
Asymmetric versus Symmetric Binary Regresion: A New Proposal with Applications



Abstract
:1. Introduction
2. Methodological Background
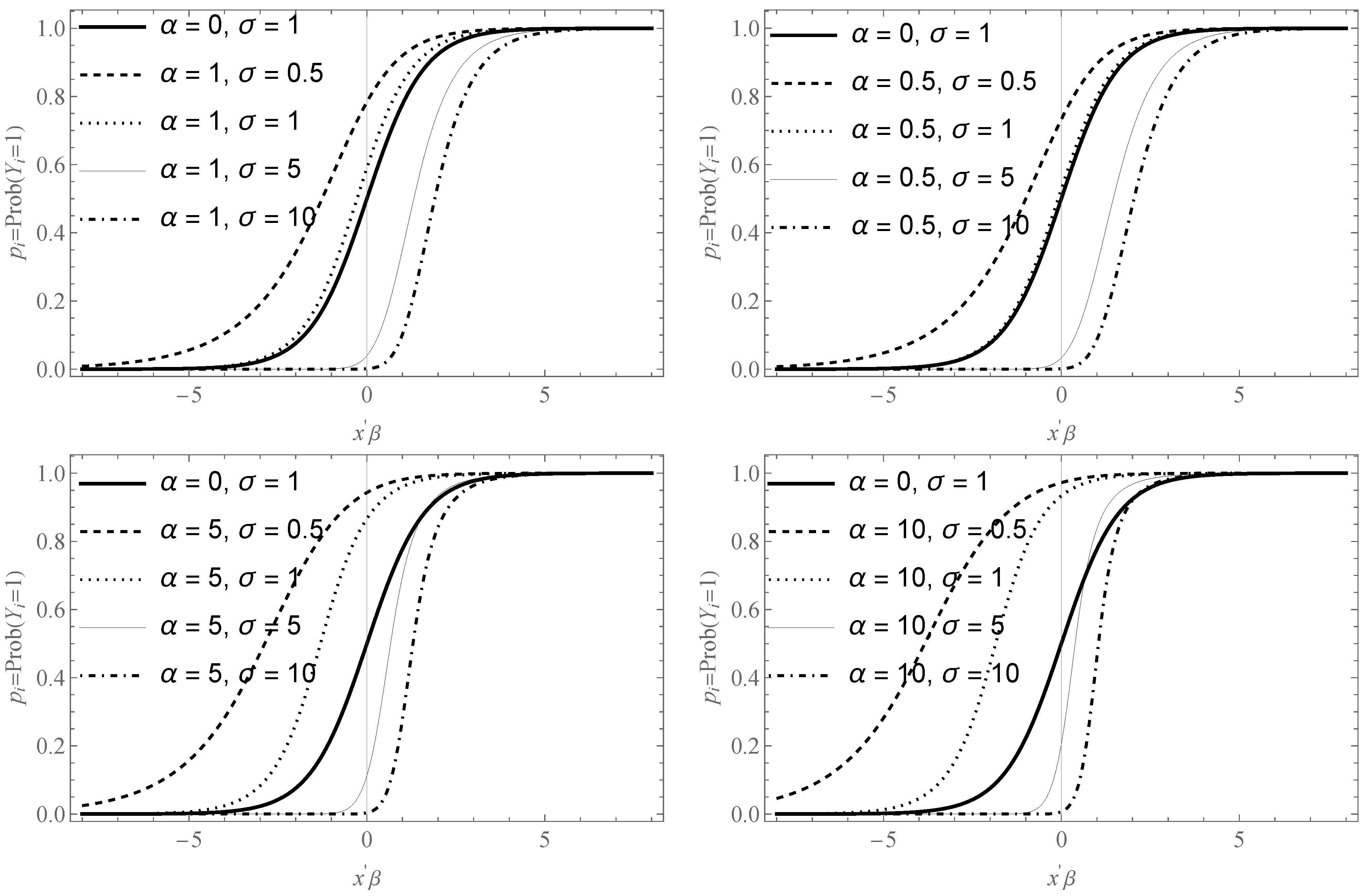
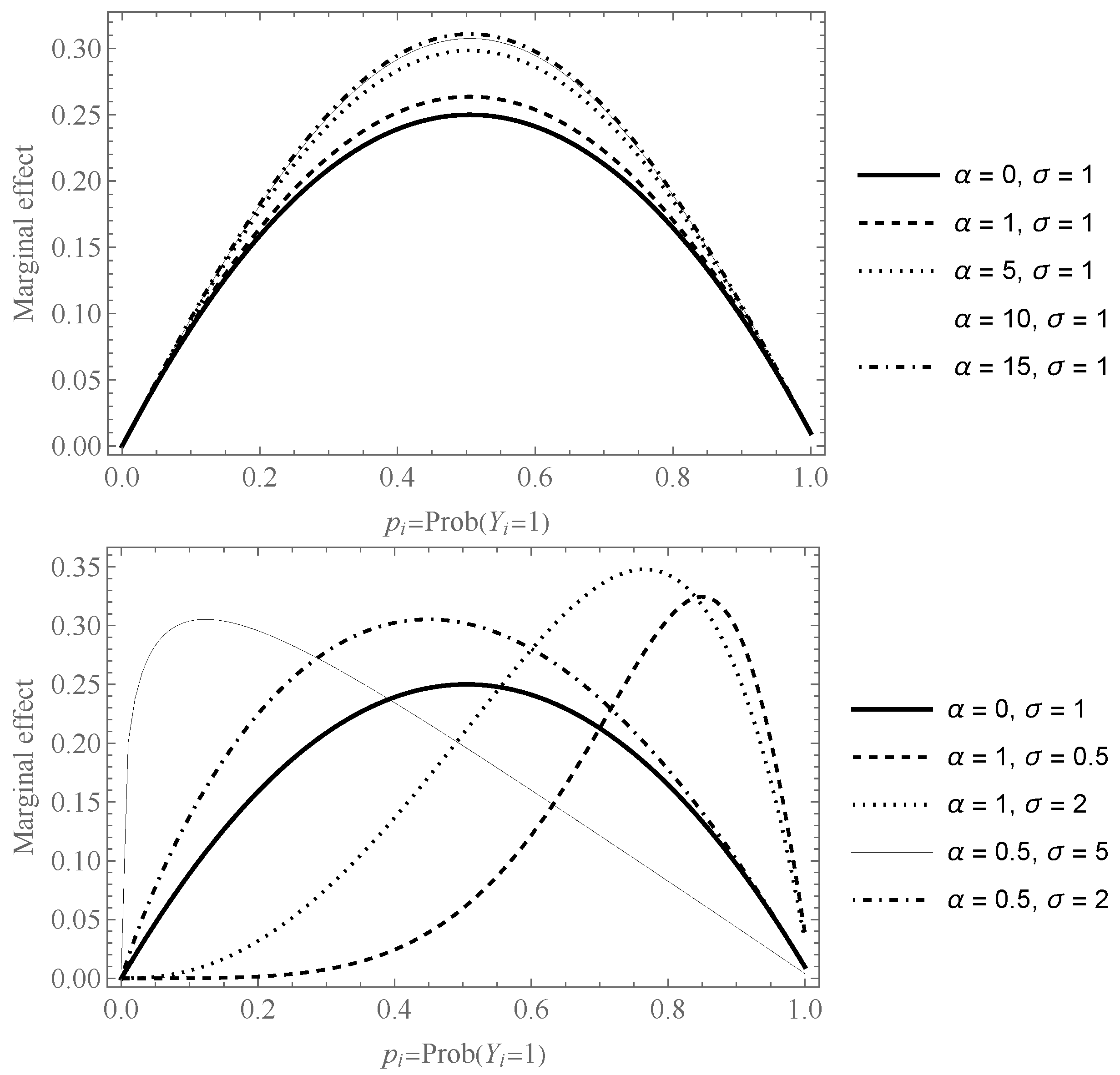
3. Asymmetric Logistic Specification
Specific Model
- (i)
- is said to be stochastically smaller than denoted by if for all x;
- (ii)
- is said to be smaller than in the hazard rate order, denoted by if for all x.
4. Empirical Application
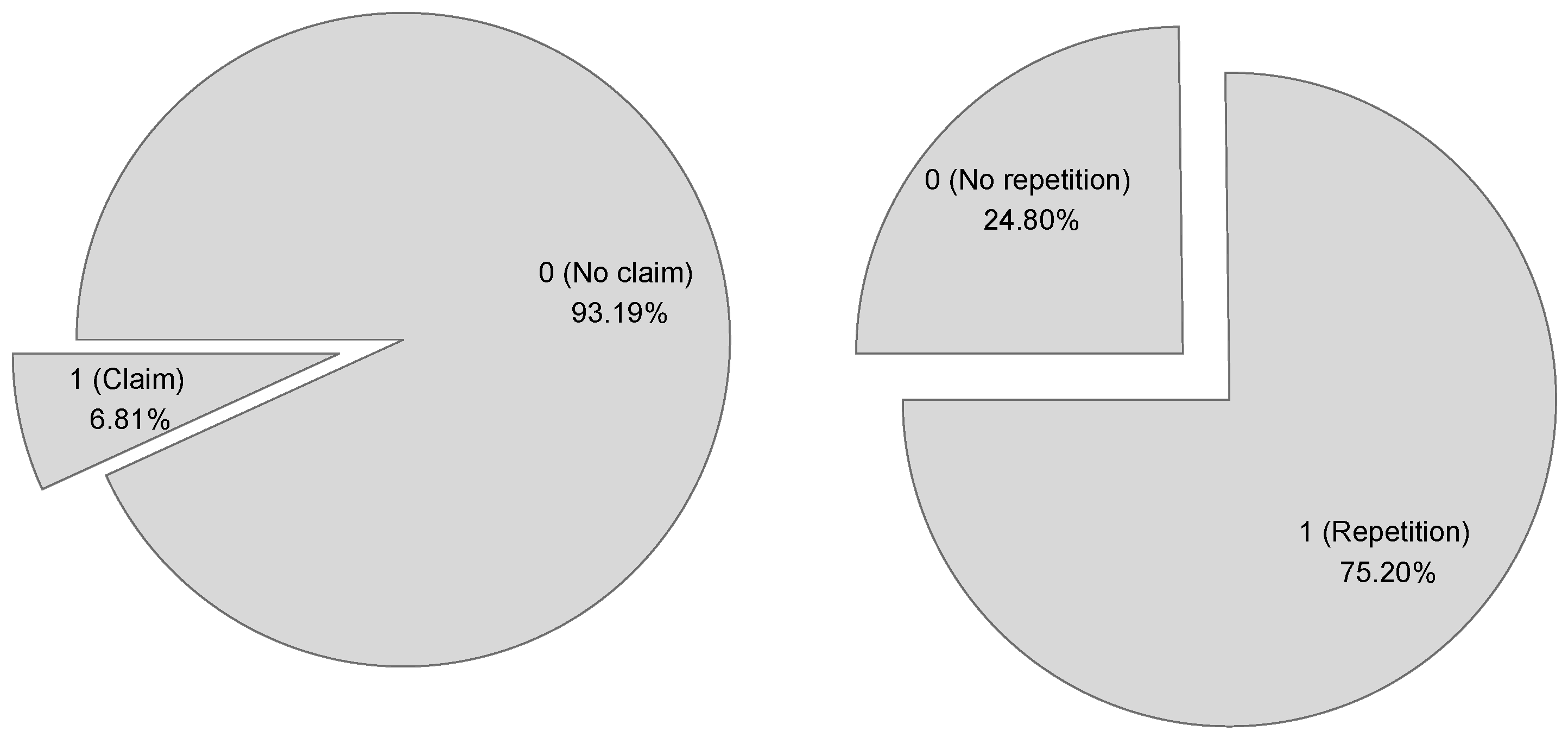
4.1. Brief Description of the Automobile Database
- Vehicle’s value (VAGE) in USD 10,000;
- The body of the vehicle, coded as, Bus (BUS), Convertible (CONVT), Coupe (COUPE), Utility (UTE), and Hatchback (HBACK);
- Area: driver’s area of residence: A, B, C, D, E (the reference variable is the driver’s area of residence F);
- Age (AGE): driver’s age category: 1 (youngest), 2, 3, 4, 5, 6 (older);
4.2. Third Database and Brief Description
- Length of stay (LS) (trip duration or number of nights) in the Canaries;
- INCOME. This is an ordered categorical variable. It takes the following values: =1, from €12,001 to €24,000; =2, from €24,001 to €36,000; =3, from €36,001 to €48,000; =4, from €48,001 to €60,000; =5, from €60,001 to €72,000; =6, from €72,001 to €84,000; and =7, higher than €84,001;
- Type of accommodation. Three types of variable are considered. First, an indicator which takes the value 1 if the tourist accommodation is a 5-star hotel/aparthotel, and the value 0 otherwise (STARSUP). Second, an indicator which takes the value 1 for a 4-star hotel/aparthotel (STAR45), and 0 otherwise. Finally, a binary variable which takes the value 1 if the accommodation is a 1, 2, or 3-star hotel/aparthotel, and 0 otherwise (STAR3). The reference category represents other types of accommodation, such as the tourists’ own property, friends or family property, or campsites or apartments;
- REPETITION. A dichotomic variable which takes the value 1 if the tourist has visited the Canaries previously, and 0 otherwise. This corresponds to the dependent variable;
- JOB. This variable contains the following categories: business owner, self employed, liberal profession, upper management employee, middle management employee, auxiliary level employee, other employee, student, retired, homemaker, and unemployed. Three dummy variables are considered. Business owner takes the value 1 if the tourist is a business owner, and 0 otherwise. Self employed takes the value 1 if the tourist is self employed or has a liberal profession and 0 otherwise. Salaried worker takes the value 1 if the tourist works for a salary and 0 otherwise. The reference category is student, retired, homemaker, and unemployed;
- LOW COST. This is an indicator that takes the value one if the tourist has travelled in a low-cost airline and 0 otherwise.
4.3. Estimation Results and Discussion
5. Final Comments
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Prentice, R.L. A generalization of the probit and logit methods for dose-response curves. Biometrika 1976, 32, 761–768. [Google Scholar] [CrossRef]
- Nagler, J. Scobit: An alternative estimator to logit and probit. Am. J. Polit. Sci. 1994, 38, 230–255. [Google Scholar] [CrossRef]
- Aranda-Ordaz, F.J. On two families of transformations to additivity for Binary Response data. Biometrika 1981, 68, 357–363. [Google Scholar] [CrossRef]
- Guerrero, V.M.; Johnson, R. Use of the Box-Cox transformation with Binary Response models. Biometrika 1982, 69, 309–314. [Google Scholar] [CrossRef]
- Albert, J.; Chib, S. Bayesian residual analysis for binary response regression models. Biometrika 1995, 82, 747–769. [Google Scholar] [CrossRef]
- Stukel, T.A. Generalized logistic models. J. Am. Stat. Assoc. 1988, 83, 426–431. [Google Scholar] [CrossRef]
- Chen, M.; Dey, D. Bayesian modeling of correlated binary responses via scales mixture of multivariate normal link models. Sankhȳa Ser. A Indian J. Stat. Spec. Issue Bayesian Anal. 1998, 60, 322–343. [Google Scholar]
- Chen, M.; Dey, D.; Shao, Q. A new skewed link model for dichotomous quantal response data. J. Am. Stat. Assoc. 1999, 94, 1172–1186. [Google Scholar] [CrossRef]
- van Niekerk, J.; Rue, H. Skewed probit regression-identifiability, contraction and reformulation. REVSTAT–Stat. J. 2021, 19, 1–22. [Google Scholar]
- Bazán, J.L.; Branco, M.S.; Bolfarine, H. A skew item response model. Bayesian Anal. 2006, 1, 861–892. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Bazán, J.L. New links for binary regression: An application to coca cultivation in Peru. Test 2006, 27, 597–617. [Google Scholar] [CrossRef]
- Caron, R.; Sinha, D.; Dey, D.K.; Polpo, A. Categorical data analysis using a skewed Weibull regression model. Entropy 2018, 20, 176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bermúdez, L.; Pérez-Sánchez, J.; Ayuso, M.; Gómez-Déniz, E.; Vázquez-Polo, F. A bayesian dichotomous model with asymmetric link for fraud in insurance. Insur. Math. Econ. 2008, 42, 779–786. [Google Scholar] [CrossRef]
- Pérez-Sánchez, J.; Negrín-Hernández, M.; García-García, C.; Gómez-Déniz, E. Bayesian asymmetric logit model for detecting risk factors in motor ratemaking. ASTIN Bull. 2014, 44, 445–457. [Google Scholar] [CrossRef]
- Tay, R. Comparison of the binary logistic and skewed logistic (Scobit) models of injury severity in motor vehicle collisions. Accid. Anal. Prev. 2016, 88, 52–55. [Google Scholar] [CrossRef]
- Alkhalaf, A.; Zumbo, B.D. The impact of predictor variable(s) with skewed cell probabilities on Wald tests in binary logistic regression. J. Mod. Appl. Stat. Methods 2017, 16, 40–80. [Google Scholar] [CrossRef]
- Mwenda, N.; Nduati, R.; Kosgei, M.; Kerich, G. Skewed logit model for analyzing correlated infant morbidity. PLoS ONE 2021, 16, e0246269. [Google Scholar] [CrossRef]
- Mirzadeh, S.; Iranmanesh, A. A new class of skew-logistic distribution. Math. Sci. 2019, 13, 375–385. [Google Scholar] [CrossRef] [Green Version]
- Esmaeili, H.; Lak, F.; Alizadeh, M.; Dehghan, M. The Alpha-Beta Skew Logistic Distribution: Properties and Applications. Stat. Optim. Inf. Comput. 2020, 8, 304–317. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, F.; Zhu, K. Modeling normalcy-dominant ordinal time series: An application to air quality level. J. Time Ser. Anal. 2022; forthcoming. [Google Scholar] [CrossRef]
- O’Connell, A. Logistic Regression Models for Ordinal Response Variables; Quantitative Applications in Social Sciences Series; SAGE Publications: Thousand Oaks, CA, USA, 2001. [Google Scholar]
- Cramer, J.S. Logit Models from Economics and Other Fields; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Brooks, C. RATS Handbook to Accompany Introductory Econometrics for Finance; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Jacob, E.; Jayakumar, K. On half-Cauchy distribution and process. Int. J. Stat. Math. 2012, 3, 77–81. [Google Scholar]
- Gómez-Déniz, E.; Calderín, E. On the use of the Pareto ArcTan distribution for describing city size in Australia and New Zealand. Phys. A—Stat. Mech. Its Appl. 2015, 436, 821–832. [Google Scholar] [CrossRef]
- Gómez-Déniz, E. A family of arctan Lorenz curves. Empir. Econ. 2016, 51, 1215–1233. [Google Scholar] [CrossRef]
- Calderín-Ojeda, E.; Azpitarte, F.; Gómez-Déniz, E. Modelling income data using two extensions of the exponential distribution. Phys. A—Stat. Mech. Its Appl. 2016, 461, 756–766. [Google Scholar] [CrossRef]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Ross, S.M. Stochastic Processes, 2nd ed.; Wiley Series in Probability; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1996. [Google Scholar]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Sarabia, J.; Castillo, E. About a class of max-stable families with applications to income distributions. METRON 2005, LXIII, 505–527. [Google Scholar]
- Bliss, C.I. The calculation of the dosage-mortality curve. Ann. Appl. Biol. 1935, 22, 134–167. [Google Scholar] [CrossRef]
- de Jong, P.; Heller, G. Generalized Linear Models for Insurance Data; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dosage | 1.6907 | 1.7242 | 1.7552 | 1.7842 | 1.8113 | 1.8369 | 1.861 | 1.8839 |
| Insects | 6 | 13 | 18 | 28 | 52 | 53 | 61 | 60 |
| Killed | 59 | 60 | 62 | 56 | 63 | 59 | 62 | 60 |
| Logit fit | 3.48 | 9.85 | 22.41 | 33.80 | 49.98 | 53.21 | 59.17 | 58.71 |
| Chi-square | 1.828 | 1.004 | 0.866 | 0.994 | 0.082 | 0.001 | 0.056 | 0.028 |
| General Scobit fit | 6.10 | 11.28 | 20.16 | 29.69 | 48.45 | 54.76 | 60.91 | 59.75 |
| Chi-square | 0.002 | 0.260 | 0.231 | 0.096 | 0.260 | 0.057 | 0.000 | 0.001 |
| Logit | Scobit | SAT | ||||
|---|---|---|---|---|---|---|
| Variable | Estimate (SE) | ME | Estimate (SE) | ME | Estimate (SE) | ME |
| VAGE | 0.057 (0.012) *** | 0.005 | 0.026 (0.006) *** | 0.001 | 0.030 (0.005) *** | 0.007 |
| BUS | 1.110 (0.371) ** | 0.134 | 0.556 (0.237) ** | 0.129 | 0.628 (0.206) ** | 0.130 |
| CONVT | −1.066 (0.598) | −0.059 | −0.425 (0.254) | −0.056 | −0.508 (0.266) * | −0.057 |
| COUPE | 0.215 (0.128) | 0.019 | 0.099 (0.063) | 0.019 | 0.114 (0.061) * | 0.019 |
| UTE | −0.244 (0.067) *** | −0.019 | −0.103 (0.030) *** | −0.017 | −0.121 (0.031) *** | −0.017 |
| HBACK | −0.006 (0.036) | −5.04 × 10 | −0.002 (0.017) | 3.54 × 10 | −0.002 (0.017) | −3.1 × 10 |
| AREA A | −0.107 (0.070) | −0.009 | −0.045 (0.031) | −0.008 | −0.053 (0.022) ** | −0.008 |
| AREA B | −0.009 (0.071) | −7.50 × 10 | −0.002 (0.031) | −3.54 × 10 | −0.003 (0.022) | −4.64 × 10 |
| AREA C | −0.067 (0.069) | −0.005 | −0.028 (0.030) | −0.005 | −0.033 (0.021) | −0.005 |
| AREA D | −0.193 (0.078) ** | −0.016 | −0.082 (0.035) ** | −0.014 | −0.096 (0.028) *** | −0.014 |
| AREA E | −0.121 (0.082) | −0.009 | −0.052 (0.038) | −0.009 | −0.061 (0.030) ** | −0.009 |
| AGE | −0.083 (0.010) *** | −0.007 | −0.036 (0.005) *** | −0.002 | −0.042 (0.004) *** | −0.010 |
| −0.226 (0.031) *** | ||||||
| 5.792 (0.074) *** | 3.276 (0.001) *** | |||||
| CONSTANT | −2.340 (0.078) *** | 0.642 (0.017) *** | −0.112 (0.001) *** | |||
| NLL | 16,820.912 | 16,820.334 | 16,820.464 | |||
| Chi-square | 7423.71 | 7245.82 | 7281.60 | |||
| Logit | Scobit | LAT | SAT | |
|---|---|---|---|---|
| Variable | Estimate (SE) | Estimate (SE) | Estimate (SE) | Estimate (SE) |
| INCOME | 0.182 (0.013) *** | 0.162 (0.011) *** | 0.156 (0.011) *** | 0.073 (0.010) *** |
| LOWCOST | −0.062 (0.055) | −0.049 (0.043) | −0.049 (0.045) | −0.018 (0.022) |
| JOB | −0.099 (0.064) | −0.084 (0.053) | −0.082 (0.053) | −0.035 (0.026) |
| STAR45 | −0.031 (0.055) | −0.031 (0.045) | −0.028 (0.045) | −0.016 (0.022) |
| STAR3 | −0.213 (0.069) ** | −0.181 (0.057) ** | −0.177 (0.057) ** | −0.075 (0.028) ** |
| STARSUP | −0.408 (0.126) *** | −0.360 (0.106) *** | −0.347 (0.103) *** | −0.160 (0.059) ** |
| LS | 0.076 (0.007) *** | 0.066 (0.006) *** | 0.064 (0.006) *** | 0.028 (0.004) *** |
| 59.817 (21.101) ** | 16.429 (6.061) ** | |||
| 36.511 (2.437) *** | 29.429 (0.001) *** | |||
| CONSTANT | 0.407 (0.153) *** | 4.238 (0.063) *** | −3.786 (0.379) *** | 2.370 (0.103) *** |
| NLL | 5424.235 | 5422.862 | 5423.053 | 5420.629 |
| Chi-square | 3493.96 | 3485.11 | 3479.47 | 3458.27 |
| Scobit | SAT | |
|---|---|---|
| Variable | Estimate (SE) | Estimate (SE) |
| INCOME | 8.041 (0.468) *** | 0.155 (0.009) *** |
| LOWCOST | −2.604 (1.621) | −0.049 (0.044) |
| JOB | −3.120 (1.584) ** | −0.081 (0.046) * |
| STAR45 | −0.965 (1.081) | −0.028 (0.045) |
| STAR3 | −11.426 (2.052) *** | −0.176 (0.055) *** |
| STARSUP | −8.876 (3.248) ** | −0.345 (0.090) *** |
| LS | 3.143 (0.146) *** | 0.064 (0.005) *** |
| −365.691 (64.688) *** | ||
| 0.004 (<0.001) *** | 1.115 (0.044) *** | |
| q | 0.628 (0.001) *** | 0.391 (0.061) *** |
| NLL | 5445.790 | 5423.030 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez-Déniz, E.; Calderín-Ojeda, E.; Gómez, H.W. Asymmetric versus Symmetric Binary Regresion: A New Proposal with Applications. Symmetry 2022, 14, 733. https://doi.org/10.3390/sym14040733
Gómez-Déniz E, Calderín-Ojeda E, Gómez HW. Asymmetric versus Symmetric Binary Regresion: A New Proposal with Applications. Symmetry. 2022; 14(4):733. https://doi.org/10.3390/sym14040733
Chicago/Turabian StyleGómez-Déniz, Emilio, Enrique Calderín-Ojeda, and Héctor W. Gómez. 2022. "Asymmetric versus Symmetric Binary Regresion: A New Proposal with Applications" Symmetry 14, no. 4: 733. https://doi.org/10.3390/sym14040733
APA StyleGómez-Déniz, E., Calderín-Ojeda, E., & Gómez, H. W. (2022). Asymmetric versus Symmetric Binary Regresion: A New Proposal with Applications. Symmetry, 14(4), 733. https://doi.org/10.3390/sym14040733