
Image Translation for Oracle Bone Character Interpretation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Related Work
2.1.1. Generative Adversarial Network
2.1.2. Conditional Generative Adversarial Network
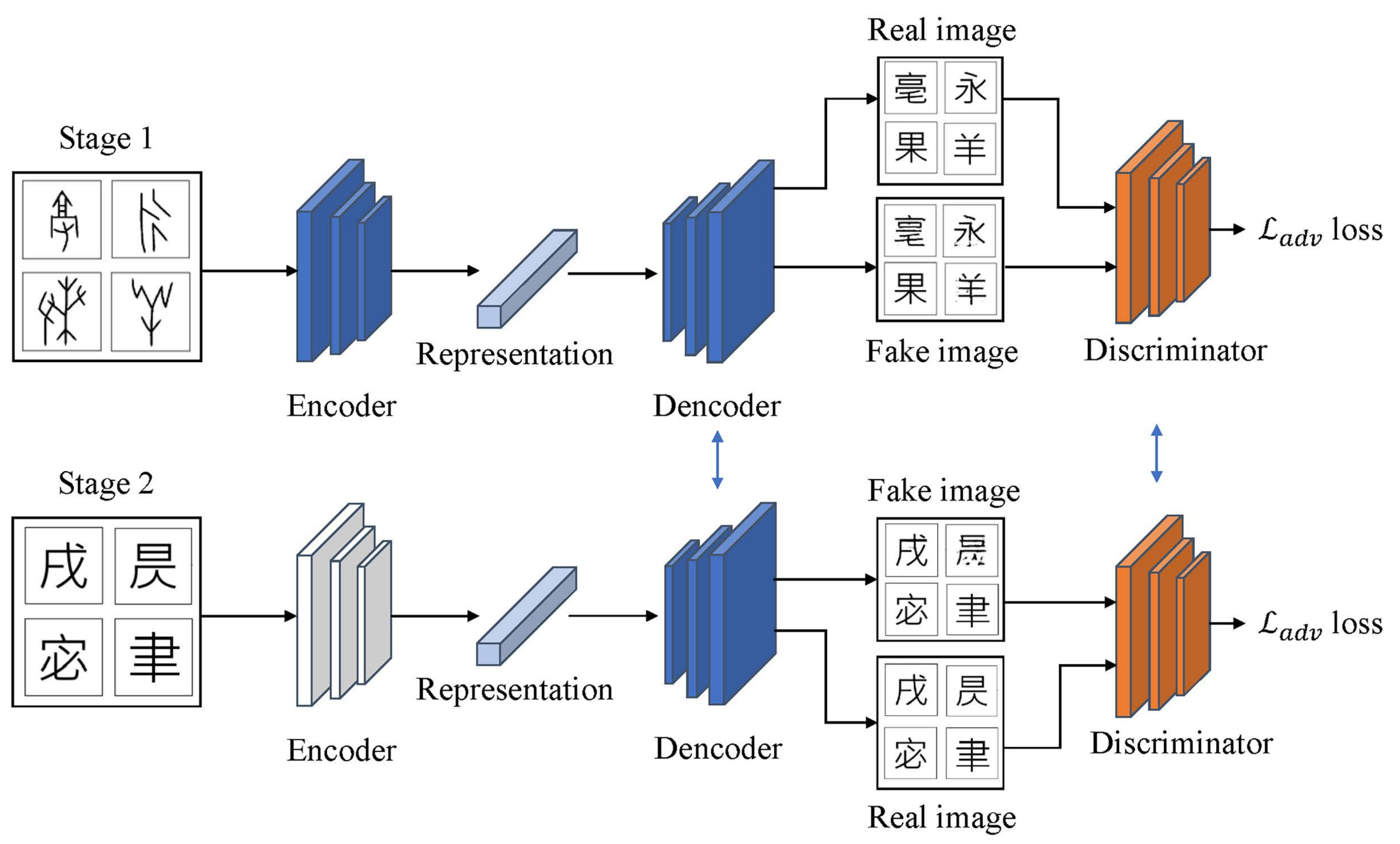
2.2. Proposed Method
2.2.1. Problem Description
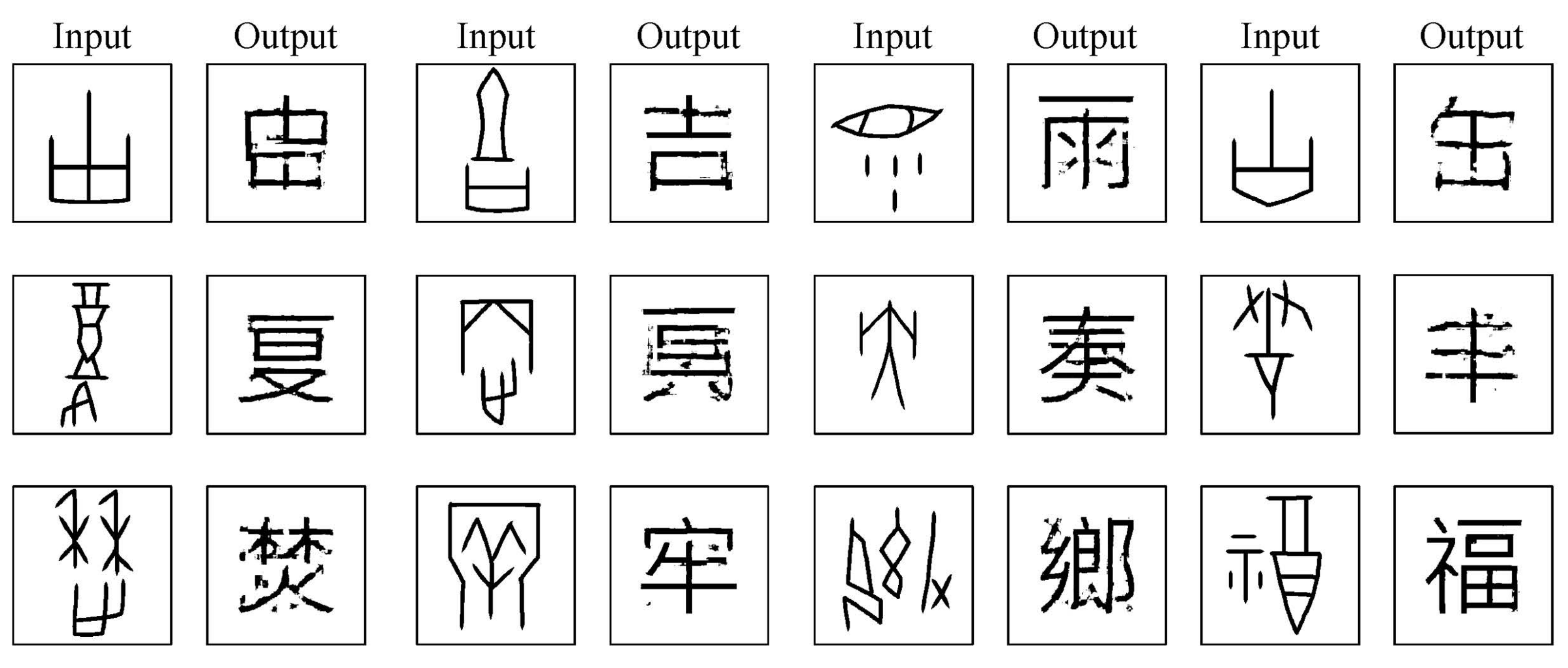
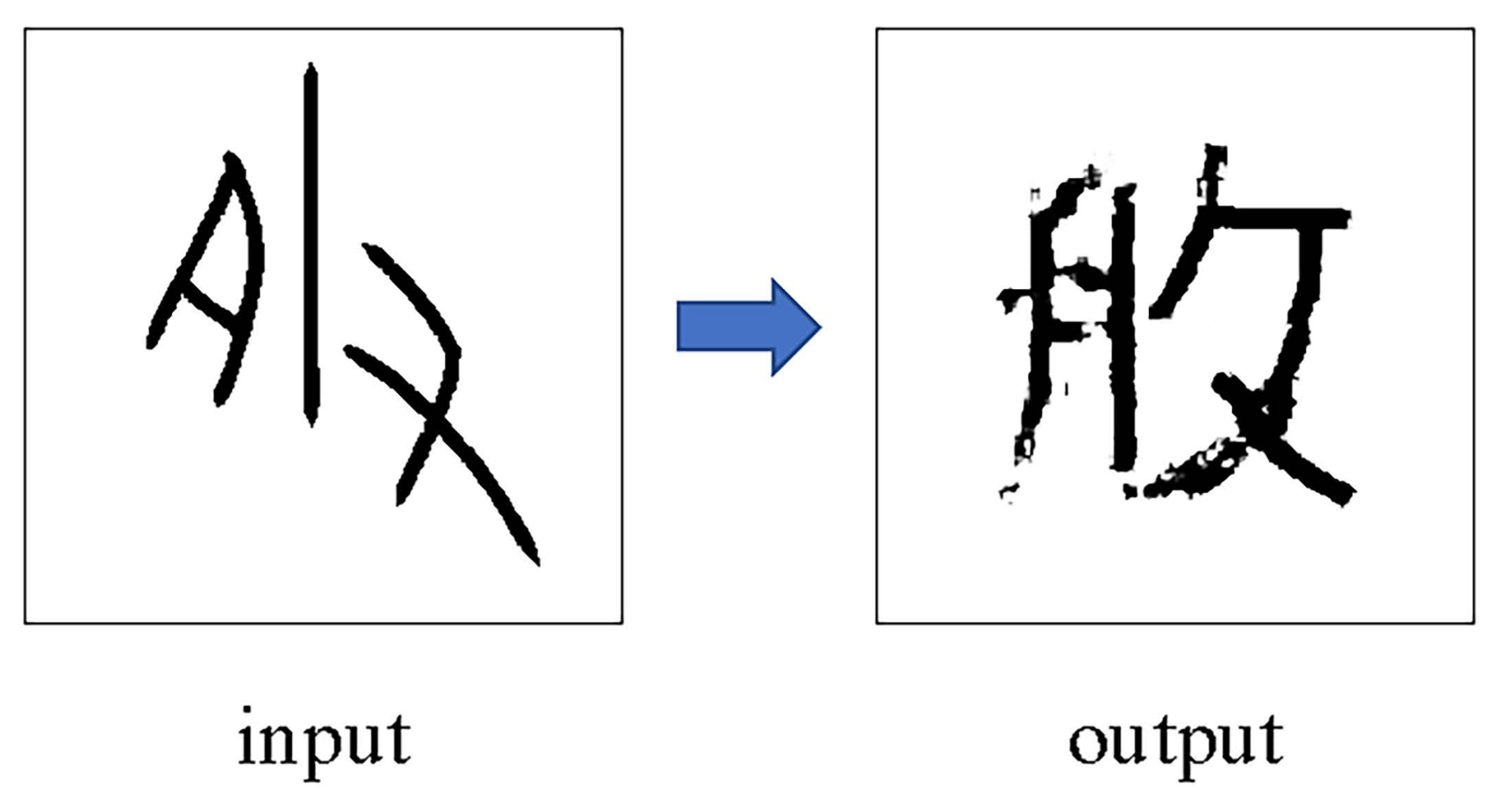
2.2.2. Symmetrical Image Translation Based on Knowledge Expansion
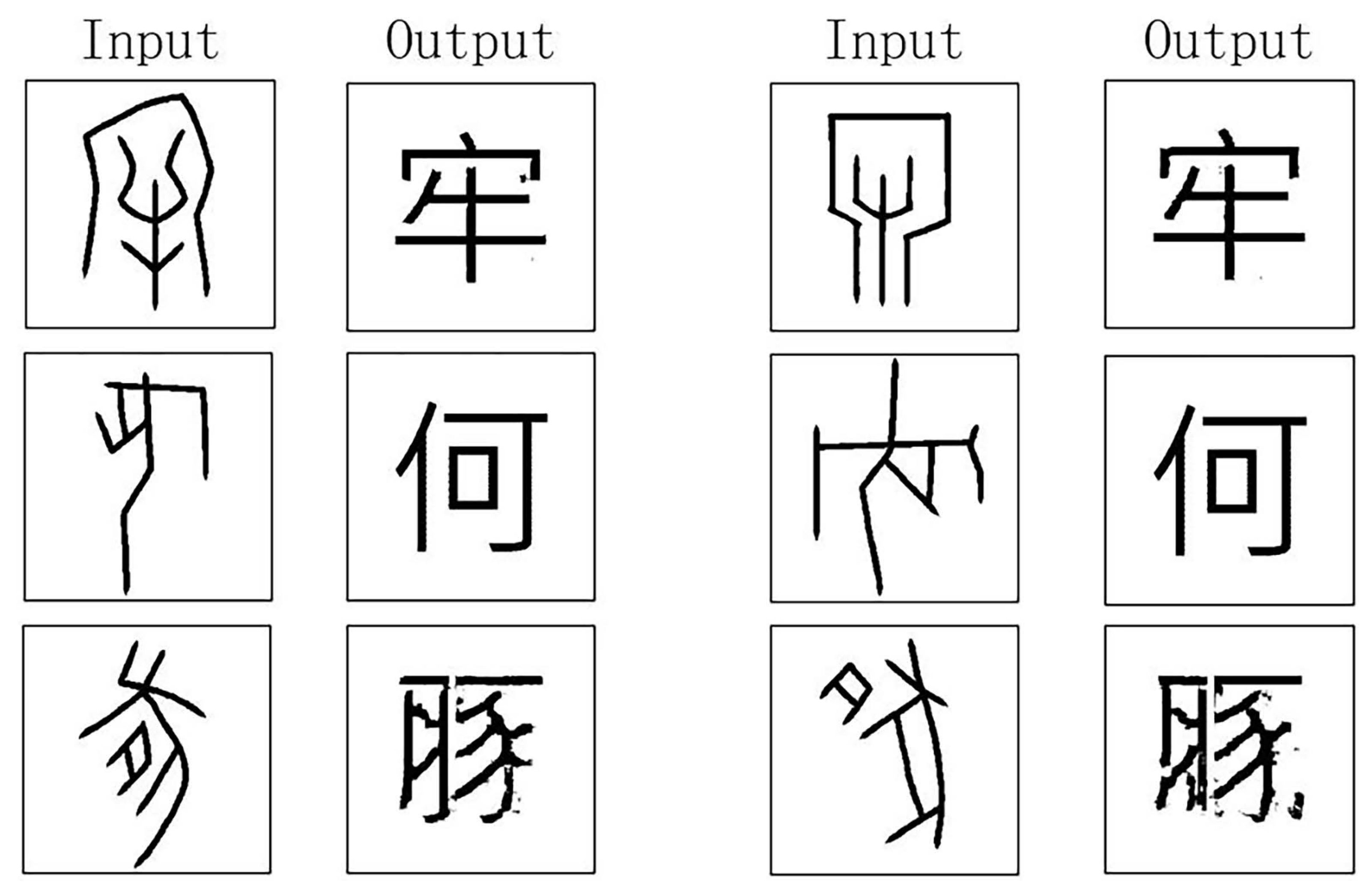
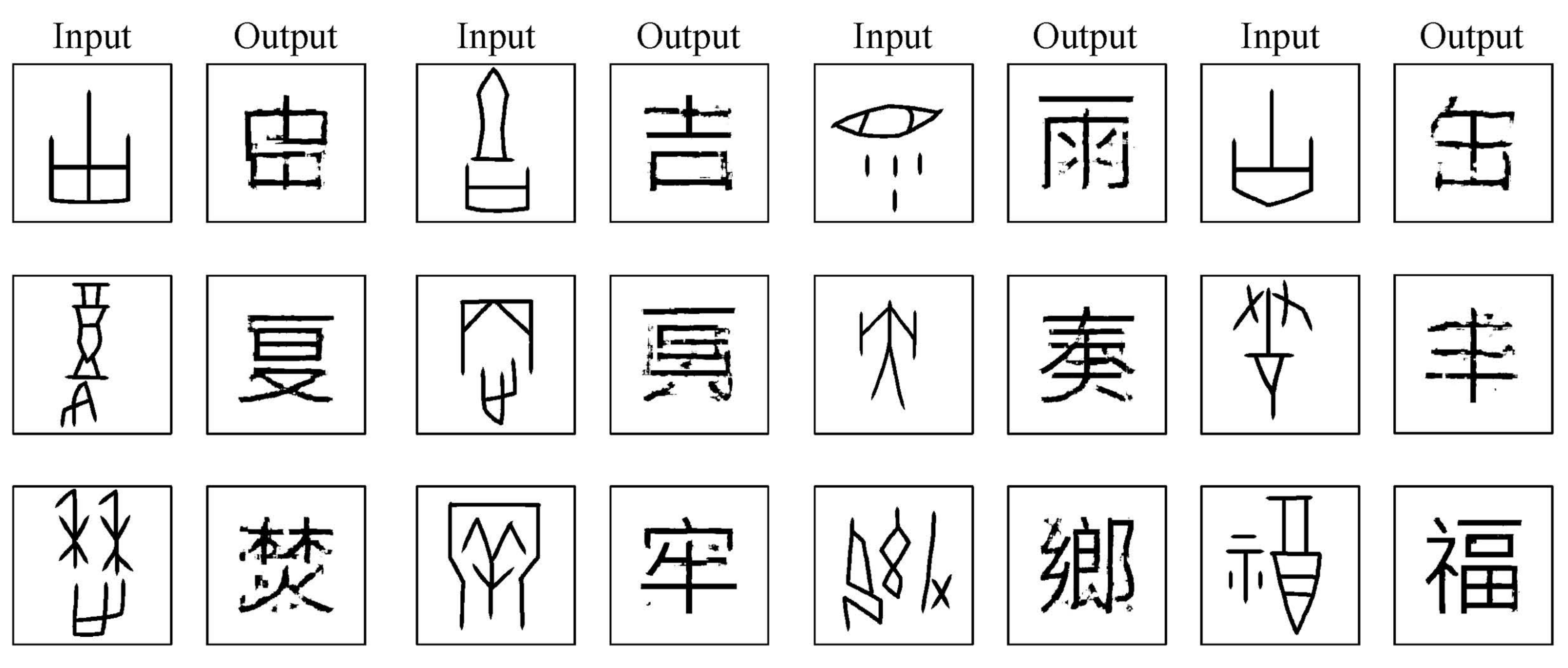
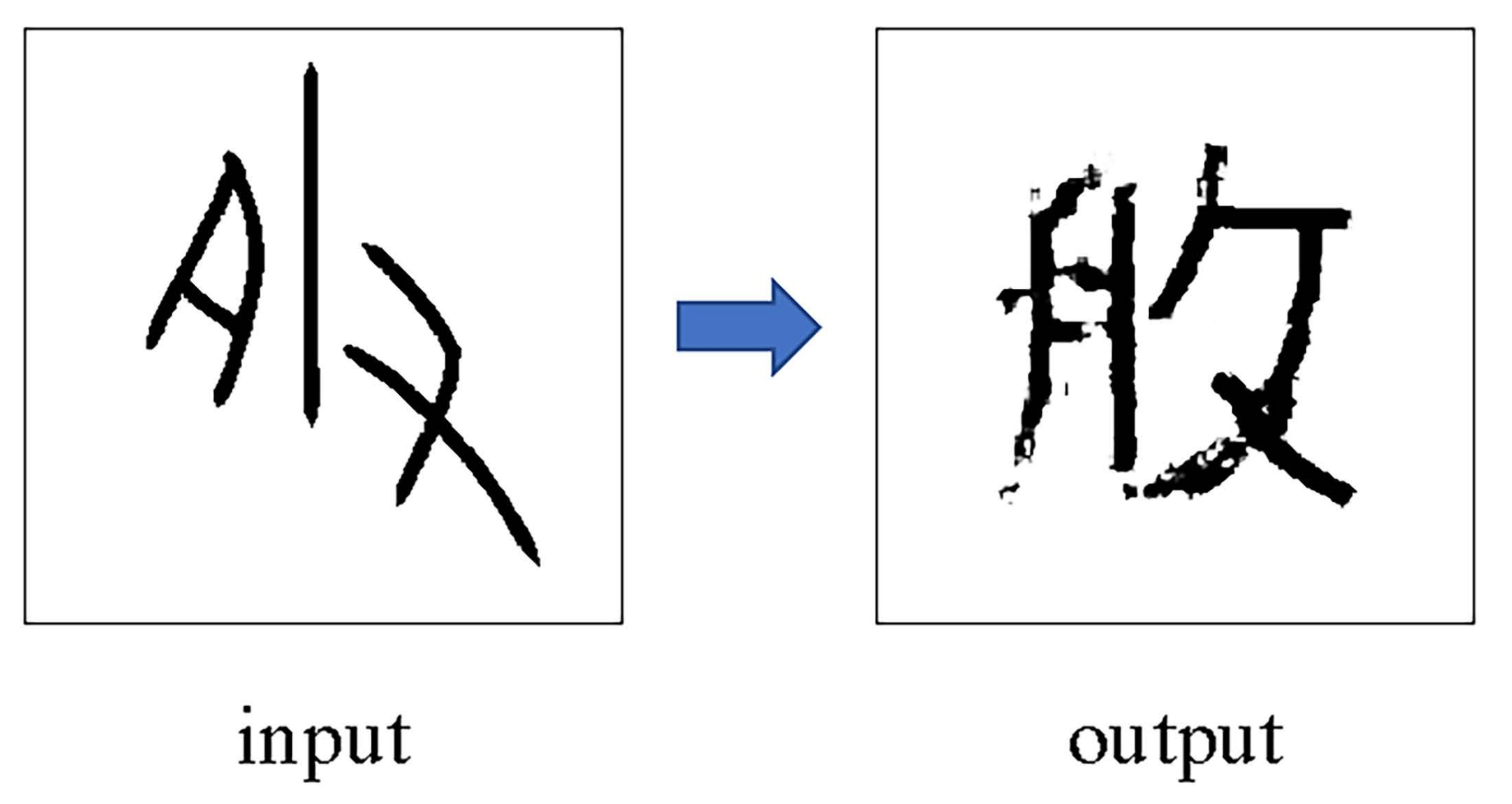
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Flad, R.K. Divination and power: A multiregional view of the development of oracle bone divination in early China. Curr. Anthropol. 2008, 49, 403–437. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Wang, H.; Liu, Y.; Shi, X.; Jin, L. Obc306: A large-scale oracle bone character recognition dataset. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 681–688. [Google Scholar]
- Li, B.; Dai, Q.; Gao, F.; Zhu, W.; Li, Q.; Liu, Y. Hwobc-a handwriting oracle bone character recognition database. J. Phys. Conf. Ser. 2020, 1651, 012050. [Google Scholar] [CrossRef]
- Zhang, C.; Zong, R.; Cao, S.; Men, Y.; Mo, B. Ai-powered oracle bone inscriptions recognition and fragments rejoining. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 11–17 July 2021; pp. 5309–5311. [Google Scholar]
- Madhu, P.; Kosti, R.; Mührenberg, L.; Bell, P.; Maier, A.; Christlein, V. Recognizing characters in art history using deep learning. In Proceedings of the 1st Workshop on Structuring and Understanding of Multimedia heritAge Contents, Nice, France, 21 October 2019; pp. 15–22. [Google Scholar]
- Vaidya, R.; Trivedi, D.; Satra, S.; Pimpale, M. Handwritten character recognition using deep-learning. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 772–775. [Google Scholar]
- Liu, G.; Chen, S.; Xiong, J.; Jiao, Q. An oracle bone inscription detector based on multi-scale gaussian kernels. Appl. Math. 2021, 12, 224–239. [Google Scholar] [CrossRef]
- Meng, L.; Lyu, B.; Zhang, Z.; Aravinda, C.; Kamitoku, N.; Yamazaki, K. Oracle bone inscription detector based on ssd. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; pp. 126–136. [Google Scholar]
- Wang, N.; Sun, Q.; Jiao, Q.; Ma, J. Oracle bone inscriptions detection in rubbings based on deep learning. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 1671–1674. [Google Scholar]
- Xing, J.; Liu, G.; Xiong, J. Oracle bone inscription detection: A survey of oracle bone inscription detection based on deep learning algorithm. In Proceedings of the International Conference on Artificial Intelligence, Information Processing and Cloud Computing, Sanya, China, 19–21 December 2019; pp. 1–8. [Google Scholar]
- Guo, J.; Wang, C.; Roman-Rangel, E.; Chao, H.; Rui, Y. Building hierarchical representations for oracle character and sketch recognition. IEEE Trans. Image Process. 2015, 25, 104–118. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Ren, X.; Lin, H.; Fu, Y.; Xue, X. Self-supervised learning of orc-bert augmentator for recognizing few-shot oracle characters. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Liu, M.; Liu, G.; Liu, Y.; Jiao, Q. Oracle-bone inscription recognition based on deep convolutional neural network. J. Image Graph. 2020, 8, 114–119. [Google Scholar] [CrossRef]
- Zhang, Y.K.; Zhang, H.; Liu, Y.G.; Yang, Q.; Liu, C.L. Oracle character recognition by nearest neighbor classification with deep metric learning. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 309–314. [Google Scholar]
- Li, J.; Wang, Q.F.; Zhang, R.; Huang, K. Mix-up augmentation for oracle character recognition with imbalanced data distribution. In Proceedings of the International Conference on Document Analysis and Recognition, Lausanne, Switzerland, 5–10 September 2021; pp. 237–251. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–14 December 2014; Volume 27. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 12104–12114. [Google Scholar]
- Zhu, J.; Shen, Y.; Zhao, D.; Zhou, B. In-domain gan inversion for real image editing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 592–608. [Google Scholar]
- Rodríguez-de-la Cruz, J.A.; Acosta-Mesa, H.G.; Mezura-Montes, E.; Cosío, F.A.; Escalante-Ramírez, B.; Montiel, J.O. Evolution of conditional-gans for the synthesis of chest X-ray images. In Proceedings of the 17th International Symposium on Medical Information Processing and Analysis, Campinas, Brazil, 17–19 November 2021; Volume 12088, pp. 85–94. [Google Scholar]
- Deng, Y.; Yang, J.; Chen, D.; Wen, F.; Tong, X. Disentangled and controllable face image generation via 3d imitative-contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5154–5163. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Top N | 10 | 20 | 30 | 50 | 100 | 200 |
| Accuracy | 90.8 | 93.5 | 96.3 | 96.7 | 97.9 | 99.4 |
| epoch | 0 | 50 | 100 | 150 |
| 244.2 | 180.7 | 173.6 | 178.3 |
| Top N | 10 | 20 | 30 | 50 | 100 | 200 |
| Accuracy | 10.4 | 15.5 | 23.1 | 27.5 | 35.6 | 49.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; Zhang, J.; Liu, Y.; Han, Y. Image Translation for Oracle Bone Character Interpretation. Symmetry 2022, 14, 743. https://doi.org/10.3390/sym14040743
Gao F, Zhang J, Liu Y, Han Y. Image Translation for Oracle Bone Character Interpretation. Symmetry. 2022; 14(4):743. https://doi.org/10.3390/sym14040743
Chicago/Turabian StyleGao, Feng, Jingping Zhang, Yongge Liu, and Yahong Han. 2022. "Image Translation for Oracle Bone Character Interpretation" Symmetry 14, no. 4: 743. https://doi.org/10.3390/sym14040743
APA StyleGao, F., Zhang, J., Liu, Y., & Han, Y. (2022). Image Translation for Oracle Bone Character Interpretation. Symmetry, 14(4), 743. https://doi.org/10.3390/sym14040743