1. Introduction
As a fundamental issue in improving software quality, software reliability must meet user satisfaction and lower the cost of software testing when the software is released to the market. Software developers need to balance between software test costs and reliability. To decrease costs throughout software testing/debugging, software developers need to consider to what extent the reliability of software has to be secured. The development process of software is managed by considering the reliability, cost, and release time into the market. Thus, estimating the reliability of software is essential to the software industry throughout the testing/debugging process and is directly related to the total cost of development. Therefore, an appropriate model for estimating the reliability and testing costs is based on the assumptions of a symmetrical Gaussian distribution of data. However, previous models were only appropriate for limited testing data, thus having limited applications. The limited data cause a problem when assuming a symmetric normal distribution of data, which is mandatory for calculating statistical parameters. Thus, a new method is required to solve such problems by finding a solution from the possible asymmetrical data for the decision of testing and releasing software to the market.
Software reliability may be related to imperfections in its coding. Imperfections were discussed for hardware production by Bucolo et al., who tried to find out the causes of the occurrence of chaotic oscillation in electronic circuits. Such unexpected and chaotic occurrence of imperfection may also occur in software development [
1]. Previously, software reliability growth models (SRGMs) have been proposed to optimally reduce software failure using the nonhomogeneous Poisson process (NHPP) to model such imperfection. The optimal approach for a reduction in imperfection is to decrease software errors such that their occurrence follows an S- or exponential shape with decreasing confidence intervals of the mean values of the frequency of error. Thus, a new SRGM is needed for improving the software reliability by representing S- and exponential-shaped confidence intervals to get rid of imprecise assumptions from the asymmetry of the data.
Software developers and testers utilize SRGMs to balance between the reliability and the testing cost of the software. It is critical to choose the best time of software release with optimal software reliability. Therefore, we present a model with a stochastic differential equation (SDE). The proposed model is proposed to evaluate the software reliability by considering S-shaped confidence intervals of mean values in software error occurrences. The model is expected to solve the problems of the previous models and help to precisely estimate the software reliability. Additionally, the optimal time for software release is estimated according to the confidence level. The result provides a new way to decide a software release time to the market with an acceptable balance between testing costs and reliability for the software.
In this paper,
Section 2 presents a brief literature review related to SRGMs.
Section 3 explains Ohba’s SRGM that uses stochastic differential equations for the error detection rate. Estimation of the specification and validation of the result of the proposed model are also presented in this section.
Section 4 describes an optimal software release model.
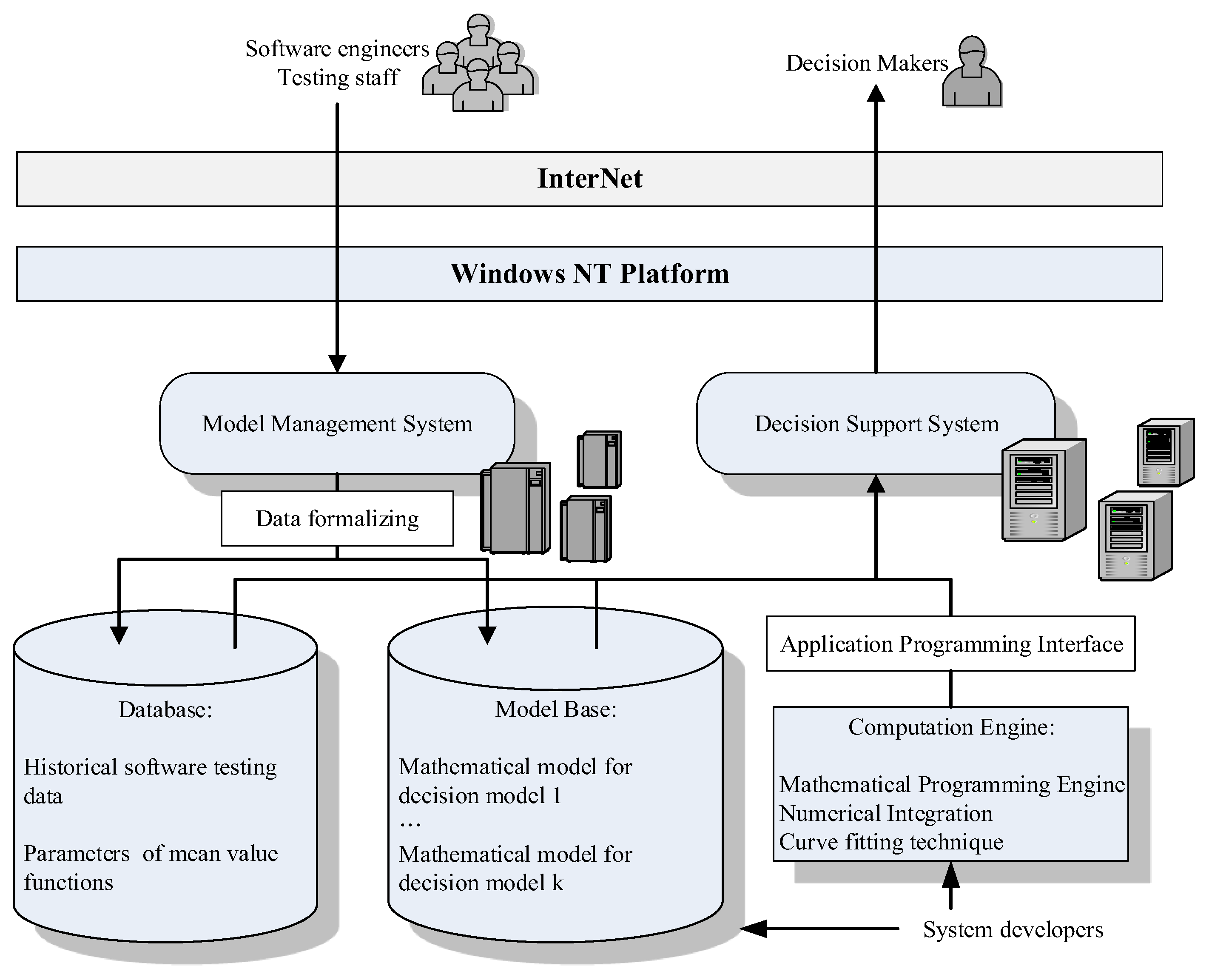
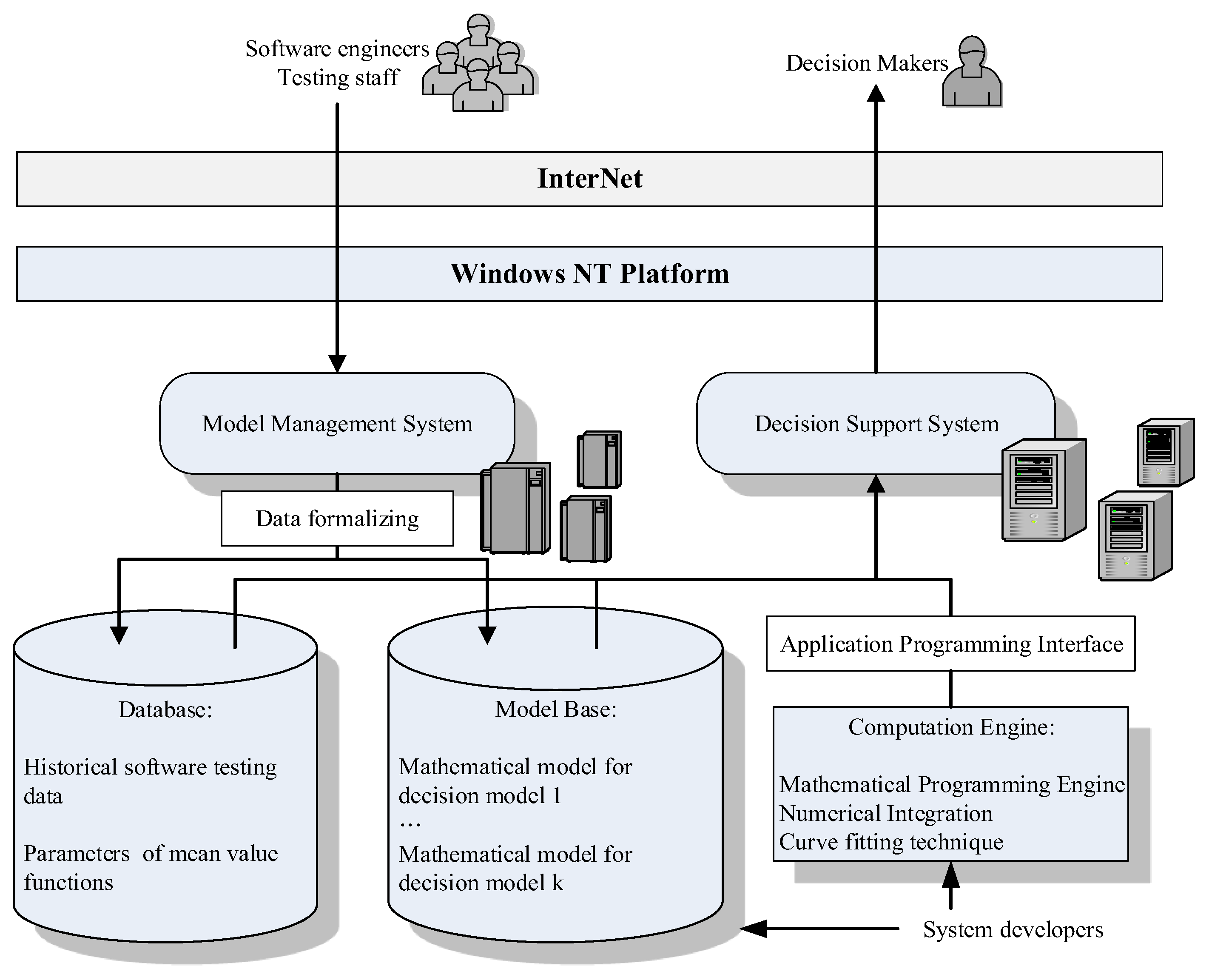
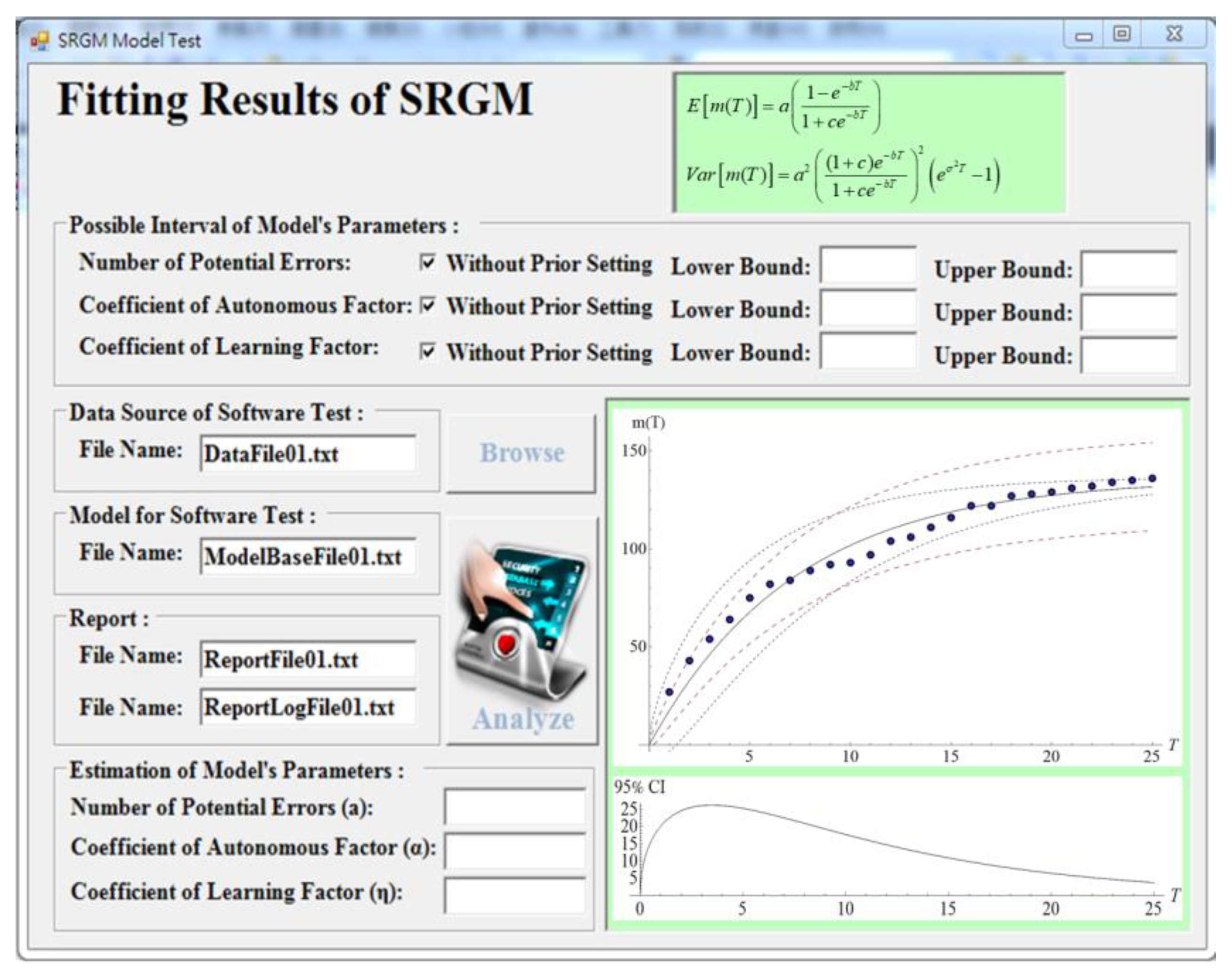
Section 5 illustrates the architecture and the designed user interface of the decision support system for the proposed model.
Section 6 summarizes the result of the model in this study to demonstrate its effectiveness. Lastly, the conclusions and suggestions for further research are presented in
Section 7.
2. Literature Review
During testing and debugging, software reliability is useful for decision making. In the software industry, increasing reliability and reducing costs are the main goals [
2]. The software developer needs to ensure the higher quality and the lower cost of the developed software as the most important objective during software development. Therefore, SRGMs are necessary to decide the release time of software and reduce its testing and debugging cost. Generally, SRGMs include exponential-shaped models, S-shaped models, or a mixture of both models [
3].
NHP is commonly used to find the causes of the failure of software development. To illustrate the error detection of software development, Goel and Okumoto (1979) and Musa (1984) proposed exponential SRGMs in different aspects [
4,
5], which were generalizations or modifications of SRGMs. Musa, Yamada et al., and Yamada and Ohba respectively proposed exponential-shaped, S-shaped, and inflection S-shaped SRGMs for increasing the reliability of data testing [
6,
7,
8]. For assessing the reliability, Pham and Zhang proposed an SRGM with combined estimations of testing and quality assurance [
9]. Moreover, to analyze system reliability and performance, Huang tried to combine a logical testing effort function with change-point parameters to construct an SRGM [
10].
The competitiveness of the project is determined by the timing of software release and quality and cost. Therefore, the accurate estimation of reliability and cost is subject to the efforts and resources of the testing project. SRGMs need to be reiterated on the basis of failure data. However, how programming designers learn from this during software testing and debugging is not considered in SRGMs. This learning effect affects the reliability of software without changing the cost of testing and debugging, as the experience of detecting errors according to the testers’ patterns is efficient. However, since software testing has uncertainties, the software developer needs to consider the risk and possible inaccuracy.
It is critical to understand a process of an accurate estimation of the confidence intervals of the mean value and the reliability of software. Most of the previous SRGMs adopted NHPP using the confidence interval of mean values. The confidence interval is calculated as
, where CR is the critical region,
is the critical value of a given area, and CR/2 is the standard normal distribution. Yamada and Osaki utilized different confidence intervals in their applications [
11]. According to their study, the maximum likelihood method is efficient in estimating confidence intervals and related parameters. They considered a variance of testing time since the standard deviation is positively correlated with testing time. The confidence interval follows the assumption of NHPP; hence, they believed that the variance increased with the time for testing. However, as the occurrence of software defects is finite, the variance decreases as the testing time elapses. Therefore, the cumulative number of software errors decreases. This is different from the result of the estimation method of NHPP for hardware.
There have been efforts to improve the estimation of the confidence interval. Lee et al. and Tamura and Yamada thought that the variance is caused by the error detecting procedure, and the mean is estimated by stochastic differential equations (SDEs) [
12,
13]. Despite the effectiveness in assessing the mean value, the inference process still has problems. For instance, Ho et al. proposed an Itô-type SDE model with a changeable error detection rate [
14]. Lee et al. (2004) extended the SRGMs [
12] from Ohba [
8] and Yamada [
6] without the estimated variance. They used an Itô-type SDE method to improve the estimation of the confidence intervals so that a decision-maker can reasonably estimate the variability of software reliability and cost of testing software. Fang and Yeh [
15] extended the SRGM of Tamura and Yamada [
13] to propose flexible SDE models. However, their model did not obtain parameters; thus, the mean value and variance were not obtained.
Accurate estimation of risk is critical for software developers in deciding software release time. An SRGM assists decision-makers in finding the right timing for software release by estimating cost, system reliability, and required constraints. The environment for testing is important for software development and its release in time. Cortellessa et al. proposed an optimization-based approach to minimize costs on the basis of reliability and performance constraints [
16]. Awad proposed to use software reliability and increased testing time to reduce system failure under limited time, resources, and cost [
17]. According to Kooli et al. [
18], there are differences in time and cost for reliability tests. Li and Pham suggested a reliability model based on the uncertainty in the operating environment [
19]. The model determines the optimal release date of software with the reliability of software and testing cost. Zhu and Pham noted [
20] that complete removal of software errors for each release is almost impossible due to limited resources. Thus, it is necessary to set an acceptable threshold for multiple software releases. Cao et al. proposed a model to minimize the cost of testing software and penalty after software releases [
21]. A threshold was adopted for effectively determining the optimal time and cost of the software. Some imperfect systems regarding electronic circuits may also cause the risk of reliability [
1]. Kim et al. [
22] developed a software reliability model under the assumption that software failures occur in a dependent manner, which is different to the general assumption of independent manner. A policy of real-time software rejuvenation was proposed by Levitin et al. [
23] by taking the distribution of transition times into account in the cost evaluation model.
On the basis of the previous study results, an improved model is proposed for the estimation of the mean and the confidence interval of system reliability and testing cost based on an SDE with an error detection function. It provides software developers with the relevant information for the risk management of software reliability and cost estimation.
3. Ohba’s DRGM with Stochastic Differential Equation
3.1. Model Development
SRGMs are effective in predicting the increase in software reliability. To fit the data into a model, the below SRGM based on NHPP is chosen. The methods of calculating error detection rate and mean value function are presented in
Table 1.
No method for calculating the confidence interval is presented in
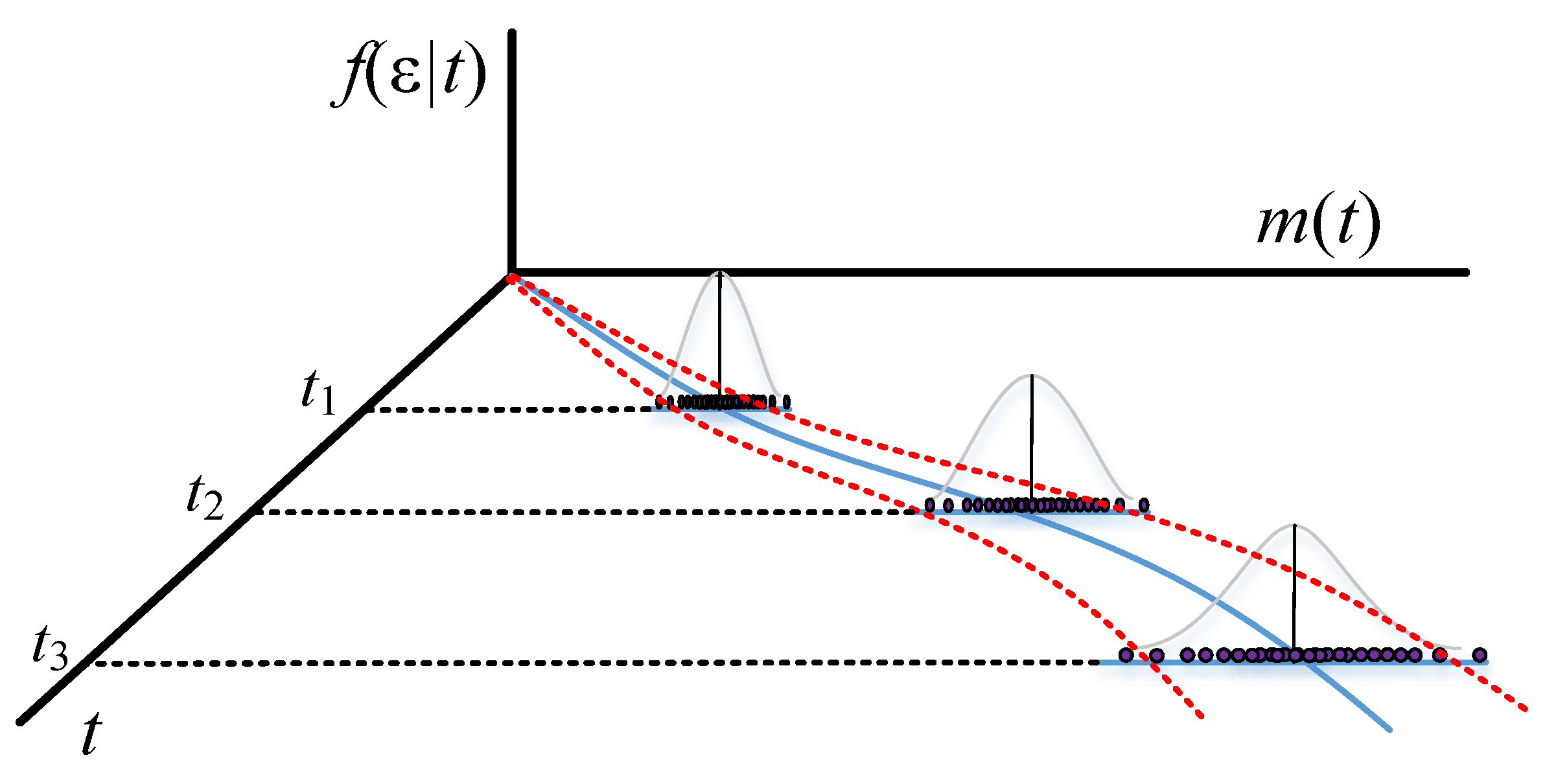
Table 1. Without it, software developers cannot estimate the increase in software reliability and cost in the testing and debugging process of software. Thus, we calculated confidence intervals using Ohba’s inflection S-shaped model as the confidence interval helps software developers evaluate potential changes in software reliability and cost to make a conservative decision for testing software. To obtain the confidence interval, the variance of the efficiency of debugging software is assumed to fluctuate with the detection rate of error and changes with testing time. The following notation is used to derive the proposed model in this study:
: the potential errors number are hidden in the system without any software debugging process;
: the mean is calculated with the expected number of detected errors in the testing time range ;
: the function of the residual error in a system at the testing time t and defined as ;
: the error detection rate at testing time t;
: the continuous-time stochastic process that indicates the magnitude of irregular fluctuations from the error detection rate ;
: the standard deviation of .
According to the definition of previous SRGMs, the error detection rate is regarded as the proportion of errors detected at time
t and residual errors in a system. The rate is represented as
. However, the fluctuation in the number of debugging software is not considered since the fluctuation originates from the function to calculate mean values. Therefore, we propose a new definition of fluctuation. In practice, the detection rate usually fluctuates during a test even with a trend due to the instability of human work. Accordingly, in debugging, the fluctuation of an error detection rate is presented as follows:
where
denotes the irregular fluctuations of the error detection rate. To deduce and solve the above equation smoothly, we define the function
that is equal to
. Therefore, substituting
for
transforms Equation (1) to
Taking a logarithm of
and making it equal to
, the following equation is obtained with Itô’s method:
As the integral of the derivative of
from 0 to
,
is defined as
where
is as follows:
Therefore, Equation (4) is arranged as
Since
is equal to
, Equation (6) is rewritten as follows:
By solving Equation (7),
is defined as
is for random variables that are normally distributed. To obtain the expected value of
, Equation (8) needs to be further processed by applying the probability theory as follows:
where
is deduced from
. Then, Equation (8) is simplified as
Due to the initial condition of
, the constant
of the equations is equal to
. Therefore, the expected mean,
is obtained as follows:
The variance of the mean
is defined as
For obtaining
, the value of
needs to be calculated first. As given by Equation (7),
is used to obtain the real form of
. The following mathematical deduction leads to
:
Furthermore, as
, Equation (13) is rewritten as
Similarly, since
,
is defined as
On the basis of Equations (14) and (15), the variance
of the mean value is obtained as
Since is mapping , according to Equation (11).
Even with the expected and the variance of the mean, practical application is required for software developers.
Section 3.3 describes how confidence intervals are applied to the decision making of the release time of software considering the testing cost and required reliability. Since the parameter of Ohba’s inflection S-shaped model needs to be estimated,
Section 3.2 presents the least-squares estimation (LSE) and the maximum likelihood estimation (MLE) for the proposed model.
3.2. Estimating Parameters
LSE and MLE are proposed for estimating the parameters
,
, and
[
24]. The MLE is used to estimate the parameters of a probability distribution by a maximized likelihood function. Suppose that the set of paired data
is collected where
is the detected number of errors until
. It is assumed that the unknown parameters of the specified SRGMs are obtained by the observed pairwise data
. Therefore, the likelihood function of SRGMs is expressed as follows:
To find the MLE, the likelihood function in Equation (17) is taken on the logarithmic scale as follows:
On the basis of the above equation, the MLE of the model’s parameters , , and is attained through the equation .
Furthermore, LSE is also used to estimate the model’s parameters. The evaluation function of the LSE is presented as
Similarly, the LSE for the parameters , , and is obtained by solving the simultaneous equations .
Moreover, the standard deviation of
is significant for measuring the confidence interval. Therefore,
needs to be determined. The relationship between
and
is recognized in Equation (16), thus defining the following equation:
where
represents the number of the estimated parameters. On the basis of the above equations, the confidence interval of the mean and the corresponding software reliability are explained in the next section.
3.3. Estimating Confidence Intervals of Mean and Software Reliability
For the estimation of confidence intervals of SRGMs, many previous studies adopted Yamada and Osaki’s estimation method [
11]. The estimation was developed for hardware reliability with the assumption of gradual increase and instability of the failure rate. The traditional method of estimating the confidence interval is as follows:
and denote the critical region and standard deviation, respectively. represents the value of critical region that follows a standard normal distribution. As the standard deviation (SD) is correlated with time positively, the confidence interval is enlarged during the test. However, in reality, the failure rate during the software debugging gradually decreases and becomes stable as the failures are removed during a testing period. Accordingly, it is inappropriate to apply Yamada and Osaki’s method.
Therefore, the confidence interval is proposed with a consideration that the variance of efficiency of debugging depends on the error detection rate. By applying the abovementioned equations, the upper and lower boundaries of the confidence interval for the mean are calculated as follows:
where
represents the critical region
of Student’s
t probability distribution with
degrees of freedom. For simplifying the equations, the upper and lower boundaries of the mean are denoted as
and
.
Traditional methods consider that the variance of the errors comes from
, while the proposed method assumes that the variance comes from
. Thus, the confidence interval of the traditional model becomes divergent in the later stage of the testing work. However, the possibility of finding new software errors decreases with testing time since the software errors are found to be much less at the end of testing than at previous stages. In other words, the variance and the fluctuation of errors decrease with testing time when the remaining errors become fewer at the end-stage. Therefore, the variance and the fluctuation of errors vary with the error detection rate, converging at the end-stage.
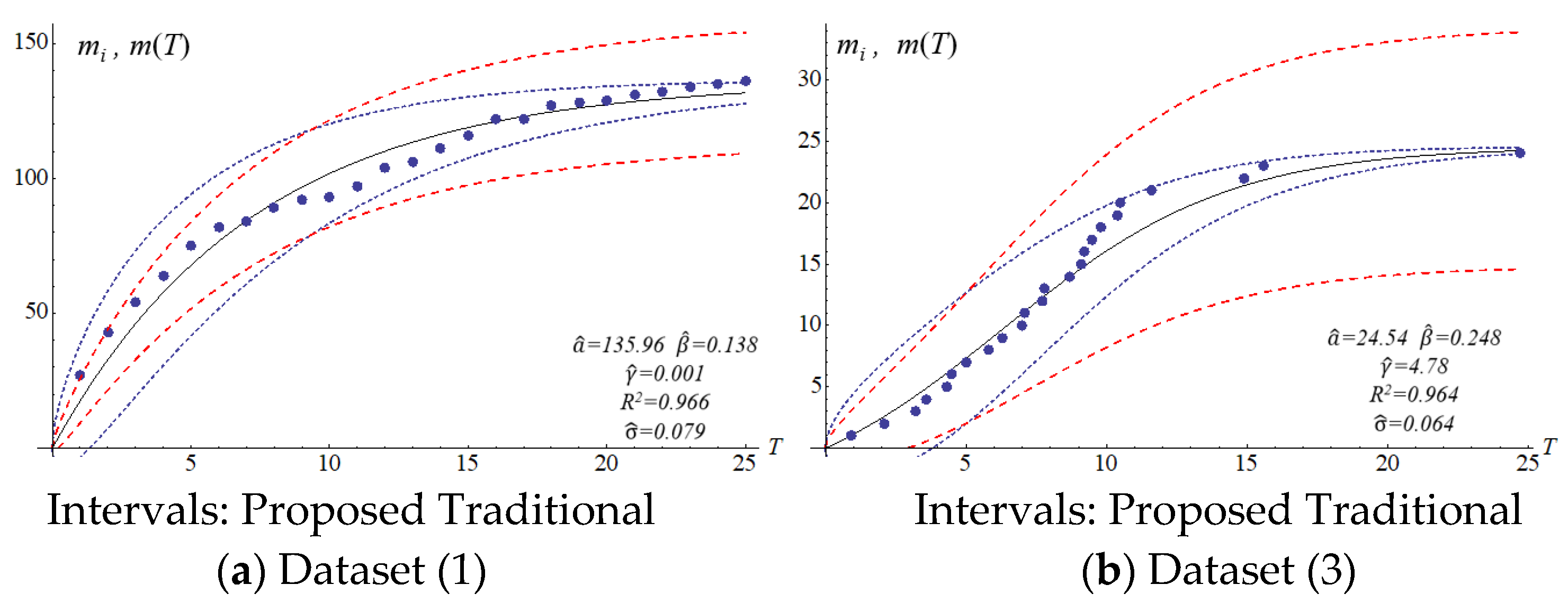
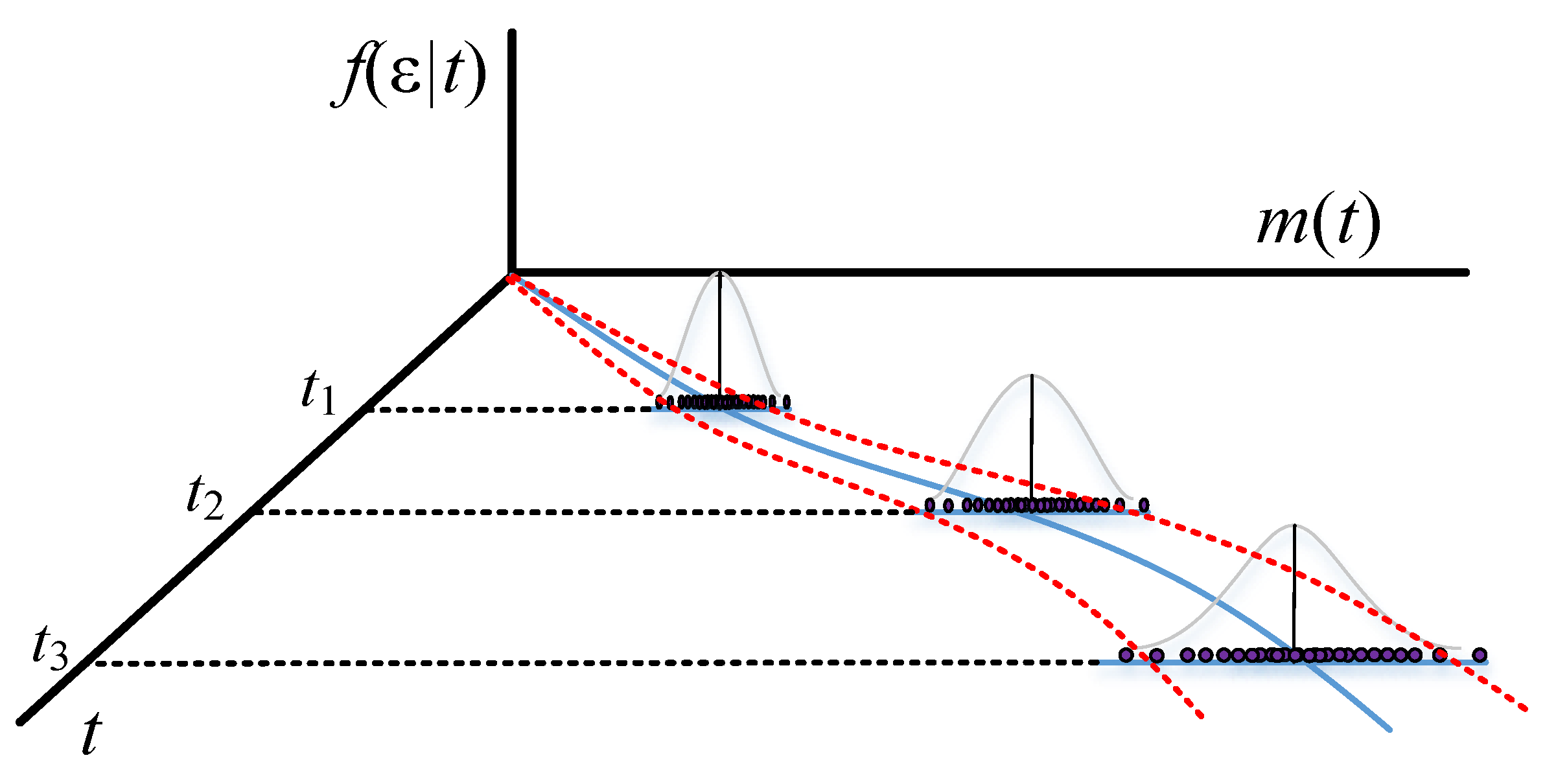
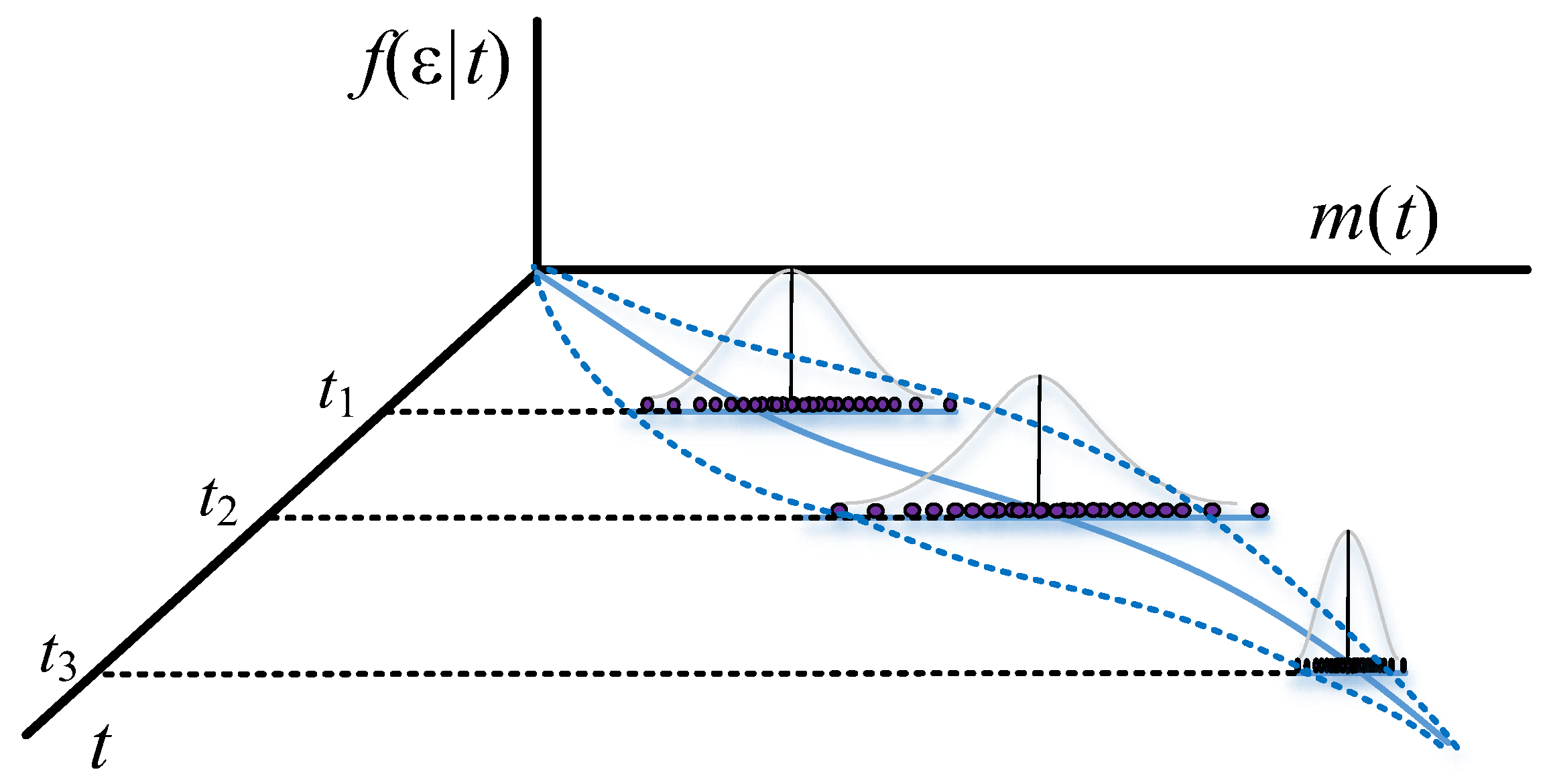
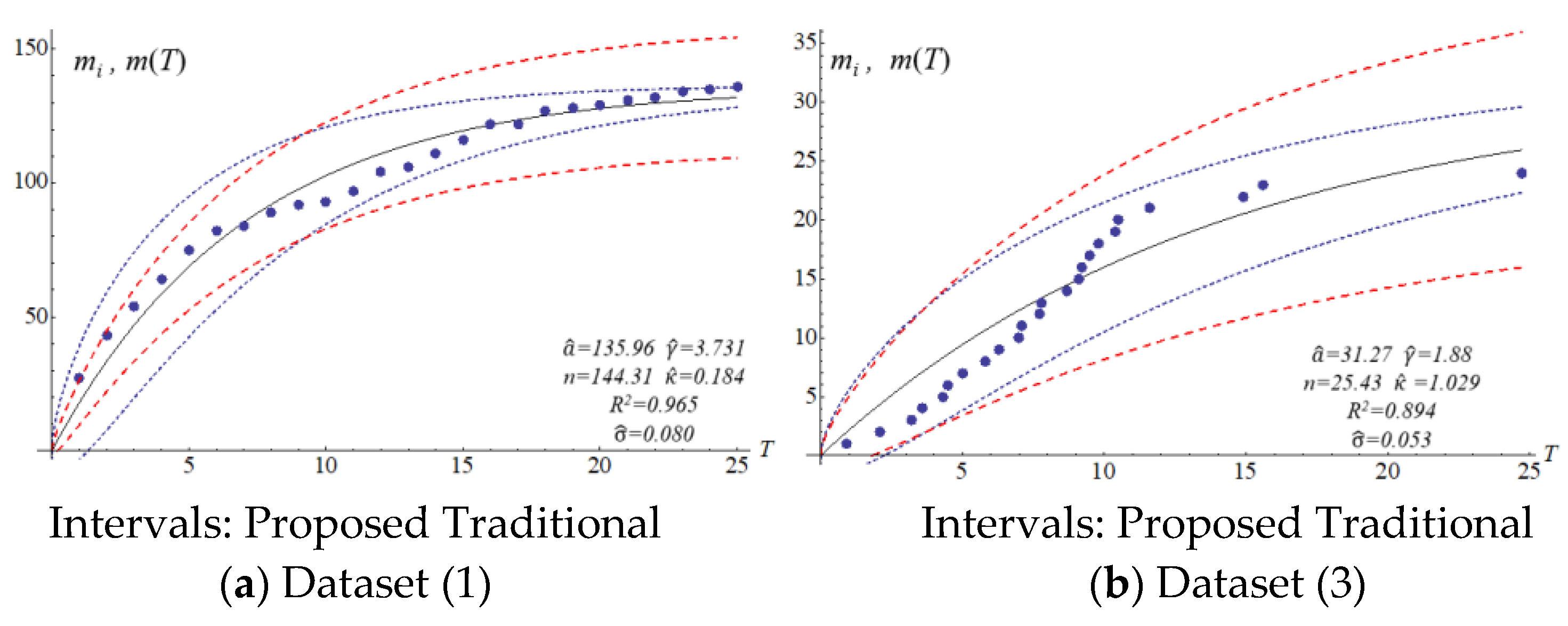
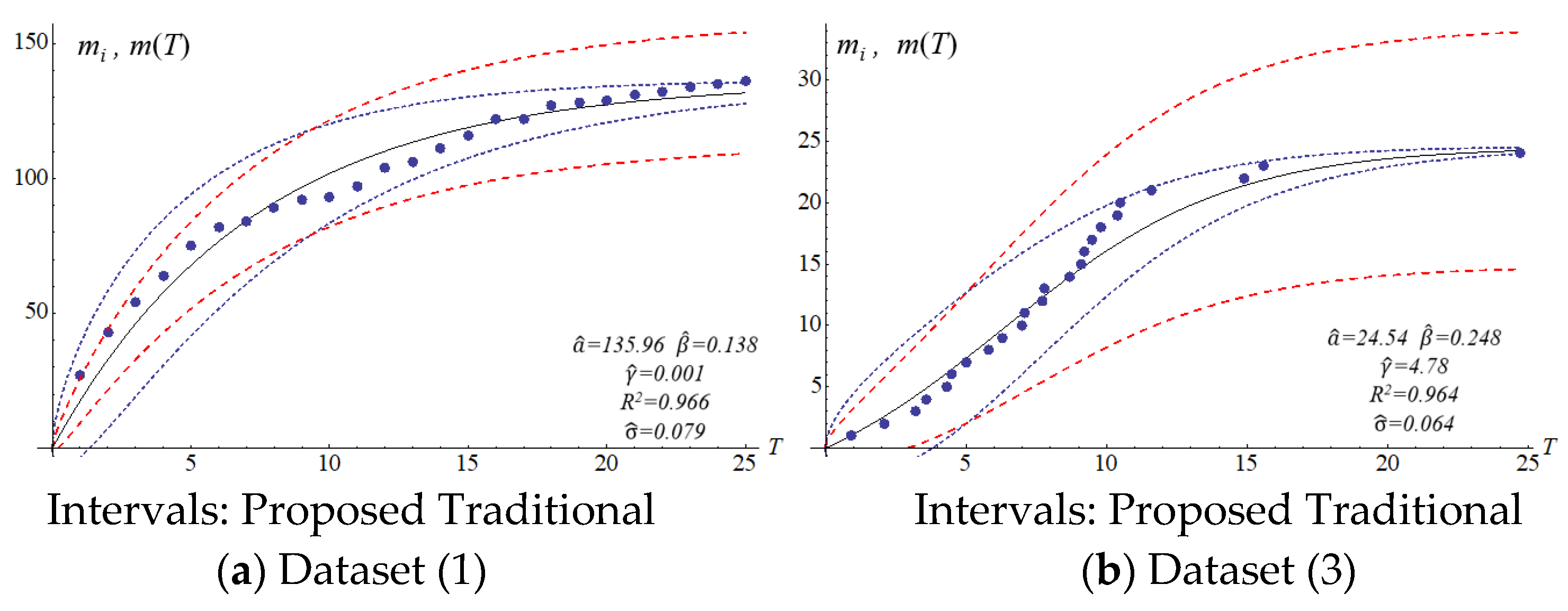
Figure 1 and
Figure 2 show the different confidence intervals between the traditional and proposed methods.
The reliability of software
is to measure the quality of a system software during a testing period, and the general definition is
is for the probability that no software error occurs during
, where
is the predefined time of software operation. On the basis of Equation (25), the upper and lower boundaries of the reliability of software are inferred as follows:
3.4. Model Validation
Various model parameters were validated in this section. Six datasets from different methods were used for evaluating the effectiveness of the estimation method in this study (
Table 2).
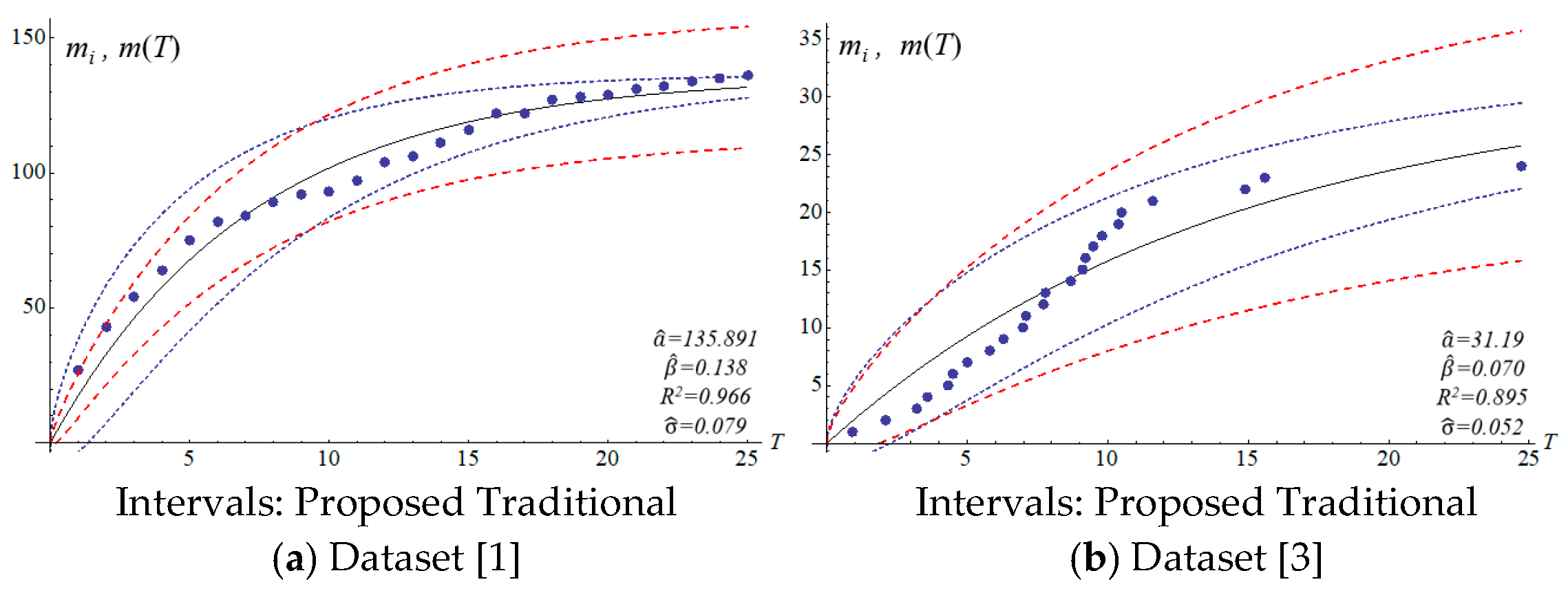
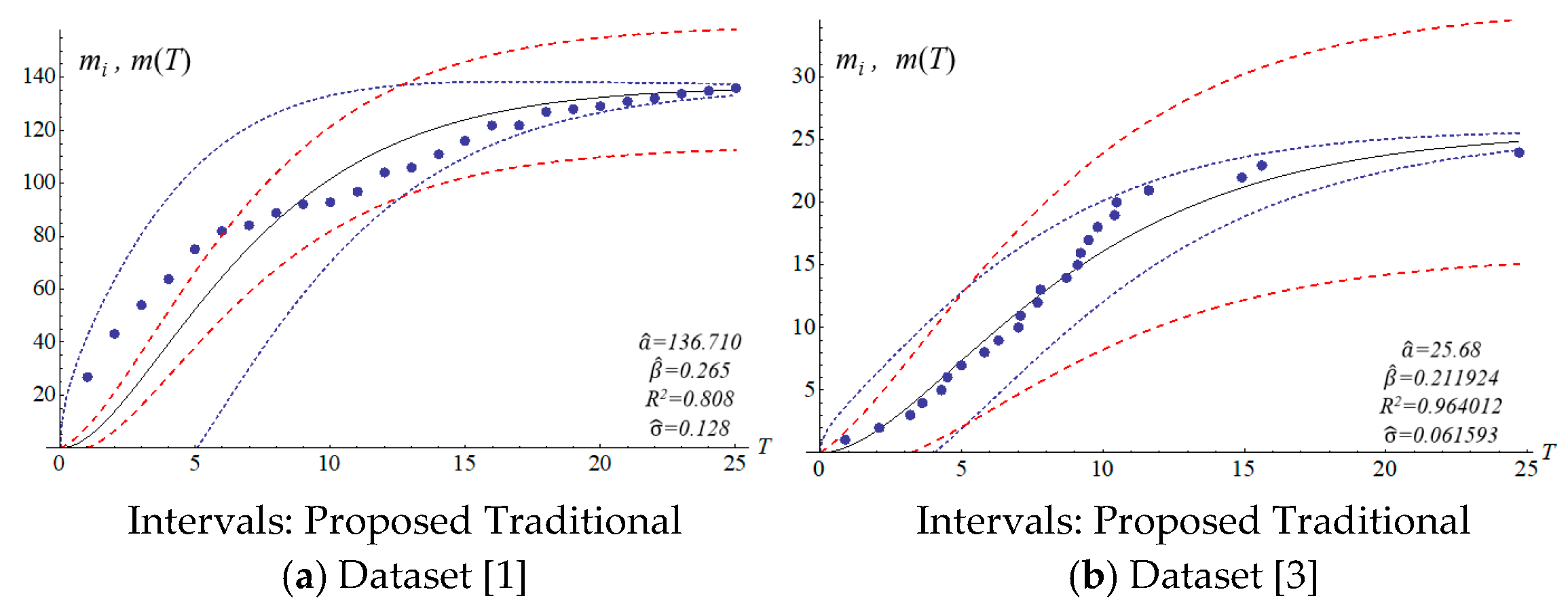
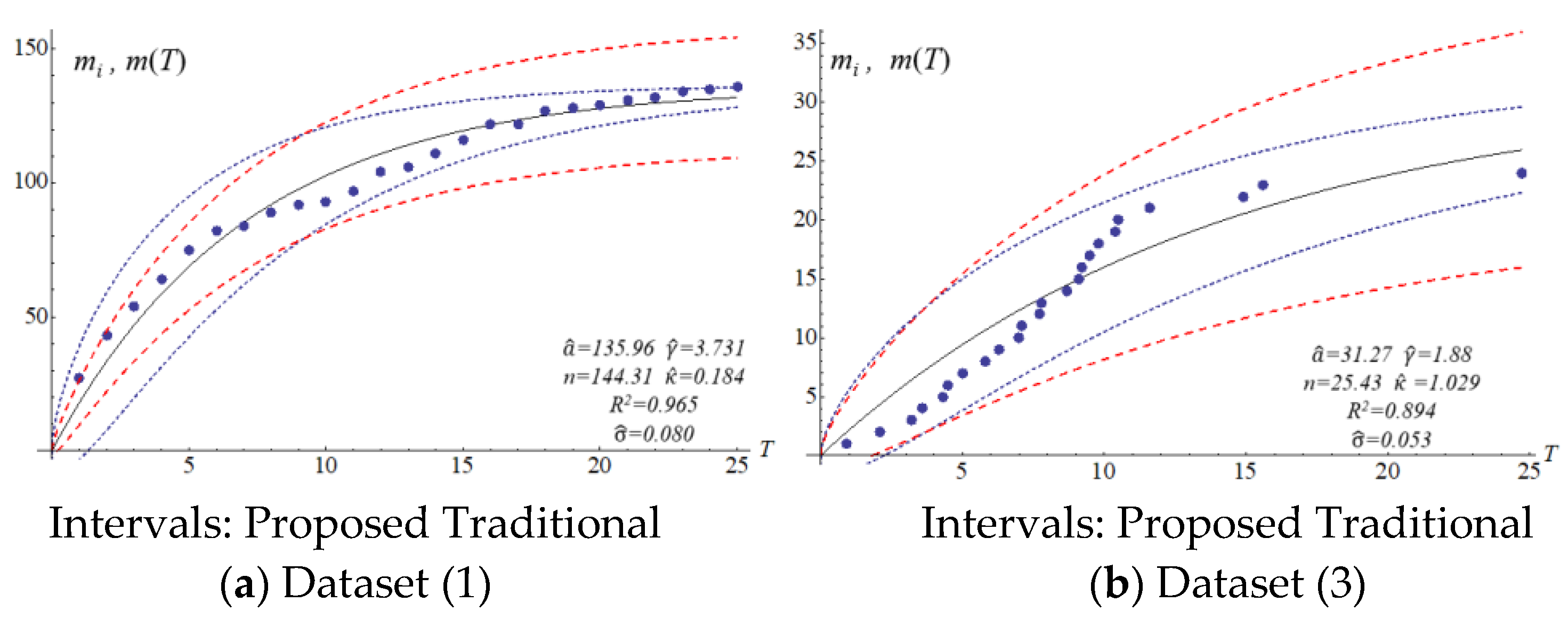
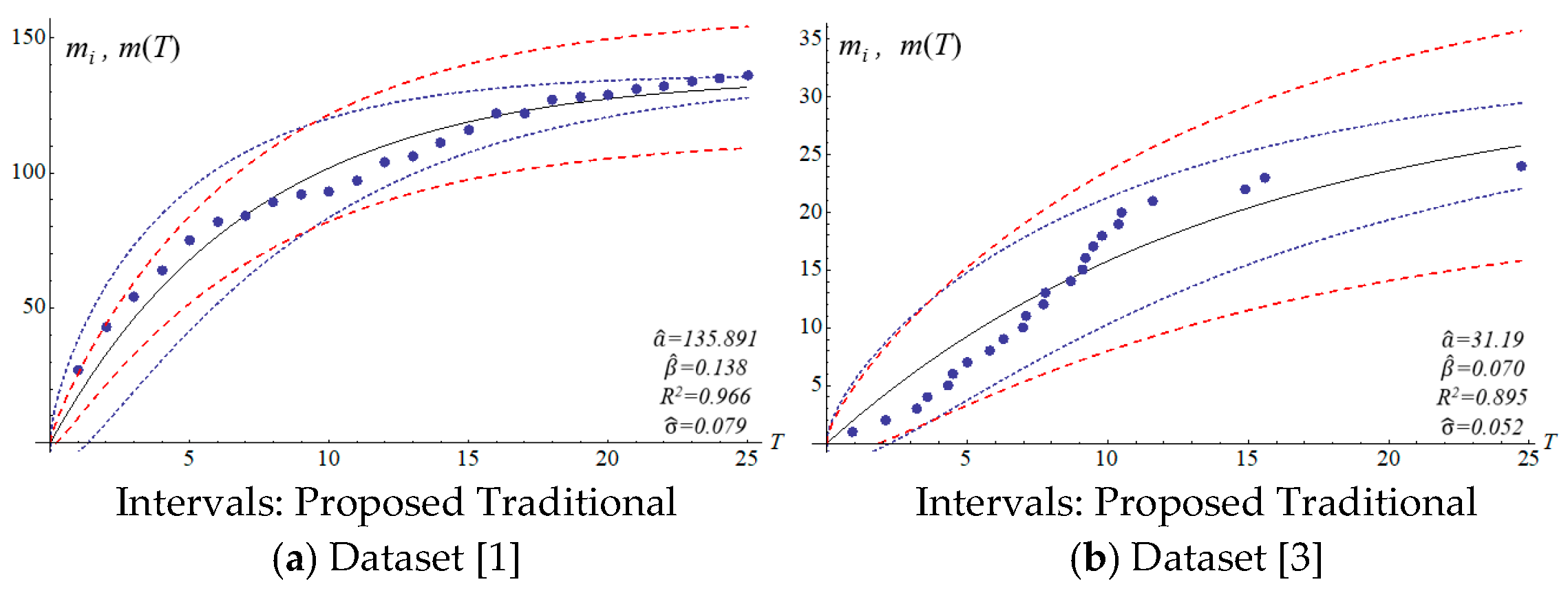
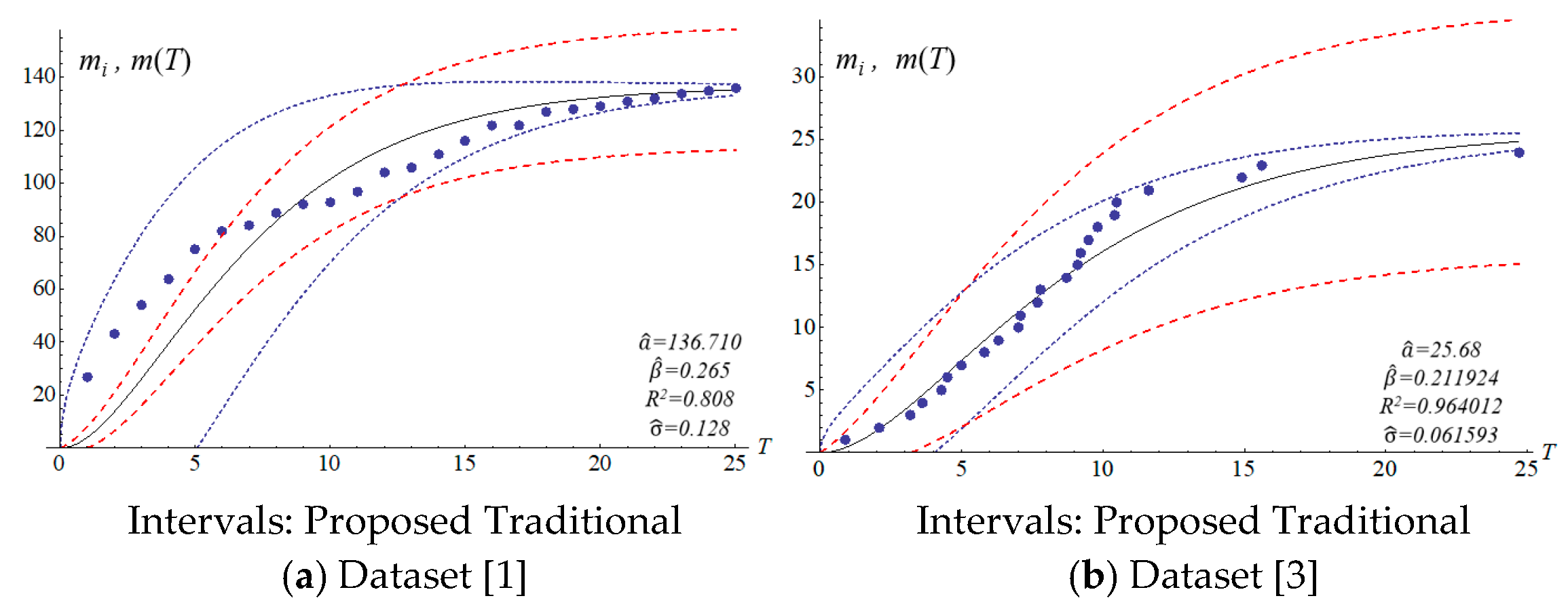
We applied the six datasets to four SRGMs to estimate their confidence intervals.
Table 3 presents the estimated parameters.
The four SRGMs and two datasets were used to compare the confidence interval of the models to that of the proposed model. Datasets (1) and (3) in
Table 2 present the data distribution of a concave and an S-shape, respectively.
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show that the variation of the confidence interval changes. The blue and red dashed lines of the figures respectively represent the estimation of confidence intervals for the traditional and proposed models. Results from the comparison show large differences in confidence intervals. The models of Goel and Okumoto and Musa with datasets (3) and (6) show
R-squared values (0.8–0.9) that are not satisfactory. There are discrepancies in the distribution of dataset (3) in
Figure 3b and
Figure 5b. Thus, the model’s accuracy needs to be determined by the scatter pattern in the dataset. Accordingly, the performance of model fitting may depend on the pattern of a dataset. A model may fit for some datasets but it may not fit for all the datasets. In other words, both Goel and Okumoto’s and Musa’s models have a constant detection rate which is opposite to the scenario of a nonconstant detection rate of the Yamada model and the proposed model (
Figure 3 and
Figure 6). As a result, the detection rates for Goel and Okumoto’s and Musa’s models cannot be used to predict the pattern of S-shaped datasets. However, Yamada’s delayed S-shaped model and Ohba’s inflection model (the proposed model) are able to accurately estimate all the datasets with S-shaped or concave datasets. In summary, the proposed confidence interval converges with the testing time to reflect the actual situation. The number of software errors decreases with testing/debugging time.
Figure 3,
Figure 4,
Figure 5 and
Figure 6 present that the difference between actual and estimated errors is the greatest when the testing/debugging process begins and then decreases with time. After debugging and testing, the actual number and the estimated number of software errors are almost identical. When compared with the traditional models, the estimation of the proposed model shows a narrower 95% confidence interval. For example, the confidence intervals for the traditional models are large and are not indicative of datasets (1) or (3).
4. Decision with Confidence Levels
Software developers aim to reduce the cost of development and secure the quality of software by deciding when testing is completed and software is released. In general, a longer testing period results in more reliable software. However, a software developer cannot prolong the testing period indefinitely as this increases the costs and loses business opportunities. Therefore, a software developer considers a trade-off between testing period and software quality. Zhang and Pham suggested a cost–reliability model for the best policy for software releases [
25]. Thus, the model was adopted in this study to develop a software release model based on different confidence levels. The proposed cost–reliability model has the following six factors in deciding when to release the software:
- (1)
Setup cost () for testing concerning necessary equipment and initial investment before the testing project begins;
- (2)
Routine expense () for testing including salary, insurance, rent, and so on during a planned testing period . denotes the routine expense per unit time, and the routine expense is calculated by ;
- (3)
Debugging expense () for removing software errors during a planned testing period . The estimation of the expense is related to the expense of omitting an error per unit time and the average required time to delete an error . Therefore, the debugging expense is calculated by ;
- (4)
The cost of risk of a software failure after its release ( is estimated by . The parameter is calculated by estimating how much risk cost for users or customers is caused by the 1% loss of software reliability at release time ;
- (5)
Opportunity cost (), as tangible and intangible losses caused by postponing software release, is defined as in this study. and are parameters for the power-law function, estimated by marketing experts. denotes the scale for base opportunity cost;
- (6)
Minimal requirement of software reliability is a standard indicator for the requirement of users or customers for which the operation of a software system must meet.
By considering the factors, the software release model for the average case is presented as follows:
Since the model is only for a general case, decision-makers cannot effectively evaluate the potential risk due to the extension of the testing schedule. Various possibilities of the delay need to be considered to handle the extra cost and prepare for postponing the software release. The reliability of software does not reach the desired level in most testing cases. Thus, decision-makers need conservative estimations for the cost and reliability, which leads to the consideration of the worst case in making decisions. Thus, according to Equation (28), the lower bound estimation
and
at a specific confidence level,
was taken into consideration to apply the decision model in this study. Equation (29) presents the proposed decision model. Decision-makers can use this model by setting an appropriate confidence level to determine the best release time of the software.
6. Discussions
A software service provider develops commercial software applications. When the coding is completed, the service provider’s manager determines an appropriate release date. The inflection S-shape model by Ohba is appropriate for the determination based on historical data and expert evaluation. According to the potential error, the model has a standard deviation of = 0.228, a potential error of up to 3350, parameter of 0.015, and parameter of 1.35. In detecting errors, each employee works 10 h a day and 24 days a month, which pertains to = $2000, = $6000, = $12,000, = $252,000, = $3800, = 1 h, = 2, = 1.6, and = 0.5 h. As a software service provider wants to meet a minimum software reliability requirement (= 0.9) at the confidence level of 95%, they need to identify the optimal software release time for general and worst cases.
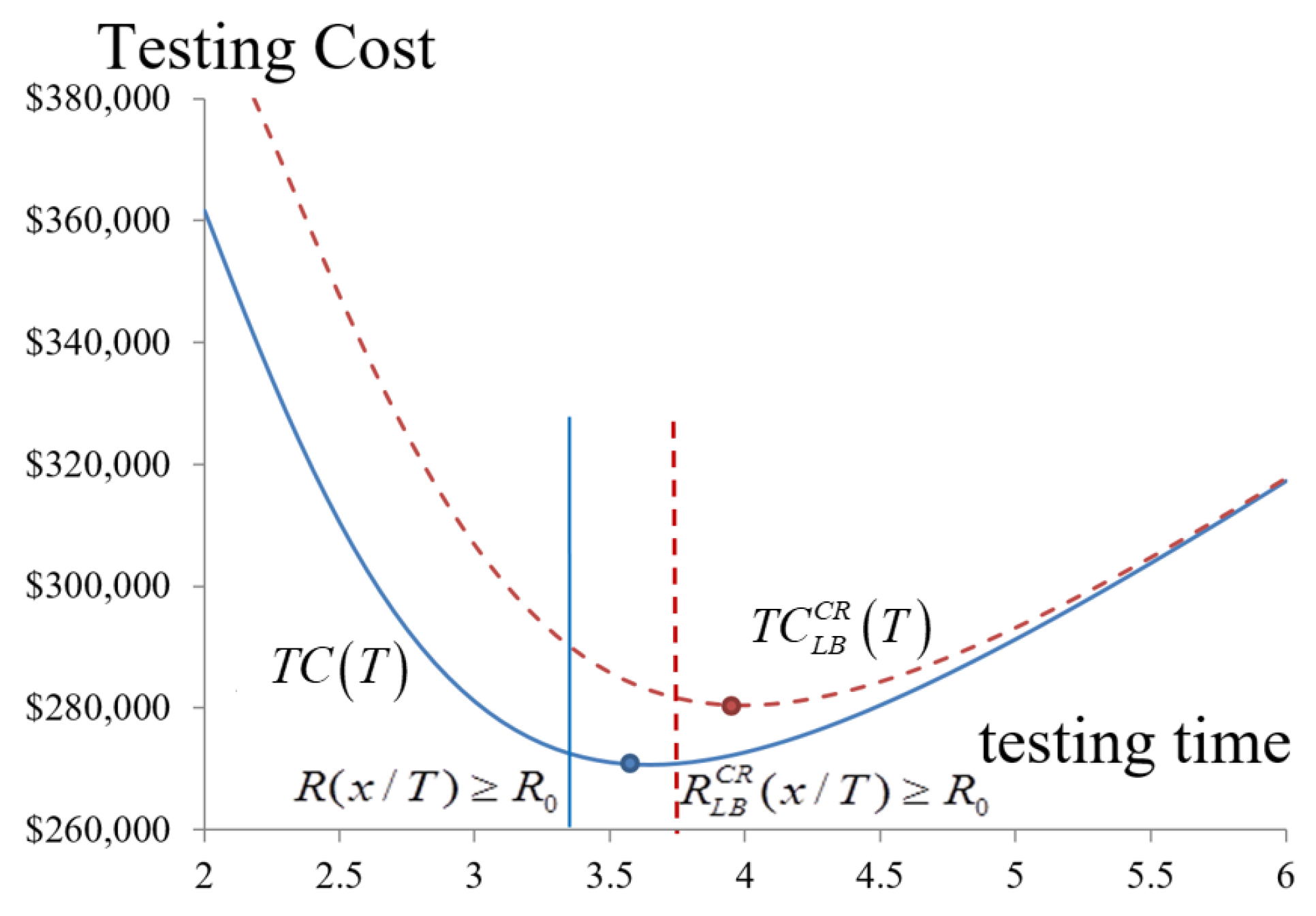
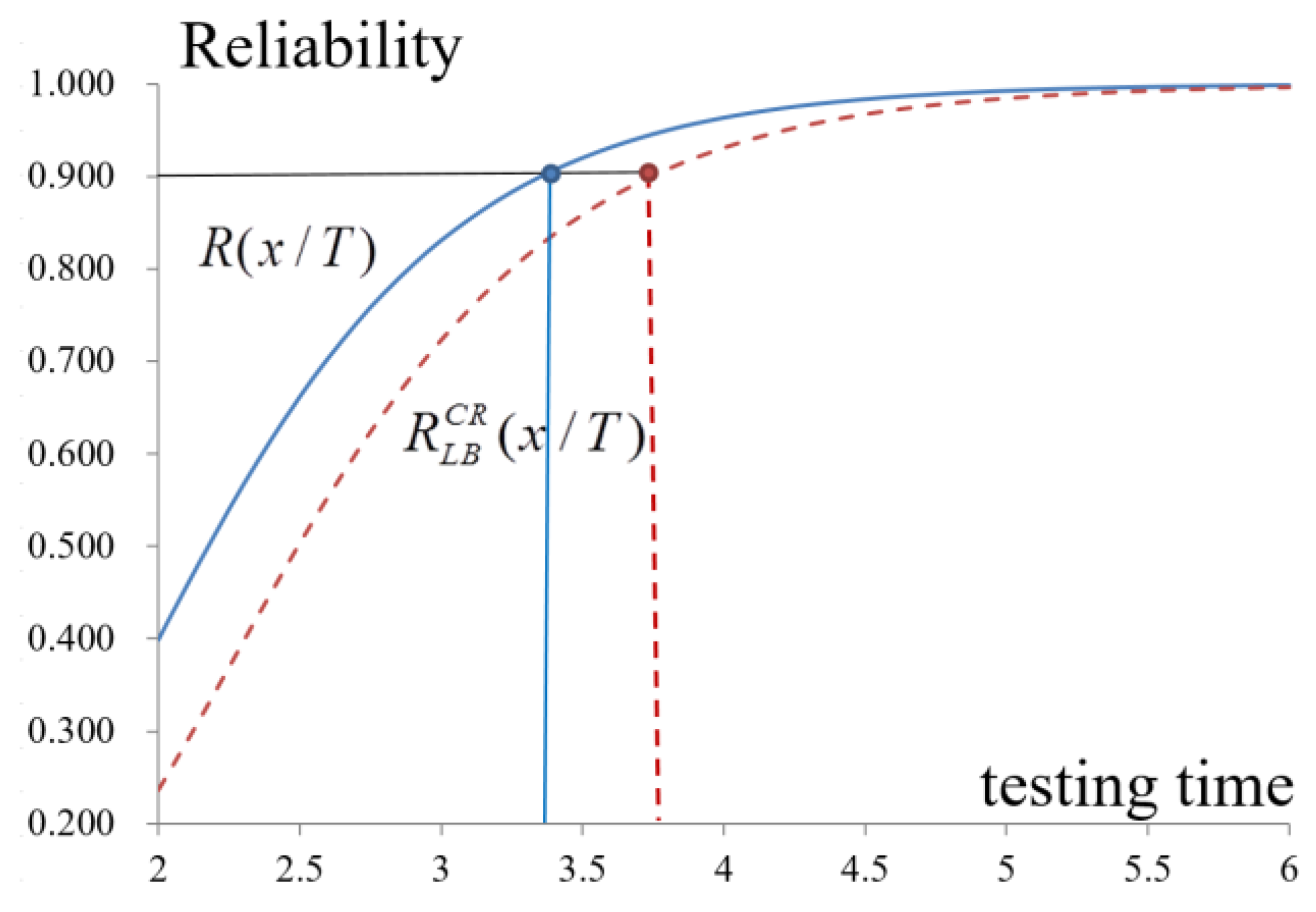
By using spectrum analysis with Equations (28) and (29), when to release a software package, the expected cost of testing, and the safety of the software package before release are determined.
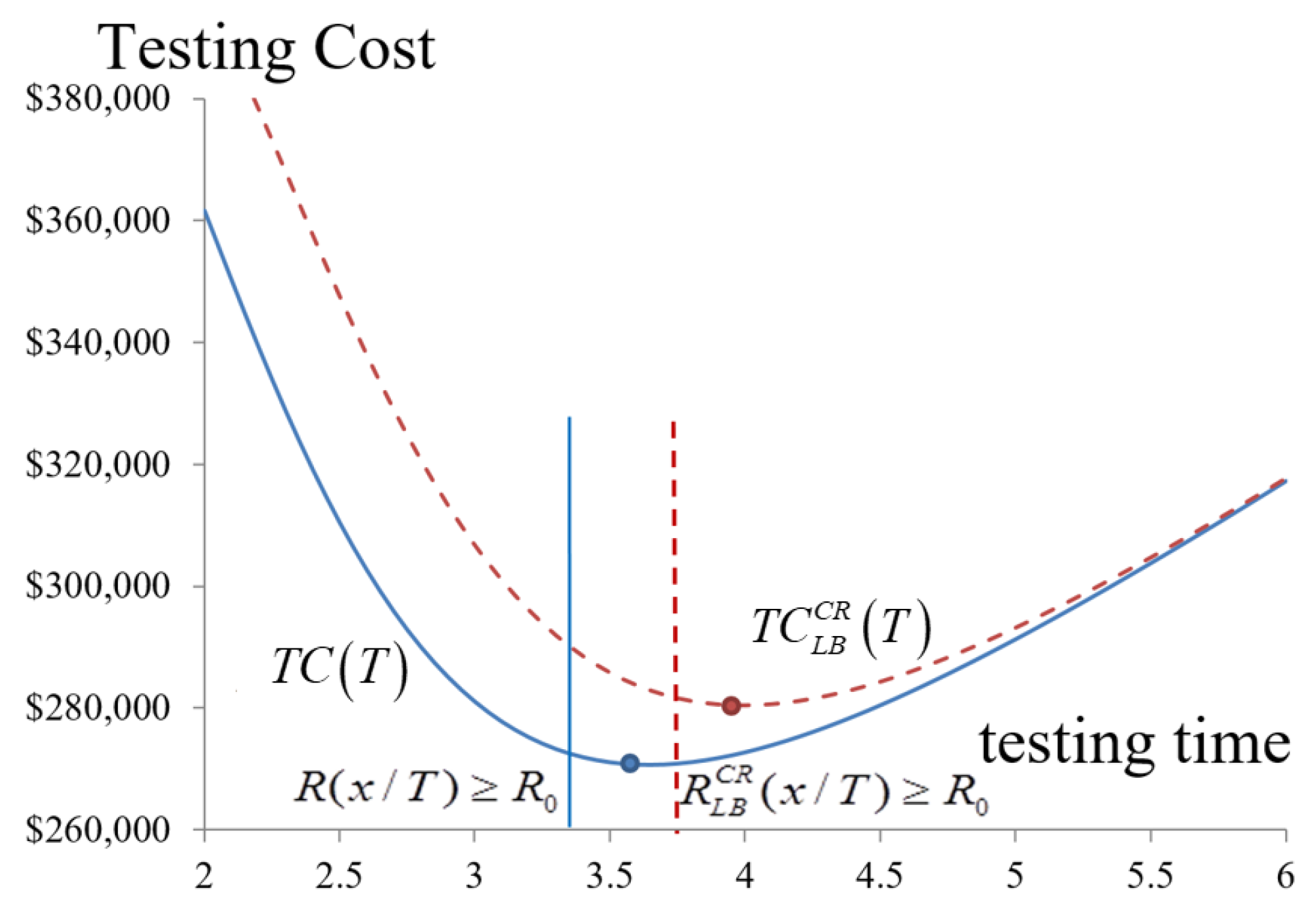
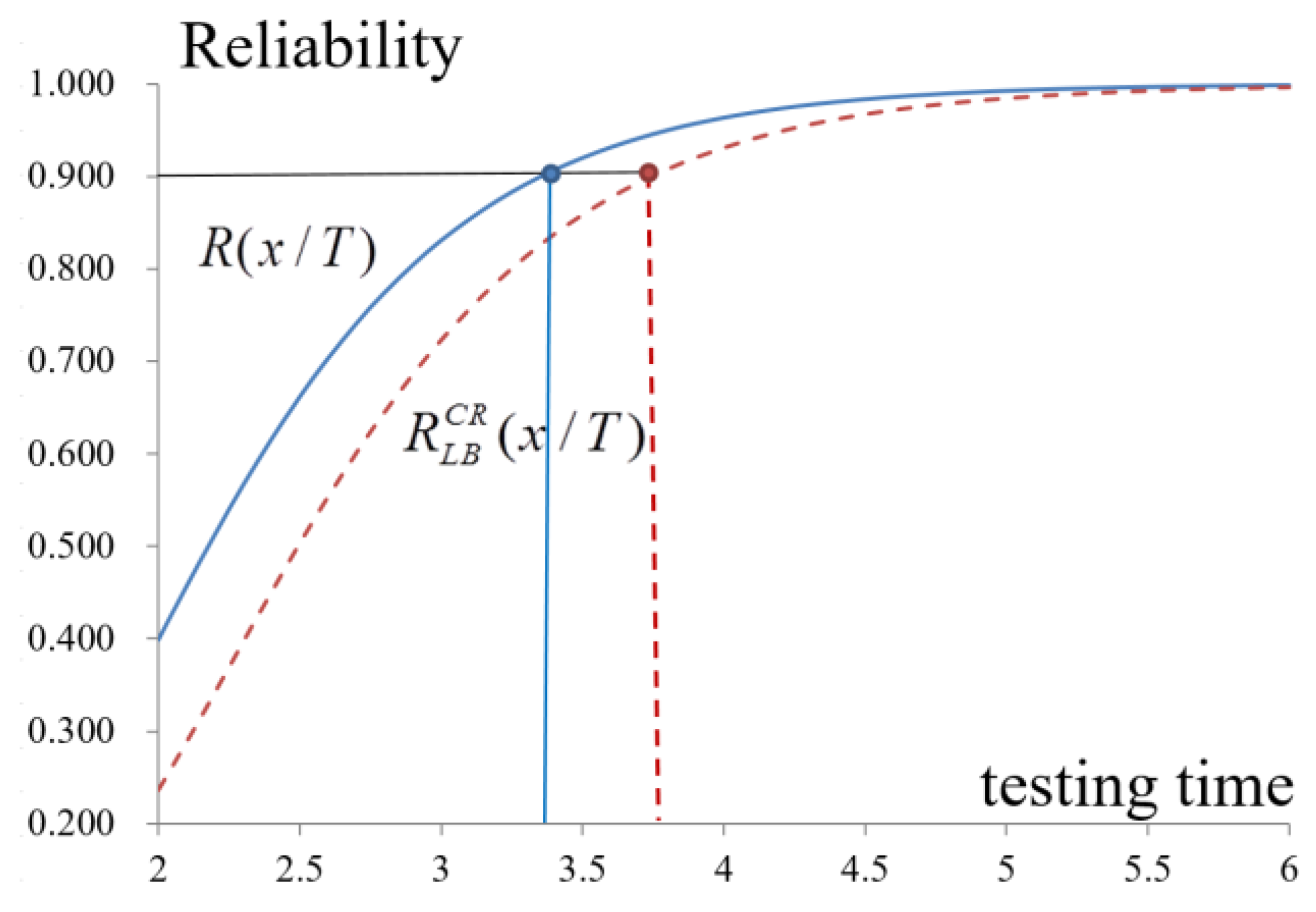
Table 4 and
Figure 9 show that the optimized release time for software,
, is 3.65 months after the beginning of debugging and testing. The total cost and the reliability are estimated to be approximately
$270,682 and 0.936 in the general case to satisfy the requirement of the reliability of software of 0.9. However, if the manager considers the possible delay of the testing at the confidence level of 0.95, the software reliability reaches 0.886, which does not meet the minimal requirement unless the testing time is prolonged to 3.75 months.
The expected testing costs decrease when the confidence level is considered (
Figure 9 and
Figure 10, and
Table 4). Debugging and testing are, therefore, extended, which increases the expected testing cost, but enhances the reliability. Therefore, even in the worst case, the software quality meets the requirement, which results in the decision-maker extending the period for testing and debugging. Therefore, the optimal release time needs to be 4 months instead of 3.65 months in the worst case, and the total cost and reliability are
$280,434 and 0.931, respectively. Managers set other confidence levels by considering actual requirements to improve the software quality to earn customer trust and confidence.
7. Conclusions
It is important for software developers to decide when to release developed software to the market with a certain level of reliability. Such a decision has been enabled with previous methods. However, the previous methods assessed the software reliability only on the basis of the confidence intervals of necessary statistics, which is not appropriate for estimating the reliability due to the asymmetry of the statistics. To refine the decision related to software testing, a more reasonable method is required for decision making. Therefore, a new method of estimating the reliability of software is proposed by using SDE that reasonably estimates confidence intervals from the fluctuation of error detection rates. By using the proposed method, software developers can precisely determine the optimal time for software release by considering different levels of confidence intervals. The result of this study indicates that the mean value and the confidence interval are highly correlated with time and variance. According to the estimation of expected quality and cost of software testing, the proposed model enables decision-makers to estimate an optimal time of software release at different statistical confidence levels.
There are two limitations of this study:
- (1)
High-performance computing capability is needed for numerical analyses to obtain the results in a tolerable period. In general, workstation-class computers are required to solve the problem of this study.
- (2)
Change-point problems of SRGM cannot be solved by the proposed model. During debugging or testing, factors can be changed, possibly leading to an increase or decrease in the failure rate.
Several problems still need to be resolved, especially with insufficient historical data. Mean values influence the estimation of the software testing cost. It is crucial to estimate the mean value accurately. In general, the decision-maker estimates the parameters from the historical data of previous software testing. For assessing the optimal release time, the data may be difficult to collect. The Bayesian approach may help solve such a problem when there is little historical information with the parameters estimated by experts or with a few specific data points. The combination of Bayesian analysis and the proposed model will provide more efficient and realistic decisions for future study.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}