
Mutual Information-Based Variable Selection on Latent Class Cluster Analysis




Abstract
:1. Introduction
2. Methods
2.1. Latent Class Cluster Analysis
2.2. Mutual Information
- 1.
- Select one of all the variable sets that maximize the MI with the output Y:
- 2.
- The next component is selected by maximizing the MI between the output Y and the selected set of variables, so the algorithm is in step and the -th variables are selected as follows:
3. Results
3.1. Mutual Information-Based Variable Selection on Latent Class Cluster Analysis
3.2. Application of Data
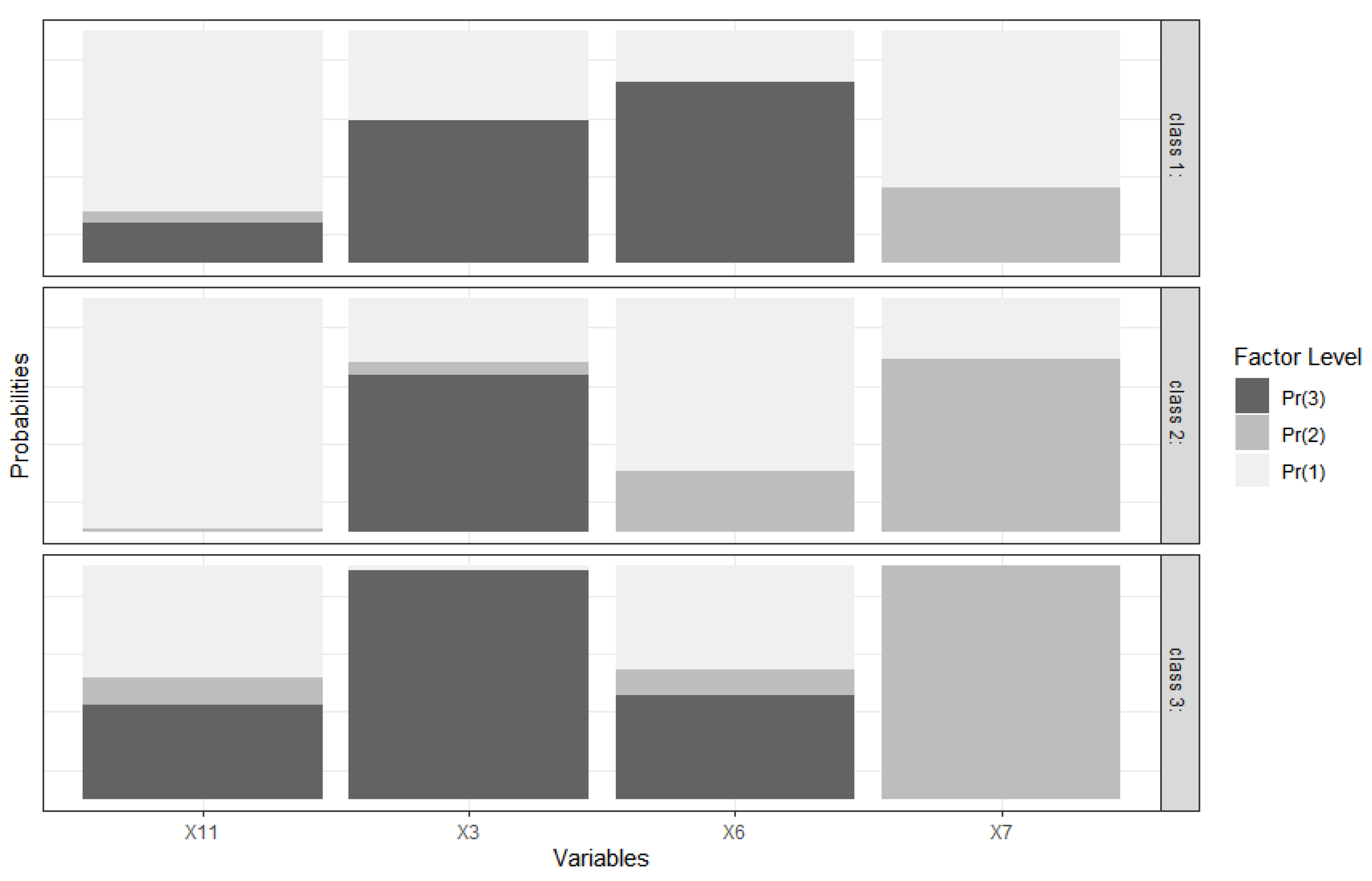
- Temporary landfill (X3) was representative of village SDG indicator number 12: environmentally aware village consumption and production.
- The existence of springs in the village (X6) was representative for village SDG indicator number 6: villages with clean water and sanitation.
- The existence of high schools and equivalent education institutions (X7) was representative of the village SDG indicator number 4: quality village education
- The existence of public transportation (X11) was representative of village SDG indicator number 9: village infrastructure and innovation according to needs.
- A total of 40 villages that were members of Cluster 1 were included in the independent village qualifications (rank 1);
- A total of 95 villages that were members of Cluster 2 were included in the advanced village qualifications (rank 2);
- A total of 166 villages belonging to Cluster 3 were included in the qualification for developing villages (rank 3).
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| X | X1 | X2 | … | Xp | Total | |||||
| Y | 1 | 2 | 1 | 2 | 1 | 2 | ||||
| Y | 1 | … | ||||||||
| 2 | … | |||||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | ⋮ | ||
| T | … | |||||||||
| Total | … | 1 | ||||||||
References
- Liu, H.; Yu, L. Toward Integrating Feature Selection Algorithms for Classification and Clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Kim, Y.S.; Steet, W.N.; Menczer, F. Feature Selection in Unsupervised Learning via Evolutionary Search. In Proceedings of the Sixth ACM SIGKDD International Conference Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 365–369. [Google Scholar]
- Dash, M.; Choi, K.; Scheuermann, P.; Liu, H. Feature Selection for Clustering—A Filter Solution. In Proceedings of the Second International Conference Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 115–122. [Google Scholar]
- Vergara, J.R.; Estevez, P.A. A Review of Feature Selection Methods Based on mutual Information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation Based Feature Selection for Discrete and Numeric Class Machine Learning. In Proceedings of the 17th International Conference Machine Learning, Standord, CA, USA, 29 June–2 July 2000; pp. 359–366. [Google Scholar]
- Liu, H.; Setiono, R. A Probabilistic Approach to Feature Selection—A Filter Solution. In Proceedings of the 13th International Conference Machine Learning, Bari, Italy, 3–6 July 1996. [Google Scholar]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. In Proceedings of the 20th International Conference Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Caruana, R.; Freitag, D. Greedy Attribute Selection. In Proceedings of the 11th International Conference Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; pp. 28–36. [Google Scholar]
- Dy, J.G.; Brodley, C.E. Feature Subset Selection and Order Identification for Unsupervised Learning. In Proceedings of the 17th International Conference Machine Learning, Standord, CA, USA, 29 June–2 July 2000; pp. 247–254. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for Feature Subset Selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Das, S. Filters, Wrappers and a Boosting-Based Hybrid for Feature Selection. In Proceedings of the 18th International Conference Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001; pp. 74–81. [Google Scholar]
- Ng, A.Y. On Feature Selection: Learning with Exponentially Many Irrelevant Feature as Training Examples. In Proceedings of the 15th International Conference Machine Learning, Madison, WI, USA, 24–27 July 1998; pp. 404–412. [Google Scholar]
- Xing, E.; Jordan, M.; Karp, R. Feature Selection for High-Dimensional Genomic Microarray Data. In Proceedings of the 15th International Conference Machine Learning, Williamstown, MA, USA, 18–24 July 2001; pp. 601–608. [Google Scholar]
- Venkatesh, B.; Anuradha, J. A Review of Feature Selection and Its Methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef] [Green Version]
- Leung, Y.; Hung, Y. A Multiple-Filter-Multiple-Wrapper Approach to Gene Selection and Microarray Data Classification. IEEE/ACM Trans. Comput. Biol. Bioinform. 2010, 7, 108–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; Nowe, A. A Survey on Filter Techniques for Feature Selection in Gene Expression Microarray Analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef] [PubMed]
- Shen, Q.; Diao, R.; Su, P. Feature Selection Ensemble. Turing-100 2012, 10, 289–306. [Google Scholar]
- Gutkin, M.; Shamir, R.; Dror, G. SlimPLS: A Method for Feature Selection in Gene Expression-Based Disease Classification. PLoS ONE 2009, 4, e6416. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vermunt, J.K.; Magidson, J. Latent Class Analysis. In The Sage Encyclopedia of Social Science Research Methods; Lewis-Beck, M.S., Liao, T.F., Eds.; SAGE Publications, Inc.: New York, NY, USA, 2004. [Google Scholar]
- Vermunt, J.K.; Magidson, J. Latent Class Models for Clustering: A Comparison with K-Means. Can. J. Mark. Res. 2002, 20, 36–43. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Sclove, L. Application of Model-Selection Criteria to Some Problems in Multivariate Analysis. Psychometrika 1987, 52, 333–343. [Google Scholar] [CrossRef]
- Schwartz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Battiti, R. Using Mutual Information for Selecting Feature in Supervised Neural Net Learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fleurit, F. Fast binary Feature Selection with Conditional Mutual Information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Doquire, G.; Verleysen, M. An Hybrid Approach to Feature Selection for Mixed Categorical and Continuous Data. In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval, Paris, France, 26–29 October 2011; pp. 386–393. [Google Scholar]
- Gomez-Verdejo, V.; Verleysen, M.; Fleury, J. Information Theoretic Feature Selection for Function Data Classification. Neurocomputing 2009, 72, 3580–3589. [Google Scholar] [CrossRef]
- Tenaga Pendamping Profesional Pusat. Pendataan SDG’s Desa 2021; Kemendesa PDT dan Trnasmigrasi: Jakarta, Indonesia, 2021. [Google Scholar]
- Yang, C. Evaluating Latent Class Analysis Models in Qualitative Phenotype Identification. Comput. Stat. Data Anal. 2006, 50, 1090–1104. [Google Scholar] [CrossRef]
- Riyanto, A.; Kuswanto, H.; Prastyo, D.D. Latent Class Cluster for Clustering Villages Based on Socio-Economic Indicators in 2018. J. Phys. Conf. Ser. 2021, 1821, 012041. [Google Scholar] [CrossRef]

{kind=link}
| Variable (n = 301) | Value | % |
|---|---|---|
| The main source of income for the majority of the population (X1) | 1 = agriculture | 75.53 |
| 2 = non-agriculture | 24.47 | |
| Cooking fuel for the majority of families in the village (X2) | 1 = LPG gas | 98.49 |
| 2 = non-LPG gas | 1.51 | |
| Temporary landfill (X3) | 1 = yes, used | 25.98 |
| 2 = yes, not used | 2.11 | |
| 3 = no | 71.91 | |
| Toilet facility usage of the majority of families (X4) | 1 = toilet | 99.09 |
| 2 = non-toilet | 0.91 | |
| A final disposal site for the stool of the majority of families (X5) | 1 = tank | 71.60 |
| 2 = non-tank | 28.40 | |
| The existence of springs in the village (X6) | 1 = yes, managed | 49.85 |
| 2 = yes, not managed | 14.80 | |
| 3 = no | 35.35 | |
| The existence of high schools and equivalent education institutions (X7) | 1 = yes | 28.70 |
| 2 = no | 71.30 | |
| The existence of health facilities (X8) | 1 = yes | 99.09 |
| 2 = no | 0.91 | |
| Extraordinary events or disease outbreaks in the past year (X9) | 1 = yes | 1.81 |
| 2 = no | 98.19 | |
| The widest type of road surface (X10) | 1 = asphalt/concrete | 99.70 |
| 2 = others | 0.30 | |
| The existence of public transportation (X11) | 1 = yes, with fixed routes | 75.53 |
| 2 = yes, without fixed routes | 6.04 | |
| 3 = no | 18.43 | |
| The existence of residents who use handphones (X12) | 1 = mostly residents | 99.40 |
| 2 = a small number of residents | 0.60 |
| Alternative Model | The Best Variables | Mutual Information |
|---|---|---|
| Model 2 (two-cluster) | X6; X8; X11 | 0.2538 |
| Model 3 (three-cluster) | X3; X6; X11 | 0.2862 |
| Model 4 (four-cluster) | X5; X6; X7; X11 | 0.3257 |
| Model 5 (five-cluster) | X5; X6; X7; X11 | 0.4413 |
| Model 6 (six-Cluster) | X3; X6; X7; X11 | 0.4561 |
| Model 7 (seven-Cluster) | X3; X5; X6; X7; X11 | 0.4396 |
| Model 8 (eight-Cluster) | X3; X5; X6; X7; X11 | 0.3956 |
| Model 9 (nine-Cluster) | X3; X5; X6; X7; X11 | 0.4223 |
| Model 10 (ten-Cluster) | X3; X5; X6; X7; X11 | 0.4440 |
| Alternative Model | Log- Likelihood | AIC | BIC | Adjusted BIC | Number of Parameters |
|---|---|---|---|---|---|
| Model 2 (two-cluster) | −837.390 | 1704.780 | 1760.386 | 1712.815 | 15 |
| Model 3 (three-cluster) | −821.723 | 1689.445 | 1774.709 | 1701.766 | 23 |
| Model 4 (four-cluster) | −817.460 | 1696.920 | 1811.841 | 1713.526 | 31 |
| Model 5 (five-cluster) | −813.988 | 1705.976 | 1850.554 | 1726.868 | 39 |
| Model 6 (six-cluster) | −812.992 | 1719.985 | 1894.219 | 1745.162 | 47 |
| Model 7 (seven-cluster) | −812.620 | 1735.239 | 1939.130 | 1764.701 | 55 |
| Model 8 (eight-cluster) | −812.620 | 1751.239 | 1984.787 | 1784.987 | 63 |
| Model 9 (nine-cluster) | −812.620 | 1767.239 | 2030.444 | 1805.282 | 71 |
| Model 10 (ten-cluster) | −812.096 | 1782.193 | 2075.054 | 1824.511 | 79 |
| The Four Selected Variables | All Variables | Sum | ||
|---|---|---|---|---|
| Cluster 1 | Cluster 2 | Cluster 3 | ||
| Cluster 1 | 37 | 2 | 1 | 40 |
| Cluster 2 | 2 | 88 | 5 | 95 |
| Cluster 3 | 0 | 0 | 166 | 166 |
| Sum | 39 | 90 | 172 | 301 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riyanto, A.; Kuswanto, H.; Prastyo, D.D. Mutual Information-Based Variable Selection on Latent Class Cluster Analysis. Symmetry 2022, 14, 908. https://doi.org/10.3390/sym14050908
Riyanto A, Kuswanto H, Prastyo DD. Mutual Information-Based Variable Selection on Latent Class Cluster Analysis. Symmetry. 2022; 14(5):908. https://doi.org/10.3390/sym14050908
Chicago/Turabian StyleRiyanto, Andreas, Heri Kuswanto, and Dedy Dwi Prastyo. 2022. "Mutual Information-Based Variable Selection on Latent Class Cluster Analysis" Symmetry 14, no. 5: 908. https://doi.org/10.3390/sym14050908
APA StyleRiyanto, A., Kuswanto, H., & Prastyo, D. D. (2022). Mutual Information-Based Variable Selection on Latent Class Cluster Analysis. Symmetry, 14(5), 908. https://doi.org/10.3390/sym14050908