1. Introduction
Nowadays, advancements in both machine learning and computer vision fields have propelled the number of studies in activity recognition applications. These studies are mostly geared towards intelligent systems that focus on monitoring and analysis of daily human activities. Furthermore, computational devices have become highly efficient and thus, contribute greatly to the development of many autonomous systems in activity recognition. In general, most of the studies have emphasized developing algorithms for classifying normal human activities, which is also known as Activities of Daily Living (ADL), such as sitting, walking, standing, and crouching down. Primarily, these algorithms are also used in assessing the physical fitness and movement quality of an individual. Apart from that, the detection of abnormal activities is similarly important, specifically for safety and security-related reason. The inability to differentiate abnormal activities can cause many potential health risks, especially towards toddlers and elderly people. Therefore, early detection of abnormal activities is indispensable to prevent any bad consequence due to delay in detecting the event.
Fall event recognition is one of the most researched abnormal activities over the past few years [
1,
2]. The World Health Organization (WHO) has defined a fall event as a situation in which a person unintentionally lays down onto a lower surface [
3]. It is usually unintentional, as such there will be a sudden change of body position from sitting or standing to a lower position [
4,
5]. Noury et al. [
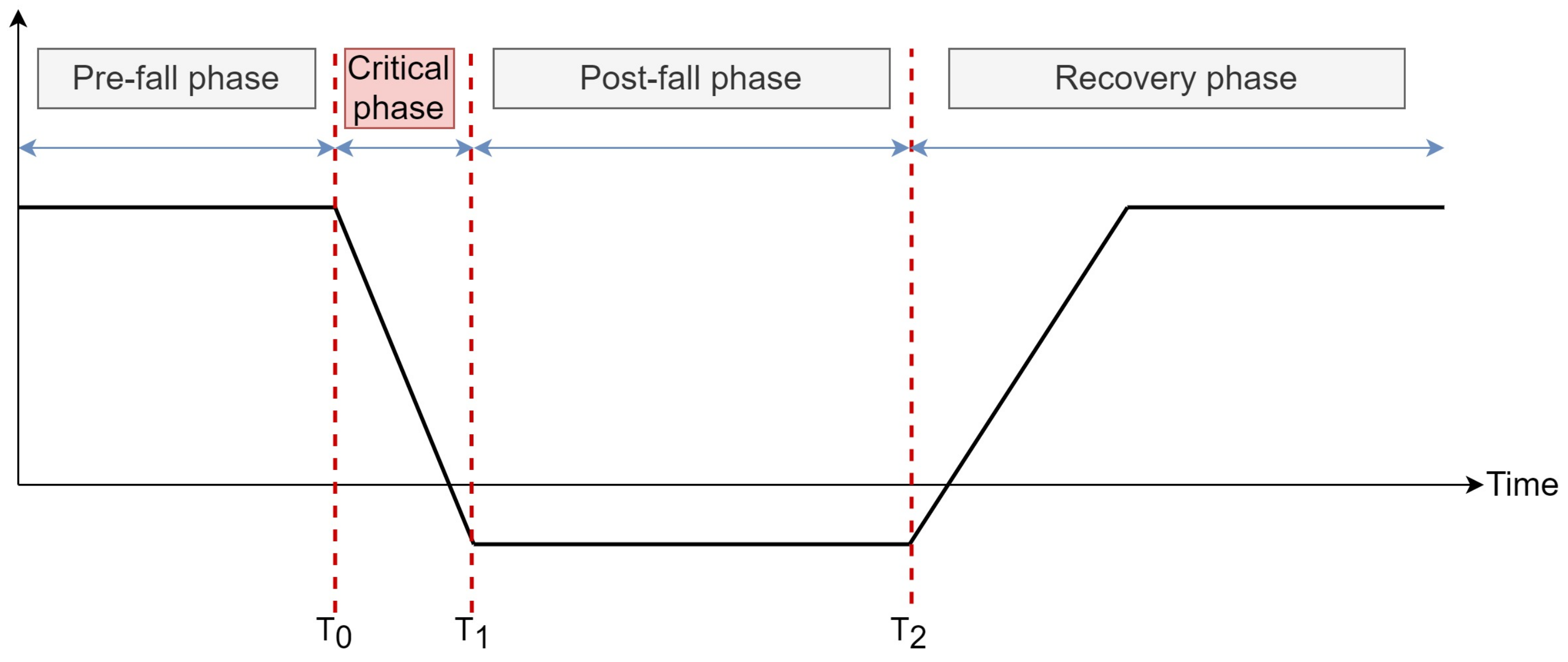
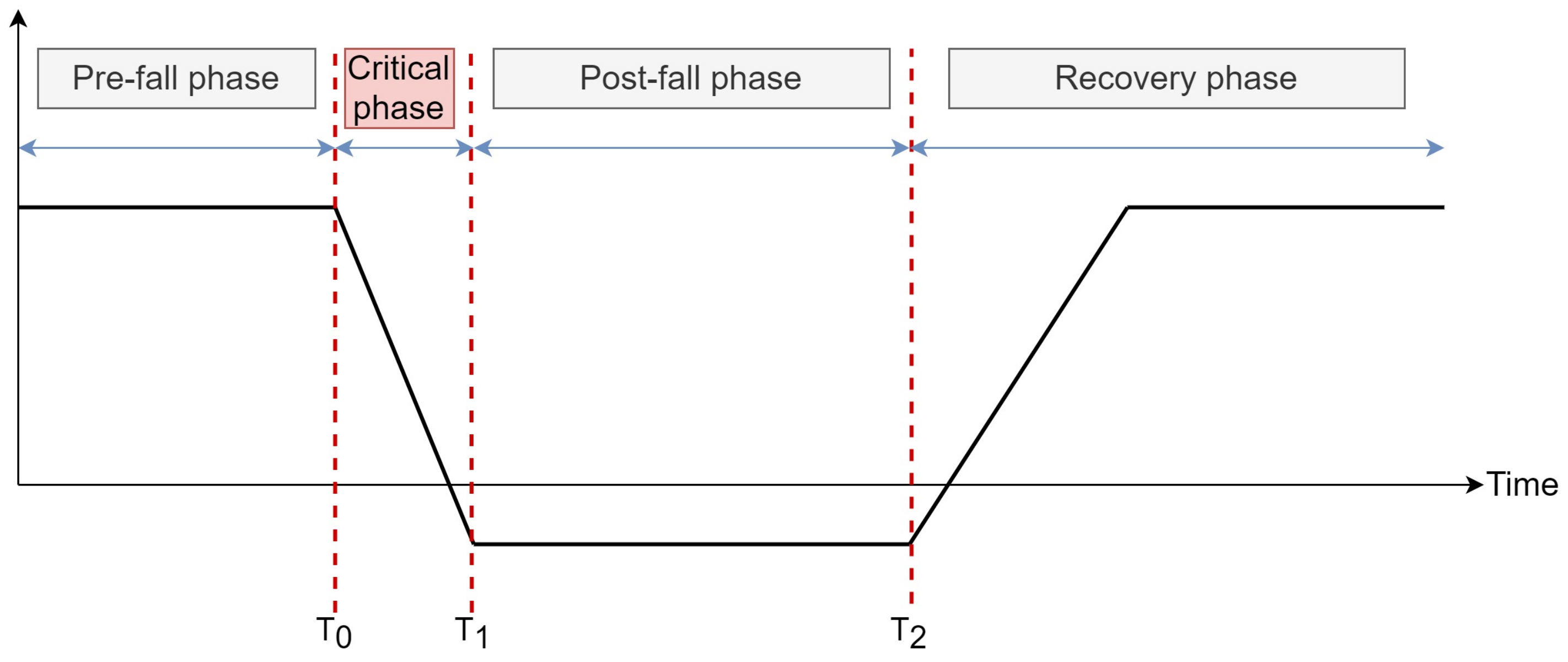
6] have categorized a fall event into four phases; pre-fall, critical, post-fall, and recovery, as illustrated in
Figure 1. The pre-fall period is the phase in which a person is doing normal activities such as walking and sitting. The critical phase is the condition when there is a large change in body movements, directed towards a lower surface and ends with a vertical stop. Let us denote the start and end period of a fall event as
and
. The inactivity period of a person after the fall is recognized as the post-fall phase. Lastly, the recovery phase is the condition when the person gets up again after the post-fall phase, where the timing is regarded as the response time,
. In general, the main cause for the occurrence of a fall event can be attributed to a loss of balance due to sudden trip or slip, or instability during movements [
7,
8]. Furthermore, WHO has also reported that the fall event is the second biggest death contributor globally with an estimate of 646,000 cases each year.
Age and frailty level are the two most contributing factors for the fall event. Generally, elderly peoples tend to have weak muscles and they are prone to experience loss of balance easily. Thus, these factors will increase the occurrence probability of a falling-down situation. This statement is supported by statistical data from the United States National Institutes of Health (NIH), which has reported that about 1.6 million elderly peoples are involved in fall event injuries [
9]. Moreover, individuals with low frailty levels, such as post-operative patients and people with mild disabilities, also belong to a high-risk group of fall event injuries. A possible consequence of a fall incident to these high-risk people is severe injury that leads to losing confidence, fear of falling, and loss of independence. Usually, a “long lie” situation, which is the total length of time of an individual to remain inactive lying on the floor after the incident, is a good indicator of the injury severity level. The long lie situation may cause loss of consciousness, hypothermia, internal bleeding, and dehydration [
10]. In addition, the fall event can also cause death in some situations if early treatment is not administered [
11]. Therefore, an early fall event recognition is very crucial and much needed to reduce the negative consequences and related injuries.
The state-of-the-art fall event recognition technology can be categorized into wearable device, ambient device, and vision-based system [
12]. Generally, wearable devices utilize gyroscopes, barometric pressure sensors, and accelerometers to automatically detect a fall event. It is known to have good accuracy, stability, and simplicity. Despite its efficacy, it requires an individual to wear the device for a prolonged time, which usually causes discomfort. Ambient devices make use of the infrared sensor, acoustic sensor, and piezoelectric sensor [
13]. This method requires the installation of several ambient sensors at selected active regions to detect the occurrence of a fall event. However, ambient sensors are easily affected by noise, which then can trigger false fall event detection. Due to these circumstances, many studies have focused on vision-based systems to alleviate the aforementioned issues, as well as to allow fast and appropriate assistance. The vision-based systems rely on either one or more surveillance cameras to detect the occurrence of a fall event. The main advantages of a vision-based system are high flexibility, less intrusion, and it does not require other complementary sensors. In this paper, we only focus on a vision-based system for fall event recognition. Presently, most of the public facilities such as shopping malls, streets, as well as housing areas have been equipped with surveillance cameras like Closed Circuit Television (CCTV) or Internet Protocol (IP) cameras. This event detection has become indispensable in ensuring safety and providing security in public areas. More importantly, surveillance cameras can provide rich and useful information about the areas, not just solely for fall event detection. Moreover, recent advancements in camera technology and high-speed computer networks have made the system more affordable for commercial purposes.
In real-life situations, a fall event is classified as a sporadic event, in which it occurs infrequently, and thus the number of training data collected for a supervised system may not be optimal [
14]. The imbalance in training data between fall and normal activities makes the development of a fall event detection system more challenging. Recently, Convolutional Neural Networks (CNNs/ConvNet) have gained tremendous achievements and attention, and have been widely used in various computer applications such as object detection [
15,
16], object tracking [
17,
18], image classification [
19,
20], image segmentation [
21,
22], machine translation [
23,
24], natural language processing [
25,
26], and physiotherapy monitoring [
27]. This is because CNNs have strong capabilities in learning the object’s features using multi-layer nonlinear transformations. Apart from that, a transfer learning method can be adopted to overcome the lack of training data by transferring a set of trained parameters from one model to a related task [
28]. Besides, the top trackers of Visual Object Tracking (VOT) Challenge in 2015 and 2016, namely MDNET [
29] and TCNN [
30], have derived CNNs to represent and train the object appearance model, which has also achieved good results in tracking performance. Thus, this outstanding capability has motivated us to employ CNN-based tracker as a feature extractor that is robust to the challenges in fall event detection.
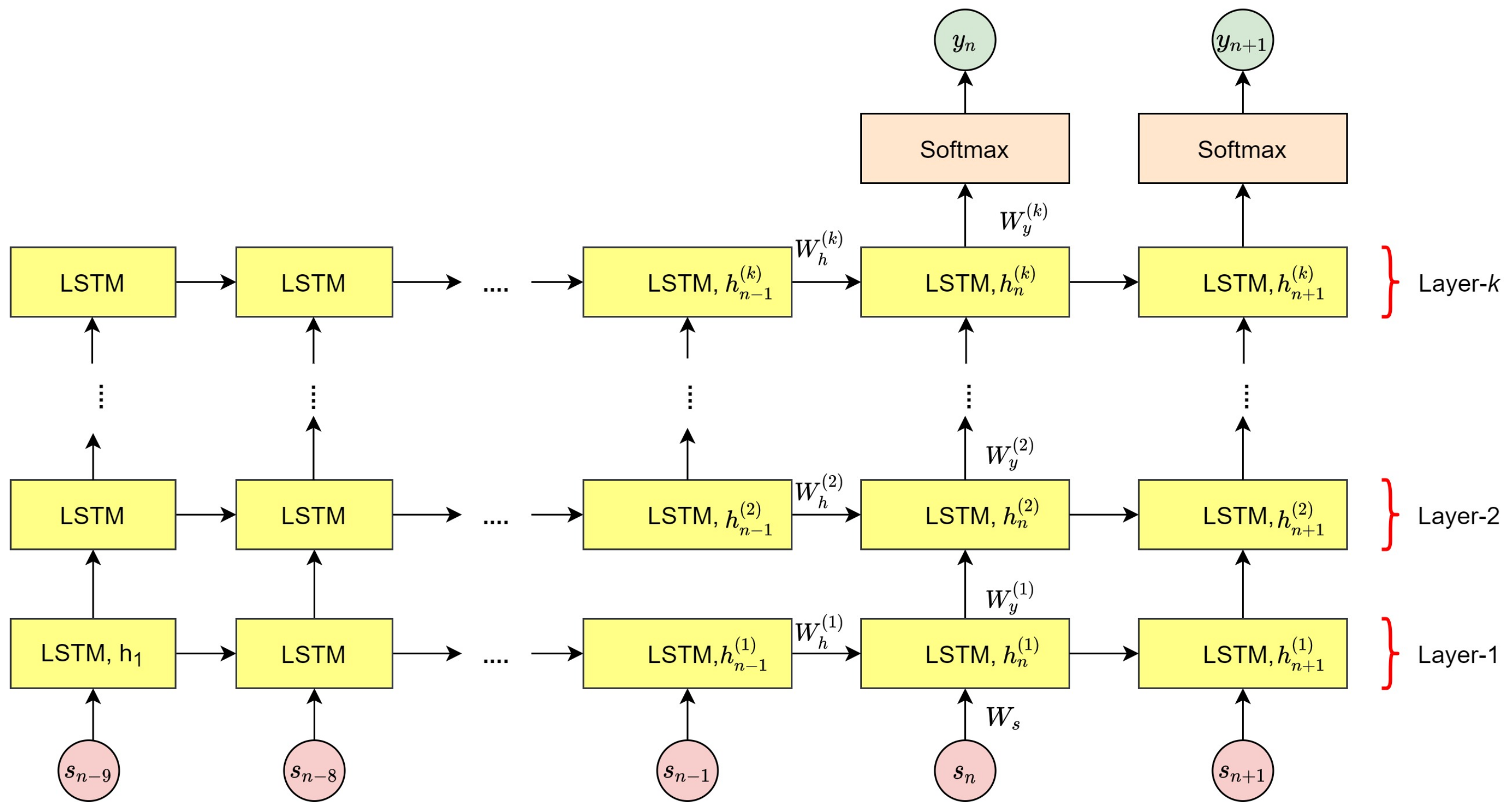
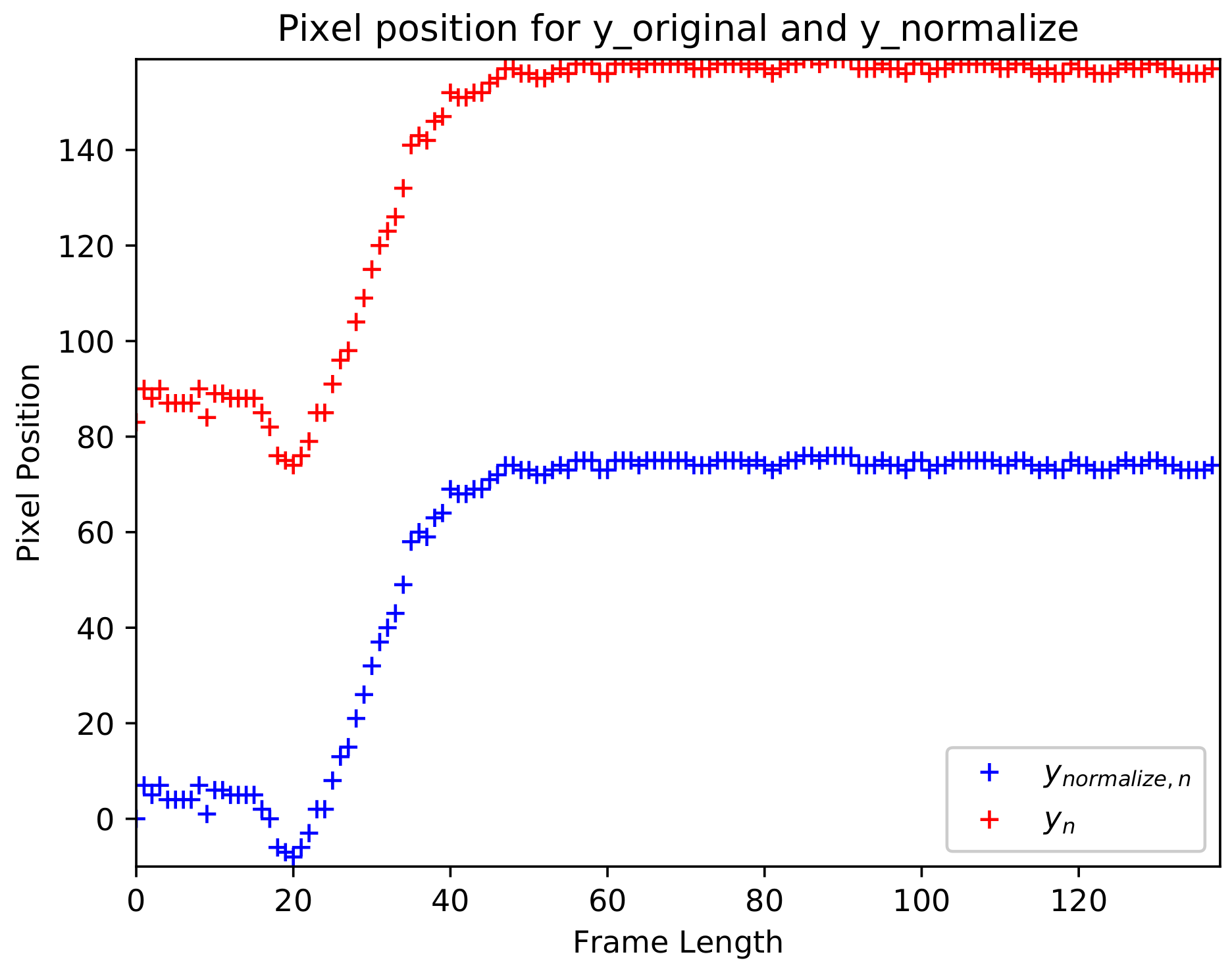
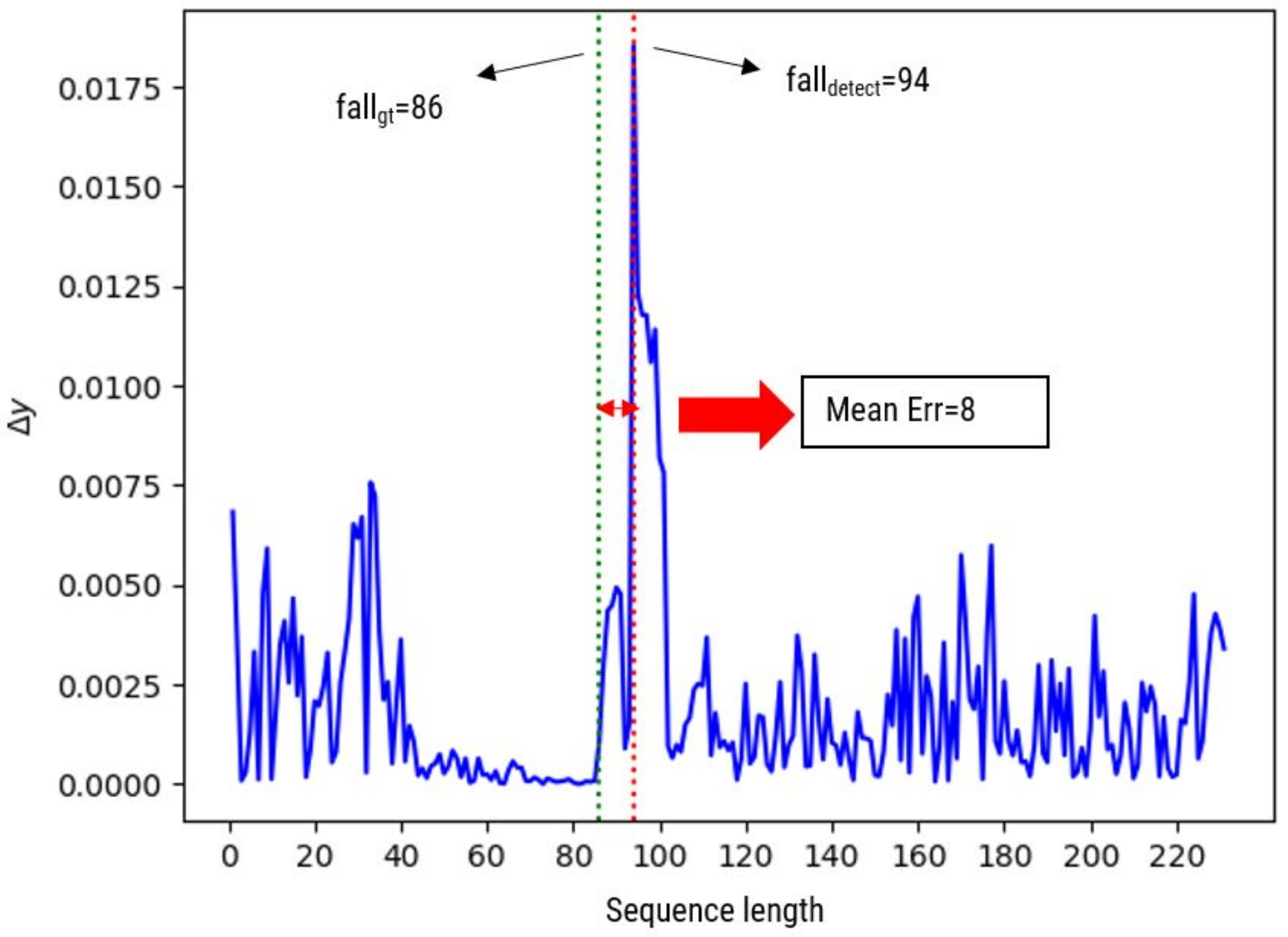
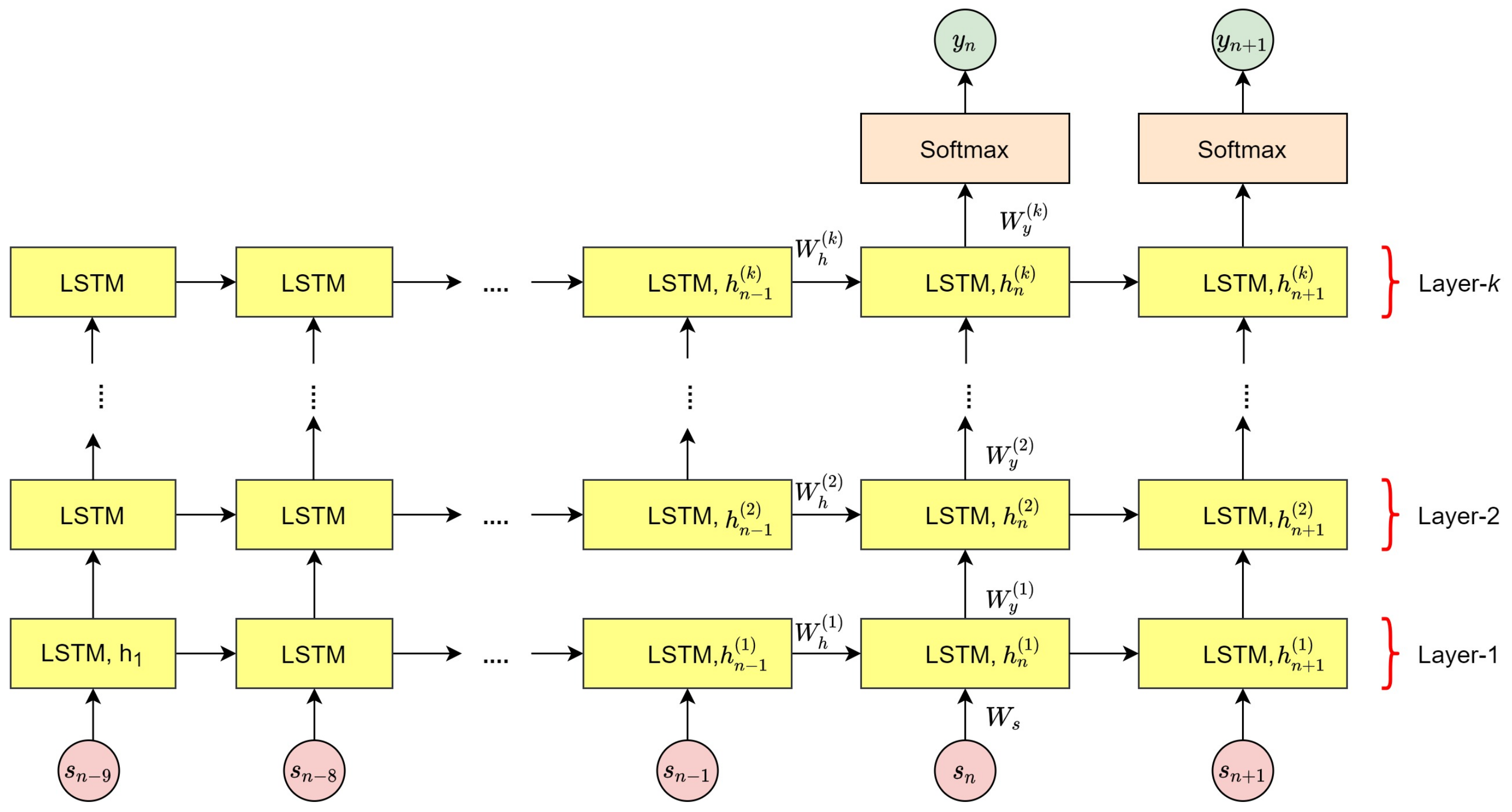
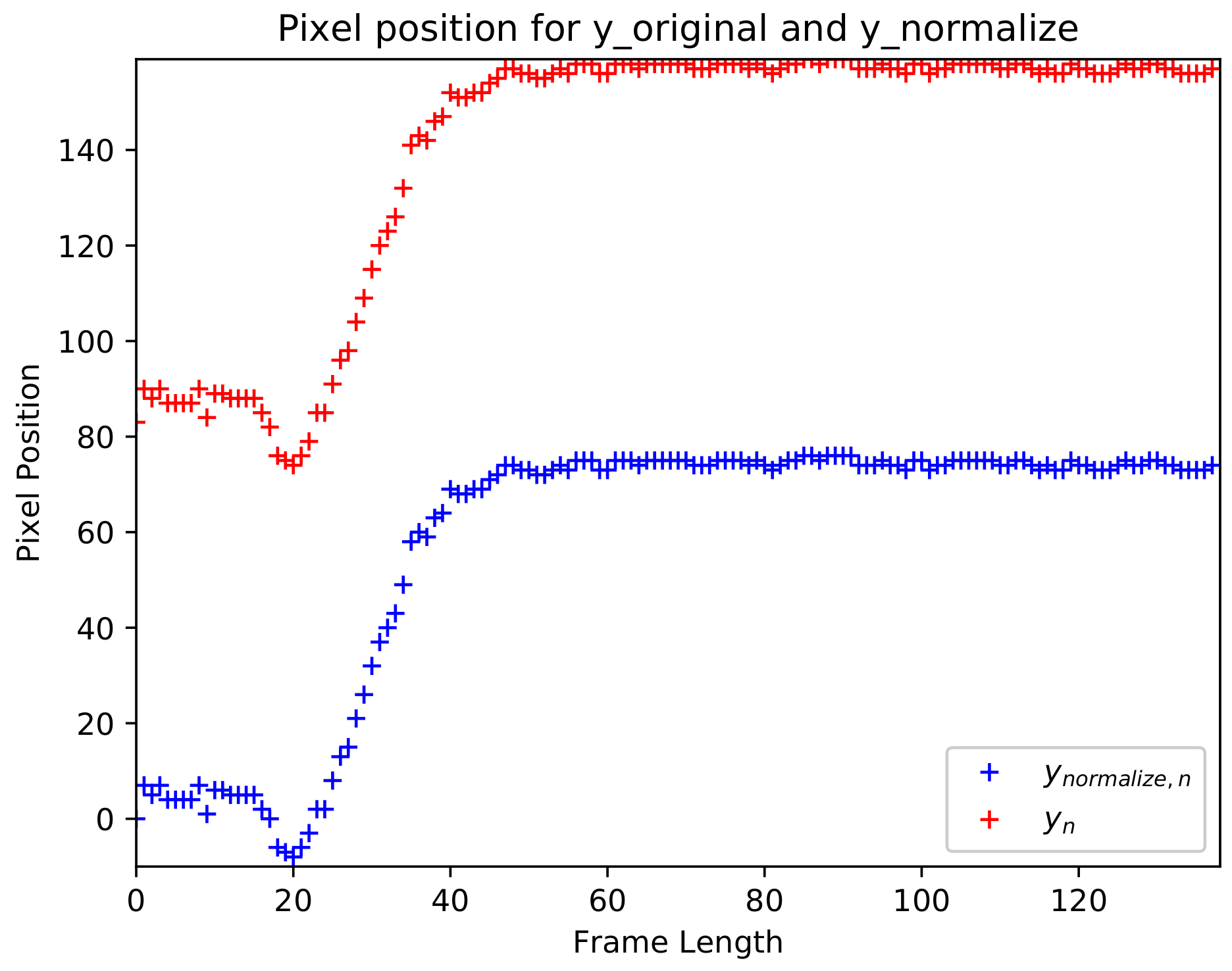
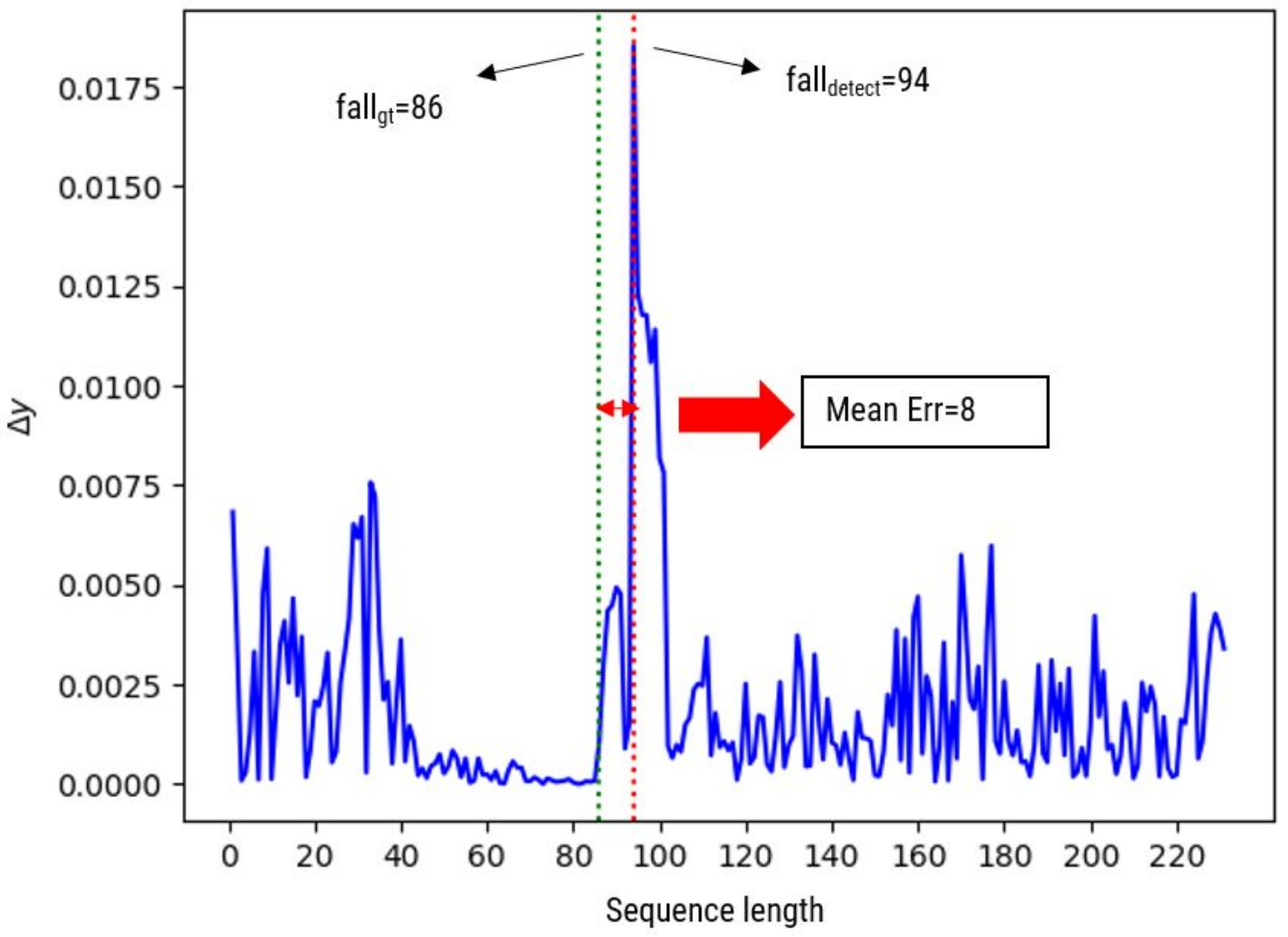
To the best of our knowledge, most of the existing fall event recognition methods only focus on classifying the presence of the fall event from normal activities throughout video sequences. However, our goal is to not only detect the fall event, but we aim to determine the exact instantaneous fall frame, falldetect in which the fall event occurs. Since time management is a vital issue in fall event detection, hence reducing the time between the occurrence of a fall event and the response time will reduce the negative consequences of fall-related injuries. Therefore, this paper introduces a two-stage fall event detection system. The first stage aims to detect the object and obtain the object’s trajectories throughout the contiguous video frames by employing a fully CNN-based tracker. The instantaneous fall frame detection will be determined in the second stage by modeling the temporal dependencies between contiguous spatial coordinates using the symmetrically stacked Recurrent Neural Networks (RNN) with underlying Long Short-Term Memory (LSTM) networks. The symmetrical stacking of the networks has managed to create a more accurate deep network that relates the possibility of a fall event to the movement trajectories. The selection of the symmetrically stacked LSTM network over Vanilla RNN is due to its better capabilities in capturing time-series relationships and its ability to overcome the issue of vanishing gradients.
2. Related Works
Over the past few years, there is a large volume of published studies on the development of machine learning approaches to fall event recognition. The previous studies have reported that machine learning approaches can provide a non-intrusive approach and be less susceptible to noise. There are various different types of features extracted from video sequences, which are then used to train a classifier to detect the fall event. Generally, machine learning can be categorized into traditional and deep learning approaches. The traditional machine learning approaches include basic neural networks, support vector machine (SVM), and hidden Markov model (HMM), which all follow a shallow learning paradigm. Meanwhile, a deep learning approach exploits many numbers of hidden layers that are capable to learn object features and representations directly with little to no prior knowledge.
The earliest work of fall event recognition using neural networks has been introduced by Alhimale et al. [
31]. Silhouette information is utilized by implementing median filter background subtraction to separate the foreground from background. Object’s binary map is then fed to the neural networks and the bounding box aspect ratio is computed for fall event identification. Utilizing a similar approach, Hsu et al. [
32] have introduced a Gaussian mixture model (GMM) background subtraction to obtain the foreground information. The bounding box aspect ratio, ellipse orientation, and vertical velocity of the object’s center point are combined to train the neural networks for fall event detection. Fall event recognition based on SVM classification has been proposed in [
33,
34,
35,
36]. In [
33], SVM is used for final fall event classification, which was trained by integrating Hu-moment and body posture information. The final fall event classification is determined if and only if there is a fall event, which is characterized by the velocity and changes in the bounding box aspect ratio. Similarly, authors in [
34] have also extracted body posture information by considering acceleration as an additional feature to cater for the situation in which velocity changes are not able to provide clear speed differential during fall event movements. In [
35], fall event detection is classified through SVM by taking the object features from the top-view depth images. They argued that the top-view depth images have less occlusion compared to the frontal-view images. Iazzi et al. [
36] has implemented multi-class SVM, which is trained using vertical and horizontal histogram representations to classify a fall event from the confounding events such as bending, sitting, and lying. Unlike others, Zerrouki et al. [
37] claimed that HMM can solve the classification problem better for sequential data. Therefore, they implemented HMM to discriminate fall events from other normal activities, which has resulted in reliable fall detection results. Meanwhile, Thuc et al. [
38] have introduced two types of HMMs to model two different scenarios. The first HMM is implemented to differentiate fall-risk event from walking scenarios, while the second HMM is employed to determine the exact fall event based on the object shape and motion features.
Nowadays, many researchers have exploited the deep learning approach in fall event recognition to handle the limitations of traditional machine learning approaches. Li et al. [
39] presented a fall event recognition method by applying CNNs to learn human shape deformation features in each video frame sequence. A similar approach has also been explored by works in [
40,
41]. However, silhouette information is obtained through background subtraction first, which is later used as the input to the CNNs architecture despite taking the whole frame information. In [
42], human pose information obtained from the OpenPose algorithm is used to train CNNs to detect the fall event. The paper [
43] has introduced two-stage training with the implementation of Principal Component Analysis Network (PCANet) as a feature extractor on colored image input. During the first-stage training, they have applied SVM to predict frame labels from each sub-video that contains walking, falling, and lying activities, while an SVM is re-applied as an action model to predict each sub-video label in the second-stage training. Conceptually, similar work has also been carried out by Wang et al. [
44]. However, they extract silhouette information using Caffe framework and combined it with histograms of oriented gradients (HOG) and local binary pattern (LBP) to increase the fall event detection performances.
Apart from that, Marcos et al. [
45] has incorporated CNNs with motion information, extracted from optical flow to detect a fall event. While, Haraldsson [
46] has employed motion history images (MHI) to learn the temporal features, which is used to classify fall events via depthwise CNNs. Additionally, the same idea is used by Kong et al. [
47], in which they have used three-stream CNNs in taking full benefit of object motion and appearance representations. The work by Abobakr et al. [
48] has developed an end-to-end deep learning framework comprising of convolutional and RNN networks. They have applied ConvNet to analyze human body features for each frame sequence using depth images and then model the temporal information to recognize fall events using LSTM architecture. The paper by Anishchenko [
49] has used a fixed second fully-connected (FC) with only two hidden nodes instead of following the exact AlexNet architecture. Interestingly, the modification has contributed to better Cohen’s kappa measurement for fall and no-fall classification. Shojaei-Hashemi et al. [
50] has introduced fall event recognition using the LSTM networks by employing the transfer learning approach to compensate for a small training data size of fall event. Firstly, the multi-class LSTM network is trained using a large number of normal human activities. Then, the learned weights are transferred so that it can be retrained for two-class LSTM for fall event recognition. Feng et al. [
51] has introduced a fall event recognition in complex scenes using object detection approach. Firstly, the You Only Look Once (YOLO) v3 architecture is used to detect the object and the tracking process is performed by implementing a Deep-Sort tracking method. Next, a CNN architecture is used to extract the object features for each trajectory, which is later fed to the LSTM network to classify the fall event.
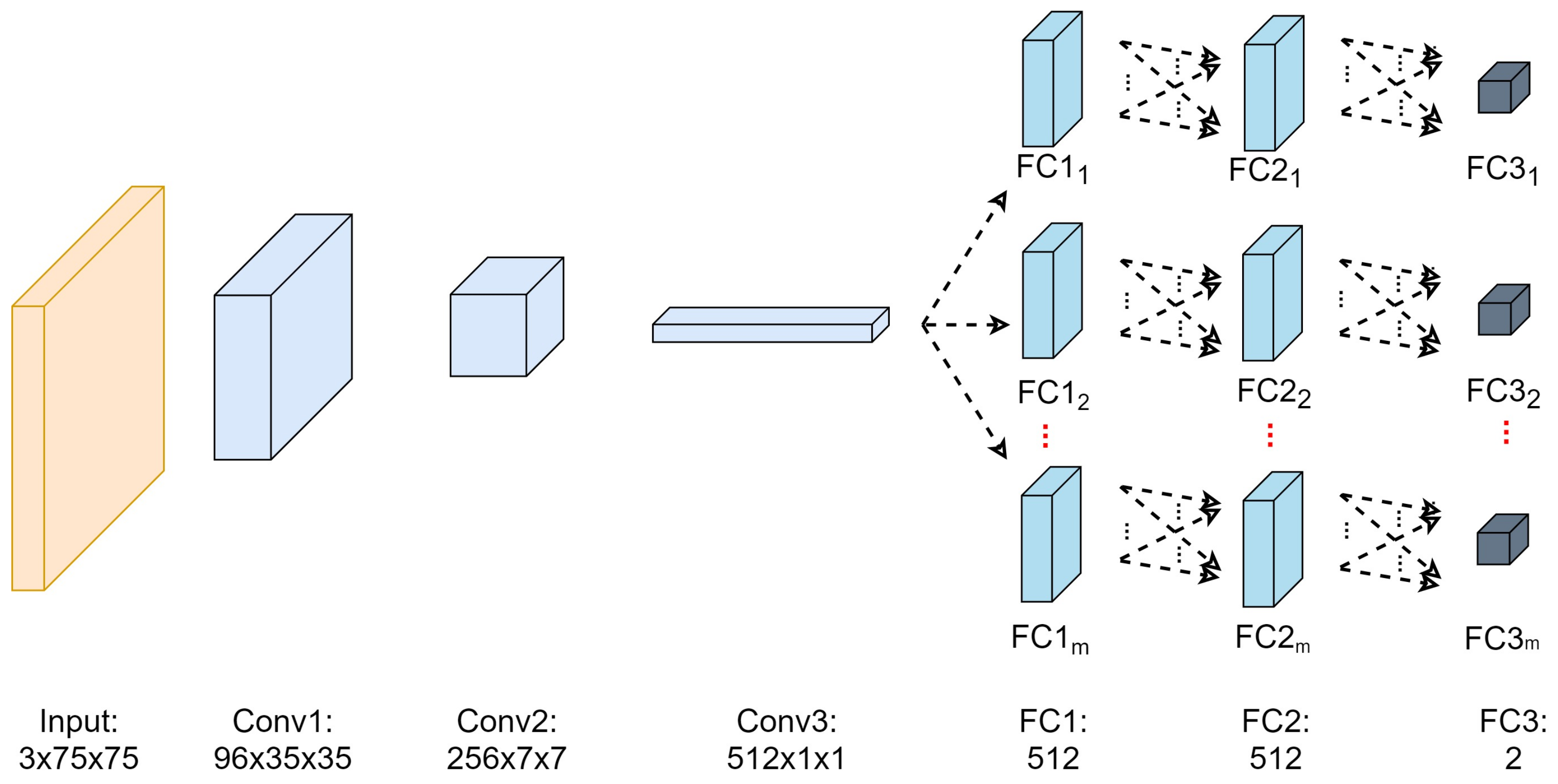
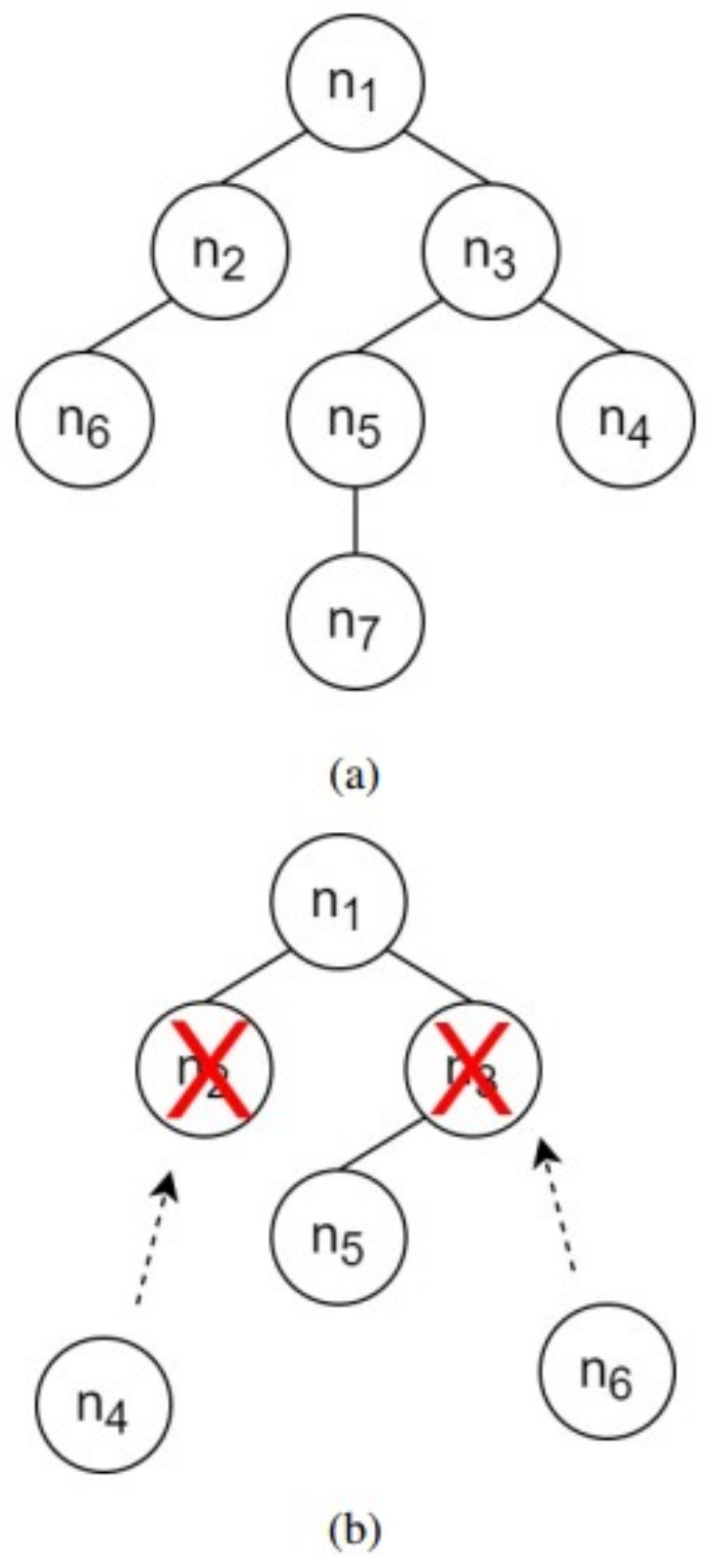
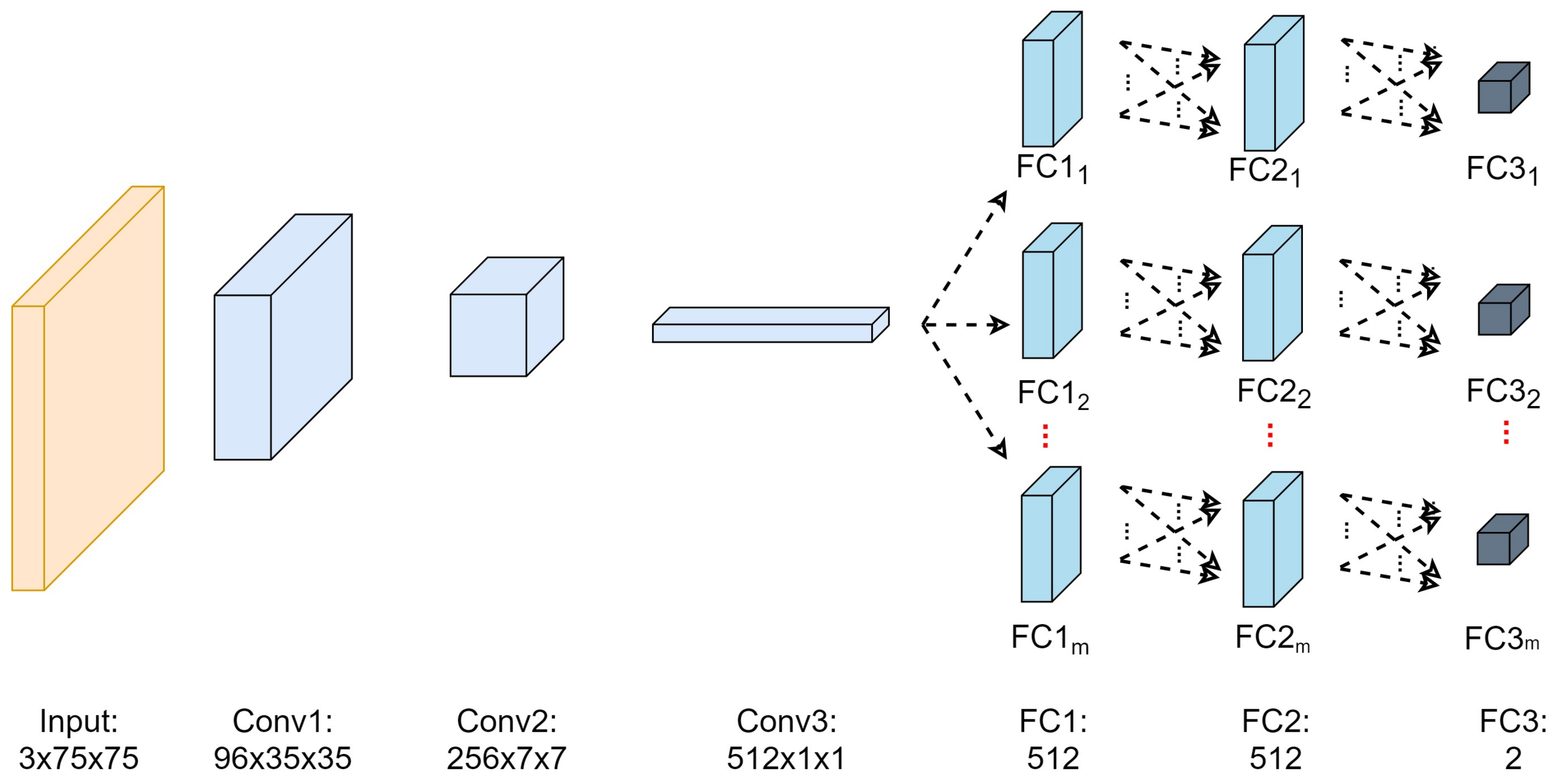
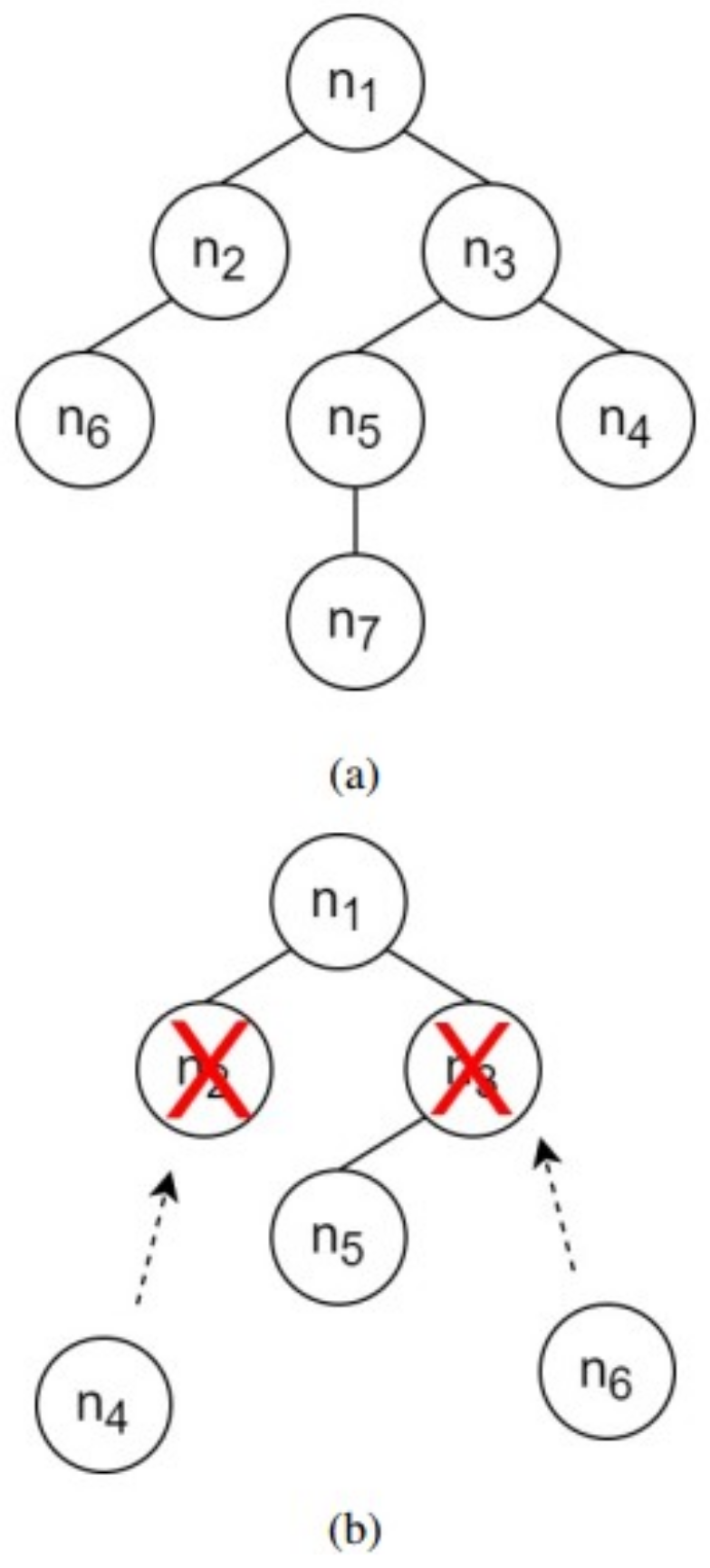
Nonetheless, the implementation of CNNs in object tracking application is less exploited, despite fruitful advantages in other computer vision domains. The difficulty in fitting the CNNs with limited training data is the major challenge to implement CNNs in object tracking purpose. This is due to the only information such as position and size of tracked object can be extracted in the first frame for a model-free tracker setting. Another drawback of CNNs is a longer training time which makes it impractical to be used in an online learning-based model update. However, the top trackers of 2015 VOT Challenge, namely TCNN and MDNET trackers have designed compact CNNs in its tracker architecture. These trackers were based on model-free tracker setting which trained and updated its object appearance model by using information that was only supplied during the first frame. Generally, these trackers shared a similar tracking fundamental, but differed a lot in handling the FC models. The TCNN tracker proposed a tree-structured to handle the FC nodes by retaining the parent node and deleting the oldest node once a new child node was spawned out. The TCNN tracker updated its FC models using the positive training data that were selected from the top matched object appearance model. However, MDNET tracker updated its FC layers by dividing them into several domains that were correspond to the most recent training samples. Each domain was trained separately and then categorized into either tracked object or background.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}