
An Efficient Algorithm for Solving the Matrix Optimization Problem in the Unsupervised Feature Selection

Abstract
:1. Introduction
2. A New Algorithm for Solving Problem 1
- (1)
- (2)
| Algorithm 1: This Algorithm attempts to Solve Problem 1. |
Input Data matrix , the number of selected features p, parameters , and . Output An index set of selected features and 1. Initialize matrix and . 2. Set . 3. Repeat 4. Fix Y and update X by (2.9); 5. Fix X and update Y by (2.10); 6. Until convergence condition has been satisfied, otherwise set and turn to step 3. 7. End for 8. Compute and sort them in a descending order to choose the top p features. |
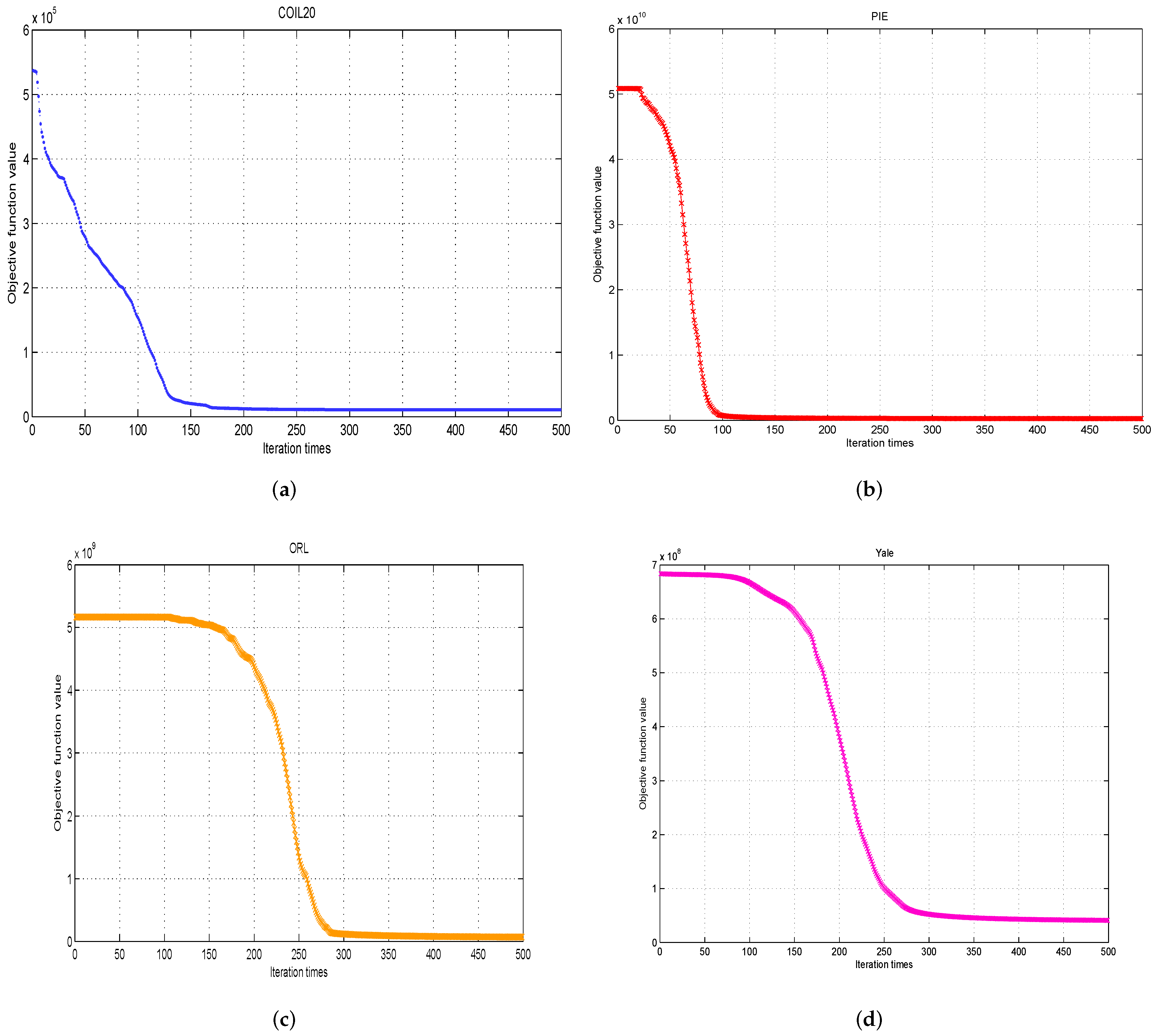
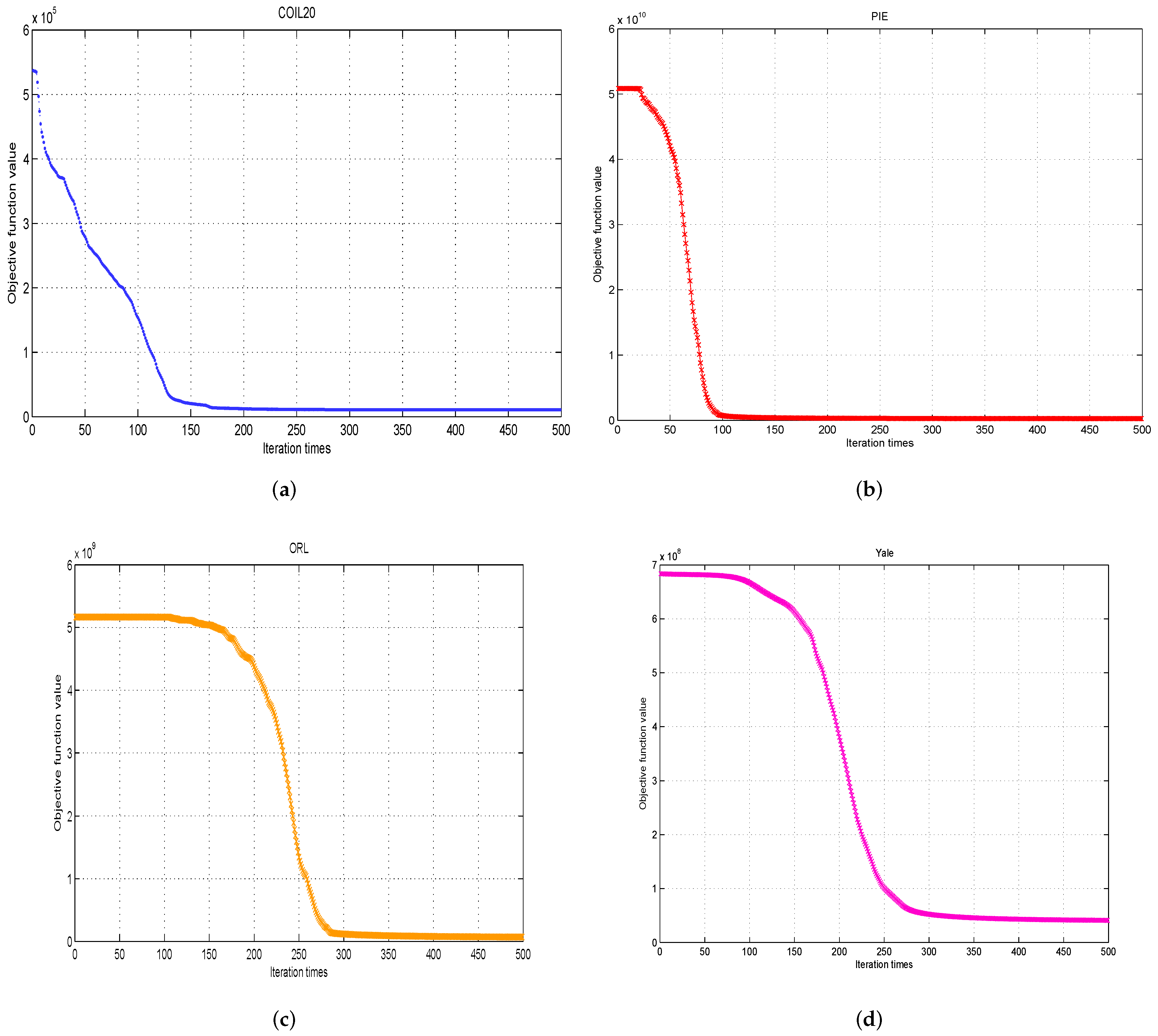
3. Convergence Analysis
4. Numerical Experiments
4.1. A Simple Example
4.2. Application to Unsupervised Feature Selection and Comparison with Existing Algorithms
4.2.1. Dataset
4.2.2. Comparison Methods
4.2.3. Parameter Settings
4.2.4. Evaluation Metrics
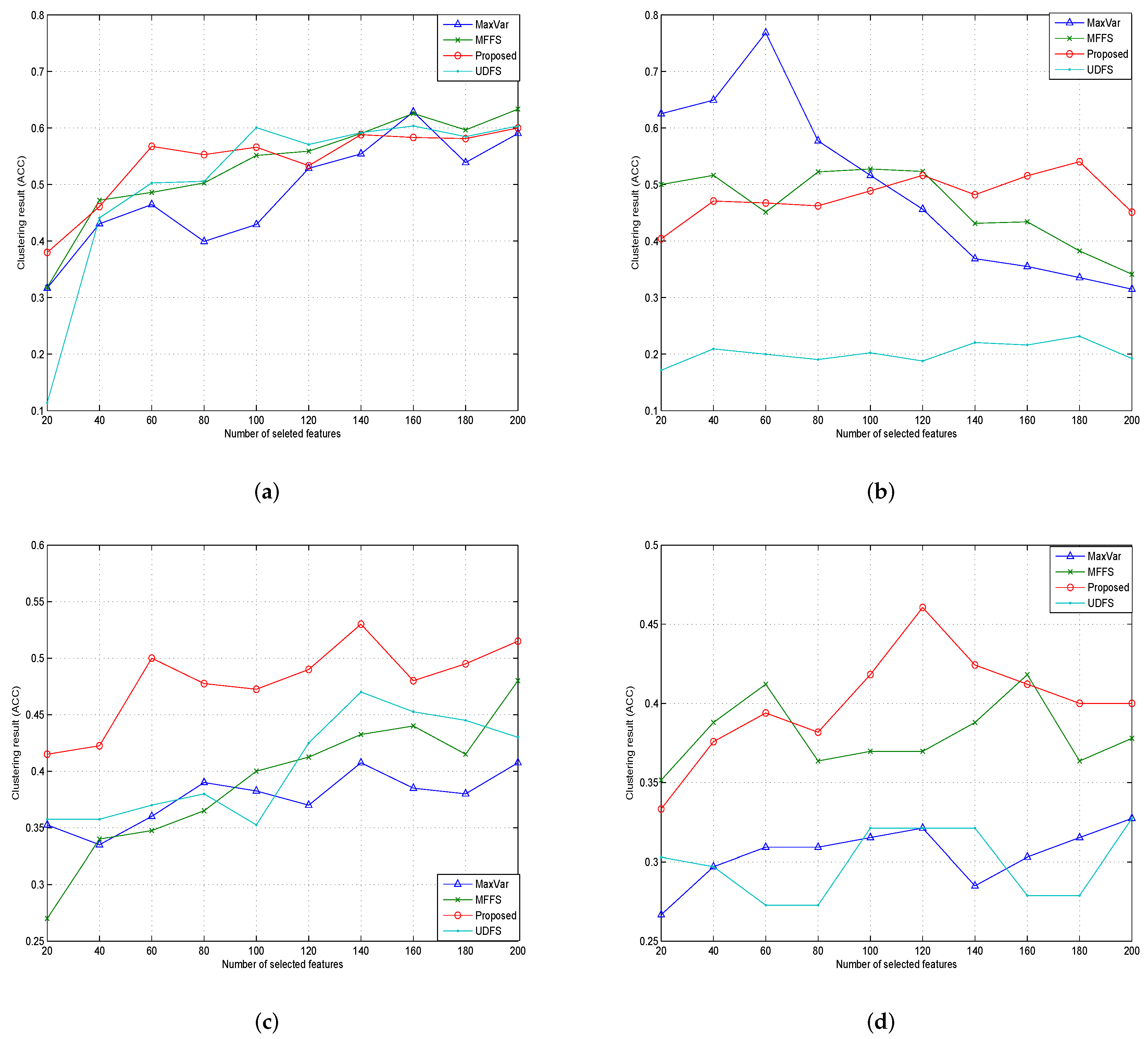
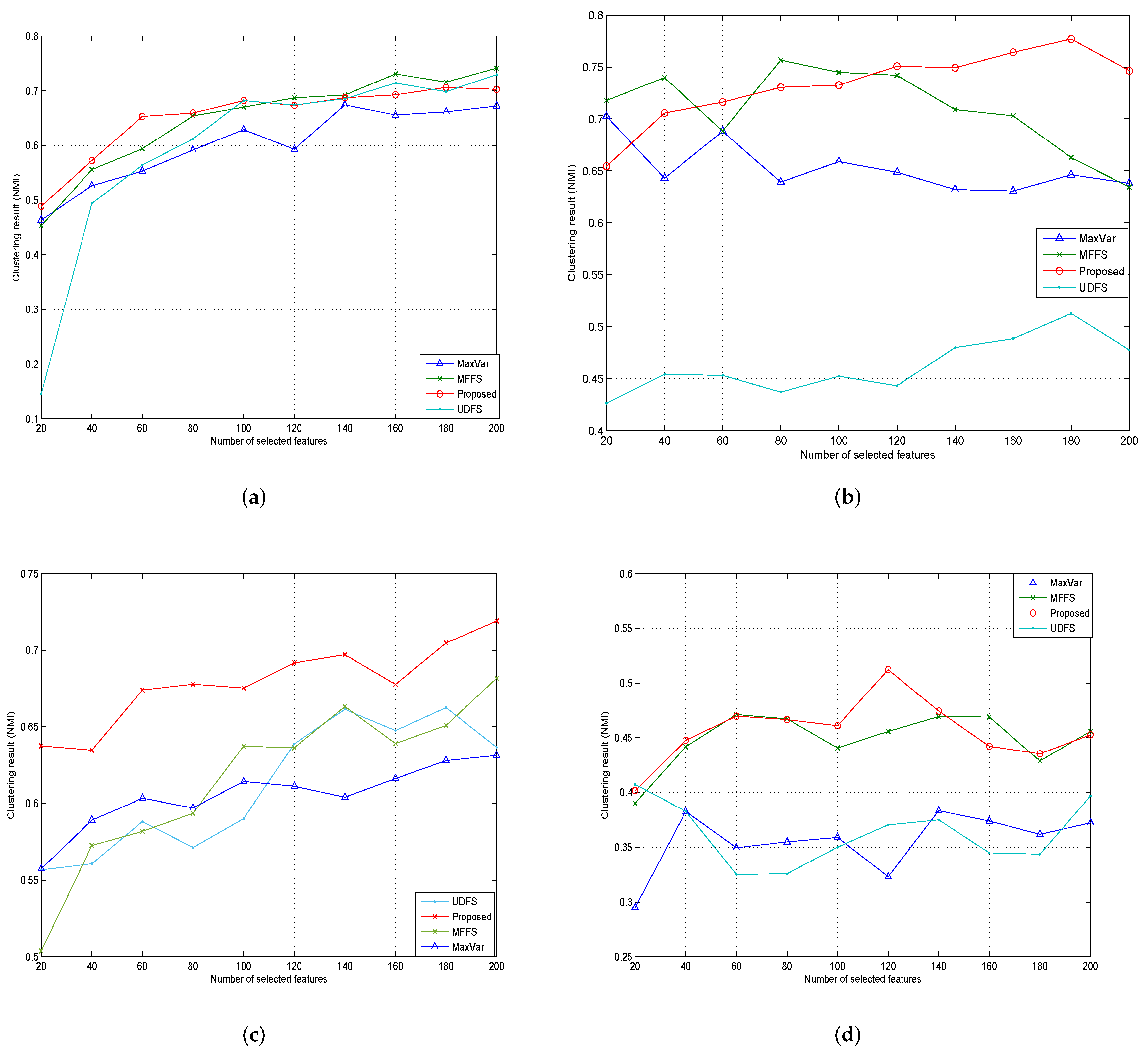
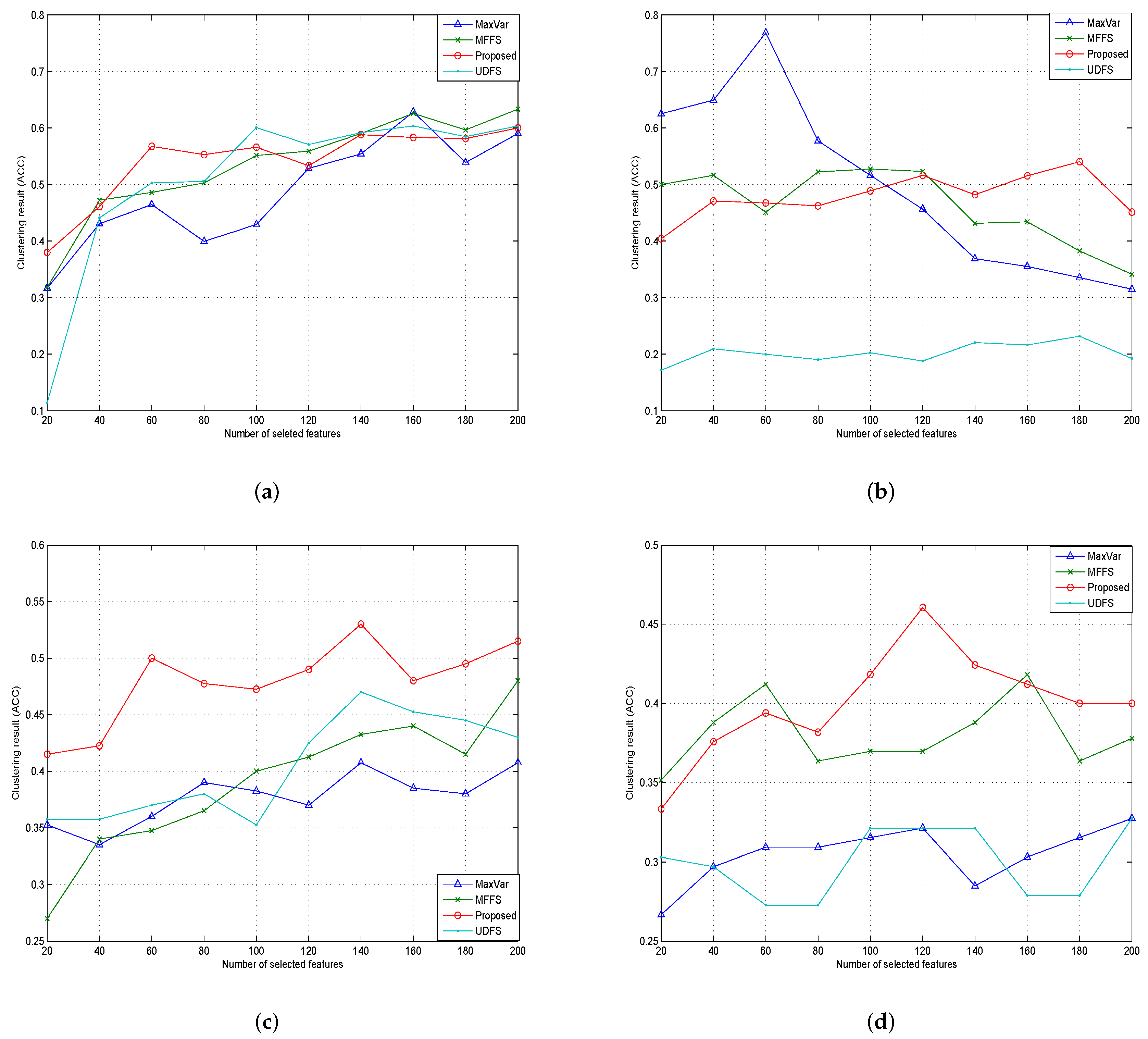
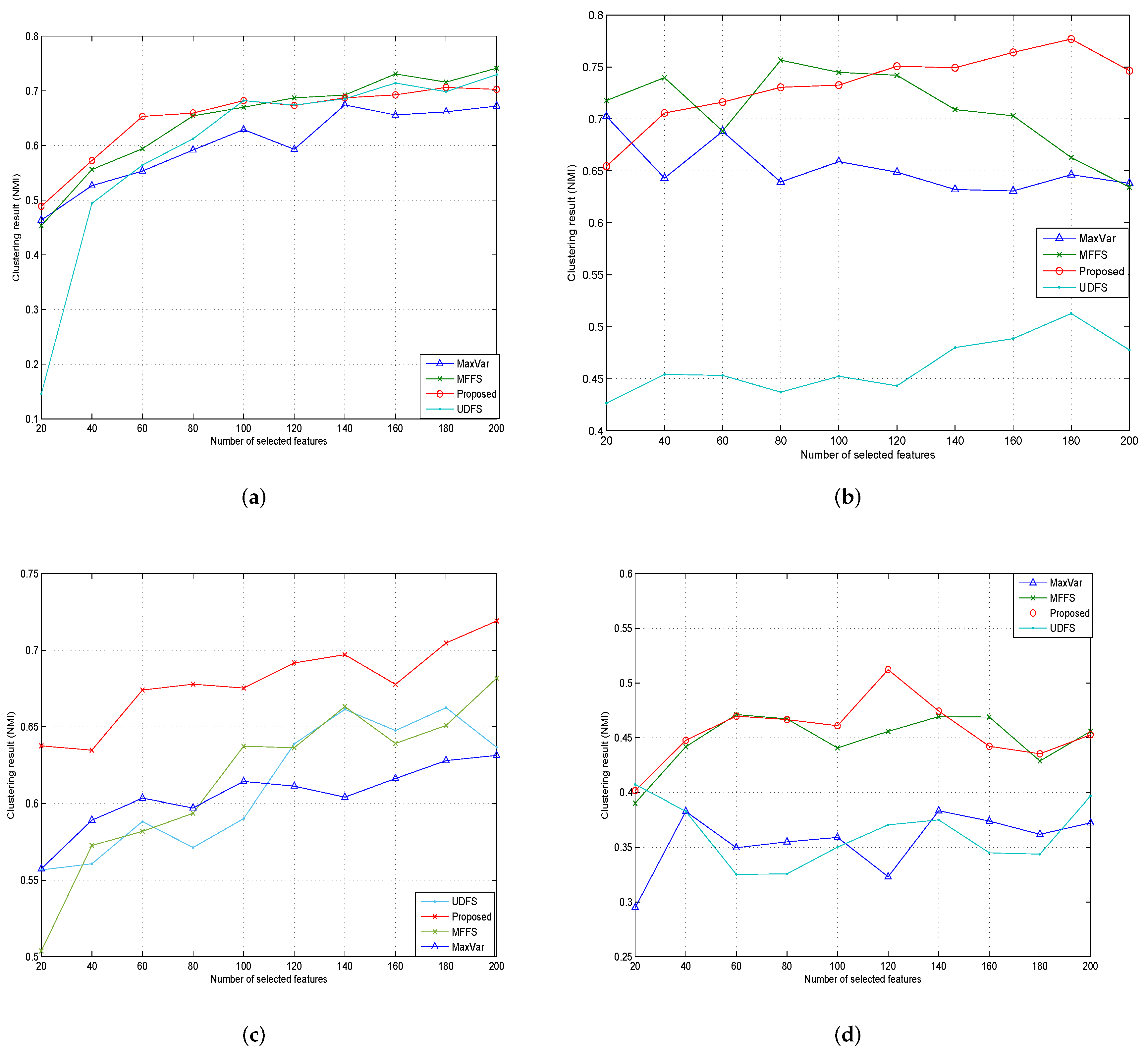
4.2.5. Experiments Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788. [Google Scholar] [CrossRef] [PubMed]
- Smaragdis, P.; Brown, J.C. Non-negative matrix factorization for polyphonic music transcription. In Proceedings of the 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (IEEE Cat. No.03TH8684), New Paltz, NY, USA, 19–22 October 2003. [Google Scholar]
- Kim, H.; Park, H. Nonnegative Matrix Factorization Based on Alternating Nonnegativity Constrained Least Squares and Active Set Method. SIAM J. Matrix Anal. Appl. 2008, 30, 713–730. [Google Scholar] [CrossRef]
- Lin, C. Projected Gradient Methods for Nonnegative Matrix Factorization. Neural Comput. 2007, 19, 2756–2779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.L.; Liu, H.W.; Zheng, X.Y. Non-monotone projection gradient method for non-negative matrix factorization. Comput. Optim. Appl. 2012, 51, 1163–1171. [Google Scholar] [CrossRef]
- Han, L.X.; Neumann, M.; Prasad, A.U. Alternating projected Barzilai-Borwein methods for Nonnegative Matrix Factorization. Electron. Trans. Numer. Anal. 2010, 36, 54–82. [Google Scholar]
- Huang, Y.K.; Liu, H.W.; Zhou, S. An efficient monotone projected Barzilai-Borwein method for nonnegative matrix factorization. Appl. Math. Lett. 2015, 45, 12–17. [Google Scholar] [CrossRef]
- Gong, P.H.; Zhang, C.S. Efficient Nonnegative Matrix Factorization via projected Newton method. Pattern Recognit. 2012, 45, 3557–3565. [Google Scholar] [CrossRef]
- Kim, D.; Sra, S.; Dhillon, I.S. Fast Newton-type Methods for the Least Squares Nonnegative Matrix Approximation Problem. In Proceedings of the SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007. [Google Scholar]
- Zdunek, R.; Cichocki, A. Non-negative matrix factorization with quasi-newton optimization. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 25–29 June 2006. [Google Scholar]
- Abrudan, T.E.; Eriksson, J.; Koivunen, V. Steepest descent algorithms for optimization under unitary matrix constraint. IEEE Trans. Signal Process. 2008, 56, 1134–1147. [Google Scholar] [CrossRef]
- Abrudan, T.E.; Eriksson, J.; Koivunen, V. Conjugate gradient algorithm for optimization under unitary matrix constraint. Signal Process. 2009, 89, 1704–1714. [Google Scholar] [CrossRef]
- Absil, P.A.; Baker, C.G.; Gallivan, K.A. Trust-Region methods on riemannian manifolds. Found. Comput. Math. 2007, 7, 303–330. [Google Scholar] [CrossRef]
- Savas, B.; Lim, L.H. Quasi-Newton methods on grassmannians and multilinear approximations of tensors. SIAM J. Sci. Comput. 2010, 2, 3352–3393. [Google Scholar] [CrossRef]
- Wen, Z.W.; Yin, W.T. A feasible method for optimization with orthogonality constraints. Math. Program. 2013, 142, 397–434. [Google Scholar] [CrossRef] [Green Version]
- Lai, R.J.; Osher, S. A splitting method for orthogonality constrained problems. J. Sci. Comput. 2014, 58, 431–449. [Google Scholar] [CrossRef]
- Chen, W.Q.; Ji, H.; You, Y.F. An augmented lagrangian method for l1-regularized optimization problems with orthogonality constraints. SIAM J. Sci. Comput. 2016, 38, 570–592. [Google Scholar] [CrossRef] [Green Version]
- Han, D.; Kim, J. Unsupervised Simultaneous Orthogonal basis Clustering Feature Selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015. [Google Scholar]
- Du, S.Q.; Ma, Y.D.; Li, S.L. Robust unsupervised feature selection via matrix factorization. Neurocomputing 2017, 241, 115–127. [Google Scholar] [CrossRef]
- Yi, Y.G.; Zhou, W.; Liu, Q.H. Ordinal preserving matrix factorization for unsupervised feature selection. Signal Process. Image Commun. 2018, 67, 118–131. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001. [Google Scholar]
- Lu, Y.J.; Cohen, I.; Zhou, X.S.; Tian, Q. Feature selection using principal feature analysis. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 24–29 September 2007. [Google Scholar]
- Yang, Y.; Shen, H.T.; Ma, Z.G. l21-norm regularized discriminative feature selection for unsupervised learning. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Wang, S.P.; Witold, P.; Zhu, Q.X. Subspace learning for unsupervised feature selection via matrix factorization. Pattern Recognit. 2015, 48, 10–19. [Google Scholar] [CrossRef]
- Lovász, L.; Plummer, M.D. Matching Theory, 1st ed.; Elsevier Science Ltd.: Amsterdam, The Netherlands, 1986. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Size | Features | Classes | Data Types |
|---|---|---|---|---|
| COIL20 | 1440 | 1024 | 20 | Object images |
| PIE | 1166 | 1024 | 53 | Face images |
| ORL | 400 | 1024 | 40 | Face images |
| Yale | 165 | 1024 | 15 | Face images |
| Dataset | Maxvar | MFFS | UDFS | Algorithm 1 |
|---|---|---|---|---|
| COIL20 | 0.4881 | 0.5335 | 0.5118 | 0.5404 |
| PIE | 0.3865 | 0.4630 | 0.2021 | 0.4799 |
| ORL | 0.3770 | 0.3903 | 0.4040 | 0.4798 |
| Yale | 0.3049 | 0.3812 | 0.2994 | 0.4000 |
| Dataset | Maxvar | MFFS | UDFS | Algorithm 1 |
|---|---|---|---|---|
| COIL20 | 0.6020 | 0.6495 | 0.6000 | 0.6518 |
| PIE | 0.6527 | 0.7098 | 0.4622 | 0.7322 |
| ORL | 0.6052 | 0.6161 | 0.6114 | 0.6790 |
| Yale | 0.3557 | 0.4489 | 0.3628 | 0.4563 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wu, W. An Efficient Algorithm for Solving the Matrix Optimization Problem in the Unsupervised Feature Selection. Symmetry 2022, 14, 462. https://doi.org/10.3390/sym14030462
Li C, Wu W. An Efficient Algorithm for Solving the Matrix Optimization Problem in the Unsupervised Feature Selection. Symmetry. 2022; 14(3):462. https://doi.org/10.3390/sym14030462
Chicago/Turabian StyleLi, Chunmei, and Wen Wu. 2022. "An Efficient Algorithm for Solving the Matrix Optimization Problem in the Unsupervised Feature Selection" Symmetry 14, no. 3: 462. https://doi.org/10.3390/sym14030462
APA StyleLi, C., & Wu, W. (2022). An Efficient Algorithm for Solving the Matrix Optimization Problem in the Unsupervised Feature Selection. Symmetry, 14(3), 462. https://doi.org/10.3390/sym14030462