
DII-GCN: Dropedge Based Deep Graph Convolutional Networks


Abstract
:1. Introduction
2. Related Works
3. Preliminary
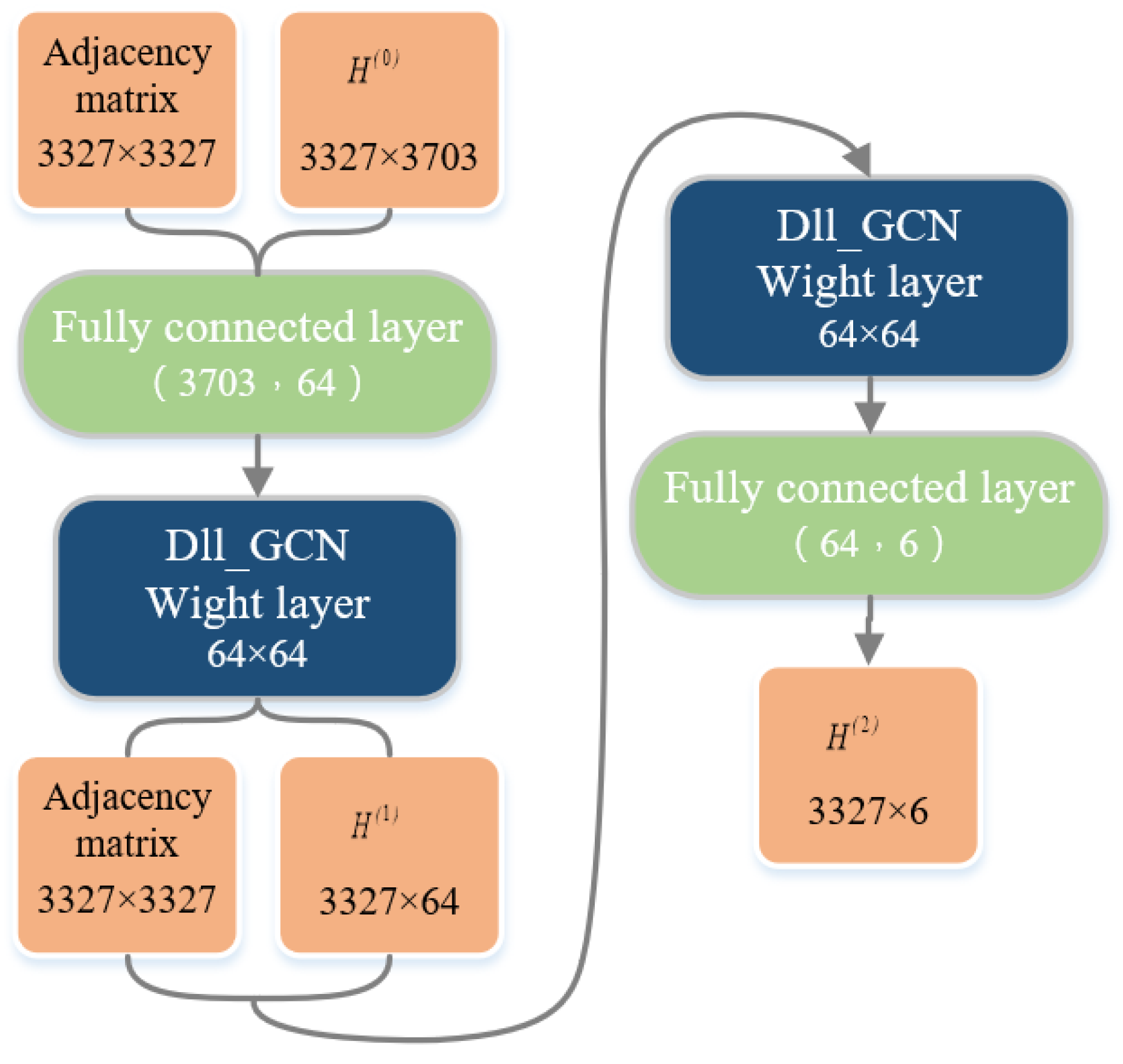
4. Proposed Model
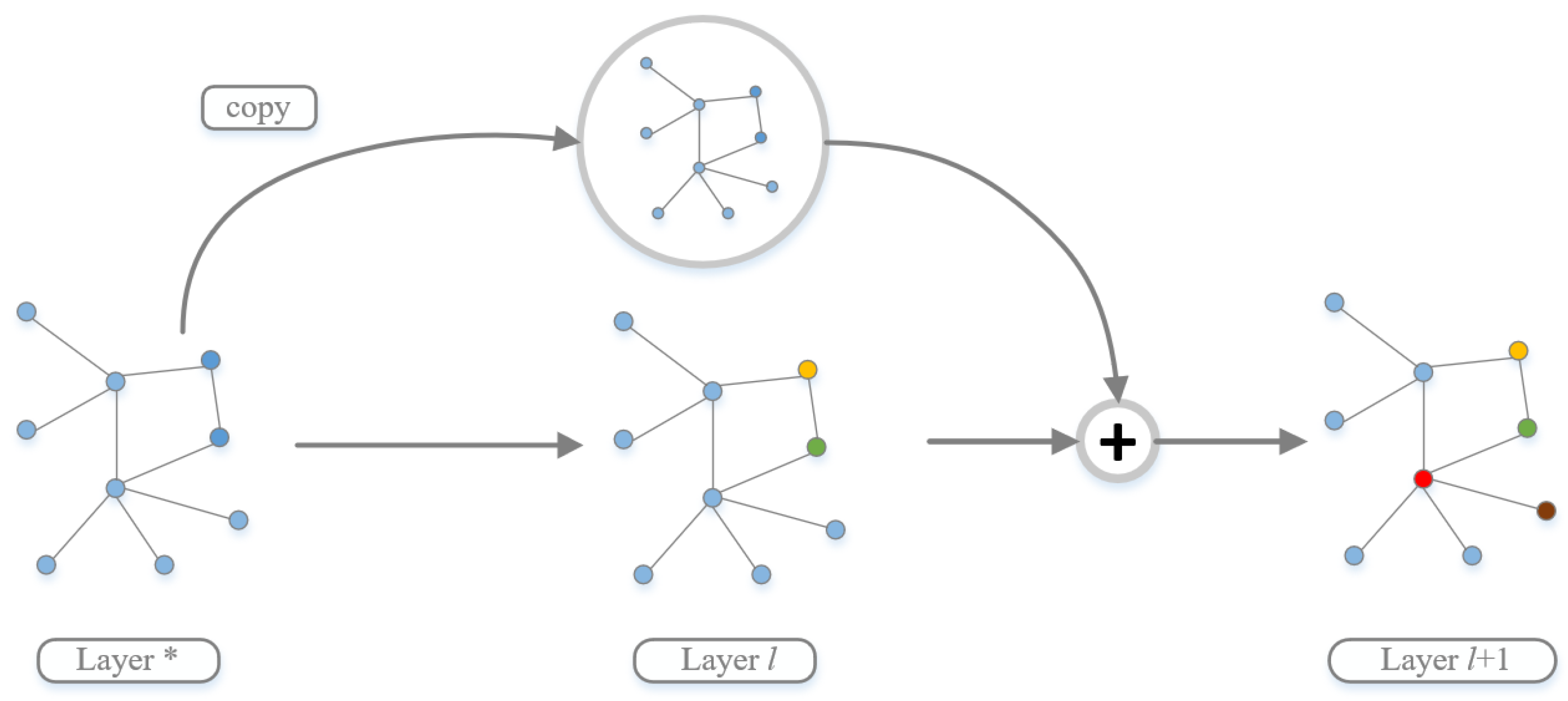
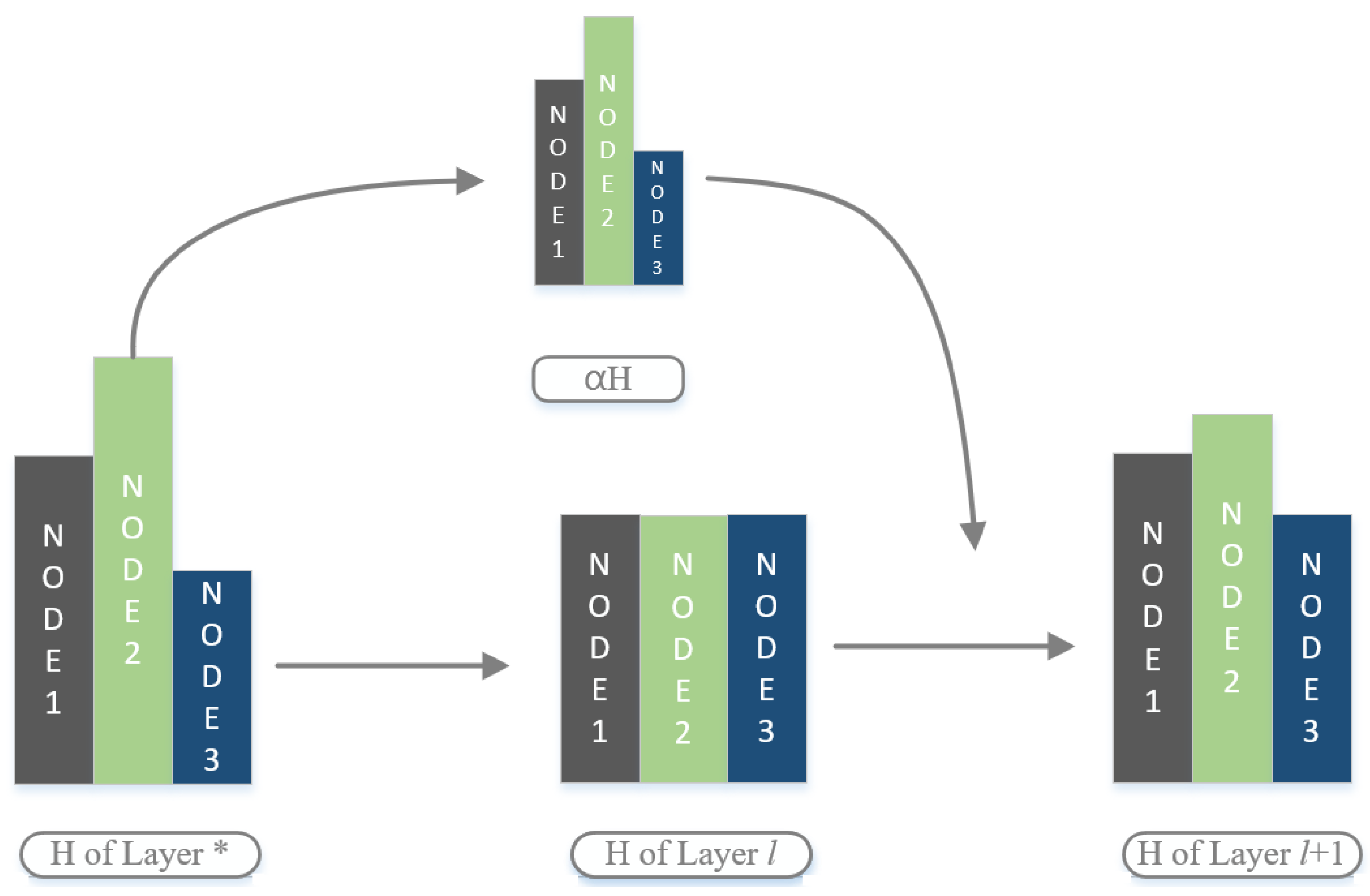
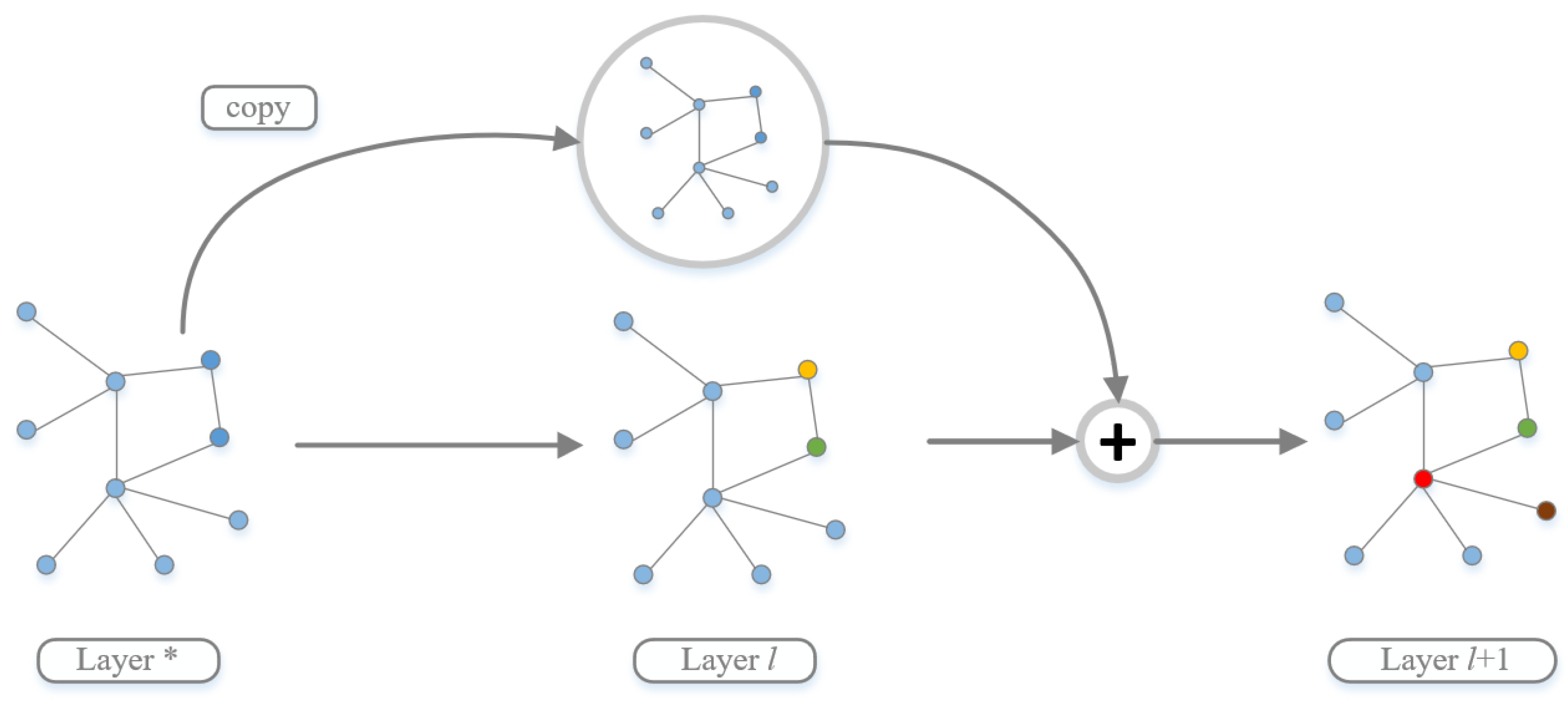
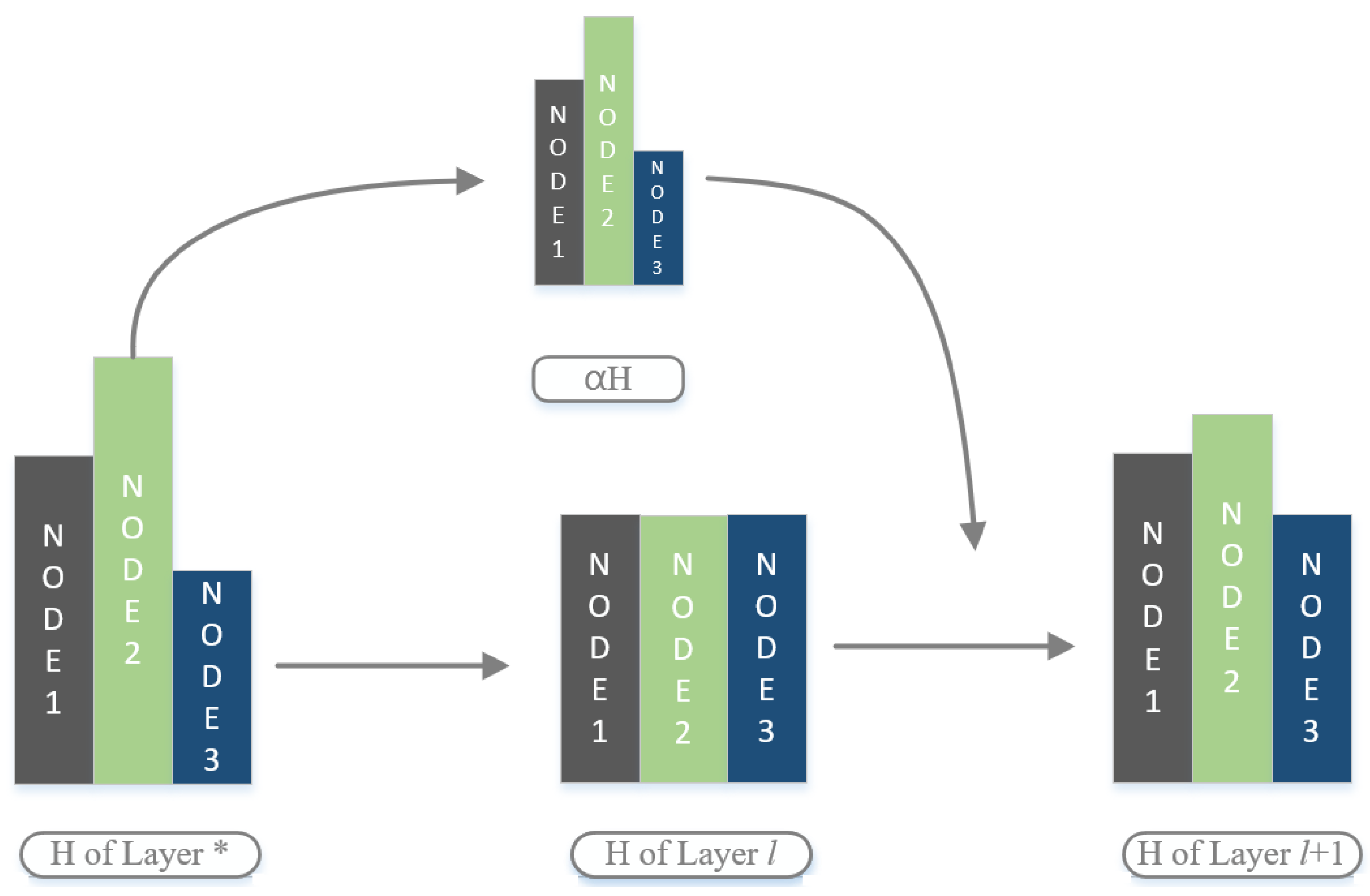
4.1. Residual Network and Cross-Layer Connection
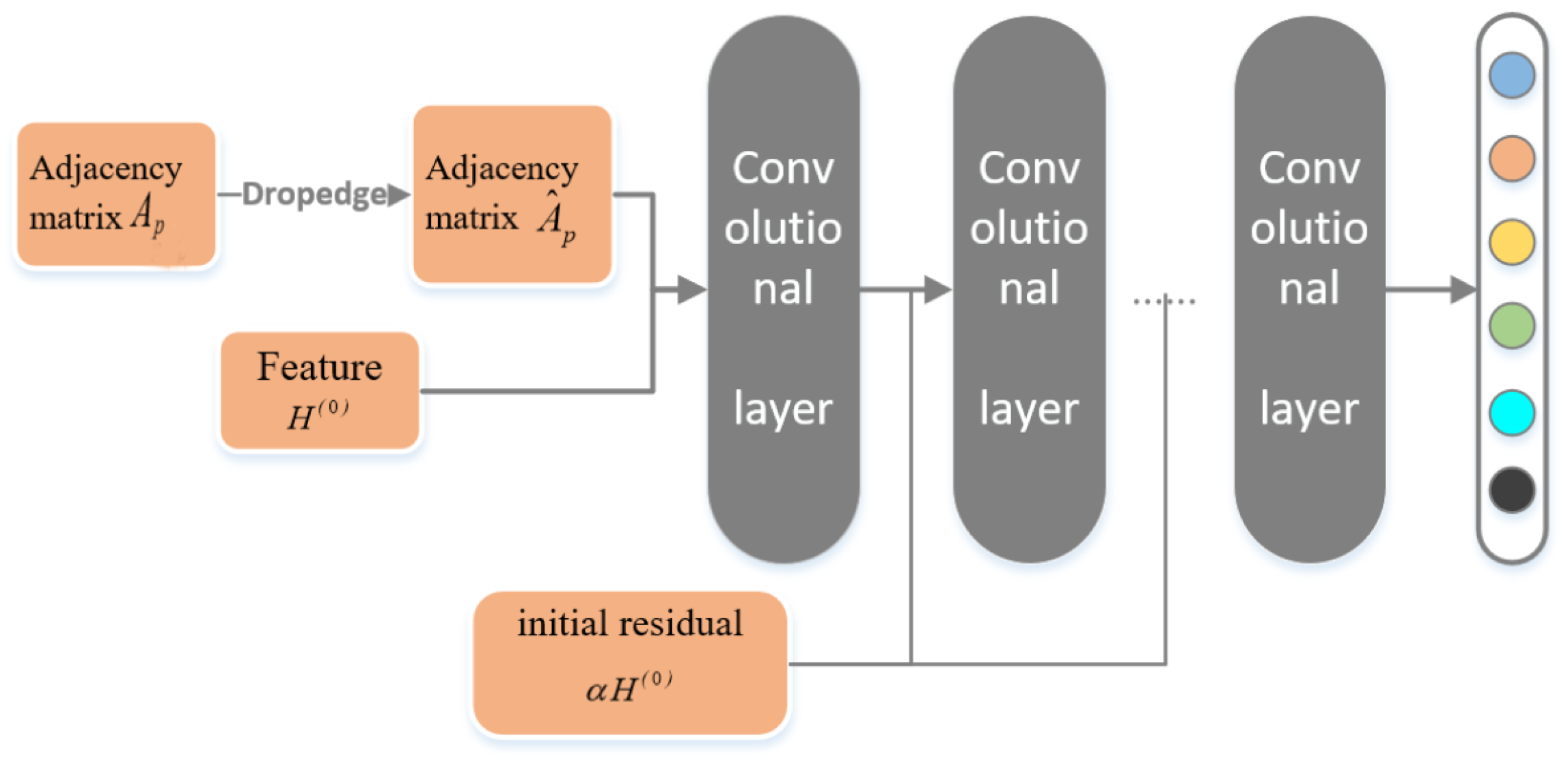
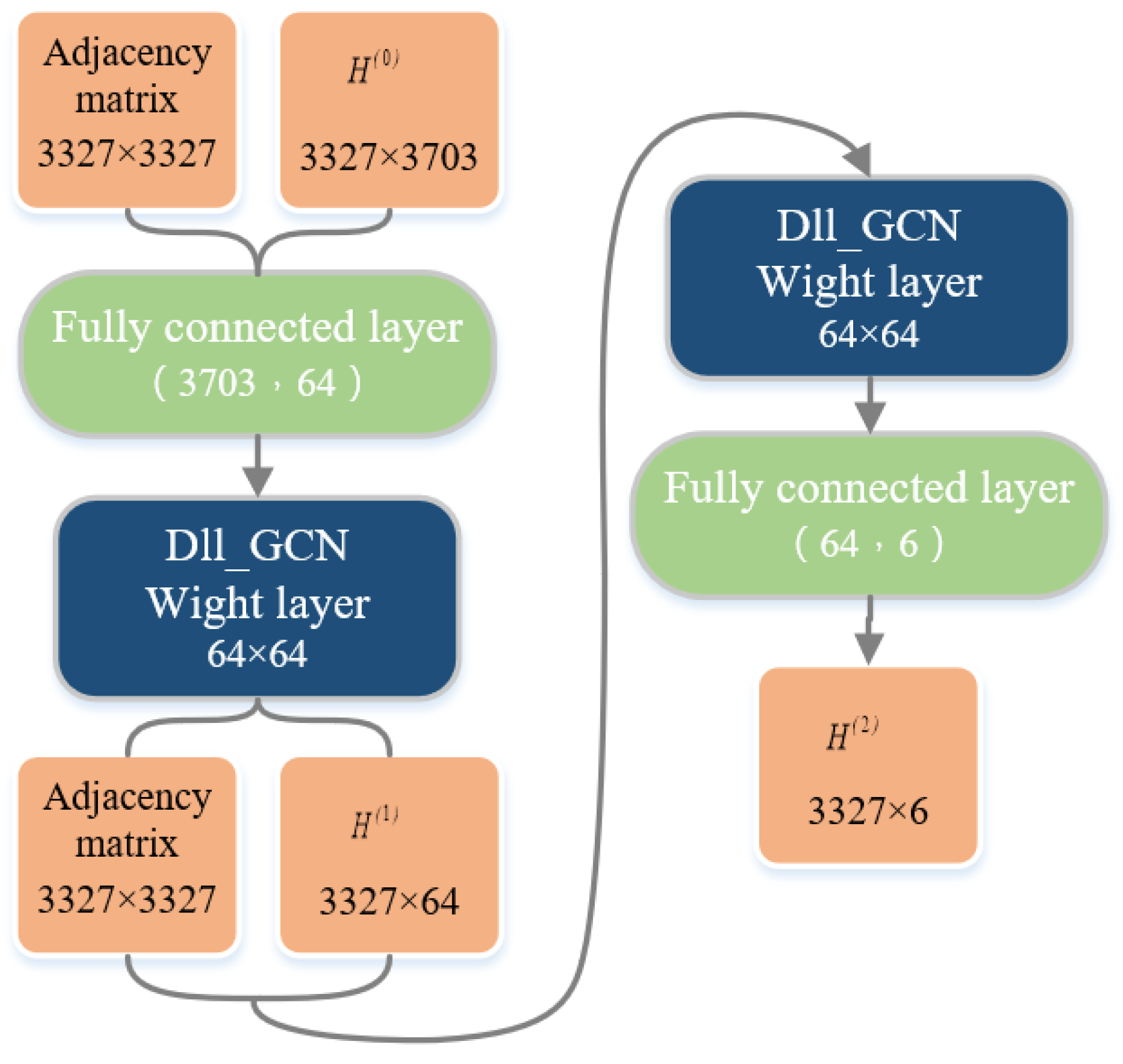
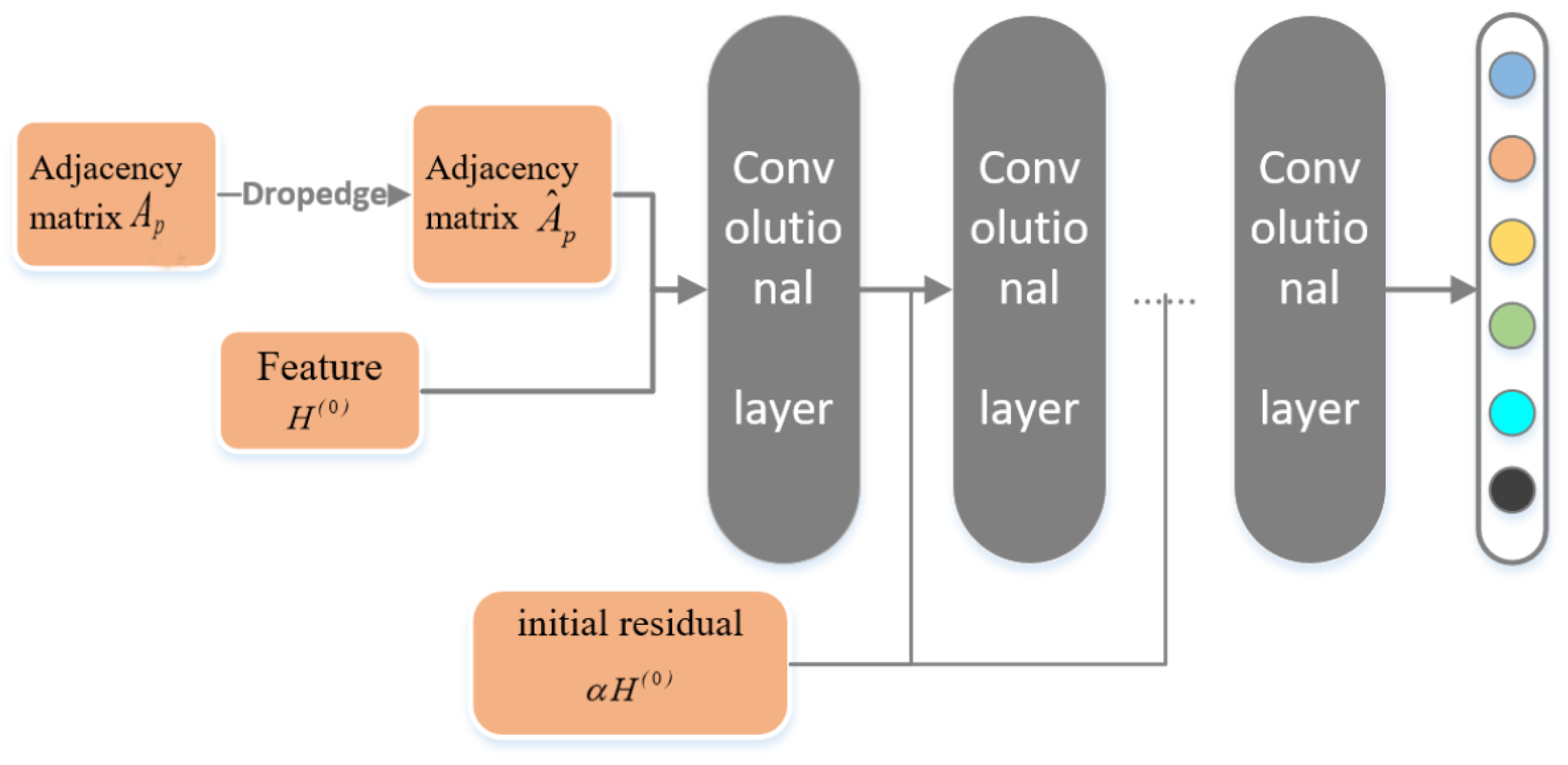
4.2. DII-GCN Model Design
5. Experiment and Analysis
5.1. A Comparative Experiment of Learning and Classification Accuracy
- (1)
- P (Positive) and N (Negative): represent the number of positive and negative examples in the training sample, respectively.
- (2)
- TP (True Positives): The number of positive examples that are correctly classified. The number of samples that are positive and classified as positive by the model.
- (3)
- FP (False Positives): The number of positive examples incorrectly classified. The number of samples is negative but classified as positive by the classifier.
- (4)
- FN (False Negatives): The number of false negatives. The number of positive samples but classified as negative by the classifier.
- (5)
- TN (True negatives): The number of negative examples correctly classified. The number of negative samples is classified as negative one.
- (i)
- Consider G separately. The typical algorithm GCN used in the experiment.
- (ii)
- Consider G+D. Rong (Rong et al., 2019) puts forward the reasons for Dropedge in GCN and demonstrates some effects. Therefore, we perfected G+D and named D-GCN for the comparative experiments in this paper.
- (iii)
- Consider G+R. GCNII is a typical representative model.
- (iv)
- Consider G+D+R. The DII-GCN model proposed in this paper belongs to this category.
- (1)
- The DII-GCN model has the highest accuracy on the three standard data sets.
- (2)
- The GCN model can obtain better learning accuracy on the 2-layer network. However, as the depth increases, the learning accuracy drops sharply, and not it is not easy to use the Dropedge method (corresponding to the G+D model) to support deep GCN construction.
- (3)
- The DII-GCN and GCNII models can support the construction of deep graph convolutional networks, and the learning accuracy of DII-GCN improved from GCNII on the three standard data sets.
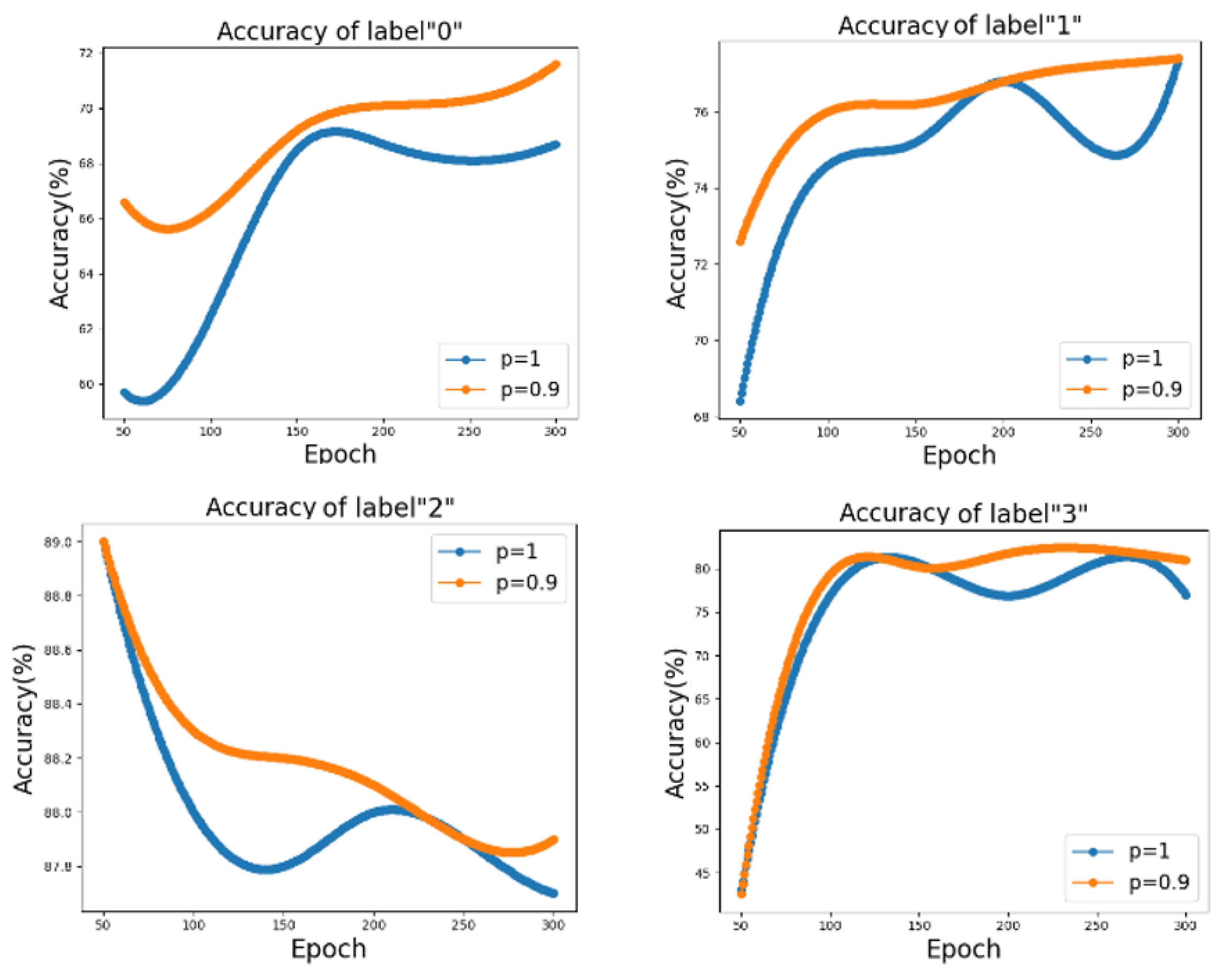
- (1)
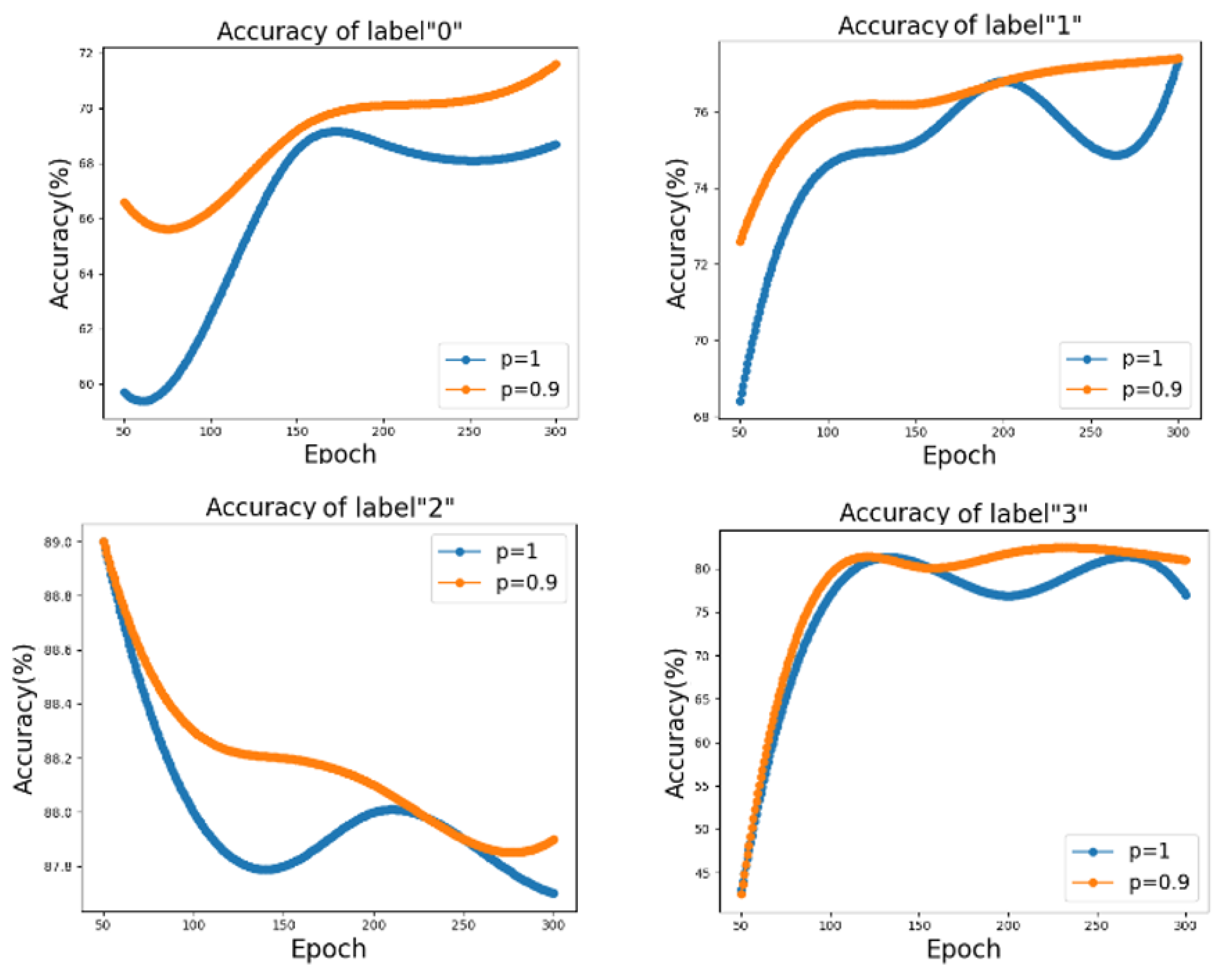
- On the Cora dataset, for the first three classes (class identifiers are 0, 1, 2), the classification accuracy after Dropedge (p = 0.9) is better than the GNN without Dropedge (p = 1) at all iteration stages; For label 2, we found that the algorithm we proposed with other algorithms showed a decreasing trend in accuracy, but DII-GCN was still better than several others. The reason for their all decreasing may be the presence of numerous missing values in this category of data.
- (2)
- For class label 3, the previous Dropedge effect is not very satisfactory, but after 270 Epochs, the Dropedge appears to have a good effect. However, in a class with poor classification accuracy, the learning process improves by an appropriate number of iterations.
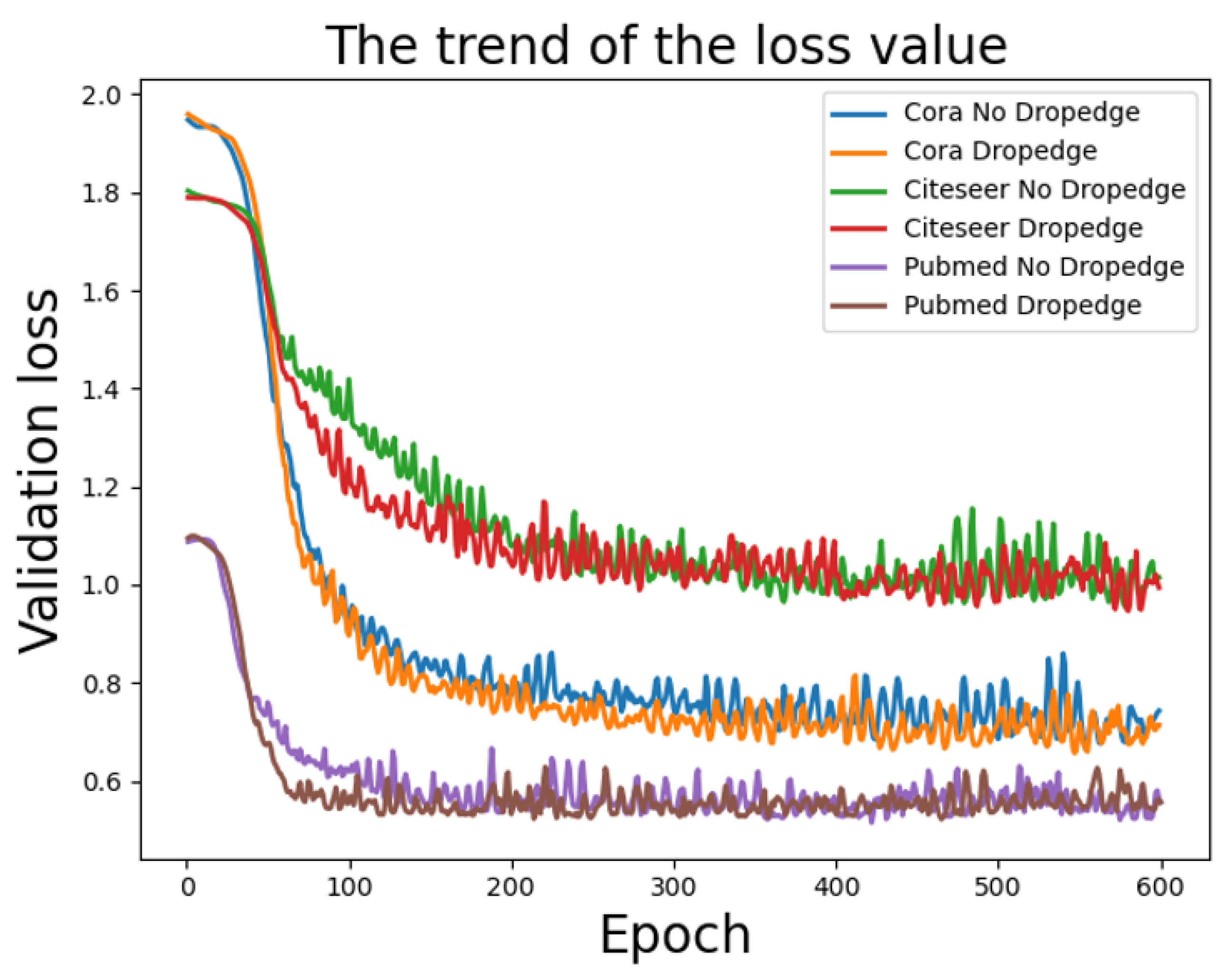
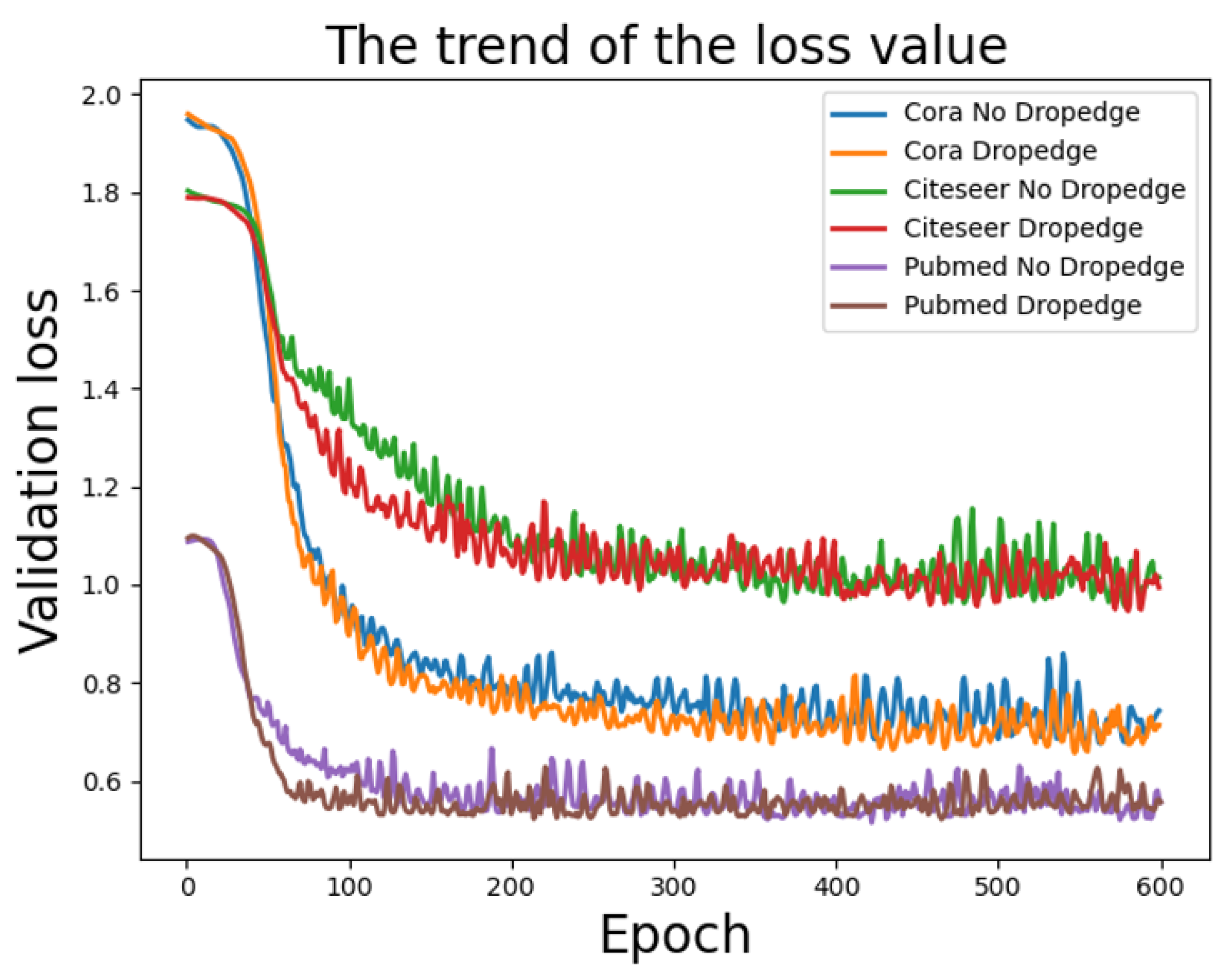
5.2. Dropedge Effectiveness Analysis
- (1)
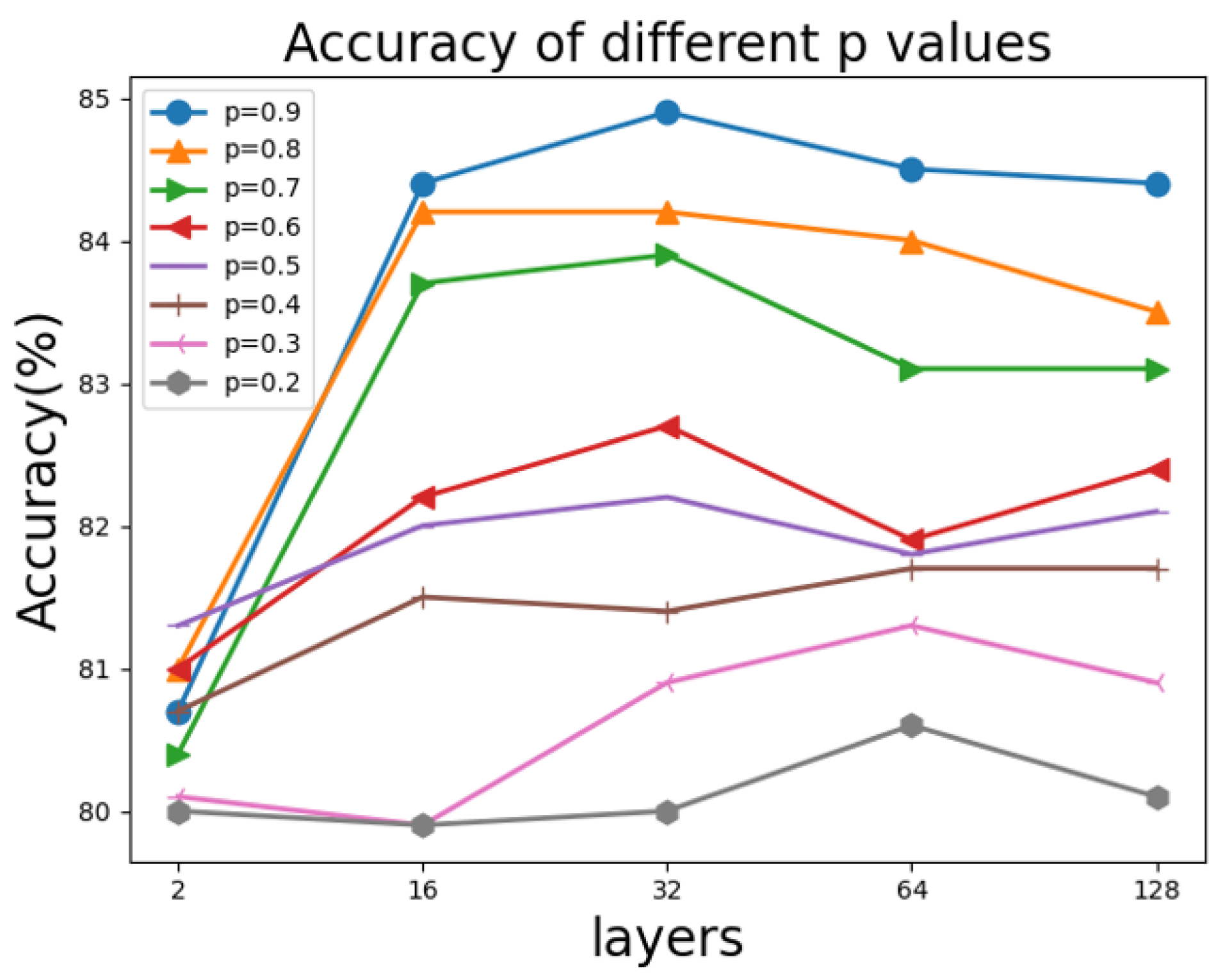
- For the Cora dataset, Dropedge coefficient p = 0.9 or 0.8, and the number of layers is over 16. Therefore, the DII-GCN model accuracy is around 84%. Furthermore, DII-GCN can deepen the network by setting the appropriate Dropedge coefficient p. As a result, the level can obtain a stable and higher learning accuracy.
- (2)
- When p is below 0.6, the DII-GCN model accuracy is not high, indicating the Dropedge effect is not ideal because too many Dropedges cause the graph data structure to be lost. It also illustrates the scientific meaning of the GNN. Using the associated information of the node can improve the node evaluation effect.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bo, B.; Yuting, L.; Chicheng, M.; Guanghui, W.; Guiying, Y.; Kai, Y.; Ming, Z.; Zhiheng, Z. Graph neural network. Sci. Sin. Math. 2020, 50, 367. [Google Scholar]
- Xinyi, Z.; Chen, L. Capsule graph neural network. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gao, L.; Zhao, W.; Zhang, J.; Jiang, B. G2S: Semantic Segment Based Semantic Parsing for Question Answering over Knowledge Graph. Acta Electonica Sin. 2021, 49, 1132. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Wang, X.; Ye, Y.; Gupta, A. Zero-shot recognition via semantic embeddings and knowledge graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6857–6866. [Google Scholar]
- Lin, W.; Ji, S.; Li, B. Adversarial attacks on link prediction algorithms based on graph neural networks. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020; pp. 370–380. [Google Scholar]
- Che, X.B.; Kang, W.Q.; Deng, B.; Yang, K.H.; Li, J. A Prediction Model of SDN Routing Performance Based on Graph Neural Network. Acta Electonica Sin. 2021, 49, 484. [Google Scholar]
- Zitnik, M.; Agrawal, M.; Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 2018, 34, i457–i466. [Google Scholar] [CrossRef] [Green Version]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards deep graph convolutional networks on node classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.i.; Jegelka, S. Representation learning on graphs with jumping knowledge networks. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholmsmassan, Stockholm, Sweden, 10–15 July 2018; pp. 5453–5462. [Google Scholar]
- Wu, H.; Gu, X. Towards dropout training for convolutional neural networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Do, T.H.; Nguyen, D.M.; Bekoulis, G.; Munteanu, A.; Deligiannis, N. Graph convolutional neural networks with node transition probability-based message passing and DropNode regularization. Expert Syst. Appl. 2021, 174, 114711. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Guo, J.; Li, R.; Zhang, Y.; Wang, G. Graph neural network based anomaly detection in dynamic networks. Ruan Jian Xue Bao. J. Softw. 2020, 31, 748–762. [Google Scholar]
- Wang, R.; Huang, C.; Wang, X. Global relation reasoning graph convolutional networks for human pose estimation. IEEE Access 2020, 8, 38472–38480. [Google Scholar] [CrossRef]
- Yu, K.; Jiang, H.; Li, T.; Han, S.; Wu, X. Data fusion oriented graph convolution network model for rumor detection. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2171–2181. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Bi, Z.; Zhang, T.; Zhou, P.; Li, Y. Knowledge transfer for out-of-knowledge-base entities: Improving graph-neural-network-based embedding using convolutional layers. IEEE Access 2020, 8, 159039–159049. [Google Scholar] [CrossRef]
- Sichao, F.; Weifeng, L.; Shuying, L.; Yicong, Z. Two-order graph convolutional networks for semi-supervised classification. IET Image Process. 2019, 13, 2763–2771. [Google Scholar] [CrossRef]
- Cai, C.; Wang, Y. A note on over-smoothing for graph neural networks. arXiv 2020, arXiv:2006.13318. [Google Scholar]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1616–1637. [Google Scholar] [CrossRef] [Green Version]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Levie, R.; Monti, F.; Bresson, X.; Bronstein, M.M. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. IEEE Trans. Signal Process. 2018, 67, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Number of nodes | 2708 | 3327 | 19,717 |
| Number of edges | 5429 | 4732 | 44,338 |
| Number of class | 7 | 6 | 3 |
| Number of Feature | 1433 | 3703 | 500 |
| Dataset | Weight Control Coefficient | Shear Output Coefficient Dropout | Dropedge Coefficient p | Residual Coefficient | Learing Rate |
|---|---|---|---|---|---|
| Citeseer | 0.5 | 0.6 | 0.9 | 0.1 | 0.01 |
| Cora | 0.5 | 0.6 | 0.9 | 0.1 | 0.01 |
| Pubmed | 0.5 | 0.6 | 0.98 | 0.1 | 0.01 |
| Dataset | Model | Layer | ||||
|---|---|---|---|---|---|---|
| 2 | 16 | 32 | 64 | 128 | ||
| Cora | GCN | 81.1 | 64.9 | 60.3 | 28.7 | — |
| D_GCN | 82.8 | 75.7 | 62.5 | 49.5 | — | |
| GCNII | 80.4 | 84 | 84.5 | 84.5 | 84.3 | |
| DII_GCN | 80.6 | 84.2 | 84.5 | 84.5 | 84.6 | |
| Dataset | Model | Layer | ||||
| 2 | 16 | 32 | 64 | 128 | ||
| Citeseer | GCN | 70.8 | 18.3 | 25 | 20 | — |
| D_GCN | 72.3 | 57.2 | 41.6 | 34.4 | — | |
| GCNII | 65.9 | 71.7 | 72.2 | 72.1 | 72 | |
| DII_GCN | 66.2 | 72 | 72.5 | 72.2 | 72.3 | |
| Dataset | Model | Layer | ||||
| 2 | 16 | 32 | 64 | 128 | ||
| Pubmed | GCN | 79 | 40.9 | 22.4 | 35.3 | — |
| D_GCN | 79.6 | 78.5 | 77 | 61.5 | — | |
| GCNII | 78.1 | 79.2 | 79.3 | 72.2 | 72.1 | |
| DII_GCN | 77.8 | 79.3 | 79.7 | 79.3 | 79.3 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Mao, G.; Jiang, C. DII-GCN: Dropedge Based Deep Graph Convolutional Networks. Symmetry 2022, 14, 798. https://doi.org/10.3390/sym14040798
Zhu J, Mao G, Jiang C. DII-GCN: Dropedge Based Deep Graph Convolutional Networks. Symmetry. 2022; 14(4):798. https://doi.org/10.3390/sym14040798
Chicago/Turabian StyleZhu, Jinde, Guojun Mao, and Chunmao Jiang. 2022. "DII-GCN: Dropedge Based Deep Graph Convolutional Networks" Symmetry 14, no. 4: 798. https://doi.org/10.3390/sym14040798
APA StyleZhu, J., Mao, G., & Jiang, C. (2022). DII-GCN: Dropedge Based Deep Graph Convolutional Networks. Symmetry, 14(4), 798. https://doi.org/10.3390/sym14040798