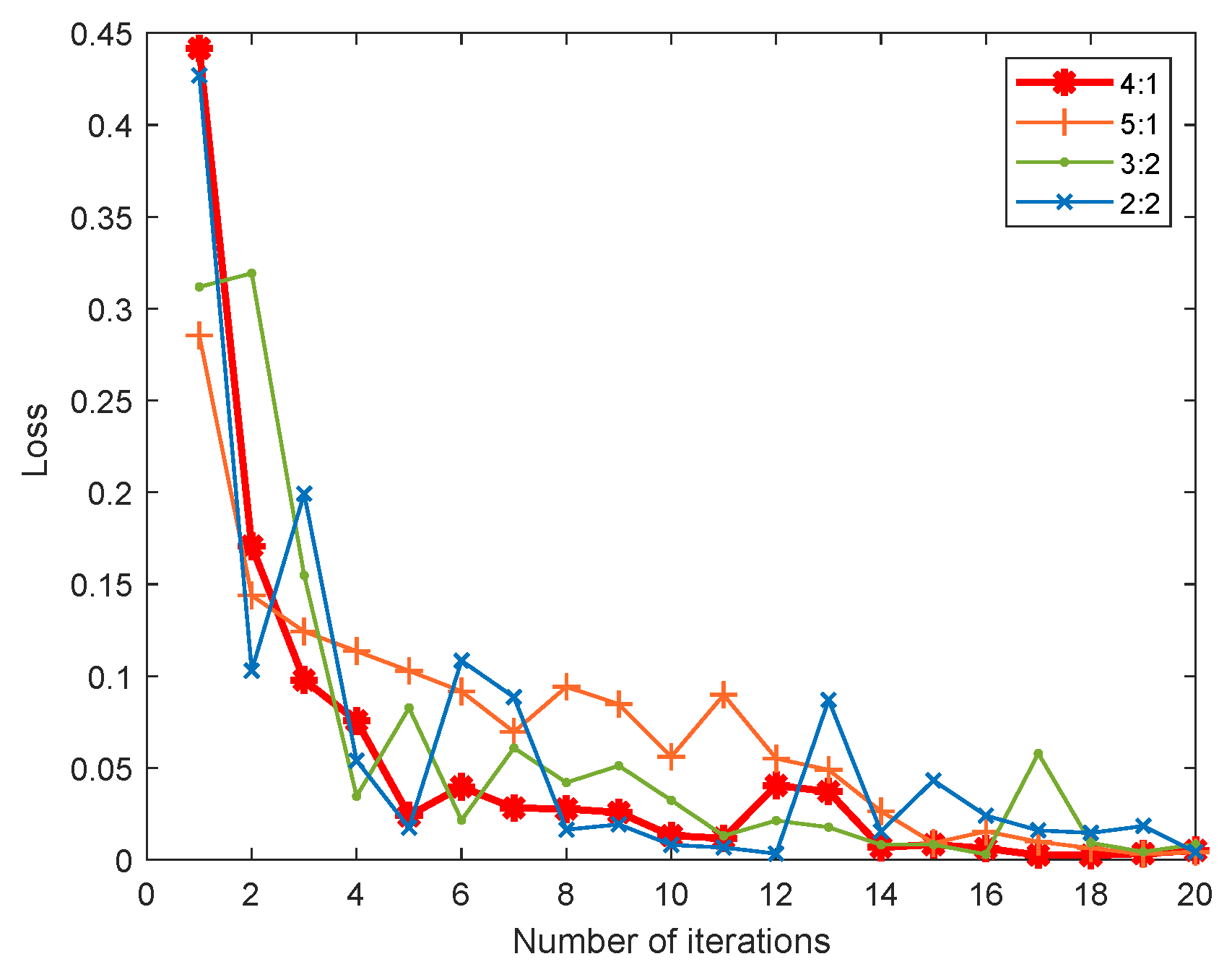
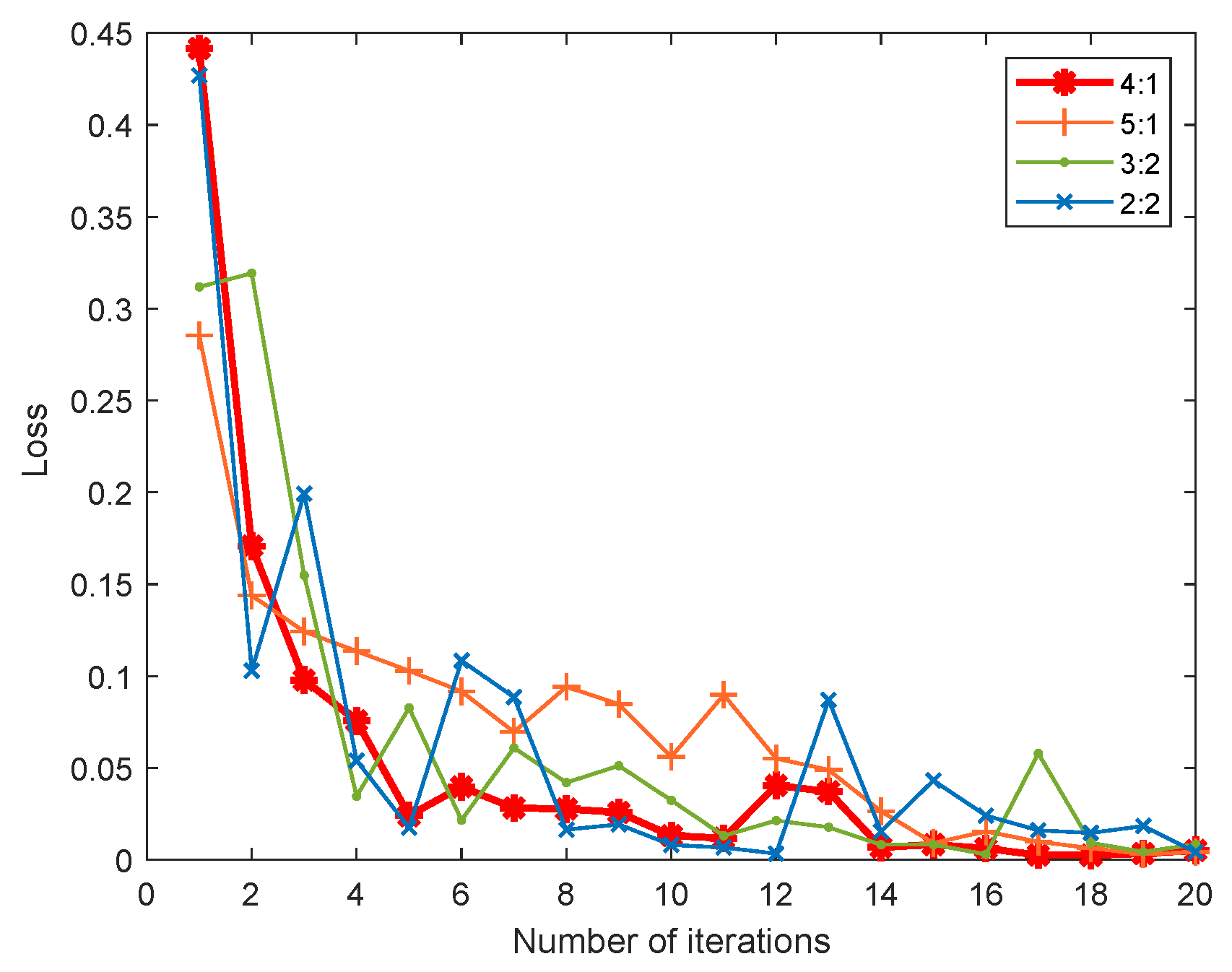
The training samples are divided into the training set and validation set. By comparing the loss rate under different ratios in
Figure 7, the ratio of the training set and validation set is configured to be 4:1 for better convergence performance. In addition, the model is implemented using the Keras library and Python 3.6. The total epoch of model training is 15,000, and the small batch size is 32. The optimal model is saved after 20 training sessions have been conducted in the experiment.
To validate the performance of the models obtained by training under different samples, the quantities 60, 90, 120, 200, 300, 600 and 900 are randomly selected on the CWRU and Laboratory datasets. The number of fault types selected in MFPT is seven. For the sake of balance of the training data, we randomly select the quantities 70, 105, 140, 210, 280, 490 and 700.
The sample pairs we input each time are randomly selected from the above training set. When they belong to the same class, they are labeled as positive samples; otherwise, they are negative samples. We also need to ensure that the number of positive and negative sample pairs is equal to ensure a balanced sample.
In Experiment 1, we vary the number of multi-scale modules in the model to determine the optimal model structure. In Experiment 2, we test the model on three datasets to verify the performance of MLS-net. In Experiment 3, we visualize the model performance using visualization tools. In Experiment 4, we calculate the model size and parameters.
The following three methods will be tested on the three datasets to compare with the new proposed model.
4.3. Determination of the Number of Multi-Size Modules
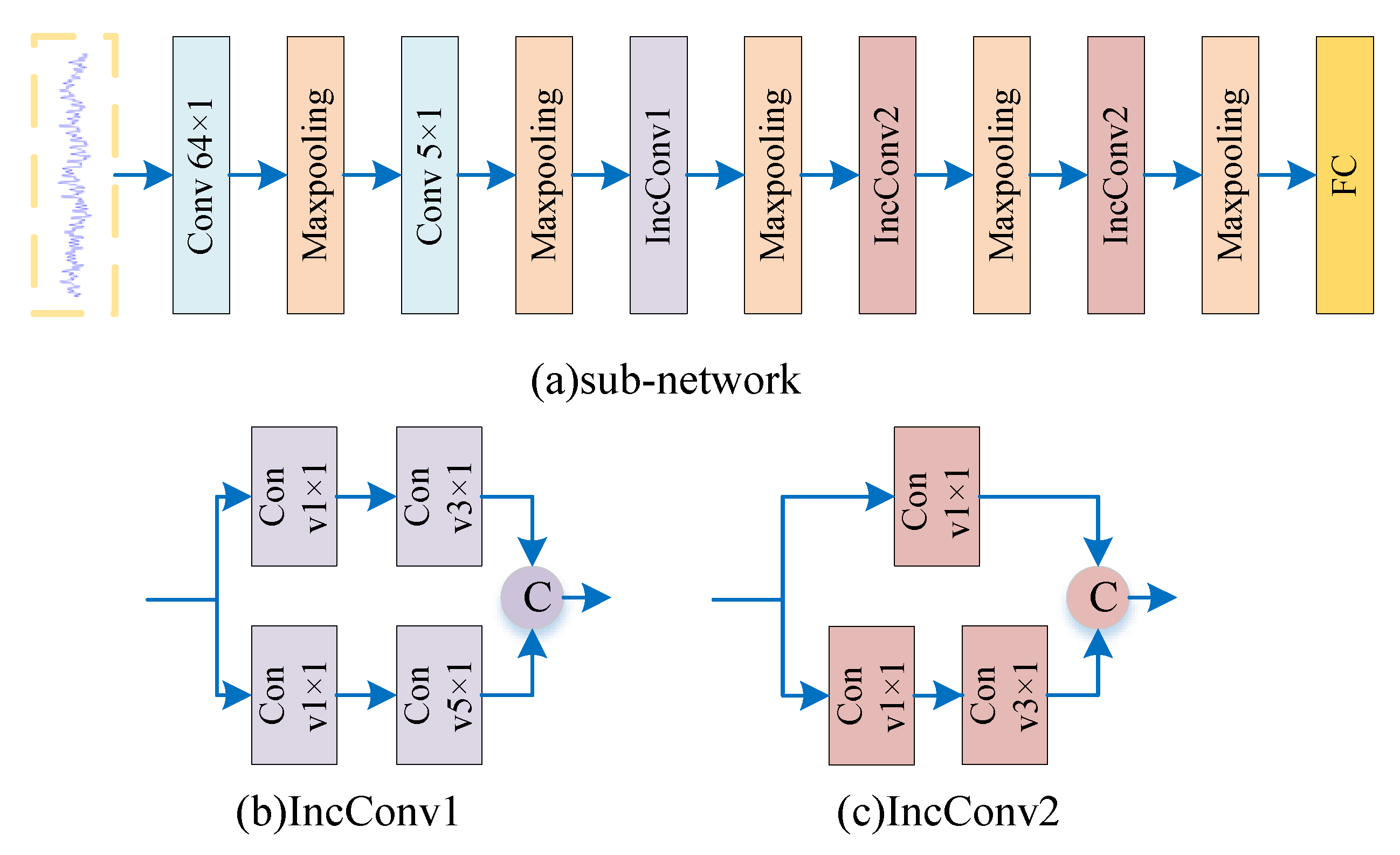
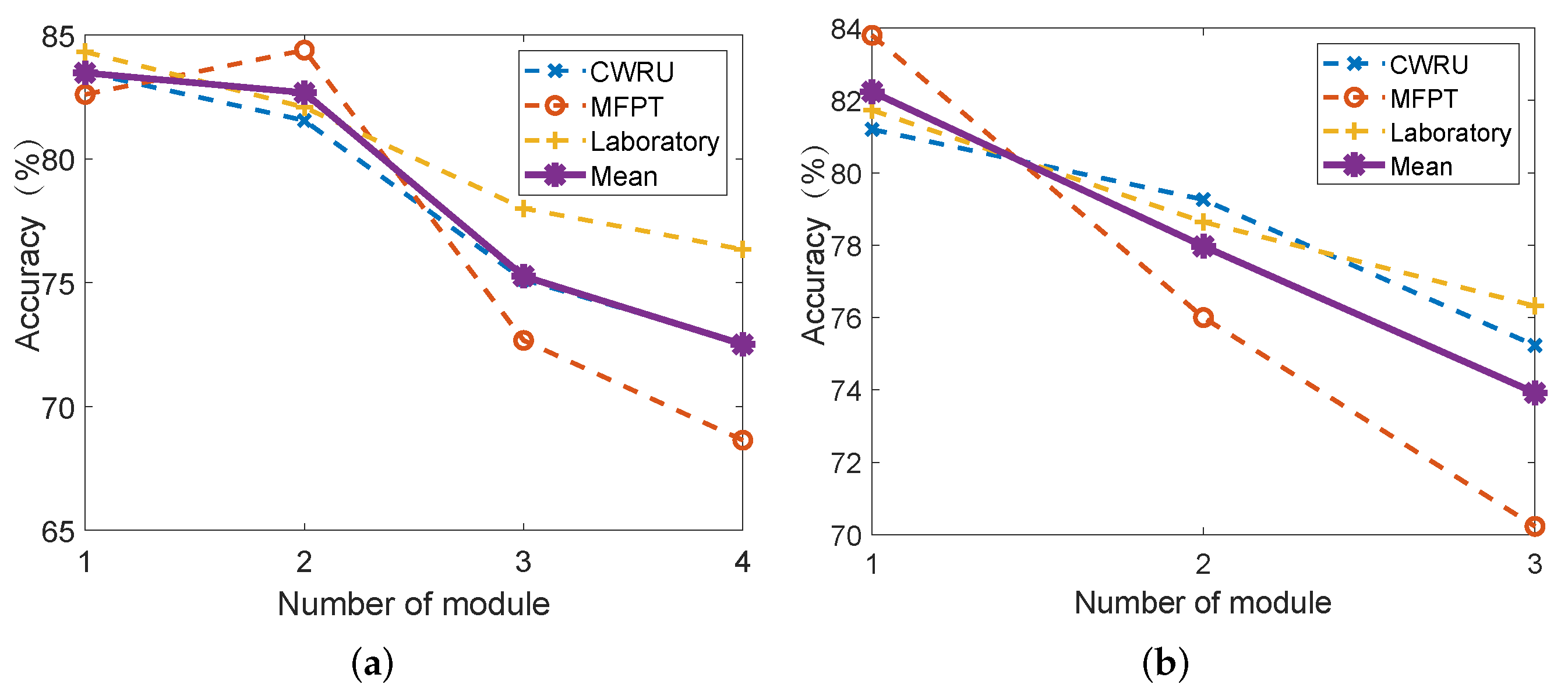
We want to determine the optimal number of multi-size modules in the model. The multi-size modules are divided into two categories by the introduction of the sub-network. The larger size is a fusion of 5 × 5 and 3 × 3, which we call IncConv1. The smaller size is a fusion of 3 × 3 and 1 × 1, which we call IncConv2. Under the premise that the sample size is set to 60, we will vary the number of these two modules to determine the optimal number of modules.
The comparison between
Table 4 and
Table 5 shows that the trend of the accuracy of the model decreases as the number of the IncConv1 increases. This shows that the number of modules for IncConv1 should be 1.
Figure 8a,b shows the variation of accuracy on each data set and the mean of the three types of data. The mean lines in both plots show that, as the number of modules increases, the accuracy rate decreases. However, our previous analysis shows that the number of IncConv1 should be 1.
Therefore, we only need to observe
Table 4 to determine the number of IncConv2. We find that the accuracy rate decreases as the number of modules increases.The accuracy of the models is similar at number 1 and 2; however, the total number of parameters is different. To balance the accuracy and the total number of parameters, we finally decided to set the number of IncConv2 to 2.
4.4. Model Effects with Different Sample Sizes
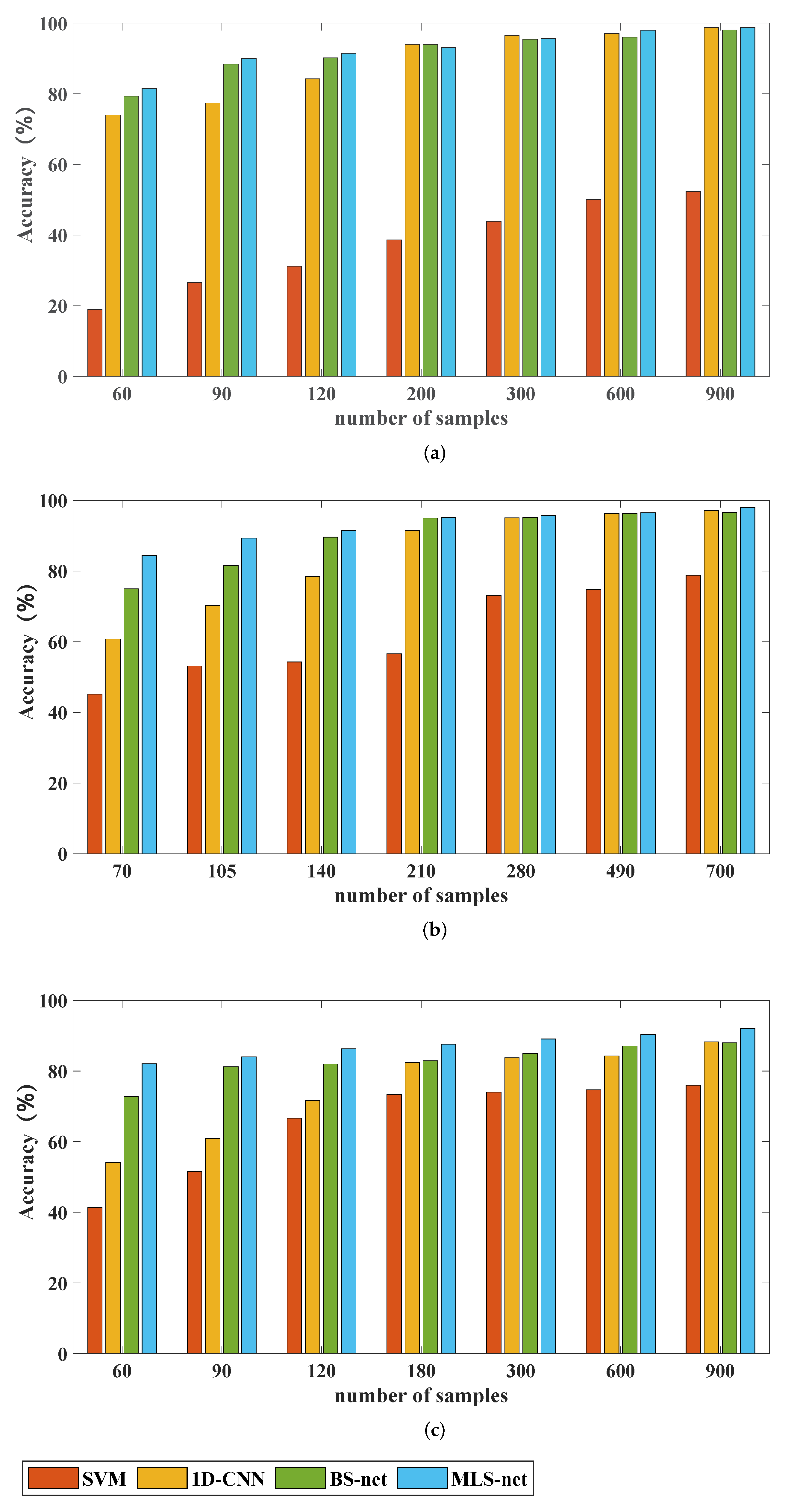
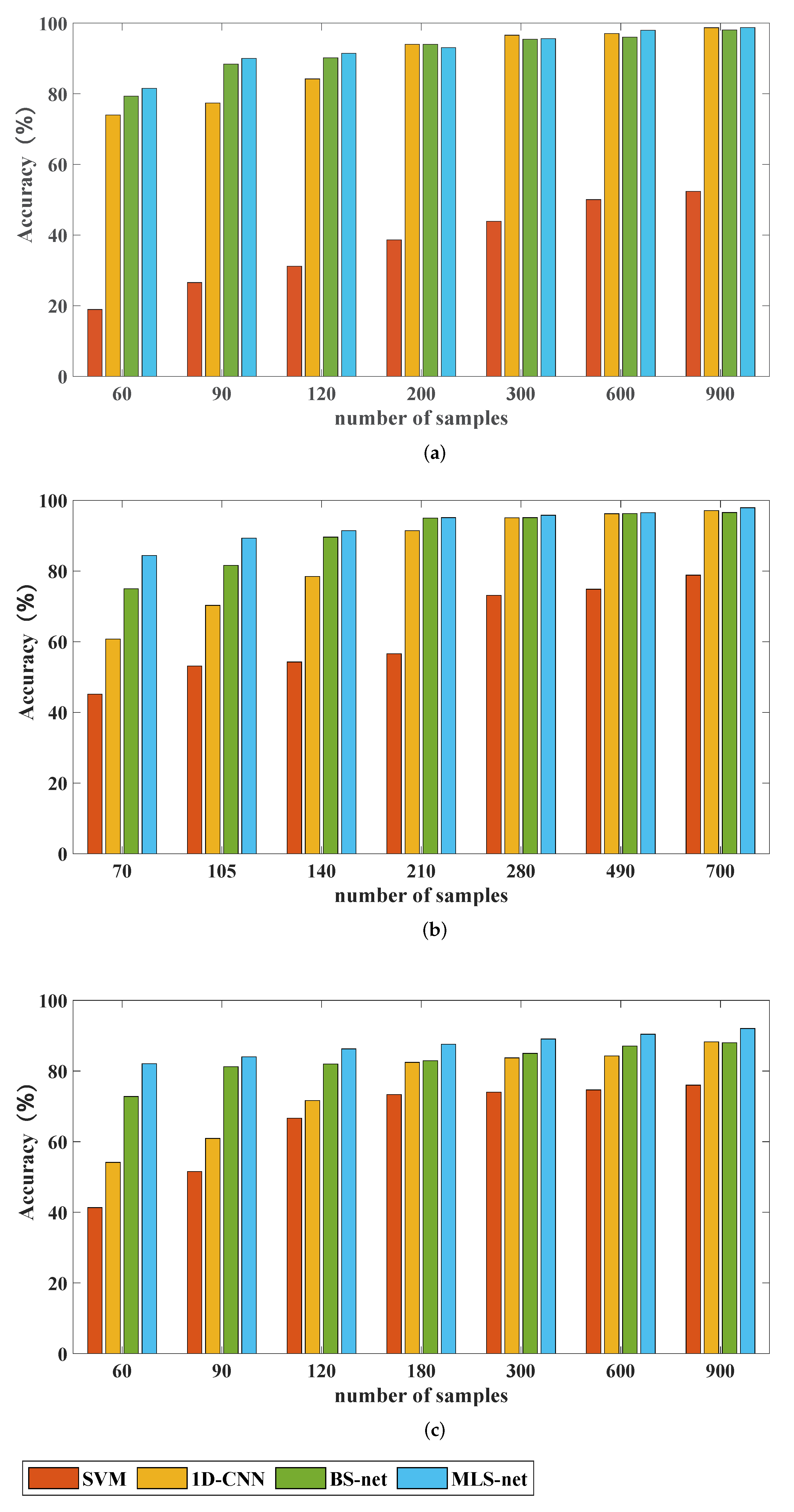
In this section, we want to verify that the proposed method performs well in the case of insufficient samples. We chose the methods described above: (SVM), 1D-CNN, BS-net and MLS-net for performance comparison. Several models are tested on three bearing fault datasets.
Table 6 and
Figure 9 show the results of the experiments.
It is clear that the MLS-net shows the most excellent results. We analyze the results of each dataset and see that the SVM method has a significant difference in accuracy compared to the other methods. The accuracy of the SVM differs from other methods by nearly 20% or more when the sample is insufficient. There is also a 10% difference in accuracy with a large number of samples. It can be seen that the deep-learning approach is far superior to SVM. Compared with 1D-CNN, the Siamese network model is more complex in structure. The model cleverly uses metrics for similarity calculation and incorporates few-shot learning methods.
This makes the ability of fault classification significantly better than 1D-CNN in the case of small samples. The MLS-net is compared with BS-net by experimental data. When the samples are insufficient, the accuracy of the MLS-net is improved in all cases. It can be seen that the introduced multi-size convolutional module can obtain richer information. With the increase of samples, the accuracy of both tends to be the same. Sometimes the accuracy of the old model is higher than that of the MLS-net. The difference between the two models is within 1%. It can be seen that there is minimal loss of accuracy when the sample is sufficient.
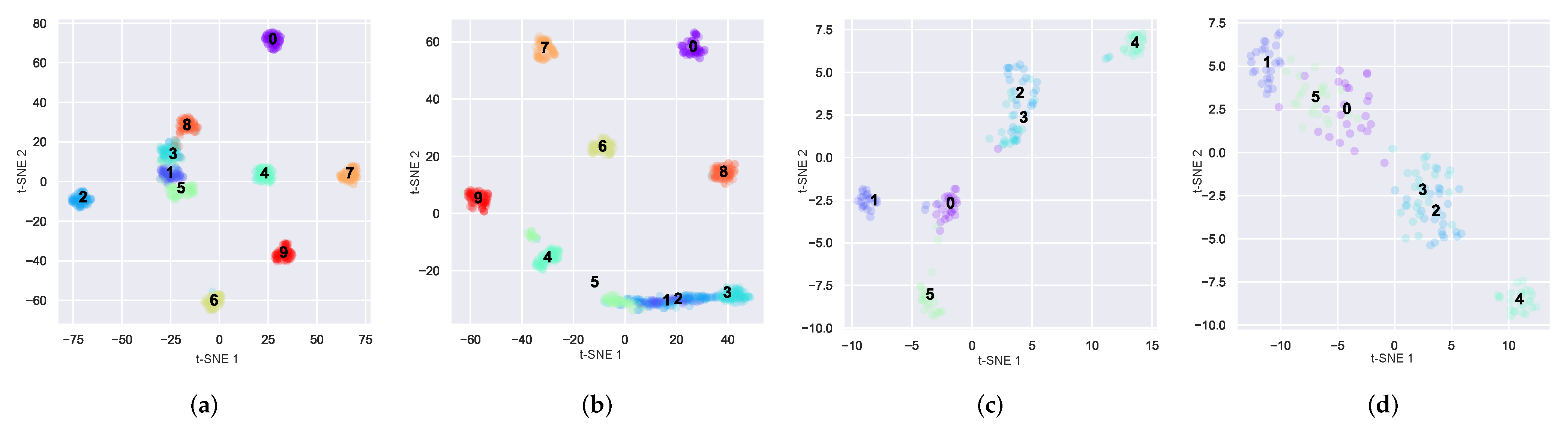
4.5. Visualization Analysis
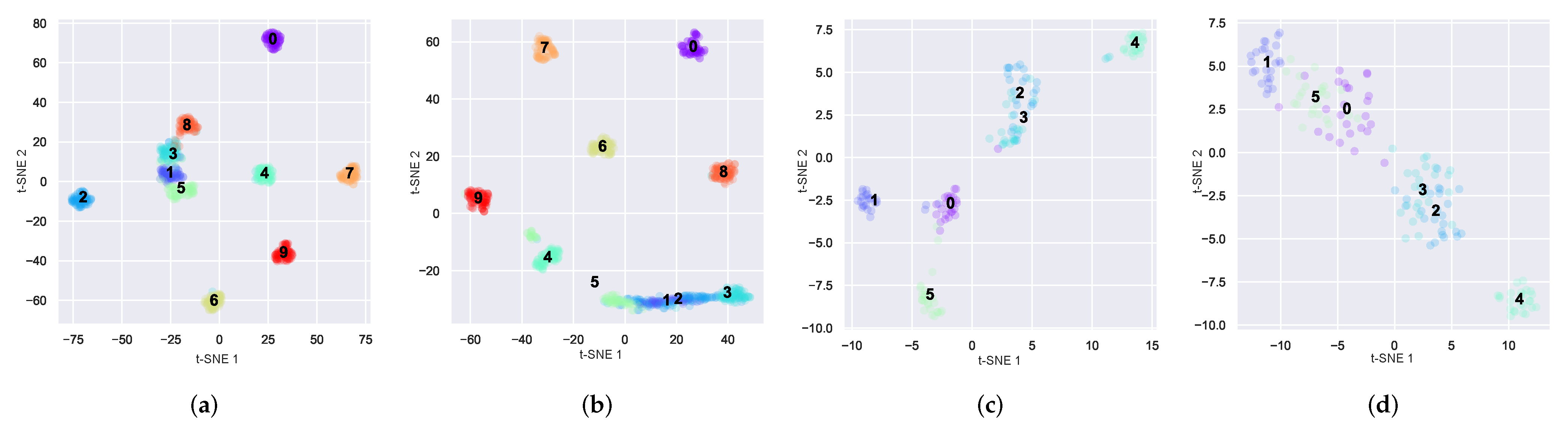
We attempted to obtain a better understanding of how well the model performs in the presence of insufficient samples. We would like to make further proof by using the feature visualization method of t-SNE and the confusion matrix of the test results. In
Figure 10, we show the visualization of the last layer of the fully connected layer on the CWRU dataset and Laboratory dataset. The number of samples for model training is set to 90. In
Figure 11, the confusion matrix plot of the test results on these two datasets is also shown. The comparison methods used in both plots are the BS-net and the MLS-net proposed in this paper.
In
Figure 10, the
Figure 10a,b are of the CWRU dataset.
Figure 10c,d are the Laboratory dataset. As can be seen in the figure on the CWRU dataset, the MLS-net can be clearly seen on categories 1, 2 and 3 with a good distinction. Whereas, on the BS-net it shows that the three categories are mixed together and cannot be clearly distinguished. It can be seen that the BS-net is not as good at classifying as the MLS-net. This problem is more apparent in the Laboratory data set. Multiple classes are mixed together and all data distribution is discrete on the BS-net. This problem is well resolved in the plots of the MLS-net. It can be seen that the MLS-net has a better ability to classify samples with small samples.
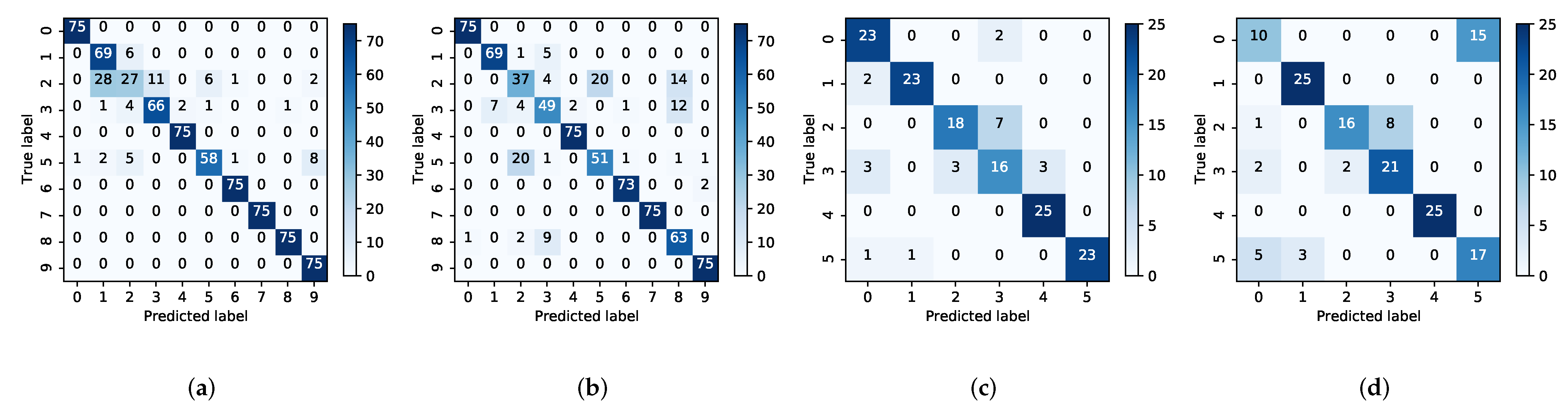
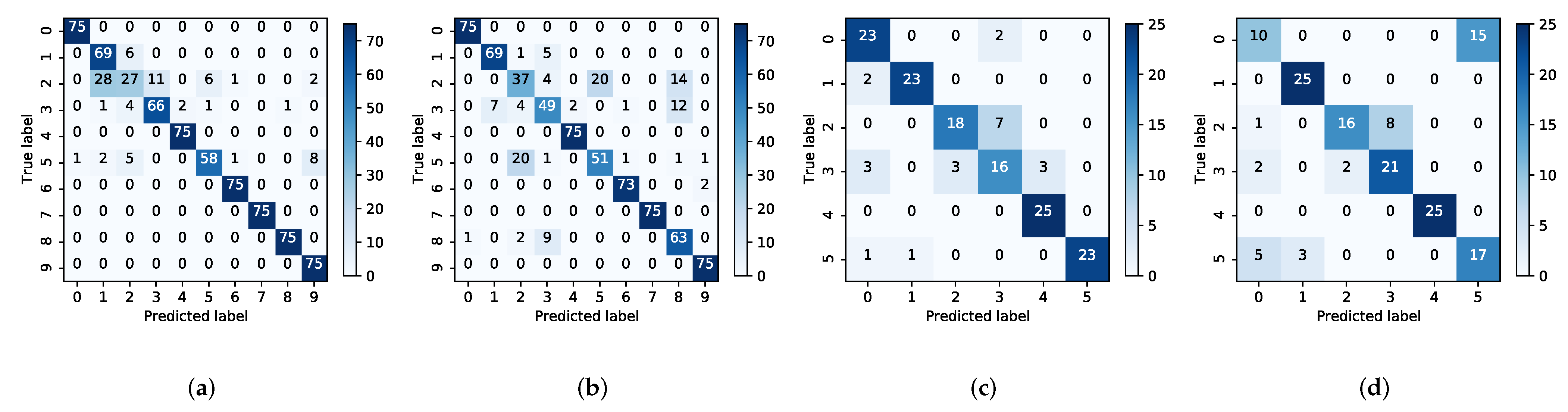
In
Figure 11,
Figure 11a,b are the CWRU bearing dataset and
Figure 11c,d are the Laboratory bearing dataset. As we can see in both
Figure 11a,b, the number of accurate judgements for each category in
Figure 11a is greater. Whereas, in
Figure 11b, it is clear that the accuracy of per category is much lower. In
Figure 11c,d, the comparison of the two models is also the same. This shows that the new model also has a superior performance in prediction compared to the BS-net. At the same time, the performance of the MLS-net is consistent across the different dataset. It means that the MLS-net can be applied to practical bearing fault diagnosis.
4.6. Model Lightweight Comparison
In this subsection, the main purpose is to analyze the comparison of model size under different models and datasets. The results of the experiment mainly contain the total number of model parameters and model sizes for SVM, 1D-CNN, BS-net and MLS-net under the three dataset. The recently proposed bearing fault diagnosis models ANS-net [
22] and LEFE-net [
23] are also compared. We jointly determine the merit of a model based on the parameters and the accuracy rate. A model that has fewer parameters while having the higher accuracy will have superior performance. The system cost and the speed of computation will be greatly increased under fewer parameters. The details are shown in the following
Figure 12 and
Table 7.
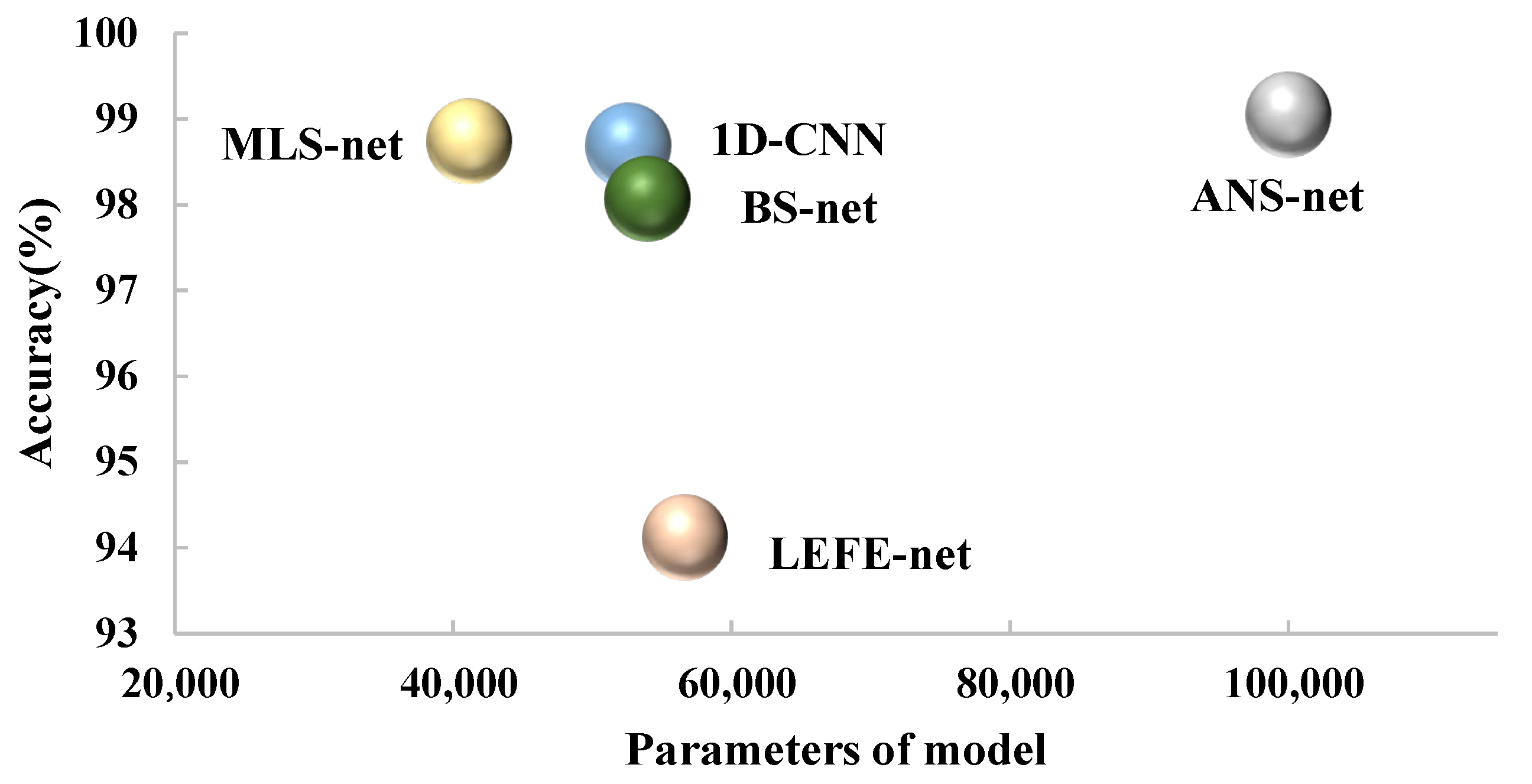
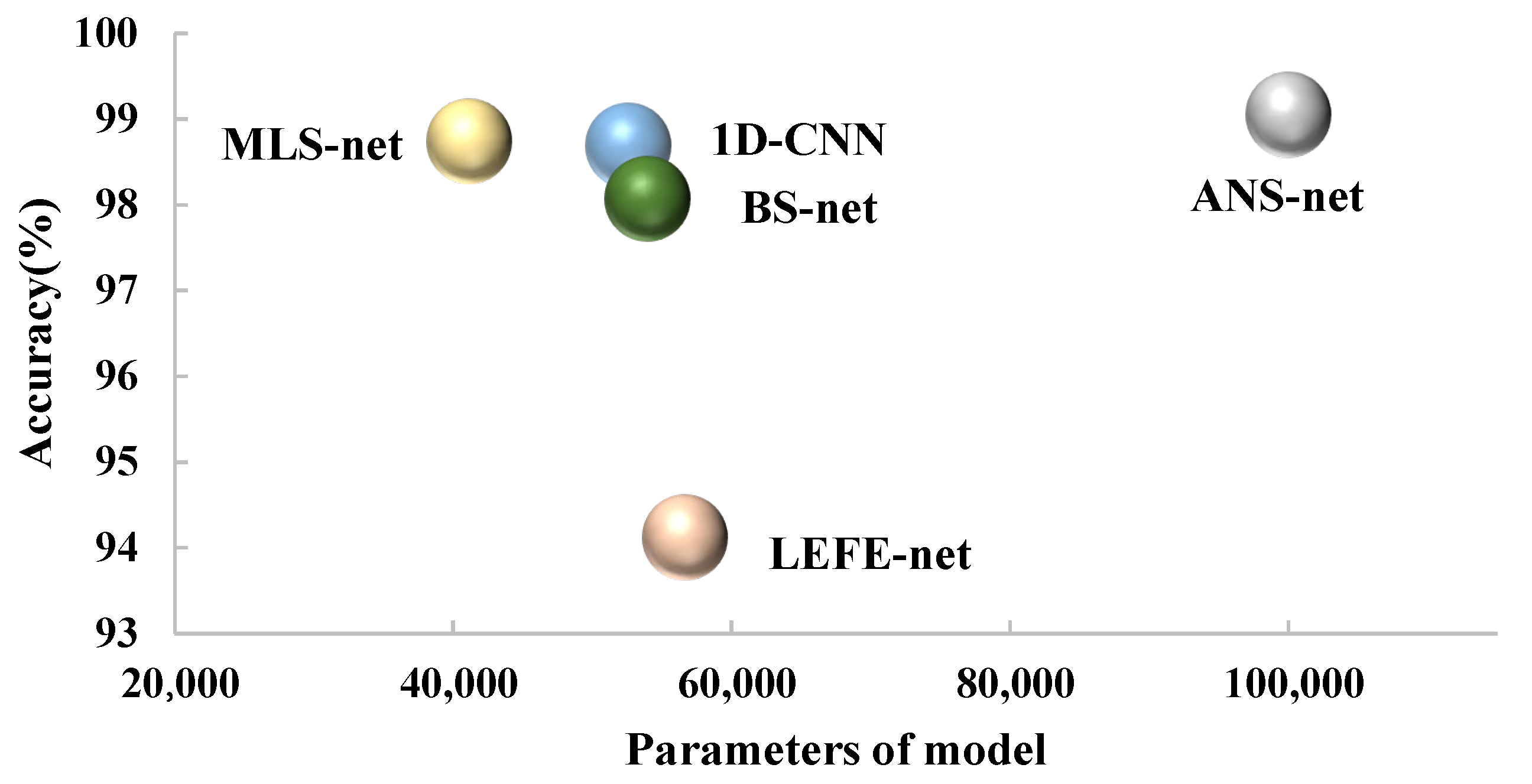
In
Figure 12, we mainly depict the relationship between model accuracy and total number of parameters. The horizontal coordinate indicates the model parameters. The vertical coordinate indicates the accuracy rate. The accuracy of each model is obtained from the experiment when the sample size is set as 900 for the CWRU dataset. As we can see from
Figure 12, MLS-net shows the better performance in terms of the model parameters and accuracy compared with 1D-CNN and BS-net.
Although ANS-net has similar accuracy with MLS-net, the number of MLS-net parameters is only 41449, which is greatly reduced. The ANS-net, on the other hand, has far more than 100,000 parameters. LEFE-net has fewer parameters than ANS-net. However, its accuracy is lower than ANS-net and MLS-net when the training sample size is 900. When the sample drops to 60, the accuracy of LEFE-net will be further greatly reduced. Overall, MLS-net is able to run efficiently with less computation cost as well as guaranteed accuracy.
From
Table 6 and
Table 7 and
Figure 12, it is clear that MLS-net has a significant improvement in model size and accuracy. Specifically, SVM is 100-times larger than MLS-net in terms of model size, while its accuracy is only 50% of MLS-net under small samples. MLS-net is also more advantageous in terms of the parameters of the model. It compresses about 20% parameters in comparison with BS-net and 1D-CNN. However, MLS-net under small samples improves the accuracy compared to 1D-CNN with an improvement of 10–15% and improves the accuracy by about 2–5% compared with BS-net.
ANS-net was recently proposed as a bearing fault diagnosis model for the small sample case. Although it has a high accuracy rate under small samples, a large number of parameters (more than 100,000) are needed to ensure the accuracy. In addition, MLS-net performs better in accuracy and lightweight than the lightweight bearing fault diagnosis model LEFE-net. Through the above experiments, MLS-net is proven to have a lighter model structure and better accuracy under small samples, which can greatly improve the efficiency of bearing fault diagnosis.
5. Conclusions
In this paper, we proposed the MLS-net for the end-to-end bearing fault diagnosis problem. The model has a great ability to classify in the case of small samples. It also has a multi-scale feature fusion module to enable further feature information to be acquired. With dimensionality reduction, the model is also able to obtain comparable accuracy with fewer parameters. The model was mainly designed based on the idea of metrics. Two symmetrical sample feature extraction modules with shared parameters are contained. These are mainly used to extract the feature vectors of the two sample pairs of the input. The similarity calculation module is used to calculate the similarity of the two extracted feature vectors. Thus, the trained model has the ability to compare the similarity probability between the standard samples and predicted samples. This enables the classification of the bearing fault.
To better validate the proposed model MLS-net, we tested it on three datasets to demonstrate its performance. The results show that the model had higher accuracy with fewer parameters when the sample was insufficient compared to recently proposed methods. This proves that MLS-net as proposed in our paper makes a good tradeoff between the accuracy and computing cost. In addition, the results were consistent across the three datasets tested. This indicates that the whole model has good generalization ability for different fault datasets.
The model showed good performance by retraining the method in this paper on multiple datasets. However, the need of retraining the model each time makes the operation cumbersome. In future work, we can focus our research more on the transfer scenarios of the model and fault diagnosis in noisy environments.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}