
Feature Extraction of Marine Water Pollution Based on Data Mining

Abstract
1. Introduction
2. Related Work
2.1. Study on the Method of Water Pollution Feature Extraction
2.2. Research Work of Data Mining Technology in the Field of Water Pollution
2.3. Research on the Advantages of K-Means Clustering in the Field of Environment
3. Study on Water Quality Anomaly Detection Based on Polygon Area Method
3.1. Marine Water Quality Anomaly Detection Technology Based on Polygon Area Method
3.2. Classification and Recognition Technology of Water Pollutants Based on K-Means Clustering
4. Experimental Design and Analysis
4.1. Analysis of Abnormal Water Quality Detection Results
4.2. Analysis of Pollutant Classification Results
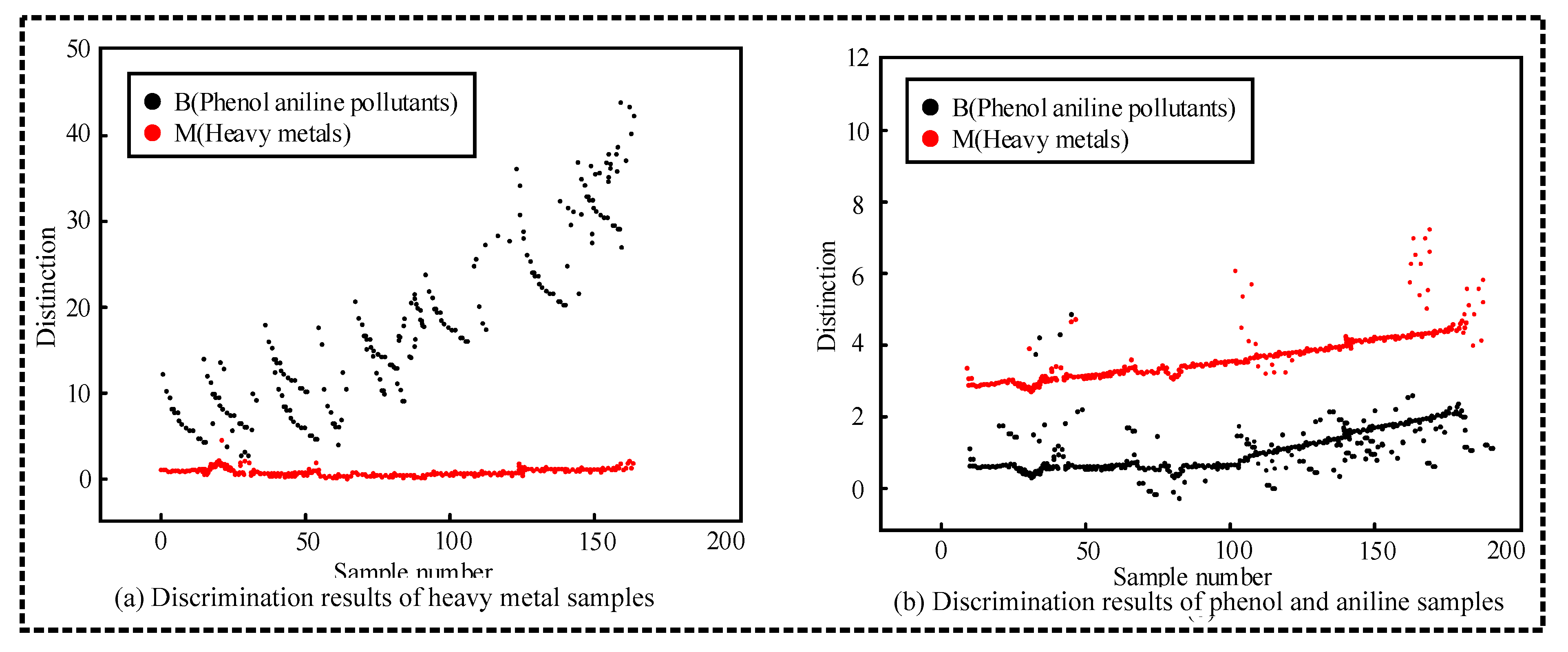
4.3. Recognition and Classification of Polluted Marine Environment by K-Means Clustering Algorithm
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Subbiah, S.; Karnjanapiboonwong, A.; Maul, J.D.; Wang, D.; Anderson, T.A. Monitoring cyanobacterial toxins in a large reservoir: Relationships with water quality parameters. PeerJ 2019, 7, e7305. [Google Scholar] [CrossRef] [PubMed]
- Farnham, D.J.; Gibson, R.A.; Hsueh, D.Y.; McGillis, W.R.; Culligan, P.J.; Zain, N.; Buchanan, R. Citizen science-based water quality monitoring: Constructing a large database to characterize the impacts of combined sewer overflow in New York City. Sci. Total Environ. 2017, 580, 168–177. [Google Scholar] [CrossRef] [PubMed]
- Griffith, J.F.; Weisberg, S.B.; Arnold, B.F.; Cao, Y.; Schiff, K.C.; Colford, J.M., Jr. Epidemiologic evaluation of multiple alternate microbial water quality monitoring indicators at three California beaches. Water Res. 2016, 94, 371–381. [Google Scholar] [CrossRef]
- Majid, N.; Muhammad, B. Evaluation of Ordinary Least Square (OLS) and Geographically Weighted Regression (GWR) for Water Quality Monitoring: A Case Study for the Estimation of Salinity. J. Ocean Univ. China 2018, 2, 305–310. [Google Scholar]
- Pérez, C.J.; Vega-Rodríguez, M.A.; Reder, K.; Flörke, M. A Multi-Objective Artificial Bee Colony-based optimization approach to design water quality monitoring networks in river basins. J. Clean. Prod. 2017, 166, 579–589. [Google Scholar] [CrossRef]
- Hamid, A.; Bhat, S.A.; Bhat, S.U.; Jehangir, A. Environmetric techniques in water quality assessment and monitoring: A case study. Environ. Earth Sci. 2016, 75, 321–334. [Google Scholar] [CrossRef]
- Delpla, I.; Florea, M.; Rodriguez, M.J. Drinking Water Source Monitoring Using Early Warning Systems Based on Data Mining Techniques. Water Resour. Manag. 2019, 33, 129–140. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, J.; Xu, X. Research and Application of Rule Updating Mining Algorithm for Marine Water Quality Monitoring Data. Pol. Marit. Res. 2018, 25, 136–140. [Google Scholar] [CrossRef]
- Cominola, A.; Nguyen, K.; Giuliani, M.; Stewart, R.A.; Maier, H.R.; Castelletti, A. Data Mining to Uncover Heterogeneous Water Use Behaviors from Smart Meter Data. Water Resour. Res. 2019, 55, 9315–9333. [Google Scholar] [CrossRef]
- Lee, S.; Hyun, Y.; Lee, M.J. Groundwater Potential Mapping Using Data Mining Models of Big Data Analysis in Goyang-si, South Korea. Sustainability 2019, 11, 1678. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019)—ScienceDirect. Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Mahajan, M.; Kumar, S.; Pant, B. Prediction of Environmental Pollution Using Hybrid PSO-K-Means Approach. Int. J. E-Health Med. Commun. (IJEHMC) 2021, 12, 65–76. [Google Scholar] [CrossRef]
- Ahmadmoazzam, M.; Birgani, Y.T.; Molla-Norouzi, M.; Dastoorpour, M. Assessment of the Water Quality of Karun River Catchment Using Artificial Neural Networks-self-Organizing Maps and K-Means Algorithm. J. Environ. Account. Manag. 2020, 9, 43–58. [Google Scholar] [CrossRef]
- Li, T.; Sun, G.; Yang, C.; Liang, K.; Ma, S.; Huang, L. Using self-organizing map for coastal water quality classification: Towards a better understanding of patterns and processes. Sci. Total Environ. 2018, 628–629, 1446–1459. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Jia, L.; Wang, J.; Pan, Y. Spatial and temporal characteristics of particulate matter in Beijing, China using the Empirical Mode Decomposition method. Sci. Total Environ. 2013, 458–460, 70–80. [Google Scholar] [CrossRef]
- Samendra, S.; Syreeta, M.; Luisa, I.; Yu, H.W.; Snyder, S.A.; Pepper, I.L. Near Real-Time Detection of E. coli in Reclaimed Water. Sensors 2018, 18, 2303. [Google Scholar] [CrossRef]
- Wang, K.; Wen, X.; Hou, D.; Tu, D.; Zhu, N.; Pingjie, H.; Guangxin, Z.; Zhang, H. Application of Least-Squares Support Vector Machines for Quantitative Evaluation of Known Contaminant in Water Distribution System Using Online Water Quality Parameters. Sensors 2018, 18, 938. [Google Scholar] [CrossRef]
- Vasilescu, J.; Marmureanu, L.; Carstea, E. Analysis of Seawater Pollution Using Neural Networks. Rom. J. Phys. 2011, 56, 530–539. [Google Scholar]
- Xu, X.; Liu, Y.; Liu, S.; Li, J.; Guo, G.; Smith, K. Real-time detection of potable-reclaimed water pipe cross-connection events by conventional water quality sensors using machine learning methods. J. Environ. Manag. 2019, 238, 201–209. [Google Scholar] [CrossRef]
- Júnez-Ferreira, H.E.; Herrera, G.S.; Saucedo, E.; Pacheco-Guerrero, A.I. Influence of available data on the geostatistical-based design of optimal spatiotemporal groundwater-level-monitoring networks. Hydrogeol. J. 2019, 27, 1207–1227. [Google Scholar] [CrossRef]
- Xie, T.; Liu, R.; Wei, Z. Improvement of the fast clustering algorithm improved by k-means in the big data. Appl. Math. Nonlinear Sci. 2020, 5, 1–10. [Google Scholar] [CrossRef]
- Wu, J.; Yuan, J.; Gao, W. Analysis of fractional factor system for data transmission in SDN. Appl. Math. Nonlinear Sci. 2019, 4, 191–196. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hexagon Area Y | Abnormal Water Quality Index S | Water Quality Status |
|---|---|---|
| ≤1 | <23.4 | Normal |
| >1 | <23.4 | Abnormal |
| >1 | ≥23.4 | Severe abnormality |
| Forecast Water Quality Abnormalities | Corresponding Parameters | Forecast of Normal Water Quality | Corresponding Parameters | |
|---|---|---|---|---|
| Actual water quality is abnormal | True positive | TP | False positive | FP |
| Actual water quality is normal | False negative | FN | True negative | TN |
| Pollutants | FP | TN | FN | TP | FAR | PD | FCR |
|---|---|---|---|---|---|---|---|
| Phenolanilines (113) | 0 | 61 | 12 | 90 | 0% | 88.2% | 7.36% |
| Heavy metals (119) | 2 | 46 | 5 | 130 | 4.17% | 96.3% | 3.83% |
| Pollutants | Molecular Method | Hyserve Method | ||||
|---|---|---|---|---|---|---|
| FAR | PD | FCR | FAR | PD | FCR | |
| Phenolanilines (113) | 10% | 91.30% | 8.63% | 7% | 84.30% | 7.36% |
| Heavy metals (119) | 12.40% | 85.50% | 7.64% | 9.23% | 74.26% | 5.97% |
| Group | Included Parameters | Classification Accuracy (%) |
|---|---|---|
| Group A | K, pH, ORP, DO, UV254, T | 90.52 |
| Group B | K, pH, ORP, DO, UV254 | 92.36 |
| Group C | T, pH, ORP, DO, UV254 | 89.74 |
| Group D | K, T, ORP, DO, UV254 | 86.13 |
| Group E | K, T, pH, ORP, UV254 | 82.37 |
| Group F | K, T, pH, DO, UV254 | 81.63 |
| Group G | K, T, pH, ORP, DO | 80.99 |
| Classification | Classification Accuracy of Heavy Metal Samples | Correct Rate of Classification of Phenol Aniline Samples | Overall Classification Accuracy |
|---|---|---|---|
| Discrimination | 94.7% | 97.8% | 96.3% |
| Cosine distance | 94.9% | 91.5% | 93.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Cui, J.; Bai, X. Feature Extraction of Marine Water Pollution Based on Data Mining. Symmetry 2021, 13, 355. https://doi.org/10.3390/sym13020355
Lin H, Cui J, Bai X. Feature Extraction of Marine Water Pollution Based on Data Mining. Symmetry. 2021; 13(2):355. https://doi.org/10.3390/sym13020355
Chicago/Turabian StyleLin, Haixia, Jianhong Cui, and Xiangwei Bai. 2021. "Feature Extraction of Marine Water Pollution Based on Data Mining" Symmetry 13, no. 2: 355. https://doi.org/10.3390/sym13020355
APA StyleLin, H., Cui, J., & Bai, X. (2021). Feature Extraction of Marine Water Pollution Based on Data Mining. Symmetry, 13(2), 355. https://doi.org/10.3390/sym13020355